+++
title = "Double Faults"
weight = 6
path = "zh-CN/double-fault-exceptions"
date = 2018-06-18
[extra]
# Please update this when updating the translation
translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
# GitHub usernames of the people that translated this post
translators = ["liuyuran"]
# GitHub usernames of the people that contributed to this translation
translation_contributors = ["JiangengDong"]
+++
在这篇文章中,我们会探索 double fault 异常的细节,它的触发条件是调用错误处理函数失败。通过捕获该异常,我们可以阻止致命的 _triple faults_ 异常导致系统重启。为了尽可能避免 triple faults ,我们会在一个独立的内核栈配置 _中断栈表_ 来捕捉 double faults。
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-06`][post branch]找到这篇文章的完整源码。
[GitHub]: https://github.com/phil-opp/blog_os
[at the bottom]: #comments
[post branch]: https://github.com/phil-opp/blog_os/tree/post-06
## 何谓 Double Fault
简而言之,double fault 就是当CPU执行错误处理函数失败时抛出的特殊异常。比如,你没有注册在 [中断描述符表][IDT] 中注册对应 page fault 异常的处理函数,然后程序偏偏就抛出了一个 page fault 异常,这时候就会接着抛出 double fault 异常。这个异常的处理函数就比较类似于具备异常处理功能的编程语言里的 catch-all 语法的效果,比如 C++ 里的 `catch(...)` 和 JAVA/C# 里的 `catch(Exception e)`。
[IDT]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
double fault 的行为和普通异常十分相似,我们可以通过在IDT中注册 `8` 号位的处理函数来拦截该异常。这个处理函数十分重要,如果你不处理这个异常,CPU就会直接抛出 _triple fault_ 异常,该异常无法被任何方式处理,而且会直接导致绝大多数硬件强制重启。
### 捕捉 Double Fault
我们先来试试看不捕捉 double fault 的情况下触发它会有什么后果:
```rust
// in src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// trigger a page fault
unsafe {
*(0xdeadbeef as *mut u8) = 42;
};
// as before
#[cfg(test)]
test_main();
println!("It did not crash!");
loop {}
}
```
这里我们使用 `unsafe` 块直接操作了一个无效的内存地址 `0xdeadbeef`,由于该虚拟地址并未在页表中映射到物理内存,所以必然会抛出 page fault 异常。我们又并未在 [IDT] 中注册对应的处理器,所以 double fault 会紧接着被抛出。
现在启动内核,我们可以看到它直接陷入了崩溃和重启的无限循环,其原因如下:
1. CPU试图向 `0xdeadbeef` 写入数据,这就造成了 page fault 异常。
2. CPU没有在IDT中找到相应的处理函数,所以又抛出了 double fault 异常。
3. CPU再一次没有在IDT中找到相应的处理函数,所以又抛出了 _triple fault_ 异常。
4. 在抛出 triple fault 之后就没有然后了,这个错误是致命级别,如同大多数硬件一样,QEMU对此的处理方式就是重置系统,也就是重启。
通过这个小实验,我们知道在这种情况下,需要提前注册 page faults 或者 double fault 的处理函数才行,但如果想要在任何场景下避免触发 triple faults 异常,则必须注册能够捕捉一切未注册异常类型的 double fault 处理函数。
## 处理 Double Fault
double fault 是一个带错误码的常规错误,所以我们可以参照 breakpoint 处理函数定义一个 double fault 处理函数:
```rust
// in src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // new
idt
};
}
// new
extern "x86-interrupt" fn double_fault_handler(
stack_frame: InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
}
```
我们的处理函数打印了一行简短的信息,并将栈帧转写了出来。其中错误码一直是0,所以没有必要把它打印出来。要说这和 breakpoint 处理函数有什么区别,那就是 double fault 的处理函数是 [发散的][_diverging_],这是因为 `x86_64` 架构不允许从 double fault 异常中返回任何东西。
[_diverging_]: https://doc.rust-lang.org/stable/rust-by-example/fn/diverging.html
那么再次启动内核,我们可以看到 double fault 的处理函数被成功调用:
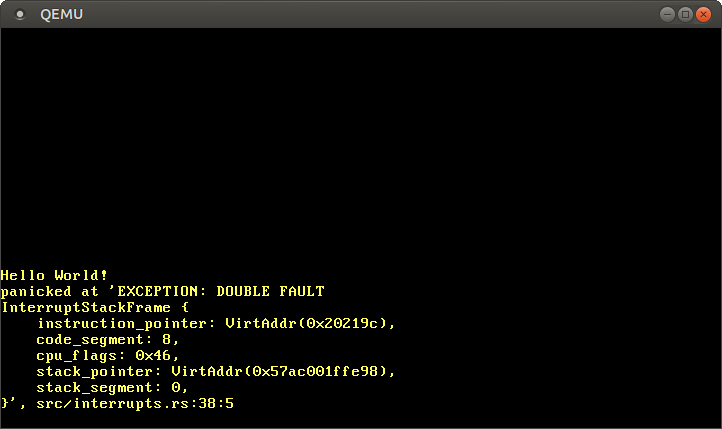
让我们来分析一下又发生了什么:
1. CPU尝试往 `0xdeadbeef` 写入数据,引发了 page fault 异常。
2. 如同上次运行一样,CPU并没有在IDT里找到对应的处理函数,所以又引发了 double fault 异常。
3. CPU又跳转到了我们刚刚定义的 double fault 处理函数。
现在 triple fault 及其衍生的重启循环不会再出现了,因为CPU已经妥善处理了 double fault 异常。
这还真是直截了当对吧,但为什么要为这点内容单独写一篇文章呢?没错,我们的确已经可以捕获 _大部分_ double faults 异常,但在部分情况下,这样的做法依然不够。
## Double Faults 的成因
在解释这些部分情况之前,我们需要先明确一下 double faults 的成因,上文中我们使用了一个模糊的定义:
> double fault 就是当CPU执行错误处理函数失败时抛出的特殊异常。
但究竟什么叫 _“调用失败”_ ?没有提供处理函数?处理函数被[换出][swapped out]内存了?或者处理函数本身也出现了异常?
[swapped out]: http://pages.cs.wisc.edu/~remzi/OSTEP/vm-beyondphys.pdf
比如以下情况出现时:
1. 如果 breakpoint 异常被触发,但其对应的处理函数已经被换出内存了?
2. 如果 page fault 异常被触发,但其对应的处理函数已经被换出内存了?
3. 如果 divide-by-zero 异常处理函数又触发了 breakpoint 异常,但 breakpoint 异常处理函数已经被换出内存了?
4. 如果我们的内核发生了栈溢出,意外访问到了 _guard page_ ?
幸运的是,AMD64手册([PDF][AMD64 manual])给出了一个准确的定义(在8.2.9这个章节中)。
根据里面的说法,“double fault” 异常 _会_ 在执行主要(一层)异常处理函数时触发二层异常时触发。
这个“会”字十分重要:只有特定的两个异常组合会触发 double fault。
这些异常组合如下:
| 一层异常 | 二层异常 |
| --------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------- |
| [Divide-by-zero],
[Invalid TSS],
[Segment Not Present],
[Stack-Segment Fault],
[General Protection Fault] | [Invalid TSS],
[Segment Not Present],
[Stack-Segment Fault],
[General Protection Fault] |
| [Page Fault] | [Page Fault],
[Invalid TSS],
[Segment Not Present],
[Stack-Segment Fault],
[General Protection Fault] |
[Divide-by-zero]: https://wiki.osdev.org/Exceptions#Division_Error
[Invalid TSS]: https://wiki.osdev.org/Exceptions#Invalid_TSS
[Segment Not Present]: https://wiki.osdev.org/Exceptions#Segment_Not_Present
[Stack-Segment Fault]: https://wiki.osdev.org/Exceptions#Stack-Segment_Fault
[General Protection Fault]: https://wiki.osdev.org/Exceptions#General_Protection_Fault
[Page Fault]: https://wiki.osdev.org/Exceptions#Page_Fault
[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
所以那些假设里的 divide-by-zero 异常处理函数触发了 page fault 并不会出问题,只会紧接着触发下一个异常处理函数。但如果 divide-by-zero 异常处理函数触发的是 general-protection fault,则一定会触发 double fault。
那么根据上表,我们可以回答刚刚的假设中的前三个:
1. 如果 breakpoint 异常被触发,但对应的处理函数被换出了内存,_page fault_ 异常就会被触发,并调用其对应的异常处理函数。
2. 如果 page fault 异常被触发,但对应的处理函数被换出了内存,那么 _double fault_ 异常就会被触发,并调用其对应的处理函数。
3. 如果 divide-by-zero 异常处理函数又触发了 breakpoint 异常,但 breakpoint 异常处理函数已经被换出内存了,那么被触发的就是 _page fault_ 异常。
实际上,因在IDT里找不到对应处理函数而抛出异常的内部机制是:当异常发生时,CPU会去试图读取对应的IDT条目,如果该条目不是一个有效的条目,即其值为0,就会触发 _general protection fault_ 异常。但我们同样没有为该异常注册处理函数,所以又一个 general protection fault 被触发了,随后 double fault 也被触发了。
### 内核栈溢出
现在让我们看一下第四个假设:
> 如果我们的内核发生了栈溢出,意外访问到了 _guard page_ ?
guard page 是一类位于栈底部的特殊内存页,所以如果发生了栈溢出,最典型的现象就是访问这里。这类内存页不会映射到物理内存中,所以访问这里只会造成 page fault 异常,而不会污染其他内存。bootloader 已经为我们的内核栈设置好了一个 guard page,所以栈溢出会导致 _page fault_ 异常。
当 page fault 发生时,CPU会在IDT寻找对应的处理函数,并尝试将 [中断栈帧][interrupt stack frame] 入栈,但此时栈指针指向了一个实际上并不存在的 guard page,然后第二个 page fault 异常就被触发了,根据上面的表格,double fault 也随之被触发了。
[interrupt stack frame]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
这时,CPU会尝试调用 _double fault_ 对应的处理函数,然而CPU依然会试图将错误栈帧入栈,由于栈指针依然指向 guard page,于是 _第三次_ page fault 发生了,最终导致 _triple fault_ 异常的抛出,系统因此重启。所以仅仅是注册错误处理函数并不能在此种情况下阻止 triple fault 的发生。
让我们来尝试一下,写一个能造成栈溢出的递归函数非常简单:
```rust
// in src/main.rs
#[no_mangle] // 禁止函数名自动修改
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // 每一次递归都会将返回地址入栈
}
// 触发 stack overflow
stack_overflow();
[…] // test_main(), println(…), and loop {}
}
```
我们在QEMU执行这段程序,然后系统就再次进入了重启循环。
所以我们要如何避免这种情况?我们无法忽略异常栈帧入栈这一步,因为这个逻辑是内置在CPU里的。所以我们需要找个办法,让栈在 double fault 异常发生后始终有效。幸运的是,x86_64 架构对于这个问题已经给出了解决方案。
## 切换栈
x86_64 架构允许在异常发生时,将栈切换为一个预定义的完好栈,这个切换是执行在硬件层次的,所以完全可以在CPU将异常栈帧入栈之前执行。
这个切换机制是由 _中断栈表_ (IST)实现的,IST是一个由7个确认可用的完好栈的指针组成的,用 Rust 语言可以表述为:
```rust
struct InterruptStackTable {
stack_pointers: [Option; 7],
}
```
对于每一个错误处理函数,我们都可以通过对应的[IDT条目][IDT entry]中的 `stack_pointers` 条目指定IST中的一个栈。比如我们可以让 double fault 对应的处理函数使用IST中的第一个栈指针,则CPU会在这个异常发生时,自动将栈切换为该栈。该切换行为会在所有入栈操作之前进行,由此可以避免进一步触发 triple fault 异常。
[IDT entry]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
### IST和TSS
中断栈表(IST)其实是一个名叫 _[任务状态段][Task State Segment](TSS)_ 的古老遗留结构的一部分。
TSS是用来存储32位任务中的零碎信息,比如处理器寄存器的状态,一般用于 [硬件上下文切换][hardware context switching]。但是硬件上下文切换已经不再适用于64位模式,并且TSS的实际数据结构也已经发生了彻底的改变。
[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
在 x86_64 架构中,TSS已经不再存储任何任务相关信息,取而代之的是两个栈表(IST正是其中之一)。
32位TSS和64位TSS唯一的共有字段恐怕就是指向 [I/O端口权限位图][I/O port permissions bitmap] 的指针了。
[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
64位TSS的格式如下:
| 字段 | 类型 |
| ---------------------------------------- | ---------- |
| (保留) | `u32` |
| 特权栈表 | `[u64; 3]` |
| (保留) | `u64` |
| 中断栈表 | `[u64; 7]` |
| (保留) | `u64` |
| (保留) | `u16` |
| I/O映射基准地址 | `u16` |
_特权栈表_ 在 CPU 特权等级变更的时候会被用到。例如当 CPU 在用户态(特权等级3)中触发一个异常时,一般情况下 CPU 会在执行错误处理函数前切换到内核态(特权等级0),在这种情况下,CPU 会切换为特权栈表的第0层(0层是目标特权等级)。但是目前我们还没有用户态的程序,所以暂且可以忽略这个表。
### 创建一个TSS
那么我们来创建一个新的包含单独的 double fault 专属栈以及中断栈表的TSS。为此我们需要一个TSS结构体,幸运的是 `x86_64` crate 也已经自带了 [`TaskStateSegment` 结构][`TaskStateSegment` struct] 用来映射它。
[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/tss/struct.TaskStateSegment.html
那么我们新建一个 `gdt` 模块(稍后会说明为何要使用这个名字)用来创建TSS:
```rust
// in src/lib.rs
pub mod gdt;
// in src/gdt.rs
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(&raw const STACK);
let stack_end = stack_start + STACK_SIZE;
stack_end
};
tss
};
}
```
这次依然是使用 `lazy_static`,Rust的静态变量求值器还没有强大到能够在编译器执行初始化代码。我们将IST的0号位定义为 double fault 的专属栈(其他IST序号也可以如此施为)。然后我们将栈的高地址指针写入0号位,之所以这样做,那是因为 x86 的栈内存分配是从高地址到低地址的。
由于我们还没有实现内存管理机制,所以目前无法直接申请新栈,但我们可以使用 `static mut` 形式的数组来在内存中模拟出栈存储区。
而且这里必须是 `static mut` 而不是不可修改的 `static`,否则 bootloader 会将其分配到只读页中。
当然,在后续的文章中,我们会将其修改为真正的栈分配。
但要注意,由于现在 double fault 获取的栈不再具有用于防止栈溢出的 guard page,所以我们不应该做任何栈密集型操作了,否则就有可能会污染到栈下方的内存区域。
#### 加载TSS
我们已经创建了一个TSS,现在的问题就是怎么让CPU使用它。不幸的是这事有点繁琐,因为TSS用到了分段系统(历史原因)。但我们可以不直接加载,而是在[全局描述符表][Global Descriptor Table](GDT)中添加一个段描述符,然后我们就可以通过[`ltr` 指令][`ltr` instruction]加上GDT序号加载我们的TSS。(这也是为什么我们将模块取名为 `gdt`。)
[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
### 全局描述符表
全局描述符表(GDT)是分页模式成为事实标准之前,用于[内存分段][memory segmentation]的遗留结构,但它在64位模式下仍然需要处理一些事情,比如内核态/用户态的配置以及TSS载入。
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
GDT是包含了程序 _段信息_ 的结构,在分页模式成为标准前,它在旧架构下起到隔离程序执行环境的作用。要了解更多关于分段的知识,可以查看 [“Three Easy Pieces” book] 这本书的同名章节。尽管GDT在64位模式下已经不再受到支持,但其依然有两个作用,切换内核空间和用户空间,以及加载TSS结构。
[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
#### 创建GDT
我们来创建一个包含了静态 `TSS` 段的 `GDT` 静态结构:
```rust
// in src/gdt.rs
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.add_entry(Descriptor::kernel_code_segment());
gdt.add_entry(Descriptor::tss_segment(&TSS));
gdt
};
}
```
就像以前一样,我们依然使用了 `lazy_static` 宏,我们通过这段代码创建了TSS和GDT两个结构。
#### 加载GDT
我们先创建一个在 `init` 函数中调用的 `gdt::init` 函数:
```rust
// in src/gdt.rs
pub fn init() {
GDT.load();
}
// in src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
}
```
现在GDT成功加载了进去(`_start` 会调用 `init` 函数),但我们依然会看到由于栈溢出引发的重启循环。
### 最终步骤
现在的问题就变成了GDT并未被激活,代码段寄存器和TSS实际上依然引用着旧的GDT,并且我们也需要修改 double fault 对应的IDT条目,使其使用新的栈。
总结一下,我们需要做这些事情:
1. **重载代码段寄存器**: 我们修改了GDT,所以就需要重载代码段寄存器 `cs`,这一步对于修改GDT信息而言是必须的,比如覆写TSS。
2. **加载TSS** : 我们已经加载了包含TSS信息的GDT,但我们还需要告诉CPU使用新的TSS。
3. **更新IDT条目**: 当TSS加载完毕后,CPU就可以访问到新的中断栈表(IST)了,下面我们需要通过修改IDT条目告诉CPU使用新的 double fault 专属栈。
通过前两步,我们可以在 `gdt::init` 函数中调用 `code_selector` 和 `tss_selector` 两个变量,我们可以将两者打包为一个 `Selectors` 结构便于使用:
```rust
// in src/gdt.rs
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}
```
现在我们可以使用这两个变量去重载代码段寄存器 `cs` 并重载 `TSS`:
```rust
// in src/gdt.rs
pub fn init() {
use x86_64::instructions::tables::load_tss;
use x86_64::instructions::segmentation::{CS, Segment};
GDT.0.load();
unsafe {
CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}
```
我们通过 [`set_cs`] 覆写了代码段寄存器,然后使用 [`load_tss`] 来重载了TSS,不过这两个函数都被标记为 `unsafe`,所以 `unsafe` 代码块是必须的。
原因很简单,如果通过这两个函数加载了无效的指针,那么很可能就会破坏掉内存安全性。
[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
现在我们已经加载了有效的TSS和中断栈表,我们可以在IDT中为 double fault 对应的处理函数设置栈序号:
```rust
// in src/interrupts.rs
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
}
idt
};
}
```
`set_stack_index` 函数也是不安全的,因为栈序号的有效性和引用唯一性是需要调用者去确保的。
搞定!现在CPU会在 double fault 异常被触发时自动切换到安全栈了,我们可以捕捉到 _所有_ 的 double fault,包括内核栈溢出:
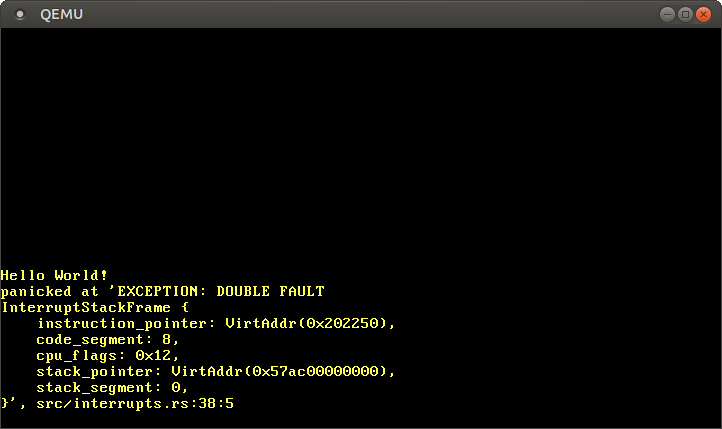
现在开始我们应该不会再看到 triple fault 了,但要确保这部分逻辑不被破坏,我们还需要为其添加一个测试。
## 栈溢出测试
要测试我们的 `gdt` 模块,并确保在栈溢出时可以正确捕捉 double fault,我们可以添加一个集成测试。基本上就是在测试函数中主动触发一个 double fault 异常,确认异常处理函数是否正确运行了。
让我们建立一个最小化框架:
```rust
// in tests/stack_overflow.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[no_mangle]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
```
就如同 `panic_handler` 这个测试一样,该测试应该是一个 [无约束测试][without a test harness],其原因就是我们无法在 double fault 被抛出后继续运行,所以连续进行多个测试其实是说不通的。要将测试修改为无约束模式,我们需要将这一段配置加入 `Cargo.toml`:
```toml
# in Cargo.toml
[[test]]
name = "stack_overflow"
harness = false
```
[without a test harness]: @/edition-2/posts/04-testing/index.md#no-harness-tests
现在 `cargo test --test stack_overflow` 命令应当可以通过编译了。但是毫无疑问的是还是会执行失败,因为 `unimplemented` 宏必然会导致程序报错。
### 实现 `_start`
`_start` 函数实现后的样子是这样的:
```rust
// in tests/stack_overflow.rs
use blog_os::serial_print;
#[no_mangle]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// trigger a stack overflow
stack_overflow();
panic!("Execution continued after stack overflow");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
}
```
我们调用了 `gdt::init` 函数来初始化GDT,但我们并没有调用 `interrupts::init_idt` 函数,而是调用了一个全新的 `init_test_idt` 函数,我们稍后来实现它。原因就是,我们需要注册一个自定义的 double fault 处理函数,在被触发的时候调用 `exit_qemu(QemuExitCode::Success)` 函数,而非使用默认的逻辑。
`stack_overflow` 函数和我们之前在 `main.rs` 中写的那个函数几乎一模一样,唯一的区别就是在函数的最后使用 [`Volatile`] 类型 加入了一个 [volatile] 读取操作,用来阻止编译器进行 [_尾调用优化_][_tail call elimination_]。除却其他乱七八糟的效果,这个优化最主要的影响就是会让编辑器将最后一行是递归语句的函数转化为普通的循环。由于没有通过递归创建新的栈帧,所以栈自然也不会出问题。
[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
在当前用例中,stack overflow 是必须要触发的,所以我们在函数尾部加入了一个无效的 volatile 读取操作来让编译器无法进行此类优化,递归也就无法被自动降级为循环了。当然,为了关闭编译器针对递归的安全警告,我们也需要为这个函数加上 `allow(unconditional_recursion)` 开关。
### 测试 IDT
作为上一小节的补充,我们说过要在测试专用的IDT中实现一个自定义的 double fault 异常处理函数,就像这样:
```rust
// in tests/stack_overflow.rs
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}
```
这和我们在 `interrupts.rs` 中实现的版本十分相似,如同正常的IDT一样,我们都为 double fault 使用IST序号设置了特殊的栈,而上文中提到的 `init_test_idt` 函数则通过 `load` 函数将配置成功装载到CPU。
### Double Fault 处理函数
那么现在就差处理函数本身了,它看起来是这样子的:
```rust
// in tests/stack_overflow.rs
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}
```
这个处理函数被调用后,我们会使用代表成功的返回值退出QEMU,以此即可标记测试完成,但由于集成测试处于完全独立的运行环境,也记得在测试入口文件的头部再次加入 `#![feature(abi_x86_interrupt)]` 开关。
现在我们可以执行 `cargo test --test stack_overflow` 运行当前测试(或者执行 `cargo test` 运行所有测试),应当可以在控制台看到 `stack_overflow... [ok]` 这样的输出。另外,也可以试一下注释掉 `set_stack_index` 这一行的命令,可以观察到失败情况下的输出。
## 总结
在本文中,我们学到了 double fault 是什么,以及触发它的原因。我们为 double fault 写了相应的处理函数、将错误信息打印到控制台并为它添加了一个集成测试。
同时,我们为 double fault 启用了栈指针切换功能,使其在栈溢出时也可以正常工作。在实现这个功能的同时,我们也学习了在旧架构中用于内存分段的任务状态段(TSS),而该结构又包含了中断栈表(IST)和全局描述符表(GDT)。
## 下期预告
在下一篇文章中,我们会展开来说外部设备(如定时器、键盘、网络控制器)中断的处理方式。这些硬件中断十分类似于上文所说的异常,都需要通过IDT进行处理,只是中断并不是由CPU抛出的。 _中断控制器_ 会代理这些中断事件,并根据中断的优先级将其转发给CPU处理。我们将会以 [Intel 8259] (PIC) 中断控制器为例对其进行探索,并实现对键盘的支持。
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259