Rename second-edition subfolder to `edition-2
@@ -1,4 +0,0 @@
|
||||
+++
|
||||
title = "Second Edition"
|
||||
template = "redirect-to-frontpage.html"
|
||||
+++
|
||||
@@ -1,7 +0,0 @@
|
||||
+++
|
||||
title = "Extra Content"
|
||||
insert_anchor_links = "left"
|
||||
render = false
|
||||
sort_by = "weight"
|
||||
page_template = "second-edition/extra.html"
|
||||
+++
|
||||
{kind=link}
|
Before Width: | Height: | Size: 287 KiB |
@@ -1,109 +0,0 @@
|
||||
+++
|
||||
title = "Building on Android"
|
||||
weight = 3
|
||||
|
||||
+++
|
||||
|
||||
I finally managed to get `blog_os` building on my Android phone using [termux](https://termux.com/). This post explains the necessary steps to set it up.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
<img src="building-on-android.png" alt="Screenshot of the compilation output from android" style="height: 50rem;" >
|
||||
|
||||
|
||||
### Install Termux and Nightly Rust
|
||||
|
||||
First, install [termux](https://termux.com/) from the [Google Play Store](https://play.google.com/store/apps/details?id=com.termux) or from [F-Droid](https://f-droid.org/packages/com.termux/). After installing, open it and perform the following steps:
|
||||
|
||||
- Install fish shell, set as default shell, and launch it:
|
||||
```
|
||||
pkg install fish
|
||||
chsh -s fish
|
||||
fish
|
||||
```
|
||||
|
||||
This step is of course optional. However, if you continue with bash you will need to adjust some of the following commands to bash syntax.
|
||||
|
||||
- Install some basic tools:
|
||||
```
|
||||
pkg install wget tar
|
||||
```
|
||||
|
||||
- Add the [community repository by its-pointless](https://wiki.termux.com/wiki/Package_Management#By_its-pointless):
|
||||
```
|
||||
wget https://its-pointless.github.io/setup-pointless-repo.sh
|
||||
bash setup-pointless-repo.sh
|
||||
```
|
||||
|
||||
- Install cargo and a nightly version of rustc:
|
||||
```
|
||||
pkg install rustc cargo rustc-nightly
|
||||
```
|
||||
|
||||
- Prepend the nightly rustc path to your `PATH` in order to use nightly (fish syntax):
|
||||
```
|
||||
set -U fish_user_paths $PREFIX/opt/rust-nightly/bin/ $fish_user_paths
|
||||
```
|
||||
|
||||
Now `rustc --version` should work and output a nightly version number.
|
||||
|
||||
### Install Git and Clone blog_os
|
||||
|
||||
We need something to compile, so let's download the `blog_os` repository:
|
||||
|
||||
- Install git:
|
||||
```
|
||||
pkg install git
|
||||
```
|
||||
|
||||
- Clone the `blog_os` repository:
|
||||
```
|
||||
git clone https://github.com/phil-opp/blog_os.git
|
||||
```
|
||||
|
||||
If you want to clone/push via SSH, you need to install the `openssh` package: `pkg install openssh`.
|
||||
|
||||
### Install Xbuild and Bootimage
|
||||
|
||||
Now we're ready to install `cargo xbuild` and `bootimage`
|
||||
|
||||
- Run `cargo install`:
|
||||
```
|
||||
cargo install cargo-xbuild bootimage
|
||||
```
|
||||
|
||||
- Add the cargo bin directory to your `PATH` (fish syntax):
|
||||
```
|
||||
set -U fish_user_paths ~/.cargo/bin/ $fish_user_paths
|
||||
```
|
||||
|
||||
Now `cargo xbuild` and `bootimage` should be available. It does not work yet because `cargo xbuild` needs access to the rust source code. By default it tries to use rustup for this, but we have no rustup support so we need a different way.
|
||||
|
||||
### Providing the Rust Source Code
|
||||
|
||||
The Rust source code corresponding to our installed nightly is available in the [`its-pointless` repository](https://github.com/its-pointless/its-pointless.github.io):
|
||||
|
||||
- Download a tar containing the source code:
|
||||
```
|
||||
wget https://github.com/its-pointless/its-pointless.github.io/raw/master/rust-src-nightly.tar.xz
|
||||
```
|
||||
|
||||
- Extract it:
|
||||
```
|
||||
tar xf rust-src-nightly.tar.xz
|
||||
```
|
||||
|
||||
- Set the `XARGO_RUST_SRC` environment variable to tell cargo-xbuild the source path (fish syntax):
|
||||
```
|
||||
set -Ux XARGO_RUST_SRC ~/rust-src-nightly/rust-src/lib/rustlib/src/rust/src
|
||||
```
|
||||
|
||||
Now cargo-xbuild should no longer complain about a missing `rust-src` component. However it will throw an I/O error after building the sysroot. The problem is that the downloaded Rust source code has a different structure than the source provided by rustup. We can fix this by adding a symbolic link:
|
||||
|
||||
```
|
||||
ln -s ~/../usr/opt/rust-nightly/bin ~/../usr/opt/rust-nightly/lib/rustlib/aarch64-linux-android/bin
|
||||
```
|
||||
|
||||
Now `cargo xbuild --target x86_64-blog_os.json` and `bootimage build` should both work!
|
||||
|
||||
I couldn't get QEMU to run yet, so you won't be able to run your kernel. If you manage to get it working, please tell me :).
|
||||
@@ -1,526 +0,0 @@
|
||||
+++
|
||||
title = " یک باینری مستقل Rust"
|
||||
weight = 1
|
||||
path = "fa/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "80136cc0474ae8d2da04f391b5281cfcda068c1a"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["hamidrezakp", "MHBahrampour"]
|
||||
rtl = true
|
||||
+++
|
||||
|
||||
اولین قدم برای نوشتن سیستمعامل، ساخت یک باینری راست (کلمه: Rust) هست که به کتابخانه استاندارد نیازمند نباشد. این باعث میشود تا بتوانیم کد راست را بدون سیستمعامل زیرین، بر روی سخت افزار [bare metal] اجرا کنیم.
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
این بلاگ بصورت آزاد بر روی [گیتهاب] توسعه داده شده. اگر مشکل یا سوالی دارید، لطفاً آنجا یک ایشو باز کنید. همچنین میتوانید [در زیر] این پست کامنت بگذارید. سورس کد کامل این پست را میتوانید در بِرَنچ [`post-01`][post branch] پیدا کنید.
|
||||
|
||||
[گیتهاب]: https://github.com/phil-opp/blog_os
|
||||
[در زیر]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## مقدمه
|
||||
برای نوشتن هسته سیستمعامل، ما به کدی نیاز داریم که به هیچ یک از ویژگیهای سیستمعامل نیازی نداشته باشد. یعنی نمیتوانیم از نخها (ترجمه: Threads)، فایلها، حافظه هیپ (کلمه: Heap)، شبکه، اعداد تصادفی، ورودی استاندارد، یا هر ویژگی دیگری که نیاز به انتزاعات سیستمعامل یا سختافزار خاصی داشته، استفاده کنیم. منطقی هم به نظر میرسد، چون ما سعی داریم سیستمعامل و درایورهای خودمان را بنویسیم.
|
||||
|
||||
نداشتن انتزاعات سیستمعامل به این معنی هست که نمیتوانیم از بخش زیادی از [کتابخانه استاندارد راست] استفاده کنیم، اما هنوز بسیاری از ویژگیهای راست هستند که میتوانیم از آنها استفاده کنیم. به عنوان مثال، میتوانیم از [iterator] ها، [closure] ها، [pattern matching]، [option]، [result]، [string formatting] و البته [سیستم ownership] استفاده کنیم. این ویژگیها به ما امکان نوشتن هسته به طور رسا، سطح بالا و بدون نگرانی درباره [رفتار تعریف نشده] و [امنیت حافظه] را میدهند.
|
||||
|
||||
[option]: https://doc.rust-lang.org/core/option/
|
||||
[result]:https://doc.rust-lang.org/core/result/
|
||||
[کتابخانه استاندارد راست]: https://doc.rust-lang.org/std/
|
||||
[iterators]: https://doc.rust-lang.org/book/ch13-02-iterators.html
|
||||
[closures]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
[pattern matching]: https://doc.rust-lang.org/book/ch06-00-enums.html
|
||||
[string formatting]: https://doc.rust-lang.org/core/macro.write.html
|
||||
[سیستم ownership]: https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html
|
||||
[رفتار تعریف نشده]: https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs
|
||||
[امنیت حافظه]: https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention
|
||||
|
||||
برای ساختن یک هسته سیستمعامل به زبان راست، باید فایل اجراییای بسازیم که بتواند بدون سیستمعامل زیرین اجرا بشود. چنین فایل اجرایی، فایل اجرایی مستقل (ترجمه: freestanding) یا فایل اجرایی “bare-metal” نامیده میشود.
|
||||
|
||||
این پست قدمهای لازم برای ساخت یک باینری مستقل راست و اینکه چرا این قدمها نیاز هستند را توضیح میدهد. اگر علاقهایی به خواندن کل توضیحات ندارید، میتوانید **[به قسمت خلاصه مراجعه کنید](#summary)**.
|
||||
|
||||
## غیر فعال کردن کتابخانه استاندارد
|
||||
به طور پیشفرض تمام کِرِیتهای راست، از [کتابخانه استاندارد] استفاده میکنند(لینک به آن دارند)، که به سیستمعامل برای قابلیتهایی مثل نخها، فایلها یا شبکه وابستگی دارد. همچنین به کتابخانه استاندارد زبان سی، `libc` هم وابسطه هست که با سرویسهای سیستمعامل تعامل نزدیکی دارند. از آنجا که قصد داریم یک سیستمعامل بنویسیم، نمیتوانیم از هیچ کتابخانهایی که به سیستمعامل نیاز داشته باشد استفاده کنیم. بنابراین باید اضافه شدن خودکار کتابخانه استاندارد را از طریق [خاصیت `no_std`] غیر فعال کنیم.
|
||||
|
||||
[کتابخانه استاندارد]: https://doc.rust-lang.org/std/
|
||||
[خاصیت `no_std`]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
|
||||
|
||||
|
||||
با ساخت یک اپلیکیشن جدید کارگو شروع میکنیم. سادهترین راه برای انجام این کار از طریق خط فرمان است:
|
||||
|
||||
```
|
||||
cargo new blog_os --bin --edition 2018
|
||||
```
|
||||
|
||||
نام پروژه را `blog_os` گذاشتم، اما شما میتوانید نام دلخواه خود را انتخاب کنید. پرچمِ (ترجمه: Flag) `bin--` مشخص میکند که ما میخواهیم یک فایل اجرایی ایجاد کنیم (به جای یک کتابخانه) و پرچمِ `edition 2018--` مشخص میکند که میخواهیم از [ویرایش 2018] زبان راست برای کریت خود استفاده کنیم. وقتی دستور را اجرا میکنیم، کارگو ساختار پوشههای زیر را برای ما ایجاد میکند:
|
||||
|
||||
[ویرایش 2018]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
|
||||
|
||||
```
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
فایل `Cargo.toml` شامل تنظیمات کریت میباشد، به عنوان مثال نام کریت، نام نویسنده، شماره [نسخه سمنتیک] و وابستگیها. فایل `src/main.rs` شامل ماژول ریشه برای کریت ما و تابع `main` است. میتوانید کریت خود را با دستور `cargo build` کامپایل کنید و سپس باینری کامپایل شده `blog_os` را در زیرپوشه `target/debug` اجرا کنید.
|
||||
|
||||
[نسخه سمنتیک]: https://semver.org/
|
||||
|
||||
### خاصیت `no_std`
|
||||
|
||||
در حال حاظر کریت ما بطور ضمنی به کتابخانه استاندارد لینک دارد. بیایید تا سعی کنیم آن را با اضافه کردن [خاصیت `no_std`] غیر فعال کنیم:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
حالا وقتی سعی میکنیم تا بیلد کنیم (با اجرای دستور `cargo build`)، خطای زیر رخ میدهد:
|
||||
|
||||
```
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src/main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
دلیل این خطا این هست که [ماکروی `println`]\(ترجمه: macro) جزوی از کتابخانه استاندارد است، که ما دیگر آن را نداریم. بنابراین نمیتوانیم چیزی را چاپ کنیم. منطقی هست زیرا `println` در [خروجی استاندارد] مینویسد، که یک توصیف کننده فایل (ترجمه: File Descriptor) خاص است که توسط سیستمعامل ارائه میشود.
|
||||
|
||||
[ماکروی `println`]: https://doc.rust-lang.org/std/macro.println.html
|
||||
[خروجی استاندارد]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
|
||||
پس بیایید قسمت مروبط به چاپ را پاک کرده و این بار با یک تابع main خالی امتحان کنیم:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
حالا کامپایلر با کمبود یک تابع `#[panic_handler]` و یک _language item_ روبرو است.
|
||||
|
||||
## پیادهسازی پنیک (کلمه: Panic)
|
||||
|
||||
خاصیت `panic_handler` تابعی را تعریف میکند که کامپایلر باید در هنگام رخ دادن یک [پنیک] اجرا کند. کتابخانه استاندارد تابع مدیریت پنیک خود را ارائه میدهد، اما در یک محیط `no_std` ما باید خودمان آن را تعریف کنیم.
|
||||
|
||||
[پنیک]: https://doc.rust-lang.org/stable/book/ch09-01-unrecoverable-errors-with-panic.html
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
[پارامتر `PanicInfo`][PanicInfo] شامل فایل و شماره خطی که پنیک رخ داده و پیام پنیکِ اختیاری میباشد. تابع هیچ وقت نباید چیزی را برگرداند به همین دلیل به عنوان یک [تابع واگرا]\(ترجمه: diverging function) بوسیله نوع برگشتی `!` [نوع ”هرگز“] علامتگذاری شده است. فعلا کار زیادی نیست که بتوانیم در این تابع انجام دهیم، بنابراین فقط یک حلقه بینهایت مینویسیم.
|
||||
|
||||
[PanicInfo]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
|
||||
[تابع واگرا]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
|
||||
[نوع ”هرگز“]: https://doc.rust-lang.org/nightly/std/primitive.never.html
|
||||
|
||||
## آیتم زبان `eh_personality`
|
||||
|
||||
آیتمهای زبان، توابع و انواع خاصی هستند که برای استفاده درون کامپایلر ضروریاند. به عنوان مثال، تِرِیت [`Copy`]\(کلمه: Trait) یک آیتم زبان است که به کامپایلر میگوید کدام انواع دارای [_مفهوم کپی_][`Copy`] هستند. وقتی به [پیادهسازی][copy code] آن نگاه میکنیم، میبینیم که یک خاصیت ویژه `#[lang = "copy"]` دارد که آن را به عنوان یک آیتم زبان تعریف میکند.
|
||||
|
||||
[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
|
||||
[copy code]: https://github.com/rust-lang/rust/blob/485397e49a02a3b7ff77c17e4a3f16c653925cb3/src/libcore/marker.rs#L296-L299
|
||||
|
||||
درحالی که میتوان پیادهسازی خاص برای آیتمهای زبان فراهم کرد، فقط باید به عنوان آخرین راه حل از آن استفاده کرد. زیرا آیتمهای زبان بسیار در جزئیات پیادهسازی ناپایدار هستند و حتی انواع آنها نیز چک نمیشود (بنابراین کامپایلر حتی چک نمیکند که آرگومان تابع نوع درست را دارد). خوشبختانه یک راه پایدارتر برای حل مشکل آیتم زبان بالا وجود دارد.
|
||||
|
||||
[آیتم زبان `eh_personality`] یک تابع را به عنوان تابعی که برای پیادهسازی [بازکردن پشته (Stack Unwinding)] استفاده شده، علامتگذاری میکند. راست بطور پیشفرض از _بازکردن_ (ترجمه: unwinding) برای اجرای نابودگرهای (ترجمه: Destructors) تمام متغیرهای زنده درون استک در مواقع [پنیک] استفاده میکند. این تضمین میکند که تمام حافظه استفاده شده آزاد میشود و به نخ اصلی اجازه میدهد پنیک را دریافت کرده و اجرا را ادامه دهد. باز کردن، یک فرآیند پیچیده است و به برخی از کتابخانههای خاص سیستمعامل (به عنوان مثال [libunwind] در لینوکس یا [مدیریت اکسپشن ساخت یافته] در ویندوز) نیاز دارد، بنابراین ما نمیخواهیم از آن برای سیستمعامل خود استفاده کنیم.
|
||||
|
||||
[آیتم زبان `eh_personality`]: https://github.com/rust-lang/rust/blob/edb368491551a77d77a48446d4ee88b35490c565/src/libpanic_unwind/gcc.rs#L11-L45
|
||||
[بازکردن پشته (Stack Unwinding)]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
[libunwind]: https://www.nongnu.org/libunwind/
|
||||
[مدیریت اکسپشن ساخت یافته]: https://docs.microsoft.com/de-de/windows/win32/debug/structured-exception-handling
|
||||
|
||||
### غیرفعال کردن Unwinding
|
||||
|
||||
موارد استفاده دیگری نیز وجود دارد که باز کردن نامطلوب است، بنابراین راست به جای آن گزینه [قطع در پنیک] را فراهم میکند. این امر تولید اطلاعات نمادها (ترجمه: Symbol) را از بین میبرد و بنابراین اندازه باینری را بطور قابل توجهی کاهش میدهد. چندین مکان وجود دارد که می توانیم باز کردن را غیرفعال کنیم. سادهترین راه این است که خطوط زیر را به `Cargo.toml` اضافه کنید:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
این استراتژی پنیک را برای دو پروفایل `dev` (در `cargo build` استفاده میشود) و پروفایل `release` (در ` cargo build --release` استفاده میشود) تنظیم میکند. اکنون آیتم زبان `eh_personality` نباید دیگر لازم باشد.
|
||||
|
||||
[قطع در پنیک]: https://github.com/rust-lang/rust/pull/32900
|
||||
|
||||
اکنون هر دو خطای فوق را برطرف کردیم. با این حال، اگر اکنون بخواهیم آن را کامپایل کنیم، خطای دیگری رخ میدهد:
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
برنامه ما آیتم زبان `start` که نقطه ورود را مشخص میکند، را ندارد.
|
||||
|
||||
## خاصیت `start`
|
||||
|
||||
ممکن است تصور شود که تابع `main` اولین تابعی است که هنگام اجرای یک برنامه فراخوانی میشود. با این حال، بیشتر زبانها دارای [سیستم رانتایم] هستند که مسئول مواردی مانند جمع آوری زباله (به عنوان مثال در جاوا) یا نخهای نرمافزار (به عنوان مثال goroutines در Go) است. این رانتایم باید قبل از `main` فراخوانی شود، زیرا باید خود را مقداردهی اولیه و آماده کند.
|
||||
|
||||
[سیستم رانتایم]: https://en.wikipedia.org/wiki/Runtime_system
|
||||
|
||||
در یک باینری معمولی راست که از کتابخانه استاندارد استفاده میکند، اجرا در یک کتابخانه رانتایم C به نام `crt0` ("زمان اجرا صفر C") شروع میشود، که محیط را برای یک برنامه C تنظیم میکند. این شامل ایجاد یک پشته و قرار دادن آرگومانها در رجیسترهای مناسب است. سپس رانتایم C [ورودی رانتایم راست][rt::lang_start] را فراخوانی میکند، که با آیتم زبان `start` مشخص شده است. راست فقط یک رانتایم بسیار کوچک دارد، که مواظب برخی از کارهای کوچک مانند راهاندازی محافظهای سرریز پشته یا چاپ backtrace با پنیک میباشد. رانتایم در نهایت تابع `main` را فراخوانی میکند.
|
||||
|
||||
[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
|
||||
|
||||
برنامه اجرایی مستقل ما به رانتایم و `crt0` دسترسی ندارد، بنابراین باید نقطه ورود را مشخص کنیم. پیادهسازی آیتم زبان `start` کمکی نخواهد کرد، زیرا همچنان به `crt0` نیاز دارد. در عوض، باید نقطه ورود `crt0` را مستقیماً بازنویسی کنیم.
|
||||
|
||||
### بازنویسی نقطه ورود
|
||||
|
||||
برای اینکه به کامپایلر راست بگوییم که نمیخواهیم از زنجیره نقطه ورودی عادی استفاده کنیم، ویژگی `#![no_main]` را اضافه میکنیم.
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
ممکن است متوجه شده باشید که ما تابع `main` را حذف کردیم. دلیل این امر این است که `main` بدون یک رانتایم اساسی که آن را صدا کند معنی ندارد. در عوض، ما در حال بازنویسی نقطه ورود سیستمعامل با تابع `start_` خود هستیم:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
با استفاده از ویژگی `[no_mangle]#` ما [name mangling] را غیرفعال می کنیم تا اطمینان حاصل کنیم که کامپایلر راست تابعی با نام `start_` را خروجی میدهد. بدون این ویژگی، کامپایلر برخی از نمادهای رمزنگاری شده `ZN3blog_os4_start7hb173fedf945531caE_` را تولید میکند تا به هر تابع یک نام منحصر به فرد بدهد. این ویژگی لازم است زیرا در مرحله بعدی باید نام تایع نقطه ورود را به لینکر (کلمه: linker) بگوییم.
|
||||
|
||||
ما همچنین باید تابع را به عنوان `"extern "C` علامتگذاری کنیم تا به کامپایلر بگوییم که باید از [قرارداد فراخوانی C] برای این تابع استفاده کند (به جای قرارداد مشخص نشده فراخوانی راست). دلیل نامگذاری تابع `start_` این است که این نام نقطه پیشفرض ورودی برای اکثر سیستمها است.
|
||||
|
||||
[name mangling]: https://en.wikipedia.org/wiki/Name_mangling
|
||||
[قرارداد فراخوانی C]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
|
||||
نوع بازگشت `!` به این معنی است که تایع واگرا است، یعنی اجازه بازگشت ندارد. این مورد لازم است زیرا نقطه ورود توسط هیچ تابعی فراخوانی نمیشود، بلکه مستقیماً توسط سیستمعامل یا بوتلودر فراخوانی میشود. بنابراین به جای بازگشت، نقطه ورود باید به عنوان مثال [فراخوان سیستمی `exit`] از سیستمعامل را فراخوانی کند. در مورد ما، خاموش کردن دستگاه میتواند اقدامی منطقی باشد، زیرا در صورت بازگشت باینری مستقل دیگر کاری برای انجام دادن وجود ندارد. در حال حاضر، ما این نیاز را با حلقههای بیپایان انجام میدهیم.
|
||||
|
||||
[فراخوان سیستمی `exit`]: https://en.wikipedia.org/wiki/Exit_(system_call)
|
||||
|
||||
حالا وقتی `cargo build` را اجرا میکنیم، با یک خطای _لینکر_ زشت مواجه میشویم.
|
||||
|
||||
## خطاهای لینکر (Linker)
|
||||
|
||||
لینکر برنامهای است که کد تولید شده را ترکیب کرده و یک فایل اجرایی میسازد. از آنجا که فرمت اجرایی بین لینوکس، ویندوز و macOS متفاوت است، هر سیستم لینکر خود را دارد که خطای متفاوتی ایجاد میکند. علت اصلی خطاها یکسان است: پیکربندی پیشفرض لینکر فرض میکند که برنامه ما به رانتایم C وابسته است، که این طور نیست.
|
||||
|
||||
برای حل خطاها، باید به لینکر بگوییم که نباید رانتایم C را اضافه کند. ما میتوانیم این کار را با اضافه کردن مجموعهای از آرگمانها به لینکر یا با ساختن یک هدف (ترجمه: Target) bare metal انجام دهیم.
|
||||
|
||||
### بیلد کردن برای یک هدف bare metal
|
||||
|
||||
راست به طور پیشفرض سعی در ایجاد یک اجرایی دارد که بتواند در محیط سیستم فعلی شما اجرا شود. به عنوان مثال، اگر از ویندوز در `x86_64` استفاده میکنید، راست سعی در ایجاد یک `exe.` اجرایی ویندوز دارد که از دستورالعملهای `x86_64` استفاده میکند. به این محیط سیستم "میزبان" شما گفته میشود.
|
||||
|
||||
راست برای توصیف محیطهای مختلف، از رشتهای به نام [_target triple_]\(سهگانه هدف) استفاده میکند. با اجرای `rustc --version --verbose` میتوانید target triple را برای سیستم میزبان خود مشاهده کنید:
|
||||
|
||||
[_target triple_]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
|
||||
```
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
خروجی فوق از یک سیستم لینوکس `x86_64` است. میبینیم که سهگانه میزبان `x86_64-unknown-linux-gnu` است که شامل معماری پردازنده (`x86_64`)، فروشنده (`ناشناخته`)، سیستمعامل (` linux`) و [ABI] (`gnu`) است.
|
||||
|
||||
[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
|
||||
|
||||
با کامپایل کردن برای سهگانه میزبانمان، کامپایلر راست و لینکر فرض میکنند که یک سیستمعامل زیرین مانند Linux یا Windows وجود دارد که به طور پیشفرض از رانتایم C استفاده میکند، که باعث خطاهای لینکر میشود. بنابراین برای جلوگیری از خطاهای لینکر، میتوانیم برای محیطی متفاوت و بدون سیستمعامل زیرین کامپایل کنیم.
|
||||
|
||||
یک مثال برای چنین محیطِ bare metal ی، سهگانه هدف `thumbv7em-none-eabihf` است، که یک سیستم [تعبیه شده][ARM] را توصیف میکند. جزئیات مهم نیستند، مهم این است که سهگانه هدف فاقد سیستمعامل زیرین باشد، که با `none` در سهگانه هدف نشان داده میشود. برای این که بتوانیم برای این هدف کامپایل کنیم، باید آن را به rustup اضافه کنیم:
|
||||
|
||||
[تعبیه شده]: https://en.wikipedia.org/wiki/Embedded_system
|
||||
[ARM]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||
|
||||
```
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
با این کار نسخهای از کتابخانه استاندارد (و core) برای سیستم بارگیری میشود. اکنون میتوانیم برای این هدف اجرایی مستقل خود را بسازیم:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
با استفاده از یک آرگومان `target--`، ما اجرایی خود را برای یک سیستم هدف bare metal [کراس کامپایل] میکنیم. از آنجا که سیستم هدف فاقد سیستمعامل است، لینکر سعی نمیکند رانتایم C را به آن پیوند دهد و بیلد ما بدون هیچ گونه خطای لینکر با موفقیت انجام میشود.
|
||||
|
||||
[کراس کامپایل]: https://en.wikipedia.org/wiki/Cross_compiler
|
||||
|
||||
این روشی است که ما برای ساخت هسته سیستمعامل خود استفاده خواهیم کرد. به جای `thumbv7em-none-eabihf`، ما از یک [هدف سفارشی] استفاده خواهیم کرد که یک محیط `x86_64` bare metal را توصیف میکند. جزئیات در پست بعدی توضیح داده خواهد شد.
|
||||
|
||||
[هدف سفارشی]: https://doc.rust-lang.org/rustc/targets/custom.html
|
||||
|
||||
### آرگومانهای لینکر
|
||||
|
||||
به جای کامپایل کردن برای یک سیستم bare metal، میتوان خطاهای لینکر را با استفاده از مجموعه خاصی از آرگومانها به لینکر حل کرد. این روشی نیست که ما برای هسته خود استفاده کنیم، بنابراین این بخش اختیاری است و فقط برای کامل بودن ارائه میشود. برای نشان دادن محتوای اختیاری، روی _"آرگومانهای لینکر"_ در زیر کلیک کنید.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>آرگومانهای لینکر</summary>
|
||||
|
||||
در این بخش، ما در مورد خطاهای لینکر که در لینوکس، ویندوز و macOS رخ میدهد بحث میکنیم و نحوه حل آنها را با استفاده از آرگومانهای اضافی به لینکر توضیح میدهیم. توجه داشته باشید که فرمت اجرایی و لینکر بین سیستمعاملها متفاوت است، بنابراین برای هر سیستم مجموعهای متفاوت از آرگومانها مورد نیاز است.
|
||||
|
||||
#### لینوکس
|
||||
|
||||
در لینوکس خطای لینکر زیر رخ میدهد (کوتاه شده):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x12): undefined reference to `__libc_csu_fini'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x19): undefined reference to `__libc_csu_init'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x25): undefined reference to `__libc_start_main'
|
||||
collect2: error: ld returned 1 exit status
|
||||
```
|
||||
|
||||
مشکل این است که لینکر به طور پیشفرض شامل روال راهاندازی رانتایم C است که به آن `start_` نیز گفته میشود. به برخی از نمادهای کتابخانه استاندارد C یعنی `libc` نیاز دارد که به دلیل ویژگی`no_std` آنها را نداریم، بنابراین لینکر نمیتواند این مراجع را پیدا کند. برای حل این مسئله، با استفاده از پرچم `nostartfiles-` میتوانیم به لینکر بگوییم که نباید روال راهاندازی C را لینک دهد.
|
||||
|
||||
یکی از راههای عبور صفات لینکر از طریق cargo، دستور `cargo rustc` است. این دستور دقیقاً مانند `cargo build` رفتار میکند، اما اجازه میدهد گزینهها را به `rustc`، کامپایلر اصلی راست انتقال دهید. `rustc` دارای پرچم`C link-arg-` است که آرگومان را به لینکر منتقل میکند. با ترکیب همه اینها، دستور بیلد جدید ما به این شکل است:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
```
|
||||
|
||||
اکنون کریت ما بصورت اجرایی مستقل در لینوکس ساخته میشود!
|
||||
|
||||
لازم نیست که صریحاً نام تابع نقطه ورود را مشخص کنیم، زیرا لینکر به طور پیشفرض به دنبال تابعی با نام `start_` میگردد.
|
||||
|
||||
#### ویندوز
|
||||
|
||||
در ویندوز، یک خطای لینکر متفاوت رخ میدهد (کوتاه شده):
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1561
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1561: entry point must be defined
|
||||
```
|
||||
|
||||
خطای "entry point must be defined" به این معنی است که لینکر نمیتواند نقطه ورود را پیدا کند. در ویندوز، نام پیشفرض نقطه ورود [بستگی به زیر سیستم استفاده شده دارد] [windows-subsystem]. برای زیر سیستم `CONSOLE` لینکر به دنبال تابعی به نام `mainCRTStartup` و برای زیر سیستم `WINDOWS` به دنبال تابعی به نام `WinMainCRTStartup` میگردد. برای بازنویسی این پیشفرض و به لینکر گفتن که در عوض به دنبال تابع `_start` ما باشد ، می توانیم یک آرگومان `ENTRY/` را به لینکر ارسال کنیم:
|
||||
|
||||
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=/ENTRY:_start
|
||||
```
|
||||
|
||||
از متفاوت بودن فرمت آرگومان، به وضوح میفهمیم که لینکر ویندوز یک برنامه کاملاً متفاوت از لینکر Linux است.
|
||||
|
||||
اکنون یک خطای لینکر متفاوت رخ داده است:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1221
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
|
||||
defined
|
||||
```
|
||||
|
||||
این خطا به این دلیل رخ میدهد که برنامههای اجرایی ویندوز میتوانند از [زیر سیستم های][windows-subsystems] مختلف استفاده کنند. برای برنامههای عادی، بسته به نام نقطه ورود استنباط می شوند: اگر نقطه ورود `main` نامگذاری شود، از زیر سیستم `CONSOLE` و اگر نقطه ورود `WinMain` نامگذاری شود، از زیر سیستم `WINDOWS` استفاده میشود. از آنجا که تابع `start_` ما نام دیگری دارد، باید زیر سیستم را صریحاً مشخص کنیم:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
```
|
||||
|
||||
ما در اینجا از زیر سیستم `CONSOLE` استفاده میکنیم، اما زیر سیستم `WINDOWS` نیز کار خواهد کرد. به جای اینکه چند بار از `C link-arg-` استفاده کنیم، از`C link-args-` استفاده میکنیم که لیستی از آرگومانها به صورت جدا شده با فاصله را دریافت میکند.
|
||||
|
||||
با استفاده از این دستور، اجرایی ما باید با موفقیت بر روی ویندوز ساخته شود.
|
||||
|
||||
#### macOS
|
||||
|
||||
در macOS، خطای لینکر زیر رخ میدهد (کوتاه شده):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: entry point (_main) undefined. for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
این پیام خطا به ما میگوید که لینکر نمیتواند یک تابع نقطه ورود را با نام پیشفرض `main` پیدا کند (به دلایلی همه توابع در macOS دارای پیشوند `_` هستند). برای تنظیم نقطه ورود به تابع `start_` ، آرگومان لینکر `e-` را استفاده میکنیم:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start"
|
||||
```
|
||||
|
||||
پرچم `e-` نام تابع نقطه ورود را مشخص میکند. از آنجا که همه توابع در macOS دارای یک پیشوند اضافی `_` هستند، ما باید به جای `start_` نقطه ورود را روی `start__` تنظیم کنیم.
|
||||
|
||||
اکنون خطای لینکر زیر رخ میدهد:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: dynamic main executables must link with libSystem.dylib
|
||||
for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
سیستمعامل مک [رسماً باینریهایی را که بطور استاتیک با هم پیوند دارند پشتیبانی نمیکند] و بطور پیشفرض به برنامههایی برای پیوند دادن کتابخانه `libSystem` نیاز دارد. برای تغییر این حالت و پیوند دادن یک باینری استاتیک، پرچم `static-` را به لینکر ارسال میکنیم:
|
||||
|
||||
[باینریهایی را که بطور استاتیک با هم پیوند دارند پشتیبانی نمیکند]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static"
|
||||
```
|
||||
|
||||
این نیز کافی نیست، سومین خطای لینکر رخ میدهد:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: library not found for -lcrt0.o
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
این خطا رخ میدهد زیرا برنامه های موجود در macOS به طور پیشفرض به `crt0` ("رانتایم صفر C") پیوند دارند. این همان خطایی است که در لینوکس داشتیم و با افزودن آرگومان لینکر `nostartfiles-` نیز قابل حل است:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
اکنون برنامه ما باید با موفقیت بر روی macOS ساخته شود.
|
||||
|
||||
#### متحد کردن دستورات Build
|
||||
|
||||
در حال حاضر بسته به سیستمعامل میزبان، دستورات ساخت متفاوتی داریم که ایده آل نیست. برای جلوگیری از این، میتوانیم فایلی با نام `cargo/config.toml.` ایجاد کنیم که حاوی آرگومانهای خاص هر پلتفرم است:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "linux")']
|
||||
rustflags = ["-C", "link-arg=-nostartfiles"]
|
||||
|
||||
[target.'cfg(target_os = "windows")']
|
||||
rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
|
||||
|
||||
[target.'cfg(target_os = "macos")']
|
||||
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
|
||||
```
|
||||
|
||||
کلید `rustflags` شامل آرگومانهایی است که بطور خودکار به هر فراخوانی `rustc` اضافه میشوند. برای کسب اطلاعات بیشتر در مورد فایل `cargo/config.toml.` به [اسناد رسمی](https://doc.rust-lang.org/cargo/reference/config.html) مراجعه کنید.
|
||||
|
||||
اکنون برنامه ما باید در هر سه سیستمعامل با یک `cargo build` ساده قابل بیلد باشد.
|
||||
|
||||
#### آیا شما باید این کار را انجام دهید؟
|
||||
|
||||
اگرچه ساخت یک اجرایی مستقل برای لینوکس، ویندوز و macOS امکان پذیر است، اما احتمالاً ایده خوبی نیست. چرا که اجرایی ما هنوز انتظار موارد مختلفی را دارد، به عنوان مثال با فراخوانی تابع `start_` یک پشته مقداردهی اولیه شده است. بدون رانتایم C، ممکن است برخی از این الزامات برآورده نشود، که ممکن است باعث شکست برنامه ما شود، به عنوان مثال از طریق `segmentation fault`.
|
||||
|
||||
اگر می خواهید یک باینری کوچک ایجاد کنید که بر روی سیستمعامل موجود اجرا شود، اضافه کردن `libc` و تنظیم ویژگی `[start]#` همانطور که [اینجا](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html) شرح داده شده است، احتمالاً ایده بهتری است.
|
||||
|
||||
</details>
|
||||
|
||||
## خلاصه
|
||||
|
||||
یک باینری مستقل مینیمال راست مانند این است:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// this function is the entry point, since the linker looks for a function
|
||||
// named `_start` by default
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# the profile used for `cargo build`
|
||||
[profile.dev]
|
||||
panic = "abort" # disable stack unwinding on panic
|
||||
|
||||
# the profile used for `cargo build --release`
|
||||
[profile.release]
|
||||
panic = "abort" # disable stack unwinding on panic
|
||||
```
|
||||
|
||||
برای ساخت این باینری، ما باید برای یک هدف bare metal مانند `thumbv7em-none-eabihf` کامپایل کنیم:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
یک راه دیگر این است که میتوانیم آن را برای سیستم میزبان با استفاده از آرگومانهای اضافی لینکر کامپایل کنیم:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
# Windows
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
# macOS
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
توجه داشته باشید که این فقط یک نمونه حداقلی از باینری مستقل راست است. این باینری انتظار چیزهای مختلفی را دارد، به عنوان مثال با فراخوانی تابع `start_` یک پشته مقداردهی اولیه میشود. **بنابراین برای هر گونه استفاده واقعی از چنین باینری، مراحل بیشتری لازم است**.
|
||||
|
||||
## بعدی چیست؟
|
||||
|
||||
[پست بعدی] مراحل مورد نیاز برای تبدیل باینری مستقل به حداقل هسته سیستمعامل را توضیح میدهد. که شامل ایجاد یک هدف سفارشی، ترکیب اجرایی ما با بوتلودر و یادگیری نحوه چاپ چیزی در صفحه است.
|
||||
|
||||
[پست بعدی]: @/second-edition/posts/02-minimal-rust-kernel/index.fa.md
|
||||
@@ -1,531 +0,0 @@
|
||||
+++
|
||||
title = "フリースタンディングな Rust バイナリ"
|
||||
weight = 1
|
||||
path = "ja/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "6f1f87215892c2be12c6973a6f753c9a25c34b7e"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["JohnTitor"]
|
||||
+++
|
||||
|
||||
私達自身のオペレーティングシステム(以下、OS)カーネルを作っていく最初のステップは標準ライブラリとリンクしない Rust の実行可能ファイルをつくることです。これにより、基盤となる OS がない[ベアメタル][bare metal]上で Rust のコードを実行することができるようになります。
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
このブログの内容は [GitHub] 上で公開・開発されています。何か問題や質問などがあれば issue をたててください (訳注: リンクは原文(英語)のものになります)。また[こちら][comments]にコメントを残すこともできます。この記事の完全なソースコードは[`post-01` ブランチ][post branch]にあります。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[comments]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 導入
|
||||
|
||||
OS カーネルを書くためには、いかなる OS の機能にも依存しないコードが必要となります。つまり、スレッドやヒープメモリ、ネットワーク、乱数、標準出力、その他 OS による抽象化や特定のハードウェアを必要とする機能は使えません。私達は自分自身で OS とそのドライバを書こうとしているので、これは理にかなっています。
|
||||
|
||||
これは [Rust の標準ライブラリ][Rust standard library]をほとんど使えないということを意味しますが、それでも私達が使うことのできる Rust の機能はたくさんあります。例えば、[イテレータ][iterators]や[クロージャ][closures]、[パターンマッチング][pattern matching]、 [`Option`][option] や [`Result`][result] 型に[文字列フォーマット][string formatting]、そしてもちろん[所有権システム][ownership system]を使うことができます。これらの機能により、[未定義動作][undefined behavior]や[メモリ安全性][memory safety]を気にせずに、高い水準で表現力豊かにカーネルを書くことができます。
|
||||
|
||||
[option]: https://doc.rust-lang.org/core/option/
|
||||
[result]:https://doc.rust-lang.org/core/result/
|
||||
[Rust standard library]: https://doc.rust-lang.org/std/
|
||||
[iterators]: https://doc.rust-lang.org/book/ch13-02-iterators.html
|
||||
[closures]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
[pattern matching]: https://doc.rust-lang.org/book/ch06-00-enums.html
|
||||
[string formatting]: https://doc.rust-lang.org/core/macro.write.html
|
||||
[ownership system]: https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html
|
||||
[undefined behavior]: https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs
|
||||
[memory safety]: https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention
|
||||
|
||||
Rust で OS カーネルを書くには、基盤となる OS なしで動く実行環境をつくる必要があります。そのような実行環境はフリースタンディング環境やベアメタルのように呼ばれます。
|
||||
|
||||
この記事では、フリースタンディングな Rust のバイナリをつくるために必要なステップを紹介し、なぜそれが必要なのかを説明します。もし最小限の説明だけを読みたいのであれば **[概要](#概要)** まで飛ばしてください。
|
||||
|
||||
## 標準ライブラリの無効化
|
||||
|
||||
デフォルトでは、全ての Rust クレートは[標準ライブラリ][standard library]にリンクされています。標準ライブラリはスレッドやファイル、ネットワークのような OS の機能に依存しています。また OS と密接な関係にある C の標準ライブラリ(`libc`)にも依存しています。私達の目的は OS を書くことなので、 OS 依存のライブラリを使うことはできません。そのため、 [`no_std` attribute] を使って標準ライブラリが自動的にリンクされるのを無効にします。
|
||||
|
||||
[standard library]: https://doc.rust-lang.org/std/
|
||||
[`no_std` attribute]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
|
||||
|
||||
新しい Cargo プロジェクトをつくるところから始めましょう。もっとも簡単なやり方はコマンドラインで以下を実行することです。
|
||||
|
||||
```bash
|
||||
cargo new blog_os --bin --edition 2018
|
||||
```
|
||||
|
||||
プロジェクト名を `blog_os` としましたが、もちろんお好きな名前をつけていただいても大丈夫です。`--bin`フラグは実行可能バイナリを作成することを、 `--edition 2018` は[2018エディション][2018 edition]を使用することを明示的に指定します。コマンドを実行すると、 Cargoは以下のようなディレクトリ構造を作成します:
|
||||
|
||||
[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
|
||||
|
||||
```bash
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
`Cargo.toml` にはクレートの名前や作者名、[セマンティックバージョニング][semantic version]に基づくバージョンナンバーや依存関係などが書かれています。`src/main.rs` には私達のクレートのルートモジュールと `main` 関数が含まれています。`cargo build` コマンドでこのクレートをコンパイルして、 `target/debug` ディレクトリの中にあるコンパイルされた `blog_os` バイナリを実行することができます。
|
||||
|
||||
[semantic version]: https://semver.org/
|
||||
|
||||
### `no_std` Attribute
|
||||
|
||||
今のところ私達のクレートは暗黙のうちに標準ライブラリをリンクしています。[`no_std` attribute]を追加してこれを無効にしてみましょう:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
(`cargo build` を実行して)ビルドしようとすると、次のようなエラーが発生します:
|
||||
|
||||
```bash
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src/main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
これは [`println` マクロ][`println` macro]が標準ライブラリに含まれているためです。`no_std` で標準ライブラリを無効にしたので、何かをプリントすることはできなくなりました。`println` は標準出力に書き込むのでこれは理にかなっています。[標準出力][standard output]は OS によって提供される特別なファイル記述子であるためです。
|
||||
|
||||
[`println` macro]: https://doc.rust-lang.org/std/macro.println.html
|
||||
[standard output]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
|
||||
では、 `println` を削除し `main` 関数を空にしてもう一度ビルドしてみましょう:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```bash
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
この状態では `#[panic_handler]` 関数と `language item` がないというエラーが発生します。
|
||||
|
||||
## Panic の実装
|
||||
|
||||
`panic_handler` attribute は[パニック]が発生したときにコンパイラが呼び出す関数を定義します。標準ライブラリには独自のパニックハンドラー関数がありますが、 `no_std` 環境では私達の手でそれを実装する必要があります:
|
||||
|
||||
[パニック]: https://doc.rust-lang.org/stable/book/ch09-01-unrecoverable-errors-with-panic.html
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// この関数はパニック時に呼ばれる
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
[`PanicInfo` パラメータ]には、パニックが発生したファイルと行、およびオプションでパニックメッセージが含まれます。この関数は戻り値を取るべきではないので、]"never" 型(`!`)][“never” type]を返すことで[発散する関数][diverging function]となります。今のところこの関数でできることは多くないので、無限にループするだけです。
|
||||
|
||||
[`PanicInfo` パラメータ]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
|
||||
[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
|
||||
[“never” type]: https://doc.rust-lang.org/nightly/std/primitive.never.html
|
||||
|
||||
## `eh_personality` Language Item
|
||||
|
||||
language item はコンパイラによって内部的に必要とされる特別な関数や型です。例えば、[`Copy`] トレイトはどの型が[コピーセマンティクス][`Copy`]を持っているかをコンパイラに伝える language item です。[実装][copy code]を見てみると、 language item として定義されている特別な `#[lang = "copy"]` attribute を持っていることが分かります。
|
||||
|
||||
[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
|
||||
[copy code]: https://github.com/rust-lang/rust/blob/485397e49a02a3b7ff77c17e4a3f16c653925cb3/src/libcore/marker.rs#L296-L299
|
||||
|
||||
独自に language item を実装することもできますが、これは最終手段として行われるべきでしょう。というのも、language item は非常に不安定な実装であり型検査も行われないからです(なので、コンパイラは関数が正しい引数の型を取っているかさえ検査しません)。幸い、上記の language item のエラーを修正するためのより安定した方法があります。
|
||||
|
||||
[`eh_personality` language item] は[スタックアンワインド][stack unwinding] を実装するための関数を定義します。デフォルトでは、パニックが起きた場合には Rust はアンワインドを使用してすべてのスタックにある変数のデストラクタを実行します。これにより、使用されている全てのメモリが確実に解放され、親スレッドはパニックを検知して実行を継続できます。しかしアンワインドは複雑であり、いくつかの OS 特有のライブラリ(例えば、Linux では [libunwind] 、Windows では[構造化例外][structured exception handling])を必要とするので、私達の OS には使いたくありません。
|
||||
|
||||
[`eh_personality` language item]: https://github.com/rust-lang/rust/blob/edb368491551a77d77a48446d4ee88b35490c565/src/libpanic_unwind/gcc.rs#L11-L45
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
[libunwind]: https://www.nongnu.org/libunwind/
|
||||
[structured exception handling]: https://docs.microsoft.com/de-de/windows/win32/debug/structured-exception-handling
|
||||
|
||||
### アンワインドの無効化
|
||||
|
||||
他にもアンワインドが望ましくないユースケースがあります。そのため、Rust には代わりに[パニックで中止する][abort on panic]オプションがあります。これにより、アンワインドのシンボル情報の生成が無効になり、バイナリサイズが大幅に削減されます。アンワインドを無効にする方法は複数あります。もっとも簡単な方法は、`Cargo.toml` に次の行を追加することです:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
これは dev プロファイル(`cargo build` に使用される)と release プロファイル(`cargo build --release` に使用される)の両方でパニックで中止するようにするための設定です。これで `eh_personality` language item が不要になりました。
|
||||
|
||||
[abort on panic]: https://github.com/rust-lang/rust/pull/32900
|
||||
|
||||
これで上の2つのエラーを修正しました。しかし、コンパイルしようとすると別のエラーが発生します:
|
||||
|
||||
```bash
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
私達のプログラムにはエントリポイントを定義する `start` language item がありません。
|
||||
|
||||
## `start` attribute
|
||||
|
||||
`main` 関数はプログラムを実行したときに最初に呼び出される関数であると思うかもしれません。しかし、ほとんどの言語には[ランタイムシステム][runtime system]があり、これはガベージコレクション(Java など)やソフトウェアスレッド(Go のゴルーチン)などを処理します。ランタイムは自身を初期化する必要があるため、`main` 関数の前に呼び出す必要があります。これにはスタック領域の作成と正しいレジスタへの引数の配置が含まれます。
|
||||
|
||||
[runtime system]: https://en.wikipedia.org/wiki/Runtime_system
|
||||
|
||||
標準ライブラリをリンクする一般的な Rust バイナリでは、`crt0` ("C runtime zero")と呼ばれる C のランタイムライブラリで実行が開始され、C アプリケーションの環境が設定されます。その後 C ランタイムは、`start` language item で定義されている [Rust ランタイムのエントリポイント][rt::lang_start]を呼び出します。Rust にはごくわずかなランタイムしかありません。これは、スタックオーバーフローを防ぐ設定やパニック時のバックトレースの表示など、いくつかの小さな処理を行います。最後に、ランタイムは `main` 関数を呼び出します。
|
||||
|
||||
[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
|
||||
|
||||
私達のフリースタンディングな実行可能ファイルは今のところ Rust ランタイムと `crt0` へアクセスできません。なので、私達は自身でエントリポイントを定義する必要があります。`start` language item を実装することは `crt0` を必要とするのでここではできません。代わりに `crt0` エントリポイントを直接上書きしなければなりません。
|
||||
|
||||
### エントリポイントの上書き
|
||||
|
||||
Rust コンパイラに通常のエントリポイントを使いたくないことを伝えるために、`#![no_main]` attribute を追加します。
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`main` 関数を削除したことに気付いたかもしれません。`main` 関数を呼び出す基盤となるランタイムなしには置いていても意味がないからです。代わりに、OS のエントリポイントを独自の `_start` 関数で上書きしていきます:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
Rust コンパイラが `_start` という名前の関数を実際に出力するように、`#[no_mangle]` attributeを用いて[名前修飾][name mangling]を無効にします。この attribute がないと、コンパイラはすべての関数にユニークな名前をつけるために、 `_ZN3blog_os4_start7hb173fedf945531caE` のようなシンボルを生成します。次のステップでエントリポイントとなる関数の名前をリンカに伝えるため、この属性が必要となります。
|
||||
|
||||
また、(指定されていない Rust の呼び出し規約の代わりに)この関数に [C の呼び出し規約][C calling convention]を使用するようコンパイラに伝えるために、関数を `extern "C"` として定義する必要があります。`_start`という名前をつける理由は、これがほとんどのシステムのデフォルトのエントリポイント名だからです。
|
||||
|
||||
[name mangling]: https://en.wikipedia.org/wiki/Name_mangling
|
||||
[C calling convention]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
|
||||
戻り値の型である `!` は関数が発散している、つまり値を返すことができないことを意味しています。エントリポイントはどの関数からも呼び出されず、OS またはブートローダから直接呼び出されるので、これは必須です。なので、値を返す代わりに、エントリポイントは例えば OS の [`exit` システムコール][`exit` system call]を呼び出します。今回はフリースタンディングなバイナリが返されたときマシンをシャットダウンするようにすると良いでしょう。今のところ、私達は無限ループを起こすことで要件を満たします。
|
||||
|
||||
[`exit` system call]: https://en.wikipedia.org/wiki/Exit_(system_call)
|
||||
|
||||
`cargo build` を実行すると、見づらいリンカエラーが発生します。
|
||||
|
||||
## リンカエラー
|
||||
|
||||
リンカは、生成されたコードを実行可能ファイルに紐付けるプログラムです。実行可能ファイルの形式は Linux や Windows、macOS でそれぞれ異なるため、各システムにはそれぞれ異なるエラーを発生させる独自のリンカがあります。エラーの根本的な原因は同じです。リンカのデフォルト設定では、プログラムが C ランタイムに依存していると仮定していますが、実際にはしていません。
|
||||
|
||||
エラーを回避するためにはリンカに C ランタイムに依存しないことを伝える必要があります。これはリンカに一連の引数を渡すか、ベアメタルターゲット用にビルドすることで可能となります。
|
||||
|
||||
### ベアメタルターゲット用にビルドする
|
||||
|
||||
デフォルトでは、Rust は現在のシステム環境に合った実行可能ファイルをビルドしようとします。例えば、`x86_64` で Windows を使用している場合、Rust は `x86_64` 用の `.exe` Windows 実行可能ファイルをビルドしようとします。このような環境は「ホスト」システムと呼ばれます。
|
||||
|
||||
様々な環境を表現するために、Rust は [_target triple_] という文字列を使います。`rustc --version --verbose` を実行すると、ホストシステムの target triple を確認できます:
|
||||
|
||||
[_target triple_]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
|
||||
```bash
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
上記の出力は `x86_64` の Linux によるものです。`host` は `x86_64-unknown-linux-gnu` です。これには CPU アーキテクチャ(`x86_64`)、ベンダー(`unknown`)、OS(`Linux`)、そして [ABI] (`gnu`)が含まれています。
|
||||
|
||||
[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
|
||||
|
||||
ホストの triple 用にコンパイルすることで、Rust コンパイラとリンカは、デフォルトで C ランタイムを使用する Linux や Windows のような基盤となる OS があると想定し、それによってリンカエラーが発生します。なのでリンカエラーを回避するために、基盤となる OS を使用せずに異なる環境用にコンパイルします。
|
||||
|
||||
このようなベアメタル環境の例としては、`thumbv7em-none-eabihf` target triple があります。これは、[組込みシステム][embedded]を表しています。詳細は省きますが、重要なのは `none` という文字列からわかるように、 この target triple に基盤となる OS がないことです。このターゲット用にコンパイルできるようにするには、 rustup にこれを追加する必要があります:
|
||||
|
||||
[embedded]: https://en.wikipedia.org/wiki/Embedded_system
|
||||
|
||||
```bash
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
これにより、この target triple 用の標準(およびコア)ライブラリのコピーがダウンロードされます。これで、このターゲット用にフリースタンディングな実行可能ファイルをビルドできます:
|
||||
|
||||
```bash
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
`--target` 引数を渡すことで、ベアメタルターゲット用に実行可能ファイルを[クロスコンパイル][cross compile]します。このターゲットシステムには OS がないため、リンカは C ランタイムをリンクしようとせず、ビルドはリンカエラーなしで成功します。
|
||||
|
||||
[cross compile]: https://en.wikipedia.org/wiki/Cross_compiler
|
||||
|
||||
これが私達の OS カーネルを書くために使うアプローチです。`thumbv7em-none-eabihf` の代わりに、`x86_64` のベアメタル環境を表す[カスタムターゲット][custom target]を使用することもできます。詳細は次のセクションで説明します。
|
||||
|
||||
[custom target]: https://doc.rust-lang.org/rustc/targets/custom.html
|
||||
|
||||
### リンカへの引数
|
||||
|
||||
ベアメタルターゲット用にコンパイルする代わりに、特定の引数のセットをリンカにわたすことでリンカエラーを回避することもできます。これは私達がカーネルに使用するアプローチではありません。したがって、このセクションはオプションであり、選択肢を増やすために書かれています。表示するには以下の「リンカへの引数」をクリックしてください。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>リンカへの引数</summary>
|
||||
|
||||
このセクションでは、Linux、Windows、および macOS で発生するリンカエラーについてと、リンカに追加の引数を渡すことによってそれらを解決する方法を説明します。実行可能ファイルの形式とリンカは OS によって異なるため、システムごとに異なる引数のセットが必要です。
|
||||
|
||||
#### Linux
|
||||
|
||||
Linux では以下のようなエラーが発生します(抜粋):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x12): undefined reference to `__libc_csu_fini'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x19): undefined reference to `__libc_csu_init'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x25): undefined reference to `__libc_start_main'
|
||||
collect2: error: ld returned 1 exit status
|
||||
```
|
||||
|
||||
問題は、デフォルトで C ランタイムの起動ルーチンがリンカに含まれていることです。これは `_start` とも呼ばれます。`no_std` attribute により、C 標準ライブラリ `libc` のいくつかのシンボルが必要となります。なので、リンカはこれらの参照を解決できません。これを解決するために、リンカに `-nostartfiles` フラグを渡して、C の起動ルーチンをリンクしないようにします。
|
||||
|
||||
Cargo を通してリンカの attribute を渡す方法の一つに、`cargo rustc` コマンドがあります。このコマンドは `cargo build` と全く同じように動作しますが、基本となる Rust コンパイラである `rustc` にオプションを渡すことができます。`rustc` にはリンカに引数を渡す `-C link-arg` フラグがあります。新しいビルドコマンドは次のようになります:
|
||||
|
||||
```bash
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
```
|
||||
|
||||
これで crate を Linux 上で独立した実行ファイルとしてビルドできます!
|
||||
|
||||
リンカはデフォルトで `_start` という名前の関数を探すので、エントリポイントとなる関数の名前を明示的に指定する必要はありません。
|
||||
|
||||
#### Windows
|
||||
|
||||
Windows では別のリンカエラーが発生します(抜粋):
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1561
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1561: entry point must be defined
|
||||
```
|
||||
|
||||
"entry point must be defined" というエラーは、リンカがエントリポイントを見つけられていないことを意味します。Windows では、デフォルトのエントリポイント名は[使用するサブシステム][windows-subsystems]によって異なります。`CONSOLE` サブシステムの場合、リンカは `mainCRTStartup` という名前の関数を探し、`WINDOWS` サブシステムの場合は、`WinMainCRTStartup` という名前の関数を探します。デフォルトの動作を無効にし、代わりに `_start` 関数を探すようにリンカに指示するには、`/ENTRY` 引数をリンカに渡します:
|
||||
|
||||
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
|
||||
|
||||
```bash
|
||||
cargo rustc -- -C link-arg=/ENTRY:_start
|
||||
```
|
||||
|
||||
引数の形式が異なることから、Windows のリンカは Linux のリンカとは全く異なるプログラムであることが分かります。
|
||||
|
||||
これにより、別のリンカエラーが発生します:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1221
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
|
||||
defined
|
||||
```
|
||||
|
||||
このエラーは Windows での実行可能ファイルが異なる [subsystems][windows-subsystems] を使用することができるために発生します。通常のプログラムでは、エントリポイント名に基づいて推定されます。エントリポイントが `main` という名前の場合は `CONSOLE` サブシステムが使用され、エントリポイント名が `WinMain` である場合には `WINDOWS` サブシステムが使用されます。`_start` 関数は別の名前を持っているので、サブシステムを明示的に指定する必要があります:
|
||||
|
||||
This error occurs because Windows executables can use different [subsystems][windows-subsystems]. For normal programs they are inferred depending on the entry point name: If the entry point is named `main`, the `CONSOLE` subsystem is used, and if the entry point is named `WinMain`, the `WINDOWS` subsystem is used. Since our `_start` function has a different name, we need to specify the subsystem explicitly:
|
||||
|
||||
```bash
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
```
|
||||
|
||||
ここでは `CONSOLE` サブシステムを使用しますが、`WINDOWS` サブシステムを使うこともできます。`-C link-arg` を複数渡す代わりに、スペースで区切られたリストを引数として取る `-C link-args` を渡します。
|
||||
|
||||
このコマンドで、実行可能ファイルが Windows 上で正しくビルドされます。
|
||||
|
||||
#### macOS
|
||||
|
||||
macOS では次のようなリンカエラーが発生します(抜粋):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: entry point (_main) undefined. for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
このエラーメッセージは、リンカがデフォルト名が `main` (いくつかの理由で、macOS 上ではすべての関数の前には `_` が付きます) であるエントリポイントとなる関数を見つけられないことを示しています。`_start` 関数をエントリポイントとして設定するには、`-e` というリンカ引数を渡します:
|
||||
|
||||
```bash
|
||||
cargo rustc -- -C link-args="-e __start"
|
||||
```
|
||||
|
||||
`-e` というフラグでエントリポイントとなる関数の名前を指定できます。macOS 上では全ての関数には `_` というプレフィックスが追加されるので、`_start` ではなく `__start` にエントリポイントを設定する必要があります。
|
||||
|
||||
これにより、次のようなリンカエラーが発生します:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: dynamic main executables must link with libSystem.dylib
|
||||
for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
macOS は[正式には静的にリンクされたバイナリをサポートしておらず][does not officially support statically linked binaries]、プログラムはデフォルトで `libSystem` ライブラリにリンクされる必要があります。これを無効にして静的バイナリをリンクするには、`-static` フラグをリンカに渡します:
|
||||
|
||||
[does not officially support statically linked binaries]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
|
||||
|
||||
```bash
|
||||
cargo rustc -- -C link-args="-e __start -static"
|
||||
```
|
||||
|
||||
これでもまだ十分ではありません、3つ目のリンカエラーが発生します:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: library not found for -lcrt0.o
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
このエラーは、macOS 上のプログラムがデフォルトで `crt0` ("C runtime zero") にリンクされるために発生します。これは Linux 上で起きたエラーと似ており、`-nostartfiles` というリンカ引数を追加することで解決できます:
|
||||
|
||||
```bash
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
これで 私達のプログラムを macOS 上で正しくビルドできます。
|
||||
|
||||
#### ビルドコマンドの統一
|
||||
|
||||
現時点では、ホストプラットフォームによって異なるビルドコマンドを使っていますが、これは理想的ではありません。これを回避するために、プラットフォーム固有の引数を含む `.cargo/config.toml` というファイルを作成します:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "linux")']
|
||||
rustflags = ["-C", "link-arg=-nostartfiles"]
|
||||
|
||||
[target.'cfg(target_os = "windows")']
|
||||
rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
|
||||
|
||||
[target.'cfg(target_os = "macos")']
|
||||
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
|
||||
```
|
||||
|
||||
`rustflags` には `rustc` を呼び出すたびに自動的に追加される引数が含まれています。`.cargo/config.toml` についての詳細は[公式のドキュメント][official documentation]を確認してください。
|
||||
|
||||
[official documentation]: https://doc.rust-lang.org/cargo/reference/config.html
|
||||
|
||||
これで私達のプログラムは3つすべてのプラットフォーム上で、シンプルに `cargo build` のみでビルドすることができるようになります。
|
||||
|
||||
#### 私達はこれをすべきですか?
|
||||
|
||||
これらの手順で Linux、Windows および macOS 用の独立した実行可能ファイルをビルドすることはできますが、おそらく良い方法ではありません。その理由は、例えば `_start` 関数が呼ばれたときにスタックが初期化されるなど、まだ色々なことを前提としているからです。C ランタイムがなければ、これらの要件のうちいくつかが満たされない可能性があり、セグメンテーション違反(segfault)などによってプログラムが失敗する可能性があります。
|
||||
|
||||
もし既存の OS 上で動作する最小限のバイナリを作成したいなら、`libc` を使って `#[start]` attribute を[ここ][no-stdlib]で説明するとおりに設定するのが良いでしょう。
|
||||
|
||||
[no-stdlib]: https://doc.rust-lang.org/1.16.0/book/no-stdlib.html
|
||||
|
||||
</details>
|
||||
|
||||
## 概要
|
||||
|
||||
最小限の独立した Rust バイナリは次のようになります:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // Rust の標準ライブラリにリンクしない
|
||||
#![no_main] // 全ての Rust レベルのエントリポイントを無効にする
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // この関数の名前修飾をしない
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// リンカはデフォルトで `_start` という名前の関数を探すので、
|
||||
// この関数がエントリポイントとなる
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// この関数はパニック時に呼ばれる
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# the profile used for `cargo build`
|
||||
[profile.dev]
|
||||
panic = "abort" # disable stack unwinding on panic
|
||||
|
||||
# the profile used for `cargo build --release`
|
||||
[profile.release]
|
||||
panic = "abort" # disable stack unwinding on panic
|
||||
```
|
||||
|
||||
このバイナリをビルドするために、`thumbv7em-none-eabihf` のようなベアメタルターゲット用にコンパイルする必要があります:
|
||||
|
||||
```bash
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
あるいは、追加のリンカ引数を渡してホストシステム用にコンパイルすることもできます:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
# Windows
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
# macOS
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
これは独立した Rust バイナリの最小の例にすぎないことに注意してください。このバイナリは `_start` 関数が呼び出されたときにスタックが初期化されるなど、さまざまなことを前提としています。**そのため、このようなバイナリを実際に使用するには、より多くの手順が必要となります**。
|
||||
|
||||
## 次は?
|
||||
|
||||
[次の記事][next post]では、この独立したバイナリを最小限の OS カーネルにするために必要なステップを説明しています。カスタムターゲットの作成、実行可能ファイルとブートローダの組み合わせ、画面に何か文字を表示する方法について説明しています。
|
||||
|
||||
[next post]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
@@ -1,519 +0,0 @@
|
||||
+++
|
||||
title = "A Freestanding Rust Binary"
|
||||
weight = 1
|
||||
path = "freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
+++
|
||||
|
||||
The first step in creating our own operating system kernel is to create a Rust executable that does not link the standard library. This makes it possible to run Rust code on the [bare metal] without an underlying operating system.
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-01`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## Introduction
|
||||
To write an operating system kernel, we need code that does not depend on any operating system features. This means that we can't use threads, files, heap memory, the network, random numbers, standard output, or any other features requiring OS abstractions or specific hardware. Which makes sense, since we're trying to write our own OS and our own drivers.
|
||||
|
||||
This means that we can't use most of the [Rust standard library], but there are a lot of Rust features that we _can_ use. For example, we can use [iterators], [closures], [pattern matching], [option] and [result], [string formatting], and of course the [ownership system]. These features make it possible to write a kernel in a very expressive, high level way without worrying about [undefined behavior] or [memory safety].
|
||||
|
||||
[option]: https://doc.rust-lang.org/core/option/
|
||||
[result]:https://doc.rust-lang.org/core/result/
|
||||
[Rust standard library]: https://doc.rust-lang.org/std/
|
||||
[iterators]: https://doc.rust-lang.org/book/ch13-02-iterators.html
|
||||
[closures]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
[pattern matching]: https://doc.rust-lang.org/book/ch06-00-enums.html
|
||||
[string formatting]: https://doc.rust-lang.org/core/macro.write.html
|
||||
[ownership system]: https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html
|
||||
[undefined behavior]: https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs
|
||||
[memory safety]: https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention
|
||||
|
||||
In order to create an OS kernel in Rust, we need to create an executable that can be run without an underlying operating system. Such an executable is often called a “freestanding” or “bare-metal” executable.
|
||||
|
||||
This post describes the necessary steps to create a freestanding Rust binary and explains why the steps are needed. If you're just interested in a minimal example, you can **[jump to the summary](#summary)**.
|
||||
|
||||
## Disabling the Standard Library
|
||||
By default, all Rust crates link the [standard library], which depends on the operating system for features such as threads, files, or networking. It also depends on the C standard library `libc`, which closely interacts with OS services. Since our plan is to write an operating system, we can not use any OS-dependent libraries. So we have to disable the automatic inclusion of the standard library through the [`no_std` attribute].
|
||||
|
||||
[standard library]: https://doc.rust-lang.org/std/
|
||||
[`no_std` attribute]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
|
||||
|
||||
We start by creating a new cargo application project. The easiest way to do this is through the command line:
|
||||
|
||||
```
|
||||
cargo new blog_os --bin --edition 2018
|
||||
```
|
||||
|
||||
I named the project `blog_os`, but of course you can choose your own name. The `--bin` flag specifies that we want to create an executable binary (in contrast to a library) and the `--edition 2018` flag specifies that we want to use the [2018 edition] of Rust for our crate. When we run the command, cargo creates the following directory structure for us:
|
||||
|
||||
[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
|
||||
|
||||
```
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
The `Cargo.toml` contains the crate configuration, for example the crate name, the author, the [semantic version] number, and dependencies. The `src/main.rs` file contains the root module of our crate and our `main` function. You can compile your crate through `cargo build` and then run the compiled `blog_os` binary in the `target/debug` subfolder.
|
||||
|
||||
[semantic version]: https://semver.org/
|
||||
|
||||
### The `no_std` Attribute
|
||||
|
||||
Right now our crate implicitly links the standard library. Let's try to disable this by adding the [`no_std` attribute]:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
When we try to build it now (by running `cargo build`), the following error occurs:
|
||||
|
||||
```
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src/main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
The reason for this error is that the [`println` macro] is part of the standard library, which we no longer include. So we can no longer print things. This makes sense, since `println` writes to [standard output], which is a special file descriptor provided by the operating system.
|
||||
|
||||
[`println` macro]: https://doc.rust-lang.org/std/macro.println.html
|
||||
[standard output]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
|
||||
So let's remove the printing and try again with an empty main function:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
Now the compiler is missing a `#[panic_handler]` function and a _language item_.
|
||||
|
||||
## Panic Implementation
|
||||
|
||||
The `panic_handler` attribute defines the function that the compiler should invoke when a [panic] occurs. The standard library provides its own panic handler function, but in a `no_std` environment we need to define it ourselves:
|
||||
|
||||
[panic]: https://doc.rust-lang.org/stable/book/ch09-01-unrecoverable-errors-with-panic.html
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
The [`PanicInfo` parameter][PanicInfo] contains the file and line where the panic happened and the optional panic message. The function should never return, so it is marked as a [diverging function] by returning the [“never” type] `!`. There is not much we can do in this function for now, so we just loop indefinitely.
|
||||
|
||||
[PanicInfo]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
|
||||
[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
|
||||
[“never” type]: https://doc.rust-lang.org/nightly/std/primitive.never.html
|
||||
|
||||
## The `eh_personality` Language Item
|
||||
|
||||
Language items are special functions and types that are required internally by the compiler. For example, the [`Copy`] trait is a language item that tells the compiler which types have [_copy semantics_][`Copy`]. When we look at the [implementation][copy code], we see it has the special `#[lang = "copy"]` attribute that defines it as a language item.
|
||||
|
||||
[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
|
||||
[copy code]: https://github.com/rust-lang/rust/blob/485397e49a02a3b7ff77c17e4a3f16c653925cb3/src/libcore/marker.rs#L296-L299
|
||||
|
||||
While providing custom implementations of language items is possible, it should only be done as a last resort. The reason is that language items are highly unstable implementation details and not even type checked (so the compiler doesn't even check if a function has the right argument types). Fortunately, there is a more stable way to fix the above language item error.
|
||||
|
||||
The [`eh_personality` language item] marks a function that is used for implementing [stack unwinding]. By default, Rust uses unwinding to run the destructors of all live stack variables in case of a [panic]. This ensures that all used memory is freed and allows the parent thread to catch the panic and continue execution. Unwinding, however, is a complicated process and requires some OS specific libraries (e.g. [libunwind] on Linux or [structured exception handling] on Windows), so we don't want to use it for our operating system.
|
||||
|
||||
[`eh_personality` language item]: https://github.com/rust-lang/rust/blob/edb368491551a77d77a48446d4ee88b35490c565/src/libpanic_unwind/gcc.rs#L11-L45
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
[libunwind]: https://www.nongnu.org/libunwind/
|
||||
[structured exception handling]: https://docs.microsoft.com/de-de/windows/win32/debug/structured-exception-handling
|
||||
|
||||
### Disabling Unwinding
|
||||
|
||||
There are other use cases as well for which unwinding is undesirable, so Rust provides an option to [abort on panic] instead. This disables the generation of unwinding symbol information and thus considerably reduces binary size. There are multiple places where we can disable unwinding. The easiest way is to add the following lines to our `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
This sets the panic strategy to `abort` for both the `dev` profile (used for `cargo build`) and the `release` profile (used for `cargo build --release`). Now the `eh_personality` language item should no longer be required.
|
||||
|
||||
[abort on panic]: https://github.com/rust-lang/rust/pull/32900
|
||||
|
||||
Now we fixed both of the above errors. However, if we try to compile it now, another error occurs:
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
Our program is missing the `start` language item, which defines the entry point.
|
||||
|
||||
## The `start` attribute
|
||||
|
||||
One might think that the `main` function is the first function called when you run a program. However, most languages have a [runtime system], which is responsible for things such as garbage collection (e.g. in Java) or software threads (e.g. goroutines in Go). This runtime needs to be called before `main`, since it needs to initialize itself.
|
||||
|
||||
[runtime system]: https://en.wikipedia.org/wiki/Runtime_system
|
||||
|
||||
In a typical Rust binary that links the standard library, execution starts in a C runtime library called `crt0` (“C runtime zero”), which sets up the environment for a C application. This includes creating a stack and placing the arguments in the right registers. The C runtime then invokes the [entry point of the Rust runtime][rt::lang_start], which is marked by the `start` language item. Rust only has a very minimal runtime, which takes care of some small things such as setting up stack overflow guards or printing a backtrace on panic. The runtime then finally calls the `main` function.
|
||||
|
||||
[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
|
||||
|
||||
Our freestanding executable does not have access to the Rust runtime and `crt0`, so we need to define our own entry point. Implementing the `start` language item wouldn't help, since it would still require `crt0`. Instead, we need to overwrite the `crt0` entry point directly.
|
||||
|
||||
### Overwriting the Entry Point
|
||||
To tell the Rust compiler that we don't want to use the normal entry point chain, we add the `#![no_main]` attribute.
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
You might notice that we removed the `main` function. The reason is that a `main` doesn't make sense without an underlying runtime that calls it. Instead, we are now overwriting the operating system entry point with our own `_start` function:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
By using the `#[no_mangle]` attribute we disable the [name mangling] to ensure that the Rust compiler really outputs a function with the name `_start`. Without the attribute, the compiler would generate some cryptic `_ZN3blog_os4_start7hb173fedf945531caE` symbol to give every function an unique name. The attribute is required because we need to tell the name of the entry point function to the linker in the next step.
|
||||
|
||||
We also have to mark the function as `extern "C"` to tell the compiler that it should use the [C calling convention] for this function (instead of the unspecified Rust calling convention). The reason for naming the function `_start` is that this is the default entry point name for most systems.
|
||||
|
||||
[name mangling]: https://en.wikipedia.org/wiki/Name_mangling
|
||||
[C calling convention]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
|
||||
The `!` return type means that the function is diverging, i.e. not allowed to ever return. This is required because the entry point is not called by any function, but invoked directly by the operating system or bootloader. So instead of returning, the entry point should e.g. invoke the [`exit` system call] of the operating system. In our case, shutting down the machine could be a reasonable action, since there's nothing left to do if a freestanding binary returns. For now, we fulfill the requirement by looping endlessly.
|
||||
|
||||
[`exit` system call]: https://en.wikipedia.org/wiki/Exit_(system_call)
|
||||
|
||||
When we run `cargo build` now, we get an ugly _linker_ error.
|
||||
|
||||
## Linker Errors
|
||||
|
||||
The linker is a program that combines the generated code into an executable. Since the executable format differs between Linux, Windows, and macOS, each system has its own linker that throws a different error. The fundamental cause of the errors is the same: the default configuration of the linker assumes that our program depends on the C runtime, which it does not.
|
||||
|
||||
To solve the errors, we need to tell the linker that it should not include the C runtime. We can do this either by passing a certain set of arguments to the linker or by building for a bare metal target.
|
||||
|
||||
### Building for a Bare Metal Target
|
||||
|
||||
By default Rust tries to build an executable that is able to run in your current system environment. For example, if you're using Windows on `x86_64`, Rust tries to build a `.exe` Windows executable that uses `x86_64` instructions. This environment is called your "host" system.
|
||||
|
||||
To describe different environments, Rust uses a string called [_target triple_]. You can see the target triple for your host system by running `rustc --version --verbose`:
|
||||
|
||||
[_target triple_]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
|
||||
```
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
The above output is from a `x86_64` Linux system. We see that the `host` triple is `x86_64-unknown-linux-gnu`, which includes the CPU architecture (`x86_64`), the vendor (`unknown`), the operating system (`linux`), and the [ABI] (`gnu`).
|
||||
|
||||
[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
|
||||
|
||||
By compiling for our host triple, the Rust compiler and the linker assume that there is an underlying operating system such as Linux or Windows that use the C runtime by default, which causes the linker errors. So to avoid the linker errors, we can compile for a different environment with no underlying operating system.
|
||||
|
||||
An example for such a bare metal environment is the `thumbv7em-none-eabihf` target triple, which describes an [embedded] [ARM] system. The details are not important, all that matters is that the target triple has no underlying operating system, which is indicated by the `none` in the target triple. To be able to compile for this target, we need to add it in rustup:
|
||||
|
||||
[embedded]: https://en.wikipedia.org/wiki/Embedded_system
|
||||
[ARM]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||
|
||||
```
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
This downloads a copy of the standard (and core) library for the system. Now we can build our freestanding executable for this target:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
By passing a `--target` argument we [cross compile] our executable for a bare metal target system. Since the target system has no operating system, the linker does not try to link the C runtime and our build succeeds without any linker errors.
|
||||
|
||||
[cross compile]: https://en.wikipedia.org/wiki/Cross_compiler
|
||||
|
||||
This is the approach that we will use for building our OS kernel. Instead of `thumbv7em-none-eabihf`, we will use a [custom target] that describes a `x86_64` bare metal environment. The details will be explained in the next post.
|
||||
|
||||
[custom target]: https://doc.rust-lang.org/rustc/targets/custom.html
|
||||
|
||||
### Linker Arguments
|
||||
|
||||
Instead of compiling for a bare metal system, it is also possible to resolve the linker errors by passing a certain set of arguments to the linker. This isn't the approach that we will use for our kernel, therefore this section is optional and only provided for completeness. Click on _"Linker Arguments"_ below to show the optional content.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Linker Arguments</summary>
|
||||
|
||||
In this section we discuss the linker errors that occur on Linux, Windows, and macOS, and explain how to solve them by passing additional arguments to the linker. Note that the executable format and the linker differ between operating systems, so that a different set of arguments is required for each system.
|
||||
|
||||
#### Linux
|
||||
|
||||
On Linux the following linker error occurs (shortened):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x12): undefined reference to `__libc_csu_fini'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x19): undefined reference to `__libc_csu_init'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x25): undefined reference to `__libc_start_main'
|
||||
collect2: error: ld returned 1 exit status
|
||||
```
|
||||
|
||||
The problem is that the linker includes the startup routine of the C runtime by default, which is also called `_start`. It requires some symbols of the C standard library `libc` that we don't include due to the `no_std` attribute, therefore the linker can't resolve these references. To solve this, we can tell the linker that it should not link the C startup routine by passing the `-nostartfiles` flag.
|
||||
|
||||
One way to pass linker attributes via cargo is the `cargo rustc` command. The command behaves exactly like `cargo build`, but allows to pass options to `rustc`, the underlying Rust compiler. `rustc` has the `-C link-arg` flag, which passes an argument to the linker. Combined, our new build command looks like this:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
```
|
||||
|
||||
Now our crate builds as a freestanding executable on Linux!
|
||||
|
||||
We didn't need to specify the name of our entry point function explicitly since the linker looks for a function with the name `_start` by default.
|
||||
|
||||
#### Windows
|
||||
|
||||
On Windows, a different linker error occurs (shortened):
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1561
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1561: entry point must be defined
|
||||
```
|
||||
|
||||
The "entry point must be defined" error means that the linker can't find the entry point. On Windows, the default entry point name [depends on the used subsystem][windows-subsystems]. For the `CONSOLE` subsystem the linker looks for a function named `mainCRTStartup` and for the `WINDOWS` subsystem it looks for a function named `WinMainCRTStartup`. To override the default and tell the linker to look for our `_start` function instead, we can pass an `/ENTRY` argument to the linker:
|
||||
|
||||
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=/ENTRY:_start
|
||||
```
|
||||
|
||||
From the different argument format we clearly see that the Windows linker is a completely different program than the Linux linker.
|
||||
|
||||
Now a different linker error occurs:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1221
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
|
||||
defined
|
||||
```
|
||||
|
||||
This error occurs because Windows executables can use different [subsystems][windows-subsystems]. For normal programs they are inferred depending on the entry point name: If the entry point is named `main`, the `CONSOLE` subsystem is used, and if the entry point is named `WinMain`, the `WINDOWS` subsystem is used. Since our `_start` function has a different name, we need to specify the subsystem explicitly:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
```
|
||||
|
||||
We use the `CONSOLE` subsystem here, but the `WINDOWS` subsystem would work too. Instead of passing `-C link-arg` multiple times, we use `-C link-args` which takes a space separated list of arguments.
|
||||
|
||||
With this command, our executable should build successfully on Windows.
|
||||
|
||||
#### macOS
|
||||
|
||||
On macOS, the following linker error occurs (shortened):
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: entry point (_main) undefined. for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
This error message tells us that the linker can't find an entry point function with the default name `main` (for some reason all functions are prefixed with a `_` on macOS). To set the entry point to our `_start` function, we pass the `-e` linker argument:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start"
|
||||
```
|
||||
|
||||
The `-e` flag specifies the name of the entry point function. Since all functions have an additional `_` prefix on macOS, we need to set the entry point to `__start` instead of `_start`.
|
||||
|
||||
Now the following linker error occurs:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: dynamic main executables must link with libSystem.dylib
|
||||
for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
macOS [does not officially support statically linked binaries] and requires programs to link the `libSystem` library by default. To override this and link a static binary, we pass the `-static` flag to the linker:
|
||||
|
||||
[does not officially support statically linked binaries]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static"
|
||||
```
|
||||
|
||||
This still does not suffice, as a third linker error occurs:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: library not found for -lcrt0.o
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
This error occurs because programs on macOS link to `crt0` (“C runtime zero”) by default. This is similar to the error we had on Linux and can be also solved by adding the `-nostartfiles` linker argument:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
Now our program should build successfully on macOS.
|
||||
|
||||
#### Unifying the Build Commands
|
||||
|
||||
Right now we have different build commands depending on the host platform, which is not ideal. To avoid this, we can create a file named `.cargo/config.toml` that contains the platform specific arguments:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "linux")']
|
||||
rustflags = ["-C", "link-arg=-nostartfiles"]
|
||||
|
||||
[target.'cfg(target_os = "windows")']
|
||||
rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
|
||||
|
||||
[target.'cfg(target_os = "macos")']
|
||||
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
|
||||
```
|
||||
|
||||
The `rustflags` key contains arguments that are automatically added to every invocation of `rustc`. For more information on the `.cargo/config.toml` file check out the [official documentation](https://doc.rust-lang.org/cargo/reference/config.html).
|
||||
|
||||
Now our program should be buildable on all three platforms with a simple `cargo build`.
|
||||
|
||||
#### Should You Do This?
|
||||
|
||||
While it's possible to build a freestanding executable for Linux, Windows, and macOS, it's probably not a good idea. The reason is that our executable still expects various things, for example that a stack is initialized when the `_start` function is called. Without the C runtime, some of these requirements might not be fulfilled, which might cause our program to fail, e.g. through a segmentation fault.
|
||||
|
||||
If you want to create a minimal binary that runs on top of an existing operating system, including `libc` and setting the `#[start]` attribute as described [here](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html) is probably a better idea.
|
||||
|
||||
</details>
|
||||
|
||||
## Summary
|
||||
|
||||
A minimal freestanding Rust binary looks like this:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// this function is the entry point, since the linker looks for a function
|
||||
// named `_start` by default
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# the profile used for `cargo build`
|
||||
[profile.dev]
|
||||
panic = "abort" # disable stack unwinding on panic
|
||||
|
||||
# the profile used for `cargo build --release`
|
||||
[profile.release]
|
||||
panic = "abort" # disable stack unwinding on panic
|
||||
```
|
||||
|
||||
To build this binary, we need to compile for a bare metal target such as `thumbv7em-none-eabihf`:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
Alternatively, we can compile it for the host system by passing additional linker arguments:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
# Windows
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
# macOS
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
Note that this is just a minimal example of a freestanding Rust binary. This binary expects various things, for example that a stack is initialized when the `_start` function is called. **So for any real use of such a binary, more steps are required**.
|
||||
|
||||
## What's next?
|
||||
|
||||
The [next post] explains the steps needed for turning our freestanding binary into a minimal operating system kernel. This includes creating a custom target, combining our executable with a bootloader, and learning how to print something to the screen.
|
||||
|
||||
[next post]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
@@ -1,299 +0,0 @@
|
||||
+++
|
||||
title = "独立式可执行程序"
|
||||
weight = 1
|
||||
path = "zh-CN/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu", "TheBegining"]
|
||||
+++
|
||||
|
||||
创建一个不链接标准库的 Rust 可执行文件,将是我们迈出的第一步。无需底层操作系统的支撑,这样才能在**裸机**([bare metal])上运行 Rust 代码。
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
此博客在 [GitHub] 上公开开发. 如果您有任何问题或疑问,请在此处打开一个 issue。 您也可以在[底部][at the bottom]发表评论. 这篇文章的完整源代码可以在 [`post-01`] [post branch] 分支中找到。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 简介
|
||||
|
||||
要编写一个操作系统内核,我们需要编写不依赖任何操作系统特性的代码。这意味着我们不能使用线程、文件、堆内存、网络、随机数、标准输出,或其它任何需要操作系统抽象和特定硬件的特性;因为我们正在编写自己的操作系统和硬件驱动。
|
||||
|
||||
实现这一点,意味着我们不能使用 [Rust标准库](https://doc.rust-lang.org/std/)的大部分;但还有很多 Rust 特性是我们依然可以使用的。比如说,我们可以使用[迭代器](https://doc.rust-lang.org/book/ch13-02-iterators.html)、[闭包](https://doc.rust-lang.org/book/ch13-01-closures.html)、[模式匹配](https://doc.rust-lang.org/book/ch06-00-enums.html)、[Option](https://doc.rust-lang.org/core/option/)、[Result](https://doc.rust-lang.org/core/result/index.html)、[字符串格式化](https://doc.rust-lang.org/core/macro.write.html),当然还有[所有权系统](https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html)。这些功能让我们能够编写表达性强、高层抽象的操作系统,而无需关心[未定义行为](https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs)和[内存安全](https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention)。
|
||||
|
||||
为了用 Rust 编写一个操作系统内核,我们需要创建一个独立于操作系统的可执行程序。这样的可执行程序常被称作**独立式可执行程序**(freestanding executable)或**裸机程序**(bare-metal executable)。
|
||||
|
||||
在这篇文章里,我们将逐步地创建一个独立式可执行程序,并且详细解释为什么每个步骤都是必须的。如果读者只对最终的代码感兴趣,可以跳转到本篇文章的小结部分。
|
||||
|
||||
## 禁用标准库
|
||||
|
||||
在默认情况下,所有的 Rust **包**(crate)都会链接**标准库**([standard library](https://doc.rust-lang.org/std/)),而标准库依赖于操作系统功能,如线程、文件系统、网络。标准库还与 **Rust 的 C 语言标准库实现库**(libc)相关联,它也是和操作系统紧密交互的。既然我们的计划是编写自己的操作系统,我们就需要不使用任何与操作系统相关的库——因此我们必须禁用**标准库自动引用**(automatic inclusion)。使用 [no_std 属性](https://doc.rust-lang.org/book/first-edition/using-rust-without-the-standard-library.html)可以实现这一点。
|
||||
|
||||
我们可以从创建一个新的 cargo 项目开始。最简单的办法是使用下面的命令:
|
||||
|
||||
```bash
|
||||
> cargo new blog_os
|
||||
```
|
||||
|
||||
在这里我把项目命名为 `blog_os`,当然读者也可以选择自己的项目名称。这里,cargo 默认为我们添加了`--bin` 选项,说明我们将要创建一个可执行文件(而不是一个库);cargo还为我们添加了`--edition 2018` 标签,指明项目的包要使用 Rust 的 **2018 版次**([2018 edition])。当我们执行这行指令的时候,cargo 为我们创建的目录结构如下:
|
||||
|
||||
[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
|
||||
|
||||
```
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
在这里,`Cargo.toml` 文件包含了包的**配置**(configuration),比如包的名称、作者、[semver版本](https://semver.org/) 和项目依赖项;`src/main.rs` 文件包含包的**根模块**(root module)和 main 函数。我们可以使用 `cargo build` 来编译这个包,然后在 `target/debug` 文件夹内找到编译好的 `blog_os` 二进制文件。
|
||||
|
||||
### no_std 属性
|
||||
|
||||
现在我们的包依然隐式地与标准库链接。为了禁用这种链接,我们可以尝试添加 [no_std 属性](https://doc.rust-lang.org/book/first-edition/using-rust-without-the-standard-library.html):
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
看起来很顺利。当我们使用 `cargo build` 来编译的时候,却出现了下面的错误:
|
||||
|
||||
```rust
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src\main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
出现这个错误的原因是:[println! 宏](https://doc.rust-lang.org/std/macro.println.html)是标准库的一部分,而我们的项目不再依赖于标准库。我们选择不再打印字符串。这也很好理解,因为 `println!` 将会向**标准输出**([standard output](https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29))打印字符,它依赖于特殊的文件描述符,而这是由操作系统提供的特性。
|
||||
|
||||
所以我们可以移除这行代码,使用一个空的 main 函数再次尝试编译:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
现在我们发现,编译器缺少一个 `#[panic_handler]` 函数和一个**语言项**(language item)。
|
||||
|
||||
## 实现 panic 处理函数
|
||||
|
||||
`panic_handler` 属性定义了一个函数,它会在一个 panic 发生时被调用。标准库中提供了自己的 panic 处理函数,但在 `no_std` 环境中,我们需要定义一个自己的 panic 处理函数:
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
类型为 [PanicInfo](https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html) 的参数包含了 panic 发生的文件名、代码行数和可选的错误信息。这个函数从不返回,所以他被标记为**发散函数**([diverging function])。发散函数的返回类型称作 **Never 类型**(["never" type](https://doc.rust-lang.org/nightly/std/primitive.never.html)),记为`!`。对这个函数,我们目前能做的很少,所以我们只需编写一个无限循环 `loop {}`。
|
||||
|
||||
[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
|
||||
|
||||
## eh_personality 语言项
|
||||
|
||||
语言项是一些编译器需求的特殊函数或类型。举例来说,Rust 的 [Copy](https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html) trait 是一个这样的语言项,告诉编译器哪些类型需要遵循**复制语义**([copy semantics](https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html))——当我们查找 `Copy` trait 的[实现](https://github.com/rust-lang/rust/blob/485397e49a02a3b7ff77c17e4a3f16c653925cb3/src/libcore/marker.rs#L296-L299)时,我们会发现,一个特殊的 `#[lang = "copy"]` 属性将它定义为了一个语言项,达到与编译器联系的目的。
|
||||
|
||||
我们可以自己实现语言项,但这是下下策:目前来看,语言项是高度不稳定的语言细节实现,它们不会经过编译期类型检查(所以编译器甚至不确保它们的参数类型是否正确)。幸运的是,我们有更稳定的方式,来修复上面的语言项错误。
|
||||
|
||||
`eh_personality` 语言项标记的函数,将被用于实现**栈展开**([stack unwinding](https://www.bogotobogo.com/cplusplus/stackunwinding.php))。在使用标准库的情况下,当 panic 发生时,Rust 将使用栈展开,来运行在栈上所有活跃的变量的**析构函数**(destructor)——这确保了所有使用的内存都被释放,允许调用程序的**父进程**(parent thread)捕获 panic,处理并继续运行。但是,栈展开是一个复杂的过程,如 Linux 的 [libunwind](https://www.nongnu.org/libunwind/) 或 Windows 的**结构化异常处理**([structured exception handling, SEH](https://docs.microsoft.com/de-de/windows/win32/debug/structured-exception-handling)),通常需要依赖于操作系统的库;所以我们不在自己编写的操作系统中使用它。
|
||||
|
||||
### 禁用栈展开
|
||||
|
||||
在其它一些情况下,栈展开并不是迫切需求的功能;因此,Rust 提供了**在 panic 时中止**([abort on panic](https://github.com/rust-lang/rust/pull/32900))的选项。这个选项能禁用栈展开相关的标志信息生成,也因此能缩小生成的二进制程序的长度。有许多方式能打开这个选项,最简单的方式是把下面的几行设置代码加入我们的 `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
这些选项能将 **dev 配置**(dev profile)和 **release 配置**(release profile)的 panic 策略设为 `abort`。`dev` 配置适用于 `cargo build`,而 `release` 配置适用于 `cargo build --release`。现在编译器应该不再要求我们提供 `eh_personality` 语言项实现。
|
||||
|
||||
现在我们已经修复了出现的两个错误,可以开始编译了。然而,尝试编译运行后,一个新的错误出现了:
|
||||
|
||||
```bash
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
## start 语言项
|
||||
|
||||
这里,我们的程序遗失了 `start` 语言项,它将定义一个程序的**入口点**(entry point)。
|
||||
|
||||
我们通常会认为,当运行一个程序时,首先被调用的是 `main` 函数。但是,大多数语言都拥有一个**运行时系统**([runtime system](https://en.wikipedia.org/wiki/Runtime_system)),它通常为**垃圾回收**(garbage collection)或**绿色线程**(software threads,或 green threads)服务,如 Java 的 GC 或 Go 语言的协程(goroutine);这个运行时系统需要在 main 函数前启动,因为它需要让程序初始化。
|
||||
|
||||
在一个典型的使用标准库的 Rust 程序中,程序运行是从一个名为 `crt0` 的运行时库开始的。`crt0` 意为 C runtime zero,它能建立一个适合运行 C 语言程序的环境,这包含了栈的创建和可执行程序参数的传入。在这之后,这个运行时库会调用 [Rust 的运行时入口点](https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73),这个入口点被称作 **start语言项**("start" language item)。Rust 只拥有一个极小的运行时,它被设计为拥有较少的功能,如爆栈检测和打印**堆栈轨迹**(stack trace)。这之后,这个运行时将会调用 main 函数。
|
||||
|
||||
我们的独立式可执行程序并不能访问 Rust 运行时或 `crt0` 库,所以我们需要定义自己的入口点。只实现一个 `start` 语言项并不能帮助我们,因为这之后程序依然要求 `crt0` 库。所以,我们要做的是,直接重写整个 `crt0` 库和它定义的入口点。
|
||||
|
||||
### 重写入口点
|
||||
|
||||
要告诉 Rust 编译器我们不使用预定义的入口点,我们可以添加 `#![no_main]` 属性。
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
读者也许会注意到,我们移除了 `main` 函数。原因很显然,既然没有底层运行时调用它,`main` 函数也失去了存在的必要性。为了重写操作系统的入口点,我们转而编写一个 `_start` 函数:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我们使用 `no_mangle` 标记这个函数,来对它禁用**名称重整**([name mangling](https://en.wikipedia.org/wiki/Name_mangling))——这确保 Rust 编译器输出一个名为 `_start` 的函数;否则,编译器可能最终生成名为 `_ZN3blog_os4_start7hb173fedf945531caE` 的函数,无法让链接器正确辨别。
|
||||
|
||||
我们还将函数标记为 `extern "C"`,告诉编译器这个函数应当使用 [C 语言的调用约定](https://en.wikipedia.org/wiki/Calling_convention),而不是 Rust 语言的调用约定。函数名为 `_start` ,是因为大多数系统默认使用这个名字作为入口点名称。
|
||||
|
||||
与前文的 `panic` 函数类似,这个函数的返回值类型为`!`——它定义了一个发散函数,或者说一个不允许返回的函数。这一点很重要,因为这个入口点不会被任何函数调用,但将直接被操作系统或**引导程序**(bootloader)调用。所以作为函数返回的替代,这个入口点应该去调用,比如操作系统提供的 **exit 系统调用**(["exit" system call](https://en.wikipedia.org/wiki/Exit_(system_call)))函数。在我们编写操作系统的情况下,关机应该是一个合适的选择,因为**当一个独立式可执行程序返回时,不会留下任何需要做的事情**(there is nothing to do if a freestanding binary returns)。现在来看,我们可以添加一个无限循环,来满足对返回值类型的需求。
|
||||
|
||||
如果我们现在编译这段程序,会出来一大段不太好看的**链接器错误**(linker error)。
|
||||
|
||||
## 链接器错误
|
||||
|
||||
**链接器**(linker)是一个程序,它将生成的目标文件组合为一个可执行文件。不同的操作系统如 Windows、macOS、Linux,规定了不同的可执行文件格式,因此也各有自己的链接器,抛出不同的错误;但这些错误的根本原因还是相同的:链接器的默认配置假定程序依赖于C语言的运行时环境,但我们的程序并不依赖于它。
|
||||
|
||||
为了解决这个错误,我们需要告诉链接器,它不应该包含(include)C 语言运行环境。我们可以选择提供特定的**链接器参数**(linker argument),也可以选择编译为**裸机目标**(bare metal target)。
|
||||
|
||||
### 编译为裸机目标
|
||||
|
||||
在默认情况下,Rust 尝试适配当前的系统环境,编译可执行程序。举个例子,如果你使用 `x86_64` 平台的 Windows 系统,Rust 将尝试编译一个扩展名为 `.exe` 的 Windows 可执行程序,并使用 `x86_64` 指令集。这个环境又被称作为你的**宿主系统**("host" system)。
|
||||
|
||||
为了描述不同的环境,Rust 使用一个称为**目标三元组**(target triple)的字符串。要查看当前系统的目标三元组,我们可以运行 `rustc --version --verbose`:
|
||||
|
||||
```
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
上面这段输出来自一个 `x86_64` 平台下的 Linux 系统。我们能看到,`host` 字段的值为三元组 `x86_64-unknown-linux-gnu`,它包含了 CPU 架构 `x86_64` 、供应商 `unknown` 、操作系统 `linux` 和[二进制接口](https://en.wikipedia.org/wiki/Application_binary_interface) `gnu`。
|
||||
|
||||
Rust 编译器尝试为当前系统的三元组编译,并假定底层有一个类似于 Windows 或 Linux 的操作系统提供C语言运行环境——然而这将导致链接器错误。所以,为了避免这个错误,我们可以另选一个底层没有操作系统的运行环境。
|
||||
|
||||
这样的运行环境被称作裸机环境,例如目标三元组 `thumbv7em-none-eabihf` 描述了一个 ARM **嵌入式系统**([embedded system](https://en.wikipedia.org/wiki/Embedded_system))。我们暂时不需要了解它的细节,只需要知道这个环境底层没有操作系统——这是由三元组中的 `none` 描述的。要为这个目标编译,我们需要使用 rustup 添加它:
|
||||
|
||||
```
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
这行命令将为目标下载一个标准库和 core 库。这之后,我们就能为这个目标构建独立式可执行程序了:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
我们传递了 `--target` 参数,来为裸机目标系统**交叉编译**([cross compile](https://en.wikipedia.org/wiki/Cross_compiler))我们的程序。我们的目标并不包括操作系统,所以链接器不会试着链接 C 语言运行环境,因此构建过程成功会完成,不会产生链接器错误。
|
||||
|
||||
我们将使用这个方法编写自己的操作系统内核。我们不会编译到 `thumbv7em-none-eabihf`,而是使用描述 `x86_64` 环境的**自定义目标**([custom target](https://doc.rust-lang.org/rustc/targets/custom.html))。在下一篇文章中,我们将详细描述一些相关的细节。
|
||||
|
||||
### 链接器参数
|
||||
|
||||
我们也可以选择不编译到裸机系统,因为传递特定的参数也能解决链接器错误问题。虽然我们不会在后面使用到这个方法,为了教程的完整性,我们也撰写了专门的短文章,来提供这个途径的解决方案。
|
||||
|
||||
## 小结
|
||||
|
||||
一个用 Rust 编写的最小化的独立式可执行程序应该长这样:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // 不链接 Rust 标准库
|
||||
#![no_main] // 禁用所有 Rust 层级的入口点
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // 不重整函数名
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// 因为编译器会寻找一个名为 `_start` 的函数,所以这个函数就是入口点
|
||||
// 默认命名为 `_start`
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# 使用 `cargo build` 编译时需要的配置
|
||||
[profile.dev]
|
||||
panic = "abort" # 禁用panic时栈展开
|
||||
|
||||
# 使用 `cargo build --release` 编译时需要的配置
|
||||
[profile.release]
|
||||
panic = "abort" # 禁用 panic 时栈展开
|
||||
```
|
||||
|
||||
选用任意一个裸机目标来编译。比如对 `thumbv7em-none-eabihf`,我们使用以下命令:
|
||||
|
||||
```bash
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
要注意的是,现在我们的代码只是一个 Rust 编写的独立式可执行程序的一个例子。运行这个二进制程序还需要很多准备,比如在 `_start` 函数之前需要一个已经预加载完毕的栈。所以为了真正运行这样的程序,我们还有很多事情需要做。
|
||||
|
||||
## 下篇预览
|
||||
|
||||
下一篇文章要做的事情基于我们这篇文章的成果,它将详细讲述编写一个最小的操作系统内核需要的步骤:如何配置特定的编译目标,如何将可执行程序与引导程序拼接,以及如何把一些特定的字符串打印到屏幕上。
|
||||
|
||||
[next post]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
@@ -1,519 +0,0 @@
|
||||
+++
|
||||
title = "獨立的 Rust 二進制檔"
|
||||
weight = 1
|
||||
path = "zh-TW/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "24d04e0e39a3395ecdce795bab0963cb6afe1bfd"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["wusyong"]
|
||||
+++
|
||||
|
||||
建立我們自己的作業系統核心的第一步是建立一個不連結標準函式庫的 Rust 執行檔,這使得無需基礎作業系統即可在[裸機][bare metal]上執行 Rust 程式碼。
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
此網誌在 [GitHub] 上公開開發,如果您有任何問題或疑問,請在那開一個 issue,您也可以在[下面][at the bottom]發表評論,這篇文章的完整開源程式碼可以在 [`post-01`][post branch] 分支中找到。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 介紹
|
||||
要編寫作業系統核心,我們需要不依賴於任何作業系統功能的程式碼。這代表我們不能使用執行緒、檔案系統、堆記憶體、網路、隨機數、標準輸出或任何其他需要作業系統抽象或特定硬體的功能。這也是理所當然的,因為我們正在嘗試寫出自己的 OS 和我們的驅動程式。
|
||||
|
||||
這意味著我們不能使用大多數的 [Rust 標準函式庫][Rust standard library],但是我們還是可以使用 _很多_ Rust 的功能。比如說我們可以使用[疊代器][iterators]、[閉包][closures]、[模式配對][pattern matching]、[option] 和 [result]、[字串格式化][string formatting],當然還有[所有權系統][ownership system]。這些功能讓我們能夠以非常有表達力且高階的方式編寫核心,而無需擔心[未定義行為][undefined behavior]或[記憶體安全][memory safety]。
|
||||
|
||||
[option]: https://doc.rust-lang.org/core/option/
|
||||
[result]:https://doc.rust-lang.org/core/result/
|
||||
[Rust standard library]: https://doc.rust-lang.org/std/
|
||||
[iterators]: https://doc.rust-lang.org/book/ch13-02-iterators.html
|
||||
[closures]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
[pattern matching]: https://doc.rust-lang.org/book/ch06-00-enums.html
|
||||
[string formatting]: https://doc.rust-lang.org/core/macro.write.html
|
||||
[ownership system]: https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html
|
||||
[undefined behavior]: https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs
|
||||
[memory safety]: https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention
|
||||
|
||||
為了在 Rust 中建立 OS 核心,我們需要建立一個無須底層作業系統即可運行的執行檔,這類的執行檔通常稱為「獨立式(freestanding)」或「裸機(bare-metal)」的執行檔。
|
||||
|
||||
這篇文章描述了建立一個獨立的 Rust 執行檔的必要步驟,並解釋為什麼需要這些步驟。如果您只對簡單的範例感興趣,可以直接跳到 **[總結](#總結)**。
|
||||
|
||||
## 停用標準函式庫
|
||||
|
||||
Rust 所有的 crate 在預設情況下都會連結[標準函式庫][standard library],而標準函式庫會依賴作業系統的功能,像式執行緒、檔案系統或是網路。它也會依賴 C 語言的標準函式庫 `libc`,因為其與作業系統緊密相關。既然我們的計劃是編寫自己的作業系統,我們就得用到 [`no_std` 屬性][`no_std` attribute]來停止標準函式庫的自動引用(automatic inclusion)。
|
||||
|
||||
[standard library]: https://doc.rust-lang.org/std/
|
||||
[`no_std` attribute]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
|
||||
|
||||
我們先從建立一個新的 cargo 專案開始,最簡單的辦法是輸入下面的命令:
|
||||
|
||||
```
|
||||
cargo new blog_os --bin --edition 2018
|
||||
```
|
||||
|
||||
我將專案命名為 `blog_os`,當然讀者也可以自己的名稱。`--bin` 選項說明我們將要建立一個執行檔(而不是一個函式庫),`--edition 2018` 選項指明我們的 crate 想使用 Rust [2018 版本][2018 edition]。當我們執行這行指令的時候,cargo 會為我們建立以下目錄結構:
|
||||
|
||||
[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
|
||||
|
||||
```
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
`Cargo.toml` 包含 crate 的設置,像是 crate 的名稱、作者、[語意化版本][semantic version]以及依賴套件。`src/main.rs` 檔案則包含 crate 的根模組(root module)以及我們的 `main` 函式。您可以用 `cargo build` 編譯您的 crate 然後在 `target/debug` 目錄下運行編譯過後的 `blog_os` 執行檔。
|
||||
|
||||
[semantic version]: https://semver.org/lang/zh-TW/
|
||||
|
||||
### no_std 屬性
|
||||
|
||||
現在我們的 crate 背後依然有和標準函式庫連結。讓我們加上 [`no_std` 屬性][`no_std` attribute] 來停用:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
當我們嘗試用 `cargo build` 編譯時會出現以下錯誤訊息:
|
||||
|
||||
```
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src/main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
出現這個錯誤的原因是因為 [`println` 巨集(macro)][`println` macro]是標準函式庫的一部份,而我們不再包含它,所以我們無法再輸出東西來。這也是理所當然因為 `println` 會寫到[標準輸出][standard output],而這是一個由作業系統提供的特殊檔案描述符。
|
||||
|
||||
[`println` macro]: https://doc.rust-lang.org/std/macro.println.html
|
||||
[standard output]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
|
||||
所以讓我們移除這行程式碼,然後用空的 main 函式再試一次:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
現在編譯氣告訴我們缺少 `#[panic_handler]` 函式以及 _language item_。
|
||||
|
||||
## 實作 panic 處理函式
|
||||
|
||||
`panic_handler` 屬性定義了當 [panic] 發生時編譯器需要呼叫的函式。在標準函式庫中有自己的 panic 處理函式,但在 `no_std` 的環境中我們得定義我們自己的:
|
||||
|
||||
[panic]: https://doc.rust-lang.org/stable/book/ch09-01-unrecoverable-errors-with-panic.html
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 此函式會在 panic 時呼叫。
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
[`PanicInfo` parameter][PanicInfo] 包含 panic 發生時的檔案、行數以及可選的錯誤訊息。這個函式不會返回,所以它被標記為[發散函式][diverging function],只會返回[“never” 型態][“never” type] `!`。現在我們什麼事可以做,所以我們只需寫一個無限迴圈。
|
||||
|
||||
[PanicInfo]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
|
||||
[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
|
||||
[“never” type]: https://doc.rust-lang.org/nightly/std/primitive.never.html
|
||||
|
||||
## eh_personality Language Item
|
||||
|
||||
Language item 是一些編譯器需求的特殊函式或類型。舉例來說,Rust 的 [`Copy`] trait 就是一個 language item,告訴編譯器哪些類型擁有[_複製的語意_][`Copy`]。當我們搜尋 `Copy` trait 的[實作][copy code]時,我們會發現一個特殊的 `#[lang = "copy"]` 屬性將它定義為一個 language item。
|
||||
|
||||
我們可以自己實現 language item,但這只應是最後的手段。因為 language item 屬於非常不穩定的實作細節,而且不會做類型檢查(所以編譯器甚至不會確保它們的參數類型是否正確)。幸運的是,我們有更穩定的方式來修復上面關於 language item 的錯誤。
|
||||
|
||||
`eh_personality` language item 標記的函式將被用於實作[堆疊回溯][stack unwinding]。在預設情況下當 panic 發生時,Rust 會使用堆疊回溯來執行所有存在堆疊上變數的解構子(destructor)。這確保所有使用的記憶體都被釋放,並讓 parent thread 獲取 panic 資訊並繼續運行。但是堆疊回溯是一個複雜的過程,通常會需要一些 OS 的函式庫如 Linux 的 [libunwind] 或 Windows 的 [structured exception handling]。所以我們並不希望在我們的作業系統中使用它。
|
||||
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
[libunwind]: https://www.nongnu.org/libunwind/
|
||||
[structured exception handling]: https://docs.microsoft.com/de-de/windows/win32/debug/structured-exception-handling
|
||||
|
||||
### 停用回溯
|
||||
|
||||
在某些狀況下回溯可能並不是我們要的功能,因此 Rust 提供了[在 panic 時中止][abort on panic]的選項。這個選項能停用回溯標誌訊息的產生,也因此能縮小生成的二進制檔案大小。我們能用許多方式開啟這個選項,而最簡單的方式就是把以下幾行設置加入我們的 `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
這些選項能將 `dev` 設置(用於 `cargo build`)和 `release` 設置(用於 `cargo build --release`)的 panic 策略設為 `abort`。現在編譯器不會再要求我們提供 `eh_personality` language item。
|
||||
|
||||
[abort on panic]: https://github.com/rust-lang/rust/pull/32900
|
||||
|
||||
現在我們已經修復了上面的錯誤,但是如果我們嘗試編譯的話,又會出現一個新的錯誤:
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
我們的程式缺少 `start` 這個用來定義入口點(entry point)的 language item。
|
||||
|
||||
## `start` 屬性
|
||||
|
||||
我們通常會認為執行一個程式時,首先被呼叫的是 `main` 函式。但是大多數語言都擁有一個[執行時系統][runtime system],它通常負責垃圾回收(garbage collection)像是 Java 或軟體執行緒(software threads)像是 Go 的 goroutines。這個執行時系統需要在 main 函式前啟動,因為它需要讓先進行初始化。
|
||||
|
||||
[runtime system]: https://en.wikipedia.org/wiki/Runtime_system
|
||||
|
||||
在一個典型使用標準函式庫的 Rust 程式中,程式運行是從一個名為 `crt0`(“C runtime zero”)的執行時函式庫開始的,它會設置 C 程式的執行環境。這包含建立堆疊和可執行程式參數的傳入。在這之後,這個執行時函式庫會呼叫 [Rust 的執行時入口點][rt::lang_start],而此處就是由 `start` language item 標記。 Rust 只有一個非常小的執行時系統,負責處理一些小事情,像是堆疊溢位或是印出 panic 時回溯的訊息。再來執行時系統最終才會呼叫 main 函式。
|
||||
|
||||
[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
|
||||
|
||||
我們的獨立式可執行檔並沒有辦法存取 Rust 執行時系統或 `crt0`,所以我們需要定義自己的入口點。實作 `start` language item 並沒有用,因為這樣還是會需要 `crt0`。所以我們要做的是直接覆寫 `crt0` 的入口點。
|
||||
|
||||
### 重寫入口點
|
||||
|
||||
為了告訴 Rust 編譯器我們不要使用一般的入口點呼叫順序,我們先加上 `#![no_main]` 屬性。
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 此函式會在 panic 時呼叫。
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
您可能會注意到我們移除了 `main` 函式,原因是因為既然沒有了底層的執行時系統呼叫,那麼 `main` 也沒必要存在。我們要重寫作業系統的入口點,定義為 `_start` 函式:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我們使用 `no_mangle` 屬性來停用[名字修飾][name mangling],確保 Rust 編譯器輸出的函式名稱會是 `_start`。沒有這個屬性的話,編譯器會產生符號像是 `_ZN3blog_os4_start7hb173fedf945531caE` 來讓每個函式的名稱都是獨一無二的。我們會需要這項屬性的原因是因為我們接下來希望連結器能夠呼叫入口點函式的名稱。
|
||||
|
||||
我們還將函式標記為 `extern "C"` 來告訴編譯器這個函式應當使用 [C 的調用約定][C calling convention],而不是 Rust 的調用約定。而函式名稱選用 `_start` 的原因是因為這是大多數系統的預設入口點名稱。
|
||||
|
||||
[name mangling]: https://en.wikipedia.org/wiki/Name_mangling
|
||||
[C calling convention]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
|
||||
`!` 返回型態代表這個函式是發散函式,它不允許返回。這是必要的因為入口點不會被任何函式呼叫,只會直接由作業系統或啟動程式(bootloader)執行。所以取代返回值的是入口點需要執行作業系統的 [`exit` 系統呼叫][`exit` system call]。在我們的例子中,關閉機器似乎是個理想的動作,因為獨立的二進制檔案返回後也沒什麼事可做。現在我們先寫一個無窮迴圈來滿足需求。
|
||||
|
||||
[`exit` system call]: https://en.wikipedia.org/wiki/Exit_(system_call)
|
||||
|
||||
當我們現在運行 `cargo build` 的話會看到很醜的 _連結器_ 錯誤。
|
||||
|
||||
## 連結器錯誤
|
||||
|
||||
連結器是用來將產生的程式碼結合起來成為執行檔的程式。因為 Linux、Windows 和 macOS 之間的執行檔格式都不同,每個系統都會有自己的連結器錯誤。不過造成錯誤的原因通常都差不多:連結器預設的設定會認為我們的程式依賴於 C 的執行時系統,但我們並沒有。
|
||||
|
||||
為了解決這個錯誤,我們需要告訴連結器它不需要包含 C 的執行時系統。我們可以選擇提供特定的連結器參數設定,或是選擇編譯為裸機目標。
|
||||
|
||||
### 編譯為裸機目標
|
||||
|
||||
Rust 在預設情況下會嘗試編譯出符合你目前系統環境的可執行檔。舉例來說,如果你正在 `x86_64` 上使用 Windows,那麼 Rust 就會嘗試編譯出 `.exe`,一個使用 `x86_64` 指令集的 Windows 執行檔。這樣的環境稱之為主機系統(host system)。
|
||||
|
||||
為了描述不同環境,Rust 使用 [_target triple_] 的字串。要查看目前系統的 target triple,你可以執行 `rustc --version --verbose`:
|
||||
|
||||
[_target triple_]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
|
||||
```
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
上面的輸出訊息來自 `x86_64` 上的 Linux 系統,我們可以看到 `host` 的 target triple 為 `x86_64-unknown-linux-gnu`,分別代表 CPU 架構 (`x86_64`)、供應商 (`unknown`) 以及作業系統 (`linux`) 和 [ABI] (`gnu`)。
|
||||
|
||||
[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
|
||||
|
||||
在依據主機的 triple 編譯時,Rust 編譯器和連結器理所當然地會認為預設是底層的作業系統並使用 C 執行時系統,這便是造成錯誤的原因。要避免這項錯誤,我們可以選擇編譯出沒有底層作業系統的不同環境。
|
||||
|
||||
其中一個裸機環境的例子是 `thumbv7em-none-eabihf` target triple,它描述了[嵌入式][embedded] [ARM] 系統。其中的細節目前並不重要,我們現在只需要知道沒有底層作業系統的 target triple 是用 `none` 描述的。想要編譯這樣的目標的話,我們需要將它新增至 rustup:
|
||||
|
||||
[embedded]: https://en.wikipedia.org/wiki/Embedded_system
|
||||
[ARM]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||
|
||||
```
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
這會下載一份該系統的標準(以及 core)函式庫,現在我們可以用此目標建立我們的獨立執行檔了:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
我們傳入 `--target` [交叉編譯][cross compile]我們在裸機系統的執行檔。因為目標系統沒有作業系統,連結器不會嘗試連結 C 執行時系統並成功建立,不會產生任何連結器錯誤。
|
||||
|
||||
[cross compile]: https://en.wikipedia.org/wiki/Cross_compiler
|
||||
|
||||
這將會是我們到時候用來建立自己的作業系統核心的方法。不過我們不會用到 `thumbv7em-none-eabihf`,我們將會使用[自訂目標][custom target]來描述一個 `x86_64` 的裸機環境。
|
||||
|
||||
[custom target]: https://doc.rust-lang.org/rustc/targets/custom.html
|
||||
|
||||
### 連結器引數
|
||||
|
||||
除了編譯裸機系統為目標以外,我們也可以傳入特定的引數組合給連結器來解決錯誤。這不會是我們到時候用在我們核心的方法,所以以下的內容不是必需的,只是用來補齊資訊。點選下面的 _「連結器引數」_ 來顯示額外資訊。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>連結器引數</summary>
|
||||
|
||||
在這部份我們將討論 Linux、Windows 和 macOS 上發生的連結器錯誤,然後解釋如何傳入額外引數給連結器以解決錯誤。注意執行檔和連結器在不同作業系統之間都會相異,所以不同系統需要傳入不同引數。
|
||||
|
||||
#### Linux
|
||||
|
||||
以下是 Linux 上會出現的(簡化過)連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x12): undefined reference to `__libc_csu_fini'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x19): undefined reference to `__libc_csu_init'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x25): undefined reference to `__libc_start_main'
|
||||
collect2: error: ld returned 1 exit status
|
||||
```
|
||||
|
||||
問題的原因是因為連結器在一開始包含了 C 的執行時系統,而且剛好也叫做 `_start`。它需要一些 C 標準函式庫 `libc` 提供的符號,但我們用 `no_std` 來停用它了,所以連結器無法找出引用來源。我們可以用 `-nostartfiles` 來告訴連結器一開始不必連結 C 的執行時系統。
|
||||
|
||||
要傳入的其中一個方法是透過 cargo 的 `cargo rustc` 命令,此命令行為和 `cargo build` 一樣,不過允許傳入一些選項到 Rust 底層的編譯器 `rustc`。`rustc` 有 `-C link-arg` 的選項會繼續將引數傳到連結器,這樣一來我們的指令會長得像這樣:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
```
|
||||
|
||||
現在我們的 crate 便能產生出 Linux 上的獨立執行檔了!
|
||||
|
||||
我們不必再指明入口點的函式名稱,因為連結器預設會尋找 `_start` 函式。
|
||||
#### Windows
|
||||
|
||||
在 Windows 上會出現不一樣的(簡化過)連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1561
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1561: entry point must be defined
|
||||
```
|
||||
|
||||
"entry point must be defined" 錯誤表示連結器找不到入口點,在 Windows 上預設的入口點名稱會[依據使用的子系統][windows-subsystems]。如果是 `CONSOLE` 子系統的話,連結器會尋找 `mainCRTStartup` 函式名稱;而 `WINDOWS` 子系統的話則會尋找 `WinMainCRTStartup` 函式名稱。要覆蓋預設的選項並讓連結器尋找我們的 `_start` 函式的話,我們可以傳入 `/ENTRY` 引數給連結器:
|
||||
|
||||
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=/ENTRY:_start
|
||||
```
|
||||
|
||||
從引數格式來看我們可以清楚理解 Windows 連結器與 Linux 連結器是完全不同的程式。
|
||||
|
||||
現在會出現另一個連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1221
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
|
||||
defined
|
||||
```
|
||||
|
||||
此錯誤出現的原因是因為 Windows 執行檔可以使用不同的[子系統][windows-subsystems]。一般的程式會依據入口點名稱來決定:如果入口點名稱為 `main` 則會使用 `CONSOLE` 子系統;如果入口點名稱為 `WinMain` 則會使用 `WINDOWS` 子系統。由於我們的函式 `_start` 名稱不一樣,我們必須指明子系統:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
```
|
||||
|
||||
我們使用 `CONSOLE` 子系統不過 `WINDOWS` 一樣也可以。與其輸入好多次 `-C link-arg` ,我們可以用 `-C link-args` 來傳入許多引數。
|
||||
|
||||
使用此命令後,我們的執行檔應當能成功在 Windows 上建立。
|
||||
|
||||
#### macOS
|
||||
|
||||
以下是 Linux 上會出現的(簡化過)連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: entry point (_main) undefined. for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
此錯誤訊息告訴我們連結器無法找到入口點函式 `main`,基於某些原因 macOS 上的函式都會加上前綴 `_`。為了設定入口點為我們的函式 `_start`,我們傳入 `-e` 連結器引數:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start"
|
||||
```
|
||||
|
||||
`-e` 表示肉口點的函式名稱,然後由於 macOS 上所有的函式都會加上前綴 `_`,我們需要設置入口點為 `__start` 而不是 `_start`。
|
||||
|
||||
接下來會出現另一個連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: dynamic main executables must link with libSystem.dylib
|
||||
for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
macOS [官方並不支援靜態連結執行檔][does not officially support statically linked binaries]且要求程式預設要連結到 `libSystem` 函式庫。要覆蓋這個設定並連結靜態執行檔,我們傳入 `-static` 給連結器:
|
||||
|
||||
[does not officially support statically linked binaries]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static"
|
||||
```
|
||||
|
||||
但這樣還不夠,我們會遇到第三個連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: library not found for -lcrt0.o
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
這錯誤出現的原因是因為 macOS 的程式預設都會連結到 `crt0` (“C runtime zero”)。這和我們在 Linux 上遇到的類似,所以也可以用 `-nostartfiles` 連結器引數來解決:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
現在我們的程式應當能成功在 macOS 上建立。
|
||||
|
||||
#### 統一建構命令
|
||||
|
||||
現在我們得依據主機平台來使用不同的建構命令,這樣感覺不是很理想。我們可以建立個檔案 `.cargo/config` 來解決,裡面會包含平台相關的引數:
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
|
||||
[target.'cfg(target_os = "linux")']
|
||||
rustflags = ["-C", "link-arg=-nostartfiles"]
|
||||
|
||||
[target.'cfg(target_os = "windows")']
|
||||
rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
|
||||
|
||||
[target.'cfg(target_os = "macos")']
|
||||
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
|
||||
```
|
||||
|
||||
`rustflags` 包含的引數會自動加到 `rustc` 如果條件符合的話。想了解更多關於 `.cargo/config` 的資訊請參考[官方文件][official documentation](https://doc.rust-lang.org/cargo/reference/config.html)。
|
||||
|
||||
這樣一來我們就能同時在三個平台只用 `cargo build` 來建立了。
|
||||
|
||||
#### 你該這麼作嗎?
|
||||
|
||||
雖然我們可以在 Linux、Windows 和 macOS 上建立獨立執行檔,不過這可能不是好主意。我們目前會需要這樣做的原因是因為我們的執行檔仍然需要仰賴一些事情,像是當 `_start` 函式呼叫時堆疊已經初始化完畢。少了 C 執行時系統,有些要求可能會無法達成,造成我們的程式失效,像是 segmentation fault。
|
||||
|
||||
如果你想要建立一個運行在已存作業系統上的最小執行檔,改用 `libc` 然後如這邊[所述](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html)設置 `#[start]` 屬性可能會是更好的做法。
|
||||
|
||||
</details>
|
||||
|
||||
## 總結
|
||||
|
||||
一個最小的 Rust 獨立執行檔會看起來像這樣:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // 不連結標準函式庫
|
||||
#![no_main] // 停用 Rust 層級的入口點
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // 不修飾函式名稱
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// 因為連結器預設會尋找 `_start` 函式名稱
|
||||
// 所以這個函式就是入口點
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// 此函式會在 panic 時呼叫
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# `cargo build` 時需要的設置
|
||||
[profile.dev]
|
||||
panic = "abort" # 停用 panic 時堆疊回溯
|
||||
|
||||
# `cargo build --release` 時需要的設置
|
||||
[profile.release]
|
||||
panic = "abort" # 停用 panic 時堆疊回溯
|
||||
```
|
||||
|
||||
要建構出此執行檔,我們需要選擇一個裸機目標來編譯像是 `thumbv7em-none-eabihf`:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
不然我們也可以用主機系統來編譯,不過要加上額外的連結器引數:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
# Windows
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
# macOS
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
注意這只是最小的 Rust 獨立執行檔範例,它還是會仰賴一些事情發生,像是當 `_start` 函式呼叫時堆疊已經初始化完畢。**所以如果想真的使用這樣的執行檔的話還需要更多步驟。**
|
||||
|
||||
## 接下來呢?
|
||||
|
||||
[下一篇文章][next post] 將會講解如何將我們的獨立執行檔轉成最小的作業系統核心。這包含建立自訂目標、用啟動程式組合我們的執行檔,還有學習如何輸出一些東西到螢幕上。
|
||||
|
||||
[next post]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
@@ -1,6 +0,0 @@
|
||||
+++
|
||||
title = "Extra Posts for Minimal Rust Kernel"
|
||||
sort_by = "weight"
|
||||
insert_anchor_links = "left"
|
||||
render = false
|
||||
+++
|
||||
@@ -1,29 +0,0 @@
|
||||
+++
|
||||
title = "Disable the Red Zone"
|
||||
weight = 1
|
||||
path = "red-zone"
|
||||
template = "second-edition/extra.html"
|
||||
+++
|
||||
|
||||
The [red zone] is an optimization of the [System V ABI] that allows functions to temporarily use the 128 bytes below its stack frame without adjusting the stack pointer:
|
||||
|
||||
[red zone]: https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64#the-red-zone
|
||||
[System V ABI]: https://wiki.osdev.org/System_V_ABI
|
||||
|
||||
<!-- more -->
|
||||
|
||||

|
||||
|
||||
The image shows the stack frame of a function with `n` local variables. On function entry, the stack pointer is adjusted to make room on the stack for the return address and the local variables.
|
||||
|
||||
The red zone is defined as the 128 bytes below the adjusted stack pointer. The function can use this area for temporary data that's not needed across function calls. Thus, the two instructions for adjusting the stack pointer can be avoided in some cases (e.g. in small leaf functions).
|
||||
|
||||
However, this optimization leads to huge problems with exceptions or hardware interrupts. Let's assume that an exception occurs while a function uses the red zone:
|
||||
|
||||

|
||||
|
||||
The CPU and the exception handler overwrite the data in red zone. But this data is still needed by the interrupted function. So the function won't work correctly anymore when we return from the exception handler. This might lead to strange bugs that [take weeks to debug].
|
||||
|
||||
[take weeks to debug]: https://forum.osdev.org/viewtopic.php?t=21720
|
||||
|
||||
To avoid such bugs when we implement exception handling in the future, we disable the red zone right from the beginning. This is achieved by adding the `"disable-redzone": true` line to our target configuration file.
|
||||
{kind=link}
@@ -1,92 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" "http://www.w3.org/TR/2001/PR-SVG-20010719/DTD/svg10.dtd">
|
||||
<svg width="17cm" height="11cm" viewBox="-60 -21 340 212" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink">
|
||||
<text font-size="9.03111" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="90" y="65.9389">
|
||||
<tspan x="90" y="65.9389"></tspan>
|
||||
</text>
|
||||
<g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="204" y1="70" x2="176.236" y2="70"/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="185.118,65 175.118,70 185.118,75 "/>
|
||||
</g>
|
||||
<text font-size="7.90222" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="208" y="72.75">
|
||||
<tspan x="208" y="72.75">Old Stack Pointer</tspan>
|
||||
</text>
|
||||
<text font-size="7.90222" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="75" y="230">
|
||||
<tspan x="75" y="230"></tspan>
|
||||
</text>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="-20" y1="70" x2="-4" y2="70"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="-20" y1="190" x2="-4" y2="190"/>
|
||||
<g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x1="-12" y1="72.2361" x2="-12" y2="187.764"/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="-7,81.118 -12,71.118 -17,81.118 "/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="-17,178.882 -12,188.882 -7,178.882 "/>
|
||||
</g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x1="0" y1="-20" x2="0" y2="0"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x1="170" y1="-20" x2="170" y2="0"/>
|
||||
<g>
|
||||
<rect style="fill: #00ff00" x="0" y="0" width="170" height="20"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="0" y="0" width="170" height="20"/>
|
||||
</g>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="85" y="13.125">
|
||||
<tspan x="85" y="13.125">Return Address</tspan>
|
||||
</text>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="84" y="4">
|
||||
<tspan x="84" y="4"></tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #dddddd" x="0" y="20" width="170" height="20"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="0" y="20" width="170" height="20"/>
|
||||
</g>
|
||||
<text font-size="9.03111" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="85" y="33.125">
|
||||
<tspan x="85" y="33.125">Local Variable 1</tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #cccccc" x="0" y="40" width="170" height="32"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x="0" y="40" width="170" height="32"/>
|
||||
</g>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="85" y="59.125">
|
||||
<tspan x="85" y="59.125">Local Variables 2..n</tspan>
|
||||
</text>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="0" y1="40" x2="170" y2="40"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="0" y1="72" x2="120" y2="72"/>
|
||||
<g>
|
||||
<rect style="fill: #ff3333" x="0" y="70" width="170" height="120"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="0" y="70" width="170" height="120"/>
|
||||
</g>
|
||||
<text font-size="9.03111" style="fill: #ffffff;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="40" y="179.125">
|
||||
<tspan x="40" y="179.125">Red Zone</tspan>
|
||||
</text>
|
||||
<text font-size="7.9021" style="fill: #000000;text-anchor:end;font-family:sans-serif;font-style:normal;font-weight:normal" x="-20" y="132.75">
|
||||
<tspan x="-20" y="132.75">128 bytes</tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #ffc200" x="30" y="70" width="140" height="30"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="30" y="70" width="140" height="30"/>
|
||||
</g>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="100" y="88.125">
|
||||
<tspan x="100" y="88.125">Exception Stack Frame</tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #ffe000" x="30" y="100" width="140" height="30"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="30" y="100" width="140" height="30"/>
|
||||
</g>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="100" y="118.125">
|
||||
<tspan x="100" y="118.125">Register Backup</tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #c6db97" x="30" y="130" width="140" height="30"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="30" y="130" width="140" height="30"/>
|
||||
</g>
|
||||
<text font-size="8.46654" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="100" y="147.925">
|
||||
<tspan x="100" y="147.925">Handler Function Stack Frame</tspan>
|
||||
</text>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #ff3333" x1="30" y1="70" x2="30" y2="160"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #ff3333" x1="30" y1="160" x2="170" y2="160"/>
|
||||
<g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="204" y1="160" x2="176.236" y2="160"/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="185.118,155 175.118,160 185.118,165 "/>
|
||||
</g>
|
||||
<text font-size="7.90222" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="208" y="162.635">
|
||||
<tspan x="208" y="162.635">New Stack Pointer</tspan>
|
||||
</text>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 6.2 KiB |
{kind=link}
@@ -1,62 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.0//EN" "http://www.w3.org/TR/2001/PR-SVG-20010719/DTD/svg10.dtd">
|
||||
<svg width="14cm" height="9cm" viewBox="-60 -21 270 172" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink">
|
||||
<text font-size="9.03111" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="90" y="65.9389">
|
||||
<tspan x="90" y="65.9389"></tspan>
|
||||
</text>
|
||||
<g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="154" y1="70" x2="126.236" y2="70"/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="135.118,65 125.118,70 135.118,75 "/>
|
||||
</g>
|
||||
<text font-size="7.90222" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="158" y="72.75">
|
||||
<tspan x="158" y="72.75">Stack Pointer</tspan>
|
||||
</text>
|
||||
<text font-size="7.90222" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="75" y="230">
|
||||
<tspan x="75" y="230"></tspan>
|
||||
</text>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="-20" y1="70" x2="-4" y2="70"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="-20" y1="150" x2="-4" y2="150"/>
|
||||
<g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x1="-12" y1="72.2361" x2="-12" y2="147.764"/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="-7,81.118 -12,71.118 -17,81.118 "/>
|
||||
<polyline style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" points="-17,138.882 -12,148.882 -7,138.882 "/>
|
||||
</g>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x1="0" y1="-20" x2="0" y2="0"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x1="120" y1="-20" x2="120" y2="0"/>
|
||||
<g>
|
||||
<rect style="fill: #00ff00" x="0" y="0" width="120" height="20"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="0" y="0" width="120" height="20"/>
|
||||
</g>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="60" y="13.125">
|
||||
<tspan x="60" y="13.125">Return Address</tspan>
|
||||
</text>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:start;font-family:sans-serif;font-style:normal;font-weight:normal" x="84" y="4">
|
||||
<tspan x="84" y="4"></tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #dddddd" x="0" y="20" width="120" height="20"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="0" y="20" width="120" height="20"/>
|
||||
</g>
|
||||
<text font-size="9.03111" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="60" y="33.125">
|
||||
<tspan x="60" y="33.125">Local Variable 1</tspan>
|
||||
</text>
|
||||
<g>
|
||||
<rect style="fill: #cccccc" x="0" y="40" width="120" height="32"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke-dasharray: 4; stroke: #000000" x="0" y="40" width="120" height="32"/>
|
||||
</g>
|
||||
<text font-size="9.03097" style="fill: #000000;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="60" y="59.125">
|
||||
<tspan x="60" y="59.125">Local Variables 2..n</tspan>
|
||||
</text>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="0" y1="40" x2="120" y2="40"/>
|
||||
<line style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x1="0" y1="72" x2="120" y2="72"/>
|
||||
<g>
|
||||
<rect style="fill: #ff3333" x="0" y="70" width="120" height="80"/>
|
||||
<rect style="fill: none; fill-opacity:0; stroke-width: 1; stroke: #000000" x="0" y="70" width="120" height="80"/>
|
||||
</g>
|
||||
<text font-size="9.03111" style="fill: #ffffff;text-anchor:middle;font-family:sans-serif;font-style:normal;font-weight:normal" x="60" y="113.125">
|
||||
<tspan x="60" y="113.125">Red Zone</tspan>
|
||||
</text>
|
||||
<text font-size="7.9021" style="fill: #000000;text-anchor:end;font-family:sans-serif;font-style:normal;font-weight:normal" x="-20" y="112.75">
|
||||
<tspan x="-20" y="112.75">128 bytes</tspan>
|
||||
</text>
|
||||
</svg>
|
||||
|
Before Width: | Height: | Size: 4.2 KiB |
@@ -1,44 +0,0 @@
|
||||
+++
|
||||
title = "Disable SIMD"
|
||||
weight = 2
|
||||
path = "disable-simd"
|
||||
template = "second-edition/extra.html"
|
||||
+++
|
||||
|
||||
[Single Instruction Multiple Data (SIMD)] instructions are able to perform an operation (e.g. addition) simultaneously on multiple data words, which can speed up programs significantly. The `x86_64` architecture supports various SIMD standards:
|
||||
|
||||
[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
|
||||
|
||||
<!-- more -->
|
||||
|
||||
- [MMX]: The _Multi Media Extension_ instruction set was introduced in 1997 and defines eight 64 bit registers called `mm0` through `mm7`. These registers are just aliases for the registers of the [x87 floating point unit].
|
||||
- [SSE]: The _Streaming SIMD Extensions_ instruction set was introduced in 1999. Instead of re-using the floating point registers, it adds a completely new register set. The sixteen new registers are called `xmm0` through `xmm15` and are 128 bits each.
|
||||
- [AVX]: The _Advanced Vector Extensions_ are extensions that further increase the size of the multimedia registers. The new registers are called `ymm0` through `ymm15` and are 256 bits each. They extend the `xmm` registers, so e.g. `xmm0` is the lower half of `ymm0`.
|
||||
|
||||
[MMX]: https://en.wikipedia.org/wiki/MMX_(instruction_set)
|
||||
[x87 floating point unit]: https://en.wikipedia.org/wiki/X87
|
||||
[SSE]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
|
||||
[AVX]: https://en.wikipedia.org/wiki/Advanced_Vector_Extensions
|
||||
|
||||
By using such SIMD standards, programs can often speed up significantly. Good compilers are able to transform normal loops into such SIMD code automatically through a process called [auto-vectorization].
|
||||
|
||||
[auto-vectorization]: https://en.wikipedia.org/wiki/Automatic_vectorization
|
||||
|
||||
However, the large SIMD registers lead to problems in OS kernels. The reason is that the kernel has to backup all registers that it uses to memory on each hardware interrupt, because they need to have their original values when the interrupted program continues. So if the kernel uses SIMD registers, it has to backup a lot more data (512–1600 bytes), which noticeably decreases performance. To avoid this performance loss, we want to disable the `sse` and `mmx` features (the `avx` feature is disabled by default).
|
||||
|
||||
We can do that through the the `features` field in our target specification. To disable the `mmx` and `sse` features we add them prefixed with a minus:
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse"
|
||||
```
|
||||
|
||||
## Floating Point
|
||||
Unfortunately for us, the `x86_64` architecture uses SSE registers for floating point operations. Thus, every use of floating point with disabled SSE causes an error in LLVM. The problem is that Rust's core library already uses floats (e.g., it implements traits for `f32` and `f64`), so avoiding floats in our kernel does not suffice.
|
||||
|
||||
Fortunately, LLVM has support for a `soft-float` feature, emulates all floating point operations through software functions based on normal integers. This makes it possible to use floats in our kernel without SSE, it will just be a bit slower.
|
||||
|
||||
To turn on the `soft-float` feature for our kernel, we add it to the `features` line in our target specification, prefixed with a plus:
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
```
|
||||
@@ -1,503 +0,0 @@
|
||||
+++
|
||||
title = "یک هسته مینیمال با Rust"
|
||||
weight = 2
|
||||
path = "fa/minimal-rust-kernel"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "7212ffaa8383122b1eb07fe1854814f99d2e1af4"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["hamidrezakp", "MHBahrampour"]
|
||||
rtl = true
|
||||
+++
|
||||
|
||||
در این پست ما برای معماری x86 یک هسته مینیمال ۶۴ بیتی به زبان راست میسازیم. با استفاده از باینری مستقل Rust از پست قبل، یک دیسک ایمیج قابل بوت میسازیم، که متنی را در صفحه چاپ کند.
|
||||
|
||||
[باینری مستقل Rust]: @/second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
<!-- more -->
|
||||
|
||||
این بلاگ بصورت آزاد روی [گیتهاب] توسعه داده شده است. اگر شما مشکل یا سوالی دارید، لطفاً آنجا یک ایشو باز کنید. شما همچنین میتوانید [در زیر] این پست کامنت بگذارید. منبع کد کامل این پست را میتوانید در بِرَنچ [`post-02`][post branch] پیدا کنید.
|
||||
|
||||
[گیتهاب]: https://github.com/phil-opp/blog_os
|
||||
[در زیر]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## فرآیند بوت شدن
|
||||
وقتی یک رایانه را روشن میکنید، شروع به اجرای کد فِرْموِر (کلمه: firmware) ذخیره شده در [ROM] مادربرد میکند. این کد یک [power-on self-test] انجام میدهد، رم موجود را تشخیص داده، و پردازنده و سخت افزار را پیش مقداردهی اولیه میکند. پس از آن به یک دنبال دیسک قابل بوت میگردد و شروع به بوت کردن هسته سیستم عامل میکند.
|
||||
|
||||
[ROM]: https://en.wikipedia.org/wiki/Read-only_memory
|
||||
[power-on self-test]: https://en.wikipedia.org/wiki/Power-on_self-test
|
||||
|
||||
در x86، دو استاندارد فِرْموِر (کلمه: firmware) وجود دارد: «سامانهٔ ورودی/خروجیِ پایه» (**[BIOS]**) و استاندارد جدیدتر «رابط فِرْموِر توسعه یافته یکپارچه» (**[UEFI]**). استاندارد BIOS قدیمی و منسوخ است، اما ساده است و از دهه ۱۹۸۰ تاکنون در هر دستگاه x86 کاملاً پشتیبانی میشود. در مقابل، UEFI مدرنتر است و ویژگیهای بسیار بیشتری دارد، اما راه اندازی آن پیچیدهتر است (حداقل به نظر من).
|
||||
|
||||
[BIOS]: https://en.wikipedia.org/wiki/BIOS
|
||||
[UEFI]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
|
||||
|
||||
در حال حاضر، ما فقط پشتیبانی BIOS را ارائه میدهیم، اما پشتیبانی از UEFI نیز برنامهریزی شده است. اگر میخواهید در این زمینه به ما کمک کنید، [ایشو گیتهاب](https://github.com/phil-opp/blog_os/issues/349) را بررسی کنید.
|
||||
|
||||
### بوت شدن BIOS
|
||||
|
||||
تقریباً همه سیستمهای x86 از بوت شدن BIOS پشتیبانی میکنند، از جمله سیستمهای جدیدترِ مبتنی بر UEFI که از BIOS شبیهسازی شده استفاده میکنند. این عالی است، زیرا شما میتوانید از منطق بوت یکسانی در تمام سیستمهای قرنهای گذشته استفاده کنید. اما این سازگاری گسترده در عین حال بزرگترین نقطه ضعف راهاندازی BIOS است، زیرا این بدان معناست که پردازنده قبل از بوت شدن در یک حالت سازگاری 16 بیتی به نام [real mode] قرار داده میشود تا بوتلودرهای قدیمی از دهه 1980 همچنان کار کنند.
|
||||
|
||||
اما بیایید از ابتدا شروع کنیم:
|
||||
|
||||
وقتی یک رایانه را روشن میکنید، BIOS را از حافظه فلش مخصوصی که روی مادربرد قرار دارد بارگذاری میکند. BIOS روالهای خودآزمایی و مقداردهی اولیه سخت افزار را اجرا می کند، سپس به دنبال دیسکهای قابل بوت میگردد. اگر یکی را پیدا کند، کنترل به _بوتلودرِ_ آن منتقل میشود، که یک قسمت ۵۱۲ بایتی از کد اجرایی است و در ابتدای دیسک ذخیره شده است. بیشتر بوتلودرها از ۵۱۲ بایت بزرگتر هستند، بنابراین بوتلودرها معمولاً به یک قسمت کوچک ابتدایی تقسیم میشوند که در ۵۱۲ بایت جای میگیرد و قسمت دوم که متعاقباً توسط قسمت اول بارگذاری میشود.
|
||||
|
||||
بوتلودر باید محل ایمیج هسته را بر روی دیسک تعیین کرده و آن را در حافظه بارگذاری کند. همچنین ابتدا باید CPU را از [real mode] (ترجمه: حالت واقعی) 16 بیتی به [protected mode] (ترجمه: حالت محافظت شده) 32 بیتی و سپس به [long mode] (ترجمه: حالت طولانی) 64 بیتی سوییچ کند، جایی که ثباتهای 64 بیتی و کل حافظه اصلی در آن در دسترس هستند. کار سوم آن پرسوجو درباره اطلاعات خاص (مانند نگاشت حافظه) از BIOS و انتقال آن به هسته سیستم عامل است.
|
||||
|
||||
[real mode]: https://en.wikipedia.org/wiki/Real_mode
|
||||
[protected mode]: https://en.wikipedia.org/wiki/Protected_mode
|
||||
[long mode]: https://en.wikipedia.org/wiki/Long_mode
|
||||
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
|
||||
نوشتن بوتلودر کمی دشوار است زیرا به زبان اسمبلی و بسیاری از مراحل غیر بصیرانه مانند "نوشتن این مقدار جادویی در این ثبات پردازنده" نیاز دارد. بنابراین ما در این پست ایجاد بوتلودر را پوشش نمیدهیم و در عوض ابزاری به نام [bootimage] را ارائه میدهیم که بوتلودر را به طور خودکار به هسته شما اضافه میکند.
|
||||
|
||||
[bootimage]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
اگر علاقهمند به ساخت بوتلودر هستید: با ما همراه باشید، مجموعهای از پستها در این زمینه از قبل برنامهریزی شده است! <!-- , check out our “_[Writing a Bootloader]_” posts, where we explain in detail how a bootloader is built. -->
|
||||
|
||||
#### استاندارد بوت چندگانه
|
||||
|
||||
برای جلوگیری از این که هر سیستم عاملی بوتلودر خود را پیادهسازی کند، که فقط با یک سیستم عامل سازگار است، [بنیاد نرم افزار آزاد] در سال 1995 یک استاندارد بوتلودر آزاد به نام [Multiboot] ایجاد کرد. این استاندارد یک رابط بین بوتلودر و سیستم عامل را تعریف میکند، به طوری که هر بوتلودر سازگار با Multiboot میتواند هر سیستم عامل سازگار با Multiboot را بارگذاری کند. پیادهسازی مرجع [GNU GRUB] است که محبوبترین بوتلودر برای سیستمهای لینوکس است.
|
||||
|
||||
[بنیاد نرم افزار آزاد]: https://en.wikipedia.org/wiki/Free_Software_Foundation
|
||||
[Multiboot]: https://wiki.osdev.org/Multiboot
|
||||
[GNU GRUB]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
|
||||
برای سازگار کردن هسته با Multiboot، کافیست یک به اصطلاح [Multiboot header] را در ابتدای فایل هسته اضافه کنید. با این کار بوت کردن سیستم عامل در GRUB بسیار آسان خواهد شد. با این حال، GRUB و استاندارد Multiboot نیز دارای برخی مشکلات هستند:
|
||||
|
||||
[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
|
||||
|
||||
- آنها فقط از حالت محافظت شده 32 بیتی پشتیبانی میکنند. این بدان معناست که شما برای تغییر به حالت طولانی 64 بیتی هنوز باید پیکربندی CPU را انجام دهید.
|
||||
- آنها برای ساده سازی بوتلودر طراحی شدهاند نه برای ساده سازی هسته. به عنوان مثال، هسته باید با [اندازه صفحه پیش فرض تنظیم شده] پیوند داده شود، زیرا GRUB در غیر اینصورت نمیتواند هدر Multiboot را پیدا کند. مثال دیگر این است که [اطلاعات بوت]، که به هسته منتقل میشوند، به جای ارائه انتزاعات تمیز و واضح، شامل ساختارها با وابستگی زیاد به معماری هستند.
|
||||
- هر دو استاندارد GRUB و Multiboot بصورت ناقص مستند شدهاند.
|
||||
- برای ایجاد یک ایمیج دیسکِ قابل بوت از فایل هسته، GRUB باید روی سیستم میزبان نصب شود. این امر باعث دشوارتر شدنِ توسعه در ویندوز یا Mac میشود.
|
||||
|
||||
[اندازه صفحه پیش فرض تنظیم شده]: https://wiki.osdev.org/Multiboot#Multiboot_2
|
||||
[اطلاعات بوت]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
|
||||
|
||||
به دلیل این اشکالات ما تصمیم گرفتیم از GRUB یا استاندارد Multiboot استفاده نکنیم. با این حال، ما قصد داریم پشتیبانی Multiboot را به ابزار [bootimage] خود اضافه کنیم، به طوری که امکان بارگذاری هسته شما بر روی یک سیستم با بوتلودر GRUB نیز وجود داشته باشد. اگر علاقهمند به نوشتن هسته سازگار با Multiboot هستید، [نسخه اول] مجموعه پستهای این وبلاگ را بررسی کنید.
|
||||
|
||||
[نسخه اول]: @/edition-1/_index.md
|
||||
|
||||
### UEFI
|
||||
|
||||
(ما در حال حاضر پشتیبانی UEFI را ارائه نمیدهیم، اما خیلی دوست داریم این کار را انجام دهیم! اگر میخواهید کمک کنید، لطفاً در [ایشو گیتهاب](https://github.com/phil-opp/blog_os/issues/349) به ما بگویید.)
|
||||
|
||||
## یک هسته مینیمال
|
||||
|
||||
اکنون که تقریباً میدانیم چگونه یک کامپیوتر بوت میشود، وقت آن است که هسته مینیمال خودمان را ایجاد کنیم. هدف ما ایجاد دیسک ایمیجی میباشد که “!Hello World” را هنگام بوت شدن چاپ کند. برای این منظور از [باینری مستقل Rust] که در پست قبل دیدید استفاده میکنیم.
|
||||
|
||||
همانطور که ممکن است به یاد داشته باشید، باینری مستقل را از طریق `cargo` ایجاد کردیم، اما با توجه به سیستم عامل، به نامهای ورودی و پرچمهای کامپایل مختلف نیاز داشتیم. به این دلیل که `cargo` به طور پیش فرض برای سیستم میزبان بیلد میکند، بطور مثال سیستمی که از آن برای نوشتن هسته استفاده میکنید. این چیزی نیست که ما برای هسته خود بخواهیم، زیرا منطقی نیست که هسته سیستم عاملمان را روی یک سیستم عامل دیگر اجرا کنیم. در عوض، ما میخواهیم هسته را برای یک _سیستم هدف_ کاملاً مشخص کامپایل کنیم.
|
||||
|
||||
### نصب Rust Nightly
|
||||
|
||||
راست دارای سه کانال انتشار است: _stable_, _beta_, and _nightly_ (ترجمه از چپ به راست: پایدار، بتا و شبانه). کتاب Rust تفاوت بین این کانالها را به خوبی توضیح میدهد، بنابراین یک دقیقه وقت بگذارید و [آن را بررسی کنید](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains). برای ساخت یک سیستم عامل به برخی از ویژگیهای آزمایشی نیاز داریم که فقط در کانال شبانه موجود است، بنابراین باید نسخه شبانه Rust را نصب کنیم.
|
||||
|
||||
برای مدیریت نصبهای Rust من به شدت [rustup] را توصیه میکنم. به شما این امکان را میدهد که کامپایلرهای شبانه، بتا و پایدار را در کنار هم نصب کنید و بروزرسانی آنها را آسان میکند. با rustup شما میتوانید از یک کامپایلر شبانه برای دایرکتوری جاری استفاده کنید، کافیست دستور `rustup override set nightly` را اجرا کنید. همچنین میتوانید فایلی به نام `rust-toolchain` را با محتوای `nightly` در دایرکتوری ریشه پروژه اضافه کنید. با اجرای `rustc --version` میتوانید چک کنید که نسخه شبانه را دارید یا نه. شماره نسخه باید در پایان شامل `nightly-` باشد.
|
||||
|
||||
[rustup]: https://www.rustup.rs/
|
||||
|
||||
کامپایلر شبانه به ما امکان میدهد با استفاده از به اصطلاح _feature flags_ در بالای فایل، از ویژگیهای مختلف آزمایشی استفاده کنیم. به عنوان مثال، میتوانیم [`asm!` macro] آزمایشی را برای اجرای دستورات اسمبلیِ اینلاین (تلفظ: inline) با اضافه کردن `[feature(asm)]!#` به بالای فایل `main.rs` فعال کنیم. توجه داشته باشید که این ویژگیهای آزمایشی، کاملاً ناپایدار هستند، به این معنی که نسخههای آتی Rust ممکن است بدون هشدار قبلی آنها را تغییر داده یا حذف کند. به همین دلیل ما فقط در صورت لزوم از آنها استفاده خواهیم کرد.
|
||||
|
||||
[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
|
||||
|
||||
### مشخصات هدف
|
||||
|
||||
کارگو (کلمه: cargo) سیستمهای هدف مختلف را از طریق `target--` پشتیبانی میکند. سیستم هدف توسط یک به اصطلاح _[target triple]_ (ترجمه: هدف سه گانه) توصیف شده است، که معماری CPU، فروشنده، سیستم عامل، و [ABI] را شامل میشود. برای مثال، هدف سه گانه `x86_64-unknown-linux-gnu` یک سیستم را توصیف میکند که دارای سیپییو `x86_64`، بدون فروشنده مشخص و یک سیستم عامل لینوکس با GNU ABI است. Rust از [هدفهای سه گانه مختلفی][platform-support] پشتیبانی میکند، شامل `arm-linux-androideabi` برای اندروید یا [`wasm32-unknown-unknown` برای وباسمبلی](https://www.hellorust.com/setup/wasm-target/).
|
||||
|
||||
[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
[ABI]: https://stackoverflow.com/a/2456882
|
||||
[platform-support]: https://forge.rust-lang.org/release/platform-support.html
|
||||
[custom-targets]: https://doc.rust-lang.org/nightly/rustc/targets/custom.html
|
||||
|
||||
برای سیستم هدف خود، به برخی از پارامترهای خاص پیکربندی نیاز داریم (به عنوان مثال، فاقد سیستم عامل زیرین)، بنابراین هیچ یک از [اهداف سه گانه موجود][platform-support] مناسب نیست. خوشبختانه Rust به ما اجازه میدهد تا [هدف خود][custom-targets] را از طریق یک فایل JSON تعریف کنیم. به عنوان مثال، یک فایل JSON که هدف `x86_64-unknown-linux-gnu` را توصیف میکند به این شکل است:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-linux-gnu",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "linux",
|
||||
"executables": true,
|
||||
"linker-flavor": "gcc",
|
||||
"pre-link-args": ["-m64"],
|
||||
"morestack": false
|
||||
}
|
||||
```
|
||||
|
||||
اکثر فیلدها برای LLVM مورد نیاز هستند تا بتواند کد را برای آن پلتفرم ایجاد کند. برای مثال، فیلد [`data-layout`] اندازه انواع مختلف عدد صحیح، مُمَیزِ شناور و انواع اشارهگر را تعریف میکند. سپس فیلدهایی وجود دارد که Rust برای کامپایل شرطی از آنها استفاده میکند، مانند `target-pointer-width`. نوع سوم فیلدها نحوه ساخت crate (تلفظ: کرِیت) را تعریف میکنند. مثلا، فیلد `pre-link-args` آرگومانهای منتقل شده به [لینکر] را مشخص میکند.
|
||||
|
||||
[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
|
||||
[لینکر]: https://en.wikipedia.org/wiki/Linker_(computing)
|
||||
|
||||
ما همچنین سیستمهای `x86_64` را با هسته خود مورد هدف قرار میدهیم، بنابراین مشخصات هدف ما بسیار شبیه به مورد بالا خواهد بود. بیایید با ایجاد یک فایل `x86_64-blog_os.json` شروع کنیم (هر اسمی را که دوست دارید انتخاب کنید) با محتوای مشترک:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true
|
||||
}
|
||||
```
|
||||
|
||||
توجه داشته باشید که ما OS را در `llvm-target` و همچنین فیلد `os` را به `none` تغییر دادیم، زیرا ما هسته را روی یک bare metal اجرا میکنیم.
|
||||
|
||||
همچنین موارد زیر که مربوط به ساخت (ترجمه: build-related) هستند را اضافه میکنیم:
|
||||
|
||||
```json
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
```
|
||||
|
||||
به جای استفاده از لینکر پیش فرض پلتفرم (که ممکن است از اهداف لینوکس پشتیبانی نکند)، ما از لینکر کراس پلتفرم [LLD] استفاده میکنیم که برای پیوند دادن هسته ما با Rust ارائه میشود.
|
||||
|
||||
[LLD]: https://lld.llvm.org/
|
||||
|
||||
```json
|
||||
"panic-strategy": "abort",
|
||||
```
|
||||
|
||||
این تنظیم مشخص میکند که هدف از [stack unwinding] درهنگام panic پشتیبانی نمیکند، بنابراین به جای آن خود برنامه باید مستقیماً متوقف شود. این همان اثر است که آپشن `panic = "abort"` در فایل Cargo.toml دارد، پس میتوانیم آن را از فایل Cargo.toml حذف کنیم.(توجه داشته باشید که این آپشنِ هدف همچنین زمانی اعمال میشود که ما کتابخانه `هسته` را مجددا در ادامه همین پست کامپایل میکنیم. بنابراین حتماً این گزینه را اضافه کنید، حتی اگر ترجیح می دهید گزینه Cargo.toml را حفظ کنید.)
|
||||
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
|
||||
```json
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
ما در حال نوشتن یک هسته هستیم، بنابراین بالاخره باید وقفهها را مدیریت کنیم. برای انجام ایمن آن، باید بهینهسازی اشارهگر پشتهای خاصی به نام _“red zone”_ (ترجمه: منطقه قرمز) را غیرفعال کنیم، زیرا در غیر این صورت باعث خراب شدن پشته میشود. برای اطلاعات بیشتر، به پست جداگانه ما در مورد [غیرفعال کردن منطقه قرمز] مراجعه کنید.
|
||||
|
||||
[غیرفعال کردن منطقه قرمز]: @/second-edition/posts/02-minimal-rust-kernel/disable-red-zone/index.md
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float",
|
||||
```
|
||||
|
||||
فیلد `features` ویژگیهای هدف را فعال/غیرفعال میکند. ما ویژگیهای `mmx` و `sse` را با گذاشتن یک منفی در ابتدای آنها غیرفعال کردیم و ویژگی `soft-float` را با اضافه کردن یک مثبت به ابتدای آن فعال کردیم. توجه داشته باشید که بین پرچمهای مختلف نباید فاصلهای وجود داشته باشد، در غیر این صورت LLVM قادر به تفسیر رشته ویژگیها نیست.
|
||||
|
||||
ویژگیهای `mmx` و `sse` پشتیبانی از دستورالعملهای [Single Instruction Multiple Data (SIMD)] را تعیین میکنند، که اغلب میتواند سرعت برنامهها را به میزان قابل توجهی افزایش دهد. با این حال، استفاده از ثباتهای بزرگ SIMD در هسته سیستم عامل منجر به مشکلات عملکردی میشود. دلیل آن این است که هسته قبل از ادامه یک برنامهی متوقف شده، باید تمام رجیسترها را به حالت اولیه خود برگرداند. این بدان معناست که هسته در هر فراخوانی سیستم یا وقفه سخت افزاری باید حالت کامل SIMD را در حافظه اصلی ذخیره کند. از آنجا که حالت SIMD بسیار بزرگ است (512-1600 بایت) و وقفهها ممکن است اغلب اتفاق بیفتند، این عملیات ذخیره و بازیابی اضافی به طور قابل ملاحظهای به عملکرد آسیب میرساند. برای جلوگیری از این، SIMD را برای هسته خود غیرفعال میکنیم (نه برای برنامههایی که از روی آن اجرا می شوند!).
|
||||
|
||||
[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
|
||||
|
||||
یک مشکل در غیرفعال کردن SIMD این است که عملیاتهای مُمَیزِ شناور (ترجمه: floating point) در `x86_64` به طور پیش فرض به ثباتهای SIMD نیاز دارد. برای حل این مشکل، ویژگی `soft-float` را اضافه میکنیم، که از طریق عملکردهای نرمافزاری مبتنی بر اعداد صحیح عادی، تمام عملیات مُمَیزِ شناور را شبیهسازی میکند.
|
||||
|
||||
For more information, see our post on [disabling SIMD](@/second-edition/posts/02-minimal-rust-kernel/disable-simd/index.md).
|
||||
|
||||
#### کنار هم قرار دادن
|
||||
فایل مشخصات هدف ما اکنون به این شکل است:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
"panic-strategy": "abort",
|
||||
"disable-redzone": true,
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
}
|
||||
```
|
||||
|
||||
### ساخت هسته
|
||||
|
||||
عملیات کامپایل کردن برای هدف جدید ما از قراردادهای لینوکس استفاده خواهد کرد (کاملاً مطمئن نیستم که چرا، تصور میکنم این فقط پیش فرض LLVM باشد). این بدان معنی است که ما به یک نقطه ورود به نام `start_` نیاز داریم همانطور که در [پست قبلی] توضیح داده شد:
|
||||
|
||||
[پست قبلی]: @/second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// this function is the entry point, since the linker looks for a function
|
||||
// named `_start` by default
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
توجه داشته باشید که بدون توجه به سیستم عامل میزبان، باید نقطه ورود را `start_` بنامید.
|
||||
|
||||
اکنون میتوانیم با نوشتن نام فایل JSON بعنوان `target--`، هسته خود را برای هدف جدید بسازیم:
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
|
||||
error[E0463]: can't find crate for `core`
|
||||
```
|
||||
|
||||
شکست میخورد! این خطا به ما میگوید که کامپایلر Rust دیگر [کتابخانه `core`] را پیدا نمیکند. این کتابخانه شامل انواع اساسی Rust مانند `Result` ، `Option` و iterators است، و به طور ضمنی به همه کریتهای `no_std` لینک است.
|
||||
|
||||
[کتابخانه `core`]: https://doc.rust-lang.org/nightly/core/index.html
|
||||
|
||||
مشکل این است که کتابخانه core همراه با کامپایلر Rust به عنوان یک کتابخانه _precompiled_ (ترجمه: از پیش کامپایل شده) توزیع میشود. بنابراین فقط برای میزبانهای سهگانه پشتیبانی شده مجاز است (مثلا، `x86_64-unknown-linux-gnu`) اما برای هدف سفارشی ما صدق نمیکند. اگر میخواهیم برای سیستمهای هدف دیگر کدی را کامپایل کنیم، ابتدا باید `core` را برای این اهداف دوباره کامپایل کنیم.
|
||||
|
||||
#### آپشن `build-std`
|
||||
|
||||
اینجاست که [ویژگی `build-std`] کارگو وارد میشود. این امکان را میدهد تا بجای استفاده از نسخههای از پیش کامپایل شده با نصب Rust، بتوانیم `core` و کریت سایر کتابخانههای استاندارد را در صورت نیاز دوباره کامپایل کنیم. این ویژگی بسیار جدید بوده و هنوز تکمیل نشده است، بنابراین بعنوان «ناپایدار» علامت گذاری شده و فقط در [نسخه شبانه کامپایلر Rust] در دسترس میباشد.
|
||||
|
||||
[ویژگی `build-std`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
|
||||
[نسخه شبانه کامپایلر Rust]: #installing-rust-nightly
|
||||
|
||||
برای استفاده از این ویژگی، ما نیاز داریم تا یک فایل [پیکربندی کارگو] در `cargo/config.toml.` با محتوای زیر بسازیم:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std = ["core", "compiler_builtins"]
|
||||
```
|
||||
|
||||
این به کارگو میگوید که باید `core` و کتابخانه `compiler_builtins` را دوباره کامپایل کند. مورد دوم لازم است زیرا یک وابستگی از `core` است. به منظور کامپایل مجدد این کتابخانهها، کارگو نیاز به دسترسی به کد منبع Rust دارد که میتوانیم آن را با `rustup component add rust-src` نصب کنیم.
|
||||
|
||||
<div class="note">
|
||||
|
||||
**یادداشت:** کلید پیکربندی `unstable.build-std` به نسخهای جدیدتر از نسخه 2020-07-15 شبانه Rust نیاز دارد.
|
||||
|
||||
</div>
|
||||
|
||||
پس از تنظیم کلید پیکربندی `unstable.build-std` و نصب مولفه `rust-src`، میتوانیم مجددا دستور بیلد (کلمه: build) را اجرا کنیم.
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
Compiling core v0.0.0 (/…/rust/src/libcore)
|
||||
Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling compiler_builtins v0.1.32
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
میبینیم که `cargo build` دوباره `core` و `rustc-std-workspace-core` (یک وابستگی از `compiler_builtins`)، و کتابخانه `compiler_builtins` را برای سیستم هدف سفارشیمان کامپایل میکند.
|
||||
|
||||
#### موارد ذاتیِ مربوط به مموری
|
||||
|
||||
کامپایلر Rust فرض میکند که مجموعه خاصی از توابع داخلی برای همه سیستمها در دسترس است. اکثر این توابع توسط کریت `compiler_builtins` ارائه میشود که ما آن را به تازگی مجددا کامپایل کردیم. با این حال، برخی از توابع مربوط به حافظه در آن کریت وجود دارد که به طور پیشفرض فعال نیستند زیرا به طور معمول توسط کتابخانه C موجود در سیستم ارائه میشوند. این توابع شامل `memset` میباشد که مجموعه تمام بایتها را در یک بلوک حافظه بر روی یک مقدار مشخص قرار میدهد، `memcpy` که یک بلوک حافظه را در دیگری کپی میکند و `memcmp` که دو بلوک حافظه را با یکدیگر مقایسه میکند. اگرچه ما در حال حاضر به هیچ یک از این توابع برای کامپایل هسته خود نیازی نداریم، اما به محض افزودن کدهای بیشتر به آن، این توابع مورد نیاز خواهند بود (برای مثال، هنگام کپی کردن یک ساختمان).
|
||||
|
||||
از آنجا که نمیتوانیم به کتابخانه C سیستم عامل لینک دهیم، به روشی جایگزین برای ارائه این توابع به کامپایلر نیاز داریم. یک رویکرد ممکن برای این کار میتواند پیادهسازی توابع `memset` و غیره و اعمال صفت `[no_mangle]#` (برای جلوگیری از تغییر نام خودکار در هنگام کامپایل کردن) بر روی آنها اعمال باشد. با این حال، این خطرناک است زیرا کوچکترین اشتباهی در اجرای این توابع میتواند منجر به یک رفتار تعریف نشده شود. به عنوان مثال، ممکن است هنگام پیادهسازی `memcpy` با استفاده از حلقه `for` یک بازگشت بیپایان داشته باشید زیرا حلقههای `for` به طور ضمنی مِتُد تریتِ (کلمه: trait) [`IntoIterator::into_iter`] را فراخوانی میکنند، که ممکن است دوباره `memcpy` را فراخوانی کند. بنابراین بهتر است به جای آن از پیاده سازیهای تست شده موجود، مجدداً استفاده کنید.
|
||||
|
||||
[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
|
||||
|
||||
خوشبختانه کریت `compiler_builtins` از قبل شامل پیاده سازی تمام توابع مورد نیازمان است، آنها فقط به طور پیش فرض غیرفعال هستند تا با پیاده سازی های کتابخانه C تداخلی نداشته باشند. ما میتوانیم آنها را با تنظیم پرچم [`build-std-features`] کارگو بر روی `["compiler-builtins-mem"]` فعال کنیم. مانند پرچم `build-std`، این پرچم میتواند به عنوان پرچم `Z-` در خط فرمان استفاده شود یا در جدول `unstable` در فایل `cargo/config.toml.` پیکربندی شود. از آنجا که همیشه میخواهیم با این پرچم بیلد کنیم، گزینه پیکربندی فایل منطقیتر است:
|
||||
|
||||
[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std-features = ["compiler-builtins-mem"]
|
||||
```
|
||||
پشتیبانی برای ویژگی `compiler-builtins-mem` [به تازگی اضافه شده](https://github.com/rust-lang/rust/pull/77284)، پس حداقل به نسخه شبانه `2020-09-30` نیاز دارید.
|
||||
|
||||
در پشت صحنه، این پرچم [ویژگی `mem`] از کریت `compiler_builtins` را فعال میکند. اثرش این است که صفت `[no_mangle]#` بر روی [پیادهسازی `memcpy` و بقیه موارد] از کریت اعمال میشود، که آنها در دسترس لینکر قرار میدهد. شایان ذکر است که این توابع در حال حاضر [بهینه نشدهاند]، بنابراین ممکن است عملکرد آنها در بهترین حالت نباشد، اما حداقل صحیح هستند. برای `x86_64` ، یک pull request باز برای [بهینه سازی این توابع با استفاده از دستورالعملهای خاص اسمبلی][memcpy rep movsb] وجود دارد.
|
||||
|
||||
[ویژگی `mem`]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L51-L52
|
||||
[پیادهسازی `memcpy` و بقیه موارد]: (https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69)
|
||||
[بهینه نشدهاند]: https://github.com/rust-lang/compiler-builtins/issues/339
|
||||
[memcpy rep movsb]: https://github.com/rust-lang/compiler-builtins/pull/365
|
||||
|
||||
با این تغییر، هسته ما برای همه توابع مورد نیاز کامپایلر، پیاده سازی معتبری دارد، بنابراین حتی اگر کد ما پیچیدهتر باشد نیز باز کامپایل میشود.
|
||||
|
||||
#### تنظیم یک هدف پیش فرض
|
||||
|
||||
برای اینکه نیاز نباشد در هر فراخوانی `cargo build` پارامتر `target--` را وارد کنیم، میتوانیم هدف پیشفرض را بازنویسی کنیم. برای این کار، ما کد زیر را به [پیکربندی کارگو] در فایل `cargo/config.toml.` اضافه میکنیم:
|
||||
|
||||
[پیکربندی کارگو]: https://doc.rust-lang.org/cargo/reference/config.html
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[build]
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
این به `cargo` میگوید در صورتی که صریحاً از `target--` استفاده نکردیم، از هدف ما یعنی `x86_64-blog_os.json` استفاده کند. در واقع اکنون میتوانیم هسته خود را با یک `cargo build` ساده بسازیم. برای اطلاعات بیشتر در مورد گزینههای پیکربندی کارگو، [اسناد رسمی][پیکربندی کارگو] را بررسی کنید.
|
||||
|
||||
اکنون میتوانیم هسته را برای یک هدف bare metal با یک `cargo build` ساده بسازیم. با این حال، نقطه ورود `start_` ما، که توسط بوت لودر فراخوانی میشود، هنوز خالی است. وقت آن است که از طریق آن، چیزی را در خروجی نمایش دهیم.
|
||||
|
||||
### چاپ روی صفحه
|
||||
|
||||
سادهترین راه برای چاپ متن در صفحه در این مرحله [بافر متن VGA] است. این یک منطقه خاص حافظه است که به سخت افزار VGA نگاشت (مَپ) شده و حاوی مطالب نمایش داده شده روی صفحه است. به طور معمول از 25 خط تشکیل شده است که هر کدام شامل 80 سلول کاراکتر هستند. هر سلول کاراکتر یک کاراکتر ASCII را با برخی از رنگهای پیش زمینه و پس زمینه نشان میدهد. خروجی صفحه به این شکل است:
|
||||
|
||||
[بافر متن VGA]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
|
||||

|
||||
|
||||
ما در پست بعدی، جایی که اولین درایور کوچک را برای آن مینویسیم، در مورد قالب دقیق بافر متن VGA بحث خواهیم کرد. برای چاپ “!Hello World”، فقط باید بدانیم که بافر در آدرس `0xb8000` قرار دارد و هر سلول کاراکتر از یک بایت ASCII و یک بایت رنگ تشکیل شده است.
|
||||
|
||||
پیادهسازی مشابه این است:
|
||||
|
||||
```rust
|
||||
static HELLO: &[u8] = b"Hello World!";
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
let vga_buffer = 0xb8000 as *mut u8;
|
||||
|
||||
for (i, &byte) in HELLO.iter().enumerate() {
|
||||
unsafe {
|
||||
*vga_buffer.offset(i as isize * 2) = byte;
|
||||
*vga_buffer.offset(i as isize * 2 + 1) = 0xb;
|
||||
}
|
||||
}
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
ابتدا عدد صحیح `0xb8000` را در یک اشارهگر خام (ترجمه: raw pointer) میریزیم. سپس روی بایتهای [رشته بایت][byte string] [استاتیک][static] `HELLO` [پیمایش][iterate] میکنیم. ما از متد [`enumerate`] برای اضافه کردن متغیر درحال اجرای `i` استفاده میکنیم. در بدنه حلقه for، از متد [`offset`] برای نوشتن بایت رشته و بایت رنگ مربوطه استفاده میکنیم (`0xb` فیروزهای روشن است).
|
||||
|
||||
[iterate]: https://doc.rust-lang.org/stable/book/ch13-02-iterators.html
|
||||
[static]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
|
||||
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
|
||||
[byte string]: https://doc.rust-lang.org/reference/tokens.html#byte-string-literals
|
||||
[اشارهگر خام]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
|
||||
|
||||
توجه داشته باشید که یک بلوک [`unsafe`] همیشه هنگام نوشتن در حافظه مورد استفاده قرار میگیرد. دلیل این امر این است که کامپایلر Rust نمیتواند معتبر بودن اشارهگرهای خام که ایجاد میکنیم را ثابت کند. آنها میتوانند به هر کجا اشاره کنند و منجر به خراب شدن دادهها شوند. با قرار دادن آنها در یک بلوک `unsafe`، ما در اصل به کامپایلر میگوییم که کاملاً از معتبر بودن عملیات اطمینان داریم. توجه داشته باشید که یک بلوک `unsafe`، بررسیهای ایمنی Rust را خاموش نمیکند. فقط به شما این امکان را میدهد که [پنج کار اضافی] انجام دهید.
|
||||
|
||||
[`unsafe`]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html
|
||||
[پنج کار اضافی]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
می خواهم تأکید کنم که **این روشی نیست که ما بخواهیم در Rust کارها را از طریق آن پبش ببریم!** به هم ریختگی هنگام کار با اشارهگرهای خام در داخل بلوکهای ناامن بسیار محتمل و ساده است، به عنوان مثال، اگر مواظب نباشیم به راحتی میتوانیم فراتر از انتهای بافر بنویسیم.
|
||||
|
||||
بنابراین ما میخواهیم تا آنجا که ممکن است استفاده از `unsafe` را به حداقل برسانیم. Rust با ایجاد انتزاعهای ایمن به ما توانایی انجام این کار را میدهد. به عنوان مثال، ما میتوانیم یک نوع بافر VGA ایجاد کنیم که تمام کدهای ناامن را در خود قرار داده و اطمینان حاصل کند که انجام هرگونه اشتباه از خارج از این انتزاع _غیرممکن_ است. به این ترتیب، ما فقط به حداقل مقادیر ناامن نیاز خواهیم داشت و میتوان اطمینان داشت که [ایمنی حافظه] را نقض نمیکنیم. در پست بعدی چنین انتزاع ایمن بافر VGA را ایجاد خواهیم کرد.
|
||||
|
||||
[ایمنی حافظه]: https://en.wikipedia.org/wiki/Memory_safety
|
||||
|
||||
## اجرای هسته
|
||||
|
||||
حال یک هسته اجرایی داریم که کار محسوسی را انجام میدهد، پس زمان اجرای آن فرا رسیده است. ابتدا، باید هسته کامپایل شده خود را با پیوند دادن آن به یک بوتلودر، به یک دیسک ایمیج قابل بوت تبدیل کنیم. سپس میتوانیم دیسک ایمیج را در ماشین مجازی [QEMU] اجرا یا با استفاده از یک درایو USB آن را بر روی سخت افزار واقعی بوت کنیم.
|
||||
|
||||
### ساخت دیسک ایمیج
|
||||
|
||||
برای تبدیل هسته کامپایل شده به یک دیسک ایمیج قابل بوت، باید آن را با یک بوت لودر پیوند دهیم. همانطور که در [بخش مربوط به بوت شدن (لینک باید اپدیت شود)] آموختیم، بوت لودر مسئول مقداردهی اولیه پردازنده و بارگیری هسته میباشد.
|
||||
|
||||
[بخش مربوط به بوت شدن]: #the-boot-process
|
||||
|
||||
به جای نوشتن یک بوت لودر مخصوص خودمان، که به تنهایی یک پروژه است، از کریت [`bootloader`] استفاده میکنیم. این کریت بوتلودر اصلی BIOS را بدون هیچگونه وابستگی به C، فقط با استفاده از Rust و اینلاین اسمبلی پیاده سازی میکند. برای استفاده از آن برای راه اندازی هسته، باید وابستگی به آن را ضافه کنیم:
|
||||
|
||||
[`bootloader`]: https://crates.io/crates/bootloader
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
```
|
||||
|
||||
افزودن بوتلودر به عنوان وابستگی برای ایجاد یک دیسک ایمیج قابل بوت کافی نیست. مشکل این است که ما باید هسته خود را با بوت لودر پیوند دهیم، اما کارگو از [اسکریپت های بعد از بیلد] پشتیبانی نمیکند.
|
||||
|
||||
[اسکریپت های بعد از بیلد]: https://github.com/rust-lang/cargo/issues/545
|
||||
|
||||
برای حل این مشکل، ما ابزاری به نام `bootimage` ایجاد کردیم که ابتدا هسته و بوت لودر را کامپایل میکند و سپس آنها را به یکدیگر پیوند میدهد تا یک ایمیج دیسک قابل بوت ایجاد کند. برای نصب ابزار، دستور زیر را در ترمینال خود اجرا کنید:
|
||||
|
||||
```
|
||||
cargo install bootimage
|
||||
```
|
||||
|
||||
برای اجرای `bootimage` و ساختن بوتلودر، شما باید `llvm-tools-preview` که یک مولفه rustup میباشد را نصب داشته باشید. شما میتوانید این کار را با اجرای دستور `rustup component add llvm-tools-preview` انجام دهید.
|
||||
|
||||
پس از نصب `bootimage` و اضافه کردن مولفه `llvm-tools-preview`، ما میتوانیم یک دیسک ایمیج قابل بوت را با اجرای این دستور ایجاد کنیم:
|
||||
|
||||
```
|
||||
> cargo bootimage
|
||||
```
|
||||
|
||||
میبینیم که این ابزار، هسته ما را با استفاده از `cargo build` دوباره کامپایل میکند، بنابراین به طور خودکار هر تغییری که ایجاد میکنید را دربر میگیرد. پس از آن بوتلودر را کامپایل میکند که ممکن است مدتی طول بکشد. مانند تمام کریتهای وابسته ، فقط یک بار بیلد میشود و سپس کش (کلمه: cache) میشود، بنابراین بیلدهای بعدی بسیار سریعتر خواهد بود. سرانجام، `bootimage`، بوتلودر و هسته شما را با یک دیسک ایمیج قابل بوت ترکیب میکند.
|
||||
|
||||
پس از اجرای این دستور، شما باید یک دیسک ایمیج قابل بوت به نام `bootimage-blog_os.bin` در مسیر `target/x86_64-blog_os/debug` ببینید. شما میتوانید آن را در یک ماشین مجازی بوت کنید یا آن را در یک درایو USB کپی کرده و روی یک سخت افزار واقعی بوت کنید. (توجه داشته باشید که این یک ایمیج CD نیست، بنابراین رایت کردن آن روی CD بیفایده است چرا که ایمیج CD دارای قالب متفاوتی است).
|
||||
|
||||
#### چگونه کار می کند؟
|
||||
|
||||
ابزار `bootimage` مراحل زیر را در پشت صحنه انجام می دهد:
|
||||
|
||||
- کرنل ما را به یک فایل [ELF] کامپایل میکند.
|
||||
- وابستگی بوتلودر را به عنوان یک اجرایی مستقل (ترجمه: standalone executable) کامپایل میکند.
|
||||
- بایتهای فایل ELF هسته را به بوتلودر پیوند میدهد.
|
||||
|
||||
[ELF]: https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[rust-osdev/bootloader]: https://github.com/rust-osdev/bootloader
|
||||
|
||||
وقتی بوت شد، بوتلودر فایل ضمیمه شده ELF را خوانده و تجزیه میکند. سپس بخشهای (ترجمه: segments) برنامه را به آدرسهای مجازی در جداول صفحه نگاشت (مپ) میکند، بخش `bss.` را صفر کرده و یک پشته را تنظیم میکند. در آخر، آدرس نقطه ورود (تابع `start_`) را خوانده و به آن پرش میکند.
|
||||
|
||||
### بوت کردن در QEMU
|
||||
|
||||
اکنون میتوانیم دیسک ایمیج را در یک ماشین مجازی بوت کنیم. برای راه اندازی آن در [QEMU]، دستور زیر را اجرا کنید:
|
||||
|
||||
[QEMU]: https://www.qemu.org/
|
||||
|
||||
```
|
||||
> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
|
||||
warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
|
||||
```
|
||||
|
||||
این یک پنجره جداگانه با این شکل باز میکند:
|
||||
|
||||

|
||||
|
||||
میبینیم که “!Hello World” بر روی صفحه قابل مشاهده است.
|
||||
|
||||
### ماشین واقعی
|
||||
|
||||
همچنین میتوانید آن را بر روی یک درایو USB رایت و بر روی یک دستگاه واقعی بوت کنید:
|
||||
|
||||
```
|
||||
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
|
||||
```
|
||||
|
||||
در اینجا `sdX` نام دستگاه USB شماست. **مراقب باشید** که نام دستگاه را به درستی انتخاب کنید، زیرا همه دادههای موجود در آن دستگاه بازنویسی میشوند.
|
||||
|
||||
پس از رایت کردن ایمیج در USB، میتوانید با بوت کردن، آن را بر روی سخت افزار واقعی اجرا کنید. برای راه اندازی از طریق USB احتمالاً باید از یک منوی بوت ویژه استفاده کنید یا ترتیب بوت را در پیکربندی BIOS تغییر دهید. توجه داشته باشید که این در حال حاضر برای دستگاههای UEFI کار نمیکند، زیرا کریت `bootloader` هنوز پشتیبانی UEFI را ندارد.
|
||||
|
||||
### استفاده از `cargo run`
|
||||
|
||||
برای سهولت اجرای هسته در QEMU، میتوانیم کلید پیکربندی `runner` را برای کارگو تنظیم کنیم:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "none")']
|
||||
runner = "bootimage runner"
|
||||
```
|
||||
جدول `'target.'cfg(target_os = "none")` برای همه اهدافی که فیلد `"os"` فایل پیکربندی هدف خود را روی `"none"` تنظیم کردهاند، اعمال میشود. این شامل هدف `x86_64-blog_os.json` نیز میشود. `runner` دستوری را که باید برای `cargo run` فراخوانی شود مشخص میکند. دستور پس از بیلد موفقیت آمیز با مسیر فایل اجرایی که به عنوان اولین آرگومان داده شده، اجرا میشود. برای جزئیات بیشتر به [اسناد کارگو][پیکربندی کارگو] مراجعه کنید.
|
||||
|
||||
دستور `bootimage runner` بصورت مشخص طراحی شده تا بعنوان یک `runner` قابل اجرا مورد استفاده قرار بگیرد. فایل اجرایی داده شده را به بوتلودر پروژه پیوند داده و سپس QEMU را اجرا میکند. برای جزئیات بیشتر و گزینههای پیکربندی احتمالی، به [توضیحات `bootimage`] مراجعه کنید.
|
||||
|
||||
[توضیحات `bootimage`]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
اکنون میتوانیم از `cargo run` برای کامپایل هسته خود و راه اندازی آن در QEMU استفاده کنیم.
|
||||
|
||||
## مرحله بعد چیست؟
|
||||
|
||||
در پست بعدی، ما بافر متن VGA را با جزئیات بیشتری بررسی خواهیم کرد و یک رابط امن برای آن مینویسیم. همچنین پشتیبانی از ماکرو `println` را نیز اضافه خواهیم کرد.
|
||||
@@ -1,501 +0,0 @@
|
||||
+++
|
||||
title = "Rustでつくる最小のカーネル"
|
||||
weight = 2
|
||||
path = "ja/minimal-rust-kernel"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "7212ffaa8383122b1eb07fe1854814f99d2e1af4"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["woodyZootopia", "JohnTitor"]
|
||||
+++
|
||||
|
||||
この記事では、Rustで最小限の64bitカーネルを作ります。前の記事で作った[フリースタンディングなRustバイナリ][freestanding Rust binary]を下敷きにして、何かを画面に出力する、ブータブルディスクイメージを作ります。
|
||||
|
||||
[freestanding Rust binary]: @/second-edition/posts/01-freestanding-rust-binary/index.ja.md
|
||||
|
||||
<!-- more -->
|
||||
|
||||
このブログの内容は [GitHub] 上で公開・開発されています。何か問題や質問などがあれば issue をたててください (訳注: リンクは原文(英語)のものになります)。また[こちら][at the bottom]にコメントを残すこともできます。この記事の完全なソースコードは[`post-02` ブランチ][post branch]にあります。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## <ruby>起動<rp> (</rp><rt>Boot</rt><rp>) </rp></ruby>のプロセス
|
||||
コンピュータを起動すると、マザーボードの [ROM] に保存されたファームウェアのコードを実行し始めます。このコードは、[<ruby>起動時の自己テスト<rp> (</rp><rt>power-on self test</rt><rp>) </rp></ruby>][power-on self-test]を実行し、使用可能なRAMを検出し、CPUとハードウェアを<ruby>事前初期化<rp> (</rp><rt>pre-initialize</rt><rp>) </rp></ruby>します。その後、<ruby>ブータブル<rp> (</rp><rt>bootable</rt><rp>) </rp></ruby>ディスクを探し、オペレーティングシステムのカーネルを<ruby>起動<rp> (</rp><rt>boot</rt><rp>) </rp></ruby>します。
|
||||
|
||||
[ROM]: https://ja.wikipedia.org/wiki/Read_only_memory
|
||||
[power-on self-test]: https://ja.wikipedia.org/wiki/Power_On_Self_Test
|
||||
|
||||
x86には2つのファームウェアの標準規格があります:"Basic Input/Output System" (**[BIOS]**) と、より新しい "Unified Extensible Firmware Interface" (**[UEFI]**) です。BIOS規格は古く時代遅れですが、シンプルでありすべてのx86のマシンで1980年代からよくサポートされています。対して、UEFIはより現代的でずっと多くの機能を持っていますが、セットアップが複雑です(少なくとも私はそう思います)。
|
||||
|
||||
[BIOS]: https://ja.wikipedia.org/wiki/Basic_Input/Output_System
|
||||
[UEFI]: https://ja.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
|
||||
|
||||
今の所、このブログではBIOSしかサポートしていませんが、UEFIのサポートも計画中です。お手伝いいただける場合は、[GitHubのissue](https://github.com/phil-opp/blog_os/issues/349)をご覧ください。
|
||||
|
||||
### BIOSの起動
|
||||
ほぼすべてのx86システムがBIOSによる起動をサポートしています。これは近年のUEFIベースのマシンも例外ではなく、それらはエミュレートされたBIOSを使います。前世紀のすべてのマシンにも同じブートロジックが使えるなんて素晴らしいですね。しかし、この広い互換性は、BIOSによる起動の最大の欠点でもあるのです。というのもこれは、1980年代の化石のようなブートローダーを動かすために、CPUが[<ruby>リアルモード<rp> (</rp><rt>real mode</rt><rp>) </rp></ruby>][real mode]と呼ばれる16bit互換モードにされてしまうということを意味しているからです。
|
||||
|
||||
まあ順を追って見ていくこととしましょう。
|
||||
|
||||
コンピュータは起動時にマザーボードにある特殊なフラッシュメモリからBIOSを読み込みます。BIOSは自己テストとハードウェアの初期化ルーチンを実行し、ブータブルディスクを探します。ディスクが見つかると、 **<ruby>ブートローダー<rp> (</rp><rt>bootloader</rt><rp>) </rp></ruby>** と呼ばれる、その先頭512バイトに保存された実行可能コードへと操作権が移ります。多くのブートローダーのサイズは512バイトより大きいため、通常は512バイトに収まる小さな最初のステージと、その最初のステージによって読み込まれる第2ステージに分けられています。
|
||||
|
||||
ブートローダーはディスク内のカーネルイメージの場所を特定し、メモリに読み込まなければなりません。また、CPUを16bitの[リアルモード][real mode]から32bitの[<ruby>プロテクトモード<rp> (</rp><rt>protected mode</rt><rp>) </rp></ruby>][protected mode]へ、そして64bitの[<ruby>ロングモード<rp> (</rp><rt>long mode</rt><rp>) </rp></ruby>][long mode]――64bitレジスタとすべてのメインメモリが利用可能になります――へと変更しなければなりません。3つ目の仕事は、特定の情報(例えばメモリーマップなどです)をBIOSから聞き出し、OSのカーネルに渡すことです。
|
||||
|
||||
[real mode]: https://ja.wikipedia.org/wiki/リアルモード
|
||||
[protected mode]: https://ja.wikipedia.org/wiki/プロテクトモード
|
||||
[long mode]: https://en.wikipedia.org/wiki/Long_mode
|
||||
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
|
||||
ブートローダーを書くのにはアセンブリ言語を必要とするうえ、「何も考えずにプロセッサーのこのレジスタにこの値を書き込んでください」のような勉強の役に立たない作業がたくさんあるので、ちょっと面倒くさいです。ですのでこの記事ではブートローダーの制作については飛ばして、代わりに[bootimage]という、自動でカーネルの前にブートローダを置いてくれるツールを使いましょう。
|
||||
|
||||
[bootimage]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
自前のブートローダーを作ることに興味がある人もご期待下さい、これに関する記事も計画中です!
|
||||
|
||||
#### Multiboot標準規格
|
||||
すべてのオペレーティングシステムが、自身にのみ対応しているブートローダーを実装するということを避けるために、1995年に[フリーソフトウェア財団][Free Software Foundation]が[Multiboot]というブートローダーの公開標準規格を策定しています。この標準規格では、ブートローダーとオペレーティングシステムのインターフェースが定義されており、Multibootに準拠したブートローダーであれば、同じくそれに準拠したすべてのオペレーティングシステムが読み込めるようになっています。そのリファレンス実装として、Linuxシステムで一番人気のブートローダーである[GNU GRUB]があります。
|
||||
|
||||
[Free Software Foundation]: https://ja.wikipedia.org/wiki/フリーソフトウェア財団
|
||||
[Multiboot]: https://wiki.osdev.org/Multiboot
|
||||
[GNU GRUB]: https://ja.wikipedia.org/wiki/GNU_GRUB
|
||||
|
||||
カーネルをMultibootに準拠させるには、カーネルファイルの先頭にいわゆる[Multiboot header]を挿入するだけで済みます。このおかげで、OSをGRUBで起動するのはとても簡単です。しかし、GRUBとMultiboot標準規格にはいくつか問題もあります:
|
||||
|
||||
[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
|
||||
|
||||
- これらは32bitプロテクトモードしかサポートしていません。そのため、64bitロングモードに変更するためのCPUの設定は依然行う必要があります。
|
||||
- これらは、カーネルではなくブートローダーがシンプルになるように設計されています。例えば、カーネルは[通常とは異なるデフォルトページサイズ][adjusted default page size]でリンクされる必要があり、そうしないとGRUBはMultiboot headerを見つけることができません。他にも、カーネルに渡される[<ruby>ブート情報<rp> (</rp><rt>boot information</rt><rp>) </rp></ruby>][boot information]は、クリーンな抽象化を与えてくれず、アーキテクチャ依存の構造を多く含んでいます。
|
||||
- GRUBもMultiboot標準規格もドキュメントが充実していません。
|
||||
- カーネルファイルからブータブルディスクイメージを作るには、ホストシステムにGRUBがインストールされている必要があります。これにより、MacとWindows上での開発は比較的難しくなっています。
|
||||
|
||||
[adjusted default page size]: https://wiki.osdev.org/Multiboot#Multiboot_2
|
||||
[boot information]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
|
||||
|
||||
これらの欠点を考慮し、私達はGRUBとMultiboot標準規格を使わないことに決めました。しかし、あなたのカーネルをGRUBシステム上で読み込めるように、私達の[bootimage]ツールにMultibootのサポートを追加することも計画しています。Multiboot準拠なカーネルを書きたい場合は、このブログシリーズの[第1版][first edition]をご覧ください。
|
||||
|
||||
[first edition]: @/edition-1/_index.md
|
||||
|
||||
### UEFI
|
||||
|
||||
(今の所UEFIのサポートは提供していませんが、ぜひともしたいと思っています!お手伝いいただける場合は、 [GitHub issue](https://github.com/phil-opp/blog_os/issues/349)で教えてください。)
|
||||
|
||||
## 最小のカーネル
|
||||
どのようにコンピュータが起動するのかについてざっくりと理解できたので、自前で最小のカーネルを書いてみましょう。目標は、起動したら画面に"Hello, World!"と出力するようなディスクイメージを作ることです。というわけで、前の記事の[<ruby>独立した<rp> (</rp><rt>freestanding</rt><rp>) </rp></ruby>Rustバイナリ][freestanding Rust binary]をもとにして作っていきます。
|
||||
|
||||
覚えていますか、この独立したバイナリは`cargo`を使ってビルドしましたが、オペレーティングシステムに依って異なるエントリポイント名とコンパイルフラグが必要なのでした。これは`cargo`は標準では **ホストシステム**(あなたの使っているシステム)向けにビルドするためです。例えばWindows上で走るカーネルというのはあまり意味がなく、私達の望む動作ではありません。代わりに、明確に定義された **ターゲットシステム** 向けにコンパイルできると理想的です。
|
||||
|
||||
### RustのNightly版をインストールする
|
||||
Rustには**stable**、**beta**、**nightly**の3つのリリースチャンネルがあります。Rust Bookはこれらの3つのチャンネルの違いをとても良く説明しているので、一度[確認してみてください](https://doc.rust-jp.rs/book-ja/appendix-07-nightly-rust.html)。オペレーティングシステムをビルドするには、nightlyチャンネルでしか利用できないいくつかの実験的機能を使う必要があるので、Rustのnightly版をインストールすることになります。
|
||||
|
||||
Rustの実行環境を管理するのには、[rustup]を強くおすすめします。nightly、beta、stable版のコンパイラをそれぞれインストールすることができますし、アップデートするのも簡単です。現在のディレクトリにnightlyコンパイラを使うようにするには、`rustup override set nightly`と実行してください。もしくは、`rust-toolchain`というファイルに`nightly`と記入してプロジェクトのルートディレクトリに置くことでも指定できます。Nightly版を使っていることは、`rustc --version`と実行することで確かめられます。表示されるバージョン名の末尾に`-nightly`とあるはずです。
|
||||
|
||||
[rustup]: https://www.rustup.rs/
|
||||
|
||||
nightlyコンパイラでは、いわゆる**feature flag**をファイルの先頭につけることで、いろいろな実験的機能を使うことを選択できます。例えば、`#![feature(asm)]`を`main.rs`の先頭につけることで、インラインアセンブリのための実験的な[`asm!`マクロ][`asm!` macro]を有効化することができます。ただし、これらの実験的機能は全くもって<ruby>不安定<rp> (</rp><rt>unstable</rt><rp>) </rp></ruby>であり、将来のRustバージョンにおいては事前の警告なく変更されたり取り除かれたりする可能性があることに注意してください。このため、絶対に必要なときにのみこれらを使うことにします。
|
||||
|
||||
[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
|
||||
|
||||
### ターゲットの仕様
|
||||
Cargoは`--target`パラメータを使ってさまざまなターゲットをサポートします。ターゲットはいわゆる[target <ruby>triple<rp> (</rp><rt>3つ組</rt><rp>) </rp></ruby>][target triple]によって表されます。これはCPUアーキテクチャ、製造元、オペレーティングシステム、そして[ABI]を表します。例えば、`x86_64-unknown-linux-gnu`というtarget tripleは、`x86_64`のCPU、製造元不明、GNU ABIのLinuxオペレーティングシステム向けのシステムを表します。Rustは[多くのtarget triple][platform-support]をサポートしており、その中にはAndroidのための`arm-linux-androideabi`や[WebAssemblyのための`wasm32-unknown-unknown`](https://www.hellorust.com/setup/wasm-target/)などがあります。
|
||||
|
||||
[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
[ABI]: https://stackoverflow.com/a/2456882
|
||||
[platform-support]: https://forge.rust-lang.org/release/platform-support.html
|
||||
[custom-targets]: https://doc.rust-lang.org/nightly/rustc/targets/custom.html
|
||||
|
||||
しかしながら、私達のターゲットシステムには、いくつか特殊な設定パラメータが必要になります(例えば、その下ではOSが走っていない、など)。なので、[既存のtarget triple][platform-support]はどれも当てはまりません。ありがたいことに、RustではJSONファイルを使って[独自のターゲット][custom-targets]を定義できます。例えば、`x86_64-unknown-linux-gnu`というターゲットを表すJSONファイルはこんな感じです。
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-linux-gnu",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "linux",
|
||||
"executables": true,
|
||||
"linker-flavor": "gcc",
|
||||
"pre-link-args": ["-m64"],
|
||||
"morestack": false
|
||||
}
|
||||
```
|
||||
|
||||
ほとんどのフィールドはLLVMがそのプラットフォーム向けのコードを生成するために必要なものです。例えば、[`data-layout`]フィールドは種々の整数、浮動小数点数、ポインタ型の大きさを定義しています。次に、`target-pointer-width`のような、条件付きコンパイルに用いられるフィールドがあります。第3の種類のフィールドはクレートがどのようにビルドされるべきかを定義します。例えば、`pre-link-args`フィールドは[<ruby>リンカ<rp> (</rp><rt>linker</rt><rp>) </rp></ruby>][linker]に渡される引数を指定しています。
|
||||
|
||||
[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
|
||||
[linker]: https://ja.wikipedia.org/wiki/リンケージエディタ
|
||||
|
||||
私達のカーネルも`x86_64`のシステムをターゲットとするので、私達のターゲット仕様も上のものと非常によく似たものになるでしょう。`x86_64-blog_os.json`というファイル(お好きな名前を選んでください)を作り、共通する要素を埋めるところから始めましょう。
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true
|
||||
}
|
||||
```
|
||||
|
||||
<ruby>ベアメタル<rp> (</rp><rt>bare metal</rt><rp>) </rp></ruby>環境で実行するので、`llvm-target`のOSを変え、`os`フィールドを`none`にしたことに注目してください。
|
||||
|
||||
以下の、ビルドに関係する項目を追加します。
|
||||
|
||||
```json
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
```
|
||||
|
||||
私達のカーネルをリンクするのに、プラットフォーム標準の(Linuxターゲットをサポートしていないかもしれない)リンカではなく、Rustに付属しているクロスプラットフォームの[LLD]リンカを使用します。
|
||||
|
||||
[LLD]: https://lld.llvm.org/
|
||||
|
||||
```json
|
||||
"panic-strategy": "abort",
|
||||
```
|
||||
|
||||
この設定は、ターゲットがパニック時の[stack unwinding]をサポートしていないので、プログラムは代わりに直接<ruby>中断<rp> (</rp><rt>abort</rt><rp>) </rp></ruby>しなければならないということを指定しています。これは、Cargo.tomlに`panic = "abort"`という設定を書くのに等しいですから、後者の設定を消しても構いません(このターゲット設定は、Cargo.tomlの設定と異なり、このあと行う`core`ライブラリの再コンパイルにも適用されます。ですので、Cargo.tomlに設定する方が好みだったとしても、この設定を追加するようにしてください)。
|
||||
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
|
||||
```json
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
カーネルを書いている以上、ある時点で<ruby>割り込み<rp> (</rp><rt>interrupt</rt><rp>) </rp></ruby>を処理しなければならなくなるでしょう。これを安全に行うために、 **"red zone"** と呼ばれる、ある種のスタックポインタ最適化を無効化する必要があります。こうしないと、スタックの<ruby>破損<rp> (</rp><rt>corruption</rt><rp>) </rp></ruby>を引き起こしてしまう恐れがあるためです。より詳しくは、[red zoneの無効化][disabling the red zone]という別記事をご覧ください。
|
||||
|
||||
[disabling the red zone]: @/second-edition/posts/02-minimal-rust-kernel/disable-red-zone/index.md
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float",
|
||||
```
|
||||
|
||||
`features`フィールドは、ターゲットの<ruby>機能<rp> (</rp><rt>features</rt><rp>) </rp></ruby>を有効化/無効化します。マイナスを前につけることで`mmx`と`sse`という機能を無効化し、プラスを前につけることで`soft-float`という機能を有効化しています。それぞれのフラグの間にスペースは入れてはならず、もしそうするとLLVMが機能文字列の解釈に失敗してしまうことに注意してください。
|
||||
|
||||
`mmx`と`sse`という機能は、[Single Instruction Multiple Data (SIMD)]命令をサポートするかを決定します。この命令は、しばしばプログラムを著しく速くしてくれます。しかし、大きなSIMDレジスタをOSカーネルで使うことは性能上の問題に繋がります。 その理由は、カーネルは、割り込まれたプログラムを再開する前に、すべてのレジスタを元に戻さないといけないためです。これは、カーネルがSIMDの状態のすべてを、システムコールやハードウェア割り込みがあるたびにメインメモリに保存しないといけないということを意味します。SIMDの状態情報はとても巨大(512〜1600 bytes)で、割り込みは非常に頻繁に起こるかもしれないので、保存・復元の操作がこのように追加されるのは性能にかなりの悪影響を及ぼします。これを避けるために、(カーネルの上で走っているアプリケーションではなく!)カーネル上でSIMDを無効化するのです。
|
||||
|
||||
[Single Instruction Multiple Data (SIMD)]: https://ja.wikipedia.org/wiki/SIMD
|
||||
|
||||
SIMDを無効化することによる問題に、`x86_64`における浮動小数点演算は標準ではSIMDレジスタを必要とするということがあります。この問題を解決するため、`soft-float`機能を追加します。これは、すべての浮動小数点演算を通常の整数に基づいたソフトウェア上の関数を使ってエミュレートするというものです。
|
||||
|
||||
より詳しくは、[SIMDを無効化する](@/second-edition/posts/02-minimal-rust-kernel/disable-simd/index.md)ことに関する私達の記事を読んでください。
|
||||
|
||||
#### まとめると
|
||||
私達のターゲット仕様ファイルは今このようになっているはずです。
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
"panic-strategy": "abort",
|
||||
"disable-redzone": true,
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
}
|
||||
```
|
||||
|
||||
### カーネルをビルドする
|
||||
私達の新しいターゲットのコンパイルにはLinuxの慣習に倣います(理由は知りません、LLVMのデフォルトであるというだけではないでしょうか)。つまり、[前の記事][previous post]で説明したように`_start`という名前のエントリポイントが要るということです。
|
||||
|
||||
[previous post]: @/second-edition/posts/01-freestanding-rust-binary/index.ja.md
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// this function is the entry point, since the linker looks for a function
|
||||
// named `_start` by default
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
ホストOSが何であるかにかかわらず、エントリポイントは`_start`という名前でなければならないことに注意してください。
|
||||
|
||||
これで、私達の新しいターゲットのためのカーネルを、JSONファイル名を`--target`として渡すことでビルドできるようになりました。
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
|
||||
error[E0463]: can't find crate for `core`
|
||||
```
|
||||
|
||||
失敗しましたね!エラーはRustコンパイラが[`core`ライブラリ][`core` library]を見つけられなくなったと言っています。このライブラリは、`Result` や `Option`、イテレータのような基本的なRustの型を持っており、暗黙のうちにすべての`no_std`なクレートにリンクされています。
|
||||
|
||||
[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
|
||||
|
||||
問題は、coreライブラリはRustコンパイラと一緒に<ruby>コンパイル済み<rp> (</rp><rt>precompiled</rt><rp>) </rp></ruby>ライブラリとして配布されているということです。そのため、これは、私達独自のターゲットではなく、サポートされているhost triple(例えば `x86_64-unknown-linux-gnu`)でのみ使えるのです。他のターゲットのためにコードをコンパイルしたいときには、`core`をそれらのターゲットに向けて再コンパイルする必要があります。
|
||||
|
||||
#### `build-std`オプション
|
||||
|
||||
ここでcargoの[`build-std`機能][`build-std` feature]の出番です。これを使うと`core`やその他の標準ライブラリクレートについて、Rustインストール時に一緒についてくるコンパイル済みバージョンを使う代わりに、必要に応じて再コンパイルすることができます。これはとても新しくまだ完成していないので、<ruby>不安定<rp> (</rp><rt>unstable</rt><rp>) </rp></ruby>機能とされており、[nightly Rustコンパイラ][nightly Rust compilers]でのみ利用可能です。
|
||||
|
||||
[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
|
||||
[nightly Rust compilers]: #installing-rust-nightly
|
||||
|
||||
この機能を使うためには、[cargoの設定][cargo configuration]ファイルを`.cargo/config.toml`に作り、次の内容を書きましょう。
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std = ["core", "compiler_builtins"]
|
||||
```
|
||||
|
||||
これはcargoに`core`と`compiler_builtins`ライブラリを再コンパイルするよう命令します。後者が必要なのは`core`がこれに依存しているためです。 これらのライブラリを再コンパイルするためには、cargoがRustのソースコードにアクセスできる必要があります。これは`rustup component add rust-src`でインストールできます。
|
||||
|
||||
<div class="note">
|
||||
|
||||
**注意:** `unstable.build-std`設定キーを使うには、少なくとも2020-07-15以降のRust nightlyが必要です。
|
||||
|
||||
</div>
|
||||
|
||||
`unstable.build-std`設定キーをセットし、`rust-src`コンポーネントをインストールしたら、ビルドコマンドをもう一度実行しましょう。
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
Compiling core v0.0.0 (/…/rust/src/libcore)
|
||||
Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling compiler_builtins v0.1.32
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
今回は、`cargo build`が`core`、`rustc-std-workspace-core` (`compiler_builtins`の依存です)、そして `compiler_builtins`を私達のカスタムターゲット向けに再コンパイルしているということがわかります。
|
||||
|
||||
#### メモリ関係の<ruby>組み込み関数<rp> (</rp><rt>intrinsics</rt><rp>) </rp></ruby>
|
||||
|
||||
Rustコンパイラは、すべてのシステムにおいて、特定の組み込み関数が利用可能であるということを前提にしています。それらの関数の多くは、私達がちょうど再コンパイルした`compiler_builtins`クレートによって提供されています。しかしながら、通常システムのCライブラリによって提供されているので標準では有効化されていない、メモリ関係の関数がいくつかあります。それらの関数には、メモリブロック内のすべてのバイトを与えられた値にセットする`memset`、メモリーブロックを他のブロックへとコピーする`memcpy`、2つのメモリーブロックを比較する`memcmp`などがあります。これらの関数はどれも、現在の段階で我々のカーネルをコンパイルするのに必要というわけではありませんが、コードを追加していくとすぐに必要になるでしょう(たとえば、構造体をコピーする、など)。
|
||||
|
||||
オペレーティングシステムのCライブラリにリンクすることはできませんので、これらの関数をコンパイラに与えてやる別の方法が必要になります。このための方法として考えられるものの一つが、自前で`memset`を実装し、(コンパイル中の自動リネームを防ぐため)`#[no_mangle]`アトリビュートをこれらに適用することでしょう。しかし、こうすると、これらの関数の実装のちょっとしたミスが未定義動作に繋がりうるため危険です。たとえば、`for`ループを使って`memcpy`を実装すると無限再帰を起こしてしまうかもしれません。なぜなら、`for`ループは暗黙のうちに[`IntoIterator::into_iter`]トレイトメソッドを呼び出しており、これが`memcpy`を再び呼び出しているかもしれないためです。なので、代わりに既存のよくテストされた実装を再利用するのが良いでしょう。
|
||||
|
||||
[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
|
||||
|
||||
ありがたいことに、`compiler_builtins`クレートにはこれらの必要な関数すべての実装が含まれており、標準ではCライブラリの実装と競合しないように無効化されているだけなのです。これはcargoの[`build-std-features`]フラグを`["computer-builtins-mem"]`に設定することで有効化できます。`build-std`フラグと同じように、このフラグはコマンドラインで`-Z`フラグとして渡すこともできれば、`.cargo/config.toml`ファイルの`unstable`テーブルで設定することもできます。ビルド時は常にこのフラグをセットしたいので、設定ファイルを使う方が良いでしょう:
|
||||
|
||||
[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std-features = ["compiler-builtins-mem"]
|
||||
```
|
||||
|
||||
(`compiler-builtins-mem`機能のサポートが追加されたのは[つい最近](https://github.com/rust-lang/rust/pull/77284)なので、`2019-09-30`以降のRust nightlyが必要です。)
|
||||
|
||||
このとき、裏で`compiler_builtins`クレートの[`mem`機能][`mem` feature]が有効化されています。これにより、このクレートの[`memcpy`などの実装][`memcpy` etc. implementations]に`#[no_mangle]`アトリビュートが適用され、リンカがこれらを利用できるようになっています。これらの関数は今のところ[最適化されておらず][not optimized]、性能は最高ではないかもしれないものの、少なくとも正しい実装ではあるということは知っておく価値があるでしょう。`x86_64`については、[これらの関数を特殊なアセンブリ命令を使って最適化する][memcpy rep movsb]プルリクエストが提出されています。
|
||||
|
||||
[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L51-L52
|
||||
[`memcpy` etc. implementations]: (https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69)
|
||||
[not optimized]: https://github.com/rust-lang/compiler-builtins/issues/339
|
||||
[memcpy rep movsb]: https://github.com/rust-lang/compiler-builtins/pull/365
|
||||
|
||||
この変更をもって、私達のカーネルはコンパイラに必要とされているすべての関数の有効な実装を手に入れたので、コードがもっと複雑になっても変わらずコンパイルできるでしょう。
|
||||
|
||||
#### 標準のターゲットをセットする
|
||||
|
||||
`cargo build`を呼び出すたびに`--target`パラメータを渡すのを避けるために、デフォルトのターゲットを書き換えることができます。これをするには、以下を`.cargo/config.toml`の[cargo設定][cargo configuration]ファイルに付け加えます:
|
||||
|
||||
[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[build]
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
これは、明示的に`--target`引数が渡されていないときは、`x86_64-blog_os.json`ターゲットを使うように`cargo`に命令します。つまり、私達はカーネルをシンプルな`cargo build`コマンドでビルドできるということです。cargoの設定のオプションについてより詳しく知るには、[公式のドキュメント][cargo configuration]を読んでください。
|
||||
|
||||
これにより、シンプルな`cargo build`コマンドで、ベアメタルのターゲットに私達のカーネルをビルドできるようになりました。しかし、ブートローダーによって呼び出される私達の`_start`エントリポイントはまだ空っぽです。そろそろここから何かを画面に出力してみましょう。
|
||||
|
||||
### 画面に出力する
|
||||
現在の段階で画面に文字を出力する最も簡単な方法は[VGAテキストバッファ][VGA text buffer]です。これは画面に出力されている内容を保持しているVGAハードウェアにマップされた特殊なメモリです。通常、これは25行からなり、それぞれの行は80文字セルからなります。それぞれの文字セルは、背景色と前景色付きのASCII文字を表示します。画面出力はこのように見えるでしょう:
|
||||
|
||||
[VGA text buffer]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
|
||||

|
||||
|
||||
次の記事では、VGAバッファの正確なレイアウトについて議論し、このためのちょっとしたドライバも書きます。"Hello World!"を出力するためには、バッファがアドレス`0xb8000`にあり、それぞれの文字セルはASCIIのバイトと色のバイトからなることを知っている必要があります。
|
||||
|
||||
実装はこんな感じになります:
|
||||
|
||||
```rust
|
||||
static HELLO: &[u8] = b"Hello World!";
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
let vga_buffer = 0xb8000 as *mut u8;
|
||||
|
||||
for (i, &byte) in HELLO.iter().enumerate() {
|
||||
unsafe {
|
||||
*vga_buffer.offset(i as isize * 2) = byte;
|
||||
*vga_buffer.offset(i as isize * 2 + 1) = 0xb;
|
||||
}
|
||||
}
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
まず、`0xb8000`という整数を[生ポインタ][raw pointer]にキャストします。次に[<ruby>静的<rp> (</rp><rt>static</rt><rp>) </rp></ruby>][static]な`HELLO`という[バイト列][byte string]変数の要素に対し[イテレート][iterate]します。[`enumerate`]メソッドを使うことで、`for` ループの実行回数を表す変数 `i` も取得します。ループの内部では、[`offset`]メソッドを使って文字列のバイトと対応する色のバイト(`0xb`は明るいシアン色)を書き込んでいます。
|
||||
|
||||
[iterate]: https://doc.rust-jp.rs/book-ja/ch13-02-iterators.html
|
||||
[static]: https://doc.rust-jp.rs/book-ja/ch10-03-lifetime-syntax.html#静的ライフタイム
|
||||
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
|
||||
[byte string]: https://doc.rust-lang.org/reference/tokens.html#byte-string-literals
|
||||
[raw pointer]: https://doc.rust-jp.rs/book-ja/ch19-01-unsafe-rust.html#生ポインタを参照外しする
|
||||
[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
|
||||
|
||||
すべてのメモリへの書き込み処理のコードを、[<ruby>`unsafe`<rp> (</rp><rt>安全でない</rt><rp>) </rp></ruby>][`unsafe`]ブロックが囲んでいることに注意してください。この理由は、私達の作った生ポインタが正しいものであることをRustコンパイラが証明できないためです。生ポインタはどんな場所でも指しうるので、データの破損につながるかもしれません。これらの操作を`unsafe`ブロックに入れることで、私達はこれが正しいことを確信しているとコンパイラに伝えているのです。ただし、`unsafe`ブロックはRustの安全性チェックを消すわけではなく、[追加で5つのことができるようになる][five additional things]だけということに注意してください。
|
||||
|
||||
<div class="note">
|
||||
|
||||
**訳注:** 翻訳時点(2020-10-20)では、リンク先のThe Rust book日本語版には「追加でできるようになること」は4つしか書かれていません。
|
||||
|
||||
</div>
|
||||
|
||||
[`unsafe`]: https://doc.rust-jp.rs/book-ja/ch19-01-unsafe-rust.html
|
||||
[five additional things]: https://doc.rust-jp.rs/book-ja/ch19-01-unsafe-rust.html#unsafeの強大な力superpower
|
||||
|
||||
強調しておきたいのですが、 **このような機能はRustでプログラミングするときに使いたいものではありません!** unsafeブロック内で生ポインタを扱うと非常にしくじりやすいです。たとえば、注意不足でバッファの終端のさらに奥に書き込みを行ってしまったりするかもしれません。
|
||||
|
||||
ですので、`unsafe`の使用は最小限にしたいです。これをするために、Rustでは安全な<ruby>abstraction<rp> (</rp><rt>抽象化されたもの</rt><rp>) </rp></ruby>を作ることができます。たとえば、VGAバッファ型を作り、この中にすべてのunsafeな操作をカプセル化し、外側からの誤った操作が**不可能**であることを保証できるでしょう。こうすれば、`unsafe`の量を最小限にでき、[メモリ安全性][memory safety]を侵していないことを確かにできます。そのような安全なVGAバッファの abstraction を次の記事で作ります。
|
||||
|
||||
[memory safety]: https://ja.wikipedia.org/wiki/メモリ安全性
|
||||
|
||||
## カーネルを実行する
|
||||
|
||||
では、目で見て分かる処理を行う実行可能ファイルを手に入れたので、実行してみましょう。まず、コンパイルした私達のカーネルを、ブートローダーとリンクすることによってブータブルディスクイメージにする必要があります。そして、そのディスクイメージを、[QEMU]バーチャルマシン内や、USBメモリを使って実際のハードウェア上で実行できます。
|
||||
|
||||
### ブートイメージを作る
|
||||
|
||||
コンパイルされた私達のカーネルをブータブルディスクイメージに変えるには、ブートローダーとリンクする必要があります。[起動のプロセスのセクション][section about booting]で学んだように、ブートローダーはCPUを初期化しカーネルをロードする役割があります。
|
||||
|
||||
[section about booting]: #the-boot-process
|
||||
|
||||
自前のブートローダーを書くと、それだけで1つのプロジェクトになってしまうので、代わりに[`bootloader`]クレートを使いましょう。このクレートは、Cに依存せず、Rustとインラインアセンブリだけで基本的なBIOSブートローダーを実装しています。私達のカーネルを起動するためにこれを依存関係に追加する必要があります:
|
||||
|
||||
[`bootloader`]: https://crates.io/crates/bootloader
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
```
|
||||
|
||||
bootloaderを依存として加えることだけでブータブルディスクイメージが実際に作れるわけではなく、私達のカーネルをコンパイル後にブートローダーにリンクする必要があります。問題は、cargoが[<ruby>ビルド後<rp> (</rp><rt>post-build</rt><rp>) </rp></ruby>にスクリプトを走らせる機能][post-build scripts]を持っていないことです。
|
||||
|
||||
[post-build scripts]: https://github.com/rust-lang/cargo/issues/545
|
||||
|
||||
この問題を解決するため、私達は`bootimage`というツールを作りました。これは、まずカーネルとブートローダーをコンパイルし、そしてこれらをリンクしてブータブルディスクイメージを作ります。このツールをインストールするには、以下のコマンドをターミナルで実行してください:
|
||||
|
||||
```
|
||||
cargo install bootimage
|
||||
```
|
||||
|
||||
`bootimage`を実行しブートローダをビルドするには、`llvm-tools-preview`というrustupコンポーネントをインストールする必要があります。これは`rustup component add llvm-tools-preview`と実行することでできます。
|
||||
|
||||
`bootimage`をインストールし、`llvm-tools-preview`を追加したら、以下のように実行することでブータブルディスクイメージを作れます:
|
||||
|
||||
```
|
||||
> cargo bootimage
|
||||
```
|
||||
|
||||
このツールが私達のカーネルを`cargo build`を使って再コンパイルしていることがわかります。そのため、あなたの行った変更を自動で検知してくれます。その後、bootloaderをビルドします。これには少し時間がかかるかもしれません。他の依存クレートと同じように、ビルドは一度しか行われず、その都度キャッシュされるので、以降のビルドはもっと早くなります。最終的に、`bootimage`はbootloaderとあなたのカーネルを合体させ、ブータブルディスクイメージにします。
|
||||
|
||||
このコマンドを実行したら、`target/x86_64-blog_os/debug`ディレクトリ内に`bootimage-blog_os.bin`という名前のブータブルディスクイメージがあるはずです。これをバーチャルマシン内で起動してもいいですし、実際のハードウェア上で起動するためにUSBメモリにコピーしてもいいでしょう(ただし、これはCDイメージではありません。CDイメージは異なるフォーマットを持つので、これをCDに焼いてもうまくいきません)。
|
||||
|
||||
#### どういう仕組みなの?
|
||||
`bootimage`ツールは、裏で以下のステップを行っています:
|
||||
|
||||
- 私達のカーネルを[ELF]ファイルにコンパイルする。
|
||||
- 依存であるbootloaderをスタンドアロンの実行ファイルとしてコンパイルする。
|
||||
- カーネルのELFファイルのバイト列をブートローダーにリンクする。
|
||||
|
||||
[ELF]: https://ja.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[rust-osdev/bootloader]: https://github.com/rust-osdev/bootloader
|
||||
|
||||
起動時、ブートローダーは追加されたELFファイルを読み、解釈します。次にプログラム部を<ruby>ページテーブル<rp> (</rp><rt>page table</rt><rp>) </rp></ruby>の<ruby>仮想アドレス<rp> (</rp><rt>virtual address</rt><rp>) </rp></ruby>にマップし、`.bss`部をゼロにし、スタックをセットアップします。最後に、エントリポイントのアドレス(私達の`_start`関数)を読み、そこにジャンプします。
|
||||
|
||||
### QEMUで起動する
|
||||
|
||||
これで、ディスクイメージを仮想マシンで起動できます。[QEMU]を使ってこれを起動するには、以下のコマンドを実行してください:
|
||||
|
||||
[QEMU]: https://www.qemu.org/
|
||||
|
||||
```
|
||||
> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
|
||||
warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
|
||||
```
|
||||
|
||||
これにより、以下のような見た目の別のウィンドウが開きます:
|
||||
|
||||

|
||||
|
||||
私達の書いた"Hello World!"が画面に見えますね。
|
||||
|
||||
### 実際のマシン
|
||||
|
||||
USBメモリにこれを書き込んで実際のマシン上で起動することも可能です:
|
||||
|
||||
```
|
||||
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
|
||||
```
|
||||
|
||||
`sdX`はあなたのUSBメモリのデバイス名です。そのデバイス上のすべてのデータが上書きされてしまうので、 **正しいデバイス名を選んでいるのかよく確認してください** 。
|
||||
|
||||
イメージをUSBメモリに書き込んだあとは、そこから起動することによって実際のハードウェア上で走らせることができます。特殊なブートメニューを使ったり、BIOS設定で起動時の優先順位を変え、USBメモリから起動することを選択する必要があるでしょう。ただし、`bootloader`クレートはUEFIをサポートしていないので、UEFIマシン上ではうまく動作しないということに注意してください。
|
||||
|
||||
### `cargo run`を使う
|
||||
|
||||
QEMU上でより簡単に私達のカーネルを走らせるために、cargoの`runner`設定が使えます。
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "none")']
|
||||
runner = "bootimage runner"
|
||||
```
|
||||
`target.'cfg(target_os = "none")'`テーブルは、`"os"`フィールドが`"none"`であるようなすべてのターゲットに適用されます。私達の`x86_64-blog_os.json`ターゲットもその1つです。`runner`キーは`cargo run`のときに呼ばれるコマンドを指定しています。このコマンドは、ビルドが成功した後に、実行可能ファイルのパスを第一引数として実行されます。詳しくは、[cargoのドキュメント][cargo configuration]を読んでください。
|
||||
|
||||
`bootimage runner`コマンドは、`runner`キーとして実行するために設計されています。このコマンドは、与えられた実行ファイルをプロジェクトの依存するbootloaderとリンクして、QEMUを立ち上げます。より詳しく知りたいときや、設定オプションについては[`bootimage`のReadme][Readme of `bootimage`]を読んでください。
|
||||
|
||||
[Readme of `bootimage`]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
これで、`cargo run`を使ってカーネルをコンパイルしQEMU内で起動することができます。
|
||||
|
||||
## 次は?
|
||||
|
||||
次の記事では、VGAテキストバッファをより詳しく学び、そのための安全なインターフェースを書きます。また、`println`マクロのサポートも行います。
|
||||
@@ -1,493 +0,0 @@
|
||||
+++
|
||||
title = "A Minimal Rust Kernel"
|
||||
weight = 2
|
||||
path = "minimal-rust-kernel"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
+++
|
||||
|
||||
In this post we create a minimal 64-bit Rust kernel for the x86 architecture. We build upon the [freestanding Rust binary] from the previous post to create a bootable disk image, that prints something to the screen.
|
||||
|
||||
[freestanding Rust binary]: @/second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-02`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## The Boot Process
|
||||
When you turn on a computer, it begins executing firmware code that is stored in motherboard [ROM]. This code performs a [power-on self-test], detects available RAM, and pre-initializes the CPU and hardware. Afterwards it looks for a bootable disk and starts booting the operating system kernel.
|
||||
|
||||
[ROM]: https://en.wikipedia.org/wiki/Read-only_memory
|
||||
[power-on self-test]: https://en.wikipedia.org/wiki/Power-on_self-test
|
||||
|
||||
On x86, there are two firmware standards: the “Basic Input/Output System“ (**[BIOS]**) and the newer “Unified Extensible Firmware Interface” (**[UEFI]**). The BIOS standard is old and outdated, but simple and well-supported on any x86 machine since the 1980s. UEFI, in contrast, is more modern and has much more features, but is more complex to set up (at least in my opinion).
|
||||
|
||||
[BIOS]: https://en.wikipedia.org/wiki/BIOS
|
||||
[UEFI]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
|
||||
|
||||
Currently, we only provide BIOS support, but support for UEFI is planned, too. If you'd like to help us with this, check out the [Github issue](https://github.com/phil-opp/blog_os/issues/349).
|
||||
|
||||
### BIOS Boot
|
||||
Almost all x86 systems have support for BIOS booting, including newer UEFI-based machines that use an emulated BIOS. This is great, because you can use the same boot logic across all machines from the last centuries. But this wide compatibility is at the same time the biggest disadvantage of BIOS booting, because it means that the CPU is put into a 16-bit compatibility mode called [real mode] before booting so that archaic bootloaders from the 1980s would still work.
|
||||
|
||||
But let's start from the beginning:
|
||||
|
||||
When you turn on a computer, it loads the BIOS from some special flash memory located on the motherboard. The BIOS runs self test and initialization routines of the hardware, then it looks for bootable disks. If it finds one, the control is transferred to its _bootloader_, which is a 512-byte portion of executable code stored at the disk's beginning. Most bootloaders are larger than 512 bytes, so bootloaders are commonly split into a small first stage, which fits into 512 bytes, and a second stage, which is subsequently loaded by the first stage.
|
||||
|
||||
The bootloader has to determine the location of the kernel image on the disk and load it into memory. It also needs to switch the CPU from the 16-bit [real mode] first to the 32-bit [protected mode], and then to the 64-bit [long mode], where 64-bit registers and the complete main memory are available. Its third job is to query certain information (such as a memory map) from the BIOS and pass it to the OS kernel.
|
||||
|
||||
[real mode]: https://en.wikipedia.org/wiki/Real_mode
|
||||
[protected mode]: https://en.wikipedia.org/wiki/Protected_mode
|
||||
[long mode]: https://en.wikipedia.org/wiki/Long_mode
|
||||
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
|
||||
Writing a bootloader is a bit cumbersome as it requires assembly language and a lot of non insightful steps like “write this magic value to this processor register”. Therefore we don't cover bootloader creation in this post and instead provide a tool named [bootimage] that automatically prepends a bootloader to your kernel.
|
||||
|
||||
[bootimage]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
If you are interested in building your own bootloader: Stay tuned, a set of posts on this topic is already planned! <!-- , check out our “_[Writing a Bootloader]_” posts, where we explain in detail how a bootloader is built. -->
|
||||
|
||||
#### The Multiboot Standard
|
||||
To avoid that every operating system implements its own bootloader, which is only compatible with a single OS, the [Free Software Foundation] created an open bootloader standard called [Multiboot] in 1995. The standard defines an interface between the bootloader and operating system, so that any Multiboot compliant bootloader can load any Multiboot compliant operating system. The reference implementation is [GNU GRUB], which is the most popular bootloader for Linux systems.
|
||||
|
||||
[Free Software Foundation]: https://en.wikipedia.org/wiki/Free_Software_Foundation
|
||||
[Multiboot]: https://wiki.osdev.org/Multiboot
|
||||
[GNU GRUB]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
|
||||
To make a kernel Multiboot compliant, one just needs to insert a so-called [Multiboot header] at the beginning of the kernel file. This makes it very easy to boot an OS in GRUB. However, GRUB and the Multiboot standard have some problems too:
|
||||
|
||||
[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
|
||||
|
||||
- They support only the 32-bit protected mode. This means that you still have to do the CPU configuration to switch to the 64-bit long mode.
|
||||
- They are designed to make the bootloader simple instead of the kernel. For example, the kernel needs to be linked with an [adjusted default page size], because GRUB can't find the Multiboot header otherwise. Another example is that the [boot information], which is passed to the kernel, contains lots of architecture dependent structures instead of providing clean abstractions.
|
||||
- Both GRUB and the Multiboot standard are only sparsely documented.
|
||||
- GRUB needs to be installed on the host system to create a bootable disk image from the kernel file. This makes development on Windows or Mac more difficult.
|
||||
|
||||
[adjusted default page size]: https://wiki.osdev.org/Multiboot#Multiboot_2
|
||||
[boot information]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
|
||||
|
||||
Because of these drawbacks we decided to not use GRUB or the Multiboot standard. However, we plan to add Multiboot support to our [bootimage] tool, so that it's possible to load your kernel on a GRUB system too. If you're interested in writing a Multiboot compliant kernel, check out the [first edition] of this blog series.
|
||||
|
||||
[first edition]: @/edition-1/_index.md
|
||||
|
||||
### UEFI
|
||||
|
||||
(We don't provide UEFI support at the moment, but we would love to! If you'd like to help, please tell us in the [Github issue](https://github.com/phil-opp/blog_os/issues/349).)
|
||||
|
||||
## A Minimal Kernel
|
||||
Now that we roughly know how a computer boots, it's time to create our own minimal kernel. Our goal is to create a disk image that prints a “Hello World!” to the screen when booted. For that we build upon the [freestanding Rust binary] from the previous post.
|
||||
|
||||
As you may remember, we built the freestanding binary through `cargo`, but depending on the operating system we needed different entry point names and compile flags. That's because `cargo` builds for the _host system_ by default, i.e. the system you're running on. This isn't something we want for our kernel, because a kernel that runs on top of e.g. Windows does not make much sense. Instead, we want to compile for a clearly defined _target system_.
|
||||
|
||||
### Installing Rust Nightly
|
||||
Rust has three release channels: _stable_, _beta_, and _nightly_. The Rust Book explains the difference between these channels really well, so take a minute and [check it out](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains). For building an operating system we will need some experimental features that are only available on the nightly channel, so we need to install a nightly version of Rust.
|
||||
|
||||
To manage Rust installations I highly recommend [rustup]. It allows you to install nightly, beta, and stable compilers side-by-side and makes it easy to update them. With rustup you can use a nightly compiler for the current directory by running `rustup override set nightly`. Alternatively, you can add a file called `rust-toolchain` with the content `nightly` to the project's root directory. You can check that you have a nightly version installed by running `rustc --version`: The version number should contain `-nightly` at the end.
|
||||
|
||||
[rustup]: https://www.rustup.rs/
|
||||
|
||||
The nightly compiler allows us to opt-in to various experimental features by using so-called _feature flags_ at the top of our file. For example, we could enable the experimental [`asm!` macro] for inline assembly by adding `#![feature(asm)]` to the top of our `main.rs`. Note that such experimental features are completely unstable, which means that future Rust versions might change or remove them without prior warning. For this reason we will only use them if absolutely necessary.
|
||||
|
||||
[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
|
||||
|
||||
### Target Specification
|
||||
Cargo supports different target systems through the `--target` parameter. The target is described by a so-called _[target triple]_, which describes the CPU architecture, the vendor, the operating system, and the [ABI]. For example, the `x86_64-unknown-linux-gnu` target triple describes a system with a `x86_64` CPU, no clear vendor and a Linux operating system with the GNU ABI. Rust supports [many different target triples][platform-support], including `arm-linux-androideabi` for Android or [`wasm32-unknown-unknown` for WebAssembly](https://www.hellorust.com/setup/wasm-target/).
|
||||
|
||||
[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
[ABI]: https://stackoverflow.com/a/2456882
|
||||
[platform-support]: https://forge.rust-lang.org/release/platform-support.html
|
||||
[custom-targets]: https://doc.rust-lang.org/nightly/rustc/targets/custom.html
|
||||
|
||||
For our target system, however, we require some special configuration parameters (e.g. no underlying OS), so none of the [existing target triples][platform-support] fits. Fortunately, Rust allows us to define [our own target][custom-targets] through a JSON file. For example, a JSON file that describes the `x86_64-unknown-linux-gnu` target looks like this:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-linux-gnu",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "linux",
|
||||
"executables": true,
|
||||
"linker-flavor": "gcc",
|
||||
"pre-link-args": ["-m64"],
|
||||
"morestack": false
|
||||
}
|
||||
```
|
||||
|
||||
Most fields are required by LLVM to generate code for that platform. For example, the [`data-layout`] field defines the size of various integer, floating point, and pointer types. Then there are fields that Rust uses for conditional compilation, such as `target-pointer-width`. The third kind of fields define how the crate should be built. For example, the `pre-link-args` field specifies arguments passed to the [linker].
|
||||
|
||||
[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
|
||||
[linker]: https://en.wikipedia.org/wiki/Linker_(computing)
|
||||
|
||||
We also target `x86_64` systems with our kernel, so our target specification will look very similar to the one above. Let's start by creating a `x86_64-blog_os.json` file (choose any name you like) with the common content:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true
|
||||
}
|
||||
```
|
||||
|
||||
Note that we changed the OS in the `llvm-target` and the `os` field to `none`, because we will run on bare metal.
|
||||
|
||||
We add the following build-related entries:
|
||||
|
||||
|
||||
```json
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
```
|
||||
|
||||
Instead of using the platform's default linker (which might not support Linux targets), we use the cross platform [LLD] linker that is shipped with Rust for linking our kernel.
|
||||
|
||||
[LLD]: https://lld.llvm.org/
|
||||
|
||||
```json
|
||||
"panic-strategy": "abort",
|
||||
```
|
||||
|
||||
This setting specifies that the target doesn't support [stack unwinding] on panic, so instead the program should abort directly. This has the same effect as the `panic = "abort"` option in our Cargo.toml, so we can remove it from there. (Note that in contrast to the Cargo.toml option, this target option also applies when we recompile the `core` library later in this post. So be sure to add this option, even if you prefer to keep the Cargo.toml option.)
|
||||
|
||||
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
|
||||
```json
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
We're writing a kernel, so we'll need to handle interrupts at some point. To do that safely, we have to disable a certain stack pointer optimization called the _“red zone”_, because it would cause stack corruptions otherwise. For more information, see our separate post about [disabling the red zone].
|
||||
|
||||
[disabling the red zone]: @/second-edition/posts/02-minimal-rust-kernel/disable-red-zone/index.md
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float",
|
||||
```
|
||||
|
||||
The `features` field enables/disables target features. We disable the `mmx` and `sse` features by prefixing them with a minus and enable the `soft-float` feature by prefixing it with a plus. Note that there must be no spaces between different flags, otherwise LLVM fails to interpret the features string.
|
||||
|
||||
The `mmx` and `sse` features determine support for [Single Instruction Multiple Data (SIMD)] instructions, which can often speed up programs significantly. However, using the large SIMD registers in OS kernels leads to performance problems. The reason is that the kernel needs to restore all registers to their original state before continuing an interrupted program. This means that the kernel has to save the complete SIMD state to main memory on each system call or hardware interrupt. Since the SIMD state is very large (512–1600 bytes) and interrupts can occur very often, these additional save/restore operations considerably harm performance. To avoid this, we disable SIMD for our kernel (not for applications running on top!).
|
||||
|
||||
[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
|
||||
|
||||
A problem with disabling SIMD is that floating point operations on `x86_64` require SIMD registers by default. To solve this problem, we add the `soft-float` feature, which emulates all floating point operations through software functions based on normal integers.
|
||||
|
||||
For more information, see our post on [disabling SIMD](@/second-edition/posts/02-minimal-rust-kernel/disable-simd/index.md).
|
||||
|
||||
#### Putting it Together
|
||||
Our target specification file now looks like this:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
"panic-strategy": "abort",
|
||||
"disable-redzone": true,
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
}
|
||||
```
|
||||
|
||||
### Building our Kernel
|
||||
Compiling for our new target will use Linux conventions (I'm not quite sure why, I assume that it's just LLVM's default). This means that we need an entry point named `_start` as described in the [previous post]:
|
||||
|
||||
[previous post]: @/second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// this function is the entry point, since the linker looks for a function
|
||||
// named `_start` by default
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
Note that the entry point needs to be called `_start` regardless of your host OS.
|
||||
|
||||
We can now build the kernel for our new target by passing the name of the JSON file as `--target`:
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
|
||||
error[E0463]: can't find crate for `core`
|
||||
```
|
||||
|
||||
It fails! The error tells us that the Rust compiler no longer finds the [`core` library]. This library contains basic Rust types such as `Result`, `Option`, and iterators, and is implicitly linked to all `no_std` crates.
|
||||
|
||||
[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
|
||||
|
||||
The problem is that the core library is distributed together with the Rust compiler as a _precompiled_ library. So it is only valid for supported host triples (e.g., `x86_64-unknown-linux-gnu`) but not for our custom target. If we want to compile code for other targets, we need to recompile `core` for these targets first.
|
||||
|
||||
#### The `build-std` Option
|
||||
|
||||
That's where the [`build-std` feature] of cargo comes in. It allows to recompile `core` and other standard library crates on demand, instead of using the precompiled versions shipped with the Rust installation. This feature is very new and still not finished, so it is marked as "unstable" and only available on [nightly Rust compilers].
|
||||
|
||||
[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
|
||||
[nightly Rust compilers]: #installing-rust-nightly
|
||||
|
||||
To use the feature, we need to create a [cargo configuration] file at `.cargo/config.toml` with the following content:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std = ["core", "compiler_builtins"]
|
||||
```
|
||||
|
||||
This tells cargo that it should recompile the `core` and `compiler_builtins` libraries. The latter is required because it is a dependency of `core`. In order to recompile these libraries, cargo needs access to the rust source code, which we can install with `rustup component add rust-src`.
|
||||
|
||||
<div class="note">
|
||||
|
||||
**Note:** The `unstable.build-std` configuration key requires at least the Rust nightly from 2020-07-15.
|
||||
|
||||
</div>
|
||||
|
||||
After setting the `unstable.build-std` configuration key and installing the `rust-src` component, we can rerun the our build command:
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
Compiling core v0.0.0 (/…/rust/src/libcore)
|
||||
Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling compiler_builtins v0.1.32
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
We see that `cargo build` now recompiles the `core`, `rustc-std-workspace-core` (a dependency of `compiler_builtins`), and `compiler_builtins` libraries for our custom target.
|
||||
|
||||
#### Memory-Related Intrinsics
|
||||
|
||||
The Rust compiler assumes that a certain set of built-in functions is available for all systems. Most of these functions are provided by the `compiler_builtins` crate that we just recompiled. However, there are some memory-related functions in that crate that are not enabled by default because they are normally provided by the C library on the system. These functions include `memset`, which sets all bytes in a memory block to a given value, `memcpy`, which copies one memory block to another, and `memcmp`, which compares two memory blocks. While we didn't need any of these functions to compile our kernel right now, they will be required as soon as we add some more code to it (e.g. when copying structs around).
|
||||
|
||||
Since we can't link to the C library of the operating system, we need an alternative way to provide these functions to the compiler. One possible approach for this could be to implement our own `memset` etc. functions and apply the `#[no_mangle]` attribute to them (to avoid the automatic renaming during compilation). However, this is dangerous since the slightest mistake in the implementation of these functions could lead to undefined behavior. For example, you might get an endless recursion when implementing `memcpy` using a `for` loop because `for` loops implicitly call the [`IntoIterator::into_iter`] trait method, which might call `memcpy` again. So it's a good idea to reuse existing well-tested implementations instead.
|
||||
|
||||
[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
|
||||
|
||||
Fortunately, the `compiler_builtins` crate already contains implementations for all the needed functions, they are just disabled by default to not collide with the implementations from the C library. We can enable them by setting cargo's [`build-std-features`] flag to `["compiler-builtins-mem"]`. Like the `build-std` flag, this flag can be either passed on the command line as `-Z` flag or configured in the `unstable` table in the `.cargo/config.toml` file. Since we always want to build with this flag, the config file option makes more sense for us:
|
||||
|
||||
[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std-features = ["compiler-builtins-mem"]
|
||||
```
|
||||
|
||||
(Support for the `compiler-builtins-mem` feature was only [added very recently](https://github.com/rust-lang/rust/pull/77284), so you need at least Rust nightly `2020-09-30` for it.)
|
||||
|
||||
Behind the scenes, this flag enables the [`mem` feature] of the `compiler_builtins` crate. The effect of this is that the `#[no_mangle]` attribute is applied to the [`memcpy` etc. implementations] of the crate, which makes them available to the linker. It's worth noting that these functions are [not optimized] right now, so their performance might not be the best, but at least they are correct. For `x86_64`, there is an open pull request to [optimize these functions using special assembly instructions][memcpy rep movsb].
|
||||
|
||||
[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L54-L55
|
||||
[`memcpy` etc. implementations]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69
|
||||
[not optimized]: https://github.com/rust-lang/compiler-builtins/issues/339
|
||||
[memcpy rep movsb]: https://github.com/rust-lang/compiler-builtins/pull/365
|
||||
|
||||
With this change, our kernel has valid implementations for all compiler-required functions, so it will continue to compile even if our code gets more complex.
|
||||
|
||||
#### Set a Default Target
|
||||
|
||||
To avoid passing the `--target` parameter on every invocation of `cargo build`, we can override the default target. To do this, we add the following to our [cargo configuration] file at `.cargo/config.toml`:
|
||||
|
||||
[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[build]
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
This tells `cargo` to use our `x86_64-blog_os.json` target when no explicit `--target` argument is passed. This means that we can now build our kernel with a simple `cargo build`. For more information on cargo configuration options, check out the [official documentation][cargo configuration].
|
||||
|
||||
We are now able to build our kernel for a bare metal target with a simple `cargo build`. However, our `_start` entry point, which will be called by the boot loader, is still empty. It's time that we output something to screen from it.
|
||||
|
||||
### Printing to Screen
|
||||
The easiest way to print text to the screen at this stage is the [VGA text buffer]. It is a special memory area mapped to the VGA hardware that contains the contents displayed on screen. It normally consists of 25 lines that each contain 80 character cells. Each character cell displays an ASCII character with some foreground and background colors. The screen output looks like this:
|
||||
|
||||
[VGA text buffer]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
|
||||

|
||||
|
||||
We will discuss the exact layout of the VGA buffer in the next post, where we write a first small driver for it. For printing “Hello World!”, we just need to know that the buffer is located at address `0xb8000` and that each character cell consists of an ASCII byte and a color byte.
|
||||
|
||||
The implementation looks like this:
|
||||
|
||||
```rust
|
||||
static HELLO: &[u8] = b"Hello World!";
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
let vga_buffer = 0xb8000 as *mut u8;
|
||||
|
||||
for (i, &byte) in HELLO.iter().enumerate() {
|
||||
unsafe {
|
||||
*vga_buffer.offset(i as isize * 2) = byte;
|
||||
*vga_buffer.offset(i as isize * 2 + 1) = 0xb;
|
||||
}
|
||||
}
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
First, we cast the integer `0xb8000` into a [raw pointer]. Then we [iterate] over the bytes of the [static] `HELLO` [byte string]. We use the [`enumerate`] method to additionally get a running variable `i`. In the body of the for loop, we use the [`offset`] method to write the string byte and the corresponding color byte (`0xb` is a light cyan).
|
||||
|
||||
[iterate]: https://doc.rust-lang.org/stable/book/ch13-02-iterators.html
|
||||
[static]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
|
||||
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
|
||||
[byte string]: https://doc.rust-lang.org/reference/tokens.html#byte-string-literals
|
||||
[raw pointer]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
|
||||
|
||||
Note that there's an [`unsafe`] block around all memory writes. The reason is that the Rust compiler can't prove that the raw pointers we create are valid. They could point anywhere and lead to data corruption. By putting them into an `unsafe` block we're basically telling the compiler that we are absolutely sure that the operations are valid. Note that an `unsafe` block does not turn off Rust's safety checks. It only allows you to do [five additional things].
|
||||
|
||||
[`unsafe`]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html
|
||||
[five additional things]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
I want to emphasize that **this is not the way we want to do things in Rust!** It's very easy to mess up when working with raw pointers inside unsafe blocks, for example, we could easily write beyond the buffer's end if we're not careful.
|
||||
|
||||
So we want to minimize the use of `unsafe` as much as possible. Rust gives us the ability to do this by creating safe abstractions. For example, we could create a VGA buffer type that encapsulates all unsafety and ensures that it is _impossible_ to do anything wrong from the outside. This way, we would only need minimal amounts of `unsafe` and can be sure that we don't violate [memory safety]. We will create such a safe VGA buffer abstraction in the next post.
|
||||
|
||||
[memory safety]: https://en.wikipedia.org/wiki/Memory_safety
|
||||
|
||||
## Running our Kernel
|
||||
|
||||
Now that we have an executable that does something perceptible, it is time to run it. First, we need to turn our compiled kernel into a bootable disk image by linking it with a bootloader. Then we can run the disk image in the [QEMU] virtual machine or boot it on real hardware using a USB stick.
|
||||
|
||||
### Creating a Bootimage
|
||||
|
||||
To turn our compiled kernel into a bootable disk image, we need to link it with a bootloader. As we learned in the [section about booting], the bootloader is responsible for initializing the CPU and loading our kernel.
|
||||
|
||||
[section about booting]: #the-boot-process
|
||||
|
||||
Instead of writing our own bootloader, which is a project on its own, we use the [`bootloader`] crate. This crate implements a basic BIOS bootloader without any C dependencies, just Rust and inline assembly. To use it for booting our kernel, we need to add a dependency on it:
|
||||
|
||||
[`bootloader`]: https://crates.io/crates/bootloader
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.8"
|
||||
```
|
||||
|
||||
Adding the bootloader as dependency is not enough to actually create a bootable disk image. The problem is that we need to link our kernel with the bootloader after compilation, but cargo has no support for [post-build scripts].
|
||||
|
||||
[post-build scripts]: https://github.com/rust-lang/cargo/issues/545
|
||||
|
||||
To solve this problem, we created a tool named `bootimage` that first compiles the kernel and bootloader, and then links them together to create a bootable disk image. To install the tool, execute the following command in your terminal:
|
||||
|
||||
```
|
||||
cargo install bootimage
|
||||
```
|
||||
|
||||
For running `bootimage` and building the bootloader, you need to have the `llvm-tools-preview` rustup component installed. You can do so by executing `rustup component add llvm-tools-preview`.
|
||||
|
||||
After installing `bootimage` and adding the `llvm-tools-preview` component, we can create a bootable disk image by executing:
|
||||
|
||||
```
|
||||
> cargo bootimage
|
||||
```
|
||||
|
||||
We see that the tool recompiles our kernel using `cargo build`, so it will automatically pick up any changes you make. Afterwards it compiles the bootloader, which might take a while. Like all crate dependencies it is only built once and then cached, so subsequent builds will be much faster. Finally, `bootimage` combines the bootloader and your kernel to a bootable disk image.
|
||||
|
||||
After executing the command, you should see a bootable disk image named `bootimage-blog_os.bin` in your `target/x86_64-blog_os/debug` directory. You can boot it in a virtual machine or copy it to an USB drive to boot it on real hardware. (Note that this is not a CD image, which have a different format, so burning it to a CD doesn't work).
|
||||
|
||||
#### How does it work?
|
||||
The `bootimage` tool performs the following steps behind the scenes:
|
||||
|
||||
- It compiles our kernel to an [ELF] file.
|
||||
- It compiles the bootloader dependency as a standalone executable.
|
||||
- It links the bytes of the kernel ELF file to the bootloader.
|
||||
|
||||
[ELF]: https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[rust-osdev/bootloader]: https://github.com/rust-osdev/bootloader
|
||||
|
||||
When booted, the bootloader reads and parses the appended ELF file. It then maps the program segments to virtual addresses in the page tables, zeroes the `.bss` section, and sets up a stack. Finally, it reads the entry point address (our `_start` function) and jumps to it.
|
||||
|
||||
### Booting it in QEMU
|
||||
|
||||
We can now boot the disk image in a virtual machine. To boot it in [QEMU], execute the following command:
|
||||
|
||||
[QEMU]: https://www.qemu.org/
|
||||
|
||||
```
|
||||
> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
|
||||
warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
|
||||
```
|
||||
|
||||
This opens a separate window with that looks like this:
|
||||
|
||||

|
||||
|
||||
We see that our "Hello World!" is visible on the screen.
|
||||
|
||||
### Real Machine
|
||||
|
||||
It is also possible to write it to an USB stick and boot it on a real machine:
|
||||
|
||||
```
|
||||
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
|
||||
```
|
||||
|
||||
Where `sdX` is the device name of your USB stick. **Be careful** to choose the correct device name, because everything on that device is overwritten.
|
||||
|
||||
After writing the image to the USB stick, you can run it on real hardware by booting from it. You probably need to use a special boot menu or change the boot order in your BIOS configuration to boot from the USB stick. Note that it currently doesn't work for UEFI machines, since the `bootloader` crate has no UEFI support yet.
|
||||
|
||||
### Using `cargo run`
|
||||
|
||||
To make it easier to run our kernel in QEMU, we can set the `runner` configuration key for cargo:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[target.'cfg(target_os = "none")']
|
||||
runner = "bootimage runner"
|
||||
```
|
||||
|
||||
The `target.'cfg(target_os = "none")'` table applies to all targets that have set the `"os"` field of their target configuration file to `"none"`. This includes our `x86_64-blog_os.json` target. The `runner` key specifies the command that should be invoked for `cargo run`. The command is run after a successful build with the executable path passed as first argument. See the [cargo documentation][cargo configuration] for more details.
|
||||
|
||||
The `bootimage runner` command is specifically designed to be usable as a `runner` executable. It links the given executable with the project's bootloader dependency and then launches QEMU. See the [Readme of `bootimage`] for more details and possible configuration options.
|
||||
|
||||
[Readme of `bootimage`]: https://github.com/rust-osdev/bootimage
|
||||
|
||||
Now we can use `cargo run` to compile our kernel and boot it in QEMU.
|
||||
|
||||
## What's next?
|
||||
|
||||
In the next post, we will explore the VGA text buffer in more detail and write a safe interface for it. We will also add support for the `println` macro.
|
||||
@@ -1,389 +0,0 @@
|
||||
+++
|
||||
title = "最小化内核"
|
||||
weight = 2
|
||||
path = "zh-CN/minimal-rust-kernel"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu"]
|
||||
+++
|
||||
|
||||
在这篇文章中,我们将基于 **x86架构**(the x86 architecture),使用 Rust 语言,编写一个最小化的 64 位内核。我们将从上一章中构建的独立式可执行程序开始,构建自己的内核;它将向显示器打印字符串,并能被打包为一个能够引导启动的**磁盘映像**(disk image)。
|
||||
|
||||
[freestanding Rust binary]: @/second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-02`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 引导启动
|
||||
|
||||
当我们启动电脑时,主板 [ROM](https://en.wikipedia.org/wiki/Read-only_memory)内存储的**固件**(firmware)将会运行:它将负责电脑的**加电自检**([power-on self test](https://en.wikipedia.org/wiki/Power-on_self-test)),**可用内存**(available RAM)的检测,以及 CPU 和其它硬件的预加载。这之后,它将寻找一个**可引导的存储介质**(bootable disk),并开始引导启动其中的**内核**(kernel)。
|
||||
|
||||
x86 架构支持两种固件标准: **BIOS**([Basic Input/Output System](https://en.wikipedia.org/wiki/BIOS))和 **UEFI**([Unified Extensible Firmware Interface](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface))。其中,BIOS 标准显得陈旧而过时,但实现简单,并为 1980 年代后的所有 x86 设备所支持;相反地,UEFI 更现代化,功能也更全面,但开发和构建更复杂(至少从我的角度看是如此)。
|
||||
|
||||
在这篇文章中,我们暂时只提供 BIOS 固件的引导启动方式。
|
||||
|
||||
### BIOS 启动
|
||||
|
||||
几乎所有的 x86 硬件系统都支持 BIOS 启动,这也包含新型的、基于 UEFI、用**模拟 BIOS**(emulated BIOS)的方式向后兼容的硬件系统。这可以说是一件好事情,因为无论是上世纪还是现在的硬件系统,你都只需编写同样的引导启动逻辑;但这种兼容性有时也是 BIOS 引导启动最大的缺点,因为这意味着在系统启动前,你的 CPU 必须先进入一个 16 位系统兼容的**实模式**([real mode](https://en.wikipedia.org/wiki/Real_mode)),这样 1980 年代古老的引导固件才能够继续使用。
|
||||
|
||||
让我们从头开始,理解一遍 BIOS 启动的过程。
|
||||
|
||||
当电脑启动时,主板上特殊的闪存中存储的 BIOS 固件将被加载。BIOS 固件将会加电自检、初始化硬件,然后它将寻找一个可引导的存储介质。如果找到了,那电脑的控制权将被转交给**引导程序**(bootloader):一段存储在存储介质的开头的、512字节长度的程序片段。大多数的引导程序长度都大于512字节——所以通常情况下,引导程序都被切分为一段优先启动、长度不超过512字节、存储在介质开头的**第一阶段引导程序**(first stage bootloader),和一段随后由其加载的、长度可能较长、存储在其它位置的**第二阶段引导程序**(second stage bootloader)。
|
||||
|
||||
引导程序必须决定内核的位置,并将内核加载到内存。引导程序还需要将 CPU 从 16 位的实模式,先切换到 32 位的**保护模式**([protected mode](https://en.wikipedia.org/wiki/Protected_mode)),最终切换到 64 位的**长模式**([long mode](https://en.wikipedia.org/wiki/Long_mode)):此时,所有的 64 位寄存器和整个**主内存**(main memory)才能被访问。引导程序的第三个作用,是从 BIOS 查询特定的信息,并将其传递到内核;如查询和传递**内存映射表**(memory map)。
|
||||
|
||||
编写一个引导程序并不是一个简单的任务,因为这需要使用汇编语言,而且必须经过许多意图并不明显的步骤——比如,把一些**魔术数字**(magic number)写入某个寄存器。因此,我们不会讲解如何编写自己的引导程序,而是推荐 [bootimage 工具](https://github.com/rust-osdev/bootimage)——它能够自动并且方便地为你的内核准备一个引导程序。
|
||||
|
||||
### Multiboot 标准
|
||||
|
||||
每个操作系统都实现自己的引导程序,而这只对单个操作系统有效。为了避免这样的僵局,1995 年,**自由软件基金会**([Free Software Foundation](https://en.wikipedia.org/wiki/Free_Software_Foundation))颁布了一个开源的引导程序标准——[Multiboot](https://wiki.osdev.org/Multiboot)。这个标准定义了引导程序和操作系统间的统一接口,所以任何适配 Multiboot 的引导程序,都能用来加载任何同样适配了 Multiboot 的操作系统。[GNU GRUB](https://en.wikipedia.org/wiki/GNU_GRUB) 是一个可供参考的 Multiboot 实现,它也是最热门的Linux系统引导程序之一。
|
||||
|
||||
要编写一款适配 Multiboot 的内核,我们只需要在内核文件开头,插入被称作 **Multiboot头**([Multiboot header](https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format))的数据片段。这让 GRUB 很容易引导任何操作系统,但是,GRUB 和 Multiboot 标准也有一些可预知的问题:
|
||||
|
||||
1. 它们只支持 32 位的保护模式。这意味着,在引导之后,你依然需要配置你的 CPU,让它切换到 64 位的长模式;
|
||||
2. 它们被设计为精简引导程序,而不是精简内核。举个例子,内核需要以调整过的**默认页长度**([default page size](https://wiki.osdev.org/Multiboot#Multiboot_2))被链接,否则 GRUB 将无法找到内核的 Multiboot 头。另一个例子是**引导信息**([boot information](https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format)),这个包含着大量与架构有关的数据,会在引导启动时,被直接传到操作系统,而不会经过一层清晰的抽象;
|
||||
3. GRUB 和 Multiboot 标准并没有被详细地解释,阅读相关文档需要一定经验;
|
||||
4. 为了创建一个能够被引导的磁盘映像,我们在开发时必须安装 GRUB:这加大了基于 Windows 或 macOS 开发内核的难度。
|
||||
|
||||
出于这些考虑,我们决定不使用 GRUB 或者 Multiboot 标准。然而,Multiboot 支持功能也在 bootimage 工具的开发计划之中,所以从原理上讲,如果选用 bootimage 工具,在未来使用 GRUB 引导你的系统内核是可能的。
|
||||
|
||||
## 最小化内核
|
||||
|
||||
现在我们已经明白电脑是如何启动的,那也是时候编写我们自己的内核了。我们的小目标是,创建一个内核的磁盘映像,它能够在启动时,向屏幕输出一行“Hello World!”;我们的工作将基于上一章构建的独立式可执行程序。
|
||||
|
||||
如果读者还有印象的话,在上一章,我们使用 `cargo` 构建了一个独立的二进制程序;但这个程序依然基于特定的操作系统平台:因平台而异,我们需要定义不同名称的函数,且使用不同的编译指令。这是因为在默认情况下,`cargo` 会为特定的**宿主系统**(host system)构建源码,比如为你正在运行的系统构建源码。这并不是我们想要的,因为我们的内核不应该基于另一个操作系统——我们想要编写的,就是这个操作系统。确切地说,我们想要的是,编译为一个特定的**目标系统**(target system)。
|
||||
|
||||
## 安装 Nightly Rust
|
||||
|
||||
Rust 语言有三个**发行频道**(release channel),分别是 stable、beta 和 nightly。《Rust 程序设计语言》中对这三个频道的区别解释得很详细,可以前往[这里](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html)看一看。为了搭建一个操作系统,我们需要一些只有 nightly 会提供的实验性功能,所以我们需要安装一个 nightly 版本的 Rust。
|
||||
|
||||
要管理安装好的 Rust,我强烈建议使用 [rustup](https://www.rustup.rs/):它允许你同时安装 nightly、beta 和 stable 版本的编译器,而且让更新 Rust 变得容易。你可以输入 `rustup override add nightly` 来选择在当前目录使用 nightly 版本的 Rust。或者,你也可以在项目根目录添加一个名称为 `rust-toolchain`、内容为 `nightly` 的文件。要检查你是否已经安装了一个 nightly,你可以运行 `rustc --version`:返回的版本号末尾应该包含`-nightly`。
|
||||
|
||||
Nightly 版本的编译器允许我们在源码的开头插入**特性标签**(feature flag),来自由选择并使用大量实验性的功能。举个例子,要使用实验性的[内联汇编(asm!宏)][asm feature],我们可以在 `main.rs` 的顶部添加 `#![feature(asm)]`。要注意的是,这样的实验性功能**不稳定**(unstable),意味着未来的 Rust 版本可能会修改或移除这些功能,而不会有预先的警告过渡。因此我们只有在绝对必要的时候,才应该使用这些特性。
|
||||
|
||||
[asm feature]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
|
||||
|
||||
### 目标配置清单
|
||||
|
||||
通过 `--target` 参数,`cargo` 支持不同的目标系统。这个目标系统可以使用一个**目标三元组**([target triple](https://clang.llvm.org/docs/CrossCompilation.html#target-triple))来描述,它描述了 CPU 架构、平台供应者、操作系统和**应用程序二进制接口**([Application Binary Interface, ABI](https://stackoverflow.com/a/2456882))。比方说,目标三元组` x86_64-unknown-linux-gnu` 描述一个基于 `x86_64` 架构 CPU 的、没有明确的平台供应者的 linux 系统,它遵循 GNU 风格的 ABI。Rust 支持[许多不同的目标三元组](https://forge.rust-lang.org/release/platform-support.html),包括安卓系统对应的 `arm-linux-androideabi` 和 [WebAssembly使用的wasm32-unknown-unknown](https://www.hellorust.com/setup/wasm-target/)。
|
||||
|
||||
为了编写我们的目标系统,并且鉴于我们需要做一些特殊的配置(比如没有依赖的底层操作系统),[已经支持的目标三元组](https://forge.rust-lang.org/release/platform-support.html)都不能满足我们的要求。幸运的是,只需使用一个 JSON 文件,Rust 便允许我们定义自己的目标系统;这个文件常被称作**目标配置清单**(target specification)。比如,一个描述 `x86_64-unknown-linux-gnu` 目标系统的配置清单大概长这样:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-linux-gnu",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "linux",
|
||||
"executables": true,
|
||||
"linker-flavor": "gcc",
|
||||
"pre-link-args": ["-m64"],
|
||||
"morestack": false
|
||||
}
|
||||
```
|
||||
|
||||
一个配置清单中包含多个**配置项**(field)。大多数的配置项都是 LLVM 需求的,它们将配置为特定平台生成的代码。打个比方,`data-layout` 配置项定义了不同的整数、浮点数、指针类型的长度;另外,还有一些 Rust 用作条件编译的配置项,如 `target-pointer-width`。还有一些类型的配置项,定义了这个包该如何被编译,例如,`pre-link-args` 配置项指定了应该向**链接器**([linker](https://en.wikipedia.org/wiki/Linker_(computing)))传入的参数。
|
||||
|
||||
我们将把我们的内核编译到 `x86_64` 架构,所以我们的配置清单将和上面的例子相似。现在,我们来创建一个名为 `x86_64-blog_os.json` 的文件——当然也可以选用自己喜欢的文件名——里面包含这样的内容:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
}
|
||||
```
|
||||
|
||||
需要注意的是,因为我们要在**裸机**(bare metal)上运行内核,我们已经修改了 `llvm-target` 的内容,并将 `os` 配置项的值改为 `none`。
|
||||
|
||||
我们还需要添加下面与编译相关的配置项:
|
||||
|
||||
```json
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
```
|
||||
|
||||
在这里,我们不使用平台默认提供的链接器,因为它可能不支持 Linux 目标系统。为了链接我们的内核,我们使用跨平台的 **LLD链接器**([LLD linker](https://lld.llvm.org/)),它是和 Rust 一起打包发布的。
|
||||
|
||||
```json
|
||||
"panic-strategy": "abort",
|
||||
```
|
||||
|
||||
这个配置项的意思是,我们的编译目标不支持 panic 时的**栈展开**([stack unwinding](https://www.bogotobogo.com/cplusplus/stackunwinding.php)),所以我们选择直接**在 panic 时中止**(abort on panic)。这和在 `Cargo.toml` 文件中添加 `panic = "abort"` 选项的作用是相同的,所以我们可以不在这里的配置清单中填写这一项。
|
||||
|
||||
```json
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
我们正在编写一个内核,所以我们应该同时处理中断。要安全地实现这一点,我们必须禁用一个与**红区**(redzone)有关的栈指针优化:因为此时,这个优化可能会导致栈被破坏。我们撰写了一篇专门的短文,来更详细地解释红区及与其相关的优化。
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float",
|
||||
```
|
||||
|
||||
`features` 配置项被用来启用或禁用某个目标 **CPU 特征**(CPU feature)。通过在它们前面添加`-`号,我们将 `mmx` 和 `sse` 特征禁用;添加前缀`+`号,我们启用了 `soft-float` 特征。
|
||||
|
||||
`mmx` 和 `sse` 特征决定了是否支持**单指令多数据流**([Single Instruction Multiple Data,SIMD](https://en.wikipedia.org/wiki/SIMD))相关指令,这些指令常常能显著地提高程序层面的性能。然而,在内核中使用庞大的 SIMD 寄存器,可能会造成较大的性能影响:因为每次程序中断时,内核不得不储存整个庞大的 SIMD 寄存器以备恢复——这意味着,对每个硬件中断或系统调用,完整的 SIMD 状态必须存到主存中。由于 SIMD 状态可能相当大(512~1600 个字节),而中断可能时常发生,这些额外的存储与恢复操作可能显著地影响效率。为解决这个问题,我们对内核禁用 SIMD(但这不意味着禁用内核之上的应用程序的 SIMD 支持)。
|
||||
|
||||
禁用 SIMD 产生的一个问题是,`x86_64` 架构的浮点数指针运算默认依赖于 SIMD 寄存器。我们的解决方法是,启用 `soft-float` 特征,它将使用基于整数的软件功能,模拟浮点数指针运算。
|
||||
|
||||
为了让读者的印象更清晰,我们撰写了一篇关于禁用 SIMD 的短文。
|
||||
|
||||
现在,我们将各个配置项整合在一起。我们的目标配置清单应该长这样:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
"panic-strategy": "abort",
|
||||
"disable-redzone": true,
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
}
|
||||
```
|
||||
|
||||
### 编译内核
|
||||
|
||||
要编译我们的内核,我们将使用 Linux 系统的编写风格(这可能是 LLVM 的默认风格)。这意味着,我们需要把前一篇文章中编写的入口点重命名为 `_start`:
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std] // 不链接 Rust 标准库
|
||||
#![no_main] // 禁用所有 Rust 层级的入口点
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[no_mangle] // 不重整函数名
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// 因为编译器会寻找一个名为 `_start` 的函数,所以这个函数就是入口点
|
||||
// 默认命名为 `_start`
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
注意的是,无论你开发使用的是哪类操作系统,你都需要将入口点命名为 `_start`。前一篇文章中编写的 Windows 系统和 macOS 对应的入口点不应该被保留。
|
||||
|
||||
通过把 JSON 文件名传入 `--target` 选项,我们现在可以开始编译我们的内核。让我们试试看:
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
|
||||
error[E0463]: can't find crate for `core`
|
||||
(或者是下面的错误)
|
||||
error[E0463]: can't find crate for `compiler_builtins`
|
||||
```
|
||||
|
||||
哇哦,编译失败了!输出的错误告诉我们,Rust 编译器找不到 `core` 或者 `compiler_builtins` 包;而所有 `no_std` 上下文都隐式地链接到这两个包。[`core` 包](https://doc.rust-lang.org/nightly/core/index.html)包含基础的 Rust 类型,如` Result`、`Option` 和迭代器等;[`compiler_builtins` 包](https://github.com/rust-lang-nursery/compiler-builtins)提供 LLVM 需要的许多底层操作,比如 `memcpy`。
|
||||
|
||||
通常状况下,`core` 库以**预编译库**(precompiled library)的形式与 Rust 编译器一同发布——这时,`core` 库只对支持的宿主系统有效,而我们自定义的目标系统无效。如果我们想为其它系统编译代码,我们需要为这些系统重新编译整个 `core` 库。
|
||||
|
||||
### Cargo xbuild
|
||||
|
||||
这就是为什么我们需要 [cargo xbuild 工具](https://github.com/rust-osdev/cargo-xbuild)。这个工具封装了 `cargo build`;但不同的是,它将自动交叉编译 `core` 库和一些**编译器内建库**(compiler built-in libraries)。我们可以用下面的命令安装它:
|
||||
|
||||
```bash
|
||||
cargo install cargo-xbuild
|
||||
```
|
||||
|
||||
这个工具依赖于Rust的源代码;我们可以使用 `rustup component add rust-src` 来安装源代码。
|
||||
|
||||
现在我们可以使用 `xbuild` 代替 `build` 重新编译:
|
||||
|
||||
```bash
|
||||
> cargo xbuild --target x86_64-blog_os.json
|
||||
Compiling core v0.0.0 (/…/rust/src/libcore)
|
||||
Compiling compiler_builtins v0.1.5
|
||||
Compiling rustc-std-workspace-core v1.0.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling alloc v0.0.0 (/tmp/xargo.PB7fj9KZJhAI)
|
||||
Finished release [optimized + debuginfo] target(s) in 45.18s
|
||||
Compiling blog_os v0.1.0 (file:///…/blog_os)
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
我们能看到,`cargo xbuild` 为我们自定义的目标交叉编译了 `core`、`compiler_builtin` 和 `alloc` 三个部件。这些部件使用了大量的**不稳定特性**(unstable features),所以只能在[nightly 版本的 Rust 编译器][installing rust nightly]中工作。这之后,`cargo xbuild` 成功地编译了我们的 `blog_os` 包。
|
||||
|
||||
[installing rust nightly]: #an-zhuang-nightly-rust
|
||||
|
||||
现在我们可以为裸机编译内核了;但是,我们提供给引导程序的入口点 `_start` 函数还是空的。我们可以添加一些东西进去,不过我们可以先做一些优化工作。
|
||||
|
||||
### 设置默认目标
|
||||
|
||||
为了避免每次使用`cargo xbuild`时传递`--target`参数,我们可以覆写默认的编译目标。我们创建一个名为`.cargo/config`的[cargo配置文件](https://doc.rust-lang.org/cargo/reference/config.html),添加下面的内容:
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
|
||||
[build]
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
这里的配置告诉 `cargo` 在没有显式声明目标的情况下,使用我们提供的 `x86_64-blog_os.json` 作为目标配置。这意味着保存后,我们可以直接使用:
|
||||
|
||||
```
|
||||
cargo xbuild
|
||||
```
|
||||
|
||||
来编译我们的内核。[官方提供的一份文档](https://doc.rust-lang.org/cargo/reference/config.html)中有对 cargo 配置文件更详细的说明。
|
||||
|
||||
### 向屏幕打印字符
|
||||
|
||||
要做到这一步,最简单的方式是写入 **VGA 字符缓冲区**([VGA text buffer](https://en.wikipedia.org/wiki/VGA-compatible_text_mode)):这是一段映射到 VGA 硬件的特殊内存片段,包含着显示在屏幕上的内容。通常情况下,它能够存储 25 行、80 列共 2000 个**字符单元**(character cell);每个字符单元能够显示一个 ASCII 字符,也能设置这个字符的**前景色**(foreground color)和**背景色**(background color)。输出到屏幕的字符大概长这样:
|
||||
|
||||

|
||||
|
||||
我们将在下篇文章中详细讨论 VGA 字符缓冲区的内存布局;目前我们只需要知道,这段缓冲区的地址是 `0xb8000`,且每个字符单元包含一个 ASCII 码字节和一个颜色字节。
|
||||
|
||||
我们的实现就像这样:
|
||||
|
||||
```rust
|
||||
static HELLO: &[u8] = b"Hello World!";
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
let vga_buffer = 0xb8000 as *mut u8;
|
||||
|
||||
for (i, &byte) in HELLO.iter().enumerate() {
|
||||
unsafe {
|
||||
*vga_buffer.offset(i as isize * 2) = byte;
|
||||
*vga_buffer.offset(i as isize * 2 + 1) = 0xb;
|
||||
}
|
||||
}
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
在这段代码中,我们预先定义了一个**字节字符串**(byte string)类型的**静态变量**(static variable),名为 `HELLO`。我们首先将整数 `0xb8000` **转换**(cast)为一个**裸指针**([raw pointer])。这之后,我们迭代 `HELLO` 的每个字节,使用 [enumerate](https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate) 获得一个额外的序号变量 `i`。在 `for` 语句的循环体中,我们使用 [offset](https://doc.rust-lang.org/std/primitive.pointer.html#method.offset) 偏移裸指针,解引用它,来将字符串的每个字节和对应的颜色字节——`0xb` 代表淡青色——写入内存位置。
|
||||
|
||||
[raw pointer]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
|
||||
要注意的是,所有的裸指针内存操作都被一个 **unsafe 语句块**([unsafe block](https://doc.rust-lang.org/stable/book/second-edition/ch19-01-unsafe-rust.html))包围。这是因为,此时编译器不能确保我们创建的裸指针是有效的;一个裸指针可能指向任何一个你内存位置;直接解引用并写入它,也许会损坏正常的数据。使用 `unsafe` 语句块时,程序员其实在告诉编译器,自己保证语句块内的操作是有效的。事实上,`unsafe` 语句块并不会关闭 Rust 的安全检查机制;它允许你多做的事情[只有四件][unsafe superpowers]。
|
||||
|
||||
[unsafe superpowers]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
使用 `unsafe` 语句块要求程序员有足够的自信,所以必须强调的一点是,**肆意使用 unsafe 语句块并不是 Rust 编程的一贯方式**。在缺乏足够经验的前提下,直接在 `unsafe` 语句块内操作裸指针,非常容易把事情弄得很糟糕;比如,在不注意的情况下,我们很可能会意外地操作缓冲区以外的内存。
|
||||
|
||||
在这样的前提下,我们希望最小化 `unsafe ` 语句块的使用。使用 Rust 语言,我们能够将不安全操作将包装为一个安全的抽象模块。举个例子,我们可以创建一个 VGA 缓冲区类型,把所有的不安全语句封装起来,来确保从类型外部操作时,无法写出不安全的代码:通过这种方式,我们只需要最少的 `unsafe` 语句块来确保我们不破坏**内存安全**([memory safety](https://en.wikipedia.org/wiki/Memory_safety))。在下一篇文章中,我们将会创建这样的 VGA 缓冲区封装。
|
||||
|
||||
## 启动内核
|
||||
|
||||
既然我们已经有了一个能够打印字符的可执行程序,是时候把它运行起来试试看了。首先,我们将编译完毕的内核与引导程序链接,来创建一个引导映像;这之后,我们可以在 QEMU 虚拟机中运行它,或者通过 U 盘在真机上运行。
|
||||
|
||||
### 创建引导映像
|
||||
|
||||
要将可执行程序转换为**可引导的映像**(bootable disk image),我们需要把它和引导程序链接。这里,引导程序将负责初始化 CPU 并加载我们的内核。
|
||||
|
||||
编写引导程序并不容易,所以我们不编写自己的引导程序,而是使用已有的 [bootloader](https://crates.io/crates/bootloader) 包;无需依赖于 C 语言,这个包基于 Rust 代码和内联汇编,实现了一个五脏俱全的 BIOS 引导程序。为了用它启动我们的内核,我们需要将它添加为一个依赖项,在 `Cargo.toml` 中添加下面的代码:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.9.3"
|
||||
```
|
||||
|
||||
只添加引导程序为依赖项,并不足以创建一个可引导的磁盘映像;我们还需要内核编译完成之后,将内核和引导程序组合在一起。然而,截至目前,原生的 cargo 并不支持在编译完成后添加其它步骤(详见[这个 issue](https://github.com/rust-lang/cargo/issues/545))。
|
||||
|
||||
为了解决这个问题,我们建议使用 `bootimage` 工具——它将会在内核编译完毕后,将它和引导程序组合在一起,最终创建一个能够引导的磁盘映像。我们可以使用下面的命令来安装这款工具:
|
||||
|
||||
```bash
|
||||
cargo install bootimage
|
||||
```
|
||||
|
||||
为了运行 `bootimage` 以及编译引导程序,我们需要安装 rustup 模块 `llvm-tools-preview`——我们可以使用 `rustup component add llvm-tools-preview` 来安装这个工具。
|
||||
|
||||
成功安装 `bootimage` 后,创建一个可引导的磁盘映像就变得相当容易。我们来输入下面的命令:
|
||||
|
||||
```bash
|
||||
> cargo bootimage
|
||||
```
|
||||
|
||||
可以看到的是,`bootimage` 工具开始使用 `cargo xbuild` 编译你的内核,所以它将增量编译我们修改后的源码。在这之后,它会编译内核的引导程序,这可能将花费一定的时间;但和所有其它依赖包相似的是,在首次编译后,产生的二进制文件将被缓存下来——这将显著地加速后续的编译过程。最终,`bootimage` 将把内核和引导程序组合为一个可引导的磁盘映像。
|
||||
|
||||
运行这行命令之后,我们应该能在 `target/x86_64-blog_os/debug` 目录内找到我们的映像文件 `bootimage-blog_os.bin`。我们可以在虚拟机内启动它,也可以刻录到 U 盘上以便在真机上启动。(需要注意的是,因为文件格式不同,这里的 bin 文件并不是一个光驱映像,所以将它刻录到光盘不会起作用。)
|
||||
|
||||
事实上,在这行命令背后,`bootimage` 工具执行了三个步骤:
|
||||
|
||||
1. 编译我们的内核为一个 **ELF**([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format))文件;
|
||||
2. 编译引导程序为独立的可执行文件;
|
||||
3. 将内核 ELF 文件**按字节拼接**(append by bytes)到引导程序的末端。
|
||||
|
||||
当机器启动时,引导程序将会读取并解析拼接在其后的 ELF 文件。这之后,它将把程序片段映射到**分页表**(page table)中的**虚拟地址**(virtual address),清零 **BSS段**(BSS segment),还将创建一个栈。最终它将读取**入口点地址**(entry point address)——我们程序中 `_start` 函数的位置——并跳转到这个位置。
|
||||
|
||||
### 在 QEMU 中启动内核
|
||||
|
||||
现在我们可以在虚拟机中启动内核了。为了在[ QEMU](https://www.qemu.org/) 中启动内核,我们使用下面的命令:
|
||||
|
||||
```bash
|
||||
> qemu-system-x86_64 -drive format=raw,file=bootimage-blog_os.bin
|
||||
```
|
||||
|
||||
|
||||
|
||||
我们可以看到,屏幕窗口已经显示出 “Hello World!” 字符串。祝贺你!
|
||||
|
||||
### 在真机上运行内核
|
||||
|
||||
我们也可以使用 dd 工具把内核写入 U 盘,以便在真机上启动。可以输入下面的命令:
|
||||
|
||||
```bash
|
||||
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
|
||||
```
|
||||
|
||||
在这里,`sdX` 是U盘的**设备名**([device name](https://en.wikipedia.org/wiki/Device_file))。请注意,**在选择设备名的时候一定要极其小心,因为目标设备上已有的数据将全部被擦除**。
|
||||
|
||||
写入到 U 盘之后,你可以在真机上通过引导启动你的系统。视情况而定,你可能需要在 BIOS 中打开特殊的启动菜单,或者调整启动顺序。需要注意的是,`bootloader` 包暂时不支持 UEFI,所以我们并不能在 UEFI 机器上启动。
|
||||
|
||||
### 使用 `cargo run`
|
||||
|
||||
要让在 QEMU 中运行内核更轻松,我们可以设置在 cargo 配置文件中设置 `runner` 配置项:
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
|
||||
[target.'cfg(target_os = "none")']
|
||||
runner = "bootimage runner"
|
||||
```
|
||||
|
||||
在这里,`target.'cfg(target_os = "none")'` 筛选了三元组中宿主系统设置为 `"none"` 的所有编译目标——这将包含我们的 `x86_64-blog_os.json` 目标。另外,`runner` 的值规定了运行 `cargo run` 使用的命令;这个命令将在成功编译后执行,而且会传递可执行文件的路径为第一个参数。[官方提供的 cargo 文档](https://doc.rust-lang.org/cargo/reference/config.html)讲述了更多的细节。
|
||||
|
||||
命令 `bootimage runner` 由 `bootimage` 包提供,参数格式经过特殊设计,可以用于 `runner` 命令。它将给定的可执行文件与项目的引导程序依赖项链接,然后在 QEMU 中启动它。`bootimage` 包的 [README文档](https://github.com/rust-osdev/bootimage) 提供了更多细节和可以传入的配置参数。
|
||||
|
||||
现在我们可以使用 `cargo xrun` 来编译内核并在 QEMU 中启动了。和 `xbuild` 类似,`xrun` 子命令将在调用 cargo 命令前编译内核所需的包。这个子命令也由 `cargo-xbuild` 工具提供,所以你不需要安装额外的工具。
|
||||
|
||||
## 下篇预告
|
||||
|
||||
在下篇文章中,我们将细致地探索 VGA 字符缓冲区,并包装它为一个安全的接口。我们还将基于它实现 `println!` 宏。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 7.5 KiB |
@@ -1,702 +0,0 @@
|
||||
+++
|
||||
title = "حالت متن VGA"
|
||||
weight = 3
|
||||
path = "fa/vga-text-mode"
|
||||
date = 2018-02-26
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "fb8b03e82d9805473fed16e8795a78a020a6b537"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["hamidrezakp", "MHBahrampour"]
|
||||
rtl = true
|
||||
+++
|
||||
|
||||
[حالت متن VGA] یک روش ساده برای چاپ متن روی صفحه است. در این پست ، با قرار دادن همه موارد غیر ایمنی در یک ماژول جداگانه ، رابطی ایجاد می کنیم که استفاده از آن را ایمن و ساده می کند. همچنین پشتیبانی از [ماکروی فرمتبندی] راست را پیاده سازی میکنیم.
|
||||
|
||||
[حالت متن VGA]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
[ماکروی فرمتبندی]: https://doc.rust-lang.org/std/fmt/#related-macros
|
||||
|
||||
<!-- more -->
|
||||
|
||||
این بلاگ بصورت آزاد بر روی [گیتهاب] توسعه داده شده. اگر مشکل یا سوالی دارید، لطفا آنجا یک ایشو باز کنید. همچنین میتوانید [در زیر] این پست کامنت بگذارید. سورس کد کامل این پست را می توانید در شاخه [`post-01`][post branch] پیدا کنید.
|
||||
|
||||
[گیتهاب]: https://github.com/phil-opp/blog_os
|
||||
[در زیر]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-03
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## بافر متن VGA
|
||||
برای چاپ یک کاراکتر روی صفحه در حالت متن VGA ، باید آن را در بافر متن سخت افزار VGA بنویسید. بافر متن VGA یک آرایه دو بعدی است که به طور معمول 25 ردیف و 80 ستون دارد که مستقیماً به صفحه نمایش داده(رندر) می شود. هر خانه آرایه یک کاراکتر صفحه نمایش را از طریق قالب زیر توصیف می کند:
|
||||
|
||||
Bit(s) | Value
|
||||
------ | ----------------
|
||||
0-7 | ASCII code point
|
||||
8-11 | Foreground color
|
||||
12-14 | Background color
|
||||
15 | Blink
|
||||
|
||||
اولین بایت کاراکتری در [کدگذاری ASCII] را نشان می دهد که باید چاپ شود. اگر بخواهیم دقیق باشیم ، دقیقاً ASCII نیست ، بلکه مجموعه ای از کاراکترها به نام [_کد صفحه 437_] با برخی کاراکتر های اضافی و تغییرات جزئی است. برای سادگی ، ما در این پست آنرا یک کاراکتر ASCII می نامیم.
|
||||
|
||||
[کدگذاری ASCII]: https://en.wikipedia.org/wiki/ASCII
|
||||
[_کد صفحه 437_]: https://en.wikipedia.org/wiki/Code_page_437
|
||||
|
||||
بایت دوم نحوه نمایش کاراکتر را مشخص می کند. چهار بیت اول رنگ پیش زمینه را مشخص می کند ، سه بیت بعدی رنگ پس زمینه و بیت آخر اینکه کاراکتر باید چشمک بزند یا نه. رنگ های زیر موجود است:
|
||||
|
||||
Number | Color | Number + Bright Bit | Bright Color
|
||||
------ | ---------- | ------------------- | -------------
|
||||
0x0 | Black | 0x8 | Dark Gray
|
||||
0x1 | Blue | 0x9 | Light Blue
|
||||
0x2 | Green | 0xa | Light Green
|
||||
0x3 | Cyan | 0xb | Light Cyan
|
||||
0x4 | Red | 0xc | Light Red
|
||||
0x5 | Magenta | 0xd | Pink
|
||||
0x6 | Brown | 0xe | Yellow
|
||||
0x7 | Light Gray | 0xf | White
|
||||
|
||||
بیت 4، بیت روشنایی است ، که به عنوان مثال آبی به آبی روشن تبدیل میکند. برای رنگ پس زمینه ، این بیت به عنوان بیت چشمک مورد استفاده قرار می گیرد.
|
||||
|
||||
بافر متن VGA از طریق [ورودی/خروجی حافظهنگاشتی] به آدرس`0xb8000` قابل دسترسی است. این بدان معنی است که خواندن و نوشتن در آن آدرس به RAM دسترسی ندارد ، بلکه مستقیماً دسترسی به بافر متن در سخت افزار VGA دارد. این بدان معنی است که می توانیم آن را از طریق عملیات حافظه عادی در آن آدرس بخوانیم و بنویسیم.
|
||||
|
||||
[ورودی/خروجی حافظهنگاشتی]: https://en.wikipedia.org/wiki/Memory-mapped_I/O
|
||||
|
||||
توجه داشته باشید که ممکن است سخت افزار حافظهنگاشتی شده از تمام عملیات معمول RAM پشتیبانی نکند. به عنوان مثال ، یک دستگاه ممکن است فقط خواندن بایتی را پشتیبانی کرده و با خواندن `u64` یک مقدار زباله را برگرداند. خوشبختانه بافر متن [از خواندن و نوشتن عادی پشتیبانی می کند] ، بنابراین مجبور نیستیم با آن به روش خاصی برخورد کنیم.
|
||||
|
||||
[از خواندن و نوشتن عادی پشتیبانی می کند]: https://web.stanford.edu/class/cs140/projects/pintos/specs/freevga/vga/vgamem.htm#manip
|
||||
|
||||
## یک ماژول راست
|
||||
اکنون که از نحوه کار بافر VGA مطلع شدیم ، می توانیم یک ماژول Rust برای مدیریت چاپ ایجاد کنیم:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
mod vga_buffer;
|
||||
```
|
||||
|
||||
برای محتوای این ماژول ما یک فایل جدید `src/vga_buffer.rs` ایجاد می کنیم. همه کدهای زیر وارد ماژول جدید ما می شوند (مگر اینکه طور دیگری مشخص شده باشد).
|
||||
|
||||
### رنگ ها
|
||||
اول ، ما رنگ های مختلف را با استفاده از یک enum نشان می دهیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[allow(dead_code)]
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u8)]
|
||||
pub enum Color {
|
||||
Black = 0,
|
||||
Blue = 1,
|
||||
Green = 2,
|
||||
Cyan = 3,
|
||||
Red = 4,
|
||||
Magenta = 5,
|
||||
Brown = 6,
|
||||
LightGray = 7,
|
||||
DarkGray = 8,
|
||||
LightBlue = 9,
|
||||
LightGreen = 10,
|
||||
LightCyan = 11,
|
||||
LightRed = 12,
|
||||
Pink = 13,
|
||||
Yellow = 14,
|
||||
White = 15,
|
||||
}
|
||||
```
|
||||
ما در اینجا از [enum مانند C] برای مشخص کردن صریح عدد برای هر رنگ استفاده می کنیم. به دلیل ویژگی `repr(u8)` هر نوع enum به عنوان یک `u8` ذخیره می شود. در واقع 4 بیت کافی است ، اما Rust نوع `u4` ندارد.
|
||||
|
||||
[enum مانند C]: https://doc.rust-lang.org/rust-by-example/custom_types/enum/c_like.html
|
||||
|
||||
به طور معمول کامپایلر برای هر نوع استفاده نشده اخطار می دهد. با استفاده از ویژگی `#[allow(dead_code)]` این هشدارها را برای enum `Color` غیرفعال می کنیم.
|
||||
|
||||
توسط [deriving] کردن تریتهای [`Copy`], [`Clone`], [`Debug`], [`PartialEq`], و [`Eq`] ما [مفهوم کپی] را برای نوع فعال کرده و آن را قابل پرینت کردن میکنیم.
|
||||
|
||||
[deriving]: https://doc.rust-lang.org/rust-by-example/trait/derive.html
|
||||
[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
|
||||
[`Clone`]: https://doc.rust-lang.org/nightly/core/clone/trait.Clone.html
|
||||
[`Debug`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Debug.html
|
||||
[`PartialEq`]: https://doc.rust-lang.org/nightly/core/cmp/trait.PartialEq.html
|
||||
[`Eq`]: https://doc.rust-lang.org/nightly/core/cmp/trait.Eq.html
|
||||
[مفهوم کپی]: https://doc.rust-lang.org/1.30.0/book/first-edition/ownership.html#copy-types
|
||||
|
||||
برای نشان دادن یک کد کامل رنگ که رنگ پیش زمینه و پس زمینه را مشخص می کند ، یک [نوع جدید] بر روی `u8` ایجاد می کنیم:
|
||||
|
||||
[نوع جدید]: https://doc.rust-lang.org/rust-by-example/generics/new_types.html
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(transparent)]
|
||||
struct ColorCode(u8);
|
||||
|
||||
impl ColorCode {
|
||||
fn new(foreground: Color, background: Color) -> ColorCode {
|
||||
ColorCode((background as u8) << 4 | (foreground as u8))
|
||||
}
|
||||
}
|
||||
```
|
||||
ساختمان `ColorCode` شامل بایت کامل رنگ است که شامل رنگ پیش زمینه و پس زمینه است. مانند قبل ، ویژگی های `Copy` و` Debug` را برای آن derive می کنیم. برای اطمینان از اینکه `ColorCode` دقیقاً ساختار داده مشابه `u8` دارد ، از ویژگی [`repr(transparent)`] استفاده می کنیم.
|
||||
|
||||
[`repr(transparent)`]: https://doc.rust-lang.org/nomicon/other-reprs.html#reprtransparent
|
||||
|
||||
### بافر متن
|
||||
اکنون می توانیم ساختمانهایی را برای نمایش یک کاراکتر صفحه و بافر متن اضافه کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(C)]
|
||||
struct ScreenChar {
|
||||
ascii_character: u8,
|
||||
color_code: ColorCode,
|
||||
}
|
||||
|
||||
const BUFFER_HEIGHT: usize = 25;
|
||||
const BUFFER_WIDTH: usize = 80;
|
||||
|
||||
#[repr(transparent)]
|
||||
struct Buffer {
|
||||
chars: [[ScreenChar; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
از آنجا که ترتیب فیلدهای ساختمانهای پیش فرض در Rust تعریف نشده است ، به ویژگی[`repr(C)`] نیاز داریم. این تضمین می کند که فیلد های ساختمان دقیقاً مانند یک ساختمان C ترسیم شده اند و بنابراین ترتیب درست را تضمین می کند. برای ساختمان `Buffer` ، ما دوباره از [`repr(transparent)`] استفاده می کنیم تا اطمینان حاصل شود که نحوه قرارگیری در حافظه دقیقا همان یک فیلد است.
|
||||
|
||||
[`repr(C)`]: https://doc.rust-lang.org/nightly/nomicon/other-reprs.html#reprc
|
||||
|
||||
برای نوشتن در صفحه ، اکنون یک نوع نویسنده ایجاد می کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub struct Writer {
|
||||
column_position: usize,
|
||||
color_code: ColorCode,
|
||||
buffer: &'static mut Buffer,
|
||||
}
|
||||
```
|
||||
نویسنده همیشه در آخرین خط مینویسد و وقتی خط پر است (یا در `\n`) ، سطرها را به سمت بالا شیفت می دهد. فیلد `column_position` موقعیت فعلی در ردیف آخر را نگهداری می کند. رنگهای پیش زمینه و پس زمینه فعلی توسط `color_code` مشخص شده و یک ارجاع (رفرنس) به بافر VGA در `buffer` ذخیره می شود. توجه داشته باشید که ما در اینجا به [طول عمر مشخصی] نیاز داریم تا به کامپایلر بگوییم تا چه مدت این ارجاع معتبر است. ظول عمر [`'static`] مشخص می کند که ارجاع برای کل مدت زمان اجرای برنامه معتبر باشد (که برای بافر متن VGA درست است).
|
||||
|
||||
[طول عمر مشخصی]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#lifetime-annotation-syntax
|
||||
[`'static`]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
|
||||
|
||||
### چاپ کردن
|
||||
اکنون می توانیم از `Writer` برای تغییر کاراکترهای بافر استفاده کنیم. ابتدا یک متد برای نوشتن یک بایت ASCII ایجاد می کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
if self.column_position >= BUFFER_WIDTH {
|
||||
self.new_line();
|
||||
}
|
||||
|
||||
let row = BUFFER_HEIGHT - 1;
|
||||
let col = self.column_position;
|
||||
|
||||
let color_code = self.color_code;
|
||||
self.buffer.chars[row][col] = ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code,
|
||||
};
|
||||
self.column_position += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn new_line(&mut self) {/* TODO */}
|
||||
}
|
||||
```
|
||||
اگر بایت، بایتِ [خط جدید] `\n` باشد، نویسنده چیزی چاپ نمی کند. در عوض متد `new_line` را فراخوانی می کند که بعداً آن را پیادهسازی خواهیم کرد. بایت های دیگر در حالت دوم match روی صفحه چاپ می شوند.
|
||||
|
||||
[خط جدید]: https://en.wikipedia.org/wiki/Newline
|
||||
|
||||
هنگام چاپ بایت ، نویسنده بررسی می کند که آیا خط فعلی پر است یا نه. در صورت پُر بودن، برای نوشتن در خط ، باید متد `new_line` صدا زده شود. سپس یک `ScreenChar` جدید در بافر در موقعیت فعلی می نویسد. سرانجام ، موقعیت ستون فعلی یکی افزایش مییابد.
|
||||
|
||||
برای چاپ کل رشته ها، می توانیم آنها را به بایت تبدیل کرده و یکی یکی چاپ کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_string(&mut self, s: &str) {
|
||||
for byte in s.bytes() {
|
||||
match byte {
|
||||
// printable ASCII byte or newline
|
||||
0x20..=0x7e | b'\n' => self.write_byte(byte),
|
||||
// not part of printable ASCII range
|
||||
_ => self.write_byte(0xfe),
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
بافر متن VGA فقط از ASCII و بایت های اضافی [کد صفحه 437] پشتیبانی می کند. رشته های راست به طور پیش فرض [UTF-8] هستند ، بنابراین ممکن است حاوی بایت هایی باشند که توسط بافر متن VGA پشتیبانی نمی شوند. ما از یک match برای تفکیک بایت های قابل چاپ ASCII (یک خط جدید یا هر چیز دیگری بین یک کاراکتر فاصله و یک کاراکتر`~`) و بایت های غیر قابل چاپ استفاده می کنیم. برای بایت های غیر قابل چاپ ، یک کاراکتر `■` چاپ می کنیم که دارای کد شانزدهای (hex) `0xfe` بر روی سخت افزار VGA است.
|
||||
|
||||
[کد صفحه 437]: https://en.wikipedia.org/wiki/Code_page_437
|
||||
[UTF-8]: https://www.fileformat.info/info/unicode/utf8.htm
|
||||
|
||||
#### امتحاناش کنید!
|
||||
برای نوشتن چند کاراکتر بر روی صفحه ، می توانید یک تابع موقتی ایجاد کنید:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello ");
|
||||
writer.write_string("Wörld!");
|
||||
}
|
||||
```
|
||||
ابتدا یک Writer جدید ایجاد می کند که به بافر VGA در `0xb8000` اشاره دارد. سینتکس این ممکن است کمی عجیب به نظر برسد: اول ، ما عدد صحیح `0xb8000` را به عنوان [اشاره گر خام] قابل تغییر در نظر می گیریم. سپس با dereferencing کردن آن (از طریق "*") و بلافاصله ارجاع مجدد (از طریق `&mut`) آن را به یک مرجع قابل تغییر تبدیل می کنیم. این تبدیل به یک [بلوک `غیرایمن`] احتیاج دارد ، زیرا کامپایلر نمی تواند صحت اشارهگر خام را تضمین کند.
|
||||
|
||||
[اشاره گر خام]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
[بلوک `غیرایمن`]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html
|
||||
|
||||
سپس بایت `b'H'` را روی آن می نویسد. پیشوند `b` یک [بایت لیترال] ایجاد می کند ، که بیانگر یک کاراکتر ASCII است. با نوشتن رشته های `"ello "` و `"Wörld!"` ، ما متد `write_string` و واکنش به کاراکترهای غیر قابل چاپ را آزمایش می کنیم. برای دیدن خروجی ، باید تابع `print_something` را از تابع `_start` فراخوانی کنیم:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
vga_buffer::print_something();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
اکنون هنگامی که ما پروژه را اجرا می کنیم ، باید یک `Hello W■■rld!` در گوشه سمت چپ _پایین_ صفحه به رنگ زرد چاپ شود:
|
||||
|
||||
[بایت لیترال]: https://doc.rust-lang.org/reference/tokens.html#byte-literals
|
||||
|
||||

|
||||
|
||||
توجه داشته باشید که `ö` به عنوان دو کاراکتر `■` چاپ شده است. به این دلیل که `ö` با دو بایت در [UTF-8] نمایش داده می شود ، که هر دو در محدوده قابل چاپ ASCII قرار نمی گیرند. در حقیقت ، این یک ویژگی اساسی UTF-8 است: هر بایت از مقادیر چند بایتی هرگز ASCII معتبر نیستند.
|
||||
|
||||
### فرّار
|
||||
ما الان دیدیم که پیام ما به درستی چاپ شده است. با این حال ، ممکن است با کامپایلرهای آینده Rust که به صورت تهاجمی تری(aggressively) بهینه می شوند ، کار نکند.
|
||||
|
||||
مشکل این است که ما فقط به `Buffer` می نویسیم و هرگز از آن نمیخوانیم. کامپایلر نمی داند که ما واقعاً به حافظه بافر VGA (به جای RAM معمولی) دسترسی پیدا می کنیم و در مورد اثر جانبی آن یعنی نمایش برخی کاراکتر ها روی صفحه چیزی نمی داند. بنابراین ممکن است تصمیم بگیرد که این نوشتن ها غیرضروری هستند و می تواند آن را حذف کند. برای جلوگیری از این بهینه سازی اشتباه ، باید این نوشتن ها را به عنوان _[فرّار]_ مشخص کنیم. این به کامپایلر می گوید که نوشتن عوارض جانبی دارد و نباید بهینه شود.
|
||||
|
||||
[فرّار]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
|
||||
|
||||
به منظور استفاده از نوشتن های فرار برای بافر VGA ، ما از کتابخانه [volatile][volatile crate] استفاده می کنیم. این _crate_ (بسته ها در جهان Rust اینطور نامیده میشوند) نوع `Volatile` را که یک نوع wrapper هست با متد های `read` و `write` فراهم می کند. این متد ها به طور داخلی از توابع [read_volatile] و [write_volatile] کتابخانه اصلی استفاده می کنند و بنابراین تضمین می کنند که خواندن/ نوشتن با بهینه شدن حذف نمیشوند.
|
||||
|
||||
[volatile crate]: https://docs.rs/volatile
|
||||
[read_volatile]: https://doc.rust-lang.org/nightly/core/ptr/fn.read_volatile.html
|
||||
[write_volatile]: https://doc.rust-lang.org/nightly/core/ptr/fn.write_volatile.html
|
||||
|
||||
ما می توانیم وابستگی به کرت (crate) `volatile` را بوسیله اضافه کردن آن به بخش `dependencies` (وابستگی های) `Cargo.toml` اضافه کنیم:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
volatile = "0.2.6"
|
||||
```
|
||||
|
||||
`0.2.6` شماره نسخه [معنایی] است. برای اطلاعات بیشتر ، به راهنمای [تعیین وابستگی ها] مستندات کارگو (cargo) مراجعه کنید.
|
||||
|
||||
[معنایی]: https://semver.org/
|
||||
[تعیین وابستگی ها]: https://doc.crates.io/specifying-dependencies.html
|
||||
|
||||
بیایید از آن برای نوشتن فرار در بافر VGA استفاده کنیم. نوع `Buffer` خود را به صورت زیر بروزرسانی می کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use volatile::Volatile;
|
||||
|
||||
struct Buffer {
|
||||
chars: [[Volatile<ScreenChar>; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
به جای `ScreenChar` ، ما اکنون از `Volatile<ScreenChar>` استفاده می کنیم. (نوع `Volatile`، [generic] است و می تواند (تقریباً) هر نوع را در خود قرار دهد). این اطمینان می دهد که ما به طور تصادفی نمی توانیم از طریق نوشتن "عادی" در آن بنویسیم. در عوض ، اکنون باید از متد `write` استفاده کنیم.
|
||||
|
||||
[generic]: https://doc.rust-lang.org/book/ch10-01-syntax.html
|
||||
|
||||
این بدان معنی است که ما باید متد `Writer::write_byte` خود را به روز کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
...
|
||||
|
||||
self.buffer.chars[row][col].write(ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code,
|
||||
});
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
به جای انتساب عادی با استفاده از `=` ، اکنون ما از متد `write` استفاده می کنیم. این تضمین می کند که کامپایلر هرگز این نوشتن را بهینه نخواهد کرد.
|
||||
|
||||
### ماکروهای قالببندی
|
||||
خوب است که از ماکروهای قالب بندی Rust نیز پشتیبانی کنید. به این ترتیب ، می توانیم انواع مختلفی مانند عدد صحیح یا شناور را به راحتی چاپ کنیم. برای پشتیبانی از آنها ، باید تریت [`core::fmt::Write`] را پیاده سازی کنیم. تنها متد مورد نیاز این تریت ،`write_str` است که کاملاً شبیه به متد `write_str` ما است ، فقط با نوع بازگشت `fmt::Result`:
|
||||
|
||||
[`core::fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use core::fmt;
|
||||
|
||||
impl fmt::Write for Writer {
|
||||
fn write_str(&mut self, s: &str) -> fmt::Result {
|
||||
self.write_string(s);
|
||||
Ok(())
|
||||
}
|
||||
}
|
||||
```
|
||||
`Ok(())` فقط نتیجه `Ok` حاوی نوع `()` است.
|
||||
|
||||
اکنون ما می توانیم از ماکروهای قالب بندی داخلی راست یعنی `write!`/`writeln!` استفاده کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
use core::fmt::Write;
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello! ");
|
||||
write!(writer, "The numbers are {} and {}", 42, 1.0/3.0).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
حالا شما باید یک `Hello! The numbers are 42 and 0.3333333333333333` در پایین صفحه ببینید. فراخوانی `write!` یک `Result` را برمی گرداند که در صورت عدم استفاده باعث هشدار می شود ، بنابراین ما تابع [`unwrap`] را روی آن فراخوانی می کنیم که در صورت بروز خطا پنیک می کند. این در مورد ما مشکلی ندارد ، زیرا نوشتن در بافر VGA هرگز شکست نمیخورد.
|
||||
|
||||
[`unwrap`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.unwrap
|
||||
|
||||
### خطوط جدید
|
||||
در حال حاضر ، ما از خطوط جدید و کاراکتر هایی که دیگر در خط نمی گنجند چشم پوشی می کنیم. درعوض ما می خواهیم هر کاراکتر را یک خط به بالا منتقل کنیم (خط بالا حذف می شود) و دوباره از ابتدای آخرین خط شروع کنیم. برای انجام این کار ، ما یک پیاده سازی برای متد `new_line` در `Writer` اضافه می کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn new_line(&mut self) {
|
||||
for row in 1..BUFFER_HEIGHT {
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
let character = self.buffer.chars[row][col].read();
|
||||
self.buffer.chars[row - 1][col].write(character);
|
||||
}
|
||||
}
|
||||
self.clear_row(BUFFER_HEIGHT - 1);
|
||||
self.column_position = 0;
|
||||
}
|
||||
|
||||
fn clear_row(&mut self, row: usize) {/* TODO */}
|
||||
}
|
||||
```
|
||||
ما تمام کاراکترهای صفحه را پیمایش می کنیم و هر کاراکتر را یک ردیف به بالا شیفت می دهیم. توجه داشته باشید که علامت گذاری دامنه (`..`) فاقد مقدار حد بالا است. ما همچنین سطر 0 را حذف می کنیم (اول محدوده از "1" شروع می شود) زیرا این سطر است که از صفحه به بیرون شیفت می شود.
|
||||
|
||||
برای تکمیل کد `newline` ، متد `clear_row` را اضافه می کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn clear_row(&mut self, row: usize) {
|
||||
let blank = ScreenChar {
|
||||
ascii_character: b' ',
|
||||
color_code: self.color_code,
|
||||
};
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
self.buffer.chars[row][col].write(blank);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
این متد با جایگزینی تمام کاراکترها با یک کاراکتر فاصله ، یک سطر را پاک می کند.
|
||||
|
||||
## یک رابط گلوبال
|
||||
برای فراهم کردن یک نویسنده گلوبال که بتواند به عنوان رابط از سایر ماژول ها بدون حمل نمونه `Writer` در اطراف استفاده شود ، سعی می کنیم یک `WRITER` ثابت ایجاد کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub static WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
```
|
||||
|
||||
با این حال ، اگر سعی کنیم اکنون آن را کامپایل کنیم ، خطاهای زیر رخ می دهد:
|
||||
|
||||
```
|
||||
error[E0015]: calls in statics are limited to constant functions, tuple structs and tuple variants
|
||||
--> src/vga_buffer.rs:7:17
|
||||
|
|
||||
7 | color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
error[E0396]: raw pointers cannot be dereferenced in statics
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ dereference of raw pointer in constant
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:13
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
```
|
||||
|
||||
برای فهمیدن آنچه در اینجا اتفاق می افتد ، باید بدانیم که ثابت ها(Statics) در زمان کامپایل مقداردهی اولیه می شوند ، برخلاف متغیرهای عادی که در زمان اجرا مقداردهی اولیه می شوند. مولفهای(component) از کامپایلر Rust که چنین عبارات مقداردهی اولیه را ارزیابی می کند ، “[const evaluator]” نامیده می شود. عملکرد آن هنوز محدود است ، اما کارهای گسترده ای برای گسترش آن در حال انجام است ، به عنوان مثال در “[Allow panicking in constants]” RFC.
|
||||
|
||||
[const evaluator]: https://rustc-dev-guide.rust-lang.org/const-eval.html
|
||||
[Allow panicking in constants]: https://github.com/rust-lang/rfcs/pull/2345
|
||||
|
||||
مسئله در مورد `ColorCode::new` با استفاده از توابع [`const` functions] قابل حل است ، اما مشکل اساسی اینجاست که Rust's const evaluator قادر به تبدیل اشارهگرهای خام به رفرنس در زمان کامپایل نیست. شاید روزی جواب دهد ، اما تا آن زمان ، ما باید راه حل دیگری پیدا کنیم.
|
||||
|
||||
[`const` functions]: https://doc.rust-lang.org/unstable-book/language-features/const-fn.html
|
||||
|
||||
### استاتیکهای تنبل (Lazy Statics)
|
||||
یکبار مقداردهی اولیه استاتیکها با توابع غیر ثابت یک مشکل رایج در راست است. خوشبختانه ، در حال حاضر راه حل خوبی در کرتی به نام [lazy_static] وجود دارد. این کرت ماکرو `lazy_static!` را فراهم می کند که یک `استاتیک` را با تنبلی مقداردهی اولیه می کند. به جای محاسبه مقدار آن در زمان کامپایل ، `استاتیک` به تنبلی هنگام اولین دسترسی به آن، خود را مقداردهی اولیه میکند. بنابراین ، مقداردهی اولیه در زمان اجرا اتفاق می افتد تا کد مقدار دهی اولیه پیچیده و دلخواه امکان پذیر باشد.
|
||||
|
||||
[lazy_static]: https://docs.rs/lazy_static/1.0.1/lazy_static/
|
||||
|
||||
بیایید کرت `lazy_static` را به پروژه خود اضافه کنیم:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies.lazy_static]
|
||||
version = "1.0"
|
||||
features = ["spin_no_std"]
|
||||
```
|
||||
|
||||
ما به ویژگی `spin_no_std` نیاز داریم ، زیرا به کتابخانه استاندارد پیوند نمی دهیم.
|
||||
|
||||
با استفاده از `lazy_static` ، می توانیم WRITER ثابت خود را بدون مشکل تعریف کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
با این حال ، این `WRITER` بسیار بی فایده است زیرا غیر قابل تغییر است. این بدان معنی است که ما نمی توانیم چیزی در آن بنویسیم (از آنجا که همه متد های نوشتن `&mut self` را در ورودی میگیرند). یک راه حل ممکن استفاده از [استاتیک قابل تغییر] است. اما پس از آن هر خواندن و نوشتن آن ناامن (unsafe) است زیرا می تواند به راحتی باعث data race و سایر موارد بد باشد. استفاده از `static mut` بسیار نهی شده است ، حتی پیشنهادهایی برای [حذف آن][remove static mut] وجود داشت. اما گزینه های دیگر چیست؟ ما می توانیم سعی کنیم از یک استاتیک تغییرناپذیر با نوع سلول مانند [RefCell] یا حتی [UnsafeCell] استفاده کنیم که [تغییر پذیری داخلی] را فراهم می کند. اما این انواع [Sync] نیستند (با دلیل کافی) ، بنابراین نمی توانیم از آنها در استاتیک استفاده کنیم.
|
||||
|
||||
[استاتیک قابل تغییر]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
|
||||
[remove static mut]: https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437
|
||||
[RefCell]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt
|
||||
[UnsafeCell]: https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html
|
||||
[تغییر پذیری داخلی]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html
|
||||
[Sync]: https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html
|
||||
|
||||
### Spinlocks
|
||||
برای دستیابی به قابلیت تغییرپذیری داخلی همزمان (synchronized) ، کاربران کتابخانه استاندارد می توانند از [Mutex] استفاده کنند. هنگامی که منبع از قبل قفل شده است ، با مسدود کردن رشته ها ، امکان انحصار متقابل را فراهم می کند. اما هسته اصلی ما هیچ پشتیبانی از مسدود کردن یا حتی مفهومی از نخ ها ندارد ، بنابراین ما هم نمی توانیم از آن استفاده کنیم. با این وجود یک نوع کاملاً پایهای از mutex در علوم کامپیوتر وجود دارد که به هیچ ویژگی سیستم عاملی نیاز ندارد: [spinlock]. به جای مسدود کردن ، نخ ها سعی می کنند آن را بارها و بارها در یک حلقه قفل کنند و بنابراین زمان پردازنده را می سوزانند تا دوباره mutex آزاد شود.
|
||||
|
||||
[Mutex]: https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html
|
||||
[spinlock]: https://en.wikipedia.org/wiki/Spinlock
|
||||
|
||||
برای استفاده از spinning mutex ، می توانیم [کرت spin] را به عنوان یک وابستگی اضافه کنیم:
|
||||
|
||||
[کرت spin]: https://crates.io/crates/spin
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
[dependencies]
|
||||
spin = "0.5.2"
|
||||
```
|
||||
|
||||
سپس می توانیم از spinning Mutex برای افزودن [تغییر پذیری داخلی] امن به `WRITER` استاتیک خود استفاده کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use spin::Mutex;
|
||||
...
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Mutex<Writer> = Mutex::new(Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
});
|
||||
}
|
||||
```
|
||||
اکنون می توانیم تابع `print_something` را حذف کرده و مستقیماً از تابع`_start` خود چاپ کنیم:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
use core::fmt::Write;
|
||||
vga_buffer::WRITER.lock().write_str("Hello again").unwrap();
|
||||
write!(vga_buffer::WRITER.lock(), ", some numbers: {} {}", 42, 1.337).unwrap();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
برای اینکه بتوانیم از توابع آن استفاده کنیم ، باید تریت `fmt::Write` را وارد کنیم.
|
||||
|
||||
### ایمنی
|
||||
توجه داشته باشید که ما فقط یک بلوک ناامن در کد خود داریم که برای ایجاد رفرنس `Buffer` با اشاره به `0xb8000` لازم است. پس از آن ، تمام عملیات ایمن هستند. Rust به طور پیش فرض از بررسی مرزها در دسترسی به آرایه استفاده می کند ، بنابراین نمی توانیم به طور اتفاقی خارج از بافر بنویسیم. بنابراین ، ما شرایط مورد نیاز را در سیستم نوع انجام میدهیم و قادر به ایجاد یک رابط ایمن به خارج هستیم.
|
||||
|
||||
### یک ماکروی println
|
||||
اکنون که یک نویسنده گلوبال داریم ، می توانیم یک ماکرو `println` اضافه کنیم که می تواند از هر کجا در کد استفاده شود. [سینتکس ماکروی] راست کمی عجیب است ، بنابراین ما سعی نمی کنیم ماکرو را از ابتدا بنویسیم. در عوض به سورس [ماکروی `println!`] در کتابخانه استاندارد نگاه می کنیم:
|
||||
|
||||
[سینتکس ماکروی]: https://doc.rust-lang.org/nightly/book/ch19-06-macros.html#declarative-macros-with-macro_rules-for-general-metaprogramming
|
||||
[ماکروی `println!`]: https://doc.rust-lang.org/nightly/std/macro.println!.html
|
||||
|
||||
```rust
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => (print!("\n"));
|
||||
($($arg:tt)*) => (print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
ماکروها از طریق یک یا چند قانون تعریف می شوند که شبیه بازوهای `match` هستند. ماکرو `println` دارای دو قانون است: اولین قانون برای فراخوانی های بدون آرگمان است (به عنوان مثال: `println!()`) ، که به `print!("\n")` گسترش می یابد، بنابراین فقط یک خط جدید را چاپ می کند. قانون دوم برای فراخوانی هایی با پارامترهایی مانند `println!("Hello")` یا `println!("Number: {}", 4)` است. همچنین با فراخوانی کل آرگومان ها و یک خط جدید `\n` اضافی در انتها ، به فراخوانی ماکرو `print!` گسترش می یابد.
|
||||
|
||||
ویژگی `#[macro_export]` ماکرو را برای کل کرت (نه فقط ماژولی که تعریف شده است) و کرت های خارجی در دسترس قرار می دهد. همچنین ماکرو را در ریشه کرت قرار می دهد ، به این معنی که ما باید ماکرو را به جای `std::macros::println` از طریق `use std::println` وارد کنیم.
|
||||
|
||||
[ماکرو `print!`] به این صورت تعریف می شود:
|
||||
|
||||
[ماکرو `print!`]: https://doc.rust-lang.org/nightly/std/macro.print!.html
|
||||
|
||||
```rust
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::io::_print(format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
ماکرو به فراخوانی [تابع `_print`] در ماژول `io` گسترش می یابد. [متغیر `$crate`] تضمین می کند که ماکرو هنگام گسترش در `std` در زمان استفاده در کرت های دیگر، در خارج از کرت `std` نیز کار می کند.
|
||||
|
||||
[ماکرو `format_args`] از آرگمان های داده شده یک نوع [fmt::Arguments] را می سازد که به `_print` ارسال می شود. [تابع `_print`] از کتابخانه استاندارد،`print_to` را فراخوانی می کند ، که بسیار پیچیده است زیرا از دستگاه های مختلف `Stdout` پشتیبانی می کند. ما به این پیچیدگی احتیاج نداریم زیرا فقط می خواهیم در بافر VGA چاپ کنیم.
|
||||
|
||||
[تابع `_print`]: https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698
|
||||
[متغیر `$crate`]: https://doc.rust-lang.org/1.30.0/book/first-edition/macros.html#the-variable-crate
|
||||
[ماکرو `format_args`]: https://doc.rust-lang.org/nightly/std/macro.format_args.html
|
||||
[fmt::Arguments]: https://doc.rust-lang.org/nightly/core/fmt/struct.Arguments.html
|
||||
|
||||
برای چاپ در بافر VGA ، ما فقط ماکروهای `println!` و `print!` را کپی می کنیم ، اما آنها را اصلاح می کنیم تا از تابع `_print` خود استفاده کنیم:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::vga_buffer::_print(format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => ($crate::print!("\n"));
|
||||
($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
چیزی که ما از تعریف اصلی `println` تغییر دادیم این است که فراخوانی ماکرو `print!` را با پیشوند `$crate` انجام می دهیم. این تضمین می کند که اگر فقط می خواهیم از `println` استفاده کنیم ، نیازی به وارد کردن ماکرو `print!` هم نداشته باشیم.
|
||||
|
||||
مانند کتابخانه استاندارد ، ویژگی `#[macro_export]` را به هر دو ماکرو اضافه می کنیم تا در همه جای کرت ما در دسترس باشند. توجه داشته باشید که این ماکروها را در فضای نام ریشه کرت قرار می دهد ، بنابراین وارد کردن آنها از طریق `use crate::vga_buffer::println` کار نمی کند. در عوض ، ما باید `use crate::println` را استفاده کنیم.
|
||||
|
||||
تابع `_print` نویسنده (`WRITER`) استاتیک ما را قفل می کند و متد`write_fmt` را روی آن فراخوانی می کند. این متد از تریت `Write` است ، ما باید این تریت را وارد کنیم. اگر چاپ موفقیت آمیز نباشد ، `unwrap()` اضافی در انتها باعث پنیک میشود. اما از آنجا که ما همیشه `Ok` را در `write_str` برمی گردانیم ، این اتفاق نمی افتد.
|
||||
|
||||
از آنجا که ماکروها باید بتوانند از خارج از ماژول، `_print` را فراخوانی کنند، تابع باید عمومی (public) باشد. با این حال ، از آنجا که این جزئیات پیاده سازی را خصوصی (private) در نظر می گیریم، [ویژگی `doc(hidden)`] را اضافه می کنیم تا از مستندات تولید شده پنهان شود.
|
||||
|
||||
[ویژگی `doc(hidden)`]: https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden
|
||||
|
||||
### Hello World توسط `println`
|
||||
اکنون می توانیم از `println` در تابع `_start` استفاده کنیم:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
توجه داشته باشید که ما مجبور نیستیم ماکرو را در تابع اصلی وارد کنیم ، زیرا در حال حاضر در فضای نام ریشه موجود است.
|
||||
|
||||
همانطور که انتظار می رفت ، اکنون یک _“Hello World!”_ روی صفحه مشاهده می کنیم:
|
||||
|
||||

|
||||
|
||||
### چاپ پیام های پنیک
|
||||
|
||||
اکنون که ماکرو `println` را داریم ، می توانیم از آن در تابع پنیک برای چاپ پیام و مکان پنیک استفاده کنیم:
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
اکنون وقتی که `panic!("Some panic message");` را در تابع `_start` خود اضافه میکنیم ، خروجی زیر را می گیریم:
|
||||
|
||||

|
||||
|
||||
بنابراین ما نه تنها میدانیم که یک پنیک رخ داده است ، بلکه پیام پنیک و اینکه در کجای کد رخ داده است را نیز میدانیم.
|
||||
|
||||
## خلاصه
|
||||
در این پست با ساختار بافر متن VGA و نحوه نوشتن آن از طریق نگاشت حافظه در آدرس `0xb8000` آشنا شدیم. ما یک ماژول راست ایجاد کردیم که عدم امنیت نوشتن را در این بافر نگاشت حافظه شده را محصور می کند و یک رابط امن و راحت به خارج ارائه می دهد.
|
||||
|
||||
همچنین دیدیم که به لطف کارگو ، اضافه کردن وابستگی به کتابخانه های دیگران چقدر آسان است. دو وابستگی که اضافه کردیم ، `lazy_static` و`spin` ، در توسعه سیستم عامل بسیار مفید هستند و ما در پست های بعدی از آنها در مکان های بیشتری استفاده خواهیم کرد.
|
||||
|
||||
## بعدی چیست؟
|
||||
در پست بعدی نحوه راه اندازی چارچوب تست واحد (Unit Test) راست توضیح داده شده است. سپس از این پست چند تست واحد اساسی برای ماژول بافر VGA ایجاد خواهیم کرد.
|
||||
@@ -1,697 +0,0 @@
|
||||
+++
|
||||
title = "VGA Text Mode"
|
||||
weight = 3
|
||||
path = "vga-text-mode"
|
||||
date = 2018-02-26
|
||||
|
||||
[extra]
|
||||
chapter = "Bare Bones"
|
||||
+++
|
||||
|
||||
The [VGA text mode] is a simple way to print text to the screen. In this post, we create an interface that makes its usage safe and simple, by encapsulating all unsafety in a separate module. We also implement support for Rust's [formatting macros].
|
||||
|
||||
[VGA text mode]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
[formatting macros]: https://doc.rust-lang.org/std/fmt/#related-macros
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-03`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-03
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## The VGA Text Buffer
|
||||
To print a character to the screen in VGA text mode, one has to write it to the text buffer of the VGA hardware. The VGA text buffer is a two-dimensional array with typically 25 rows and 80 columns, which is directly rendered to the screen. Each array entry describes a single screen character through the following format:
|
||||
|
||||
Bit(s) | Value
|
||||
------ | ----------------
|
||||
0-7 | ASCII code point
|
||||
8-11 | Foreground color
|
||||
12-14 | Background color
|
||||
15 | Blink
|
||||
|
||||
The first byte represents the character that should be printed in the [ASCII encoding]. To be exact, it isn't exactly ASCII, but a character set named [_code page 437_] with some additional characters and slight modifications. For simplicity, we proceed to call it an ASCII character in this post.
|
||||
|
||||
[ASCII encoding]: https://en.wikipedia.org/wiki/ASCII
|
||||
[_code page 437_]: https://en.wikipedia.org/wiki/Code_page_437
|
||||
|
||||
The second byte defines how the character is displayed. The first four bits define the foreground color, the next three bits the background color, and the last bit whether the character should blink. The following colors are available:
|
||||
|
||||
Number | Color | Number + Bright Bit | Bright Color
|
||||
------ | ---------- | ------------------- | -------------
|
||||
0x0 | Black | 0x8 | Dark Gray
|
||||
0x1 | Blue | 0x9 | Light Blue
|
||||
0x2 | Green | 0xa | Light Green
|
||||
0x3 | Cyan | 0xb | Light Cyan
|
||||
0x4 | Red | 0xc | Light Red
|
||||
0x5 | Magenta | 0xd | Pink
|
||||
0x6 | Brown | 0xe | Yellow
|
||||
0x7 | Light Gray | 0xf | White
|
||||
|
||||
Bit 4 is the _bright bit_, which turns for example blue into light blue. For the background color, this bit is repurposed as the blink bit.
|
||||
|
||||
The VGA text buffer is accessible via [memory-mapped I/O] to the address `0xb8000`. This means that reads and writes to that address don't access the RAM, but directly the text buffer on the VGA hardware. This means that we can read and write it through normal memory operations to that address.
|
||||
|
||||
[memory-mapped I/O]: https://en.wikipedia.org/wiki/Memory-mapped_I/O
|
||||
|
||||
Note that memory-mapped hardware might not support all normal RAM operations. For example, a device could only support byte-wise reads and return junk when an `u64` is read. Fortunately, the text buffer [supports normal reads and writes], so that we don't have to treat it in special way.
|
||||
|
||||
[supports normal reads and writes]: https://web.stanford.edu/class/cs140/projects/pintos/specs/freevga/vga/vgamem.htm#manip
|
||||
|
||||
## A Rust Module
|
||||
Now that we know how the VGA buffer works, we can create a Rust module to handle printing:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
mod vga_buffer;
|
||||
```
|
||||
|
||||
For the content of this module we create a new `src/vga_buffer.rs` file. All of the code below goes into our new module (unless specified otherwise).
|
||||
|
||||
### Colors
|
||||
First, we represent the different colors using an enum:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[allow(dead_code)]
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u8)]
|
||||
pub enum Color {
|
||||
Black = 0,
|
||||
Blue = 1,
|
||||
Green = 2,
|
||||
Cyan = 3,
|
||||
Red = 4,
|
||||
Magenta = 5,
|
||||
Brown = 6,
|
||||
LightGray = 7,
|
||||
DarkGray = 8,
|
||||
LightBlue = 9,
|
||||
LightGreen = 10,
|
||||
LightCyan = 11,
|
||||
LightRed = 12,
|
||||
Pink = 13,
|
||||
Yellow = 14,
|
||||
White = 15,
|
||||
}
|
||||
```
|
||||
We use a [C-like enum] here to explicitly specify the number for each color. Because of the `repr(u8)` attribute each enum variant is stored as an `u8`. Actually 4 bits would be sufficient, but Rust doesn't have an `u4` type.
|
||||
|
||||
[C-like enum]: https://doc.rust-lang.org/rust-by-example/custom_types/enum/c_like.html
|
||||
|
||||
Normally the compiler would issue a warning for each unused variant. By using the `#[allow(dead_code)]` attribute we disable these warnings for the `Color` enum.
|
||||
|
||||
By [deriving] the [`Copy`], [`Clone`], [`Debug`], [`PartialEq`], and [`Eq`] traits, we enable [copy semantics] for the type and make it printable and comparable.
|
||||
|
||||
[deriving]: https://doc.rust-lang.org/rust-by-example/trait/derive.html
|
||||
[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
|
||||
[`Clone`]: https://doc.rust-lang.org/nightly/core/clone/trait.Clone.html
|
||||
[`Debug`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Debug.html
|
||||
[`PartialEq`]: https://doc.rust-lang.org/nightly/core/cmp/trait.PartialEq.html
|
||||
[`Eq`]: https://doc.rust-lang.org/nightly/core/cmp/trait.Eq.html
|
||||
[copy semantics]: https://doc.rust-lang.org/1.30.0/book/first-edition/ownership.html#copy-types
|
||||
|
||||
To represent a full color code that specifies foreground and background color, we create a [newtype] on top of `u8`:
|
||||
|
||||
[newtype]: https://doc.rust-lang.org/rust-by-example/generics/new_types.html
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(transparent)]
|
||||
struct ColorCode(u8);
|
||||
|
||||
impl ColorCode {
|
||||
fn new(foreground: Color, background: Color) -> ColorCode {
|
||||
ColorCode((background as u8) << 4 | (foreground as u8))
|
||||
}
|
||||
}
|
||||
```
|
||||
The `ColorCode` struct contains the full color byte, containing foreground and background color. Like before, we derive the `Copy` and `Debug` traits for it. To ensure that the `ColorCode` has the exact same data layout as an `u8`, we use the [`repr(transparent)`] attribute.
|
||||
|
||||
[`repr(transparent)`]: https://doc.rust-lang.org/nomicon/other-reprs.html#reprtransparent
|
||||
|
||||
### Text Buffer
|
||||
Now we can add structures to represent a screen character and the text buffer:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(C)]
|
||||
struct ScreenChar {
|
||||
ascii_character: u8,
|
||||
color_code: ColorCode,
|
||||
}
|
||||
|
||||
const BUFFER_HEIGHT: usize = 25;
|
||||
const BUFFER_WIDTH: usize = 80;
|
||||
|
||||
#[repr(transparent)]
|
||||
struct Buffer {
|
||||
chars: [[ScreenChar; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
Since the field ordering in default structs is undefined in Rust, we need the [`repr(C)`] attribute. It guarantees that the struct's fields are laid out exactly like in a C struct and thus guarantees the correct field ordering. For the `Buffer` struct, we use [`repr(transparent)`] again to ensure that it has the same memory layout as its single field.
|
||||
|
||||
[`repr(C)`]: https://doc.rust-lang.org/nightly/nomicon/other-reprs.html#reprc
|
||||
|
||||
To actually write to screen, we now create a writer type:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub struct Writer {
|
||||
column_position: usize,
|
||||
color_code: ColorCode,
|
||||
buffer: &'static mut Buffer,
|
||||
}
|
||||
```
|
||||
The writer will always write to the last line and shift lines up when a line is full (or on `\n`). The `column_position` field keeps track of the current position in the last row. The current foreground and background colors are specified by `color_code` and a reference to the VGA buffer is stored in `buffer`. Note that we need an [explicit lifetime] here to tell the compiler how long the reference is valid. The [`'static`] lifetime specifies that the reference is valid for the whole program run time (which is true for the VGA text buffer).
|
||||
|
||||
[explicit lifetime]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#lifetime-annotation-syntax
|
||||
[`'static`]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
|
||||
|
||||
### Printing
|
||||
Now we can use the `Writer` to modify the buffer's characters. First we create a method to write a single ASCII byte:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
if self.column_position >= BUFFER_WIDTH {
|
||||
self.new_line();
|
||||
}
|
||||
|
||||
let row = BUFFER_HEIGHT - 1;
|
||||
let col = self.column_position;
|
||||
|
||||
let color_code = self.color_code;
|
||||
self.buffer.chars[row][col] = ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code,
|
||||
};
|
||||
self.column_position += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn new_line(&mut self) {/* TODO */}
|
||||
}
|
||||
```
|
||||
If the byte is the [newline] byte `\n`, the writer does not print anything. Instead it calls a `new_line` method, which we'll implement later. Other bytes get printed to the screen in the second match case.
|
||||
|
||||
[newline]: https://en.wikipedia.org/wiki/Newline
|
||||
|
||||
When printing a byte, the writer checks if the current line is full. In that case, a `new_line` call is required before to wrap the line. Then it writes a new `ScreenChar` to the buffer at the current position. Finally, the current column position is advanced.
|
||||
|
||||
To print whole strings, we can convert them to bytes and print them one-by-one:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_string(&mut self, s: &str) {
|
||||
for byte in s.bytes() {
|
||||
match byte {
|
||||
// printable ASCII byte or newline
|
||||
0x20..=0x7e | b'\n' => self.write_byte(byte),
|
||||
// not part of printable ASCII range
|
||||
_ => self.write_byte(0xfe),
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The VGA text buffer only supports ASCII and the additional bytes of [code page 437]. Rust strings are [UTF-8] by default, so they might contain bytes that are not supported by the VGA text buffer. We use a match to differentiate printable ASCII bytes (a newline or anything in between a space character and a `~` character) and unprintable bytes. For unprintable bytes, we print a `■` character, which has the hex code `0xfe` on the VGA hardware.
|
||||
|
||||
[code page 437]: https://en.wikipedia.org/wiki/Code_page_437
|
||||
[UTF-8]: https://www.fileformat.info/info/unicode/utf8.htm
|
||||
|
||||
#### Try it out!
|
||||
To write some characters to the screen, you can create a temporary function:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello ");
|
||||
writer.write_string("Wörld!");
|
||||
}
|
||||
```
|
||||
It first creates a new Writer that points to the VGA buffer at `0xb8000`. The syntax for this might seem a bit strange: First, we cast the integer `0xb8000` as an mutable [raw pointer]. Then we convert it to a mutable reference by dereferencing it (through `*`) and immediately borrowing it again (through `&mut`). This conversion requires an [`unsafe` block], since the compiler can't guarantee that the raw pointer is valid.
|
||||
|
||||
[raw pointer]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
[`unsafe` block]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html
|
||||
|
||||
Then it writes the byte `b'H'` to it. The `b` prefix creates a [byte literal], which represents an ASCII character. By writing the strings `"ello "` and `"Wörld!"`, we test our `write_string` method and the handling of unprintable characters. To see the output, we need to call the `print_something` function from our `_start` function:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
vga_buffer::print_something();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
When we run our project now, a `Hello W■■rld!` should be printed in the _lower_ left corner of the screen in yellow:
|
||||
|
||||
[byte literal]: https://doc.rust-lang.org/reference/tokens.html#byte-literals
|
||||
|
||||

|
||||
|
||||
Notice that the `ö` is printed as two `■` characters. That's because `ö` is represented by two bytes in [UTF-8], which both don't fall into the printable ASCII range. In fact, this is a fundamental property of UTF-8: the individual bytes of multi-byte values are never valid ASCII.
|
||||
|
||||
### Volatile
|
||||
We just saw that our message was printed correctly. However, it might not work with future Rust compilers that optimize more aggressively.
|
||||
|
||||
The problem is that we only write to the `Buffer` and never read from it again. The compiler doesn't know that we really access VGA buffer memory (instead of normal RAM) and knows nothing about the side effect that some characters appear on the screen. So it might decide that these writes are unnecessary and can be omitted. To avoid this erroneous optimization, we need to specify these writes as _[volatile]_. This tells the compiler that the write has side effects and should not be optimized away.
|
||||
|
||||
[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
|
||||
|
||||
In order to use volatile writes for the VGA buffer, we use the [volatile][volatile crate] library. This _crate_ (this is how packages are called in the Rust world) provides a `Volatile` wrapper type with `read` and `write` methods. These methods internally use the [read_volatile] and [write_volatile] functions of the core library and thus guarantee that the reads/writes are not optimized away.
|
||||
|
||||
[volatile crate]: https://docs.rs/volatile
|
||||
[read_volatile]: https://doc.rust-lang.org/nightly/core/ptr/fn.read_volatile.html
|
||||
[write_volatile]: https://doc.rust-lang.org/nightly/core/ptr/fn.write_volatile.html
|
||||
|
||||
We can add a dependency on the `volatile` crate by adding it to the `dependencies` section of our `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
volatile = "0.2.6"
|
||||
```
|
||||
|
||||
The `0.2.6` is the [semantic] version number. For more information, see the [Specifying Dependencies] guide of the cargo documentation.
|
||||
|
||||
[semantic]: https://semver.org/
|
||||
[Specifying Dependencies]: https://doc.crates.io/specifying-dependencies.html
|
||||
|
||||
Let's use it to make writes to the VGA buffer volatile. We update our `Buffer` type as follows:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use volatile::Volatile;
|
||||
|
||||
struct Buffer {
|
||||
chars: [[Volatile<ScreenChar>; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
Instead of a `ScreenChar`, we're now using a `Volatile<ScreenChar>`. (The `Volatile` type is [generic] and can wrap (almost) any type). This ensures that we can't accidentally write to it through a “normal” write. Instead, we have to use the `write` method now.
|
||||
|
||||
[generic]: https://doc.rust-lang.org/book/ch10-01-syntax.html
|
||||
|
||||
This means that we have to update our `Writer::write_byte` method:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
...
|
||||
|
||||
self.buffer.chars[row][col].write(ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code,
|
||||
});
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
Instead of a normal assignment using `=`, we're now using the `write` method. This guarantees that the compiler will never optimize away this write.
|
||||
|
||||
### Formatting Macros
|
||||
It would be nice to support Rust's formatting macros, too. That way, we can easily print different types like integers or floats. To support them, we need to implement the [`core::fmt::Write`] trait. The only required method of this trait is `write_str` that looks quite similar to our `write_string` method, just with a `fmt::Result` return type:
|
||||
|
||||
[`core::fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use core::fmt;
|
||||
|
||||
impl fmt::Write for Writer {
|
||||
fn write_str(&mut self, s: &str) -> fmt::Result {
|
||||
self.write_string(s);
|
||||
Ok(())
|
||||
}
|
||||
}
|
||||
```
|
||||
The `Ok(())` is just a `Ok` Result containing the `()` type.
|
||||
|
||||
Now we can use Rust's built-in `write!`/`writeln!` formatting macros:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
use core::fmt::Write;
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello! ");
|
||||
write!(writer, "The numbers are {} and {}", 42, 1.0/3.0).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
Now you should see a `Hello! The numbers are 42 and 0.3333333333333333` at the bottom of the screen. The `write!` call returns a `Result` which causes a warning if not used, so we call the [`unwrap`] function on it, which panics if an error occurs. This isn't a problem in our case, since writes to the VGA buffer never fail.
|
||||
|
||||
[`unwrap`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.unwrap
|
||||
|
||||
### Newlines
|
||||
Right now, we just ignore newlines and characters that don't fit into the line anymore. Instead we want to move every character one line up (the top line gets deleted) and start at the beginning of the last line again. To do this, we add an implementation for the `new_line` method of `Writer`:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn new_line(&mut self) {
|
||||
for row in 1..BUFFER_HEIGHT {
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
let character = self.buffer.chars[row][col].read();
|
||||
self.buffer.chars[row - 1][col].write(character);
|
||||
}
|
||||
}
|
||||
self.clear_row(BUFFER_HEIGHT - 1);
|
||||
self.column_position = 0;
|
||||
}
|
||||
|
||||
fn clear_row(&mut self, row: usize) {/* TODO */}
|
||||
}
|
||||
```
|
||||
We iterate over all screen characters and move each character one row up. Note that the range notation (`..`) is exclusive the upper bound. We also omit the 0th row (the first range starts at `1`) because it's the row that is shifted off screen.
|
||||
|
||||
To finish the newline code, we add the `clear_row` method:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn clear_row(&mut self, row: usize) {
|
||||
let blank = ScreenChar {
|
||||
ascii_character: b' ',
|
||||
color_code: self.color_code,
|
||||
};
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
self.buffer.chars[row][col].write(blank);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
This method clears a row by overwriting all of its characters with a space character.
|
||||
|
||||
## A Global Interface
|
||||
To provide a global writer that can be used as an interface from other modules without carrying a `Writer` instance around, we try to create a static `WRITER`:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub static WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
```
|
||||
|
||||
However, if we try to compile it now, the following errors occur:
|
||||
|
||||
```
|
||||
error[E0015]: calls in statics are limited to constant functions, tuple structs and tuple variants
|
||||
--> src/vga_buffer.rs:7:17
|
||||
|
|
||||
7 | color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
error[E0396]: raw pointers cannot be dereferenced in statics
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ dereference of raw pointer in constant
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:13
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
```
|
||||
|
||||
To understand what's happening here, we need to know that statics are initialized at compile time, in contrast to normal variables that are initialized at run time. The component of the Rust compiler that evaluates such initialization expressions is called the “[const evaluator]”. Its functionality is still limited, but there is ongoing work to expand it, for example in the “[Allow panicking in constants]” RFC.
|
||||
|
||||
[const evaluator]: https://rustc-dev-guide.rust-lang.org/const-eval.html
|
||||
[Allow panicking in constants]: https://github.com/rust-lang/rfcs/pull/2345
|
||||
|
||||
The issue about `ColorCode::new` would be solvable by using [`const` functions], but the fundamental problem here is that Rust's const evaluator is not able to convert raw pointers to references at compile time. Maybe it will work someday, but until then, we have to find another solution.
|
||||
|
||||
[`const` functions]: https://doc.rust-lang.org/unstable-book/language-features/const-fn.html
|
||||
|
||||
### Lazy Statics
|
||||
The one-time initialization of statics with non-const functions is a common problem in Rust. Fortunately, there already exists a good solution in a crate named [lazy_static]. This crate provides a `lazy_static!` macro that defines a lazily initialized `static`. Instead of computing its value at compile time, the `static` laziliy initializes itself when it's accessed the first time. Thus, the initialization happens at runtime so that arbitrarily complex initialization code is possible.
|
||||
|
||||
[lazy_static]: https://docs.rs/lazy_static/1.0.1/lazy_static/
|
||||
|
||||
Let's add the `lazy_static` crate to our project:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies.lazy_static]
|
||||
version = "1.0"
|
||||
features = ["spin_no_std"]
|
||||
```
|
||||
|
||||
We need the `spin_no_std` feature, since we don't link the standard library.
|
||||
|
||||
With `lazy_static`, we can define our static `WRITER` without problems:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
However, this `WRITER` is pretty useless since it is immutable. This means that we can't write anything to it (since all the write methods take `&mut self`). One possible solution would be to use a [mutable static]. But then every read and write to it would be unsafe since it could easily introduce data races and other bad things. Using `static mut` is highly discouraged, there were even proposals to [remove it][remove static mut]. But what are the alternatives? We could try to use a immutable static with a cell type like [RefCell] or even [UnsafeCell] that provides [interior mutability]. But these types aren't [Sync] \(with good reason), so we can't use them in statics.
|
||||
|
||||
[mutable static]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
|
||||
[remove static mut]: https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437
|
||||
[RefCell]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt
|
||||
[UnsafeCell]: https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html
|
||||
[interior mutability]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html
|
||||
[Sync]: https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html
|
||||
|
||||
### Spinlocks
|
||||
To get synchronized interior mutability, users of the standard library can use [Mutex]. It provides mutual exclusion by blocking threads when the resource is already locked. But our basic kernel does not have any blocking support or even a concept of threads, so we can't use it either. However there is a really basic kind of mutex in computer science that requires no operating system features: the [spinlock]. Instead of blocking, the threads simply try to lock it again and again in a tight loop and thus burn CPU time until the mutex is free again.
|
||||
|
||||
[Mutex]: https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html
|
||||
[spinlock]: https://en.wikipedia.org/wiki/Spinlock
|
||||
|
||||
To use a spinning mutex, we can add the [spin crate] as a dependency:
|
||||
|
||||
[spin crate]: https://crates.io/crates/spin
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
[dependencies]
|
||||
spin = "0.5.2"
|
||||
```
|
||||
|
||||
Then we can use the spinning Mutex to add safe [interior mutability] to our static `WRITER`:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use spin::Mutex;
|
||||
...
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Mutex<Writer> = Mutex::new(Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
});
|
||||
}
|
||||
```
|
||||
Now we can delete the `print_something` function and print directly from our `_start` function:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
use core::fmt::Write;
|
||||
vga_buffer::WRITER.lock().write_str("Hello again").unwrap();
|
||||
write!(vga_buffer::WRITER.lock(), ", some numbers: {} {}", 42, 1.337).unwrap();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
We need to import the `fmt::Write` trait in order to be able to use its functions.
|
||||
|
||||
### Safety
|
||||
Note that we only have a single unsafe block in our code, which is needed to create a `Buffer` reference pointing to `0xb8000`. Afterwards, all operations are safe. Rust uses bounds checking for array accesses by default, so we can't accidentally write outside the buffer. Thus, we encoded the required conditions in the type system and are able to provide a safe interface to the outside.
|
||||
|
||||
### A println Macro
|
||||
Now that we have a global writer, we can add a `println` macro that can be used from anywhere in the codebase. Rust's [macro syntax] is a bit strange, so we won't try to write a macro from scratch. Instead we look at the source of the [`println!` macro] in the standard library:
|
||||
|
||||
[macro syntax]: https://doc.rust-lang.org/nightly/book/ch19-06-macros.html#declarative-macros-with-macro_rules-for-general-metaprogramming
|
||||
[`println!` macro]: https://doc.rust-lang.org/nightly/std/macro.println!.html
|
||||
|
||||
```rust
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => (print!("\n"));
|
||||
($($arg:tt)*) => (print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
Macros are defined through one or more rules, which are similar to `match` arms. The `println` macro has two rules: The first rule for is invocations without arguments (e.g `println!()`), which is expanded to `print!("\n")` and thus just prints a newline. the second rule is for invocations with parameters such as `println!("Hello")` or `println!("Number: {}", 4)`. It is also expanded to an invocation of the `print!` macro, passing all arguments and an additional newline `\n` at the end.
|
||||
|
||||
The `#[macro_export]` attribute makes the macro available to the whole crate (not just the module it is defined) and external crates. It also places the macro at the crate root, which means that we have to import the macro through `use std::println` instead of `std::macros::println`.
|
||||
|
||||
The [`print!` macro] is defined as:
|
||||
|
||||
[`print!` macro]: https://doc.rust-lang.org/nightly/std/macro.print!.html
|
||||
|
||||
```rust
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::io::_print(format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
The macro expands to a call of the [`_print` function] in the `io` module. The [`$crate` variable] ensures that the macro also works from outside the `std` crate by expanding to `std` when it's used in other crates.
|
||||
|
||||
The [`format_args` macro] builds a [fmt::Arguments] type from the passed arguments, which is passed to `_print`. The [`_print` function] of libstd calls `print_to`, which is rather complicated because it supports different `Stdout` devices. We don't need that complexity since we just want to print to the VGA buffer.
|
||||
|
||||
[`_print` function]: https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698
|
||||
[`$crate` variable]: https://doc.rust-lang.org/1.30.0/book/first-edition/macros.html#the-variable-crate
|
||||
[`format_args` macro]: https://doc.rust-lang.org/nightly/std/macro.format_args.html
|
||||
[fmt::Arguments]: https://doc.rust-lang.org/nightly/core/fmt/struct.Arguments.html
|
||||
|
||||
To print to the VGA buffer, we just copy the `println!` and `print!` macros, but modify them to use our own `_print` function:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::vga_buffer::_print(format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => ($crate::print!("\n"));
|
||||
($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
One thing that we changed from the original `println` definition is that we prefixed the invocations of the `print!` macro with `$crate` too. This ensures that we don't need to have to import the `print!` macro too if we only want to use `println`.
|
||||
|
||||
Like in the standard library, we add the `#[macro_export]` attribute to both macros to make them available everywhere in our crate. Note that this places the macros in the root namespace of the crate, so importing them via `use crate::vga_buffer::println` does not work. Instead, we have to do `use crate::println`.
|
||||
|
||||
The `_print` function locks our static `WRITER` and calls the `write_fmt` method on it. This method is from the `Write` trait, we need to import that trait. The additional `unwrap()` at the end panics if printing isn't successful. But since we always return `Ok` in `write_str`, that should not happen.
|
||||
|
||||
Since the macros need to be able to call `_print` from outside of the module, the function needs to be public. However, since we consider this a private implementation detail, we add the [`doc(hidden)` attribute] to hide it from the generated documentation.
|
||||
|
||||
[`doc(hidden)` attribute]: https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden
|
||||
|
||||
### Hello World using `println`
|
||||
Now we can use `println` in our `_start` function:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
Note that we don't have to import the macro in the main function, because it already lives in the root namespace.
|
||||
|
||||
As expected, we now see a _“Hello World!”_ on the screen:
|
||||
|
||||

|
||||
|
||||
### Printing Panic Messages
|
||||
|
||||
Now that we have a `println` macro, we can use it in our panic function to print the panic message and the location of the panic:
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
When we now insert `panic!("Some panic message");` in our `_start` function, we get the following output:
|
||||
|
||||

|
||||
|
||||
So we know not only that a panic has occurred, but also the panic message and where in the code it happened.
|
||||
|
||||
## Summary
|
||||
In this post we learned about the structure of the VGA text buffer and how it can be written through the memory mapping at address `0xb8000`. We created a Rust module that encapsulates the unsafety of writing to this memory mapped buffer and presents a safe and convenient interface to the outside.
|
||||
|
||||
We also saw how easy it is to add dependencies on third-party libraries, thanks to cargo. The two dependencies that we added, `lazy_static` and `spin`, are very useful in OS development and we will use them in more places in future posts.
|
||||
|
||||
## What's next?
|
||||
The next post explains how to set up Rust's built in unit test framework. We will then create some basic unit tests for the VGA buffer module from this post.
|
||||
@@ -1,646 +0,0 @@
|
||||
+++
|
||||
title = "VGA 字符模式"
|
||||
weight = 3
|
||||
path = "zh-CN/vga-text-mode"
|
||||
date = 2018-02-26
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu"]
|
||||
+++
|
||||
|
||||
**VGA 字符模式**([VGA text mode])是打印字符到屏幕的一种简单方式。在这篇文章中,为了包装这个模式为一个安全而简单的接口,我们将包装 unsafe 代码到独立的模块。我们还将实现对 Rust 语言**格式化宏**([formatting macros])的支持。
|
||||
|
||||
[VGA text mode]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
[formatting macros]: https://doc.rust-lang.org/std/fmt/#related-macros
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-03`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-03
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## VGA 字符缓冲区
|
||||
|
||||
为了在 VGA 字符模式中向屏幕打印字符,我们必须将它写入硬件提供的 **VGA 字符缓冲区**(VGA text buffer)。通常状况下,VGA 字符缓冲区是一个 25 行、80 列的二维数组,它的内容将被实时渲染到屏幕。这个数组的元素被称作**字符单元**(character cell),它使用下面的格式描述一个屏幕上的字符:
|
||||
|
||||
| Bit(s) | Value |
|
||||
|-----|----------------|
|
||||
| 0-7 | ASCII code point |
|
||||
| 8-11 | Foreground color |
|
||||
| 12-14 | Background color |
|
||||
| 15 | Blink |
|
||||
|
||||
其中,**前景色**(foreground color)和**背景色**(background color)取值范围如下:
|
||||
|
||||
| Number | Color | Number + Bright Bit | Bright Color |
|
||||
|-----|----------|------|--------|
|
||||
| 0x0 | Black | 0x8 | Dark Gray |
|
||||
| 0x1 | Blue | 0x9 | Light Blue |
|
||||
| 0x2 | Green | 0xa | Light Green |
|
||||
| 0x3 | Cyan | 0xb | Light Cyan |
|
||||
| 0x4 | Red | 0xc | Light Red |
|
||||
| 0x5 | Magenta | 0xd | Pink |
|
||||
| 0x6 | Brown | 0xe | Yellow |
|
||||
| 0x7 | Light Gray | 0xf | White |
|
||||
|
||||
每个颜色的第四位称为**加亮位**(bright bit)。
|
||||
|
||||
要修改 VGA 字符缓冲区,我们可以通过**存储器映射输入输出**([memory-mapped I/O](https://en.wikipedia.org/wiki/Memory-mapped_I/O))的方式,读取或写入地址 `0xb8000`;这意味着,我们可以像操作普通的内存区域一样操作这个地址。
|
||||
|
||||
需要注意的是,一些硬件虽然映射到存储器,但可能不会完全支持所有的内存操作:可能会有一些设备支持按 `u8` 字节读取,但在读取 `u64` 时返回无效的数据。幸运的是,字符缓冲区都[支持标准的读写操作](https://web.stanford.edu/class/cs140/projects/pintos/specs/freevga/vga/vgamem.htm#manip),所以我们不需要用特殊的标准对待它。
|
||||
|
||||
## 包装到 Rust 模块
|
||||
|
||||
既然我们已经知道 VGA 文字缓冲区如何工作,也是时候创建一个 Rust 模块来处理文字打印了。我们输入这样的代码:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
mod vga_buffer;
|
||||
```
|
||||
|
||||
这行代码定义了一个 Rust 模块,它的内容应当保存在 `src/vga_buffer.rs` 文件中。使用 **2018 版次**(2018 edition)的 Rust 时,我们可以把模块的**子模块**(submodule)文件直接保存到 `src/vga_buffer/` 文件夹下,与 `vga_buffer.rs` 文件共存,而无需创建一个 `mod.rs` 文件。
|
||||
|
||||
我们的模块暂时不需要添加子模块,所以我们将它创建为 `src/vga_buffer.rs` 文件。除非另有说明,本文中的代码都保存到这个文件中。
|
||||
|
||||
### 颜色
|
||||
|
||||
首先,我们使用 Rust 的**枚举**(enum)表示一种颜色:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[allow(dead_code)]
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u8)]
|
||||
pub enum Color {
|
||||
Black = 0,
|
||||
Blue = 1,
|
||||
Green = 2,
|
||||
Cyan = 3,
|
||||
Red = 4,
|
||||
Magenta = 5,
|
||||
Brown = 6,
|
||||
LightGray = 7,
|
||||
DarkGray = 8,
|
||||
LightBlue = 9,
|
||||
LightGreen = 10,
|
||||
LightCyan = 11,
|
||||
LightRed = 12,
|
||||
Pink = 13,
|
||||
Yellow = 14,
|
||||
White = 15,
|
||||
}
|
||||
```
|
||||
|
||||
我们使用**类似于 C 语言的枚举**(C-like enum),为每个颜色明确指定一个数字。在这里,每个用 `repr(u8)` 注记标注的枚举类型,都会以一个 `u8` 的形式存储——事实上 4 个二进制位就足够了,但 Rust 语言并不提供 `u4` 类型。
|
||||
|
||||
通常来说,编译器会对每个未使用的变量发出**警告**(warning);使用 `#[allow(dead_code)]`,我们可以对 `Color` 枚举类型禁用这个警告。
|
||||
|
||||
我们还**生成**([derive])了 [`Copy`](https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html)、[`Clone`](https://doc.rust-lang.org/nightly/core/clone/trait.Clone.html)、[`Debug`](https://doc.rust-lang.org/nightly/core/fmt/trait.Debug.html)、[`PartialEq`](https://doc.rust-lang.org/nightly/core/cmp/trait.PartialEq.html) 和 [`Eq`](https://doc.rust-lang.org/nightly/core/cmp/trait.Eq.html) 这几个 trait:这让我们的类型遵循**复制语义**([copy semantics]),也让它可以被比较、被调试和打印。
|
||||
|
||||
[derive]: https://doc.rust-lang.org/rust-by-example/trait/derive.html
|
||||
[copy semantics]: https://doc.rust-lang.org/1.30.0/book/first-edition/ownership.html#copy-types
|
||||
|
||||
为了描述包含前景色和背景色的、完整的**颜色代码**(color code),我们基于 `u8` 创建一个新类型:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(transparent)]
|
||||
struct ColorCode(u8);
|
||||
|
||||
impl ColorCode {
|
||||
fn new(foreground: Color, background: Color) -> ColorCode {
|
||||
ColorCode((background as u8) << 4 | (foreground as u8))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里,`ColorCode` 类型包装了一个完整的颜色代码字节,它包含前景色和背景色信息。和 `Color` 类型类似,我们为它生成 `Copy` 和 `Debug` 等一系列 trait。为了确保 `ColorCode` 和 `u8` 有完全相同的内存布局,我们添加 [repr(transparent) 标记](https://doc.rust-lang.org/nomicon/other-reprs.html#reprtransparent)。
|
||||
|
||||
### 字符缓冲区
|
||||
|
||||
现在,我们可以添加更多的结构体,来描述屏幕上的字符和整个字符缓冲区:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(C)]
|
||||
struct ScreenChar {
|
||||
ascii_character: u8,
|
||||
color_code: ColorCode,
|
||||
}
|
||||
|
||||
const BUFFER_HEIGHT: usize = 25;
|
||||
const BUFFER_WIDTH: usize = 80;
|
||||
|
||||
#[repr(transparent)]
|
||||
struct Buffer {
|
||||
chars: [[ScreenChar; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
|
||||
在内存布局层面,Rust 并不保证按顺序布局成员变量。因此,我们需要使用 `#[repr(C)]` 标记结构体;这将按 C 语言约定的顺序布局它的成员变量,让我们能正确地映射内存片段。对 `Buffer` 类型,我们再次使用 `repr(transparent)`,来确保类型和它的单个成员有相同的内存布局。
|
||||
|
||||
为了输出字符到屏幕,我们来创建一个 `Writer` 类型:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub struct Writer {
|
||||
column_position: usize,
|
||||
color_code: ColorCode,
|
||||
buffer: &'static mut Buffer,
|
||||
}
|
||||
```
|
||||
|
||||
我们将让这个 `Writer` 类型将字符写入屏幕的最后一行,并在一行写满或接收到换行符 `\n` 的时候,将所有的字符向上位移一行。`column_position` 变量将跟踪光标在最后一行的位置。当前字符的前景和背景色将由 `color_code` 变量指定;另外,我们存入一个 VGA 字符缓冲区的可变借用到`buffer`变量中。需要注意的是,这里我们对借用使用**显式生命周期**([explicit lifetime](https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#lifetime-annotation-syntax)),告诉编译器这个借用在何时有效:我们使用** `'static` 生命周期 **(['static lifetime](https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime)),意味着这个借用应该在整个程序的运行期间有效;这对一个全局有效的 VGA 字符缓冲区来说,是非常合理的。
|
||||
|
||||
### 打印字符
|
||||
|
||||
现在我们可以使用 `Writer` 类型来更改缓冲区内的字符了。首先,为了写入一个 ASCII 码字节,我们创建这样的函数:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
if self.column_position >= BUFFER_WIDTH {
|
||||
self.new_line();
|
||||
}
|
||||
|
||||
let row = BUFFER_HEIGHT - 1;
|
||||
let col = self.column_position;
|
||||
|
||||
let color_code = self.color_code;
|
||||
self.buffer.chars[row][col] = ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code,
|
||||
};
|
||||
self.column_position += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn new_line(&mut self) {/* TODO */}
|
||||
}
|
||||
```
|
||||
|
||||
如果这个字节是一个**换行符**([line feed](https://en.wikipedia.org/wiki/Newline))字节 `\n`,我们的 `Writer` 不应该打印新字符,相反,它将调用我们稍后会实现的 `new_line` 方法;其它的字节应该将在 `match` 语句的第二个分支中被打印到屏幕上。
|
||||
|
||||
当打印字节时,`Writer` 将检查当前行是否已满。如果已满,它将首先调用 `new_line` 方法来将这一行字向上提升,再将一个新的 `ScreenChar` 写入到缓冲区,最终将当前的光标位置前进一位。
|
||||
|
||||
要打印整个字符串,我们把它转换为字节并依次输出:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_string(&mut self, s: &str) {
|
||||
for byte in s.bytes() {
|
||||
match byte {
|
||||
// 可以是能打印的 ASCII 码字节,也可以是换行符
|
||||
0x20...0x7e | b'\n' => self.write_byte(byte),
|
||||
// 不包含在上述范围之内的字节
|
||||
_ => self.write_byte(0xfe),
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
VGA 字符缓冲区只支持 ASCII 码字节和**代码页 437**([Code page 437](https://en.wikipedia.org/wiki/Code_page_437))定义的字节。Rust 语言的字符串默认编码为 [UTF-8](https://www.fileformat.info/info/unicode/utf8.htm),也因此可能包含一些 VGA 字符缓冲区不支持的字节:我们使用 `match` 语句,来区别可打印的 ASCII 码或换行字节,和其它不可打印的字节。对每个不可打印的字节,我们打印一个 `■` 符号;这个符号在 VGA 硬件中被编码为十六进制的 `0xfe`。
|
||||
|
||||
我们可以亲自试一试已经编写的代码。为了这样做,我们可以临时编写一个函数:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello ");
|
||||
writer.write_string("Wörld!");
|
||||
}
|
||||
```
|
||||
|
||||
这个函数首先创建一个指向 `0xb8000` 地址VGA缓冲区的 `Writer`。实现这一点,我们需要编写的代码可能看起来有点奇怪:首先,我们把整数 `0xb8000` 强制转换为一个可变的**裸指针**([raw pointer](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer));之后,通过运算符`*`,我们将这个裸指针解引用;最后,我们再通过 `&mut`,再次获得它的可变借用。这些转换需要 **`unsafe` 语句块**([unsafe block](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html)),因为编译器并不能保证这个裸指针是有效的。
|
||||
|
||||
然后它将字节 `b'H'` 写入缓冲区内. 前缀 `b` 创建了一个字节常量([byte literal](https://doc.rust-lang.org/reference/tokens.html#byte-literals)),表示单个 ASCII 码字符;通过尝试写入 `"ello "` 和 `"Wörld!"`,我们可以测试 `write_string` 方法和其后对无法打印字符的处理逻辑。为了观察输出,我们需要在 `_start` 函数中调用 `print_something` 方法:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
vga_buffer::print_something();
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
编译运行后,黄色的 `Hello W■■rld!` 字符串将会被打印在屏幕的左下角:
|
||||
|
||||
|
||||
|
||||
需要注意的是,`ö` 字符被打印为两个 `■` 字符。这是因为在 [UTF-8](https://www.fileformat.info/info/unicode/utf8.htm) 编码下,字符 `ö` 是由两个字节表述的——而这两个字节并不处在可打印的 ASCII 码字节范围之内。事实上,这是 UTF-8 编码的基本特点之一:**如果一个字符占用多个字节,那么每个组成它的独立字节都不是有效的 ASCII 码字节**(the individual bytes of multi-byte values are never valid ASCII)。
|
||||
|
||||
### 易失操作
|
||||
|
||||
我们刚才看到,自己想要输出的信息被正确地打印到屏幕上。然而,未来 Rust 编译器更暴力的优化可能让这段代码不按预期工作。
|
||||
|
||||
产生问题的原因在于,我们只向 `Buffer` 写入,却不再从它读出数据。此时,编译器不知道我们事实上已经在操作 VGA 缓冲区内存,而不是在操作普通的 RAM——因此也不知道产生的**副效应**(side effect),即会有几个字符显示在屏幕上。这时,编译器也许会认为这些写入操作都没有必要,甚至会选择忽略这些操作!所以,为了避免这些并不正确的优化,这些写入操作应当被指定为[易失操作](https://en.wikipedia.org/wiki/Volatile_(computer_programming))。这将告诉编译器,这些写入可能会产生副效应,不应该被优化掉。
|
||||
|
||||
为了在我们的 VGA 缓冲区中使用易失的写入操作,我们使用 [volatile](https://docs.rs/volatile) 库。这个**包**(crate)提供一个名为 `Volatile` 的**包装类型**(wrapping type)和它的 `read`、`write` 方法;这些方法包装了 `core::ptr` 内的 [read_volatile](https://doc.rust-lang.org/nightly/core/ptr/fn.read_volatile.html) 和 [write_volatile](https://doc.rust-lang.org/nightly/core/ptr/fn.write_volatile.html) 函数,从而保证读操作或写操作不会被编译器优化。
|
||||
|
||||
要添加 `volatile` 包为项目的**依赖项**(dependency),我们可以在 `Cargo.toml` 文件的 `dependencies` 中添加下面的代码:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
volatile = "0.2.6"
|
||||
```
|
||||
|
||||
`0.2.6` 表示一个**语义版本号**([semantic version number](https://semver.org/)),在 cargo 文档的[《指定依赖项》章节](https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html)可以找到与它相关的使用指南。
|
||||
|
||||
现在,我们使用它来完成 VGA 缓冲区的 volatile 写入操作。我们将 `Buffer` 类型的定义修改为下列代码:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use volatile::Volatile;
|
||||
|
||||
struct Buffer {
|
||||
chars: [[Volatile<ScreenChar>; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
|
||||
在这里,我们不使用 `ScreenChar` ,而选择使用 `Volatile<ScreenChar>` ——在这里,`Volatile` 类型是一个**泛型**([generic](https://doc.rust-lang.org/book/ch10-01-syntax.html)),可以包装几乎所有的类型——这确保了我们不会通过普通的写入操作,意外地向它写入数据;我们转而使用提供的 `write` 方法。
|
||||
|
||||
这意味着,我们必须要修改我们的 `Writer::write_byte` 方法:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
...
|
||||
|
||||
self.buffer.chars[row][col].write(ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code: color_code,
|
||||
});
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
正如代码所示,我们不再使用普通的 `=` 赋值,而使用了 `write` 方法:这能确保编译器不再优化这个写入操作。
|
||||
|
||||
### 格式化宏
|
||||
|
||||
支持 Rust 提供的**格式化宏**(formatting macros)也是一个很好的思路。通过这种途径,我们可以轻松地打印不同类型的变量,如整数或浮点数。为了支持它们,我们需要实现 [`core::fmt::Write`](https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html) trait;要实现它,唯一需要提供的方法是 `write_str`,它和我们先前编写的 `write_string` 方法差别不大,只是返回值类型变成了 `fmt::Result`:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use core::fmt;
|
||||
|
||||
impl fmt::Write for Writer {
|
||||
fn write_str(&mut self, s: &str) -> fmt::Result {
|
||||
self.write_string(s);
|
||||
Ok(())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里,`Ok(())` 属于 `Result` 枚举类型中的 `Ok`,包含一个值为 `()` 的变量。
|
||||
|
||||
现在我们就可以使用 Rust 内置的格式化宏 `write!` 和 `writeln!` 了:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
use core::fmt::Write;
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello! ");
|
||||
write!(writer, "The numbers are {} and {}", 42, 1.0/3.0).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
现在,你应该在屏幕下端看到一串 `Hello! The numbers are 42 and 0.3333333333333333`。`write!` 宏返回的 `Result` 类型必须被使用,所以我们调用它的 [`unwrap`](https://doc.rust-lang.org/core/result/enum.Result.html#method.unwrap) 方法,它将在错误发生时 panic。这里的情况下应该不会发生这样的问题,因为写入 VGA 字符缓冲区并没有可能失败。
|
||||
|
||||
### 换行
|
||||
|
||||
在之前的代码中,我们忽略了换行符,因此没有处理超出一行字符的情况。当换行时,我们想要把每个字符向上移动一行——此时最顶上的一行将被删除——然后在最后一行的起始位置继续打印。要做到这一点,我们要为 `Writer` 实现一个新的 `new_line` 方法:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn new_line(&mut self) {
|
||||
for row in 1..BUFFER_HEIGHT {
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
let character = self.buffer.chars[row][col].read();
|
||||
self.buffer.chars[row - 1][col].write(character);
|
||||
}
|
||||
}
|
||||
self.clear_row(BUFFER_HEIGHT - 1);
|
||||
self.column_position = 0;
|
||||
}
|
||||
|
||||
fn clear_row(&mut self, row: usize) {/* TODO */}
|
||||
}
|
||||
```
|
||||
|
||||
我们遍历每个屏幕上的字符,把每个字符移动到它上方一行的相应位置。这里,`..` 符号是**区间标号**(range notation)的一种;它表示左闭右开的区间,因此不包含它的上界。在外层的枚举中,我们从第 1 行开始,省略了对第 0 行的枚举过程——因为这一行应该被移出屏幕,即它将被下一行的字符覆写。
|
||||
|
||||
所以我们实现的 `clear_row` 方法代码如下:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn clear_row(&mut self, row: usize) {
|
||||
let blank = ScreenChar {
|
||||
ascii_character: b' ',
|
||||
color_code: self.color_code,
|
||||
};
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
self.buffer.chars[row][col].write(blank);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
通过向对应的缓冲区写入空格字符,这个方法能清空一整行的字符位置。
|
||||
|
||||
## 全局接口
|
||||
|
||||
编写其它模块时,我们希望无需随时拥有 `Writer` 实例,便能使用它的方法。我们尝试创建一个静态的 `WRITER` 变量:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub static WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
```
|
||||
|
||||
我们尝试编译这些代码,却发生了下面的编译错误:
|
||||
|
||||
```
|
||||
error[E0015]: calls in statics are limited to constant functions, tuple structs and tuple variants
|
||||
--> src/vga_buffer.rs:7:17
|
||||
|
|
||||
7 | color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
error[E0396]: raw pointers cannot be dereferenced in statics
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ dereference of raw pointer in constant
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:13
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
```
|
||||
|
||||
为了明白现在发生了什么,我们需要知道一点:一般的变量在运行时初始化,而静态变量在编译时初始化。Rust编译器规定了一个称为**常量求值器**([const evaluator](https://rustc-dev-guide.rust-lang.org/const-eval.html))的组件,它应该在编译时处理这样的初始化工作。虽然它目前的功能较为有限,但对它的扩展工作进展活跃,比如允许在常量中 panic 的[一篇 RFC 文档](https://github.com/rust-lang/rfcs/pull/2345)。
|
||||
|
||||
关于 `ColorCode::new` 的问题应该能使用**常函数**([`const` functions](https://doc.rust-lang.org/unstable-book/language-features/const-fn.html))解决,但常量求值器还存在不完善之处,它还不能在编译时直接转换裸指针到变量的引用——也许未来这段代码能够工作,但在那之前,我们需要寻找另外的解决方案。
|
||||
|
||||
### 延迟初始化
|
||||
|
||||
使用非常函数初始化静态变量是 Rust 程序员普遍遇到的问题。幸运的是,有一个叫做 [lazy_static](https://docs.rs/lazy_static/1.0.1/lazy_static/) 的包提供了一个很棒的解决方案:它提供了名为 `lazy_static!` 的宏,定义了一个**延迟初始化**(lazily initialized)的静态变量;这个变量的值将在第一次使用时计算,而非在编译时计算。这时,变量的初始化过程将在运行时执行,任意的初始化代码——无论简单或复杂——都是能够使用的。
|
||||
|
||||
现在,我们将 `lazy_static` 包导入到我们的项目:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies.lazy_static]
|
||||
version = "1.0"
|
||||
features = ["spin_no_std"]
|
||||
```
|
||||
|
||||
在这里,由于程序不连接标准库,我们需要启用 `spin_no_std` 特性。
|
||||
|
||||
使用 `lazy_static` 我们就可以定义一个不出问题的 `WRITER` 变量:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
然而,这个 `WRITER` 可能没有什么用途,因为它目前还是**不可变变量**(immutable variable):这意味着我们无法向它写入数据,因为所有与写入数据相关的方法都需要实例的可变引用 `&mut self`。一种解决方案是使用**可变静态**([mutable static](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable))的变量,但所有对它的读写操作都被规定为不安全的(unsafe)操作,因为这很容易导致数据竞争或发生其它不好的事情——使用 `static mut` 极其不被赞成,甚至有一些提案认为[应该将它删除](https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437)。也有其它的替代方案,比如可以尝试使用比如 [RefCell](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt) 或甚至 [UnsafeCell](https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html) 等类型提供的**内部可变性**([interior mutability](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html));但这些类型都被设计为非同步类型,即不满足 [Sync](https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html) 约束,所以我们不能在静态变量中使用它们。
|
||||
|
||||
### 自旋锁
|
||||
|
||||
要定义同步的内部可变性,我们往往使用标准库提供的互斥锁类 [Mutex](https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html),它通过提供当资源被占用时将线程**阻塞**(block)的**互斥条件**(mutual exclusion)实现这一点;但我们初步的内核代码还没有线程和阻塞的概念,我们将不能使用这个类。不过,我们还有一种较为基础的互斥锁实现方式——**自旋锁**([spinlock](https://en.wikipedia.org/wiki/Spinlock))。自旋锁并不会调用阻塞逻辑,而是在一个小的无限循环中反复尝试获得这个锁,也因此会一直占用 CPU 时间,直到互斥锁被它的占用者释放。
|
||||
|
||||
为了使用自旋的互斥锁,我们添加 [spin包](https://crates.io/crates/spin) 到项目的依赖项列表:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
[dependencies]
|
||||
spin = "0.4.9"
|
||||
```
|
||||
|
||||
现在,我们能够使用自旋的互斥锁,为我们的 `WRITER` 类实现安全的[内部可变性](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html):
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use spin::Mutex;
|
||||
...
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Mutex<Writer> = Mutex::new(Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以删除 `print_something` 函数,尝试直接在 `_start` 函数中打印字符:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
use core::fmt::Write;
|
||||
vga_buffer::WRITER.lock().write_str("Hello again").unwrap();
|
||||
write!(vga_buffer::WRITER.lock(), ", some numbers: {} {}", 42, 1.337).unwrap();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
在这里,我们需要导入名为 `fmt::Write` 的 trait,来使用实现它的类的相应方法。
|
||||
|
||||
### 安全性
|
||||
|
||||
经过上面的努力后,我们现在的代码只剩一个 unsafe 语句块,它用于创建一个指向 `0xb8000` 地址的 `Buffer` 类型引用;在这步之后,所有的操作都是安全的。Rust 将为每个数组访问检查边界,所以我们不会在不经意间越界到缓冲区之外。因此,我们把需要的条件编码到 Rust 的类型系统,这之后,我们为外界提供的接口就符合内存安全原则了。
|
||||
|
||||
### `println!` 宏
|
||||
|
||||
现在我们有了一个全局的 `Writer` 实例,我们就可以基于它实现 `println!` 宏,这样它就能被任意地方的代码使用了。Rust 提供的[宏定义语法](https://doc.rust-lang.org/nightly/book/ch19-06-macros.html#declarative-macros-with-macro_rules-for-general-metaprogramming)需要时间理解,所以我们将不从零开始编写这个宏。我们先看看标准库中 [`println!` 宏的实现源码](https://doc.rust-lang.org/nightly/std/macro.println!.html):
|
||||
|
||||
```rust
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => (print!("\n"));
|
||||
($($arg:tt)*) => (print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
宏是通过一个或多个**规则**(rule)定义的,这就像 `match` 语句的多个分支。`println!` 宏有两个规则:第一个规则不要求传入参数——就比如 `println!()` ——它将被扩展为 `print!("\n")`,因此只会打印一个新行;第二个要求传入参数——好比 `println!("Rust 能够编写操作系统")` 或 `println!("我学习 Rust 已经{}年了", 3)`——它将使用 `print!` 宏扩展,传入它需求的所有参数,并在输出的字符串最后加入一个换行符 `\n`。
|
||||
|
||||
这里,`#[macro_export]` 属性让整个包(crate)和基于它的包都能访问这个宏,而不仅限于定义它的模块(module)。它还将把宏置于包的根模块(crate root)下,这意味着比如我们需要通过 `use std::println` 来导入这个宏,而不是通过 `std::macros::println`。
|
||||
|
||||
[`print!` 宏](https://doc.rust-lang.org/nightly/std/macro.print!.html)是这样定义的:
|
||||
|
||||
```
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::io::_print(format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
这个宏将扩展为一个对 `io` 模块中 [`_print` 函数](https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698)的调用。[`$crate` 变量](https://doc.rust-lang.org/1.30.0/book/first-edition/macros.html#the-variable-crate)将在 `std` 包之外被解析为 `std` 包,保证整个宏在 `std` 包之外也可以使用。
|
||||
|
||||
[`format_args!` 宏](https://doc.rust-lang.org/nightly/std/macro.format_args.html)将传入的参数搭建为一个 [fmt::Arguments](https://doc.rust-lang.org/nightly/core/fmt/struct.Arguments.html) 类型,这个类型将被传入 `_print` 函数。`std` 包中的 [`_print` 函数](https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698)将调用复杂的私有函数 `print_to`,来处理对不同 `Stdout` 设备的支持。我们不需要编写这样的复杂函数,因为我们只需要打印到 VGA 字符缓冲区。
|
||||
|
||||
要打印到字符缓冲区,我们把 `println!` 和 `print!` 两个宏复制过来,但修改部分代码,让这些宏使用我们定义的 `_print` 函数:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::vga_buffer::_print(format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => ($crate::print!("\n"));
|
||||
($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
我们首先修改了 `println!` 宏,在每个使用的 `print!` 宏前面添加了 `$crate` 变量。这样我们在只需要使用 `println!` 时,不必也编写代码导入 `print!` 宏。
|
||||
|
||||
就像标准库做的那样,我们为两个宏都添加了 `#[macro_export]` 属性,这样在包的其它地方也可以使用它们。需要注意的是,这将占用包的**根命名空间**(root namespace),所以我们不能通过 `use crate::vga_buffer::println` 来导入它们;我们应该使用 `use crate::println`。
|
||||
|
||||
另外,`_print` 函数将占有静态变量 `WRITER` 的锁,并调用它的 `write_fmt` 方法。这个方法是从名为 `Write` 的 trait 中获得的,所以我们需要导入这个 trait。额外的 `unwrap()` 函数将在打印不成功的时候 panic;但既然我们的 `write_str` 总是返回 `Ok`,这种情况不应该发生。
|
||||
|
||||
如果这个宏将能在模块外访问,它们也应当能访问 `_print` 函数,因此这个函数必须是公有的(public)。然而,考虑到这是一个私有的实现细节,我们添加一个 [`doc(hidden)` 属性](https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden),防止它在生成的文档中出现。
|
||||
|
||||
### 使用 `println!` 的 Hello World
|
||||
|
||||
现在,我们可以在 `_start` 里使用 `println!` 了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
要注意的是,我们在入口函数中不需要导入这个宏——因为它已经被置于包的根命名空间了。
|
||||
|
||||
运行这段代码,和我们预料的一样,一个 *“Hello World!”* 字符串被打印到了屏幕上:
|
||||
|
||||
|
||||
|
||||
### 打印 panic 信息
|
||||
|
||||
既然我们已经有了 `println!` 宏,我们可以在 panic 处理函数中,使用它打印 panic 信息和 panic 产生的位置:
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
/// 这个函数将在 panic 发生时被调用
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
当我们在 `_start` 函数中插入一行 `panic!("Some panic message");` 后,我们得到了这样的输出:
|
||||
|
||||
|
||||
|
||||
所以,现在我们不仅能知道 panic 已经发生,还能够知道 panic 信息和产生 panic 的代码。
|
||||
|
||||
## 小结
|
||||
|
||||
这篇文章中,我们学习了 VGA 字符缓冲区的结构,以及如何在 `0xb8000` 的内存映射地址访问它。我们将所有的不安全操作包装为一个 Rust 模块,以便在外界安全地访问它。
|
||||
|
||||
我们也发现了——感谢便于使用的 cargo——在 Rust 中使用第三方提供的包是及其容易的。我们添加的两个依赖项,`lazy_static` 和 `spin`,都在操作系统开发中及其有用;我们将在未来的文章中多次使用它们。
|
||||
|
||||
## 下篇预告
|
||||
|
||||
下一篇文章中,我们将会讲述如何配置 Rust 内置的单元测试框架。我们还将为本文编写的 VGA 缓冲区模块添加基础的单元测试项目。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 7.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.3 KiB |
@@ -1,931 +0,0 @@
|
||||
+++
|
||||
title = "内核测试"
|
||||
weight = 4
|
||||
path = "zh-CN/testing"
|
||||
date = 2019-04-27
|
||||
|
||||
[extra]
|
||||
# Please update this when updating the translation
|
||||
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["luojia65", "Rustin-Liu"]
|
||||
+++
|
||||
|
||||
本文主要讲述了在`no_std`环境下进行单元测试和集成测试的方法。我们将通过Rust的自定义测试框架来在我们的内核中执行一些测试函数。为了将结果反馈到QEMU上,我们需要使用QEMU的一些其他的功能以及`bootimage`工具。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部]留言。你可以在[这里][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-04
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 阅读要求
|
||||
|
||||
这篇文章替换了此前的(现在已经过时了) [_单元测试(Unit Testing)_] 和 [_集成测试(Integration Tests)_] 两篇文章。这里我将假定你是在2019-04-27日后阅读的[_最小Rust内核_]一文。总而言之,本文要求你已经有一个[设置默认目标]的 `.cargo/config` 文件且[定义了一个runner可执行文件]。
|
||||
|
||||
[_单元测试(Unit Testing)_]: @/second-edition/posts/deprecated/04-unit-testing/index.md
|
||||
[_集成测试(Integration Tests)_]: @/second-edition/posts/deprecated/05-integration-tests/index.md
|
||||
[_最小Rust内核_]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
[设置默认目标]: @/second-edition/posts/02-minimal-rust-kernel/index.md#set-a-default-target
|
||||
[定义了一个runner可执行文件]: @/second-edition/posts/02-minimal-rust-kernel/index.md#using-cargo-run
|
||||
|
||||
## Rust中的测试
|
||||
|
||||
Rust有一个**内置的测试框架**([built-in test framework]):无需任何设置就可以进行单元测试,只需要创建一个通过assert来检查结果的函数并在函数的头部加上`#[test]`属性即可。然后`cargo test`会自动找到并执行你的crate中的所有测试函数。
|
||||
|
||||
[built-in test framework]: https://doc.rust-lang.org/book/second-edition/ch11-00-testing.html
|
||||
|
||||
不幸的是,对于一个`no_std`的应用,比如我们的内核,这有点点复杂。现在的问题是,Rust的测试框架会隐式的调用内置的[`test`]库,但是这个库依赖于标准库。这也就是说我们的 `#[no_std]`内核无法使用默认的测试框架。
|
||||
|
||||
[`test`]: https://doc.rust-lang.org/test/index.html
|
||||
|
||||
当我们试图在我们的项目中执行`cargo xtest`时,我们可以看到如下信息:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
error[E0463]: can't find crate for `test`
|
||||
```
|
||||
|
||||
由于`test`crate依赖于标准库,所以它在我们的裸机目标上并不可用。虽然将`test`crate移植到一个 `#[no_std]` 上下文环境中是[可能的][utest],但是这样做是高度不稳定的并且还会需要一些特殊的hacks,例如重定义 `panic` 宏。
|
||||
|
||||
[utest]: https://github.com/japaric/utest
|
||||
|
||||
### 自定义测试框架
|
||||
|
||||
幸运的是,Rust支持通过使用不稳定的**自定义测试框架**([`custom_test_frameworks`]) 功能来替换默认的测试框架。该功能不需要额外的库,因此在 `#[no_std]`环境中它也可以工作。它的工作原理是收集所有标注了 `#[test_case]`属性的函数,然后将这个测试函数的列表作为参数传递给用户指定的runner函数。因此,它实现了对测试过程的最大控制。
|
||||
|
||||
[`custom_test_frameworks`]: https://doc.rust-lang.org/unstable-book/language-features/custom-test-frameworks.html
|
||||
|
||||
与默认的测试框架相比,它的缺点是有一些高级功能诸如 [`should_panic` tests]都不可用了。相对的,如果需要这些功能,我们需要自己来实现。当然,这点对我们来说是好事,因为我们的环境非常特殊,在这个环境里,这些高级功能的默认实现无论如何都是无法工作的,举个例子, `#[should_panic]`属性依赖于堆栈展开来捕获内核panic,而我的内核早已将其禁用了。
|
||||
|
||||
[`should_panic` tests]: https://doc.rust-lang.org/book/ch11-01-writing-tests.html#checking-for-panics-with-should_panic
|
||||
|
||||
要为我们的内核实现自定义测试框架,我们需要将如下代码添加到我们的`main.rs`中去:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(crate::test_runner)]
|
||||
|
||||
#[cfg(test)]
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们的runner会打印一个简短的debug信息然后调用列表中的每个测试函数。参数类型 `&[&dyn Fn()]` 是[_Fn()_] trait的 [_trait object_] 引用的一个 [_slice_]。它基本上可以被看做一个可以像函数一样被调用的类型的引用列表。由于这个函数在不进行测试的时候没有什么用,这里我们使用 `#[cfg(test)]`属性保证它只会出现在测试中。
|
||||
|
||||
[_slice_]: https://doc.rust-lang.org/std/primitive.slice.html
|
||||
[_trait object_]: https://doc.rust-lang.org/1.30.0/book/first-edition/trait-objects.html
|
||||
[_Fn()_]: https://doc.rust-lang.org/std/ops/trait.Fn.html
|
||||
|
||||
现在当我们运行 `cargo xtest` ,我们可以发现运行成功了。然而,我们看到的仍然是"Hello World"而不是我们的 `test_runner`传递来的信息。这是由于我们的入口点仍然是 `_start` 函数——自定义测试框架会生成一个`main`函数来调用`test_runner`,但是由于我们使用了 `#[no_main]`并提供了我们自己的入口点,所以这个`main`函数就被忽略了。
|
||||
|
||||
为了修复这个问题,我们需要通过 `reexport_test_harness_main`属性来将生成的函数的名称更改为与`main`不同的名称。然后我们可以在我们的`_start`函数里调用这个重命名的函数:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我们将测试框架的入口函数的名字设置为`test_main`,并在我们的 `_start`入口点里调用它。通过使用**条件编译**([conditional compilation]),我们能够只在上下文环境为测试(test)时调用`test_main`,因为该函数将不在非测试上下文中生成。
|
||||
|
||||
[ conditional compilation ]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
|
||||
|
||||
现在当我们执行 `cargo xtest`时,我们可以看到我们的`test_runner`将"Running 0 tests"信息显示在屏幕上了。我们可以创建第一个测试函数了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[test_case]
|
||||
fn trivial_assertion() {
|
||||
print!("trivial assertion... ");
|
||||
assert_eq!(1, 1);
|
||||
println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
现在,当我们运行 `cargo xtest`时,我们可以看到如下输出:
|
||||
|
||||
![QEMU printing "Hello World!", "Running 1 tests", and "trivial assertion... [ok]"](https://os.phil-opp.com/testing/qemu-test-runner-output.png)
|
||||
|
||||
传递给 `test_runner`函数的`tests`切片里包含了一个 `trivial_assertion` 函数的引用,从屏幕上输出的 `trivial assertion... [ok]`信息可见,我们的测试已被调用并且顺利通过。
|
||||
|
||||
在执行完tests后, `test_runner`会将结果返回给 `test_main`函数,而这个函数又返回到 `_start`入口点函数——这样我们就进入了一个死循环,因为入口点函数是不允许返回的。这将导致一个问题:我们希望`cargo xtest`在所有的测试运行完毕后,才返回并退出。
|
||||
|
||||
## 退出QEMU
|
||||
|
||||
现在我们在`_start`函数结束后进入了一个死循环,所以每次执行完`cargo xtest`后我们都需要手动去关闭QEMU;但是我们还想在没有用户交互的脚本环境下执行 `cargo xtest`。解决这个问题的最佳方式,是实现一个合适的方法来关闭我们的操作系统——不幸的是,这个方式实现起来相对有些复杂,因为这要求我们实现对[APM]或[ACPI]电源管理标准的支持。
|
||||
|
||||
[APM]: https://wiki.osdev.org/APM
|
||||
[ACPI]: https://wiki.osdev.org/ACPI
|
||||
|
||||
幸运的是,还有一个绕开这些问题的办法:QEMU支持一种名为 `isa-debug-exit`的特殊设备,它提供了一种从客户系统(guest system)里退出QEMU的简单方式。为了使用这个设备,我们需要向QEMU传递一个`-device`参数。当然,我们也可以通过将 `package.metadata.bootimage.test-args` 配置关键字添加到我们的`Cargo.toml`来达到目的:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
|
||||
```
|
||||
|
||||
`bootimage runner` 会在QEMU的默认测试命令后添加`test-args` 参数。(对于`cargo xrun`命令,这个参数会被忽略。)
|
||||
|
||||
在传递设备名 (`isa-debug-exit`)的同时,我们还传递了两个参数,`iobase` 和 `iosize` 。这两个参数指定了一个_I/O 端口_,我们的内核将通过它来访问设备。
|
||||
|
||||
### I/O 端口
|
||||
在x86平台上,CPU和外围硬件通信通常有两种方式,**内存映射I/O**和**端口映射I/O**。之前,我们已经使用内存映射的方式,通过内存地址`0xb8000`访问了[VGA文本缓冲区]。该地址并没有映射到RAM,而是映射到了VGA设备的一部分内存上。
|
||||
|
||||
[VGA text buffer]: @/second-edition/posts/03-vga-text-buffer/index.md
|
||||
|
||||
与内存映射不同,端口映射I/O使用独立的I/O总线来进行通信。每个外围设备都有一个或数个端口号。CPU采用了特殊的`in`和`out`指令来和端口通信,这些指令要求一个端口号和一个字节的数据作为参数(有些这种指令的变体也允许发送`u16`或是`u32`长度的数据)。
|
||||
|
||||
`isa-debug-exit`设备使用的就是端口映射I/O。其中, `iobase` 参数指定了设备对应的端口地址(在x86中,`0xf4`是一个[通常未被使用的端口][list of x86 I/O ports]),而`iosize`则指定了端口的大小(`0x04`代表4字节)。
|
||||
|
||||
[list of x86 I/O ports]: https://wiki.osdev.org/I/O_Ports#The_list
|
||||
|
||||
### 使用退出(Exit)设备
|
||||
|
||||
`isa-debug-exit`设备的功能非常简单。当一个 `value`写入`iobase`指定的端口时,它会导致QEMU以**退出状态**([exit status])`(value << 1) | 1`退出。也就是说,当我们向端口写入`0`时,QEMU将以退出状态`(0 << 1) | 1 = 1`退出,而当我们向端口写入`1`时,它将以退出状态`(1 << 1) | 1 = 3`退出。
|
||||
|
||||
[exit status]: https://en.wikipedia.org/wiki/Exit_status
|
||||
|
||||
这里我们使用 [`x86_64`] crate提供的抽象,而不是手动调用`in`或`out`指令。为了添加对该crate的依赖,我们可以将其添加到我们的 `Cargo.toml`中的 `dependencies` 小节中去:
|
||||
|
||||
|
||||
[`x86_64`]: https://docs.rs/x86_64/0.7.5/x86_64/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
x86_64 = "0.11.0"
|
||||
```
|
||||
|
||||
现在我们可以使用crate中提供的[`Port`] 类型来创建一个`exit_qemu` 函数了:
|
||||
|
||||
[`Port`]: https://docs.rs/x86_64/0.7.0/x86_64/instructions/port/struct.Port.html
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u32)]
|
||||
pub enum QemuExitCode {
|
||||
Success = 0x10,
|
||||
Failed = 0x11,
|
||||
}
|
||||
|
||||
pub fn exit_qemu(exit_code: QemuExitCode) {
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
unsafe {
|
||||
let mut port = Port::new(0xf4);
|
||||
port.write(exit_code as u32);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
该函数在`0xf4`处创建了一个新的端口,该端口同时也是 `isa-debug-exit` 设备的 `iobase` 。然后它会向端口写入传递的退出代码。这里我们使用`u32`来传递数据,因为我们之前已经将 `isa-debug-exit`设备的 `iosize` 指定为4字节了。上述两个操作都是`unsafe`的,因为I/O端口的写入操作通常会导致一些不可预知的行为。
|
||||
|
||||
为了指定退出状态,我们创建了一个 `QemuExitCode`枚举。思路大体上是,如果所有的测试均成功,就以成功退出码退出;否则就以失败退出码退出。这个枚举类型被标记为 `#[repr(u32)]`,代表每个变量都是一个`u32`的整数类型。我们使用退出代码`0x10`代表成功,`0x11`代表失败。 实际的退出代码并不重要,只要它们不与QEMU的默认退出代码冲突即可。 例如,使用退出代码0表示成功可能并不是一个好主意,因为它在转换后就变成了`(0 << 1) | 1 = 1` ,而`1`是QEMU运行失败时的默认退出代码。 这样,我们就无法将QEMU错误与成功的测试运行区分开来了。
|
||||
|
||||
现在我们来更新`test_runner`的代码,让程序在运行所有测试完毕后退出QEMU:
|
||||
|
||||
```rust
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
}
|
||||
/// new
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
```
|
||||
|
||||
当我们现在运行`cargo xtest`时,QEMU会在测试运行后立刻退出。现在的问题是,即使我们传递了表示成功(`Success`)的退出代码, `cargo test`依然会将所有的测试都视为失败:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-5804fc7d2dd4c9be
|
||||
Building bootloader
|
||||
Compiling bootloader v0.5.3 (/home/philipp/Documents/bootloader)
|
||||
Finished release [optimized + debuginfo] target(s) in 1.07s
|
||||
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
|
||||
deps/bootimage-blog_os-5804fc7d2dd4c9be.bin -device isa-debug-exit,iobase=0xf4,
|
||||
iosize=0x04`
|
||||
error: test failed, to rerun pass '--bin blog_os'
|
||||
```
|
||||
|
||||
这里的问题在于,`cargo test`会将所有非`0`的错误码都视为测试失败。
|
||||
|
||||
### 成功退出(Exit)代码
|
||||
|
||||
为了解决这个问题, `bootimage`提供了一个 `test-success-exit-code`配置项,可以将指定的退出代码映射到退出代码`0`:
|
||||
|
||||
```toml
|
||||
[package.metadata.bootimage]
|
||||
test-args = […]
|
||||
test-success-exit-code = 33 # (0x10 << 1) | 1
|
||||
```
|
||||
|
||||
有了这个配置,`bootimage`就会将我们的成功退出码映射到退出码0;这样一来, `cargo xtest`就能正确的识别出测试成功的情况,而不会将其视为测试失败。
|
||||
|
||||
我们的测试runner现在会在正确报告测试结果后自动关闭QEMU。我们可以看到QEMU的窗口只会显示很短的时间——我们不容易看清测试的结果。如果测试结果会打印在控制台上而不是QEMU里,让我们能在QEMU退出后仍然能看到测试结果就好了。
|
||||
|
||||
## 打印到控制台
|
||||
|
||||
要在控制台上查看测试输出,我们需要以某种方式将数据从内核发送到宿主系统。 有多种方法可以实现这一点,例如通过TCP网络接口来发送数据。但是,设置网络堆栈是一项很复杂的任务——这里我们选择更简单的解决方案。
|
||||
|
||||
### 串口
|
||||
|
||||
发送数据的一个简单的方式是通过[串行端口],这是一个现代电脑中已经不存在的旧标准接口(译者注:玩过单片机的同学应该知道,其实译者上大学的时候有些同学的笔记本电脑还有串口的,没有串口的同学在烧录单片机程序的时候也都会需要usb转串口线,一般是51,像stm32有st-link,这个另说,不过其实也可以用串口来下载)。串口非常易于编程,QEMU可以将通过串口发送的数据重定向到宿主机的标准输出或是文件中。
|
||||
|
||||
[串行端口]: https://en.wikipedia.org/wiki/Serial_port
|
||||
|
||||
用来实现串行接口的芯片被称为 [UARTs]。在x86上,有[很多UART模型],但是幸运的是,它们之间仅有的那些不同之处都是我们用不到的高级功能。目前通用的UARTs都会兼容[16550 UART],所以我们在我们测试框架里采用该模型。
|
||||
|
||||
[UARTs]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter
|
||||
[很多UART模型]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
|
||||
[16550 UART]: https://en.wikipedia.org/wiki/16550_UART
|
||||
|
||||
我们使用[`uart_16550`] crate来初始化UART,并通过串口来发送数据。为了将该crate添加为依赖,我们将我们的`Cargo.toml`和`main.rs`修改为如下:
|
||||
|
||||
[`uart_16550`]: https://docs.rs/uart_16550
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
uart_16550 = "0.2.0"
|
||||
```
|
||||
|
||||
`uart_16550` crate包含了一个代表UART寄存器的`SerialPort`结构体,但是我们仍然需要自己来创建一个相应的实例。我们使用以下内容来创建一个新的串口模块`serial`:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
mod serial;
|
||||
```
|
||||
|
||||
```rust
|
||||
// in src/serial.rs
|
||||
|
||||
use uart_16550::SerialPort;
|
||||
use spin::Mutex;
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
pub static ref SERIAL1: Mutex<SerialPort> = {
|
||||
let mut serial_port = unsafe { SerialPort::new(0x3F8) };
|
||||
serial_port.init();
|
||||
Mutex::new(serial_port)
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
就像[VGA文本缓冲区][vga lazy-static]一样,我们使用 `lazy_static` 和一个自旋锁来创建一个 `static` writer实例。通过使用 `lazy_static` ,我们可以保证`init`方法只会在该示例第一次被使用使被调用。
|
||||
|
||||
和 `isa-debug-exit`设备一样,UART也是用过I/O端口进行编程的。由于UART相对来讲更加复杂,它使用多个I/O端口来对不同的设备寄存器进行编程。不安全的`SerialPort::new`函数需要UART的第一个I/O端口的地址作为参数,从该地址中可以计算出所有所需端口的地址。我们传递的端口地址为`0x3F8` ,该地址是第一个串行接口的标准端口号。
|
||||
|
||||
[vga lazy-static]: @/second-edition/posts/03-vga-text-buffer/index.md#lazy-statics
|
||||
|
||||
为了使串口更加易用,我们添加了 `serial_print!` 和 `serial_println!`宏:
|
||||
|
||||
```rust
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: ::core::fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
SERIAL1.lock().write_fmt(args).expect("Printing to serial failed");
|
||||
}
|
||||
|
||||
/// Prints to the host through the serial interface.
|
||||
#[macro_export]
|
||||
macro_rules! serial_print {
|
||||
($($arg:tt)*) => {
|
||||
$crate::serial::_print(format_args!($($arg)*));
|
||||
};
|
||||
}
|
||||
|
||||
/// Prints to the host through the serial interface, appending a newline.
|
||||
#[macro_export]
|
||||
macro_rules! serial_println {
|
||||
() => ($crate::serial_print!("\n"));
|
||||
($fmt:expr) => ($crate::serial_print!(concat!($fmt, "\n")));
|
||||
($fmt:expr, $($arg:tt)*) => ($crate::serial_print!(
|
||||
concat!($fmt, "\n"), $($arg)*));
|
||||
}
|
||||
```
|
||||
|
||||
该实现和我们此前的`print`和`println`宏的实现非常类似。 由于`SerialPort`类型已经实现了`fmt::Write` trait,所以我们不需要提供我们自己的实现了。
|
||||
|
||||
[`fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
|
||||
|
||||
现在我们可以从测试代码里向串行接口打印而不是向VGA文本缓冲区打印了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[cfg(test)]
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
[…]
|
||||
}
|
||||
|
||||
#[test_case]
|
||||
fn trivial_assertion() {
|
||||
serial_print!("trivial assertion... ");
|
||||
assert_eq!(1, 1);
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
注意,由于我们使用了 `#[macro_export]` 属性, `serial_println`宏直接位于根命名空间下——所以通过`use crate::serial::serial_println` 来导入该宏是不起作用的。
|
||||
|
||||
### QEMU参数
|
||||
|
||||
为了查看QEMU的串行输出,我们需要使用`-serial`参数将输出重定向到stdout:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = [
|
||||
"-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio"
|
||||
]
|
||||
```
|
||||
|
||||
现在,当我们运行 `cargo xtest`时,我们可以直接在控制台里看到测试输出了:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
|
||||
Building bootloader
|
||||
Finished release [optimized + debuginfo] target(s) in 0.02s
|
||||
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
|
||||
deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
|
||||
isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
|
||||
Running 1 tests
|
||||
trivial assertion... [ok]
|
||||
```
|
||||
|
||||
然而,当测试失败时,我们仍然会在QEMU内看到输出结果,因为我们的panic handler还是用了`println`。为了模拟这个过程,我们将我们的 `trivial_assertion` test中的断言(assertion)修改为 `assert_eq!(0, 1)`:
|
||||
|
||||
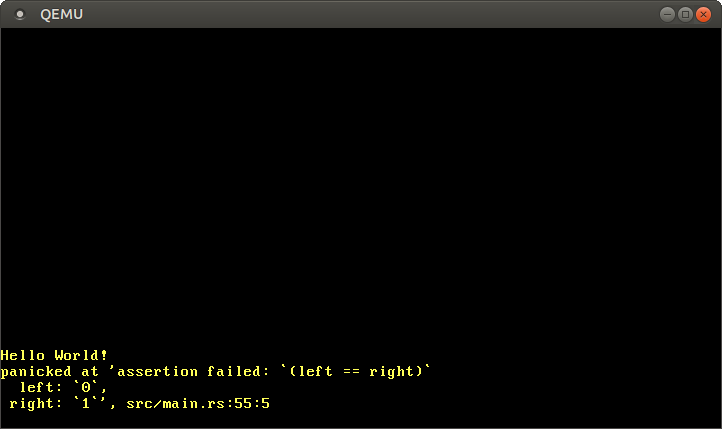
|
||||
|
||||
可以看到,panic信息被打印到了VGA缓冲区里,而测试输出则被打印到串口上了。panic信息非常有用,所以我们希望能够在控制台中来查看它。
|
||||
|
||||
### 在panic时打印一个错误信息
|
||||
|
||||
为了在panic时使用错误信息来退出QEMU,我们可以使用**条件编译**([conditional compilation])在测试模式下使用(与非测试模式下)不同的panic处理方式:
|
||||
|
||||
[conditional compilation]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
|
||||
|
||||
```rust
|
||||
// our existing panic handler
|
||||
#[cfg(not(test))] // new attribute
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
|
||||
// our panic handler in test mode
|
||||
#[cfg(test)]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
在我们的测试panic处理中,我们用 `serial_println`来代替`println` 并使用失败代码来退出QEMU。注意,在`exit_qemu`调用后,我们仍然需要一个无限循环的`loop`因为编译器并不知道 `isa-debug-exit`设备会导致程序退出。
|
||||
|
||||
现在,即使在测试失败的情况下QEMU仍然会存在,并会将一些有用的错误信息打印到控制台:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
|
||||
Building bootloader
|
||||
Finished release [optimized + debuginfo] target(s) in 0.02s
|
||||
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
|
||||
deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
|
||||
isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
|
||||
Running 1 tests
|
||||
trivial assertion... [failed]
|
||||
|
||||
Error: panicked at 'assertion failed: `(left == right)`
|
||||
left: `0`,
|
||||
right: `1`', src/main.rs:65:5
|
||||
```
|
||||
|
||||
由于现在所有的测试都将输出到控制台上,我们不再需要让QEMU窗口弹出一小会儿了——我们完全可以把窗口藏起来。
|
||||
|
||||
### 隐藏 QEMU
|
||||
|
||||
由于我们使用`isa-debug-exit`设备和串行端口来报告完整的测试结果,所以我们不再需要QMEU的窗口了。我们可以通过向QEMU传递 `-display none`参数来将其隐藏:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = [
|
||||
"-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio",
|
||||
"-display", "none"
|
||||
]
|
||||
```
|
||||
|
||||
现在QEMU完全在后台运行且没有任何窗口会被打开。这不仅不那么烦人,还允许我们的测试框架在没有图形界面的环境里,诸如CI服务器或是[SSH]连接里运行。
|
||||
|
||||
[SSH]: https://en.wikipedia.org/wiki/Secure_Shell
|
||||
|
||||
### 超时
|
||||
|
||||
由于 `cargo xtest` 会等待test runner退出,如果一个测试永远不返回那么它就会一直阻塞test runner。幸运的是,在实际应用中这并不是一个大问题,因为无限循环通常是很容易避免的。在我们的这个例子里,无限循环会发生在以下几种不同的情况中:
|
||||
|
||||
|
||||
- bootloader加载内核失败,导致系统不停重启;
|
||||
- BIOS/UEFI固件加载bootloader失败,同样会导致无限重启;
|
||||
- CPU在某些函数结束时进入一个`loop {}`语句,例如因为QEMU的exit设备无法正常工作而导致死循环;
|
||||
- 硬件触发了系统重置,例如未捕获CPU异常时(后续的文章将会详细解释)。
|
||||
|
||||
由于无限循环可能会在各种情况中发生,因此, `bootimage` 工具默认为每个可执行测试设置了一个长度为5分钟的超时时间。如果测试未在此时间内完成,则将其标记为失败,并向控制台输出"Timed Out(超时)"错误。这个功能确保了那些卡在无限循环里的测试不会一直阻塞`cargo xtest`。
|
||||
|
||||
你可以将`loop {}`语句添加到 `trivial_assertion`测试中来进行尝试。当你运行 `cargo xtest`时,你可以发现该测试会在五分钟后被标记为超时。超时持续的时间可以通过Cargo.toml中的`test-timeout`来进行[配置][bootimage config]:
|
||||
|
||||
[bootimage config]: https://github.com/rust-osdev/bootimage#configuration
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-timeout = 300 # (in seconds)
|
||||
```
|
||||
|
||||
如果你不想为了观察`trivial_assertion` 测试超时等待5分钟之久,你可以暂时降低将上述值。
|
||||
|
||||
此后,我们不再需要 `trivial_assertion` 测试,所以我们可以将其删除。
|
||||
|
||||
## 测试VGA缓冲区
|
||||
|
||||
现在我们已经有了一个可以工作的测试框架了,我们可以为我们的VGA缓冲区实现创建一些测试。首先,我们创建了一个非常简单的测试来验证 `println`是否正常运行而不会panic:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[cfg(test)]
|
||||
use crate::{serial_print, serial_println};
|
||||
|
||||
#[test_case]
|
||||
fn test_println_simple() {
|
||||
serial_print!("test_println... ");
|
||||
println!("test_println_simple output");
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
这个测试所做的仅仅是将一些内容打印到VGA缓冲区。如果它正常结束并且没有panic,也就意味着`println`调用也没有panic。由于我们只需要将 `serial_println` 导入到测试模式里,所以我们添加了 `cfg(test)` 属性(attribute)来避免正常模式下 `cargo xbuild`会出现的未使用导入警告(unused import warning)。
|
||||
|
||||
为了确保即使打印很多行且有些行超出屏幕的情况下也没有panic发生,我们可以创建另一个测试:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_many() {
|
||||
serial_print!("test_println_many... ");
|
||||
for _ in 0..200 {
|
||||
println!("test_println_many output");
|
||||
}
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
我们还可以创建另一个测试函数,来验证打印的几行字符是否真的出现在了屏幕上:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
serial_print!("test_println_output... ");
|
||||
|
||||
let s = "Some test string that fits on a single line";
|
||||
println!("{}", s);
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
该函数定义了一个测试字符串,并通过 `println`将其输出,然后遍历静态 `WRITER`也就是vga字符缓冲区的屏幕字符。由于`println`在将字符串打印到屏幕上最后一行后会立刻附加一个新行(即输出完后有一个换行符),所以这个字符串应该会出现在第 `BUFFER_HEIGHT - 2`行。
|
||||
|
||||
通过使用[`enumerate`] ,我们统计了变量`i`的迭代次数,然后用它来加载对应于`c`的屏幕字符。 通过比较屏幕字符的`ascii_character`和`c` ,我们可以确保字符串的每个字符确实出现在vga文本缓冲区中。
|
||||
|
||||
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
|
||||
|
||||
如你所想,我们可以创建更多的测试函数:例如一个用来测试当打印一个很长的且包装正确的行时是否会发生panic的函数,或是一个用于测试换行符、不可打印字符、非unicode字符是否能被正确处理的函数。
|
||||
|
||||
在这篇文章的剩余部分,我们还会解释如何创建一个_集成测试_以测试不同组建之间的交互。
|
||||
|
||||
|
||||
## 集成测试
|
||||
|
||||
在Rust中,**集成测试**([integration tests])的约定是将其放到项目根目录中的`tests`目录下(即`src`的同级目录)。无论是默认测试框架还是自定义测试框架都将自动获取并执行该目录下所有的测试。
|
||||
|
||||
[integration tests]: https://doc.rust-lang.org/book/ch11-03-test-organization.html#integration-tests
|
||||
|
||||
所有的集成测试都是它们自己的可执行文件,并且与我们的`main.rs`完全独立。这也就意味着每个测试都需要定义它们自己的函数入口点。让我们创建一个名为`basic_boot`的例子来看看集成测试的工作细节吧:
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(crate::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
unimplemented!();
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
由于集成测试都是单独的可执行文件,所以我们需要再次提供所有的crate属性(`no_std`, `no_main`, `test_runner`, 等等)。我们还需要创建一个新的入口点函数`_start`,用于调用测试入口函数`test_main`。我们不需要任何的`cfg(test)` attributes(属性),因为集成测试的二进制文件在非测试模式下根本不会被编译构建。
|
||||
|
||||
这里我们采用[`unimplemented`]宏,充当`test_runner`暂未实现的占位符;添加简单的`loop {}`循环,作为`panic`处理器的内容。理想情况下,我们希望能向我们在`main.rs`里所做的一样使用`serial_println`宏和`exit_qemu`函数来实现这个函数。但问题是,由于这些测试的构建和我们的`main.rs`的可执行文件是完全独立的,我们没有办法使用这些函数。
|
||||
|
||||
[`unimplemented`]: https://doc.rust-lang.org/core/macro.unimplemented.html
|
||||
|
||||
如果现阶段你运行`cargo xtest`,你将进入一个无限循环,因为目前panic的处理就是进入无限循环。你需要使用快捷键`Ctrl+c`,才可以退出QEMU。
|
||||
|
||||
### 创建一个库
|
||||
为了让这些函数能在我们的集成测试中使用,我们需要从我们的`main.rs`中分割出一个库,这个库应当可以被其他的crate和集成测试可执行文件使用。为了达成这个目的,我们创建了一个新文件,`src/lib.rs`:
|
||||
|
||||
```rust
|
||||
// src/lib.rs
|
||||
|
||||
#![no_std]
|
||||
```
|
||||
|
||||
和`main.rs`一样,`lib.rs`也是一个可以被cargo自动识别的特殊文件。该库是一个独立的编译单元,所以我们需要再次指定`#![no_std]` 属性。
|
||||
|
||||
为了让我们的库可以和`cargo xtest`一起协同工作,我们还需要移动以下测试函数和属性:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
#![cfg_attr(test, no_main)]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(crate::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
pub fn test_runner(tests: &[&dyn Fn()]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
}
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
|
||||
pub fn test_panic_handler(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// Entry point for `cargo xtest`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
test_main();
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
为了能在可执行文件和集成测试中使用`test_runner`,我们不对其应用`cfg(test)` attribute(属性),并将其设置为public。同时,我们还将panic的处理程序分解为public函数`test_panic_handler`,这样一来它也可以用于可执行文件了。
|
||||
|
||||
由于我们的`lib.rs`是独立于`main.rs`进行测试的,因此当该库实在测试模式下编译时我们需要添加一个`_start`入口点和一个panic处理程序。通过使用[`cfg_attr`] ,我们可以在这种情况下有条件地启用`no_main` 属性。
|
||||
|
||||
[`cfg_attr`]: https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute
|
||||
|
||||
我们还将`QemuExitCode`枚举和`exit_qemu`函数从main.rs移动过来,并将其设置为公有函数:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u32)]
|
||||
pub enum QemuExitCode {
|
||||
Success = 0x10,
|
||||
Failed = 0x11,
|
||||
}
|
||||
|
||||
pub fn exit_qemu(exit_code: QemuExitCode) {
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
unsafe {
|
||||
let mut port = Port::new(0xf4);
|
||||
port.write(exit_code as u32);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
现在,可执行文件和集成测试都可以从库中导入这些函数,而不需要实现自己的定义。为了使`println` 和 `serial_println`可用,我们将以下的模块声明代码也移动到`lib.rs`中:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod serial;
|
||||
pub mod vga_buffer;
|
||||
```
|
||||
|
||||
我们将这些模块设置为public(公有),这样一来我们在库的外部也一样能使用它们了。由于这两者都用了该模块内的`_print`函数,所以这也是让`println` 和 `serial_println`宏可用的必要条件。
|
||||
|
||||
现在我们修改我们的`main.rs`代码来使用该库:
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(blog_os::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
use blog_os::println;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,这个库用起来就像一个普通的外部crate。它的调用方法与其它crate无异;在我们的这个例子中,位置可能为`blog_os`。上述代码使用了`test_runner` attribute中的`blog_os::test_runner`函数和`cfg(test)`的panic处理中的`blog_os::test_panic_handler`函数。它还导入了`println`宏,这样一来,我们可以在我们的`_start` 和 `panic`中使用它了。
|
||||
|
||||
与此同时,`cargo xrun` 和 `cargo xtest`可以再次正常工作了。当然了,`cargo xtest`仍然会进入无限循环(你可以通过`ctrl+c`来退出)。接下来让我们在我们的集成测试中通过所需要的库函数来修复这个问题吧。
|
||||
|
||||
### 完成集成测试
|
||||
|
||||
就像我们的`src/main.rs`,我们的`tests/basic_boot.rs`可执行文件同样可以从我们的新库中导入类型。这也就意味着我们可以导入缺失的组件来完成我们的测试。
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
#![test_runner(blog_os::test_runner)]
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
这里我们使用我们的库中的`test_runner`函数,而不是重新实现一个test runner。至于panic处理,调用`blog_os::test_panic_handler`函数即可,就像我们之前在我们的`main.rs`里面做的一样。
|
||||
|
||||
现在,`cargo xtest`又可以正常退出了。当你运行该命令时,你会发现它为我们的`lib.rs`, `main.rs`, 和 `basic_boot.rs`分别构建并运行了测试。其中,对于 `main.rs` 和 `basic_boot`的集成测试,它会报告"Running 0 tests"(正在运行0个测试),因为这些文件里面没有任何用 `#[test_case]`标注的函数。
|
||||
|
||||
现在我们可以在`basic_boot.rs`中添加测试了。举个例子,我们可以测试`println`是否能够正常工作而不panic,就像我们之前在vga缓冲区测试中做的那样:
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
use blog_os::{println, serial_print, serial_println};
|
||||
|
||||
#[test_case]
|
||||
fn test_println() {
|
||||
serial_print!("test_println... ");
|
||||
println!("test_println output");
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
现在当我们运行`cargo xtest`时,我们可以看到它会寻找并执行这些测试函数。
|
||||
|
||||
由于该测试和vga缓冲区测试中的一个几乎完全相同,所以目前它看起来似乎没什么用。然而,在将来,我们的`main.rs`和`lib.rs`中的`_start`函数的内容会不断增长,并且在运行`test_main`之前需要调用一系列的初始化进程,所以这两个测试将会运行在完全不同的环境中(译者注:也就是说虽然现在看起来差不多,但是在将来该测试和vga buffer中的测试会很不一样,有必要单独拿出来,这两者并没有重复)。
|
||||
|
||||
通过在`basic_boot`环境里不掉用任何初始化例程的`_start`中测试`println`函数,我们可以确保`println`在启动(boot)后可以正常工作。这一点非常重要,因为我们有很多部分依赖于`println`,例如打印panic信息。
|
||||
|
||||
### 未来的测试
|
||||
|
||||
集成测试的强大之处在于,它们可以被看成是完全独立的可执行文件;这也给了它们完全控制环境的能力,使得他们能够测试代码和CPU或是其他硬件的交互是否正确。
|
||||
|
||||
我们的`basic_boot`测试正是集成测试的一个非常简单的例子。在将来,我们的内核的功能会变得更多,和硬件交互的方式也会变得多种多样。通过添加集成测试,我们可以保证这些交互按预期工作(并一直保持工作)。下面是一些对于未来的测试的设想:
|
||||
|
||||
- **CPU异常**:当代码执行无效操作(例如除以零)时,CPU就会抛出异常。内核会为这些异常注册处理函数。集成测试可以验证在CPU异常时是否调用了正确的异常处理程序,或者在可解析的异常之后程序是否能正确执行;
|
||||
- **页表**:页表定义了哪些内存区域是有效且可访问的。通过修改页表,可以重新分配新的内存区域,例如,当你启动一个软件的时候。我们可以在集成测试中调整`_start`函数中的一些页表项,并确认这些改动是否会对`#[test_case]`的函数产生影响;
|
||||
- **用户空间程序**:用户空间程序是只能访问有限的系统资源的程序。例如,他们无法访问内核数据结构或是其他应用程序的内存。集成测试可以启动执行禁止操作的用户空间程序验证认内核是否会将这些操作全都阻止。
|
||||
|
||||
可以想象,还有更多的测试可以进行。通过添加各种各样的测试,我们确保在为我们的内核添加新功能或是重构代码时,不会意外地破坏他们。这一点在我们的内核变得更大和更复杂的时候显得尤为重要。
|
||||
|
||||
### 那些应该Panic的测试
|
||||
|
||||
标准库的测试框架支持允许构造失败测试的[`#[should_panic]` attribute][should_panic]。这个功能对于验证传递无效参数时函数是否会失败非常有用。不幸的是,这个属性需要标准库的支持,因此,在`#[no_std]`环境下无法使用。
|
||||
|
||||
[should_panic]: https://doc.rust-lang.org/rust-by-example/testing/unit_testing.html#testing-panics
|
||||
|
||||
尽管我们不能在我们的内核中使用`#[should_panic]` 属性,但是通过创建一个集成测试我们可以达到类似的效果——该集成测试可以从panic处理程序中返回一个成功错误代码。接下来让我一起来创建一个如上所述名为`should_panic`的测试吧:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
use blog_os::{QemuExitCode, exit_qemu, serial_println};
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
这个测试还没有完成,因为它尚未定义`_start`函数或是其他自定义的test runner attributes。让我们来补充缺少的内容吧:
|
||||
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
|
||||
pub fn test_runner(tests: &[&dyn Fn()]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
serial_println!("[test did not panic]");
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
}
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
```
|
||||
|
||||
这个测试定义了自己的`test_runner`函数,而不是复用`lib.rs`中的`test_runner`,该函数会在测试没有panic而是正常退出时返回一个错误退出代码(因为这里我们希望测试会panic)。如果没有定义测试函数,runner就会以一个成功错误代码退出。由于这个runner总是在执行完单个的测试后就退出,因此定义超过一个`#[test_case]`的函数都是没有意义的。
|
||||
|
||||
现在我们来创建一个应该失败的测试:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
use blog_os::serial_print;
|
||||
|
||||
#[test_case]
|
||||
fn should_fail() {
|
||||
serial_print!("should_fail... ");
|
||||
assert_eq!(0, 1);
|
||||
}
|
||||
```
|
||||
|
||||
该测试用 `assert_eq`来断言(assert)`0`和`1`是否相等。毫无疑问,这当然会失败(`0`当然不等于`1`),所以我们的测试就会像我们想要的那样panic。
|
||||
|
||||
当我们通过`cargo xtest --test should_panic`运行该测试时,我们会发现成功了因为该测试如我们预期的那样panic了。当我们将断言部分(即`assert_eq!(0, 1);`)注释掉后,我们就会发现测试失败并返回了_"test did not panic"_的信息。
|
||||
|
||||
这种方法的缺点是它只使用于单个的测试函数。对于多个`#[test_case]`函数,它只会执行第一个函数因为程序无法在panic处理被调用后继续执行。我目前没有想到解决这个问题的方法,如果你有任何想法,请务必告诉我!
|
||||
|
||||
### 无约束测试
|
||||
|
||||
对于那些只有单个测试函数的集成测试而言(例如我们的`should_panic`测试),其实并不需要test runner。对于这种情况,我们可以完全禁用test runner,直接在`_start`函数中直接运行我们的测试。
|
||||
|
||||
这里的关键就是在`Cargo.toml`中为测试禁用 `harness` flag,这个标志(flag)定义了是否将test runner用于集成测试中。如果该标志位被设置为`false`,那么默认的test runner和自定义的test runner功能都将被禁用,这样一来该测试就可以像一个普通的可执行程序一样运行了。
|
||||
|
||||
现在让我们为我们的`should_panic`测试禁用`harness` flag吧:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[[test]]
|
||||
name = "should_panic"
|
||||
harness = false
|
||||
```
|
||||
|
||||
现在我们通过移除test runner相关的代码,大大简化了我们的`should_panic`测试。结果看起来如下:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
use blog_os::{QemuExitCode, exit_qemu, serial_println};
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
should_fail();
|
||||
serial_println!("[test did not panic]");
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
loop{}
|
||||
}
|
||||
|
||||
fn should_fail() {
|
||||
serial_print!("should_fail... ");
|
||||
assert_eq!(0, 1);
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以通过我们的`_start`函数来直接调用`should_fail`函数了,如果返回则返回一个失败退出代码并退出。现在当我们执行`cargo xtest --test should_panic`时,我们可以发现测试的行为和之前完全一样。
|
||||
|
||||
除了创建`should_panic`测试,禁用`harness` attribute对复杂集成测试也很有用,例如,当单个测试函数会产生一些边际效应需要通过特定的顺序执行时。
|
||||
|
||||
## 总结
|
||||
|
||||
测试是一种非常有用的技术,它能确保特定的部件拥有我们期望的行为。即使它们不能显示是否有bug,它们仍然是用来寻找bug的利器,尤其是用来避免回归。
|
||||
|
||||
本文讲述了如何为我们的Rust kernel创建一个测试框架。我们使用Rust的自定义框架功能为我们的裸机环境实现了一个简单的`#[test_case]` attribute支持。通过使用QEMU的`isa-debug-exit`设备,我们的test runner可以在运行测试后退出QEMU并报告测试状态。我们还为串行端口实现了一个简单的驱动,使得错误信息可以被打印到控制台而不是VGA buffer中。
|
||||
|
||||
在为我们的`println`宏创建了一些测试后,我们在本文的后半部分还探索了集成测试。我们了解到它们位于`tests`目录中,并被视为完全独立的可执行文件。为了使他们能够使用`exit_qemu` 函数和 `serial_println` 宏,我们将大部分代码移动到一个库里,使其能够被导入到所有可执行文件和集成测试中。由于集成测试在各自独立的环境中运行,所以能够测试与硬件的交互或是创建应该panic的测试。
|
||||
|
||||
我们现在有了一个在QEMU内部真是环境中运行的测试框架。在未来的文章里,我们会创建更多的测试,从而让我们的内核在变得更复杂的同时保持可维护性。
|
||||
|
||||
## 下期预告
|
||||
|
||||
在下一篇文章中,我们将会探索_CPU异常_。这些异常将在一些非法事件发生时由CPU抛出,例如抛出除以零或是访问没有映射的内存页(通常也被称为`page fault`即缺页异常)。能够捕获和检查这些异常,对将来的调试来说是非常重要的。异常处理与键盘支持所需的硬件中断处理十分相似。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 8.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.2 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.3 KiB |
@@ -1,467 +0,0 @@
|
||||
+++
|
||||
title = "CPU Exceptions"
|
||||
weight = 5
|
||||
path = "cpu-exceptions"
|
||||
date = 2018-06-17
|
||||
|
||||
[extra]
|
||||
chapter = "Interrupts"
|
||||
+++
|
||||
|
||||
CPU exceptions occur in various erroneous situations, for example when accessing an invalid memory address or when dividing by zero. To react to them we have to set up an _interrupt descriptor table_ that provides handler functions. At the end of this post, our kernel will be able to catch [breakpoint exceptions] and to resume normal execution afterwards.
|
||||
|
||||
[breakpoint exceptions]: https://wiki.osdev.org/Exceptions#Breakpoint
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-05`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-05
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## Overview
|
||||
An exception signals that something is wrong with the current instruction. For example, the CPU issues an exception if the current instruction tries to divide by 0. When an exception occurs, the CPU interrupts its current work and immediately calls a specific exception handler function, depending on the exception type.
|
||||
|
||||
On x86 there are about 20 different CPU exception types. The most important are:
|
||||
|
||||
- **Page Fault**: A page fault occurs on illegal memory accesses. For example, if the current instruction tries to read from an unmapped page or tries to write to a read-only page.
|
||||
- **Invalid Opcode**: This exception occurs when the current instruction is invalid, for example when we try to use newer [SSE instructions] on an old CPU that does not support them.
|
||||
- **General Protection Fault**: This is the exception with the broadest range of causes. It occurs on various kinds of access violations such as trying to execute a privileged instruction in user level code or writing reserved fields in configuration registers.
|
||||
- **Double Fault**: When an exception occurs, the CPU tries to call the corresponding handler function. If another exception occurs _while calling the exception handler_, the CPU raises a double fault exception. This exception also occurs when there is no handler function registered for an exception.
|
||||
- **Triple Fault**: If an exception occurs while the CPU tries to call the double fault handler function, it issues a fatal _triple fault_. We can't catch or handle a triple fault. Most processors react by resetting themselves and rebooting the operating system.
|
||||
|
||||
[SSE instructions]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
|
||||
|
||||
For the full list of exceptions check out the [OSDev wiki][exceptions].
|
||||
|
||||
[exceptions]: https://wiki.osdev.org/Exceptions
|
||||
|
||||
### The Interrupt Descriptor Table
|
||||
In order to catch and handle exceptions, we have to set up a so-called _Interrupt Descriptor Table_ (IDT). In this table we can specify a handler function for each CPU exception. The hardware uses this table directly, so we need to follow a predefined format. Each entry must have the following 16-byte structure:
|
||||
|
||||
Type| Name | Description
|
||||
----|--------------------------|-----------------------------------
|
||||
u16 | Function Pointer [0:15] | The lower bits of the pointer to the handler function.
|
||||
u16 | GDT selector | Selector of a code segment in the [global descriptor table].
|
||||
u16 | Options | (see below)
|
||||
u16 | Function Pointer [16:31] | The middle bits of the pointer to the handler function.
|
||||
u32 | Function Pointer [32:63] | The remaining bits of the pointer to the handler function.
|
||||
u32 | Reserved |
|
||||
|
||||
[global descriptor table]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
The options field has the following format:
|
||||
|
||||
Bits | Name | Description
|
||||
------|-----------------------------------|-----------------------------------
|
||||
0-2 | Interrupt Stack Table Index | 0: Don't switch stacks, 1-7: Switch to the n-th stack in the Interrupt Stack Table when this handler is called.
|
||||
3-7 | Reserved |
|
||||
8 | 0: Interrupt Gate, 1: Trap Gate | If this bit is 0, interrupts are disabled when this handler is called.
|
||||
9-11 | must be one |
|
||||
12 | must be zero |
|
||||
13‑14 | Descriptor Privilege Level (DPL) | The minimal privilege level required for calling this handler.
|
||||
15 | Present |
|
||||
|
||||
Each exception has a predefined IDT index. For example the invalid opcode exception has table index 6 and the page fault exception has table index 14. Thus, the hardware can automatically load the corresponding IDT entry for each exception. The [Exception Table][exceptions] in the OSDev wiki shows the IDT indexes of all exceptions in the “Vector nr.” column.
|
||||
|
||||
When an exception occurs, the CPU roughly does the following:
|
||||
|
||||
1. Push some registers on the stack, including the instruction pointer and the [RFLAGS] register. (We will use these values later in this post.)
|
||||
2. Read the corresponding entry from the Interrupt Descriptor Table (IDT). For example, the CPU reads the 14-th entry when a page fault occurs.
|
||||
3. Check if the entry is present. Raise a double fault if not.
|
||||
4. Disable hardware interrupts if the entry is an interrupt gate (bit 40 not set).
|
||||
5. Load the specified [GDT] selector into the CS segment.
|
||||
6. Jump to the specified handler function.
|
||||
|
||||
[RFLAGS]: https://en.wikipedia.org/wiki/FLAGS_register
|
||||
[GDT]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
Don't worry about steps 4 and 5 for now, we will learn about the global descriptor table and hardware interrupts in future posts.
|
||||
|
||||
## An IDT Type
|
||||
Instead of creating our own IDT type, we will use the [`InterruptDescriptorTable` struct] of the `x86_64` crate, which looks like this:
|
||||
|
||||
[`InterruptDescriptorTable` struct]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
|
||||
``` rust
|
||||
#[repr(C)]
|
||||
pub struct InterruptDescriptorTable {
|
||||
pub divide_by_zero: Entry<HandlerFunc>,
|
||||
pub debug: Entry<HandlerFunc>,
|
||||
pub non_maskable_interrupt: Entry<HandlerFunc>,
|
||||
pub breakpoint: Entry<HandlerFunc>,
|
||||
pub overflow: Entry<HandlerFunc>,
|
||||
pub bound_range_exceeded: Entry<HandlerFunc>,
|
||||
pub invalid_opcode: Entry<HandlerFunc>,
|
||||
pub device_not_available: Entry<HandlerFunc>,
|
||||
pub double_fault: Entry<HandlerFuncWithErrCode>,
|
||||
pub invalid_tss: Entry<HandlerFuncWithErrCode>,
|
||||
pub segment_not_present: Entry<HandlerFuncWithErrCode>,
|
||||
pub stack_segment_fault: Entry<HandlerFuncWithErrCode>,
|
||||
pub general_protection_fault: Entry<HandlerFuncWithErrCode>,
|
||||
pub page_fault: Entry<PageFaultHandlerFunc>,
|
||||
pub x87_floating_point: Entry<HandlerFunc>,
|
||||
pub alignment_check: Entry<HandlerFuncWithErrCode>,
|
||||
pub machine_check: Entry<HandlerFunc>,
|
||||
pub simd_floating_point: Entry<HandlerFunc>,
|
||||
pub virtualization: Entry<HandlerFunc>,
|
||||
pub security_exception: Entry<HandlerFuncWithErrCode>,
|
||||
// some fields omitted
|
||||
}
|
||||
```
|
||||
|
||||
The fields have the type [`idt::Entry<F>`], which is a struct that represents the fields of an IDT entry (see the table above). The type parameter `F` defines the expected handler function type. We see that some entries require a [`HandlerFunc`] and some entries require a [`HandlerFuncWithErrCode`]. The page fault even has its own special type: [`PageFaultHandlerFunc`].
|
||||
|
||||
[`idt::Entry<F>`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.Entry.html
|
||||
[`HandlerFunc`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/type.HandlerFunc.html
|
||||
[`HandlerFuncWithErrCode`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/type.HandlerFuncWithErrCode.html
|
||||
[`PageFaultHandlerFunc`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/type.PageFaultHandlerFunc.html
|
||||
|
||||
Let's look at the `HandlerFunc` type first:
|
||||
|
||||
```rust
|
||||
type HandlerFunc = extern "x86-interrupt" fn(_: &mut InterruptStackFrame);
|
||||
```
|
||||
|
||||
It's a [type alias] for an `extern "x86-interrupt" fn` type. The `extern` keyword defines a function with a [foreign calling convention] and is often used to communicate with C code (`extern "C" fn`). But what is the `x86-interrupt` calling convention?
|
||||
|
||||
[type alias]: https://doc.rust-lang.org/book/ch19-04-advanced-types.html#creating-type-synonyms-with-type-aliases
|
||||
[foreign calling convention]: https://doc.rust-lang.org/nomicon/ffi.html#foreign-calling-conventions
|
||||
|
||||
## The Interrupt Calling Convention
|
||||
Exceptions are quite similar to function calls: The CPU jumps to the first instruction of the called function and executes it. Afterwards the CPU jumps to the return address and continues the execution of the parent function.
|
||||
|
||||
However, there is a major difference between exceptions and function calls: A function call is invoked voluntary by a compiler inserted `call` instruction, while an exception might occur at _any_ instruction. In order to understand the consequences of this difference, we need to examine function calls in more detail.
|
||||
|
||||
[Calling conventions] specify the details of a function call. For example, they specify where function parameters are placed (e.g. in registers or on the stack) and how results are returned. On x86_64 Linux, the following rules apply for C functions (specified in the [System V ABI]):
|
||||
|
||||
[Calling conventions]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
[System V ABI]: https://refspecs.linuxbase.org/elf/x86_64-abi-0.99.pdf
|
||||
|
||||
- the first six integer arguments are passed in registers `rdi`, `rsi`, `rdx`, `rcx`, `r8`, `r9`
|
||||
- additional arguments are passed on the stack
|
||||
- results are returned in `rax` and `rdx`
|
||||
|
||||
Note that Rust does not follow the C ABI (in fact, [there isn't even a Rust ABI yet][rust abi]), so these rules apply only to functions declared as `extern "C" fn`.
|
||||
|
||||
[rust abi]: https://github.com/rust-lang/rfcs/issues/600
|
||||
|
||||
### Preserved and Scratch Registers
|
||||
The calling convention divides the registers in two parts: _preserved_ and _scratch_ registers.
|
||||
|
||||
The values of _preserved_ registers must remain unchanged across function calls. So a called function (the _“callee”_) is only allowed to overwrite these registers if it restores their original values before returning. Therefore these registers are called _“callee-saved”_. A common pattern is to save these registers to the stack at the function's beginning and restore them just before returning.
|
||||
|
||||
In contrast, a called function is allowed to overwrite _scratch_ registers without restrictions. If the caller wants to preserve the value of a scratch register across a function call, it needs to backup and restore it before the function call (e.g. by pushing it to the stack). So the scratch registers are _caller-saved_.
|
||||
|
||||
On x86_64, the C calling convention specifies the following preserved and scratch registers:
|
||||
|
||||
preserved registers | scratch registers
|
||||
---|---
|
||||
`rbp`, `rbx`, `rsp`, `r12`, `r13`, `r14`, `r15` | `rax`, `rcx`, `rdx`, `rsi`, `rdi`, `r8`, `r9`, `r10`, `r11`
|
||||
_callee-saved_ | _caller-saved_
|
||||
|
||||
The compiler knows these rules, so it generates the code accordingly. For example, most functions begin with a `push rbp`, which backups `rbp` on the stack (because it's a callee-saved register).
|
||||
|
||||
### Preserving all Registers
|
||||
In contrast to function calls, exceptions can occur on _any_ instruction. In most cases we don't even know at compile time if the generated code will cause an exception. For example, the compiler can't know if an instruction causes a stack overflow or a page fault.
|
||||
|
||||
Since we don't know when an exception occurs, we can't backup any registers before. This means that we can't use a calling convention that relies on caller-saved registers for exception handlers. Instead, we need a calling convention means that preserves _all registers_. The `x86-interrupt` calling convention is such a calling convention, so it guarantees that all register values are restored to their original values on function return.
|
||||
|
||||
Note that this does not mean that all registers are saved to the stack at function entry. Instead, the compiler only backs up the registers that are overwritten by the function. This way, very efficient code can be generated for short functions that only use a few registers.
|
||||
|
||||
### The Interrupt Stack Frame
|
||||
On a normal function call (using the `call` instruction), the CPU pushes the return address before jumping to the target function. On function return (using the `ret` instruction), the CPU pops this return address and jumps to it. So the stack frame of a normal function call looks like this:
|
||||
|
||||

|
||||
|
||||
For exception and interrupt handlers, however, pushing a return address would not suffice, since interrupt handlers often run in a different context (stack pointer, CPU flags, etc.). Instead, the CPU performs the following steps when an interrupt occurs:
|
||||
|
||||
1. **Aligning the stack pointer**: An interrupt can occur at any instructions, so the stack pointer can have any value, too. However, some CPU instructions (e.g. some SSE instructions) require that the stack pointer is aligned on a 16 byte boundary, therefore the CPU performs such an alignment right after the interrupt.
|
||||
2. **Switching stacks** (in some cases): A stack switch occurs when the CPU privilege level changes, for example when a CPU exception occurs in an user mode program. It is also possible to configure stack switches for specific interrupts using the so-called _Interrupt Stack Table_ (described in the next post).
|
||||
3. **Pushing the old stack pointer**: The CPU pushes the values of the stack pointer (`rsp`) and the stack segment (`ss`) registers at the time when the interrupt occurred (before the alignment). This makes it possible to restore the original stack pointer when returning from an interrupt handler.
|
||||
4. **Pushing and updating the `RFLAGS` register**: The [`RFLAGS`] register contains various control and status bits. On interrupt entry, the CPU changes some bits and pushes the old value.
|
||||
5. **Pushing the instruction pointer**: Before jumping to the interrupt handler function, the CPU pushes the instruction pointer (`rip`) and the code segment (`cs`). This is comparable to the return address push of a normal function call.
|
||||
6. **Pushing an error code** (for some exceptions): For some specific exceptions such as page faults, the CPU pushes an error code, which describes the cause of the exception.
|
||||
7. **Invoking the interrupt handler**: The CPU reads the address and the segment descriptor of the interrupt handler function from the corresponding field in the IDT. It then invokes this handler by loading the values into the `rip` and `cs` registers.
|
||||
|
||||
[`RFLAGS`]: https://en.wikipedia.org/wiki/FLAGS_register
|
||||
|
||||
So the _interrupt stack frame_ looks like this:
|
||||
|
||||

|
||||
|
||||
In the `x86_64` crate, the interrupt stack frame is represented by the [`InterruptStackFrame`] struct. It is passed to interrupt handlers as `&mut` and can be used to retrieve additional information about the exception's cause. The struct contains no error code field, since only some few exceptions push an error code. These exceptions use the separate [`HandlerFuncWithErrCode`] function type, which has an additional `error_code` argument.
|
||||
|
||||
[`InterruptStackFrame`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.InterruptStackFrame.html
|
||||
|
||||
### Behind the Scenes
|
||||
The `x86-interrupt` calling convention is a powerful abstraction that hides almost all of the messy details of the exception handling process. However, sometimes it's useful to know what's happening behind the curtain. Here is a short overview of the things that the `x86-interrupt` calling convention takes care of:
|
||||
|
||||
- **Retrieving the arguments**: Most calling conventions expect that the arguments are passed in registers. This is not possible for exception handlers, since we must not overwrite any register values before backing them up on the stack. Instead, the `x86-interrupt` calling convention is aware that the arguments already lie on the stack at a specific offset.
|
||||
- **Returning using `iretq`**: Since the interrupt stack frame completely differs from stack frames of normal function calls, we can't return from handlers functions through the normal `ret` instruction. Instead, the `iretq` instruction must be used.
|
||||
- **Handling the error code**: The error code, which is pushed for some exceptions, makes things much more complex. It changes the stack alignment (see the next point) and needs to be popped off the stack before returning. The `x86-interrupt` calling convention handles all that complexity. However, it doesn't know which handler function is used for which exception, so it needs to deduce that information from the number of function arguments. That means that the programmer is still responsible to use the correct function type for each exception. Luckily, the `InterruptDescriptorTable` type defined by the `x86_64` crate ensures that the correct function types are used.
|
||||
- **Aligning the stack**: There are some instructions (especially SSE instructions) that require a 16-byte stack alignment. The CPU ensures this alignment whenever an exception occurs, but for some exceptions it destroys it again later when it pushes an error code. The `x86-interrupt` calling convention takes care of this by realigning the stack in this case.
|
||||
|
||||
If you are interested in more details: We also have a series of posts that explains exception handling using [naked functions] linked [at the end of this post][too-much-magic].
|
||||
|
||||
[naked functions]: https://github.com/rust-lang/rfcs/blob/master/text/1201-naked-fns.md
|
||||
[too-much-magic]: #too-much-magic
|
||||
|
||||
## Implementation
|
||||
Now that we've understood the theory, it's time to handle CPU exceptions in our kernel. We'll start by creating a new interrupts module in `src/interrupts.rs`, that first creates an `init_idt` function that creates a new `InterruptDescriptorTable`:
|
||||
|
||||
``` rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod interrupts;
|
||||
|
||||
// in src/interrupts.rs
|
||||
|
||||
use x86_64::structures::idt::InterruptDescriptorTable;
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
}
|
||||
```
|
||||
|
||||
Now we can add handler functions. We start by adding a handler for the [breakpoint exception]. The breakpoint exception is the perfect exception to test exception handling. Its only purpose is to temporarily pause a program when the breakpoint instruction `int3` is executed.
|
||||
|
||||
[breakpoint exception]: https://wiki.osdev.org/Exceptions#Breakpoint
|
||||
|
||||
The breakpoint exception is commonly used in debuggers: When the user sets a breakpoint, the debugger overwrites the corresponding instruction with the `int3` instruction so that the CPU throws the breakpoint exception when it reaches that line. When the user wants to continue the program, the debugger replaces the `int3` instruction with the original instruction again and continues the program. For more details, see the ["_How debuggers work_"] series.
|
||||
|
||||
["_How debuggers work_"]: https://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
For our use case, we don't need to overwrite any instructions. Instead, we just want to print a message when the breakpoint instruction is executed and then continue the program. So let's create a simple `breakpoint_handler` function and add it to our IDT:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
|
||||
use crate::println;
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn breakpoint_handler(
|
||||
stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
|
||||
}
|
||||
```
|
||||
|
||||
Our handler just outputs a message and pretty-prints the interrupt stack frame.
|
||||
|
||||
When we try to compile it, the following error occurs:
|
||||
|
||||
```
|
||||
error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
|
||||
--> src/main.rs:53:1
|
||||
|
|
||||
53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: &mut InterruptStackFrame) {
|
||||
54 | | println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
|
||||
55 | | }
|
||||
| |_^
|
||||
|
|
||||
= help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
|
||||
```
|
||||
|
||||
This error occurs because the `x86-interrupt` calling convention is still unstable. To use it anyway, we have to explicitly enable it by adding `#![feature(abi_x86_interrupt)]` on the top of our `lib.rs`.
|
||||
|
||||
### Loading the IDT
|
||||
In order that the CPU uses our new interrupt descriptor table, we need to load it using the [`lidt`] instruction. The `InterruptDescriptorTable` struct of the `x86_64` provides a [`load`][InterruptDescriptorTable::load] method function for that. Let's try to use it:
|
||||
|
||||
[`lidt`]: https://www.felixcloutier.com/x86/lgdt:lidt
|
||||
[InterruptDescriptorTable::load]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.InterruptDescriptorTable.html#method.load
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt.load();
|
||||
}
|
||||
```
|
||||
|
||||
When we try to compile it now, the following error occurs:
|
||||
|
||||
```
|
||||
error: `idt` does not live long enough
|
||||
--> src/interrupts/mod.rs:43:5
|
||||
|
|
||||
43 | idt.load();
|
||||
| ^^^ does not live long enough
|
||||
44 | }
|
||||
| - borrowed value only lives until here
|
||||
|
|
||||
= note: borrowed value must be valid for the static lifetime...
|
||||
```
|
||||
|
||||
So the `load` methods expects a `&'static self`, that is a reference that is valid for the complete runtime of the program. The reason is that the CPU will access this table on every interrupt until we load a different IDT. So using a shorter lifetime than `'static` could lead to use-after-free bugs.
|
||||
|
||||
In fact, this is exactly what happens here. Our `idt` is created on the stack, so it is only valid inside the `init` function. Afterwards the stack memory is reused for other functions, so the CPU would interpret random stack memory as IDT. Luckily, the `InterruptDescriptorTable::load` method encodes this lifetime requirement in its function definition, so that the Rust compiler is able to prevent this possible bug at compile time.
|
||||
|
||||
In order to fix this problem, we need to store our `idt` at a place where it has a `'static` lifetime. To achieve this we could allocate our IDT on the heap using [`Box`] and then convert it to a `'static` reference, but we are writing an OS kernel and thus don't have a heap (yet).
|
||||
|
||||
[`Box`]: https://doc.rust-lang.org/std/boxed/struct.Box.html
|
||||
|
||||
|
||||
As an alternative we could try to store the IDT as a `static`:
|
||||
|
||||
```rust
|
||||
static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
|
||||
|
||||
pub fn init_idt() {
|
||||
IDT.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
However, there is a problem: Statics are immutable, so we can't modify the breakpoint entry from our `init` function. We could solve this problem by using a [`static mut`]:
|
||||
|
||||
[`static mut`]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
|
||||
|
||||
```rust
|
||||
static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
|
||||
|
||||
pub fn init_idt() {
|
||||
unsafe {
|
||||
IDT.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
IDT.load();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This variant compiles without errors but it's far from idiomatic. `static mut`s are very prone to data races, so we need an [`unsafe` block] on each access.
|
||||
|
||||
[`unsafe` block]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
|
||||
|
||||
#### Lazy Statics to the Rescue
|
||||
Fortunately the `lazy_static` macro exists. Instead of evaluating a `static` at compile time, the macro performs the initialization when the `static` is referenced the first time. Thus, we can do almost everything in the initialization block and are even able to read runtime values.
|
||||
|
||||
We already imported the `lazy_static` crate when we [created an abstraction for the VGA text buffer][vga text buffer lazy static]. So we can directly use the `lazy_static!` macro to create our static IDT:
|
||||
|
||||
[vga text buffer lazy static]: @/second-edition/posts/03-vga-text-buffer/index.md#lazy-statics
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_idt() {
|
||||
IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
Note how this solution requires no `unsafe` blocks. The `lazy_static!` macro does use `unsafe` behind the scenes, but it is abstracted away in a safe interface.
|
||||
|
||||
### Running it
|
||||
|
||||
The last step for making exceptions work in our kernel is to call the `init_idt` function from our `main.rs`. Instead of calling it directly, we introduce a general `init` function in our `lib.rs`:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
interrupts::init_idt();
|
||||
}
|
||||
```
|
||||
|
||||
With this function we now have a central place for initialization routines that can be shared between the different `_start` functions in our `main.rs`, `lib.rs`, and integration tests.
|
||||
|
||||
Now we can update the `_start` function of our `main.rs` to call `init` and then trigger a breakpoint exception:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init(); // new
|
||||
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::interrupts::int3(); // new
|
||||
|
||||
// as before
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
When we run it in QEMU now (using `cargo run`), we see the following:
|
||||
|
||||

|
||||
|
||||
It works! The CPU successfully invokes our breakpoint handler, which prints the message, and then returns back to the `_start` function, where the `It did not crash!` message is printed.
|
||||
|
||||
We see that the interrupt stack frame tells us the instruction and stack pointers at the time when the exception occurred. This information is very useful when debugging unexpected exceptions.
|
||||
|
||||
### Adding a Test
|
||||
|
||||
Let's create a test that ensures that the above continues to work. First, we update the `_start` function to also call `init`:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
/// Entry point for `cargo test`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init(); // new
|
||||
test_main();
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
Remember, this `_start` function is used when running `cargo test --lib`, since Rust's tests the `lib.rs` completely independent of the `main.rs`. We need to call `init` here to set up an IDT before running the tests.
|
||||
|
||||
Now we can create a `test_breakpoint_exception` test:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_breakpoint_exception() {
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::interrupts::int3();
|
||||
}
|
||||
```
|
||||
|
||||
The test invokes the `int3` function to trigger a breakpoint exception. By checking that the execution continues afterwards, we verify that our breakpoint handler is working correctly.
|
||||
|
||||
You can try this new test by running `cargo test` (all tests) or `cargo test --lib` (only tests of `lib.rs` and its modules). You should see the following in the output:
|
||||
|
||||
```
|
||||
blog_os::interrupts::test_breakpoint_exception... [ok]
|
||||
```
|
||||
|
||||
## Too much Magic?
|
||||
The `x86-interrupt` calling convention and the [`InterruptDescriptorTable`] type made the exception handling process relatively straightforward and painless. If this was too much magic for you and you like to learn all the gory details of exception handling, we got you covered: Our [“Handling Exceptions with Naked Functions”] series shows how to handle exceptions without the `x86-interrupt` calling convention and also creates its own IDT type. Historically, these posts were the main exception handling posts before the `x86-interrupt` calling convention and the `x86_64` crate existed. Note that these posts are based on the [first edition] of this blog and might be out of date.
|
||||
|
||||
[“Handling Exceptions with Naked Functions”]: @/edition-1/extra/naked-exceptions/_index.md
|
||||
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
[first edition]: @/edition-1/_index.md
|
||||
|
||||
## What's next?
|
||||
We've successfully caught our first exception and returned from it! The next step is to ensure that we catch all exceptions, because an uncaught exception causes a fatal [triple fault], which leads to a system reset. The next post explains how we can avoid this by correctly catching [double faults].
|
||||
|
||||
[triple fault]: https://wiki.osdev.org/Triple_Fault
|
||||
[double faults]: https://wiki.osdev.org/Double_Fault#Double_Fault
|
||||
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
@@ -1,550 +0,0 @@
|
||||
+++
|
||||
title = "Double Faults"
|
||||
weight = 6
|
||||
path = "double-fault-exceptions"
|
||||
date = 2018-06-18
|
||||
|
||||
[extra]
|
||||
chapter = "Interrupts"
|
||||
+++
|
||||
|
||||
This post explores the double fault exception in detail, which occurs when the CPU fails to invoke an exception handler. By handling this exception we avoid fatal _triple faults_ that cause a system reset. To prevent triple faults in all cases we also set up an _Interrupt Stack Table_ to catch double faults on a separate kernel stack.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-06`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-06
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## What is a Double Fault?
|
||||
In simplified terms, a double fault is a special exception that occurs when the CPU fails to invoke an exception handler. For example, it occurs when a page fault is triggered but there is no page fault handler registered in the [Interrupt Descriptor Table][IDT] (IDT). So it's kind of similar to catch-all blocks in programming languages with exceptions, e.g. `catch(...)` in C++ or `catch(Exception e)` in Java or C#.
|
||||
|
||||
[IDT]: @/second-edition/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
|
||||
|
||||
A double fault behaves like a normal exception. It has the vector number `8` and we can define a normal handler function for it in the IDT. It is really important to provide a double fault handler, because if a double fault is unhandled a fatal _triple fault_ occurs. Triple faults can't be caught and most hardware reacts with a system reset.
|
||||
|
||||
### Triggering a Double Fault
|
||||
Let's provoke a double fault by triggering an exception for that we didn't define a handler function:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
// trigger a page fault
|
||||
unsafe {
|
||||
*(0xdeadbeef as *mut u64) = 42;
|
||||
};
|
||||
|
||||
// as before
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
We use `unsafe` to write to the invalid address `0xdeadbeef`. The virtual address is not mapped to a physical address in the page tables, so a page fault occurs. We haven't registered a page fault handler in our [IDT], so a double fault occurs.
|
||||
|
||||
When we start our kernel now, we see that it enters an endless boot loop. The reason for the boot loop is the following:
|
||||
|
||||
1. The CPU tries to write to `0xdeadbeef`, which causes a page fault.
|
||||
2. The CPU looks at the corresponding entry in the IDT and sees that no handler function is specified. Thus, it can't call the page fault handler and a double fault occurs.
|
||||
3. The CPU looks at the IDT entry of the double fault handler, but this entry does not specify a handler function either. Thus, a _triple_ fault occurs.
|
||||
4. A triple fault is fatal. QEMU reacts to it like most real hardware and issues a system reset.
|
||||
|
||||
So in order to prevent this triple fault, we need to either provide a handler function for page faults or a double fault handler. We want to avoid triple faults in all cases, so let's start with a double fault handler that is invoked for all unhandled exception types.
|
||||
|
||||
## A Double Fault Handler
|
||||
A double fault is a normal exception with an error code, so we can specify a handler function similar to our breakpoint handler:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt.double_fault.set_handler_fn(double_fault_handler); // new
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
// new
|
||||
extern "x86-interrupt" fn double_fault_handler(
|
||||
stack_frame: &mut InterruptStackFrame, _error_code: u64) -> !
|
||||
{
|
||||
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
|
||||
}
|
||||
```
|
||||
|
||||
Our handler prints a short error message and dumps the exception stack frame. The error code of the double fault handler is always zero, so there's no reason to print it. One difference to the breakpoint handler is that the double fault handler is [_diverging_]. The reason is that the `x86_64` architecture does not permit returning from a double fault exception.
|
||||
|
||||
[_diverging_]: https://doc.rust-lang.org/stable/rust-by-example/fn/diverging.html
|
||||
|
||||
When we start our kernel now, we should see that the double fault handler is invoked:
|
||||
|
||||

|
||||
|
||||
It worked! Here is what happens this time:
|
||||
|
||||
1. The CPU tries to write to `0xdeadbeef`, which causes a page fault.
|
||||
2. Like before, the CPU looks at the corresponding entry in the IDT and sees that no handler function is defined. Thus, a double fault occurs.
|
||||
3. The CPU jumps to the – now present – double fault handler.
|
||||
|
||||
The triple fault (and the boot-loop) no longer occurs, since the CPU can now call the double fault handler.
|
||||
|
||||
That was quite straightforward! So why do we need a whole post for this topic? Well, we're now able to catch _most_ double faults, but there are some cases where our current approach doesn't suffice.
|
||||
|
||||
## Causes of Double Faults
|
||||
Before we look at the special cases, we need to know the exact causes of double faults. Above, we used a pretty vague definition:
|
||||
|
||||
> A double fault is a special exception that occurs when the CPU fails to invoke an exception handler.
|
||||
|
||||
What does _“fails to invoke”_ mean exactly? The handler is not present? The handler is [swapped out]? And what happens if a handler causes exceptions itself?
|
||||
|
||||
[swapped out]: http://pages.cs.wisc.edu/~remzi/OSTEP/vm-beyondphys.pdf
|
||||
|
||||
For example, what happens if:
|
||||
|
||||
1. a breakpoint exception occurs, but the corresponding handler function is swapped out?
|
||||
2. a page fault occurs, but the page fault handler is swapped out?
|
||||
3. a divide-by-zero handler causes a breakpoint exception, but the breakpoint handler is swapped out?
|
||||
4. our kernel overflows its stack and the _guard page_ is hit?
|
||||
|
||||
Fortunately, the AMD64 manual ([PDF][AMD64 manual]) has an exact definition (in Section 8.2.9). According to it, a “double fault exception _can_ occur when a second exception occurs during the handling of a prior (first) exception handler”. The _“can”_ is important: Only very specific combinations of exceptions lead to a double fault. These combinations are:
|
||||
|
||||
First Exception | Second Exception
|
||||
----------------|-----------------
|
||||
[Divide-by-zero],<br>[Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault] | [Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault]
|
||||
[Page Fault] | [Page Fault],<br>[Invalid TSS],<br>[Segment Not Present],<br>[Stack-Segment Fault],<br>[General Protection Fault]
|
||||
|
||||
[Divide-by-zero]: https://wiki.osdev.org/Exceptions#Divide-by-zero_Error
|
||||
[Invalid TSS]: https://wiki.osdev.org/Exceptions#Invalid_TSS
|
||||
[Segment Not Present]: https://wiki.osdev.org/Exceptions#Segment_Not_Present
|
||||
[Stack-Segment Fault]: https://wiki.osdev.org/Exceptions#Stack-Segment_Fault
|
||||
[General Protection Fault]: https://wiki.osdev.org/Exceptions#General_Protection_Fault
|
||||
[Page Fault]: https://wiki.osdev.org/Exceptions#Page_Fault
|
||||
|
||||
|
||||
[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
|
||||
|
||||
So for example a divide-by-zero fault followed by a page fault is fine (the page fault handler is invoked), but a divide-by-zero fault followed by a general-protection fault leads to a double fault.
|
||||
|
||||
With the help of this table, we can answer the first three of the above questions:
|
||||
|
||||
1. If a breakpoint exception occurs and the corresponding handler function is swapped out, a _page fault_ occurs and the _page fault handler_ is invoked.
|
||||
2. If a page fault occurs and the page fault handler is swapped out, a _double fault_ occurs and the _double fault handler_ is invoked.
|
||||
3. If a divide-by-zero handler causes a breakpoint exception, the CPU tries to invoke the breakpoint handler. If the breakpoint handler is swapped out, a _page fault_ occurs and the _page fault handler_ is invoked.
|
||||
|
||||
In fact, even the case of an exception without a handler function in the IDT follows this scheme: When the exception occurs, the CPU tries to read the corresponding IDT entry. Since the entry is 0, which is not a valid IDT entry, a _general protection fault_ occurs. We did not define a handler function for the general protection fault either, so another general protection fault occurs. According to the table, this leads to a double fault.
|
||||
|
||||
### Kernel Stack Overflow
|
||||
Let's look at the fourth question:
|
||||
|
||||
> What happens if our kernel overflows its stack and the guard page is hit?
|
||||
|
||||
A guard page is a special memory page at the bottom of a stack that makes it possible to detect stack overflows. The page is not mapped to any physical frame, so accessing it causes a page fault instead of silently corrupting other memory. The bootloader sets up a guard page for our kernel stack, so a stack overflow causes a _page fault_.
|
||||
|
||||
When a page fault occurs the CPU looks up the page fault handler in the IDT and tries to push the [interrupt stack frame] onto the stack. However, the current stack pointer still points to the non-present guard page. Thus, a second page fault occurs, which causes a double fault (according to the above table).
|
||||
|
||||
[interrupt stack frame]: @/second-edition/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
|
||||
|
||||
So the CPU tries to call the _double fault handler_ now. However, on a double fault the CPU tries to push the exception stack frame, too. The stack pointer still points to the guard page, so a _third_ page fault occurs, which causes a _triple fault_ and a system reboot. So our current double fault handler can't avoid a triple fault in this case.
|
||||
|
||||
Let's try it ourselves! We can easily provoke a kernel stack overflow by calling a function that recurses endlessly:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // for each recursion, the return address is pushed
|
||||
}
|
||||
|
||||
// trigger a stack overflow
|
||||
stack_overflow();
|
||||
|
||||
[…] // test_main(), println(…), and loop {}
|
||||
}
|
||||
```
|
||||
|
||||
When we try this code in QEMU, we see that the system enters a boot-loop again.
|
||||
|
||||
So how can we avoid this problem? We can't omit the pushing of the exception stack frame, since the CPU itself does it. So we need to ensure somehow that the stack is always valid when a double fault exception occurs. Fortunately, the x86_64 architecture has a solution to this problem.
|
||||
|
||||
## Switching Stacks
|
||||
The x86_64 architecture is able to switch to a predefined, known-good stack when an exception occurs. This switch happens at hardware level, so it can be performed before the CPU pushes the exception stack frame.
|
||||
|
||||
The switching mechanism is implemented as an _Interrupt Stack Table_ (IST). The IST is a table of 7 pointers to known-good stacks. In Rust-like pseudo code:
|
||||
|
||||
```rust
|
||||
struct InterruptStackTable {
|
||||
stack_pointers: [Option<StackPointer>; 7],
|
||||
}
|
||||
```
|
||||
|
||||
For each exception handler, we can choose a stack from the IST through the `stack_pointers` field in the corresponding [IDT entry]. For example, we could use the first stack in the IST for our double fault handler. Then the CPU would automatically switch to this stack whenever a double fault occurs. This switch would happen before anything is pushed, so it would prevent the triple fault.
|
||||
|
||||
[IDT entry]: @/second-edition/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
|
||||
|
||||
### The IST and TSS
|
||||
The Interrupt Stack Table (IST) is part of an old legacy structure called _[Task State Segment]_ \(TSS). The TSS used to hold various information (e.g. processor register state) about a task in 32-bit mode and was for example used for [hardware context switching]. However, hardware context switching is no longer supported in 64-bit mode and the format of the TSS changed completely.
|
||||
|
||||
[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
|
||||
[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
|
||||
|
||||
On x86_64, the TSS no longer holds any task specific information at all. Instead, it holds two stack tables (the IST is one of them). The only common field between the 32-bit and 64-bit TSS is the pointer to the [I/O port permissions bitmap].
|
||||
|
||||
[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
|
||||
|
||||
The 64-bit TSS has the following format:
|
||||
|
||||
Field | Type
|
||||
------ | ----------------
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u32`
|
||||
Privilege Stack Table | `[u64; 3]`
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u64`
|
||||
Interrupt Stack Table | `[u64; 7]`
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u64`
|
||||
<span style="opacity: 0.5">(reserved)</span> | `u16`
|
||||
I/O Map Base Address | `u16`
|
||||
|
||||
The _Privilege Stack Table_ is used by the CPU when the privilege level changes. For example, if an exception occurs while the CPU is in user mode (privilege level 3), the CPU normally switches to kernel mode (privilege level 0) before invoking the exception handler. In that case, the CPU would switch to the 0th stack in the Privilege Stack Table (since 0 is the target privilege level). We don't have any user mode programs yet, so we ignore this table for now.
|
||||
|
||||
### Creating a TSS
|
||||
Let's create a new TSS that contains a separate double fault stack in its interrupt stack table. For that we need a TSS struct. Fortunately, the `x86_64` crate already contains a [`TaskStateSegment` struct] that we can use.
|
||||
|
||||
[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.12.1/x86_64/structures/tss/struct.TaskStateSegment.html
|
||||
|
||||
We create the TSS in a new `gdt` module (the name will make sense later):
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod gdt;
|
||||
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::VirtAddr;
|
||||
use x86_64::structures::tss::TaskStateSegment;
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
|
||||
|
||||
lazy_static! {
|
||||
static ref TSS: TaskStateSegment = {
|
||||
let mut tss = TaskStateSegment::new();
|
||||
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
|
||||
const STACK_SIZE: usize = 4096 * 5;
|
||||
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
|
||||
|
||||
let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
|
||||
let stack_end = stack_start + STACK_SIZE;
|
||||
stack_end
|
||||
};
|
||||
tss
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
We use `lazy_static` because Rust's const evaluator is not yet powerful enough to do this initialization at compile time. We define that the 0th IST entry is the double fault stack (any other IST index would work too). Then we write the top address of a double fault stack to the 0th entry. We write the top address because stacks on x86 grow downwards, i.e. from high addresses to low addresses.
|
||||
|
||||
We don't have implemented memory management yet, so we don't have a proper way to allocate a new stack. Instead, we use a `static mut` array as stack storage for now. The `unsafe` is required because the compiler can't guarantee race freedom when mutable statics are accessed. It is important that it is a `static mut` and not an immutable `static`, because otherwise the bootloader will map it to a read-only page. We will replace this with a proper stack allocation in a later post, then the `unsafe` will be no longer needed at this place.
|
||||
|
||||
Note that this double fault stack has no guard page that protects against stack overflow. This means that we should not do anything stack intensive in our double fault handler because a stack overflow might corrupt the memory below the stack.
|
||||
|
||||
#### Loading the TSS
|
||||
Now that we created a new TSS, we need a way to tell the CPU that it should use it. Unfortunately this is a bit cumbersome, since the TSS uses the segmentation system (for historical reasons). Instead of loading the table directly, we need to add a new segment descriptor to the [Global Descriptor Table] \(GDT). Then we can load our TSS invoking the [`ltr` instruction] with the respective GDT index. (This is the reason why we named our module `gdt`.)
|
||||
|
||||
[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
|
||||
[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
|
||||
|
||||
### The Global Descriptor Table
|
||||
The Global Descriptor Table (GDT) is a relict that was used for [memory segmentation] before paging became the de facto standard. It is still needed in 64-bit mode for various things such as kernel/user mode configuration or TSS loading.
|
||||
|
||||
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
|
||||
The GDT is a structure that contains the _segments_ of the program. It was used on older architectures to isolate programs from each other, before paging became the standard. For more information about segmentation check out the equally named chapter of the free [“Three Easy Pieces” book]. While segmentation is no longer supported in 64-bit mode, the GDT still exists. It is mostly used for two things: Switching between kernel space and user space, and loading a TSS structure.
|
||||
|
||||
[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
|
||||
|
||||
#### Creating a GDT
|
||||
Let's create a static `GDT` that includes a segment for our `TSS` static:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
|
||||
|
||||
lazy_static! {
|
||||
static ref GDT: GlobalDescriptorTable = {
|
||||
let mut gdt = GlobalDescriptorTable::new();
|
||||
gdt.add_entry(Descriptor::kernel_code_segment());
|
||||
gdt.add_entry(Descriptor::tss_segment(&TSS));
|
||||
gdt
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
We use `lazy_static` again, because Rust's const evaluator is not powerful enough yet. We create a new GDT with a code segment and a TSS segment.
|
||||
|
||||
#### Loading the GDT
|
||||
|
||||
To load our GDT we create a new `gdt::init` function, that we call from our `init` function:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
pub fn init() {
|
||||
GDT.load();
|
||||
}
|
||||
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
}
|
||||
```
|
||||
|
||||
Now our GDT is loaded (since the `_start` function calls `init`), but we still see the boot loop on stack overflow.
|
||||
|
||||
### The final Steps
|
||||
|
||||
The problem is that the GDT segments are not yet active because the segment and TSS registers still contain the values from the old GDT. We also need to modify the double fault IDT entry so that it uses the new stack.
|
||||
|
||||
In summary, we need to do the following:
|
||||
|
||||
1. **Reload code segment register**: We changed our GDT, so we should reload `cs`, the code segment register. This is required since the old segment selector could point a different GDT descriptor now (e.g. a TSS descriptor).
|
||||
2. **Load the TSS** : We loaded a GDT that contains a TSS selector, but we still need to tell the CPU that it should use that TSS.
|
||||
3. **Update the IDT entry**: As soon as our TSS is loaded, the CPU has access to a valid interrupt stack table (IST). Then we can tell the CPU that it should use our new double fault stack by modifying our double fault IDT entry.
|
||||
|
||||
For the first two steps, we need access to the `code_selector` and `tss_selector` variables in our `gdt::init` function. We can achieve this by making them part of the static through a new `Selectors` struct:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
use x86_64::structures::gdt::SegmentSelector;
|
||||
|
||||
lazy_static! {
|
||||
static ref GDT: (GlobalDescriptorTable, Selectors) = {
|
||||
let mut gdt = GlobalDescriptorTable::new();
|
||||
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
|
||||
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
|
||||
(gdt, Selectors { code_selector, tss_selector })
|
||||
};
|
||||
}
|
||||
|
||||
struct Selectors {
|
||||
code_selector: SegmentSelector,
|
||||
tss_selector: SegmentSelector,
|
||||
}
|
||||
```
|
||||
|
||||
Now we can use the selectors to reload the `cs` segment register and load our `TSS`:
|
||||
|
||||
```rust
|
||||
// in src/gdt.rs
|
||||
|
||||
pub fn init() {
|
||||
use x86_64::instructions::segmentation::set_cs;
|
||||
use x86_64::instructions::tables::load_tss;
|
||||
|
||||
GDT.0.load();
|
||||
unsafe {
|
||||
set_cs(GDT.1.code_selector);
|
||||
load_tss(GDT.1.tss_selector);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We reload the code segment register using [`set_cs`] and to load the TSS using [`load_tss`]. The functions are marked as `unsafe`, so we need an `unsafe` block to invoke them. The reason is that it might be possible to break memory safety by loading invalid selectors.
|
||||
|
||||
[`set_cs`]: https://docs.rs/x86_64/0.12.1/x86_64/instructions/segmentation/fn.set_cs.html
|
||||
[`load_tss`]: https://docs.rs/x86_64/0.12.1/x86_64/instructions/tables/fn.load_tss.html
|
||||
|
||||
Now that we loaded a valid TSS and interrupt stack table, we can set the stack index for our double fault handler in the IDT:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use crate::gdt;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
unsafe {
|
||||
idt.double_fault.set_handler_fn(double_fault_handler)
|
||||
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
|
||||
}
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
The `set_stack_index` method is unsafe because the the caller must ensure that the used index is valid and not already used for another exception.
|
||||
|
||||
That's it! Now the CPU should switch to the double fault stack whenever a double fault occurs. Thus, we are able to catch _all_ double faults, including kernel stack overflows:
|
||||
|
||||

|
||||
|
||||
From now on we should never see a triple fault again! To ensure that we don't accidentally break the above, we should add a test for this.
|
||||
|
||||
## A Stack Overflow Test
|
||||
|
||||
To test our new `gdt` module and ensure that the double fault handler is correctly called on a stack overflow, we can add an integration test. The idea is to do provoke a double fault in the test function and verify that the double fault handler is called.
|
||||
|
||||
Let's start with a minimal skeleton:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
unimplemented!();
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
Like our `panic_handler` test, the test will run [without a test harness]. The reason is that we can't continue execution after a double fault, so more than one test doesn't make sense. To disable, the test harness for the test, we add the following to our `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[[test]]
|
||||
name = "stack_overflow"
|
||||
harness = false
|
||||
```
|
||||
|
||||
[without a test harness]: @/second-edition/posts/04-testing/index.md#no-harness-tests
|
||||
|
||||
Now `cargo test --test stack_overflow` should compile successfully. The test fails of course, since the `unimplemented` macro panics.
|
||||
|
||||
### Implementing `_start`
|
||||
|
||||
The implementation of the `_start` function looks like this:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use blog_os::serial_print;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
serial_print!("stack_overflow::stack_overflow...\t");
|
||||
|
||||
blog_os::gdt::init();
|
||||
init_test_idt();
|
||||
|
||||
// trigger a stack overflow
|
||||
stack_overflow();
|
||||
|
||||
panic!("Execution continued after stack overflow");
|
||||
}
|
||||
|
||||
#[allow(unconditional_recursion)]
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // for each recursion, the return address is pushed
|
||||
volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
|
||||
}
|
||||
```
|
||||
|
||||
We call our `gdt::init` function to initialize a new GDT. Instead of calling our `interrupts::init_idt` function, we call a `init_test_idt` function that will be explained in a moment. The reason is that we want to register a custom double fault handler that does a `exit_qemu(QemuExitCode::Success)` instead of panicking.
|
||||
|
||||
The `stack_overflow` function is almost identical to the function in our `main.rs`. The only difference is that we do an additional [volatile] read at the end of the function using the [`Volatile`] type to prevent a compiler optimization called [_tail call elimination_]. Among other things, this optimization allows the compiler to transform a function whose last statement is a recursive function call into a normal loop. Thus, no additional stack frame is created for the function call, so that the stack usage does remain constant.
|
||||
|
||||
[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
|
||||
[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
|
||||
[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
|
||||
|
||||
In our case, however, we want that the stack overflow happens, so we add a dummy volatile read statement at the end of the function, which the compiler is not allowed to remove. Thus, the function is no longer _tail recursive_ and the transformation into a loop is prevented. We also add the `allow(unconditional_recursion)` attribute to silence the compiler warning that the function recurses endlessly.
|
||||
|
||||
### The Test IDT
|
||||
|
||||
As noted above, the test needs its own IDT with a custom double fault handler. The implementation looks like this:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
use x86_64::structures::idt::InterruptDescriptorTable;
|
||||
|
||||
lazy_static! {
|
||||
static ref TEST_IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
unsafe {
|
||||
idt.double_fault
|
||||
.set_handler_fn(test_double_fault_handler)
|
||||
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
|
||||
}
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_test_idt() {
|
||||
TEST_IDT.load();
|
||||
}
|
||||
```
|
||||
|
||||
The implementation is very similar to our normal IDT in `interrupts.rs`. Like in the normal IDT, we set a stack index into the IST for the double fault handler in order to switch to a separate stack. The `init_test_idt` function loads the IDT on the CPU through the `load` method.
|
||||
|
||||
### The Double Fault Handler
|
||||
|
||||
The only missing piece is our double fault handler. It looks like this:
|
||||
|
||||
```rust
|
||||
// in tests/stack_overflow.rs
|
||||
|
||||
use blog_os::{exit_qemu, QemuExitCode, serial_println};
|
||||
use x86_64::structures::idt::InterruptStackFrame;
|
||||
|
||||
extern "x86-interrupt" fn test_double_fault_handler(
|
||||
_stack_frame: &mut InterruptStackFrame,
|
||||
_error_code: u64,
|
||||
) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
When the double fault handler is called, we exit QEMU with a success exit code, which marks the test as passed. Since integration tests are completely separate executables, we need to set `#![feature(abi_x86_interrupt)]` attribute again at the top of our test file.
|
||||
|
||||
Now we can run our test through `cargo test --test stack_overflow` (or `cargo test` to run all tests). As expected, we see the `stack_overflow... [ok]` output in the console. Try to comment out the `set_stack_index` line: it should cause the test to fail.
|
||||
|
||||
## Summary
|
||||
In this post we learned what a double fault is and under which conditions it occurs. We added a basic double fault handler that prints an error message and added an integration test for it.
|
||||
|
||||
We also enabled the hardware supported stack switching on double fault exceptions so that it also works on stack overflow. While implementing it, we learned about the task state segment (TSS), the contained interrupt stack table (IST), and the global descriptor table (GDT), which was used for segmentation on older architectures.
|
||||
|
||||
## What's next?
|
||||
The next post explains how to handle interrupts from external devices such as timers, keyboards, or network controllers. These hardware interrupts are very similar to exceptions, e.g. they are also dispatched through the IDT. However, unlike exceptions, they don't arise directly on the CPU. Instead, an _interrupt controller_ aggregates these interrupts and forwards them to CPU depending on their priority. In the next we will explore the [Intel 8259] \(“PIC”) interrupt controller and learn how to implement keyboard support.
|
||||
|
||||
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
|
||||
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
@@ -1,733 +0,0 @@
|
||||
+++
|
||||
title = "Hardware Interrupts"
|
||||
weight = 7
|
||||
path = "hardware-interrupts"
|
||||
date = 2018-10-22
|
||||
|
||||
[extra]
|
||||
chapter = "Interrupts"
|
||||
+++
|
||||
|
||||
In this post we set up the programmable interrupt controller to correctly forward hardware interrupts to the CPU. To handle these interrupts we add new entries to our interrupt descriptor table, just like we did for our exception handlers. We will learn how to get periodic timer interrupts and how to get input from the keyboard.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-07`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-07
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## Overview
|
||||
|
||||
Interrupts provide a way to notify the CPU from attached hardware devices. So instead of letting the kernel periodically check the keyboard for new characters (a process called [_polling_]), the keyboard can notify the kernel of each keypress. This is much more efficient because the kernel only needs to act when something happened. It also allows faster reaction times, since the kernel can react immediately and not only at the next poll.
|
||||
|
||||
[_polling_]: https://en.wikipedia.org/wiki/Polling_(computer_science)
|
||||
|
||||
Connecting all hardware devices directly to the CPU is not possible. Instead, a separate _interrupt controller_ aggregates the interrupts from all devices and then notifies the CPU:
|
||||
|
||||
```
|
||||
____________ _____
|
||||
Timer ------------> | | | |
|
||||
Keyboard ---------> | Interrupt |---------> | CPU |
|
||||
Other Hardware ---> | Controller | |_____|
|
||||
Etc. -------------> |____________|
|
||||
|
||||
```
|
||||
|
||||
Most interrupt controllers are programmable, which means that they support different priority levels for interrupts. For example, this allows to give timer interrupts a higher priority than keyboard interrupts to ensure accurate timekeeping.
|
||||
|
||||
Unlike exceptions, hardware interrupts occur _asynchronously_. This means that they are completely independent from the executed code and can occur at any time. Thus we suddenly have a form of concurrency in our kernel with all the potential concurrency-related bugs. Rust's strict ownership model helps us here because it forbids mutable global state. However, deadlocks are still possible, as we will see later in this post.
|
||||
|
||||
## The 8259 PIC
|
||||
|
||||
The [Intel 8259] is a programmable interrupt controller (PIC) introduced in 1976. It has long been replaced by the newer [APIC], but its interface is still supported on current systems for backwards compatibility reasons. The 8259 PIC is significantly easier to set up than the APIC, so we will use it to introduce ourselves to interrupts before we switch to the APIC in a later post.
|
||||
|
||||
[APIC]: https://en.wikipedia.org/wiki/Intel_APIC_Architecture
|
||||
|
||||
The 8259 has 8 interrupt lines and several lines for communicating with the CPU. The typical systems back then were equipped with two instances of the 8259 PIC, one primary and one secondary PIC connected to one of the interrupt lines of the primary:
|
||||
|
||||
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
|
||||
|
||||
```
|
||||
____________ ____________
|
||||
Real Time Clock --> | | Timer -------------> | |
|
||||
ACPI -------------> | | Keyboard-----------> | | _____
|
||||
Available --------> | Secondary |----------------------> | Primary | | |
|
||||
Available --------> | Interrupt | Serial Port 2 -----> | Interrupt |---> | CPU |
|
||||
Mouse ------------> | Controller | Serial Port 1 -----> | Controller | |_____|
|
||||
Co-Processor -----> | | Parallel Port 2/3 -> | |
|
||||
Primary ATA ------> | | Floppy disk -------> | |
|
||||
Secondary ATA ----> |____________| Parallel Port 1----> |____________|
|
||||
|
||||
```
|
||||
|
||||
This graphic shows the typical assignment of interrupt lines. We see that most of the 15 lines have a fixed mapping, e.g. line 4 of the secondary PIC is assigned to the mouse.
|
||||
|
||||
Each controller can be configured through two [I/O ports], one “command” port and one “data” port. For the primary controller these ports are `0x20` (command) and `0x21` (data). For the secondary controller they are `0xa0` (command) and `0xa1` (data). For more information on how the PICs can be configured see the [article on osdev.org].
|
||||
|
||||
[I/O ports]: @/second-edition/posts/04-testing/index.md#i-o-ports
|
||||
[article on osdev.org]: https://wiki.osdev.org/8259_PIC
|
||||
|
||||
### Implementation
|
||||
|
||||
The default configuration of the PICs is not usable, because it sends interrupt vector numbers in the range 0–15 to the CPU. These numbers are already occupied by CPU exceptions, for example number 8 corresponds to a double fault. To fix this overlapping issue, we need to remap the PIC interrupts to different numbers. The actual range doesn't matter as long as it does not overlap with the exceptions, but typically the range 32–47 is chosen, because these are the first free numbers after the 32 exception slots.
|
||||
|
||||
The configuration happens by writing special values to the command and data ports of the PICs. Fortunately there is already a crate called [`pic8259_simple`], so we don't need to write the initialization sequence ourselves. In case you are interested how it works, check out [its source code][pic crate source], it's fairly small and well documented.
|
||||
|
||||
[pic crate source]: https://docs.rs/crate/pic8259_simple/0.2.0/source/src/lib.rs
|
||||
|
||||
To add the crate as dependency, we add the following to our project:
|
||||
|
||||
[`pic8259_simple`]: https://docs.rs/pic8259_simple/0.2.0/pic8259_simple/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
pic8259_simple = "0.2.0"
|
||||
```
|
||||
|
||||
The main abstraction provided by the crate is the [`ChainedPics`] struct that represents the primary/secondary PIC layout we saw above. It is designed to be used in the following way:
|
||||
|
||||
[`ChainedPics`]: https://docs.rs/pic8259_simple/0.2.0/pic8259_simple/struct.ChainedPics.html
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use pic8259_simple::ChainedPics;
|
||||
use spin;
|
||||
|
||||
pub const PIC_1_OFFSET: u8 = 32;
|
||||
pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
|
||||
|
||||
pub static PICS: spin::Mutex<ChainedPics> =
|
||||
spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
|
||||
```
|
||||
|
||||
We're setting the offsets for the pics to the range 32–47 as we noted above. By wrapping the `ChainedPics` struct in a `Mutex` we are able to get safe mutable access (through the [`lock` method][spin mutex lock]), which we need in the next step. The `ChainedPics::new` function is unsafe because wrong offsets could cause undefined behavior.
|
||||
|
||||
[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
|
||||
|
||||
We can now initialize the 8259 PIC in our `init` function:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
unsafe { interrupts::PICS.lock().initialize() }; // new
|
||||
}
|
||||
```
|
||||
|
||||
We use the [`initialize`] function to perform the PIC initialization. Like the `ChainedPics::new` function, this function is also unsafe because it can cause undefined behavior if the PIC is misconfigured.
|
||||
|
||||
[`initialize`]: https://docs.rs/pic8259_simple/0.2.0/pic8259_simple/struct.ChainedPics.html#method.initialize
|
||||
|
||||
If all goes well we should continue to see the "It did not crash" message when executing `cargo run`.
|
||||
|
||||
## Enabling Interrupts
|
||||
|
||||
Until now nothing happened because interrupts are still disabled in the CPU configuration. This means that the CPU does not listen to the interrupt controller at all, so no interrupts can reach the CPU. Let's change that:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn init() {
|
||||
gdt::init();
|
||||
interrupts::init_idt();
|
||||
unsafe { interrupts::PICS.lock().initialize() };
|
||||
x86_64::instructions::interrupts::enable(); // new
|
||||
}
|
||||
```
|
||||
|
||||
The `interrupts::enable` function of the `x86_64` crate executes the special `sti` instruction (“set interrupts”) to enable external interrupts. When we try `cargo run` now, we see that a double fault occurs:
|
||||
|
||||

|
||||
|
||||
The reason for this double fault is that the hardware timer (the [Intel 8253] to be exact) is enabled by default, so we start receiving timer interrupts as soon as we enable interrupts. Since we didn't define a handler function for it yet, our double fault handler is invoked.
|
||||
|
||||
[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
|
||||
|
||||
## Handling Timer Interrupts
|
||||
|
||||
As we see from the graphic [above](#the-8259-pic), the timer uses line 0 of the primary PIC. This means that it arrives at the CPU as interrupt 32 (0 + offset 32). Instead of hardcoding index 32, we store it in an `InterruptIndex` enum:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
#[repr(u8)]
|
||||
pub enum InterruptIndex {
|
||||
Timer = PIC_1_OFFSET,
|
||||
}
|
||||
|
||||
impl InterruptIndex {
|
||||
fn as_u8(self) -> u8 {
|
||||
self as u8
|
||||
}
|
||||
|
||||
fn as_usize(self) -> usize {
|
||||
usize::from(self.as_u8())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The enum is a [C-like enum] so that we can directly specify the index for each variant. The `repr(u8)` attribute specifies that each variant is represented as an `u8`. We will add more variants for other interrupts in the future.
|
||||
|
||||
[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
|
||||
|
||||
Now we can add a handler function for the timer interrupt:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
use crate::print;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
[…]
|
||||
idt[InterruptIndex::Timer.as_usize()]
|
||||
.set_handler_fn(timer_interrupt_handler); // new
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn timer_interrupt_handler(
|
||||
_stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
print!(".");
|
||||
}
|
||||
```
|
||||
|
||||
Our `timer_interrupt_handler` has the same signature as our exception handlers, because the CPU reacts identically to exceptions and external interrupts (the only difference is that some exceptions push an error code). The [`InterruptDescriptorTable`] struct implements the [`IndexMut`] trait, so we can access individual entries through array indexing syntax.
|
||||
|
||||
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.InterruptDescriptorTable.html
|
||||
[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
|
||||
|
||||
In our timer interrupt handler, we print a dot to the screen. As the timer interrupt happens periodically, we would expect to see a dot appearing on each timer tick. However, when we run it we see that only a single dot is printed:
|
||||
|
||||

|
||||
|
||||
### End of Interrupt
|
||||
|
||||
The reason is that the PIC expects an explicit “end of interrupt” (EOI) signal from our interrupt handler. This signal tells the controller that the interrupt was processed and that the system is ready to receive the next interrupt. So the PIC thinks we're still busy processing the first timer interrupt and waits patiently for the EOI signal before sending the next one.
|
||||
|
||||
To send the EOI, we use our static `PICS` struct again:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn timer_interrupt_handler(
|
||||
_stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
print!(".");
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The `notify_end_of_interrupt` figures out whether the primary or secondary PIC sent the interrupt and then uses the `command` and `data` ports to send an EOI signal to respective controllers. If the secondary PIC sent the interrupt both PICs need to be notified because the secondary PIC is connected to an input line of the primary PIC.
|
||||
|
||||
We need to be careful to use the correct interrupt vector number, otherwise we could accidentally delete an important unsent interrupt or cause our system to hang. This is the reason that the function is unsafe.
|
||||
|
||||
When we now execute `cargo run` we see dots periodically appearing on the screen:
|
||||
|
||||

|
||||
|
||||
### Configuring the Timer
|
||||
|
||||
The hardware timer that we use is called the _Progammable Interval Timer_ or PIT for short. Like the name says, it is possible to configure the interval between two interrupts. We won't go into details here because we will switch to the [APIC timer] soon, but the OSDev wiki has an extensive article about the [configuring the PIT].
|
||||
|
||||
[APIC timer]: https://wiki.osdev.org/APIC_timer
|
||||
[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
|
||||
|
||||
## Deadlocks
|
||||
|
||||
We now have a form of concurrency in our kernel: The timer interrupts occur asynchronously, so they can interrupt our `_start` function at any time. Fortunately Rust's ownership system prevents many types of concurrency related bugs at compile time. One notable exception are deadlocks. Deadlocks occur if a thread tries to acquire a lock that will never become free. Thus the thread hangs indefinitely.
|
||||
|
||||
We can already provoke a deadlock in our kernel. Remember, our `println` macro calls the `vga_buffer::_print` function, which [locks a global `WRITER`][vga spinlock] using a spinlock:
|
||||
|
||||
[vga spinlock]: @/second-edition/posts/03-vga-text-buffer/index.md#spinlocks
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
[…]
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
It locks the `WRITER`, calls `write_fmt` on it, and implicitly unlocks it at the end of the function. Now imagine that an interrupt occurs while the `WRITER` is locked and the interrupt handler tries to print something too:
|
||||
|
||||
Timestep | _start | interrupt_handler
|
||||
---------|------|------------------
|
||||
0 | calls `println!` |
|
||||
1 | `print` locks `WRITER` |
|
||||
2 | | **interrupt occurs**, handler begins to run
|
||||
3 | | calls `println!` |
|
||||
4 | | `print` tries to lock `WRITER` (already locked)
|
||||
5 | | `print` tries to lock `WRITER` (already locked)
|
||||
… | | …
|
||||
_never_ | _unlock `WRITER`_ |
|
||||
|
||||
The `WRITER` is locked, so the interrupt handler waits until it becomes free. But this never happens, because the `_start` function only continues to run after the interrupt handler returns. Thus the complete system hangs.
|
||||
|
||||
### Provoking a Deadlock
|
||||
|
||||
We can easily provoke such a deadlock in our kernel by printing something in the loop at the end of our `_start` function:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
[…]
|
||||
loop {
|
||||
use blog_os::print;
|
||||
print!("-"); // new
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
When we run it in QEMU we get output of the form:
|
||||
|
||||

|
||||
|
||||
We see that only a limited number of hyphens is printed, until the first timer interrupt occurs. Then the system hangs because the timer interrupt handler deadlocks when it tries to print a dot. This is the reason that we see no dots in the above output.
|
||||
|
||||
The actual number of hyphens varies between runs because the timer interrupt occurs asynchronously. This non-determinism is what makes concurrency related bugs so difficult to debug.
|
||||
|
||||
### Fixing the Deadlock
|
||||
|
||||
To avoid this deadlock, we can disable interrupts as long as the `Mutex` is locked:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
/// Prints the given formatted string to the VGA text buffer
|
||||
/// through the global `WRITER` instance.
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts; // new
|
||||
|
||||
interrupts::without_interrupts(|| { // new
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
The [`without_interrupts`] function takes a [closure] and executes it in an interrupt-free environment. We use it to ensure that no interrupt can occur as long as the `Mutex` is locked. When we run our kernel now we see that it keeps running without hanging. (We still don't notice any dots, but this is because they're scrolling by too fast. Try to slow down the printing, e.g. by putting a `for _ in 0..10000 {}` inside the loop.)
|
||||
|
||||
[`without_interrupts`]: https://docs.rs/x86_64/0.12.1/x86_64/instructions/interrupts/fn.without_interrupts.html
|
||||
[closure]: https://doc.rust-lang.org/book/second-edition/ch13-01-closures.html
|
||||
|
||||
We can apply the same change to our serial printing function to ensure that no deadlocks occur with it either:
|
||||
|
||||
```rust
|
||||
// in src/serial.rs
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: ::core::fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts; // new
|
||||
|
||||
interrupts::without_interrupts(|| { // new
|
||||
SERIAL1
|
||||
.lock()
|
||||
.write_fmt(args)
|
||||
.expect("Printing to serial failed");
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
Note that disabling interrupts shouldn't be a general solution. The problem is that it increases the worst case interrupt latency, i.e. the time until the system reacts to an interrupt. Therefore interrupts should be only disabled for a very short time.
|
||||
|
||||
## Fixing a Race Condition
|
||||
|
||||
If you run `cargo test` you might see the `test_println_output` test failing:
|
||||
|
||||
```
|
||||
> cargo test --lib
|
||||
[…]
|
||||
Running 4 tests
|
||||
test_breakpoint_exception...[ok]
|
||||
test_println... [ok]
|
||||
test_println_many... [ok]
|
||||
test_println_output... [failed]
|
||||
|
||||
Error: panicked at 'assertion failed: `(left == right)`
|
||||
left: `'.'`,
|
||||
right: `'S'`', src/vga_buffer.rs:205:9
|
||||
```
|
||||
|
||||
The reason is a _race condition_ between the test and our timer handler. Remember, the test looks like this:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
let s = "Some test string that fits on a single line";
|
||||
println!("{}", s);
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The test prints a string to the VGA buffer and then checks the output by manually iterating over the `buffer_chars` array. The race condition occurs because the timer interrupt handler might run between the `println` and the reading of the screen characters. Note that this isn't a dangerous _data race_, which Rust completely prevents at compile time. See the [_Rustonomicon_][nomicon-races] for details.
|
||||
|
||||
[nomicon-races]: https://doc.rust-lang.org/nomicon/races.html
|
||||
|
||||
To fix this, we need to keep the `WRITER` locked for the complete duration of the test, so that the timer handler can't write a `.` to the screen in between. The fixed test looks like this:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
use core::fmt::Write;
|
||||
use x86_64::instructions::interrupts;
|
||||
|
||||
let s = "Some test string that fits on a single line";
|
||||
interrupts::without_interrupts(|| {
|
||||
let mut writer = WRITER.lock();
|
||||
writeln!(writer, "\n{}", s).expect("writeln failed");
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
We performed the following changes:
|
||||
|
||||
- We keep the writer locked for the complete test by using the `lock()` method explicitly. Instead of `println`, we use the [`writeln`] macro that allows printing to an already locked writer.
|
||||
- To avoid another deadlock, we disable interrupts for the tests duration. Otherwise the test might get interrupted while the writer is still locked.
|
||||
- Since the timer interrupt handler can still run before the test, we print an additional newline `\n` before printing the string `s`. This way, we avoid test failure when the timer handler already printed some `.` characters to the current line.
|
||||
|
||||
[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
|
||||
|
||||
With the above changes, `cargo test` now deterministically succeeds again.
|
||||
|
||||
This was a very harmless race condition that only caused a test failure. As you can imagine, other race conditions can be much more difficult to debug due to their non-deterministic nature. Luckily, Rust prevents us from data races, which are the most serious class of race conditions since they can cause all kinds of undefined behavior, including system crashes and silent memory corruptions.
|
||||
|
||||
## The `hlt` Instruction
|
||||
|
||||
Until now we used a simple empty loop statement at the end of our `_start` and `panic` functions. This causes the CPU to spin endlessly and thus works as expected. But it is also very inefficient, because the CPU continues to run at full speed even though there's no work to do. You can see this problem in your task manager when you run your kernel: The QEMU process needs close to 100% CPU the whole time.
|
||||
|
||||
What we really want to do is to halt the CPU until the next interrupt arrives. This allows the CPU to enter a sleep state in which it consumes much less energy. The [`hlt` instruction] does exactly that. Let's use this instruction to create an energy efficient endless loop:
|
||||
|
||||
[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub fn hlt_loop() -> ! {
|
||||
loop {
|
||||
x86_64::instructions::hlt();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The `instructions::hlt` function is just a [thin wrapper] around the assembly instruction. It is safe because there's no way it can compromise memory safety.
|
||||
|
||||
[thin wrapper]: https://github.com/rust-osdev/x86_64/blob/5e8e218381c5205f5777cb50da3ecac5d7e3b1ab/src/instructions/mod.rs#L16-L22
|
||||
|
||||
We can now use this `hlt_loop` instead of the endless loops in our `_start` and `panic` functions:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
[…]
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop(); // new
|
||||
}
|
||||
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
blog_os::hlt_loop(); // new
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Let's update our `lib.rs` as well:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
/// Entry point for `cargo test`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init();
|
||||
test_main();
|
||||
hlt_loop(); // new
|
||||
}
|
||||
|
||||
pub fn test_panic_handler(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
hlt_loop(); // new
|
||||
}
|
||||
```
|
||||
|
||||
When we run our kernel now in QEMU, we see a much lower CPU usage.
|
||||
|
||||
## Keyboard Input
|
||||
|
||||
Now that we are able to handle interrupts from external devices we are finally able to add support for keyboard input. This will allow us to interact with our kernel for the first time.
|
||||
|
||||
<aside class="post_aside">
|
||||
|
||||
Note that we only describe how to handle [PS/2] keyboards here, not USB keyboards. However the mainboard emulates USB keyboards as PS/2 devices to support older software, so we can safely ignore USB keyboards until we have USB support in our kernel.
|
||||
|
||||
</aside>
|
||||
|
||||
[PS/2]: https://en.wikipedia.org/wiki/PS/2_port
|
||||
|
||||
Like the hardware timer, the keyboard controller is already enabled by default. So when you press a key the keyboard controller sends an interrupt to the PIC, which forwards it to the CPU. The CPU looks for a handler function in the IDT, but the corresponding entry is empty. Therefore a double fault occurs.
|
||||
|
||||
So let's add a handler function for the keyboard interrupt. It's quite similar to how we defined the handler for the timer interrupt, it just uses a different interrupt number:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
#[repr(u8)]
|
||||
pub enum InterruptIndex {
|
||||
Timer = PIC_1_OFFSET,
|
||||
Keyboard, // new
|
||||
}
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
[…]
|
||||
// new
|
||||
idt[InterruptIndex::Keyboard.as_usize()]
|
||||
.set_handler_fn(keyboard_interrupt_handler);
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
print!("k");
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
As we see from the graphic [above](#the-8259-pic), the keyboard uses line 1 of the primary PIC. This means that it arrives at the CPU as interrupt 33 (1 + offset 32). We add this index as a new `Keyboard` variant to the `InterruptIndex` enum. We don't need to specify the value explicitly, since it defaults to the previous value plus one, which is also 33. In the interrupt handler, we print a `k` and send the end of interrupt signal to the interrupt controller.
|
||||
|
||||
We now see that a `k` appears on the screen when we press a key. However, this only works for the first key we press, even if we continue to press keys no more `k`s appear on the screen. This is because the keyboard controller won't send another interrupt until we have read the so-called _scancode_ of the pressed key.
|
||||
|
||||
### Reading the Scancodes
|
||||
|
||||
To find out _which_ key was pressed, we need to query the keyboard controller. We do this by reading from the data port of the PS/2 controller, which is the [I/O port] with number `0x60`:
|
||||
|
||||
[I/O port]: @/second-edition/posts/04-testing/index.md#i-o-ports
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
let mut port = Port::new(0x60);
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
print!("{}", scancode);
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We use the [`Port`] type of the `x86_64` crate to read a byte from the keyboard's data port. This byte is called the [_scancode_] and is a number that represents the key press/release. We don't do anything with the scancode yet, we just print it to the screen:
|
||||
|
||||
[`Port`]: https://docs.rs/x86_64/0.12.1/x86_64/instructions/port/struct.Port.html
|
||||
[_scancode_]: https://en.wikipedia.org/wiki/Scancode
|
||||
|
||||

|
||||
|
||||
The above image shows me slowly typing "123". We see that adjacent keys have adjacent scancodes and that pressing a key causes a different scancode than releasing it. But how do we translate the scancodes to the actual key actions exactly?
|
||||
|
||||
### Interpreting the Scancodes
|
||||
There are three different standards for the mapping between scancodes and keys, the so-called _scancode sets_. All three go back to the keyboards of early IBM computers: the [IBM XT], the [IBM 3270 PC], and the [IBM AT]. Later computers fortunately did not continue the trend of defining new scancode sets, but rather emulated the existing sets and extended them. Today most keyboards can be configured to emulate any of the three sets.
|
||||
|
||||
[IBM XT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer_XT
|
||||
[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
|
||||
[IBM AT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer/AT
|
||||
|
||||
By default, PS/2 keyboards emulate scancode set 1 ("XT"). In this set, the lower 7 bits of a scancode byte define the key, and the most significant bit defines whether it's a press ("0") or a release ("1"). Keys that were not present on the original [IBM XT] keyboard, such as the enter key on the keypad, generate two scancodes in succession: a `0xe0` escape byte and then a byte representing the key. For a list of all set 1 scancodes and their corresponding keys, check out the [OSDev Wiki][scancode set 1].
|
||||
|
||||
[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
|
||||
|
||||
To translate the scancodes to keys, we can use a match statement:
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
let mut port = Port::new(0x60);
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
|
||||
// new
|
||||
let key = match scancode {
|
||||
0x02 => Some('1'),
|
||||
0x03 => Some('2'),
|
||||
0x04 => Some('3'),
|
||||
0x05 => Some('4'),
|
||||
0x06 => Some('5'),
|
||||
0x07 => Some('6'),
|
||||
0x08 => Some('7'),
|
||||
0x09 => Some('8'),
|
||||
0x0a => Some('9'),
|
||||
0x0b => Some('0'),
|
||||
_ => None,
|
||||
};
|
||||
if let Some(key) = key {
|
||||
print!("{}", key);
|
||||
}
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The above code translates keypresses of the number keys 0-9 and ignores all other keys. It uses a [match] statement to assign a character or `None` to each scancode. It then uses [`if let`] to destructure the optional `key`. By using the same variable name `key` in the pattern, we [shadow] the previous declaration, which is a common pattern for destructuring `Option` types in Rust.
|
||||
|
||||
[match]: https://doc.rust-lang.org/book/ch06-02-match.html
|
||||
[`if let`]: https://doc.rust-lang.org/book/ch18-01-all-the-places-for-patterns.html#conditional-if-let-expressions
|
||||
[shadow]: https://doc.rust-lang.org/book/ch03-01-variables-and-mutability.html#shadowing
|
||||
|
||||
Now we can write numbers:
|
||||
|
||||

|
||||
|
||||
Translating the other keys works in the same way. Fortunately there is a crate named [`pc-keyboard`] for translating scancodes of scancode sets 1 and 2, so we don't have to implement this ourselves. To use the crate, we add it to our `Cargo.toml` and import it in our `lib.rs`:
|
||||
|
||||
[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
pc-keyboard = "0.5.0"
|
||||
```
|
||||
|
||||
Now we can use this crate to rewrite our `keyboard_interrupt_handler`:
|
||||
|
||||
```rust
|
||||
// in/src/interrupts.rs
|
||||
|
||||
extern "x86-interrupt" fn keyboard_interrupt_handler(
|
||||
_stack_frame: &mut InterruptStackFrame)
|
||||
{
|
||||
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
|
||||
use spin::Mutex;
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
lazy_static! {
|
||||
static ref KEYBOARD: Mutex<Keyboard<layouts::Us104Key, ScancodeSet1>> =
|
||||
Mutex::new(Keyboard::new(layouts::Us104Key, ScancodeSet1,
|
||||
HandleControl::Ignore)
|
||||
);
|
||||
}
|
||||
|
||||
let mut keyboard = KEYBOARD.lock();
|
||||
let mut port = Port::new(0x60);
|
||||
|
||||
let scancode: u8 = unsafe { port.read() };
|
||||
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
|
||||
if let Some(key) = keyboard.process_keyevent(key_event) {
|
||||
match key {
|
||||
DecodedKey::Unicode(character) => print!("{}", character),
|
||||
DecodedKey::RawKey(key) => print!("{:?}", key),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
unsafe {
|
||||
PICS.lock()
|
||||
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We use the `lazy_static` macro to create a static [`Keyboard`] object protected by a Mutex. We initialize the `Keyboard` with an US keyboard layout and the scancode set 1. The [`HandleControl`] parameter allows to map `ctrl+[a-z]` to the Unicode characters `U+0001` through `U+001A`. We don't want to do that, so we use the `Ignore` option to handle the `ctrl` like normal keys.
|
||||
|
||||
[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
|
||||
|
||||
On each interrupt, we lock the Mutex, read the scancode from the keyboard controller and pass it to the [`add_byte`] method, which translates the scancode into an `Option<KeyEvent>`. The [`KeyEvent`] contains which key caused the event and whether it was a press or release event.
|
||||
|
||||
[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
|
||||
[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
|
||||
[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
|
||||
|
||||
To interpret this key event, we pass it to the [`process_keyevent`] method, which translates the key event to a character if possible. For example, translates a press event of the `A` key to either a lowercase `a` character or an uppercase `A` character, depending on whether the shift key was pressed.
|
||||
|
||||
[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
|
||||
|
||||
With this modified interrupt handler we can now write text:
|
||||
|
||||

|
||||
|
||||
### Configuring the Keyboard
|
||||
|
||||
It's possible to configure some aspects of a PS/2 keyboard, for example which scancode set it should use. We won't cover it here because this post is already long enough, but the OSDev Wiki has an overview of possible [configuration commands].
|
||||
|
||||
[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
|
||||
|
||||
## Summary
|
||||
|
||||
This post explained how to enable and handle external interrupts. We learned about the 8259 PIC and its primary/secondary layout, the remapping of the interrupt numbers, and the "end of interrupt" signal. We implemented handlers for the hardware timer and the keyboard and learned about the `hlt` instruction, which halts the CPU until the next interrupt.
|
||||
|
||||
Now we are able to interact with our kernel and have some fundamental building blocks for creating a small shell or simple games.
|
||||
|
||||
## What's next?
|
||||
|
||||
Timer interrupts are essential for an operating system, because they provide a way to periodically interrupt the running process and regain control in the kernel. The kernel can then switch to a different process and create the illusion that multiple processes run in parallel.
|
||||
|
||||
But before we can create processes or threads, we need a way to allocate memory for them. The next posts will explore memory management to provide this fundamental building block.
|
||||
{kind=link}
|
Before Width: | Height: | Size: 8.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 10 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 4.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 2.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.1 KiB |
@@ -1,416 +0,0 @@
|
||||
+++
|
||||
title = "Introduction to Paging"
|
||||
weight = 8
|
||||
path = "paging-introduction"
|
||||
date = 2019-01-14
|
||||
|
||||
[extra]
|
||||
chapter = "Memory Management"
|
||||
+++
|
||||
|
||||
This post introduces _paging_, a very common memory management scheme that we will also use for our operating system. It explains why memory isolation is needed, how _segmentation_ works, what _virtual memory_ is, and how paging solves memory fragmentation issues. It also explores the layout of multilevel page tables on the x86_64 architecture.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-08`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-08
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## Memory Protection
|
||||
|
||||
One main task of an operating system is to isolate programs from each other. Your web browser shouldn't be able to interfere with your text editor, for example. To achieve this goal, operating systems utilize hardware functionality to ensure that memory areas of one process are not accessible by other processes. There are different approaches, depending on the hardware and the OS implementation.
|
||||
|
||||
As an example, some ARM Cortex-M processors (used for embedded systems) have a [_Memory Protection Unit_] (MPU), which allows you to define a small number (e.g. 8) of memory regions with different access permissions (e.g. no access, read-only, read-write). On each memory access the MPU ensures that the address is in a region with correct access permissions and throws an exception otherwise. By changing the regions and access permissions on each process switch, the operating system can ensure that each process only accesses its own memory, and thus isolate processes from each other.
|
||||
|
||||
[_Memory Protection Unit_]: https://developer.arm.com/docs/ddi0337/e/memory-protection-unit/about-the-mpu
|
||||
|
||||
On x86, the hardware supports two different approaches to memory protection: [segmentation] and [paging].
|
||||
|
||||
[segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
|
||||
[paging]: https://en.wikipedia.org/wiki/Virtual_memory#Paged_virtual_memory
|
||||
|
||||
## Segmentation
|
||||
|
||||
Segmentation was already introduced in 1978, originally to increase the amount of addressable memory. The situation back then was that CPUs only used 16-bit addresses, which limited the amount of addressable memory to 64KiB. To make more than these 64KiB accessible, additional segment registers were introduced, each containing an offset address. The CPU automatically added this offset on each memory access, so that up to 1MiB of memory were accessible.
|
||||
|
||||
The segment register is chosen automatically by the CPU, depending on the kind of memory access: For fetching instructions the code segment `CS` is used and for stack operations (push/pop) the stack segment `SS` is used. Other instructions use data segment `DS` or the extra segment `ES`. Later two additional segment registers `FS` and `GS` were added, which can be used freely.
|
||||
|
||||
In the first version of segmentation, the segment registers directly contained the offset and no access control was performed. This was changed later with the introduction of the [_protected mode_]. When the CPU runs in this mode, the segment descriptors contain an index into a local or global [_descriptor table_], which contains – in addition to an offset address – the segment size and access permissions. By loading separate global/local descriptor tables for each process that confine memory accesses to the process's own memory areas, the OS can isolate processes from each other.
|
||||
|
||||
[_protected mode_]: https://en.wikipedia.org/wiki/X86_memory_segmentation#Protected_mode
|
||||
[_descriptor table_]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
|
||||
|
||||
By modifying the memory addresses before the actual access, segmentation already employed a technique that is now used almost everywhere: _virtual memory_.
|
||||
|
||||
### Virtual Memory
|
||||
|
||||
The idea behind virtual memory is to abstract away the memory addresses from the underlying physical storage device. Instead of directly accessing the storage device, a translation step is performed first. For segmentation, the translation step is to add the offset address of the active segment. Imagine a program accessing memory address `0x1234000` in a segment with offset `0x1111000`: The address that is really accessed is `0x2345000`.
|
||||
|
||||
To differentiate the two address types, addresses before the translation are called _virtual_ and addresses after the translation are called _physical_. One important difference between these two kinds of addresses is that physical addresses are unique and always refer to the same, distinct memory location. Virtual addresses on the other hand depend on the translation function. It is entirely possible that two different virtual addresses refer to the same physical address. Also, identical virtual addresses can refer to different physical addresses when they use different translation functions.
|
||||
|
||||
An example where this property is useful is running the same program twice in parallel:
|
||||
|
||||
|
||||

|
||||
|
||||
Here the same program runs twice, but with different translation functions. The first instance has an segment offset of 100, so that its virtual addresses 0–150 are translated to the physical addresses 100–250. The second instance has offset 300, which translates its virtual addresses 0–150 to physical addresses 300–450. This allows both programs to run the same code and use the same virtual addresses without interfering with each other.
|
||||
|
||||
Another advantage is that programs can be placed at arbitrary physical memory locations now, even if they use completely different virtual addresses. Thus, the OS can utilize the full amount of available memory without needing to recompile programs.
|
||||
|
||||
### Fragmentation
|
||||
|
||||
The differentiation between virtual and physical addresses makes segmentation really powerful. However, it has the problem of fragmentation. As an example, imagine that we want to run a third copy of the program we saw above:
|
||||
|
||||

|
||||
|
||||
There is no way to map the third instance of the program to virtual memory without overlapping, even though there is more than enough free memory available. The problem is that we need _continuous_ memory and can't use the small free chunks.
|
||||
|
||||
One way to combat this fragmentation is to pause execution, move the used parts of the memory closer together, update the translation, and then resume execution:
|
||||
|
||||

|
||||
|
||||
Now there is enough continuous space to start the third instance of our program.
|
||||
|
||||
The disadvantage of this defragmentation process is that is needs to copy large amounts of memory which decreases performance. It also needs to be done regularly before the memory becomes too fragmented. This makes performance unpredictable, since programs are paused at random times and might become unresponsive.
|
||||
|
||||
The fragmentation problem is one of the reasons that segmentation is no longer used by most systems. In fact, segmentation is not even supported in 64-bit mode on x86 anymore. Instead _paging_ is used, which completely avoids the fragmentation problem.
|
||||
|
||||
## Paging
|
||||
|
||||
The idea is to divide both the virtual and the physical memory space into small, fixed-size blocks. The blocks of the virtual memory space are called _pages_ and the blocks of the physical address space are called _frames_. Each page can be individually mapped to a frame, which makes it possible to split larger memory regions across non-continuous physical frames.
|
||||
|
||||
The advantage of this becomes visible if we recap the example of the fragmented memory space, but use paging instead of segmentation this time:
|
||||
|
||||

|
||||
|
||||
In this example we have a page size of 50 bytes, which means that each of our memory regions is split across three pages. Each page is mapped to a frame individually, so a continuous virtual memory region can be mapped to non-continuous physical frames. This allows us to start the third instance of the program without performing any defragmentation before.
|
||||
|
||||
### Hidden Fragmentation
|
||||
|
||||
Compared to segmentation, paging uses lots of small, fixed sized memory regions instead of a few large, variable sized regions. Since every frame has the same size, there are no frames that are too small to be used so that no fragmentation occurs.
|
||||
|
||||
Or it _seems_ like no fragmentation occurs. There is still some hidden kind of fragmentation, the so-called _internal fragmentation_. Internal fragmentation occurs because not every memory region is an exact multiple of the page size. Imagine a program of size 101 in the above example: It would still need three pages of size 50, so it would occupy 49 bytes more than needed. To differentiate the two types of fragmentation, the kind of fragmentation that happens when using segmentation is called _external fragmentation_.
|
||||
|
||||
Internal fragmentation is unfortunate, but often better than the external fragmentation that occurs with segmentation. It still wastes memory, but does not require defragmentation and makes the amount of fragmentation predictable (on average half a page per memory region).
|
||||
|
||||
### Page Tables
|
||||
|
||||
We saw that each of the potentially millions of pages is individually mapped to a frame. This mapping information needs to be stored somewhere. Segmentation uses an individual segment selector register for each active memory region, which is not possible for paging since there are way more pages than registers. Instead paging uses a table structure called _page table_ to store the mapping information.
|
||||
|
||||
For our above example the page tables would look like this:
|
||||
|
||||

|
||||
|
||||
We see that each program instance has its own page table. A pointer to the currently active table is stored in a special CPU register. On `x86`, this register is called `CR3`. It is the job of the operating system to load this register with the pointer to the correct page table before running each program instance.
|
||||
|
||||
On each memory access, the CPU reads the table pointer from the register and looks up the mapped frame for the accessed page in the table. This is entirely done in hardware and completely transparent to the running program. To speed up the translation process, many CPU architectures have a special cache that remembers the results of the last translations.
|
||||
|
||||
Depending on the architecture, page table entries can also store attributes such as access permissions in a flags field. In the above example, the "r/w" flag makes the page both readable and writable.
|
||||
|
||||
### Multilevel Page Tables
|
||||
|
||||
The simple page tables we just saw have a problem in larger address spaces: they waste memory. For example, imagine a program that uses the four virtual pages `0`, `1_000_000`, `1_000_050`, and `1_000_100` (we use `_` as a thousands separator):
|
||||
|
||||

|
||||
|
||||
It only needs 4 physical frames, but the page table has over a million entries. We can't omit the empty entries because then the CPU would no longer be able to jump directly to the correct entry in the translation process (e.g. it is no longer guaranteed that the fourth page uses the fourth entry).
|
||||
|
||||
To reduce the wasted memory, we can use a **two-level page table**. The idea is that we use different page tables for different address regions. An additional table called _level 2_ page table contains the mapping between address regions and (level 1) page tables.
|
||||
|
||||
This is best explained by an example. Let's define that each level 1 page table is responsible for a region of size `10_000`. Then the following tables would exist for the above example mapping:
|
||||
|
||||

|
||||
|
||||
Page 0 falls into the first `10_000` byte region, so it uses the first entry of the level 2 page table. This entry points to level 1 page table T1, which specifies that page `0` points to frame `0`.
|
||||
|
||||
The pages `1_000_000`, `1_000_050`, and `1_000_100` all fall into the 100th `10_000` byte region, so they use the 100th entry of the level 2 page table. This entry points at a different level 1 page table T2, which maps the three pages to frames `100`, `150`, and `200`. Note that the page address in level 1 tables does not include the region offset, so e.g. the entry for page `1_000_050` is just `50`.
|
||||
|
||||
We still have 100 empty entries in the level 2 table, but much fewer than the million empty entries before. The reason for this savings is that we don't need to create level 1 page tables for the unmapped memory regions between `10_000` and `1_000_000`.
|
||||
|
||||
The principle of two-level page tables can be extended to three, four, or more levels. Then the page table register points at the highest level table, which points to the next lower level table, which points to the next lower level, and so on. The level 1 page table then points at the mapped frame. The principle in general is called a _multilevel_ or _hierarchical_ page table.
|
||||
|
||||
Now that we know how paging and multilevel page tables works, we can look at how paging is implemented in the x86_64 architecture (we assume in the following that the CPU runs in 64-bit mode).
|
||||
|
||||
## Paging on x86_64
|
||||
|
||||
The x86_64 architecture uses a 4-level page table and a page size of 4KiB. Each page table, independent of the level, has a fixed size of 512 entries. Each entry has a size of 8 bytes, so each table is 512 * 8B = 4KiB large and thus fits exactly into one page.
|
||||
|
||||
The page table index for level is derived directly from the virtual address:
|
||||
|
||||

|
||||
|
||||
We see that each table index consists of 9 bits, which makes sense because each table has 2^9 = 512 entries. The lowest 12 bits are the offset in the 4KiB page (2^12 bytes = 4KiB). Bits 48 to 64 are discarded, which means that x86_64 is not really 64-bit since it only supports 48-bit addresses.
|
||||
|
||||
[5-level page table]: https://en.wikipedia.org/wiki/Intel_5-level_paging
|
||||
|
||||
Even though bits 48 to 64 are discarded, they can't be set to arbitrary values. Instead all bits in this range have to be copies of bit 47 in order to keep addresses unique and allow future extensions like the 5-level page table. This is called _sign-extension_ because it's very similar to the [sign extension in two's complement]. When an address is not correctly sign-extended, the CPU throws an exception.
|
||||
|
||||
[sign extension in two's complement]: https://en.wikipedia.org/wiki/Two's_complement#Sign_extension
|
||||
|
||||
It's worth noting that the recent "Ice Lake" Intel CPUs optionally support [5-level page tables] to extends virtual addresses from 48-bit to 57-bit. Given that optimizing our kernel for a specific CPU does not make sense at this stage, we will only work with standard 4-level page tables in this post.
|
||||
|
||||
[5-level page tables]: https://en.wikipedia.org/wiki/Intel_5-level_paging
|
||||
|
||||
### Example Translation
|
||||
|
||||
Let's go through an example to understand how the translation process works in detail:
|
||||
|
||||

|
||||
|
||||
The physical address of the currently active level 4 page table, which is the root of the 4-level page table, is stored in the `CR3` register. Each page table entry then points to the physical frame of the next level table. The entry of the level 1 table then points to the mapped frame. Note that all addresses in the page tables are physical instead of virtual, because otherwise the CPU would need to translate those addresses too (which could cause a never-ending recursion).
|
||||
|
||||
The above page table hierarchy maps two pages (in blue). From the page table indices we can deduce that the virtual addresses of these two pages are `0x803FE7F000` and `0x803FE00000`. Let's see what happens when the program tries to read from address `0x803FE7F5CE`. First, we convert the address to binary and determine the page table indices and the page offset for the address:
|
||||
|
||||

|
||||
|
||||
With these indices, we can now walk the page table hierarchy to determine the mapped frame for the address:
|
||||
|
||||
- We start by reading the address of the level 4 table out of the `CR3` register.
|
||||
- The level 4 index is 1, so we look at the entry with index 1 of that table, which tells us that the level 3 table is stored at address 16KiB.
|
||||
- We load the level 3 table from that address and look at the entry with index 0, which points us to the level 2 table at 24KiB.
|
||||
- The level 2 index is 511, so we look at the last entry of that page to find out the address of the level 1 table.
|
||||
- Through the entry with index 127 of the level 1 table we finally find out that the page is mapped to frame 12KiB, or 0x3000 in hexadecimal.
|
||||
- The final step is to add the page offset to the frame address to get the physical address 0x3000 + 0x5ce = 0x35ce.
|
||||
|
||||

|
||||
|
||||
The permissions for the page in the level 1 table are `r`, which means read-only. The hardware enforces these permissions and would throw an exception if we tried to write to that page. Permissions in higher level pages restrict the possible permissions in lower level, so if we set the level 3 entry to read-only, no pages that use this entry can be writable, even if lower levels specify read/write permissions.
|
||||
|
||||
It's important to note that even though this example used only a single instance of each table, there are typically multiple instances of each level in each address space. At maximum, there are:
|
||||
|
||||
- one level 4 table,
|
||||
- 512 level 3 tables (because the level 4 table has 512 entries),
|
||||
- 512 * 512 level 2 tables (because each of the 512 level 3 tables has 512 entries), and
|
||||
- 512 * 512 * 512 level 1 tables (512 entries for each level 2 table).
|
||||
|
||||
### Page Table Format
|
||||
|
||||
Page tables on the x86_64 architecture are basically an array of 512 entries. In Rust syntax:
|
||||
|
||||
```rust
|
||||
#[repr(align(4096))]
|
||||
pub struct PageTable {
|
||||
entries: [PageTableEntry; 512],
|
||||
}
|
||||
```
|
||||
|
||||
As indicated by the `repr` attribute, page tables need to be page aligned, i.e. aligned on a 4KiB boundary. This requirement guarantees that a page table always fills a complete page and allows an optimization that makes entries very compact.
|
||||
|
||||
Each entry is 8 bytes (64 bits) large and has the following format:
|
||||
|
||||
Bit(s) | Name | Meaning
|
||||
------ | ---- | -------
|
||||
0 | present | the page is currently in memory
|
||||
1 | writable | it's allowed to write to this page
|
||||
2 | user accessible | if not set, only kernel mode code can access this page
|
||||
3 | write through caching | writes go directly to memory
|
||||
4 | disable cache | no cache is used for this page
|
||||
5 | accessed | the CPU sets this bit when this page is used
|
||||
6 | dirty | the CPU sets this bit when a write to this page occurs
|
||||
7 | huge page/null | must be 0 in P1 and P4, creates a 1GiB page in P3, creates a 2MiB page in P2
|
||||
8 | global | page isn't flushed from caches on address space switch (PGE bit of CR4 register must be set)
|
||||
9-11 | available | can be used freely by the OS
|
||||
12-51 | physical address | the page aligned 52bit physical address of the frame or the next page table
|
||||
52-62 | available | can be used freely by the OS
|
||||
63 | no execute | forbid executing code on this page (the NXE bit in the EFER register must be set)
|
||||
|
||||
We see that only bits 12–51 are used to store the physical frame address, the remaining bits are used as flags or can be freely used by the operating system. This is possible because we always point to a 4096-byte aligned address, either to a page-aligned page table or to the start of a mapped frame. This means that bits 0–11 are always zero, so there is no reason to store these bits because the hardware can just set them to zero before using the address. The same is true for bits 52–63, because the x86_64 architecture only supports 52-bit physical addresses (similar to how it only supports 48-bit virtual addresses).
|
||||
|
||||
Let's take a closer look at the available flags:
|
||||
|
||||
- The `present` flag differentiates mapped pages from unmapped ones. It can be used to temporarily swap out pages to disk when main memory becomes full. When the page is accessed subsequently, a special exception called _page fault_ occurs, to which the operating system can react by reloading the missing page from disk and then continuing the program.
|
||||
- The `writable` and `no execute` flags control whether the contents of the page are writable or contain executable instructions respectively.
|
||||
- The `accessed` and `dirty` flags are automatically set by the CPU when a read or write to the page occurs. This information can be leveraged by the operating system e.g. to decide which pages to swap out or whether the page contents were modified since the last save to disk.
|
||||
- The `write through caching` and `disable cache` flags allow to control the caches for every page individually.
|
||||
- The `user accessible` flag makes a page available to userspace code, otherwise it is only accessible when the CPU is in kernel mode. This feature can be used to make [system calls] faster by keeping the kernel mapped while an userspace program is running. However, the [Spectre] vulnerability can allow userspace programs to read these pages nonetheless.
|
||||
- The `global` flag signals to the hardware that a page is available in all address spaces and thus does not need to be removed from the translation cache (see the section about the TLB below) on address space switches. This flag is commonly used together with a cleared `user accessible` flag to map the kernel code to all address spaces.
|
||||
- The `huge page` flag allows to create pages of larger sizes by letting the entries of the level 2 or level 3 page tables directly point to a mapped frame. With this bit set, the page size increases by factor 512 to either 2MiB = 512 * 4KiB for level 2 entries or even 1GiB = 512 * 2MiB for level 3 entries. The advantage of using larger pages is that fewer lines of the translation cache and fewer page tables are needed.
|
||||
|
||||
[system calls]: https://en.wikipedia.org/wiki/System_call
|
||||
[Spectre]: https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
|
||||
|
||||
The `x86_64` crate provides types for [page tables] and their [entries], so we don't need to create these structures ourselves.
|
||||
|
||||
[page tables]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/page_table/struct.PageTable.html
|
||||
[entries]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/page_table/struct.PageTableEntry.html
|
||||
|
||||
### The Translation Lookaside Buffer
|
||||
|
||||
A 4-level page table makes the translation of virtual addresses expensive, because each translation requires 4 memory accesses. To improve performance, the x86_64 architecture caches the last few translations in the so-called _translation lookaside buffer_ (TLB). This allows to skip the translation when the translation is still cached.
|
||||
|
||||
Unlike the other CPU caches, the TLB is not fully transparent and does not update or remove translations when the contents of page tables change. This means that the kernel must manually update the TLB whenever it modifies a page table. To do this, there is a special CPU instruction called [`invlpg`] (“invalidate page”) that removes the translation for the specified page from the TLB, so that it is loaded again from the page table on the next access. The TLB can also be flushed completely by reloading the `CR3` register, which simulates an address space switch. The `x86_64` crate provides Rust functions for both variants in the [`tlb` module].
|
||||
|
||||
[`invlpg`]: https://www.felixcloutier.com/x86/INVLPG.html
|
||||
[`tlb` module]: https://docs.rs/x86_64/0.12.1/x86_64/instructions/tlb/index.html
|
||||
|
||||
It is important to remember flushing the TLB on each page table modification because otherwise the CPU might keep using the old translation, which can lead to non-deterministic bugs that are very hard to debug.
|
||||
|
||||
## Implementation
|
||||
|
||||
One thing that we did not mention yet: **Our kernel already runs on paging**. The bootloader that we added in the ["A minimal Rust Kernel"] post already set up a 4-level paging hierarchy that maps every page of our kernel to a physical frame. The bootloader does this because paging is mandatory in 64-bit mode on x86_64.
|
||||
|
||||
["A minimal Rust kernel"]: @/second-edition/posts/02-minimal-rust-kernel/index.md#creating-a-bootimage
|
||||
|
||||
This means that every memory address that we used in our kernel was a virtual address. Accessing the VGA buffer at address `0xb8000` only worked because the bootloader _identity mapped_ that memory page, which means that it mapped the virtual page `0xb8000` to the physical frame `0xb8000`.
|
||||
|
||||
Paging makes our kernel already relatively safe, since every memory access that is out of bounds causes a page fault exception instead of writing to random physical memory. The bootloader even set the correct access permissions for each page, which means that only the pages containing code are executable and only data pages are writable.
|
||||
|
||||
### Page Faults
|
||||
|
||||
Let's try to cause a page fault by accessing some memory outside of our kernel. First, we create a page fault handler and register it in our IDT, so that we see a page fault exception instead of a generic [double fault] :
|
||||
|
||||
[double fault]: @/second-edition/posts/06-double-faults/index.md
|
||||
|
||||
```rust
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
|
||||
[…]
|
||||
|
||||
idt.page_fault.set_handler_fn(page_fault_handler); // new
|
||||
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
use x86_64::structures::idt::PageFaultErrorCode;
|
||||
use crate::hlt_loop;
|
||||
|
||||
extern "x86-interrupt" fn page_fault_handler(
|
||||
stack_frame: &mut InterruptStackFrame,
|
||||
error_code: PageFaultErrorCode,
|
||||
) {
|
||||
use x86_64::registers::control::Cr2;
|
||||
|
||||
println!("EXCEPTION: PAGE FAULT");
|
||||
println!("Accessed Address: {:?}", Cr2::read());
|
||||
println!("Error Code: {:?}", error_code);
|
||||
println!("{:#?}", stack_frame);
|
||||
hlt_loop();
|
||||
}
|
||||
```
|
||||
|
||||
The [`CR2`] register is automatically set by the CPU on a page fault and contains the accessed virtual address that caused the page fault. We use the [`Cr2::read`] function of the `x86_64` crate to read and print it. The [`PageFaultErrorCode`] type provides more information about the type of memory access that caused the page fault, for example whether it was caused by a read or write operation. For this reason we print it too. We can't continue execution without resolving the page fault, so we enter a [`hlt_loop`] at the end.
|
||||
|
||||
[`CR2`]: https://en.wikipedia.org/wiki/Control_register#CR2
|
||||
[`Cr2::read`]: https://docs.rs/x86_64/0.12.1/x86_64/registers/control/struct.Cr2.html#method.read
|
||||
[`PageFaultErrorCode`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.PageFaultErrorCode.html
|
||||
[LLVM bug]: https://github.com/rust-lang/rust/issues/57270
|
||||
[`hlt_loop`]: @/second-edition/posts/07-hardware-interrupts/index.md#the-hlt-instruction
|
||||
|
||||
Now we can try to access some memory outside our kernel:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
// new
|
||||
let ptr = 0xdeadbeaf as *mut u32;
|
||||
unsafe { *ptr = 42; }
|
||||
|
||||
// as before
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop();
|
||||
}
|
||||
```
|
||||
|
||||
When we run it, we see that our page fault handler is called:
|
||||
|
||||

|
||||
|
||||
The `CR2` register indeed contains `0xdeadbeaf`, the address that we tried to access. The error code tells us through the [`CAUSED_BY_WRITE`] that the fault occurred while trying to perform a write operation. It tells us even more through the [bits that are _not_ set][`PageFaultErrorCode`]. For example, the fact that the `PROTECTION_VIOLATION` flag is not set means that the page fault occurred because the target page wasn't present.
|
||||
|
||||
[`CAUSED_BY_WRITE`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.CAUSED_BY_WRITE
|
||||
|
||||
We see that the current instruction pointer is `0x2031b2`, so we know that this address points to a code page. Code pages are mapped read-only by the bootloader, so reading from this address works but writing causes a page fault. You can try this by changing the `0xdeadbeaf` pointer to `0x2031b2`:
|
||||
|
||||
```rust
|
||||
// Note: The actual address might be different for you. Use the address that
|
||||
// your page fault handler reports.
|
||||
let ptr = 0x2031b2 as *mut u32;
|
||||
|
||||
// read from a code page
|
||||
unsafe { let x = *ptr; }
|
||||
println!("read worked");
|
||||
|
||||
// write to a code page
|
||||
unsafe { *ptr = 42; }
|
||||
println!("write worked");
|
||||
```
|
||||
|
||||
By commenting out the last line, we see that the read access works, but the write access causes a page fault:
|
||||
|
||||

|
||||
|
||||
We see that the _"read worked"_ message is printed, which indicates that the read operation did not cause any errors. However, instead of the _"write worked"_ message a page fault occurs. This time the [`PROTECTION_VIOLATION`] flag is set in addition to the [`CAUSED_BY_WRITE`] flag, which indicates that the page was present, but the operation was not allowed on it. In this case, writes to the page are not allowed since code pages are mapped as read-only.
|
||||
|
||||
[`PROTECTION_VIOLATION`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.PROTECTION_VIOLATION
|
||||
|
||||
### Accessing the Page Tables
|
||||
|
||||
Let's try to take a look at the page tables that define how our kernel is mapped:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::init();
|
||||
|
||||
use x86_64::registers::control::Cr3;
|
||||
|
||||
let (level_4_page_table, _) = Cr3::read();
|
||||
println!("Level 4 page table at: {:?}", level_4_page_table.start_address());
|
||||
|
||||
[…] // test_main(), println(…), and hlt_loop()
|
||||
}
|
||||
```
|
||||
|
||||
The [`Cr3::read`] function of the `x86_64` returns the currently active level 4 page table from the `CR3` register. It returns a tuple of a [`PhysFrame`] and a [`Cr3Flags`] type. We are only interested in the frame, so we ignore the second element of the tuple.
|
||||
|
||||
[`Cr3::read`]: https://docs.rs/x86_64/0.12.1/x86_64/registers/control/struct.Cr3.html#method.read
|
||||
[`PhysFrame`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/frame/struct.PhysFrame.html
|
||||
[`Cr3Flags`]: https://docs.rs/x86_64/0.12.1/x86_64/registers/control/struct.Cr3Flags.html
|
||||
|
||||
When we run it, we see the following output:
|
||||
|
||||
```
|
||||
Level 4 page table at: PhysAddr(0x1000)
|
||||
```
|
||||
|
||||
So the currently active level 4 page table is stored at address `0x1000` in _physical_ memory, as indicated by the [`PhysAddr`] wrapper type. The question now is: how can we access this table from our kernel?
|
||||
|
||||
[`PhysAddr`]: https://docs.rs/x86_64/0.12.1/x86_64/addr/struct.PhysAddr.html
|
||||
|
||||
Accessing physical memory directly is not possible when paging is active, since programs could easily circumvent memory protection and access memory of other programs otherwise. So the only way to access the table is through some virtual page that is mapped to the physical frame at address `0x1000`. This problem of creating mappings for page table frames is a general problem, since the kernel needs to access the page tables regularly, for example when allocating a stack for a new thread.
|
||||
|
||||
Solutions to this problem are explained in detail in the next post.
|
||||
|
||||
## Summary
|
||||
|
||||
This post introduced two memory protection techniques: segmentation and paging. While the former uses variable-sized memory regions and suffers from external fragmentation, the latter uses fixed-sized pages and allows much more fine-grained control over access permissions.
|
||||
|
||||
Paging stores the mapping information for pages in page tables with one or more levels. The x86_64 architecture uses 4-level page tables and a page size of 4KiB. The hardware automatically walks the page tables and caches the resulting translations in the translation lookaside buffer (TLB). This buffer is not updated transparently and needs to be flushed manually on page table changes.
|
||||
|
||||
We learned that our kernel already runs on top of paging and that illegal memory accesses cause page fault exceptions. We tried to access the currently active page tables, but we weren't able to do it because the CR3 register stores a physical address that we can't access directly from our kernel.
|
||||
|
||||
## What's next?
|
||||
|
||||
The next post explains how to implement support for paging in our kernel. It presents different ways to access physical memory from our kernel, which makes it possible to access the page tables that our kernel runs on. At this point we are able to implement functions for translating virtual to physical addresses and for creating new mappings in the page tables.
|
||||
{kind=link}
|
Before Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 20 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 30 KiB |
{kind=link}
|
Before Width: | Height: | Size: 24 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB |
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
{kind=link}
|
Before Width: | Height: | Size: 51 KiB |
{kind=link}
|
Before Width: | Height: | Size: 51 KiB |
{kind=link}
|
Before Width: | Height: | Size: 52 KiB |
{kind=link}
|
Before Width: | Height: | Size: 46 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 21 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 10 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
@@ -1,796 +0,0 @@
|
||||
+++
|
||||
title = "Heap Allocation"
|
||||
weight = 10
|
||||
path = "heap-allocation"
|
||||
date = 2019-06-26
|
||||
|
||||
[extra]
|
||||
chapter = "Memory Management"
|
||||
+++
|
||||
|
||||
This post adds support for heap allocation to our kernel. First, it gives an introduction to dynamic memory and shows how the borrow checker prevents common allocation errors. It then implements the basic allocation interface of Rust, creates a heap memory region, and sets up an allocator crate. At the end of this post all the allocation and collection types of the built-in `alloc` crate will be available to our kernel.
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-10`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-10
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## Local and Static Variables
|
||||
|
||||
We currently use two types of variables in our kernel: local variables and `static` variables. Local variables are stored on the [call stack] and are only valid until the surrounding function returns. Static variables are stored at a fixed memory location and always live for the complete lifetime of the program.
|
||||
|
||||
### Local Variables
|
||||
|
||||
Local variables are stored on the [call stack], which is a [stack data structure] that supports `push` and `pop` operations. On each function entry, the parameters, the return address, and the local variables of the called function are pushed by the compiler:
|
||||
|
||||
[call stack]: https://en.wikipedia.org/wiki/Call_stack
|
||||
[stack data structure]: https://en.wikipedia.org/wiki/Stack_(abstract_data_type)
|
||||
|
||||

|
||||
|
||||
The above example shows the call stack after an `outer` function called an `inner` function. We see that the call stack contains the local variables of `outer` first. On the `inner` call, the parameter `1` and the return address for the function were pushed. Then control was transferred to `inner`, which pushed its local variables.
|
||||
|
||||
After the `inner` function returns, its part of the call stack is popped again and only the local variables of `outer` remain:
|
||||
|
||||

|
||||
|
||||
We see that the local variables of `inner` only live until the function returns. The Rust compiler enforces these lifetimes and throws an error when we use a value too long, for example when we try to return a reference to a local variable:
|
||||
|
||||
```rust
|
||||
fn inner(i: usize) -> &'static u32 {
|
||||
let z = [1, 2, 3];
|
||||
&z[i]
|
||||
}
|
||||
```
|
||||
|
||||
([run the example on the playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=6186a0f3a54f468e1de8894996d12819))
|
||||
|
||||
While returning a reference makes no sense in this example, there are cases where we want a variable to live longer than the function. We already saw such a case in our kernel when we tried to [load an interrupt descriptor table] and had to use a `static` variable to extend the lifetime.
|
||||
|
||||
[load an interrupt descriptor table]: @/second-edition/posts/05-cpu-exceptions/index.md#loading-the-idt
|
||||
|
||||
### Static Variables
|
||||
|
||||
Static variables are stored at a fixed memory location separate from the stack. This memory location is assigned at compile time by the linker and encoded in the executable. Statics live for the complete runtime of the program, so they have the `'static` lifetime and can always be referenced from local variables:
|
||||
|
||||
![The same outer/inner example with the difference that inner has a `static Z: [u32; 3] = [1,2,3];` and returns a `&Z[i]` reference](call-stack-static.svg)
|
||||
|
||||
When the `inner` function returns in the above example, it's part of the call stack is destroyed. The static variables live in a separate memory range that is never destroyed, so the `&Z[1]` reference is still valid after the return.
|
||||
|
||||
Apart from the `'static` lifetime, static variables also have the useful property that their location is known at compile time, so that no reference is needed for accessing it. We utilized that property for our `println` macro: By using a [static `Writer`] internally there is no `&mut Writer` reference needed to invoke the macro, which is very useful in [exception handlers] where we don't have access to any additional variables.
|
||||
|
||||
[static `Writer`]: @/second-edition/posts/03-vga-text-buffer/index.md#a-global-interface
|
||||
[exception handlers]: @/second-edition/posts/05-cpu-exceptions/index.md#implementation
|
||||
|
||||
However, this property of static variables brings a crucial drawback: They are read-only by default. Rust enforces this because a [data race] would occur if e.g. two threads modify a static variable at the same time. The only way to modify a static variable is to encapsulate it in a [`Mutex`] type, which ensures that only a single `&mut` reference exists at any point in time. We already used a `Mutex` for our [static VGA buffer `Writer`][vga mutex].
|
||||
|
||||
[data race]: https://doc.rust-lang.org/nomicon/races.html
|
||||
[`Mutex`]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html
|
||||
[vga mutex]: @/second-edition/posts/03-vga-text-buffer/index.md#spinlocks
|
||||
|
||||
## Dynamic Memory
|
||||
|
||||
Local and static variables are already very powerful together and enable most use cases. However, we saw that they both have their limitations:
|
||||
|
||||
- Local variables only live until the end of the surrounding function or block. This is because they live on the call stack and are destroyed after the surrounding function returns.
|
||||
- Static variables always live for the complete runtime of the program, so there is no way to reclaim and reuse their memory when they're no longer needed. Also, they have unclear ownership semantics and are accessible from all functions, so they need to be protected by a [`Mutex`] when we want to modify them.
|
||||
|
||||
Another limitation of local and static variables is that they have a fixed size. So they can't store a collection that dynamically grows when more elements are added. (There are proposals for [unsized rvalues] in Rust that would allow dynamically sized local variables, but they only work in some specific cases.)
|
||||
|
||||
[unsized rvalues]: https://github.com/rust-lang/rust/issues/48055
|
||||
|
||||
To circumvent these drawbacks, programming languages often support a third memory region for storing variables called the **heap**. The heap supports _dynamic memory allocation_ at runtime through two functions called `allocate` and `deallocate`. It works in the following way: The `allocate` function returns a free chunk of memory of the specified size that can be used to store a variable. This variable then lives until it is freed by calling the `deallocate` function with a reference to the variable.
|
||||
|
||||
Let's go through an example:
|
||||
|
||||
![The inner function calls `allocate(size_of([u32; 3]))`, writes `z.write([1,2,3]);`, and returns `(z as *mut u32).offset(i)`. The outer function does `deallocate(y, size_of(u32))` on the returned value `y`.](call-stack-heap.svg)
|
||||
|
||||
Here the `inner` function uses heap memory instead of static variables for storing `z`. It first allocates a memory block of the required size, which returns a `*mut u32` [raw pointer]. It then uses the [`ptr::write`] method to write the array `[1,2,3]` to it. In the last step, it uses the [`offset`] function to calculate a pointer to the `i`th element and then returns it. (Note that we omitted some required casts and unsafe blocks in this example function for brevity.)
|
||||
|
||||
[raw pointer]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
|
||||
[`ptr::write`]: https://doc.rust-lang.org/core/ptr/fn.write.html
|
||||
[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
|
||||
|
||||
The allocated memory lives until it is explicitly freed through a call to `deallocate`. Thus, the returned pointer is still valid even after `inner` returned and its part of the call stack was destroyed. The advantage of using heap memory compared to static memory is that the memory can be reused after it is freed, which we do through the `deallocate` call in `outer`. After that call, the situation looks like this:
|
||||
|
||||
![The call stack contains the local variables of outer, the heap contains z[0] and z[2], but no longer z[1].](call-stack-heap-freed.svg)
|
||||
|
||||
We see that the `z[1]` slot is free again and can be reused for the next `allocate` call. However, we also see that `z[0]` and `z[2]` are never freed because we never deallocate them. Such a bug is called a _memory leak_ and often the cause of excessive memory consumption of programs (just imagine what happens when we call `inner` repeatedly in a loop). This might seem bad, but there are much more dangerous types of bugs that can happen with dynamic allocation.
|
||||
|
||||
### Common Errors
|
||||
|
||||
Apart from memory leaks, which are unfortunate but don't make the program vulnerable to attackers, there are two common types of bugs with more severe consequences:
|
||||
|
||||
- When we accidentally continue to use a variable after calling `deallocate` on it, we have a so-called **use-after-free** vulnerability. Such a bug causes undefined behavior and can often exploited by attackers to execute arbitrary code.
|
||||
- When we accidentally free a variable twice, we have a **double-free** vulnerability. This is problematic because it might free a different allocation that was allocated in the same spot after the first `deallocate` call. Thus, it can lead to an use-after-free vulnerability again.
|
||||
|
||||
These types of vulnerabilities are commonly known, so one might expect that people learned how to avoid them by now. But no, such vulnerabilities are still regularly found, for example this recent [use-after-free vulnerability in Linux][linux vulnerability] that allowed arbitrary code execution. This shows that even the best programmers are not always able to correctly handle dynamic memory in complex projects.
|
||||
|
||||
[linux vulnerability]: https://securityboulevard.com/2019/02/linux-use-after-free-vulnerability-found-in-linux-2-6-through-4-20-11/
|
||||
|
||||
To avoid these issues, many languages such as Java or Python manage dynamic memory automatically using a technique called [_garbage collection_]. The idea is that the programmer never invokes `deallocate` manually. Instead, the program is regularly paused and scanned for unused heap variables, which are then automatically deallocated. Thus, the above vulnerabilities can never occur. The drawbacks are the performance overhead of the regular scan and the probably long pause times.
|
||||
|
||||
[_garbage collection_]: https://en.wikipedia.org/wiki/Garbage_collection_(computer_science)
|
||||
|
||||
Rust takes a different approach to the problem: It uses a concept called [_ownership_] that is able to check the correctness of dynamic memory operations at compile time. Thus no garbage collection is needed to avoid the mentioned vulnerabilities, which means that there is no performance overhead. Another advantage of this approach is that the programmer still has fine-grained control over the use of dynamic memory, just like with C or C++.
|
||||
|
||||
[_ownership_]: https://doc.rust-lang.org/book/ch04-01-what-is-ownership.html
|
||||
|
||||
### Allocations in Rust
|
||||
|
||||
Instead of letting the programmer manually call `allocate` and `deallocate`, the Rust standard library provides abstraction types that call these functions implicitly. The most important type is [**`Box`**], which is an abstraction for a heap-allocated value. It provides a [`Box::new`] constructor function that takes a value, calls `allocate` with the size of the value, and then moves the value to the newly allocated slot on the heap. To free the heap memory again, the `Box` type implements the [`Drop` trait] to call `deallocate` when it goes out of scope:
|
||||
|
||||
[**`Box`**]: https://doc.rust-lang.org/std/boxed/index.html
|
||||
[`Box::new`]: https://doc.rust-lang.org/alloc/boxed/struct.Box.html#method.new
|
||||
[`Drop` trait]: https://doc.rust-lang.org/book/ch15-03-drop.html
|
||||
|
||||
```rust
|
||||
{
|
||||
let z = Box::new([1,2,3]);
|
||||
[…]
|
||||
} // z goes out of scope and `deallocate` is called
|
||||
```
|
||||
|
||||
This pattern has the strange name [_resource acquisition is initialization_] (or _RAII_ for short). It originated in C++, where it is used to implement a similar abstraction type called [`std::unique_ptr`].
|
||||
|
||||
[_resource acquisition is initialization_]: https://en.wikipedia.org/wiki/Resource_acquisition_is_initialization
|
||||
[`std::unique_ptr`]: https://en.cppreference.com/w/cpp/memory/unique_ptr
|
||||
|
||||
Such a type alone does not suffice to prevent all use-after-free bugs since programmers can still hold on to references after the `Box` goes out of scope and the corresponding heap memory slot is deallocated:
|
||||
|
||||
```rust
|
||||
let x = {
|
||||
let z = Box::new([1,2,3]);
|
||||
&z[1]
|
||||
}; // z goes out of scope and `deallocate` is called
|
||||
println!("{}", x);
|
||||
```
|
||||
|
||||
This is where Rust's ownership comes in. It assigns an abstract [lifetime] to each reference, which is the scope in which the reference is valid. In the above example, the `x` reference is taken from the `z` array, so it becomes invalid after `z` goes out of scope. When you [run the above example on the playground][playground-2] you see that the Rust compiler indeed throws an error:
|
||||
|
||||
[lifetime]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html
|
||||
[playground-2]: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=28180d8de7b62c6b4a681a7b1f745a48
|
||||
|
||||
```
|
||||
error[E0597]: `z[_]` does not live long enough
|
||||
--> src/main.rs:4:9
|
||||
|
|
||||
2 | let x = {
|
||||
| - borrow later stored here
|
||||
3 | let z = Box::new([1,2,3]);
|
||||
4 | &z[1]
|
||||
| ^^^^^ borrowed value does not live long enough
|
||||
5 | }; // z goes out of scope and `deallocate` is called
|
||||
| - `z[_]` dropped here while still borrowed
|
||||
```
|
||||
|
||||
The terminology can be a bit confusing at first. Taking a reference to a value is called _borrowing_ the value since it's similar to a borrow in real life: You have temporary access to an object but need to return it sometime and you must not destroy it. By checking that all borrows end before an object is destroyed, the Rust compiler can guarantee that no use-after-free situation can occur.
|
||||
|
||||
Rust's ownership system goes even further and does not only prevent use-after-free bugs, but provides complete [_memory safety_] like garbage collected languages like Java or Python do. Additionally, it guarantees [_thread safety_] and is thus even safer than those languages in multi-threaded code. And most importantly, all these checks happen at compile time, so there is no runtime overhead compared to hand written memory management in C.
|
||||
|
||||
[_memory safety_]: https://en.wikipedia.org/wiki/Memory_safety
|
||||
[_thread safety_]: https://en.wikipedia.org/wiki/Thread_safety
|
||||
|
||||
### Use Cases
|
||||
|
||||
We now know the basics of dynamic memory allocation in Rust, but when should we use it? We've come really far with our kernel without dynamic memory allocation, so why do we need it now?
|
||||
|
||||
First, dynamic memory allocation always comes with a bit of performance overhead, since we need to find a free slot on the heap for every allocation. For this reason local variables are generally preferable, especially in performance sensitive kernel code. However, there are cases where dynamic memory allocation is the best choice.
|
||||
|
||||
As a basic rule, dynamic memory is required for variables that have a dynamic lifetime or a variable size. The most important type with a dynamic lifetime is [**`Rc`**], which counts the references to its wrapped value and deallocates it after all references went out of scope. Examples for types with a variable size are [**`Vec`**], [**`String`**], and other [collection types] that dynamically grow when more elements are added. These types work by allocating a larger amount of memory when they become full, copying all elements over, and then deallocating the old allocation.
|
||||
|
||||
[**`Rc`**]: https://doc.rust-lang.org/alloc/rc/index.html
|
||||
[**`Vec`**]: https://doc.rust-lang.org/alloc/vec/index.html
|
||||
[**`String`**]: https://doc.rust-lang.org/alloc/string/index.html
|
||||
[collection types]: https://doc.rust-lang.org/alloc/collections/index.html
|
||||
|
||||
For our kernel we will mostly need the collection types, for example for storing a list of active tasks when implementing multitasking in future posts.
|
||||
|
||||
## The Allocator Interface
|
||||
|
||||
The first step in implementing a heap allocator is to add a dependency on the built-in [`alloc`] crate. Like the [`core`] crate, it is a subset of the standard library that additionally contains the allocation and collection types. To add the dependency on `alloc`, we add the following to our `lib.rs`:
|
||||
|
||||
[`alloc`]: https://doc.rust-lang.org/alloc/
|
||||
[`core`]: https://doc.rust-lang.org/core/
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
extern crate alloc;
|
||||
```
|
||||
|
||||
Contrary to normal dependencies, we don't need to modify the `Cargo.toml`. The reason is that the `alloc` crate ships with the Rust compiler as part of the standard library, so the compiler already knows about the crate. By adding this `extern crate` statement, we specify that the compiler should try to include it. (Historically, all dependencies needed an `extern crate` statement, which is now optional).
|
||||
|
||||
Since we are compiling for a custom target, we can't use the precompiled version of `alloc` that is shipped with the Rust installation. Instead, we have to tell cargo to recompile the crate from source. We can do that, by adding it to the `unstable.build-std` array in our `.cargo/config.toml` file:
|
||||
|
||||
```toml
|
||||
# in .cargo/config.toml
|
||||
|
||||
[unstable]
|
||||
build-std = ["core", "compiler_builtins", "alloc"]
|
||||
````
|
||||
|
||||
Now the compiler will recompile and include the `alloc` crate in our kernel.
|
||||
|
||||
The reason that the `alloc` crate is disabled by default in `#[no_std]` crates is that it has additional requirements. We can see these requirements as errors when we try to compile our project now:
|
||||
|
||||
```
|
||||
error: no global memory allocator found but one is required; link to std or add
|
||||
#[global_allocator] to a static item that implements the GlobalAlloc trait.
|
||||
|
||||
error: `#[alloc_error_handler]` function required, but not found
|
||||
```
|
||||
|
||||
The first error occurs because the `alloc` crate requires an heap allocator, which is an object that provides the `allocate` and `deallocate` functions. In Rust, heap allocators are described by the [`GlobalAlloc`] trait, which is mentioned in the error message. To set the heap allocator for the crate, the `#[global_allocator]` attribute must be applied to a `static` variable that implements the `GlobalAlloc` trait.
|
||||
|
||||
The second error occurs because calls to `allocate` can fail, most commonly when there is no more memory available. Our program must be able to react to this case, which is what the `#[alloc_error_handler]` function is for.
|
||||
|
||||
[`GlobalAlloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html
|
||||
|
||||
We will describe these traits and attributes in detail in the following sections.
|
||||
|
||||
### The `GlobalAlloc` Trait
|
||||
|
||||
The [`GlobalAlloc`] trait defines the functions that a heap allocator must provide. The trait is special because it is almost never used directly by the programmer. Instead, the compiler will automatically insert the appropriate calls to the trait methods when using the allocation and collection types of `alloc`.
|
||||
|
||||
Since we will need to implement the trait for all our allocator types, it is worth taking a closer look at its declaration:
|
||||
|
||||
```rust
|
||||
pub unsafe trait GlobalAlloc {
|
||||
unsafe fn alloc(&self, layout: Layout) -> *mut u8;
|
||||
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
|
||||
|
||||
unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
|
||||
unsafe fn realloc(
|
||||
&self,
|
||||
ptr: *mut u8,
|
||||
layout: Layout,
|
||||
new_size: usize
|
||||
) -> *mut u8 { ... }
|
||||
}
|
||||
```
|
||||
|
||||
It defines the two required methods [`alloc`] and [`dealloc`], which correspond to the `allocate` and `deallocate` functions we used in our examples:
|
||||
- The [`alloc`] method takes a [`Layout`] instance as argument, which describes the desired size and alignment that the allocated memory should have. It returns a [raw pointer] to the first byte of the allocated memory block. Instead of an explicit error value, the `alloc` method returns a null pointer to signal an allocation error. This is a bit non-idiomatic, but it has the advantage that wrapping existing system allocators is easy, since they use the same convention.
|
||||
- The [`dealloc`] method is the counterpart and responsible for freeing a memory block again. It receives two arguments, the pointer returned by `alloc` and the `Layout` that was used for the allocation.
|
||||
|
||||
[`alloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.alloc
|
||||
[`dealloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.dealloc
|
||||
[`Layout`]: https://doc.rust-lang.org/alloc/alloc/struct.Layout.html
|
||||
|
||||
The trait additionally defines the two methods [`alloc_zeroed`] and [`realloc`] with default implementations:
|
||||
|
||||
- The [`alloc_zeroed`] method is equivalent to calling `alloc` and then setting the allocated memory block to zero, which is exactly what the provided default implementation does. An allocator implementation can override the default implementations with a more efficient custom implementation if possible.
|
||||
- The [`realloc`] method allows to grow or shrink an allocation. The default implementation allocates a new memory block with the desired size and copies over all the content from the previous allocation. Again, an allocator implementation can probably provide a more efficient implementation of this method, for example by growing/shrinking the allocation in-place if possible.
|
||||
|
||||
[`alloc_zeroed`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#method.alloc_zeroed
|
||||
[`realloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#method.realloc
|
||||
|
||||
#### Unsafety
|
||||
|
||||
One thing to notice is that both the trait itself and all trait methods are declared as `unsafe`:
|
||||
|
||||
- The reason for declaring the trait as `unsafe` is that the programmer must guarantee that the trait implementation for an allocator type is correct. For example, the `alloc` method must never return a memory block that is already used somewhere else because this would cause undefined behavior.
|
||||
- Similarly, the reason that the methods are `unsafe` is that the caller must ensure various invariants when calling the methods, for example that the `Layout` passed to `alloc` specifies a non-zero size. This is not really relevant in practice since the methods are normally called directly by the compiler, which ensures that the requirements are met.
|
||||
|
||||
### A `DummyAllocator`
|
||||
|
||||
Now that we know what an allocator type should provide, we can create a simple dummy allocator. For that we create a new `allocator` module:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod allocator;
|
||||
```
|
||||
|
||||
Our dummy allocator does the absolute minimum to implement the trait and always return an error when `alloc` is called. It looks like this:
|
||||
|
||||
```rust
|
||||
// in src/allocator.rs
|
||||
|
||||
use alloc::alloc::{GlobalAlloc, Layout};
|
||||
use core::ptr::null_mut;
|
||||
|
||||
pub struct Dummy;
|
||||
|
||||
unsafe impl GlobalAlloc for Dummy {
|
||||
unsafe fn alloc(&self, _layout: Layout) -> *mut u8 {
|
||||
null_mut()
|
||||
}
|
||||
|
||||
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
|
||||
panic!("dealloc should be never called")
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The struct does not need any fields, so we create it as a [zero sized type]. As mentioned above, we always return the null pointer from `alloc`, which corresponds to an allocation error. Since the allocator never returns any memory, a call to `dealloc` should never occur. For this reason we simply panic in the `dealloc` method. The `alloc_zeroed` and `realloc` methods have default implementations, so we don't need to provide implementations for them.
|
||||
|
||||
[zero sized type]: https://doc.rust-lang.org/nomicon/exotic-sizes.html#zero-sized-types-zsts
|
||||
|
||||
We now have a simple allocator, but we still have to tell the Rust compiler that it should use this allocator. This is where the `#[global_allocator]` attribute comes in.
|
||||
|
||||
### The `#[global_allocator]` Attribute
|
||||
|
||||
The `#[global_allocator]` attribute tells the Rust compiler which allocator instance it should use as the global heap allocator. The attribute is only applicable to a `static` that implements the `GlobalAlloc` trait. Let's register an instance of our `Dummy` allocator as the global allocator:
|
||||
|
||||
```rust
|
||||
// in src/allocator.rs
|
||||
|
||||
#[global_allocator]
|
||||
static ALLOCATOR: Dummy = Dummy;
|
||||
```
|
||||
|
||||
Since the `Dummy` allocator is a [zero sized type], we don't need to specify any fields in the initialization expression.
|
||||
|
||||
When we now try to compile it, the first error should be gone. Let's fix the remaining second error:
|
||||
|
||||
```
|
||||
error: `#[alloc_error_handler]` function required, but not found
|
||||
```
|
||||
|
||||
### The `#[alloc_error_handler]` Attribute
|
||||
|
||||
As we learned when discussing the `GlobalAlloc` trait, the `alloc` function can signal an allocation error by returning a null pointer. The question is: how should the Rust runtime react to such an allocation failure? This is where the `#[alloc_error_handler]` attribute comes in. It specifies a function that is called when an allocation error occurs, similar to how our panic handler is called when a panic occurs.
|
||||
|
||||
Let's add such a function to fix the compilation error:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
#![feature(alloc_error_handler)] // at the top of the file
|
||||
|
||||
#[alloc_error_handler]
|
||||
fn alloc_error_handler(layout: alloc::alloc::Layout) -> ! {
|
||||
panic!("allocation error: {:?}", layout)
|
||||
}
|
||||
```
|
||||
|
||||
The `alloc_error_handler` function is still unstable, so we need a feature gate to enable it. The function receives a single argument: the `Layout` instance that was passed to `alloc` when the allocation failure occurred. There's nothing we can do to resolve the failure, so we just panic with a message that contains the `Layout` instance.
|
||||
|
||||
With this function, the compilation errors should be fixed. Now we can use the allocation and collection types of `alloc`, for example we can use a [`Box`] to allocate a value on the heap:
|
||||
|
||||
[`Box`]: https://doc.rust-lang.org/alloc/boxed/struct.Box.html
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
extern crate alloc;
|
||||
|
||||
use alloc::boxed::Box;
|
||||
|
||||
fn kernel_main(boot_info: &'static BootInfo) -> ! {
|
||||
// […] print "Hello World!", call `init`, create `mapper` and `frame_allocator`
|
||||
|
||||
let x = Box::new(41);
|
||||
|
||||
// […] call `test_main` in test mode
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Note that we need to specify the `extern crate alloc` statement in our `main.rs` too. This is required because the `lib.rs` and `main.rs` part are treated as separate crates. However, we don't need to create another `#[global_allocator]` static because the global allocator applies to all crates in the project. In fact, specifying an additional allocator in another crate would be an error.
|
||||
|
||||
When we run the above code, we see that our `alloc_error_handler` function is called:
|
||||
|
||||

|
||||
|
||||
The error handler is called because the `Box::new` function implicitly calls the `alloc` function of the global allocator. Our dummy allocator always returns a null pointer, so every allocation fails. To fix this we need to create an allocator that actually returns usable memory.
|
||||
|
||||
## Creating a Kernel Heap
|
||||
|
||||
Before we can create a proper allocator, we first need to create a heap memory region from which the allocator can allocate memory. To do this, we need to define a virtual memory range for the heap region and then map this region to physical frames. See the [_"Introduction To Paging"_] post for an overview of virtual memory and page tables.
|
||||
|
||||
[_"Introduction To Paging"_]: @/second-edition/posts/08-paging-introduction/index.md
|
||||
|
||||
The first step is to define a virtual memory region for the heap. We can choose any virtual address range that we like, as long as it is not already used for a different memory region. Let's define it as the memory starting at address `0x_4444_4444_0000` so that we can easily recognize a heap pointer later:
|
||||
|
||||
```rust
|
||||
// in src/allocator.rs
|
||||
|
||||
pub const HEAP_START: usize = 0x_4444_4444_0000;
|
||||
pub const HEAP_SIZE: usize = 100 * 1024; // 100 KiB
|
||||
```
|
||||
|
||||
We set the heap size to 100 KiB for now. If we need more space in the future, we can simply increase it.
|
||||
|
||||
If we tried to use this heap region now, a page fault would occur since the virtual memory region is not mapped to physical memory yet. To resolve this, we create an `init_heap` function that maps the heap pages using the [`Mapper` API] that we introduced in the [_"Paging Implementation"_] post:
|
||||
|
||||
[`Mapper` API]: @/second-edition/posts/09-paging-implementation/index.md#using-offsetpagetable
|
||||
[_"Paging Implementation"_]: @/second-edition/posts/09-paging-implementation/index.md
|
||||
|
||||
```rust
|
||||
// in src/allocator.rs
|
||||
|
||||
use x86_64::{
|
||||
structures::paging::{
|
||||
mapper::MapToError, FrameAllocator, Mapper, Page, PageTableFlags, Size4KiB,
|
||||
},
|
||||
VirtAddr,
|
||||
};
|
||||
|
||||
pub fn init_heap(
|
||||
mapper: &mut impl Mapper<Size4KiB>,
|
||||
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
|
||||
) -> Result<(), MapToError<Size4KiB>> {
|
||||
let page_range = {
|
||||
let heap_start = VirtAddr::new(HEAP_START as u64);
|
||||
let heap_end = heap_start + HEAP_SIZE - 1u64;
|
||||
let heap_start_page = Page::containing_address(heap_start);
|
||||
let heap_end_page = Page::containing_address(heap_end);
|
||||
Page::range_inclusive(heap_start_page, heap_end_page)
|
||||
};
|
||||
|
||||
for page in page_range {
|
||||
let frame = frame_allocator
|
||||
.allocate_frame()
|
||||
.ok_or(MapToError::FrameAllocationFailed)?;
|
||||
let flags = PageTableFlags::PRESENT | PageTableFlags::WRITABLE;
|
||||
unsafe {
|
||||
mapper.map_to(page, frame, flags, frame_allocator)?.flush()
|
||||
};
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
```
|
||||
|
||||
The function takes mutable references to a [`Mapper`] and a [`FrameAllocator`] instance, both limited to 4KiB pages by using [`Size4KiB`] as generic parameter. The return value of the function is a [`Result`] with the unit type `()` as success variant and a [`MapToError`] as error variant, which is the error type returned by the [`Mapper::map_to`] method. Reusing the error type makes sense here because the `map_to` method is the main source of errors in this function.
|
||||
|
||||
[`Mapper`]:https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/mapper/trait.Mapper.html
|
||||
[`FrameAllocator`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/trait.FrameAllocator.html
|
||||
[`Size4KiB`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/page/enum.Size4KiB.html
|
||||
[`Result`]: https://doc.rust-lang.org/core/result/enum.Result.html
|
||||
[`MapToError`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/mapper/enum.MapToError.html
|
||||
[`Mapper::map_to`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/mapper/trait.Mapper.html#method.map_to
|
||||
|
||||
The implementation can be broken down into two parts:
|
||||
|
||||
- **Creating the page range:**: To create a range of the pages that we want to map, we convert the `HEAP_START` pointer to a [`VirtAddr`] type. Then we calculate the heap end address from it by adding the `HEAP_SIZE`. We want an inclusive bound (the address of the last byte of the heap), so we subtract 1. Next, we convert the addresses into [`Page`] types using the [`containing_address`] function. Finally, we create a page range from the start and end pages using the [`Page::range_inclusive`] function.
|
||||
|
||||
- **Mapping the pages:** The second step is to map all pages of the page range we just created. For that we iterate over the pages in that range using a `for` loop. For each page, we do the following:
|
||||
|
||||
- We allocate a physical frame that the page should be mapped to using the [`FrameAllocator::allocate_frame`] method. This method returns [`None`] when there are no more frames left. We deal with that case by mapping it to a [`MapToError::FrameAllocationFailed`] error through the [`Option::ok_or`] method and then apply the [question mark operator] to return early in the case of an error.
|
||||
|
||||
- We set the required `PRESENT` flag and the `WRITABLE` flag for the page. With these flags both read and write accesses are allowed, which makes sense for heap memory.
|
||||
|
||||
- We use the [`Mapper::map_to`] method for creating the mapping in the active page table. The method can fail, therefore we use the [question mark operator] again to forward the error to the caller. On success, the method returns a [`MapperFlush`] instance that we can use to update the [_translation lookaside buffer_] using the [`flush`] method.
|
||||
|
||||
[`VirtAddr`]: https://docs.rs/x86_64/0.12.1/x86_64/addr/struct.VirtAddr.html
|
||||
[`Page`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/page/struct.Page.html
|
||||
[`containing_address`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/page/struct.Page.html#method.containing_address
|
||||
[`Page::range_inclusive`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/page/struct.Page.html#method.range_inclusive
|
||||
[`FrameAllocator::allocate_frame`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/trait.FrameAllocator.html#tymethod.allocate_frame
|
||||
[`None`]: https://doc.rust-lang.org/core/option/enum.Option.html#variant.None
|
||||
[`MapToError::FrameAllocationFailed`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/mapper/enum.MapToError.html#variant.FrameAllocationFailed
|
||||
[`Option::ok_or`]: https://doc.rust-lang.org/core/option/enum.Option.html#method.ok_or
|
||||
[question mark operator]: https://doc.rust-lang.org/edition-guide/rust-2018/error-handling-and-panics/the-question-mark-operator-for-easier-error-handling.html
|
||||
[`MapperFlush`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/mapper/struct.MapperFlush.html
|
||||
[_translation lookaside buffer_]: @/second-edition/posts/08-paging-introduction/index.md#the-translation-lookaside-buffer
|
||||
[`flush`]: https://docs.rs/x86_64/0.12.1/x86_64/structures/paging/mapper/struct.MapperFlush.html#method.flush
|
||||
|
||||
The final step is to call this function from our `kernel_main`:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
fn kernel_main(boot_info: &'static BootInfo) -> ! {
|
||||
use blog_os::allocator; // new import
|
||||
use blog_os::memory::{self, BootInfoFrameAllocator};
|
||||
|
||||
println!("Hello World{}", "!");
|
||||
blog_os::init();
|
||||
|
||||
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
|
||||
let mut mapper = unsafe { memory::init(phys_mem_offset) };
|
||||
let mut frame_allocator = unsafe {
|
||||
BootInfoFrameAllocator::init(&boot_info.memory_map)
|
||||
};
|
||||
|
||||
// new
|
||||
allocator::init_heap(&mut mapper, &mut frame_allocator)
|
||||
.expect("heap initialization failed");
|
||||
|
||||
let x = Box::new(41);
|
||||
|
||||
// […] call `test_main` in test mode
|
||||
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop();
|
||||
}
|
||||
```
|
||||
|
||||
We show the full function for context here. The only new lines are the `blog_os::allocator` import and the call to `allocator::init_heap` function. In case the `init_heap` function returns an error, we panic using the [`Result::expect`] method since there is currently no sensible way for us to handle this error.
|
||||
|
||||
[`Result::expect`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.expect
|
||||
|
||||
We now have a mapped heap memory region that is ready to be used. The `Box::new` call still uses our old `Dummy` allocator, so you will still see the "out of memory" error when you run it. Let's fix this by using a proper allocator.
|
||||
|
||||
## Using an Allocator Crate
|
||||
|
||||
Since implementing an allocator is somewhat complex, we start by using an external allocator crate. We will learn how to implement our own allocator in the next post.
|
||||
|
||||
A simple allocator crate for `no_std` applications is the [`linked_list_allocator`] crate. It's name comes from the fact that it uses a linked list data structure to keep track of deallocated memory regions. See the next post for a more detailed explanation of this approach.
|
||||
|
||||
To use the crate, we first need to add a dependency on it in our `Cargo.toml`:
|
||||
|
||||
[`linked_list_allocator`]: https://github.com/phil-opp/linked-list-allocator/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
linked_list_allocator = "0.8.0"
|
||||
```
|
||||
|
||||
Then we can replace our dummy allocator with the allocator provided by the crate:
|
||||
|
||||
```rust
|
||||
// in src/allocator.rs
|
||||
|
||||
use linked_list_allocator::LockedHeap;
|
||||
|
||||
#[global_allocator]
|
||||
static ALLOCATOR: LockedHeap = LockedHeap::empty();
|
||||
```
|
||||
|
||||
The struct is named `LockedHeap` because it uses the [`spinning_top::Spinlock`] type for synchronization. This is required because multiple threads could access the `ALLOCATOR` static at the same time. As always when using a spinlock or a mutex, we need to be careful to not accidentally cause a deadlock. This means that we shouldn't perform any allocations in interrupt handlers, since they can run at an arbitrary time and might interrupt an in-progress allocation.
|
||||
|
||||
[`spinning_top::Spinlock`]: https://docs.rs/spinning_top/0.1.0/spinning_top/type.Spinlock.html
|
||||
|
||||
Setting the `LockedHeap` as global allocator is not enough. The reason is that we use the [`empty`] constructor function, which creates an allocator without any backing memory. Like our dummy allocator, it always returns an error on `alloc`. To fix this, we need to initialize the allocator after creating the heap:
|
||||
|
||||
[`empty`]: https://docs.rs/linked_list_allocator/0.8.0/linked_list_allocator/struct.LockedHeap.html#method.empty
|
||||
|
||||
```rust
|
||||
// in src/allocator.rs
|
||||
|
||||
pub fn init_heap(
|
||||
mapper: &mut impl Mapper<Size4KiB>,
|
||||
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
|
||||
) -> Result<(), MapToError<Size4KiB>> {
|
||||
// […] map all heap pages to physical frames
|
||||
|
||||
// new
|
||||
unsafe {
|
||||
ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE);
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
```
|
||||
|
||||
We use the [`lock`] method on the inner spinlock of the `LockedHeap` type to get an exclusive reference to the wrapped [`Heap`] instance, on which we then call the [`init`] method with the heap bounds as arguments. It is important that we initialize the heap _after_ mapping the heap pages, since the [`init`] function already tries to write to the heap memory.
|
||||
|
||||
[`lock`]: https://docs.rs/lock_api/0.3.3/lock_api/struct.Mutex.html#method.lock
|
||||
[`Heap`]: https://docs.rs/linked_list_allocator/0.8.0/linked_list_allocator/struct.Heap.html
|
||||
[`init`]: https://docs.rs/linked_list_allocator/0.8.0/linked_list_allocator/struct.Heap.html#method.init
|
||||
|
||||
After initializing the heap, we can now use all allocation and collection types of the built-in [`alloc`] crate without error:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
use alloc::{boxed::Box, vec, vec::Vec, rc::Rc};
|
||||
|
||||
fn kernel_main(boot_info: &'static BootInfo) -> ! {
|
||||
// […] initialize interrupts, mapper, frame_allocator, heap
|
||||
|
||||
// allocate a number on the heap
|
||||
let heap_value = Box::new(41);
|
||||
println!("heap_value at {:p}", heap_value);
|
||||
|
||||
// create a dynamically sized vector
|
||||
let mut vec = Vec::new();
|
||||
for i in 0..500 {
|
||||
vec.push(i);
|
||||
}
|
||||
println!("vec at {:p}", vec.as_slice());
|
||||
|
||||
// create a reference counted vector -> will be freed when count reaches 0
|
||||
let reference_counted = Rc::new(vec![1, 2, 3]);
|
||||
let cloned_reference = reference_counted.clone();
|
||||
println!("current reference count is {}", Rc::strong_count(&cloned_reference));
|
||||
core::mem::drop(reference_counted);
|
||||
println!("reference count is {} now", Rc::strong_count(&cloned_reference));
|
||||
|
||||
// […] call `test_main` in test context
|
||||
println!("It did not crash!");
|
||||
blog_os::hlt_loop();
|
||||
}
|
||||
```
|
||||
|
||||
This code example shows some uses of the [`Box`], [`Vec`], and [`Rc`] types. For the `Box` and `Vec` types we print the underlying heap pointers using the [`{:p}` formatting specifier]. For showcasing `Rc`, we create a reference counted heap value and use the [`Rc::strong_count`] function to print the current reference count, before and after dropping an instance (using [`core::mem::drop`]).
|
||||
|
||||
[`Vec`]: https://doc.rust-lang.org/alloc/vec/
|
||||
[`Rc`]: https://doc.rust-lang.org/alloc/rc/
|
||||
[`{:p}` formatting specifier]: https://doc.rust-lang.org/core/fmt/trait.Pointer.html
|
||||
[`Rc::strong_count`]: https://doc.rust-lang.org/alloc/rc/struct.Rc.html#method.strong_count
|
||||
[`core::mem::drop`]: https://doc.rust-lang.org/core/mem/fn.drop.html
|
||||
|
||||
When we run it, we see the following:
|
||||
|
||||

|
||||
|
||||
As expected, we see that the `Box` and `Vec` values live on the heap, as indicated by the pointer starting with the `0x_4444_4444_*` prefix. The reference counted value also behaves as expected, with the reference count being 2 after the `clone` call, and 1 again after one of the instances was dropped.
|
||||
|
||||
The reason that the vector starts at offset `0x800` is not that the boxed value is `0x800` bytes large, but the [reallocations] that occur when the vector needs to increase its capacity. For example, when the vector's capacity is 32 and we try to add the next element, the vector allocates a new backing array with capacity 64 behind the scenes and copies all elements over. Then it frees the old allocation.
|
||||
|
||||
[reallocations]: https://doc.rust-lang.org/alloc/vec/struct.Vec.html#capacity-and-reallocation
|
||||
|
||||
Of course there are many more allocation and collection types in the `alloc` crate that we can now all use in our kernel, including:
|
||||
|
||||
- the thread-safe reference counted pointer [`Arc`]
|
||||
- the owned string type [`String`] and the [`format!`] macro
|
||||
- [`LinkedList`]
|
||||
- the growable ring buffer [`VecDeque`]
|
||||
- the [`BinaryHeap`] priority queue
|
||||
- [`BTreeMap`] and [`BTreeSet`]
|
||||
|
||||
[`Arc`]: https://doc.rust-lang.org/alloc/sync/struct.Arc.html
|
||||
[`String`]: https://doc.rust-lang.org/alloc/string/struct.String.html
|
||||
[`format!`]: https://doc.rust-lang.org/alloc/macro.format.html
|
||||
[`LinkedList`]: https://doc.rust-lang.org/alloc/collections/linked_list/struct.LinkedList.html
|
||||
[`VecDeque`]: https://doc.rust-lang.org/alloc/collections/vec_deque/struct.VecDeque.html
|
||||
[`BinaryHeap`]: https://doc.rust-lang.org/alloc/collections/binary_heap/struct.BinaryHeap.html
|
||||
[`BTreeMap`]: https://doc.rust-lang.org/alloc/collections/btree_map/struct.BTreeMap.html
|
||||
[`BTreeSet`]: https://doc.rust-lang.org/alloc/collections/btree_set/struct.BTreeSet.html
|
||||
|
||||
These types will become very useful when we want to implement thread lists, scheduling queues, or support for async/await.
|
||||
|
||||
## Adding a Test
|
||||
|
||||
To ensure that we don't accidentally break our new allocation code, we should add an integration test for it. We start by creating a new `tests/heap_allocation.rs` file with the following content:
|
||||
|
||||
```rust
|
||||
// in tests/heap_allocation.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(blog_os::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
extern crate alloc;
|
||||
|
||||
use bootloader::{entry_point, BootInfo};
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
entry_point!(main);
|
||||
|
||||
fn main(boot_info: &'static BootInfo) -> ! {
|
||||
unimplemented!();
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
We reuse the `test_runner` and `test_panic_handler` functions from our `lib.rs`. Since we want to test allocations, we enable the `alloc` crate through the `extern crate alloc` statement. For more information about the test boilerplate check out the [_Testing_] post.
|
||||
|
||||
[_Testing_]: @/second-edition/posts/04-testing/index.md
|
||||
|
||||
The implementation of the `main` function looks like this:
|
||||
|
||||
```rust
|
||||
// in tests/heap_allocation.rs
|
||||
|
||||
fn main(boot_info: &'static BootInfo) -> ! {
|
||||
use blog_os::allocator;
|
||||
use blog_os::memory::{self, BootInfoFrameAllocator};
|
||||
use x86_64::VirtAddr;
|
||||
|
||||
blog_os::init();
|
||||
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
|
||||
let mut mapper = unsafe { memory::init(phys_mem_offset) };
|
||||
let mut frame_allocator = unsafe {
|
||||
BootInfoFrameAllocator::init(&boot_info.memory_map)
|
||||
};
|
||||
allocator::init_heap(&mut mapper, &mut frame_allocator)
|
||||
.expect("heap initialization failed");
|
||||
|
||||
test_main();
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
It is very similar to the `kernel_main` function in our `main.rs`, with the differences that we don't invoke `println`, don't include any example allocations, and call `test_main` unconditionally.
|
||||
|
||||
Now we're ready to add a few test cases. First, we add a test that performs some simple allocations using [`Box`] and checks the allocated values, to ensure that basic allocations work:
|
||||
|
||||
```rust
|
||||
// in tests/heap_allocation.rs
|
||||
|
||||
use blog_os::{serial_print, serial_println};
|
||||
use alloc::boxed::Box;
|
||||
|
||||
#[test_case]
|
||||
fn simple_allocation() {
|
||||
let heap_value_1 = Box::new(41);
|
||||
let heap_value_2 = Box::new(13);
|
||||
assert_eq!(*heap_value_1, 41);
|
||||
assert_eq!(*heap_value_2, 13);
|
||||
}
|
||||
```
|
||||
|
||||
Most importantly, this test verifies that no allocation error occurs.
|
||||
|
||||
Next, we iteratively build a large vector, to test both large allocations and multiple allocations (due to reallocations):
|
||||
|
||||
```rust
|
||||
// in tests/heap_allocation.rs
|
||||
|
||||
use alloc::vec::Vec;
|
||||
|
||||
#[test_case]
|
||||
fn large_vec() {
|
||||
let n = 1000;
|
||||
let mut vec = Vec::new();
|
||||
for i in 0..n {
|
||||
vec.push(i);
|
||||
}
|
||||
assert_eq!(vec.iter().sum::<u64>(), (n - 1) * n / 2);
|
||||
}
|
||||
```
|
||||
|
||||
We verify the sum by comparing it with the formula for the [n-th partial sum]. This gives us some confidence that the allocated values are all correct.
|
||||
|
||||
[n-th partial sum]: https://en.wikipedia.org/wiki/1_%2B_2_%2B_3_%2B_4_%2B_%E2%8B%AF#Partial_sums
|
||||
|
||||
As a third test, we create ten thousand allocations after each other:
|
||||
|
||||
```rust
|
||||
// in tests/heap_allocation.rs
|
||||
|
||||
use blog_os::allocator::HEAP_SIZE;
|
||||
|
||||
#[test_case]
|
||||
fn many_boxes() {
|
||||
for i in 0..HEAP_SIZE {
|
||||
let x = Box::new(i);
|
||||
assert_eq!(*x, i);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This test ensures that the allocator reuses freed memory for subsequent allocations since it would run out of memory otherwise. This might seem like an obvious requirement for an allocator, but there are allocator designs that don't do this. An example is the bump allocator design that will be explained in the next post.
|
||||
|
||||
Let's run our new integration test:
|
||||
|
||||
```
|
||||
> cargo test --test heap_allocation
|
||||
[…]
|
||||
Running 3 tests
|
||||
simple_allocation... [ok]
|
||||
large_vec... [ok]
|
||||
many_boxes... [ok]
|
||||
```
|
||||
|
||||
All three tests succeeded! You can also invoke `cargo test` (without `--test` argument) to run all unit and integration tests.
|
||||
|
||||
## Summary
|
||||
|
||||
This post gave an introduction to dynamic memory and explained why and where it is needed. We saw how Rust's borrow checker prevents common vulnerabilities and learned how Rust's allocation API works.
|
||||
|
||||
After creating a minimal implementation of Rust's allocator interface using a dummy allocator, we created a proper heap memory region for our kernel. For that we defined a virtual address range for the heap and then mapped all pages of that range to physical frames using the `Mapper` and `FrameAllocator` from the previous post.
|
||||
|
||||
Finally, we added a dependency on the `linked_list_allocator` crate to add a proper allocator to our kernel. With this allocator, we were able to use `Box`, `Vec`, and other allocation and collection types from the `alloc` crate.
|
||||
|
||||
## What's next?
|
||||
|
||||
While we already added heap allocation support in this post, we left most of the work to the `linked_list_allocator` crate. The next post will show in detail how an allocator can be implemented from scratch. It will present multiple possible allocator designs, shows how to implement simple versions of them, and explain their advantages and drawbacks.
|
||||
{kind=link}
|
Before Width: | Height: | Size: 9.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 11 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 45 KiB |
{kind=link}
|
Before Width: | Height: | Size: 41 KiB |
{kind=link}
|
Before Width: | Height: | Size: 47 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.5 KiB |