mirror of
https://github.com/phil-opp/blog_os.git
synced 2025-12-16 22:37:49 +00:00
Merge branch 'master' into hardware-interrupts
This commit is contained in:
@@ -60,10 +60,10 @@ install:
|
||||
- echo %cd%
|
||||
- mkdir "C:\Program Files\qemu"
|
||||
- cd "C:\Program Files\qemu"
|
||||
- if %target%==i686-pc-windows-msvc appveyor DownloadFile "https://qemu.weilnetz.de/w32/qemu-w32-setup-20180519.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==i686-pc-windows-gnu appveyor DownloadFile "https://qemu.weilnetz.de/w32/qemu-w32-setup-20180519.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==x86_64-pc-windows-msvc appveyor DownloadFile "https://qemu.weilnetz.de/w64/qemu-w64-setup-20180519.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==x86_64-pc-windows-gnu appveyor DownloadFile "https://qemu.weilnetz.de/w64/qemu-w64-setup-20180519.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==i686-pc-windows-msvc appveyor DownloadFile "https://qemu.weilnetz.de/w32/2018/qemu-w32-setup-20180801.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==i686-pc-windows-gnu appveyor DownloadFile "https://qemu.weilnetz.de/w32/2018/qemu-w32-setup-20180801.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==x86_64-pc-windows-msvc appveyor DownloadFile "https://qemu.weilnetz.de/w64/2018/qemu-w64-setup-20180801.exe" -FileName "qemu-setup.exe"
|
||||
- if %target%==x86_64-pc-windows-gnu appveyor DownloadFile "https://qemu.weilnetz.de/w64/2018/qemu-w64-setup-20180801.exe" -FileName "qemu-setup.exe"
|
||||
- 7z x qemu-setup.exe
|
||||
- set PATH=%PATH%;C:\Program Files\qemu
|
||||
- cd "C:\projects\blog-os"
|
||||
|
||||
@@ -18,6 +18,7 @@ rust:
|
||||
os:
|
||||
- linux
|
||||
- osx
|
||||
- windows
|
||||
|
||||
cache:
|
||||
cargo: true
|
||||
@@ -31,6 +32,7 @@ addons:
|
||||
|
||||
install:
|
||||
- if [ $TRAVIS_OS_NAME = osx ]; then brew update; brew install qemu; fi
|
||||
- if [ $TRAVIS_OS_NAME = windows ]; then wget https://qemu.weilnetz.de/w64/2018/qemu-w64-setup-20180801.exe; 7z x qemu-w64-setup-20180801.exe; fi
|
||||
|
||||
before_script:
|
||||
- rustup component add rust-src
|
||||
|
||||
@@ -429,7 +429,7 @@ When we discussed calling conventions above, we assummed that a x86_64 CPU only
|
||||
|
||||
However, modern CPUs also have a set of _special purpose registers_, which can be used to improve performance in several use cases. On x86_64, the most important set of special purpose registers are the _multimedia registers_. These registers are larger than the general purpose registers and can be used to speed up audio/video processing or matrix calculations. For example, we could use them to add two 4-dimensional vectors _in a single CPU instruction_:
|
||||
|
||||
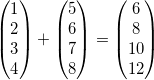
|
||||

|
||||
|
||||
Such multimedia instructions are called [Single Instruction Multiple Data (SIMD)] instructions, because they simultaneously perform an operation (e.g. addition) on multiple data words. Good compilers are able to transform normal loops into such SIMD code automatically. This process is called [auto-vectorization] and can lead to huge performance improvements.
|
||||
|
||||
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 2.2 KiB |
@@ -29,7 +29,7 @@ The [first edition] required several C-tools for building:
|
||||
[linker script]: http://www.scoberlin.de/content/media/http/informatik/gcc_docs/ld_3.html
|
||||
[`make`]: https://www.gnu.org/software/make/
|
||||
|
||||
We got lots of feedback that this setup was difficult to get to run [under macOS] and Windows. As a workaround, we [added support for docker], but that still required users to install and understand an additional dependency. So when we decided to create a second edition of the blog, originally because the order of posts led to jumps in difficulty, we thought about how we could avoid these C-dependencies.
|
||||
We got lots of feedback that this setup was difficult to get running [under macOS] and Windows. As a workaround, we [added support for docker], but that still required users to install and understand an additional dependency. So when we decided to create a second edition of the blog - originally because the order of posts led to jumps in difficulty - we thought about how we could avoid these C-dependencies.
|
||||
|
||||
[under macOS]: https://github.com/phil-opp/blog_os/issues/55
|
||||
[added support for docker]: https://github.com/phil-opp/blog_os/pull/373
|
||||
|
||||
@@ -134,9 +134,7 @@ This sets the panic strategy to `abort` for both the `dev` profile (used for `ca
|
||||
|
||||
### Panic Implementation
|
||||
|
||||
The `panic_impl` language item defines the function that the compiler should invoke when a [panic] occurs. Instead of providing the language item directly, we can use the [`panic_implementation`] attribute to create a `panic` function:
|
||||
|
||||
[`panic_implementation`]: https://github.com/rust-lang/rfcs/blob/master/text/2070-panic-implementation.md#panic_implementation
|
||||
The `panic_impl` language item defines the function that the compiler should invoke when a [panic] occurs. Instead of providing the language item directly, we can use the [`panic_handler`] attribute to create a `panic` function.
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
@@ -144,9 +142,8 @@ The `panic_impl` language item defines the function that the compiler should inv
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
@@ -157,22 +154,6 @@ The [`PanicInfo` parameter][PanicInfo] contains the file and line where the pani
|
||||
[diverging function]: https://doc.rust-lang.org/book/first-edition/functions.html#diverging-functions
|
||||
[“never” type]: https://doc.rust-lang.org/nightly/std/primitive.never.html
|
||||
|
||||
When we try `cargo build` now, we get an error that “#[panic_implementation] is an unstable feature”.
|
||||
|
||||
#### Enabling Unstable Features
|
||||
|
||||
The `panic_implementation` attribute was recently added and is thus still unstable and protected by a so-called _feature gate_. A feature gate is a special attribute that you have to specify at the top of your `main.rs` in order to use the corresponding feature. By doing this you basically say: “I know that this feature is unstable and that it might stop working without any warnings. I want to use it anyway.”
|
||||
|
||||
Feature gates are not available in the stable or beta Rust compilers, only [nightly Rust] makes it possible to opt-in. This means that you have to use a nightly compiler for OS development for the near future (until all unstable features that we need are added are stabilized).
|
||||
|
||||
[nightly Rust]: https://doc.rust-lang.org/book/first-edition/release-channels.html
|
||||
|
||||
To manage Rust installations I highly recommend [rustup]. It allows you to install nightly, beta, and stable compilers side-by-side and makes it easy to update them. To use a nightly compiler for the current directory, you can run `rustup override add nightly`. Alternatively, you can add a file called `rust-toolchain` with the content `nightly` to the project's root directory.
|
||||
|
||||
[rustup]: https://www.rustup.rs/
|
||||
|
||||
After installing a nightly Rust compiler, you can enable the unstable `panic_implementation` feature by inserting `#![feature(panic_implementation)]` right at the top of `main.rs`.
|
||||
|
||||
Now we fixed both language item errors. However, if we try to compile it now, another language item is required:
|
||||
|
||||
```
|
||||
@@ -196,16 +177,14 @@ Our freestanding executable does not have access to the Rust runtime and `crt0`,
|
||||
To tell the Rust compiler that we don't want to use the normal entry point chain, we add the `#![no_main]` attribute.
|
||||
|
||||
```rust
|
||||
#![feature(panic_implementation)]
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
@@ -215,7 +194,7 @@ You might notice that we removed the `main` function. The reason is that a `main
|
||||
The entry point convention depends on your operating system. I recommend you to read the Linux section even if you're on a different OS because we will use this convention for our kernel.
|
||||
|
||||
#### Linux
|
||||
On Linux, the default entry point is called `_start`. The linker just looks for a function with that name and sets this function as entry point the executable. So to overwrite the entry point, we define our own `_start` function:
|
||||
On Linux, the default entry point is called `_start`. The linker just looks for a function with that name and sets this function as entry point to the executable. So, to overwrite the entry point, we define our own `_start` function:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
@@ -311,16 +290,14 @@ A minimal freestanding Rust binary looks like this:
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![feature(panic_implementation)] // required for defining the panic handler
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@ date = 2018-02-10
|
||||
template = "second-edition/page.html"
|
||||
+++
|
||||
|
||||
In this post we create a minimal 64-bit Rust kernel for the x86 architecture. We built upon the [freestanding Rust binary] from the previous post to create a bootable disk image, that prints something to the screen.
|
||||
In this post we create a minimal 64-bit Rust kernel for the x86 architecture. We build upon the [freestanding Rust binary] from the previous post to create a bootable disk image, that prints something to the screen.
|
||||
|
||||
[freestanding Rust binary]: ./second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
@@ -57,7 +57,7 @@ To avoid that every operating system implements its own bootloader, which is onl
|
||||
[Multiboot]: https://wiki.osdev.org/Multiboot
|
||||
[GNU GRUB]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
|
||||
To make a kernel Multiboot compliant, one just needs to insert a so-called [Multiboot header] at the beginning of the kernel file. This makes it very easy to boot an OS in GRUB. However, GRUB and the the Multiboot standard have some problems too:
|
||||
To make a kernel Multiboot compliant, one just needs to insert a so-called [Multiboot header] at the beginning of the kernel file. This makes it very easy to boot an OS in GRUB. However, GRUB and the Multiboot standard have some problems too:
|
||||
|
||||
[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
|
||||
|
||||
@@ -199,16 +199,14 @@ Compiling for our new target will use Linux conventions (I'm not quite sure why,
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![feature(panic_implementation)] // required for defining the panic handler
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![no_main] // disable all Rust-level entry points
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
@@ -239,7 +237,7 @@ It fails! The error tells us that the Rust compiler no longer finds the `core` o
|
||||
The problem is that the core library is distributed together with the Rust compiler as a _precompiled_ library. So it is only valid for supported host triples (e.g., `x86_64-unknown-linux-gnu`) but not for our custom target. If we want to compile code for other targets, we need to recompile `core` for these targets first.
|
||||
|
||||
#### Cargo xbuild
|
||||
That's where [`cargo xbuild`] comes in. It is a wrapper for `cargo build` that automatically cross-compiles the built-in libraries. We can install it by executing:
|
||||
That's where [`cargo xbuild`] comes in. It is a wrapper for `cargo build` that automatically cross-compiles `core` and other built-in libraries. We can install it by executing:
|
||||
|
||||
[`cargo xbuild`]: https://github.com/rust-osdev/cargo-xbuild
|
||||
|
||||
@@ -249,7 +247,27 @@ cargo install cargo-xbuild
|
||||
|
||||
The command depends on the rust source code, which we can install with `rustup component add rust-src`.
|
||||
|
||||
We now can rerun the above command with `xbuild` instead of `build`:
|
||||
Now we can rerun the above command with `xbuild` instead of `build`:
|
||||
|
||||
```
|
||||
> cargo xbuild --target x86_64-blog_os.json
|
||||
```
|
||||
|
||||
Depending on your version of the Rust compiler you might get the following error:
|
||||
|
||||
```
|
||||
error: The sysroot can't be built for the Stable channel. Switch to nightly.
|
||||
```
|
||||
|
||||
To understand this error, you need to know that the Rust compiler has three release channels: _stable_, _beta_, and _nightly_. The Rust Book explains the difference between these channels really well, so take a minute and [check it out](https://doc.rust-lang.org/book/second-edition/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains).
|
||||
|
||||
Some experimental features are only available on the nightly channel. Since Rust uses many of these features for the internal implementation of `core` and other built-in libraries, we need to use a nightly compiler when invoking `cargo xbuild` (since it rebuilds these libraries).
|
||||
|
||||
To manage Rust installations I highly recommend [rustup]. It allows you to install nightly, beta, and stable compilers side-by-side and makes it easy to update them. With rustup you can use a nightly compiler for the current directory by running `rustup override add nightly`. Alternatively, you can add a file called `rust-toolchain` with the content `nightly` to the project's root directory.
|
||||
|
||||
[rustup]: https://www.rustup.rs/
|
||||
|
||||
With a nightly compiler the build finally succeeds:
|
||||
|
||||
```
|
||||
> cargo xbuild --target x86_64-blog_os.json
|
||||
@@ -261,7 +279,7 @@ We now can rerun the above command with `xbuild` instead of `build`:
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
It worked! We see that `cargo xbuild` cross-compiled the `core`, `compiler_builtin`, and `alloc` libraries for our new custom target and then continued to compile our `blog_os` crate.
|
||||
We see that `cargo xbuild` cross-compiled the `core`, `compiler_builtin`, and `alloc` libraries for our new custom target and then continued to compile our `blog_os` crate.
|
||||
|
||||
Now we are able to build our kernel for a bare metal target. However, our `_start` entry point, which will be called by the boot loader, is still empty. So let's output something to screen from it.
|
||||
|
||||
|
||||
@@ -347,7 +347,7 @@ pub fn print_something() {
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_str("ello! ").unwrap();
|
||||
writer.write_string("ello! ");
|
||||
write!(writer, "The numbers are {} and {}", 42, 1.0/3.0).unwrap();
|
||||
}
|
||||
```
|
||||
@@ -627,9 +627,8 @@ Now that we have a `println` macro, we can use it in our panic function to print
|
||||
// in main.rs
|
||||
|
||||
/// This function is called on panic.
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
|
||||
@@ -28,7 +28,7 @@ Unfortunately it's a bit more complicated for `no_std` applications such as our
|
||||
error[E0152]: duplicate lang item found: `panic_impl`.
|
||||
--> src/main.rs:35:1
|
||||
|
|
||||
35 | / pub fn panic(info: &PanicInfo) -> ! {
|
||||
35 | / fn panic(info: &PanicInfo) -> ! {
|
||||
36 | | println!("{}", info);
|
||||
37 | | loop {}
|
||||
38 | | }
|
||||
@@ -37,7 +37,7 @@ error[E0152]: duplicate lang item found: `panic_impl`.
|
||||
= note: first defined in crate `std`.
|
||||
```
|
||||
|
||||
The problem is that unit tests are built for the host machine, with the `std` library included. This makes sense because they should be able to run as a normal application on the host operating system. Since the standard library has it's own `panic_implementation` function, we get the above error. To fix it, we use [conditional compilation] to include our implementation of the panic handler only in non-test environments:
|
||||
The problem is that unit tests are built for the host machine, with the `std` library included. This makes sense because they should be able to run as a normal application on the host operating system. Since the standard library has it's own `panic_handler` function, we get the above error. To fix it, we use [conditional compilation] to include our implementation of the panic handler only in non-test environments:
|
||||
|
||||
[conditional compilation]: https://doc.rust-lang.org/reference/attributes.html#conditional-compilation
|
||||
|
||||
@@ -48,9 +48,8 @@ The problem is that unit tests are built for the host machine, with the `std` li
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[cfg(not(test))] // only compile when the test flag is not set
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
|
||||
@@ -329,7 +329,6 @@ Cargo allows to add [additional executables] to a project by putting them inside
|
||||
```rust
|
||||
// src/bin/test-something.rs
|
||||
|
||||
#![feature(panic_implementation)]
|
||||
#![no_std]
|
||||
#![cfg_attr(not(test), no_main)]
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -344,9 +343,8 @@ pub extern "C" fn _start() -> ! {
|
||||
}
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
@@ -402,7 +400,6 @@ pub unsafe fn exit_qemu() {
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![feature(panic_implementation)] // required for defining the panic handler
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![cfg_attr(not(test), no_main)] // disable all Rust-level entry points
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -425,9 +422,8 @@ pub extern "C" fn _start() -> ! {
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
@@ -464,7 +460,6 @@ We are finally able to create our first integration test executable. We start si
|
||||
```rust
|
||||
// in src/bin/test-basic-boot.rs
|
||||
|
||||
#![feature(panic_implementation)] // required for defining the panic handler
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![cfg_attr(not(test), no_main)] // disable all Rust-level entry points
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -490,9 +485,8 @@ pub extern "C" fn _start() -> ! {
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
serial_println!("failed");
|
||||
|
||||
serial_println!("{}", info);
|
||||
@@ -531,7 +525,6 @@ To test that our panic handler is really invoked on a panic, we create a `test-p
|
||||
```rust
|
||||
// in src/bin/test-panic.rs
|
||||
|
||||
#![feature(panic_implementation)]
|
||||
#![no_std]
|
||||
#![cfg_attr(not(test), no_main)]
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -549,9 +542,8 @@ pub extern "C" fn _start() -> ! {
|
||||
}
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
serial_println!("ok");
|
||||
|
||||
unsafe { exit_qemu(); }
|
||||
|
||||
@@ -204,10 +204,14 @@ If you are interested in more details: We also have a series of posts that expla
|
||||
[too-much-magic]: #too-much-magic
|
||||
|
||||
## Implementation
|
||||
Now that we've understood the theory, it's time to handle CPU exceptions in our kernel. We start by creating an `init_idt` function that creates a new `InterruptDescriptorTable`:
|
||||
Now that we've understood the theory, it's time to handle CPU exceptions in our kernel. We'll start by creating a new interrupts module in `src/interrupts.rs`, that first creates an `init_idt` function that creates a new `InterruptDescriptorTable`:
|
||||
|
||||
``` rust
|
||||
// in src/main.rs
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod interrupts;
|
||||
|
||||
// in src/interrupts.rs
|
||||
|
||||
extern crate x86_64;
|
||||
use x86_64::structures::idt::InterruptDescriptorTable;
|
||||
@@ -228,7 +232,7 @@ The breakpoint exception is commonly used in debuggers: When the user sets a bre
|
||||
For our use case, we don't need to overwrite any instructions. Instead, we just want to print a message when the breakpoint instruction is executed and then continue the program. So let's create a simple `breakpoint_handler` function and add it to our IDT:
|
||||
|
||||
```rust
|
||||
/// in src/main.rs
|
||||
// in src/interrupts.rs
|
||||
|
||||
use x86_64::structures::idt::{InterruptDescriptorTable, ExceptionStackFrame};
|
||||
|
||||
@@ -246,7 +250,7 @@ extern "x86-interrupt" fn breakpoint_handler(
|
||||
|
||||
Our handler just outputs a message and pretty-prints the exception stack frame.
|
||||
|
||||
When we try to compile it, the following error occurs:
|
||||
When we try to compile it, the following errors occur:
|
||||
|
||||
```
|
||||
error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
|
||||
@@ -260,7 +264,45 @@ error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue
|
||||
= help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
|
||||
```
|
||||
|
||||
This error occurs because the `x86-interrupt` calling convention is still unstable. To use it anyway, we have to explicitly enable it by adding `#![feature(abi_x86_interrupt)]` on the top of our `main.rs`.
|
||||
This error occurs because the `x86-interrupt` calling convention is still unstable. To use it anyway, we have to explicitly enable it by adding `#![feature(abi_x86_interrupt)]` on the top of our `lib.rs`.
|
||||
|
||||
```
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src/interrupts.rs:40:5
|
||||
|
|
||||
40 | println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
|
||||
| ^^^^^^^
|
||||
|
|
||||
= help: have you added the `#[macro_use]` on the module/import?
|
||||
```
|
||||
|
||||
This happened because we forgot to add `#[macro_use]` before our import of the `vga_buffer` module.
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod gdt;
|
||||
pub mod interrupts;
|
||||
pub mod serial;
|
||||
#[macro_use] // new
|
||||
pub mod vga_buffer;
|
||||
```
|
||||
|
||||
However, after adding `#[macro_use]` before the module import, we still get the same error. Sometimes this can be confusing, but it's actually a quirk of how Rust's macro system works. Macros _must be defined_ before you can use them. This is one case where import order matters in Rust. We can easily fix this by ensuring the order of our imports places the macros first:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
#[macro_use]
|
||||
pub mod vga_buffer; // import this before other modules so its macros may be used
|
||||
pub mod gdt;
|
||||
pub mod interrupts;
|
||||
pub mod serial;
|
||||
```
|
||||
|
||||
Now we can use our `print!` and `println!` macros in `interrupts.rs`. If you'd like to know more about the ins and outs of macros and how they differ from functions [you can find more information here][in-depth-rust-macros].
|
||||
|
||||
[in-depth-rust-macros]: https://doc.rust-lang.org/book/second-edition/appendix-04-macros.html
|
||||
|
||||
### Loading the IDT
|
||||
In order that the CPU uses our new interrupt descriptor table, we need to load it using the [`lidt`] instruction. The `InterruptDescriptorTable` struct of the `x86_64` provides a [`load`][InterruptDescriptorTable::load] method function for that. Let's try to use it:
|
||||
@@ -269,7 +311,7 @@ In order that the CPU uses our new interrupt descriptor table, we need to load i
|
||||
[InterruptDescriptorTable::load]: https://docs.rs/x86_64/0.2.8/x86_64/structures/idt/struct.InterruptDescriptorTable.html#method.load
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
// in src/interrupts.rs
|
||||
|
||||
pub fn init_idt() {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
@@ -339,10 +381,7 @@ We already imported the `lazy_static` crate when we [created an abstraction for
|
||||
[vga text buffer lazy static]: ./second-edition/posts/03-vga-text-buffer/index.md#lazy-statics
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[macro_use]
|
||||
extern crate lazy_static;
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
@@ -370,7 +409,7 @@ Now we should be able to handle breakpoint exceptions! Let's try it in our `_sta
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
init_idt();
|
||||
blog_os::interrupts::init_idt();
|
||||
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::int3();
|
||||
@@ -395,15 +434,14 @@ Let's create an integration test that ensures that the above continues to work.
|
||||
```rust
|
||||
// in src/bin/test-exception-breakpoint.rs
|
||||
|
||||
use blog_os::exit_qemu;
|
||||
[…]
|
||||
use core::sync::atomic::{AtomicUsize, Ordering};
|
||||
|
||||
static BREAKPOINT_HANDLER_CALLED: AtomicUsize = AtomicUsize::new(0);
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init_idt();
|
||||
init_test_idt();
|
||||
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::int3();
|
||||
@@ -424,16 +462,31 @@ pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn breakpoint_handler(_: &mut ExceptionStackFrame) {
|
||||
|
||||
lazy_static! {
|
||||
static ref TEST_IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_test_idt() {
|
||||
TEST_IDT.load();
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn breakpoint_handler(
|
||||
_stack_frame: &mut ExceptionStackFrame)
|
||||
{
|
||||
BREAKPOINT_HANDLER_CALLED.fetch_add(1, Ordering::SeqCst);
|
||||
}
|
||||
|
||||
// […]
|
||||
[…]
|
||||
```
|
||||
|
||||
For space reasons we don't show the full content here. You can find the full file [on Github](https://github.com/phil-opp/blog_os/blob/master/src/bin/test-exception-breakpoint.rs).
|
||||
|
||||
It is basically a copy of our `main.rs` with some modifications to `_start` and `breakpoint_handler`. The most interesting part is the `BREAKPOINT_HANDLER_CALLER` static. It is an [`AtomicUsize`], an integer type that can be safely concurrently modifies because all of its operations are atomic. We increment it when the `breakpoint_handler` is called and verify in our `_start` function that the handler was called exactly once.
|
||||
It is similar to our `main.rs`, but uses a custom IDT called `TEST_IDT` and different `_start` and `breakpoint_handler` functions. The most interesting part is the `BREAKPOINT_HANDLER_CALLER` static. It is an [`AtomicUsize`], an integer type that can be safely concurrently modifies because all of its operations are atomic. We increment it when the `breakpoint_handler` is called and verify in our `_start` function that the handler was called exactly once.
|
||||
|
||||
[`AtomicUsize`]: https://doc.rust-lang.org/core/sync/atomic/struct.AtomicUsize.html
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@ Let's provoke a double fault by triggering an exception for that we didn't defin
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
init_idt();
|
||||
blog_os::interrupts::init_idt();
|
||||
|
||||
// trigger a page fault
|
||||
unsafe {
|
||||
@@ -60,7 +60,7 @@ So in order to prevent this triple fault, we need to either provide a handler fu
|
||||
A double fault is a normal exception with an error code, so we can specify a handler function similar to our breakpoint handler:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
// in src/interrupts.rs
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
@@ -162,7 +162,7 @@ Let's try it ourselves! We can easily provoke a kernel stack overflow by calling
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
init_idt();
|
||||
blog_os::interrupts::init_idt();
|
||||
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // for each recursion, the return address is pushed
|
||||
@@ -314,7 +314,7 @@ pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
blog_os::gdt::init();
|
||||
init_idt();
|
||||
blog_os::interrupts::init_idt();
|
||||
|
||||
[…]
|
||||
}
|
||||
@@ -380,7 +380,9 @@ We reload the code segment register using [`set_cs`] and to load the TSS using [
|
||||
Now that we loaded a valid TSS and interrupt stack table, we can set the stack index for our double fault handler in the IDT:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
// in src/interrupts.rs
|
||||
|
||||
use gdt;
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
@@ -388,7 +390,7 @@ lazy_static! {
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
unsafe {
|
||||
idt.double_fault.set_handler_fn(double_fault_handler)
|
||||
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX); // new
|
||||
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
|
||||
}
|
||||
|
||||
idt
|
||||
|
||||
@@ -54,6 +54,21 @@
|
||||
})();
|
||||
</script>
|
||||
<!-- End Piwik Code -->
|
||||
|
||||
<!-- Fathom - simple website analytics - https://github.com/usefathom/fathom -->
|
||||
<script>
|
||||
(function(f, a, t, h, o, m){
|
||||
a[h]=a[h]||function(){
|
||||
(a[h].q=a[h].q||[]).push(arguments)
|
||||
};
|
||||
o=f.createElement('script'),
|
||||
m=f.getElementsByTagName('script')[0];
|
||||
o.async=1; o.src=t; o.id='fathom-script';
|
||||
m.parentNode.insertBefore(o,m)
|
||||
})(document, window, '//fathom.phil-opp.com/tracker.js', 'fathom');
|
||||
fathom('trackPageview');
|
||||
</script>
|
||||
<!-- / Fathom -->
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
@@ -9,6 +9,7 @@
|
||||
<meta name="description" content="{{ config.description }}">
|
||||
<meta name="author" content="{{ config.extra.author.name }}">
|
||||
|
||||
<link rel="canonical" href="{{ current_url | safe }}" />
|
||||
<link href="/css/poole.css" rel="stylesheet">
|
||||
<link href="/css/main.css" rel="stylesheet">
|
||||
|
||||
@@ -54,6 +55,21 @@
|
||||
})();
|
||||
</script>
|
||||
<!-- End Piwik Code -->
|
||||
|
||||
<!-- Fathom - simple website analytics - https://github.com/usefathom/fathom -->
|
||||
<script>
|
||||
(function(f, a, t, h, o, m){
|
||||
a[h]=a[h]||function(){
|
||||
(a[h].q=a[h].q||[]).push(arguments)
|
||||
};
|
||||
o=f.createElement('script'),
|
||||
m=f.getElementsByTagName('script')[0];
|
||||
o.async=1; o.src=t; o.id='fathom-script';
|
||||
m.parentNode.insertBefore(o,m)
|
||||
})(document, window, '//fathom.phil-opp.com/tracker.js', 'fathom');
|
||||
fathom('trackPageview');
|
||||
</script>
|
||||
<!-- / Fathom -->
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
status = [
|
||||
"continuous-integration/travis-ci/push",
|
||||
"continuous-integration/appveyor/branch",
|
||||
]
|
||||
delete_merged_branches = true
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
#![feature(panic_implementation)] // required for defining the panic handler
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![cfg_attr(not(test), no_main)] // disable all Rust-level entry points
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -25,9 +24,8 @@ pub extern "C" fn _start() -> ! {
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
serial_println!("failed");
|
||||
|
||||
serial_println!("{}", info);
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
#![feature(panic_implementation)]
|
||||
#![feature(abi_x86_interrupt)]
|
||||
#![no_std]
|
||||
#![cfg_attr(not(test), no_main)]
|
||||
@@ -19,7 +18,7 @@ static BREAKPOINT_HANDLER_CALLED: AtomicUsize = AtomicUsize::new(0);
|
||||
#[cfg(not(test))]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
init_idt();
|
||||
init_test_idt();
|
||||
|
||||
// invoke a breakpoint exception
|
||||
x86_64::instructions::int3();
|
||||
@@ -45,9 +44,8 @@ pub extern "C" fn _start() -> ! {
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
serial_println!("failed");
|
||||
serial_println!("{}", info);
|
||||
|
||||
@@ -61,15 +59,15 @@ pub fn panic(info: &PanicInfo) -> ! {
|
||||
use x86_64::structures::idt::{ExceptionStackFrame, InterruptDescriptorTable};
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
static ref TEST_IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
idt.breakpoint.set_handler_fn(breakpoint_handler);
|
||||
idt
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_idt() {
|
||||
IDT.load();
|
||||
pub fn init_test_idt() {
|
||||
TEST_IDT.load();
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn breakpoint_handler(_stack_frame: &mut ExceptionStackFrame) {
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
#![feature(panic_implementation)]
|
||||
#![feature(abi_x86_interrupt)]
|
||||
#![no_std]
|
||||
#![cfg_attr(not(test), no_main)]
|
||||
@@ -18,7 +17,7 @@ use core::panic::PanicInfo;
|
||||
#[allow(unconditional_recursion)]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
blog_os::gdt::init();
|
||||
init_idt();
|
||||
init_test_idt();
|
||||
|
||||
fn stack_overflow() {
|
||||
stack_overflow(); // for each recursion, the return address is pushed
|
||||
@@ -39,9 +38,8 @@ pub extern "C" fn _start() -> ! {
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
serial_println!("failed");
|
||||
serial_println!("{}", info);
|
||||
|
||||
@@ -55,7 +53,7 @@ pub fn panic(info: &PanicInfo) -> ! {
|
||||
use x86_64::structures::idt::{ExceptionStackFrame, InterruptDescriptorTable};
|
||||
|
||||
lazy_static! {
|
||||
static ref IDT: InterruptDescriptorTable = {
|
||||
static ref TEST_IDT: InterruptDescriptorTable = {
|
||||
let mut idt = InterruptDescriptorTable::new();
|
||||
unsafe {
|
||||
idt.double_fault
|
||||
@@ -67,8 +65,8 @@ lazy_static! {
|
||||
};
|
||||
}
|
||||
|
||||
pub fn init_idt() {
|
||||
IDT.load();
|
||||
pub fn init_test_idt() {
|
||||
TEST_IDT.load();
|
||||
}
|
||||
|
||||
extern "x86-interrupt" fn double_fault_handler(
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
#![feature(panic_implementation)]
|
||||
#![no_std]
|
||||
#![cfg_attr(not(test), no_main)]
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -16,9 +15,8 @@ pub extern "C" fn _start() -> ! {
|
||||
}
|
||||
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(_info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
serial_println!("ok");
|
||||
|
||||
unsafe {
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
#![feature(panic_implementation)] // required for defining the panic handler
|
||||
#![feature(abi_x86_interrupt)]
|
||||
#![no_std] // don't link the Rust standard library
|
||||
#![cfg_attr(not(test), no_main)] // disable all Rust-level entry points
|
||||
#![cfg_attr(test, allow(dead_code, unused_macros, unused_imports))]
|
||||
@@ -29,9 +27,8 @@ pub extern "C" fn _start() -> ! {
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_implementation]
|
||||
#[no_mangle]
|
||||
pub fn panic(info: &PanicInfo) -> ! {
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
blog_os::hlt_loop();
|
||||
}
|
||||
|
||||
Reference in New Issue
Block a user