mirror of
https://github.com/phil-opp/blog_os.git
synced 2025-12-16 14:27:49 +00:00
Compare commits
16 Commits
2f1918bf71
...
ac94309114
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ac94309114 | ||
|
|
3183dc92e9 | ||
|
|
19150682df | ||
|
|
912566167c | ||
|
|
82f205956a | ||
|
|
d456410da2 | ||
|
|
48c3532c40 | ||
|
|
0c79f42e39 | ||
|
|
399eee2e19 | ||
|
|
2a338cf045 | ||
|
|
31eb517b4d | ||
|
|
2844d0fc8c | ||
|
|
b63ce2dc3c | ||
|
|
184db36e7c | ||
|
|
a108367d71 | ||
|
|
c1639cb9c2 |
1
blog/.gitignore
vendored
1
blog/.gitignore
vendored
@@ -1 +1,2 @@
|
||||
/public
|
||||
zola
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
+++
|
||||
title = "A Freestanding Rust Binary"
|
||||
title = "Un binaire Rust autonome"
|
||||
weight = 1
|
||||
path = "fr/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
@@ -12,8 +12,7 @@ translation_based_on_commit = "c1af4e31b14e562826029999b9ab1dce86396b93"
|
||||
translators = ["JOE1994", "Quqqu"]
|
||||
+++
|
||||
|
||||
운영체제 커널을 만드는 첫 단계는 표준 라이브러리(standard library)를 링크하지 않는 Rust 실행파일을 만드는 것입니다.
|
||||
이러한 실행파일은 운영체제가 없는 [bare metal] 시스템에서 동작할 수 있습니다.
|
||||
운영체제 커널을 만드는 첫 단계는 표준 라이브러리(standard library)를 링크하지 않는 Rust 실행파일을 만드는 것입니다. 이 실행파일은 운영체제가 없는 [bare metal] 시스템에서 동작할 수 있습니다.
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
|
||||
@@ -6,9 +6,11 @@ date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu", "TheBegining"]
|
||||
translators = ["luojia65", "Rustin-Liu", "TheBegining", "liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong"]
|
||||
+++
|
||||
|
||||
创建一个不链接标准库的 Rust 可执行文件,将是我们迈出的第一步。无需底层操作系统的支撑,这样才能在**裸机**([bare metal])上运行 Rust 代码。
|
||||
@@ -43,10 +45,10 @@ translators = ["luojia65", "Rustin-Liu", "TheBegining"]
|
||||
我们可以从创建一个新的 cargo 项目开始。最简单的办法是使用下面的命令:
|
||||
|
||||
```bash
|
||||
> cargo new blog_os
|
||||
cargo new blog_os --bin --edition 2018
|
||||
```
|
||||
|
||||
在这里我把项目命名为 `blog_os`,当然读者也可以选择自己的项目名称。这里,cargo 默认为我们添加了`--bin` 选项,说明我们将要创建一个可执行文件(而不是一个库);cargo还为我们添加了`--edition 2018` 标签,指明项目的包要使用 Rust 的 **2018 版次**([2018 edition])。当我们执行这行指令的时候,cargo 为我们创建的目录结构如下:
|
||||
在这里我把项目命名为 `blog_os`,当然读者也可以选择自己的项目名称。默认情况下,即使不显式指定,cargo 也会为我们添加`--bin` 选项,说明我们将要创建一个可执行文件(而不是一个库); 另外 `--edition 2018` 参数指明了项目的包要使用 Rust 的 **2018 版次**([2018 edition]),但在默认情况下,该参数会指向本地安装的最新版本。当我们成功执行这行指令后,cargo 为我们创建的目录结构如下:
|
||||
|
||||
[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
|
||||
|
||||
@@ -158,7 +160,7 @@ error: requires `start` lang_item
|
||||
|
||||
我们通常会认为,当运行一个程序时,首先被调用的是 `main` 函数。但是,大多数语言都拥有一个**运行时系统**([runtime system](https://en.wikipedia.org/wiki/Runtime_system)),它通常为**垃圾回收**(garbage collection)或**绿色线程**(software threads,或 green threads)服务,如 Java 的 GC 或 Go 语言的协程(goroutine);这个运行时系统需要在 main 函数前启动,因为它需要让程序初始化。
|
||||
|
||||
在一个典型的使用标准库的 Rust 程序中,程序运行是从一个名为 `crt0` 的运行时库开始的。`crt0` 意为 C runtime zero,它能建立一个适合运行 C 语言程序的环境,这包含了栈的创建和可执行程序参数的传入。在这之后,这个运行时库会调用 [Rust 的运行时入口点](https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73),这个入口点被称作 **start语言项**("start" language item)。Rust 只拥有一个极小的运行时,它被设计为拥有较少的功能,如爆栈检测和打印**堆栈轨迹**(stack trace)。这之后,这个运行时将会调用 main 函数。
|
||||
在一个典型的使用标准库的 Rust 程序中,程序运行是从一个名为 `crt0` 的运行时库开始的。`crt0` 意为 C runtime zero,它能建立一个适合运行 C 语言程序的环境,这包含了栈的创建和可执行程序参数的传入。在这之后,这个运行时库会调用 [Rust 的运行时入口点](https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73),这个入口点被称作 **start语言项**("start" language item)。Rust 只拥有一个极小的运行时,它被设计为拥有较少的功能,如爆栈检测和打印**栈轨迹**(stack trace)。这之后,这个运行时将会调用 main 函数。
|
||||
|
||||
我们的独立式可执行程序并不能访问 Rust 运行时或 `crt0` 库,所以我们需要定义自己的入口点。只实现一个 `start` 语言项并不能帮助我们,因为这之后程序依然要求 `crt0` 库。所以,我们要做的是,直接重写整个 `crt0` 库和它定义的入口点。
|
||||
|
||||
@@ -241,6 +243,172 @@ cargo build --target thumbv7em-none-eabihf
|
||||
### 链接器参数
|
||||
|
||||
我们也可以选择不编译到裸机系统,因为传递特定的参数也能解决链接器错误问题。虽然我们不会在后面使用到这个方法,为了教程的完整性,我们也撰写了专门的短文章,来提供这个途径的解决方案。
|
||||
如有需要,请点击下方的 _"链接器参数"_ 按钮来展开可选内容。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>链接器参数</summary>
|
||||
|
||||
在本章节中,我们讨论了Linux、Windows和macOS中遇到的链接错误,并阐述如何通过传递额外参数来解决这些错误。注意,由于不同操作系统的可执行文件内在格式不同,所以对于不同操作系统而言,所适用的额外参数也有所不同。
|
||||
|
||||
#### Linux
|
||||
|
||||
在Linux下,会触发以下链接错误(简化版):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x12): undefined reference to `__libc_csu_fini'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x19): undefined reference to `__libc_csu_init'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x25): undefined reference to `__libc_start_main'
|
||||
collect2: error: ld returned 1 exit status
|
||||
```
|
||||
|
||||
这里的问题在于,链接器默认包含了C启动例程,即构建名为 `_start` 的入口函数的地方。但其依赖一些C标准库 `libc` 中的符号,而我们已经使用 `no_std` 开关排除掉了这些符号,所以链接器报告了这些错误。要解决这个问题,我们需要通过 `-nostartfiles` 参数来告诉链接器不要使用C启动例程功能。
|
||||
|
||||
通过 `cargo rustc` 可以传递链接器参数,该命令和 `cargo build` 的效果完全一致,但是可以将参数传递给rust的底层编译器 `rustc`。`rustc` 支持 `-C link-arg` 参数,此参数可以传递参数给配套的链接器。那么以此推断,我们的编译语句可以这样写:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
```
|
||||
|
||||
现在我们编译出的程序就可以在Linux上独立运行了。
|
||||
|
||||
我们并不需要显式指定入口函数名,链接器默认会查找 `_start` 函数作为入口点。
|
||||
|
||||
#### Windows
|
||||
|
||||
|
||||
在Windows下,会触发以下链接错误(简化版):
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1561
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1561: entry point must be defined
|
||||
```
|
||||
|
||||
错误信息 “entry point must be defined” 意味着链接器没有找到程序入口点。在Windows环境下,默认入口点[取决于使用的子系统][windows-subsystems]。对于 `CONSOLE` 子系统,链接器会寻找 `mainCRTStartup` 函数作为入口,而对于 `WINDOWS` 子系统,入口函数名叫做 `WinMainCRTStartup`。要复写掉入口函数名的默认设定,使其使用我们已经定义的 `_start` 函数,可以将 `/ENTRY` 参数传递给链接器:
|
||||
|
||||
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=/ENTRY:_start
|
||||
```
|
||||
|
||||
显而易见,从链接参数上看,Windows平台使用的链接器和Linux平台是完全不同的。
|
||||
|
||||
此时可能你还会遇到这个链接错误:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1221
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
|
||||
defined
|
||||
```
|
||||
|
||||
该错误的原因是Windows平台下的可执行文件可以使用不同的[子系统][windows-subsystems]。一般而言,操作系统会如此判断:如果入口函数名叫 `main` ,则会使用 `CONSOLE` 子系统;若名叫 `WinMain` ,则会使用 `WINDOWS` 子系统。然而此时我们使用的入口函数名叫 `_start` ,两者都不是,此时就需要显式指定子系统:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
```
|
||||
|
||||
这里我们使用了 `CONSOLE` 子系统,如果使用 `WINDOWS` 子系统其实也可以。但是多次使用 `-C link-arg` 参数大可不必,我们可以如上面一样,将一个引号包裹起来的以空格分隔的列表传递给 `-C link-arg` 参数。
|
||||
|
||||
现在我们编译出的程序就可以在Windows平台成功运行了。
|
||||
|
||||
#### macOS
|
||||
|
||||
在macOS下,会触发以下链接错误(简化版):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: entry point (_main) undefined. for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
该错误告诉我们链接器找不到入口函数 `main` (由于某些原因,macOS平台下,所有函数都会具有 `_` 前缀)。要重设入口函数名,我们可以传入链接器参数 `-e` :
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start"
|
||||
```
|
||||
|
||||
`-e` 参数可用于重设入口函数名。由于在macOS平台下,所有函数都具有 `_` 前缀,所以需要传入 `__start` ,而不是 `_start` 。
|
||||
|
||||
接下来,会出现一个新的链接错误:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: dynamic main executables must link with libSystem.dylib
|
||||
for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
macOS [并未官方支持静态链接][does not officially support statically linked binaries] ,并且在默认情况下程序会链接 `libSystem` 库。要复写这个设定并进行静态链接,我们可以传入链接器参数 `-static` :
|
||||
|
||||
[does not officially support statically linked binaries]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static"
|
||||
```
|
||||
|
||||
然而问题并没有解决,链接器再次抛出了一个错误:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: library not found for -lcrt0.o
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
该错误的原因是macOS平台下的程序会默认链接 `crt0` (即“C runtime zero”)。 这个错误实际上和Linux平台上的错误类似,可以添加链接器参数 `-nostartfiles` 解决:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
现在,我们的程序可以在macOS下编译成功了。
|
||||
|
||||
#### 统一编译命令
|
||||
|
||||
经过上面的章节,我们知道了在各个平台使用的编译命令是不同的,这十分不优雅。要解决这个问题,我们可以创建一个 `.cargo/config.toml` 文件,分别配置不同平台下所使用的参数:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "linux")']
|
||||
rustflags = ["-C", "link-arg=-nostartfiles"]
|
||||
|
||||
[target.'cfg(target_os = "windows")']
|
||||
rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
|
||||
|
||||
[target.'cfg(target_os = "macos")']
|
||||
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
|
||||
```
|
||||
|
||||
对应的 `rustflags` 配置项的值可以自动被填充到 `rustc` 的运行参数中。要寻找 `.cargo/config.toml` 更多的用法,可以看一下 [官方文档](https://doc.rust-lang.org/cargo/reference/config.html)。
|
||||
|
||||
现在只需要运行 `cargo build` 即可在全部三个平台编译我们的程序了。
|
||||
|
||||
#### 我们真的需要做这些?
|
||||
|
||||
尽管我们可以在Linux、Windows和macOS编译出可执行程序,但这可能并非是个好主意。
|
||||
因为我们的程序少了不少本该存在的东西,比如 `_start` 执行时的栈初始化。
|
||||
失去了C运行时,部分基于它的依赖项很可能无法正确执行,这会造成程序出现各式各样的异常,比如segmentation fault(段错误)。
|
||||
|
||||
如果你希望创建一个基于已存在的操作系统的最小类库,建议引用 `libc` ,阅读 [这里](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html) 并恰当设定 `#[start]` 比较好。
|
||||
|
||||
</details>
|
||||
|
||||
## 小结
|
||||
|
||||
@@ -291,7 +459,18 @@ panic = "abort" # 禁用 panic 时栈展开
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
要注意的是,现在我们的代码只是一个 Rust 编写的独立式可执行程序的一个例子。运行这个二进制程序还需要很多准备,比如在 `_start` 函数之前需要一个已经预加载完毕的栈。所以为了真正运行这样的程序,我们还有很多事情需要做。
|
||||
另外,我们也可以选择以本地操作系统为目标进行编译:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
# Windows
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
# macOS
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
要注意的是,现在我们的代码只是一个 Rust 编写的独立式可执行程序的一个例子。运行这个二进制程序还需要很多准备,比如在 `_start` 函数之前需要一个已经预加载完毕的栈。所以为了真正运行这样的程序,**我们还有很多事情需要做**。
|
||||
|
||||
## 下篇预览
|
||||
|
||||
|
||||
@@ -0,0 +1,29 @@
|
||||
+++
|
||||
title = "Disable the Red Zone"
|
||||
weight = 1
|
||||
path = "zh-CN/red-zone"
|
||||
template = "edition-2/extra.html"
|
||||
+++
|
||||
|
||||
[红区][red zone] 是 [System V ABI] 提供的一种优化技术,它使得函数可以在不修改栈指针的前提下,临时使用其栈帧下方的128个字节。
|
||||
|
||||
[red zone]: https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64#the-red-zone
|
||||
[System V ABI]: https://wiki.osdev.org/System_V_ABI
|
||||
|
||||
<!-- more -->
|
||||
|
||||

|
||||
|
||||
上图展示了一个包含了 `n` 个局部变量的栈帧。当方法开始执行时,栈指针会被调整到一个合适的位置,为返回值和局部变量留出足够的空间。
|
||||
|
||||
红区是位于调整后的栈指针下方,长度为128字节的区域,函数会使用这部分空间存储不会被跨函数调用的临时数据。所以在某些情况下(比如逻辑简短的叶函数),红区可以节省用于调整栈指针的两条机器指令。
|
||||
|
||||
然而红区优化有时也会引发无法处理的巨大问题(异常或者硬件中断),如果使用红区时发生了某种异常:
|
||||
|
||||

|
||||
|
||||
CPU和异常处理机制会把红色区域内的数据覆盖掉,但是被中断的函数依然在引用着这些数据。当函数从错误中恢复时,错误的数据就会引发更大的错误,这类错误往往需要[追踪数周][take weeks to debug]才能找到。
|
||||
|
||||
[take weeks to debug]: https://forum.osdev.org/viewtopic.php?t=21720
|
||||
|
||||
要在编写异常处理机制时避免这些隐蔽而难以追踪的bug,我们需要从一开始就禁用红区优化,具体到配置文件中的配置项,就是 `"disable-redzone": true`。
|
||||
@@ -0,0 +1,44 @@
|
||||
+++
|
||||
title = "Disable SIMD"
|
||||
weight = 2
|
||||
path = "zh-CN/disable-simd"
|
||||
template = "edition-2/extra.html"
|
||||
+++
|
||||
|
||||
[单指令多数据][Single Instruction Multiple Data (SIMD)] 指令允许在一个操作符(比如加法)内传入多组数据,以此加速程序执行速度。`x86_64` 架构支持多种SIMD标准:
|
||||
|
||||
[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
|
||||
|
||||
<!-- more -->
|
||||
|
||||
- [MMX]: _多媒体扩展_ 指令集于1997年发布,定义了8个64位寄存器,分别被称为 `mm0` 到 `mm7`,不过,这些寄存器只是 [x87浮点执行单元][x87 floating point unit] 中寄存器的映射而已。
|
||||
- [SSE]: _流处理SIMD扩展_ 指令集于1999年发布,不同于MMX的复用浮点执行单元,该指令集加入了一个完整的新寄存器组,即被称为 `xmm0` 到 `xmm15` 的16个128位寄存器。
|
||||
- [AVX]: _先进矢量扩展_ 用于进一步扩展多媒体寄存器的数量,它定义了 `ymm0` 到 `ymm15` 共16个256位寄存器,但是这些寄存器继承于 `xmm`,例如 `xmm0` 寄存器是 `ymm0` 的低128位。
|
||||
|
||||
[MMX]: https://en.wikipedia.org/wiki/MMX_(instruction_set)
|
||||
[x87 floating point unit]: https://en.wikipedia.org/wiki/X87
|
||||
[SSE]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
|
||||
[AVX]: https://en.wikipedia.org/wiki/Advanced_Vector_Extensions
|
||||
|
||||
通过应用这些SIMD标准,计算机程序可以显著提高执行速度。优秀的编译器可以将常规循环自动优化为适用SIMD的代码,这种优化技术被称为 [自动矢量化][auto-vectorization]。
|
||||
|
||||
[auto-vectorization]: https://en.wikipedia.org/wiki/Automatic_vectorization
|
||||
|
||||
尽管如此,SIMD会让操作系统内核出现一些问题。具体来说,就是操作系统在处理硬件中断时,需要保存所有寄存器信息到内存中,在中断结束后再将其恢复以供使用。所以说,如果内核需要使用SIMD寄存器,那么每次处理中断需要备份非常多的数据(512-1600字节),这会显著地降低性能。要避免这部分性能损失,我们需要禁用 `sse` 和 `mmx` 这两个特性(`avx` 默认已禁用)。
|
||||
|
||||
我们可以在编译配置文件中的 `features` 配置项做出如下修改,加入以减号为前缀的 `mmx` 和 `sse` 即可:
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse"
|
||||
```
|
||||
|
||||
## 浮点数
|
||||
还有一件不幸的事,`x86_64` 架构在处理浮点数计算时,会用到 `sse` 寄存器,因此,禁用SSE的前提下使用浮点数计算LLVM都一定会报错。 更大的问题在于Rust核心库里就存在着为数不少的浮点数运算(如 `f32` 和 `f64` 的数个trait),所以试图避免使用浮点数是不可能的。
|
||||
|
||||
幸运的是,LLVM支持 `soft-float` 特性,这个特性可以使用整型运算在软件层面模拟浮点数运算,使得我们为内核关闭SSE成为了可能,只需要牺牲一点点性能。
|
||||
|
||||
要为内核打开 `soft-float` 特性,我们只需要在编译配置文件中的 `features` 配置项做出如下修改即可:
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
```
|
||||
@@ -414,7 +414,7 @@ pub extern "C" fn _start() -> ! {
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
bootloader = "0.9.23"
|
||||
```
|
||||
|
||||
افزودن بوتلودر به عنوان وابستگی برای ایجاد یک دیسک ایمیج قابل بوت کافی نیست. مشکل این است که ما باید هسته خود را با بوت لودر پیوند دهیم، اما کارگو از [اسکریپت های بعد از بیلد] پشتیبانی نمیکند.
|
||||
|
||||
@@ -14,7 +14,7 @@ translators = ["TheMimiCodes", "maximevaillancourt"]
|
||||
translation_contributors = ["alaincao"]
|
||||
+++
|
||||
|
||||
Dans cet article, nous créons un noyau Rust 64-bit minimal pour l'architecture x86. Nous continuons le travail fait dans l'article précédent ([freestanding Rust binary][binaire Rust autonome]) pour créer une image de disque amorçable qui affiche quelque chose à l'écran.
|
||||
Dans cet article, nous créons un noyau Rust 64-bit minimal pour l'architecture x86. Nous continuons le travail fait dans l'article précédent “[Un binaire Rust autonome][freestanding Rust binary]” pour créer une image de disque amorçable qui affiche quelque chose à l'écran.
|
||||
|
||||
[freestanding Rust binary]: @/edition-2/posts/01-freestanding-rust-binary/index.fr.md
|
||||
|
||||
@@ -30,7 +30,7 @@ Cet article est développé de manière ouverte sur [GitHub]. Si vous avez des p
|
||||
<!-- toc -->
|
||||
|
||||
## Le processus d'amorçage
|
||||
Quand vous allumez un ordinateur, il commence par exécuter le code du micrologiciel qui est enregistré dans la carte mère ([ROM]). Ce code performe un [power-on self-test][test d'auto-diagnostic de démarrage], détecte la mémoire volatile disponible, et pré-initialise le processeur et le matériel. Par la suite, il recherche un disque amorçable et commence le processus d'amorçage du noyau du système d'exploitation.
|
||||
Quand vous allumez un ordinateur, il commence par exécuter le code du micrologiciel qui est enregistré dans la carte mère ([ROM]). Ce code performe un [test d'auto-diagnostic de démarrage][power-on self-test], détecte la mémoire volatile disponible, et pré-initialise le processeur et le matériel. Par la suite, il recherche un disque amorçable et commence le processus d'amorçage du noyau du système d'exploitation.
|
||||
|
||||
[ROM]: https://fr.wikipedia.org/wiki/M%C3%A9moire_morte
|
||||
[power-on self-test]: https://fr.wikipedia.org/wiki/Power-on_self-test_(informatique)
|
||||
@@ -69,19 +69,19 @@ Pour éviter que chaque système d'exploitation implémente son propre bootloade
|
||||
[Multiboot]: https://wiki.osdev.org/Multiboot
|
||||
[GNU GRUB]: https://fr.wikipedia.org/wiki/GNU_GRUB
|
||||
|
||||
Pour créer un noyau compatible Multiboot, il suffit d'insérer une [Multiboot header][en-tête Multiboot] au début du fichier du noyau. Cela rend très simple l'amorçage d'un système d'exploitation depuis GRUB. Cependant, GRUB et le standard Multiboot présentent aussi quelques problèmes :
|
||||
Pour créer un noyau compatible Multiboot, il suffit d'insérer une [en-tête Multiboot][Multiboot header] au début du fichier du noyau. Cela rend très simple l'amorçage d'un système d'exploitation depuis GRUB. Cependant, GRUB et le standard Multiboot présentent aussi quelques problèmes :
|
||||
|
||||
[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
|
||||
|
||||
- Ils supportent seulement le "protected mode" 32-bit. Cela signifie que vous devez encore effectuer la configuration du processeur pour passer au "long mode" 64-bit.
|
||||
- Ils sont conçus pour simplifier le bootloader plutôt que le noyau. Par exemple, le noyau doit être lié avec une [adjusted default page size][taille de page prédéfinie], étant donné que GRUB ne peut pas trouver les entêtes Multiboot autrement. Un autre exemple est que l'[boot information][information de boot], qui est fournies au noyau, contient plusieurs structures spécifiques à l'architecture au lieu de fournir des abstractions pures.
|
||||
- Ils sont conçus pour simplifier le bootloader plutôt que le noyau. Par exemple, le noyau doit être lié avec une [taille de page prédéfinie][adjusted default page size], étant donné que GRUB ne peut pas trouver les entêtes Multiboot autrement. Un autre exemple est que l'[information de boot][boot information], qui est fournies au noyau, contient plusieurs structures spécifiques à l'architecture au lieu de fournir des abstractions pures.
|
||||
- GRUB et le standard Multiboot sont peu documentés.
|
||||
- GRUB doit être installé sur un système hôte pour créer une image de disque amorçable depuis le fichier du noyau. Cela rend le développement sur Windows ou sur Mac plus difficile.
|
||||
|
||||
[adjusted default page size]: https://wiki.osdev.org/Multiboot#Multiboot_2
|
||||
[boot information]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
|
||||
|
||||
En raison de ces désavantages, nous avons décidé de ne pas utiliser GRUB ou le standard Multiboot. Cependant, nous avons l'intention d'ajouter le support Multiboot à notre outil [bootimage], afin qu'il soit aussi possible de charger le noyau sur un système GRUB. Si vous êtes interessé par l'écriture d'un noyau Multiboot conforme, consultez la [first edition][première édition] de cette série d'articles.
|
||||
En raison de ces désavantages, nous avons décidé de ne pas utiliser GRUB ou le standard Multiboot. Cependant, nous avons l'intention d'ajouter le support Multiboot à notre outil [bootimage], afin qu'il soit aussi possible de charger le noyau sur un système GRUB. Si vous êtes interessé par l'écriture d'un noyau Multiboot conforme, consultez la [première édition][first edition] de cette série d'articles.
|
||||
|
||||
[first edition]: @/edition-1/_index.md
|
||||
|
||||
@@ -90,7 +90,7 @@ En raison de ces désavantages, nous avons décidé de ne pas utiliser GRUB ou l
|
||||
(Nous ne fournissons pas le support UEFI à l'heure actuelle, mais nous aimerions bien! Si vous voulez aider, dites-le nous dans cette [_issue_ GitHub](https://github.com/phil-opp/blog_os/issues/349).)
|
||||
|
||||
## Un noyau minimal
|
||||
Maintenant que nous savons à peu près comment un ordinateur démarre, il est temps de créer notre propre noyau minimal. Notre objectif est de créer une image de disque qui affiche “Hello World!” à l'écran lorsqu'il démarre. Nous ferons ceci en améliorant le [freestanding Rust binary][binaire Rust autonome] du dernier article.
|
||||
Maintenant que nous savons à peu près comment un ordinateur démarre, il est temps de créer notre propre noyau minimal. Notre objectif est de créer une image de disque qui affiche “Hello World!” à l'écran lorsqu'il démarre. Nous ferons ceci en améliorant le [binaire Rust autonome][freestanding Rust binary] du dernier article.
|
||||
|
||||
Comme vous vous en rappelez peut-être, nous avons créé un binaire autonome grâce à `cargo`, mais selon le système d'exploitation, nous avions besoin de différents points d'entrée et d'options de compilation. C'est dû au fait que `cargo` construit pour _système hôte_ par défaut, c'est-à-dire le système que vous utilisez. Ce n'est pas ce que nous voulons pour notre noyau, car un noyau qui s'exécute, par exemple, sur Windows n'a pas de sens. Nous voulons plutôt compiler pour un _système cible_ bien défini.
|
||||
|
||||
@@ -101,12 +101,12 @@ Pour gérer l'installation de Rust, je recommande fortement [rustup]. Il vous pe
|
||||
|
||||
[rustup]: https://www.rustup.rs/
|
||||
|
||||
La version nocturne du compilateur nous permet d'activer certaines fonctionnalités expérimentales en utilisant certains _drapeaux de fonctionalité_ dans le haut de notre fichier. Par exemple, nous pourrions activer [`asm!` macro][macro expérimentale `asm!`] pour écrire du code assembleur intégré en ajoutant `#![feature(asm)]` au haut de notre `main.rs`. Notez que ces fonctionnalités expérimentales sont tout à fait instables, ce qui veut dire que des versions futures de Rust pourraient les changer ou les retirer sans préavis. Pour cette raison, nous les utiliserons seulement lorsque strictement nécessaire.
|
||||
La version nocturne du compilateur nous permet d'activer certaines fonctionnalités expérimentales en utilisant certains _drapeaux de fonctionalité_ dans le haut de notre fichier. Par exemple, nous pourrions activer [macro expérimentale `asm!`][`asm!` macro] pour écrire du code assembleur intégré en ajoutant `#![feature(asm)]` au haut de notre `main.rs`. Notez que ces fonctionnalités expérimentales sont tout à fait instables, ce qui veut dire que des versions futures de Rust pourraient les changer ou les retirer sans préavis. Pour cette raison, nous les utiliserons seulement lorsque strictement nécessaire.
|
||||
|
||||
[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
|
||||
|
||||
### Spécification de la cible
|
||||
Cargo supporte différent systèmes cibles avec le paramètre `--target`. La cible est définie par un soi-disant _[target triple][triplet de cible]_, qui décrit l'architecteur du processeur, le fabricant, le système d'exploitation, et l'interface binaire d'application ([ABI]). Par exemple, le triplet `x86_64-unknown-linux-gnu` décrit un système avec un processeur `x86_64`, sans fabricant défini, et un système d'exploitation Linux avec l'interface binaire d'application GNU. Rust supporte [plusieurs différents triplets de cible][platform-support], incluant `arm-linux-androideabi` pour Android ou [`wasm32-unknown-unknown` pour WebAssembly](https://www.hellorust.com/setup/wasm-target/).
|
||||
Cargo supporte différent systèmes cibles avec le paramètre `--target`. La cible est définie par un soi-disant _[triplet de cible][target triple]_, qui décrit l'architecteur du processeur, le fabricant, le système d'exploitation, et l'interface binaire d'application ([ABI]). Par exemple, le triplet `x86_64-unknown-linux-gnu` décrit un système avec un processeur `x86_64`, sans fabricant défini, et un système d'exploitation Linux avec l'interface binaire d'application GNU. Rust supporte [plusieurs différents triplets de cible][platform-support], incluant `arm-linux-androideabi` pour Android ou [`wasm32-unknown-unknown` pour WebAssembly](https://www.hellorust.com/setup/wasm-target/).
|
||||
|
||||
[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
[ABI]: https://stackoverflow.com/a/2456882
|
||||
@@ -131,7 +131,7 @@ Pour notre système cible toutefois, nous avons besoin de paramètres de configu
|
||||
}
|
||||
```
|
||||
|
||||
La plupart des champs sont requis par LLVM pour générer le code pour cette plateforme. Par exemple, le champ [`data-layout`] définit la taille de divers types d'entiers, de nombres à virgule flottante, et de pointeurs. Puis, il y a des champs que Rust utilise pour de la compilation conditionelle, comme `target-pointer-width`. Le troisième type de champ définit comment la crate doit être construite. Par exemple, le champ `pre-link-args` spécifie les arguments fournis au [linker][lieur].
|
||||
La plupart des champs sont requis par LLVM pour générer le code pour cette plateforme. Par exemple, le champ [`data-layout`] définit la taille de divers types d'entiers, de nombres à virgule flottante, et de pointeurs. Puis, il y a des champs que Rust utilise pour de la compilation conditionelle, comme `target-pointer-width`. Le troisième type de champ définit comment la crate doit être construite. Par exemple, le champ `pre-link-args` spécifie les arguments fournis au [lieur][linker].
|
||||
|
||||
[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
|
||||
[linker]: https://en.wikipedia.org/wiki/Linker_(computing)
|
||||
@@ -169,7 +169,7 @@ Plutôt que d'utiliser le lieur par défaut de la plateforme (qui pourrait ne pa
|
||||
"panic-strategy": "abort",
|
||||
```
|
||||
|
||||
Ce paramètre spécifie que la cible ne permet pas le [stack unwinding][déroulement de la pile] lorsque le noyau panique, alors le système devrait plutôt s'arrêter directement. Ceci mène au même résultat que l'option `panic = "abort"` dans notre Cargo.toml, alors nous pouvons la retirer de ce fichier. (Notez que, contrairement à l'option Cargo.toml, cette option de cible s'applique aussi quand nous recompilerons la bibliothèque `core` plus loin dans cet article. Ainsi, même si vous préférez garder l'option Cargo.toml, gardez cette option.)
|
||||
Ce paramètre spécifie que la cible ne permet pas le [déroulement de la pile][stack unwinding] lorsque le noyau panique, alors le système devrait plutôt s'arrêter directement. Ceci mène au même résultat que l'option `panic = "abort"` dans notre Cargo.toml, alors nous pouvons la retirer de ce fichier. (Notez que, contrairement à l'option Cargo.toml, cette option de cible s'applique aussi quand nous recompilerons la bibliothèque `core` plus loin dans cet article. Ainsi, même si vous préférez garder l'option Cargo.toml, gardez cette option.)
|
||||
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
|
||||
@@ -177,7 +177,7 @@ Ce paramètre spécifie que la cible ne permet pas le [stack unwinding][déroule
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
Nous écrivons un noyau, donc nous devrons éventuellement gérer les interruptions. Pour ce faire en toute sécurité, nous devons désactiver une optimisation de pointeur de pile nommée la _“zone rouge"_, puisqu'elle causerait une corruption de la pile autrement. Pour plus d'informations, lire notre article séparé à propos de la [disabling the red zone][désactivation de la zone rouge].
|
||||
Nous écrivons un noyau, donc nous devrons éventuellement gérer les interruptions. Pour ce faire en toute sécurité, nous devons désactiver une optimisation de pointeur de pile nommée la _“zone rouge"_, puisqu'elle causerait une corruption de la pile autrement. Pour plus d'informations, lire notre article séparé à propos de la [désactivation de la zone rouge][disabling the red zone].
|
||||
|
||||
[disabling the red zone]: @/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md
|
||||
|
||||
@@ -217,7 +217,7 @@ Notre fichier de spécification de cible ressemble maintenant à ceci :
|
||||
```
|
||||
|
||||
### Construction de notre noyau
|
||||
Compiler pour notre nouvelle cible utilisera les conventions Linux (je ne suis pas trop certain pourquoi; j'assume que c'est simplement le comportement par défaut de LLVM). Cela signifie que nos avons besoin d'un point d'entrée nommé `_start` comme décrit dans [previous post][l'article précédent]:
|
||||
Compiler pour notre nouvelle cible utilisera les conventions Linux (je ne suis pas trop certain pourquoi; j'assume que c'est simplement le comportement par défaut de LLVM). Cela signifie que nos avons besoin d'un point d'entrée nommé `_start` comme décrit dans [l'article précédent][previous post]:
|
||||
|
||||
[previous post]: @/edition-2/posts/01-freestanding-rust-binary/index.fr.md
|
||||
|
||||
@@ -253,7 +253,7 @@ Nous pouvons maintenant construire le noyau pour notre nouvelle cible en fournis
|
||||
error[E0463]: can't find crate for `core`
|
||||
```
|
||||
|
||||
Cela échoue! L'erreur nous dit que le compilateur ne trouve plus la [`core` library][bibliothèque `core`]. Cette bibliothèque contient les types de base Rust comme `Result`, `Option`, les itérateurs, et est implicitement liée à toutes les crates `no_std`.
|
||||
Cela échoue! L'erreur nous dit que le compilateur ne trouve plus la [bibliothèque `core`][`core` library]. Cette bibliothèque contient les types de base Rust comme `Result`, `Option`, les itérateurs, et est implicitement liée à toutes les crates `no_std`.
|
||||
|
||||
[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
|
||||
|
||||
@@ -261,12 +261,12 @@ Le problème est que la bibliothèque `core` est distribuée avec le compilateur
|
||||
|
||||
#### L'option `build-std`
|
||||
|
||||
C'est ici que la [`build-std` feature][fonctionnalité `build-std`] de cargo entre en jeu. Elle permet de recompiler `core` et d'autres crates de la bibliothèque standard sur demande, plutôt que d'utiliser des versions précompilées incluses avec l'installation de Rust. Cette fonctionnalité est très récente et n'est pas encore complète, donc elle est définie comme instable et est seulement disponible avec les [nightly Rust compilers][versions nocturnes du compilateur Rust].
|
||||
C'est ici que la [fonctionnalité `build-std`][`build-std` feature] de cargo entre en jeu. Elle permet de recompiler `core` et d'autres crates de la bibliothèque standard sur demande, plutôt que d'utiliser des versions précompilées incluses avec l'installation de Rust. Cette fonctionnalité est très récente et n'est pas encore complète, donc elle est définie comme instable et est seulement disponible avec les [versions nocturnes du compilateur Rust][nightly Rust compilers].
|
||||
|
||||
[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
|
||||
[nightly Rust compilers]: #installing-rust-nightly
|
||||
[nightly Rust compilers]: #installer-une-version-nocturne-de-rust
|
||||
|
||||
Pour utiliser cette fonctionnalité, nous devons créer un fichier de [cargo configuration][configuration cargo] dans `.cargo/config.toml` avec le contenu suivant:
|
||||
Pour utiliser cette fonctionnalité, nous devons créer un fichier de [configuration cargo][cargo configuration] dans `.cargo/config.toml` avec le contenu suivant:
|
||||
|
||||
```toml
|
||||
# dans .cargo/config.toml
|
||||
@@ -318,7 +318,7 @@ build-std = ["core", "compiler_builtins"]
|
||||
|
||||
(Le support pour la fonctionnalité `compiler-builtins-mem` a [été ajouté assez récemment](https://github.com/rust-lang/rust/pull/77284), donc vous aurez besoin de la version nocturne `2020-09-30` de Rust ou plus récent pour l'utiliser.)
|
||||
|
||||
Dans les coulisses, ce drapeau active la [`mem` feature][fonctionnalité `mem`] de la caisse `compiler_builtins`. Le résultat est que l'attribut `#[no_mangle]` est appliqué aux [`memcpy` etc. implementations][implémentations `memcpy` et autres] de la caise, ce qui les rend disponible au lieur.
|
||||
Dans les coulisses, ce drapeau active la [fonctionnalité `mem`][`mem` feature] de la crate `compiler_builtins`. Le résultat est que l'attribut `#[no_mangle]` est appliqué aux [implémentations `memcpy` et autres][`memcpy` etc. implementations] de la caise, ce qui les rend disponible au lieur.
|
||||
|
||||
[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L54-L55
|
||||
[`memcpy` etc. implementations]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69
|
||||
@@ -327,7 +327,7 @@ Avec ce changement, notre noyau a des implémentations valides pour toutes les f
|
||||
|
||||
#### Définir une cible par défaut
|
||||
|
||||
Pour ne pas avoir à fournir le paramètre `--target` à chaque invocation de `cargo build`, nous pouvons définir la cible par défaut. Pour ce faire, nous ajoutons le code suivant à notre fichier de [cargo configuration][configuration Cargo] dans `.cargo/config.toml`:
|
||||
Pour ne pas avoir à fournir le paramètre `--target` à chaque invocation de `cargo build`, nous pouvons définir la cible par défaut. Pour ce faire, nous ajoutons le code suivant à notre fichier de [configuration Cargo][cargo configuration] dans `.cargo/config.toml`:
|
||||
|
||||
[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
|
||||
|
||||
@@ -338,7 +338,7 @@ Pour ne pas avoir à fournir le paramètre `--target` à chaque invocation de `c
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
Ceci indique à `cargo` d'utiliser notre cible `x86_64-blog_os.json` quand il n'y a pas d'argument de cible `--target` explicitement fourni. Ceci veut dire que nous pouvons maintenant construire notre noyau avec un simple `cargo build`. Pour plus d'informations sur les options de configuration cargo, jetez un coup d'oeil à la [official documentation][documentation officielle de cargo].
|
||||
Ceci indique à `cargo` d'utiliser notre cible `x86_64-blog_os.json` quand il n'y a pas d'argument de cible `--target` explicitement fourni. Ceci veut dire que nous pouvons maintenant construire notre noyau avec un simple `cargo build`. Pour plus d'informations sur les options de configuration cargo, jetez un coup d'oeil à la [documentation officielle de cargo][cargo configuration].
|
||||
|
||||
Nous pouvons maintenant construire notre noyau pour une cible "bare metal" avec un simple `cargo build`. Toutefois, notre point d'entrée `_start`, qui sera appelé par le bootloader, est encore vide. Il est temps de lui faire afficher quelque chose à l'écran.
|
||||
|
||||
@@ -371,7 +371,7 @@ pub extern "C" fn _start() -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
D'abord, nous transformons l'entier `0xb8000` en un [raw pointer][pointeur brut]. Puis nous [iterate][parcourons] les octets de la [byte string][chaîne d'octets] [static][statique] `HELLO`. Nous utilisons la méthode [`enumerate`] pour aussi obtenir une variable `i`. Dans le corps de la boucle `for`, nous utilisons la méthode [`offset`] pour écrire la chaîne d'octets et l'octet de couleur correspondant(`0xb` est un cyan pâle).
|
||||
D'abord, nous transformons l'entier `0xb8000` en un [pointeur brut][raw pointer]. Puis nous [parcourons][iterate] les octets de la [chaîne d'octets][byte string] [statique][static] `HELLO`. Nous utilisons la méthode [`enumerate`] pour aussi obtenir une variable `i`. Dans le corps de la boucle `for`, nous utilisons la méthode [`offset`] pour écrire la chaîne d'octets et l'octet de couleur correspondant(`0xb` est un cyan pâle).
|
||||
|
||||
[iterate]: https://doc.rust-lang.org/stable/book/ch13-02-iterators.html
|
||||
[static]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
|
||||
@@ -380,14 +380,14 @@ D'abord, nous transformons l'entier `0xb8000` en un [raw pointer][pointeur brut]
|
||||
[raw pointer]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
|
||||
|
||||
Notez qu'il y a un bloc [`unsafe`] qui enveloppe les écritures mémoire. La raison en est que le compilateur Rust ne peut pas prouver que les pointeurs bruts que nous créons sont valides. Ils pourraient pointer n'importe où et mener à une corruption de données. En les mettant dans un bloc `unsafe`, nous disons fondamentalement au compilateur que nous sommes absolument certains que les opérations sont valides. Notez qu'un bloc `unsafe` ne désactive pas les contrôles de sécurité de Rust. Il permet seulement de faire [five additional things][cinq choses supplémentaires].
|
||||
Notez qu'il y a un bloc [`unsafe`] qui enveloppe les écritures mémoire. La raison en est que le compilateur Rust ne peut pas prouver que les pointeurs bruts que nous créons sont valides. Ils pourraient pointer n'importe où et mener à une corruption de données. En les mettant dans un bloc `unsafe`, nous disons fondamentalement au compilateur que nous sommes absolument certains que les opérations sont valides. Notez qu'un bloc `unsafe` ne désactive pas les contrôles de sécurité de Rust. Il permet seulement de faire [cinq choses supplémentaires][five additional things].
|
||||
|
||||
[`unsafe`]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html
|
||||
[five additional things]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
Je veux souligner que **ce n'est pas comme cela que les choses se font en Rust!** Il est très facile de faire des erreurs en travaillant avec des pointeurs bruts à l'intérieur de blocs `unsafe`. Par exemple, nous pourrions facilement écrire au-delà de la fin du tampon si nous ne sommes pas prudents.
|
||||
|
||||
Alors nous voulons minimiser l'utilisation de `unsafe` autant que possible. Rust nous offre la possibilité de le faire en créant des abstractions de sécurité. Par exemple, nous pourrions créer un type tampon VGA qui encapsule les risques et qui s'assure qu'il est impossible de faire quoi que ce soit d'incorrect à l'extérieur de ce type. Ainsi, nous aurions besoin de très peu de code `unsafe` et nous serions certains que nous ne violons pas la [memory safety][sécurité de mémoire]. Nous allons créer une telle abstraction de tampon VGA buffer dans le prochain article.
|
||||
Alors nous voulons minimiser l'utilisation de `unsafe` autant que possible. Rust nous offre la possibilité de le faire en créant des abstractions de sécurité. Par exemple, nous pourrions créer un type tampon VGA qui encapsule les risques et qui s'assure qu'il est impossible de faire quoi que ce soit d'incorrect à l'extérieur de ce type. Ainsi, nous aurions besoin de très peu de code `unsafe` et nous serions certains que nous ne violons pas la [sécurité de mémoire][memory safety]. Nous allons créer une telle abstraction de tampon VGA buffer dans le prochain article.
|
||||
|
||||
[memory safety]: https://en.wikipedia.org/wiki/Memory_safety
|
||||
|
||||
@@ -397,9 +397,9 @@ Maintenant que nous avons un exécutable qui fait quelque chose de perceptible,
|
||||
|
||||
### Créer une image d'amorçage
|
||||
|
||||
Pour transformer notre noyau compilé en image de disque amorçable, nous devons le lier avec un bootloader. Comme nous l'avons appris dans la [section about booting][section à propos du lancement], le bootloader est responsable de l'initialisation du processeur et du chargement de notre noyau.
|
||||
Pour transformer notre noyau compilé en image de disque amorçable, nous devons le lier avec un bootloader. Comme nous l'avons appris dans la [section à propos du lancement][section about booting], le bootloader est responsable de l'initialisation du processeur et du chargement de notre noyau.
|
||||
|
||||
[section about booting]: #the-boot-process
|
||||
[section about booting]: #le-processus-d-amorcage
|
||||
|
||||
Plutôt que d'écrire notre propre bootloader, ce qui est un projet en soi, nous utilisons la crate [`bootloader`]. Cette crate propose un bootloader BIOS de base sans dépendance C. Seulement du code Rust et de l'assembleur intégré. Pour l'utiliser afin de lancer notre noyau, nous devons ajouter une dépendance à cette crate:
|
||||
|
||||
@@ -412,7 +412,7 @@ Plutôt que d'écrire notre propre bootloader, ce qui est un projet en soi, nous
|
||||
bootloader = "0.9.8"
|
||||
```
|
||||
|
||||
Ajouter le bootloader comme dépendance n'est pas suffisant pour réellement créer une image de disque amorçable. Le problème est que nous devons lier notre noyau avec le bootloader après la compilation, mais cargo ne supporte pas les [post-build scripts][scripts post-build].
|
||||
Ajouter le bootloader comme dépendance n'est pas suffisant pour réellement créer une image de disque amorçable. Le problème est que nous devons lier notre noyau avec le bootloader après la compilation, mais cargo ne supporte pas les [scripts post-build][post-build scripts].
|
||||
|
||||
[post-build scripts]: https://github.com/rust-lang/cargo/issues/545
|
||||
|
||||
@@ -474,7 +474,7 @@ Il est aussi possible d'écrire l'image disque sur une clé USB et de le lancer
|
||||
|
||||
Où `sdX` est le nom du périphérique de votre clé USB.
|
||||
|
||||
Après l'écriture de l'image sur votre clé USB, vous pouvez l'exécuter sur du véritable matériel en l'amorçant à partir de la clé USB. Vous devrez probablement utiliser un menu d'amorçage spécial ou changer l'ordre d'amorçage dans votre configuration BIOS pour amorcer à partir de la clé USB. Notez que cela ne fonctionne actuellement pas avec des ordinateurs UEFI, puisque la caisse `bootloader` ne supporte pas encore UEFI.
|
||||
Après l'écriture de l'image sur votre clé USB, vous pouvez l'exécuter sur du véritable matériel en l'amorçant à partir de la clé USB. Vous devrez probablement utiliser un menu d'amorçage spécial ou changer l'ordre d'amorçage dans votre configuration BIOS pour amorcer à partir de la clé USB. Notez que cela ne fonctionne actuellement pas avec des ordinateurs UEFI, puisque la crate `bootloader` ne supporte pas encore UEFI.
|
||||
|
||||
### Utilisation de `cargo run`
|
||||
|
||||
@@ -489,7 +489,7 @@ runner = "bootimage runner"
|
||||
|
||||
La table `target.'cfg(target_os = "none")'` s'applique à toutes les cibles dont le champ `"os"` dans le fichier de configuration est défini à `"none"`. Ceci inclut notre cible `x86_64-blog_os.json`. La clé `runner` key spécifie la commande qui doit être invoquée pour `cargo run`. La commande est exécutée après une build réussie avec le chemin de l'exécutable comme premier argument. Voir la [configuration cargo][cargo configuration] pour plus de détails.
|
||||
|
||||
La commande `bootimage runner` est spécifiquement conçue pour être utilisable comme un exécutable `runner`. Elle lie l'exécutable fourni avec le bootloader duquel dépend le projet et lance ensuite QEMU. Voir le [Readme of `bootimage`][README de `bootimage`] pour plus de détails et les options de configuration possibles.
|
||||
La commande `bootimage runner` est spécifiquement conçue pour être utilisable comme un exécutable `runner`. Elle lie l'exécutable fourni avec le bootloader duquel dépend le projet et lance ensuite QEMU. Voir le [README de `bootimage`][Readme of `bootimage`] pour plus de détails et les options de configuration possibles.
|
||||
|
||||
[Readme of `bootimage`]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
|
||||
@@ -411,7 +411,7 @@ pub extern "C" fn _start() -> ! {
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
bootloader = "0.9.23"
|
||||
```
|
||||
|
||||
bootloaderを依存として加えることだけでブータブルディスクイメージが実際に作れるわけではなく、私達のカーネルをコンパイル後にブートローダーにリンクする必要があります。問題は、cargoが[<ruby>ビルド後<rp> (</rp><rt>post-build</rt><rp>) </rp></ruby>にスクリプトを走らせる機能][post-build scripts]を持っていないことです。
|
||||
|
||||
@@ -418,7 +418,7 @@ pub extern "C" fn _start() -> ! {
|
||||
# Cargo.toml 에 들어갈 내용
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
bootloader = "0.9.23"
|
||||
```
|
||||
|
||||
부트로더를 의존 크레이트로 추가하는 것만으로는 부팅 가능한 디스크 이미지를 만들 수 없습니다. 커널 컴파일이 끝난 후 커널을 부트로더와 함께 링크할 수 있어야 하는데, cargo는 현재 [빌드 직후 스크립트 실행][post-build scripts] 기능을 지원하지 않습니다.
|
||||
|
||||
@@ -403,7 +403,7 @@ Instead of writing our own bootloader, which is a project on its own, we use the
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
bootloader = "0.9.23"
|
||||
```
|
||||
|
||||
Adding the bootloader as a dependency is not enough to actually create a bootable disk image. The problem is that we need to link our kernel with the bootloader after compilation, but cargo has no support for [post-build scripts].
|
||||
|
||||
@@ -411,7 +411,7 @@ pub extern "C" fn _start() -> ! {
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
bootloader = "0.9.23"
|
||||
```
|
||||
|
||||
Добавление загрузчика в качестве зависимости недостаточно для создания загрузочного образа диска. Проблема в том, что нам нужно связать наше ядро с загрузчиком после компиляции, но в cargo нет поддержки [скриптов после сборки][post-build scripts].
|
||||
|
||||
@@ -1,23 +1,25 @@
|
||||
+++
|
||||
title = "最小化内核"
|
||||
title = "最小内核"
|
||||
weight = 2
|
||||
path = "zh-CN/minimal-rust-kernel"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu"]
|
||||
translators = ["luojia65", "Rustin-Liu", "liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong"]
|
||||
+++
|
||||
|
||||
在这篇文章中,我们将基于 **x86架构**(the x86 architecture),使用 Rust 语言,编写一个最小化的 64 位内核。我们将从上一章中构建的独立式可执行程序开始,构建自己的内核;它将向显示器打印字符串,并能被打包为一个能够引导启动的**磁盘映像**(disk image)。
|
||||
在这篇文章中,我们将基于 **x86架构**(the x86 architecture),使用 Rust 语言,编写一个最小化的 64 位内核。我们将从上一章中构建的[独立式可执行程序][freestanding-rust-binary]开始,构建自己的内核;它将向显示器打印字符串,并能被打包为一个能够引导启动的**磁盘映像**(disk image)。
|
||||
|
||||
[freestanding Rust binary]: @/edition-2/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-02`][post branch] branch.
|
||||
此博客在 [GitHub] 上公开开发. 如果您有任何问题或疑问,请在此处打开一个 issue。 您也可以在[底部][at the bottom]发表评论. 这篇文章的完整源代码可以在 [`post-02`] [post branch] 分支中找到。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
@@ -32,7 +34,7 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
|
||||
|
||||
x86 架构支持两种固件标准: **BIOS**([Basic Input/Output System](https://en.wikipedia.org/wiki/BIOS))和 **UEFI**([Unified Extensible Firmware Interface](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface))。其中,BIOS 标准显得陈旧而过时,但实现简单,并为 1980 年代后的所有 x86 设备所支持;相反地,UEFI 更现代化,功能也更全面,但开发和构建更复杂(至少从我的角度看是如此)。
|
||||
|
||||
在这篇文章中,我们暂时只提供 BIOS 固件的引导启动方式。
|
||||
在这篇文章中,我们暂时只提供 BIOS 固件的引导启动方式,但是UEFI支持也已经在计划中了。如果你希望帮助我们推进它,请查阅这份 [Github issue](https://github.com/phil-opp/blog_os/issues/349)。
|
||||
|
||||
### BIOS 启动
|
||||
|
||||
@@ -57,11 +59,17 @@ x86 架构支持两种固件标准: **BIOS**([Basic Input/Output System](htt
|
||||
3. GRUB 和 Multiboot 标准并没有被详细地解释,阅读相关文档需要一定经验;
|
||||
4. 为了创建一个能够被引导的磁盘映像,我们在开发时必须安装 GRUB:这加大了基于 Windows 或 macOS 开发内核的难度。
|
||||
|
||||
出于这些考虑,我们决定不使用 GRUB 或者 Multiboot 标准。然而,Multiboot 支持功能也在 bootimage 工具的开发计划之中,所以从原理上讲,如果选用 bootimage 工具,在未来使用 GRUB 引导你的系统内核是可能的。
|
||||
出于这些考虑,我们决定不使用 GRUB 或者 Multiboot 标准。然而,Multiboot 支持功能也在 bootimage 工具的开发计划之中,所以从原理上讲,如果选用 bootimage 工具,在未来使用 GRUB 引导你的系统内核是可能的。 如果你对编写一个支持 Mutiboot 标准的内核有兴趣,可以查阅 [初版文档][first edition]。
|
||||
|
||||
## 最小化内核
|
||||
[first edition]: @/edition-1/_index.md
|
||||
|
||||
现在我们已经明白电脑是如何启动的,那也是时候编写我们自己的内核了。我们的小目标是,创建一个内核的磁盘映像,它能够在启动时,向屏幕输出一行“Hello World!”;我们的工作将基于上一章构建的独立式可执行程序。
|
||||
### UEFI
|
||||
|
||||
(截至此时,我们并未提供UEFI相关教程,但我们确实有此意向。如果你愿意提供一些帮助,请在 [Github issue](https://github.com/phil-opp/blog_os/issues/349) 告知我们,不胜感谢。)
|
||||
|
||||
## 最小内核
|
||||
|
||||
现在我们已经明白电脑是如何启动的,那也是时候编写我们自己的内核了。我们的小目标是,创建一个内核的磁盘映像,它能够在启动时,向屏幕输出一行“Hello World!”;我们的工作将基于上一章构建的[独立式可执行程序][freestanding Rust binary]。
|
||||
|
||||
如果读者还有印象的话,在上一章,我们使用 `cargo` 构建了一个独立的二进制程序;但这个程序依然基于特定的操作系统平台:因平台而异,我们需要定义不同名称的函数,且使用不同的编译指令。这是因为在默认情况下,`cargo` 会为特定的**宿主系统**(host system)构建源码,比如为你正在运行的系统构建源码。这并不是我们想要的,因为我们的内核不应该基于另一个操作系统——我们想要编写的,就是这个操作系统。确切地说,我们想要的是,编译为一个特定的**目标系统**(target system)。
|
||||
|
||||
@@ -135,7 +143,9 @@ Nightly 版本的编译器允许我们在源码的开头插入**特性标签**
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
我们正在编写一个内核,所以我们应该同时处理中断。要安全地实现这一点,我们必须禁用一个与**红区**(redzone)有关的栈指针优化:因为此时,这个优化可能会导致栈被破坏。我们撰写了一篇专门的短文,来更详细地解释红区及与其相关的优化。
|
||||
我们正在编写一个内核,所以我们迟早要处理中断。要安全地实现这一点,我们必须禁用一个与**红区**(redzone)有关的栈指针优化:因为此时,这个优化可能会导致栈被破坏。如果需要更详细的资料,请查阅我们的一篇关于 [禁用红区][disabling the red zone] 的短文。
|
||||
|
||||
[disabling the red zone]: @/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.zh-CN.md
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float",
|
||||
@@ -147,7 +157,7 @@ Nightly 版本的编译器允许我们在源码的开头插入**特性标签**
|
||||
|
||||
禁用 SIMD 产生的一个问题是,`x86_64` 架构的浮点数指针运算默认依赖于 SIMD 寄存器。我们的解决方法是,启用 `soft-float` 特征,它将使用基于整数的软件功能,模拟浮点数指针运算。
|
||||
|
||||
为了让读者的印象更清晰,我们撰写了一篇关于禁用 SIMD 的短文。
|
||||
为了让读者的印象更清晰,我们撰写了一篇关于 [禁用 SIMD][disabling SIMD](@/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.zh-CN.md) 的短文。
|
||||
|
||||
现在,我们将各个配置项整合在一起。我们的目标配置清单应该长这样:
|
||||
|
||||
@@ -171,7 +181,9 @@ Nightly 版本的编译器允许我们在源码的开头插入**特性标签**
|
||||
|
||||
### 编译内核
|
||||
|
||||
要编译我们的内核,我们将使用 Linux 系统的编写风格(这可能是 LLVM 的默认风格)。这意味着,我们需要把前一篇文章中编写的入口点重命名为 `_start`:
|
||||
要编译我们的内核,我们将使用 Linux 系统的编写风格(这可能是 LLVM 的默认风格)。这意味着,我们需要把[前一篇文章][previous post]中编写的入口点重命名为 `_start`:
|
||||
|
||||
[previous post]: @/edition-2/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
@@ -203,61 +215,99 @@ pub extern "C" fn _start() -> ! {
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
|
||||
error[E0463]: can't find crate for `core`
|
||||
(或者是下面的错误)
|
||||
error[E0463]: can't find crate for `compiler_builtins`
|
||||
```
|
||||
|
||||
哇哦,编译失败了!输出的错误告诉我们,Rust 编译器找不到 `core` 或者 `compiler_builtins` 包;而所有 `no_std` 上下文都隐式地链接到这两个包。[`core` 包](https://doc.rust-lang.org/nightly/core/index.html)包含基础的 Rust 类型,如` Result`、`Option` 和迭代器等;[`compiler_builtins` 包](https://github.com/rust-lang-nursery/compiler-builtins)提供 LLVM 需要的许多底层操作,比如 `memcpy`。
|
||||
毫不意外的编译失败了,错误信息告诉我们编译器没有找到 [`core`][`core` library] 这个crate,它包含了Rust语言中的部分基础类型,如 `Result`、`Option`、迭代器等等,并且它还会隐式链接到 `no_std` 特性里面。
|
||||
|
||||
通常状况下,`core` 库以**预编译库**(precompiled library)的形式与 Rust 编译器一同发布——这时,`core` 库只对支持的宿主系统有效,而我们自定义的目标系统无效。如果我们想为其它系统编译代码,我们需要为这些系统重新编译整个 `core` 库。
|
||||
[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
|
||||
|
||||
### Cargo xbuild
|
||||
通常状况下,`core` crate以**预编译库**(precompiled library)的形式与 Rust 编译器一同发布——这时,`core` crate只对支持的宿主系统有效,而对我们自定义的目标系统无效。如果我们想为其它系统编译代码,我们需要为这些系统重新编译整个 `core` crate。
|
||||
|
||||
这就是为什么我们需要 [cargo xbuild 工具](https://github.com/rust-osdev/cargo-xbuild)。这个工具封装了 `cargo build`;但不同的是,它将自动交叉编译 `core` 库和一些**编译器内建库**(compiler built-in libraries)。我们可以用下面的命令安装它:
|
||||
#### `build-std` 选项
|
||||
|
||||
```bash
|
||||
cargo install cargo-xbuild
|
||||
此时就到了cargo中 [`build-std` 特性][`build-std` feature] 登场的时刻,该特性允许你按照自己的需要重编译 `core` 等标准crate,而不需要使用Rust安装程序内置的预编译版本。 但是该特性是全新的功能,到目前为止尚未完全完成,所以它被标记为 "unstable" 且仅被允许在 [nightly Rust 编译器][nightly Rust compilers] 环境下调用。
|
||||
|
||||
[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
|
||||
[nightly Rust compilers]: #安装 Nightly Rust
|
||||
|
||||
要启用该特性,你需要创建一个 [cargo 配置][cargo configuration] 文件,即 `.cargo/config.toml`,并写入以下语句:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std = ["core", "compiler_builtins"]
|
||||
```
|
||||
|
||||
这个工具依赖于Rust的源代码;我们可以使用 `rustup component add rust-src` 来安装源代码。
|
||||
该配置会告知cargo需要重新编译 `core` 和 `compiler_builtins` 这两个crate,其中 `compiler_builtins` 是 `core` 的必要依赖。 另外重编译需要提供源码,我们可以使用 `rustup component add rust-src` 命令来下载它们。
|
||||
|
||||
现在我们可以使用 `xbuild` 代替 `build` 重新编译:
|
||||
<div class="note">
|
||||
|
||||
```bash
|
||||
> cargo xbuild --target x86_64-blog_os.json
|
||||
**Note:** 仅 `2020-07-15` 之后的Rust nightly版本支持 `unstable.build-std` 配置项。
|
||||
|
||||
</div>
|
||||
|
||||
在设定 `unstable.build-std` 配置项并安装 `rust-src` 组件之后,我们就可以开始编译了:
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
Compiling core v0.0.0 (/…/rust/src/libcore)
|
||||
Compiling compiler_builtins v0.1.5
|
||||
Compiling rustc-std-workspace-core v1.0.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling alloc v0.0.0 (/tmp/xargo.PB7fj9KZJhAI)
|
||||
Finished release [optimized + debuginfo] target(s) in 45.18s
|
||||
Compiling blog_os v0.1.0 (file:///…/blog_os)
|
||||
Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling compiler_builtins v0.1.32
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
我们能看到,`cargo xbuild` 为我们自定义的目标交叉编译了 `core`、`compiler_builtin` 和 `alloc` 三个部件。这些部件使用了大量的**不稳定特性**(unstable features),所以只能在[nightly 版本的 Rust 编译器][installing rust nightly]中工作。这之后,`cargo xbuild` 成功地编译了我们的 `blog_os` 包。
|
||||
如你所见,在执行 `cargo build` 之后, `core`、`rustc-std-workspace-core` (`compiler_builtins` 的依赖)和 `compiler_builtins` crate被重新编译了。
|
||||
|
||||
[installing rust nightly]: #an-zhuang-nightly-rust
|
||||
#### 内存相关函数
|
||||
|
||||
现在我们可以为裸机编译内核了;但是,我们提供给引导程序的入口点 `_start` 函数还是空的。我们可以添加一些东西进去,不过我们可以先做一些优化工作。
|
||||
目前来说,Rust编译器假定所有内置函数(`built-in functions`)在所有系统内都是存在且可用的。事实上这个前提只对了一半,
|
||||
绝大多数内置函数都可以被 `compiler_builtins` 提供,而这个crate刚刚已经被我们重编译过了,然而部分内存相关函数是需要操作系统相关的标准C库提供的。
|
||||
比如,`memset`(该函数可以为一个内存块内的所有比特进行赋值)、`memcpy`(将一个内存块里的数据拷贝到另一个内存块)以及`memcmp`(比较两个内存块的数据)。
|
||||
好在我们的内核暂时还不需要用到这些函数,但是不要高兴的太早,当我们编写更丰富的功能(比如拷贝数据结构)时就会用到了。
|
||||
|
||||
### 设置默认目标
|
||||
现在我们当然无法提供操作系统相关的标准C库,所以我们需要使用其他办法提供这些东西。一个显而易见的途径就是自己实现 `memset` 这些函数,但不要忘记加入 `#[no_mangle]` 语句,以避免编译时被自动重命名。 当然,这样做很危险,底层函数中最细微的错误也会将程序导向不可预知的未来。比如,你可能在实现 `memcpy` 时使用了一个 `for` 循环,然而 `for` 循环本身又会调用 [`IntoIterator::into_iter`] 这个trait方法,这个方法又会再次调用 `memcpy`,此时一个无限递归就产生了,所以还是使用经过良好测试的既存实现更加可靠。
|
||||
|
||||
为了避免每次使用`cargo xbuild`时传递`--target`参数,我们可以覆写默认的编译目标。我们创建一个名为`.cargo/config`的[cargo配置文件](https://doc.rust-lang.org/cargo/reference/config.html),添加下面的内容:
|
||||
[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
|
||||
|
||||
幸运的是,`compiler_builtins` 事实上自带了所有相关函数的实现,只是在默认情况下,出于避免和标准C库发生冲突的考量被禁用掉了,此时我们需要将 [`build-std-features`] 配置项设置为 `["compiler-builtins-mem"]` 来启用这个特性。如同 `build-std` 配置项一样,该特性可以使用 `-Z` 参数启用,也可以在 `.cargo/config.toml` 中使用 `unstable` 配置集启用。现在我们的配置文件中的相关部分是这样子的:
|
||||
|
||||
[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std-features = ["compiler-builtins-mem"]
|
||||
build-std = ["core", "compiler_builtins"]
|
||||
```
|
||||
|
||||
(`compiler-builtins-mem` 特性是在 [这个PR](https://github.com/rust-lang/rust/pull/77284) 中被引入的,所以你的Rust nightly更新时间必须晚于 `2020-09-30`。)
|
||||
|
||||
该参数为 `compiler_builtins` 启用了 [`mem` 特性][`mem` feature],至于具体效果,就是已经在内部通过 `#[no_mangle]` 向链接器提供了 [`memcpy` 等函数的实现][`memcpy` etc. implementations]。
|
||||
|
||||
[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L54-L55
|
||||
[`memcpy` etc. implementations]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69
|
||||
|
||||
经过这些修改,我们的内核已经完成了所有编译所必需的函数,那么让我们继续对代码进行完善。
|
||||
|
||||
#### 设置默认编译目标
|
||||
|
||||
每次调用 `cargo build` 命令都需要传入 `--target` 参数很麻烦吧?其实我们可以复写掉默认值,从而省略这个参数,只需要在 `.cargo/config.toml` 中加入以下 [cargo 配置][cargo configuration]:
|
||||
|
||||
[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[build]
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
这里的配置告诉 `cargo` 在没有显式声明目标的情况下,使用我们提供的 `x86_64-blog_os.json` 作为目标配置。这意味着保存后,我们可以直接使用:
|
||||
这个配置会告知 `cargo` 使用 `x86_64-blog_os.json` 这个文件作为默认的 `--target` 参数,此时只输入短短的一句 `cargo build` 就可以编译到指定平台了。如果你对其他配置项感兴趣,亦可以查阅 [官方文档][cargo configuration]。
|
||||
|
||||
```
|
||||
cargo xbuild
|
||||
```
|
||||
|
||||
来编译我们的内核。[官方提供的一份文档](https://doc.rust-lang.org/cargo/reference/config.html)中有对 cargo 配置文件更详细的说明。
|
||||
那么现在我们已经可以用 `cargo build` 完成程序编译了,然而被成功调用的 `_start` 函数的函数体依然是一个空空如也的循环,是时候往屏幕上输出一点什么了。
|
||||
|
||||
### 向屏幕打印字符
|
||||
|
||||
@@ -313,7 +363,7 @@ pub extern "C" fn _start() -> ! {
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.3"
|
||||
bootloader = "0.9.23"
|
||||
```
|
||||
|
||||
只添加引导程序为依赖项,并不足以创建一个可引导的磁盘映像;我们还需要内核编译完成之后,将内核和引导程序组合在一起。然而,截至目前,原生的 cargo 并不支持在编译完成后添加其它步骤(详见[这个 issue](https://github.com/rust-lang/cargo/issues/545))。
|
||||
@@ -332,7 +382,7 @@ cargo install bootimage
|
||||
> cargo bootimage
|
||||
```
|
||||
|
||||
可以看到的是,`bootimage` 工具开始使用 `cargo xbuild` 编译你的内核,所以它将增量编译我们修改后的源码。在这之后,它会编译内核的引导程序,这可能将花费一定的时间;但和所有其它依赖包相似的是,在首次编译后,产生的二进制文件将被缓存下来——这将显著地加速后续的编译过程。最终,`bootimage` 将把内核和引导程序组合为一个可引导的磁盘映像。
|
||||
可以看到的是,`bootimage` 工具开始使用 `cargo build` 编译你的内核,所以它将增量编译我们修改后的源码。在这之后,它会编译内核的引导程序,这可能将花费一定的时间;但和所有其它依赖包相似的是,在首次编译后,产生的二进制文件将被缓存下来——这将显著地加速后续的编译过程。最终,`bootimage` 将把内核和引导程序组合为一个可引导的磁盘映像。
|
||||
|
||||
运行这行命令之后,我们应该能在 `target/x86_64-blog_os/debug` 目录内找到我们的映像文件 `bootimage-blog_os.bin`。我们可以在虚拟机内启动它,也可以刻录到 U 盘上以便在真机上启动。(需要注意的是,因为文件格式不同,这里的 bin 文件并不是一个光驱映像,所以将它刻录到光盘不会起作用。)
|
||||
|
||||
@@ -349,10 +399,13 @@ cargo install bootimage
|
||||
现在我们可以在虚拟机中启动内核了。为了在[ QEMU](https://www.qemu.org/) 中启动内核,我们使用下面的命令:
|
||||
|
||||
```bash
|
||||
> qemu-system-x86_64 -drive format=raw,file=bootimage-blog_os.bin
|
||||
> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
|
||||
warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
|
||||
```
|
||||
|
||||
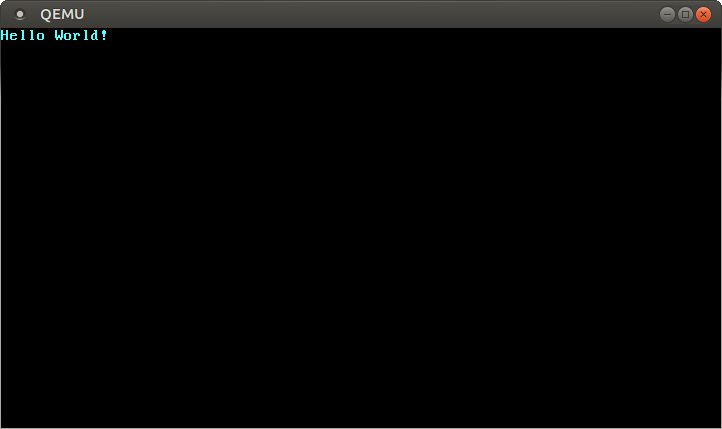
|
||||
然后就会弹出一个独立窗口:
|
||||
|
||||

|
||||
|
||||
我们可以看到,屏幕窗口已经显示出 “Hello World!” 字符串。祝贺你!
|
||||
|
||||
@@ -383,7 +436,7 @@ runner = "bootimage runner"
|
||||
|
||||
命令 `bootimage runner` 由 `bootimage` 包提供,参数格式经过特殊设计,可以用于 `runner` 命令。它将给定的可执行文件与项目的引导程序依赖项链接,然后在 QEMU 中启动它。`bootimage` 包的 [README文档](https://github.com/rust-osdev/bootimage) 提供了更多细节和可以传入的配置参数。
|
||||
|
||||
现在我们可以使用 `cargo xrun` 来编译内核并在 QEMU 中启动了。和 `xbuild` 类似,`xrun` 子命令将在调用 cargo 命令前编译内核所需的包。这个子命令也由 `cargo-xbuild` 工具提供,所以你不需要安装额外的工具。
|
||||
现在我们可以使用 `cargo run` 来编译内核并在 QEMU 中启动了。
|
||||
|
||||
## 下篇预告
|
||||
|
||||
|
||||
@@ -12,7 +12,7 @@ translation_based_on_commit = "1c9b5edd6a5a667e282ca56d6103d3ff1fd7cfcb"
|
||||
translators = ["JOE1994", "Quqqu"]
|
||||
+++
|
||||
|
||||
[VGA 텍스트 모드][VGA text mode]를 통해 쉽게 화면에 텍스트를 출력할 수 있습니다. 이 포스트에서는 안전하지 않은 작업들을 분리된 모듈에 격리하여 쉽고 안전하게 VGA 텍스트 모드를 이용할 수 있는 인터페이스를 구현할 것입니다. 또한 Rust의 [서식 정렬 매크로 (formatting macro)][formatting macros]를 지원하도록 구현을 추가할 것입니다.
|
||||
[VGA 텍스트 모드][VGA text mode]를 통해 쉽게 화면에 텍스트를 출력할 수 있습니다. 이 글에서는 안전하지 않은 작업들을 분리된 모듈에 격리해 쉽고 안전하게 VGA 텍스트 모드를 이용할 수 있는 인터페이스를 구현합니다. 또한 Rust의 [서식 정렬 매크로 (formatting macro)][formatting macros]에 대한 지원을 추가할 것입니다.
|
||||
|
||||
[VGA text mode]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
[formatting macros]: https://doc.rust-lang.org/std/fmt/#related-macros
|
||||
@@ -523,7 +523,7 @@ lazy_static! {
|
||||
}
|
||||
```
|
||||
|
||||
현재 `WRITER`는 immutable (읽기 가능, 쓰기 불가능) 하여 실질적인 쓸모가 없습니다. 모든 쓰기 함수들은 첫 인자로 `&mut self`를 받기 때문에 `WRITER`로 어떤 쓰기 작업도 할 수가 없습니다. 이에 대한 해결책으로 [mutable static]은 어떨까요? 이 선택지를 고른다면 모든 읽기 및 쓰기 작업이 데이터 경쟁 상태 (data race) 및 기타 위험에 노출되기에 안전을 보장할 수 없게 됩니다. Rust에서 `static mut`는 웬만하면 사용하지 않도록 권장되며, 심지어 [Rust 언어에서 완전히 `static mut`를 제거하자는 제안][remove static mut]이 나오기도 했습니다. 이것 이외에도 대안이 있을까요? [내부 가변성 (interior mutability)][interior mutability]을 제공하는 [RefCell] 혹은 [UnsafeCell] 을 통해 immutable한 정적 변수를 만드는 것은 어떨까요? 이 타입들은 중요한 이유로 [Sync] 트레이트를 구현하지 않기에 정적 변수를 선언할 때에는 사용할 수 없습니다.
|
||||
현재 `WRITER`는 immutable (읽기 가능, 쓰기 불가능) 하여 실질적인 쓸모가 없습니다. 모든 쓰기 함수들은 첫 인자로 `&mut self`를 받기 때문에 `WRITER`로 어떤 쓰기 작업도 할 수가 없습니다. 이에 대한 해결책으로 [mutable static]은 어떨까요? 이 선택지를 고른다면 모든 읽기 및 쓰기 작업이 데이터 레이스 (data race) 및 기타 위험에 노출되기에 안전을 보장할 수 없게 됩니다. Rust에서 `static mut`는 웬만하면 사용하지 않도록 권장되며, 심지어 [Rust 언어에서 완전히 `static mut`를 제거하자는 제안][remove static mut]이 나오기도 했습니다. 이것 이외에도 대안이 있을까요? [내부 가변성 (interior mutability)][interior mutability]을 제공하는 [RefCell] 혹은 [UnsafeCell] 을 통해 immutable한 정적 변수를 만드는 것은 어떨까요? 이 타입들은 중요한 이유로 [Sync] 트레이트를 구현하지 않기에 정적 변수를 선언할 때에는 사용할 수 없습니다.
|
||||
|
||||
[mutable static]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
|
||||
[remove static mut]: https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437
|
||||
|
||||
@@ -9,6 +9,8 @@ date = 2018-02-26
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["liuyuran"]
|
||||
+++
|
||||
|
||||
**VGA 字符模式**([VGA text mode])是打印字符到屏幕的一种简单方式。在这篇文章中,为了包装这个模式为一个安全而简单的接口,我们将包装 unsafe 代码到独立的模块。我们还将实现对 Rust 语言**格式化宏**([formatting macros])的支持。
|
||||
@@ -18,7 +20,7 @@ translators = ["luojia65", "Rustin-Liu"]
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-03`][post branch] branch.
|
||||
此博客在 [GitHub] 上公开开发. 如果您有任何问题或疑问,请在此处打开一个 issue。 您也可以在[底部][at the bottom]发表评论. 这篇文章的完整源代码可以在 [`post-03`] [post branch] 分支中找到。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
@@ -31,27 +33,32 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
|
||||
|
||||
为了在 VGA 字符模式中向屏幕打印字符,我们必须将它写入硬件提供的 **VGA 字符缓冲区**(VGA text buffer)。通常状况下,VGA 字符缓冲区是一个 25 行、80 列的二维数组,它的内容将被实时渲染到屏幕。这个数组的元素被称作**字符单元**(character cell),它使用下面的格式描述一个屏幕上的字符:
|
||||
|
||||
| Bit(s) | Value |
|
||||
|-----|----------------|
|
||||
| 0-7 | ASCII code point |
|
||||
| 8-11 | Foreground color |
|
||||
| 12-14 | Background color |
|
||||
| 15 | Blink |
|
||||
| Bit(s) | Value |
|
||||
| ------ | ---------------- |
|
||||
| 0-7 | ASCII code point |
|
||||
| 8-11 | Foreground color |
|
||||
| 12-14 | Background color |
|
||||
| 15 | Blink |
|
||||
|
||||
其中,**前景色**(foreground color)和**背景色**(background color)取值范围如下:
|
||||
第一个字节表示了应当输出的 [ASCII 编码][ASCII encoding],更加准确的说,类似于 [437 字符编码表][_code page 437_] 中字符对应的编码,但又有细微的不同。 这里为了简化表达,我们在文章里将其简称为ASCII字符。
|
||||
|
||||
| Number | Color | Number + Bright Bit | Bright Color |
|
||||
|-----|----------|------|--------|
|
||||
| 0x0 | Black | 0x8 | Dark Gray |
|
||||
| 0x1 | Blue | 0x9 | Light Blue |
|
||||
| 0x2 | Green | 0xa | Light Green |
|
||||
| 0x3 | Cyan | 0xb | Light Cyan |
|
||||
| 0x4 | Red | 0xc | Light Red |
|
||||
| 0x5 | Magenta | 0xd | Pink |
|
||||
| 0x6 | Brown | 0xe | Yellow |
|
||||
| 0x7 | Light Gray | 0xf | White |
|
||||
[ASCII encoding]: https://en.wikipedia.org/wiki/ASCII
|
||||
[_code page 437_]: https://en.wikipedia.org/wiki/Code_page_437
|
||||
|
||||
每个颜色的第四位称为**加亮位**(bright bit)。
|
||||
第二个字节则定义了字符的显示方式,前四个比特定义了前景色,中间三个比特定义了背景色,最后一个比特则定义了该字符是否应该闪烁,以下是可用的颜色列表:
|
||||
|
||||
| Number | Color | Number + Bright Bit | Bright Color |
|
||||
| ------ | ---------- | ------------------- | ------------ |
|
||||
| 0x0 | Black | 0x8 | Dark Gray |
|
||||
| 0x1 | Blue | 0x9 | Light Blue |
|
||||
| 0x2 | Green | 0xa | Light Green |
|
||||
| 0x3 | Cyan | 0xb | Light Cyan |
|
||||
| 0x4 | Red | 0xc | Light Red |
|
||||
| 0x5 | Magenta | 0xd | Pink |
|
||||
| 0x6 | Brown | 0xe | Yellow |
|
||||
| 0x7 | Light Gray | 0xf | White |
|
||||
|
||||
每个颜色的第四位称为**加亮位**(bright bit),比如blue加亮后就变成了light blue,但对于背景色,这个比特会被用于标记是否闪烁。
|
||||
|
||||
要修改 VGA 字符缓冲区,我们可以通过**存储器映射输入输出**([memory-mapped I/O](https://en.wikipedia.org/wiki/Memory-mapped_I/O))的方式,读取或写入地址 `0xb8000`;这意味着,我们可以像操作普通的内存区域一样操作这个地址。
|
||||
|
||||
@@ -66,13 +73,11 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
|
||||
mod vga_buffer;
|
||||
```
|
||||
|
||||
这行代码定义了一个 Rust 模块,它的内容应当保存在 `src/vga_buffer.rs` 文件中。使用 **2018 版次**(2018 edition)的 Rust 时,我们可以把模块的**子模块**(submodule)文件直接保存到 `src/vga_buffer/` 文件夹下,与 `vga_buffer.rs` 文件共存,而无需创建一个 `mod.rs` 文件。
|
||||
|
||||
我们的模块暂时不需要添加子模块,所以我们将它创建为 `src/vga_buffer.rs` 文件。除非另有说明,本文中的代码都保存到这个文件中。
|
||||
|
||||
### 颜色
|
||||
|
||||
首先,我们使用 Rust 的**枚举**(enum)表示一种颜色:
|
||||
首先,我们使用 Rust 的**枚举**(enum)表示特定的颜色:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
@@ -486,16 +491,16 @@ lazy_static! {
|
||||
|
||||
然而,这个 `WRITER` 可能没有什么用途,因为它目前还是**不可变变量**(immutable variable):这意味着我们无法向它写入数据,因为所有与写入数据相关的方法都需要实例的可变引用 `&mut self`。一种解决方案是使用**可变静态**([mutable static](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable))的变量,但所有对它的读写操作都被规定为不安全的(unsafe)操作,因为这很容易导致数据竞争或发生其它不好的事情——使用 `static mut` 极其不被赞成,甚至有一些提案认为[应该将它删除](https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437)。也有其它的替代方案,比如可以尝试使用比如 [RefCell](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt) 或甚至 [UnsafeCell](https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html) 等类型提供的**内部可变性**([interior mutability](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html));但这些类型都被设计为非同步类型,即不满足 [Sync](https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html) 约束,所以我们不能在静态变量中使用它们。
|
||||
|
||||
### 自旋锁
|
||||
### spinlock
|
||||
|
||||
要定义同步的内部可变性,我们往往使用标准库提供的互斥锁类 [Mutex](https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html),它通过提供当资源被占用时将线程**阻塞**(block)的**互斥条件**(mutual exclusion)实现这一点;但我们初步的内核代码还没有线程和阻塞的概念,我们将不能使用这个类。不过,我们还有一种较为基础的互斥锁实现方式——**自旋锁**([spinlock](https://en.wikipedia.org/wiki/Spinlock))。自旋锁并不会调用阻塞逻辑,而是在一个小的无限循环中反复尝试获得这个锁,也因此会一直占用 CPU 时间,直到互斥锁被它的占用者释放。
|
||||
|
||||
为了使用自旋的互斥锁,我们添加 [spin包](https://crates.io/crates/spin) 到项目的依赖项列表:
|
||||
为了使用自旋互斥锁,我们添加 [spin包](https://crates.io/crates/spin) 到项目的依赖项列表:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
[dependencies]
|
||||
spin = "0.4.9"
|
||||
spin = "0.5.2"
|
||||
```
|
||||
|
||||
现在,我们能够使用自旋的互斥锁,为我们的 `WRITER` 类实现安全的[内部可变性](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html):
|
||||
|
||||
@@ -978,7 +978,7 @@ fn should_fail() {
|
||||
|
||||
이 방식의 큰 문제는 바로 테스트 함수를 하나밖에 쓸 수 없다는 점입니다. 패닉 핸들러가 호출된 후에는 다른 테스트의 실행을 계속할 수가 없어서, `#[test_case]` 속성이 붙은 함수가 여럿 있더라도 첫 함수만 실행이 됩니다. 이 문제의 해결책을 알고 계신다면 제게 꼭 알려주세요!
|
||||
|
||||
### 테스트 하네스 (test harness)를 쓰지 않는 테스트
|
||||
### 테스트 하네스 (test harness)를 쓰지 않는 테스트 {#no-harness-tests}
|
||||
|
||||
테스트 함수가 1개인 통합 테스트 (예: 우리의 `should_panic` 테스트)는 별도의 test_runner가 필요하지 않습니다.
|
||||
이런 테스트들은 test_runner 사용을 해제하고 `_start` 함수에서 직접 실행해도 됩니다.
|
||||
|
||||
@@ -6,16 +6,18 @@ date = 2019-04-27
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu"]
|
||||
translators = ["luojia65", "Rustin-Liu", "liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong"]
|
||||
+++
|
||||
|
||||
本文主要讲述了在`no_std`环境下进行单元测试和集成测试的方法。我们将通过Rust的自定义测试框架来在我们的内核中执行一些测试函数。为了将结果反馈到QEMU上,我们需要使用QEMU的一些其他的功能以及`bootimage`工具。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部]留言。你可以在[这里][post branch]找到这篇文章的完整源码。
|
||||
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-04`][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
@@ -26,33 +28,33 @@ translators = ["luojia65", "Rustin-Liu"]
|
||||
|
||||
## 阅读要求
|
||||
|
||||
这篇文章替换了此前的(现在已经过时了) [_单元测试(Unit Testing)_] 和 [_集成测试(Integration Tests)_] 两篇文章。这里我将假定你是在2019-04-27日后阅读的[_最小Rust内核_]一文。总而言之,本文要求你已经有一个[设置默认目标]的 `.cargo/config` 文件且[定义了一个runner可执行文件]。
|
||||
这篇文章替换了此前的(现在已经过时了) [_单元测试(Unit Testing)_][_Unit Testing_] 和 [_集成测试(Integration Tests)_][_Integration Tests_] 两篇文章。这里我将假定你是在2019-04-27日后阅读的[_最小Rust内核_][_A Minimal Rust Kernel_]一文。总而言之,本文要求你已经有一个[已设置默认目标][sets a default target]的 `.cargo/config` 文件且[定义了一个runner可执行文件][defines a runner executable]。
|
||||
|
||||
[_单元测试(Unit Testing)_]: @/edition-2/posts/deprecated/04-unit-testing/index.md
|
||||
[_集成测试(Integration Tests)_]: @/edition-2/posts/deprecated/05-integration-tests/index.md
|
||||
[_最小Rust内核_]: @/edition-2/posts/02-minimal-rust-kernel/index.md
|
||||
[设置默认目标]: @/edition-2/posts/02-minimal-rust-kernel/index.md#set-a-default-target
|
||||
[定义了一个runner可执行文件]: @/edition-2/posts/02-minimal-rust-kernel/index.md#using-cargo-run
|
||||
[_Unit Testing_]: @/edition-2/posts/deprecated/04-unit-testing/index.md
|
||||
[_Integration Tests_]: @/edition-2/posts/deprecated/05-integration-tests/index.md
|
||||
[_A Minimal Rust Kernel_]: @/edition-2/posts/02-minimal-rust-kernel/index.md
|
||||
[sets a default target]: @/edition-2/posts/02-minimal-rust-kernel/index.md#set-a-default-target
|
||||
[defines a runner executable]: @/edition-2/posts/02-minimal-rust-kernel/index.md#using-cargo-run
|
||||
|
||||
## Rust中的测试
|
||||
|
||||
Rust有一个**内置的测试框架**([built-in test framework]):无需任何设置就可以进行单元测试,只需要创建一个通过assert来检查结果的函数并在函数的头部加上`#[test]`属性即可。然后`cargo test`会自动找到并执行你的crate中的所有测试函数。
|
||||
Rust有一个**内置的测试框架**([built-in test framework]):无需任何设置就可以进行单元测试,只需要创建一个通过assert来检查结果的函数并在函数的头部加上 `#[test]` 属性即可。然后 `cargo test` 会自动找到并执行你的crate中的所有测试函数。
|
||||
|
||||
[built-in test framework]: https://doc.rust-lang.org/book/second-edition/ch11-00-testing.html
|
||||
|
||||
不幸的是,对于一个`no_std`的应用,比如我们的内核,这有点点复杂。现在的问题是,Rust的测试框架会隐式的调用内置的[`test`]库,但是这个库依赖于标准库。这也就是说我们的 `#[no_std]`内核无法使用默认的测试框架。
|
||||
不幸的是,对于一个 `no_std` 的应用,比如我们的内核,这就有点复杂了。现在的问题是,Rust的测试框架会隐式的调用内置的[`test`]库,但是这个库依赖于标准库。这也就是说我们的 `#[no_std]` 内核无法使用默认的测试框架。
|
||||
|
||||
[`test`]: https://doc.rust-lang.org/test/index.html
|
||||
|
||||
当我们试图在我们的项目中执行`cargo xtest`时,我们可以看到如下信息:
|
||||
当我们试图在我们的项目中执行 `cargo test` 时,我们可以看到如下信息:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
> cargo test
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
error[E0463]: can't find crate for `test`
|
||||
```
|
||||
|
||||
由于`test`crate依赖于标准库,所以它在我们的裸机目标上并不可用。虽然将`test`crate移植到一个 `#[no_std]` 上下文环境中是[可能的][utest],但是这样做是高度不稳定的并且还会需要一些特殊的hacks,例如重定义 `panic` 宏。
|
||||
由于 `test` 库依赖于标准库,所以它在我们的裸机目标上并不可用。虽然将 `test` 库移植到一个 `#[no_std]` 上下文环境中是[可能的][utest],但是这样做是高度不稳定的,并且还会需要一些特殊的hacks,例如重定义 `panic` 宏。
|
||||
|
||||
[utest]: https://github.com/japaric/utest
|
||||
|
||||
@@ -62,11 +64,11 @@ error[E0463]: can't find crate for `test`
|
||||
|
||||
[`custom_test_frameworks`]: https://doc.rust-lang.org/unstable-book/language-features/custom-test-frameworks.html
|
||||
|
||||
与默认的测试框架相比,它的缺点是有一些高级功能诸如 [`should_panic` tests]都不可用了。相对的,如果需要这些功能,我们需要自己来实现。当然,这点对我们来说是好事,因为我们的环境非常特殊,在这个环境里,这些高级功能的默认实现无论如何都是无法工作的,举个例子, `#[should_panic]`属性依赖于堆栈展开来捕获内核panic,而我的内核早已将其禁用了。
|
||||
与默认的测试框架相比,它的缺点是有一些高级功能诸如 [`should_panic` tests] 都不可用了。相对的,如果需要这些功能,我们需要自己来实现。当然,这点对我们来说是好事,因为我们的环境非常特殊,在这个环境里,这些高级功能的默认实现无论如何都是无法工作的,举个例子, `#[should_panic]` 属性依赖于栈展开来捕获内核panic,而我们的内核早已将其禁用了。
|
||||
|
||||
[`should_panic` tests]: https://doc.rust-lang.org/book/ch11-01-writing-tests.html#checking-for-panics-with-should_panic
|
||||
|
||||
要为我们的内核实现自定义测试框架,我们需要将如下代码添加到我们的`main.rs`中去:
|
||||
要为我们的内核实现自定义测试框架,我们需要将如下代码添加到我们的 `main.rs` 中去:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
@@ -89,7 +91,13 @@ fn test_runner(tests: &[&dyn Fn()]) {
|
||||
[_trait object_]: https://doc.rust-lang.org/1.30.0/book/first-edition/trait-objects.html
|
||||
[_Fn()_]: https://doc.rust-lang.org/std/ops/trait.Fn.html
|
||||
|
||||
现在当我们运行 `cargo xtest` ,我们可以发现运行成功了。然而,我们看到的仍然是"Hello World"而不是我们的 `test_runner`传递来的信息。这是由于我们的入口点仍然是 `_start` 函数——自定义测试框架会生成一个`main`函数来调用`test_runner`,但是由于我们使用了 `#[no_main]`并提供了我们自己的入口点,所以这个`main`函数就被忽略了。
|
||||
现在当我们运行 `cargo test` ,我们可以发现运行成功了。然而,我们看到的仍然是"Hello World"而不是我们的 `test_runner`传递来的信息。这是由于我们的入口点仍然是 `_start` 函数——自定义测试框架会生成一个`main`函数来调用`test_runner`,但是由于我们使用了 `#[no_main]`并提供了我们自己的入口点,所以这个`main`函数就被忽略了。
|
||||
|
||||
<div class = "warning">
|
||||
|
||||
**Note:** cargo目前有个bug,就是某些测试用例会在执行 `cargo test` 时抛出 `duplicate lang item` 错误。目前已知的复现条件是在你的 `Cargo.toml` 中配置 `panic = "abort"`,只要移除掉,`cargo test` 即可正常执行。如果你对这个bug感兴趣,可以关注一下这个 [cargo issue](https://github.com/rust-lang/cargo/issues/7359)。
|
||||
|
||||
</div>
|
||||
|
||||
为了修复这个问题,我们需要通过 `reexport_test_harness_main`属性来将生成的函数的名称更改为与`main`不同的名称。然后我们可以在我们的`_start`函数里调用这个重命名的函数:
|
||||
|
||||
@@ -109,11 +117,9 @@ pub extern "C" fn _start() -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
我们将测试框架的入口函数的名字设置为`test_main`,并在我们的 `_start`入口点里调用它。通过使用**条件编译**([conditional compilation]),我们能够只在上下文环境为测试(test)时调用`test_main`,因为该函数将不在非测试上下文中生成。
|
||||
我们将测试框架的入口函数的名字设置为`test_main`,并在我们的 `_start`入口点里调用它。通过使用**条件编译**([conditional compilation]),我们能够只在上下文环境为测试(test)时调用 `test_main` ,因为该函数将不在非测试上下文中生成。
|
||||
|
||||
[ conditional compilation ]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
|
||||
|
||||
现在当我们执行 `cargo xtest`时,我们可以看到我们的`test_runner`将"Running 0 tests"信息显示在屏幕上了。我们可以创建第一个测试函数了:
|
||||
现在当我们执行 `cargo test`时,我们可以看到我们的`test_runner`将"Running 0 tests"信息显示在屏幕上了。我们可以创建第一个测试函数了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
@@ -126,22 +132,22 @@ fn trivial_assertion() {
|
||||
}
|
||||
```
|
||||
|
||||
现在,当我们运行 `cargo xtest`时,我们可以看到如下输出:
|
||||
现在,当我们运行 `cargo test` 时,我们可以看到如下输出:
|
||||
|
||||
![QEMU printing "Hello World!", "Running 1 tests", and "trivial assertion... [ok]"](https://os.phil-opp.com/testing/qemu-test-runner-output.png)
|
||||
|
||||
传递给 `test_runner`函数的`tests`切片里包含了一个 `trivial_assertion` 函数的引用,从屏幕上输出的 `trivial assertion... [ok]`信息可见,我们的测试已被调用并且顺利通过。
|
||||
传递给 `test_runner`函数的`tests`切片里包含了一个 `trivial_assertion` 函数的引用,从屏幕上输出的 `trivial assertion... [ok]` 信息可见,我们的测试已被调用并且顺利通过。
|
||||
|
||||
在执行完tests后, `test_runner`会将结果返回给 `test_main`函数,而这个函数又返回到 `_start`入口点函数——这样我们就进入了一个死循环,因为入口点函数是不允许返回的。这将导致一个问题:我们希望`cargo xtest`在所有的测试运行完毕后,才返回并退出。
|
||||
在执行完tests后, `test_runner` 会将结果返回给 `test_main` 函数,而这个函数又返回到 `_start` 入口点函数——这样我们就进入了一个死循环,因为入口点函数是不允许返回的。这将导致一个问题:我们希望 `cargo test` 在所有的测试运行完毕后,直接返回并退出。
|
||||
|
||||
## 退出QEMU
|
||||
|
||||
现在我们在`_start`函数结束后进入了一个死循环,所以每次执行完`cargo xtest`后我们都需要手动去关闭QEMU;但是我们还想在没有用户交互的脚本环境下执行 `cargo xtest`。解决这个问题的最佳方式,是实现一个合适的方法来关闭我们的操作系统——不幸的是,这个方式实现起来相对有些复杂,因为这要求我们实现对[APM]或[ACPI]电源管理标准的支持。
|
||||
现在我们在 `_start` 函数结束后进入了一个死循环,所以每次执行完 `cargo test` 后我们都需要手动去关闭QEMU;但是我们还想在没有用户交互的脚本环境下执行 `cargo test`。解决这个问题的最佳方式,是实现一个合适的方法来关闭我们的操作系统——不幸的是,这个方式实现起来相对有些复杂,因为这要求我们实现对[APM]或[ACPI]电源管理标准的支持。
|
||||
|
||||
[APM]: https://wiki.osdev.org/APM
|
||||
[ACPI]: https://wiki.osdev.org/ACPI
|
||||
|
||||
幸运的是,还有一个绕开这些问题的办法:QEMU支持一种名为 `isa-debug-exit`的特殊设备,它提供了一种从客户系统(guest system)里退出QEMU的简单方式。为了使用这个设备,我们需要向QEMU传递一个`-device`参数。当然,我们也可以通过将 `package.metadata.bootimage.test-args` 配置关键字添加到我们的`Cargo.toml`来达到目的:
|
||||
幸运的是,还有一个绕开这些问题的办法:QEMU支持一种名为 `isa-debug-exit` 的特殊设备,它提供了一种从客户系统(guest system)里退出QEMU的简单方式。为了使用这个设备,我们需要向QEMU传递一个 `-device` 参数。当然,我们也可以通过将 `package.metadata.bootimage.test-args` 配置关键字添加到我们的 `Cargo.toml` 来达到目的:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
@@ -150,29 +156,29 @@ fn trivial_assertion() {
|
||||
test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
|
||||
```
|
||||
|
||||
`bootimage runner` 会在QEMU的默认测试命令后添加`test-args` 参数。(对于`cargo xrun`命令,这个参数会被忽略。)
|
||||
`bootimage runner` 会在QEMU的默认测试命令后添加 `test-args` 参数。(对于 `cargo run` 命令,这个参数会被忽略。)
|
||||
|
||||
在传递设备名 (`isa-debug-exit`)的同时,我们还传递了两个参数,`iobase` 和 `iosize` 。这两个参数指定了一个_I/O 端口_,我们的内核将通过它来访问设备。
|
||||
|
||||
### I/O 端口
|
||||
在x86平台上,CPU和外围硬件通信通常有两种方式,**内存映射I/O**和**端口映射I/O**。之前,我们已经使用内存映射的方式,通过内存地址`0xb8000`访问了[VGA文本缓冲区]。该地址并没有映射到RAM,而是映射到了VGA设备的一部分内存上。
|
||||
|
||||
在x86平台上,CPU和外围硬件通信通常有两种方式,**内存映射I/O**和**端口映射I/O**。之前,我们已经使用内存映射的方式,通过内存地址 `0xb8000` 访问了[VGA文本缓冲区]。该地址并没有映射到RAM,而是映射到了VGA设备的一部分内存上。
|
||||
|
||||
[VGA text buffer]: @/edition-2/posts/03-vga-text-buffer/index.md
|
||||
|
||||
与内存映射不同,端口映射I/O使用独立的I/O总线来进行通信。每个外围设备都有一个或数个端口号。CPU采用了特殊的`in`和`out`指令来和端口通信,这些指令要求一个端口号和一个字节的数据作为参数(有些这种指令的变体也允许发送`u16`或是`u32`长度的数据)。
|
||||
与内存映射不同,端口映射I/O使用独立的I/O总线来进行通信。每个外围设备都有一个或数个端口号。CPU采用了特殊的`in`和`out`指令来和端口通信,这些指令要求一个端口号和一个字节的数据作为参数(有些这种指令的变体也允许发送 `u16` 或是 `u32` 长度的数据)。
|
||||
|
||||
`isa-debug-exit`设备使用的就是端口映射I/O。其中, `iobase` 参数指定了设备对应的端口地址(在x86中,`0xf4`是一个[通常未被使用的端口][list of x86 I/O ports]),而`iosize`则指定了端口的大小(`0x04`代表4字节)。
|
||||
`isa-debug-exit` 设备使用的就是端口映射I/O。其中, `iobase` 参数指定了设备对应的端口地址(在x86中,`0xf4` 是一个[通常未被使用的端口][list of x86 I/O ports]),而 `iosize` 则指定了端口的大小(`0x04` 代表4字节)。
|
||||
|
||||
[list of x86 I/O ports]: https://wiki.osdev.org/I/O_Ports#The_list
|
||||
|
||||
### 使用退出(Exit)设备
|
||||
|
||||
`isa-debug-exit`设备的功能非常简单。当一个 `value`写入`iobase`指定的端口时,它会导致QEMU以**退出状态**([exit status])`(value << 1) | 1`退出。也就是说,当我们向端口写入`0`时,QEMU将以退出状态`(0 << 1) | 1 = 1`退出,而当我们向端口写入`1`时,它将以退出状态`(1 << 1) | 1 = 3`退出。
|
||||
`isa-debug-exit` 设备的功能非常简单。当一个 `value` 写入 `iobase` 指定的端口时,它会导致QEMU以**退出状态**([exit status])`(value << 1) | 1` 退出。也就是说,当我们向端口写入 `0` 时,QEMU将以退出状态 `(0 << 1) | 1 = 1` 退出,而当我们向端口写入`1`时,它将以退出状态 `(1 << 1) | 1 = 3` 退出。
|
||||
|
||||
[exit status]: https://en.wikipedia.org/wiki/Exit_status
|
||||
|
||||
这里我们使用 [`x86_64`] crate提供的抽象,而不是手动调用`in`或`out`指令。为了添加对该crate的依赖,我们可以将其添加到我们的 `Cargo.toml`中的 `dependencies` 小节中去:
|
||||
|
||||
这里我们使用 [`x86_64`] crate提供的抽象,而不是手动调用 `in` 或 `out` 指令。为了添加对该crate的依赖,我们可以将其添加到我们的 `Cargo.toml`中的 `dependencies` 小节中去:
|
||||
|
||||
[`x86_64`]: https://docs.rs/x86_64/0.14.2/x86_64/
|
||||
|
||||
@@ -183,7 +189,7 @@ test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
|
||||
x86_64 = "0.14.2"
|
||||
```
|
||||
|
||||
现在我们可以使用crate中提供的[`Port`] 类型来创建一个`exit_qemu` 函数了:
|
||||
现在我们可以使用crate中提供的 [`Port`] 类型来创建一个 `exit_qemu` 函数了:
|
||||
|
||||
[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
|
||||
|
||||
@@ -207,13 +213,15 @@ pub fn exit_qemu(exit_code: QemuExitCode) {
|
||||
}
|
||||
```
|
||||
|
||||
该函数在`0xf4`处创建了一个新的端口,该端口同时也是 `isa-debug-exit` 设备的 `iobase` 。然后它会向端口写入传递的退出代码。这里我们使用`u32`来传递数据,因为我们之前已经将 `isa-debug-exit`设备的 `iosize` 指定为4字节了。上述两个操作都是`unsafe`的,因为I/O端口的写入操作通常会导致一些不可预知的行为。
|
||||
该函数在 `0xf4` 处创建了一个新的端口,该端口同时也是 `isa-debug-exit` 设备的 `iobase` 。然后它会向端口写入传递的退出代码。这里我们使用 `u32` 来传递数据,因为我们之前已经将 `isa-debug-exit` 设备的 `iosize` 指定为4字节了。上述两个操作都是 `unsafe` 的,因为I/O端口的写入操作通常会导致一些不可预知的行为。
|
||||
|
||||
为了指定退出状态,我们创建了一个 `QemuExitCode`枚举。思路大体上是,如果所有的测试均成功,就以成功退出码退出;否则就以失败退出码退出。这个枚举类型被标记为 `#[repr(u32)]`,代表每个变量都是一个`u32`的整数类型。我们使用退出代码`0x10`代表成功,`0x11`代表失败。 实际的退出代码并不重要,只要它们不与QEMU的默认退出代码冲突即可。 例如,使用退出代码0表示成功可能并不是一个好主意,因为它在转换后就变成了`(0 << 1) | 1 = 1` ,而`1`是QEMU运行失败时的默认退出代码。 这样,我们就无法将QEMU错误与成功的测试运行区分开来了。
|
||||
为了指定退出状态,我们创建了一个 `QemuExitCode` 枚举。思路大体上是,如果所有的测试均成功,就以成功退出码退出;否则就以失败退出码退出。这个枚举类型被标记为 `#[repr(u32)]`,代表每个变量都是一个 `u32` 的整数类型。我们使用退出代码 `0x10` 代表成功,`0x11` 代表失败。 实际的退出代码并不重要,只要它们不与QEMU的默认退出代码冲突即可。 例如,使用退出代码0表示成功可能并不是一个好主意,因为它在转换后就变成了 `(0 << 1) | 1 = 1` ,而 `1` 是QEMU运行失败时的默认退出代码。 这样,我们就无法将QEMU错误与成功的测试运行区分开来了。
|
||||
|
||||
现在我们来更新`test_runner`的代码,让程序在运行所有测试完毕后退出QEMU:
|
||||
现在我们来更新 `test_runner` 的代码,让程序在运行所有测试完毕后退出QEMU:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
@@ -224,10 +232,10 @@ fn test_runner(tests: &[&dyn Fn()]) {
|
||||
}
|
||||
```
|
||||
|
||||
当我们现在运行`cargo xtest`时,QEMU会在测试运行后立刻退出。现在的问题是,即使我们传递了表示成功(`Success`)的退出代码, `cargo test`依然会将所有的测试都视为失败:
|
||||
当我们现在运行 `cargo test` 时,QEMU会在测试运行后立刻退出。现在的问题是,即使我们传递了表示成功(`Success`)的退出代码, `cargo test` 依然会将所有的测试都视为失败:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
> cargo test
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-5804fc7d2dd4c9be
|
||||
Building bootloader
|
||||
@@ -239,39 +247,41 @@ Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/d
|
||||
error: test failed, to rerun pass '--bin blog_os'
|
||||
```
|
||||
|
||||
这里的问题在于,`cargo test`会将所有非`0`的错误码都视为测试失败。
|
||||
这里的问题在于,`cargo test` 会将所有非 `0` 的错误码都视为测试失败。
|
||||
|
||||
### 成功退出(Exit)代码
|
||||
|
||||
为了解决这个问题, `bootimage`提供了一个 `test-success-exit-code`配置项,可以将指定的退出代码映射到退出代码`0`:
|
||||
为了解决这个问题, `bootimage` 提供了一个 `test-success-exit-code` 配置项,可以将指定的退出代码映射到退出代码 `0`:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = […]
|
||||
test-success-exit-code = 33 # (0x10 << 1) | 1
|
||||
```
|
||||
|
||||
有了这个配置,`bootimage`就会将我们的成功退出码映射到退出码0;这样一来, `cargo xtest`就能正确的识别出测试成功的情况,而不会将其视为测试失败。
|
||||
有了这个配置,`bootimage` 就会将我们的成功退出码映射到退出码0;这样一来, `cargo test` 就能正确地识别出测试成功的情况,而不会将其视为测试失败。
|
||||
|
||||
我们的测试runner现在会在正确报告测试结果后自动关闭QEMU。我们可以看到QEMU的窗口只会显示很短的时间——我们不容易看清测试的结果。如果测试结果会打印在控制台上而不是QEMU里,让我们能在QEMU退出后仍然能看到测试结果就好了。
|
||||
我们的 test runner 现在会在正确报告测试结果后自动关闭QEMU。我们可以看到QEMU的窗口只会显示很短的时间——我们很难看清测试的结果。如果测试结果会打印在控制台上而不是QEMU里,让我们能在QEMU退出后仍然能看到测试结果就好了。
|
||||
|
||||
## 打印到控制台
|
||||
|
||||
要在控制台上查看测试输出,我们需要以某种方式将数据从内核发送到宿主系统。 有多种方法可以实现这一点,例如通过TCP网络接口来发送数据。但是,设置网络堆栈是一项很复杂的任务——这里我们选择更简单的解决方案。
|
||||
要在控制台上查看测试输出,我们需要以某种方式将数据从内核发送到宿主系统。 有多种方法可以实现这一点,例如通过TCP网络接口来发送数据。但是,设置网络堆栈是一项很复杂的任务,这里我们可以选择更简单的解决方案。
|
||||
|
||||
### 串口
|
||||
|
||||
发送数据的一个简单的方式是通过[串行端口],这是一个现代电脑中已经不存在的旧标准接口(译者注:玩过单片机的同学应该知道,其实译者上大学的时候有些同学的笔记本电脑还有串口的,没有串口的同学在烧录单片机程序的时候也都会需要usb转串口线,一般是51,像stm32有st-link,这个另说,不过其实也可以用串口来下载)。串口非常易于编程,QEMU可以将通过串口发送的数据重定向到宿主机的标准输出或是文件中。
|
||||
发送数据的一个简单的方式是通过[串行端口][serial port],这是一个现代电脑中已经不存在的旧标准接口(译者注:玩过单片机的同学应该知道,其实译者上大学的时候有些同学的笔记本电脑还有串口的,没有串口的同学在烧录单片机程序的时候也都会需要usb转串口线,一般是51,像stm32有st-link,这个另说,不过其实也可以用串口来下载)。串口非常易于编程,QEMU可以将通过串口发送的数据重定向到宿主机的标准输出或是文件中。
|
||||
|
||||
[串行端口]: https://en.wikipedia.org/wiki/Serial_port
|
||||
[serial port]: https://en.wikipedia.org/wiki/Serial_port
|
||||
|
||||
用来实现串行接口的芯片被称为 [UARTs]。在x86上,有[很多UART模型],但是幸运的是,它们之间仅有的那些不同之处都是我们用不到的高级功能。目前通用的UARTs都会兼容[16550 UART],所以我们在我们测试框架里采用该模型。
|
||||
用来实现串行接口的芯片被称为 [UARTs]。在x86上,有[很多UART模型][lots of UART models],但是幸运的是,它们之间仅有的那些不同之处都是我们用不到的高级功能。目前通用的UARTs都会兼容[16550 UART],所以我们在我们测试框架里采用该模型。
|
||||
|
||||
[UARTs]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter
|
||||
[很多UART模型]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
|
||||
[lots of UART models]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
|
||||
[16550 UART]: https://en.wikipedia.org/wiki/16550_UART
|
||||
|
||||
我们使用[`uart_16550`] crate来初始化UART,并通过串口来发送数据。为了将该crate添加为依赖,我们将我们的`Cargo.toml`和`main.rs`修改为如下:
|
||||
我们使用 [`uart_16550`] crate来初始化UART,并通过串口来发送数据。为了将该crate添加为依赖,我们需要将 `Cargo.toml` 和 `main.rs` 修改为如下:
|
||||
|
||||
[`uart_16550`]: https://docs.rs/uart_16550
|
||||
|
||||
@@ -282,7 +292,7 @@ test-success-exit-code = 33 # (0x10 << 1) | 1
|
||||
uart_16550 = "0.2.0"
|
||||
```
|
||||
|
||||
`uart_16550` crate包含了一个代表UART寄存器的`SerialPort`结构体,但是我们仍然需要自己来创建一个相应的实例。我们使用以下内容来创建一个新的串口模块`serial`:
|
||||
`uart_16550` crate包含了一个代表UART寄存器的 `SerialPort` 结构体,但是我们仍然需要自己来创建一个相应的实例。我们使用以下代码来创建一个新的串口模块 `serial`:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
@@ -306,15 +316,17 @@ lazy_static! {
|
||||
}
|
||||
```
|
||||
|
||||
就像[VGA文本缓冲区][vga lazy-static]一样,我们使用 `lazy_static` 和一个自旋锁来创建一个 `static` writer实例。通过使用 `lazy_static` ,我们可以保证`init`方法只会在该示例第一次被使用使被调用。
|
||||
就像[VGA文本缓冲区][vga lazy-static]一样,我们使用 `lazy_static` 和一个自旋锁来创建一个 `static` writer实例。通过使用 `lazy_static` ,我们可以保证 `init` 方法只会在该示例第一次被使用使被调用。
|
||||
|
||||
和 `isa-debug-exit`设备一样,UART也是用过I/O端口进行编程的。由于UART相对来讲更加复杂,它使用多个I/O端口来对不同的设备寄存器进行编程。不安全的`SerialPort::new`函数需要UART的第一个I/O端口的地址作为参数,从该地址中可以计算出所有所需端口的地址。我们传递的端口地址为`0x3F8` ,该地址是第一个串行接口的标准端口号。
|
||||
和 `isa-debug-exit` 设备一样,UART也是通过I/O端口进行编程的。由于UART相对来讲更加复杂,它使用多个I/O端口来对不同的设备寄存器进行编程。`unsafe` 的 `SerialPort::new` 函数需要UART的第一个I/O端口的地址作为参数,从该地址中可以计算出所有所需端口的地址。我们传递的端口地址为 `0x3F8` ,该地址是第一个串行接口的标准端口号。
|
||||
|
||||
[vga lazy-static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
|
||||
|
||||
为了使串口更加易用,我们添加了 `serial_print!` 和 `serial_println!`宏:
|
||||
|
||||
```rust
|
||||
// in src/serial.rs
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: ::core::fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
@@ -339,7 +351,7 @@ macro_rules! serial_println {
|
||||
}
|
||||
```
|
||||
|
||||
该实现和我们此前的`print`和`println`宏的实现非常类似。 由于`SerialPort`类型已经实现了`fmt::Write` trait,所以我们不需要提供我们自己的实现了。
|
||||
该实现和我们此前的 `print` 和 `println` 宏的实现非常类似。 由于 `SerialPort` 类型已经实现了 [`fmt::Write`] trait,所以我们不需要提供我们自己的实现了。
|
||||
|
||||
[`fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
|
||||
|
||||
@@ -362,11 +374,11 @@ fn trivial_assertion() {
|
||||
}
|
||||
```
|
||||
|
||||
注意,由于我们使用了 `#[macro_export]` 属性, `serial_println`宏直接位于根命名空间下——所以通过`use crate::serial::serial_println` 来导入该宏是不起作用的。
|
||||
注意,由于我们使用了 `#[macro_export]` 属性, `serial_println` 宏直接位于根命名空间下,所以通过 `use crate::serial::serial_println` 来导入该宏是不起作用的。
|
||||
|
||||
### QEMU参数
|
||||
|
||||
为了查看QEMU的串行输出,我们需要使用`-serial`参数将输出重定向到stdout:
|
||||
为了查看QEMU的串行输出,我们需要使用 `-serial` 参数将输出重定向到stdout:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
@@ -377,10 +389,10 @@ test-args = [
|
||||
]
|
||||
```
|
||||
|
||||
现在,当我们运行 `cargo xtest`时,我们可以直接在控制台里看到测试输出了:
|
||||
现在,当我们运行 `cargo test` 时,我们可以直接在控制台里看到测试输出了:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
> cargo test
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
|
||||
Building bootloader
|
||||
@@ -392,7 +404,7 @@ Running 1 tests
|
||||
trivial assertion... [ok]
|
||||
```
|
||||
|
||||
然而,当测试失败时,我们仍然会在QEMU内看到输出结果,因为我们的panic handler还是用了`println`。为了模拟这个过程,我们将我们的 `trivial_assertion` test中的断言(assertion)修改为 `assert_eq!(0, 1)`:
|
||||
然而,当测试失败时,我们仍然会在QEMU内看到输出结果,因为我们的panic handler还是用了 `println`。为了模拟这个过程,我们将我们的 `trivial_assertion` test中的断言(assertion)修改为 `assert_eq!(0, 1)`:
|
||||
|
||||
|
||||
@@ -406,6 +418,8 @@ trivial assertion... [ok]
|
||||
[conditional compilation]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
// our existing panic handler
|
||||
#[cfg(not(test))] // new attribute
|
||||
#[panic_handler]
|
||||
@@ -425,12 +439,12 @@ fn panic(info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
在我们的测试panic处理中,我们用 `serial_println`来代替`println` 并使用失败代码来退出QEMU。注意,在`exit_qemu`调用后,我们仍然需要一个无限循环的`loop`因为编译器并不知道 `isa-debug-exit`设备会导致程序退出。
|
||||
在我们的测试panic处理中,我们用 `serial_println` 来代替 `println` 并使用失败代码来退出QEMU。注意,在 `exit_qemu` 调用后,我们仍然需要一个无限循环的 `loop` 因为编译器并不知道 `isa-debug-exit` 设备会导致程序退出。
|
||||
|
||||
现在,即使在测试失败的情况下QEMU仍然会存在,并会将一些有用的错误信息打印到控制台:
|
||||
现在,即使在测试失败的情况下QEMU仍然会退出,并会将一些有用的错误信息打印到控制台:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
> cargo test
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
|
||||
Building bootloader
|
||||
@@ -450,7 +464,7 @@ Error: panicked at 'assertion failed: `(left == right)`
|
||||
|
||||
### 隐藏 QEMU
|
||||
|
||||
由于我们使用`isa-debug-exit`设备和串行端口来报告完整的测试结果,所以我们不再需要QMEU的窗口了。我们可以通过向QEMU传递 `-display none`参数来将其隐藏:
|
||||
由于我们使用 `isa-debug-exit` 设备和串行端口来报告完整的测试结果,所以我们不再需要QEMU的窗口了。我们可以通过向QEMU传递 `-display none` 参数来将其隐藏:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
@@ -462,23 +476,22 @@ test-args = [
|
||||
]
|
||||
```
|
||||
|
||||
现在QEMU完全在后台运行且没有任何窗口会被打开。这不仅不那么烦人,还允许我们的测试框架在没有图形界面的环境里,诸如CI服务器或是[SSH]连接里运行。
|
||||
现在QEMU完全在后台运行,且没有任何窗口会被打开。这不仅很清爽,还允许我们的测试框架在没有图形界面的环境里,诸如CI服务器或是[SSH]连接里运行。
|
||||
|
||||
[SSH]: https://en.wikipedia.org/wiki/Secure_Shell
|
||||
|
||||
### 超时
|
||||
|
||||
由于 `cargo xtest` 会等待test runner退出,如果一个测试永远不返回那么它就会一直阻塞test runner。幸运的是,在实际应用中这并不是一个大问题,因为无限循环通常是很容易避免的。在我们的这个例子里,无限循环会发生在以下几种不同的情况中:
|
||||
|
||||
由于 `cargo test` 会等待test runner退出,如果一个测试永远不返回那么它就会一直阻塞test runner。幸运的是,在实际应用中这并不是一个大问题,因为无限循环通常是很容易避免的。在我们的这个例子里,无限循环会发生在以下几种不同的情况中:
|
||||
|
||||
- bootloader加载内核失败,导致系统不停重启;
|
||||
- BIOS/UEFI固件加载bootloader失败,同样会导致无限重启;
|
||||
- CPU在某些函数结束时进入一个`loop {}`语句,例如因为QEMU的exit设备无法正常工作而导致死循环;
|
||||
- CPU在某些函数结束时进入一个 `loop {}` 语句,例如因为QEMU的exit设备无法正常工作而导致死循环;
|
||||
- 硬件触发了系统重置,例如未捕获CPU异常时(后续的文章将会详细解释)。
|
||||
|
||||
由于无限循环可能会在各种情况中发生,因此, `bootimage` 工具默认为每个可执行测试设置了一个长度为5分钟的超时时间。如果测试未在此时间内完成,则将其标记为失败,并向控制台输出"Timed Out(超时)"错误。这个功能确保了那些卡在无限循环里的测试不会一直阻塞`cargo xtest`。
|
||||
由于无限循环可能会在各种情况中发生,因此, `bootimage` 工具默认为每个可执行测试设置了一个长度为5分钟的超时时间。如果测试未在此时间内完成,则将其标记为失败,并向控制台输出"Timed Out(超时)"错误。这个功能确保了那些卡在无限循环里的测试不会一直阻塞 `cargo test`。
|
||||
|
||||
你可以将`loop {}`语句添加到 `trivial_assertion`测试中来进行尝试。当你运行 `cargo xtest`时,你可以发现该测试会在五分钟后被标记为超时。超时持续的时间可以通过Cargo.toml中的`test-timeout`来进行[配置][bootimage config]:
|
||||
你可以将`loop {}`语句添加到 `trivial_assertion` 测试中来进行尝试。当你运行 `cargo test` 时,你可以发现该测试会在五分钟后被标记为超时。超时持续的时间可以通过Cargo.toml中的 `test-timeout` 配置项来进行[配置][bootimage config]:
|
||||
|
||||
[bootimage config]: https://github.com/rust-osdev/bootimage#configuration
|
||||
|
||||
@@ -489,9 +502,93 @@ test-args = [
|
||||
test-timeout = 300 # (in seconds)
|
||||
```
|
||||
|
||||
如果你不想为了观察`trivial_assertion` 测试超时等待5分钟之久,你可以暂时降低将上述值。
|
||||
如果你不想为了观察 `trivial_assertion` 测试超时等待5分钟之久,你可以将这个配置数值调低一些。
|
||||
|
||||
此后,我们不再需要 `trivial_assertion` 测试,所以我们可以将其删除。
|
||||
### 自动添加打印语句
|
||||
|
||||
`trivial_assertion` 测试仅能使用 `serial_print!`/`serial_println!` 输出自己的状态信息:
|
||||
|
||||
```rust
|
||||
#[test_case]
|
||||
fn trivial_assertion() {
|
||||
serial_print!("trivial assertion... ");
|
||||
assert_eq!(1, 1);
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
为每一个测试手动添加固定的日志实在是太烦琐了,所以我们可以修改一下 `test_runner` 把这部分逻辑改进一下,使其可以自动添加日志输出。那么我们先建立一个 `Testable` trait:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
pub trait Testable {
|
||||
fn run(&self) -> ();
|
||||
}
|
||||
```
|
||||
|
||||
下面这个 trick 将会实现上面书写的 trait,并约束只有满足 [`Fn()` trait] 的泛型可使用这个实现:
|
||||
|
||||
[`Fn()` trait]: https://doc.rust-lang.org/stable/core/ops/trait.Fn.html
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
impl<T> Testable for T
|
||||
where
|
||||
T: Fn(),
|
||||
{
|
||||
fn run(&self) {
|
||||
serial_print!("{}...\t", core::any::type_name::<T>());
|
||||
self();
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们实现的 `run` 函数中,首先使用 [`any::type_name`] 输出了函数名,这个函数事实上是被编译器实现的,可以返回任意类型的字符串形式。对于函数而言,其类型的字符串形式就是它的函数名,而函数名也正是我们想要的测试用例名称。至于 `\t` 则代表 [制表符][tab character],其作用是为后面的 `[ok]` 输出增加一点左边距。
|
||||
|
||||
[`any::type_name`]: https://doc.rust-lang.org/stable/core/any/fn.type_name.html
|
||||
[tab character]: https://en.wikipedia.org/wiki/Tab_key#Tab_characters
|
||||
|
||||
输出函数名之后,我们通过 `self()` 调用了测试函数本身,该调用方式属于 `Fn()` trait 独有,如果测试函数顺利执行完毕,则 `[ok]` 也会被输出出来。
|
||||
|
||||
最后一步就是给 `test_runner` 的参数附加上 `Testable` trait:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[cfg(test)]
|
||||
pub fn test_runner(tests: &[&dyn Testable]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test.run(); // new
|
||||
}
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
```
|
||||
|
||||
仅有的两处修改,就是将 `tests` 参数的类型从 `&[&dyn Fn()]` 改为了 `&[&dyn Testable]`,以及将函数调用方式从 `test()` 改成了 `test.run()`。
|
||||
|
||||
由于我们已经完成了首尾输出的自动化,所以 `trivial_assertion` 里那两行输出语句也就可以删掉了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[test_case]
|
||||
fn trivial_assertion() {
|
||||
assert_eq!(1, 1);
|
||||
}
|
||||
```
|
||||
|
||||
现在 `cargo test` 的输出就变成了下面这样:
|
||||
|
||||
```
|
||||
Running 1 tests
|
||||
blog_os::trivial_assertion... [ok]
|
||||
```
|
||||
|
||||
如你所见,自动生成的函数名包含了完整的内部路径,但是也因此可以区分不同模块下的同名函数。除此之外,其输出和之前看起来完全相同,我们也就不再需要在测试函数内部加输出语句了。
|
||||
|
||||
## 测试VGA缓冲区
|
||||
|
||||
@@ -500,18 +597,13 @@ test-timeout = 300 # (in seconds)
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[cfg(test)]
|
||||
use crate::{serial_print, serial_println};
|
||||
|
||||
#[test_case]
|
||||
fn test_println_simple() {
|
||||
serial_print!("test_println... ");
|
||||
println!("test_println_simple output");
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
这个测试所做的仅仅是将一些内容打印到VGA缓冲区。如果它正常结束并且没有panic,也就意味着`println`调用也没有panic。由于我们只需要将 `serial_println` 导入到测试模式里,所以我们添加了 `cfg(test)` 属性(attribute)来避免正常模式下 `cargo xbuild`会出现的未使用导入警告(unused import warning)。
|
||||
这个测试所做的仅仅是将一些内容打印到VGA缓冲区。如果它正常结束并且没有panic,也就意味着 `println` 调用也没有panic。
|
||||
|
||||
为了确保即使打印很多行且有些行超出屏幕的情况下也没有panic发生,我们可以创建另一个测试:
|
||||
|
||||
@@ -520,11 +612,9 @@ fn test_println_simple() {
|
||||
|
||||
#[test_case]
|
||||
fn test_println_many() {
|
||||
serial_print!("test_println_many... ");
|
||||
for _ in 0..200 {
|
||||
println!("test_println_many output");
|
||||
}
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
@@ -535,22 +625,18 @@ fn test_println_many() {
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
serial_print!("test_println_output... ");
|
||||
|
||||
let s = "Some test string that fits on a single line";
|
||||
println!("{}", s);
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
该函数定义了一个测试字符串,并通过 `println`将其输出,然后遍历静态 `WRITER`也就是vga字符缓冲区的屏幕字符。由于`println`在将字符串打印到屏幕上最后一行后会立刻附加一个新行(即输出完后有一个换行符),所以这个字符串应该会出现在第 `BUFFER_HEIGHT - 2`行。
|
||||
该函数定义了一个测试字符串,并通过 `println`将其输出,然后遍历静态 `WRITER` 也就是vga字符缓冲区的屏幕字符。由于 `println` 在将字符串打印到屏幕上最后一行后会立刻附加一个新行(即输出完后有一个换行符),所以这个字符串应该会出现在第 `BUFFER_HEIGHT - 2`行。
|
||||
|
||||
通过使用[`enumerate`] ,我们统计了变量`i`的迭代次数,然后用它来加载对应于`c`的屏幕字符。 通过比较屏幕字符的`ascii_character`和`c` ,我们可以确保字符串的每个字符确实出现在vga文本缓冲区中。
|
||||
通过使用[`enumerate`] ,我们统计了变量 `i` 的迭代次数,然后用它来加载对应于`c`的屏幕字符。 通过比较屏幕字符的 `ascii_character` 和 `c` ,我们可以确保字符串的每个字符确实出现在vga文本缓冲区中。
|
||||
|
||||
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
|
||||
|
||||
@@ -558,14 +644,13 @@ fn test_println_output() {
|
||||
|
||||
在这篇文章的剩余部分,我们还会解释如何创建一个_集成测试_以测试不同组建之间的交互。
|
||||
|
||||
|
||||
## 集成测试
|
||||
|
||||
在Rust中,**集成测试**([integration tests])的约定是将其放到项目根目录中的`tests`目录下(即`src`的同级目录)。无论是默认测试框架还是自定义测试框架都将自动获取并执行该目录下所有的测试。
|
||||
在Rust中,**集成测试**([integration tests])的约定是将其放到项目根目录中的 `tests` 目录下(即 `src` 的同级目录)。无论是默认测试框架还是自定义测试框架都将自动获取并执行该目录下所有的测试。
|
||||
|
||||
[integration tests]: https://doc.rust-lang.org/book/ch11-03-test-organization.html#integration-tests
|
||||
|
||||
所有的集成测试都是它们自己的可执行文件,并且与我们的`main.rs`完全独立。这也就意味着每个测试都需要定义它们自己的函数入口点。让我们创建一个名为`basic_boot`的例子来看看集成测试的工作细节吧:
|
||||
所有的集成测试都是它们自己的可执行文件,并且与我们的 `main.rs` 完全独立。这也就意味着每个测试都需要定义它们自己的函数入口点。让我们创建一个名为 `basic_boot` 的例子来看看集成测试的工作细节吧:
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
@@ -595,26 +680,28 @@ fn panic(info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
由于集成测试都是单独的可执行文件,所以我们需要再次提供所有的crate属性(`no_std`, `no_main`, `test_runner`, 等等)。我们还需要创建一个新的入口点函数`_start`,用于调用测试入口函数`test_main`。我们不需要任何的`cfg(test)` attributes(属性),因为集成测试的二进制文件在非测试模式下根本不会被编译构建。
|
||||
由于集成测试都是单独的可执行文件,所以我们需要再次提供所有的crate属性(`no_std`, `no_main`, `test_runner`, 等等)。我们还需要创建一个新的入口点函数 `_start`,用于调用测试入口函数 `test_main`。我们不需要任何的 `cfg(test)` 属性,因为集成测试的二进制文件在非测试模式下根本不会被编译构建。
|
||||
|
||||
这里我们采用[`unimplemented`]宏,充当`test_runner`暂未实现的占位符;添加简单的`loop {}`循环,作为`panic`处理器的内容。理想情况下,我们希望能向我们在`main.rs`里所做的一样使用`serial_println`宏和`exit_qemu`函数来实现这个函数。但问题是,由于这些测试的构建和我们的`main.rs`的可执行文件是完全独立的,我们没有办法使用这些函数。
|
||||
这里我们采用[`unimplemented`]宏,充当 `test_runner` 暂未实现的占位符;添加简单的 `loop {}` 循环,作为 `panic` 处理器的内容。理想情况下,我们希望能向我们在 `main.rs` 里所做的一样使用 `serial_println` 宏和 `exit_qemu` 函数来实现这个函数。但问题是,由于这些测试的构建和我们的 `main.rs` 的可执行文件是完全独立的,我们没有办法使用这些函数。
|
||||
|
||||
[`unimplemented`]: https://doc.rust-lang.org/core/macro.unimplemented.html
|
||||
|
||||
如果现阶段你运行`cargo xtest`,你将进入一个无限循环,因为目前panic的处理就是进入无限循环。你需要使用快捷键`Ctrl+c`,才可以退出QEMU。
|
||||
如果现阶段你运行 `cargo test`,你将进入一个无限循环,因为目前panic的处理就是进入无限循环。你需要使用快捷键 `Ctrl+c`,才可以退出QEMU。
|
||||
|
||||
### 创建一个库
|
||||
为了让这些函数能在我们的集成测试中使用,我们需要从我们的`main.rs`中分割出一个库,这个库应当可以被其他的crate和集成测试可执行文件使用。为了达成这个目的,我们创建了一个新文件,`src/lib.rs`:
|
||||
|
||||
为了让这些函数能在我们的集成测试中使用,我们需要从我们的 `main.rs` 中分割出一个库,这个库应当可以被其他的crate和集成测试可执行文件使用。为了达成这个目的,我们创建了一个新文件,`src/lib.rs`:
|
||||
|
||||
```rust
|
||||
// src/lib.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
```
|
||||
|
||||
和`main.rs`一样,`lib.rs`也是一个可以被cargo自动识别的特殊文件。该库是一个独立的编译单元,所以我们需要再次指定`#![no_std]` 属性。
|
||||
和 `main.rs` 一样,`lib.rs` 也是一个可以被cargo自动识别的特殊文件。该库是一个独立的编译单元,所以我们需要再次指定 `#![no_std]` 属性。
|
||||
|
||||
为了让我们的库可以和`cargo xtest`一起协同工作,我们还需要移动以下测试函数和属性:
|
||||
为了让我们的库可以和 `cargo test` 一起协同工作,我们还需要移动以下测试函数和属性:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
@@ -626,10 +713,25 @@ fn panic(info: &PanicInfo) -> ! {
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
pub fn test_runner(tests: &[&dyn Fn()]) {
|
||||
pub trait Testable {
|
||||
fn run(&self) -> ();
|
||||
}
|
||||
|
||||
impl<T> Testable for T
|
||||
where
|
||||
T: Fn(),
|
||||
{
|
||||
fn run(&self) {
|
||||
serial_print!("{}...\t", core::any::type_name::<T>());
|
||||
self();
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
}
|
||||
|
||||
pub fn test_runner(tests: &[&dyn Testable]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
test.run();
|
||||
}
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
@@ -641,7 +743,7 @@ pub fn test_panic_handler(info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// Entry point for `cargo xtest`
|
||||
/// Entry point for `cargo test`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
@@ -656,13 +758,13 @@ fn panic(info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
为了能在可执行文件和集成测试中使用`test_runner`,我们不对其应用`cfg(test)` attribute(属性),并将其设置为public。同时,我们还将panic的处理程序分解为public函数`test_panic_handler`,这样一来它也可以用于可执行文件了。
|
||||
为了能在可执行文件和集成测试中使用 `test_runner`,我们不对其应用 `cfg(test)` 属性,并将其设置为public。同时,我们还将panic的处理程序分解为public函数 `test_panic_handler`,这样一来它也可以用于可执行文件了。
|
||||
|
||||
由于我们的`lib.rs`是独立于`main.rs`进行测试的,因此当该库实在测试模式下编译时我们需要添加一个`_start`入口点和一个panic处理程序。通过使用[`cfg_attr`] ,我们可以在这种情况下有条件地启用`no_main` 属性。
|
||||
由于我们的 `lib.rs` 是独立于 `main.rs` 进行测试的,因此当该库实在测试模式下编译时我们需要添加一个 `_start` 入口点和一个panic处理程序。通过使用[`cfg_attr`] ,我们可以在这种情况下有条件地启用 `no_main` 属性。
|
||||
|
||||
[`cfg_attr`]: https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute
|
||||
|
||||
我们还将`QemuExitCode`枚举和`exit_qemu`函数从main.rs移动过来,并将其设置为公有函数:
|
||||
我们还将 `QemuExitCode` 枚举和 `exit_qemu` 函数从main.rs移动过来,并将其设置为公有函数:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
@@ -684,7 +786,7 @@ pub fn exit_qemu(exit_code: QemuExitCode) {
|
||||
}
|
||||
```
|
||||
|
||||
现在,可执行文件和集成测试都可以从库中导入这些函数,而不需要实现自己的定义。为了使`println` 和 `serial_println`可用,我们将以下的模块声明代码也移动到`lib.rs`中:
|
||||
现在,可执行文件和集成测试都可以从库中导入这些函数,而不需要实现自己的定义。为了使 `println` 和 `serial_println` 可用,我们将以下的模块声明代码也移动到 `lib.rs` 中:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
@@ -693,9 +795,9 @@ pub mod serial;
|
||||
pub mod vga_buffer;
|
||||
```
|
||||
|
||||
我们将这些模块设置为public(公有),这样一来我们在库的外部也一样能使用它们了。由于这两者都用了该模块内的`_print`函数,所以这也是让`println` 和 `serial_println`宏可用的必要条件。
|
||||
我们将这些模块设置为public(公有),这样一来我们在库的外部也一样能使用它们了。由于这两者都用了该模块内的 `_print` 函数,所以这也是让 `println` 和 `serial_println` 宏可用的必要条件。
|
||||
|
||||
现在我们修改我们的`main.rs`代码来使用该库:
|
||||
现在我们修改我们的 `main.rs` 代码来使用该库:
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
@@ -734,13 +836,13 @@ fn panic(info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,这个库用起来就像一个普通的外部crate。它的调用方法与其它crate无异;在我们的这个例子中,位置可能为`blog_os`。上述代码使用了`test_runner` attribute中的`blog_os::test_runner`函数和`cfg(test)`的panic处理中的`blog_os::test_panic_handler`函数。它还导入了`println`宏,这样一来,我们可以在我们的`_start` 和 `panic`中使用它了。
|
||||
可以看到,这个库用起来就像一个普通的外部crate。它的调用方法与其它crate无异;在我们的这个例子中,位置可能为 `blog_os`。上述代码使用了 `test_runner` 属性中的 `blog_os::test_runner` 函数和 `cfg(test)` 的panic处理中的 `blog_os::test_panic_handler` 函数。它还导入了 `println` 宏,这样一来,我们可以在我们的 `_start` 和 `panic` 中使用它了。
|
||||
|
||||
与此同时,`cargo xrun` 和 `cargo xtest`可以再次正常工作了。当然了,`cargo xtest`仍然会进入无限循环(你可以通过`ctrl+c`来退出)。接下来让我们在我们的集成测试中通过所需要的库函数来修复这个问题吧。
|
||||
与此同时,`cargo run` 和 `cargo test`可以再次正常工作了。当然了,`cargo test`仍然会进入无限循环(你可以通过`ctrl+c`来退出),接下来我们将在集成测试中通过所需要的库函数来修复这个问题。
|
||||
|
||||
### 完成集成测试
|
||||
|
||||
就像我们的`src/main.rs`,我们的`tests/basic_boot.rs`可执行文件同样可以从我们的新库中导入类型。这也就意味着我们可以导入缺失的组件来完成我们的测试。
|
||||
就像我们的 `src/main.rs`,我们的 `tests/basic_boot.rs` 可执行文件同样可以从我们的新库中导入类型。这也就意味着我们可以导入缺失的组件来完成我们的测试。
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
@@ -753,50 +855,48 @@ fn panic(info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
这里我们使用我们的库中的`test_runner`函数,而不是重新实现一个test runner。至于panic处理,调用`blog_os::test_panic_handler`函数即可,就像我们之前在我们的`main.rs`里面做的一样。
|
||||
这里我们使用我们的库中的 `test_runner` 函数,而不是重新实现一个test runner。至于panic处理,调用 `blog_os::test_panic_handler` 函数即可,就像我们之前在我们的 `main.rs` 里面做的一样。
|
||||
|
||||
现在,`cargo xtest`又可以正常退出了。当你运行该命令时,你会发现它为我们的`lib.rs`, `main.rs`, 和 `basic_boot.rs`分别构建并运行了测试。其中,对于 `main.rs` 和 `basic_boot`的集成测试,它会报告"Running 0 tests"(正在运行0个测试),因为这些文件里面没有任何用 `#[test_case]`标注的函数。
|
||||
现在,`cargo test`又可以正常退出了。当你运行该命令时,你会发现它为我们的 `lib.rs`, `main.rs`, 和 `basic_boot.rs` 分别构建并运行了测试。其中,对于 `main.rs` 和 `basic_boot` 的集成测试,它会报告"Running 0 tests"(正在运行0个测试),因为这些文件里面没有任何用 `#[test_case]`标注的函数。
|
||||
|
||||
现在我们可以在`basic_boot.rs`中添加测试了。举个例子,我们可以测试`println`是否能够正常工作而不panic,就像我们之前在vga缓冲区测试中做的那样:
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
use blog_os::{println, serial_print, serial_println};
|
||||
use blog_os::println;
|
||||
|
||||
#[test_case]
|
||||
fn test_println() {
|
||||
serial_print!("test_println... ");
|
||||
println!("test_println output");
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
现在当我们运行`cargo xtest`时,我们可以看到它会寻找并执行这些测试函数。
|
||||
现在当我们运行`cargo test`时,我们可以看到它会寻找并执行这些测试函数。
|
||||
|
||||
由于该测试和vga缓冲区测试中的一个几乎完全相同,所以目前它看起来似乎没什么用。然而,在将来,我们的`main.rs`和`lib.rs`中的`_start`函数的内容会不断增长,并且在运行`test_main`之前需要调用一系列的初始化进程,所以这两个测试将会运行在完全不同的环境中(译者注:也就是说虽然现在看起来差不多,但是在将来该测试和vga buffer中的测试会很不一样,有必要单独拿出来,这两者并没有重复)。
|
||||
由于该测试和vga缓冲区测试中的一个几乎完全相同,所以目前它看起来似乎没什么用。然而在将来,我们的 `main.rs` 和 `lib.rs` 中的 `_start` 函数的内容会不断增长,并且在运行 `test_main` 之前需要调用一系列的初始化进程,所以这两个测试将会运行在完全不同的环境中(译者注:也就是说虽然现在看起来差不多,但是在将来该测试和vga buffer中的测试会很不一样,有必要单独拿出来,这两者并没有重复)。
|
||||
|
||||
通过在`basic_boot`环境里不掉用任何初始化例程的`_start`中测试`println`函数,我们可以确保`println`在启动(boot)后可以正常工作。这一点非常重要,因为我们有很多部分依赖于`println`,例如打印panic信息。
|
||||
通过在 `basic_boot` 环境里不调用任何初始化例程的 `_start` 中测试 `println` 函数,我们可以确保 `println` 在启动(boot)后可以正常工作。这一点非常重要,因为我们有很多部分依赖于 `println`,例如打印panic信息。
|
||||
|
||||
### 未来的测试
|
||||
|
||||
集成测试的强大之处在于,它们可以被看成是完全独立的可执行文件;这也给了它们完全控制环境的能力,使得他们能够测试代码和CPU或是其他硬件的交互是否正确。
|
||||
|
||||
我们的`basic_boot`测试正是集成测试的一个非常简单的例子。在将来,我们的内核的功能会变得更多,和硬件交互的方式也会变得多种多样。通过添加集成测试,我们可以保证这些交互按预期工作(并一直保持工作)。下面是一些对于未来的测试的设想:
|
||||
我们的 `basic_boot` 测试正是集成测试的一个非常简单的例子。在将来,我们的内核的功能会变得更多,和硬件交互的方式也会变得多种多样。通过添加集成测试,我们可以保证这些交互按预期工作(并一直保持工作)。下面是一些对于未来的测试的设想:
|
||||
|
||||
- **CPU异常**:当代码执行无效操作(例如除以零)时,CPU就会抛出异常。内核会为这些异常注册处理函数。集成测试可以验证在CPU异常时是否调用了正确的异常处理程序,或者在可解析的异常之后程序是否能正确执行;
|
||||
- **页表**:页表定义了哪些内存区域是有效且可访问的。通过修改页表,可以重新分配新的内存区域,例如,当你启动一个软件的时候。我们可以在集成测试中调整`_start`函数中的一些页表项,并确认这些改动是否会对`#[test_case]`的函数产生影响;
|
||||
- **页表**:页表定义了哪些内存区域是有效且可访问的。通过修改页表,可以重新分配新的内存区域,例如,当你启动一个软件的时候。我们可以在集成测试中调整 `_start` 函数中的一些页表项,并确认这些改动是否会对 `#[test_case]` 的函数产生影响;
|
||||
- **用户空间程序**:用户空间程序是只能访问有限的系统资源的程序。例如,他们无法访问内核数据结构或是其他应用程序的内存。集成测试可以启动执行禁止操作的用户空间程序验证认内核是否会将这些操作全都阻止。
|
||||
|
||||
可以想象,还有更多的测试可以进行。通过添加各种各样的测试,我们确保在为我们的内核添加新功能或是重构代码时,不会意外地破坏他们。这一点在我们的内核变得更大和更复杂的时候显得尤为重要。
|
||||
|
||||
### 那些应该Panic的测试
|
||||
|
||||
标准库的测试框架支持允许构造失败测试的[`#[should_panic]` attribute][should_panic]。这个功能对于验证传递无效参数时函数是否会失败非常有用。不幸的是,这个属性需要标准库的支持,因此,在`#[no_std]`环境下无法使用。
|
||||
标准库的测试框架支持 [`#[should_panic]` 属性][should_panic],这允许我们构造理应失败的测试。这个功能对于验证传递无效参数时函数是否会失败非常有用。不幸的是,这个属性需要标准库的支持,因此,在 `#[no_std]` 环境下无法使用。
|
||||
|
||||
[should_panic]: https://doc.rust-lang.org/rust-by-example/testing/unit_testing.html#testing-panics
|
||||
|
||||
尽管我们不能在我们的内核中使用`#[should_panic]` 属性,但是通过创建一个集成测试我们可以达到类似的效果——该集成测试可以从panic处理程序中返回一个成功错误代码。接下来让我一起来创建一个如上所述名为`should_panic`的测试吧:
|
||||
尽管我们不能在我们的内核中使用 `#[should_panic]` 属性,但是通过创建一个集成测试我们可以达到类似的效果——该集成测试可以从panic处理程序中返回一个成功错误代码。接下来让我一起来创建一个如上所述名为 `should_panic` 的测试吧:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
@@ -815,8 +915,7 @@ fn panic(_info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
这个测试还没有完成,因为它尚未定义`_start`函数或是其他自定义的test runner attributes。让我们来补充缺少的内容吧:
|
||||
|
||||
这个测试还没有完成,因为它尚未定义 `_start` 函数或是其他自定义的test runner属性。让我们来补充缺少的内容吧:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
@@ -843,7 +942,7 @@ pub fn test_runner(tests: &[&dyn Fn()]) {
|
||||
}
|
||||
```
|
||||
|
||||
这个测试定义了自己的`test_runner`函数,而不是复用`lib.rs`中的`test_runner`,该函数会在测试没有panic而是正常退出时返回一个错误退出代码(因为这里我们希望测试会panic)。如果没有定义测试函数,runner就会以一个成功错误代码退出。由于这个runner总是在执行完单个的测试后就退出,因此定义超过一个`#[test_case]`的函数都是没有意义的。
|
||||
这个测试定义了自己的 `test_runner` 函数,而不是复用 `lib.rs` 中的 `test_runner`,该函数会在测试没有panic而是正常退出时返回一个错误退出代码(因为这里我们希望测试会panic)。如果没有定义测试函数,runner就会以一个成功错误代码退出。由于这个runner总是在执行完单个的测试后就退出,因此定义超过一个 `#[test_case]` 的函数都是没有意义的。
|
||||
|
||||
现在我们来创建一个应该失败的测试:
|
||||
|
||||
@@ -859,19 +958,19 @@ fn should_fail() {
|
||||
}
|
||||
```
|
||||
|
||||
该测试用 `assert_eq`来断言(assert)`0`和`1`是否相等。毫无疑问,这当然会失败(`0`当然不等于`1`),所以我们的测试就会像我们想要的那样panic。
|
||||
该测试用 `assert_eq`来断言(assert)`0` 和 `1` 是否相等。毫无疑问,这当然会失败(`0` 当然不等于 `1`),所以我们的测试就会像我们想要的那样panic。
|
||||
|
||||
当我们通过`cargo xtest --test should_panic`运行该测试时,我们会发现成功了因为该测试如我们预期的那样panic了。当我们将断言部分(即`assert_eq!(0, 1);`)注释掉后,我们就会发现测试失败并返回了_"test did not panic"_的信息。
|
||||
当我们通过 `cargo test --test should_panic` 运行该测试时,我们会发现测试成功,该测试如我们预期的那样panic了。当我们将断言部分(即 `assert_eq!(0, 1);`)注释掉后,我们就会发现测试失败,并返回了 _"test did not panic"_ 的信息。
|
||||
|
||||
这种方法的缺点是它只使用于单个的测试函数。对于多个`#[test_case]`函数,它只会执行第一个函数因为程序无法在panic处理被调用后继续执行。我目前没有想到解决这个问题的方法,如果你有任何想法,请务必告诉我!
|
||||
这种方法的缺点是它只使用于单个的测试函数。对于多个 `#[test_case]` 函数,它只会执行第一个函数,因为程序无法在panic处理被调用后继续执行。我目前没有想到解决这个问题的方法,如果你有任何想法,请务必告诉我!
|
||||
|
||||
### 无约束测试
|
||||
|
||||
对于那些只有单个测试函数的集成测试而言(例如我们的`should_panic`测试),其实并不需要test runner。对于这种情况,我们可以完全禁用test runner,直接在`_start`函数中直接运行我们的测试。
|
||||
对于那些只有单个测试函数的集成测试而言(例如我们的 `should_panic` 测试),其实并不需要test runner。对于这种情况,我们可以完全禁用test runner,直接在 `_start` 函数中直接运行我们的测试。
|
||||
|
||||
这里的关键就是在`Cargo.toml`中为测试禁用 `harness` flag,这个标志(flag)定义了是否将test runner用于集成测试中。如果该标志位被设置为`false`,那么默认的test runner和自定义的test runner功能都将被禁用,这样一来该测试就可以像一个普通的可执行程序一样运行了。
|
||||
这里的关键就是在 `Cargo.toml` 中为测试禁用 `harness` flag,这个标志(flag)定义了是否将test runner用于集成测试中。如果该标志位被设置为 `false`,那么默认的test runner和自定义的test runner功能都将被禁用,这样一来该测试就可以像一个普通的可执行程序一样运行了。
|
||||
|
||||
现在让我们为我们的`should_panic`测试禁用`harness` flag吧:
|
||||
现在为我们的 `should_panic` 测试禁用 `harness` flag吧:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
@@ -881,7 +980,7 @@ name = "should_panic"
|
||||
harness = false
|
||||
```
|
||||
|
||||
现在我们通过移除test runner相关的代码,大大简化了我们的`should_panic`测试。结果看起来如下:
|
||||
现在我们通过移除test runner相关的代码,大大简化了我们的 `should_panic` 测试。结果看起来如下:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
@@ -913,20 +1012,20 @@ fn panic(_info: &PanicInfo) -> ! {
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以通过我们的`_start`函数来直接调用`should_fail`函数了,如果返回则返回一个失败退出代码并退出。现在当我们执行`cargo xtest --test should_panic`时,我们可以发现测试的行为和之前完全一样。
|
||||
现在我们可以通过我们的 `_start` 函数来直接调用 `should_fail` 函数了,如果返回则返回一个失败退出代码并退出。现在当我们执行 `cargo test --test should_panic` 时,我们可以发现测试的行为和之前完全一样。
|
||||
|
||||
除了创建`should_panic`测试,禁用`harness` attribute对复杂集成测试也很有用,例如,当单个测试函数会产生一些边际效应需要通过特定的顺序执行时。
|
||||
除了创建 `should_panic` 测试,禁用 `harness` 属性对复杂集成测试也很有用,例如,当单个测试函数会产生一些边际效应,需要通过特定的顺序执行时。
|
||||
|
||||
## 总结
|
||||
|
||||
测试是一种非常有用的技术,它能确保特定的部件拥有我们期望的行为。即使它们不能显示是否有bug,它们仍然是用来寻找bug的利器,尤其是用来避免回归。
|
||||
|
||||
本文讲述了如何为我们的Rust kernel创建一个测试框架。我们使用Rust的自定义框架功能为我们的裸机环境实现了一个简单的`#[test_case]` attribute支持。通过使用QEMU的`isa-debug-exit`设备,我们的test runner可以在运行测试后退出QEMU并报告测试状态。我们还为串行端口实现了一个简单的驱动,使得错误信息可以被打印到控制台而不是VGA buffer中。
|
||||
本文讲述了如何为我们的Rust kernel创建一个测试框架。我们使用Rust的自定义框架功能为我们的裸机环境实现了一个简单的 `#[test_case]` 属性支持。通过使用QEMU的 `isa-debug-exit` 设备,我们的test runner可以在运行测试后退出QEMU并报告测试状态。我们还为串行端口实现了一个简单的驱动,使得错误信息可以被打印到控制台而不是VGA buffer中。
|
||||
|
||||
在为我们的`println`宏创建了一些测试后,我们在本文的后半部分还探索了集成测试。我们了解到它们位于`tests`目录中,并被视为完全独立的可执行文件。为了使他们能够使用`exit_qemu` 函数和 `serial_println` 宏,我们将大部分代码移动到一个库里,使其能够被导入到所有可执行文件和集成测试中。由于集成测试在各自独立的环境中运行,所以能够测试与硬件的交互或是创建应该panic的测试。
|
||||
在为我们的 `println` 宏创建了一些测试后,我们在本文的后半部分还探索了集成测试。我们了解到它们位于 `tests` 目录中,并被视为完全独立的可执行文件。为了使他们能够使用 `exit_qemu` 函数和 `serial_println` 宏,我们将大部分代码移动到一个库里,使其能够被导入到所有可执行文件和集成测试中。由于集成测试在各自独立的环境中运行,所以能够测试与硬件的交互或是创建应该panic的测试。
|
||||
|
||||
我们现在有了一个在QEMU内部真是环境中运行的测试框架。在未来的文章里,我们会创建更多的测试,从而让我们的内核在变得更复杂的同时保持可维护性。
|
||||
|
||||
## 下期预告
|
||||
|
||||
在下一篇文章中,我们将会探索_CPU异常_。这些异常将在一些非法事件发生时由CPU抛出,例如抛出除以零或是访问没有映射的内存页(通常也被称为`page fault`即缺页异常)。能够捕获和检查这些异常,对将来的调试来说是非常重要的。异常处理与键盘支持所需的硬件中断处理十分相似。
|
||||
在下一篇文章中,我们将会探索_CPU异常_。这些异常将在一些非法事件发生时由CPU抛出,例如抛出除以零或是访问没有映射的内存页(通常也被称为 `page fault` 即页异常)。能够捕获和检查这些异常,对将来的调试来说是非常重要的。异常处理与键盘支持所需的硬件中断处理十分相似。
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
+++
|
||||
title = "CPU Exceptions"
|
||||
title = "CPU 예외 (Exception)"
|
||||
weight = 5
|
||||
path = "ko/cpu-exceptions"
|
||||
date = 2018-06-17
|
||||
@@ -14,7 +14,7 @@ translators = ["JOE1994"]
|
||||
translation_contributors = ["KimWang906"]
|
||||
+++
|
||||
|
||||
CPU 예외 (exception)는 유효하지 않은 메모리 주소에 접근하거나 분모가 0인 나누기 연산을 하는 등 허용되지 않은 작업이 실행 시 발생합니다. CPU 예외를 포착하고 처리할 수 있으려면 예외 처리 함수 정보를 제공하는 _인터럽트 서술자 테이블 (interrupt descriptor table; IDT)_ 을 설정해 두어야 합니다. 이 글에서는 커널이 [breakpoint 예외][breakpoint exceptions]를 처리한 후 정상 실행을 재개할 수 있게 구현하는 과정을 다룹니다.
|
||||
CPU 예외 (exception)는 유효하지 않은 메모리 주소에 접근하거나 분모가 0인 나누기 연산을 하는 등 허용되지 않은 작업 실행 시 발생합니다. CPU 예외를 처리할 수 있으려면 예외 처리 함수 정보를 제공하는 _인터럽트 서술자 테이블 (interrupt descriptor table; IDT)_ 을 설정해 두어야 합니다. 이 글에서는 커널이 [breakpoint 예외][breakpoint exceptions]를 처리한 후 정상 실행을 재개할 수 있도록 구현할 것입니다.
|
||||
|
||||
[breakpoint exceptions]: https://wiki.osdev.org/Exceptions#Breakpoint
|
||||
|
||||
@@ -46,14 +46,14 @@ x86 아키텍처에는 20가지 정도의 CPU 예외가 존재합니다. 그 중
|
||||
|
||||
[exceptions]: https://wiki.osdev.org/Exceptions
|
||||
|
||||
### 인터럽트 서술사 테이블 (Interrupt Descriptor Table)
|
||||
### 인터럽트 서술사 테이블 (Interrupt Descriptor Table) {#the-interrupt-descriptor-table}
|
||||
예외 발생을 포착하고 대응할 수 있으려면 _인터럽트 서술자 테이블 (Interrupt Descriptor Table; IDT)_ 이 필요합니다.
|
||||
이 테이블을 통해 우리는 각각의 CPU 예외를 어떤 예외 처리 함수가 처리할지 지정합니다. 하드웨어에서 이 테이블을 직접 사용하므로 테이블의 형식은 정해진 표준에 따라야 합니다. 테이블의 각 엔트리는 아래와 같은 16 바이트 구조를 따릅니다:
|
||||
|
||||
| 타입 | 이름 | 설명 |
|
||||
| ---- | ------------------------ | ------------------------------------------------------------------------------------------------------------- |
|
||||
| u16 | Function Pointer [0:15] | 예외 처리 함수에 대한 64비트 포인터의 하위 16비트 |
|
||||
| u16 | GDT selector | [글로벌 디스크립터 테이블 (global descriptor table)][global descriptor table]에서 코드 세그먼트를 선택하는 값 |
|
||||
| u16 | GDT selector | [전역 서술자 테이블 (global descriptor table)][global descriptor table]에서 코드 세그먼트를 선택하는 값 |
|
||||
| u16 | Options | (표 아래의 설명 참조) |
|
||||
| u16 | Function Pointer [16:31] | 예외 처리 함수에 대한 64비트 포인터의 2번째 하위 16비트 |
|
||||
| u32 | Function Pointer [32:63] | 예외 처리 함수에 대한 64비트 포인터의 상위 32비트 |
|
||||
@@ -87,7 +87,7 @@ Options 필드는 아래의 형식을 갖습니다:
|
||||
[RFLAGS]: https://en.wikipedia.org/wiki/FLAGS_register
|
||||
[GDT]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
위의 4단계와 5단계가 잘 이해되지 않아도 걱정 마세요. 글로벌 디스크립터 테이블 (Global Descriptor Table; GDT)과 하드웨어 인터럽트는 이후에 다른 글에서 더 설명할 것입니다.
|
||||
위의 4단계와 5단계가 잘 이해되지 않아도 걱정 마세요. 전역 서술자 테이블 (Global Descriptor Table; GDT)과 하드웨어 인터럽트는 이후에 다른 글에서 더 설명할 것입니다.
|
||||
|
||||
## IDT 타입
|
||||
IDT를 나타내는 타입을 직접 구현하지 않고 `x86_64` 크레이트의 [`InterruptDescriptorTable` 구조체][`InterruptDescriptorTable` struct] 타입을 사용합니다:
|
||||
@@ -180,7 +180,7 @@ x86_64에서는 C 함수 호출 규약이 preserved 레지스터와 scratch 레
|
||||
|
||||
함수 실행 시작 시 모든 레지스터들의 값이 스택에 저장된다는 뜻은 아닙니다. 호출된 함수가 덮어 쓸 레지스터들만을 컴파일러가 스택에 백업합니다. 이렇게 하면 적은 수의 레지스터를 사용하는 함수를 컴파일 할 때 짧고 효율적인 코드를 생성할 수 있습니다.
|
||||
|
||||
### 인터럽트 스택 프레임
|
||||
### 인터럽트 스택 프레임 {# the-interrupt-stack-frame}
|
||||
일반적인 함수 호출 시 (`call` 명령어 이용), CPU는 호출된 함수로 제어 흐름을 넘기기 전에 반환 주소를 스택에 push (저장)합니다. 함수 반환 시 (`ret` 명령어 이용), CPU는 스택에 저장해뒀던 반환 주소를 읽어온 후 해당 주소로 점프합니다. 일반적인 함수 호출 시 스택 프레임의 모습은 아래와 같습니다:
|
||||
|
||||

|
||||
@@ -348,7 +348,7 @@ pub fn init_idt() {
|
||||
}
|
||||
```
|
||||
|
||||
이제 컴파일 오류가 발생하지는 않지만, Rust에서 `static mut`의 사용은 권장되지 않습니다. `static mut`는 데이터 경쟁 상태 (data race)를 일으키기 쉽기에, `static mut` 변수에 접근할 때마다 [`unsafe` 블록][`unsafe` block]을 반드시 사용해야 합니다.
|
||||
이제 컴파일 오류가 발생하지는 않지만, Rust에서 `static mut`의 사용은 권장되지 않습니다. `static mut`는 데이터 레이스 (data race)를 일으키기 쉽기에, `static mut` 변수에 접근할 때마다 [`unsafe` 블록][`unsafe` block]을 반드시 사용해야 합니다.
|
||||
|
||||
[`unsafe` block]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
|
||||
473
blog/content/edition-2/posts/05-cpu-exceptions/index.zh-CN.md
Normal file
473
blog/content/edition-2/posts/05-cpu-exceptions/index.zh-CN.md
Normal file
@@ -0,0 +1,473 @@
|
||||
+++
|
||||
title = "CPU异常处理"
|
||||
weight = 5
|
||||
path = "zh-CN/cpu-exceptions"
|
||||
date = 2018-06-17
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong", "Byacrya"]
|
||||
+++
|
||||
|
||||
CPU异常在很多情况下都有可能发生,比如访问无效的内存地址,或者在除法运算里除以0。为了处理这些错误,我们需要设置一个 _中断描述符表_ 来提供异常处理函数。在文章的最后,我们的内核将能够捕获 [断点异常][breakpoint exceptions] 并在处理后恢复正常执行。
|
||||
|
||||
[breakpoint exceptions]: https://wiki.osdev.org/Exceptions#Breakpoint
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-05`][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
<!-- fix for zola anchor checker (target is in template): <a id="comments"> -->
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-05
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 简述
|
||||
异常信号会在当前指令触发错误时被触发,例如执行了除数为0的除法。当异常发生后,CPU会中断当前的工作,并立即根据异常类型调用对应的错误处理函数。
|
||||
|
||||
在x86架构中,存在20种不同的CPU异常类型,以下为最重要的几种:
|
||||
|
||||
- **Page Fault**: 页错误是被非法内存访问触发的,例如当前指令试图访问未被映射过的页,或者试图写入只读页。
|
||||
- **Invalid Opcode**: 该错误是说当前指令操作符无效,比如在不支持SSE的旧式CPU上执行了 [SSE 指令][SSE instructions]。
|
||||
- **General Protection Fault**: 该错误的原因有很多,主要原因就是权限异常,即试图使用用户态代码执行核心指令,或是修改配置寄存器的保留字段。
|
||||
- **Double Fault**: 当错误发生时,CPU会尝试调用错误处理函数,但如果 _在调用错误处理函数过程中_ 再次发生错误,CPU就会触发该错误。另外,如果没有注册错误处理函数也会触发该错误。
|
||||
- **Triple Fault**: 如果CPU调用了对应 `Double Fault` 异常的处理函数依然没有成功,该错误会被抛出。这是一个致命级别的 _三重异常_,这意味着我们已经无法捕捉它,对于大多数操作系统而言,此时就应该重置数据并重启操作系统。
|
||||
|
||||
[SSE instructions]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
|
||||
|
||||
在 [OSDev wiki][exceptions] 可以看到完整的异常类型列表。
|
||||
|
||||
[exceptions]: https://wiki.osdev.org/Exceptions
|
||||
|
||||
### 中断描述符表
|
||||
要捕捉CPU异常,我们需要设置一个 _中断描述符表_ (_Interrupt Descriptor Table_, IDT),用来捕获每一个异常。由于硬件层面会不加验证的直接使用,所以我们需要根据预定义格式直接写入数据。符表的每一行都遵循如下的16字节结构。
|
||||
|
||||
| Type | Name | Description |
|
||||
| ---- | ------------------------ | ------------------------------------------------------- |
|
||||
| u16 | Function Pointer [0:15] | 处理函数地址的低位(最后16位) |
|
||||
| u16 | GDT selector | [全局描述符表][global descriptor table]中的代码段标记。 |
|
||||
| u16 | Options | (如下所述) |
|
||||
| u16 | Function Pointer [16:31] | 处理函数地址的中位(中间16位) |
|
||||
| u32 | Function Pointer [32:63] | 处理函数地址的高位(剩下的所有位) |
|
||||
| u32 | Reserved |
|
||||
|
||||
[global descriptor table]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
Options字段的格式如下:
|
||||
|
||||
| Bits | Name | Description |
|
||||
| ----- | -------------------------------- | --------------------------------------------------------------- |
|
||||
| 0-2 | Interrupt Stack Table Index | 0: 不要切换栈, 1-7: 当处理函数被调用时,切换到中断栈表的第n层。 |
|
||||
| 3-7 | Reserved |
|
||||
| 8 | 0: Interrupt Gate, 1: Trap Gate | 如果该比特被置为0,当处理函数被调用时,中断会被禁用。 |
|
||||
| 9-11 | must be one |
|
||||
| 12 | must be zero |
|
||||
| 13‑14 | Descriptor Privilege Level (DPL) | 执行处理函数所需的最小特权等级。 |
|
||||
| 15 | Present |
|
||||
|
||||
每个异常都具有一个预定义的IDT序号,比如 invalid opcode 异常对应6号,而 page fault 异常对应14号,因此硬件可以直接寻找到对应的IDT条目。 OSDev wiki中的 [异常对照表][exceptions] 可以查到所有异常的IDT序号(在Vector nr.列)。
|
||||
|
||||
通常而言,当异常发生时,CPU会执行如下步骤:
|
||||
|
||||
1. 将一些寄存器数据入栈,包括指令指针以及 [RFLAGS] 寄存器。(我们会在文章稍后些的地方用到这些数据。)
|
||||
2. 读取中断描述符表(IDT)的对应条目,比如当发生 page fault 异常时,调用14号条目。
|
||||
3. 判断该条目确实存在,如果不存在,则触发 double fault 异常。
|
||||
4. 如果该条目属于中断门(interrupt gate,bit 40 被设置为0),则禁用硬件中断。
|
||||
5. 将 [GDT] 选择器载入代码段寄存器(CS segment)。
|
||||
6. 跳转执行处理函数。
|
||||
|
||||
[RFLAGS]: https://en.wikipedia.org/wiki/FLAGS_register
|
||||
[GDT]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
不过现在我们不必为4和5多加纠结,未来我们会单独讲解全局描述符表和硬件中断的。
|
||||
|
||||
## IDT类型
|
||||
与其创建我们自己的IDT类型映射,不如直接使用 `x86_64` crate 内置的 [`InterruptDescriptorTable` 结构][`InterruptDescriptorTable` struct],其实现是这样的:
|
||||
|
||||
[`InterruptDescriptorTable` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
|
||||
``` rust
|
||||
#[repr(C)]
|
||||
pub struct InterruptDescriptorTable {
|
||||
pub divide_by_zero: Entry<HandlerFunc>,
|
||||
pub debug: Entry<HandlerFunc>,
|
||||
pub non_maskable_interrupt: Entry<HandlerFunc>,
|
||||
pub breakpoint: Entry<HandlerFunc>,
|
||||
pub overflow: Entry<HandlerFunc>,
|
||||
pub bound_range_exceeded: Entry<HandlerFunc>,
|
||||
pub invalid_opcode: Entry<HandlerFunc>,
|
||||
pub device_not_available: Entry<HandlerFunc>,
|
||||
pub double_fault: Entry<HandlerFuncWithErrCode>,
|
||||
pub invalid_tss: Entry<HandlerFuncWithErrCode>,
|
||||
pub segment_not_present: Entry<HandlerFuncWithErrCode>,
|
||||
pub stack_segment_fault: Entry<HandlerFuncWithErrCode>,
|
||||
pub general_protection_fault: Entry<HandlerFuncWithErrCode>,
|
||||
pub page_fault: Entry<PageFaultHandlerFunc>,
|
||||
pub x87_floating_point: Entry<HandlerFunc>,
|
||||
pub alignment_check: Entry<HandlerFuncWithErrCode>,
|
||||
pub machine_check: Entry<HandlerFunc>,
|
||||
pub simd_floating_point: Entry<HandlerFunc>,
|
||||
pub virtualization: Entry<HandlerFunc>,
|
||||
pub security_exception: Entry<HandlerFuncWithErrCode>,
|
||||
// some fields omitted
|
||||
}
|
||||
```
|
||||
|
||||
每一个字段都是 [`idt::Entry<F>`] 类型,这个类型包含了一条完整的IDT条目(定义参见上文)。 其泛型参数 `F` 定义了中断处理函数的类型,在有些字段中该参数为 [`HandlerFunc`],而有些则是 [`HandlerFuncWithErrCode`],而对于 page fault 这种特殊异常,则为 [`PageFaultHandlerFunc`]。
|
||||
|
||||
[`idt::Entry<F>`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.Entry.html
|
||||
[`HandlerFunc`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.HandlerFunc.html
|
||||
[`HandlerFuncWithErrCode`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.HandlerFuncWithErrCode.html
|
||||
[`PageFaultHandlerFunc`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.PageFaultHandlerFunc.html
|
||||
|
||||
首先让我们看一看 `HandlerFunc` 类型的定义:
|
||||
|
||||
```rust
|
||||
type HandlerFunc = extern "x86-interrupt" fn(_: InterruptStackFrame);
|
||||
```
|
||||
|
||||
这是一个针对 `extern "x86-interrupt" fn` 类型的 [类型别名][type alias]。`extern` 关键字使用 [外部调用约定][foreign calling convention] 定义了一个函数,这种定义方式多用于和C语言代码通信(`extern "C" fn`),那么这里的外部调用约定又究竟调用了哪些东西?
|
||||
|
||||
[type alias]: https://doc.rust-lang.org/book/ch19-04-advanced-types.html#creating-type-synonyms-with-type-aliases
|
||||
[foreign calling convention]: https://doc.rust-lang.org/nomicon/ffi.html#foreign-calling-conventions
|
||||
|
||||
## 中断调用约定
|
||||
异常触发十分类似于函数调用:CPU会直接跳转到处理函数的第一个指令处开始执行,执行结束后,CPU会跳转到返回地址,并继续执行之前的函数调用。
|
||||
|
||||
然而两者最大的不同点是:函数调用是由编译器通过 `call` 指令主动发起的,而错误处理函数则可能会由 _任何_ 指令触发。要了解这两者所造成影响的不同,我们需要更深入的追踪函数调用。
|
||||
|
||||
[调用约定][Calling conventions] 指定了函数调用的详细信息,比如可以指定函数的参数存放在哪里(寄存器,或者栈,或者别的什么地方)以及如何返回结果。在 x86_64 Linux 中,以下规则适用于C语言函数(指定于 [System V ABI] 标准):
|
||||
|
||||
[Calling conventions]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
[System V ABI]: https://refspecs.linuxbase.org/elf/x86_64-abi-0.99.pdf
|
||||
|
||||
- 前六个整型参数从寄存器传入 `rdi`, `rsi`, `rdx`, `rcx`, `r8`, `r9`
|
||||
- 其他参数从栈传入
|
||||
- 函数返回值存放在 `rax` 和 `rdx`
|
||||
|
||||
注意,Rust并不遵循C ABI,而是遵循自己的一套规则,即 [尚未正式发布的 Rust ABI 草案][rust abi],所以这些规则仅在使用 `extern "C" fn` 对函数进行定义时才会使用。
|
||||
|
||||
[rust abi]: https://github.com/rust-lang/rfcs/issues/600
|
||||
|
||||
### 保留寄存器和临时寄存器
|
||||
调用约定将寄存器分为两部分:_保留寄存器_ 和 _临时寄存器_ 。
|
||||
|
||||
_保留寄存器_ 的值应当在函数调用时保持不变,所以被调用的函数( _"callee"_ )只有在保证"返回之前将这些寄存器的值恢复到初始值"的前提下,才被允许覆写这些寄存器的值, 在函数开始时将这类寄存器的值存入栈中,并在返回之前将之恢复到寄存器中是一种十分常见的做法。
|
||||
|
||||
而 _临时寄存器_ 则相反,被调用函数可以无限制的反复写入寄存器,若调用者希望此类寄存器在函数调用后保持数值不变,则需要自己来处理备份和恢复过程(例如将其数值保存在栈中),因而这类寄存器又被称为 _caller-saved_。
|
||||
|
||||
在 x86_64 架构下,C调用约定指定了这些寄存器分类:
|
||||
|
||||
| 保留寄存器 | 临时寄存器 |
|
||||
| ----------------------------------------------- | ----------------------------------------------------------- |
|
||||
| `rbp`, `rbx`, `rsp`, `r12`, `r13`, `r14`, `r15` | `rax`, `rcx`, `rdx`, `rsi`, `rdi`, `r8`, `r9`, `r10`, `r11` |
|
||||
| _callee-saved_ | _caller-saved_ |
|
||||
|
||||
编译器已经内置了这些规则,因而可以自动生成保证程序正常执行的指令。例如绝大多数函数的汇编指令都以 `push rbp` 开头,也就是将 `rbp` 的值备份到栈中(因为它是 `callee-saved` 型寄存器)。
|
||||
|
||||
### 保存所有寄存器数据
|
||||
区别于函数调用,异常在执行 _任何_ 指令时都有可能发生。在大多数情况下,我们在编译期不可能知道程序跑起来会发生什么异常。比如编译器无法预知某条指令是否会触发 page fault 或者 stack overflow。
|
||||
|
||||
正因我们不知道异常会何时发生,所以我们无法预先保存寄存器。这意味着我们无法使用依赖调用方备份 (caller-saved) 的寄存器的调用传统作为异常处理程序。因此,我们需要一个保存所有寄存器的传统。x86-interrupt 恰巧就是其中之一,它可以保证在函数返回时,寄存器里的值均返回原样。
|
||||
|
||||
但请注意,这并不意味着所有寄存器都会在进入函数时备份入栈。编译器仅会备份被函数覆写的寄存器,继而为只使用几个寄存器的短小函数生成高效的代码。
|
||||
|
||||
### 中断栈帧
|
||||
当一个常规函数调用发生时(使用 `call` 指令),CPU会在跳转目标函数之前,将返回地址入栈。当函数返回时(使用 `ret` 指令),CPU会在跳回目标函数之前弹出返回地址。所以常规函数调用的栈帧看起来是这样的:
|
||||
|
||||

|
||||
|
||||
对于错误和中断处理函数,仅仅压入一个返回地址并不足够,因为中断处理函数通常会运行在一个不那么一样的上下文中(栈指针、CPU flags等等)。所以CPU在遇到中断发生时是这么处理的:
|
||||
|
||||
1. **对齐栈指针**: 任何指令都有可能触发中断,所以栈指针可能是任何值,而部分CPU指令(比如部分SSE指令)需要栈指针16字节边界对齐,因此CPU会在中断触发后立刻为其进行对齐。
|
||||
2. **切换栈** (部分情况下): 当CPU特权等级改变时,例如当一个用户态程序触发CPU异常时,会触发栈切换。该行为也可能被所谓的 _中断栈表_ 配置,在特定中断中触发,关于该表,我们会在下一篇文章做出讲解。
|
||||
3. **压入旧的栈指针**: 当中断发生后,栈指针对齐之前,CPU会将栈指针寄存器(`rsp`)和栈段寄存器(`ss`)的数据入栈,由此可在中断处理函数返回后,恢复上一层的栈指针。
|
||||
4. **压入并更新 `RFLAGS` 寄存器**: [`RFLAGS`] 寄存器包含了各式各样的控制位和状态位,当中断发生时,CPU会改变其中的部分数值,并将旧值入栈。
|
||||
5. **压入指令指针**: 在跳转中断处理函数之前,CPU会将指令指针寄存器(`rip`)和代码段寄存器(`cs`)的数据入栈,此过程与常规函数调用中返回地址入栈类似。
|
||||
6. **压入错误码** (针对部分异常): 对于部分特定的异常,比如 page faults ,CPU会推入一个错误码用于标记错误的成因。
|
||||
7. **执行中断处理函数**: CPU会读取对应IDT条目中描述的中断处理函数对应的地址和段描述符,将两者载入 `rip` 和 `cs` 以开始运行处理函数。
|
||||
|
||||
[`RFLAGS`]: https://en.wikipedia.org/wiki/FLAGS_register
|
||||
|
||||
所以 _中断栈帧_ 看起来是这样的:
|
||||
|
||||

|
||||
|
||||
在 `x86_64` crate 中,中断栈帧已经被 [`InterruptStackFrame`] 结构完整表达,该结构会以 `&mut` 的形式传入处理函数,并可以用于查询错误发生的更详细的原因。但该结构并不包含错误码字段,因为只有极少量的错误会传入错误码,所以对于这类需要传入 `error_code` 的错误,其函数类型变为了 [`HandlerFuncWithErrCode`]。
|
||||
|
||||
[`InterruptStackFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptStackFrame.html
|
||||
|
||||
### 幕后花絮
|
||||
`x86-interrupt` 调用约定是一个十分厉害的抽象,它几乎隐藏了所有错误处理函数中的凌乱细节,但尽管如此,了解一下水面下发生的事情还是有用的。我们来简单介绍一下被 `x86-interrupt` 隐藏起来的行为:
|
||||
|
||||
- **传递参数**: 绝大多数指定参数的调用约定都是期望通过寄存器取得参数的,但事实上这是无法实现的,因为我们不能在备份寄存器数据之前就将其复写。`x86-interrupt` 的解决方案时,将参数以指定的偏移量放到栈上。
|
||||
- **使用 `iretq` 返回**: 由于中断栈帧和普通函数调用的栈帧是完全不同的,我们无法通过 `ret` 指令直接返回,所以此时必须使用 `iretq` 指令。
|
||||
- **处理错误码**: 部分异常传入的错误码会让错误处理更加复杂,它会造成栈指针对齐失效(见下一条),而且需要在返回之前从栈中弹出去。好在 `x86-interrupt` 为我们挡住了这些额外的复杂度。但是它无法判断哪个异常对应哪个处理函数,所以它需要从函数参数数量上推断一些信息,因此程序员需要为每个异常使用正确的函数类型。当然你已经不需要烦恼这些, `x86_64` crate 中的 `InterruptDescriptorTable` 已经帮助你完成了定义。
|
||||
- **对齐栈**: 对于一些指令(尤其是SSE指令)而言,它们需要提前进行16字节边界对齐操作,通常而言CPU在异常发生之后就会自动完成这一步。但是部分异常会由于传入错误码而破坏掉本应完成的对齐操作,此时 `x86-interrupt` 会为我们重新完成对齐。
|
||||
|
||||
如果你对更多细节有兴趣:我们还有关于使用 [裸函数][naked functions] 展开异常处理的一个系列章节,参见 [文末][too-much-magic]。
|
||||
|
||||
[naked functions]: https://github.com/rust-lang/rfcs/blob/master/text/1201-naked-fns.md
|
||||
[too-much-magic]: #hei-mo-fa-you-dian-duo
|
||||
|
||||
## 实现
|
||||
那么理论知识暂且到此为止,该开始为我们的内核实现CPU异常处理了。首先我们在 `src/interrupts.rs` 创建一个模块,并加入函数 `init_idt` 用来创建一个新的 `InterruptDescriptorTable`:
|
||||
|
||||
``` rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod interrupts;
|
||||
|
||||
// in src/interrupts.rs
|
||||
|
||||
use x86_64::structures::idt::InterruptDescriptorTable;
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
}
|
||||
```
|
||||
|
||||
现在我们就可以添加处理函数了,首先给 [breakpoint exception] 添加。该异常是一个绝佳的测试途径,因为它唯一的目的就是在 `int3` 指令执行时暂停程序运行。
|
||||
|
||||
[breakpoint exception]: https://wiki.osdev.org/Exceptions#Breakpoint
|
||||
|
||||
breakpoint exception 通常被用在调试器中:当程序员为程序打上断点,调试器会将对应的位置覆写为 `int3` 指令,CPU执行该指令后,就会抛出 breakpoint exception 异常。在调试完毕,需要程序继续运行时,调试器就会将原指令覆写回 `int3` 的位置。如果要了解更多细节,请查阅 ["_调试器是如何工作的_"]["_How debuggers work_"] 系列。
|
||||
|
||||
["_How debuggers work_"]: https://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
不过现在我们还不需要覆写指令,只需要打印一行日志,表明接收到了这个异常,然后让程序继续运行即可。那么我们就来创建一个简单的 `breakpoint_handler` 方法并加入IDT中:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
|
||||
use crate::println;
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn breakpoint_handler(
|
||||
stack_frame: InterruptStackFrame)
|
||||
{
|
||||
println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
|
||||
}
|
||||
```
|
||||
|
||||
现在,我们的处理函数应当会输出一行信息以及完整的栈帧。
|
||||
|
||||
但当我们尝试编译的时候,报出了下面的错误:
|
||||
|
||||
```
|
||||
error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
|
||||
--> src/main.rs:53:1
|
||||
|
|
||||
53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: InterruptStackFrame) {
|
||||
54 | | println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
|
||||
55 | | }
|
||||
| |_^
|
||||
|
|
||||
= help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
|
||||
```
|
||||
|
||||
这是因为 `x86-interrupt` 并不是稳定特性,需要手动启用,只需要在我们的 `lib.rs` 中加入 `#![feature(abi_x86_interrupt)]` 开关即可。
|
||||
|
||||
### 载入 IDT
|
||||
要让CPU使用新的中断描述符表,我们需要使用 [`lidt`] 指令来装载一下,`x86_64` 的 `InterruptDescriptorTable` 结构提供了 [`load`][InterruptDescriptorTable::load] 函数用来实现这个需求。让我们来试一下:
|
||||
|
||||
[`lidt`]: https://www.felixcloutier.com/x86/lgdt:lidt
|
||||
[InterruptDescriptorTable::load]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html#method.load
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt.load();
|
||||
}
|
||||
```
|
||||
|
||||
再次尝试编译,又出现了新的错误:
|
||||
|
||||
```
|
||||
error: `idt` does not live long enough
|
||||
--> src/interrupts/mod.rs:43:5
|
||||
|
|
||||
43 | idt.load();
|
||||
| ^^^ does not live long enough
|
||||
44 | }
|
||||
| - borrowed value only lives until here
|
||||
|
|
||||
= note: borrowed value must be valid for the static lifetime...
|
||||
```
|
||||
|
||||
原来 `load` 函数要求的生命周期为 `&'static self` ,也就是整个程序的生命周期,其原因就是CPU在接收到下一个IDT之前会一直使用这个描述符表。如果生命周期小于 `'static` ,很可能就会出现使用已释放对象的bug。
|
||||
|
||||
问题至此已经很清晰了,我们的 `idt` 是创建在栈上的,它的生命周期仅限于 `init` 函数执行期间,之后这部分栈内存就会被其他函数调用,CPU再来访问IDT的话,只会读取到一段随机数据。好在 `InterruptDescriptorTable::load` 被严格定义了函数生命周期限制,这样 Rust 编译器就可以在编译时就发现这些潜在问题。
|
||||
|
||||
要修复这些错误很简单,让 `idt` 具备 `'static` 类型的生命周期即可,我们可以使用 [`Box`] 在堆上申请一段内存,并转化为 `'static` 指针即可,但问题是我们正在写的东西是操作系统内核,(暂时)并没有堆这种东西。
|
||||
|
||||
[`Box`]: https://doc.rust-lang.org/std/boxed/struct.Box.html
|
||||
|
||||
|
||||
作为替代,我们可以试着直接将IDT定义为 `'static` 变量:
|
||||
|
||||
```rust
|
||||
static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
|
||||
|
||||
pub fn init_idt() {
|
||||
IDT.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
然而这样就会引入一个新问题:静态变量是不可修改的,这样我们就无法在 `init` 函数中修改里面的数据了,所以需要把变量类型修改为 [`static mut`]:
|
||||
|
||||
[`static mut`]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
|
||||
|
||||
```rust
|
||||
static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
|
||||
|
||||
pub fn init_idt() {
|
||||
unsafe {
|
||||
IDT.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
IDT.load();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这样就不会有编译错误了,但是这并不符合官方推荐的编码习惯,因为理论上说 `static mut` 类型的变量很容易形成数据竞争,所以需要用 [`unsafe` 代码块][`unsafe` block] 修饰调用语句。
|
||||
|
||||
[`unsafe` block]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
#### 懒加载拯救世界
|
||||
好在还有 `lazy_static` 宏可以用,区别于普通 `static` 变量在编译器求值,这个宏可以使代码块内的 `static` 变量在第一次取值时求值。所以,我们完全可以把初始化代码写在变量定义的代码块里,同时也不影响后续的取值。
|
||||
|
||||
在 [创建VGA字符缓冲的单例][vga text buffer lazy static] 时我们已经引入了 `lazy_static` crate,所以我们可以直接使用 `lazy_static!` 来创建IDT:
|
||||
|
||||
[vga text buffer lazy static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_idt() {
|
||||
IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
现在碍眼的 `unsafe` 代码块成功被去掉了,尽管 `lazy_static!` 的内部依然使用了 `unsafe` 代码块,但是至少它已经抽象为了一个安全接口。
|
||||
|
||||
### 跑起来
|
||||
|
||||
最后一步就是在 `main.rs` 里执行 `init_idt` 函数以在我们的内核里装载IDT,但不要直接调用,而应在 `lib.rs` 里封装一个 `init` 函数出来:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
interrupts::init_idt();
|
||||
}
|
||||
```
|
||||
|
||||
这样我们就可以把所有初始化逻辑都集中在一个函数里,从而让 `main.rs` 、 `lib.rs` 以及单元测试中的 `_start` 共享初始化逻辑。
|
||||
|
||||
现在我们更新一下 `main.rs` 中的 `_start` 函数,调用 `init` 并手动触发一次 breakpoint exception:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init(); // new
|
||||
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::interrupts::int3(); // new
|
||||
|
||||
// as before
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
当我们在QEMU中运行之后(`cargo run`),效果是这样的:
|
||||
|
||||

|
||||
|
||||
成功了!CPU成功调用了中断处理函数并打印出了信息,然后返回 `_start` 函数打印出了 `It did not crash!`。
|
||||
|
||||
我们可以看到,中断栈帧告诉了我们当错误发生时指令和栈指针的具体数值,这些信息在我们调试意外错误的时候非常有用。
|
||||
|
||||
### 添加测试
|
||||
|
||||
那么让我们添加一个测试用例,用来确保以上工作成果可以顺利运行。首先需要在 `_start` 函数中调用 `init`:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
/// Entry point for `cargo test`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init(); // new
|
||||
test_main();
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
注意,这里的 `_start` 会在 `cargo test --lib` 这条命令的上下文中运行,而 `lib.rs` 的执行环境完全独立于 `main.rs`,所以我们需要在运行测试之前调用 `init` 装载IDT。
|
||||
|
||||
那么我们接着创建一个测试用例 `test_breakpoint_exception`:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_breakpoint_exception() {
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::interrupts::int3();
|
||||
}
|
||||
```
|
||||
|
||||
该测试仅调用了 `int3` 函数以触发 breakpoint exception,通过查看这个函数是否能够继续运行下去,就可以确认我们对应的中断处理函数是否工作正常。
|
||||
|
||||
现在,你可以执行 `cargo test` 来运行所有测试,或者执行 `cargo test --lib` 来运行 `lib.rs` 及其子模块中包含的测试,最终输出如下:
|
||||
|
||||
```
|
||||
blog_os::interrupts::test_breakpoint_exception... [ok]
|
||||
```
|
||||
|
||||
## 黑魔法有点多?
|
||||
相对来说,`x86-interrupt` 调用约定和 [`InterruptDescriptorTable`] 类型让错误处理变得直截了当,如果这对你来说太过于神奇,进而想要了解错误处理中的所有隐秘细节,我们推荐读一下这些:[“使用裸函数处理错误”][“Handling Exceptions with Naked Functions”] 系列文章展示了如何在不使用 `x86-interrupt` 的前提下创建IDT。但是需要注意的是,这些文章都是在 `x86-interrupt` 调用约定和 `x86_64` crate 出现之前的产物,这些东西属于博客的 [第一版][first edition],不排除信息已经过期了的可能。
|
||||
|
||||
[“Handling Exceptions with Naked Functions”]: @/edition-1/extra/naked-exceptions/_index.md
|
||||
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
[first edition]: @/edition-1/_index.md
|
||||
|
||||
## 接下来是?
|
||||
我们已经成功捕获了第一个异常,并从异常中成功恢复,下一步就是试着捕获所有异常,如果有未捕获的异常就会触发致命的[triple fault],那就只能重启整个系统了。下一篇文章会展开说我们如何通过正确捕捉[double faults]来避免这种情况。
|
||||
|
||||
[triple fault]: https://wiki.osdev.org/Triple_Fault
|
||||
[double faults]: https://wiki.osdev.org/Double_Fault#Double_Fault
|
||||
558
blog/content/edition-2/posts/06-double-faults/index.ko.md
Normal file
558
blog/content/edition-2/posts/06-double-faults/index.ko.md
Normal file
@@ -0,0 +1,558 @@
|
||||
+++
|
||||
title = "더블 폴트 (Double Fault)"
|
||||
weight = 6
|
||||
path = "ko/double-fault-exceptions"
|
||||
date = 2018-06-18
|
||||
|
||||
[extra]
|
||||
chapter = "Interrupts"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "a108367d712ef97c28e8e4c1a22da4697ba6e6cd"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["JOE1994"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["dalinaum"]
|
||||
+++
|
||||
|
||||
이번 글에서는 CPU가 예외 처리 함수를 호출하는 데에 실패할 때 발생하는 더블 폴트 (double fault) 예외에 대해 자세히 다룹니다. 더블 폴트 예외를 처리함으로써 시스템 재부팅을 발생시키는 치명적인 _트리플 폴트 (triple fault)_ 예외를 피할 수 있습니다. 트리플 폴트가 발생할 수 있는 모든 경우에 대비하기 위해 _Interrupt Stack Table_ 을 만들고 별도의 커널 스택에서 더블 폴트를 처리할 것입니다.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-06 브랜치`][post branch]에서 확인하실 수 있습니다.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
<!-- fix for zola anchor checker (target is in template): <a id="comments"> -->
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-06
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 더블 폴트 (Double Fault)란 무엇일까요?
|
||||
간단히 말하면, 더블 폴트는 CPU가 예외 처리 함수를 호출하는 것에 실패했을 때 발생하는 예외입니다. 예를 들면 페이지 폴트가 발생했는데 [인터럽트 서술자 테이블 (Interrupt Descriptor Table; IDT)][IDT] 에 등록된 페이지 폴트 처리 함수가 없을 때 더블 폴트가 예외가 발생합니다. 비유한다면 C++의 `catch(..)`문이나 Java 및 C#의 `catch(Exception e)`문처럼 모든 종류의 예외를 처리할 수 있다는 점에서 유사합니다.
|
||||
|
||||
[IDT]: @/edition-2/posts/05-cpu-exceptions/index.ko.md#the-interrupt-descriptor-table
|
||||
|
||||
더블 폴트는 다른 예외들과 다를 게 없습니다. IDT 내에서 배정된 벡터 인덱스(`8`)가 있고, IDT에 해당 예외를 처리할 일반 함수를 정의할 수 있습니다. 더블 폴트 처리 함수를 제공하는 것은 매우 중요한데, 더블 폴트가 처리되지 않으면 치명적인 _트리플 폴트_ 가 발생하기 때문입니다. 트리플 폴트를 처리하는 것은 불가능해서 대부분의 하드웨어는 시스템을 리셋하는 방식으로 대응합니다.
|
||||
|
||||
### 더블 폴트 일으키기
|
||||
예외 처리 함수가 등록되지 않은 예외를 발생시켜 더블 폴트를 일으켜 보겠습니다.
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
// 페이지 폴트 일으키기
|
||||
unsafe {
|
||||
*(0xdeadbeef as *mut u64) = 42;
|
||||
};
|
||||
|
||||
// 이전과 동일
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`unsafe` 키워드를 사용해 유효하지 않은 메모리 주소 `0xdeadbeef`에 값을 씁니다. 페이지 테이블에서 해당 가상 주소는 실제 물리 주소에 매핑되지 않았기에 페이지 폴트가 발생합니다. 아직 우리가 [IDT]에 페이지 폴트 처리 함수를 등록하지 않았기 때문에 이어서 더블 폴트가 발생합니다.
|
||||
|
||||
이제 커널을 실행시키면 커널이 무한히 부팅하는 루프에 갇히는 것을 확인하실 수 있습니다. 커널이 루프에 갇히는 이유는 아래와 같습니다.
|
||||
|
||||
1. CPU가 메모리 주소 `0xdeadbeef`에 값을 쓰려고 시도한 것 때문에 페이지 폴트가 발생합니다.
|
||||
2. CPU는 IDT에서 페이지 폴트에 대응하는 엔트리를 확인하지만, 페이지 폴트 처리 함수가 등록되어 있지 않습니다. 호출할 수 있는 페이지 폴트 처리 함수가 없어 더블 폴트가 발생합니다.
|
||||
3. CPU는 IDT에서 더블 폴트에 대응하는 엔트리를 확인하지만, 더블 폴트 처리 함수가 등록되어 있지 않습니다. 이후 _트리플 폴트_ 가 발생합니다.
|
||||
4. 트리플 폴트는 치명적입니다. 다른 실제 하드웨어들처럼 QEMU 또한 시스템을 리셋합니다.
|
||||
|
||||
이런 상황에서 트리플 폴트 발생을 막으려면 페이지 폴트 또는 더블 폴트의 처리 함수를 등록해야 합니다. 어떤 경우에서든 트리플 폴트만은 막아야 하므로, 처리되지 않은 예외가 있을 때 호출되는 더블 폴트의 처리 함수부터 먼저 작성하겠습니다.
|
||||
|
||||
## 더블 폴트 처리 함수
|
||||
더블 폴트도 일반적인 예외로서 오류 코드를 가집니다. 따라서 더블 폴트 처리 함수를 작성할 때 이전에 작성한 breakpoint 예외 처리 함수와 비슷하게 작성할 수 있습니다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt.double_fault.set_handler_fn(double_fault_handler); // 새롭게 추가함
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
// 새롭게 추가함
|
||||
extern "x86-interrupt" fn double_fault_handler(
|
||||
stack_frame: InterruptStackFrame, _error_code: u64) -> !
|
||||
{
|
||||
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
|
||||
}
|
||||
```
|
||||
|
||||
우리가 작성한 더블 폴트 처리 함수는 짧은 오류 메시지와 함께 예외 스택 프레임의 정보를 출력합니다. 더블 폴트 처리 함수의 오류 코드가 0인 것은 이미 아는 사실이니 굳이 출력할 필요가 없습니다. breakpoint 예외 처리 함수와 비교해 하나 다른 점은 더블 폴트 처리 함수가 [발산하는][_diverging_] 함수라는 것인데, 그 이유는 더블 폴트로부터 반환하는 것을 `x86_64` 아키텍처에서 허용하지 않기 때문입니다.
|
||||
|
||||
[_diverging_]: https://doc.rust-lang.org/stable/rust-by-example/fn/diverging.html
|
||||
|
||||
이제 커널을 실행시키면 더블 폴트 처리 함수가 호출되는 것을 확인하실 수 있습니다.
|
||||
|
||||

|
||||
|
||||
성공입니다! 어떤 일들이 일어났는지 단계별로 살펴보겠습니다.
|
||||
|
||||
1. CPU가 메모리 주소 `0xdeadbeef`에 값을 적으려 하고, 그 결과 페이지 폴트가 발생합니다.
|
||||
2. 이전처럼 CPU는 IDT에서 페이지 폴트에 대응하는 엔트리를 확인하지만, 등록된 처리 함수가 없음을 확인합니다. 그 결과 더블 폴트가 발생합니다.
|
||||
3. CPU의 제어 흐름이 등록된 더블 폴트 처리 함수로 점프합니다.
|
||||
|
||||
CPU가 더블 폴트 처리 함수를 호출할 수 있기에, 트리플 폴트와 무한 재부팅 루프는 더 이상 발생하지 않습니다.
|
||||
|
||||
별로 어렵지 않군요! 그럼에도 이 주제 하나에 이 글 전체를 할애한 이유가 궁금하신가요? 사실, 현재 우리는 _대부분의_ 더블 폴트를 처리할 수는 있지만, 현재의 커널 구현으로는 더블 폴트를 처리하지 못하는 특수한 경우들이 아직 남아 있습니다.
|
||||
|
||||
## 더블 폴트의 원인들
|
||||
특수한 경우들을 살펴보기 전에, 우선 더블 폴트가 일어나는 엄밀한 원인에 대해 파악해야 합니다. 본문의 윗부분에서는 더블 폴트를 설명할 때 다소 애매하고 느슨한 정의를 사용했습니다.
|
||||
|
||||
> 더블 폴트는 CPU가 예외 처리 함수를 호출하는 것에 실패했을 때 발생하는 예외입니다.
|
||||
|
||||
_“예외 처리 함수를 호출하는 것에 실패했을 때”_ 라는 게 정확히 무슨 뜻일까요? 예외 처리 함수가 등록되어 있지 않아 호출에 실패했다? 예외 처리 함수가 [스왑-아웃][swapped out] 되어 있어 호출에 실패했다? 그리고 예외 처리 함수 자체가 다시 예외를 발생시키면 어떻게 될까요?
|
||||
|
||||
[swapped out]: http://pages.cs.wisc.edu/~remzi/OSTEP/vm-beyondphys.pdf
|
||||
|
||||
예를 들어, 아래의 각각의 상황들을 가정했을 때 무슨 일이 일어날지 고민해 봅시다.
|
||||
|
||||
1. breakpoint 예외가 발생한 시점에 breakpoint 예외 처리 함수가 스왑-아웃 되어 있는 경우?
|
||||
2. 페이지 폴트가 발생한 시점에 페이지 폴트 처리 함수가 스왓-아웃 되어 있는 경우?
|
||||
3. divide-by-zero 예외 처리 함수가 breakpoint 예외를 발생시킨 시점에 breakpoint 예외 처리 함수가 스왑-아웃 되어 있는 경우?
|
||||
4. 커널이 스택 오버 플로우를 일으켜 _보호 페이지 (guard page)_ 에 접근하는 경우?
|
||||
|
||||
다행히 AMD64 매뉴얼 ([PDF][AMD64 manual])에서 더블 폴트의 명확한 정의를 제시합니다 (매뉴얼 섹션 8.2.9 참조). 매뉴얼의 정의에 따르면, “더블 폴트 예외는 1번째 발생한 예외를 처리하는 도중 2번째 예외가 발생한 경우에 _발생할 수 있다_” 합니다. 여기서 _“발생할 수 있다”_ 라는 표현이 중요한데, 더블 폴트는 아래의 표에서 보이는 것처럼 특수한 조합의 예외들이 순서대로 일어났을 때에만 발생합니다.
|
||||
|
||||
1번째 발생한 예외 | 2번째 발생한 예외
|
||||
----------------|-----------------
|
||||
[Divide-by-zero],<br>[Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault] | [Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault]
|
||||
[Page Fault] | [Page Fault],<br>[Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault]
|
||||
|
||||
[Divide-by-zero]: https://wiki.osdev.org/Exceptions#Divide-by-zero_Error
|
||||
[Invalid TSS]: https://wiki.osdev.org/Exceptions#Invalid_TSS
|
||||
[Segment Not Present]: https://wiki.osdev.org/Exceptions#Segment_Not_Present
|
||||
[Stack-Segment Fault]: https://wiki.osdev.org/Exceptions#Stack-Segment_Fault
|
||||
[General Protection Fault]: https://wiki.osdev.org/Exceptions#General_Protection_Fault
|
||||
[Page Fault]: https://wiki.osdev.org/Exceptions#Page_Fault
|
||||
|
||||
|
||||
[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
|
||||
|
||||
예를 들면 divide-by-zero 예외 뒤에 페이지 폴트가 발생하는 것은 괜찮지만 (페이지 폴트 처리 함수가 호출됨), divide-by-zero 예외 뒤에 general-protection fault 예외가 발생하면 더블 폴트가 발생합니다.
|
||||
|
||||
위 테이블을 이용하면 위에서 했던 질문 중 첫 3개에 대해 대답할 수 있습니다.
|
||||
|
||||
1. breakpoint 예외가 발생한 시점에 해당 예외 처리 함수가 스왑-아웃 되어 있는 경우, _페이지 폴트_ 가 발생하고 _페이지 폴트 처리 함수_ 가 호출됩니다.
|
||||
2. 페이지 폴트가 발생한 시점에 페이지 폴트 처리 함수가 스왑-아웃 되어 있는 경우, _더블 폴트_ 가 발생하고 _더블 폴트 처리 함수_ 가 호출됩니다.
|
||||
3. divide-by-zero 예외 처리 함수가 breakpoint 예외를 일으키는 경우, CPU가 breakpoint 예외 처리 함수의 호출을 시도합니다. breakpoint 예외 처리 함수가 스왑-아웃 되어 있는 경우, _페이지 폴트_ 가 발생하고 _페이지 폴트 처리 함수_ 가 호출됩니다.
|
||||
|
||||
사실 임의의 예외에 대한 처리 함수가 IDT에 없다는 것만으로 더블 폴트가 발생하는 것이 아닙니다. 예외가 발생하면 CPU는 그 예외에 대응하는 IDT 엔트리를 참조합니다. 해당 엔트리 값이 0인 경우 (= 예외 처리 함수가 등록되어 있지 않음), _general protection fault_ 예외가 발생합니다. 우리는 해당 예외를 처리할 함수를 등록하지 않았기 때문에, 새로운 general protection fault 예외가 또 발생합니다. general protection fault가 이어서 2번 일어났으니, 위 테이블에 따라 더블 폴트가 발생합니다.
|
||||
|
||||
### 커널 스택 오버플로우
|
||||
이제 위의 질문들 중 마지막 4번째 질문을 살펴보겠습니다.
|
||||
|
||||
> 커널이 스택 오버 플로우를 일으켜 _보호 페이지 (guard page)_ 에 접근하는 경우, 무슨 일이 일어날까요?
|
||||
|
||||
보호 페이지는 스택의 맨 아래에 위치하면서 스택 오버플로우를 감지하는 특별한 메모리 페이지입니다. 해당 페이지는 어떤 물리 프레임에도 매핑되지 않으며, CPU가 해당 페이지에 접근하면 물리 메모리에 접근하는 대신 페이지 폴트가 발생합니다. 부트로더가 커널 스택의 보호 페이지를 초기화하며, 이후 커널 스택 오버플로우가 발생하면 _페이지 폴트_ 가 발생합니다.
|
||||
|
||||
페이지 폴트가 발생하면 CPU는 IDT에서 페이지 폴트 처리 함수를 찾고 스택에 [인터럽트 스택 프레임 (interrupt stack frame)][interrupt stack frame]을 push 하려고 합니다. 하지만 현재의 스택 포인터는 물리 프레임이 매핑되지 않은 보호 페이지를 가리키고 있습니다. 따라서 2번째 페이지 폴트가 발생하고, 그 결과 더블 폴트가 발생합니다 (위 테이블 참조).
|
||||
|
||||
[interrupt stack frame]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
|
||||
|
||||
CPU는 이제 _더블 폴트 처리 함수_ 를 호출하려고 시도합니다. 하지만, 더블 폴트 발생 시 CPU는 또 예외 스택 프레임 (= 인터럽트 스택 프레임)을 스택에 push하려고 합니다. 스택 포인터는 여전히 보호 페이지를 가리키고, 따라서 _3번째_ 페이지 폴트 발생 후 _트리플 폴트_ 가 발생하고 시스템이 재부팅 됩니다. 우리가 지금 가진 더블 폴트 처리 함수로는 이 상황에서 트리플 폴트를 막을 수 없습니다.
|
||||
|
||||
역시 백문이 불여일견이죠! 무한 재귀 함수를 호출해 손쉽게 커널 스택오버플로우를 일으켜 봅시다.
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle] // 이 함수의 이름을 mangle하지 않습니다
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // 재귀 호출할 때마다 스택에 반환 주소를 push 합니다
|
||||
}
|
||||
|
||||
// 스택 오버플로우 일으키기
|
||||
stack_overflow();
|
||||
|
||||
[…] // test_main(), println(…), and loop {}
|
||||
}
|
||||
```
|
||||
|
||||
이 코드를 QEMU에서 실행하면 시스템이 또 무한 재부팅 루프에 갇히는 것을 확인할 수 있습니다.
|
||||
|
||||
이 문제를 어떻게 피할 수 있을까요? CPU 하드웨어가 예외 스택 프레임을 push 하는 것이라서, 커널 코드를 통해 스택 프레임의 push 과정을 생략할 수는 없습니다. 그래서 더블 폴트가 발생한 시점에는 늘 커널 스택이 유효하도록 보장할 수 있는 방법을 찾아야 합니다. 다행히도, x86_64 아키텍처는 이 문제에 대한 해답을 가지고 있습니다.
|
||||
|
||||
## 스택 교체하기
|
||||
x86_64 아키텍처는 예외 발생 시 스택을 미리 지정한 다른 안전한 스택으로 교체하는 것이 가능합니다. 이러한 스택 교체는 하드웨어 단에서 일어나고, 따라서 CPU가 예외 스택 프레임을 스택에 push 하기 전에 스택을 교체하는 것이 가능합니다.
|
||||
|
||||
이러한 스택 교체는 _인터럽트 스택 테이블 (Interrupt Stack Table; IST)_ 을 사용해 진행됩니다. IST는 안전한 것으로 알려진 7개의 다른 스택들의 주소를 저장하는 테이블입니다. IST의 구조를 Rust 코드 형식으로 표현하자면 아래와 같습니다.
|
||||
|
||||
```rust
|
||||
struct InterruptStackTable {
|
||||
stack_pointers: [Option<StackPointer>; 7],
|
||||
}
|
||||
```
|
||||
|
||||
각 예외 처리 함수는 [IDT 엔트리][IDT entry]의 `stack_pointers` 필드를 통해 IST의 스택 중 하나를 사용하도록 선택할 수 있습니다. 예를 들어, 우리의 더블 폴트 처리 함수가 IST의 1번째 스택을 사용하도록 설정할 수 있습니다. 그 후에는 더블 폴트가 발생할 때마다 CPU가 스택을 IST의 1번째 스택으로 교체합니다. 스택에 새로운 데이터가 push 되기 전에 스택 교체가 이뤄지기 때문에 트리플 폴트를 피할 수 있습니다.
|
||||
|
||||
[IDT entry]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
|
||||
|
||||
### IST와 TSS
|
||||
인터럽트 스택 테이블 (IST)은 오래되어 이젠 구식이 된 _[Task State Segment]_ (TSS)라는 구조체의 일부입니다. 예전에 TSS는 다양한 정보 (예: 프로세서 레지스터들의 상태 값)를 저장하거나 [하드웨어를 이용한 컨텍스트 스위치][hardware context switching]을 지원하는 용도로 사용됐습니다. 하지만 하드웨어를 이용한 컨텍스트 스위치를 64비트 모드에서부터는 지원하지 않게 되었고, 그 이후 TSS의 구조는 완전히 바뀌었습니다.
|
||||
|
||||
[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
|
||||
[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
|
||||
|
||||
x86_64 아키텍처에서 TSS는 특정 태스크 (task) 관련 정보를 보관하지 않습니다. 대신 TSS는 두 개의 스택 테이블을 보관합니다 (IST가 그중 하나입니다). 32비트 시스템의 TSS와 64비트 시스템의 TSS의 유일한 공통 필드는 [I/O port permissions bitmap]에 대한 포인터 하나 뿐입니다.
|
||||
|
||||
[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
|
||||
|
||||
64비트 TSS는 아래의 구조를 가집니다.
|
||||
|
||||
Field | Type
|
||||
------ | ----------------
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u32`
|
||||
Privilege Stack Table | `[u64; 3]`
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u64`
|
||||
Interrupt Stack Table | `[u64; 7]`
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u64`
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u16`
|
||||
I/O Map Base Address | `u16`
|
||||
|
||||
CPU가 특권 레벨을 교체할 때 _Privilege Stack Table_ 을 사용합니다. CPU가 사용자 모드일 때 (특권 레벨 = 3) 예외가 발생하면, CPU는 예외 처리 함수를 호출에 앞서 커널 모드로 전환합니다 (특권 레벨 = 0). 이 경우 CPU는 스택을 Privilege Stack Table의 0번째 스택으로 교체합니다 (특권 레벨이 0이라서). 아직 우리의 커널에서 동작하는 사용자 모드 프로그램이 없으므로, 일단은 이 테이블에 대해 걱정하지 않아도 됩니다.
|
||||
|
||||
### TSS 생성하기
|
||||
새로운 TSS를 생성하고 TSS의 인터럽트 스택 테이블에 별도의 더블 폴트 스택을 갖추도록 코드를 작성하겠습니다. 우선 TSS를 나타낼 구조체가 필요하기에, `x86_64` 크레이트가 제공하는 [`TaskStateSegment` 구조체][`TaskStateSegment` struct]를 사용하겠습니다.
|
||||
|
||||
[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/tss/struct.TaskStateSegment.html
|
||||
|
||||
새로운 모듈 `gdt`에 TSS를 생성합니다 (모듈 이름이 왜 gdt인지는 이후에 납득이 가실 겁니다).
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod gdt;
|
||||
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::VirtAddr;
|
||||
use x86_64::structures::tss::TaskStateSegment;
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
|
||||
|
||||
lazy_static! {
|
||||
static ref TSS: TaskStateSegment = {
|
||||
let mut tss = TaskStateSegment::new();
|
||||
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
|
||||
const STACK_SIZE: usize = 4096 * 5;
|
||||
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
|
||||
|
||||
let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
|
||||
let stack_end = stack_start + STACK_SIZE;
|
||||
stack_end
|
||||
};
|
||||
tss
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
Rust의 const evaluator가 위와 같은 TSS의 초기화를 컴파일 중에 진행하지 못해서 `lazy_static`을 사용합니다. IST의 0번째 엔트리가 더블 폴트 스택이 되도록 정합니다 (꼭 0번째일 필요는 없음). 그다음 더블 폴트 스택의 최상단 주소를 IST의 0번째 엔트리에 저장합니다. 스택의 최상단 주소를 저장하는 이유는 x86 시스템에서 스택은 높은 주소에서 출발해 낮은 주소 영역 쪽으로 성장하기 때문입니다.
|
||||
|
||||
우리가 아직 커널에 메모리 관리 (memory management) 기능을 구현하지 않아서 스택을 할당할 정규적인 방법이 없습니다. 임시방편으로 `static mut` 배열을 스택 메모리인 것처럼 사용할 것입니다. 값 변경이 가능한 static 변수에 접근하는 경우 컴파일러가 데이터 경쟁 상태 (data race)의 부재를 보장하지 못해 `unsafe` 키워드가 필요합니다. 배열은 꼭 `static`이 아닌 `static mut`로 설정해야 하는데, 그 이유는 부트로더가 `static` 변수를 읽기 전용 메모리 페이지에 배치하기 때문입니다. 이후에 다른 글에서 이 임시적인 스택 메모리 구현을 정석적인 구현으로 수정할 계획이며, 그 후에는 스택 메모리 접근에 더 이상 `unsafe`가 필요하지 않을 것입니다.
|
||||
|
||||
이 더블 폴트 스택에 스택 오버플로우를 감지하기 위한 보호 페이지가 없다는 것에 유의해야 합니다. 더블 폴트 스택에서 스택 오버플로우가 발생하면 스택 아래의 메모리 영역을 일부 덮어쓸 수 있기 때문에, 더블 폴트 처리 함수 안에서 스택 메모리를 과도하게 소모해서는 안됩니다.
|
||||
|
||||
#### TSS 불러오기
|
||||
새로운 TSS도 만들었으니, 이제 CPU에게 이 TSS를 쓰도록 지시할 방법이 필요합니다. TSS가 역사적 이유로 인해 세그멘테이션 (segmentation) 시스템을 사용하는 탓에, CPU에 TSS를 쓰도록 지시하는 과정이 꽤 번거롭습니다. TSS를 직접 불러오는 대신, [전역 서술자 테이블 (Global Descriptor Table; GDT)][Global Descriptor Table]을 가리키는 새로운 세그먼트 서술자 (segment descriptor)를 추가해야 합니다. 그 후 [`ltr` 명령어][`ltr` instruction]에 GDT 안에서의 TSS의 인덱스를 주고 호출하여 TSS를 불러올 수 있습니다. (이것이 모듈 이름을 `gdt`로 설정한 이유입니다.)
|
||||
|
||||
[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
|
||||
[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
|
||||
|
||||
### 전역 서술자 테이블 (Global Descriptor Table)
|
||||
전역 서술자 테이블 (Global Descriptor Table; GDT)는 메모리 페이징이 표준이 되기 이전, [메모리 세그멘테이션 (memory segmentation)][memory segmentation]을 지원하는 데 쓰인 오래된 물건입니다. 64비트 모드에서도 여전히 여러 쓰임새가 있는데, 커널/사용자 모드 설정 및 TSS 불러오기 등의 용도에 쓰입니다.
|
||||
|
||||
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
|
||||
GDT는 프로그램의 _세그먼트_ 들을 저장하는 구조체입니다. 메모리 페이징이 표준화되어 쓰이기 이전의 오래된 아키텍처들에서 프로그램들을 서로 격리할 때 GDT를 사용했습니다. 세그멘테이션에 대한 자세한 정보는 무료 공개된 [책 “Three Easy Pieces”][“Three Easy Pieces” book]의 Segmentation 챕터를 참고해 주세요. 세그멘테이션은 64비트 모드에서는 더 이상 지원되지 않지만, 그래도 GDT는 남아 있습니다. GDT는 대체로 2가지 용도에 쓰입니다: 1) 커널 공간과 사용자 공간 사이 교체를 진행할 때. 2) TSS 구조체를 불러올 때.
|
||||
|
||||
[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
|
||||
|
||||
#### GDT 만들기
|
||||
static 변수 `TSS`의 세그먼트를 포함하는 static `GDT`를 만듭니다.
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
|
||||
|
||||
lazy_static! {
|
||||
static ref GDT: GlobalDescriptorTable = {
|
||||
let mut gdt = GlobalDescriptorTable::new();
|
||||
gdt.add_entry(Descriptor::kernel_code_segment());
|
||||
gdt.add_entry(Descriptor::tss_segment(&TSS));
|
||||
gdt
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
이전처럼 `lazy_static`을 사용했습니다. 코드 세그먼트와 TSS 세그먼트를 포함하는 GDT를 만듭니다.
|
||||
|
||||
#### GDT 불러오기
|
||||
|
||||
GDT를 불러오는 용도의 함수 `gdt::init` 함수를 만들고, `init` 함수로부터 해당 함수를 호출합니다.
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
pub fn init() {
|
||||
GDT.load();
|
||||
}
|
||||
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
}
|
||||
```
|
||||
|
||||
이제 GDT를 불러온 상태입니다만 (`_start` 함수가 `init` 함수를 호출했기 때문에), 여전히 커널 스택 오버플로우 발생 시 커널이 무한 재부팅 루프에 갇힙니다.
|
||||
|
||||
### 최종 단계
|
||||
|
||||
세그먼트 레지스터 및 TSS 레지스터가 기존의 GDT로부터 읽어온 값들을 저장하고 있는 탓에, 우리가 만든 GDT의 세그먼트들이 활성화되지 않은 상황입니다. 또한 더블 폴트 처리 함수가 새로운 스택을 쓰도록 IDT에서 더블 폴트 처리 함수의 엔트리를 알맞게 수정해야 합니다.
|
||||
|
||||
정리하자면 우리는 아래의 작업을 순차적으로 진행해야 합니다.
|
||||
|
||||
1. **code segment 레지스터의 값 갱신하기**: GDT를 변경하였으니 코드 세그먼트 레지스터 `cs`의 값도 갱신해야 합니다. 기존의 세그먼트 선택자는 새 GDT 안에서 코드 세그먼트가 아닌 다른 세그먼트의 선택자와 동일할 수도 있습니다 (예: TSS 선택자).
|
||||
2. **TSS 불러오기**: GDT와 TSS 선택자를 불러오고, 그 후 CPU가 해당 TSS를 사용하도록 지시해야 합니다.
|
||||
3. **IDT 엔트리 수정하기**: TSS를 불러온 시점부터 CPU는 유효한 인터럽트 스택 테이블 (IST)에 접근할 수 있습니다. 앞으로 더블 폴트 발생 시 CPU가 새로운 더블 폴트 스택으로 교체하도록, IDT에서 더블 폴트에 대응하는 엔트리를 알맞게 수정합니다.
|
||||
|
||||
첫 두 단계를 수행하려면 `gdt::init` 함수에서 두 변수 `code_selector`와 `tss_selector`에 대한 접근할 수 있어야 합니다. `Selectors` 라는 새로운 구조체를 통해 해당 변수들을 `gdt::init` 함수에서 접근할 수 있게 만듭니다.
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::structures::gdt::SegmentSelector;
|
||||
|
||||
lazy_static! {
|
||||
static ref GDT: (GlobalDescriptorTable, Selectors) = {
|
||||
let mut gdt = GlobalDescriptorTable::new();
|
||||
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
|
||||
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
|
||||
(gdt, Selectors { code_selector, tss_selector })
|
||||
};
|
||||
}
|
||||
|
||||
struct Selectors {
|
||||
code_selector: SegmentSelector,
|
||||
tss_selector: SegmentSelector,
|
||||
}
|
||||
```
|
||||
|
||||
이제 접근 가능해진 선택자들을 사용해 `cs` 레지스터의 값을 갱신하고 우리가 만든 `TSS`를 불러옵니다.
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
pub fn init() {
|
||||
use x86_64::instructions::tables::load_tss;
|
||||
use x86_64::instructions::segmentation::{CS, Segment};
|
||||
|
||||
GDT.0.load();
|
||||
unsafe {
|
||||
CS::set_reg(GDT.1.code_selector);
|
||||
load_tss(GDT.1.tss_selector);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
[`set_cs`] 함수로 코드 세그먼트 레지스터의 값을 갱신하고, [`load_tss`] 함수로 우리가 만든 TSS를 불러옵니다. 이 함수들은 `unsafe` 함수로 정의되어 있어 `unsafe` 블록 안에서만 호출할 수 있습니다. 이 함수들이 `unsafe`로 정의된 이유는 해당 함수들에 유효하지 않은 선택자를 전달할 경우 메모리 안전성을 해칠 수 있기 때문입니다.
|
||||
|
||||
[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
|
||||
[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
|
||||
|
||||
유효한 TSS와 인터럽트 스택 테이블을 불러왔으니, 이제 더블 폴트 처리 함수가 사용할 스택의 인덱스를 IDT에서 지정해 봅시다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use crate::gdt;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
unsafe {
|
||||
idt.double_fault.set_handler_fn(double_fault_handler)
|
||||
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // 새롭게 추가함
|
||||
}
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
`set_stack_index`가 unsafe 함수인 이유는, 이 함수를 호출하는 측에서 인덱스가 유효하고 다른 예외 처리 시 사용 중이지 않다는 것을 보장해야 하기 때문입니다.
|
||||
|
||||
수고하셨습니다! 이제부터 더블 폴트가 일어난다면 CPU는 스택을 더블 폴트 스택으로 교체할 것입니다. 드디어 커널 스택 오버플로우가 발생하는 상황을 포함하여 더블 폴트가 일어나는 _어떤 경우라도_ 더블 폴트를 처리할 수 있게 됐습니다.
|
||||
|
||||

|
||||
|
||||
앞으로 트리플 폴트를 볼 일은 없을 겁니다! 위에서 구현한 내용을 우리가 미래에 실수로라도 훼손하지 않도록, 위 구현의 작동을 점검하는 테스트를 추가해 보겠습니다.
|
||||
|
||||
## 커널 스택 오버플로우 테스트
|
||||
|
||||
`gdt` 모듈을 테스트하고 커널 스택 오버플로우 발생 시 더블 폴트 처리 함수가 호출되는지 확인하는 용도의 통합 테스트를 추가할 것입니다. 테스트 함수에서 더블 폴트를 일으킨 후에 더블 폴트 처리 함수가 호출되었는지 확인하는 테스트를 작성하겠습니다.
|
||||
|
||||
최소한의 뼈대 코드에서부터 테스트 작성을 시작해 봅시다.
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
unimplemented!();
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
이전에 작성한 `panic_handler` 테스트처럼 이 테스트 또한 [테스트 하네스 (test harness) 없이][without a test harness] 실행될 것입니다. 그 이유는 더블 폴트가 발생한 후에는 프로그램의 정상 실행을 재개할 수가 없기 때문에 어차피 1개 이상의 테스트를 두는 것이 의미가 없기 때문입니다. 테스트 하네스를 사용하지 않도록 `Cargo.toml`에 아래의 코드를 추가합니다.
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[[test]]
|
||||
name = "stack_overflow"
|
||||
harness = false
|
||||
```
|
||||
|
||||
[without a test harness]: @/edition-2/posts/04-testing/index.ko.md#no-harness-tests
|
||||
|
||||
`cargo test --test stack_overflow` 실행 시 컴파일은 성공할 것이고, 테스트 내의 `unimplemented` 매크로 때문에 테스트 실행은 실패할 것입니다.
|
||||
|
||||
### `_start` 함수 구현
|
||||
|
||||
`_start` 함수의 코드 구현은 아래와 같습니다.
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use blog_os::serial_print;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
serial_print!("stack_overflow::stack_overflow...\t");
|
||||
|
||||
blog_os::gdt::init();
|
||||
init_test_idt();
|
||||
|
||||
// 스택 오버플로우 일으키기
|
||||
stack_overflow();
|
||||
|
||||
panic!("Execution continued after stack overflow");
|
||||
}
|
||||
|
||||
#[allow(unconditional_recursion)]
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // 재귀 호출할 때마다 반환 주소가 스택에 push 됩니다
|
||||
volatile::Volatile::new(0).read(); // "tail call elimination" 방지하기
|
||||
}
|
||||
```
|
||||
|
||||
`gdt::init` 함수를 호출해 새 GDT를 초기화합니다. `interrupts::init_idt` 함수 대신 `init_test_idt` 함수를 호출하는데, 그 이유는 패닉하지 않고 `exit_qemu(QemuExitCode::Success)`를 호출하는 새로운 더블 폴트 처리 함수를 등록해 사용할 것이기 때문입니다.
|
||||
|
||||
`stack_overflow` 함수는 `main.rs`에서 작성했던 것과 거의 동일합니다. 유일한 차이점은 함수 마지막에 추가로 [`Volatile`] 타입을 이용한 [volatile] 읽기를 통해 [_tail call elimination_]을 방지한다는 것입니다. 주어진 함수의 맨 마지막 구문이 재귀 함수에 대한 호출인 경우, 컴파일러는 tail call elimination 기법을 통해 재귀 함수 호출을 평범한 반복문으로 변환할 수 있습니다. 그렇게 하면 재귀 함수 호출 시 새로운 스택 프레임이 생성되지 않고, 스택 메모리 사용량은 일정하게 유지됩니다.
|
||||
|
||||
[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
|
||||
[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
|
||||
[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
|
||||
|
||||
이 테스트에서 우리는 스택 오버플로우가 발생하기를 원하기 때문에, 함수의 맨 마지막에 컴파일러가 제거할 수 없는 volatile 읽기 작업을 삽입합니다. 따라서 `stack_overflow` 함수는 더 이상 _꼬리 재귀 (tail recursive)_ 함수가 아니게 되고, tail call elimination 기법을 통한 최적화 역시 할 수 없게 됩니다. 또 `allow(unconditional_recursion)` 속성을 함수에 추가해 "함수가 무한히 재귀한다"는 경고 메시지가 출력되지 않게 합니다.
|
||||
|
||||
### 테스트용 IDT
|
||||
|
||||
위에서 언급했듯이, 살짝 변경된 새로운 더블 폴트 처리 함수가 등록된 테스트용 IDT가 필요합니다. 테스트 용 IDT의 구현은 아래와 같습니다.
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
use x86_64::structures::idt::InterruptDescriptorTable;
|
||||
|
||||
lazy_static! {
|
||||
static ref TEST_IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
unsafe {
|
||||
idt.double_fault
|
||||
.set_handler_fn(test_double_fault_handler)
|
||||
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
|
||||
}
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_test_idt() {
|
||||
TEST_IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
코드 구현은 우리가 `interrupts.rs`에서 작성한 IDT와 매우 흡사합니다. 기존과 마찬가지로 더블 폴트 처리 함수가 사용할 스택의 인덱스를 정해줍니다. `init_test_idt` 함수는 `load` 함수를 통해 테스트 용 IDT를 CPU로 불러옵니다.
|
||||
|
||||
### 더블 폴트 처리 함수
|
||||
|
||||
마지막 남은 단계는 더블 폴트 처리 함수를 작성하는 것입니다. 코드 구현은 아래와 같습니다.
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use blog_os::{exit_qemu, QemuExitCode, serial_println};
|
||||
use x86_64::structures::idt::InterruptStackFrame;
|
||||
|
||||
extern "x86-interrupt" fn test_double_fault_handler(
|
||||
_stack_frame: InterruptStackFrame,
|
||||
_error_code: u64,
|
||||
) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
더블 폴트 처리 함수가 호출되면 우리는 성공 종료 코드와 함께 QEMU를 종료시키고, 테스트는 성공한 것으로 처리됩니다. 통합 테스트는 완전히 독립적인 실행 파일로 간주하기 때문에, 다시 한번 테스트 파일의 맨 위에 `#![feature(abi_x86_interrupt)]` 속성을 추가해야 합니다.
|
||||
|
||||
`cargo test --test stack_overflow`를 통해 새로 작성한 테스트를 실행할 수 있습니다 (또는 `cargo test`로 모든 테스트 실행). 예상대로 콘솔에
|
||||
`stack_overflow... [ok]` 라는 메시지가 출력될 것입니다. 테스트 코드에서 `set_stack_index`를 호출하지 않게 주석 처리한 후 테스트를 실행하면 테스트가 실패하는 것 또한 확인할 수 있을 것입니다.
|
||||
|
||||
## 정리
|
||||
이 글에서는 더블 폴트와 더블 폴트의 발생 조건에 대해 배웠습니다. 오류 메시지를 출력하는 간단한 더블 폴트 처리 함수를 커널에 추가했고, 해당 함수의 올바른 동작을 점검하는 통합 테스트도 추가했습니다.
|
||||
|
||||
또한 우리는 더블 폴트 발생 시 하드웨어의 스택 교체 기능을 통해 커널 스택 오버 플로우 발생 시에도 더블 폴트가 제대로 처리되도록 구현했습니다. 구현 과정에서 Task State Segment (TSS)와 그 안에 포함된 인터럽트 스택 테이블 (Interrupt Stack Table; IST), 그리고 오래된 아키텍처들에서 세그멘테이션 (segmentation)에 사용됐던 전역 서술자 테이블 (Global Descriptor Table; GDT)에 대해 배웠습니다.
|
||||
|
||||
## 다음 단계는 무엇일까요?
|
||||
다음 글에서는 타이머, 키보드, 네트워크 컨트롤러 등의 외부 장치로부터 전송되어 오는 인터럽트들을 처리하는 방법에 대해 설명하겠습니다. 이러한 하드웨어 인터럽트들은 예외와 마찬가지로 IDT에 등록된 처리 함수를 통해 처리된다는 점에서 유사합니다. 인터럽트가 예외와 다른 점은 예외와 달리 CPU로부터 발생하지 않는다는 것입니다. 대신에 _인터럽트 컨트롤러 (interrupt controller)_ 가 외부 장치로부터 전송되어 오는 인터럽트들을 수합한 후 인터럽트 우선 순위에 맞춰 CPU로 인터럽트들을 전달합니다. 다음 글에서 [Intel 8259] (“PIC”) 인터럽트 컨트롤러에 대해 알아보고, 키보드 입력을 지원하는 법을 배울 것입니다.
|
||||
|
||||
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
|
||||
562
blog/content/edition-2/posts/06-double-faults/index.zh-CN.md
Normal file
562
blog/content/edition-2/posts/06-double-faults/index.zh-CN.md
Normal file
@@ -0,0 +1,562 @@
|
||||
+++
|
||||
title = "Double Faults"
|
||||
weight = 6
|
||||
path = "zh-CN/double-fault-exceptions"
|
||||
date = 2018-06-18
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong"]
|
||||
+++
|
||||
|
||||
在这篇文章中,我们会探索 double fault 异常的细节,它的触发条件是调用错误处理函数失败。通过捕获该异常,我们可以阻止致命的 _triple faults_ 异常导致系统重启。为了尽可能避免 triple faults ,我们会在一个独立的内核栈配置 _中断栈表_ 来捕捉 double faults。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-06`][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
<!-- fix for zola anchor checker (target is in template): <a id="comments"> -->
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-06
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 何谓 Double Fault
|
||||
简而言之,double fault 就是当CPU执行错误处理函数失败时抛出的特殊异常。比如,你没有注册在 [中断描述符表][IDT] 中注册对应 page fault 异常的处理函数,然后程序偏偏就抛出了一个 page fault 异常,这时候就会接着抛出 double fault 异常。这个异常的处理函数就比较类似于具备异常处理功能的编程语言里的 catch-all 语法的效果,比如 C++ 里的 `catch(...)` 和 JAVA/C# 里的 `catch(Exception e)`。
|
||||
|
||||
[IDT]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
|
||||
|
||||
double fault 的行为和普通异常十分相似,我们可以通过在IDT中注册 `8` 号位的处理函数来拦截该异常。这个处理函数十分重要,如果你不处理这个异常,CPU就会直接抛出 _triple fault_ 异常,该异常无法被任何方式处理,而且会直接导致绝大多数硬件强制重启。
|
||||
|
||||
### 捕捉 Double Fault
|
||||
我们先来试试看不捕捉 double fault 的情况下触发它会有什么后果:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
// trigger a page fault
|
||||
unsafe {
|
||||
*(0xdeadbeef as *mut u64) = 42;
|
||||
};
|
||||
|
||||
// as before
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
这里我们使用 `unsafe` 块直接操作了一个无效的内存地址 `0xdeadbeef`,由于该虚拟地址并未在页表中映射到物理内存,所以必然会抛出 page fault 异常。我们又并未在 [IDT] 中注册对应的处理器,所以 double fault 会紧接着被抛出。
|
||||
|
||||
现在启动内核,我们可以看到它直接陷入了崩溃和重启的无限循环,其原因如下:
|
||||
|
||||
1. CPU试图向 `0xdeadbeef` 写入数据,这就造成了 page fault 异常。
|
||||
2. CPU没有在IDT中找到相应的处理函数,所以又抛出了 double fault 异常。
|
||||
3. CPU再一次没有在IDT中找到相应的处理函数,所以又抛出了 _triple fault_ 异常。
|
||||
4. 在抛出 triple fault 之后就没有然后了,这个错误是致命级别,如同大多数硬件一样,QEMU对此的处理方式就是重置系统,也就是重启。
|
||||
|
||||
通过这个小实验,我们知道在这种情况下,需要提前注册 page faults 或者 double fault 的处理函数才行,但如果想要在任何场景下避免触发 triple faults 异常,则必须注册能够捕捉一切未注册异常类型的 double fault 处理函数。
|
||||
|
||||
## 处理 Double Fault
|
||||
double fault 是一个带错误码的常规错误,所以我们可以参照 breakpoint 处理函数定义一个 double fault 处理函数:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt.double_fault.set_handler_fn(double_fault_handler); // new
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
// new
|
||||
extern "x86-interrupt" fn double_fault_handler(
|
||||
stack_frame: InterruptStackFrame, _error_code: u64) -> !
|
||||
{
|
||||
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
|
||||
}
|
||||
```
|
||||
|
||||
我们的处理函数打印了一行简短的信息,并将栈帧转写了出来。其中错误码一直是0,所以没有必要把它打印出来。要说这和 breakpoint 处理函数有什么区别,那就是 double fault 的处理函数是 [发散的][_diverging_],这是因为 `x86_64` 架构不允许从 double fault 异常中返回任何东西。
|
||||
|
||||
[_diverging_]: https://doc.rust-lang.org/stable/rust-by-example/fn/diverging.html
|
||||
|
||||
那么再次启动内核,我们可以看到 double fault 的处理函数被成功调用:
|
||||
|
||||

|
||||
|
||||
让我们来分析一下又发生了什么:
|
||||
|
||||
1. CPU尝试往 `0xdeadbeef` 写入数据,引发了 page fault 异常。
|
||||
2. 如同上次运行一样,CPU并没有在IDT里找到对应的处理函数,所以又引发了 double fault 异常。
|
||||
3. CPU又跳转到了我们刚刚定义的 double fault 处理函数。
|
||||
|
||||
现在 triple fault 及其衍生的重启循环不会再出现了,因为CPU已经妥善处理了 double fault 异常。
|
||||
|
||||
这还真是直截了当对吧,但为什么要为这点内容单独写一篇文章呢?没错,我们的确已经可以捕获 _大部分_ double faults 异常,但在部分情况下,这样的做法依然不够。
|
||||
|
||||
## Double Faults 的成因
|
||||
在解释这些部分情况之前,我们需要先明确一下 double faults 的成因,上文中我们使用了一个模糊的定义:
|
||||
|
||||
> double fault 就是当CPU执行错误处理函数失败时抛出的特殊异常。
|
||||
|
||||
但究竟什么叫 _“调用失败”_ ?没有提供处理函数?处理函数被[换出][swapped out]内存了?或者处理函数本身也出现了异常?
|
||||
|
||||
[swapped out]: http://pages.cs.wisc.edu/~remzi/OSTEP/vm-beyondphys.pdf
|
||||
|
||||
比如以下情况出现时:
|
||||
|
||||
1. 如果 breakpoint 异常被触发,但其对应的处理函数已经被换出内存了?
|
||||
2. 如果 page fault 异常被触发,但其对应的处理函数已经被换出内存了?
|
||||
3. 如果 divide-by-zero 异常处理函数又触发了 breakpoint 异常,但 breakpoint 异常处理函数已经被换出内存了?
|
||||
4. 如果我们的内核发生了栈溢出,意外访问到了 _guard page_ ?
|
||||
|
||||
幸运的是,AMD64手册([PDF][AMD64 manual])给出了一个准确的定义(在8.2.9这个章节中)。
|
||||
根据里面的说法,“double fault” 异常 _会_ 在执行主要(一层)异常处理函数时触发二层异常时触发。
|
||||
这个“会”字十分重要:只有特定的两个异常组合会触发 double fault。
|
||||
这些异常组合如下:
|
||||
|
||||
| 一层异常 | 二层异常 |
|
||||
| --------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| [Divide-by-zero],<br>[Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault] | [Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault] |
|
||||
| [Page Fault] | [Page Fault],<br>[Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault] |
|
||||
|
||||
[Divide-by-zero]: https://wiki.osdev.org/Exceptions#Divide-by-zero_Error
|
||||
[Invalid TSS]: https://wiki.osdev.org/Exceptions#Invalid_TSS
|
||||
[Segment Not Present]: https://wiki.osdev.org/Exceptions#Segment_Not_Present
|
||||
[Stack-Segment Fault]: https://wiki.osdev.org/Exceptions#Stack-Segment_Fault
|
||||
[General Protection Fault]: https://wiki.osdev.org/Exceptions#General_Protection_Fault
|
||||
[Page Fault]: https://wiki.osdev.org/Exceptions#Page_Fault
|
||||
|
||||
|
||||
[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
|
||||
|
||||
所以那些假设里的 divide-by-zero 异常处理函数触发了 page fault 并不会出问题,只会紧接着触发下一个异常处理函数。但如果 divide-by-zero 异常处理函数触发的是 general-protection fault,则一定会触发 double fault。
|
||||
|
||||
那么根据上表,我们可以回答刚刚的假设中的前三个:
|
||||
|
||||
1. 如果 breakpoint 异常被触发,但对应的处理函数被换出了内存,_page fault_ 异常就会被触发,并调用其对应的异常处理函数。
|
||||
2. 如果 page fault 异常被触发,但对应的处理函数被换出了内存,那么 _double fault_ 异常就会被触发,并调用其对应的处理函数。
|
||||
3. 如果 divide-by-zero 异常处理函数又触发了 breakpoint 异常,但 breakpoint 异常处理函数已经被换出内存了,那么被触发的就是 _page fault_ 异常。
|
||||
|
||||
实际上,因在IDT里找不到对应处理函数而抛出异常的内部机制是:当异常发生时,CPU会去试图读取对应的IDT条目,如果该条目不是一个有效的条目,即其值为0,就会触发 _general protection fault_ 异常。但我们同样没有为该异常注册处理函数,所以又一个 general protection fault 被触发了,随后 double fault 也被触发了。
|
||||
|
||||
### 内核栈溢出
|
||||
现在让我们看一下第四个假设:
|
||||
|
||||
> 如果我们的内核发生了栈溢出,意外访问到了 _guard page_ ?
|
||||
|
||||
guard page 是一类位于栈底部的特殊内存页,所以如果发生了栈溢出,最典型的现象就是访问这里。这类内存页不会映射到物理内存中,所以访问这里只会造成 page fault 异常,而不会污染其他内存。bootloader 已经为我们的内核栈设置好了一个 guard page,所以栈溢出会导致 _page fault_ 异常。
|
||||
|
||||
当 page fault 发生时,CPU会在IDT寻找对应的处理函数,并尝试将 [中断栈帧][interrupt stack frame] 入栈,但此时栈指针指向了一个实际上并不存在的 guard page,然后第二个 page fault 异常就被触发了,根据上面的表格,double fault 也随之被触发了。
|
||||
|
||||
[interrupt stack frame]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
|
||||
|
||||
这时,CPU会尝试调用 _double fault_ 对应的处理函数,然而CPU依然会试图将错误栈帧入栈,由于栈指针依然指向 guard page,于是 _第三次_ page fault 发生了,最终导致 _triple fault_ 异常的抛出,系统因此重启。所以仅仅是注册错误处理函数并不能在此种情况下阻止 triple fault 的发生。
|
||||
|
||||
让我们来尝试一下,写一个能造成栈溢出的递归函数非常简单:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle] // 禁止函数名自动修改
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // 每一次递归都会将返回地址入栈
|
||||
}
|
||||
|
||||
// 触发 stack overflow
|
||||
stack_overflow();
|
||||
|
||||
[…] // test_main(), println(…), and loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我们在QEMU执行这段程序,然后系统就再次进入了重启循环。
|
||||
|
||||
所以我们要如何避免这种情况?我们无法忽略异常栈帧入栈这一步,因为这个逻辑是内置在CPU里的。所以我们需要找个办法,让栈在 double fault 异常发生后始终有效。幸运的是,x86_64 架构对于这个问题已经给出了解决方案。
|
||||
|
||||
## 切换栈
|
||||
x86_64 架构允许在异常发生时,将栈切换为一个预定义的完好栈,这个切换是执行在硬件层次的,所以完全可以在CPU将异常栈帧入栈之前执行。
|
||||
|
||||
这个切换机制是由 _中断栈表_ (IST)实现的,IST是一个由7个确认可用的完好栈的指针组成的,用 Rust 语言可以表述为:
|
||||
|
||||
```rust
|
||||
struct InterruptStackTable {
|
||||
stack_pointers: [Option<StackPointer>; 7],
|
||||
}
|
||||
```
|
||||
|
||||
对于每一个错误处理函数,我们都可以通过对应的[IDT条目][IDT entry]中的 `stack_pointers` 条目指定IST中的一个栈。比如我们可以让 double fault 对应的处理函数使用IST中的第一个栈指针,则CPU会在这个异常发生时,自动将栈切换为该栈。该切换行为会在所有入栈操作之前进行,由此可以避免进一步触发 triple fault 异常。
|
||||
|
||||
[IDT entry]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
|
||||
|
||||
### IST和TSS
|
||||
中断栈表(IST)其实是一个名叫 _[任务状态段][Task State Segment](TSS)_ 的古老遗留结构的一部分。
|
||||
TSS是用来存储32位任务中的零碎信息,比如处理器寄存器的状态,一般用于 [硬件上下文切换][hardware context switching]。但是硬件上下文切换已经不再适用于64位模式,并且TSS的实际数据结构也已经发生了彻底的改变。
|
||||
|
||||
[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
|
||||
[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
|
||||
|
||||
在 x86_64 架构中,TSS已经不再存储任何任务相关信息,取而代之的是两个栈表(IST正是其中之一)。
|
||||
32位TSS和64位TSS唯一的共有字段恐怕就是指向 [I/O端口权限位图][I/O port permissions bitmap] 的指针了。
|
||||
|
||||
[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
|
||||
|
||||
64位TSS的格式如下:
|
||||
|
||||
| 字段 | 类型 |
|
||||
| ---------------------------------------- | ---------- |
|
||||
| <span style="opacity: 0.5">(保留)</span> | `u32` |
|
||||
| 特权栈表 | `[u64; 3]` |
|
||||
| <span style="opacity: 0.5">(保留)</span> | `u64` |
|
||||
| 中断栈表 | `[u64; 7]` |
|
||||
| <span style="opacity: 0.5">(保留)</span> | `u64` |
|
||||
| <span style="opacity: 0.5">(保留)</span> | `u16` |
|
||||
| I/O映射基准地址 | `u16` |
|
||||
|
||||
_特权栈表_ 在 CPU 特权等级变更的时候会被用到。例如当 CPU 在用户态(特权等级3)中触发一个异常时,一般情况下 CPU 会在执行错误处理函数前切换到内核态(特权等级0),在这种情况下,CPU 会切换为特权栈表的第0层(0层是目标特权等级)。但是目前我们还没有用户态的程序,所以暂且可以忽略这个表。
|
||||
|
||||
### 创建一个TSS
|
||||
那么我们来创建一个新的包含单独的 double fault 专属栈以及中断栈表的TSS。为此我们需要一个TSS结构体,幸运的是 `x86_64` crate 也已经自带了 [`TaskStateSegment` 结构][`TaskStateSegment` struct] 用来映射它。
|
||||
|
||||
[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/tss/struct.TaskStateSegment.html
|
||||
|
||||
那么我们新建一个 `gdt` 模块(稍后会说明为何要使用这个名字)用来创建TSS:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod gdt;
|
||||
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::VirtAddr;
|
||||
use x86_64::structures::tss::TaskStateSegment;
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
|
||||
|
||||
lazy_static! {
|
||||
static ref TSS: TaskStateSegment = {
|
||||
let mut tss = TaskStateSegment::new();
|
||||
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
|
||||
const STACK_SIZE: usize = 4096 * 5;
|
||||
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
|
||||
|
||||
let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
|
||||
let stack_end = stack_start + STACK_SIZE;
|
||||
stack_end
|
||||
};
|
||||
tss
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
这次依然是使用 `lazy_static`,Rust的静态变量求值器还没有强大到能够在编译器执行初始化代码。我们将IST的0号位定义为 double fault 的专属栈(其他IST序号也可以如此施为)。然后我们将栈的高地址指针写入0号位,之所以这样做,那是因为 x86 的栈内存分配是从高地址到低地址的。
|
||||
|
||||
由于我们还没有实现内存管理机制,所以目前无法直接申请新栈,但我们可以使用 `static mut` 形式的数组来在内存中模拟出栈存储区。`unsafe` 块也是必须的,因为编译器认为这种可以被竞争的变量是不安全的,而且这里必须是 `static mut` 而不是不可修改的 `static`,否则 bootloader 会将其分配到只读页中。当然,在后续的文章中,我们会将其修改为真正的栈分配,`unsafe` 块也一定会去掉的。
|
||||
|
||||
但要注意,由于现在 double fault 获取的栈不再具有用于防止栈溢出的 guard page,所以我们不应该做任何栈密集型操作了,否则就有可能会污染到栈下方的内存区域。
|
||||
|
||||
#### 加载TSS
|
||||
我们已经创建了一个TSS,现在的问题就是怎么让CPU使用它。不幸的是这事有点繁琐,因为TSS用到了分段系统(历史原因)。但我们可以不直接加载,而是在[全局描述符表][Global Descriptor Table](GDT)中添加一个段描述符,然后我们就可以通过[`ltr` 指令][`ltr` instruction]加上GDT序号加载我们的TSS。(这也是为什么我们将模块取名为 `gdt`。)
|
||||
|
||||
[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
|
||||
[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
|
||||
|
||||
### 全局描述符表
|
||||
全局描述符表(GDT)是分页模式成为事实标准之前,用于[内存分段][memory segmentation]的遗留结构,但它在64位模式下仍然需要处理一些事情,比如内核态/用户态的配置以及TSS载入。
|
||||
|
||||
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
|
||||
GDT是包含了程序 _段信息_ 的结构,在分页模式成为标准前,它在旧架构下起到隔离程序执行环境的作用。要了解更多关于分段的知识,可以查看 [“Three Easy Pieces” book] 这本书的同名章节。尽管GDT在64位模式下已经不再受到支持,但其依然有两个作用,切换内核空间和用户空间,以及加载TSS结构。
|
||||
|
||||
[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
|
||||
|
||||
#### 创建GDT
|
||||
我们来创建一个包含了静态 `TSS` 段的 `GDT` 静态结构:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
|
||||
|
||||
lazy_static! {
|
||||
static ref GDT: GlobalDescriptorTable = {
|
||||
let mut gdt = GlobalDescriptorTable::new();
|
||||
gdt.add_entry(Descriptor::kernel_code_segment());
|
||||
gdt.add_entry(Descriptor::tss_segment(&TSS));
|
||||
gdt
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
就像以前一样,我们依然使用了 `lazy_static` 宏,我们通过这段代码创建了TSS和GDT两个结构。
|
||||
|
||||
#### 加载GDT
|
||||
|
||||
我们先创建一个在 `init` 函数中调用的 `gdt::init` 函数:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
pub fn init() {
|
||||
GDT.load();
|
||||
}
|
||||
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
}
|
||||
```
|
||||
|
||||
现在GDT成功加载了进去(`_start` 会调用 `init` 函数),但我们依然会看到由于栈溢出引发的重启循环。
|
||||
|
||||
### 最终步骤
|
||||
|
||||
现在的问题就变成了GDT并未被激活,代码段寄存器和TSS实际上依然引用着旧的GDT,并且我们也需要修改 double fault 对应的IDT条目,使其使用新的栈。
|
||||
|
||||
总结一下,我们需要做这些事情:
|
||||
|
||||
1. **重载代码段寄存器**: 我们修改了GDT,所以就需要重载代码段寄存器 `cs`,这一步对于修改GDT信息而言是必须的,比如覆写TSS。
|
||||
2. **加载TSS** : 我们已经加载了包含TSS信息的GDT,但我们还需要告诉CPU使用新的TSS。
|
||||
3. **更新IDT条目**: 当TSS加载完毕后,CPU就可以访问到新的中断栈表(IST)了,下面我们需要通过修改IDT条目告诉CPU使用新的 double fault 专属栈。
|
||||
|
||||
通过前两步,我们可以在 `gdt::init` 函数中调用 `code_selector` 和 `tss_selector` 两个变量,我们可以将两者打包为一个 `Selectors` 结构便于使用:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::structures::gdt::SegmentSelector;
|
||||
|
||||
lazy_static! {
|
||||
static ref GDT: (GlobalDescriptorTable, Selectors) = {
|
||||
let mut gdt = GlobalDescriptorTable::new();
|
||||
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
|
||||
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
|
||||
(gdt, Selectors { code_selector, tss_selector })
|
||||
};
|
||||
}
|
||||
|
||||
struct Selectors {
|
||||
code_selector: SegmentSelector,
|
||||
tss_selector: SegmentSelector,
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以使用这两个变量去重载代码段寄存器 `cs` 并重载 `TSS`:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
pub fn init() {
|
||||
use x86_64::instructions::tables::load_tss;
|
||||
use x86_64::instructions::segmentation::{CS, Segment};
|
||||
|
||||
GDT.0.load();
|
||||
unsafe {
|
||||
CS::set_reg(GDT.1.code_selector);
|
||||
load_tss(GDT.1.tss_selector);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们通过 [`set_cs`] 覆写了代码段寄存器,然后使用 [`load_tss`] 来重载了TSS,不过这两个函数都被标记为 `unsafe`,所以 `unsafe` 代码块是必须的。
|
||||
原因很简单,如果通过这两个函数加载了无效的指针,那么很可能就会破坏掉内存安全性。
|
||||
|
||||
[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
|
||||
[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
|
||||
|
||||
现在我们已经加载了有效的TSS和中断栈表,我们可以在IDT中为 double fault 对应的处理函数设置栈序号:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use crate::gdt;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
unsafe {
|
||||
idt.double_fault.set_handler_fn(double_fault_handler)
|
||||
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
|
||||
}
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
`set_stack_index` 函数也是不安全的,因为栈序号的有效性和引用唯一性是需要调用者去确保的。
|
||||
|
||||
搞定!现在CPU会在 double fault 异常被触发时自动切换到安全栈了,我们可以捕捉到 _所有_ 的 double fault,包括内核栈溢出:
|
||||
|
||||

|
||||
|
||||
现在开始我们应该不会再看到 triple fault 了,但要确保这部分逻辑不被破坏,我们还需要为其添加一个测试。
|
||||
|
||||
## 栈溢出测试
|
||||
|
||||
要测试我们的 `gdt` 模块,并确保在栈溢出时可以正确捕捉 double fault,我们可以添加一个集成测试。基本上就是在测试函数中主动触发一个 double fault 异常,确认异常处理函数是否正确运行了。
|
||||
|
||||
让我们建立一个最小化框架:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
unimplemented!();
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
就如同 `panic_handler` 这个测试一样,该测试应该是一个 [无约束测试][without a test harness],其原因就是我们无法在 double fault 被抛出后继续运行,所以连续进行多个测试其实是说不通的。要将测试修改为无约束模式,我们需要将这一段配置加入 `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[[test]]
|
||||
name = "stack_overflow"
|
||||
harness = false
|
||||
```
|
||||
|
||||
[without a test harness]: @/edition-2/posts/04-testing/index.md#no-harness-tests
|
||||
|
||||
现在 `cargo test --test stack_overflow` 命令应当可以通过编译了。但是毫无疑问的是还是会执行失败,因为 `unimplemented` 宏必然会导致程序报错。
|
||||
|
||||
### 实现 `_start`
|
||||
|
||||
`_start` 函数实现后的样子是这样的:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use blog_os::serial_print;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
serial_print!("stack_overflow::stack_overflow...\t");
|
||||
|
||||
blog_os::gdt::init();
|
||||
init_test_idt();
|
||||
|
||||
// trigger a stack overflow
|
||||
stack_overflow();
|
||||
|
||||
panic!("Execution continued after stack overflow");
|
||||
}
|
||||
|
||||
#[allow(unconditional_recursion)]
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // for each recursion, the return address is pushed
|
||||
volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
|
||||
}
|
||||
```
|
||||
|
||||
我们调用了 `gdt::init` 函数来初始化GDT,但我们并没有调用 `interrupts::init_idt` 函数,而是调用了一个全新的 `init_test_idt` 函数,我们稍后来实现它。原因就是,我们需要注册一个自定义的 double fault 处理函数,在被触发的时候调用 `exit_qemu(QemuExitCode::Success)` 函数,而非使用默认的逻辑。
|
||||
|
||||
`stack_overflow` 函数和我们之前在 `main.rs` 中写的那个函数几乎一模一样,唯一的区别就是在函数的最后使用 [`Volatile`] 类型 加入了一个 [volatile] 读取操作,用来阻止编译器进行 [_尾调用优化_][_tail call elimination_]。除却其他乱七八糟的效果,这个优化最主要的影响就是会让编辑器将最后一行是递归语句的函数转化为普通的循环。由于没有通过递归创建新的栈帧,所以栈自然也不会出问题。
|
||||
|
||||
[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
|
||||
[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
|
||||
[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
|
||||
|
||||
在当前用例中,stack overflow 是必须要触发的,所以我们在函数尾部加入了一个无效的 volatile 读取操作来让编译器无法进行此类优化,递归也就无法被自动降级为循环了。当然,为了关闭编译器针对递归的安全警告,我们也需要为这个函数加上 `allow(unconditional_recursion)` 开关。
|
||||
|
||||
### 测试 IDT
|
||||
|
||||
作为上一小节的补充,我们说过要在测试专用的IDT中实现一个自定义的 double fault 异常处理函数,就像这样:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
use x86_64::structures::idt::InterruptDescriptorTable;
|
||||
|
||||
lazy_static! {
|
||||
static ref TEST_IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
unsafe {
|
||||
idt.double_fault
|
||||
.set_handler_fn(test_double_fault_handler)
|
||||
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
|
||||
}
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_test_idt() {
|
||||
TEST_IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
这和我们在 `interrupts.rs` 中实现的版本十分相似,如同正常的IDT一样,我们都为 double fault 使用IST序号设置了特殊的栈,而上文中提到的 `init_test_idt` 函数则通过 `load` 函数将配置成功装载到CPU。
|
||||
|
||||
### Double Fault 处理函数
|
||||
|
||||
那么现在就差处理函数本身了,它看起来是这样子的:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use blog_os::{exit_qemu, QemuExitCode, serial_println};
|
||||
use x86_64::structures::idt::InterruptStackFrame;
|
||||
|
||||
extern "x86-interrupt" fn test_double_fault_handler(
|
||||
_stack_frame: InterruptStackFrame,
|
||||
_error_code: u64,
|
||||
) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
这个处理函数被调用后,我们会使用代表成功的返回值退出QEMU,以此即可标记测试完成,但由于集成测试处于完全独立的运行环境,也记得在测试入口文件的头部再次加入 `#![feature(abi_x86_interrupt)]` 开关。
|
||||
|
||||
现在我们可以执行 `cargo test --test stack_overflow` 运行当前测试(或者执行 `cargo test` 运行所有测试),应当可以在控制台看到 `stack_overflow... [ok]` 这样的输出。另外,也可以试一下注释掉 `set_stack_index` 这一行的命令,可以观察到失败情况下的输出。
|
||||
|
||||
## 总结
|
||||
在本文中,我们学到了 double fault 是什么,以及触发它的原因。我们为 double fault 写了相应的处理函数、将错误信息打印到控制台并为它添加了一个集成测试。
|
||||
|
||||
同时,我们为 double fault 启用了栈指针切换功能,使其在栈溢出时也可以正常工作。在实现这个功能的同时,我们也学习了在旧架构中用于内存分段的任务状态段(TSS),而该结构又包含了中断栈表(IST)和全局描述符表(GDT)。
|
||||
|
||||
## 下期预告
|
||||
在下一篇文章中,我们会展开来说外部设备(如定时器、键盘、网络控制器)中断的处理方式。这些硬件中断十分类似于上文所说的异常,都需要通过IDT进行处理,只是中断并不是由CPU抛出的。 _中断控制器_ 会代理这些中断事件,并根据中断的优先级将其转发给CPU处理。我们将会以 [Intel 8259] (PIC) 中断控制器为例对其进行探索,并实现对键盘的支持。
|
||||
|
||||
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
|
||||
740
blog/content/edition-2/posts/07-hardware-interrupts/index.ko.md
Normal file
740
blog/content/edition-2/posts/07-hardware-interrupts/index.ko.md
Normal file
@@ -0,0 +1,740 @@
|
||||
+++
|
||||
title = "하드웨어 인터럽트"
|
||||
weight = 7
|
||||
path = "ko/hardware-interrupts"
|
||||
date = 2018-10-22
|
||||
|
||||
[extra]
|
||||
chapter = "Interrupts"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "a108367d712ef97c28e8e4c1a22da4697ba6e6cd"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["JOE1994"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["dalinaum"]
|
||||
+++
|
||||
|
||||
이 글에서는 프로그래밍 할 수 있는 인터럽트 컨트롤러가 인터럽트들을 CPU로 정확히 전달하도록 설정할 것입니다. 새로운 인터럽트들을 처리하기 위해 인터럽트 서술자 테이블 (interrupt descriptor table)에 새로운 엔트리들을 추가할 것입니다 (이전에 예외 처리 함수를 등록했듯이). 또한 일정 주기마다 타이머 인터럽트를 일으키는 방법 및 키보드 입력 받는 방법도 알아볼 것입니다.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-07 브랜치`][post branch]에서 확인하실 수 있습니다.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
<!-- fix for zola anchor checker (target is in template): <a id="comments"> -->
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-07
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 개요
|
||||
|
||||
CPU에 연결된 주변 장치들은 인터럽트를 통해 CPU에 알림을 보낼 수 있습니다. 그래서 커널이 주기적으로 키보드 입력이 들어왔는지 확인하게 하는 대신 (이를 [_폴링(polling)_][_polling_] 방식이라고 합니다), 키보드 입력이 들어올 때마다 키보드가 직접 커널에 알림을 보낼 수 있습니다. 이 방식을 사용하면 이벤트 발생 시에만 커널이 행동을 취하면 되므로 에너지 효율성이 더 좋습니다. 또한 이벤트가 발생 시 커널이 다음 poll까지 기다리지 않고 바로 반응할 수 있기에 이벤트에 대한 반응 속도도 더 빠릅니다.
|
||||
|
||||
[_polling_]: https://en.wikipedia.org/wiki/Polling_(computer_science)
|
||||
|
||||
하드웨어 장치들을 모두 CPU에 직접 연결하는 것은 불가능합니다. 대신 별도의 _인터럽트 컨트롤러 (interrupt controller)_ 가 주변 장치로부터 전송된 인터럽트들을 수합한 뒤 CPU에 알림을 보냅니다.
|
||||
|
||||
```
|
||||
____________ _____
|
||||
Timer ------------> | | | |
|
||||
Keyboard ---------> | Interrupt |---------> | CPU |
|
||||
Other Hardware ---> | Controller | |_____|
|
||||
Etc. -------------> |____________|
|
||||
|
||||
```
|
||||
|
||||
대부분의 인터럽트 컨트롤러들은 프로그래밍을 통해 인터럽트마다 다른 우선순위 레벨을 배정하는 것이 가능합니다. 예를 들어, 키보드 인터럽트보다 타이머 인터럽트에 더 높은 우선순위 레벨을 배정하여 CPU에서 시간을 더 정확히 측정할 수 있습니다.
|
||||
|
||||
예외와 달리 하드웨어 인터럽트는 _비동기적으로 (asynchronously)_ 일어납니다. 즉 CPU에서 실행 중인 코드와 별개로 인터럽트는 언제든 발생할 수 있다는 것입니다. 따라서, 커널에 인터럽트를 도입하면서 동시성(concurrency)의 형태가 등장하고 동시성 관련 버그 발생의 가능성도 생깁니다. Rust의 엄격한 소유권 (ownership) 모델이 전역 가변 변수 사용을 금지해 동시성 관련 버그 발생 가능성을 줄여주지만, 교착 상태(deadlock)를 막아주지는 못하며 이는 본문 아래에서 곧 확인하실 수 있습니다.
|
||||
|
||||
## 8259 PIC
|
||||
|
||||
[Intel 8259] 는 프로그래밍 가능한 인터럽트 컨트롤러 (PIC; Programmable Interrupt Controller)이며, 1976년에 처음 도입되었습니다. 이 장치는 오래전에 신형 장치 [APIC]로 대체됐지만, 이전 버전과의 호환성 유지를 위해 그 인터페이스만은 최신 시스템들도 지원하고 있습니다. 8259 PIC를 다루는 것이 APIC를 다루는 것보다 쉽습니다. 그렇기에 인터럽트에 대해 배우고 입문하는 현재 단계에서는 8259 PIC를 쓰고, 이 블로그 시리즈의 이후 글에서는 APIC로 교체하여 사용하겠습니다.
|
||||
|
||||
[APIC]: https://en.wikipedia.org/wiki/Intel_APIC_Architecture
|
||||
|
||||
Intel 8259 PIC는 8개의 인터럽트 통신선과 CPU와 통신하기 위한 몇 개의 통신선을 가집니다. 과거의 전형적인 PC 시스템은 8259 PIC를 2개 장착하고 있었는데 (주 PIC와 부 PIC), 주 PIC의 인터럽트 통신선 중 하나를 부 PIC에 연결했습니다.
|
||||
|
||||
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
|
||||
|
||||
```
|
||||
____________ ____________
|
||||
Real Time Clock --> | | Timer -------------> | |
|
||||
ACPI -------------> | | Keyboard-----------> | | _____
|
||||
Available --------> | Secondary |----------------------> | Primary | | |
|
||||
Available --------> | Interrupt | Serial Port 2 -----> | Interrupt |---> | CPU |
|
||||
Mouse ------------> | Controller | Serial Port 1 -----> | Controller | |_____|
|
||||
Co-Processor -----> | | Parallel Port 2/3 -> | |
|
||||
Primary ATA ------> | | Floppy disk -------> | |
|
||||
Secondary ATA ----> |____________| Parallel Port 1----> |____________|
|
||||
|
||||
```
|
||||
|
||||
위 도표는 인터럽트 통신선을 배정하는 전형적인 방식을 보여줍니다. 15개의 선 중 대부분은 어떤 장치와 연결할지 이미 정해져 있습니다. 예를 들어, 부 PIC의 4번 통신선은 마우스에 연결됩니다.
|
||||
|
||||
각 컨트롤러는 "command" 포트와 "data" 포트, 이 2개의 [입출력 포트][I/O ports]들을 사용해 설정합니다. 주 PIC는 `0x20`번 포트가 command 포트, `0x21`번 포트가 data 포트입니다. 부 PIC는 `0xa0`번 포트가 command 포트, `0xa1` 포트가 data 포트입니다. PIC를 설정하는 자세한 방법에 대해서는 [osdev.org의 글][article on osdev.org]을 찾아보시길 바랍니다.
|
||||
|
||||
[I/O ports]: @/edition-2/posts/04-testing/index.md#i-o-ports
|
||||
[article on osdev.org]: https://wiki.osdev.org/8259_PIC
|
||||
|
||||
### 구현
|
||||
|
||||
위 PIC들의 기본 설정에서 PIC는 0-15 구간의 인터럽트 벡터 번호를 CPU에 전송합니다. IDT에서 이 구간의 인터럽트 벡터 번호들은 이미 CPU 예외들에 배정되어 있기에, PIC의 기본 설정을 그대로 사용하지 못합니다. 예를 들면 벡터 번호 8은 더블 폴트에 배정되어 있습니다. 벡터 번호가 중복되는 문제를 해결하려면 PIC가 전송하는 인터럽트들을 다른 벡터 번호에 재배정 해야 합니다. 기존 예외들의 벡터 번호와 겹치지 않는 이상 인터럽트들에 어떤 번호를 배정하는지는 크게 중요하지 않습니다만, 예외들에 배정된 첫 32개의 슬롯 다음 비는 32-47 구간의 벡터 번호를 고르는 것이 일반적입니다.
|
||||
|
||||
PIC 장치의 command 포트 및 data 포트에 특수한 값을 쓰면 장치 설정을 변경할 수 있습니다. 운 좋게도 [`pic8259`] 크레이트 덕에 우리가 장치 설정 초기화/변경 로직을 직접 작성할 필요는 없습니다. 작동 원리가 궁금하시다면 해당 크레이트의 [소스 코드][pic crate source]를 직접 확인해보세요. 코드양이 많지 않고 문서화도 잘 되어 있습니다.
|
||||
|
||||
[pic crate source]: https://docs.rs/crate/pic8259/0.10.1/source/src/lib.rs
|
||||
|
||||
의존 크레이트로 해당 크레이트를 추가하기 위해 아래의 코드를 추가합니다.
|
||||
|
||||
[`pic8259`]: https://docs.rs/pic8259/0.10.1/pic8259/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
pic8259 = "0.10.1"
|
||||
```
|
||||
|
||||
이 크레이트의 [`ChainedPics`] 구조체는 위에서 봤던 주/부 PIC 연결 방식을 적절한 추상 레벨에서 표현합니다. 이 구조체는 아래처럼 사용하도록 설계되었습니다.
|
||||
|
||||
[`ChainedPics`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use pic8259::ChainedPics;
|
||||
use spin;
|
||||
|
||||
pub const PIC_1_OFFSET: u8 = 32;
|
||||
pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
|
||||
|
||||
pub static PICS: spin::Mutex<ChainedPics> =
|
||||
spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
|
||||
```
|
||||
|
||||
위에서 언급했듯이 PIC들이 사용할 벡터 번호의 오프셋을 32-47 구간에서 선택합니다. `ChainedPics` 구조체를 감싼 `Mutex`의 `lock` 함수를 통해 안전하게 값을 수정할 수 있는데, 이는 다음 단계에서 유용합니다. `ChainedPics::new` 함수에 잘못된 오프셋을 넘기면 undefined behavior가 일어날 수 있어 이 함수는 unsafe 함수로 정의되었습니다.
|
||||
|
||||
[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
|
||||
|
||||
이제 `init` 함수에서 8259 PIC 장치를 초기화할 수 있습니다.
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
unsafe { interrupts::PICS.lock().initialize() }; // 새로 추가함
|
||||
}
|
||||
```
|
||||
|
||||
[`initialize`] 함수를 사용해 PIC 장치를 초기화합니다. PIC 장치를 잘못 초기화하면 undefined behavior를 일으킬 수 있으므로, `ChainedPics::new` 함수와 마찬가지로 이 함수도 unsafe 함수로 정의되었습니다.
|
||||
|
||||
[`initialize`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html#method.initialize
|
||||
|
||||
추가한 코드에 문제가 없었다면, 다시 `cargo run`을 실행해도 예전처럼 "It did not crash"라는 메시지가 출력될 것입니다.
|
||||
|
||||
## 인터럽트 활성화하기
|
||||
|
||||
CPU 설정에서 인터럽트 사용이 해제되어 있었기에 아직 아무 일도 일어나지 않았습니다. 인터럽트 사용이 해제되어 있으면 CPU는 인터럽트 컨트롤러부터 오는 신호를 전혀 받지 않고, 따라서 어떤 인터럽트도 CPU에 도달할 수 없습니다. CPU 설정을 바꿔보겠습니다.
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
unsafe { interrupts::PICS.lock().initialize() };
|
||||
x86_64::instructions::interrupts::enable(); // 새로 추가함
|
||||
}
|
||||
```
|
||||
|
||||
`x86_64` 크레이트의 `interrupts::enable` 함수는 `sti` 명령어 (“set interrupts”)를 실행해 외부 인터럽트를 사용하도록 설정합니다. 이제 `cargo run`을 실행하면 더블 폴트가 발생하는 것을 확인할 수 있습니다.
|
||||
|
||||

|
||||
|
||||
더블 폴트가 발생하는 이유는, [Intel 8253] 장치에서 기본적으로 하드웨어 타이머를 사용하도록 설정이 되어 있고, CPU에서 인터럽트 사용을 활성화한 직후부터 타이머 인터럽트가 CPU로 전송되기 때문입니다. 우리가 아직 타이머 인터럽트 처리 함수를 정의하지 않았기 때문에 더블 폴트 처리 함수가 호출됩니다.
|
||||
|
||||
[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
|
||||
|
||||
## 타이머 인터럽트 처리하기
|
||||
|
||||
[위 도표](#8259-pic)를 보면 타이머는 주 PIC의 0번 통신선을 사용합니다. 이는 즉 타이머 인터럽트가 CPU에 인터럽트 벡터 번호가 32 (0 + 오프셋 32)인 인터럽트로 전송된다는 것을 뜻합니다. 코드에 번호 32를 그대로 적지 않고 `InterruptIndex` enum에 저장합니다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
#[repr(u8)]
|
||||
pub enum InterruptIndex {
|
||||
Timer = PIC_1_OFFSET,
|
||||
}
|
||||
|
||||
impl InterruptIndex {
|
||||
fn as_u8(self) -> u8 {
|
||||
self as u8
|
||||
}
|
||||
|
||||
fn as_usize(self) -> usize {
|
||||
usize::from(self.as_u8())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
[C언어의 enum][C-like enum]처럼 이 enum은 각 분류에 사용할 인덱스 값을 지정할 수 있습니다. `repr(u8)` 속성은 해당 enum을 `u8` 타입으로서 저장 및 표현되도록 합니다. 향후에 새로운 인터럽트들을 지원해야 할 때 이 enum에 새로운 분류를 추가할 것입니다.
|
||||
|
||||
[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
|
||||
|
||||
이제 타이머 인터럽트를 처리할 함수를 작성할 수 있습니다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use crate::print;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
[…]
|
||||
idt[InterruptIndex::Timer.as_usize()]
|
||||
.set_handler_fn(timer_interrupt_handler); // 새로 추가함
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn timer_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
print!(".");
|
||||
}
|
||||
```
|
||||
|
||||
`timer_interrupt_handler` 함수는 우리가 가진 다른 예외 처리 함수들과 같은 함수 원형을 가지는데, 그 이유는 CPU가 예외와 인터럽트에 같은 방식으로 대응하기 때문입니다 (유일한 차이점은 일부 예외들이 오류 코드를 추가로 push한다는 것). [`InterruptDescriptorTable`] 구조체는 [`IndexMut`] 트레이트를 구현해서 배열을 색인하는 것과 동일한 문법을 써서 테이블의 각 엔트리에 접근할 수 있습니다.
|
||||
|
||||
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
|
||||
|
||||
우리가 작성한 타이머 인트럽트 처리 함수는 화면에 점을 출력합니다. 타이머 인터럽트는 주기적으로 발생하므로, 타이머 주기마다 화면에 새로운 점이 출력되기를 기대하는 것이 자연스럽습니다. 하지만 커널을 실행해 보면 화면에 점이 단 1개만 출력될 것입니다.
|
||||
|
||||

|
||||
|
||||
### End of Interrupt
|
||||
|
||||
점이 1개만 출력되는 이유는 PIC가 인터럽트 처리 함수로부터 명시적으로 “end of interrupt” (EOI) 신호가 전송되어 오기를 기다리기 때문입니다. 이 신호는 PIC에 해당 인터럽트가 처리되었으며 시스템이 다음 인터럽트를 받을 준비가 된 것을 알립니다. 신호를 받지 못한 PIC는 시스템이 아직 첫 타이머 인터럽트를 처리 중이라 생각하고 EOI 신호가 올 때까지 다음 인터럽트를 보내지 않고 기다리는 것입니다.
|
||||
|
||||
static으로 선언된 `PICS` 구조체를 다시 사용해 EOI 신호를 보냅니다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn timer_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
print!(".");
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`notify_end_of_interrupt` 함수는 주 PIC와 부 PIC 중 누가 인터럽트를 보냈었는지 파악하고, 그 후 `command` 포트와 `data` 포트를 사용해 인터럽트를 전송했던 PIC로 EOI 신호를 보냅니다. 부 PIC가 인터럽트를 보냈었다면, 부 PIC가 주 PIC의 입력 통신선에 연결되어 있다 보니 두 PIC 모두 EOI 신호를 받게 됩니다.
|
||||
|
||||
여기서 우리는 올바른 인터럽트 벡터 번호를 사용하도록 주의해야 합니다. 잘못된 번호를 쓰면, 아직 CPU로 전송하지 않은 중요한 인터럽트가 소실되거나 시스템이 아무 반응도 하지 않게 될 수 있습니다. 이런 이유로 `notify_end_of_interrupt` 함수가 `unsafe`로 선언된 것입니다.
|
||||
|
||||
다시 `cargo run`을 실행하면 화면에 주기적으로 점이 찍히는 것을 확인할 수 있습니다.
|
||||
|
||||

|
||||
|
||||
### 타이머 설정하기
|
||||
|
||||
우리가 쓰는 하드웨어 타이머는 _Programmable Interval Timer_, 또는 줄여서 PIT라고 부릅니다. 이름에서 알 수 있듯이, 프로그래밍을 통해 인터럽트 사이 시간 간격을 조정할 수 있습니다. 곧 [APIC 타이머][APIC timer]로 교체해 사용할 것이기 때문에 PIT에 대해 자세히 다루지는 않겠습니다만, OSDev 위키에 [PIT를 설정하는 방법][configuring the PIT]에 대한 자세한 글이 있으니 참고하시기 바랍니다.
|
||||
|
||||
[APIC timer]: https://wiki.osdev.org/APIC_timer
|
||||
[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
|
||||
|
||||
## 교착 상태 (Deadlock)
|
||||
|
||||
이제 우리의 커널에 동시성의 개념이 등장했습니다. 타이머 인터럽트는 비동기적으로 발생하기에 `_start` 함수 실행 중 언제든 발생할 수 있습니다. Rust의 소유권 (ownership) 시스템이 다양한 동시성 관련 버그를 컴파일 시간에 방지하지만, 교착 상태는 막지 못합니다. 스레드(thread)가 해제되지 않을 lock을 얻으려고 할 때 교착 상태가 일어나며, 해당 스레드는 영원히 대기 상태에 갇히게 됩니다.
|
||||
|
||||
현재 우리의 커널에서 교착 상태를 일으킬 수 있습니다. 우리가 쓰는 `println` 매크로가 호출하는 `vga_buffer::_print` 함수는 스핀 락(spinlock)을 통해 [전역 변수 `WRITER`에 대한 lock을 잠급니다][vga spinlock].
|
||||
|
||||
[vga spinlock]: @/edition-2/posts/03-vga-text-buffer/index.md#spinlocks
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
[…]
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
위 함수는 `WRITER`에 대한 lock을 잠그고 `write_fmt`를 호출하며, 위 함수의 반환 직전에 `WRITER`에 대한 lock을 암묵적으로 해제합니다. `WRITER`에 대한 lock이 잠긴 상태에서 인터럽트가 발생하고, 해당 인터럽트의 처리 함수가 화면에 뭔가 출력하려 한다고 가정해봅시다.
|
||||
|
||||
| 시간 순서 | _start | 인터럽트 처리 함수 |
|
||||
| --------- | ------------------------- | ----------------------------------------------- |
|
||||
| 0 | `println!` 호출 | |
|
||||
| 1 | `print`가 `WRITER`를 잠금 | |
|
||||
| 2 | | **인터럽트 발생**, 인터럽트 처리 함수 실행 시작 |
|
||||
| 3 | | `println!` 호출 |
|
||||
| 4 | | `print`가 이미 잠긴 `WRITER`를 또 잠그려고 함 |
|
||||
| 5 | | `print`가 이미 잠긴 `WRITER`를 또 잠그려고 함 |
|
||||
| … | | … |
|
||||
| _never_ | _`WRITER` 잠금 해제_ |
|
||||
|
||||
`WRITER`에 대한 lock이 잠겨 있으니, 인터럽트 처리 함수는 해당 lock이 풀릴 때까지 기다립니다. 하지만 `_start` 함수는 인터럽트 처리 함수가 반환한 후에 실행을 재개하기 때문에 lock이 풀리지 않습니다. 그 결과, 시스템 전체가 응답 불가 상태가 됩니다.
|
||||
|
||||
### 교착 상태 일으키기
|
||||
|
||||
`_start` 함수의 맨 마지막 loop 안에서 화면에 출력을 시도하면 쉽게 커널에 교착 상태를 일으킬 수 있습니다.
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
[…]
|
||||
loop {
|
||||
use blog_os::print;
|
||||
print!("-"); // 새로 추가함
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
QEMU에서 실행하면 아래와 같은 출력을 얻게 됩니다.
|
||||
|
||||

|
||||
|
||||
첫 타이머 인터럽트 발생 전까지는 제한된 수의 붙임표(`-`)가 출력됩니다. 첫 타이머 인터럽트 후, 타이머 인터럽트 처리 함수가 온점(`.`)을 출력하려다 교착 상태에 빠지고 시스템은 아무 반응을 하지 않습니다. 이것이 출력 내용에 온점이 전혀 없는 이유입니다.
|
||||
|
||||
타이머 인터럽트가 비동기적으로 발생하다보니 커널을 실행할 때마다 출력되는 붙임표의 수가 다를 수 있습니다. 동시성 관련 버그들은 실행 결과가 이렇게 비결정론적(non-deterministic)인 경우가 많아 디버깅하기 쉽지 않습니다.
|
||||
|
||||
### 교착 상태 방지하기
|
||||
|
||||
`Mutex`가 잠긴 동안 인터럽트를 해제하면 교착 상태를 방지할 수 있습니다.
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
/// Prints the given formatted string to the VGA text buffer
|
||||
/// through the global `WRITER` instance.
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts; // 새로 추가함
|
||||
|
||||
interrupts::without_interrupts(|| { // 새로 추가함
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
[`without_interrupts`] 함수는 인자로 받은 [클로저(closure)][closure]를 인터럽트가 없는 환경에서 실행합니다. 이 함수를 통해 `Mutex`가 잠긴 동안 인터럽트가 발생하지 않게 보장합니다. 커널을 다시 실행하면 커널이 응답 불가 상태에 빠지지 않고 계속 실행되는 것을 확인할 수 있습니다. (화면 스크롤이 너무 빠르게 내려가다 보니 화면에 점이 출력되는 것을 확인하기 어려울 수 있습니다. `_start` 함수의 loop 안에 `for _ in 0..10000 {}`를 삽입하는 등의 방법으로 출력 속도를 늦춰 보세요.)
|
||||
|
||||
[`without_interrupts`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/interrupts/fn.without_interrupts.html
|
||||
[closure]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
|
||||
직렬 포트를 이용한 출력 함수 코드 역시 같은 방식으로 수정하여 교착 상태를 방지합니다.
|
||||
|
||||
```rust
|
||||
// in src/serial.rs
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: ::core::fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts; // 새로 추가함
|
||||
|
||||
interrupts::without_interrupts(|| { // 새로 추가함
|
||||
SERIAL1
|
||||
.lock()
|
||||
.write_fmt(args)
|
||||
.expect("Printing to serial failed");
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
인터럽트를 해제하는 것이 일반적으로 사용할 해결 방식이 아니라는 것을 아셔야 합니다. 인터럽트를 해제하면 인터럽트가 최대로 많이 몰렸을 때 시스템이 인터럽트에 반응할 수 있는 시간 (worst-case interrupt latency)이 늦어집니다. 따라서 인터럽트를 해제하려면 아주 짧은 시간 동안만 해야 합니다.
|
||||
|
||||
## 경쟁 상태 (Race Condition) 예방하기
|
||||
|
||||
`cargo test`를 실행하면 테스트 `test_println_output`가 때때로 실패하는 것을 확인할 수 있습니다:
|
||||
|
||||
```
|
||||
> cargo test --lib
|
||||
[…]
|
||||
Running 4 tests
|
||||
test_breakpoint_exception...[ok]
|
||||
test_println... [ok]
|
||||
test_println_many... [ok]
|
||||
test_println_output... [failed]
|
||||
|
||||
Error: panicked at 'assertion failed: `(left == right)`
|
||||
left: `'.'`,
|
||||
right: `'S'`', src/vga_buffer.rs:205:9
|
||||
```
|
||||
|
||||
이 테스트가 때때로 실패하는 것은 이 테스트와 우리가 작성한 타이머 처리 함수 간 _경쟁 상태 (race condition)_ 때문입니다. 예전에 작성했던 이 테스트의 코드를 다시 살펴보겠습니다.
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
let s = "Some test string that fits on a single line";
|
||||
println!("{}", s);
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
이 테스트는 VGA 버퍼에 문자열에 출력한 후 `buffer_chars` 배열을 직접 순회하여 출력된 내용을 확인합니다. 경쟁 상태가 생기는 이유는, `println`과 `screen_char`를 읽는 코드 사이에 타이머 인터럽트 처리 함수가 호출될 수 있기 때문입니다. 이는 컴파일 시간에 Rust가 막아주는 위험한 _데이터 레이스 (data race)_ 와는 다릅니다. 자세한 내용은 [_Rustonomicon_][nomicon-races]을 참고해주세요.
|
||||
|
||||
[nomicon-races]: https://doc.rust-lang.org/nomicon/races.html
|
||||
|
||||
이 문제를 고치려면 위 테스트가 실행 중에 `WRITER`에 대한 lock을 계속 잠그고 있어야 합니다. 그렇게 해야 타이머 처리 함수가 그 사이에 `.`을 출력하지 못합니다. 아래와 같이 테스트를 수정합니다.
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts;
|
||||
|
||||
let s = "Some test string that fits on a single line";
|
||||
interrupts::without_interrupts(|| {
|
||||
let mut writer = WRITER.lock();
|
||||
writeln!(writer, "\n{}", s).expect("writeln failed");
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
변경 사항들을 정리하면 아래와 같습니다.
|
||||
|
||||
- 테스트 실행 중에는 `lock()` 함수를 사용해 WRITER를 잠가 놓습니다. `println` 대신 [`writeln`] 매크로를 써서 이미 잠긴 WRITER를 이용해 메시지를 출력합니다.
|
||||
- 또 다른 교착 상태를 피하려고 테스트 중에는 인터럽트의 사용을 해제합니다. 그렇게 하지 않으면 테스트 실행 중 WRITER가 잠긴 상태에서 발생한 다른 인터럽트가 테스트 실행을 방해할 수 있습니다.
|
||||
- 테스트 실행 시작 전에 타이머 인터럽트 처리 함수가 실행될 수 있으니 문자열 `s` 출력 전에 개행 문자 `\n`을 출력합니다. 이렇게 하면 타이머 인터럽트 처리 함수가 현재 행에 이미 `.` 문자를 여럿 출력했더라도 이 테스트가 실패하지 않을 것입니다.
|
||||
|
||||
[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
|
||||
|
||||
이제 다시 `cargo test`를 실행하면 항상 성공하는 것을 확인하실 수 있습니다.
|
||||
|
||||
위에서 다룬 경쟁 상태 (race condition)는 테스트 실패를 일으키는 것 외에 큰 해를 끼치지는 않았습니다. 하지만 비결정론적인 결과를 낳는다는 본질적인 특성 때문에 이보다 디버깅하기 더 까다로운 경쟁 상태 역시 존재할 수 있습니다. 데이터 레이스(data race)라는 가장 위험한 종류의 경쟁 상태는 시스템 크래시나 메모리 커럽션 (memory corruption) 등 온갖 undefined behavior를 일으킬 수 있지만, 다행히 Rust가 우리를 데이터 레이스로부터 지켜줍니다.
|
||||
|
||||
## `hlt` 명령어
|
||||
|
||||
여태까지는 `_start` 및 `panic` 함수들의 맨 마지막에 간단한 빈 loop를 사용했습니다. 이 loop 때문에 CPU는 실행을 종료하지 않는데, CPU가 딱히 할 일이 없는데 CPU를 최고 속도로 가동하는 것은 에너지 효율성 측면에서 매우 비효율적입니다. 커널 실행 후 태스크 매니저를 보시면 QEMU 프로세스가 항상 CPU 시간을 100% 가까이 사용하고 있을 것입니다.
|
||||
|
||||
우리가 정말 해야 할 일은 다음 인터럽트 전까지 CPU가 정지하도록 하는 것입니다. CPU는 저전력 상태의 대기 모드에서 실행을 정지하고 대기할 수 있습니다. `hlt` 명령어를 쓰면 CPU가 저전력 대기 상태에 들어가게 할 수 있습니다. 이 명령어를 사용해 에너지를 효율적으로 사용하는 무한 루프를 작성합니다.
|
||||
|
||||
[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn hlt_loop() -> ! {
|
||||
loop {
|
||||
x86_64::instructions::hlt();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
함수 `instructions::hlt`는 그저 hlt 어셈블리 명령어를 [얇게 감싸 포장][thin wrapper]합니다. 이 명령어로는 메모리 안전성을 해칠 방법이 없어 안전합니다.
|
||||
|
||||
[thin wrapper]: https://github.com/rust-osdev/x86_64/blob/5e8e218381c5205f5777cb50da3ecac5d7e3b1ab/src/instructions/mod.rs#L16-L22
|
||||
|
||||
`_start` 및 `panic` 함수에서 사용하던 무한 루프를 방금 작성한 `hlt_loop`로 교체합니다.
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
[…]
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop(); // 새로 추가함
|
||||
}
|
||||
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
blog_os::hlt_loop(); // 새로 추가함
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
`lib.rs` 또한 마찬가지로 수정합니다.
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
/// `cargo test`의 실행 시작 지점
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init();
|
||||
test_main();
|
||||
hlt_loop(); // 새로 추가함
|
||||
}
|
||||
|
||||
pub fn test_panic_handler(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
hlt_loop(); // 새로 추가함
|
||||
}
|
||||
```
|
||||
|
||||
이제 QEMU에서 커널을 실행하면 CPU 사용량이 훨씬 감소한 것을 확인할 수 있습니다.
|
||||
|
||||
## 키보드 입력
|
||||
|
||||
외부 장치로부터 오는 인터럽트를 커널에서 처리할 수 있게 되었으니, 이제 드디어 커널이 키보드 입력을 지원하도록 만들 차례입니다. 키보드 입력을 지원함으로써 커널과 상호작용할 수 있게 될 것입니다.
|
||||
|
||||
<aside class="post_aside">
|
||||
|
||||
이 글에서는 [PS/2] 키보드에 대해서만 다루고 USB 키보드는 다루지 않습니다. 하지만 메인보드가 구식 소프트웨어를 지원하기 위해 USB 키보드를 PS/2 장치로 에뮬레이팅하기 때문에, 추후 커널에 정식으로 USB 지원을 추가하기 전까지는 USB 키보드에 대해 고민하지 않아도 됩니다.
|
||||
|
||||
</aside>
|
||||
|
||||
[PS/2]: https://en.wikipedia.org/wiki/PS/2_port
|
||||
|
||||
하드웨어 타이머와 마찬가지로, 키보드 컨트롤러의 인터럽트도 기본적으로 사용이 활성화되어 있습니다. 키보드 키를 누르면 키보드 컨트롤러는 PIC로 인터럽트를 보내고, PIC는 다시 그 인터럽트를 CPU로 전달합니다. CPU는 IDT에서 키보드 인터럽트의 엔트리를 조회하지만, 등록된 인터럽트 처리 함수가 없어 더블 폴트가 발생합니다.
|
||||
|
||||
키보드 인터럽트를 처리하는 함수를 추가합니다. 다른 인터럽트 번호를 사용한다는 점을 빼면, 이전에 타이머 인터럽트 처리 함수를 작성했던 것과 매우 유사합니다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
#[repr(u8)]
|
||||
pub enum InterruptIndex {
|
||||
Timer = PIC_1_OFFSET,
|
||||
Keyboard, // 새로 추가함
|
||||
}
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
[…]
|
||||
// 새로 추가함
|
||||
idt[InterruptIndex::Keyboard.as_usize()]
|
||||
.set_handler_fn(keyboard_interrupt_handler);
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
print!("k");
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
[위 도표](#8259-pic)를 보면 키보드는 주 PIC의 1번 통신선을 사용합니다. 즉 CPU에 전달된 키보드 인터럽트의 벡터 번호는 33 (1 + 오프셋 32)이 됩니다. 해당 번호를 `InterruptIndex` enum의 새 분류 `Keyboard`에 배정합니다. `Keyboard`의 값을 명시적으로 정해주지 않아도 바로 이전 분류의 값에 1을 더한 값(=33)이 배정됩니다. 인터럽트 처리 함수는 `k`를 출력한 후 인터럽트 컨트롤러에 EOI 신호를 전송합니다.
|
||||
|
||||
이제 아무 키를 하나 입력하면 화면에 `k`가 출력됩니다. 하지만 아무 키를 하나 새로 입력하면 화면에 `k`가 새로 출력되지 않습니다. 그 이유는 기존에 입력된 키의 _스캔 코드 (scancode)_ 를 우리가 읽어 가지 않는 한 키보드 컨트롤러가 새 인터럽트를 보내지 않기 때문입니다.
|
||||
|
||||
### 스캔 코드 읽기
|
||||
|
||||
_어떤_ 키가 입력됐는지 확인하려면 키보드 컨트롤러에 저장된 정보를 확인해야 합니다. PS/2 컨트롤러의 데이터 포트, 즉 `0x60`번 [입출력 포트 (I/O port)][I/O port]를 읽어 들여 어떤 키가 입력됐는지 확인할 수 있습니다.
|
||||
|
||||
[I/O port]: @/edition-2/posts/04-testing/index.md#i-o-ports
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
let mut port = Port::new(0x60);
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
print!("{}", scancode);
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`x86_64` 크레이트의 [`Port`] 타입을 사용해 키보드의 데이터 포트로부터 1바이트를 읽어옵니다. 이 1바이트의 데이터를 [_스캔 코드 (scancode)_][_scancode_]라고 부르며, 누른 키 또는 누른 상태에서 뗀 키의 정보를 가집니다. 일단은 스캔 코드를 출력하기만 할 뿐, 읽은 스캔 코드 값을 이용한 작업은 하지 않습니다.
|
||||
|
||||
[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
|
||||
[_scancode_]: https://en.wikipedia.org/wiki/Scancode
|
||||
|
||||

|
||||
|
||||
위 이미지는 제가 키보드로 천천히 "123"을 입력했을 때의 화면을 보여줍니다. 이를 통해 인접한 키들은 인접한 값의 스캔 코드를 가진다는 것, 그리고 키를 누를 때와 누른 키를 뗄 때 서로 다른 스캔 코드가 발생한다는 것을 알 수 있습니다. 근데 각 스캔 코드는 실제 키 누름/뗌에 어떤 기준으로 배정된 것일까요?
|
||||
|
||||
### 스캔 코드 해석하기
|
||||
스캔 코드를 키보드 키에 배정하는 표준을 _스캔코드 셋 (scancode set)_ 이라 부르며, 서로 다른 3가지 표준이 존재합니다. 셋 모두 초기의 IBM 컴퓨터들 ([IBM XT], [IBM 3270 PC], [IBM AT])로부터 기원합니다. 이후의 컴퓨터들은 새로운 스캔코드 셋을 정의하는 대신 기존의 것들을 지원하거나 확장해 사용했습니다. 오늘날 대부분의 키보드는 에뮬레이팅을 통해 이 3가지 셋 중 어느 것이든 사용할 수 있습니다.
|
||||
|
||||
[IBM XT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer_XT
|
||||
[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
|
||||
[IBM AT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer/AT
|
||||
|
||||
PS/2 키보드는 기본적으로 1번 스캔 코드 셋 ("XT")를 사용하게 되어 있습니다. 이 셋에서 스캔 코드의 하위 7비트는 입력된 키를 표현하고, 최상위 비트는 키를 누른 것인지 ("0") 혹은 키에서 손을 뗀 것인지 ("1") 표현합니다. 엔터 키처럼 [IBM XT] 키보드에 없었던 키들은 2개의 스캔 코드 (`0xe0` 그리고 그 후 키를 나타내는 1바이트)를 연이어 생성합니다. [OSDev Wiki][scancode set 1]를 보시면 1번 스캔코드 셋의 모든 스캔 코드와 그에 대응하는 키를 확인하실 수 있습니다.
|
||||
|
||||
[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
|
||||
|
||||
`match`문을 사용해 스캔 코드를 알맞는 키에 대응시켜 해석합니다.
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
let mut port = Port::new(0x60);
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
|
||||
// 새로 추가함
|
||||
let key = match scancode {
|
||||
0x02 => Some('1'),
|
||||
0x03 => Some('2'),
|
||||
0x04 => Some('3'),
|
||||
0x05 => Some('4'),
|
||||
0x06 => Some('5'),
|
||||
0x07 => Some('6'),
|
||||
0x08 => Some('7'),
|
||||
0x09 => Some('8'),
|
||||
0x0a => Some('9'),
|
||||
0x0b => Some('0'),
|
||||
_ => None,
|
||||
};
|
||||
if let Some(key) = key {
|
||||
print!("{}", key);
|
||||
}
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
위 코드는 0-9의 숫자 키 누름을 인식하고 출력하며, 다른 키는 무시합니다. [match]문을 사용해 각 스캔코드에 문자 또는 `None`을 배정합니다. 그 후 [`if let`]을 사용해 스캔 코드에 배정된 문자 `key`를 추출합니다. 이미 존재하던 변수 `key`와 같은 이름을 패턴에서 사용해 기존 변수의 정의를 [shadow]하는데, 이는 Rust에서 `Option` 타입 안의 값을 추출할 때 자주 사용되는 방식입니다.
|
||||
|
||||
[match]: https://doc.rust-lang.org/book/ch06-02-match.html
|
||||
[`if let`]: https://doc.rust-lang.org/book/ch18-01-all-the-places-for-patterns.html#conditional-if-let-expressions
|
||||
[shadow]: https://doc.rust-lang.org/book/ch03-01-variables-and-mutability.html#shadowing
|
||||
|
||||
이제 키보드로 숫자를 입력할 수 있습니다.
|
||||
|
||||

|
||||
|
||||
나머지 키를 인식하는 것도 위와 마찬가지 방법으로 진행하면 됩니다. 다행히도, [`pc-keyboard`] 크레이트가 1번/2번 스캔코드 셋을 해석하는 기능을 제공합니다. `Cargo.toml`에 이 크레이트를 추가하고 `lib.rs`에서 불러와 사용합니다.
|
||||
|
||||
[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
pc-keyboard = "0.5.0"
|
||||
```
|
||||
|
||||
`pc-keyboard` 크레이트를 사용해 `keyboard_interrupt_handler` 함수를 새로 작성합니다.
|
||||
|
||||
```rust
|
||||
// in/src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
|
||||
use spin::Mutex;
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
lazy_static! {
|
||||
static ref KEYBOARD: Mutex<Keyboard<layouts::Us104Key, ScancodeSet1>> =
|
||||
Mutex::new(Keyboard::new(layouts::Us104Key, ScancodeSet1,
|
||||
HandleControl::Ignore)
|
||||
);
|
||||
}
|
||||
|
||||
let mut keyboard = KEYBOARD.lock();
|
||||
let mut port = Port::new(0x60);
|
||||
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
|
||||
if let Some(key) = keyboard.process_keyevent(key_event) {
|
||||
match key {
|
||||
DecodedKey::Unicode(character) => print!("{}", character),
|
||||
DecodedKey::RawKey(key) => print!("{:?}", key),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`lazy_static` 매크로를 사용해 Mutex로 감싼 [`Keyboard`] 타입의 static 오브젝트를 얻습니다. `Keyboard`가 미국 키보드 레이아웃과 1번 스캔코드 셋을 사용하도록 초기화합니다. [`HandleControl`] 매개변수를 사용하면 `ctrl+[a-z]` 키 입력을 유니코드 `U+0001`에서 `U+001A`까지 값에 대응시킬 수 있습니다. 우리는 그렇게 하지 않기 위해 해당 매개변수에 `Ignore` 옵션을 주고 `ctrl` 키를 일반 키로서 취급합니다.
|
||||
|
||||
[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
|
||||
|
||||
인터럽트마다 우리는 Mutex를 잠그고 키보드 컨트롤러로부터 스캔 코드를 읽어온 후, 그 스캔 코드를 [`add_byte`] 함수에 전달합니다. 이 함수는 스캔 코드를 `Option<KeyEvent>`으로 변환합니다. [`KeyEvent`] 타입은 입력된 키의 정보와 키의 누름/뗌 정보를 저장합니다.
|
||||
|
||||
[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
|
||||
[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
|
||||
[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
|
||||
|
||||
[`process_keyevent`] 함수가 인자로 받은 `KeyEvent`를 변환하여 입력된 키의 문자를 반환합니다 (변환 불가한 경우 `None` 반환). 예를 들어, `A`키 입력 시 shift키 입력 여부에 따라 소문자 `a` 또는 대문자 `A`를 얻습니다.
|
||||
|
||||
[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
|
||||
|
||||
수정한 인터럽트 처리 함수를 통해 텍스트를 입력한 대로 화면에 출력할 수 있습니다.
|
||||
|
||||

|
||||
|
||||
### 키보드 설정하기
|
||||
|
||||
PS/2 키보드의 일부 설정을 변경하는 것이 가능한데, 예를 들면 어떤 스캔 코드 집합을 사용할지 지정할 수 있습니다. 본문이 너무 길어지니 해당 내용까지 다루지는 않겠지만, OSDev 위키를 확인하시면 [키보드 설정을 변경할 때 사용할 수 있는 명령어][configuration commands]들의 목록을 보실 수 있습니다.
|
||||
|
||||
[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
|
||||
|
||||
## 정리
|
||||
|
||||
이 글에서는 인터럽트를 활성화하고 외부 인터럽트를 처리하는 방법에 대해 설명했습니다. 우리는 8259 PIC 장치, 주 PIC와 부 PIC를 연결하는 방식, 인터럽트 번호를 재배정하는 방법, 그리고 "end of interrupt" 신호 등에 대해 배웠습니다. 우리는 하드웨어 타이머와 키보드의 인터럽트 처리 함수를 구현했고, CPU를 다음 인터럽트까지 멈추는 `hlt` 명령어에 대해 배웠습니다.
|
||||
|
||||
이제 커널과 상호작용할 수 있게 되었으니, 간단한 커맨드 쉘이나 게임을 작성할 기본적인 도구를 갖춘 셈입니다.
|
||||
|
||||
## 다음 단계는 무엇일까요?
|
||||
|
||||
운영체제에서 타이머 인터럽트는 필수적인 존재입니다. 그 이유는 타이머 인터럽트를 사용해 주기적으로 실행 중인 프로세스를 멈추고 커널로 제어 흐름을 가져올 수 있기 때문입니다. 그 후 커널은 다른 프로세스를 실행시킬 수 있고, 여러 프로세스가 동시에 실행 중인 듯한 사용자 경험을 제공할 수 있습니다.
|
||||
|
||||
프로세스나 스레드를 만들려면 우선 그들이 사용할 메모리를 할당할 방법이 필요합니다. 다음 몇 글들에서는 메모리 할당 기능을 제공하기 위한 메모리 관리 (memory management)에 대해 알아보겠습니다.
|
||||
@@ -0,0 +1,740 @@
|
||||
+++
|
||||
title = "硬件中断"
|
||||
weight = 7
|
||||
path = "zh-CN/hardware-interrupts"
|
||||
date = 2018-10-22
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong"]
|
||||
+++
|
||||
|
||||
在本文中,我们会对可编程的中断控制器进行设置,以将硬件中断转发给CPU,而要处理这些中断,只需要像处理异常一样在中断描述符表中加入一个新条目即可,在这里我们会以获取周期计时器的中断和获取键盘输入为例进行讲解。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的 blog 在[GitHub]上开放开发,如果你有任何问题,请在这里开一个 issue 来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-07`][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
<!-- fix for zola anchor checker (target is in template): <a id="comments"> -->
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-07
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 前言
|
||||
|
||||
中断是其他硬件对CPU发送通知的一种方式,所以除了使用 [_轮询_][_polling_] 进程在内核层面定时检查键盘输入以外,由键盘主动通知内核按键输入的结果也是个可行的方案。相比之下,后者可能还更加有用,此时内核只需要处理接收到的事件即可。这也可以极大降低系统的反应延时,因为内核无需等待下一次轮询周期。
|
||||
|
||||
[_polling_]: https://en.wikipedia.org/wiki/Polling_(computer_science)
|
||||
|
||||
根据常识,将所有硬件直连CPU是不可能的,所以需要一个统一的 _中断控制器_ 对所有设备中断进行代理,并由它间接通知CPU:
|
||||
|
||||
```
|
||||
____________ _____
|
||||
Timer ------------> | | | |
|
||||
Keyboard ---------> | Interrupt |---------> | CPU |
|
||||
Other Hardware ---> | Controller | |_____|
|
||||
Etc. -------------> |____________|
|
||||
|
||||
```
|
||||
|
||||
绝大多数中断控制器都是可编程的,也就是说可以自行设定中断的优先级,比如我们可以为计时器中断设定比键盘中断更高的优先级,以保证系统时间的精确性。
|
||||
|
||||
和异常不同,硬件中断完全是 _异步的_ ,也就是说它们可以在任何时候发生,且时序完全独立于正在运行的代码。所以我们的内核里就突然添加了一种异步的逻辑形式,并且也引入了所有潜在的与异步逻辑相关的Bug可能性。此时Rust严格的所有权模型此时就开始具备优势,因为它从根本上禁止了可变的全局状态。但尽管如此,死锁很难完全避免,这个问题我们会在文章稍后的部分进行说明。
|
||||
|
||||
## The 8259 PIC
|
||||
|
||||
[Intel 8259] 是一款于1976年发布的可编程中断控制器(PIC),事实上,它已经被更先进的 [APIC] 替代很久了,但其接口依然出于兼容问题被现有系统所支持。但是 8259 PIC 的设置方式比起APIC实在简单太多了,所以我们先以前者为例解说一下基本原理,在下一篇文章中再切换为APIC。
|
||||
|
||||
[APIC]: https://en.wikipedia.org/wiki/Intel_APIC_Architecture
|
||||
|
||||
8529具有8个中断管脚和一个和CPU通信的独立管脚,而当年的典型系统一般会安装两片 8259 PIC ,一个作为主芯片,另一个则作为副芯片,就像下面这样:
|
||||
|
||||
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
|
||||
|
||||
```
|
||||
____________ ____________
|
||||
Real Time Clock --> | | Timer -------------> | |
|
||||
ACPI -------------> | | Keyboard-----------> | | _____
|
||||
Available --------> | Secondary |----------------------> | Primary | | |
|
||||
Available --------> | Interrupt | Serial Port 2 -----> | Interrupt |---> | CPU |
|
||||
Mouse ------------> | Controller | Serial Port 1 -----> | Controller | |_____|
|
||||
Co-Processor -----> | | Parallel Port 2/3 -> | |
|
||||
Primary ATA ------> | | Floppy disk -------> | |
|
||||
Secondary ATA ----> |____________| Parallel Port 1----> |____________|
|
||||
|
||||
```
|
||||
|
||||
上图展示了中断管脚的典型逻辑定义,我们可以看到,实际上可定义的管脚共有15个,例如副PIC的4号管脚被定义为了鼠标。
|
||||
|
||||
每个控制器都可以通过两个 [I/O 端口][I/O ports] 进行配置,一个是“指令”端口,另一个是“数据”端口。对于主控制器,端口地址是 `0x20`(指令)和 `0x21`(数据),而对于副控制器,端口地址是 `0xa0`(指令)和 `0xa1`(数据)。要查看更多关于PIC配置的细节,请参见 [article on osdev.org]。
|
||||
|
||||
[I/O ports]: @/edition-2/posts/04-testing/index.md#i-o-ports
|
||||
[article on osdev.org]: https://wiki.osdev.org/8259_PIC
|
||||
|
||||
### 实现
|
||||
|
||||
PIC默认的配置其实是无法使用的,因为它仅仅是将0-15之间的中断向量编号发送给了CPU,然而这些编号已经用在了CPU的异常编号中了,比如8号代指 double fault 异常。要修复这个错误,我们需要对PIC中断序号进行重映射,新的序号只需要避开已被定义的CPU异常即可,CPU定义的异常数量有32个,所以通常会使用32-47这个区段。
|
||||
|
||||
我们需要通过往指令和数据端口写入特定数据才能对配置进行编程,幸运的是已经有了一个名叫 [`pic8259`] 的crate封装了这些东西,我们无需自己去处理这些初始化方面的细节。
|
||||
如果你十分好奇其中的细节,这里是 [它的源码][pic crate source],他的内部逻辑其实十分简洁,而且具备完善的文档。
|
||||
|
||||
[pic crate source]: https://docs.rs/crate/pic8259/0.10.1/source/src/lib.rs
|
||||
|
||||
我们可以这样将 crate 作为依赖加入工程中:
|
||||
|
||||
[`pic8259`]: https://docs.rs/pic8259/0.10.1/pic8259/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
pic8259 = "0.10.1"
|
||||
```
|
||||
|
||||
这个 crate 提供的主要抽象结构就是 [`ChainedPics`],用于映射上文所说的主副PIC的映射布局,它可以这样使用:
|
||||
|
||||
[`ChainedPics`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use pic8259::ChainedPics;
|
||||
use spin;
|
||||
|
||||
pub const PIC_1_OFFSET: u8 = 32;
|
||||
pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
|
||||
|
||||
pub static PICS: spin::Mutex<ChainedPics> =
|
||||
spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
|
||||
```
|
||||
|
||||
我们成功将PIC的中断编号范围设定为了32–47。我们使用 `Mutex` 容器包裹了 `ChainedPics`,这样就可以通过([`lock` 函数][spin mutex lock])拿到被定义为安全的变量修改权限,我们在下文会用到这个权限。`ChainedPics::new` 处于unsafe块,因为错误的偏移量可能会导致一些未定义行为。
|
||||
|
||||
[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
|
||||
|
||||
那么现在,我们就可以在 `init` 函数中初始化 8259 PIC 配置了:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
unsafe { interrupts::PICS.lock().initialize() }; // new
|
||||
}
|
||||
```
|
||||
|
||||
我们使用 [`initialize`] 函数进行PIC的初始化。正如 `ChainedPics::new` ,这个函数也是 unsafe 的,因为里面的不安全逻辑可能会导致PIC配置失败,进而出现一些未定义行为。
|
||||
|
||||
[`initialize`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html#method.initialize
|
||||
|
||||
如果一切顺利,我们在运行 `cargo run` 后应当能看到诸如 "It did not crash" 此类的输出信息。
|
||||
|
||||
## 启用中断
|
||||
|
||||
不过现在什么都不会发生,因为CPU配置里面中断还是禁用状态呢,也就是说CPU现在根本不会监听来自中断控制器的信息,即任何中断都无法到达CPU。我们来启用它:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
unsafe { interrupts::PICS.lock().initialize() };
|
||||
x86_64::instructions::interrupts::enable(); // new
|
||||
}
|
||||
```
|
||||
|
||||
`x86_64` crate 中的 `interrupts::enable` 会执行特殊的 `sti` (“set interrupts”) 指令来启用外部中断。当我们试着执行 `cargo run` 后,double fault 异常几乎是立刻就被抛出了:
|
||||
|
||||

|
||||
|
||||
其原因就是硬件计时器(准确的说,是[Intel 8253])默认是被启用的,所以在启用中断控制器之后,CPU开始接收到计时器中断信号,而我们又并未设定相对应的处理函数,所以就抛出了 double fault 异常。
|
||||
|
||||
[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
|
||||
|
||||
## 处理计时器中断
|
||||
|
||||
我们已经知道 [计时器组件](#the-8259-pic) 使用了主PIC的0号管脚,根据上文中我们定义的序号偏移量32,所以计时器对应的中断序号也是32。但是不要将32硬编码进去,我们将其存储到枚举类型 `InterruptIndex` 中:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
#[repr(u8)]
|
||||
pub enum InterruptIndex {
|
||||
Timer = PIC_1_OFFSET,
|
||||
}
|
||||
|
||||
impl InterruptIndex {
|
||||
fn as_u8(self) -> u8 {
|
||||
self as u8
|
||||
}
|
||||
|
||||
fn as_usize(self) -> usize {
|
||||
usize::from(self.as_u8())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这是一个 [C语言风格的枚举][C-like enum],我们可以为每个枚举值指定其对应的数值,`repr(u8)` 开关使枚举值对应的数值以 `u8` 格式进行存储,这样未来我们可以在这里加入更多的中断枚举。
|
||||
|
||||
[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
|
||||
|
||||
那么开始为计时器中断添加一个处理函数:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use crate::print;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
[…]
|
||||
idt[InterruptIndex::Timer.as_usize()]
|
||||
.set_handler_fn(timer_interrupt_handler); // new
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn timer_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
print!(".");
|
||||
}
|
||||
```
|
||||
|
||||
`timer_interrupt_handler` 和错误处理函数具有相同的函数签名,这是因为CPU对异常和外部中断的处理方式是相同的(除了个别异常会传入错误码以外)。[`InterruptDescriptorTable`] 结构实现了 [`IndexMut`] trait,所以我们可以通过序号来单独修改某一个条目。
|
||||
|
||||
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
|
||||
|
||||
在我们刚刚写好的处理函数中,我们会往屏幕上输出一个点,随着计时器中断周期性触发,我们应该能看到每一个计时周期过后屏幕上都会多出一个点。然而事实却并不是如此,我们只能在屏幕上看到一个点:
|
||||
|
||||

|
||||
|
||||
### 结束中断
|
||||
|
||||
这是因为PIC还在等着我们的处理函数返回 “中断结束” (EOI) 信号。该信号会通知控制器终端已处理,系统已准备好接收下一个中断。所以如果始终不发送EOI信号,那么PIC就会认为我们还在一直处理第一个计时器中断,然后暂停了后续的中断信号发送,直到接收到EOI信号。
|
||||
|
||||
要发送EOI信号,我们可以再使用一下 `PICS`:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn timer_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
print!(".");
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`notify_end_of_interrupt` 会自行判断中断信号发送的源头(主PIC或者副PIC),并使用指令和数据端口将信号发送到目标控制器。当然,如果是要发送到副PIC,那么结果上必然等同于同时发送到两个PIC,因为副PIC的输入管脚连在主PIC上面。
|
||||
|
||||
请注意,这里的中断编码一定不可以写错,不然可能会导致某个中断信号迟迟得不到回应导致系统整体挂起。这也是该函数被标记为不安全的原因。
|
||||
|
||||
现在我们再次运行 `cargo run`,就可以看到屏幕上开始正常输出点号了:
|
||||
|
||||

|
||||
|
||||
### 配置计时器
|
||||
|
||||
我们所使用的硬件计时器叫做 _可编程周期计时器_ (PIT),就如同字面上的意思一样,其两次中断之间的间隔是可配置的。当然,不会在此展开说,因为我们很快就会使用 [APIC计时器][APIC timer] 来代替它,但是你可以在OSDev wiki中找到一些关于[配置PIT计时器][configuring the PIT]的拓展文章。
|
||||
|
||||
[APIC timer]: https://wiki.osdev.org/APIC_timer
|
||||
[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
|
||||
|
||||
## 死锁
|
||||
|
||||
现在,我们的内核里就出现了一种全新的异步逻辑:计时器中断是异步的,所以它可能会在任何时候中断 `_start` 函数的运行。幸运的是Rust的所有权体系为我们在编译期避免了相当比例的bug,其中最典型的就是死锁 —— 当一个线程试图使用一个永远不会被释放的锁时,这个线程就会被永久性挂起。
|
||||
|
||||
我们可以在内核里主动引发一次死锁看看,请回忆一下,我们的 `println` 宏调用了 `vga_buffer::_print` 函数,而这个函数又使用了 [`WRITER`][vga spinlock] 变量,该变量被定义为带同步锁的变量:
|
||||
|
||||
[vga spinlock]: @/edition-2/posts/03-vga-text-buffer/index.md#spinlocks
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
[…]
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
获取到 `WRITER` 变量的锁后,调用其内部的 `write_fmt` 函数,然后在结尾隐式解锁该变量。但是假如在函数执行一半的时候,中断处理函数触发,同样试图打印日志的话:
|
||||
|
||||
| Timestep | _start | interrupt_handler |
|
||||
| -------- | ---------------------- | ----------------------------------------------- |
|
||||
| 0 | calls `println!` | |
|
||||
| 1 | `print` locks `WRITER` | |
|
||||
| 2 | | **interrupt occurs**, handler begins to run |
|
||||
| 3 | | calls `println!` |
|
||||
| 4 | | `print` tries to lock `WRITER` (already locked) |
|
||||
| 5 | | `print` tries to lock `WRITER` (already locked) |
|
||||
| … | | … |
|
||||
| _never_ | _unlock `WRITER`_ |
|
||||
|
||||
`WRITER` 被锁定,所以中断处理函数就会一直等待到它被解锁为止,然而后续永远不会发生了,因为只有当中断处理函数返回,`_start` 函数才会继续运行,`WRITER` 才可能被解锁,所以整个系统就这么挂起了。
|
||||
|
||||
### 引发死锁
|
||||
|
||||
基于这个原理,我们可以通过在 `_start` 函数中构建一个输出循环来很轻易地触发死锁:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
[…]
|
||||
loop {
|
||||
use blog_os::print;
|
||||
print!("-"); // new
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在QEMU中运行后,输出是这样的:
|
||||
|
||||

|
||||
|
||||
我们可以看到,这段程序只输出了有限的中划线,在第一次计时器中断触发后就不再动弹了,这是因为计时器中断对应的处理函数触发了输出宏中潜在的死锁,这也是为什么我们没有在上面的输出中看到点号的原因。
|
||||
|
||||
由于计时器中断是完全异步的,所以每次运行能够输出的中划线数量都是不确定的,这种特性也导致和并发相关的bug非常难以调试。
|
||||
|
||||
### 修复死锁
|
||||
|
||||
要避免死锁,我们可以在 `Mutex` 被锁定时禁用中断:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
/// Prints the given formatted string to the VGA text buffer
|
||||
/// through the global `WRITER` instance.
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts; // new
|
||||
|
||||
interrupts::without_interrupts(|| { // new
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
[`without_interrupts`] 函数可以使一个 [闭包][closure] 代码块在无中断环境下执行,由此我们可以让 `Mutex` 变量在锁定期间的执行逻辑不会被中断信号打断。再次运行我们的内核,此时程序就不会被挂起了。(然而我们依然不会看到任何点号,因为输出速度实在是太快了,试着降低一下输出速度就可以了,比如在循环里插入一句 `for _ in 0..10000 {}`。)
|
||||
|
||||
[`without_interrupts`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/interrupts/fn.without_interrupts.html
|
||||
[closure]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
|
||||
我们也可以在串行输出函数里也加入同样的逻辑来避免死锁:
|
||||
|
||||
```rust
|
||||
// in src/serial.rs
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: ::core::fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts; // new
|
||||
|
||||
interrupts::without_interrupts(|| { // new
|
||||
SERIAL1
|
||||
.lock()
|
||||
.write_fmt(args)
|
||||
.expect("Printing to serial failed");
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
但请注意,禁用中断不应是被广泛使用的手段,它可能会造成中断的处理延迟增加,比如操作系统是依靠中断信号进行计时的。因此,中断仅应在极短的时间内被禁用。
|
||||
|
||||
## 修复竞态条件
|
||||
|
||||
如果你运行 `cargo test` 命令,则会发现`test_println_output` 测试执行失败:
|
||||
|
||||
```
|
||||
> cargo test --lib
|
||||
[…]
|
||||
Running 4 tests
|
||||
test_breakpoint_exception...[ok]
|
||||
test_println... [ok]
|
||||
test_println_many... [ok]
|
||||
test_println_output... [failed]
|
||||
|
||||
Error: panicked at 'assertion failed: `(left == right)`
|
||||
left: `'.'`,
|
||||
right: `'S'`', src/vga_buffer.rs:205:9
|
||||
```
|
||||
|
||||
其原因就是测试函数和计时器中断处理函数出现了 _竞态条件_,测试函数是这样的:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
let s = "Some test string that fits on a single line";
|
||||
println!("{}", s);
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
该测试将一串字符打印到VGA缓冲区,并通过一个循环检测 `buffer_chars` 数组的内容。竞态条件出现的原因就是在 `println` 和检测逻辑之间触发了计时器中断,其处理函数同样调用了输出语句。不过这并非危险的 _数据竞争_,该种竞争可以被Rust语言在编译期完全避免。如果你对此感兴趣,可以查阅一下 [_Rustonomicon_][nomicon-races]。
|
||||
|
||||
[nomicon-races]: https://doc.rust-lang.org/nomicon/races.html
|
||||
|
||||
要修复这个问题,我们需要让 `WRITER` 加锁的范围扩大到整个测试函数,使计时器中断处理函数无法输出 `.`,就像这样:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts;
|
||||
|
||||
let s = "Some test string that fits on a single line";
|
||||
interrupts::without_interrupts(|| {
|
||||
let mut writer = WRITER.lock();
|
||||
writeln!(writer, "\n{}", s).expect("writeln failed");
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
我们进行了如下修改:
|
||||
|
||||
- 我们使用 `lock()` 函数显式加锁,然后将 `println` 改为 [`writeln`] 宏,以此绕开输出必须加锁的限制。
|
||||
- 为了避免死锁,我们同时在测试函数执行期间禁用中断,否则中断处理函数可能会意外被触发。
|
||||
- 为了防止在测试执行前计时器中断被触发所造成的干扰,我们先输出一句 `\n`,即可避免行首出现多余的 `.` 造成的干扰。
|
||||
|
||||
[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
|
||||
|
||||
经过以上修改,`cargo test` 就可以正确运行了。
|
||||
|
||||
好在这是一种十分无害的竞态条件,仅仅会导致测试失败,但如你所想,其它形式的竞态条件可能会更加难以调试。幸运的是,更加恶性的数据竞争已经被Rust从根本上避免了,大部分数据竞争都会造成无法预知的行为,比如系统崩溃,或者悄无声息的内存破坏。
|
||||
|
||||
## `hlt` 指令
|
||||
|
||||
目前我们在 `_start` 和 `panic` 函数的末尾都使用了一个空白的循环,这的确能让整体逻辑正常运行,但也会让CPU全速运转 —— 尽管此时并没有什么需要计算的工作。如果你在执行内核时打开任务管理器,便会发现QEMU的CPU占用率全程高达100%。
|
||||
|
||||
但是,我们可以让CPU在下一个中断触发之前休息一下,也就是进入休眠状态来节省一点点能源。[`hlt` instruction][`hlt` 指令] 可以让我们做到这一点,那就来用它写一个节能的无限循环:
|
||||
|
||||
[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn hlt_loop() -> ! {
|
||||
loop {
|
||||
x86_64::instructions::hlt();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`instructions::hlt` 只是对应汇编指令的 [薄包装][thin wrapper],并且它是内存安全的,没有破坏内存的风险。
|
||||
|
||||
[thin wrapper]: https://github.com/rust-osdev/x86_64/blob/5e8e218381c5205f5777cb50da3ecac5d7e3b1ab/src/instructions/mod.rs#L16-L22
|
||||
|
||||
现在我们来试着在 `_start` 和 `panic` 中使用 `hlt_loop`:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
[…]
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop(); // new
|
||||
}
|
||||
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
blog_os::hlt_loop(); // new
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
接下来再更新一下 `lib.rs` :
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
/// Entry point for `cargo test`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init();
|
||||
test_main();
|
||||
hlt_loop(); // new
|
||||
}
|
||||
|
||||
pub fn test_panic_handler(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
hlt_loop(); // new
|
||||
}
|
||||
```
|
||||
|
||||
再次在QEMU中执行我们的内核,CPU使用率已经降低到了比较低的水平了。
|
||||
|
||||
## 键盘输入
|
||||
|
||||
现在,我们已经知道了如何接收外部设备的中断信号,我们可以进一步对键盘添加支持,由此我们可以与内核进行交互。
|
||||
|
||||
<aside class="post_aside">
|
||||
|
||||
注意,我们仅仅会讲解 [PS/2] 键盘的兼容方式,而非USB键盘。不过好在主板往往会将USB键盘模拟为 PS/2 设备来支持旧时代的软件,所以我们暂时可以不考虑USB键盘这种情况。
|
||||
|
||||
</aside>
|
||||
|
||||
[PS/2]: https://en.wikipedia.org/wiki/PS/2_port
|
||||
|
||||
就如同硬件计时器一样,键盘控制器也是默认启用的,所以当你敲击键盘上某个按键时,键盘控制器就会经由PIC向CPU发送中断信号。然而CPU此时是无法在IDT找到相关的中断处理函数的,所以 double fault 异常会被抛出。
|
||||
|
||||
所以我们需要为键盘中断添加一个处理函数,它十分类似于计时器中断处理的实现,只不过需要对中断编号做出一点小小的修改:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
#[repr(u8)]
|
||||
pub enum InterruptIndex {
|
||||
Timer = PIC_1_OFFSET,
|
||||
Keyboard, // new
|
||||
}
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
[…]
|
||||
// new
|
||||
idt[InterruptIndex::Keyboard.as_usize()]
|
||||
.set_handler_fn(keyboard_interrupt_handler);
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
print!("k");
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
[上文](#the-8259-pic) 提到,键盘使用的是主PIC的1号管脚,在CPU的中断编号为33(1 + 偏移量32)。我们需要在 `InterruptIndex` 枚举类型里添加一个 `Keyboard`,但是无需显式指定对应值,因为在默认情况下,它的对应值是上一个枚举对应值加一也就是33。在处理函数中,我们先输出一个 `k`,并发送结束信号来结束中断。
|
||||
|
||||
现在当我们按下任意一个按键,就会在屏幕上输出一个 `k`,然而这只会生效一次,因为键盘控制器在我们 _获取扫描码_ 之前,是不会发送下一个中断的。
|
||||
|
||||
### 读取扫描码
|
||||
|
||||
要找到哪个按键被按下,我们还需要询问一下键盘控制器,我们可以从 PS/2 控制器(即地址为 `0x60` 的 [I/O端口][I/O port])的数据端口获取到该信息:
|
||||
|
||||
[I/O port]: @/edition-2/posts/04-testing/index.md#i-o-ports
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
let mut port = Port::new(0x60);
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
print!("{}", scancode);
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们使用了 `x86_64` crate 中的 [`Port`] 来从键盘数据端口中读取名为 [_扫描码_] 的随着按键按下/释放而不断变化的数字。我们暂且不处理它,只是在屏幕上打印出来:
|
||||
|
||||
[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
|
||||
[_scancode_]: https://en.wikipedia.org/wiki/Scancode
|
||||
|
||||

|
||||
|
||||
在上图中,演示的正是缓慢输入 `123` 的结果。我们可以看到,相邻的按键具备相邻的扫描码,而按下按键和松开按键也会出现不同的扫描码,那么问题来了,我们该如何对这些扫描码进行译码?
|
||||
|
||||
### 扫描码转义
|
||||
关于按键与键位码之间的映射关系,目前存在三种不同的标准(所谓的 _扫描码映射集_)。三种标准都可以追溯到早期的IBM电脑键盘:[IBM XT]、 [IBM 3270 PC]和[IBM AT]。好在之后的电脑并未另起炉灶定义新的扫描码映射集,但也对现有类型进行模拟并加以扩展,如今的绝大多数键盘都可以模拟成这三种类型之一。
|
||||
|
||||
[IBM XT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer_XT
|
||||
[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
|
||||
[IBM AT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer/AT
|
||||
|
||||
默认情况下,PS/2 键盘会模拟Set-1(XT),在该布局下,扫描码的低7位表示按键,而其他的比特位则定义了是按下(0)还是释放(1)。不过这些按键并非都存在于原本的 [IBM XT] 键盘上,比如小键盘的回车键,此时就会连续生成两个扫描码:`0xe0` 以及一个自定义的代表该键位的数字。[OSDev Wiki][scancode set 1] 可以查阅到Set-1下的扫描码对照表。
|
||||
|
||||
[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
|
||||
|
||||
要将扫描码译码成按键,我们可以用一个match匹配语句:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
let mut port = Port::new(0x60);
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
|
||||
// new
|
||||
let key = match scancode {
|
||||
0x02 => Some('1'),
|
||||
0x03 => Some('2'),
|
||||
0x04 => Some('3'),
|
||||
0x05 => Some('4'),
|
||||
0x06 => Some('5'),
|
||||
0x07 => Some('6'),
|
||||
0x08 => Some('7'),
|
||||
0x09 => Some('8'),
|
||||
0x0a => Some('9'),
|
||||
0x0b => Some('0'),
|
||||
_ => None,
|
||||
};
|
||||
if let Some(key) = key {
|
||||
print!("{}", key);
|
||||
}
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
以上代码可以对数字按键0-9进行转义,并忽略其他键位。具体到程序逻辑中,就是使用 [match] 匹配映射数字0-9,对于其他扫描码则返回 `None`,然后使用 [`if let`] 语句对 `key` 进行解构取值,在这个语法中,代码块中的 `key` 会 [遮蔽][shadow] 掉代码块外的同名 `Option` 型变量。
|
||||
|
||||
[match]: https://doc.rust-lang.org/book/ch06-02-match.html
|
||||
[`if let`]: https://doc.rust-lang.org/book/ch18-01-all-the-places-for-patterns.html#conditional-if-let-expressions
|
||||
[shadow]: https://doc.rust-lang.org/book/ch03-01-variables-and-mutability.html#shadowing
|
||||
|
||||
现在我们就可以向控制台写入数字了:
|
||||
|
||||

|
||||
|
||||
其他扫描码也可以通过同样的手段进行译码,不过真的很麻烦,好在 [`pc-keyboard`] crate 已经帮助我们实现了Set-1和Set-2的译码工作,所以无需自己去实现。所以我们只需要将下述内容添加到 `Cargo.toml`,并在 `lib.rs` 里进行引用:
|
||||
|
||||
[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
pc-keyboard = "0.5.0"
|
||||
```
|
||||
|
||||
现在我们可以使用新的crate对 `keyboard_interrupt_handler` 进行改写:
|
||||
|
||||
```rust
|
||||
// in/src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: InterruptStackFrame)
|
||||
{
|
||||
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
|
||||
use spin::Mutex;
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
lazy_static! {
|
||||
static ref KEYBOARD: Mutex<Keyboard<layouts::Us104Key, ScancodeSet1>> =
|
||||
Mutex::new(Keyboard::new(layouts::Us104Key, ScancodeSet1,
|
||||
HandleControl::Ignore)
|
||||
);
|
||||
}
|
||||
|
||||
let mut keyboard = KEYBOARD.lock();
|
||||
let mut port = Port::new(0x60);
|
||||
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
|
||||
if let Some(key) = keyboard.process_keyevent(key_event) {
|
||||
match key {
|
||||
DecodedKey::Unicode(character) => print!("{}", character),
|
||||
DecodedKey::RawKey(key) => print!("{:?}", key),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
首先我们使用 `lazy_static` 宏创建一个受到Mutex同步锁保护的 [`Keyboard`] 对象,初始化参数为美式键盘布局以及Set-1。至于 [`HandleControl`],它可以设定为将 `ctrl+[a-z]` 映射为Unicode字符 `U+0001` 至 `U+001A`,但我们不想这样,所以使用了 `Ignore` 选项让 `ctrl` 仅仅表现为一个正常键位。
|
||||
|
||||
[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
|
||||
|
||||
对于每一个中断,我们都会为 KEYBOARD 加锁,从键盘控制器获取扫描码并将其传入 [`add_byte`] 函数,并将其转化为 `Option<KeyEvent>` 结构。[`KeyEvent`] 包括了触发本次中断的按键信息,以及子动作是按下还是释放。
|
||||
|
||||
[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
|
||||
[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
|
||||
[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
|
||||
|
||||
要处理KeyEvent,我们还需要将其传入 [`process_keyevent`] 函数,将其转换为人类可读的字符,若果有必要,也会对字符进行一些处理。典型例子就是,要判断 `A` 键按下后输入的是小写 `a` 还是大写 `A`,这要取决于shift键是否同时被按下。
|
||||
|
||||
[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
|
||||
|
||||
进行这些修改之后,我们就可以正常输入英文了:
|
||||
|
||||

|
||||
|
||||
### 配置键盘
|
||||
|
||||
PS/2 键盘可以配置的地方其实还有很多,比如设定它使用何种扫描码映射集,然而这篇文章已经够长了,就不在此展开说明,如果有兴趣,可以在OSDev wiki查看[更详细的资料][configuration commands]。
|
||||
|
||||
[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
|
||||
|
||||
## 小结
|
||||
|
||||
本文描述了如何启用并处理外部中断。我们学习了关于8259 PIC的主副布局、重映射中断编号以及结束中断信号的基础知识,实现了简单的硬件计时器和键盘的中断处理器,以及如何使用 `hlt` 指令让CPU休眠至下次接收到中断信号。
|
||||
|
||||
现在我们已经可以和内核进行交互,满足了创建简易控制台或简易游戏的基础条件。
|
||||
|
||||
## 下文预告
|
||||
|
||||
计时器中断对操作系统而言至关重要,它可以使内核定期重新获得控制权,由此内核可以对线程进行调度,创造出多个线程并行执行的错觉。
|
||||
|
||||
然而在我们创建进程或线程之前,我们还需要解决内存分配问题。下一篇文章中,我们就会对内存管理进行阐述,以提供后续功能会使用到的基础设施。
|
||||
@@ -0,0 +1,423 @@
|
||||
+++
|
||||
title = "内存分页初探"
|
||||
weight = 8
|
||||
path = "zh-CN/paging-introduction"
|
||||
date = 2019-01-14
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["liuyuran"]
|
||||
# GitHub usernames of the people that contributed to this translation
|
||||
translation_contributors = ["JiangengDong"]
|
||||
+++
|
||||
|
||||
本文主要讲解 _内存分页_ 机制,一种我们将会应用到操作系统里的十分常见的内存模型。同时,也会展开说明为何需要进行内存隔离、_分段机制_ 是如何运作的、_虚拟内存_ 是什么,以及内存分页是如何解决内存碎片问题的,同时也会对x86_64的多级页表布局进行探索。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的 blog 在[GitHub]上开放开发,如果你有任何问题,请在这里开一个 issue 来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-08`][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
<!-- fix for zola anchor checker (target is in template): <a id="comments"> -->
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-08
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 内存保护
|
||||
|
||||
操作系统的主要任务之一就是隔离各个应用程序的执行环境,比如你的浏览器不应对你的文本编辑器造成影响,因此,操作系统会利用硬件级别的功能确保一个进程无法访问另一个进程的内存区域,但具体实现方式因硬件和操作系统实现而异。
|
||||
|
||||
比如一些 ARM Cortex-M 处理器(用于嵌入式系统)搭载了 [_内存保护单元_][_Memory Protection Unit_] (MPU),该单元允许你定义少量具有不同读写权限的内存区域。MPU可以确保每一次对内存的访问都需要具备对应的权限,否则就会抛出异常。而操作系统则会在进程切换时,确保当前进程仅能访问自己所持有的内存区域,由此实现内存隔离。
|
||||
|
||||
[_Memory Protection Unit_]: https://developer.arm.com/docs/ddi0337/e/memory-protection-unit/about-the-mpu
|
||||
|
||||
在x86架构下,硬件层次为内存保护提供了两种不同的途径:[段][segmentation] 和 [页][paging]。
|
||||
|
||||
[segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
[paging]: https://en.wikipedia.org/wiki/Virtual_memory#Paged_virtual_memory
|
||||
|
||||
## 内存分段
|
||||
|
||||
内存分段技术出现于1978年,初衷是用于扩展可用内存,该技术的最初背景是当时的CPU仅使用16位地址,而可使用的内存也只有64KiB。为了扩展可用内存,用于存储偏移量的段寄存器这个概念应运而生,CPU可以据此访问更多的内存,因此可用内存被成功扩展到了1MiB。
|
||||
|
||||
CPU可根据内存访问方式自动确定段寄存器的定义:对于指令获取操作,使用代码段寄存器 `CS`;对于栈操作(入栈/出栈),使用栈段寄存器 `SS`;对于其他指令,则使用数据段寄存器 `DS` 或额外段寄存器 `ES`。另外还有两个后来添加的扩展段寄存器 `FS` 和 `GS`,可以随意使用。
|
||||
|
||||
在最初版本的内存分段中,段寄存器仅仅是直接包含了偏移量,并不包含任何权限控制,直到 [_保护模式_][_protected mode_] 这个概念的出现。当CPU进入此模式后,段描述符会包含一个本地或全局的 [_描述符表_][_descriptor table_] 索引,它对应的数据包含了偏移量、段的大小和访问权限。通过加载各个进程所属的全局/本地描述符表,可以实现进程仅能访问属于自己的内存区域的效果,操作系统也由此实现了进程隔离。
|
||||
|
||||
[_protected mode_]: https://en.wikipedia.org/wiki/X86_memory_segmentation#Protected_mode
|
||||
[_descriptor table_]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
针对在判断权限前如何更正内存地址这个问题,内存分段使用了一个如今已经高度普及的技术:_虚拟内存_。
|
||||
|
||||
### 虚拟内存
|
||||
|
||||
所谓虚拟内存,就是将物理存储器地址抽象为一段完全独立的内存区域,在直接访问物理存储器之前,加入了一个地址转换的步骤。对于内存分页机制而言,地址转换就是在虚拟地址的基础上加入偏移量,如在偏移量为 `0x1111000` 的段中,虚拟地址 `0x1234000` 的对应的物理内存地址是 `0x2345000`。
|
||||
|
||||
首先我们需要明确两个名词,执行地址转换步骤之前的地址叫做 _虚拟地址_,而转换后的地址叫做 _物理地址_,两者最显著的区别就是物理地址是全局唯一的,而两个虚拟地址理论上可能指向同一个物理地址。同样的,如果使用不同的地址偏移量,同一个虚拟地址可能会对应不同的物理地址。
|
||||
|
||||
最直观的例子就是同时执行两个相同的程序:
|
||||
|
||||
|
||||

|
||||
|
||||
如你所见,这就是两个相同程序的内存分配情况,两者具有不同的地址偏移量(即 _段基址_)。第一个程序实例的段基址为100,所以其虚拟地址范围0-150换算成物理地址就是100-250。第二个程序实例的段基址为300,所以其虚拟地址范围0-150换算成物理地址就是300-450。所以该机制允许程序共用同一套代码逻辑,使用同样的虚拟地址,并且不会干扰到彼此。
|
||||
|
||||
该机制的另一个优点就是让程序不局限于特定的某一段物理内存,而是依赖另一套虚拟内存地址,从而让操作系统在不重编译程序的前提下使用全部的内存区域。
|
||||
|
||||
### 内存碎片
|
||||
|
||||
虚拟内存机制已经让内存分段机制十分强大,但也有碎片化的问题,请看,如果我们同时执行三个程序实例的话:
|
||||
|
||||

|
||||
|
||||
在不能重叠使用的前提下,我们完全找不到足够的地方来容纳第三个程序,因为剩余的连续空间已经不够了。此时的问题在于,我们需要使用 _连续_ 的内存区域,不要将那些中间的空白部分白白浪费掉。
|
||||
|
||||
比较合适的办法就是暂停程序运行,将内存块移动到一个连续区间内,更新段基址信息,然后恢复程序运行:
|
||||
|
||||

|
||||
|
||||
这样我们就有足够的内存空间来运行第三个程序实例了。
|
||||
|
||||
但这样做也有一些问题,内存整理程序往往需要拷贝一段比较大的内存,这会很大程度上影响性能,但是又必须在碎片问题变得过于严重前完成这个操作。同时由于其消耗时间的不可预测性,程序很可能会随机挂起,甚至在用户视角下失去响应。
|
||||
|
||||
这也是大多数系统放弃内存分段技术的原因之一,事实上,该技术已经被x86平台的64位模式所抛弃,因为 _内存分页技术_ 已经完全解决了碎片化问题。
|
||||
|
||||
## 内存分页
|
||||
|
||||
内存分页的思想依然是使用虚拟地址映射物理地址,但是其分配单位变成了固定长度的较小的内存区域。这些虚拟内存块被称为 _页_,而其对应的物理内存则被称为 _页帧_,每一页都可以映射到一个对应的页帧中。这也就意味着我们可以将程序所使用的一大块内存区域打散到所有物理内存中,而不必分配一块连续的区域。
|
||||
|
||||
其优势就在于,如果我们遇到上文中提到的内存碎片问题时,内存分页技术会这样解决它:
|
||||
|
||||

|
||||
|
||||
例如我们将页的单位设置为50字节,也就是说我们的每一个程序实例所使用的内存都被分割为三页。每一页都可以独立映射到一个页帧中,因此连续的虚拟内存并不一定需要对应连续的物理内存区域,因此也就无需进行内存碎片整理了。
|
||||
|
||||
### 潜在碎片
|
||||
|
||||
对比内存分段,内存分页选择用较多的较小且固定长度的内存区域代替较少的较大且长度不固定的内存区域。正因为如此,不会有页帧因为长度过小而产生内存碎片。
|
||||
|
||||
然而这只是 _表面上如此_,实际上依然存在着名为 _内部碎片_ 的隐蔽内存碎片,造成内部碎片的原因是并非每个内存区域都是分页单位的整数倍。比如一个程序需要101字节的内存,但它依然需要分配3个长度为50字节的页,最终造成了49字节的内存浪费,区别于内存分段造成的内存碎片,这种情况被称为 _内部碎片_。
|
||||
|
||||
内部碎片虽然也很可恶,但是无论如何也比内存分段造成的内存碎片要好得多,尽管其依然会浪费内存空间,但是无需碎片整理,且碎片数量是可预测的(每一个虚拟内存空间平均会造成半个页帧的内存浪费)。
|
||||
|
||||
### 页表
|
||||
|
||||
我们应当预见到,在操作系统开始运行后,会存在数以百万计的页-页帧映射关系,这些映射关系需要存储在某个地方。分段技术可以为每个活动的内存区域都指定一个段寄存器,但是分页技术不行,因为其使用到的页的数量实在是太多了,远多于寄存器数量,所以分页技术采用了一种叫做 _页表_ 的结构来存储映射信息。
|
||||
|
||||
以上面的应用场合为例,页表看起来是这样子的:
|
||||
|
||||

|
||||
|
||||
我们可以看到每个程序实例都有其专有的页表,但当前正在活跃的页表指针会被存储到特定的CPU寄存器中,在 `x86` 架构中,该寄存器被称为 `CR3`。操作系统的任务之一,就是在程序运行前,把当前所使用的页表指针推进对应的寄存器中。
|
||||
|
||||
每次内存访问CPU都会从寄存器获取页表指针,并从页表中获取虚拟地址所对应的页帧,这一步操作完全由硬件完成,对于程序而言是完全透明的。为了加快地址转换的速度,许多CPU架构都加入了一个能够存储最后一次地址转换相关信息的特殊缓存。
|
||||
|
||||
根据架构实现的不同,页表也可以在 flags 字段存储一些额外的属性,如访问权限之类。在上面的场景下。 "r/w" 这个 flag 可以使该页同时能够读和写。
|
||||
|
||||
### 多级页表
|
||||
|
||||
上文中的简单页表在较大的地址空间下会有个问题:太浪费内存了。打个比方,一个程序需要使用4个虚拟内存页 `0`、`1_000_000`、`1_000_050` 和 `1_000_100`(假设以 `_` 为千位分隔符):
|
||||
|
||||

|
||||
|
||||
尽管它仅仅会使用4个页帧,但是页表中有百万级别的映射条目,而我们还不能释放那些空白的条目,因为这会对地址转换造成很大的风险(比如可能无法保证4号页依然对应4号页帧)。
|
||||
|
||||
我们可以使用 **两级页表** 来避免内存浪费,其基本思路就是对不同的地址区域使用不同的页表。地址区域和一级页表的映射关系被存储在一个被称为 _二级页表_ 的额外表格中。
|
||||
|
||||
举个例子,我们先假设每个一级页表映射 `10_000` 字节的内存空间,在上文所述的应用场合下,此时的页表结构看上去是这样的:
|
||||
|
||||

|
||||
|
||||
页 `0` 位于第一个 `10_000` 字节的内存区域内,位于内存区域 `0` 内,对应一级页表 `T1`,所以它所在的内存位置也可以被表述为 `页 0 帧 0`.
|
||||
|
||||
页 `1_000_000`、 `1_000_050` 和 `1_000_100` 均可以映射到第100个 `10_000` 字节的内存区域内,所以位于内存区域 `1_000_100` 中,该内存区域指向一级页表 T2。但这三个页分别对应该一级页表 T2 中的页帧 `100`、`150` 和 `200`,因为一级页表中是不存储内存区域偏移量的。
|
||||
|
||||
在这个场合中,二级页表中还是出现了100个被浪费的位置,不过无论如何也比之前数以百万计的浪费好多了,因为我们没有额外创建指向 `10_000` 到 `1_000_000` 这段内存区域的一级页表。
|
||||
|
||||
同理,两级页表的原理可以扩展到三级、四级甚至更多的级数。通常而言,可以让页表寄存器指向最高级数的表,然后一层一层向下寻址,直到抵达一级页表,获取页帧地址。这种技术就叫做 _多级_ 或 _多层_ 页表。
|
||||
|
||||
那么现在我们已经明白了内存分页和多级页表机制的工作原理,下面我们会探索一下在 x86_64 平台下内存分页机制是如何实现的(假设CPU运行在64位模式下)。
|
||||
|
||||
## x86_64中的分页
|
||||
|
||||
x86_64 平台使用4级页表,页大小为4KiB,无论层级,每个页表均具有512个条目,每个条目占用8字节,所以每个页表固定占用 512 * 8B = 4KiB,正好占满一个内存页。
|
||||
|
||||
每一级的页表索引号都可以通过虚拟地址推导出来:
|
||||
|
||||

|
||||
|
||||
我们可以看到,每个表索引号占据9个字节,这当然是有道理的,每个表都有 2^9 = 512 个条目,低12位用来表示内存页的偏移量(2^12 bytes = 4KiB,而上文提到页大小为4KiB)。第48-64位毫无用处,这也就意味着 x86_64 并非真正的64位,因为它实际上支持48位地址。
|
||||
|
||||
[5-level page table]: https://en.wikipedia.org/wiki/Intel_5-level_paging
|
||||
|
||||
尽管48-64位毫无用处,但依然不被允许随意赋值,而是必须将其设置为与47位相同的值以保证地址唯一性,由此留出未来对此进行扩展的可能性,如实现5级页表。该技术被称为 _符号扩展_,理由是它与 [二进制补码][sign extension in two's complement] 机制真的太相似了。当地址不符合该机制定义的规则时,CPU会抛出异常。
|
||||
|
||||
[sign extension in two's complement]: https://en.wikipedia.org/wiki/Two's_complement#Sign_extension
|
||||
|
||||
值得注意的是,英特尔最近发布了一款代号是冰湖的CPU,它的新功能之一就是可选支持能够将虚拟地址从48位扩展到57位的 [5级页表][5-level page tables]。但是针对一款特定的CPU做优化在现阶段并没有多少意义,所以本文仅会涉及标准的4级页表。
|
||||
|
||||
[5-level page tables]: https://en.wikipedia.org/wiki/Intel_5-level_paging
|
||||
|
||||
### 地址转换范例
|
||||
|
||||
请看下图,这就是一个典型的地址转换过程的范例:
|
||||
|
||||

|
||||
|
||||
`CR3` 寄存器中存储着指向4级页表的物理地址,而在每一级的页表(除一级页表外)中,都存在着指向下一级页表的指针,1级页表则存放着直接指向页帧地址的指针。注意,这里的指针,都是指页表的物理地址,而非虚拟地址,否则CPU会因为需要进行额外的地址转换而陷入无限递归中。
|
||||
|
||||
最终,寻址结果是上图中的两个蓝色区域,根据页表查询结果,它们的虚拟地址分别是 `0x803FE7F000` 和 `0x803FE00000`,那么让我们看一看当程序尝试访问内存地址 `0x803FE7F5CE` 时会发生什么事情。首先我们需要把地址转换为二进制,然后确定该地址所对应的页表索引和页偏移量:
|
||||
|
||||

|
||||
|
||||
通过这些索引,我们就可以通过依次查询多级页表来定位最终要指向的页帧:
|
||||
|
||||
- 首先,我们需要从 `CR3` 寄存器中读出4级页表的物理地址。
|
||||
- 4级页表的索引号是1,所以我们可以看到3级页表的地址是16KiB。
|
||||
- 载入3级页表,根据索引号0,确定2级页表的地址是24KiB。
|
||||
- 载入2级页表,根据索引号511,确定1级页表的地址是32KiB。
|
||||
- 载入1级页表,根据索引号127,确定该地址所对应的页帧地址为12KiB,使用Hex表达可写作 0x3000。
|
||||
- 最终步骤就是将最后的页偏移量拼接到页帧地址上,即可得到物理地址,即 0x3000 + 0x5ce = 0x35ce。
|
||||
|
||||

|
||||
|
||||
由上图可知,该页帧在一级页表中的权限被标记为 `r`,即只读,硬件层面已经确保当我们试图写入数据的时候会抛出异常。较高级别的页表的权限设定会覆盖较低级别的页表,如3级页表中设定为只读的区域,其所关联的所有下级页表对应的内存区域均会被认为是只读,低级别的页表本身的设定会被忽略。
|
||||
|
||||
注意,示例图片中为了简化显示,看起来每个页表都只有一个条目,但实际上,4级以下的页表每一层都可能存在多个实例,其数量上限如下:
|
||||
|
||||
- 1个4级页表
|
||||
- 512个3级页表(因为4级页表可以有512个条目)
|
||||
- 512*512个2级页表(因为每个3级页表可以有512个条目)
|
||||
- 512*512*512个1级页表(因为每个2级页表可以有512个条目)
|
||||
|
||||
### 页表格式
|
||||
|
||||
在 x86_64 平台下,页表是一个具有512个条目的数组,于Rust而言就是这样:
|
||||
|
||||
```rust
|
||||
#[repr(align(4096))]
|
||||
pub struct PageTable {
|
||||
entries: [PageTableEntry; 512],
|
||||
}
|
||||
```
|
||||
|
||||
`repr` 属性定义了内存页的大小,这里将其设定为了4KiB,该设置确保了页表总是能填满一整个内存页,并允许编译器进行一些优化,使其存储方式更加紧凑。
|
||||
|
||||
每个页表条目长度都是8字节(64比特),其内部结构如下:
|
||||
|
||||
| Bit(s) | 名字 | 含义 |
|
||||
| ------ | --------------------- | ----------------------------------------------------------------------------- |
|
||||
| 0 | present | 该页目前在内存中 |
|
||||
| 1 | writable | 该页可写 |
|
||||
| 2 | user accessible | 如果没有设定,仅内核代码可以访问该页 |
|
||||
| 3 | write through caching | 写操作直接应用到内存 |
|
||||
| 4 | disable cache | 对该页禁用缓存 |
|
||||
| 5 | accessed | 当该页正在被使用时,CPU设置该比特的值 |
|
||||
| 6 | dirty | 当该页正在被写入时,CPU设置该比特的值 |
|
||||
| 7 | huge page/null | 在P1和P4状态时必须为0,在P3时创建一个1GiB的内存页,在P2时创建一个2MiB的内存页 |
|
||||
| 8 | global | 当地址空间切换时,该页尚未应用更新(CR4寄存器中的PGE比特位必须一同被设置) |
|
||||
| 9-11 | available | 可被操作系统自由使用 |
|
||||
| 12-51 | physical address | 经过52比特对齐过的页帧地址,或下一级的页表地址 |
|
||||
| 52-62 | available | 可被操作系统自由使用 |
|
||||
| 63 | no execute | 禁止在该页中运行代码(EFER寄存器中的NXE比特位必须一同被设置) |
|
||||
|
||||
我们可以看到,仅12–51位会用于存储页帧地址或页表地址,其余比特都用于存储标志位,或由操作系统自由使用。
|
||||
其原因就是,该地址总是指向一个4096比特对齐的地址、页表或者页帧的起始地址。
|
||||
这也就意味着0-11位始终为0,没有必要存储这些东西,硬件层面在使用该地址之前,也会将这12位比特设置为0,52-63位同理,因为x86_64平台仅支持52位物理地址(类似于上文中提到的仅支持48位虚拟地址的原因)。
|
||||
|
||||
进一步说明一下可用的标志位:
|
||||
|
||||
- `present` 标志位并非是指未映射的页,而是指其对应的内存页由于物理内存已满而被交换到硬盘中,如果该页在换出之后再度被访问,则会抛出 _page fault_ 异常,此时操作系统应该将此页重新载入物理内存以继续执行程序。
|
||||
- `writable` 和 `no execute` 标志位分别控制该页是否可写,以及是否包含可执行指令。
|
||||
- `accessed` 和 `dirty` 标志位由CPU在读写该页时自动设置,该状态信息可用于辅助操作系统的内存控制,如判断哪些页可以换出,以及换出到硬盘后页里的内容是否已被修改。
|
||||
- `write through caching` 和 `disable cache` 标志位可以单独控制每一个页对应的缓存。
|
||||
- `user accessible` 标志位决定了页中是否包含用户态的代码,否则它仅当CPU处于核心态时可访问。该特性可用于在用户态程序运行时保持内核代码映射以加速[系统调用][system calls]。然而,[Spectre] 漏洞会允许用户态程序读取到此类页的数据。
|
||||
- `global` 标志位决定了该页是否会在所有地址空间都存在,即使切换地址空间,也不会从地址转换缓存(参见下文中关于TLB的章节)中被移除。一般和 `user accessible` 标志位共同使用,在所有地址空间映射内核代码。
|
||||
- `huge page` 标志位允许2级页表或3级页表直接指向页帧来分配一块更大的内存空间,该标志位被启用后,页大小会增加512倍。就结果而言,对于2级页表的条目,其会直接指向一个 2MiB = 512 * 4KiB 大小的大型页帧,而对于3级页表的条目,就会直接指向一个 1GiB = 512 * 2MiB 大小的巨型页帧。通常而言,这个功能会用于节省地址转换缓存的空间,以及降低逐层查找页表的耗时。
|
||||
|
||||
[system calls]: https://en.wikipedia.org/wiki/System_call
|
||||
[Spectre]: https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
|
||||
|
||||
`x86_64` crate 为我们提供了 [page tables] 的结构封装,以及其内部条目 [entries],所以我们无需自己实现具体的结构。
|
||||
|
||||
[page tables]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTable.html
|
||||
[entries]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTableEntry.html
|
||||
|
||||
### 地址转换后备缓冲区(TLB)
|
||||
|
||||
显而易见,4级页表使地址转换过程变得有点慢,每次转换都需要进行4次内存访问。为了改善这个问题,x86_64平台将最后几次转换结果放在所谓的 _地址转换后备缓冲区_(TLB)中,这样对同样地址的连续重复转换就可以直接返回缓存中存储的结果。
|
||||
|
||||
不同于CPU缓存,TLB并非是完全对外透明的,它在页表变化时并不会自动更新或删除被缓存的结果。这也就是说,内核需要在页表发生变化时,自己来处理TLB的更新。针对这个需要,CPU也提供了一个用于从TLB删除特定页的缓存的指令 [`invlpg`] (“invalidate page”),调用该指令之后,下次访问该页就会重新生成缓存。不过还有一个更彻底的办法,通过手动写入 `CR3` 寄存器可以制造出模拟地址空间切换的效果,TLB也会被完全刷新。`x86_64` crate 中的 [`tlb` module] 提供了上面的两种手段,并封装了对应的函数。
|
||||
|
||||
[`invlpg`]: https://www.felixcloutier.com/x86/INVLPG.html
|
||||
[`tlb` module]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tlb/index.html
|
||||
|
||||
请注意,在修改页表之后,同步修改TLB是十分十分重要的事情,不然CPU可能会返回一个错误的物理地址,因为这种原因造成的bug是非常难以追踪和调试的。
|
||||
|
||||
## 具体实现
|
||||
|
||||
有件事我们还没有提过:**我们的内核已经是在页上运行的**。在前文 ["最小内核"]["A minimal Rust Kernel"] 中,我们添加的bootloader已经搭建了一个4级页表结构,并将内核中使用的每个页都映射到了物理页帧上,其原因就是,在64位的 x86_64 平台下分页是被强制使用的。
|
||||
|
||||
["A minimal Rust kernel"]: @/edition-2/posts/02-minimal-rust-kernel/index.md#creating-a-bootimage
|
||||
|
||||
这也就是说,我们在内核中所使用的每一个内存地址其实都是虚拟地址,VGA缓冲区是唯一的例外,因为bootloader为这个地址使用了 _一致映射_,令其直接指向地址 `0xb8000`。所谓一致映射,就是能将虚拟页 `0xb8000` 直接映射到物理页帧 `0xb8000`。
|
||||
|
||||
使用分页技术后,我们的内核在某种意义上已经十分安全了,因为越界的内存访问会导致 page fault 异常而不是访问到一个随机物理地址。bootloader已经为每一个页都设置了正确的权限,比如仅代码页具有执行权限、仅数据页具有写权限。
|
||||
|
||||
### Page Faults
|
||||
|
||||
那么我们来通过内存越界访问手动触发一次 page fault,首先我们先写一个错误处理函数并注册到IDT中,这样我们就可以正常接收到这个异常,而非 [double fault] 了:
|
||||
|
||||
[double fault]: @/edition-2/posts/06-double-faults/index.md
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
|
||||
[…]
|
||||
|
||||
idt.page_fault.set_handler_fn(page_fault_handler); // new
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
use x86_64::structures::idt::PageFaultErrorCode;
|
||||
use crate::hlt_loop;
|
||||
|
||||
extern "x86-interrupt" fn page_fault_handler(
|
||||
stack_frame: InterruptStackFrame,
|
||||
error_code: PageFaultErrorCode,
|
||||
) {
|
||||
use x86_64::registers::control::Cr2;
|
||||
|
||||
println!("EXCEPTION: PAGE FAULT");
|
||||
println!("Accessed Address: {:?}", Cr2::read());
|
||||
println!("Error Code: {:?}", error_code);
|
||||
println!("{:#?}", stack_frame);
|
||||
hlt_loop();
|
||||
}
|
||||
```
|
||||
|
||||
[`CR2`] 寄存器会在 page fault 发生时,被CPU自动写入导致异常的虚拟地址,我们可以用 `x86_64` crate 提供的 [`Cr2::read`] 函数来读取并打印该寄存器。[`PageFaultErrorCode`] 类型为我们提供了内存访问型异常的具体信息,比如究竟是因为读取还是写入操作,我们同样将其打印出来。并且不要忘记,在显式结束异常处理前,程序是不会恢复运行的,所以要在最后调用 [`hlt_loop`] 函数。
|
||||
|
||||
[`CR2`]: https://en.wikipedia.org/wiki/Control_register#CR2
|
||||
[`Cr2::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr2.html#method.read
|
||||
[`PageFaultErrorCode`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html
|
||||
[LLVM bug]: https://github.com/rust-lang/rust/issues/57270
|
||||
[`hlt_loop`]: @/edition-2/posts/07-hardware-interrupts/index.md#the-hlt-instruction
|
||||
|
||||
那么可以开始触发内存越界访问了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
// new
|
||||
let ptr = 0xdeadbeaf as *mut u32;
|
||||
unsafe { *ptr = 42; }
|
||||
|
||||
// as before
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop();
|
||||
}
|
||||
```
|
||||
|
||||
启动执行后,我们可以看到,page fault 的处理函数被触发了:
|
||||
|
||||

|
||||
|
||||
`CR2` 确实保存了导致异常的虚拟地址 `0xdeadbeaf`,而错误码 [`CAUSED_BY_WRITE`] 也说明了导致异常的操作是写入。甚至于可以通过 [未设置的比特位][`PageFaultErrorCode`] 看出更多的信息,例如 `PROTECTION_VIOLATION` 未被设置说明目标页根本就不存在。
|
||||
|
||||
[`CAUSED_BY_WRITE`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.CAUSED_BY_WRITE
|
||||
|
||||
并且我们可以看到当前指令指针是 `0x2031b2`,根据上文的知识,我们知道它应该属于一个代码页。而代码页被bootloader设定为只读权限,所以读取是正常的,但写入就会触发 page fault 异常。比如你可以试着将上面代码中的 `0xdeadbeaf` 换成 `0x2031b2`:
|
||||
|
||||
```rust
|
||||
// Note: The actual address might be different for you. Use the address that
|
||||
// your page fault handler reports.
|
||||
let ptr = 0x2031b2 as *mut u32;
|
||||
|
||||
// read from a code page
|
||||
unsafe { let x = *ptr; }
|
||||
println!("read worked");
|
||||
|
||||
// write to a code page
|
||||
unsafe { *ptr = 42; }
|
||||
println!("write worked");
|
||||
```
|
||||
|
||||
执行后,我们可以看到读取操作成功了,但写入操作抛出了 page fault 异常:
|
||||
|
||||

|
||||
|
||||
我们可以看到 _"read worked"_ 这条日志,说明读操作没有出问题,而 _"write worked"_ 这条日志则没有被打印,起而代之的是一个异常日志。这一次 [`PROTECTION_VIOLATION`] 标志位的 [`CAUSED_BY_WRITE`] 比特位被设置,说明异常正是被非法写入操作引发的,因为我们之前为该页设置了只读权限。
|
||||
|
||||
[`PROTECTION_VIOLATION`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.PROTECTION_VIOLATION
|
||||
|
||||
### 访问页表
|
||||
|
||||
那么我们来看看内核中页表的存储方式:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
use x86_64::registers::control::Cr3;
|
||||
|
||||
let (level_4_page_table, _) = Cr3::read();
|
||||
println!("Level 4 page table at: {:?}", level_4_page_table.start_address());
|
||||
|
||||
[…] // test_main(), println(…), and hlt_loop()
|
||||
}
|
||||
```
|
||||
`x86_64` crate 中的 [`Cr3::read`] 函数可以返回 `CR3` 寄存器中的当前使用的4级页表,它返回的是 [`PhysFrame`] 和 [`Cr3Flags`] 两个类型组成的元组结构。不过此时我们只关心页帧信息,所以第二个元素暂且不管。
|
||||
|
||||
[`Cr3::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr3.html#method.read
|
||||
[`PhysFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/frame/struct.PhysFrame.html
|
||||
[`Cr3Flags`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr3Flags.html
|
||||
|
||||
然后我们会看到如下输出:
|
||||
|
||||
```
|
||||
Level 4 page table at: PhysAddr(0x1000)
|
||||
```
|
||||
|
||||
所以当前的4级页表存储在 _物理地址_ `0x1000` 处,而且地址的外层数据结构是 [`PhysAddr`],那么问题来了:我们如何在内核中直接访问这个页表?
|
||||
|
||||
[`PhysAddr`]: https://docs.rs/x86_64/0.14.2/x86_64/addr/struct.PhysAddr.html
|
||||
|
||||
当分页功能启用时,直接访问物理内存是被禁止的,否则程序就可以很轻易的侵入其他程序的内存,所以唯一的途径就是通过某些手段构建一个指向 `0x1000` 的虚拟页。那么问题就变成了如何手动创建页映射,但其实该功能在很多地方都会用到,例如内核在创建新的线程时需要额外创建栈,同样需要用到该功能。
|
||||
|
||||
我们将在下一篇文章中对此问题进行展开。
|
||||
|
||||
## 小结
|
||||
|
||||
本文介绍了两种内存保护技术:分段和分页。前者每次分配的内存区域大小是可变的,但会受到内存碎片的影响;而后者使用固定大小的页,并允许对访问权限进行精确控制。
|
||||
|
||||
分页技术将映射信息存储在一级或多级页表中,x86_64 平台使用4级页表和4KiB的页大小,硬件会自动逐级寻址并将地址转换结果存储在地址转换后备缓冲区(TLB)中,然而此缓冲区并非完全对用户透明,需要在页表发生变化时进行手动干预。
|
||||
|
||||
并且我们知道了内核已经被预定义了一个分页机制,内存越界访问会导致 page fault 异常。并且我们暂时无法访问当前正在使用的页表,因为 CR3 寄存器存储的地址无法在内核中直接访问。
|
||||
|
||||
## 下文预告
|
||||
|
||||
在下一篇文章中,我们会详细讲解如何在内核中实现对分页机制的支持,这会提供一种直接访问物理内存的特别手段,也就是说我们可以直接访问页表。由此,我们可以在程序中实现虚拟地址到物理地址的转换函数,也使得在页表中手动创建映射成为了可能。
|
||||
@@ -281,7 +281,7 @@ frame.map(|frame| frame.start_address() + u64::from(addr.page_offset()))
|
||||
|
||||
```toml
|
||||
[dependencies]
|
||||
bootloader = { version = "0.9.8", features = ["map_physical_memory"]}
|
||||
bootloader = { version = "0.9.23", features = ["map_physical_memory"]}
|
||||
```
|
||||
|
||||
この機能を有効化すると、ブートローダは物理メモリの全体を、ある未使用の仮想アドレス空間にマッピングします。この仮想アドレスの範囲をカーネルに伝えるために、ブートローダは**boot information**構造体を渡します。
|
||||
|
||||
@@ -278,7 +278,7 @@ We choose the first approach for our kernel since it is simple, platform-indepen
|
||||
|
||||
```toml
|
||||
[dependencies]
|
||||
bootloader = { version = "0.9.8", features = ["map_physical_memory"]}
|
||||
bootloader = { version = "0.9.23", features = ["map_physical_memory"]}
|
||||
```
|
||||
|
||||
With this feature enabled, the bootloader maps the complete physical memory to some unused virtual address range. To communicate the virtual address range to our kernel, the bootloader passes a _boot information_ structure.
|
||||
@@ -292,6 +292,7 @@ The `bootloader` crate defines a [`BootInfo`] struct that contains all the infor
|
||||
|
||||
- The `memory_map` field contains an overview of the available physical memory. This tells our kernel how much physical memory is available in the system and which memory regions are reserved for devices such as the VGA hardware. The memory map can be queried from the BIOS or UEFI firmware, but only very early in the boot process. For this reason, it must be provided by the bootloader because there is no way for the kernel to retrieve it later. We will need the memory map later in this post.
|
||||
- The `physical_memory_offset` tells us the virtual start address of the physical memory mapping. By adding this offset to a physical address, we get the corresponding virtual address. This allows us to access arbitrary physical memory from our kernel.
|
||||
- This physical memory offset can be customized by adding a `[package.metadata.bootloader]` table in Cargo.toml and setting the field `physical-memory-offset = "0x0000f00000000000"` (or any other value). However, note that the bootloader can panic if it runs into physical address values that start to overlap with the the space beyond the offset, i.e., areas it would have previously mapped to some other early physical addresses. So in general, the higher the value (> 1 TiB), the better.
|
||||
|
||||
The bootloader passes the `BootInfo` struct to our kernel in the form of a `&'static BootInfo` argument to our `_start` function. We don't have this argument declared in our function yet, so let's add it:
|
||||
|
||||
|
||||
Reference in New Issue
Block a user