+++
title = "ページング入門"
weight = 8
path = "ja/paging-introduction"
date = 2019-01-14
[extra]
chapter = "Memory Management"
# Please update this when updating the translation
translation_based_on_commit = "3315bfe2f63571f5e6e924d58ed32afd8f39f892"
# GitHub usernames of the people that translated this post
translators = ["woodyZootopia", "JohnTitor"]
+++
この記事では**ページング**を紹介します。これは、私達のオペレーティングシステムにも使う、とても一般的なメモリ管理方式です。なぜメモリの分離が必要なのか、**セグメンテーション**がどういう仕組みなのか、**仮想メモリ**とは何なのか、ページングがいかにしてメモリ断片化の問題を解決するのかを説明します。また、x86_64アーキテクチャにおける、マルチレベルページテーブルのレイアウトについても説明します。
このブログの内容は [GitHub] 上で公開・開発されています。何か問題や質問などがあれば issue をたててください(訳注: リンクは原文(英語)のものになります)。また[こちら][at the bottom]にコメントを残すこともできます。この記事の完全なソースコードは[`post-08` ブランチ][post branch]にあります。
[GitHub]: https://github.com/phil-opp/blog_os
[at the bottom]: #comments
[post branch]: https://github.com/phil-opp/blog_os/tree/post-08
## メモリの保護
オペレーティングシステムの主な役割の一つに、プログラムを互いに分離するということがあります。例えば、ウェブブラウザがテキストエディタに干渉してはいけません。この目的を達成するために、オペレーティングシステムはハードウェアの機能を利用して、あるプロセスのメモリ領域に他のプロセスがアクセスできないようにします。ハードウェアやOSの実装によって、さまざまなアプローチがあります。
例として、ARM Cortex-Mプロセッサ(組み込みシステムに使われています)のいくつかには、[メモリ保護ユニット][_Memory Protection Unit_] (Memory Protection Unit, MPU) が搭載されており、異なるアクセス権限(例えば、アクセス不可、読み取り専用、読み書きなど)を持つメモリ領域を少数(例えば8個)定義できます。MPUは、メモリアクセスのたびに、そのアドレスが正しいアクセス権限を持つ領域にあるかどうかを確認し、そうでなければ例外を投げます。プロセスを変更するごとにその領域とアクセス権限を変更すれば、オペレーティングシステムはそれぞれのプロセスが自身のメモリにのみアクセスすることを保証し、したがってプロセスを互いに分離できます。
[_Memory Protection Unit_]: https://developer.arm.com/docs/ddi0337/e/memory-protection-unit/about-the-mpu
x86においては、ハードウェアは2つの異なるメモリ保護の方法をサポートしています:[セグメンテーション][segmentation]と[ページング][paging]です。
[segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
[paging]: https://en.wikipedia.org/wiki/Virtual_memory#Paged_virtual_memory
## セグメンテーション
セグメンテーションは1978年にはすでに導入されており、当初の目的はアドレス可能なメモリの量を増やすことでした。当時、CPUは16bitのアドレスしか使えなかったので、アドレス可能なメモリは64KiBに限られていました。この64KiBを超えてアクセスするために、セグメントレジスタが追加され、このそれぞれにオフセットアドレスを格納するようになりました。CPUがメモリにアクセスするとき、毎回このオフセットを自動的に加算するようにすることで、最大1MiBのメモリにアクセスできるようになりました。
メモリアクセスの種類によって、セグメントレジスタは自動的にCPUによって選ばれます。命令の引き出しにはコードセグメント`CS`が使用され、スタック操作(プッシュ・ポップ)にはスタックセグメント`SS`が使用されます。その他の命令では、データセグメント`DS`やエクストラセグメント`ES`が使用されます。その後、自由に使用できる`FS`と`GS`というセグメントレジスタも追加されました。
セグメンテーションの初期バージョンでは、セグメントレジスタは直接オフセットを格納しており、アクセス制御は行われていませんでした。これは後に[プロテクトモード][_protected mode_]が導入されたことで変更されました。CPUがこのモードで動作している時、セグメント記述子は局所または大域[**記述子表**][_descriptor table_]を格納します。これには(オフセットアドレスに加えて)セグメントのサイズとアクセス権限が格納されます。それぞれのプロセスに対し、メモリアクセスをプロセスのメモリ領域にのみ制限するような大域/局所記述子表をロードすることで、OSはプロセスを互いに隔離できます。
[_protected mode_]: https://en.wikipedia.org/wiki/X86_memory_segmentation#Protected_mode
[_descriptor table_]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
メモリアドレスを実際にアクセスされる前に変更するという点において、セグメンテーションは今やほぼすべての場所で使われている**仮想メモリ**というテクニックをすでに採用していたと言えます。
### 仮想メモリ
仮想メモリの背景にある考え方は、下層にある物理的なストレージデバイスからメモリアドレスを抽象化することです。ストレージデバイスに直接アクセスするのではなく、先に何らかの変換ステップが踏まれます。セグメンテーションの場合、この変換ステップとはアクティブなセグメントのオフセットアドレスを追加することです。例えば、オフセット`0x1111000`のセグメントにあるプログラムが`0x1234000`というメモリアドレスにアクセスすると、実際にアクセスされるアドレスは`0x2345000`になります。
この2種類のアドレスを区別するため、変換前のアドレスを **仮想(アドレス)** と、変換後のアドレスを **物理(アドレス)** と呼びます。この2種類のアドレスの重要な違いの一つは、物理アドレスは常に同じ一意なメモリ位置を指すということです。いっぽう仮想アドレス(の指す場所)は変換する関数に依存します。二つの異なる仮想アドレスが同じ物理アドレスを指すということは十分にありえます。また、変換関数が異なっていれば、同じ仮想アドレスが別の物理アドレスを示すということもありえます。
この特性が役立つ例として、同じプログラムを2つ並行して実行するという状況が挙げられます。

同じプログラムを2つ実行していますが、別の変換関数が使われています。1つ目の実体ではセグメントのオフセットが100なので、0から150の仮想アドレスは100から250に変換されます。2つ目のインスタンスではオフセットが300なので、0から150の仮想アドレスが300から450に変換されます。これにより、プログラムが互いに干渉することなく同じコード、同じ仮想アドレスを使うことができます。
もう一つの利点は、プログラムが全く異なる仮想アドレスを使っていたとしても、物理メモリ上の任意の場所に置けるということです。したがって、OSはプログラムを再コンパイルすることなく利用可能なメモリをフルに活用できます。
### 断片化
物理アドレスと仮想アドレスを分けることにより、セグメンテーションは非常に強力なものとなっています。しかし、これにより断片化という問題が発生します。例として、上で見たプログラムの3つ目を実行したいとしましょう:

開放されているメモリは十分にあるにも関わらず、プログラムのインスタンスを重ねることなく物理メモリに対応づけることはできません。ここで必要なのは **連続した** メモリであり、開放されているメモリが小さな塊であっては使えないためです。
この断片化に対処する方法の一つは、実行を一時停止し、メモリの使用されている部分を寄せ集めて、変換関数を更新し、実行を再開することでしょう:

これで、プログラムの3つ目のインスタンスを開始するのに十分な連続したスペースができました。
このデフラグメンテーションという処理の欠点は、大量のメモリをコピーしなければならず、パフォーマンスを低下させてしまうことです。また、メモリが断片化しすぎる前に定期的に実行しないといけません。そうすると、プログラムが時々一時停止して反応がなくなるので、性能が予測不可能になってしまいます。
ほとんどのシステムでセグメンテーションが用いられなくなった理由の一つに、この断片化の問題があります。実際、x86の64ビットモードでは、セグメンテーションはもはやサポートされていません。代わりに **ページング** が使用されており、これにより断片化の問題は完全に回避されます。
## ページング
ページングの考え方は、仮想メモリ空間と物理メモリ空間の両方を、サイズの固定された小さなブロックに分割するというものです。仮想メモリ空間のブロックは **ページ** と呼ばれ、物理アドレス空間のブロックは **フレーム** と呼ばれます。各ページはフレームに独立してマッピングできるので、大きなメモリ領域を連続していない物理フレームに分割することが可能です。
この方法の利点は、上のメモリ空間断片化の状況をもう一度、セグメンテーションの代わりにページングを使って見てみれば明らかになります:

この例では、ページサイズは50バイトなので、それぞれのメモリ領域が3つのページに分割されます。それぞれのページは個別にフレームに対応付けられるので、連続した仮想メモリ領域を非連続な物理フレームへと対応付けられるのです。これにより、デフラグを事前に実行することなく、3つ目のプログラムのインスタンスを開始できるようになります。
### 隠された断片化
少ない数の可変なサイズのメモリ領域を使っていたセグメンテーションと比べると、ページングでは大量の小さい固定サイズのメモリ領域を使います。すべてのフレームが同じ大きさなので、「小さすぎて使えないフレーム」などというものは存在せず、したがって断片化も起きません。
というより、**目に見える** 断片化は起きていない、という方が正しいでしょう。**内部断片化**と呼ばれる、目に見えない断片化は依然として起こっています。内部断片化は、すべてのメモリ領域がページサイズの整数倍ぴったりにはならないために生じます。例えば、上の例でサイズが101のプログラムを考えてみてください:この場合でもサイズ50のページが3つ必要で、必要な量より49バイト多く占有します。これらの2種類の断片化を区別するため、セグメンテーションを使うときに起きる断片化は **外部断片化** と呼ばれます。
内部断片化が起こるのは残念なことですが、セグメンテーションで発生していた外部断片化よりも優れていることが多いです。確かにメモリ領域は無駄にしますが、デフラグメンテーションをする必要がなく、また断片化の量も予想できるからです(平均するとメモリ領域ごとにページの半分)。
### ページテーブル
最大で何百万ものページがそれぞれ独立にフレームに対応付けられることを見てきました。この対応付けの情報はどこかに保存されなければなりません。セグメンテーションでは、有効なメモリ領域ごとに個別のセグメントセレクタを使っていましたが、ページングではレジスタよりも遥かに多くのページが使われるので、これは不可能です。代わりにページングでは **ページテーブル** と呼ばれる表構造を使って対応付の情報を保存します。
上の例では、ページテーブルは以下のようになります:

それぞれのプログラムのインスタンスが独自のページテーブルを持っているのが分かります。現在有効なテーブルへのポインタは、特殊なCPUのレジスタに格納されます。`x86`においては、このレジスタは`CR3`と呼ばれています。それぞれのプログラムのインスタンスを実行する前に、正しいページテーブルを指すポインタをこのレジスタにロードするのはOSの役割です。
それぞれのメモリアクセスにおいて、CPUはテーブルへのポインタをレジスタから読み出し、テーブル内のアクセスされたページから対応するフレームを見つけ出します。これは完全にハードウェア内で行われ、実行しているプログラムからはこの動作は見えません。変換プロセスを高速化するために、多くのCPUアーキテクチャは前回の変換の結果を覚えておく専用のキャッシュを持っています。
アーキテクチャによっては、ページテーブルのエントリは"Flags"フィールドにあるアクセス権限のような属性も保持できます。上の例では、"r/w"フラグがあることにより、このページは読み書きのどちらも可能だということを示しています。
### 複数層ページテーブル
上で見たシンプルなページテーブルは、アドレス空間が大きくなってくると問題が発生します:メモリが無駄になるのです。たとえば、`0`, `1_000_000`, `1_000_050` および `1_000_100`(3ケタごとの区切りとして`_`を用いています)の4つの仮想ページを使うプログラムを考えてみましょう。

このプログラムはたった4つしか物理フレームを必要としていないのに、テーブルには100万以上ものエントリが存在してしまっています。空のエントリを省略した場合、変換プロセスにおいてCPUが正しいエントリに直接ジャンプできなくなってしまうので、それはできません(たとえば、4つめのページが4つめのエントリを使っていることが保証されなくなってしまいます)。
この無駄になるメモリを減らせる、 **2層ページテーブル** を使ってみましょう。発想としては、それぞれのアドレス領域に異なるページテーブルを使うというものです。**レベル2** ページテーブルと呼ばれる追加のページテーブルは、アドレス領域と(レベル1の)ページテーブルのあいだの対応を格納します。
これを理解するには、例を見るのが一番です。それぞれのレベル1テーブルは大きさ`10_000`の領域に対応するとします。すると、以下のテーブルが上のマッピングの例に対応するものとなります:

ページ0は最初の`10_000`バイト領域に入るので、レベル2ページテーブルの最初のエントリを使います。このエントリはT1というレベル1ページテーブルを指し、このページテーブルはページ`0`がフレーム`0`に対応すると指定します。
ページ`1_000_000`, `1_000_050`および`1_000_100`はすべて、`10_000`バイトの大きさの領域100個目に入るので、レベル2ページテーブルの100個目のエントリを使います。このエントリは、T2という別のレベル1テーブルを指しており、このレベル1テーブルはこれらの3つのページをフレーム`100`, `150`および`200`に対応させています。レベル1テーブルにおけるページアドレスには領域のオフセットは含まれていない、つまり例えば、ページ`1_000_050`のエントリは単に`50`である、ということに注意してください。
レベル2テーブルにはまだ100個の空のエントリがありますが、前の100万にくらべればこれはずっと少ないです。このように節約できる理由は、`10_000`から`10_000_000`の、対応付けのないメモリ領域のためのレベル1テーブルを作る必要がないためです。
2層ページテーブルの原理は、3、4、それ以上に多くの層に拡張できます。このとき、ページテーブルレジスタは最も高いレベルのテーブルを指し、そのテーブルは次に低いレベルのテーブルを指し、それはさらに低いレベルのものを、と続きます。そして、レベル1のテーブルは対応するフレームを指します。この原理は一般に **複数層** ページテーブルや、 **階層型** ページテーブルと呼ばれます。
ページングと複数層ページテーブルの仕組みが理解できたので、x86_64アーキテクチャにおいてどのようにページングが実装されているのかについて見ていきましょう(以下では、CPUは64ビットモードで動いているとします)。
## x86_64におけるページング
x86_64アーキテクチャは4層ページテーブルを使っており、ページサイズは4KiBです。それぞれのページテーブルは、層によらず512のエントリを持っています。それぞれのエントリの大きさは8バイトなので、それぞれのテーブルは512 * 8B = 4KiBであり、よってぴったり1ページに収まります。
(各)レベルのページテーブルインデックスは、仮想アドレスから直接求められます:

それぞれのテーブルインデックスは9ビットからなることがわかります。それぞれのテーブルに2^9 = 512エントリあることを考えるとこれは妥当です。最下位の12ビットは4KiBページ内でのオフセット(2^12バイト = 4KiB)です。48ビットから64ビットは捨てられます。つまり、x86_64は48ビットのアドレスにしか対応しておらず、そのため(64ビットアーキテクチャなどとよく呼ばれるが)実際には64ビットではないということです。
[5-level page table]: https://en.wikipedia.org/wiki/Intel_5-level_paging
48ビットから64ビットが捨てられるからといって、任意の値にしてよいということではありません。アドレスを一意にし、5層ページテーブルのような将来の拡張に備えるため、この範囲のすべてのビットは47ビットの値と同じにしないといけません。これは、[2の補数における符号拡張][sign extension in two's complement]によく似ているので、 **符号拡張** とよばれています。アドレスが適切に符号拡張されていない場合、CPUは例外を投げます。
[sign extension in two's complement]: https://en.wikipedia.org/wiki/Two's_complement#Sign_extension
近年発売されたIntelのIce LakeというCPUは、[5層ページテーブル][5-level page tables]を使用することもでき、そうすると仮想アドレスが48ビットから57ビットまで延長されるということは書いておく価値があるでしょう。いまの段階で私たちのカーネルをこの特定のCPUに最適化する意味はないので、この記事では標準の4層ページテーブルのみを使うことにします。
[5-level page tables]: https://en.wikipedia.org/wiki/Intel_5-level_paging
### 変換の例
この変換の仕組みをより詳細に理解するために、例を挙げて見てみましょう。

現在有効なレベル4ページテーブルの物理アドレス、つまりレベル4ページテーブルの「根」は`CR3`レジスタに格納されています。それぞれのページテーブルエントリは、次のレベルのテーブルの物理フレームを指しています。そして、レベル1のテーブルは対応するフレームを指しています。なお、ページテーブル内のアドレスは全て仮想ではなく物理アドレスであることに注意してください。さもなければ、CPUは(変換プロセス中に)それらのアドレスも変換しなくてはならず、無限再帰に陥ってしまうかもしれないからです。
上のページテーブル階層構造は、最終的に(青色の)2つのページへの対応を行っています。ページテーブルのインデックスから、これらの2つのページの仮想アドレスは`0x803FE7F000`と`0x803FE00000`であると推論できます。プログラムがアドレス`0x803FE7F5CE`から読み込もうとしたときに何が起こるかを見てみましょう。まず、アドレスを2進数に変換し、アドレスのページテーブルインデックスとページオフセットが何であるかを決定します:

これらのインデックス情報をもとにページテーブル階層構造を移動して、このアドレスに対応するフレームを決定します:
- まず、`CR3`レジスタからレベル4テーブルのアドレスを読み出します。
- レベル4のインデックスは1なので、このテーブルの1つ目のインデックスを見ます。すると、レベル3テーブルはアドレス16KiBに格納されていると分かります。
- レベル3テーブルをそのアドレスから読み出し、インデックス0のエントリを見ると、レベル2テーブルは24KiBにあると教えてくれます。
- レベル2のインデックスは511なので、このページの最後のエントリを見て、レベル1テーブルのアドレスを見つけます。
- レベル1テーブルの127番目のエントリを読むことで、ついに対象のページは12KiB(16進数では0x3000)のフレームに対応づけられていると分かります。
- 最後のステップは、ページオフセットをフレームアドレスに足して、物理アドレスを得ることです。0x3000 + 0x5ce = 0x35ce

レベル1テーブルにあるこのページの権限は`r`であり、これは読み込み専用という意味です。これらのような権限に対する侵害はハードウェアによって保護されており、このページに書き込もうとした場合は例外が投げられます。より高いレベルのページにおける権限は、下のレベルにおいて可能な権限を制限します。たとえばレベル3エントリを読み込み専用にした場合、下のレベルで読み書きを許可したとしても、このエントリを使うページはすべて書き込み不可になります。
この例ではそれぞれのテーブルの実体を1つずつしか使いませんでしたが、普通、それぞれのアドレス空間において、各レベルに対して複数のインスタンスが使われるということは知っておく価値があるでしょう。最大で
- 1個のレベル4テーブル
- 512個のレベル3テーブル(レベル4テーブルには512エントリあるので)
- 512 * 512個のレベル2テーブル(512個のレベル3テーブルそれぞれに512エントリあるので)
- 512 * 512 * 512個のレベル1テーブル(それぞれのレベル2テーブルに512エントリあるので)
があります。
### ページテーブルの形式
x86_64アーキテクチャにおけるページテーブルは詰まるところ512個のエントリの配列です。Rustの構文では以下のようになります:
```rust
#[repr(align(4096))]
pub struct PageTable {
entries: [PageTableEntry; 512],
}
```
`repr`属性で示されるように、ページテーブルはアラインされる必要があります。つまり4KiBごとの境界に揃えられる必要がある、ということです。この条件により、ページテーブルはつねにページひとつを完全に使うので、エントリをとてもコンパクトにできる最適化が可能になります。
それぞれのエントリは8バイト(64ビット)の大きさであり、以下の形式です:
ビット | 名前 | 意味
------ | ---- | -------
0 | present | このページはメモリ内にある
1 | writable | このページへの書き込みは許可されている
2 | user accessible | 0の場合、カーネルモードのみこのページにアクセスできる
3 | write through caching | 書き込みはメモリに対して直接行われる
4 | disable cache | このページにキャッシュを使わない
5 | accessed | このページが使われているとき、CPUはこのビットを1にする
6 | dirty | このページへの書き込みが行われたとき、CPUはこのビットを1にする
7 | huge page/null | P1とP4においては0で、P3においては1GiBのページを、P2においては2MiBのページを作る
8 | global | キャッシュにあるこのページはアドレス空間変更の際に初期化されない(CR4レジスタのPGEビットが1である必要がある)
9-11 | available | OSが自由に使える
12-51 | physical address | ページ単位にアラインされた、フレームまたは次のページテーブルの52bit物理アドレス
52-62 | available | OSが自由に使える
63 | no execute | このページにおいてプログラムを実行することを禁じる(EFERレジスタのNXEビットが1である必要がある)
12-51ビットだけが物理フレームアドレスを格納するのに使われていて、残りのビットはフラグやオペレーティングシステムが自由に使うようになっていることがわかります。これが可能なのは、常に4096バイト単位のページに揃えられたアドレス(ページテーブルか、対応づけられたフレームの先頭)を指しているからです。これは、0-11ビットは常にゼロであることを意味し、したがってこれらのビットを格納しておく必要はありません。アドレスを使用する前に、ハードウェアがそれらのビットをゼロとして(追加して)やれば良いからです。また、52-63ビットについても格納しておく必要はありません。なぜならx86_64アーキテクチャは52ビットの物理アドレスしかサポートしていないからです(仮想アドレスを48ビットしかサポートしていないのと似ています)。
上のフラグについてより詳しく見てみましょう:
- `present`フラグは、対応付けられているページとそうでないページを区別します。このフラグは、メインメモリが一杯になったとき、ページを一時的にディスクにスワップしたいときに使うことができます。後でページがアクセスされたら、 **ページフォルト** という特別な例外が発生するので、オペレーティングシステムは不足しているページをディスクから読み出すことでこれに対応し、プログラムを再開します。
- `writable`と`no execute`フラグはそれぞれ、このページの中身が書き込み可能かと、実行可能な命令であるかを制御します。
- `accessed`と`dirty`フラグは、ページへの読み込みか書き込みが行われたときにCPUによって自動的に1にセットされます。この情報はオペレーティングシステムによって活用でき、例えば、どのページをスワップするかや、ページの中身が最後にディスクに保存されて以降に修正されたかを確認できます。
- `write through caching`と`disable cache`フラグで、キャッシュの制御をページごとに独立して行うことができます。
- `user accessible`フラグはページをユーザー空間のコードが利用できるようにします。このフラグが1になっていない場合、CPUがカーネルモードのときにのみアクセスできます。この機能は、ユーザ空間のプログラムが実行している間もカーネル(の使用しているメモリ)を対応付けたままにしておくことで、[システムコール][system calls]を高速化するために使うことができます。しかし、[Spectre]脆弱性を使うと、この機能があるにもかかわらず、ユーザ空間プログラムがこれらのページを読むことができてしまいます。
- `global`フラグは、このページはすべてのアドレス空間で利用可能であり、よってアドレス空間の変更時に変換キャッシュ(TLBに関する下のセクションを読んでください)から取り除く必要がないことをハードウェアに伝えます。このフラグはカーネルコードをすべてのアドレス空間に対応付けるため、一般的に`user accsessible`フラグと一緒に使われます。
- `huge page`フラグを使うと、レベル2か3のページが対応付けられたフレームを直接指すようにすることで、より大きいサイズのページを作ることができます。このビットが1のとき、ページの大きさは512倍になるので、レベル2のエントリの場合は2MiB = 512 * 4KiBに、レベル3のエントリの場合は1GiB = 512 * 2MiBにもなります。大きいページを使うことのメリットは、必要な変換キャッシュのラインの数やページテーブルの数が少なくなることです。
[system calls]: https://en.wikipedia.org/wiki/System_call
[Spectre]: https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
`x86_64`クレートが[ページテーブル][page tables]とその[エントリ][entries]のための型を提供してくれているので、これらの構造体を私達自身で作る必要はありません。
[page tables]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTable.html
[entries]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTableEntry.html
### トランスレーション・ルックアサイド・バッファ
4層ページテーブルを使うと、仮想アドレスを変換するたびに4回メモリアクセスを行わないといけないので、変換のコストは大きくなります。性能改善のために、x86_64アーキテクチャは、直前数回の変換内容を **トランスレーション・ルックアサイド・バッファ (translation lookaside buffer, TLB)** と呼ばれるところにキャッシュします。これにより、前の変換がまだキャッシュされているなら、変換をスキップできます。
他のCPUキャッシュと異なり、TLBは完全に透明ではなく、ページテーブルの内容が変わったときに変換内容を更新したり取り除いたりしてくれません(訳注:キャッシュが透明であるとは、利用者がキャッシュの存在を意識する必要がないという意味)。つまり、カーネルがページテーブルを変更したときは、カーネル自らTLBを更新しないといけないということです。これを行うために、[`invlpg`]("invalidate page"、ページを無効化の意)という特別なCPU命令があります。これは指定されたページの変換をTLBから取り除き、次のアクセスの際に再び読み込まれるようにします。また、TLBは`CR3`レジスタを再設定することでもflushできます。`CR3`レジスタの再設定は、アドレス空間が変更されたという状況を模擬するのです。`x86_64`クレートの[`tlb`モジュール][`tlb` module]が、両方のやり方のRust関数を提供しています。
**訳注:** flushは「(溜まった水を)どっと流す」「(トイレなどを)水で洗い流す」という意味の言葉です。そのためコンピュータサイエンスにおいて「キャッシュなどに溜められていたデータを(場合によっては適切な出力先に書き込みながら)削除する」という意味を持つようになりました。ここではどこかに出力しているわけではないので、「初期化」と同じような意味と考えて差し支えないでしょう。
[`invlpg`]: https://www.felixcloutier.com/x86/INVLPG.html
[`tlb` module]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tlb/index.html
ページテーブルを修正したときは毎回TLBをflushしないといけないということはしっかりと覚えておいてください。これを行わないと、CPUは古い変換を使いつづけるかもしれず、これはデバッグの非常に難しい、予測不能なバグに繋がるかもしれないためです。
## 実装
ひとつ言っていなかったことがあります:**わたしたちのカーネルはすでにページングを使っています**。[Rustでつくる最小のカーネル]["A minimal Rust Kernel"]の記事で追加したブートローダは、すでに私たちのカーネルのすべてのページを物理フレームに対応付けるような4層ページ階層構造を設定しているのです。ブートローダがこれを行う理由は、x86_64の64ビットモードにおいてページングは必須となっているからです。
["A minimal Rust kernel"]: @/edition-2/posts/02-minimal-rust-kernel/index.ja.md#butoimeziwozuo-ru
つまり、私達がカーネルにおいて使ってきたすべてのメモリアドレスは、仮想アドレスだったということです。アドレス`0xb8000`にあるVGAバッファへのアクセスが上手くいっていたのは、ひとえにブートローダがこのメモリページを **恒等対応** させていた、つまり、仮想ページ`0xb8000`を物理フレーム`0xb8000`に対応させていたからです。
ページングにより、境界外メモリアクセスをしてもおかしな物理メモリに書き込むのではなくページフォルト例外を起こすようになっているため、私達のカーネルはすでに比較的安全になっていました。ブートローダはそれぞれのページに正しい権限を設定することさえしてくれるので、コードを含むページだけが実行可能であり、データを含むページだけが書き込み可能になっています。
### ページフォルト
カーネルの外のメモリにアクセスすることによって、ページフォルトを引き起こしてみましょう。まず、通常の[ダブルフォルト][double fault]ではなくページフォルト例外が得られるように、ページフォルト処理関数を作ってIDTに追加しましょう:
[double fault]: @/edition-2/posts/06-double-faults/index.ja.md
```rust
// in src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
[…]
idt.page_fault.set_handler_fn(page_fault_handler); // ここを追加
idt
};
}
use x86_64::structures::idt::PageFaultErrorCode;
use crate::hlt_loop;
extern "x86-interrupt" fn page_fault_handler(
stack_frame: InterruptStackFrame,
error_code: PageFaultErrorCode,
) {
use x86_64::registers::control::Cr2;
println!("EXCEPTION: PAGE FAULT");
println!("Accessed Address: {:?}", Cr2::read());
println!("Error Code: {:?}", error_code);
println!("{:#?}", stack_frame);
hlt_loop();
}
```
[`CR2`]レジスタは、ページフォルト時にCPUによって自動的に設定されており、その値はアクセスされページフォルトを引き起こした仮想アドレスになっています。`x86_64`クレートの[`Cr2::read`]関数を使ってこれを読み込み出力します。[`PageFaultErrorCode`]型は、ページフォルトを引き起こしたメモリアクセスの種類についてより詳しい情報を提供します(例えば、読み込みと書き込みのどちらによるものなのか、など)。そのため、これも出力します。ページフォルトを解決しない限り実行を継続することはできないので、最後は[`hlt_loop`]に入ります。
[`CR2`]: https://en.wikipedia.org/wiki/Control_register#CR2
[`Cr2::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr2.html#method.read
[`PageFaultErrorCode`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html
[LLVM bug]: https://github.com/rust-lang/rust/issues/57270
[`hlt_loop`]: @/edition-2/posts/07-hardware-interrupts/index.md#the-hlt-instruction
それではカーネル外のメモリにアクセスしてみましょう:
```rust
// in src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// ここを追加
let ptr = 0xdeadbeaf as *mut u8;
unsafe { *ptr = 42; }
// ここはこれまでと同じ
#[cfg(test)]
test_main();
println!("It did not crash!");
blog_os::hlt_loop();
}
```
これを実行すると、ページフォルトハンドラが呼びだされたのを見ることができます:
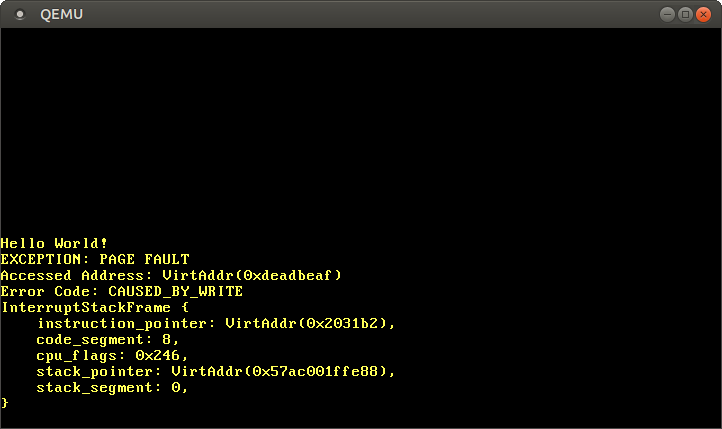
`CR2`レジスタは確かに私達がアクセスしようとしていたアドレスである`0xdeadbeaf`を格納しています。エラーコードが[`CAUSED_BY_WRITE`]なので、この障害はwrite操作の実行中に発生したのだと分かります。更に、[1にセットされていないビット][`PageFaultErrorCode`]からも情報を得ることができます。例えば、`PROTECTION_VIOLATION`フラグが1にセットされていないことから、ページフォルトは対象のページが存在しなかったために発生したのだと分かります。
[`CAUSED_BY_WRITE`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.CAUSED_BY_WRITE
ページフォルトを起こした時点での命令ポインタは`0x2031b2`であるので、このアドレスはコードページを指しているとわかります。コードページはブートローダによって読み込み専用に指定されているので、このアドレスからの読み込みは大丈夫ですが、このページへの書き込みはページフォルトを起こします。`0xdeadbeaf`へのポインタを`0x2031b2`に変更して、これを試してみましょう。
```rust
// 注意:実際のアドレスは個々人で違うかもしれません。
// あなたのページフォルトハンドラが報告した値を使ってください。
let ptr = 0x2031b2 as *mut u8;
// コードページから読み込む
unsafe { let x = *ptr; }
println!("read worked");
// コードページへと書き込む
unsafe { *ptr = 42; }
println!("write worked");
```
最後の2行をコメントアウトすると、読み込みアクセスだけになるので実行は成功しますが、そうしなかった場合ページフォルトが発生します:
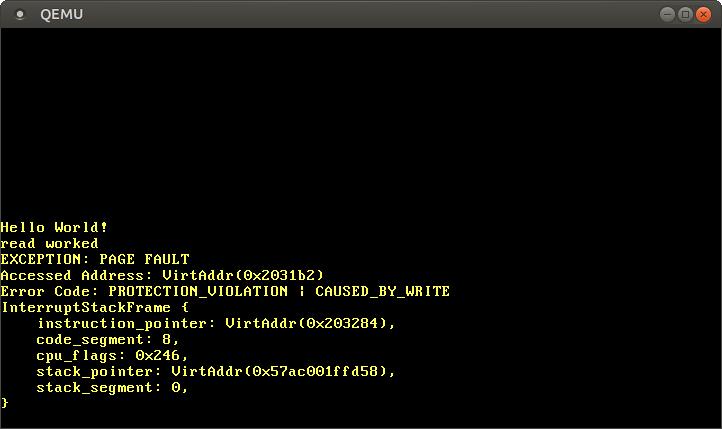
"read worked"というメッセージが表示されますが、これは読み込み操作が何のエラーも発生させなかったことを示しています。しかし、"write worked"のメッセージではなく、ページフォルトが発生してしまいました。今回は[`CAUSED_BY_WRITE`]フラグに加えて[`PROTECTION_VIOLATION`]フラグがセットされています。これは、ページは存在していたものの、それに対する今回の操作が許可されていなかったということを示します。今回の場合、ページへの書き込みは、コードページが読み込み専用に指定されているため許可されていませんでした。
[`PROTECTION_VIOLATION`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.PROTECTION_VIOLATION
### ページテーブルへのアクセス
私達のカーネルがどのように(物理メモリに)対応づけられているのかを定義しているページテーブルを見てみましょう。
```rust
// in src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
use x86_64::registers::control::Cr3;
let (level_4_page_table, _) = Cr3::read();
println!("Level 4 page table at: {:?}", level_4_page_table.start_address());
[…] // test_main(), println(…), hlt_loop() などが続く
}
```
`x86_64`クレートの[`Cr3::read`]関数は、現在有効なレベル4ページテーブルを`CR3`レジスタから読みとって返します。この関数は[`PhysFrame`]型と[`Cr3Flags`]型のタプルを返します。私達はフレームにしか興味がないので、タプルの2つ目の要素は無視しました。
[`Cr3::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr3.html#method.read
[`PhysFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/frame/struct.PhysFrame.html
[`Cr3Flags`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr3Flags.html
これを実行すると、以下の出力を得ます:
```
Level 4 page table at: PhysAddr(0x1000)
```
というわけで、現在有効なレベル4ページテーブルは、[`PhysAddr`]ラッパ型が示すように、 **物理** メモリのアドレス`0x1000`に格納されています。ここで疑問が生まれます:このテーブルに私達のカーネルからアクセスするにはどうすればいいのでしょう?
[`PhysAddr`]: https://docs.rs/x86_64/0.14.2/x86_64/addr/struct.PhysAddr.html
ページングが有効なとき、物理メモリに直接アクセスすることはできません。もしそれができたとしたら、プログラムは容易くメモリ保護を回避して他のプログラムのメモリにアクセスできてしまうだろうからです。ですので、テーブルにアクセスする唯一の方法は、アドレス`0x1000`の物理フレームに対応づけられているような仮想ページにアクセスすることです。ページテーブルの存在するフレームへの対応づけは(実用上も必要になる)一般的な問題です。なぜなら、例えば新しいスレッドのためにスタックを割り当てるときなど、カーネルは日常的にページテーブルにアクセスする必要があるためです。
この問題への解決策は次の記事で詳細に論じます。
## まとめ
この記事では2つのメモリ保護技術を紹介しました:セグメンテーションとページングです。前者は可変サイズのメモリ領域を使用するため外部断片化の問題が存在するのに対し、後者は固定サイズのページを使用するためアクセス権限に関して遥かに細やかな制御が可能となっていました。
ページングは、(仮想メモリと物理メモリの)対応情報を1層以上のページテーブルに格納します。x86_64アーキテクチャにおいては4層ページテーブルが使用され、ページサイズは4KiBです。ハードウェアは自動的にページテーブルを辿り、変換の結果をトランスレーション・ルックアサイド・バッファ (TLB) にキャッシュします。このバッファは自動的に更新されない(「透明ではない」)ので、ページテーブルの変更時には明示的にflushする必要があります。
私達のカーネルは既にページングによって動いており、不正なメモリアクセスはページフォルト例外を発生させるということを学びました。現在有効なページテーブルへとアクセスしたかったのですが、CR3レジスタに格納されている物理アドレスはカーネルから直接アクセスできないものであるため、それはできませんでした。
## 次は?
次の記事では、私達のカーネルをページングに対応させる方法について説明します。私達のカーネルから物理メモリにアクセスする幾つかの方法を示すので、これらを用いれば私達のカーネルが動作しているページテーブルにアクセスできます。そうすると、仮想アドレスを物理アドレスに変換する関数を実装でき、ページテーブルに新しい対応づけを作れるようになります。