diff --git a/.github/workflows/blog.yml b/.github/workflows/blog.yml
index fd51ce5f..9981287e 100644
--- a/.github/workflows/blog.yml
+++ b/.github/workflows/blog.yml
@@ -20,7 +20,7 @@ jobs:
- uses: actions/checkout@v1
- name: 'Download Zola'
- run: curl -sL https://github.com/getzola/zola/releases/download/v0.15.3/zola-v0.15.3-x86_64-unknown-linux-gnu.tar.gz | tar zxv
+ run: curl -sL https://github.com/getzola/zola/releases/download/v0.16.1/zola-v0.16.1-x86_64-unknown-linux-gnu.tar.gz | tar zxv
- name: 'Install Python Libraries'
run: python -m pip install --user -r requirements.txt
working-directory: "blog"
@@ -38,20 +38,6 @@ jobs:
name: generated_site
path: blog/public
- zola_check:
- name: "Zola Check"
- runs-on: ubuntu-latest
-
- steps:
- - uses: actions/checkout@v1
-
- - name: 'Download Zola'
- run: curl -sL https://github.com/getzola/zola/releases/download/v0.15.3/zola-v0.15.3-x86_64-unknown-linux-gnu.tar.gz | tar zxv
-
- - name: "Run zola check"
- run: ../zola check
- working-directory: "blog"
-
check_spelling:
name: "Check Spelling"
runs-on: ubuntu-latest
diff --git a/.github/workflows/check-links.yml b/.github/workflows/check-links.yml
new file mode 100644
index 00000000..1cab057a
--- /dev/null
+++ b/.github/workflows/check-links.yml
@@ -0,0 +1,27 @@
+name: Check Links
+
+on:
+ push:
+ branches:
+ - "*"
+ - "!staging.tmp"
+ tags:
+ - "*"
+ pull_request:
+ schedule:
+ - cron: "0 0 1/4 * *" # every 4 days
+
+jobs:
+ zola_check:
+ name: "Zola Link Check"
+ runs-on: ubuntu-latest
+
+ steps:
+ - uses: actions/checkout@v1
+
+ - name: "Download Zola"
+ run: curl -sL https://github.com/getzola/zola/releases/download/v0.16.1/zola-v0.16.1-x86_64-unknown-linux-gnu.tar.gz | tar zxv
+
+ - name: "Run zola check"
+ run: ../zola check
+ working-directory: "blog"
diff --git a/blog/.gitignore b/blog/.gitignore
index c75eeccc..0e46e61e 100644
--- a/blog/.gitignore
+++ b/blog/.gitignore
@@ -1 +1,2 @@
/public
+zola
diff --git a/blog/config.toml b/blog/config.toml
index 3b93fb2b..700e625b 100644
--- a/blog/config.toml
+++ b/blog/config.toml
@@ -5,7 +5,7 @@ feed_filename = "rss.xml"
compile_sass = true
minify_html = false
-ignored_content = ["*/README.md", "LICENSE-CC-BY-NC"]
+ignored_content = ["*/README.md", "*/LICENSE-CC-BY-NC"]
[markdown]
highlight_code = true
@@ -14,23 +14,25 @@ smart_punctuation = true
[link_checker]
skip_prefixes = [
- "https://crates.io/crates", # see https://github.com/rust-lang/crates.io/issues/788
- "https://www.amd.com/system/files/TechDocs/", # seems to have problems with PDFs
+ "https://crates.io/crates", # see https://github.com/rust-lang/crates.io/issues/788
+ "https://www.amd.com/system/files/TechDocs/", # seems to have problems with PDFs
"https://developer.apple.com/library/archive/qa/qa1118/_index.html", # results in a 401 (I don't know why)
- "https://github.com", # rate limiting often leads to "Error 429 Too Many Requests"
- "https://www.linkedin.com/", # seems to send invalid HTTP status codes
+ "https://github.com", # rate limiting often leads to "Error 429 Too Many Requests"
+ "https://www.linkedin.com/", # seems to send invalid HTTP status codes
]
skip_anchor_prefixes = [
- "https://github.com/", # see https://github.com/getzola/zola/issues/805
- "https://docs.rs/x86_64/0.1.2/src/", # source code highlight
- "https://doc.rust-jp.rs/book-ja/", # seems like Zola has problems with Japanese anchor names
+ "https://github.com/", # see https://github.com/getzola/zola/issues/805
+ "https://docs.rs/x86_64/0.1.2/src/", # source code highlight
+ "https://doc.rust-jp.rs/book-ja/", # seems like Zola has problems with Japanese anchor names
+ "https://doc.rust-jp.rs/edition-guide/rust-2018", # seems like Zola has problems with Japanese anchor names
+ "https://doc.rust-jp.rs/rust-nomicon-ja/", # seems like Zola has problems with Japanese anchor names
]
[extra]
subtitle = "by Philipp Oppermann"
author = { name = "Philipp Oppermann" }
default_language = "en"
-languages = ["en", "zh-CN", "zh-TW", "fr", "ja", "fa", "ru"]
+languages = ["en", "zh-CN", "zh-TW", "fr", "ja", "fa", "ru", "ko"]
[languages.en]
title = "Writing an OS in Rust"
@@ -46,6 +48,7 @@ not_translated = "(This post is not translated yet.)"
translated_content = "Translated Content:"
translated_content_notice = "This is a community translation of the _original.title_ post. It might be incomplete, outdated or contain errors. Please report any issues!"
translated_by = "Translation by"
+translation_contributors = "With contributions from"
word_separator = "and"
# Chinese (simplified)
@@ -63,6 +66,7 @@ not_translated = "(该文章还没有被翻译。)"
translated_content = "翻译内容:"
translated_content_notice = "这是对原文章 _original.title_ 的社区中文翻译。它可能不完整,过时或者包含错误。可以在 这个 Issue 上评论和提问!"
translated_by = "翻译者:"
+translation_contributors = "With contributions from"
word_separator = "和"
# Chinese (traditional)
@@ -80,6 +84,7 @@ not_translated = "(該文章還沒有被翻譯。)"
translated_content = "翻譯內容:"
translated_content_notice = "這是對原文章 _original.title_ 的社區中文翻譯。它可能不完整,過時或者包含錯誤。可以在 這個 Issue 上評論和提問!"
translated_by = "翻譯者:"
+translation_contributors = "With contributions from"
word_separator = "和"
# Japanese
@@ -97,6 +102,7 @@ not_translated = "(この記事はまだ翻訳されていません。)"
translated_content = "この記事は翻訳されたものです:"
translated_content_notice = "この記事は_original.title_をコミュニティの手により翻訳したものです。そのため、翻訳が完全・最新でなかったり、原文にない誤りを含んでいる可能性があります。問題があればこのissue上で報告してください!"
translated_by = "翻訳者:"
+translation_contributors = "With contributions from"
word_separator = "及び"
# Persian
@@ -114,6 +120,7 @@ not_translated = "(.این پست هنوز ترجمه نشده است)"
translated_content = "محتوای ترجمه شده:"
translated_content_notice = "این یک ترجمه از جامعه کاربران برای پست _original.title_ است. ممکن است ناقص، منسوخ شده یا دارای خطا باشد. لطفا هر گونه مشکل را در این ایشو گزارش دهید!"
translated_by = "ترجمه توسط"
+translation_contributors = "With contributions from"
word_separator = "و"
# Russian
@@ -131,6 +138,7 @@ not_translated = "(Этот пост еще не переведен.)"
translated_content = "Переведенное содержание:"
translated_content_notice = "Это перевод сообщества поста _original.title_. Он может быть неполным, устаревшим или содержать ошибки. Пожалуйста, сообщайте о любых проблемах!"
translated_by = "Перевод сделан"
+translation_contributors = "With contributions from"
word_separator = "и"
# French
@@ -148,4 +156,23 @@ not_translated = "(Cet article n'est pas encore traduit.)"
translated_content = "Contenu traduit : "
translated_content_notice = "Ceci est une traduction communautaire de l'article _original.title_. Il peut être incomplet, obsolète ou contenir des erreurs. Veuillez signaler les quelconques problèmes !"
translated_by = "Traduit par : "
+translation_contributors = "With contributions from"
word_separator = "et"
+
+# Korean
+[languages.ko]
+title = "Writing an OS in Rust"
+description = "This blog series creates a small operating system in the Rust programming language. Each post is a small tutorial and includes all needed code."
+[languages.ko.translations]
+lang_name = "Korean"
+toc = "목차"
+all_posts = "« 모든 게시글"
+comments = "댓글"
+comments_notice = "댓글은 가능하면 영어로 작성해주세요."
+readmore = "더 읽기 »"
+not_translated = "(아직 번역이 완료되지 않은 게시글입니다)"
+translated_content = "번역된 내용 : "
+translated_content_notice = "이것은 커뮤니티 멤버가 _original.title_ 포스트를 번역한 글입니다. 부족한 설명이나 오류, 혹은 시간이 지나 더 이상 유효하지 않은 정보를 발견하시면 제보해주세요!"
+translated_by = "번역한 사람 : "
+translation_contributors = "With contributions from"
+word_separator = "와"
diff --git a/blog/content/_index.ko.md b/blog/content/_index.ko.md
new file mode 100644
index 00000000..6fddbf94
--- /dev/null
+++ b/blog/content/_index.ko.md
@@ -0,0 +1,14 @@
++++
+template = "edition-2/index.html"
++++
+
+
Rust로 OS 구현하기
+
+
+
+이 블로그 시리즈는 [Rust 프로그래밍 언어](https://www.rust-lang.org/)로 작은 OS를 구현하는 것을 주제로 합니다.
+각 포스트는 구현에 필요한 소스 코드를 포함한 작은 튜토리얼 형식으로 구성되어 있습니다. 소스 코드는 이 블로그의 [Github 저장소](https://github.com/phil-opp/blog_os)에서도 확인하실 수 있습니다.
+
+최신 포스트:
+
+
diff --git a/blog/content/edition-1/posts/03-set-up-rust/index.md b/blog/content/edition-1/posts/03-set-up-rust/index.md
index 660b4743..c0dcf287 100644
--- a/blog/content/edition-1/posts/03-set-up-rust/index.md
+++ b/blog/content/edition-1/posts/03-set-up-rust/index.md
@@ -406,9 +406,7 @@ So the linker can't find a function named `_Unwind_Resume` that is referenced e.
[iterator.rs:389]: https://github.com/rust-lang/rust/blob/c58c928e658d2e45f816fd05796a964aa83759da/src/libcore/iter/iterator.rs#L389
-By default, the destructors of all stack variables are run when a `panic` occurs. This is called _unwinding_ and allows parent threads to [recover from panics]. However, it requires a platform specific gcc library, which isn't available in our kernel.
-
-[recover from panics]: https://www.howtobuildsoftware.com/index.php/how-do/fFH/rust-recovering-from-panic-in-another-thread
+By default, the destructors of all stack variables are run when a `panic` occurs. This is called _unwinding_ and allows parent threads to recover from panics. However, it requires a platform specific gcc library, which isn't available in our kernel.
Fortunately, Rust allows us to disable unwinding for our target. For that we add the following line to our `x86_64-blog_os.json` file:
diff --git a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.fr.md b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.fr.md
index 5c70882a..838f2691 100644
--- a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.fr.md
+++ b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.fr.md
@@ -1,5 +1,5 @@
+++
-title = "A Freestanding Rust Binary"
+title = "Un binaire Rust autonome"
weight = 1
path = "fr/freestanding-rust-binary"
date = 2018-02-10
@@ -9,7 +9,7 @@ chapter = "Bare Bones"
# Please update this when updating the translation
translation_based_on_commit = "3e87916b6c2ed792d1bdb8c0947906aef9013ac1"
# GitHub usernames of the people that translated this post
-translators = ["Alekzus"]
+translators = ["AlexandreMarcq", "alaincao"]
+++
La première étape pour créer notre propre noyau de système d'exploitation est de créer un exécutable Rust qui ne relie pas la bibliothèque standard. Cela rend possible l'exécution du code Rust sur la ["bare machine"][machine nue] sans système d'exploitation sous-jacent.
@@ -29,7 +29,7 @@ Ce blog est développé sur [GitHub]. Si vous avez un problème ou une question,
## Introduction
Pour écrire un noyau de système d'exploitation, nous avons besoin d'un code qui ne dépend pas de fonctionnalités de système d'exploitation. Cela signifie que nous ne pouvons pas utiliser les fils d'exécution, les fichiers, la mémoire sur le tas, le réseau, les nombres aléatoires, la sortie standard ou tout autre fonctionnalité nécessitant une abstraction du système d'exploitation ou un matériel spécifique. Cela a du sens, étant donné que nous essayons d'écrire notre propre OS et nos propres pilotes.
-Cela signifie que nous ne pouvons pas utiliser la majeure partie de la [bibliothèque standard de Rust]. Il y a néanmoins beaucoup de fonctionnalités de Rust que nous _pouvons_ utiliser. Par exemple, nous pouvons utiliser les [iterators], les [closures], le [pattern matching], l'[option] et le [result], le [string formatting], et bien-sûr l'[ownership system]. Ces fonctionnalités permettent l'écriture d'un noyeau d'une façon expressive et haut-niveau sans se soucier des [comportements indéfinis] ou de la [sécurité de la mémoire].
+Cela signifie que nous ne pouvons pas utiliser la majeure partie de la [bibliothèque standard de Rust]. Il y a néanmoins beaucoup de fonctionnalités de Rust que nous _pouvons_ utiliser. Par exemple, nous pouvons utiliser les [iterators], les [closures], le [pattern matching], l'[option] et le [result], le [string formatting], et bien-sûr l'[ownership system]. Ces fonctionnalités permettent l'écriture d'un noyau d'une façon expressive et haut-niveau sans se soucier des [comportements indéfinis] ou de la [sécurité de la mémoire].
[option]: https://doc.rust-lang.org/core/option/
[result]:https://doc.rust-lang.org/core/result/
@@ -195,7 +195,7 @@ Dans un exécutable Rust classique qui relie la bibliothèque standard, l'exécu
[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
-Notre exécutable autoporté n'a pas accès à l'environnement d'exécution de Rust ni à `crt0`. Nous avons donc besion de définir notre propre point d'entrée. Implémenter l'objet de langage `start` n'aiderait pas car nous aurions toujours besoin de `crt0`. Nous avons plutôt besoin de réécrire le point d'entrée de `crt0` directement.
+Notre exécutable autoporté n'a pas accès à l'environnement d'exécution de Rust ni à `crt0`. Nous avons donc besoin de définir notre propre point d'entrée. Implémenter l'objet de langage `start` n'aiderait pas car nous aurions toujours besoin de `crt0`. Nous avons plutôt besoin de réécrire le point d'entrée de `crt0` directement.
### Réécrire le Point d'Entrée
@@ -266,7 +266,7 @@ La sortie ci-dessus provient d'un système Linux `x86_64`. Nous pouvons voir que
En compilant pour notre triplé hôte, le compilateur Rust ainsi que le linker supposent qu'il y a un système d'exploitation sous-jacent comme Linux ou Windows qui utilise l'environnement d'exécution C par défaut, ce qui cause les erreurs de linker. Donc pour éviter ces erreurs, nous pouvons compiler pour un environnement différent sans système d'exploitation sous-jacent.
-Un exemple d'un tel envrironnement est le triplé cible `thumbv7em-none-eabihf`, qui décrit un système [ARM] [embarqué]. Les détails ne sont pas importants, tout ce qui compte est que le triplé cible n'a pas de système d'exploitation sous-jacent, ce qui est indiqué par le `none` dans le triplé cible. Pour pouvoir compilé pour cette cible, nous avons besoin de l'ajouter dans rustup :
+Un exemple d'un tel envrironnement est le triplé cible `thumbv7em-none-eabihf`, qui décrit un système [ARM] [embarqué]. Les détails ne sont pas importants, tout ce qui compte est que le triplé cible n'a pas de système d'exploitation sous-jacent, ce qui est indiqué par le `none` dans le triplé cible. Pour pouvoir compiler pour cette cible, nous avons besoin de l'ajouter dans rustup :
[embarqué]: https://fr.wikipedia.org/wiki/Syst%C3%A8me_embarqu%C3%A9
[ARM]: https://fr.wikipedia.org/wiki/Architecture_ARM
@@ -449,7 +449,7 @@ Maintenant notre programme devrait être compilable sur les trois plateformes av
#### Devriez-vous Faire Ça ?
-Bien qu'il soit possible de compiler un exécutable autoporté pour Linux, Windows et macOS, ce n'est probablement pas une bonne idée. La raison est que notre exécutable s'attend toujours à trouver certaines choses, par exemple une pile initialisée lorsque la fonction `_start` est appelée. Sans l'environnement d'exécution C, certains de ces conditions peuvent ne pas être remplies, ce qui pourrait faire planter notre programme, avec par exemple une erreur de segmentation.
+Bien qu'il soit possible de compiler un exécutable autoporté pour Linux, Windows et macOS, ce n'est probablement pas une bonne idée. La raison est que notre exécutable s'attend toujours à trouver certaines choses, par exemple une pile initialisée lorsque la fonction `_start` est appelée. Sans l'environnement d'exécution C, certaines de ces conditions peuvent ne pas être remplies, ce qui pourrait faire planter notre programme, avec par exemple une erreur de segmentation.
Si vous voulez créer un exécutable minimal qui tourne sur un système d'exploitation existant, include `libc` et mettre l'attribut `#[start]` come décrit [ici](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html) semble être une meilleure idée.
diff --git a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ja.md b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ja.md
index f25e4182..9d3e28f3 100644
--- a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ja.md
+++ b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ja.md
@@ -140,8 +140,7 @@ fn panic(_info: &PanicInfo) -> ! {
loop {}
}
```
-
-[`PanicInfo` パラメータ]には、パニックが発生したファイルと行、およびオプションでパニックメッセージが含まれます。この関数は戻り値を取るべきではないので、]"never" 型(`!`)][“never” type]を返すことで[発散する関数][diverging function]となります。今のところこの関数でできることは多くないので、無限にループするだけです。
+[`PanicInfo` パラメータ]には、パニックが発生したファイルと行、およびオプションでパニックメッセージが含まれます。この関数は戻り値を取るべきではないので、["never" 型(`!`)][“never” type]を返すことで[発散する関数][diverging function]となります。今のところこの関数でできることは多くないので、無限にループするだけです。
[`PanicInfo` パラメータ]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
diff --git a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ko.md b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ko.md
new file mode 100644
index 00000000..e95f9a3b
--- /dev/null
+++ b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ko.md
@@ -0,0 +1,546 @@
++++
+title = "Rust로 'Freestanding 실행파일' 만들기"
+weight = 1
+path = "ko/freestanding-rust-binary"
+date = 2018-02-10
+
+[extra]
+chapter = "Bare Bones"
+# Please update this when updating the translation
+translation_based_on_commit = "c1af4e31b14e562826029999b9ab1dce86396b93"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994", "Quqqu"]
++++
+
+운영체제 커널을 만드는 첫 단계는 표준 라이브러리(standard library)를 링크하지 않는 Rust 실행파일을 만드는 것입니다. 이 실행파일은 운영체제가 없는 [bare metal] 시스템에서 동작할 수 있습니다.
+
+[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-01 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
+
+
+
+## 소개
+운영체제 커널을 만드려면 운영체제에 의존하지 않는 코드가 필요합니다. 자세히 설명하자면, 스레드, 파일, 동적 메모리, 네트워크, 난수 생성기, 표준 출력 및 기타 운영체제의 추상화 또는 특정 하드웨어의 기능을 필요로 하는 것들은 전부 사용할 수 없다는 뜻입니다. 우리는 스스로 운영체제 및 드라이버를 직접 구현하려는 상황이니 어찌 보면 당연한 조건입니다.
+
+운영체제에 의존하지 않으려면 [Rust 표준 라이브러리][Rust standard library]의 많은 부분을 사용할 수 없습니다.
+그래도 우리가 이용할 수 있는 Rust 언어 자체의 기능들은 많이 남아 있습니다. 예를 들어 [반복자][iterators], [클로저][closures], [패턴 매칭][pattern matching], [option] / [result], [문자열 포맷 설정][string formatting], 그리고 [소유권 시스템][ownership system] 등이 있습니다. 이러한 기능들은 우리가 커널을 작성할 때 [undefined behavior]나 [메모리 안전성][memory safety]에 대한 걱정 없이 큰 흐름 단위의 코드를 작성하는 데에 집중할 수 있도록 해줍니다.
+
+[option]: https://doc.rust-lang.org/core/option/
+[result]:https://doc.rust-lang.org/core/result/
+[Rust standard library]: https://doc.rust-lang.org/std/
+[iterators]: https://doc.rust-lang.org/book/ch13-02-iterators.html
+[closures]: https://doc.rust-lang.org/book/ch13-01-closures.html
+[pattern matching]: https://doc.rust-lang.org/book/ch06-00-enums.html
+[string formatting]: https://doc.rust-lang.org/core/macro.write.html
+[ownership system]: https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html
+[undefined behavior]: https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs
+[memory safety]: https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention
+
+Rust로 운영체제 커널을 작성하려면, 운영체제 없이도 실행가능한 실행파일이 필요합니다. 이러한 실행파일은
+보통 "freestanding 실행파일" 혹은 "bare-metal 실행파일" 이라고 불립니다.
+
+이 포스트에서는 "freestanding 실행 파일" 을 만드는 데 필요한 것들을 여러 단계로 나누고, 각 단계가 왜 필요한지에 대해 설명해드립니다. 중간 과정은 생략하고 그저 최소한의 예제 코드만 확인하고 싶으시면 **[요약 섹션으로 넘어가시면 됩니다](#summary)**.
+
+## Rust 표준 라이브러리 링크 해제하기
+모든 Rust 프로그램들은 Rust 표준 라이브러리를 링크하는데, 이 라이브러리는 스레드, 파일, 네트워킹 등의 기능을 제공하기 위해 운영체제에 의존합니다. Rust 표준 라이브러리는 또한 C 표준 라이브러리인 `libc`에도 의존합니다 (`libc`는 운영체제의 여러 기능들을 이용합니다).
+우리가 운영체제를 직접 구현하기 위해서는 운영체제를 이용하는 라이브러리들은 사용할 수 없습니다. 그렇기에 우선 [`no_std` 속성][`no_std` attribute]을 이용해 자동으로 Rust 표준 라이브러리가 링크되는 것을 막아야 합니다.
+
+[standard library]: https://doc.rust-lang.org/std/
+[`no_std` attribute]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
+
+제일 먼저 아래의 명령어를 통해 새로운 cargo 애플리케이션 크레이트를 만듭니다.
+
+```
+cargo new blog_os --bin --edition 2018
+```
+
+프로젝트 이름은 `blog_os` 또는 원하시는 이름으로 정해주세요. `--bin` 인자는 우리가 cargo에게 실행 파일 (라이브러리와 대조됨)을 만들겠다고 알려주고, `--edition 2018` 인자는 cargo에게 우리가 [Rust 2018 에디션][2018 edition]을 사용할 것이라고 알려줍니다.
+위 명령어를 실행하고 나면, cargo가 아래와 같은 크레이트 디렉토리를 만들어줍니다.
+
+[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
+
+```
+blog_os
+├── Cargo.toml
+└── src
+ └── main.rs
+```
+
+크레이트 설정은 `Cargo.toml`에 전부 기록해야 합니다 (크레이트 이름, 크레이트 원작자, [semantic version] 번호, 의존 라이브러리 목록 등).
+`src/main.rs` 파일에 크레이트 실행 시 맨 처음 호출되는 `main` 함수를 포함한 중추 모듈이 있습니다.
+`cargo build` 명령어를 통해 크레이트를 빌드하면 `target/debug` 디렉토리에 `blog_os` 실행파일이 생성됩니다.
+
+[semantic version]: https://semver.org/
+
+### `no_std` 속성
+
+현재 우리가 만든 크레이트는 암시적으로 Rust 표준 라이브러리를 링크합니다. 아래와 같이 [`no_std` 속성]을 이용해 더 이상 표준 라이브러리가 링크되지 않게 해줍니다.
+
+```rust
+// main.rs
+
+#![no_std]
+
+fn main() {
+ println!("Hello, world!");
+}
+```
+
+이제 `cargo build` 명령어를 다시 실행하면 아래와 같은 오류 메세지가 뜰 것입니다:
+
+```
+error: cannot find macro `println!` in this scope
+ --> src/main.rs:4:5
+ |
+4 | println!("Hello, world!");
+ | ^^^^^^^
+```
+
+이 오류가 뜨는 이유는 [`println` 매크로][`println` macro]를 제공하는 Rust 표준 라이브러리를 우리의 크레이트에 링크하지 않게 되었기 때문입니다.
+`println`은 [표준 입출력][standard output] (운영체제가 제공하는 특별한 파일 서술자)으로 데이터를 쓰기 때문에, 우리는 이제 `println`을 이용해 메세지를 출력할 수 없습니다.
+
+[`println` macro]: https://doc.rust-lang.org/std/macro.println.html
+[standard output]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
+
+`println` 매크로 호출 코드를 지운 후 크레이트를 다시 빌드해봅시다.
+
+```rust
+// main.rs
+
+#![no_std]
+
+fn main() {}
+```
+
+```
+> cargo build
+error: `#[panic_handler]` function required, but not found
+error: language item required, but not found: `eh_personality`
+```
+
+오류 메세지를 통해 컴파일러가 `#[panic_handler]` 함수와 _language item_ 을 필요로 함을 확인할 수 있습니다.
+
+## 패닉 (Panic) 시 호출되는 함수 구현하기
+
+컴파일러는 [패닉][panic]이 일어날 경우 `panic_handler` 속성이 적용된 함수가 호출되도록 합니다. 표준 라이브러리는 패닉 시 호출되는 함수가 제공되지만, `no_std` 환경에서는 우리가 패닉 시 호출될 함수를 직접 설정해야 합니다.
+
+[panic]: https://doc.rust-lang.org/stable/book/ch09-01-unrecoverable-errors-with-panic.html
+
+```rust
+// in main.rs
+
+use core::panic::PanicInfo;
+
+/// 패닉이 일어날 경우, 이 함수가 호출됩니다.
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ loop {}
+}
+```
+
+[`PanicInfo` 인자][PanicInfo]는 패닉이 일어난 파일명, 패닉이 파일 내 몇 번째 줄에서 일어났는지, 그리고 패닉시 전달된 메세지에 대한 정보를 가진 구조체입니다.
+위 `panic` 함수는 절대로 반환하지 않기에 ["never" 타입][“never” type] `!`을 반환하도록 적어 컴파일러에게 이 함수가 [반환 함수][diverging function]임을 알립니다.
+당장 이 함수에서 우리가 하고자 하는 일은 없기에 그저 함수가 반환하지 않도록 무한루프를 넣어줍니다.
+
+[PanicInfo]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
+[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
+[“never” type]: https://doc.rust-lang.org/nightly/std/primitive.never.html
+
+## `eh_personality` Language Item
+
+Language item은 컴파일러가 내부적으로 요구하는 특별한 함수 및 타입들을 가리킵니다. 예를 들어 [`Copy`] 트레잇은 어떤 타입들이 [_copy semantics_][`Copy`] 를 가지는지 컴파일러에게 알려주는 language item 입니다.
+[`Copy` 트레잇이 구현된 코드][copy code]에 있는 `#[lang = "copy"]` 속성을 통해 이 트레잇이 language item으로 선언되어 있음을 확인할 수 있습니다.
+
+[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
+[copy code]: https://github.com/rust-lang/rust/blob/485397e49a02a3b7ff77c17e4a3f16c653925cb3/src/libcore/marker.rs#L296-L299
+
+임의로 구현한 language item을 사용할 수는 있지만, 위험할 수도 있기에 주의해야 합니다.
+그 이유는 language item의 구현 코드는 매우 자주 변경되어 불안정하며, language item에 대해서 컴파일러가 타입 체크 조차 하지 않습니다 (예시: language item 함수의 인자 타입이 정확한지 조차 체크하지 않습니다).
+임의로 구현한 language item을 이용하는 것보다 더 안정적으로 위의 language item 오류를 고칠 방법이 있습니다.
+
+[`eh_personality` language item]은 [스택 되감기 (stack unwinding)][stack unwinding]을 구현하는 함수를 가리킵니다. 기본적으로 Rust는 [패닉][panic]이 일어났을 때 스택 되감기를 통해 스택에 살아있는 각 변수의 소멸자를 호출합니다. 이를 통해 자식 스레드에서 사용 중이던 모든 메모리 리소스가 반환되고, 부모 스레드가 패닉에 대처한 후 계속 실행될 수 있게 합니다. 스택 되감기는 복잡한 과정으로 이루어지며 운영체제마다 특정한 라이브러리를 필요로 하기에 (예: Linux는 [libunwind], Windows는 [structured exception handling]), 우리가 구현할 운영체제에서는 이 기능을 사용하지 않을 것입니다.
+
+[`eh_personality` language item]: https://github.com/rust-lang/rust/blob/edb368491551a77d77a48446d4ee88b35490c565/src/libpanic_unwind/gcc.rs#L11-L45
+[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
+[libunwind]: https://www.nongnu.org/libunwind/
+[structured exception handling]: https://docs.microsoft.com/en-us/windows/win32/debug/structured-exception-handling
+
+### 스택 되감기를 해제하는 방법
+
+스택 되감기가 불필요한 상황들이 여럿 있기에, Rust 언어는 [패닉 시 실행 종료][abort on panic] 할 수 있는 선택지를 제공합니다. 이는 스택 되감기에 필요한 심볼 정보 생성을 막아주어 실행 파일의 크기 자체도 많이 줄어들게 됩니다. 스택 되감기를 해제하는 방법은 여러가지 있지만, 가장 쉬운 방법은 `Cargo.toml` 파일에 아래의 코드를 추가하는 것입니다.
+
+```toml
+[profile.dev]
+panic = "abort"
+
+[profile.release]
+panic = "abort"
+```
+
+위의 코드를 통해 `dev` 빌드 (`cargo build` 실행)와 `release` 빌드 (`cargo build --release` 실행) 에서 모두 패닉 시 실행이 종료되도록 설정되었습니다.
+이제 더 이상 컴파일러가 `eh_personality` language item을 필요로 하지 않습니다.
+
+[abort on panic]: https://github.com/rust-lang/rust/pull/32900
+
+위에서 본 오류들을 고쳤지만, 크레이트를 빌드하려고 하면 새로운 오류가 뜰 것입니다:
+
+```
+> cargo build
+error: requires `start` lang_item
+```
+
+우리의 프로그램에는 프로그램 실행 시 최초 실행 시작 지점을 지정해주는 `start` language item이 필요합니다.
+
+## `start` 속성
+
+혹자는 프로그램 실행 시 언제나 `main` 함수가 가장 먼저 호출된다고 생각할지도 모릅니다. 대부분의 프로그래밍 언어들은 [런타임 시스템][runtime system]을 가지고 있는데, 이는 가비지 컬렉션 (예시: Java) 혹은 소프트웨어 스레드 (예시: GoLang의 goroutine) 등의 기능을 담당합니다.
+이러한 런타임 시스템은 프로그램 실행 이전에 초기화 되어야 하기에 `main` 함수 호출 이전에 먼저 호출됩니다.
+
+[runtime system]: https://en.wikipedia.org/wiki/Runtime_system
+
+러스트 표준 라이브러리를 링크하는 전형적인 러스트 실행 파일의 경우, 프로그램 실행 시 C 런타임 라이브러리인 `crt0` (“C runtime zero”) 에서 실행이 시작됩니다. `crt0`는 C 프로그램의 환경을 설정하고 초기화하는 런타임 시스템으로, 스택을 만들고 프로그램에 주어진 인자들을 적절한 레지스터에 배치합니다. `crt0`가 작업을 마친 후 `start` language item으로 지정된 [Rust 런타임의 실행 시작 함수][rt::lang_start]를 호출합니다.
+Rust는 최소한의 런타임 시스템을 가지며, 주요 기능은 스택 오버플로우 가드를 초기화하고 패닉 시 역추적 (backtrace) 정보를 출력하는 것입니다. Rust 런타임의 초기화 작업이 끝난 후에야 `main` 함수가 호출됩니다.
+
+[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
+
+우리의 "freestanding 실행 파일" 은 Rust 런타임이나 `crt0`에 접근할 수 없기에, 우리가 직접 프로그램 실행 시작 지점을 지정해야 합니다.
+`crt0`가 `start` language item을 호출해주는 방식으로 동작하기에, `start` language item을 구현하고 지정하는 것만으로는 문제를 해결할 수 없습니다.
+대신 우리가 직접 `crt0`의 시작 지점을 대체할 새로운 실행 시작 지점을 제공해야 합니다.
+
+### 실행 시작 지점 덮어쓰기
+`#![no_main]` 속성을 이용해 Rust 컴파일러에게 우리가 일반적인 실행 시작 호출 단계를 이용하지 않겠다고 선언합니다.
+
+```rust
+#![no_std]
+#![no_main]
+
+use core::panic::PanicInfo;
+
+/// 패닉이 일어날 경우, 이 함수가 호출됩니다.
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ loop {}
+}
+```
+
+`main` 함수가 사라진 것을 눈치채셨나요? `main` 함수를 호출해주는 런타임 시스템이 없는 이상 `main` 함수의 존재도 더 이상 의미가 없습니다.
+우리는 운영체제가 호출하는 프로그램 실행 시작 지점 대신 우리의 새로운 `_start` 함수를 실행 시작 지점으로 대체할 것입니다.
+
+```rust
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ loop {}
+}
+```
+
+`#[no_mangle]` 속성을 통해 [name mangling]을 해제하여 Rust 컴파일러가 `_start` 라는 이름 그대로 함수를 만들도록 합니다. 이 속성이 없다면, 컴파일러가 각 함수의 이름을 고유하게 만드는 과정에서 이 함수의 실제 이름을 `_ZN3blog_os4_start7hb173fedf945531caE` 라는 이상한 이름으로 바꿔 생성합니다. 우리가 원하는 실제 시작 지점 함수의 이름을 정확히 알고 있어야 링커 (linker)에도 그 이름을 정확히 전달할 수 있기에 (후속 단계에서 진행) `#[no_mangle]` 속성이 필요합니다.
+
+또한 우리는 이 함수에 `extern "C"`라는 표시를 추가하여 이 함수가 Rust 함수 호출 규약 대신에 [C 함수 호출 규약][C calling convention]을 사용하도록 합니다. 함수의 이름을 `_start`로 지정한 이유는 그저 런타임 시스템들의 실행 시작 함수 이름이 대부분 `_start`이기 때문입니다.
+
+[name mangling]: https://en.wikipedia.org/wiki/Name_mangling
+[C calling convention]: https://en.wikipedia.org/wiki/Calling_convention
+
+`!` 반환 타입은 이 함수가 발산 함수라는 것을 의미합니다. 시작 지점 함수는 오직 운영체제나 부트로더에 의해서만 직접 호출됩니다. 따라서 시작 지점 함수는 반환하는 대신 운영체제의 [`exit` 시스템콜][`exit` system call]을 이용해 종료됩니다. 우리의 "freestanding 실행 파일" 은 실행 종료 후 더 이상 실행할 작업이 없기에, 시작 지점 함수가 작업을 마친 후 기기를 종료하는 것이 합리적입니다. 여기서는 일단 `!` 타입의 조건을 만족시키기 위해 무한루프를 넣어 줍니다.
+
+[`exit` system call]: https://en.wikipedia.org/wiki/Exit_(system_call)
+
+다시 `cargo build`를 실행하면, 끔찍한 _링커_ 오류를 마주하게 됩니다.
+
+## 링커 오류
+
+링커는 컴파일러가 생성한 코드들을 묶어 실행파일로 만드는 프로그램입니다. 실행 파일 형식은 Linux, Windows, macOS 마다 전부 다르기에 각 운영체제는 자신만의 링커가 있고 링커마다 다른 오류 메세지를 출력할 것입니다.
+오류가 나는 근본적인 원인은 모두 동일한데, 링커는 주어진 프로그램이 C 런타임 시스템을 이용할 것이라고 가정하는 반면 우리의 크레이트는 그렇지 않기 때문입니다.
+
+이 링커 오류를 해결하려면 링커에게 C 런타임을 링크하지 말라고 알려줘야 합니다. 두 가지 방법이 있는데, 하나는 링커에 특정 인자들을 주는 것이고, 또다른 하나는 크레이트 컴파일 대상 기기를 bare metal 기기로 설정하는 것입니다.
+
+### Bare Metal 시스템을 목표로 빌드하기
+
+기본적으로 Rust는 당신의 현재 시스템 환경에서 실행할 수 있는 실행파일을 생성하고자 합니다. 예를 들어 Windows `x86_64` 사용자의 경우, Rust는 `x86_64` 명령어 셋을 사용하는 `.exe` 확장자 실행파일을 생성합니다. 사용자의 기본 시스템 환경을 "호스트" 시스템이라고 부릅니다.
+
+여러 다른 시스템 환경들을 표현하기 위해 Rust는 [_target triple_]이라는 문자열을 이용합니다. 현재 호스트 시스템의 target triple이 궁금하시다면 `rustc --version --verbose` 명령어를 실행하여 확인 가능합니다.
+
+[_target triple_]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
+
+```
+rustc 1.35.0-nightly (474e7a648 2019-04-07)
+binary: rustc
+commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
+commit-date: 2019-04-07
+host: x86_64-unknown-linux-gnu
+release: 1.35.0-nightly
+LLVM version: 8.0
+```
+
+위의 출력 내용은 `x86_64` Linux 시스템에서 얻은 것입니다. 호스트 target triple이 `x86_64-unknown-linux-gnu`으로 나오는데, 이는 CPU 아키텍쳐 정보 (`x86_64`)와 하드웨어 판매자 (`unknown`), 운영체제 (`linux`) 그리고 [응용 프로그램 이진 인터페이스 (ABI)][ABI] (`gnu`) 정보를 모두 담고 있습니다.
+
+[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
+
+우리의 호스트 시스템 triple을 위해 컴파일하는 경우, Rust 컴파일러와 링커는 Linux나 Windows와 같은 운영체제가 있다고 가정하고 또한 운영체제가 C 런타임 시스템을 사용할 것이라고 가정하기 때문에 링커 오류 메세지가 출력된 것입니다. 이런 링커 오류를 피하려면 운영체제가 없는 시스템 환경에서 코드가 구동하는 것을 목표로 컴파일해야 합니다.
+
+운영체제가 없는 bare metal 시스템 환경의 한 예시로 `thumbv7em-none-eabihf` target triple이 있습니다 (이는 [임베디드][embedded] [ARM] 시스템을 가리킵니다). Target triple의 `none`은 시스템에 운영체제가 동작하지 않음을 의미하며, 이 target triple의 나머지 부분의 의미는 아직 모르셔도 괜찮습니다. 이 시스템 환경에서 구동 가능하도록 컴파일하려면 rustup에서 해당 시스템 환경을 추가해야 합니다.
+
+[embedded]: https://en.wikipedia.org/wiki/Embedded_system
+[ARM]: https://en.wikipedia.org/wiki/ARM_architecture
+
+```
+rustup target add thumbv7em-none-eabihf
+```
+
+위 명령어를 실행하면 해당 시스템을 위한 Rust 표준 라이브러리 및 코어 라이브러리를 설치합니다. 이제 해당 target triple을 목표로 하는 freestanding 실행파일을 만들 수 있습니다.
+
+```
+cargo build --target thumbv7em-none-eabihf
+```
+
+`--target` 인자를 통해 우리가 해당 bare metal 시스템을 목표로 [크로스 컴파일][cross compile]할 것이라는 것을 cargo에게 알려줍니다. 목표 시스템 환경에 운영체제가 없는 것을 링커도 알기 때문에 C 런타임을 링크하려고 시도하지 않으며 이제는 링커 에러 없이 빌드가 성공할 것입니다.
+
+[cross compile]: https://en.wikipedia.org/wiki/Cross_compiler
+
+우리는 이 방법을 이용하여 우리의 운영체제 커널을 빌드해나갈 것입니다. 위에서 보인 `thumbv7em-none-eabihf` 시스템 환경 대신 bare metal `x86_64` 시스템 환경을 묘사하는 [커스텀 시스템 환경][custom target]을 설정하여 빌드할 것입니다. 더 자세한 내용은 다음 포스트에서 더 설명하겠습니다.
+
+[custom target]: https://doc.rust-lang.org/rustc/targets/custom.html
+
+### 링커 인자
+
+Bare metal 시스템을 목표로 컴파일하는 대신, 링커에게 특정 인자들을 추가로 주어 링커 오류를 해결하는 방법도 있습니다.
+이 방법은 앞으로 우리가 작성해나갈 커널 코드를 빌드할 때는 사용하지 않을 것이지만, 더 알고싶어 하실 분들을 위해서 이 섹션을 준비했습니다.
+아래의 _"링커 인자"_ 텍스트를 눌러 이 섹션의 내용을 확인하세요.
+
+
+
+링커 인자
+
+이 섹션에서는 Linux, Windows 그리고 macOS 각각의 운영체제에서 나타나는 링커 오류에 대해 다루고 각 운영체제마다 링커에 어떤 추가 인자들을 주어 링커 오류를 해결할 수 있는지 설명할 것입니다.
+
+#### Linux
+
+Linux 에서는 아래와 같은 링커 오류 메세지가 출력됩니다 (일부 생략됨):
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
+ (.text+0x12): undefined reference to `__libc_csu_fini'
+ /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
+ (.text+0x19): undefined reference to `__libc_csu_init'
+ /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
+ (.text+0x25): undefined reference to `__libc_start_main'
+ collect2: error: ld returned 1 exit status
+```
+
+이 상황을 설명하자면 링커가 기본적으로 C 런타임의 실행 시작 루틴을 링크하는데, 이 루틴 역시 `_start`라는 이름을 가집니다. 이 `_start` 루틴은 C 표준 라이브러리 (`libc`)가 포함하는 여러 symbol들을 필요로 하지만, 우리는 `no_std` 속성을 이용해 크레이트에서 `libc`를 링크하지 않기 때문에 링커가 몇몇 symbol들의 출처를 찾지 못하여 위와 같은 링커 오류 메세지가 출력되는 것입니다. 이 문제를 해결하려면, 링커에게 `--nostartfiles` 인자를 전달하여 더 이상 링커가 C 런타임의 실행 시작 루틴을 링크하지 않도록 해야 합니다.
+
+링커에 인자를 전달하는 한 방법은 `cargo rustc` 명령어를 이용하는 것입니다. 이 명령어는 `cargo build`와 유사하게 동작하나, `rustc`(Rust 컴파일러)에 직접 인자를 전달할 수 있게 해줍니다. `rustc`는 `-C link-arg` 인자를 통해 링커에게 인자를 전달할 수 있게 해줍니다. 우리가 이용할 새로운 빌드 명령어는 아래와 같습니다:
+
+```
+cargo rustc -- -C link-arg=-nostartfiles
+```
+
+이제 우리의 크레이트가 성공적으로 빌드되고 Linux에서 동작하는 freestanding 실행파일이 생성됩니다!
+
+우리는 위의 빌드 명령어에서 실행 시작 함수의 이름을 명시적으로 전달하지 않았는데, 그 이유는 링커가 기본적으로 `_start` 라는 이름의 함수를 찾아 그 함수를 실행 시작 함수로 이용하기 때문입니다.
+
+#### Windows
+
+Windows에서는 다른 링커 오류를 마주하게 됩니다 (일부 생략):
+
+```
+error: linking with `link.exe` failed: exit code: 1561
+ |
+ = note: "C:\\Program Files (x86)\\…\\link.exe" […]
+ = note: LINK : fatal error LNK1561: entry point must be defined
+```
+
+오류 메세지 "entry point must be defined"는 링커가 실행 시작 지점을 찾을 수 없다는 것을 알려줍니다. Windows에서는 기본 실행 시작 지점의 이름이 [사용 중인 서브시스템(subsystem)에 따라 다릅니다][windows-subsystems]. `CONSOLE` 서브시스템의 경우 링커가 `mainCRTStartup`이라는 함수를 실행 시작 지점으로 간주하고, `WINDOWS` 서브시스템의 경우 링커가 `WinMainCRTStartup`이라는 이름의 함수를 실행 시작 지점으로 간주합니다. 이러한 기본값을 변경하여 링커가 `_start`라는 이름의 함수를 실행 시작 지점으로 간주하도록 만드려면 링커에 `/ENTRY` 인자를 넘겨주어야 합니다:
+
+[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
+
+```
+cargo rustc -- -C link-arg=/ENTRY:_start
+```
+
+Linux에서와는 다른 인자 형식을 통해 Windows의 링커는 Linux의 링커와 완전히 다른 프로그램이라는 것을 유추할 수 있습니다.
+
+이제 또 다른 링커 오류가 발생합니다:
+
+```
+error: linking with `link.exe` failed: exit code: 1221
+ |
+ = note: "C:\\Program Files (x86)\\…\\link.exe" […]
+ = note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
+ defined
+```
+
+이 오류가 뜨는 이유는 Windows 실행파일들은 여러 가지 [서브시스템][windows-subsystems]을 사용할 수 있기 때문입니다. 일반적인 프로그램들의 경우, 실행 시작 지점 함수의 이름에 따라 어떤 서브시스템을 사용하는지 추론합니다: 실행 시작 지점의 이름이 `main`인 경우 `CONSOLE` 서브시스템이 사용 중이라는 것을 알 수 있으며, 실행 시작 지점의 이름이 `WinMain`인 경우 `WINDOWS` 서브시스템이 사용 중이라는 것을 알 수 있습니다. 우리는 `_start`라는 새로운 이름의 실행 시작 지점을 이용할 것이기에, 우리가 어떤 서브시스템을 사용할 것인지 인자를 통해 명시적으로 링커에게 알려줘야 합니다:
+
+```
+cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
+```
+
+위 명령어에서는 `CONSOLE` 서브시스템을 서용했지만, `WINDOWS` 서브시스템을 적용해도 괜찮습니다. `-C link-arg` 인자를 반복해서 쓰는 대신, `-C link-args`인자를 이용해 여러 인자들을 빈칸으로 구분하여 전달할 수 있습니다.
+
+이 명령어를 통해 우리의 실행 파일을 Windows에서도 성공적으로 빌드할 수 있을 것입니다.
+
+#### macOS
+
+macOS에서는 아래와 같은 링커 오류가 출력됩니다 (일부 생략):
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: ld: entry point (_main) undefined. for architecture x86_64
+ clang: error: linker command failed with exit code 1 […]
+```
+
+위 오류 메세지는 우리에게 링커가 실행 시작 지점 함수의 기본값 이름 `main`을 찾지 못했다는 것을 알려줍니다 (macOS에서는 무슨 이유에서인지 모든 함수들의 이름 맨 앞에 `_` 문자가 앞에 붙습니다). 실행 시작 지점 함수의 이름을 `_start`로 새롭게 지정해주기 위해 아래와 같이 링커 인자 `-e`를 이용합니다:
+
+```
+cargo rustc -- -C link-args="-e __start"
+```
+
+`-e` 인자를 통해 실행 시작 지점 함수 이름을 설정합니다. macOS에서는 모든 함수의 이름 앞에 추가로 `_` 문자가 붙기에, 실행 시작 지점 함수의 이름을 `_start` 대신 `__start`로 지정해줍니다.
+
+이제 아래와 같은 링커 오류가 나타날 것입니다:
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: ld: dynamic main executables must link with libSystem.dylib
+ for architecture x86_64
+ clang: error: linker command failed with exit code 1 […]
+```
+
+macOS는 [공식적으로는 정적으로 링크된 실행파일을 지원하지 않으며][does not officially support statically linked binaries], 기본적으로 모든 프로그램이 `libSystem` 라이브러리를 링크하도록 요구합니다. 이러한 기본 요구사항을 무시하고 정적으로 링크된 실행 파일을 만드려면 링커에게 `-static` 인자를 주어야 합니다:
+
+[does not officially support statically linked binaries]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
+
+```
+cargo rustc -- -C link-args="-e __start -static"
+```
+
+아직도 충분하지 않았는지, 세 번째 링커 오류가 아래와 같이 출력됩니다:
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: ld: library not found for -lcrt0.o
+ clang: error: linker command failed with exit code 1 […]
+```
+
+이 오류가 뜨는 이유는 macOS에서 모든 프로그램은 기본적으로 `crt0` (“C runtime zero”)를 링크하기 때문입니다. 이 오류는 우리가 Linux에서 봤던 오류와 유사한 것으로, 똑같이 링커에 `-nostartfiles` 인자를 주어 해결할 수 있습니다:
+
+```
+cargo rustc -- -C link-args="-e __start -static -nostartfiles"
+```
+
+이제는 우리의 프로그램을 macOS에서 성공적으로 빌드할 수 있을 것입니다.
+
+#### 플랫폼 별 빌드 명령어들을 하나로 통합하기
+
+위에서 살펴본 대로 호스트 플랫폼 별로 상이한 빌드 명령어가 필요한데, `.cargo/config.toml` 이라는 파일을 만들고 플랫폼 마다 필요한 상이한 인자들을 명시하여 여러 빌드 명령어들을 하나로 통합할 수 있습니다.
+
+```toml
+# in .cargo/config.toml
+
+[target.'cfg(target_os = "linux")']
+rustflags = ["-C", "link-arg=-nostartfiles"]
+
+[target.'cfg(target_os = "windows")']
+rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
+
+[target.'cfg(target_os = "macos")']
+rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
+```
+
+`rustflags`에 포함된 인자들은 `rustc`가 실행될 때마다 자동적으로 `rustc`에 인자로 전달됩니다. `.cargo/config.toml`에 대한 더 자세한 정보는 [공식 안내 문서](https://doc.rust-lang.org/cargo/reference/config.html)를 통해 확인해주세요.
+
+이제 `cargo build` 명령어 만으로 세 가지 플랫폼 어디에서도 우리의 프로그램을 성공적으로 빌드할 수 있습니다.
+
+#### 이렇게 하는 것이 괜찮나요?
+
+Linux, Windows 또는 macOS 위에서 동작하는 freestanding 실행파일을 빌드하는 것이 가능하긴 해도 좋은 방법은 아닙니다. 운영체제가 갖춰진 환경을 목표로 빌드를 한다면, 실행 파일 동작 시 다른 많은 조건들이 런타임에 의해 제공될 것이라는 가정 하에 빌드가 이뤄지기 때문입니다 (예: 실행 파일이 `_start` 함수가 호출되는 시점에 이미 스택이 초기화되어있을 것이라고 간주하고 작동합니다). C 런타임 없이는 실행 파일이 필요로 하는 조건들이 갖춰지지 않아 결국 세그멘테이션 오류가 나는 등 프로그램이 제대로 실행되지 못할 수 있습니다.
+
+이미 존재하는 운영체제 위에서 동작하는 최소한의 실행 파일을 만들고 싶다면, `libc`를 링크하고 [이 곳의 설명](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html)에 따라 `#[start]` 속성을 설정하는 것이 더 좋은 방법일 것입니다.
+
+
+
+## 요약 {#summary}
+
+아래와 같은 최소한의 코드로 "freestanding" Rust 실행파일을 만들 수 있습니다:
+
+`src/main.rs`:
+
+```rust
+#![no_std] // Rust 표준 라이브러리를 링크하지 않도록 합니다
+#![no_main] // Rust 언어에서 사용하는 실행 시작 지점 (main 함수)을 사용하지 않습니다
+
+use core::panic::PanicInfo;
+
+#[no_mangle] // 이 함수의 이름을 mangle하지 않습니다
+pub extern "C" fn _start() -> ! {
+ // 링커는 기본적으로 '_start' 라는 이름을 가진 함수를 실행 시작 지점으로 삼기에,
+ // 이 함수는 실행 시작 지점이 됩니다
+ loop {}
+}
+
+/// 패닉이 일어날 경우, 이 함수가 호출됩니다.
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ loop {}
+}
+```
+
+`Cargo.toml`:
+
+```toml
+[package]
+name = "crate_name"
+version = "0.1.0"
+authors = ["Author Name "]
+
+# `cargo build` 실행 시 이용되는 빌드 설정
+[profile.dev]
+panic = "abort" # 패닉 시 스택 되감기를 하지 않고 바로 프로그램 종료
+
+# `cargo build --release` 실행 시 이용되는 빌드 설정
+[profile.release]
+panic = "abort" # 패닉 시 스택 되감기를 하지 않고 바로 프로그램 종료
+```
+
+이 실행 파일을 빌드하려면, `thumbv7em-none-eabihf`와 같은 bare metal 시스템 환경을 목표로 컴파일해야 합니다:
+
+```
+cargo build --target thumbv7em-none-eabihf
+```
+
+또다른 방법으로, 각 호스트 시스템마다 추가적인 링커 인자들을 전달해주어 호스트 시스템 환경을 목표로 컴파일할 수도 있습니다:
+
+```bash
+# Linux
+cargo rustc -- -C link-arg=-nostartfiles
+# Windows
+cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
+# macOS
+cargo rustc -- -C link-args="-e __start -static -nostartfiles"
+```
+
+주의할 것은 이것이 정말 최소한의 freestanding Rust 실행 파일이라는 것입니다. 실행 파일은 여러 가지 조건들을 가정하는데, 그 예로 실행파일 동작 시 `_start` 함수가 호출될 때 스택이 초기화되어 있을 것을 가정합니다. **이 freestanding 실행 파일을 이용해 실제로 유용한 작업을 처리하려면 아직 더 많은 코드 구현이 필요합니다**.
+
+## 다음 단계는 무엇일까요?
+
+[다음 포스트][next post]에서는 우리의 freestanding 실행 파일을 최소한의 기능을 갖춘 운영체제 커널로 만드는 과정을 단게별로 설명할 것입니다.
+예시로 커스텀 시스템 환경을 설정하는 방법, 우리의 실행 파일을 부트로더와 합치는 방법, 그리고 화면에 메세지를 출력하는 방법 등에 대해 다루겠습니다.
+
+[next post]: @/edition-2/posts/02-minimal-rust-kernel/index.md
diff --git a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.md b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.md
index 6ba6829c..afe21cd3 100644
--- a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.md
+++ b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.md
@@ -44,7 +44,7 @@ In order to create an OS kernel in Rust, we need to create an executable that ca
This post describes the necessary steps to create a freestanding Rust binary and explains why the steps are needed. If you're just interested in a minimal example, you can **[jump to the summary](#summary)**.
## Disabling the Standard Library
-By default, all Rust crates link the [standard library], which depends on the operating system for features such as threads, files, or networking. It also depends on the C standard library `libc`, which closely interacts with OS services. Since our plan is to write an operating system, we can not use any OS-dependent libraries. So we have to disable the automatic inclusion of the standard library through the [`no_std` attribute].
+By default, all Rust crates link the [standard library], which depends on the operating system for features such as threads, files, or networking. It also depends on the C standard library `libc`, which closely interacts with OS services. Since our plan is to write an operating system, we can't use any OS-dependent libraries. So we have to disable the automatic inclusion of the standard library through the [`no_std` attribute].
[standard library]: https://doc.rust-lang.org/std/
[`no_std` attribute]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
@@ -150,7 +150,7 @@ Language items are special functions and types that are required internally by t
While providing custom implementations of language items is possible, it should only be done as a last resort. The reason is that language items are highly unstable implementation details and not even type checked (so the compiler doesn't even check if a function has the right argument types). Fortunately, there is a more stable way to fix the above language item error.
-The [`eh_personality` language item] marks a function that is used for implementing [stack unwinding]. By default, Rust uses unwinding to run the destructors of all live stack variables in case of a [panic]. This ensures that all used memory is freed and allows the parent thread to catch the panic and continue execution. Unwinding, however, is a complicated process and requires some OS specific libraries (e.g. [libunwind] on Linux or [structured exception handling] on Windows), so we don't want to use it for our operating system.
+The [`eh_personality` language item] marks a function that is used for implementing [stack unwinding]. By default, Rust uses unwinding to run the destructors of all live stack variables in case of a [panic]. This ensures that all used memory is freed and allows the parent thread to catch the panic and continue execution. Unwinding, however, is a complicated process and requires some OS-specific libraries (e.g. [libunwind] on Linux or [structured exception handling] on Windows), so we don't want to use it for our operating system.
[`eh_personality` language item]: https://github.com/rust-lang/rust/blob/edb368491551a77d77a48446d4ee88b35490c565/src/libpanic_unwind/gcc.rs#L11-L45
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
@@ -219,7 +219,7 @@ pub extern "C" fn _start() -> ! {
}
```
-By using the `#[no_mangle]` attribute we disable the [name mangling] to ensure that the Rust compiler really outputs a function with the name `_start`. Without the attribute, the compiler would generate some cryptic `_ZN3blog_os4_start7hb173fedf945531caE` symbol to give every function an unique name. The attribute is required because we need to tell the name of the entry point function to the linker in the next step.
+By using the `#[no_mangle]` attribute, we disable [name mangling] to ensure that the Rust compiler really outputs a function with the name `_start`. Without the attribute, the compiler would generate some cryptic `_ZN3blog_os4_start7hb173fedf945531caE` symbol to give every function a unique name. The attribute is required because we need to tell the name of the entry point function to the linker in the next step.
We also have to mark the function as `extern "C"` to tell the compiler that it should use the [C calling convention] for this function (instead of the unspecified Rust calling convention). The reason for naming the function `_start` is that this is the default entry point name for most systems.
@@ -240,7 +240,7 @@ To solve the errors, we need to tell the linker that it should not include the C
### Building for a Bare Metal Target
-By default Rust tries to build an executable that is able to run in your current system environment. For example, if you're using Windows on `x86_64`, Rust tries to build a `.exe` Windows executable that uses `x86_64` instructions. This environment is called your "host" system.
+By default Rust tries to build an executable that is able to run in your current system environment. For example, if you're using Windows on `x86_64`, Rust tries to build an `.exe` Windows executable that uses `x86_64` instructions. This environment is called your "host" system.
To describe different environments, Rust uses a string called [_target triple_]. You can see the target triple for your host system by running `rustc --version --verbose`:
@@ -260,9 +260,9 @@ The above output is from a `x86_64` Linux system. We see that the `host` triple
[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
-By compiling for our host triple, the Rust compiler and the linker assume that there is an underlying operating system such as Linux or Windows that use the C runtime by default, which causes the linker errors. So to avoid the linker errors, we can compile for a different environment with no underlying operating system.
+By compiling for our host triple, the Rust compiler and the linker assume that there is an underlying operating system such as Linux or Windows that uses the C runtime by default, which causes the linker errors. So, to avoid the linker errors, we can compile for a different environment with no underlying operating system.
-An example for such a bare metal environment is the `thumbv7em-none-eabihf` target triple, which describes an [embedded] [ARM] system. The details are not important, all that matters is that the target triple has no underlying operating system, which is indicated by the `none` in the target triple. To be able to compile for this target, we need to add it in rustup:
+An example of such a bare metal environment is the `thumbv7em-none-eabihf` target triple, which describes an [embedded] [ARM] system. The details are not important, all that matters is that the target triple has no underlying operating system, which is indicated by the `none` in the target triple. To be able to compile for this target, we need to add it in rustup:
[embedded]: https://en.wikipedia.org/wiki/Embedded_system
[ARM]: https://en.wikipedia.org/wiki/ARM_architecture
@@ -335,7 +335,7 @@ error: linking with `link.exe` failed: exit code: 1561
= note: LINK : fatal error LNK1561: entry point must be defined
```
-The "entry point must be defined" error means that the linker can't find the entry point. On Windows, the default entry point name [depends on the used subsystem][windows-subsystems]. For the `CONSOLE` subsystem the linker looks for a function named `mainCRTStartup` and for the `WINDOWS` subsystem it looks for a function named `WinMainCRTStartup`. To override the default and tell the linker to look for our `_start` function instead, we can pass an `/ENTRY` argument to the linker:
+The "entry point must be defined" error means that the linker can't find the entry point. On Windows, the default entry point name [depends on the used subsystem][windows-subsystems]. For the `CONSOLE` subsystem, the linker looks for a function named `mainCRTStartup` and for the `WINDOWS` subsystem, it looks for a function named `WinMainCRTStartup`. To override the default and tell the linker to look for our `_start` function instead, we can pass an `/ENTRY` argument to the linker:
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
@@ -355,7 +355,7 @@ error: linking with `link.exe` failed: exit code: 1221
defined
```
-This error occurs because Windows executables can use different [subsystems][windows-subsystems]. For normal programs they are inferred depending on the entry point name: If the entry point is named `main`, the `CONSOLE` subsystem is used, and if the entry point is named `WinMain`, the `WINDOWS` subsystem is used. Since our `_start` function has a different name, we need to specify the subsystem explicitly:
+This error occurs because Windows executables can use different [subsystems][windows-subsystems]. For normal programs, they are inferred depending on the entry point name: If the entry point is named `main`, the `CONSOLE` subsystem is used, and if the entry point is named `WinMain`, the `WINDOWS` subsystem is used. Since our `_start` function has a different name, we need to specify the subsystem explicitly:
```
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
@@ -377,7 +377,7 @@ error: linking with `cc` failed: exit code: 1
clang: error: linker command failed with exit code 1 […]
```
-This error message tells us that the linker can't find an entry point function with the default name `main` (for some reason all functions are prefixed with a `_` on macOS). To set the entry point to our `_start` function, we pass the `-e` linker argument:
+This error message tells us that the linker can't find an entry point function with the default name `main` (for some reason, all functions are prefixed with a `_` on macOS). To set the entry point to our `_start` function, we pass the `-e` linker argument:
```
cargo rustc -- -C link-args="-e __start"
@@ -414,7 +414,7 @@ error: linking with `cc` failed: exit code: 1
clang: error: linker command failed with exit code 1 […]
```
-This error occurs because programs on macOS link to `crt0` (“C runtime zero”) by default. This is similar to the error we had on Linux and can be also solved by adding the `-nostartfiles` linker argument:
+This error occurs because programs on macOS link to `crt0` (“C runtime zero”) by default. This is similar to the error we had on Linux and can also be solved by adding the `-nostartfiles` linker argument:
```
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
@@ -424,7 +424,7 @@ Now our program should build successfully on macOS.
#### Unifying the Build Commands
-Right now we have different build commands depending on the host platform, which is not ideal. To avoid this, we can create a file named `.cargo/config.toml` that contains the platform specific arguments:
+Right now we have different build commands depending on the host platform, which is not ideal. To avoid this, we can create a file named `.cargo/config.toml` that contains the platform-specific arguments:
```toml
# in .cargo/config.toml
@@ -439,7 +439,7 @@ rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
```
-The `rustflags` key contains arguments that are automatically added to every invocation of `rustc`. For more information on the `.cargo/config.toml` file check out the [official documentation](https://doc.rust-lang.org/cargo/reference/config.html).
+The `rustflags` key contains arguments that are automatically added to every invocation of `rustc`. For more information on the `.cargo/config.toml` file, check out the [official documentation](https://doc.rust-lang.org/cargo/reference/config.html).
Now our program should be buildable on all three platforms with a simple `cargo build`.
@@ -511,7 +511,7 @@ cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
```
-Note that this is just a minimal example of a freestanding Rust binary. This binary expects various things, for example that a stack is initialized when the `_start` function is called. **So for any real use of such a binary, more steps are required**.
+Note that this is just a minimal example of a freestanding Rust binary. This binary expects various things, for example, that a stack is initialized when the `_start` function is called. **So for any real use of such a binary, more steps are required**.
## What's next?
diff --git a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ru.md b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ru.md
index d6192f0b..3c59f65f 100644
--- a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ru.md
+++ b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.ru.md
@@ -158,7 +158,7 @@ fn panic(_info: &PanicInfo) -> ! {
[language item]: https://github.com/rust-lang/rust/blob/edb368491551a77d77a48446d4ee88b35490c565/src/libpanic_unwind/gcc.rs#L11-L45
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
[libunwind]: https://www.nongnu.org/libunwind/
-[structured exception handling]: https://docs.microsoft.com/de-de/windows/win32/debug/structured-exception-handling
+[structured exception handling]: https://docs.microsoft.com/ru-ru/windows/win32/debug/structured-exception-handling
### Отключение раскрутки
diff --git a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.zh-CN.md b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.zh-CN.md
index 6be3b1df..8ef04385 100644
--- a/blog/content/edition-2/posts/01-freestanding-rust-binary/index.zh-CN.md
+++ b/blog/content/edition-2/posts/01-freestanding-rust-binary/index.zh-CN.md
@@ -6,9 +6,11 @@ date = 2018-02-10
[extra]
# Please update this when updating the translation
-translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
# GitHub usernames of the people that translated this post
-translators = ["luojia65", "Rustin-Liu", "TheBegining"]
+translators = ["luojia65", "Rustin-Liu", "TheBegining", "liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong"]
+++
创建一个不链接标准库的 Rust 可执行文件,将是我们迈出的第一步。无需底层操作系统的支撑,这样才能在**裸机**([bare metal])上运行 Rust 代码。
@@ -43,10 +45,10 @@ translators = ["luojia65", "Rustin-Liu", "TheBegining"]
我们可以从创建一个新的 cargo 项目开始。最简单的办法是使用下面的命令:
```bash
-> cargo new blog_os
+cargo new blog_os --bin --edition 2018
```
-在这里我把项目命名为 `blog_os`,当然读者也可以选择自己的项目名称。这里,cargo 默认为我们添加了`--bin` 选项,说明我们将要创建一个可执行文件(而不是一个库);cargo还为我们添加了`--edition 2018` 标签,指明项目的包要使用 Rust 的 **2018 版次**([2018 edition])。当我们执行这行指令的时候,cargo 为我们创建的目录结构如下:
+在这里我把项目命名为 `blog_os`,当然读者也可以选择自己的项目名称。默认情况下,即使不显式指定,cargo 也会为我们添加`--bin` 选项,说明我们将要创建一个可执行文件(而不是一个库); 另外 `--edition 2018` 参数指明了项目的包要使用 Rust 的 **2018 版次**([2018 edition]),但在默认情况下,该参数会指向本地安装的最新版本。当我们成功执行这行指令后,cargo 为我们创建的目录结构如下:
[2018 edition]: https://doc.rust-lang.org/nightly/edition-guide/rust-2018/index.html
@@ -158,7 +160,7 @@ error: requires `start` lang_item
我们通常会认为,当运行一个程序时,首先被调用的是 `main` 函数。但是,大多数语言都拥有一个**运行时系统**([runtime system](https://en.wikipedia.org/wiki/Runtime_system)),它通常为**垃圾回收**(garbage collection)或**绿色线程**(software threads,或 green threads)服务,如 Java 的 GC 或 Go 语言的协程(goroutine);这个运行时系统需要在 main 函数前启动,因为它需要让程序初始化。
-在一个典型的使用标准库的 Rust 程序中,程序运行是从一个名为 `crt0` 的运行时库开始的。`crt0` 意为 C runtime zero,它能建立一个适合运行 C 语言程序的环境,这包含了栈的创建和可执行程序参数的传入。在这之后,这个运行时库会调用 [Rust 的运行时入口点](https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73),这个入口点被称作 **start语言项**("start" language item)。Rust 只拥有一个极小的运行时,它被设计为拥有较少的功能,如爆栈检测和打印**堆栈轨迹**(stack trace)。这之后,这个运行时将会调用 main 函数。
+在一个典型的使用标准库的 Rust 程序中,程序运行是从一个名为 `crt0` 的运行时库开始的。`crt0` 意为 C runtime zero,它能建立一个适合运行 C 语言程序的环境,这包含了栈的创建和可执行程序参数的传入。在这之后,这个运行时库会调用 [Rust 的运行时入口点](https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73),这个入口点被称作 **start语言项**("start" language item)。Rust 只拥有一个极小的运行时,它被设计为拥有较少的功能,如爆栈检测和打印**栈轨迹**(stack trace)。这之后,这个运行时将会调用 main 函数。
我们的独立式可执行程序并不能访问 Rust 运行时或 `crt0` 库,所以我们需要定义自己的入口点。只实现一个 `start` 语言项并不能帮助我们,因为这之后程序依然要求 `crt0` 库。所以,我们要做的是,直接重写整个 `crt0` 库和它定义的入口点。
@@ -241,6 +243,172 @@ cargo build --target thumbv7em-none-eabihf
### 链接器参数
我们也可以选择不编译到裸机系统,因为传递特定的参数也能解决链接器错误问题。虽然我们不会在后面使用到这个方法,为了教程的完整性,我们也撰写了专门的短文章,来提供这个途径的解决方案。
+如有需要,请点击下方的 _"链接器参数"_ 按钮来展开可选内容。
+
+
+
+链接器参数
+
+在本章节中,我们讨论了Linux、Windows和macOS中遇到的链接错误,并阐述如何通过传递额外参数来解决这些错误。注意,由于不同操作系统的可执行文件内在格式不同,所以对于不同操作系统而言,所适用的额外参数也有所不同。
+
+#### Linux
+
+在Linux下,会触发以下链接错误(简化版):
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
+ (.text+0x12): undefined reference to `__libc_csu_fini'
+ /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
+ (.text+0x19): undefined reference to `__libc_csu_init'
+ /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
+ (.text+0x25): undefined reference to `__libc_start_main'
+ collect2: error: ld returned 1 exit status
+```
+
+这里的问题在于,链接器默认包含了C启动例程,即构建名为 `_start` 的入口函数的地方。但其依赖一些C标准库 `libc` 中的符号,而我们已经使用 `no_std` 开关排除掉了这些符号,所以链接器报告了这些错误。要解决这个问题,我们需要通过 `-nostartfiles` 参数来告诉链接器不要使用C启动例程功能。
+
+通过 `cargo rustc` 可以传递链接器参数,该命令和 `cargo build` 的效果完全一致,但是可以将参数传递给rust的底层编译器 `rustc`。`rustc` 支持 `-C link-arg` 参数,此参数可以传递参数给配套的链接器。那么以此推断,我们的编译语句可以这样写:
+
+```
+cargo rustc -- -C link-arg=-nostartfiles
+```
+
+现在我们编译出的程序就可以在Linux上独立运行了。
+
+我们并不需要显式指定入口函数名,链接器默认会查找 `_start` 函数作为入口点。
+
+#### Windows
+
+
+在Windows下,会触发以下链接错误(简化版):
+
+```
+error: linking with `link.exe` failed: exit code: 1561
+ |
+ = note: "C:\\Program Files (x86)\\…\\link.exe" […]
+ = note: LINK : fatal error LNK1561: entry point must be defined
+```
+
+错误信息 “entry point must be defined” 意味着链接器没有找到程序入口点。在Windows环境下,默认入口点[取决于使用的子系统][windows-subsystems]。对于 `CONSOLE` 子系统,链接器会寻找 `mainCRTStartup` 函数作为入口,而对于 `WINDOWS` 子系统,入口函数名叫做 `WinMainCRTStartup`。要复写掉入口函数名的默认设定,使其使用我们已经定义的 `_start` 函数,可以将 `/ENTRY` 参数传递给链接器:
+
+[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
+
+```
+cargo rustc -- -C link-arg=/ENTRY:_start
+```
+
+显而易见,从链接参数上看,Windows平台使用的链接器和Linux平台是完全不同的。
+
+此时可能你还会遇到这个链接错误:
+
+```
+error: linking with `link.exe` failed: exit code: 1221
+ |
+ = note: "C:\\Program Files (x86)\\…\\link.exe" […]
+ = note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
+ defined
+```
+
+该错误的原因是Windows平台下的可执行文件可以使用不同的[子系统][windows-subsystems]。一般而言,操作系统会如此判断:如果入口函数名叫 `main` ,则会使用 `CONSOLE` 子系统;若名叫 `WinMain` ,则会使用 `WINDOWS` 子系统。然而此时我们使用的入口函数名叫 `_start` ,两者都不是,此时就需要显式指定子系统:
+
+```
+cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
+```
+
+这里我们使用了 `CONSOLE` 子系统,如果使用 `WINDOWS` 子系统其实也可以。但是多次使用 `-C link-arg` 参数大可不必,我们可以如上面一样,将一个引号包裹起来的以空格分隔的列表传递给 `-C link-arg` 参数。
+
+现在我们编译出的程序就可以在Windows平台成功运行了。
+
+#### macOS
+
+在macOS下,会触发以下链接错误(简化版):
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: ld: entry point (_main) undefined. for architecture x86_64
+ clang: error: linker command failed with exit code 1 […]
+```
+
+该错误告诉我们链接器找不到入口函数 `main` (由于某些原因,macOS平台下,所有函数都会具有 `_` 前缀)。要重设入口函数名,我们可以传入链接器参数 `-e` :
+
+```
+cargo rustc -- -C link-args="-e __start"
+```
+
+`-e` 参数可用于重设入口函数名。由于在macOS平台下,所有函数都具有 `_` 前缀,所以需要传入 `__start` ,而不是 `_start` 。
+
+接下来,会出现一个新的链接错误:
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: ld: dynamic main executables must link with libSystem.dylib
+ for architecture x86_64
+ clang: error: linker command failed with exit code 1 […]
+```
+
+macOS [并未官方支持静态链接][does not officially support statically linked binaries] ,并且在默认情况下程序会链接 `libSystem` 库。要复写这个设定并进行静态链接,我们可以传入链接器参数 `-static` :
+
+[does not officially support statically linked binaries]: https://developer.apple.com/library/archive/qa/qa1118/_index.html
+
+```
+cargo rustc -- -C link-args="-e __start -static"
+```
+
+然而问题并没有解决,链接器再次抛出了一个错误:
+
+```
+error: linking with `cc` failed: exit code: 1
+ |
+ = note: "cc" […]
+ = note: ld: library not found for -lcrt0.o
+ clang: error: linker command failed with exit code 1 […]
+```
+
+该错误的原因是macOS平台下的程序会默认链接 `crt0` (即“C runtime zero”)。 这个错误实际上和Linux平台上的错误类似,可以添加链接器参数 `-nostartfiles` 解决:
+
+```
+cargo rustc -- -C link-args="-e __start -static -nostartfiles"
+```
+
+现在,我们的程序可以在macOS下编译成功了。
+
+#### 统一编译命令
+
+经过上面的章节,我们知道了在各个平台使用的编译命令是不同的,这十分不优雅。要解决这个问题,我们可以创建一个 `.cargo/config.toml` 文件,分别配置不同平台下所使用的参数:
+
+```toml
+# in .cargo/config.toml
+
+[target.'cfg(target_os = "linux")']
+rustflags = ["-C", "link-arg=-nostartfiles"]
+
+[target.'cfg(target_os = "windows")']
+rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
+
+[target.'cfg(target_os = "macos")']
+rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
+```
+
+对应的 `rustflags` 配置项的值可以自动被填充到 `rustc` 的运行参数中。要寻找 `.cargo/config.toml` 更多的用法,可以看一下 [官方文档](https://doc.rust-lang.org/cargo/reference/config.html)。
+
+现在只需要运行 `cargo build` 即可在全部三个平台编译我们的程序了。
+
+#### 我们真的需要做这些?
+
+尽管我们可以在Linux、Windows和macOS编译出可执行程序,但这可能并非是个好主意。
+因为我们的程序少了不少本该存在的东西,比如 `_start` 执行时的栈初始化。
+失去了C运行时,部分基于它的依赖项很可能无法正确执行,这会造成程序出现各式各样的异常,比如segmentation fault(段错误)。
+
+如果你希望创建一个基于已存在的操作系统的最小类库,建议引用 `libc` ,阅读 [这里](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html) 并恰当设定 `#[start]` 比较好。
+
+
## 小结
@@ -291,7 +459,18 @@ panic = "abort" # 禁用 panic 时栈展开
cargo build --target thumbv7em-none-eabihf
```
-要注意的是,现在我们的代码只是一个 Rust 编写的独立式可执行程序的一个例子。运行这个二进制程序还需要很多准备,比如在 `_start` 函数之前需要一个已经预加载完毕的栈。所以为了真正运行这样的程序,我们还有很多事情需要做。
+另外,我们也可以选择以本地操作系统为目标进行编译:
+
+```bash
+# Linux
+cargo rustc -- -C link-arg=-nostartfiles
+# Windows
+cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
+# macOS
+cargo rustc -- -C link-args="-e __start -static -nostartfiles"
+```
+
+要注意的是,现在我们的代码只是一个 Rust 编写的独立式可执行程序的一个例子。运行这个二进制程序还需要很多准备,比如在 `_start` 函数之前需要一个已经预加载完毕的栈。所以为了真正运行这样的程序,**我们还有很多事情需要做**。
## 下篇预览
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.ko.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.ko.md
new file mode 100644
index 00000000..b817732e
--- /dev/null
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.ko.md
@@ -0,0 +1,29 @@
++++
+title = "Red Zone 기능 해제하기"
+weight = 1
+path = "ko/red-zone"
+template = "edition-2/extra.html"
++++
+
+[red zone]은 [System V ABI]에서 사용 가능한 최적화 기법으로, 스택 포인터를 변경하지 않은 채로 함수들이 임시적으로 스택 프레임 아래의 128 바이트 공간을 사용할 수 있게 해줍니다:
+
+[red zone]: https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64#the-red-zone
+[System V ABI]: https://wiki.osdev.org/System_V_ABI
+
+
+
+
+
+위 사진은 `n`개의 지역 변수를 가진 함수의 스택 프레임을 보여줍니다. 함수가 호출되었을 때, 함수의 반환 주소 및 지역 변수들을 스택에 저장할 수 있도록 스택 포인터의 값이 조정됩니다.
+
+red zone은 조정된 스택 포인터 아래의 128바이트의 메모리 구간을 가리킵니다. 함수가 또 다른 함수를 호출하지 않는 구간에서만 사용하는 임시 데이터의 경우, 함수가 이 구간에 해당 데이터를 저장하는 데 이용할 수 있습니다. 따라서 스택 포인터를 조정하기 위해 필요한 명령어 두 개를 생략할 수 있는 상황이 종종 있습니다 (예: 다른 함수를 호출하지 않는 함수).
+
+하지만 이 최적화 기법을 사용하는 도중 소프트웨어 예외(exception) 혹은 하드웨어 인터럽트가 일어날 경우 큰 문제가 생깁니다. 함수가 red zone을 사용하던 도중 예외가 발생한 상황을 가정해보겠습니다:
+
+
+
+CPU와 예외 처리 핸들러가 red zone에 있는 데이터를 덮어씁니다. 하지만 이 데이터는 인터럽트된 함수가 사용 중이었던 것입니다. 따라서 예외 처리 핸들러로부터 반환하여 다시 인터럽트된 함수가 계속 실행되게 되었을 때 변경된 red zone의 데이터로 인해 함수가 오작동할 수 있습니다. 이런 현상으로 인해 [디버깅하는 데에 몇 주씩 걸릴 수 있는 이상한 버그][take weeks to debug]가 발생할지도 모릅니다.
+
+[take weeks to debug]: https://forum.osdev.org/viewtopic.php?t=21720
+
+미래에 예외 처리 로직을 구현할 때 이러한 오류가 일어나는 것을 피하기 위해 우리는 미리 red zone 최적화 기법을 해제한 채로 프로젝트를 진행할 것입니다. 컴파일 대상 환경 설정 파일에 `"disable-redzone": true` 줄을 추가함으로써 해당 기능을 해제할 수 있습니다.
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md
index 1829ac4e..f5599608 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md
@@ -5,7 +5,7 @@ path = "red-zone"
template = "edition-2/extra.html"
+++
-The [red zone] is an optimization of the [System V ABI] that allows functions to temporarily use the 128 bytes below its stack frame without adjusting the stack pointer:
+The [red zone] is an optimization of the [System V ABI] that allows functions to temporarily use the 128 bytes below their stack frame without adjusting the stack pointer:
[red zone]: https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64#the-red-zone
[System V ABI]: https://wiki.osdev.org/System_V_ABI
@@ -22,7 +22,7 @@ However, this optimization leads to huge problems with exceptions or hardware in

-The CPU and the exception handler overwrite the data in red zone. But this data is still needed by the interrupted function. So the function won't work correctly anymore when we return from the exception handler. This might lead to strange bugs that [take weeks to debug].
+The CPU and the exception handler overwrite the data in the red zone. But this data is still needed by the interrupted function. So the function won't work correctly anymore when we return from the exception handler. This might lead to strange bugs that [take weeks to debug].
[take weeks to debug]: https://forum.osdev.org/viewtopic.php?t=21720
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.zh-CN.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.zh-CN.md
new file mode 100644
index 00000000..6c1c3fc4
--- /dev/null
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.zh-CN.md
@@ -0,0 +1,29 @@
++++
+title = "Disable the Red Zone"
+weight = 1
+path = "zh-CN/red-zone"
+template = "edition-2/extra.html"
++++
+
+[红区][red zone] 是 [System V ABI] 提供的一种优化技术,它使得函数可以在不修改栈指针的前提下,临时使用其栈帧下方的128个字节。
+
+[red zone]: https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64#the-red-zone
+[System V ABI]: https://wiki.osdev.org/System_V_ABI
+
+
+
+
+
+上图展示了一个包含了 `n` 个局部变量的栈帧。当方法开始执行时,栈指针会被调整到一个合适的位置,为返回值和局部变量留出足够的空间。
+
+红区是位于调整后的栈指针下方,长度为128字节的区域,函数会使用这部分空间存储不会被跨函数调用的临时数据。所以在某些情况下(比如逻辑简短的叶函数),红区可以节省用于调整栈指针的两条机器指令。
+
+然而红区优化有时也会引发无法处理的巨大问题(异常或者硬件中断),如果使用红区时发生了某种异常:
+
+
+
+CPU和异常处理机制会把红色区域内的数据覆盖掉,但是被中断的函数依然在引用着这些数据。当函数从错误中恢复时,错误的数据就会引发更大的错误,这类错误往往需要[追踪数周][take weeks to debug]才能找到。
+
+[take weeks to debug]: https://forum.osdev.org/viewtopic.php?t=21720
+
+要在编写异常处理机制时避免这些隐蔽而难以追踪的bug,我们需要从一开始就禁用红区优化,具体到配置文件中的配置项,就是 `"disable-redzone": true`。
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.ko.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.ko.md
new file mode 100644
index 00000000..0d3d9476
--- /dev/null
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.ko.md
@@ -0,0 +1,45 @@
++++
+title = "SIMD 해제하기"
+weight = 2
+path = "ko/disable-simd"
+template = "edition-2/extra.html"
++++
+
+[Single Instruction Multiple Data (SIMD)] 명령어들은 여러 데이터 word에 동시에 덧셈 등의 작업을 실행할 수 있으며, 이를 통해 프로그램의 실행 시간을 상당히 단축할 수 있습니다. `x86_64` 아키텍처는 다양한 SIMD 표준들을 지원합니다:
+
+[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
+
+
+
+- [MMX]: _Multi Media Extension_ 명령어 집합은 1997년에 등장하였으며, `mm0`에서 `mm7`까지 8개의 64비트 레지스터들을 정의합니다. 이 레지스터들은 그저 [x87 부동 소수점 장치][x87 floating point unit]의 레지스터들을 가리키는 별칭입니다.
+- [SSE]: _Streaming SIMD Extensions_ 명령어 집합은 1999년에 등장하였습니다. 부동 소수점 연산용 레지스터를 재사용하는 대신 새로운 레지스터 집합을 도입했습니다. `xmm0`에서 `xmm15`까지 16개의 새로운 128비트 레지스터를 정의합니다.
+- [AVX]: _Advanced Vector Extensions_ 은 SSE에 추가로 멀티미디어 레지스터의 크기를 늘리는 확장 표준입니다. `ymm0`에서 `ymm15`까지 16개의 새로운 256비트 레지스터를 정의합니다. `ymm` 레지스터들은 기존의 `xmm` 레지스터를 확장합니다 (`xmm0`이 `ymm0` 레지스터의 하부 절반을 차지하는 식으로 다른 15개의 짝에도 같은 방식의 확장이 적용됩니다).
+
+[MMX]: https://en.wikipedia.org/wiki/MMX_(instruction_set)
+[x87 floating point unit]: https://en.wikipedia.org/wiki/X87
+[SSE]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
+[AVX]: https://en.wikipedia.org/wiki/Advanced_Vector_Extensions
+
+이러한 SIMD 표준들을 사용하면 프로그램 실행 속도를 많이 향상할 수 있는 경우가 많습니다. 우수한 컴파일러는 [자동 벡터화 (auto-vectorization)][auto-vectorization]이라는 과정을 통해 일반적인 반복문을 SIMD 코드로 변환할 수 있습니다.
+
+[auto-vectorization]: https://en.wikipedia.org/wiki/Automatic_vectorization
+
+하지만 운영체제 커널은 크기가 큰 SIMD 레지스터들을 사용하기에 문제가 있습니다. 그 이유는 하드웨어 인터럽트가 일어날 때마다 커널이 사용 중이던 레지스터들의 상태를 전부 메모리에 백업해야 하기 때문입니다. 이렇게 하지 않으면 인터럽트 되었던 프로그램의 실행이 다시 진행될 때 인터럽트 당시의 프로그램 상태를 보존할 수가 없습니다. 따라서 커널이 SIMD 레지스터들을 사용하는 경우, 커널이 백업해야 하는 데이터 양이 많이 늘어나게 되어 (512-1600 바이트) 커널의 성능이 눈에 띄게 나빠집니다. 이러한 성능 손실을 피하기 위해서 `sse` 및 `mmx` 기능을 해제하는 것이 바람직합니다 (`avx` 기능은 해제된 상태가 기본 상태입니다).
+
+컴파일 대상 환경 설정 파일의 `features` 필드를 이용해 해당 기능들을 해제할 수 있습니다. `mmx` 및 `sse` 기능을 해제하려면 아래와 같이 해당 기능 이름 앞에 빼기 기호를 붙여주면 됩니다:
+
+```json
+"features": "-mmx,-sse"
+```
+
+## 부동소수점 (Floating Point)
+
+우리의 입장에서는 안타깝게도, `x86_64` 아키텍처는 부동 소수점 계산에 SSE 레지스터를 사용합니다. 따라서 SSE 기능이 해제된 상태에서 부동 소수점 계산을 컴파일하면 LLVM이 오류를 일으킵니다. Rust의 core 라이브러리는 이미 부동 소수점 숫자들을 사용하기에 (예: `f32` 및 `f64` 에 대한 각종 trait들을 정의함), 우리의 커널에서 부동 소수점 계산을 피하더라도 부동 소수점 계산을 컴파일하는 것을 피할 수 없습니다.
+
+다행히도 LLVM은 `soft-float` 기능을 지원합니다. 이 기능을 통해 정수 계만으로 모든 부동소수점 연산 결과를 모방하여 산출할 수 있습니다. 일반 부동소수점 계산보다는 느리겠지만, 이 기능을 통해 우리의 커널에서도 SSE 기능 없이 부동소수점을 사용할 수 있습니다.
+
+우리의 커널에서 `soft-float` 기능을 사용하려면 컴파일 대상 환경 설정 파일의 `features` 필드에 덧셈 기호와 함께 해당 기능의 이름을 적어주면 됩니다:
+
+```json
+"features": "-mmx,-sse,+soft-float"
+```
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.md
index d9949a37..883cc838 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.md
@@ -5,13 +5,13 @@ path = "disable-simd"
template = "edition-2/extra.html"
+++
-[Single Instruction Multiple Data (SIMD)] instructions are able to perform an operation (e.g. addition) simultaneously on multiple data words, which can speed up programs significantly. The `x86_64` architecture supports various SIMD standards:
+[Single Instruction Multiple Data (SIMD)] instructions are able to perform an operation (e.g., addition) simultaneously on multiple data words, which can speed up programs significantly. The `x86_64` architecture supports various SIMD standards:
[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
-- [MMX]: The _Multi Media Extension_ instruction set was introduced in 1997 and defines eight 64 bit registers called `mm0` through `mm7`. These registers are just aliases for the registers of the [x87 floating point unit].
+- [MMX]: The _Multi Media Extension_ instruction set was introduced in 1997 and defines eight 64-bit registers called `mm0` through `mm7`. These registers are just aliases for the registers of the [x87 floating point unit].
- [SSE]: The _Streaming SIMD Extensions_ instruction set was introduced in 1999. Instead of re-using the floating point registers, it adds a completely new register set. The sixteen new registers are called `xmm0` through `xmm15` and are 128 bits each.
- [AVX]: The _Advanced Vector Extensions_ are extensions that further increase the size of the multimedia registers. The new registers are called `ymm0` through `ymm15` and are 256 bits each. They extend the `xmm` registers, so e.g. `xmm0` is the lower half of `ymm0`.
@@ -26,7 +26,7 @@ By using such SIMD standards, programs can often speed up significantly. Good co
However, the large SIMD registers lead to problems in OS kernels. The reason is that the kernel has to backup all registers that it uses to memory on each hardware interrupt, because they need to have their original values when the interrupted program continues. So if the kernel uses SIMD registers, it has to backup a lot more data (512–1600 bytes), which noticeably decreases performance. To avoid this performance loss, we want to disable the `sse` and `mmx` features (the `avx` feature is disabled by default).
-We can do that through the the `features` field in our target specification. To disable the `mmx` and `sse` features we add them prefixed with a minus:
+We can do that through the `features` field in our target specification. To disable the `mmx` and `sse` features, we add them prefixed with a minus:
```json
"features": "-mmx,-sse"
@@ -35,7 +35,7 @@ We can do that through the the `features` field in our target specification. To
## Floating Point
Unfortunately for us, the `x86_64` architecture uses SSE registers for floating point operations. Thus, every use of floating point with disabled SSE causes an error in LLVM. The problem is that Rust's core library already uses floats (e.g., it implements traits for `f32` and `f64`), so avoiding floats in our kernel does not suffice.
-Fortunately, LLVM has support for a `soft-float` feature, emulates all floating point operations through software functions based on normal integers. This makes it possible to use floats in our kernel without SSE, it will just be a bit slower.
+Fortunately, LLVM has support for a `soft-float` feature that emulates all floating point operations through software functions based on normal integers. This makes it possible to use floats in our kernel without SSE; it will just be a bit slower.
To turn on the `soft-float` feature for our kernel, we add it to the `features` line in our target specification, prefixed with a plus:
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.zh-CN.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.zh-CN.md
new file mode 100644
index 00000000..87894c88
--- /dev/null
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.zh-CN.md
@@ -0,0 +1,44 @@
++++
+title = "Disable SIMD"
+weight = 2
+path = "zh-CN/disable-simd"
+template = "edition-2/extra.html"
++++
+
+[单指令多数据][Single Instruction Multiple Data (SIMD)] 指令允许在一个操作符(比如加法)内传入多组数据,以此加速程序执行速度。`x86_64` 架构支持多种SIMD标准:
+
+[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
+
+
+
+- [MMX]: _多媒体扩展_ 指令集于1997年发布,定义了8个64位寄存器,分别被称为 `mm0` 到 `mm7`,不过,这些寄存器只是 [x87浮点执行单元][x87 floating point unit] 中寄存器的映射而已。
+- [SSE]: _流处理SIMD扩展_ 指令集于1999年发布,不同于MMX的复用浮点执行单元,该指令集加入了一个完整的新寄存器组,即被称为 `xmm0` 到 `xmm15` 的16个128位寄存器。
+- [AVX]: _先进矢量扩展_ 用于进一步扩展多媒体寄存器的数量,它定义了 `ymm0` 到 `ymm15` 共16个256位寄存器,但是这些寄存器继承于 `xmm`,例如 `xmm0` 寄存器是 `ymm0` 的低128位。
+
+[MMX]: https://en.wikipedia.org/wiki/MMX_(instruction_set)
+[x87 floating point unit]: https://en.wikipedia.org/wiki/X87
+[SSE]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
+[AVX]: https://en.wikipedia.org/wiki/Advanced_Vector_Extensions
+
+通过应用这些SIMD标准,计算机程序可以显著提高执行速度。优秀的编译器可以将常规循环自动优化为适用SIMD的代码,这种优化技术被称为 [自动矢量化][auto-vectorization]。
+
+[auto-vectorization]: https://en.wikipedia.org/wiki/Automatic_vectorization
+
+尽管如此,SIMD会让操作系统内核出现一些问题。具体来说,就是操作系统在处理硬件中断时,需要保存所有寄存器信息到内存中,在中断结束后再将其恢复以供使用。所以说,如果内核需要使用SIMD寄存器,那么每次处理中断需要备份非常多的数据(512-1600字节),这会显著地降低性能。要避免这部分性能损失,我们需要禁用 `sse` 和 `mmx` 这两个特性(`avx` 默认已禁用)。
+
+我们可以在编译配置文件中的 `features` 配置项做出如下修改,加入以减号为前缀的 `mmx` 和 `sse` 即可:
+
+```json
+"features": "-mmx,-sse"
+```
+
+## 浮点数
+还有一件不幸的事,`x86_64` 架构在处理浮点数计算时,会用到 `sse` 寄存器,因此,禁用SSE的前提下使用浮点数计算LLVM都一定会报错。 更大的问题在于Rust核心库里就存在着为数不少的浮点数运算(如 `f32` 和 `f64` 的数个trait),所以试图避免使用浮点数是不可能的。
+
+幸运的是,LLVM支持 `soft-float` 特性,这个特性可以使用整型运算在软件层面模拟浮点数运算,使得我们为内核关闭SSE成为了可能,只需要牺牲一点点性能。
+
+要为内核打开 `soft-float` 特性,我们只需要在编译配置文件中的 `features` 配置项做出如下修改即可:
+
+```json
+"features": "-mmx,-sse,+soft-float"
+```
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fa.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fa.md
index b5396c8c..a4f9b94f 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fa.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fa.md
@@ -106,7 +106,7 @@ rtl = true
کامپایلر شبانه به ما امکان میدهد با استفاده از به اصطلاح _feature flags_ در بالای فایل، از ویژگیهای مختلف آزمایشی استفاده کنیم. به عنوان مثال، میتوانیم [`asm!` macro] آزمایشی را برای اجرای دستورات اسمبلیِ اینلاین (تلفظ: inline) با اضافه کردن `[feature(asm)]!#` به بالای فایل `main.rs` فعال کنیم. توجه داشته باشید که این ویژگیهای آزمایشی، کاملاً ناپایدار هستند، به این معنی که نسخههای آتی Rust ممکن است بدون هشدار قبلی آنها را تغییر داده یا حذف کند. به همین دلیل ما فقط در صورت لزوم از آنها استفاده خواهیم کرد.
-[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
+[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
### مشخصات هدف
@@ -414,7 +414,7 @@ pub extern "C" fn _start() -> ! {
# in Cargo.toml
[dependencies]
-bootloader = "0.9.8"
+bootloader = "0.9.23"
```
افزودن بوتلودر به عنوان وابستگی برای ایجاد یک دیسک ایمیج قابل بوت کافی نیست. مشکل این است که ما باید هسته خود را با بوت لودر پیوند دهیم، اما کارگو از [اسکریپت های بعد از بیلد] پشتیبانی نمیکند.
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fr.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fr.md
new file mode 100644
index 00000000..6cbbf0e0
--- /dev/null
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.fr.md
@@ -0,0 +1,500 @@
++++
+title = "Un noyau Rust minimal"
+weight = 2
+path = "fr/minimal-rust-kernel"
+date = 2018-02-10
+
+[extra]
+chapter = "Bare Bones"
+# Please update this when updating the translation
+translation_based_on_commit = "c689ecf810f8e93f6b2fb3c4e1e8b89b8a0998eb"
+# GitHub usernames of the people that translated this post
+translators = ["TheMimiCodes", "maximevaillancourt"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["alaincao"]
++++
+
+Dans cet article, nous créons un noyau Rust 64-bit minimal pour l'architecture x86. Nous continuons le travail fait dans l'article précédent “[Un binaire Rust autonome][freestanding Rust binary]” pour créer une image de disque amorçable qui affiche quelque chose à l'écran.
+
+[freestanding Rust binary]: @/edition-2/posts/01-freestanding-rust-binary/index.fr.md
+
+
+
+Cet article est développé de manière ouverte sur [GitHub]. Si vous avez des problèmes ou des questions, veuillez ouvrir une _Issue_ sur GitHub. Vous pouvez aussi laisser un commentaire [au bas de la page]. Le code source complet pour cet article se trouve dans la branche [`post-02`][post branch].
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[au bas de la page]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
+
+
+
+## Le processus d'amorçage
+Quand vous allumez un ordinateur, il commence par exécuter le code du micrologiciel qui est enregistré dans la carte mère ([ROM]). Ce code performe un [test d'auto-diagnostic de démarrage][power-on self-test], détecte la mémoire volatile disponible, et pré-initialise le processeur et le matériel. Par la suite, il recherche un disque amorçable et commence le processus d'amorçage du noyau du système d'exploitation.
+
+[ROM]: https://fr.wikipedia.org/wiki/M%C3%A9moire_morte
+[power-on self-test]: https://fr.wikipedia.org/wiki/Power-on_self-test_(informatique)
+
+Sur x86, il existe deux standards pour les micrologiciels : le “Basic Input/Output System“ (**[BIOS]**) et le nouvel “Unified Extensible Firmware Interface” (**[UEFI]**). Le BIOS standard est vieux et dépassé, mais il est simple et bien supporté sur toutes les machines x86 depuis les années 1980. Au contraire, l'UEFI est moderne et offre davantage de fonctionnalités. Cependant, il est plus complexe à installer (du moins, selon moi).
+
+[BIOS]: https://fr.wikipedia.org/wiki/BIOS_(informatique)
+[UEFI]: https://fr.wikipedia.org/wiki/UEFI
+
+Actuellement, nous offrons seulement un support BIOS, mais nous planifions aussi du support pour l'UEFI. Si vous aimeriez nous aider avec cela, consultez l'[_issue_ sur GitHub](https://github.com/phil-opp/blog_os/issues/349).
+
+### Amorçage BIOS
+Presque tous les systèmes x86 peuvent amorcer le BIOS, y compris les nouvelles machines UEFI qui utilisent un BIOS émulé. C'est une bonne chose car cela permet d'utiliser la même logique d'amorçage sur toutes les machines du dernier siècle. Cependant, cette grande compatibilité est aussi le plus grand inconvénient de l'amorçage BIOS, car cela signifie que le CPU est mis dans un mode de compatibilité 16-bit appelé _[real mode]_ avant l'amorçage afin que les bootloaders archaïques des années 1980 puissent encore fonctionner.
+
+Mais commençons par le commencement :
+
+Quand vous allumez votre ordinateur, il charge le BIOS provenant d'un emplacement de mémoire flash spéciale localisée sur la carte mère. Le BIOS exécute des tests d'auto-diagnostic et des routines d'initialisation du matériel, puis il cherche des disques amorçables. S'il en trouve un, le contrôle est transféré à son _bootloader_, qui est une portion de 512 octets de code exécutable enregistré au début du disque. Vu que la plupart des bootloaders dépassent 512 octets, ils sont généralement divisés en deux phases: la première, plus petite, tient dans ces 512 octets, tandis que la seconde phase est chargée subséquemment.
+
+Le bootloader doit déterminer l'emplacement de l'image de noyau sur le disque et la charger en mémoire. Il doit aussi passer le processeur de 16-bit ([real mode]) à 32-bit ([protected mode]), puis à 64-bit ([long mode]), dans lequel les registres 64-bit et la totalité de la mémoire principale sont disponibles. Sa troisième responsabilité est de récupérer certaines informations (telle que les associations mémoires) du BIOS et de les transférer au noyau du système d'exploitation.
+
+[real mode]: https://fr.wikipedia.org/wiki/Mode_r%C3%A9el
+[protected mode]: https://fr.wikipedia.org/wiki/Mode_prot%C3%A9g%C3%A9
+[long mode]: https://en.wikipedia.org/wiki/Long_mode
+[memory segmentation]: https://fr.wikipedia.org/wiki/Segmentation_(informatique)
+
+Implémenter un bootloader est fastidieux car cela requiert l'écriture en language assembleur ainsi que plusieurs autres étapes particulières comme “écrire une valeur magique dans un registre du processeur". Par conséquent, nous ne couvrons pas la création d'un bootloader dans cet article et fournissons plutôt un outil appelé [bootimage] qui ajoute automatiquement un bootloader au noyau.
+
+[bootimage]: https://github.com/rust-osdev/bootimage
+
+Si vous êtes intéressé par la création de votre propre booloader : restez dans le coin, plusieurs articles sur ce sujet sont déjà prévus à ce sujet!
+
+#### Le standard Multiboot
+Pour éviter que chaque système d'exploitation implémente son propre bootloader, qui est seulement compatible avec un seul système d'exploitation, la [Free Software Foundation] a créé en 1995 un bootloader standard public appelé [Multiboot]. Le standard définit une interface entre le bootloader et le système d'exploitation afin que n'importe quel bootloader compatible Multiboot puisse charger n'importe quel système d'exploitation compatible Multiboot. L'implémentation de référence est [GNU GRUB], qui est le bootloader le plus populaire pour les systèmes Linux.
+
+[Free Software Foundation]: https://fr.wikipedia.org/wiki/Free_Software_Foundation
+[Multiboot]: https://wiki.osdev.org/Multiboot
+[GNU GRUB]: https://fr.wikipedia.org/wiki/GNU_GRUB
+
+Pour créer un noyau compatible Multiboot, il suffit d'insérer une [en-tête Multiboot][Multiboot header] au début du fichier du noyau. Cela rend très simple l'amorçage d'un système d'exploitation depuis GRUB. Cependant, GRUB et le standard Multiboot présentent aussi quelques problèmes :
+
+[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
+
+- Ils supportent seulement le "protected mode" 32-bit. Cela signifie que vous devez encore effectuer la configuration du processeur pour passer au "long mode" 64-bit.
+- Ils sont conçus pour simplifier le bootloader plutôt que le noyau. Par exemple, le noyau doit être lié avec une [taille de page prédéfinie][adjusted default page size], étant donné que GRUB ne peut pas trouver les entêtes Multiboot autrement. Un autre exemple est que l'[information de boot][boot information], qui est fournies au noyau, contient plusieurs structures spécifiques à l'architecture au lieu de fournir des abstractions pures.
+- GRUB et le standard Multiboot sont peu documentés.
+- GRUB doit être installé sur un système hôte pour créer une image de disque amorçable depuis le fichier du noyau. Cela rend le développement sur Windows ou sur Mac plus difficile.
+
+[adjusted default page size]: https://wiki.osdev.org/Multiboot#Multiboot_2
+[boot information]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
+
+En raison de ces désavantages, nous avons décidé de ne pas utiliser GRUB ou le standard Multiboot. Cependant, nous avons l'intention d'ajouter le support Multiboot à notre outil [bootimage], afin qu'il soit aussi possible de charger le noyau sur un système GRUB. Si vous êtes interessé par l'écriture d'un noyau Multiboot conforme, consultez la [première édition][first edition] de cette série d'articles.
+
+[first edition]: @/edition-1/_index.md
+
+### UEFI
+
+(Nous ne fournissons pas le support UEFI à l'heure actuelle, mais nous aimerions bien! Si vous voulez aider, dites-le nous dans cette [_issue_ GitHub](https://github.com/phil-opp/blog_os/issues/349).)
+
+## Un noyau minimal
+Maintenant que nous savons à peu près comment un ordinateur démarre, il est temps de créer notre propre noyau minimal. Notre objectif est de créer une image de disque qui affiche “Hello World!” à l'écran lorsqu'il démarre. Nous ferons ceci en améliorant le [binaire Rust autonome][freestanding Rust binary] du dernier article.
+
+Comme vous vous en rappelez peut-être, nous avons créé un binaire autonome grâce à `cargo`, mais selon le système d'exploitation, nous avions besoin de différents points d'entrée et d'options de compilation. C'est dû au fait que `cargo` construit pour _système hôte_ par défaut, c'est-à-dire le système que vous utilisez. Ce n'est pas ce que nous voulons pour notre noyau, car un noyau qui s'exécute, par exemple, sur Windows n'a pas de sens. Nous voulons plutôt compiler pour un _système cible_ bien défini.
+
+### Installer une version nocturne de Rust
+Rust a trois canaux de distribution : _stable_, _beta_, et _nightly_. Le Livre de Rust explique bien les différences entre ces canaux, alors prenez une minute et [jetez y un coup d'oeil](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains). Pour construire un système d'exploitation, nous aurons besoin de fonctionalités expérimentales qui sont disponibles uniquement sur le canal de distribution nocturne. Donc nous devons installer une version nocturne de Rust.
+
+Pour gérer l'installation de Rust, je recommande fortement [rustup]. Il vous permet d'installer les versions nocturne, beta et stable du compilateur côte-à-côte et facilite leurs mises à jour. Avec rustup, vous pouvez utiliser un canal de distribution nocturne pour le dossier actuel en exécutant `rustup override set nightly`. Par ailleurs, vous pouvez ajouter un fichier appelé `rust-toolchain` avec le contenu `nightly` au dossier racine du projet. Vous pouvez vérifier que vous avez une version nocturne installée en exécutant `rustc --version`: Le numéro de la version devrait comprendre `-nightly` à la fin.
+
+[rustup]: https://www.rustup.rs/
+
+La version nocturne du compilateur nous permet d'activer certaines fonctionnalités expérimentales en utilisant certains _drapeaux de fonctionalité_ dans le haut de notre fichier. Par exemple, nous pourrions activer [macro expérimentale `asm!`][`asm!` macro] pour écrire du code assembleur intégré en ajoutant `#![feature(asm)]` au haut de notre `main.rs`. Notez que ces fonctionnalités expérimentales sont tout à fait instables, ce qui veut dire que des versions futures de Rust pourraient les changer ou les retirer sans préavis. Pour cette raison, nous les utiliserons seulement lorsque strictement nécessaire.
+
+[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
+
+### Spécification de la cible
+Cargo supporte différent systèmes cibles avec le paramètre `--target`. La cible est définie par un soi-disant _[triplet de cible][target triple]_, qui décrit l'architecteur du processeur, le fabricant, le système d'exploitation, et l'interface binaire d'application ([ABI]). Par exemple, le triplet `x86_64-unknown-linux-gnu` décrit un système avec un processeur `x86_64`, sans fabricant défini, et un système d'exploitation Linux avec l'interface binaire d'application GNU. Rust supporte [plusieurs différents triplets de cible][platform-support], incluant `arm-linux-androideabi` pour Android ou [`wasm32-unknown-unknown` pour WebAssembly](https://www.hellorust.com/setup/wasm-target/).
+
+[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
+[ABI]: https://stackoverflow.com/a/2456882
+[platform-support]: https://forge.rust-lang.org/release/platform-support.html
+[custom-targets]: https://doc.rust-lang.org/nightly/rustc/targets/custom.html
+
+Pour notre système cible toutefois, nous avons besoin de paramètres de configuration spéciaux (par exemple, pas de système d'explotation sous-jacent), donc aucun des [triplets de cible existants][platform-support] ne convient. Heureusement, Rust nous permet de définir [notre propre cible][custom-targets] par l'entremise d'un fichier JSON. Par exemple, un fichier JSON qui décrit une cible `x86_64-unknown-linux-gnu` ressemble à ceci:
+
+```json
+{
+ "llvm-target": "x86_64-unknown-linux-gnu",
+ "data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
+ "arch": "x86_64",
+ "target-endian": "little",
+ "target-pointer-width": "64",
+ "target-c-int-width": "32",
+ "os": "linux",
+ "executables": true,
+ "linker-flavor": "gcc",
+ "pre-link-args": ["-m64"],
+ "morestack": false
+}
+```
+
+La plupart des champs sont requis par LLVM pour générer le code pour cette plateforme. Par exemple, le champ [`data-layout`] définit la taille de divers types d'entiers, de nombres à virgule flottante, et de pointeurs. Puis, il y a des champs que Rust utilise pour de la compilation conditionelle, comme `target-pointer-width`. Le troisième type de champ définit comment la crate doit être construite. Par exemple, le champ `pre-link-args` spécifie les arguments fournis au [lieur][linker].
+
+[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
+[linker]: https://en.wikipedia.org/wiki/Linker_(computing)
+
+Nous pouvons aussi cibler les systèmes `x86_64` avec notre noyau, donc notre spécification de cible ressemblera beaucoup à celle plus haut. Commençons par créer un fichier `x86_64-blog_os.json` (utilisez le nom de votre choix) avec ce contenu commun:
+
+```json
+{
+ "llvm-target": "x86_64-unknown-none",
+ "data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
+ "arch": "x86_64",
+ "target-endian": "little",
+ "target-pointer-width": "64",
+ "target-c-int-width": "32",
+ "os": "none",
+ "executables": true
+}
+```
+
+Notez que nous avons changé le système d'exploitation dans le champs `llvm-target` et `os` en `none`, puisque nous ferons l'exécution sur du "bare metal" (donc, sans système d'exploitation sous-jacent).
+
+Nous ajoutons ensuite les champs suivants reliés à la construction:
+
+
+```json
+"linker-flavor": "ld.lld",
+"linker": "rust-lld",
+```
+
+Plutôt que d'utiliser le lieur par défaut de la plateforme (qui pourrait ne pas supporter les cibles Linux), nous utilisons le lieur multi-plateforme [LLD] qui est inclut avec Rust pour lier notre noyau.
+
+[LLD]: https://lld.llvm.org/
+
+```json
+"panic-strategy": "abort",
+```
+
+Ce paramètre spécifie que la cible ne permet pas le [déroulement de la pile][stack unwinding] lorsque le noyau panique, alors le système devrait plutôt s'arrêter directement. Ceci mène au même résultat que l'option `panic = "abort"` dans notre Cargo.toml, alors nous pouvons la retirer de ce fichier. (Notez que, contrairement à l'option Cargo.toml, cette option de cible s'applique aussi quand nous recompilerons la bibliothèque `core` plus loin dans cet article. Ainsi, même si vous préférez garder l'option Cargo.toml, gardez cette option.)
+
+[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
+
+```json
+"disable-redzone": true,
+```
+
+Nous écrivons un noyau, donc nous devrons éventuellement gérer les interruptions. Pour ce faire en toute sécurité, nous devons désactiver une optimisation de pointeur de pile nommée la _“zone rouge"_, puisqu'elle causerait une corruption de la pile autrement. Pour plus d'informations, lire notre article séparé à propos de la [désactivation de la zone rouge][disabling the red zone].
+
+[disabling the red zone]: @/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md
+
+```json
+"features": "-mmx,-sse,+soft-float",
+```
+
+Le champ `features` active/désactive des fonctionalités de la cible. Nous désactivons les fonctionalités `mmx` et `sse` en les précédant d'un signe "moins" et activons la fonctionnalité `soft-float` en la précédant d'un signe "plus". Notez qu'il ne doit pas y avoir d'espace entre les différentes fonctionnalités, sinon LLVM n'arrive pas à analyser la chaîne de caractères des fonctionnalités.
+
+Les fonctionnalités `mmx` et `sse` déterminent le support les instructions [Single Instruction Multiple Data (SIMD)], qui peuvent souvent significativement accélérer les programmes. Toutefois, utiliser les grands registres SIMD dans les noyaux des systèmes d'exploitation mène à des problèmes de performance. Ceci parce que le noyau a besoin de restaurer tous les registres à leur état original avant de continuer un programme interrompu. Cela signifie que le noyau doit enregistrer l'état SIMD complet dans la mémoire principale à chaque appel système ou interruption matérielle. Puisque l'état SIMD est très grand (512–1600 octets) et que les interruptions peuvent survenir très fréquemment, ces opérations d'enregistrement/restauration additionnelles nuisent considérablement à la performance. Pour prévenir cela, nous désactivons SIMD pour notre noyau (pas pour les applications qui s'exécutent dessus!).
+
+[Single Instruction Multiple Data (SIMD)]: https://fr.wikipedia.org/wiki/Single_instruction_multiple_data
+
+Un problème avec la désactivation de SIMD est que les opérations sur les nombres à virgule flottante sur `x86_64` nécessitent les registres SIMD par défaut. Pour résoudre ce problème, nous ajoutons la fonctionnalité `soft-float`, qui émule toutes les opérations à virgule flottante avec des fonctions logicielles utilisant des entiers normaux.
+
+Pour plus d'informations, voir notre article sur la [désactivation de SIMD](@/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.md).
+
+#### Assembler le tout
+Notre fichier de spécification de cible ressemble maintenant à ceci :
+
+```json
+{
+ "llvm-target": "x86_64-unknown-none",
+ "data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
+ "arch": "x86_64",
+ "target-endian": "little",
+ "target-pointer-width": "64",
+ "target-c-int-width": "32",
+ "os": "none",
+ "executables": true,
+ "linker-flavor": "ld.lld",
+ "linker": "rust-lld",
+ "panic-strategy": "abort",
+ "disable-redzone": true,
+ "features": "-mmx,-sse,+soft-float"
+}
+```
+
+### Construction de notre noyau
+Compiler pour notre nouvelle cible utilisera les conventions Linux (je ne suis pas trop certain pourquoi; j'assume que c'est simplement le comportement par défaut de LLVM). Cela signifie que nos avons besoin d'un point d'entrée nommé `_start` comme décrit dans [l'article précédent][previous post]:
+
+[previous post]: @/edition-2/posts/01-freestanding-rust-binary/index.fr.md
+
+```rust
+// src/main.rs
+
+#![no_std] // ne pas lier la bibliothèque standard Rust
+#![no_main] // désactiver tous les points d'entrée Rust
+
+use core::panic::PanicInfo;
+
+/// Cette fonction est invoquée lorsque le système panique
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ loop {}
+}
+
+#[no_mangle] // ne pas massacrer le nom de cette fonction
+pub extern "C" fn _start() -> ! {
+ // cette fonction est le point d'entrée, puisque le lieur cherche une fonction
+ // nommée `_start` par défaut
+ loop {}
+}
+```
+
+Notez que le point d'entrée doit être appelé `_start` indépendamment du système d'exploitation hôte.
+
+Nous pouvons maintenant construire le noyau pour notre nouvelle cible en fournissant le nom du fichier JSON comme `--target`:
+
+```
+> cargo build --target x86_64-blog_os.json
+
+error[E0463]: can't find crate for `core`
+```
+
+Cela échoue! L'erreur nous dit que le compilateur ne trouve plus la [bibliothèque `core`][`core` library]. Cette bibliothèque contient les types de base Rust comme `Result`, `Option`, les itérateurs, et est implicitement liée à toutes les crates `no_std`.
+
+[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
+
+Le problème est que la bibliothèque `core` est distribuée avec le compilateur Rust comme biliothèque _precompilée_. Donc, elle est seulement valide pour les triplets d'hôtes supportés (par exemple, `x86_64-unknown-linux-gnu`) mais pas pour notre cible personnalisée. Si nous voulons compiler du code pour d'autres cibles, nous devons d'abord recompiler `core` pour ces cibles.
+
+#### L'option `build-std`
+
+C'est ici que la [fonctionnalité `build-std`][`build-std` feature] de cargo entre en jeu. Elle permet de recompiler `core` et d'autres crates de la bibliothèque standard sur demande, plutôt que d'utiliser des versions précompilées incluses avec l'installation de Rust. Cette fonctionnalité est très récente et n'est pas encore complète, donc elle est définie comme instable et est seulement disponible avec les [versions nocturnes du compilateur Rust][nightly Rust compilers].
+
+[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
+[nightly Rust compilers]: #installer-une-version-nocturne-de-rust
+
+Pour utiliser cette fonctionnalité, nous devons créer un fichier de [configuration cargo][cargo configuration] dans `.cargo/config.toml` avec le contenu suivant:
+
+```toml
+# dans .cargo/config.toml
+
+[unstable]
+build-std = ["core", "compiler_builtins"]
+```
+
+Ceci indique à cargo qu'il doit recompiler les bibliothèques `core` et `compiler_builtins`. Celle-ci est nécessaire pour qu'elle ait une dépendance de `core`. Afin de recompiler ces bibliothèques, cargo doit avoir accès au code source de Rust, que nous pouvons installer avec `rustup component add rust-src`.
+
+
+
+**Note:** La clé de configuration `unstable.build-std` nécessite une version nocturne de Rust plus récente que 2020-07-15.
+
+
+
+Après avoir défini la clé de configuration `unstable.build-std` et installé la composante `rust-src`, nous pouvons exécuter notre commande de construction à nouveau:
+
+```
+> cargo build --target x86_64-blog_os.json
+ Compiling core v0.0.0 (/…/rust/src/libcore)
+ Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
+ Compiling compiler_builtins v0.1.32
+ Compiling blog_os v0.1.0 (/…/blog_os)
+ Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
+```
+
+Nous voyons que `cargo build` recompile maintenant les bibliothèques `core`, `rustc-std-workspace-core` (une dépendance de `compiler_builtins`), et `compiler_builtins` pour notre cible personnalisée.
+
+#### Détails reliés à la mémoire
+
+Le compilateur Rust assume qu'un certain ensemble de fonctions intégrées sont disponibles pour tous les systèmes. La plupart de ces fonctions sont fournies par la crate `compiler_builtins` que nous venons de recompiler. Toutefois, certaines fonctions liées à la mémoire dans cette crate ne sont pas activées par défaut puisqu'elles sont normalement fournies par la bibliothèque C sur le système. Parmi ces fonctions, on retrouve `memset`, qui définit tous les octets dans un bloc mémoire à une certaine valeur, `memcpy`, qui copie un bloc mémoire vers un autre, et `memcmp`, qui compare deux blocs mémoire. Alors que nous n'avions pas besoin de ces fonctions pour compiler notre noyau maintenant, elles seront nécessaires aussitôt que nous lui ajouterons plus de code (par exemple, lorsque nous copierons des `struct`).
+
+Puisque nous ne pouvons pas lier avec la bibliothèque C du système d'exploitation, nous avons besoin d'une méthode alternative de fournir ces fonctions au compilateur. Une approche possible pour ce faire serait d'implémenter nos propre fonctions `memset`, etc. et de leur appliquer l'attribut `#[no_mangle]` (pour prévenir le changement de nom automatique pendant la compilation). Or, ceci est dangereux puisque toute erreur dans l'implémentation pourrait mener à un comportement indéterminé. Par exemple, implémenter `memcpy` avec une boucle `for` pourrait mener à une recursion infinie puisque les boucles `for` invoquent implicitement la méthode _trait_ [`IntoIterator::into_iter`], qui pourrait invoquer `memcpy` de nouveau. C'est donc une bonne idée de plutôt réutiliser des implémentations existantes et éprouvées.
+
+[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
+
+Heureusement, la crate `compiler_builtins` contient déjà des implémentations pour toutes les fonctions nécessaires, elles sont seulement désactivées par défaut pour ne pas interférer avec les implémentations de la bibliothèque C. Nous pouvons les activer en définissant le drapeau [`build-std-features`] de cargo à `["compiler-builtins-mem"]`. Comme pour le drapeau `build-std`, ce drapeau peut être soit fourni en ligne de commande avec `-Z` ou configuré dans la table `unstable` du fichier `.cargo/config.toml`. Puisque nous voulons toujours construire avec ce drapeau, l'option du fichier de configuration fait plus de sens pour nous:
+
+[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
+
+```toml
+# dans .cargo/config.toml
+
+[unstable]
+build-std-features = ["compiler-builtins-mem"]
+build-std = ["core", "compiler_builtins"]
+```
+
+(Le support pour la fonctionnalité `compiler-builtins-mem` a [été ajouté assez récemment](https://github.com/rust-lang/rust/pull/77284), donc vous aurez besoin de la version nocturne `2020-09-30` de Rust ou plus récent pour l'utiliser.)
+
+Dans les coulisses, ce drapeau active la [fonctionnalité `mem`][`mem` feature] de la crate `compiler_builtins`. Le résultat est que l'attribut `#[no_mangle]` est appliqué aux [implémentations `memcpy` et autres][`memcpy` etc. implementations] de la caise, ce qui les rend disponible au lieur.
+
+[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L54-L55
+[`memcpy` etc. implementations]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69
+
+Avec ce changement, notre noyau a des implémentations valides pour toutes les fonctions requises par le compilateur, donc il peut continuer à compiler même si notre code devient plus complexe.
+
+#### Définir une cible par défaut
+
+Pour ne pas avoir à fournir le paramètre `--target` à chaque invocation de `cargo build`, nous pouvons définir la cible par défaut. Pour ce faire, nous ajoutons le code suivant à notre fichier de [configuration Cargo][cargo configuration] dans `.cargo/config.toml`:
+
+[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
+
+```toml
+# dans .cargo/config.toml
+
+[build]
+target = "x86_64-blog_os.json"
+```
+
+Ceci indique à `cargo` d'utiliser notre cible `x86_64-blog_os.json` quand il n'y a pas d'argument de cible `--target` explicitement fourni. Ceci veut dire que nous pouvons maintenant construire notre noyau avec un simple `cargo build`. Pour plus d'informations sur les options de configuration cargo, jetez un coup d'oeil à la [documentation officielle de cargo][cargo configuration].
+
+Nous pouvons maintenant construire notre noyau pour une cible "bare metal" avec un simple `cargo build`. Toutefois, notre point d'entrée `_start`, qui sera appelé par le bootloader, est encore vide. Il est temps de lui faire afficher quelque chose à l'écran.
+
+### Afficher à l'écran
+La façon la plus facile d'afficher à l'écran à ce stade est grâce au tampon texte VGA. C'est un emplacement mémoire spécial associé au matériel VGA qui contient le contenu affiché à l'écran. Il consiste normalement en 25 lines qui contiennent chacune 80 cellules de caractère. Chaque cellule de caractère affiche un caractère ASCII avec des couleurs d'avant-plan et d'arrière-plan. Le résultat à l'écran ressemble à ceci:
+
+[VGA text buffer]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
+
+
+
+Nous discuterons de la disposition exacte du tampon VGA dans le prochain article, où nous lui écrirons un premier petit pilote. Pour afficher “Hello World!”, nous devons seulement savoir que le tampon est situé à l'adresse `0xb8000` et que chaque cellule de caractère consiste en un octet ASCII et un octet de couleur.
+
+L'implémentation ressemble à ceci :
+
+```rust
+static HELLO: &[u8] = b"Hello World!";
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ let vga_buffer = 0xb8000 as *mut u8;
+
+ for (i, &byte) in HELLO.iter().enumerate() {
+ unsafe {
+ *vga_buffer.offset(i as isize * 2) = byte;
+ *vga_buffer.offset(i as isize * 2 + 1) = 0xb;
+ }
+ }
+
+ loop {}
+}
+```
+
+D'abord, nous transformons l'entier `0xb8000` en un [pointeur brut][raw pointer]. Puis nous [parcourons][iterate] les octets de la [chaîne d'octets][byte string] [statique][static] `HELLO`. Nous utilisons la méthode [`enumerate`] pour aussi obtenir une variable `i`. Dans le corps de la boucle `for`, nous utilisons la méthode [`offset`] pour écrire la chaîne d'octets et l'octet de couleur correspondant(`0xb` est un cyan pâle).
+
+[iterate]: https://doc.rust-lang.org/stable/book/ch13-02-iterators.html
+[static]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
+[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
+[byte string]: https://doc.rust-lang.org/reference/tokens.html#byte-string-literals
+[raw pointer]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
+[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
+
+Notez qu'il y a un bloc [`unsafe`] qui enveloppe les écritures mémoire. La raison en est que le compilateur Rust ne peut pas prouver que les pointeurs bruts que nous créons sont valides. Ils pourraient pointer n'importe où et mener à une corruption de données. En les mettant dans un bloc `unsafe`, nous disons fondamentalement au compilateur que nous sommes absolument certains que les opérations sont valides. Notez qu'un bloc `unsafe` ne désactive pas les contrôles de sécurité de Rust. Il permet seulement de faire [cinq choses supplémentaires][five additional things].
+
+[`unsafe`]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html
+[five additional things]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#unsafe-superpowers
+
+Je veux souligner que **ce n'est pas comme cela que les choses se font en Rust!** Il est très facile de faire des erreurs en travaillant avec des pointeurs bruts à l'intérieur de blocs `unsafe`. Par exemple, nous pourrions facilement écrire au-delà de la fin du tampon si nous ne sommes pas prudents.
+
+Alors nous voulons minimiser l'utilisation de `unsafe` autant que possible. Rust nous offre la possibilité de le faire en créant des abstractions de sécurité. Par exemple, nous pourrions créer un type tampon VGA qui encapsule les risques et qui s'assure qu'il est impossible de faire quoi que ce soit d'incorrect à l'extérieur de ce type. Ainsi, nous aurions besoin de très peu de code `unsafe` et nous serions certains que nous ne violons pas la [sécurité de mémoire][memory safety]. Nous allons créer une telle abstraction de tampon VGA buffer dans le prochain article.
+
+[memory safety]: https://en.wikipedia.org/wiki/Memory_safety
+
+## Exécuter notre noyau
+
+Maintenant que nous avons un exécutable qui fait quelque chose de perceptible, il est temps de l'exécuter. D'abord, nous devons transformer notre noyau compilé en une image de disque amorçable en le liant à un bootloader. Ensuite, nous pourrons exécuter l'image de disque dans une machine virtuelle [QEMU] ou l'amorcer sur du véritable matériel en utilisant une clé USB.
+
+### Créer une image d'amorçage
+
+Pour transformer notre noyau compilé en image de disque amorçable, nous devons le lier avec un bootloader. Comme nous l'avons appris dans la [section à propos du lancement][section about booting], le bootloader est responsable de l'initialisation du processeur et du chargement de notre noyau.
+
+[section about booting]: #le-processus-d-amorcage
+
+Plutôt que d'écrire notre propre bootloader, ce qui est un projet en soi, nous utilisons la crate [`bootloader`]. Cette crate propose un bootloader BIOS de base sans dépendance C. Seulement du code Rust et de l'assembleur intégré. Pour l'utiliser afin de lancer notre noyau, nous devons ajouter une dépendance à cette crate:
+
+[`bootloader`]: https://crates.io/crates/bootloader
+
+```toml
+# dans Cargo.toml
+
+[dependencies]
+bootloader = "0.9.8"
+```
+
+Ajouter le bootloader comme dépendance n'est pas suffisant pour réellement créer une image de disque amorçable. Le problème est que nous devons lier notre noyau avec le bootloader après la compilation, mais cargo ne supporte pas les [scripts post-build][post-build scripts].
+
+[post-build scripts]: https://github.com/rust-lang/cargo/issues/545
+
+Pour résoudre ce problème, nous avons créé un outil nommé `bootimage` qui compile d'abord le noyau et le bootloader, et les lie ensuite ensemble pour créer une image de disque amorçable. Pour installer cet outil, exécutez la commande suivante dans votre terminal:
+
+```
+cargo install bootimage
+```
+
+Pour exécuter `bootimage` et construire le bootloader, vous devez avoir la composante rustup `llvm-tools-preview` installée. Vous pouvez l'installer en exécutant `rustup component add llvm-tools-preview`.
+
+Après avoir installé `bootimage` et ajouté la composante `llvm-tools-preview`, nous pouvons créer une image de disque amorçable en exécutant:
+
+```
+> cargo bootimage
+```
+
+Nous voyons que l'outil recompile notre noyau en utilisant `cargo build`, donc il utilisera automatiquement tout changements que vous faites. Ensuite, il compile le bootloader, ce qui peut prendre un certain temps. Comme toutes les dépendances de crates, il est seulement construit une fois puis il est mis en cache, donc les builds subséquentes seront beaucoup plus rapides. Enfin, `bootimage` combine le bootloader et le noyau en une image de disque amorçable.
+
+Après avoir exécuté la commande, vous devriez voir une image de disque amorçable nommée `bootimage-blog_os.bin` dans votre dossier `target/x86_64-blog_os/debug`. Vous pouvez la lancer dans une machine virtuelle ou la copier sur une clé USB pour la lancer sur du véritable matériel. (Notez que ceci n'est pas une image CD, qui est un format différent, donc la graver sur un CD ne fonctionne pas).
+
+#### Comment cela fonctionne-t-il?
+
+L'outil `bootimage` effectue les étapes suivantes en arrière-plan:
+
+- Il compile notre noyau en un fichier [ELF].
+- Il compile notre dépendance bootloader en exécutable autonome.
+- Il lie les octets du fichier ELF noyau au bootloader.
+
+[ELF]: https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
+[rust-osdev/bootloader]: https://github.com/rust-osdev/bootloader
+
+Lorsque lancé, le bootloader lit et analyse le fichier ELF ajouté. Il associe ensuite les segments du programme aux adresses virtuelles dans les tables de pages, réinitialise la section `.bss`, puis met en place une pile. Finalement, il lit le point d'entrée (notre fonction `_start`) et s'y rend.
+
+### Amorçage dans QEMU
+
+Nous pouvons maintenant lancer l'image disque dans une machine virtuelle. Pour la démarrer dans [QEMU], exécutez la commande suivante :
+
+[QEMU]: https://www.qemu.org/
+
+```
+> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
+warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
+```
+
+Ceci ouvre une fenêtre séparée qui devrait ressembler à cela:
+
+
+
+Nous voyoons que notre "Hello World!" est visible à l'écran.
+
+### Véritable ordinateur
+
+Il est aussi possible d'écrire l'image disque sur une clé USB et de le lancer sur un véritable ordinateur, **mais soyez prudent** et choisissez le bon nom de périphérique, parce que **tout sur ce périphérique sera écrasé**:
+
+```
+> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
+```
+
+Où `sdX` est le nom du périphérique de votre clé USB.
+
+Après l'écriture de l'image sur votre clé USB, vous pouvez l'exécuter sur du véritable matériel en l'amorçant à partir de la clé USB. Vous devrez probablement utiliser un menu d'amorçage spécial ou changer l'ordre d'amorçage dans votre configuration BIOS pour amorcer à partir de la clé USB. Notez que cela ne fonctionne actuellement pas avec des ordinateurs UEFI, puisque la crate `bootloader` ne supporte pas encore UEFI.
+
+### Utilisation de `cargo run`
+
+Pour faciliter l'exécution de notre noyau dans QEMU, nous pouvons définir la clé de configuration `runner` pour cargo:
+
+```toml
+# dans .cargo/config.toml
+
+[target.'cfg(target_os = "none")']
+runner = "bootimage runner"
+```
+
+La table `target.'cfg(target_os = "none")'` s'applique à toutes les cibles dont le champ `"os"` dans le fichier de configuration est défini à `"none"`. Ceci inclut notre cible `x86_64-blog_os.json`. La clé `runner` key spécifie la commande qui doit être invoquée pour `cargo run`. La commande est exécutée après une build réussie avec le chemin de l'exécutable comme premier argument. Voir la [configuration cargo][cargo configuration] pour plus de détails.
+
+La commande `bootimage runner` est spécifiquement conçue pour être utilisable comme un exécutable `runner`. Elle lie l'exécutable fourni avec le bootloader duquel dépend le projet et lance ensuite QEMU. Voir le [README de `bootimage`][Readme of `bootimage`] pour plus de détails et les options de configuration possibles.
+
+[Readme of `bootimage`]: https://github.com/rust-osdev/bootimage
+
+Nous pouvons maintenant utiliser `cargo run` pour compiler notre noyau et le lancer dans QEMU.
+
+## Et ensuite?
+
+Dans le prochain article, nous explorerons le tampon texte VGA plus en détails et nous écrirons une interface sécuritaire pour l'utiliser. Nous allons aussi mettre en place la macro `println`.
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ja.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ja.md
index 2858a722..deb3e1ac 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ja.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ja.md
@@ -101,7 +101,7 @@ Rustの実行環境を管理するのには、[rustup]を強くおすすめし
nightlyコンパイラでは、いわゆる**feature flag**をファイルの先頭につけることで、いろいろな実験的機能を使うことを選択できます。例えば、`#![feature(asm)]`を`main.rs`の先頭につけることで、インラインアセンブリのための実験的な[`asm!`マクロ][`asm!` macro]を有効化することができます。ただし、これらの実験的機能は全くもって不安定であり、将来のRustバージョンにおいては事前の警告なく変更されたり取り除かれたりする可能性があることに注意してください。このため、絶対に必要なときにのみこれらを使うことにします。
-[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
+[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
### ターゲットの仕様
Cargoは`--target`パラメータを使ってさまざまなターゲットをサポートします。ターゲットはいわゆる[target triple][target triple]によって表されます。これはCPUアーキテクチャ、製造元、オペレーティングシステム、そして[ABI]を表します。例えば、`x86_64-unknown-linux-gnu`というtarget tripleは、`x86_64`のCPU、製造元不明、GNU ABIのLinuxオペレーティングシステム向けのシステムを表します。Rustは[多くのtarget triple][platform-support]をサポートしており、その中にはAndroidのための`arm-linux-androideabi`や[WebAssemblyのための`wasm32-unknown-unknown`](https://www.hellorust.com/setup/wasm-target/)などがあります。
@@ -411,7 +411,7 @@ pub extern "C" fn _start() -> ! {
# in Cargo.toml
[dependencies]
-bootloader = "0.9.8"
+bootloader = "0.9.23"
```
bootloaderを依存として加えることだけでブータブルディスクイメージが実際に作れるわけではなく、私達のカーネルをコンパイル後にブートローダーにリンクする必要があります。問題は、cargoが[ビルド後にスクリプトを走らせる機能][post-build scripts]を持っていないことです。
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ko.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ko.md
new file mode 100644
index 00000000..b95aefe1
--- /dev/null
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ko.md
@@ -0,0 +1,511 @@
++++
+title = "최소 기능을 갖춘 커널"
+weight = 2
+path = "ko/minimal-rust-kernel"
+date = 2018-02-10
+
+[extra]
+chapter = "Bare Bones"
+# Please update this when updating the translation
+translation_based_on_commit = "c1af4e31b14e562826029999b9ab1dce86396b93"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994", "Quqqu"]
++++
+
+이번 포스트에서는 x86 아키텍처에서 최소한의 기능으로 동작하는 64비트 Rust 커널을 함께 만들 것입니다. 지난 포스트 [Rust로 'Freestanding 실행파일' 만들기][freestanding Rust binary] 에서 작업한 것을 토대로 부팅 가능한 디스크 이미지를 만들고 화면에 데이터를 출력해볼 것입니다.
+
+[freestanding Rust binary]: @/edition-2/posts/01-freestanding-rust-binary/index.md
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-02 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
+
+
+
+## 부팅 과정 {#the-boot-process}
+
+전원이 켜졌을 때 컴퓨터가 맨 처음 하는 일은 바로 마더보드의 [롬 (ROM)][ROM]에 저장된 펌웨어 코드를 실행하는 것입니다.
+이 코드는 [시동 자체 시험][power-on self-test]을 진행하고, 사용 가능한 램 (RAM)을 확인하며, CPU 및 하드웨어의 초기화 작업을 진행합니다.
+그 후에는 부팅 가능한 디스크를 감지하고 운영체제 커널을 부팅하기 시작합니다.
+
+[ROM]: https://en.wikipedia.org/wiki/Read-only_memory
+[power-on self-test]: https://en.wikipedia.org/wiki/Power-on_self-test
+
+x86 시스템에는 두 가지 펌웨어 표준이 존재합니다: 하나는 "Basic Input/Output System"(**[BIOS]**)이고 다른 하나는 "Unified Extensible Firmware Interface" (**[UEFI]**) 입니다. BIOS 표준은 구식 표준이지만, 간단하며 1980년대 이후 출시된 어떤 x86 하드웨어에서도 지원이 잘 됩니다. UEFI는 신식 표준으로서 더 많은 기능들을 갖추었지만, 제대로 설정하고 구동시키기까지의 과정이 더 복잡합니다 (적어도 제 주관적 입장에서는 그렇게 생각합니다).
+
+[BIOS]: https://en.wikipedia.org/wiki/BIOS
+[UEFI]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
+
+우리가 만들 운영체제에서는 BIOS 표준만을 지원할 것이지만, UEFI 표준도 지원하고자 하는 계획이 있습니다. UEFI 표준을 지원할 수 있도록 도와주시고 싶다면 [해당 깃헙 이슈][Github issue]를 확인해주세요.
+
+### BIOS 부팅
+
+UEFI 표준으로 동작하는 최신 기기들도 가상 BIOS를 지원하기에, 존재하는 거의 모든 x86 시스템들이 BIOS 부팅을 지원합니다. 덕분에 하나의 BIOS 부팅 로직을 구현하면 여태 만들어진 거의 모든 컴퓨터를 부팅시킬 수 있습니다. 동시에 이 방대한 호환성이 BIOS의 가장 큰 약점이기도 한데,
+그 이유는 1980년대의 구식 부트로더들에 대한 하위 호환성을 유지하기 위해 부팅 전에는 항상 CPU를 16비트 호환 모드 ([real mode]라고도 불림)로 설정해야 하기 때문입니다.
+
+이제 BIOS 부팅 과정의 첫 단계부터 살펴보겠습니다:
+
+여러분이 컴퓨터의 전원을 켜면, 제일 먼저 컴퓨터는 마더보드의 특별한 플래시 메모리로부터 BIOS 이미지를 로드합니다. BIOS 이미지는 자가 점검 및 하드웨어 초기화 작업을 처리한 후에 부팅 가능한 디스크가 있는지 탐색합니다. 부팅 가능한 디스크가 있다면, 제어 흐름은 해당 디스크의 _부트로더 (bootloader)_ 에게 넘겨집니다. 이 부트로더는 디스크의 가장 앞 주소 영역에 저장되는 512 바이트 크기의 실행 파일입니다. 대부분의 부트로더들의 경우 로직을 저장하는 데에 512 바이트보다 더 큰 용량이 필요하기에, 부트로더의 로직을 둘로 쪼개어 첫 단계 로직을 첫 512 바이트 안에 담고, 두 번째 단계 로직은 첫 단계 로직에 의해 로드된 이후 실행됩니다.
+
+부트로더는 커널 이미지가 디스크의 어느 주소에 저장되어있는지 알아낸 후 메모리에 커널 이미지를 로드해야 합니다. 그다음 CPU를 16비트 [real mode]에서 32비트 [protected mode]로 전환하고, 그 후에 다시 CPU를 64비트 [long mode]로 전환한 이후부터 64비트 레지스터 및 메인 메모리의 모든 주소를 사용할 수 있게 됩니다. 부트로더가 세 번째로 할 일은 BIOS로부터 메모리 매핑 정보 등의 필요한 정보를 알아내어 운영체제 커널에 전달하는 것입니다.
+
+[real mode]: https://en.wikipedia.org/wiki/Real_mode
+[protected mode]: https://en.wikipedia.org/wiki/Protected_mode
+[long mode]: https://en.wikipedia.org/wiki/Long_mode
+[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
+
+부트로더를 작성하는 것은 상당히 성가신 작업인데, 그 이유는 어셈블리 코드도 작성해야 하고 "A 레지스터에 B 값을 저장하세요" 와 같이 원리를 단번에 이해하기 힘든 작업이 많이 수반되기 때문입니다. 따라서 이 포스트에서는 부트로더를 만드는 것 자체를 다루지는 않고, 대신 운영체제 커널의 맨 앞에 부트로더를 자동으로 추가해주는 [bootimage]라는 도구를 제공합니다.
+
+[bootimage]: https://github.com/rust-osdev/bootimage
+
+본인의 부트로더를 직접 작성하는 것에 흥미가 있으시다면, 이 주제로 여러 포스트가 나올 계획이니 기대해주세요!
+
+#### Multiboot 표준
+
+운영체제마다 부트로더 구현 방법이 다르다면 한 운영체제에서 동작하는 부트로더가 다른 운영체제에서는 호환이 되지 않을 것입니다. 이런 불편한 점을 막기 위해 [Free Software Foundation]에서 1995년에 [Multiboot]라는 부트로더 표준을 개발했습니다. 이 표준은 부트로더와 운영체제 사이의 상호 작용 방식을 정의하였는데, 이 Multiboot 표준에 따르는 부트로더는 Multiboot 표준을 지원하는 어떤 운영체제에서도 동작합니다. 이 표준을 구현한 대표적인 예로 리눅스 시스템에서 가장 인기 있는 부트로더인 [GNU GRUB]이 있습니다.
+
+[Free Software Foundation]: https://en.wikipedia.org/wiki/Free_Software_Foundation
+[Multiboot]: https://wiki.osdev.org/Multiboot
+[GNU GRUB]: https://en.wikipedia.org/wiki/GNU_GRUB
+
+운영체제 커널이 Multiboot를 지원하게 하려면 커널 파일의 맨 앞에 [Multiboot 헤더][Multiboot header]를 삽입해주면 됩니다. 이렇게 하면 GRUB에서 운영체제를 부팅하는 것이 매우 쉬워집니다. 하지만 GRUB 및 Multiboot 표준도 몇 가지 문제점들을 안고 있습니다:
+
+[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
+
+- 오직 32비트 protected mode만을 지원합니다. 64비트 long mode를 이용하고 싶다면 CPU 설정을 별도로 변경해주어야 합니다.
+- Multiboot 표준 및 GRUB은 부트로더 구현의 단순화를 우선시하여 개발되었기에, 이에 호응하는 커널 측의 구현이 번거로워진다는 단점이 있습니다. 예를 들어, GRUB이 Multiboot 헤더를 제대로 찾을 수 있으려면 커널 측에서 [조정된 기본 페이지 크기 (adjusted default page size)][adjusted default page size]를 링크하는 것이 강제됩니다. 또한, 부트로더가 커널로 전달하는 [부팅 정보][boot information]는 적절한 추상 레벨에서 표준화된 형태로 전달되는 대신 하드웨어 아키텍처마다 상이한 형태로 제공됩니다.
+- GRUB 및 Multiboot 표준에 대한 문서화 작업이 덜 되어 있습니다.
+- GRUB이 호스트 시스템에 설치되어 있어야만 커널 파일로부터 부팅 가능한 디스크 이미지를 만들 수 있습니다. 이 때문에 Windows 및 Mac에서는 부트로더를 개발하는 것이 Linux보다 어렵습니다.
+
+[adjusted default page size]: https://wiki.osdev.org/Multiboot#Multiboot_2
+[boot information]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
+
+이러한 단점들 때문에 우리는 GRUB 및 Multiboot 표준을 사용하지 않을 것입니다. 하지만 미래에 우리의 [bootimage] 도구가 Multiboot 표준을 지원하도록 하는 것도 계획 중입니다. Multiboot 표준을 지원하는 운영체제를 커널을 개발하는 것에 관심이 있으시다면, 이 블로그 시리즈의 [첫 번째 에디션][first edition]을 확인해주세요.
+
+[first edition]: @/edition-1/_index.md
+
+### UEFI
+
+(아직 UEFI 표준을 지원하지 않지만, UEFI 표준을 지원할 수 있도록 도와주시려면 해당 [깃헙 이슈](https://github.com/phil-opp/blog_os/issues/349)에 댓글을 남겨주세요!)
+
+## 최소한의 기능을 갖춘 운영체제 커널
+컴퓨터의 부팅 과정에 대해서 대략적으로 알게 되었으니, 이제 우리 스스로 최소한의 기능을 갖춘 운영체제 커널을 작성해볼 차례입니다. 우리의 목표는 부팅 이후 화면에 "Hello World!" 라는 메세지를 출력하는 디스크 이미지를 만드는 것입니다. 지난 포스트에서 만든 [freestanding Rust 실행파일][freestanding Rust binary] 을 토대로 작업을 이어나갑시다.
+
+지난 포스트에서 우리는 `cargo`를 통해 freestanding 실행파일을 만들었었는데, 호스트 시스템의 운영체제에 따라 프로그램 실행 시작 지점의 이름 및 컴파일 인자들을 다르게 설정해야 했습니다. 이것은 `cargo`가 기본적으로 _호스트 시스템_ (여러 분이 실행 중인 컴퓨터 시스템) 을 목표로 빌드하기 때문이었습니다. 우리의 커널은 다른 운영체제 (예를 들어 Windows) 위에서 실행될 것이 아니기에, 호스트 시스템에 설정 값을 맞추는 대신에 우리가 명확히 정의한 _목표 시스템 (target system)_ 을 목표로 컴파일할 것입니다.
+
+### Rust Nightly 설치하기 {#installing-rust-nightly}
+Rust는 _stable_, _beta_ 그리고 _nightly_ 이렇게 세 가지의 채널을 통해 배포됩니다. Rust Book에 [세 채널들 간의 차이에 대해 잘 정리한 챕터]((https://doc.rust-lang.org/book/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains))가 있습니다. 운영체제를 빌드하기 위해서는 _nightly_ 채널에서만 제공하는 실험적인 기능들을 이용해야 하기에 _nightly_ 버전의 Rust를 설치하셔야 합니다.
+
+여러 버전의 Rust 언어 설치 파일들을 관리할 때 [rustup]을 사용하는 것을 강력 추천합니다. rustup을 통해 nightly, beta 그리고 stable 컴파일러들을 모두 설치하고 업데이트할 수 있습니다. `rustup override set nightly` 명령어를 통해 현재 디렉토리에서 항상 nightly 버전의 Rust를 사용하도록 설정할 수 있습니다.
+`rust-toolchain`이라는 파일을 프로젝트 루트 디렉토리에 만들고 이 파일에 `nightly`라는 텍스트를 적어 놓아도 같은 효과를 볼 수 있습니다. `rustc --version` 명령어를 통해 현재 nightly 버전이 설치되어 있는지 확인할 수 있습니다 (출력되는 버전 넘버가 `-nightly`라는 텍스트로 끝나야 합니다).
+
+[rustup]: https://www.rustup.rs/
+
+nightly 컴파일러는 _feature 플래그_ 를 소스코드의 맨 위에 추가함으로써 여러 실험적인 기능들을 선별해 이용할 수 있게 해줍니다. 예를 들어, `#![feature(asm)]` 를 `main.rs`의 맨 위에 추가하면 [`asm!` 매크로][`asm!` macro]를 사용할 수 있습니다. `asm!` 매크로는 인라인 어셈블리 코드를 작성할 때 사용합니다.
+이런 실험적인 기능들은 말 그대로 "실험적인" 기능들이기에 미래의 Rust 버전들에서는 예고 없이 변경되거나 삭제될 수도 있습니다. 그렇기에 우리는 이 실험적인 기능들을 최소한으로만 사용할 것입니다.
+
+[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
+
+### 컴파일 대상 정의하기
+Cargo는 `--target` 인자를 통해 여러 컴파일 대상 시스템들을 지원합니다. 컴파일 대상은 소위 _[target triple]_ 을 통해 표현되는데, CPU 아키텍쳐와 CPU 공급 업체, 운영체제, 그리고 [ABI]를 파악할 수 있습니다. 예를 들어 `x86_64-unknown-linux-gnu`는 `x86_64` CPU, 임의의 CPU 공급 업체, Linux 운영체제, 그리고 GNU ABI를 갖춘 시스템을 나타냅니다. Rust는 Android를 위한 `arm-linux-androideabi`와 [WebAssembly를 위한 `wasm32-unknown-unknown`](https://www.hellorust.com/setup/wasm-target/)를 비롯해 [다양한 target triple들][platform-support]을 지원합니다.
+
+[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
+[ABI]: https://stackoverflow.com/a/2456882
+[platform-support]: https://forge.rust-lang.org/release/platform-support.html
+[custom-targets]: https://doc.rust-lang.org/nightly/rustc/targets/custom.html
+
+우리가 목표로 하는 컴파일 대상 환경 (운영체제가 따로 없는 환경)을 정의하려면 몇 가지 특별한 설정 인자들을 사용해야 하기에 [Rust 에서 기본적으로 지원하는 target triple][platform-support] 중에서는 우리가 쓸 수 있는 것은 없습니다. 다행히도 Rust에서는 JSON 파일을 이용해 [우리가 목표로 하는 컴파일 대상 환경][custom-targets]을 직접 정의할 수 있습니다. 예를 들어, `x86_64-unknown-linux-gnu` 환경을 직접 정의하는 JSON 파일의 내용은 아래와 같습니다:
+
+```json
+{
+ "llvm-target": "x86_64-unknown-linux-gnu",
+ "data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
+ "arch": "x86_64",
+ "target-endian": "little",
+ "target-pointer-width": "64",
+ "target-c-int-width": "32",
+ "os": "linux",
+ "executables": true,
+ "linker-flavor": "gcc",
+ "pre-link-args": ["-m64"],
+ "morestack": false
+}
+```
+
+대부분의 필드 값들은 LLVM이 해당 환경을 목표로 코드를 생성하는 과정에서 필요합니다. 예시로, [`data-layout`] 필드는 다양한 정수, 부동소수점 표기 소수, 포인터 등의 메모리 상 실제 크기를 지정합니다. 또한 `target-pointer-width`와 같이 Rust가 조건부 컴파일을 하는 과정에서 이용하는 필드들도 있습니다.
+마지막 남은 종류의 필드들은 crate가 어떻게 빌드되어야 하는지 결정합니다. 예를 들어 `pre-link-args` 필드는 [링커][linker]에 전달될 인자들을 설정합니다.
+
+[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
+[linker]: https://en.wikipedia.org/wiki/Linker_(computing)
+
+우리도 `x86_64` 시스템에서 구동할 운영체제 커널을 작성할 것이기에, 우리가 사용할 컴파일 대상 환경 환경 설정 파일 (JSON 파일) 또한 위의 내용과 많이 유사할 것입니다. 일단 `x86_64-blog_os.json`이라는 파일을 만들고 아래와 같이 파일 내용을 작성해주세요:
+
+```json
+{
+ "llvm-target": "x86_64-unknown-none",
+ "data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
+ "arch": "x86_64",
+ "target-endian": "little",
+ "target-pointer-width": "64",
+ "target-c-int-width": "32",
+ "os": "none",
+ "executables": true
+}
+```
+
+우리의 운영체제는 bare metal 환경에서 동작할 것이기에, `llvm-target` 필드의 운영체제 값과 `os` 필드의 값은 `none`입니다.
+
+아래의 빌드 관련 설정들을 추가해줍니다:
+
+
+```json
+"linker-flavor": "ld.lld",
+"linker": "rust-lld",
+```
+
+현재 사용 중인 플랫폼의 기본 링커 대신 Rust와 함께 배포되는 크로스 플랫폼 [LLD] 링커를 사용해 커널을 링크합니다 (기본 링커는 리눅스 환경을 지원하지 않을 수 있습니다).
+
+[LLD]: https://lld.llvm.org/
+
+```json
+"panic-strategy": "abort",
+```
+
+해당 환경이 패닉 시 [스택 되감기][stack unwinding]을 지원하지 않기에, 위 설정을 통해 패닉 시 프로그램이 즉시 실행 종료되도록 합니다. 위 설정은 Cargo.toml 파일에 `panic = "abort"` 설정을 추가하는 것과 비슷한 효과이기에, Cargo.toml에서는 해당 설정을 지우셔도 괜찮습니다 (다만, Cargo.toml에서의 설정과는 달리 이 설정은 이후 단계에서 우리가 `core` 라이브러리를 재컴파일할 때에도 유효하게 적용된다는 점이 중요합니다. 위 설정은 꼭 추가해주세요!).
+
+[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
+
+```json
+"disable-redzone": true,
+```
+
+커널을 작성하려면, 커널이 인터럽트에 대해 어떻게 대응하는지에 대한 로직도 작성하게 될 것입니다. 안전하게 이런 로직을 작성하기 위해서는 _“red zone”_ 이라고 불리는 스택 포인터 최적화 기능을 해제해야 합니다 (그렇지 않으면 해당 기능으로 인해 스택 메모리가 우리가 원치 않는 값으로 덮어쓰일 수 있습니다). 이 내용에 대해 더 자세히 알고 싶으시면 [red zone 기능 해제][disabling the red zone] 포스트를 확인해주세요.
+
+[disabling the red zone]: @/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.ko.md
+
+```json
+"features": "-mmx,-sse,+soft-float",
+```
+
+`features` 필드는 컴파일 대상 환경의 기능들을 활성화/비활성화 하는 데 이용합니다. 우리는 `-` 기호를 통해 `mmx`와 `sse` 기능들을 비활성화시키고 `+` 기호를 통해 `soft-float` 기능을 활성화시킬 것입니다. `features` 필드의 문자열 내부 플래그들 사이에 빈칸이 없도록 해야 합니다. 그렇지 않으면 LLVM이 `features` 필드의 문자열 값을 제대로 해석하지 못하기 때문입니다.
+
+`mmx`와 `sse`는 [Single Instruction Multiple Data (SIMD)] 명령어들의 사용 여부를 결정하는데, 해당 명령어들은 프로그램의 실행 속도를 훨씬 빠르게 만드는 데에 도움을 줄 수 있습니다. 하지만 운영체제에서 큰 SIMD 레지스터를 사용할 경우 커널의 성능에 문제가 생길 수 있습니다. 그 이유는 커널이 인터럽트 되었던 프로그램을 다시 실행하기 전에 모든 레지스터 값들을 인터럽트 직전 시점의 상태로 복원시켜야 하기 때문입니다. 커널이 SIMD 레지스터를 사용하려면 각 시스템 콜 및 하드웨어 인터럽트가 일어날 때마다 모든 SIMD 레지스터에 저장된 값들을 메인 메모리에 저장해야 할 것입니다. SIMD 레지스터들이 총 차지하는 용량은 매우 크고 (512-1600 바이트) 인터럽트 또한 자주 일어날 수 있기에,
+SIMD 레지스터 값들을 메모리에 백업하고 또 다시 복구하는 과정은 커널의 성능을 심각하게 해칠 수 있습니다. 이를 피하기 위해 커널이 SIMD 명령어를 사용하지 않도록 설정합니다 (물론 우리의 커널 위에서 구동할 프로그램들은 SIMD 명령어들을 사용할 수 있습니다!).
+
+[Single Instruction Multiple Data (SIMD)]: https://en.wikipedia.org/wiki/SIMD
+
+`x86_64` 환경에서 SIMD 기능을 비활성화하는 것에는 걸림돌이 하나 있는데, 그것은 바로 `x86_64` 환경에서 부동소수점 계산 시 기본적으로 SIMD 레지스터가 사용된다는 것입니다. 이 문제를 해결하기 위해 `soft-float` 기능 (일반 정수 계산만을 이용해 부동소수점 계산을 소프트웨어 단에서 모방)을 활성화시킵니다.
+
+더 자세히 알고 싶으시다면, 저희가 작성한 [SIMD 기능 해제](@/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.ko.md)에 관한 포스트를 확인해주세요.
+
+#### 요약
+컴파일 대상 환경 설정 파일을 아래와 같이 작성합니다:
+
+```json
+{
+ "llvm-target": "x86_64-unknown-none",
+ "data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
+ "arch": "x86_64",
+ "target-endian": "little",
+ "target-pointer-width": "64",
+ "target-c-int-width": "32",
+ "os": "none",
+ "executables": true,
+ "linker-flavor": "ld.lld",
+ "linker": "rust-lld",
+ "panic-strategy": "abort",
+ "disable-redzone": true,
+ "features": "-mmx,-sse,+soft-float"
+}
+```
+
+### 커널 빌드하기
+우리가 정의한 새로운 컴파일 대상 환경을 목표로 컴파일할 때에 리눅스 시스템의 관례를 따를 것입니다 (LLVM이 기본적으로 리눅스 시스템 관례를 따르기에 그렇습니다). 즉, [지난 포스트][previous post]에서 설명한 것처럼 우리는 실행 시작 지점의 이름을 `_start`로 지정할 것입니다:
+
+[previous post]: @/edition-2/posts/01-freestanding-rust-binary/index.md
+
+```rust
+// src/main.rs
+
+#![no_std] // Rust 표준 라이브러리를 링크하지 않도록 합니다
+#![no_main] // Rust 언어에서 사용하는 실행 시작 지점 (main 함수)을 사용하지 않습니다
+
+use core::panic::PanicInfo;
+
+/// 패닉이 일어날 경우, 이 함수가 호출됩니다.
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ loop {}
+}
+
+#[no_mangle] // 이 함수의 이름을 mangle하지 않습니다
+pub extern "C" fn _start() -> ! {
+ // 링커는 기본적으로 '_start' 라는 이름을 가진 함수를 실행 시작 지점으로 삼기에,
+ // 이 함수는 실행 시작 지점이 됩니다
+ loop {}
+}
+```
+
+호스트 운영체제에 관계 없이 실행 시작 지점 함수의 이름은 `_start`로 지정해야 함을 기억해주세요.
+
+이제 `--target` 인자를 통해 위에서 다룬 JSON 파일의 이름을 전달하여 우리가 정의한 새로운 컴파일 대상 환경을 목표로 커널을 빌드할 수 있습니다:
+
+```
+> cargo build --target x86_64-blog_os.json
+
+error[E0463]: can't find crate for `core`
+```
+
+실패하였군요! 이 오류는 Rust 컴파일러가 더 이상 [`core` 라이브러리][`core` library]를 찾지 못한다는 것을 알려줍니다. 이 라이브러리는 `Result`와 `Option` 그리고 반복자 등 Rust의 기본적인 타입들을 포함하며, 모든 `no_std` 크레이트에 암시적으로 링크됩니다.
+
+[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
+
+문제는 core 라이브러리가 _미리 컴파일된 상태_ 의 라이브러리로 Rust 컴파일러와 함께 배포된다는 것입니다. `x86_64-unknown-linux-gnu` 등 배포된 라이브러리가 지원하는 컴파일 목표 환경을 위해 빌드하는 경우 문제가 없지만, 우리가 정의한 커스텀 환경을 위해 빌드하는 경우에는 라이브러리를 이용할 수 없습니다. 기본적으로 지원되지 않는 새로운 시스템 환경을 위해 코드를 빌드하기 위해서는 새로운 시스템 환경에서 구동 가능하도록 `core` 라이브러리를 새롭게 빌드해야 합니다.
+
+#### `build-std` 기능
+
+이제 cargo의 [`build-std 기능`][`build-std` feature]이 필요한 시점이 왔습니다. Rust 언어 설치파일에 함께 배포된 `core` 및 다른 표준 라이브러리 크레이트 버전을 사용하는 대신, 이 기능을 이용하여 해당 크레이트들을 직접 재컴파일하여 사용할 수 있습니다. 이 기능은 아직 비교적 새로운 기능이며 아직 완성된 기능이 아니기에, "unstable" 한 기능으로 표기되며 [nightly 버전의 Rust 컴파일러][nightly Rust compilers]에서만 이용가능합니다.
+
+[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
+[nightly Rust compilers]: #installing-rust-nightly
+
+해당 기능을 사용하려면, [cargo 설정][cargo configuration] 파일 `.cargo/config.toml`을 아래와 같이 만들어야 합니다:
+
+```toml
+# .cargo/config.toml 에 들어갈 내용
+
+[unstable]
+build-std = ["core", "compiler_builtins"]
+```
+
+위 설정은 cargo에게 `core`와 `compiler_builtins` 라이브러리를 새로 컴파일하도록 지시합니다. `compiler_builtins`는 `core`가 사용하는 라이브러리입니다. 해당 라이브러리들의 소스 코드가 있어야 새로 컴파일할 수 있기에, `rustup component add rust-src` 명령어를 통해 소스 코드를 설치합니다.
+
+
+
+**주의:** `unstable.build-std` 설정 키를 이용하려면 2020-07-15 혹은 그 이후에 출시된 Rust nightly 버전을 사용하셔야 합니다.
+
+
+
+cargo 설정 키 `unstable.build-std`를 설정하고 `rust-src` 컴포넌트를 설치한 후에 다시 빌드 명령어를 실행합니다:
+
+```
+> cargo build --target x86_64-blog_os.json
+ Compiling core v0.0.0 (/…/rust/src/libcore)
+ Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
+ Compiling compiler_builtins v0.1.32
+ Compiling blog_os v0.1.0 (/…/blog_os)
+ Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
+```
+
+이제 `cargo build` 명령어가 `core`, `rustc-std-workspace-cord` (`compiler_builtins`가 필요로 하는 라이브러리) 그리고 `compiler_builtins` 라이브러리를 우리의 커스텀 컴파일 대상을 위해 다시 컴파일하는 것을 확인할 수 있습니다.
+
+#### 메모리 관련 내장 함수
+
+Rust 컴파일러는 특정 군의 내장 함수들이 (built-in function) 모든 시스템에서 주어진다고 가정합니다. 대부분의 내장 함수들은 우리가 방금 컴파일한 `compiler_builtins` 크레이트가 이미 갖추고 있습니다. 하지만 그중 몇몇 메모리 관련 함수들은 기본적으로 사용 해제 상태가 되어 있는데, 그 이유는 해당 함수들을 호스트 시스템의 C 라이브러리가 제공하는 것이 관례이기 때문입니다. `memset`(메모리 블럭 전체에 특정 값 저장하기), `memcpy` (한 메모리 블럭의 데이터를 다른 메모리 블럭에 옮겨쓰기), `memcmp` (메모리 블럭 두 개의 데이터를 비교하기) 등이 이 분류에 해당합니다. 여태까지는 우리가 이 함수들 중 어느 하나도 사용하지 않았지만, 운영체제 구현을 더 추가하다 보면 필수적으로 사용될 함수들입니다 (예를 들어, 구조체를 복사하여 다른 곳에 저장할 때).
+
+우리는 운영체제의 C 라이브러리를 링크할 수 없기에, 다른 방식으로 이러한 내장 함수들을 컴파일러에 전달해야 합니다. 한 방법은 우리가 직접 `memset` 등의 내장함수들을 구현하고 컴파일 과정에서 함수명이 바뀌지 않도록 `#[no_mangle]` 속성을 적용하는 것입니다. 하지만 이 방법의 경우 우리가 직접 구현한 함수 로직에 아주 작은 실수만 있어도 undefined behavior를 일으킬 수 있기에 위험합니다. 예를 들어 `memcpy`를 구현하는 데에 `for`문을 사용한다면 무한 재귀 루프가 발생할 수 있는데, 그 이유는 `for`문의 구현이 내부적으로 trait 함수인 [`IntoIterator::into_iter`]를 호출하고 이 함수가 다시 `memcpy` 를 호출할 수 있기 때문입니다. 그렇기에 충분히 검증된 기존의 구현 중 하나를 사용하는 것이 바람직합니다.
+
+[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
+
+다행히도 `compiler_builtins` 크레이트가 이미 필요한 내장함수 구현을 전부 갖추고 있으며, C 라이브러리에서 오는 내장함수 구현과 충돌하지 않도록 사용 해제되어 있었던 것 뿐입니다. cargo의 [`build-std-features`] 플래그를 `["compiler-builtins-mem"]`으로 설정함으로써 `compiler_builtins`에 포함된 내장함수 구현을 사용할 수 있습니다. `build-std` 플래그와 유사하게 이 플래그 역시 커맨드 라인에서 `-Z` 플래그를 이용해 인자로 전달하거나 `.cargo/config.toml`의 `[unstable]` 테이블에서 설정할 수 있습니다. 우리는 매번 이 플래그를 사용하여 빌드할 예정이기에 `.cargo/config.toml`을 통해 설정을 하는 것이 장기적으로 더 편리할 것입니다:
+
+[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
+
+```toml
+# .cargo/config.toml 에 들어갈 내용
+
+[unstable]
+build-std-features = ["compiler-builtins-mem"]
+build-std = ["core", "compiler_builtins"]
+```
+
+(`compiler-builtins-mem` 기능에 대한 지원이 [굉장히 최근에 추가되었기에](https://github.com/rust-lang/rust/pull/77284), Rust nightly `2020-09-30` 이상의 버전을 사용하셔야 합니다.)
+
+이 기능은 `compiler_builtins` 크레이트의 [`mem` 기능 (feature)][`mem` feature]를 활성화 시킵니다. 이는 `#[no_mangle]` 속성이 [`memcpy` 등의 함수 구현][`memcpy` etc. implementations]에 적용되게 하여 링크가 해당 함수들을 식별하고 사용할 수 있게 합니다.
+
+[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L54-L55
+[`memcpy` etc. implementations]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69
+
+이제 우리의 커널은 컴파일러가 요구하는 함수들에 대한 유효한 구현을 모두 갖추게 되었기에, 커널 코드가 더 복잡해지더라도 상관 없이 컴파일하는 데에 문제가 없을 것입니다.
+
+#### 기본 컴파일 대상 환경 설정하기
+
+기본 컴파일 대상 환경을 지정하여 설정해놓으면 `cargo build` 명령어를 실행할 때마다 `--target` 인자를 넘기지 않아도 됩니다. [cargo 설정][cargo configuration] 파일인 `.cargo/config.toml`에 아래의 내용을 추가해주세요:
+
+[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
+
+```toml
+# .cargo/config.toml 에 들어갈 내용
+
+[build]
+target = "x86_64-blog_os.json"
+```
+
+이로써 `cargo`는 명시적으로 `--target` 인자가 주어지지 않으면 `x86_64-blog_os.json`에 명시된 컴파일 대상 환경을 기본 값으로 이용합니다. `cargo build` 만으로 간단히 커널을 빌드할 수 있게 되었습니다. cargo 설정 옵션들에 대해 더 자세한 정보를 원하시면 [공식 문서][cargo configuration]을 확인해주세요.
+
+`cargo build`만으로 이제 bare metal 환경을 목표로 커널을 빌드할 수 있지만, 아직 실행 시작 지점 함수 `_start`는 텅 비어 있습니다.
+이제 이 함수에 코드를 추가하여 화면에 메세지를 출력해볼 것입니다.
+
+### 화면에 출력하기
+현재 단계에서 가장 쉽게 화면에 문자를 출력할 수 있는 방법은 바로 [VGA 텍스트 버퍼][VGA text buffer]를 이용하는 것입니다. 이것은 VGA 하드웨어에 매핑되는 특수한 메모리 영역이며 화면에 출력될 내용이 저장됩니다. 주로 이 버퍼는 주로 25행 80열 (행마다 80개의 문자 저장)로 구성됩니다. 각 문자는 ASCII 문자로서 전경색 혹은 배경색과 함께 화면에 출력됩니다. 화면 출력 결과의 모습은 아래와 같습니다:
+
+[VGA text buffer]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
+
+
+
+VGA 버퍼가 정확히 어떤 구조를 하고 있는지는 다음 포스트에서 VGA 버퍼 드라이버를 작성하면서 다룰 것입니다. "Hello World!" 메시지를 출력하는 데에는 그저 버퍼의 시작 주소가 `0xb8000`이라는 것, 그리고 각 문자는 ASCII 문자를 위한 1바이트와 색상 표기를 위한 1바이트가 필요하다는 것만 알면 충분합니다.
+
+코드 구현은 아래와 같습니다:
+
+```rust
+static HELLO: &[u8] = b"Hello World!";
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ let vga_buffer = 0xb8000 as *mut u8;
+
+ for (i, &byte) in HELLO.iter().enumerate() {
+ unsafe {
+ *vga_buffer.offset(i as isize * 2) = byte;
+ *vga_buffer.offset(i as isize * 2 + 1) = 0xb;
+ }
+ }
+
+ loop {}
+}
+```
+
+우선 정수 `0xb8000`을 [raw 포인터][raw pointer]로 형변환 합니다. 그 다음 [static (정적 변수)][static] [바이트 문자열][byte string] `HELLO`의 반복자를 통해 각 바이트를 읽고, [`enumerate`] 함수를 통해 각 바이트의 문자열 내에서의 인덱스 값 `i`를 얻습니다. for문의 내부에서는 [`offset`] 함수를 통해 VGA 버퍼에 문자열의 각 바이트 및 색상 코드를 저장합니다 (`0xb`: light cyan 색상 코드).
+
+[iterate]: https://doc.rust-lang.org/stable/book/ch13-02-iterators.html
+[static]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
+[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
+[byte string]: https://doc.rust-lang.org/reference/tokens.html#byte-string-literals
+[raw pointer]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
+[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
+
+메모리 쓰기 작업을 위한 코드 주변에 [`unsafe`] 블록이 있는 것에 주목해주세요. 여기서 `unsafe` 블록이 필요한 이유는 Rust 컴파일러가 우리가 만든 raw 포인터가 유효한 포인터인지 검증할 능력이 없기 때문입니다. `unsafe` 블록 안에 포인터에 대한 쓰기 작업 코드를 적음으로써, 우리는 컴파일러에게 해당 메모리 쓰기 작업이 확실히 안전하다고 선언한 것입니다. `unsafe` 블록이 Rust의 모든 안전성 체크를 해제하는 것은 아니며, `unsafe` 블록 안에서만 [다섯 가지 작업들을 추가적으로][five additional things] 할 수 있습니다.
+
+[`unsafe`]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html
+[five additional things]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#unsafe-superpowers
+
+**이런 식의 Rust 코드를 작성하는 것은 절대 바람직하지 않다는 것을 강조드립니다!** unsafe 블록 안에서 raw pointer를 쓰다보면 메모리 버퍼 크기를 넘어선 메모리 주소에 데이터를 저장하는 등의 실수를 범하기 매우 쉽습니다.
+
+그렇기에 `unsafe` 블록의 사용을 최소화하는 것이 바람직하며, 그렇게 하기 위해 Rust에서 우리는 안전한 추상 계층을 만들어 이용할 수 있습니다. 예를 들어, 모든 위험한 요소들을 전부 캡슐화한 VGA 버퍼 타입을 만들어 외부 사용자가 해당 타입을 사용 중에 메모리 안전성을 해칠 가능성을 _원천 차단_ 할 수 있습니다. 이런 설계를 통해 최소한의 `unsafe` 블록만을 사용하면서 동시에 우리가 [메모리 안전성][memory safety]을 해치는 일이 없을 것이라 자신할 수 있습니다. 이러한 안전한 추상 레벨을 더한 VGA 버퍼 타입은 다음 포스트에서 만들게 될 것입니다.
+
+[memory safety]: https://en.wikipedia.org/wiki/Memory_safety
+
+## 커널 실행시키기
+
+이제 우리가 얻은 실행 파일을 실행시켜볼 차례입니다. 우선 컴파일 완료된 커널을 부트로더와 링크하여 부팅 가능한 디스크 이미지를 만들어야 합니다. 그 다음에 해당 디스크 이미지를 QEMU 가상머신에서 실행시키거나 USB 드라이브를 이용해 실제 컴퓨터에서 부팅할 수 있습니다.
+
+### 부팅 가능한 디스크 이미지 만들기
+
+부팅 가능한 디스크 이미지를 만들기 위해서는 컴파일된 커널을 부트로더와 링크해야합니다. [부팅에 대한 섹션][section about booting]에서 알아봤듯이, 부트로더는 CPU를 초기화하고 커널을 불러오는 역할을 합니다.
+
+[section about booting]: #the-boot-process
+
+우리는 부트로더를 직접 작성하는 대신에 [`bootloader`] 크레이트를 사용할 것입니다. 이 크레이트는 Rust와 인라인 어셈블리만으로 간단한 BIOS 부트로더를 구현합니다. 운영체제 커널을 부팅하는 데에 이 크레이트를 쓰기 위해 의존 크레이트 목록에 추가해줍니다:
+
+[`bootloader`]: https://crates.io/crates/bootloader
+
+```toml
+# Cargo.toml 에 들어갈 내용
+
+[dependencies]
+bootloader = "0.9.23"
+```
+
+부트로더를 의존 크레이트로 추가하는 것만으로는 부팅 가능한 디스크 이미지를 만들 수 없습니다. 커널 컴파일이 끝난 후 커널을 부트로더와 함께 링크할 수 있어야 하는데, cargo는 현재 [빌드 직후 스크립트 실행][post-build scripts] 기능을 지원하지 않습니다.
+
+[post-build scripts]: https://github.com/rust-lang/cargo/issues/545
+
+이 문제를 해결하기 위해 저희가 `bootimage` 라는 도구를 만들었습니다. 이 도구는 커널과 부트로더를 각각 컴파일 한 이후에 둘을 링크하여 부팅 가능한 디스크 이미지를 생성해줍니다. 이 도구를 설치하려면 터미널에서 아래의 명령어를 실행해주세요.
+
+```
+cargo install bootimage
+```
+
+`bootimage` 도구를 실행시키고 부트로더를 빌드하려면 `llvm-tools-preview` 라는 rustup 컴포넌트가 필요합니다. 명령어 `rustup component add llvm-tools-preview`를 통해 해당 컴포넌트를 설치합니다.
+
+`bootimage` 도구를 설치하고 `llvm-tools-preview` 컴포넌트를 추가하셨다면, 이제 아래의 명령어를 통해 부팅 가능한 디스크 이미지를 만들 수 있습니다:
+
+```
+> cargo bootimage
+```
+
+이 도구가 `cargo build`를 통해 커널을 다시 컴파일한다는 것을 확인하셨을 것입니다. 덕분에 커널 코드가 변경되어도 `cargo bootimage` 명령어 만으로도 해당 변경 사항이 바로 빌드에 반영됩니다. 그 다음 단계로 이 도구가 부트로더를 컴파일 할 것인데, 시간이 제법 걸릴 수 있습니다. 일반적인 의존 크레이트들과 마찬가지로 한 번 빌드한 후에 빌드 결과가 캐시(cache)되기 때문에, 두 번째 빌드부터는 소요 시간이 훨씬 적습니다. 마지막 단계로 `bootimage` 도구가 부트로더와 커널을 하나로 합쳐 부팅 가능한 디스크 이미지를 생성합니다.
+
+명령어 실행이 끝난 후, `target/x86_64-blog_os/debug` 디렉토리에 `bootimage-blog_os.bin`이라는 부팅 가능한 디스크 이미지가 생성되어 있을 것입니다. 이것을 가상머신에서 부팅하거나 USB 드라이브에 복사한 뒤 실제 컴퓨터에서 부팅할 수 있습니다 (우리가 만든 디스크 이미지는 CD 이미지와는 파일 형식이 다르기 때문에 CD에 복사해서 부팅하실 수는 없습니다).
+
+#### 어떻게 동작하는 걸까요?
+
+`bootimage` 도구는 아래의 작업들을 순서대로 진행합니다:
+
+- 커널을 컴파일하여 [ELF] 파일 생성
+- 부트로더 크레이트를 독립된 실행파일로서 컴파일
+- 커널의 ELF 파일을 부트로더에 링크
+
+[ELF]: https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
+[rust-osdev/bootloader]: https://github.com/rust-osdev/bootloader
+
+부팅이 시작되면, 부트로더는 커널의 ELF 파일을 읽고 파싱합니다. 그 다음 프로그램의 세그먼트들을 페이지 테이블의 가상 주소에 매핑하고, `bss` 섹션의 모든 메모리 값을 0으로 초기화하며, 스택을 초기화합니다. 마지막으로, 프로그램 실행 시작 지점의 주소 (`_start` 함수의 주소)에서 제어 흐름이 계속되도록 점프합니다.
+
+### QEMU에서 커널 부팅하기
+
+이제 우리의 커널 디스크 이미지를 가상 머신에서 부팅할 수 있습니다. [QEMU]에서 부팅하려면 아래의 명령어를 실행하세요:
+
+[QEMU]: https://www.qemu.org/
+
+```
+> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
+warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
+```
+
+위 명령어를 실행하면 아래와 같은 새로운 창이 열릴 것입니다:
+
+
+
+화면에 "Hello World!" 메세지가 출력된 것을 확인하실 수 있습니다.
+
+### 실제 컴퓨터에서 부팅하기
+
+USB 드라이브에 우리의 커널을 저장한 후 실제 컴퓨터에서 부팅하는 것도 가능합니다:
+
+```
+> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
+```
+
+`sdX` 대신 여러분이 소지한 USB 드라이브의 기기명을 입력하시면 됩니다. 해당 기기에 쓰인 데이터는 전부 덮어씌워지기 때문에 정확한 기기명을 입력하도록 주의해주세요.
+
+이미지를 USB 드라이브에 다 덮어썼다면, 이제 실제 하드웨어에서 해당 이미지를 통해 부트하여 실행할 수 있습니다. 아마 특별한 부팅 메뉴를 사용하거나 BIOS 설정에서 부팅 순서를 변경하여 USB로부터 부팅하도록 설정해야 할 것입니다. `bootloader` 크레이트가 아직 UEFI를 지원하지 않기에, UEFI 표준을 사용하는 기기에서는 부팅할 수 없습니다.
+
+### `cargo run` 명령어 사용하기
+
+QEMU에서 커널을 쉽게 실행할 수 있게 아래처럼 `runner`라는 새로운 cargo 설정 키 값을 추가합니다.
+
+```toml
+# .cargo/config.toml 에 들어갈 내용
+
+[target.'cfg(target_os = "none")']
+runner = "bootimage runner"
+```
+
+`target.'cfg(target_os = "none")'`가 붙은 키 값은 `"os"` 필드 설정이 `"none"`으로 되어 있는 컴파일 대상 환경에만 적용됩니다. 따라서 우리의 `x86_64-blog_os.json` 또한 적용 대상에 포함됩니다. `runner` 키 값은 `cargo run` 명령어 실행 시 어떤 명령어를 실행할지 지정합니다. 빌드가 성공적으로 끝난 후에 `runner` 키 값의 명령어가 실행됩니다. [cargo 공식 문서][cargo configuration]를 통해 더 자세한 내용을 확인하실 수 있습니다.
+
+명령어 `bootimage runner`는 프로젝트의 부트로더 라이브러리를 링크한 후에 QEMU를 실행시킵니다.
+그렇기에 일반적인 `runner` 실행파일을 실행하듯이 `bootimage runner` 명령어를 사용하실 수 있습니다. [`bootimage` 도구의 Readme 문서][Readme of `bootimage`]를 통해 더 자세한 내용 및 다른 가능한 설정 옵션들을 확인하세요.
+
+[Readme of `bootimage`]: https://github.com/rust-osdev/bootimage
+
+이제 `cargo run` 명령어를 통해 우리의 커널을 컴파일하고 QEMU에서 부팅할 수 있습니다.
+
+## 다음 단계는 무엇일까요?
+
+다음 글에서는 VGA 텍스트 버퍼 (text buffer)에 대해 더 알아보고 VGA text buffer와 안전하게 상호작용할 수 있는 방법을 구현할 것입니다.
+또한 `println` 매크로를 사용할 수 있도록 기능을 추가할 것입니다.
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.md
index 7e5fa8c3..5d4a0bbc 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.md
@@ -8,7 +8,7 @@ date = 2018-02-10
chapter = "Bare Bones"
+++
-In this post we create a minimal 64-bit Rust kernel for the x86 architecture. We build upon the [freestanding Rust binary] from the previous post to create a bootable disk image, that prints something to the screen.
+In this post, we create a minimal 64-bit Rust kernel for the x86 architecture. We build upon the [freestanding Rust binary] from the previous post to create a bootable disk image that prints something to the screen.
[freestanding Rust binary]: @/edition-2/posts/01-freestanding-rust-binary/index.md
@@ -24,7 +24,7 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
## The Boot Process
-When you turn on a computer, it begins executing firmware code that is stored in motherboard [ROM]. This code performs a [power-on self-test], detects available RAM, and pre-initializes the CPU and hardware. Afterwards it looks for a bootable disk and starts booting the operating system kernel.
+When you turn on a computer, it begins executing firmware code that is stored in motherboard [ROM]. This code performs a [power-on self-test], detects available RAM, and pre-initializes the CPU and hardware. Afterwards, it looks for a bootable disk and starts booting the operating system kernel.
[ROM]: https://en.wikipedia.org/wiki/Read-only_memory
[power-on self-test]: https://en.wikipedia.org/wiki/Power-on_self-test
@@ -37,11 +37,11 @@ On x86, there are two firmware standards: the “Basic Input/Output System“ (*
Currently, we only provide BIOS support, but support for UEFI is planned, too. If you'd like to help us with this, check out the [Github issue](https://github.com/phil-opp/blog_os/issues/349).
### BIOS Boot
-Almost all x86 systems have support for BIOS booting, including newer UEFI-based machines that use an emulated BIOS. This is great, because you can use the same boot logic across all machines from the last centuries. But this wide compatibility is at the same time the biggest disadvantage of BIOS booting, because it means that the CPU is put into a 16-bit compatibility mode called [real mode] before booting so that archaic bootloaders from the 1980s would still work.
+Almost all x86 systems have support for BIOS booting, including newer UEFI-based machines that use an emulated BIOS. This is great, because you can use the same boot logic across all machines from the last century. But this wide compatibility is at the same time the biggest disadvantage of BIOS booting, because it means that the CPU is put into a 16-bit compatibility mode called [real mode] before booting so that archaic bootloaders from the 1980s would still work.
But let's start from the beginning:
-When you turn on a computer, it loads the BIOS from some special flash memory located on the motherboard. The BIOS runs self test and initialization routines of the hardware, then it looks for bootable disks. If it finds one, the control is transferred to its _bootloader_, which is a 512-byte portion of executable code stored at the disk's beginning. Most bootloaders are larger than 512 bytes, so bootloaders are commonly split into a small first stage, which fits into 512 bytes, and a second stage, which is subsequently loaded by the first stage.
+When you turn on a computer, it loads the BIOS from some special flash memory located on the motherboard. The BIOS runs self-test and initialization routines of the hardware, then it looks for bootable disks. If it finds one, control is transferred to its _bootloader_, which is a 512-byte portion of executable code stored at the disk's beginning. Most bootloaders are larger than 512 bytes, so bootloaders are commonly split into a small first stage, which fits into 512 bytes, and a second stage, which is subsequently loaded by the first stage.
The bootloader has to determine the location of the kernel image on the disk and load it into memory. It also needs to switch the CPU from the 16-bit [real mode] first to the 32-bit [protected mode], and then to the 64-bit [long mode], where 64-bit registers and the complete main memory are available. Its third job is to query certain information (such as a memory map) from the BIOS and pass it to the OS kernel.
@@ -50,32 +50,32 @@ The bootloader has to determine the location of the kernel image on the disk and
[long mode]: https://en.wikipedia.org/wiki/Long_mode
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
-Writing a bootloader is a bit cumbersome as it requires assembly language and a lot of non insightful steps like “write this magic value to this processor register”. Therefore we don't cover bootloader creation in this post and instead provide a tool named [bootimage] that automatically prepends a bootloader to your kernel.
+Writing a bootloader is a bit cumbersome as it requires assembly language and a lot of non insightful steps like “write this magic value to this processor register”. Therefore, we don't cover bootloader creation in this post and instead provide a tool named [bootimage] that automatically prepends a bootloader to your kernel.
[bootimage]: https://github.com/rust-osdev/bootimage
If you are interested in building your own bootloader: Stay tuned, a set of posts on this topic is already planned!
#### The Multiboot Standard
-To avoid that every operating system implements its own bootloader, which is only compatible with a single OS, the [Free Software Foundation] created an open bootloader standard called [Multiboot] in 1995. The standard defines an interface between the bootloader and operating system, so that any Multiboot compliant bootloader can load any Multiboot compliant operating system. The reference implementation is [GNU GRUB], which is the most popular bootloader for Linux systems.
+To avoid that every operating system implements its own bootloader, which is only compatible with a single OS, the [Free Software Foundation] created an open bootloader standard called [Multiboot] in 1995. The standard defines an interface between the bootloader and the operating system, so that any Multiboot-compliant bootloader can load any Multiboot-compliant operating system. The reference implementation is [GNU GRUB], which is the most popular bootloader for Linux systems.
[Free Software Foundation]: https://en.wikipedia.org/wiki/Free_Software_Foundation
[Multiboot]: https://wiki.osdev.org/Multiboot
[GNU GRUB]: https://en.wikipedia.org/wiki/GNU_GRUB
-To make a kernel Multiboot compliant, one just needs to insert a so-called [Multiboot header] at the beginning of the kernel file. This makes it very easy to boot an OS in GRUB. However, GRUB and the Multiboot standard have some problems too:
+To make a kernel Multiboot compliant, one just needs to insert a so-called [Multiboot header] at the beginning of the kernel file. This makes it very easy to boot an OS from GRUB. However, GRUB and the Multiboot standard have some problems too:
[Multiboot header]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format
- They support only the 32-bit protected mode. This means that you still have to do the CPU configuration to switch to the 64-bit long mode.
-- They are designed to make the bootloader simple instead of the kernel. For example, the kernel needs to be linked with an [adjusted default page size], because GRUB can't find the Multiboot header otherwise. Another example is that the [boot information], which is passed to the kernel, contains lots of architecture dependent structures instead of providing clean abstractions.
+- They are designed to make the bootloader simple instead of the kernel. For example, the kernel needs to be linked with an [adjusted default page size], because GRUB can't find the Multiboot header otherwise. Another example is that the [boot information], which is passed to the kernel, contains lots of architecture-dependent structures instead of providing clean abstractions.
- Both GRUB and the Multiboot standard are only sparsely documented.
- GRUB needs to be installed on the host system to create a bootable disk image from the kernel file. This makes development on Windows or Mac more difficult.
[adjusted default page size]: https://wiki.osdev.org/Multiboot#Multiboot_2
[boot information]: https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format
-Because of these drawbacks we decided to not use GRUB or the Multiboot standard. However, we plan to add Multiboot support to our [bootimage] tool, so that it's possible to load your kernel on a GRUB system too. If you're interested in writing a Multiboot compliant kernel, check out the [first edition] of this blog series.
+Because of these drawbacks, we decided to not use GRUB or the Multiboot standard. However, we plan to add Multiboot support to our [bootimage] tool, so that it's possible to load your kernel on a GRUB system too. If you're interested in writing a Multiboot compliant kernel, check out the [first edition] of this blog series.
[first edition]: @/edition-1/_index.md
@@ -84,23 +84,23 @@ Because of these drawbacks we decided to not use GRUB or the Multiboot standard.
(We don't provide UEFI support at the moment, but we would love to! If you'd like to help, please tell us in the [Github issue](https://github.com/phil-opp/blog_os/issues/349).)
## A Minimal Kernel
-Now that we roughly know how a computer boots, it's time to create our own minimal kernel. Our goal is to create a disk image that prints a “Hello World!” to the screen when booted. For that we build upon the [freestanding Rust binary] from the previous post.
+Now that we roughly know how a computer boots, it's time to create our own minimal kernel. Our goal is to create a disk image that prints a “Hello World!” to the screen when booted. We do this by extending the previous post's [freestanding Rust binary].
-As you may remember, we built the freestanding binary through `cargo`, but depending on the operating system we needed different entry point names and compile flags. That's because `cargo` builds for the _host system_ by default, i.e. the system you're running on. This isn't something we want for our kernel, because a kernel that runs on top of e.g. Windows does not make much sense. Instead, we want to compile for a clearly defined _target system_.
+As you may remember, we built the freestanding binary through `cargo`, but depending on the operating system, we needed different entry point names and compile flags. That's because `cargo` builds for the _host system_ by default, i.e., the system you're running on. This isn't something we want for our kernel, because a kernel that runs on top of, e.g., Windows, does not make much sense. Instead, we want to compile for a clearly defined _target system_.
### Installing Rust Nightly
-Rust has three release channels: _stable_, _beta_, and _nightly_. The Rust Book explains the difference between these channels really well, so take a minute and [check it out](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains). For building an operating system we will need some experimental features that are only available on the nightly channel, so we need to install a nightly version of Rust.
+Rust has three release channels: _stable_, _beta_, and _nightly_. The Rust Book explains the difference between these channels really well, so take a minute and [check it out](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html#choo-choo-release-channels-and-riding-the-trains). For building an operating system, we will need some experimental features that are only available on the nightly channel, so we need to install a nightly version of Rust.
-To manage Rust installations I highly recommend [rustup]. It allows you to install nightly, beta, and stable compilers side-by-side and makes it easy to update them. With rustup you can use a nightly compiler for the current directory by running `rustup override set nightly`. Alternatively, you can add a file called `rust-toolchain` with the content `nightly` to the project's root directory. You can check that you have a nightly version installed by running `rustc --version`: The version number should contain `-nightly` at the end.
+To manage Rust installations, I highly recommend [rustup]. It allows you to install nightly, beta, and stable compilers side-by-side and makes it easy to update them. With rustup, you can use a nightly compiler for the current directory by running `rustup override set nightly`. Alternatively, you can add a file called `rust-toolchain` with the content `nightly` to the project's root directory. You can check that you have a nightly version installed by running `rustc --version`: The version number should contain `-nightly` at the end.
[rustup]: https://www.rustup.rs/
-The nightly compiler allows us to opt-in to various experimental features by using so-called _feature flags_ at the top of our file. For example, we could enable the experimental [`asm!` macro] for inline assembly by adding `#![feature(asm)]` to the top of our `main.rs`. Note that such experimental features are completely unstable, which means that future Rust versions might change or remove them without prior warning. For this reason we will only use them if absolutely necessary.
+The nightly compiler allows us to opt-in to various experimental features by using so-called _feature flags_ at the top of our file. For example, we could enable the experimental [`asm!` macro] for inline assembly by adding `#![feature(asm)]` to the top of our `main.rs`. Note that such experimental features are completely unstable, which means that future Rust versions might change or remove them without prior warning. For this reason, we will only use them if absolutely necessary.
-[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
+[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
### Target Specification
-Cargo supports different target systems through the `--target` parameter. The target is described by a so-called _[target triple]_, which describes the CPU architecture, the vendor, the operating system, and the [ABI]. For example, the `x86_64-unknown-linux-gnu` target triple describes a system with a `x86_64` CPU, no clear vendor and a Linux operating system with the GNU ABI. Rust supports [many different target triples][platform-support], including `arm-linux-androideabi` for Android or [`wasm32-unknown-unknown` for WebAssembly](https://www.hellorust.com/setup/wasm-target/).
+Cargo supports different target systems through the `--target` parameter. The target is described by a so-called _[target triple]_, which describes the CPU architecture, the vendor, the operating system, and the [ABI]. For example, the `x86_64-unknown-linux-gnu` target triple describes a system with an `x86_64` CPU, no clear vendor, and a Linux operating system with the GNU ABI. Rust supports [many different target triples][platform-support], including `arm-linux-androideabi` for Android or [`wasm32-unknown-unknown` for WebAssembly](https://www.hellorust.com/setup/wasm-target/).
[target triple]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
[ABI]: https://stackoverflow.com/a/2456882
@@ -125,12 +125,12 @@ For our target system, however, we require some special configuration parameters
}
```
-Most fields are required by LLVM to generate code for that platform. For example, the [`data-layout`] field defines the size of various integer, floating point, and pointer types. Then there are fields that Rust uses for conditional compilation, such as `target-pointer-width`. The third kind of fields define how the crate should be built. For example, the `pre-link-args` field specifies arguments passed to the [linker].
+Most fields are required by LLVM to generate code for that platform. For example, the [`data-layout`] field defines the size of various integer, floating point, and pointer types. Then there are fields that Rust uses for conditional compilation, such as `target-pointer-width`. The third kind of field defines how the crate should be built. For example, the `pre-link-args` field specifies arguments passed to the [linker].
[`data-layout`]: https://llvm.org/docs/LangRef.html#data-layout
[linker]: https://en.wikipedia.org/wiki/Linker_(computing)
-We also target `x86_64` systems with our kernel, so our target specification will look very similar to the one above. Let's start by creating a `x86_64-blog_os.json` file (choose any name you like) with the common content:
+We also target `x86_64` systems with our kernel, so our target specification will look very similar to the one above. Let's start by creating an `x86_64-blog_os.json` file (choose any name you like) with the common content:
```json
{
@@ -155,7 +155,7 @@ We add the following build-related entries:
"linker": "rust-lld",
```
-Instead of using the platform's default linker (which might not support Linux targets), we use the cross platform [LLD] linker that is shipped with Rust for linking our kernel.
+Instead of using the platform's default linker (which might not support Linux targets), we use the cross-platform [LLD] linker that is shipped with Rust for linking our kernel.
[LLD]: https://lld.llvm.org/
@@ -163,7 +163,7 @@ Instead of using the platform's default linker (which might not support Linux ta
"panic-strategy": "abort",
```
-This setting specifies that the target doesn't support [stack unwinding] on panic, so instead the program should abort directly. This has the same effect as the `panic = "abort"` option in our Cargo.toml, so we can remove it from there. (Note that in contrast to the Cargo.toml option, this target option also applies when we recompile the `core` library later in this post. So be sure to add this option, even if you prefer to keep the Cargo.toml option.)
+This setting specifies that the target doesn't support [stack unwinding] on panic, so instead the program should abort directly. This has the same effect as the `panic = "abort"` option in our Cargo.toml, so we can remove it from there. (Note that, in contrast to the Cargo.toml option, this target option also applies when we recompile the `core` library later in this post. So, even if you prefer to keep the Cargo.toml option, make sure to include this option.)
[stack unwinding]: https://www.bogotobogo.com/cplusplus/stackunwinding.php
@@ -171,7 +171,7 @@ This setting specifies that the target doesn't support [stack unwinding] on pani
"disable-redzone": true,
```
-We're writing a kernel, so we'll need to handle interrupts at some point. To do that safely, we have to disable a certain stack pointer optimization called the _“red zone”_, because it would cause stack corruptions otherwise. For more information, see our separate post about [disabling the red zone].
+We're writing a kernel, so we'll need to handle interrupts at some point. To do that safely, we have to disable a certain stack pointer optimization called the _“red zone”_, because it would cause stack corruption otherwise. For more information, see our separate post about [disabling the red zone].
[disabling the red zone]: @/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.md
@@ -211,7 +211,7 @@ Our target specification file now looks like this:
```
### Building our Kernel
-Compiling for our new target will use Linux conventions (I'm not quite sure why, I assume that it's just LLVM's default). This means that we need an entry point named `_start` as described in the [previous post]:
+Compiling for our new target will use Linux conventions (I'm not quite sure why; I assume it's just LLVM's default). This means that we need an entry point named `_start` as described in the [previous post]:
[previous post]: @/edition-2/posts/01-freestanding-rust-binary/index.md
@@ -277,7 +277,7 @@ This tells cargo that it should recompile the `core` and `compiler_builtins` lib
-After setting the `unstable.build-std` configuration key and installing the `rust-src` component, we can rerun the our build command:
+After setting the `unstable.build-std` configuration key and installing the `rust-src` component, we can rerun our build command:
```
> cargo build --target x86_64-blog_os.json
@@ -294,11 +294,11 @@ We see that `cargo build` now recompiles the `core`, `rustc-std-workspace-core`
The Rust compiler assumes that a certain set of built-in functions is available for all systems. Most of these functions are provided by the `compiler_builtins` crate that we just recompiled. However, there are some memory-related functions in that crate that are not enabled by default because they are normally provided by the C library on the system. These functions include `memset`, which sets all bytes in a memory block to a given value, `memcpy`, which copies one memory block to another, and `memcmp`, which compares two memory blocks. While we didn't need any of these functions to compile our kernel right now, they will be required as soon as we add some more code to it (e.g. when copying structs around).
-Since we can't link to the C library of the operating system, we need an alternative way to provide these functions to the compiler. One possible approach for this could be to implement our own `memset` etc. functions and apply the `#[no_mangle]` attribute to them (to avoid the automatic renaming during compilation). However, this is dangerous since the slightest mistake in the implementation of these functions could lead to undefined behavior. For example, you might get an endless recursion when implementing `memcpy` using a `for` loop because `for` loops implicitly call the [`IntoIterator::into_iter`] trait method, which might call `memcpy` again. So it's a good idea to reuse existing well-tested implementations instead.
+Since we can't link to the C library of the operating system, we need an alternative way to provide these functions to the compiler. One possible approach for this could be to implement our own `memset` etc. functions and apply the `#[no_mangle]` attribute to them (to avoid the automatic renaming during compilation). However, this is dangerous since the slightest mistake in the implementation of these functions could lead to undefined behavior. For example, implementing `memcpy` with a `for` loop may result in an infinite recursion because `for` loops implicitly call the [`IntoIterator::into_iter`] trait method, which may call `memcpy` again. So it's a good idea to reuse existing, well-tested implementations instead.
[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
-Fortunately, the `compiler_builtins` crate already contains implementations for all the needed functions, they are just disabled by default to not collide with the implementations from the C library. We can enable them by setting cargo's [`build-std-features`] flag to `["compiler-builtins-mem"]`. Like the `build-std` flag, this flag can be either passed on the command line as `-Z` flag or configured in the `unstable` table in the `.cargo/config.toml` file. Since we always want to build with this flag, the config file option makes more sense for us:
+Fortunately, the `compiler_builtins` crate already contains implementations for all the needed functions, they are just disabled by default to not collide with the implementations from the C library. We can enable them by setting cargo's [`build-std-features`] flag to `["compiler-builtins-mem"]`. Like the `build-std` flag, this flag can be either passed on the command line as a `-Z` flag or configured in the `unstable` table in the `.cargo/config.toml` file. Since we always want to build with this flag, the config file option makes more sense for us:
[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
@@ -374,14 +374,14 @@ First, we cast the integer `0xb8000` into a [raw pointer]. Then we [iterate] ove
[raw pointer]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
-Note that there's an [`unsafe`] block around all memory writes. The reason is that the Rust compiler can't prove that the raw pointers we create are valid. They could point anywhere and lead to data corruption. By putting them into an `unsafe` block we're basically telling the compiler that we are absolutely sure that the operations are valid. Note that an `unsafe` block does not turn off Rust's safety checks. It only allows you to do [five additional things].
+Note that there's an [`unsafe`] block around all memory writes. The reason is that the Rust compiler can't prove that the raw pointers we create are valid. They could point anywhere and lead to data corruption. By putting them into an `unsafe` block, we're basically telling the compiler that we are absolutely sure that the operations are valid. Note that an `unsafe` block does not turn off Rust's safety checks. It only allows you to do [five additional things].
[`unsafe`]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html
[five additional things]: https://doc.rust-lang.org/stable/book/ch19-01-unsafe-rust.html#unsafe-superpowers
-I want to emphasize that **this is not the way we want to do things in Rust!** It's very easy to mess up when working with raw pointers inside unsafe blocks, for example, we could easily write beyond the buffer's end if we're not careful.
+I want to emphasize that **this is not the way we want to do things in Rust!** It's very easy to mess up when working with raw pointers inside unsafe blocks. For example, we could easily write beyond the buffer's end if we're not careful.
-So we want to minimize the use of `unsafe` as much as possible. Rust gives us the ability to do this by creating safe abstractions. For example, we could create a VGA buffer type that encapsulates all unsafety and ensures that it is _impossible_ to do anything wrong from the outside. This way, we would only need minimal amounts of `unsafe` and can be sure that we don't violate [memory safety]. We will create such a safe VGA buffer abstraction in the next post.
+So we want to minimize the use of `unsafe` as much as possible. Rust gives us the ability to do this by creating safe abstractions. For example, we could create a VGA buffer type that encapsulates all unsafety and ensures that it is _impossible_ to do anything wrong from the outside. This way, we would only need minimal amounts of `unsafe` code and can be sure that we don't violate [memory safety]. We will create such a safe VGA buffer abstraction in the next post.
[memory safety]: https://en.wikipedia.org/wiki/Memory_safety
@@ -403,10 +403,10 @@ Instead of writing our own bootloader, which is a project on its own, we use the
# in Cargo.toml
[dependencies]
-bootloader = "0.9.8"
+bootloader = "0.9.23"
```
-Adding the bootloader as dependency is not enough to actually create a bootable disk image. The problem is that we need to link our kernel with the bootloader after compilation, but cargo has no support for [post-build scripts].
+Adding the bootloader as a dependency is not enough to actually create a bootable disk image. The problem is that we need to link our kernel with the bootloader after compilation, but cargo has no support for [post-build scripts].
[post-build scripts]: https://github.com/rust-lang/cargo/issues/545
@@ -424,9 +424,9 @@ After installing `bootimage` and adding the `llvm-tools-preview` component, we c
> cargo bootimage
```
-We see that the tool recompiles our kernel using `cargo build`, so it will automatically pick up any changes you make. Afterwards it compiles the bootloader, which might take a while. Like all crate dependencies it is only built once and then cached, so subsequent builds will be much faster. Finally, `bootimage` combines the bootloader and your kernel to a bootable disk image.
+We see that the tool recompiles our kernel using `cargo build`, so it will automatically pick up any changes you make. Afterwards, it compiles the bootloader, which might take a while. Like all crate dependencies, it is only built once and then cached, so subsequent builds will be much faster. Finally, `bootimage` combines the bootloader and your kernel into a bootable disk image.
-After executing the command, you should see a bootable disk image named `bootimage-blog_os.bin` in your `target/x86_64-blog_os/debug` directory. You can boot it in a virtual machine or copy it to an USB drive to boot it on real hardware. (Note that this is not a CD image, which have a different format, so burning it to a CD doesn't work).
+After executing the command, you should see a bootable disk image named `bootimage-blog_os.bin` in your `target/x86_64-blog_os/debug` directory. You can boot it in a virtual machine or copy it to a USB drive to boot it on real hardware. (Note that this is not a CD image, which has a different format, so burning it to a CD doesn't work).
#### How does it work?
The `bootimage` tool performs the following steps behind the scenes:
@@ -448,10 +448,9 @@ We can now boot the disk image in a virtual machine. To boot it in [QEMU], execu
```
> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
-warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
```
-This opens a separate window with that looks like this:
+This opens a separate window which should look similar to this:

@@ -459,13 +458,13 @@ We see that our "Hello World!" is visible on the screen.
### Real Machine
-It is also possible to write it to an USB stick and boot it on a real machine:
+It is also possible to write it to a USB stick and boot it on a real machine, **but be careful** to choose the correct device name, because **everything on that device is overwritten**:
```
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
```
-Where `sdX` is the device name of your USB stick. **Be careful** to choose the correct device name, because everything on that device is overwritten.
+Where `sdX` is the device name of your USB stick.
After writing the image to the USB stick, you can run it on real hardware by booting from it. You probably need to use a special boot menu or change the boot order in your BIOS configuration to boot from the USB stick. Note that it currently doesn't work for UEFI machines, since the `bootloader` crate has no UEFI support yet.
@@ -480,7 +479,7 @@ To make it easier to run our kernel in QEMU, we can set the `runner` configurati
runner = "bootimage runner"
```
-The `target.'cfg(target_os = "none")'` table applies to all targets that have set the `"os"` field of their target configuration file to `"none"`. This includes our `x86_64-blog_os.json` target. The `runner` key specifies the command that should be invoked for `cargo run`. The command is run after a successful build with the executable path passed as first argument. See the [cargo documentation][cargo configuration] for more details.
+The `target.'cfg(target_os = "none")'` table applies to all targets whose target configuration file's `"os"` field is set to `"none"`. This includes our `x86_64-blog_os.json` target. The `runner` key specifies the command that should be invoked for `cargo run`. The command is run after a successful build with the executable path passed as the first argument. See the [cargo documentation][cargo configuration] for more details.
The `bootimage runner` command is specifically designed to be usable as a `runner` executable. It links the given executable with the project's bootloader dependency and then launches QEMU. See the [Readme of `bootimage`] for more details and possible configuration options.
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ru.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ru.md
index 6f3690b8..c50b85b8 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ru.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.ru.md
@@ -103,7 +103,7 @@ Rust имеет три релизных канала: _stable_, _beta_ и _night
Nightly версия компилятора позволяет нам подключать различные экспериментальные возможности с помощью так называемых _флагов_ в верхней части нашего файла. Например, мы можем включить экспериментальный [макрос `asm!``asm!` macro] для встроенного ассемблера, добавив `#![feature(asm)]` в начало нашего `main.rs`. Обратите внимание, что такие экспериментальные возможности совершенно нестабильны, что означает, что будущие версии Rust могут изменить или удалить их без предварительного предупреждения. По этой причине мы будем использовать их только в случае крайней необходимости.
-[`asm!` macro]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
+[`asm!` macro]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
### Спецификация целевой платформы
@@ -411,7 +411,7 @@ pub extern "C" fn _start() -> ! {
# in Cargo.toml
[dependencies]
-bootloader = "0.9.8"
+bootloader = "0.9.23"
```
Добавление загрузчика в качестве зависимости недостаточно для создания загрузочного образа диска. Проблема в том, что нам нужно связать наше ядро с загрузчиком после компиляции, но в cargo нет поддержки [скриптов после сборки][post-build scripts].
diff --git a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.zh-CN.md b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.zh-CN.md
index 8a7076d6..89ecad24 100644
--- a/blog/content/edition-2/posts/02-minimal-rust-kernel/index.zh-CN.md
+++ b/blog/content/edition-2/posts/02-minimal-rust-kernel/index.zh-CN.md
@@ -1,23 +1,25 @@
+++
-title = "最小化内核"
+title = "最小内核"
weight = 2
path = "zh-CN/minimal-rust-kernel"
date = 2018-02-10
[extra]
# Please update this when updating the translation
-translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
# GitHub usernames of the people that translated this post
-translators = ["luojia65", "Rustin-Liu"]
+translators = ["luojia65", "Rustin-Liu", "liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong"]
+++
-在这篇文章中,我们将基于 **x86架构**(the x86 architecture),使用 Rust 语言,编写一个最小化的 64 位内核。我们将从上一章中构建的独立式可执行程序开始,构建自己的内核;它将向显示器打印字符串,并能被打包为一个能够引导启动的**磁盘映像**(disk image)。
+在这篇文章中,我们将基于 **x86架构**(the x86 architecture),使用 Rust 语言,编写一个最小化的 64 位内核。我们将从上一章中构建的[独立式可执行程序][freestanding-rust-binary]开始,构建自己的内核;它将向显示器打印字符串,并能被打包为一个能够引导启动的**磁盘映像**(disk image)。
[freestanding Rust binary]: @/edition-2/posts/01-freestanding-rust-binary/index.md
-This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-02`][post branch] branch.
+此博客在 [GitHub] 上公开开发. 如果您有任何问题或疑问,请在此处打开一个 issue。 您也可以在[底部][at the bottom]发表评论. 这篇文章的完整源代码可以在 [`post-02`] [post branch] 分支中找到。
[GitHub]: https://github.com/phil-opp/blog_os
[at the bottom]: #comments
@@ -32,7 +34,7 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
x86 架构支持两种固件标准: **BIOS**([Basic Input/Output System](https://en.wikipedia.org/wiki/BIOS))和 **UEFI**([Unified Extensible Firmware Interface](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface))。其中,BIOS 标准显得陈旧而过时,但实现简单,并为 1980 年代后的所有 x86 设备所支持;相反地,UEFI 更现代化,功能也更全面,但开发和构建更复杂(至少从我的角度看是如此)。
-在这篇文章中,我们暂时只提供 BIOS 固件的引导启动方式。
+在这篇文章中,我们暂时只提供 BIOS 固件的引导启动方式,但是UEFI支持也已经在计划中了。如果你希望帮助我们推进它,请查阅这份 [Github issue](https://github.com/phil-opp/blog_os/issues/349)。
### BIOS 启动
@@ -57,11 +59,17 @@ x86 架构支持两种固件标准: **BIOS**([Basic Input/Output System](htt
3. GRUB 和 Multiboot 标准并没有被详细地解释,阅读相关文档需要一定经验;
4. 为了创建一个能够被引导的磁盘映像,我们在开发时必须安装 GRUB:这加大了基于 Windows 或 macOS 开发内核的难度。
-出于这些考虑,我们决定不使用 GRUB 或者 Multiboot 标准。然而,Multiboot 支持功能也在 bootimage 工具的开发计划之中,所以从原理上讲,如果选用 bootimage 工具,在未来使用 GRUB 引导你的系统内核是可能的。
+出于这些考虑,我们决定不使用 GRUB 或者 Multiboot 标准。然而,Multiboot 支持功能也在 bootimage 工具的开发计划之中,所以从原理上讲,如果选用 bootimage 工具,在未来使用 GRUB 引导你的系统内核是可能的。 如果你对编写一个支持 Mutiboot 标准的内核有兴趣,可以查阅 [初版文档][first edition]。
-## 最小化内核
+[first edition]: @/edition-1/_index.md
-现在我们已经明白电脑是如何启动的,那也是时候编写我们自己的内核了。我们的小目标是,创建一个内核的磁盘映像,它能够在启动时,向屏幕输出一行“Hello World!”;我们的工作将基于上一章构建的独立式可执行程序。
+### UEFI
+
+(截至此时,我们并未提供UEFI相关教程,但我们确实有此意向。如果你愿意提供一些帮助,请在 [Github issue](https://github.com/phil-opp/blog_os/issues/349) 告知我们,不胜感谢。)
+
+## 最小内核
+
+现在我们已经明白电脑是如何启动的,那也是时候编写我们自己的内核了。我们的小目标是,创建一个内核的磁盘映像,它能够在启动时,向屏幕输出一行“Hello World!”;我们的工作将基于上一章构建的[独立式可执行程序][freestanding Rust binary]。
如果读者还有印象的话,在上一章,我们使用 `cargo` 构建了一个独立的二进制程序;但这个程序依然基于特定的操作系统平台:因平台而异,我们需要定义不同名称的函数,且使用不同的编译指令。这是因为在默认情况下,`cargo` 会为特定的**宿主系统**(host system)构建源码,比如为你正在运行的系统构建源码。这并不是我们想要的,因为我们的内核不应该基于另一个操作系统——我们想要编写的,就是这个操作系统。确切地说,我们想要的是,编译为一个特定的**目标系统**(target system)。
@@ -73,7 +81,7 @@ Rust 语言有三个**发行频道**(release channel),分别是 stable、b
Nightly 版本的编译器允许我们在源码的开头插入**特性标签**(feature flag),来自由选择并使用大量实验性的功能。举个例子,要使用实验性的[内联汇编(asm!宏)][asm feature],我们可以在 `main.rs` 的顶部添加 `#![feature(asm)]`。要注意的是,这样的实验性功能**不稳定**(unstable),意味着未来的 Rust 版本可能会修改或移除这些功能,而不会有预先的警告过渡。因此我们只有在绝对必要的时候,才应该使用这些特性。
-[asm feature]: https://doc.rust-lang.org/unstable-book/library-features/asm.html
+[asm feature]: https://doc.rust-lang.org/stable/reference/inline-assembly.html
### 目标配置清单
@@ -135,7 +143,9 @@ Nightly 版本的编译器允许我们在源码的开头插入**特性标签**
"disable-redzone": true,
```
-我们正在编写一个内核,所以我们应该同时处理中断。要安全地实现这一点,我们必须禁用一个与**红区**(redzone)有关的栈指针优化:因为此时,这个优化可能会导致栈被破坏。我们撰写了一篇专门的短文,来更详细地解释红区及与其相关的优化。
+我们正在编写一个内核,所以我们迟早要处理中断。要安全地实现这一点,我们必须禁用一个与**红区**(redzone)有关的栈指针优化:因为此时,这个优化可能会导致栈被破坏。如果需要更详细的资料,请查阅我们的一篇关于 [禁用红区][disabling the red zone] 的短文。
+
+[disabling the red zone]: @/edition-2/posts/02-minimal-rust-kernel/disable-red-zone/index.zh-CN.md
```json
"features": "-mmx,-sse,+soft-float",
@@ -147,7 +157,7 @@ Nightly 版本的编译器允许我们在源码的开头插入**特性标签**
禁用 SIMD 产生的一个问题是,`x86_64` 架构的浮点数指针运算默认依赖于 SIMD 寄存器。我们的解决方法是,启用 `soft-float` 特征,它将使用基于整数的软件功能,模拟浮点数指针运算。
-为了让读者的印象更清晰,我们撰写了一篇关于禁用 SIMD 的短文。
+为了让读者的印象更清晰,我们撰写了一篇关于 [禁用 SIMD][disabling SIMD](@/edition-2/posts/02-minimal-rust-kernel/disable-simd/index.zh-CN.md) 的短文。
现在,我们将各个配置项整合在一起。我们的目标配置清单应该长这样:
@@ -171,7 +181,9 @@ Nightly 版本的编译器允许我们在源码的开头插入**特性标签**
### 编译内核
-要编译我们的内核,我们将使用 Linux 系统的编写风格(这可能是 LLVM 的默认风格)。这意味着,我们需要把前一篇文章中编写的入口点重命名为 `_start`:
+要编译我们的内核,我们将使用 Linux 系统的编写风格(这可能是 LLVM 的默认风格)。这意味着,我们需要把[前一篇文章][previous post]中编写的入口点重命名为 `_start`:
+
+[previous post]: @/edition-2/posts/01-freestanding-rust-binary/index.md
```rust
// src/main.rs
@@ -203,61 +215,99 @@ pub extern "C" fn _start() -> ! {
> cargo build --target x86_64-blog_os.json
error[E0463]: can't find crate for `core`
-(或者是下面的错误)
-error[E0463]: can't find crate for `compiler_builtins`
```
-哇哦,编译失败了!输出的错误告诉我们,Rust 编译器找不到 `core` 或者 `compiler_builtins` 包;而所有 `no_std` 上下文都隐式地链接到这两个包。[`core` 包](https://doc.rust-lang.org/nightly/core/index.html)包含基础的 Rust 类型,如` Result`、`Option` 和迭代器等;[`compiler_builtins` 包](https://github.com/rust-lang-nursery/compiler-builtins)提供 LLVM 需要的许多底层操作,比如 `memcpy`。
+毫不意外的编译失败了,错误信息告诉我们编译器没有找到 [`core`][`core` library] 这个crate,它包含了Rust语言中的部分基础类型,如 `Result`、`Option`、迭代器等等,并且它还会隐式链接到 `no_std` 特性里面。
-通常状况下,`core` 库以**预编译库**(precompiled library)的形式与 Rust 编译器一同发布——这时,`core` 库只对支持的宿主系统有效,而我们自定义的目标系统无效。如果我们想为其它系统编译代码,我们需要为这些系统重新编译整个 `core` 库。
+[`core` library]: https://doc.rust-lang.org/nightly/core/index.html
-### Cargo xbuild
+通常状况下,`core` crate以**预编译库**(precompiled library)的形式与 Rust 编译器一同发布——这时,`core` crate只对支持的宿主系统有效,而对我们自定义的目标系统无效。如果我们想为其它系统编译代码,我们需要为这些系统重新编译整个 `core` crate。
-这就是为什么我们需要 [cargo xbuild 工具](https://github.com/rust-osdev/cargo-xbuild)。这个工具封装了 `cargo build`;但不同的是,它将自动交叉编译 `core` 库和一些**编译器内建库**(compiler built-in libraries)。我们可以用下面的命令安装它:
+#### `build-std` 选项
-```bash
-cargo install cargo-xbuild
+此时就到了cargo中 [`build-std` 特性][`build-std` feature] 登场的时刻,该特性允许你按照自己的需要重编译 `core` 等标准crate,而不需要使用Rust安装程序内置的预编译版本。 但是该特性是全新的功能,到目前为止尚未完全完成,所以它被标记为 "unstable" 且仅被允许在 [nightly Rust 编译器][nightly Rust compilers] 环境下调用。
+
+[`build-std` feature]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std
+[nightly Rust compilers]: #安装 Nightly Rust
+
+要启用该特性,你需要创建一个 [cargo 配置][cargo configuration] 文件,即 `.cargo/config.toml`,并写入以下语句:
+
+```toml
+# in .cargo/config.toml
+
+[unstable]
+build-std = ["core", "compiler_builtins"]
```
-这个工具依赖于Rust的源代码;我们可以使用 `rustup component add rust-src` 来安装源代码。
+该配置会告知cargo需要重新编译 `core` 和 `compiler_builtins` 这两个crate,其中 `compiler_builtins` 是 `core` 的必要依赖。 另外重编译需要提供源码,我们可以使用 `rustup component add rust-src` 命令来下载它们。
-现在我们可以使用 `xbuild` 代替 `build` 重新编译:
+
+
+在设定 `unstable.build-std` 配置项并安装 `rust-src` 组件之后,我们就可以开始编译了:
+
+```
+> cargo build --target x86_64-blog_os.json
Compiling core v0.0.0 (/…/rust/src/libcore)
- Compiling compiler_builtins v0.1.5
- Compiling rustc-std-workspace-core v1.0.0 (/…/rust/src/tools/rustc-std-workspace-core)
- Compiling alloc v0.0.0 (/tmp/xargo.PB7fj9KZJhAI)
- Finished release [optimized + debuginfo] target(s) in 45.18s
- Compiling blog_os v0.1.0 (file:///…/blog_os)
+ Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
+ Compiling compiler_builtins v0.1.32
+ Compiling blog_os v0.1.0 (/…/blog_os)
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
```
-我们能看到,`cargo xbuild` 为我们自定义的目标交叉编译了 `core`、`compiler_builtin` 和 `alloc` 三个部件。这些部件使用了大量的**不稳定特性**(unstable features),所以只能在[nightly 版本的 Rust 编译器][installing rust nightly]中工作。这之后,`cargo xbuild` 成功地编译了我们的 `blog_os` 包。
+如你所见,在执行 `cargo build` 之后, `core`、`rustc-std-workspace-core` (`compiler_builtins` 的依赖)和 `compiler_builtins` crate被重新编译了。
-[installing rust nightly]: #an-zhuang-nightly-rust
+#### 内存相关函数
-现在我们可以为裸机编译内核了;但是,我们提供给引导程序的入口点 `_start` 函数还是空的。我们可以添加一些东西进去,不过我们可以先做一些优化工作。
+目前来说,Rust编译器假定所有内置函数(`built-in functions`)在所有系统内都是存在且可用的。事实上这个前提只对了一半,
+绝大多数内置函数都可以被 `compiler_builtins` 提供,而这个crate刚刚已经被我们重编译过了,然而部分内存相关函数是需要操作系统相关的标准C库提供的。
+比如,`memset`(该函数可以为一个内存块内的所有比特进行赋值)、`memcpy`(将一个内存块里的数据拷贝到另一个内存块)以及`memcmp`(比较两个内存块的数据)。
+好在我们的内核暂时还不需要用到这些函数,但是不要高兴的太早,当我们编写更丰富的功能(比如拷贝数据结构)时就会用到了。
-### 设置默认目标
+现在我们当然无法提供操作系统相关的标准C库,所以我们需要使用其他办法提供这些东西。一个显而易见的途径就是自己实现 `memset` 这些函数,但不要忘记加入 `#[no_mangle]` 语句,以避免编译时被自动重命名。 当然,这样做很危险,底层函数中最细微的错误也会将程序导向不可预知的未来。比如,你可能在实现 `memcpy` 时使用了一个 `for` 循环,然而 `for` 循环本身又会调用 [`IntoIterator::into_iter`] 这个trait方法,这个方法又会再次调用 `memcpy`,此时一个无限递归就产生了,所以还是使用经过良好测试的既存实现更加可靠。
-为了避免每次使用`cargo xbuild`时传递`--target`参数,我们可以覆写默认的编译目标。我们创建一个名为`.cargo/config`的[cargo配置文件](https://doc.rust-lang.org/cargo/reference/config.html),添加下面的内容:
+[`IntoIterator::into_iter`]: https://doc.rust-lang.org/stable/core/iter/trait.IntoIterator.html#tymethod.into_iter
+
+幸运的是,`compiler_builtins` 事实上自带了所有相关函数的实现,只是在默认情况下,出于避免和标准C库发生冲突的考量被禁用掉了,此时我们需要将 [`build-std-features`] 配置项设置为 `["compiler-builtins-mem"]` 来启用这个特性。如同 `build-std` 配置项一样,该特性可以使用 `-Z` 参数启用,也可以在 `.cargo/config.toml` 中使用 `unstable` 配置集启用。现在我们的配置文件中的相关部分是这样子的:
+
+[`build-std-features`]: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#build-std-features
```toml
-# in .cargo/config
+# in .cargo/config.toml
+
+[unstable]
+build-std-features = ["compiler-builtins-mem"]
+build-std = ["core", "compiler_builtins"]
+```
+
+(`compiler-builtins-mem` 特性是在 [这个PR](https://github.com/rust-lang/rust/pull/77284) 中被引入的,所以你的Rust nightly更新时间必须晚于 `2020-09-30`。)
+
+该参数为 `compiler_builtins` 启用了 [`mem` 特性][`mem` feature],至于具体效果,就是已经在内部通过 `#[no_mangle]` 向链接器提供了 [`memcpy` 等函数的实现][`memcpy` etc. implementations]。
+
+[`mem` feature]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/Cargo.toml#L54-L55
+[`memcpy` etc. implementations]: https://github.com/rust-lang/compiler-builtins/blob/eff506cd49b637f1ab5931625a33cef7e91fbbf6/src/mem.rs#L12-L69
+
+经过这些修改,我们的内核已经完成了所有编译所必需的函数,那么让我们继续对代码进行完善。
+
+#### 设置默认编译目标
+
+每次调用 `cargo build` 命令都需要传入 `--target` 参数很麻烦吧?其实我们可以复写掉默认值,从而省略这个参数,只需要在 `.cargo/config.toml` 中加入以下 [cargo 配置][cargo configuration]:
+
+[cargo configuration]: https://doc.rust-lang.org/cargo/reference/config.html
+
+```toml
+# in .cargo/config.toml
[build]
target = "x86_64-blog_os.json"
```
-这里的配置告诉 `cargo` 在没有显式声明目标的情况下,使用我们提供的 `x86_64-blog_os.json` 作为目标配置。这意味着保存后,我们可以直接使用:
+这个配置会告知 `cargo` 使用 `x86_64-blog_os.json` 这个文件作为默认的 `--target` 参数,此时只输入短短的一句 `cargo build` 就可以编译到指定平台了。如果你对其他配置项感兴趣,亦可以查阅 [官方文档][cargo configuration]。
-```
-cargo xbuild
-```
-
-来编译我们的内核。[官方提供的一份文档](https://doc.rust-lang.org/cargo/reference/config.html)中有对 cargo 配置文件更详细的说明。
+那么现在我们已经可以用 `cargo build` 完成程序编译了,然而被成功调用的 `_start` 函数的函数体依然是一个空空如也的循环,是时候往屏幕上输出一点什么了。
### 向屏幕打印字符
@@ -313,7 +363,7 @@ pub extern "C" fn _start() -> ! {
# in Cargo.toml
[dependencies]
-bootloader = "0.9.3"
+bootloader = "0.9.23"
```
只添加引导程序为依赖项,并不足以创建一个可引导的磁盘映像;我们还需要内核编译完成之后,将内核和引导程序组合在一起。然而,截至目前,原生的 cargo 并不支持在编译完成后添加其它步骤(详见[这个 issue](https://github.com/rust-lang/cargo/issues/545))。
@@ -332,7 +382,7 @@ cargo install bootimage
> cargo bootimage
```
-可以看到的是,`bootimage` 工具开始使用 `cargo xbuild` 编译你的内核,所以它将增量编译我们修改后的源码。在这之后,它会编译内核的引导程序,这可能将花费一定的时间;但和所有其它依赖包相似的是,在首次编译后,产生的二进制文件将被缓存下来——这将显著地加速后续的编译过程。最终,`bootimage` 将把内核和引导程序组合为一个可引导的磁盘映像。
+可以看到的是,`bootimage` 工具开始使用 `cargo build` 编译你的内核,所以它将增量编译我们修改后的源码。在这之后,它会编译内核的引导程序,这可能将花费一定的时间;但和所有其它依赖包相似的是,在首次编译后,产生的二进制文件将被缓存下来——这将显著地加速后续的编译过程。最终,`bootimage` 将把内核和引导程序组合为一个可引导的磁盘映像。
运行这行命令之后,我们应该能在 `target/x86_64-blog_os/debug` 目录内找到我们的映像文件 `bootimage-blog_os.bin`。我们可以在虚拟机内启动它,也可以刻录到 U 盘上以便在真机上启动。(需要注意的是,因为文件格式不同,这里的 bin 文件并不是一个光驱映像,所以将它刻录到光盘不会起作用。)
@@ -349,10 +399,13 @@ cargo install bootimage
现在我们可以在虚拟机中启动内核了。为了在[ QEMU](https://www.qemu.org/) 中启动内核,我们使用下面的命令:
```bash
-> qemu-system-x86_64 -drive format=raw,file=bootimage-blog_os.bin
+> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
+warning: TCG doesn't support requested feature: CPUID.01H:ECX.vmx [bit 5]
```
-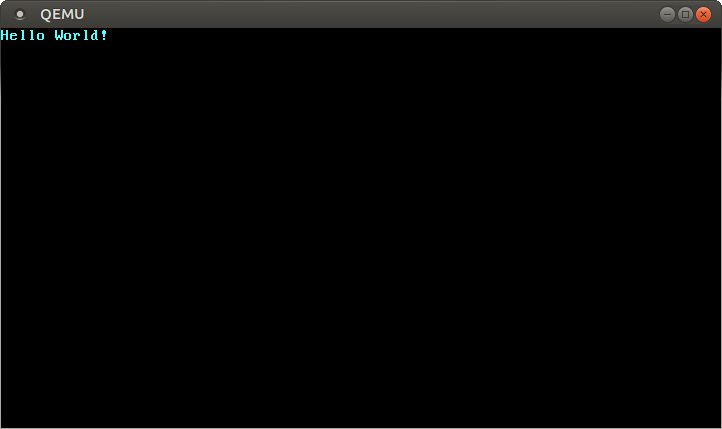
+然后就会弹出一个独立窗口:
+
+
我们可以看到,屏幕窗口已经显示出 “Hello World!” 字符串。祝贺你!
@@ -383,7 +436,7 @@ runner = "bootimage runner"
命令 `bootimage runner` 由 `bootimage` 包提供,参数格式经过特殊设计,可以用于 `runner` 命令。它将给定的可执行文件与项目的引导程序依赖项链接,然后在 QEMU 中启动它。`bootimage` 包的 [README文档](https://github.com/rust-osdev/bootimage) 提供了更多细节和可以传入的配置参数。
-现在我们可以使用 `cargo xrun` 来编译内核并在 QEMU 中启动了。和 `xbuild` 类似,`xrun` 子命令将在调用 cargo 命令前编译内核所需的包。这个子命令也由 `cargo-xbuild` 工具提供,所以你不需要安装额外的工具。
+现在我们可以使用 `cargo run` 来编译内核并在 QEMU 中启动了。
## 下篇预告
diff --git a/blog/content/edition-2/posts/03-vga-text-buffer/index.fa.md b/blog/content/edition-2/posts/03-vga-text-buffer/index.fa.md
index cdf40906..ea2cc4c7 100644
--- a/blog/content/edition-2/posts/03-vga-text-buffer/index.fa.md
+++ b/blog/content/edition-2/posts/03-vga-text-buffer/index.fa.md
@@ -651,7 +651,7 @@ pub fn _print(args: fmt::Arguments) {
از آنجا که ماکروها باید بتوانند از خارج از ماژول، `_print` را فراخوانی کنند، تابع باید عمومی (public) باشد. با این حال ، از آنجا که این جزئیات پیاده سازی را خصوصی (private) در نظر می گیریم، [ویژگی `doc(hidden)`] را اضافه می کنیم تا از مستندات تولید شده پنهان شود.
-[ویژگی `doc(hidden)`]: https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden
+[ویژگی `doc(hidden)`]: https://doc.rust-lang.org/nightly/rustdoc/write-documentation/the-doc-attribute.html#hidden
### Hello World توسط `println`
اکنون می توانیم از `println` در تابع `_start` استفاده کنیم:
diff --git a/blog/content/edition-2/posts/03-vga-text-buffer/index.ja.md b/blog/content/edition-2/posts/03-vga-text-buffer/index.ja.md
index dd9fac5a..d5ade97c 100644
--- a/blog/content/edition-2/posts/03-vga-text-buffer/index.ja.md
+++ b/blog/content/edition-2/posts/03-vga-text-buffer/index.ja.md
@@ -664,7 +664,7 @@ pub fn _print(args: fmt::Arguments) {
マクロは`_print`をモジュールの外側から呼び出せる必要があるので、この関数は公開されていなければなりません。しかし、これは非公開の実装の詳細であると考え、[`doc(hidden)`属性][`doc(hidden)` attribute]をつけることで、生成されたドキュメントから隠すようにします。
-[`doc(hidden)` attribute]: https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden
+[`doc(hidden)` attribute]: https://doc.rust-lang.org/nightly/rustdoc/write-documentation/the-doc-attribute.html#hidden
### `println`を使ってHello World
こうすることで、`_start`関数で`println`を使えるようになります:
diff --git a/blog/content/edition-2/posts/03-vga-text-buffer/index.ko.md b/blog/content/edition-2/posts/03-vga-text-buffer/index.ko.md
new file mode 100644
index 00000000..443a381c
--- /dev/null
+++ b/blog/content/edition-2/posts/03-vga-text-buffer/index.ko.md
@@ -0,0 +1,703 @@
++++
+title = "VGA 텍스트 모드"
+weight = 3
+path = "ko/vga-text-mode"
+date = 2018-02-26
+
+[extra]
+chapter = "Bare Bones"
+# Please update this when updating the translation
+translation_based_on_commit = "1c9b5edd6a5a667e282ca56d6103d3ff1fd7cfcb"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994", "Quqqu"]
++++
+
+[VGA 텍스트 모드][VGA text mode]를 통해 쉽게 화면에 텍스트를 출력할 수 있습니다. 이 글에서는 안전하지 않은 작업들을 분리된 모듈에 격리해 쉽고 안전하게 VGA 텍스트 모드를 이용할 수 있는 인터페이스를 구현합니다. 또한 Rust의 [서식 정렬 매크로 (formatting macro)][formatting macros]에 대한 지원을 추가할 것입니다.
+
+[VGA text mode]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
+[formatting macros]: https://doc.rust-lang.org/std/fmt/#related-macros
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-03 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-03
+
+
+
+## VGA 텍스트 버퍼
+VGA 텍스트 모드에서 화면에 문자를 출력하려면 VGA 하드웨어의 텍스트 버퍼에 해당 문자를 저장해야 합니다. VGA 텍스트 버퍼는 보통 25행 80열 크기의 2차원 배열이며, 해당 버퍼에 저장된 값들은 즉시 화면에 렌더링 됩니다. 배열의 각 원소는 화면에 출력될 문자를 아래의 형식으로 표현합니다:
+
+비트 | 값
+------ | ----------------
+0-7 | ASCII 코드
+8-11 | 전경색
+12-14 | 배경색
+15 | 깜빡임 여부
+
+첫 바이트는 [ASCII 인코딩][ASCII encoding]으로 출력될 문자를 나타냅니다. 엄밀히 따지자면 ASCII 인코딩이 아닌, 해당 인코딩에 문자들을 추가하고 살짝 변형한 [_code page 437_] 이라는 인코딩을 이용합니다. 설명을 간소화하기 위해 이하 본문에서는 그냥 ASCII 문자로 지칭하겠습니다.
+
+[ASCII encoding]: https://en.wikipedia.org/wiki/ASCII
+[_code page 437_]: https://en.wikipedia.org/wiki/Code_page_437
+
+두 번째 바이트는 표현하는 문자가 어떻게 표시될 것인지를 정의합니다. 두 번째 바이트의 첫 4비트는 전경색을 나타내고, 그 다음 3비트는 배경색을 나타내며, 마지막 비트는 해당 문자가 화면에서 깜빡이도록 할지 결정합니다. 아래의 색상들을 이용할 수 있습니다:
+
+숫자 값 | 색상 | 색상 + 밝기 조정 비트 | 밝기 조정 후 최종 색상
+------ | ---------- | ------------------- | -------------
+0x0 | Black | 0x8 | Dark Gray
+0x1 | Blue | 0x9 | Light Blue
+0x2 | Green | 0xa | Light Green
+0x3 | Cyan | 0xb | Light Cyan
+0x4 | Red | 0xc | Light Red
+0x5 | Magenta | 0xd | Pink
+0x6 | Brown | 0xe | Yellow
+0x7 | Light Gray | 0xf | White
+
+두 번째 바이트의 네 번째 비트 (_밝기 조정 비트_)를 통해 파란색을 하늘색으로 조정하는 등 색의 밝기를 변경할 수 있습니다. 배경색을 지정하는 3비트 이후의 마지막 비트는 깜빡임 여부를 지정합니다.
+
+[메모리 맵 입출력 (memory-mapped I/O)][memory-mapped I/O]으로 메모리 주소 `0xb8000`을 통해 VGA 텍스트 버퍼에 접근할 수 있습니다. 해당 주소에 읽기/쓰기 작업을 하면 RAM 대신 VGA 텍스트 버퍼에 직접 읽기/쓰기가 적용됩니다.
+
+[memory-mapped I/O]: https://en.wikipedia.org/wiki/Memory-mapped_I/O
+
+메모리 맵 입출력 적용 대상 하드웨어가 일부 RAM 작업을 지원하지 않을 가능성을 염두해야 합니다. 예를 들어, 바이트 단위 읽기만 지원하는 장치로부터 메모리 맵 입출력을 통해 `u64`를 읽어들일 경우 쓰레기 값이 반환될 수도 있습니다. 다행히 텍스트 버퍼는 [일반적인 읽기/쓰기 작업들을 모두 지원하기에][supports normal reads and writes] 읽기/쓰기를 위한 특수 처리가 필요하지 않습니다.
+
+[supports normal reads and writes]: https://web.stanford.edu/class/cs140/projects/pintos/specs/freevga/vga/vgamem.htm#manip
+
+## Rust 모듈
+이제 VGA 버퍼가 어떻게 작동하는지 알았으니, 버퍼를 이용해 출력하는 것을 담당할 Rust 모듈을 만들어봅시다:
+
+```rust
+// in src/main.rs
+mod vga_buffer;
+```
+
+새로운 모듈 `vga_buffer`를 위해 파일 `src/vga_buffer.rs`을 만듭니다. 이후 나타나는 모든 코드는 이 모듈에 들어갈 내용입니다 (별도의 지시 사항이 붙는 경우 제외).
+
+### 색상
+우선 enum을 이용하여 사용 가능한 여러 색상들을 표현합니다:
+
+```rust
+// in src/vga_buffer.rs
+
+#[allow(dead_code)]
+#[derive(Debug, Clone, Copy, PartialEq, Eq)]
+#[repr(u8)]
+pub enum Color {
+ Black = 0,
+ Blue = 1,
+ Green = 2,
+ Cyan = 3,
+ Red = 4,
+ Magenta = 5,
+ Brown = 6,
+ LightGray = 7,
+ DarkGray = 8,
+ LightBlue = 9,
+ LightGreen = 10,
+ LightCyan = 11,
+ LightRed = 12,
+ Pink = 13,
+ Yellow = 14,
+ White = 15,
+}
+```
+각 색상마다 고유 숫자 값을 배정할 수 있도록 우리는 [C언어와 같은 enum][C-like enum]을 사용합니다. `repr(u8)` 속성 때문에 enum의 각 분류 값은 `u8` 타입으로 저장됩니다. 사실 저장 공간은 4 비트만으로도 충분하지만, Rust에는 `u4` 타입이 없습니다.
+
+[C-like enum]: https://doc.rust-lang.org/rust-by-example/custom_types/enum/c_like.html
+
+사용되지 않는 enum 분류 값이 있을 때마다 컴파일러는 불필요한 코드가 있다는 경고 메시지를 출력합니다. 하지만 위처럼 `#[allow(dead_code)]` 속성을 적용하면 `Color` enum에 대해서는 컴파일러가 해당 경고 메시지를 출력하지 않습니다.
+
+`Color` 타입에 [`Copy`], [`Clone`], [`Debug`], [`PartialEq`] 그리고 [`Eq`] 트레이트들을 [구현 (derive)][deriving] 함으로써 `Color` 타입이 [copy semantics] 를 따르도록 하고 또한 `Color` 타입 변수를 출력하거나 두 `Color` 타입 변수를 서로 비교할 수 있도록 합니다.
+
+[deriving]: https://doc.rust-lang.org/rust-by-example/trait/derive.html
+[`Copy`]: https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html
+[`Clone`]: https://doc.rust-lang.org/nightly/core/clone/trait.Clone.html
+[`Debug`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Debug.html
+[`PartialEq`]: https://doc.rust-lang.org/nightly/core/cmp/trait.PartialEq.html
+[`Eq`]: https://doc.rust-lang.org/nightly/core/cmp/trait.Eq.html
+[copy semantics]: https://doc.rust-lang.org/1.30.0/book/first-edition/ownership.html#copy-types
+
+전경색과 배경색을 모두 표현할 수 있는 색상 코드를 표현하기 위해 `u8` 타입을 감싸는 [newtype]을 선언합니다:
+
+[newtype]: https://doc.rust-lang.org/rust-by-example/generics/new_types.html
+
+```rust
+// in src/vga_buffer.rs
+
+#[derive(Debug, Clone, Copy, PartialEq, Eq)]
+#[repr(transparent)]
+struct ColorCode(u8);
+
+impl ColorCode {
+ fn new(foreground: Color, background: Color) -> ColorCode {
+ ColorCode((background as u8) << 4 | (foreground as u8))
+ }
+}
+```
+`ColorCode` 구조체는 전경색 및 배경색을 모두 표현하는 색상 바이트 전체의 정보를 지닙니다. 이전처럼 `Copy` 및 `Debug` 트레이트를 구현 (derive) 해줍니다. `ColorCode` 구조체가 메모리 상에서 `u8` 타입과 같은 저장 형태를 가지도록 [`repr(transparent)`] 속성을 적용합니다.
+
+[`repr(transparent)`]: https://doc.rust-lang.org/nomicon/other-reprs.html#reprtransparent
+
+### 텍스트 버퍼
+스크린 상의 문자 및 텍스트 버퍼를 표현하는 구조체들을 아래와 같이 추가합니다:
+
+```rust
+// in src/vga_buffer.rs
+
+#[derive(Debug, Clone, Copy, PartialEq, Eq)]
+#[repr(C)]
+struct ScreenChar {
+ ascii_character: u8,
+ color_code: ColorCode,
+}
+
+const BUFFER_HEIGHT: usize = 25;
+const BUFFER_WIDTH: usize = 80;
+
+#[repr(transparent)]
+struct Buffer {
+ chars: [[ScreenChar; BUFFER_WIDTH]; BUFFER_HEIGHT],
+}
+```
+Rust에서는 구조체 정의 코드에서의 필드 정렬 순서와 메모리 상에서 구조체의 각 필드가 저장되는 순서가 동일하지 않을 수 있습니다. 구조체의 각 필드 정렬 순서가 컴파일 중에 바뀌지 않도록 하려면 [`repr(C)`] 속성이 필요합니다. 이 속성을 사용하면 C언어의 구조체처럼 컴파일러가 구조체 내 각 필드의 정렬 순서를 임의로 조정할 수 없게 되기에, 우리는 메모리 상에서 구조체의 각 필드가 어떤 순서로 저장되는지 확신할 수 있습니다. 또한 `Buffer` 구조체에 [`repr(transparent)`] 속성을 적용하여 메모리 상에서 해당 구조체가 저장되는 형태가 `chars` 필드의 저장 형태와 동일하도록 해줍니다.
+
+[`repr(C)`]: https://doc.rust-lang.org/nightly/nomicon/other-reprs.html#reprc
+
+이제 아래와 같은 Writer 타입을 만들어 실제로 화면에 출력하는 데에 이용할 것입니다:
+
+```rust
+// in src/vga_buffer.rs
+
+pub struct Writer {
+ column_position: usize,
+ color_code: ColorCode,
+ buffer: &'static mut Buffer,
+}
+```
+Writer는 언제나 가장 마지막 행에 값을 작성할 것이며, 작성 중인 행이 꽉 차거나 개행문자를 입력받은 경우에는 작성 중이던 행을 마치고 새로운 행으로 넘어갈 것입니다. 전경색 및 배경색은 `color_code`를 통해 표현되고 `buffer`에 VGA 버퍼에 대한 레퍼런스를 저장합니다. `buffer`에 대한 레퍼런스가 유효한 기간을 컴파일러에게 알리기 위해서 [명시적인 lifetime][explicit lifetime]이 필요합니다. [`'static`] lifetime 표기는 VGA 버퍼에 대한 레퍼런스가 프로그램 실행 시간 내내 유효하다는 것을 명시합니다.
+
+[explicit lifetime]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#lifetime-annotation-syntax
+[`'static`]: https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime
+
+### 출력하기
+이제 `Writer`를 이용하여 VGA 버퍼에 저장된 문자들을 변경할 수 있게 되었습니다. 우선 아래와 같이 하나의 ASCII 바이트를 출력하는 함수를 만듭니다:
+
+```rust
+// in src/vga_buffer.rs
+
+impl Writer {
+ pub fn write_byte(&mut self, byte: u8) {
+ match byte {
+ b'\n' => self.new_line(),
+ byte => {
+ if self.column_position >= BUFFER_WIDTH {
+ self.new_line();
+ }
+
+ let row = BUFFER_HEIGHT - 1;
+ let col = self.column_position;
+
+ let color_code = self.color_code;
+ self.buffer.chars[row][col] = ScreenChar {
+ ascii_character: byte,
+ color_code,
+ };
+ self.column_position += 1;
+ }
+ }
+ }
+
+ fn new_line(&mut self) {/* TODO */}
+}
+```
+주어진 바이트 값이 [개행 문자][newline] `\n`일 경우, Writer는 아무것도 출력하지 않고 대신 `new_line` 함수 (아래에서 함께 구현할 예정)를 호출합니다. 다른 바이트 값들은 match문의 두 번째 패턴에 매치되어 화면에 출력됩니다.
+
+[newline]: https://en.wikipedia.org/wiki/Newline
+
+바이트를 출력할 때, Writer는 현재 행이 가득 찼는지 확인합니다. 현재 행이 가득 찬 경우, 개행을 위해 `new_line` 함수를 먼저 호출해야 합니다. 그 후 버퍼에서의 현재 위치에 새로운 `ScreenChar`를 저장합니다. 마지막으로 현재 열 위치 값을 한 칸 올립니다.
+
+위에서 구현한 함수로 문자열의 각 문자를 하나씩 출력함으로써 문자열 전체를 출력할 수도 있습니다:
+
+```rust
+// in src/vga_buffer.rs
+
+impl Writer {
+ pub fn write_string(&mut self, s: &str) {
+ for byte in s.bytes() {
+ match byte {
+ // 출력 가능한 ASCII 바이트 혹은 개행 문자
+ 0x20..=0x7e | b'\n' => self.write_byte(byte),
+ // ASCII 코드 범위 밖의 값
+ _ => self.write_byte(0xfe),
+ }
+
+ }
+ }
+}
+```
+
+VGA 텍스트 버퍼는 ASCII 문자 및 [코드 페이지 437][code page 437] 인코딩의 문자들만 지원합니다. Rust의 문자열은 기본 인코딩이 [UTF-8]이기에 VGA 텍스트 버퍼가 지원하지 않는 바이트들을 포함할 수 있습니다. 그렇기에 위 함수에서 `match`문을 통해 VGA 버퍼를 통해 출력 가능한 문자 (개행 문자 및 스페이스 문자와 `~` 문자 사이의 모든 문자)와 그렇지 않은 문자를 구분하여 처리합니다. 출력 불가능한 문자의 경우, VGA 하드웨어에서 16진수 코드 `0xfe`를 가지는 문자 (`■`)을 출력합니다.
+
+[code page 437]: https://en.wikipedia.org/wiki/Code_page_437
+[UTF-8]: https://www.fileformat.info/info/unicode/utf8.htm
+
+#### 테스트 해봅시다!
+간단한 함수를 하나 만들어 화면에 문자들을 출력해봅시다:
+
+```rust
+// in src/vga_buffer.rs
+
+pub fn print_something() {
+ let mut writer = Writer {
+ column_position: 0,
+ color_code: ColorCode::new(Color::Yellow, Color::Black),
+ buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ };
+
+ writer.write_byte(b'H');
+ writer.write_string("ello ");
+ writer.write_string("Wörld!");
+}
+```
+우선 메모리 주소 `0xb8000`을 가리키는 새로운 Writer 인스턴스를 생성합니다. 이를 구현한 코드가 다소 난해하게 느껴질 수 있으니 단계별로 나누어 설명드리겠습니다: 먼저 정수 `0xb8000`을 읽기/쓰기 모두 가능한 (mutable) [포인터][raw pointer]로 타입 변환합니다. 그 후 `*` 연산자를 통해 이 포인터를 역참조 (dereference) 하고 `&mut`를 통해 즉시 borrow 함으로써 해당 주소에 저장된 값을 변경할 수 있는 레퍼런스 (mutable reference)를 만듭니다. 여기서 Rust 컴파일러는 포인터의 유효성 및 안전성을 보증할 수 없기에, [`unsafe` 블록][`unsafe` block]을 사용해야만 포인터를 레퍼런스로 변환할 수 있습니다.
+
+[raw pointer]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
+[`unsafe` block]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html
+
+그 다음 Writer 인스턴스에 바이트 `b'H'`를 적습니다. 접두사 `b`는 ASCII 문자를 나타내는 [바이트 상수 (literal)][byte literal] 를 생성합니다. 문자열 `"ello "`와 `"Wörld!"`를 적음으로써 `write_string` 함수 및 출력 불가능한 문자에 대한 특수 처리가 잘 구현되었는지 테스트 해봅니다. 화면에 메시지가 출력되는지 확인하기 위해 `print_something` 함수를 `_start` 함수에서 호출합니다:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ vga_buffer::print_something();
+
+ loop {}
+}
+```
+
+프로젝트를 실행하면 `Hello W■■rld!` 라는 메시지가 화면 왼쪽 _아래_ 구석에 노란 텍스트로 출력됩니다:
+
+[byte literal]: https://doc.rust-lang.org/reference/tokens.html#byte-literals
+
+
+
+문자 `ö` 대신 두 개의 `■` 문자가 출력되었습니다. 문자 `ö`는 [UTF-8] 인코딩에서 두 바이트로 표현되는데, 각각의 바이트가 출력 가능한 ASCII 문자 범위에 있지 않기 때문입니다. 이는 사실 UTF-8 인코딩의 핵심 특징으로, 두 바이트 이상으로 표현되는 문자들의 각 바이트는 유효한 ASCII 값을 가질 수 없습니다.
+
+### Volatile
+위에서 화면에 메시지가 출력되는 것을 확인했습니다. 하지만 미래의 Rust 컴파일러가 더 공격적으로 프로그램 최적화를 하게 된다면 메시지가 출력되지 않을 수 있습니다.
+
+여기서 주목해야 할 것은 우리가 `Buffer`에 데이터를 쓰기만 할 뿐 읽지는 않는다는 점입니다. 컴파일러는 우리가 일반 RAM 메모리가 아닌 VGA 버퍼 메모리에 접근한다는 사실을 알지 못하며, 해당 버퍼에 쓰인 값이 화면에 출력되는 현상 (외부에서 관찰 가능한 상태 변화)에 대해서도 이해하지 못합니다. 그렇기에 컴파일러가 VGA 버퍼에 대한 쓰기 작업이 불필요하다고 판단하여 프로그램 최적화 중에 해당 작업들을 삭제할 수도 있습니다. 이를 방지하려면 VGA 버퍼에 대한 쓰기 작업이 _[volatile]_ 하다고 명시함으로써 해당 쓰기 작업이 관찰 가능한 상태 변화 (side effect)를 일으킨다는 것을 컴파일러에게 알려야 합니다.
+
+[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
+
+VGA 버퍼에 volatile한 방식으로 데이터를 쓰기 위해 우리는 [volatile][volatile crate] 크레이트를 사용합니다. 이 _크레이트_ (패키지 형태의 Rust 라이브러리) 는 `Volatile` 이라는 포장 타입 (wrapper type)과 함께 `read` 및 `write` 함수들을 제공합니다. 이 함수들은 내부적으로 Rust 코어 라이브러리의 [read_volatile] 및 [write_volatile] 함수들을 사용함으로써 읽기/쓰기 작업이 프로그램 최적화 중에 제거되지 않게 합니다.
+
+[volatile crate]: https://docs.rs/volatile
+[read_volatile]: https://doc.rust-lang.org/nightly/core/ptr/fn.read_volatile.html
+[write_volatile]: https://doc.rust-lang.org/nightly/core/ptr/fn.write_volatile.html
+
+`Cargo.toml`의 `dependencies` 섹션에 `volatile` 크레이트를 추가합니다:
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+volatile = "0.2.6"
+```
+
+꼭 `volatile` 크레이트의 `0.2.6` 버전을 사용하셔야 합니다. 그 이후 버전의 `volatile` 크레이트는 이 포스트의 코드와 호환되지 않습니다. `0.2.6`은 [semantic] 버전 넘버를 나타내는데, 자세한 내용은 cargo 문서의 [Specifying Dependencies] 챕터를 확인해주세요.
+
+[semantic]: https://semver.org/
+[Specifying Dependencies]: https://doc.crates.io/specifying-dependencies.html
+
+이제 이 크레이트를 써서 VGA 버퍼에 대한 쓰기 작업이 volatile 하도록 만들 것입니다. `Buffer` 타입을 정의하는 코드를 아래처럼 수정해주세요:
+
+```rust
+// in src/vga_buffer.rs
+
+use volatile::Volatile;
+
+struct Buffer {
+ chars: [[Volatile; BUFFER_WIDTH]; BUFFER_HEIGHT],
+}
+```
+`ScreenChar` 대신 `Volatile`를 사용합니다. (`Volatile` 타입은 [제네릭 (generic)][generic] 타입이며 거의 모든 타입을 감쌀 수 있습니다). 이로써 해당 타입에 대해 실수로 “일반” 쓰기 작업을 하는 실수를 방지할 수 있게 되었습니다. 이제 쓰기 작업 구현 시 `write` 함수만을 이용해야 합니다.
+
+[generic]: https://doc.rust-lang.org/book/ch10-01-syntax.html
+
+`Writer::write_byte` 함수가 `write`함수를 사용하도록 아래처럼 변경합니다:
+
+```rust
+// in src/vga_buffer.rs
+
+impl Writer {
+ pub fn write_byte(&mut self, byte: u8) {
+ match byte {
+ b'\n' => self.new_line(),
+ byte => {
+ ...
+
+ self.buffer.chars[row][col].write(ScreenChar {
+ ascii_character: byte,
+ color_code,
+ });
+ ...
+ }
+ }
+ }
+ ...
+}
+```
+
+일반 대입 연산자 `=` 대신에 `write` 함수를 사용하였기에, 컴파일러는 최적화 단계에 절대로 해당 쓰기 작업을 삭제하지 않을 것입니다.
+
+### 서식 정렬 매크로
+`Writer` 타입이 Rust의 서식 정렬 매크로 (formatting macro) 를 지원한다면 정수나 부동 소수점 값 등 다양한 타입의 값들을 편리하고 쉽게 출력할 수 있을 것입니다. `Writer`가 Rust의 서식 정렬 매크로를 지원하려면 [`core::fmt::Write`] 트레이트를 구현해야 합니다. 해당 트레이트를 구현하기 위해서는 `write_str` 함수만 구현하면 되는데, 이 함수는 우리가 위에서 구현한 `write_string` 함수와 거의 유사하나 반환 타입이 `fmt::Result` 타입인 함수입니다:
+
+[`core::fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
+
+```rust
+// in src/vga_buffer.rs
+
+use core::fmt;
+
+impl fmt::Write for Writer {
+ fn write_str(&mut self, s: &str) -> fmt::Result {
+ self.write_string(s);
+ Ok(())
+ }
+}
+```
+반환 값 `Ok(())` 는 `()` 타입을 감싸는 `Result` 타입의 `Ok` 입니다.
+
+이제 Rust에서 기본적으로 제공되는 서식 정렬 매크로 `write!`/`writeln!`을 사용할 수 있습니다:
+
+```rust
+// in src/vga_buffer.rs
+
+pub fn print_something() {
+ use core::fmt::Write;
+ let mut writer = Writer {
+ column_position: 0,
+ color_code: ColorCode::new(Color::Yellow, Color::Black),
+ buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ };
+
+ writer.write_byte(b'H');
+ writer.write_string("ello! ");
+ write!(writer, "The numbers are {} and {}", 42, 1.0/3.0).unwrap();
+}
+```
+
+화면 맨 아래에 메시지 `Hello! The numbers are 42 and 0.3333333333333333`가 출력될 것입니다. `write!` 매크로는 `Result`를 반환하는데, `Result`가 사용되지 않았다는 오류가 출력되지 않도록 [`unwrap`] 함수를 호출합니다. 반환된 `Result`가 `Err()`일 경우 프로그램이 패닉 (panic) 하겠지만, 우리가 작성한 코드는 VGA 버퍼에 대한 쓰기 후 언제나 `Ok()`를 반환하기에 패닉이 발생하지 않습니다.
+
+[`unwrap`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.unwrap
+
+### 개행
+현재 행이 꽉 찬 상태에서 입력받은 문자 및 개행 문자에 대해 우리는 아직 아무런 대응을 하지 않습니다. 이러한 경우 현재 행의 모든 문자들을 한 행씩 위로 올려 출력하고 (맨 위 행은 지우고) 비워진 현재 행의 맨 앞 칸에서부터 다시 시작해야 합니다. 아래의 `new_line` 함수를 통해 해당 작업을 구현합니다:
+
+```rust
+// in src/vga_buffer.rs
+
+impl Writer {
+ fn new_line(&mut self) {
+ for row in 1..BUFFER_HEIGHT {
+ for col in 0..BUFFER_WIDTH {
+ let character = self.buffer.chars[row][col].read();
+ self.buffer.chars[row - 1][col].write(character);
+ }
+ }
+ self.clear_row(BUFFER_HEIGHT - 1);
+ self.column_position = 0;
+ }
+
+ fn clear_row(&mut self, row: usize) {/* TODO */}
+}
+```
+화면에 출력된 각 문자들을 순회하며 전부 한 행씩 위로 올려 출력합니다. 범위를 나타내는 `..` 표기는 범위의 상한 값을 포함하지 않는다는 것을 주의해 주세요. 0번째 행은 화면 밖으로 사라질 행이기에 순회하지 않습니다.
+
+아래의 `clear_row` 함수를 추가하여 개행 문자 처리 코드를 완성합니다:
+
+```rust
+// in src/vga_buffer.rs
+
+impl Writer {
+ fn clear_row(&mut self, row: usize) {
+ let blank = ScreenChar {
+ ascii_character: b' ',
+ color_code: self.color_code,
+ };
+ for col in 0..BUFFER_WIDTH {
+ self.buffer.chars[row][col].write(blank);
+ }
+ }
+}
+```
+이 함수는 한 행의 모든 문자를 스페이스 문자로 덮어쓰는 방식으로 한 행의 내용을 전부 지웁니다.
+
+## 전역 접근 가능한 인터페이스
+`Writer` 인스턴스를 이리저리 옮겨다닐 필요가 없도록 전역 접근 가능한 `Writer`를 제공하기 위해 정적 변수 `WRITER`를 만들어 봅시다:
+
+```rust
+// in src/vga_buffer.rs
+
+pub static WRITER: Writer = Writer {
+ column_position: 0,
+ color_code: ColorCode::new(Color::Yellow, Color::Black),
+ buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+};
+```
+
+컴파일 시 아래의 오류 메시지가 출력될 것입니다:
+
+```
+error[E0015]: calls in statics are limited to constant functions, tuple structs and tuple variants
+ --> src/vga_buffer.rs:7:17
+ |
+7 | color_code: ColorCode::new(Color::Yellow, Color::Black),
+ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+
+error[E0396]: raw pointers cannot be dereferenced in statics
+ --> src/vga_buffer.rs:8:22
+ |
+8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ dereference of raw pointer in constant
+
+error[E0017]: references in statics may only refer to immutable values
+ --> src/vga_buffer.rs:8:22
+ |
+8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
+
+error[E0017]: references in statics may only refer to immutable values
+ --> src/vga_buffer.rs:8:13
+ |
+8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
+```
+
+여기서 오류가 왜 발생했는지 이해하려면 우선 알아야 할 것이 있습니다. 그것은 바로 일반 자동 변수들이 프로그램 실행 시간에 초기화 되는 반면에 정적 (static) 변수들은 컴파일 시간에 초기화된다는 점입니다. Rust 컴파일러의 "[const evaluator]" 컴포넌트가 정적 변수를 컴파일 시간에 초기화합니다. 아직 구현된 기능이 많지는 않지만, 해당 컴포넌트의 기능을 확장하는 작업이 진행 중입니다 (예시: “[Allow panicking in constants]” RFC).
+
+[const evaluator]: https://rustc-dev-guide.rust-lang.org/const-eval.html
+[Allow panicking in constants]: https://github.com/rust-lang/rfcs/pull/2345
+
+`ColorCode::new`에 대한 오류는 [`const` 함수][`const` functions]를 이용해 쉽게 해결할 수 있습니다. 더 큰 문제는 바로 Rust의 const evaluator가 컴파일 시간에 raw pointer를 레퍼런스로 전환하지 못한다는 것입니다. 미래에는 이것이 가능해질 수도 있겠지만, 현재로서는 다른 해법을 찾아야 합니다.
+
+[`const` functions]: https://doc.rust-lang.org/reference/const_eval.html#const-functions
+
+### 정적 변수의 초기화 지연
+Rust 개발을 하다 보면 const가 아닌 함수를 이용해 1회에 한해 정적 변수의 값을 설정해야 하는 상황이 자주 발생합니다. [lazy_static] 크레이트의 `lazy_static!` 매크로를 이용하면, 정적 변수의 값을 컴파일 시간에 결정하지 않고 초기화 시점을 해당 프로그램 실행 중 변수에 대한 접근이 처음 일어나는 시점까지 미룰 수 있습니다. 즉, 정적 변수 초기화가 프로그램 실행 시간에 진행되기에 초기 값을 계산할 때 const가 아닌 복잡한 함수들을 사용할 수 있습니다.
+
+[lazy_static]: https://docs.rs/lazy_static/1.0.1/lazy_static/
+
+프로젝트 의존 라이브러리로서 `lazy_static` 크레이트를 추가해줍니다:
+
+```toml
+# in Cargo.toml
+
+[dependencies.lazy_static]
+version = "1.0"
+features = ["spin_no_std"]
+```
+
+우리는 러스트 표준 라이브러리를 링크하지 않기에 `spin_no_std` 기능이 필요합니다.
+
+`lazy_static` 크레이트 덕분에 이제 오류 없이 `WRITER`를 정의할 수 있습니다:
+
+```rust
+// in src/vga_buffer.rs
+
+use lazy_static::lazy_static;
+
+lazy_static! {
+ pub static ref WRITER: Writer = Writer {
+ column_position: 0,
+ color_code: ColorCode::new(Color::Yellow, Color::Black),
+ buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ };
+}
+```
+
+현재 `WRITER`는 immutable (읽기 가능, 쓰기 불가능) 하여 실질적인 쓸모가 없습니다. 모든 쓰기 함수들은 첫 인자로 `&mut self`를 받기 때문에 `WRITER`로 어떤 쓰기 작업도 할 수가 없습니다. 이에 대한 해결책으로 [mutable static]은 어떨까요? 이 선택지를 고른다면 모든 읽기 및 쓰기 작업이 데이터 레이스 (data race) 및 기타 위험에 노출되기에 안전을 보장할 수 없게 됩니다. Rust에서 `static mut`는 웬만하면 사용하지 않도록 권장되며, 심지어 [Rust 언어에서 완전히 `static mut`를 제거하자는 제안][remove static mut]이 나오기도 했습니다. 이것 이외에도 대안이 있을까요? [내부 가변성 (interior mutability)][interior mutability]을 제공하는 [RefCell] 혹은 [UnsafeCell] 을 통해 immutable한 정적 변수를 만드는 것은 어떨까요? 이 타입들은 중요한 이유로 [Sync] 트레이트를 구현하지 않기에 정적 변수를 선언할 때에는 사용할 수 없습니다.
+
+[mutable static]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
+[remove static mut]: https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437
+[RefCell]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt
+[UnsafeCell]: https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html
+[interior mutability]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html
+[Sync]: https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html
+
+### 스핀 락 (Spinlocks)
+표준 라이브러리의 [Mutex]는 동기화된 내부 가변성 (interior mutability)을 제공합니다. Mutex는 접근하려는 리소스가 잠겼을 때 현재 스레드를 블로킹 (blocking) 하는 것으로 상호 배제 (mutual exclusion)를 구현합니다. 우리의 커널은 스레드 블로킹은 커녕 스레드의 개념조차 구현하지 않기에 [Mutex]를 사용할 수 없습니다. 그 대신 우리에게는 운영체제 기능이 필요 없는 원시적인 [스핀 락 (spinlock)][spinlock]이 있습니다. 스핀 락은 Mutex와 달리 스레드를 블로킹하지 않고, 리소스의 잠김이 풀릴 때까지 반복문에서 계속 리소스 취득을 시도하면서 CPU 시간을 소모합니다.
+
+[Mutex]: https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html
+[spinlock]: https://en.wikipedia.org/wiki/Spinlock
+
+스핀 락을 사용하기 위해 [spin 크레이트][spin crate] 를 의존 크레이트 목록에 추가합니다:
+
+[spin crate]: https://crates.io/crates/spin
+
+```toml
+# in Cargo.toml
+[dependencies]
+spin = "0.5.2"
+```
+
+이제 스핀 락을 이용해 전역 변수 `WRITER`에 안전하게 [내부 가변성 (interior mutability)][interior mutability] 을 구현할 수 있습니다:
+
+```rust
+// in src/vga_buffer.rs
+
+use spin::Mutex;
+...
+lazy_static! {
+ pub static ref WRITER: Mutex = Mutex::new(Writer {
+ column_position: 0,
+ color_code: ColorCode::new(Color::Yellow, Color::Black),
+ buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
+ });
+}
+```
+`print_something` 함수를 삭제하고 `_start` 함수에서 직접 메시지를 출력할 수 있습니다:
+
+```rust
+// in src/main.rs
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ use core::fmt::Write;
+ vga_buffer::WRITER.lock().write_str("Hello again").unwrap();
+ write!(vga_buffer::WRITER.lock(), ", some numbers: {} {}", 42, 1.337).unwrap();
+
+ loop {}
+}
+```
+`fmt::Write` 트레이트를 가져와야 이 트레이트가 제공하는 함수들을 사용할 수 있습니다.
+
+### 메모리 안전성
+우리가 작성한 코드에는 unsafe 블록이 단 하나 존재합니다. 이 unsafe 블록은 주소 `0xb8000`을 가리키는 레퍼런스 `Buffer`를 초기화 하는 로직을 담기 위해 필요합니다. `Buffer`에 대한 초기화 이외 모든 작업들은 안전합니다 (메모리 안전성 측면에서). Rust는 배열의 원소에 접근하는 코드에는 인덱스 값과 배열의 길이를 비교하는 로직을 자동으로 삽입하기에, 버퍼의 정해진 공간 밖에 실수로 데이터를 쓰는 것은 불가능합니다. 타입 시스템에서 요구하는 조건들을 코드에 알맞게 구현함으로써 외부 사용자에게 안전한 인터페이스를 제공할 수 있게 되었습니다.
+
+### println 매크로
+전역 변수 `Writer`도 갖추었으니 이제 프로젝트 내 어디서든 사용할 수 있는 `println` 매크로를 추가할 수 있습니다. Rust의 [매크로 문법][macro syntax]은 다소 난해하기에, 우리에게 필요한 매크로를 밑바닥부터 작성하지는 않을 것입니다. 그 대신 표준 라이브러리의 [`println!` 매크로][`println!` macro] 구현 코드를 참조할 것입니다:
+
+[macro syntax]: https://doc.rust-lang.org/nightly/book/ch19-06-macros.html#declarative-macros-with-macro_rules-for-general-metaprogramming
+[`println!` macro]: https://doc.rust-lang.org/nightly/std/macro.println!.html
+
+```rust
+#[macro_export]
+macro_rules! println {
+ () => (print!("\n"));
+ ($($arg:tt)*) => (print!("{}\n", format_args!($($arg)*)));
+}
+```
+
+매크로는 `match`문의 여러 패턴들을 선언하듯 한 개 이상의 규칙을 통해 정의됩니다. `println` 매크로는 두 개의 규칙을 가집니다: 첫 번째 규칙은 매크로에 아무 인자도 전달되지 않았을 때 (예: `println!()`)에 적용되어 개행 문자를 출력하는 `print!("\n")` 코드를 생성합니다. 두 번째 규칙은 매크로에 여러 인자들이 주어졌을 때 적용됩니다 (예: `println!("Hello")` 혹은 `println!("Number: {}", 4)`). 두 번째 규칙은 주어진 인자들을 그대로 `print!` 매크로에 전달하고 인자 문자열 끝에 개행 문자를 추가한 코드를 생성합니다.
+
+`#[macro_export]` 속성이 적용된 매크로는 외부 크레이트 및 현재 크레이트 내 어디서든 사용 가능해집니다 (기본적으로는 매크로가 정의된 모듈 내에서만 그 매크로를 쓸 수 있습니다). 또한 이 속성이 적용된 매크로는 크레이트의 최고 상위 네임스페이스에 배치되기에, 매크로를 쓰기 위해 가져올 때 `use std::println` 대신 `use std::macros::println`을 적어야 합니다.
+
+[`print!` 매크로][`print!` macro]는 아래와 같이 정의되어 있습니다:
+
+[`print!` macro]: https://doc.rust-lang.org/nightly/std/macro.print!.html
+
+```rust
+#[macro_export]
+macro_rules! print {
+ ($($arg:tt)*) => ($crate::io::_print(format_args!($($arg)*)));
+}
+```
+
+이 매크로는 `io` 모듈의 [`print` 함수][`_print` function]를 호출하는 코드로 변환됩니다. [변수 `$crate`][`$crate` variable]가 `std`로 변환되기에 다른 크레이트에서도 이 매크로를 사용할 수 있습니다.
+
+[`format_args` 매크로][`format_args` macro]는 주어진 인자들로부터 [fmt::Arguments] 타입 오브젝트를 만들고, 이 오브젝트가 `_print` 함수에 전달됩니다. 표준 라이브러리의 [`_print` 함수][`_print` function]는 `print_to` 함수를 호출합니다. `print_to` 함수는 다양한 `Stdout` (표준 출력) 장치들을 모두 지원하기에 구현이 제법 복잡합니다. 우리는 VGA 버퍼에 출력하는 것만을 목표로 하기에 굳이 `print_to` 함수의 복잡한 구현을 가져올 필요가 없습니다.
+
+[`_print` function]: https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698
+[`$crate` variable]: https://doc.rust-lang.org/1.30.0/book/first-edition/macros.html#the-variable-crate
+[`format_args` macro]: https://doc.rust-lang.org/nightly/std/macro.format_args.html
+[fmt::Arguments]: https://doc.rust-lang.org/nightly/core/fmt/struct.Arguments.html
+
+VGA 버퍼에 메시지를 출력하기 위해 `println!` 및 `print!` 매크로 구현 코드를 복사해 온 뒤 우리가 직접 정의한 `_print` 함수를 사용하도록 변경해줍니다:
+
+```rust
+// in src/vga_buffer.rs
+
+#[macro_export]
+macro_rules! print {
+ ($($arg:tt)*) => ($crate::vga_buffer::_print(format_args!($($arg)*)));
+}
+
+#[macro_export]
+macro_rules! println {
+ () => ($crate::print!("\n"));
+ ($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*)));
+}
+
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ WRITER.lock().write_fmt(args).unwrap();
+}
+```
+
+기존 `println` 구현에서 `print!` 매크로를 호출하는 코드에 우리는 `$crate` 접두어를 추가했습니다.
+이로써 `println` 매크로만 사용하고 싶은 경우에 `print` 매크로를 별도로 import 하지 않아도 됩니다.
+
+표준 라이브러리의 구현과 마찬가지로, 두 매크로에 `#[macro_export]` 속성을 추가하여 크레이트 어디에서나 사용할 수 있도록 합니다. 이 속성이 추가된 두 매크로는 크레이트의 최고 상위 네임스페이스에 배정되기에, `use crate::vga_buffer::println` 대신 `use crate::println`을 사용하여 import 합니다.
+
+`_print` 함수는 정적 변수 `WRITER`를 잠그고 `write_fmt` 함수를 호출합니다. 이 함수는 `Write` 트레이트를 통해 제공되기에, 이 트레이트를 import 해야 합니다. `write_fmt` 함수 호출 이후의 `unwrap()`으로 인해 출력이 실패할 경우 패닉이 발생합니다. 하지만 `write_str` 함수가 언제나 `Ok`를 반환하기에 패닉이 일어날 일은 없습니다.
+
+우리의 매크로들이 모듈 밖에서 `_print` 함수를 호출할 수 있으려면 이 함수를 public 함수로 설정해야 합니다. public 함수이지만 구체적인 구현 방식은 드러나지 않도록 [`doc(hidden)` 속성][`doc(hidden)` attribute]을 추가하여 이 함수가 프로젝트 문서에 노출되지 않게 합니다.
+
+[`doc(hidden)` attribute]: https://doc.rust-lang.org/nightly/rustdoc/write-documentation/the-doc-attribute.html#hidden
+
+### `println`을 이용해 "Hello World" 출력하기
+이제 `_start` 함수에서 `println`을 사용할 수 있습니다:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() {
+ println!("Hello World{}", "!");
+
+ loop {}
+}
+```
+
+`println!` 매크로가 이미 루트 네임스페이스에 배정되었기에, main 함수에서 사용하기 위해 다시 매크로를 import 할 필요가 없습니다.
+
+예상한 대로, 화면에 _“Hello World!”_ 가 출력된 것을 확인할 수 있습니다:
+
+
+
+### 패닉 메시지 출력하기
+`println` 매크로를 이용하여 `panic` 함수에서도 패닉 메시지 및 패닉이 발생한 코드 위치를 출력할 수 있게 되었습니다:
+
+```rust
+// in main.rs
+
+/// This function is called on panic.
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ println!("{}", info);
+ loop {}
+}
+```
+
+`_start` 함수에 `panic!("Some panic message")` 을 추가한 후 빌드 및 실행하면 아래와 같은 출력 내용을 확인할 수 있을 것입니다:
+
+
+
+출력 내용을 통해 패닉 발생 여부, 패닉 메시지 그리고 패닉이 일어난 코드 위치까지도 알 수 있습니다.
+
+## 정리
+이 포스트에서는 VGA 텍스트 버퍼의 구조 및 메모리 주소 `0xb8000`로의 메모리 매핑을 통해 어떻게 VGA 텍스트 버퍼에 쓰기 작업을 할 수 있는지에 대해 다뤘습니다. 또한 메모리 매핑 된 버퍼에 대한 쓰기 기능 (안전하지 않은 작업)을 안전하고 편리한 인터페이스로 제공하는 Rust 모듈을 작성했습니다.
+
+또한 cargo를 이용하여 의존 크레이트를 추가하는 것이 얼마나 쉬운지 직접 확인해볼 수 있었습니다.
+이번 포스트에서 추가한 의존 크레이트 `lazy_static`과 `spin`은 운영체제 개발에 매우 유용하기에 이후 포스트에서도 자주 사용할 것입니다.
+
+## 다음 단계는 무엇일까요?
+다음 포스트에서는 Rust의 자체 유닛 테스트 프레임워크를 설정하는 법에 대해 설명할 것입니다. 그리고 나서 이번 포스트에서 작성한 VGA 버퍼 모듈을 위한 기본적인 유닛 테스트들을 작성할 것입니다.
diff --git a/blog/content/edition-2/posts/03-vga-text-buffer/index.md b/blog/content/edition-2/posts/03-vga-text-buffer/index.md
index 9176ba4d..82d432bd 100644
--- a/blog/content/edition-2/posts/03-vga-text-buffer/index.md
+++ b/blog/content/edition-2/posts/03-vga-text-buffer/index.md
@@ -8,7 +8,7 @@ date = 2018-02-26
chapter = "Bare Bones"
+++
-The [VGA text mode] is a simple way to print text to the screen. In this post, we create an interface that makes its usage safe and simple, by encapsulating all unsafety in a separate module. We also implement support for Rust's [formatting macros].
+The [VGA text mode] is a simple way to print text to the screen. In this post, we create an interface that makes its usage safe and simple by encapsulating all unsafety in a separate module. We also implement support for Rust's [formatting macros].
[VGA text mode]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
[formatting macros]: https://doc.rust-lang.org/std/fmt/#related-macros
@@ -34,7 +34,7 @@ Bit(s) | Value
12-14 | Background color
15 | Blink
-The first byte represents the character that should be printed in the [ASCII encoding]. To be exact, it isn't exactly ASCII, but a character set named [_code page 437_] with some additional characters and slight modifications. For simplicity, we proceed to call it an ASCII character in this post.
+The first byte represents the character that should be printed in the [ASCII encoding]. To be more specific, it isn't exactly ASCII, but a character set named [_code page 437_] with some additional characters and slight modifications. For simplicity, we will proceed to call it an ASCII character in this post.
[ASCII encoding]: https://en.wikipedia.org/wiki/ASCII
[_code page 437_]: https://en.wikipedia.org/wiki/Code_page_437
@@ -52,13 +52,13 @@ Number | Color | Number + Bright Bit | Bright Color
0x6 | Brown | 0xe | Yellow
0x7 | Light Gray | 0xf | White
-Bit 4 is the _bright bit_, which turns for example blue into light blue. For the background color, this bit is repurposed as the blink bit.
+Bit 4 is the _bright bit_, which turns, for example, blue into light blue. For the background color, this bit is repurposed as the blink bit.
-The VGA text buffer is accessible via [memory-mapped I/O] to the address `0xb8000`. This means that reads and writes to that address don't access the RAM, but directly the text buffer on the VGA hardware. This means that we can read and write it through normal memory operations to that address.
+The VGA text buffer is accessible via [memory-mapped I/O] to the address `0xb8000`. This means that reads and writes to that address don't access the RAM but directly access the text buffer on the VGA hardware. This means we can read and write it through normal memory operations to that address.
[memory-mapped I/O]: https://en.wikipedia.org/wiki/Memory-mapped_I/O
-Note that memory-mapped hardware might not support all normal RAM operations. For example, a device could only support byte-wise reads and return junk when an `u64` is read. Fortunately, the text buffer [supports normal reads and writes], so that we don't have to treat it in special way.
+Note that memory-mapped hardware might not support all normal RAM operations. For example, a device could only support byte-wise reads and return junk when a `u64` is read. Fortunately, the text buffer [supports normal reads and writes], so we don't have to treat it in a special way.
[supports normal reads and writes]: https://web.stanford.edu/class/cs140/projects/pintos/specs/freevga/vga/vgamem.htm#manip
@@ -70,7 +70,7 @@ Now that we know how the VGA buffer works, we can create a Rust module to handle
mod vga_buffer;
```
-For the content of this module we create a new `src/vga_buffer.rs` file. All of the code below goes into our new module (unless specified otherwise).
+For the content of this module, we create a new `src/vga_buffer.rs` file. All of the code below goes into our new module (unless specified otherwise).
### Colors
First, we represent the different colors using an enum:
@@ -100,11 +100,11 @@ pub enum Color {
White = 15,
}
```
-We use a [C-like enum] here to explicitly specify the number for each color. Because of the `repr(u8)` attribute each enum variant is stored as an `u8`. Actually 4 bits would be sufficient, but Rust doesn't have an `u4` type.
+We use a [C-like enum] here to explicitly specify the number for each color. Because of the `repr(u8)` attribute, each enum variant is stored as a `u8`. Actually 4 bits would be sufficient, but Rust doesn't have a `u4` type.
[C-like enum]: https://doc.rust-lang.org/rust-by-example/custom_types/enum/c_like.html
-Normally the compiler would issue a warning for each unused variant. By using the `#[allow(dead_code)]` attribute we disable these warnings for the `Color` enum.
+Normally the compiler would issue a warning for each unused variant. By using the `#[allow(dead_code)]` attribute, we disable these warnings for the `Color` enum.
By [deriving] the [`Copy`], [`Clone`], [`Debug`], [`PartialEq`], and [`Eq`] traits, we enable [copy semantics] for the type and make it printable and comparable.
@@ -133,7 +133,7 @@ impl ColorCode {
}
}
```
-The `ColorCode` struct contains the full color byte, containing foreground and background color. Like before, we derive the `Copy` and `Debug` traits for it. To ensure that the `ColorCode` has the exact same data layout as an `u8`, we use the [`repr(transparent)`] attribute.
+The `ColorCode` struct contains the full color byte, containing foreground and background color. Like before, we derive the `Copy` and `Debug` traits for it. To ensure that the `ColorCode` has the exact same data layout as a `u8`, we use the [`repr(transparent)`] attribute.
[`repr(transparent)`]: https://doc.rust-lang.org/nomicon/other-reprs.html#reprtransparent
@@ -209,11 +209,11 @@ impl Writer {
fn new_line(&mut self) {/* TODO */}
}
```
-If the byte is the [newline] byte `\n`, the writer does not print anything. Instead it calls a `new_line` method, which we'll implement later. Other bytes get printed to the screen in the second match case.
+If the byte is the [newline] byte `\n`, the writer does not print anything. Instead, it calls a `new_line` method, which we'll implement later. Other bytes get printed to the screen in the second `match` case.
[newline]: https://en.wikipedia.org/wiki/Newline
-When printing a byte, the writer checks if the current line is full. In that case, a `new_line` call is required before to wrap the line. Then it writes a new `ScreenChar` to the buffer at the current position. Finally, the current column position is advanced.
+When printing a byte, the writer checks if the current line is full. In that case, a `new_line` call is used to wrap the line. Then it writes a new `ScreenChar` to the buffer at the current position. Finally, the current column position is advanced.
To print whole strings, we can convert them to bytes and print them one-by-one:
@@ -235,7 +235,7 @@ impl Writer {
}
```
-The VGA text buffer only supports ASCII and the additional bytes of [code page 437]. Rust strings are [UTF-8] by default, so they might contain bytes that are not supported by the VGA text buffer. We use a match to differentiate printable ASCII bytes (a newline or anything in between a space character and a `~` character) and unprintable bytes. For unprintable bytes, we print a `■` character, which has the hex code `0xfe` on the VGA hardware.
+The VGA text buffer only supports ASCII and the additional bytes of [code page 437]. Rust strings are [UTF-8] by default, so they might contain bytes that are not supported by the VGA text buffer. We use a `match` to differentiate printable ASCII bytes (a newline or anything in between a space character and a `~` character) and unprintable bytes. For unprintable bytes, we print a `■` character, which has the hex code `0xfe` on the VGA hardware.
[code page 437]: https://en.wikipedia.org/wiki/Code_page_437
[UTF-8]: https://www.fileformat.info/info/unicode/utf8.htm
@@ -258,7 +258,7 @@ pub fn print_something() {
writer.write_string("Wörld!");
}
```
-It first creates a new Writer that points to the VGA buffer at `0xb8000`. The syntax for this might seem a bit strange: First, we cast the integer `0xb8000` as an mutable [raw pointer]. Then we convert it to a mutable reference by dereferencing it (through `*`) and immediately borrowing it again (through `&mut`). This conversion requires an [`unsafe` block], since the compiler can't guarantee that the raw pointer is valid.
+It first creates a new Writer that points to the VGA buffer at `0xb8000`. The syntax for this might seem a bit strange: First, we cast the integer `0xb8000` as a mutable [raw pointer]. Then we convert it to a mutable reference by dereferencing it (through `*`) and immediately borrowing it again (through `&mut`). This conversion requires an [`unsafe` block], since the compiler can't guarantee that the raw pointer is valid.
[raw pointer]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
[`unsafe` block]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html
@@ -307,7 +307,7 @@ volatile = "0.2.6"
```
Make sure to specify `volatile` version `0.2.6`. Newer versions of the crate are not compatible with this post.
-The `0.2.6` is the [semantic] version number. For more information, see the [Specifying Dependencies] guide of the cargo documentation.
+`0.2.6` is the [semantic] version number. For more information, see the [Specifying Dependencies] guide of the cargo documentation.
[semantic]: https://semver.org/
[Specifying Dependencies]: https://doc.crates.io/specifying-dependencies.html
@@ -323,7 +323,7 @@ struct Buffer {
chars: [[Volatile; BUFFER_WIDTH]; BUFFER_HEIGHT],
}
```
-Instead of a `ScreenChar`, we're now using a `Volatile`. (The `Volatile` type is [generic] and can wrap (almost) any type). This ensures that we can't accidentally write to it through a “normal” write. Instead, we have to use the `write` method now.
+Instead of a `ScreenChar`, we're now using a `Volatile`. (The `Volatile` type is [generic] and can wrap (almost) any type). This ensures that we can't accidentally write to it “normally”. Instead, we have to use the `write` method now.
[generic]: https://doc.rust-lang.org/book/ch10-01-syntax.html
@@ -351,10 +351,10 @@ impl Writer {
}
```
-Instead of a normal assignment using `=`, we're now using the `write` method. This guarantees that the compiler will never optimize away this write.
+Instead of a typical assignment using `=`, we're now using the `write` method. Now we can guarantee that the compiler will never optimize away this write.
### Formatting Macros
-It would be nice to support Rust's formatting macros, too. That way, we can easily print different types like integers or floats. To support them, we need to implement the [`core::fmt::Write`] trait. The only required method of this trait is `write_str` that looks quite similar to our `write_string` method, just with a `fmt::Result` return type:
+It would be nice to support Rust's formatting macros, too. That way, we can easily print different types, like integers or floats. To support them, we need to implement the [`core::fmt::Write`] trait. The only required method of this trait is `write_str`, which looks quite similar to our `write_string` method, just with a `fmt::Result` return type:
[`core::fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
@@ -396,7 +396,7 @@ Now you should see a `Hello! The numbers are 42 and 0.3333333333333333` at the b
[`unwrap`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.unwrap
### Newlines
-Right now, we just ignore newlines and characters that don't fit into the line anymore. Instead we want to move every character one line up (the top line gets deleted) and start at the beginning of the last line again. To do this, we add an implementation for the `new_line` method of `Writer`:
+Right now, we just ignore newlines and characters that don't fit into the line anymore. Instead, we want to move every character one line up (the top line gets deleted) and start at the beginning of the last line again. To do this, we add an implementation for the `new_line` method of `Writer`:
```rust
// in src/vga_buffer.rs
@@ -416,7 +416,7 @@ impl Writer {
fn clear_row(&mut self, row: usize) {/* TODO */}
}
```
-We iterate over all screen characters and move each character one row up. Note that the range notation (`..`) is exclusive the upper bound. We also omit the 0th row (the first range starts at `1`) because it's the row that is shifted off screen.
+We iterate over all the screen characters and move each character one row up. Note that the upper bound of the range notation (`..`) is exclusive. We also omit the 0th row (the first range starts at `1`) because it's the row that is shifted off screen.
To finish the newline code, we add the `clear_row` method:
@@ -483,12 +483,12 @@ To understand what's happening here, we need to know that statics are initialize
[const evaluator]: https://rustc-dev-guide.rust-lang.org/const-eval.html
[Allow panicking in constants]: https://github.com/rust-lang/rfcs/pull/2345
-The issue about `ColorCode::new` would be solvable by using [`const` functions], but the fundamental problem here is that Rust's const evaluator is not able to convert raw pointers to references at compile time. Maybe it will work someday, but until then, we have to find another solution.
+The issue with `ColorCode::new` would be solvable by using [`const` functions], but the fundamental problem here is that Rust's const evaluator is not able to convert raw pointers to references at compile time. Maybe it will work someday, but until then, we have to find another solution.
[`const` functions]: https://doc.rust-lang.org/reference/const_eval.html#const-functions
### Lazy Statics
-The one-time initialization of statics with non-const functions is a common problem in Rust. Fortunately, there already exists a good solution in a crate named [lazy_static]. This crate provides a `lazy_static!` macro that defines a lazily initialized `static`. Instead of computing its value at compile time, the `static` laziliy initializes itself when it's accessed the first time. Thus, the initialization happens at runtime so that arbitrarily complex initialization code is possible.
+The one-time initialization of statics with non-const functions is a common problem in Rust. Fortunately, there already exists a good solution in a crate named [lazy_static]. This crate provides a `lazy_static!` macro that defines a lazily initialized `static`. Instead of computing its value at compile time, the `static` lazily initializes itself when accessed for the first time. Thus, the initialization happens at runtime, so arbitrarily complex initialization code is possible.
[lazy_static]: https://docs.rs/lazy_static/1.0.1/lazy_static/
@@ -520,7 +520,7 @@ lazy_static! {
}
```
-However, this `WRITER` is pretty useless since it is immutable. This means that we can't write anything to it (since all the write methods take `&mut self`). One possible solution would be to use a [mutable static]. But then every read and write to it would be unsafe since it could easily introduce data races and other bad things. Using `static mut` is highly discouraged, there were even proposals to [remove it][remove static mut]. But what are the alternatives? We could try to use a immutable static with a cell type like [RefCell] or even [UnsafeCell] that provides [interior mutability]. But these types aren't [Sync] \(with good reason), so we can't use them in statics.
+However, this `WRITER` is pretty useless since it is immutable. This means that we can't write anything to it (since all the write methods take `&mut self`). One possible solution would be to use a [mutable static]. But then every read and write to it would be unsafe since it could easily introduce data races and other bad things. Using `static mut` is highly discouraged. There were even proposals to [remove it][remove static mut]. But what are the alternatives? We could try to use an immutable static with a cell type like [RefCell] or even [UnsafeCell] that provides [interior mutability]. But these types aren't [Sync] \(with good reason), so we can't use them in statics.
[mutable static]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
[remove static mut]: https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437
@@ -530,7 +530,7 @@ However, this `WRITER` is pretty useless since it is immutable. This means that
[Sync]: https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html
### Spinlocks
-To get synchronized interior mutability, users of the standard library can use [Mutex]. It provides mutual exclusion by blocking threads when the resource is already locked. But our basic kernel does not have any blocking support or even a concept of threads, so we can't use it either. However there is a really basic kind of mutex in computer science that requires no operating system features: the [spinlock]. Instead of blocking, the threads simply try to lock it again and again in a tight loop and thus burn CPU time until the mutex is free again.
+To get synchronized interior mutability, users of the standard library can use [Mutex]. It provides mutual exclusion by blocking threads when the resource is already locked. But our basic kernel does not have any blocking support or even a concept of threads, so we can't use it either. However, there is a really basic kind of mutex in computer science that requires no operating system features: the [spinlock]. Instead of blocking, the threads simply try to lock it again and again in a tight loop, thus burning CPU time until the mutex is free again.
[Mutex]: https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html
[spinlock]: https://en.wikipedia.org/wiki/Spinlock
@@ -545,7 +545,7 @@ To use a spinning mutex, we can add the [spin crate] as a dependency:
spin = "0.5.2"
```
-Then we can use the spinning Mutex to add safe [interior mutability] to our static `WRITER`:
+Then we can use the spinning mutex to add safe [interior mutability] to our static `WRITER`:
```rust
// in src/vga_buffer.rs
@@ -579,7 +579,7 @@ We need to import the `fmt::Write` trait in order to be able to use its function
Note that we only have a single unsafe block in our code, which is needed to create a `Buffer` reference pointing to `0xb8000`. Afterwards, all operations are safe. Rust uses bounds checking for array accesses by default, so we can't accidentally write outside the buffer. Thus, we encoded the required conditions in the type system and are able to provide a safe interface to the outside.
### A println Macro
-Now that we have a global writer, we can add a `println` macro that can be used from anywhere in the codebase. Rust's [macro syntax] is a bit strange, so we won't try to write a macro from scratch. Instead we look at the source of the [`println!` macro] in the standard library:
+Now that we have a global writer, we can add a `println` macro that can be used from anywhere in the codebase. Rust's [macro syntax] is a bit strange, so we won't try to write a macro from scratch. Instead, we look at the source of the [`println!` macro] in the standard library:
[macro syntax]: https://doc.rust-lang.org/nightly/book/ch19-06-macros.html#declarative-macros-with-macro_rules-for-general-metaprogramming
[`println!` macro]: https://doc.rust-lang.org/nightly/std/macro.println!.html
@@ -592,9 +592,9 @@ macro_rules! println {
}
```
-Macros are defined through one or more rules, which are similar to `match` arms. The `println` macro has two rules: The first rule for is invocations without arguments (e.g `println!()`), which is expanded to `print!("\n")` and thus just prints a newline. the second rule is for invocations with parameters such as `println!("Hello")` or `println!("Number: {}", 4)`. It is also expanded to an invocation of the `print!` macro, passing all arguments and an additional newline `\n` at the end.
+Macros are defined through one or more rules, similar to `match` arms. The `println` macro has two rules: The first rule is for invocations without arguments, e.g., `println!()`, which is expanded to `print!("\n")` and thus just prints a newline. The second rule is for invocations with parameters such as `println!("Hello")` or `println!("Number: {}", 4)`. It is also expanded to an invocation of the `print!` macro, passing all arguments and an additional newline `\n` at the end.
-The `#[macro_export]` attribute makes the macro available to the whole crate (not just the module it is defined) and external crates. It also places the macro at the crate root, which means that we have to import the macro through `use std::println` instead of `std::macros::println`.
+The `#[macro_export]` attribute makes the macro available to the whole crate (not just the module it is defined in) and external crates. It also places the macro at the crate root, which means we have to import the macro through `use std::println` instead of `std::macros::println`.
The [`print!` macro] is defined as:
@@ -639,15 +639,15 @@ pub fn _print(args: fmt::Arguments) {
}
```
-One thing that we changed from the original `println` definition is that we prefixed the invocations of the `print!` macro with `$crate` too. This ensures that we don't need to have to import the `print!` macro too if we only want to use `println`.
+One thing that we changed from the original `println` definition is that we prefixed the invocations of the `print!` macro with `$crate` too. This ensures that we don't need to import the `print!` macro too if we only want to use `println`.
Like in the standard library, we add the `#[macro_export]` attribute to both macros to make them available everywhere in our crate. Note that this places the macros in the root namespace of the crate, so importing them via `use crate::vga_buffer::println` does not work. Instead, we have to do `use crate::println`.
-The `_print` function locks our static `WRITER` and calls the `write_fmt` method on it. This method is from the `Write` trait, we need to import that trait. The additional `unwrap()` at the end panics if printing isn't successful. But since we always return `Ok` in `write_str`, that should not happen.
+The `_print` function locks our static `WRITER` and calls the `write_fmt` method on it. This method is from the `Write` trait, which we need to import. The additional `unwrap()` at the end panics if printing isn't successful. But since we always return `Ok` in `write_str`, that should not happen.
Since the macros need to be able to call `_print` from outside of the module, the function needs to be public. However, since we consider this a private implementation detail, we add the [`doc(hidden)` attribute] to hide it from the generated documentation.
-[`doc(hidden)` attribute]: https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden
+[`doc(hidden)` attribute]: https://doc.rust-lang.org/nightly/rustdoc/write-documentation/the-doc-attribute.html#hidden
### Hello World using `println`
Now we can use `println` in our `_start` function:
@@ -691,9 +691,9 @@ When we now insert `panic!("Some panic message");` in our `_start` function, we
So we know not only that a panic has occurred, but also the panic message and where in the code it happened.
## Summary
-In this post we learned about the structure of the VGA text buffer and how it can be written through the memory mapping at address `0xb8000`. We created a Rust module that encapsulates the unsafety of writing to this memory mapped buffer and presents a safe and convenient interface to the outside.
+In this post, we learned about the structure of the VGA text buffer and how it can be written through the memory mapping at address `0xb8000`. We created a Rust module that encapsulates the unsafety of writing to this memory-mapped buffer and presents a safe and convenient interface to the outside.
-We also saw how easy it is to add dependencies on third-party libraries, thanks to cargo. The two dependencies that we added, `lazy_static` and `spin`, are very useful in OS development and we will use them in more places in future posts.
+Thanks to cargo, we also saw how easy it is to add dependencies on third-party libraries. The two dependencies that we added, `lazy_static` and `spin`, are very useful in OS development and we will use them in more places in future posts.
## What's next?
-The next post explains how to set up Rust's built in unit test framework. We will then create some basic unit tests for the VGA buffer module from this post.
+The next post explains how to set up Rust's built-in unit test framework. We will then create some basic unit tests for the VGA buffer module from this post.
diff --git a/blog/content/edition-2/posts/03-vga-text-buffer/index.zh-CN.md b/blog/content/edition-2/posts/03-vga-text-buffer/index.zh-CN.md
index c5eaf2db..8ffd4bec 100644
--- a/blog/content/edition-2/posts/03-vga-text-buffer/index.zh-CN.md
+++ b/blog/content/edition-2/posts/03-vga-text-buffer/index.zh-CN.md
@@ -9,6 +9,8 @@ date = 2018-02-26
translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
# GitHub usernames of the people that translated this post
translators = ["luojia65", "Rustin-Liu"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["liuyuran"]
+++
**VGA 字符模式**([VGA text mode])是打印字符到屏幕的一种简单方式。在这篇文章中,为了包装这个模式为一个安全而简单的接口,我们将包装 unsafe 代码到独立的模块。我们还将实现对 Rust 语言**格式化宏**([formatting macros])的支持。
@@ -18,7 +20,7 @@ translators = ["luojia65", "Rustin-Liu"]
-This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-03`][post branch] branch.
+此博客在 [GitHub] 上公开开发. 如果您有任何问题或疑问,请在此处打开一个 issue。 您也可以在[底部][at the bottom]发表评论. 这篇文章的完整源代码可以在 [`post-03`] [post branch] 分支中找到。
[GitHub]: https://github.com/phil-opp/blog_os
[at the bottom]: #comments
@@ -31,27 +33,32 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
为了在 VGA 字符模式中向屏幕打印字符,我们必须将它写入硬件提供的 **VGA 字符缓冲区**(VGA text buffer)。通常状况下,VGA 字符缓冲区是一个 25 行、80 列的二维数组,它的内容将被实时渲染到屏幕。这个数组的元素被称作**字符单元**(character cell),它使用下面的格式描述一个屏幕上的字符:
-| Bit(s) | Value |
-|-----|----------------|
-| 0-7 | ASCII code point |
-| 8-11 | Foreground color |
-| 12-14 | Background color |
-| 15 | Blink |
+| Bit(s) | Value |
+| ------ | ---------------- |
+| 0-7 | ASCII code point |
+| 8-11 | Foreground color |
+| 12-14 | Background color |
+| 15 | Blink |
-其中,**前景色**(foreground color)和**背景色**(background color)取值范围如下:
+第一个字节表示了应当输出的 [ASCII 编码][ASCII encoding],更加准确的说,类似于 [437 字符编码表][_code page 437_] 中字符对应的编码,但又有细微的不同。 这里为了简化表达,我们在文章里将其简称为ASCII字符。
-| Number | Color | Number + Bright Bit | Bright Color |
-|-----|----------|------|--------|
-| 0x0 | Black | 0x8 | Dark Gray |
-| 0x1 | Blue | 0x9 | Light Blue |
-| 0x2 | Green | 0xa | Light Green |
-| 0x3 | Cyan | 0xb | Light Cyan |
-| 0x4 | Red | 0xc | Light Red |
-| 0x5 | Magenta | 0xd | Pink |
-| 0x6 | Brown | 0xe | Yellow |
-| 0x7 | Light Gray | 0xf | White |
+[ASCII encoding]: https://en.wikipedia.org/wiki/ASCII
+[_code page 437_]: https://en.wikipedia.org/wiki/Code_page_437
-每个颜色的第四位称为**加亮位**(bright bit)。
+第二个字节则定义了字符的显示方式,前四个比特定义了前景色,中间三个比特定义了背景色,最后一个比特则定义了该字符是否应该闪烁,以下是可用的颜色列表:
+
+| Number | Color | Number + Bright Bit | Bright Color |
+| ------ | ---------- | ------------------- | ------------ |
+| 0x0 | Black | 0x8 | Dark Gray |
+| 0x1 | Blue | 0x9 | Light Blue |
+| 0x2 | Green | 0xa | Light Green |
+| 0x3 | Cyan | 0xb | Light Cyan |
+| 0x4 | Red | 0xc | Light Red |
+| 0x5 | Magenta | 0xd | Pink |
+| 0x6 | Brown | 0xe | Yellow |
+| 0x7 | Light Gray | 0xf | White |
+
+每个颜色的第四位称为**加亮位**(bright bit),比如blue加亮后就变成了light blue,但对于背景色,这个比特会被用于标记是否闪烁。
要修改 VGA 字符缓冲区,我们可以通过**存储器映射输入输出**([memory-mapped I/O](https://en.wikipedia.org/wiki/Memory-mapped_I/O))的方式,读取或写入地址 `0xb8000`;这意味着,我们可以像操作普通的内存区域一样操作这个地址。
@@ -66,13 +73,11 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
mod vga_buffer;
```
-这行代码定义了一个 Rust 模块,它的内容应当保存在 `src/vga_buffer.rs` 文件中。使用 **2018 版次**(2018 edition)的 Rust 时,我们可以把模块的**子模块**(submodule)文件直接保存到 `src/vga_buffer/` 文件夹下,与 `vga_buffer.rs` 文件共存,而无需创建一个 `mod.rs` 文件。
-
我们的模块暂时不需要添加子模块,所以我们将它创建为 `src/vga_buffer.rs` 文件。除非另有说明,本文中的代码都保存到这个文件中。
### 颜色
-首先,我们使用 Rust 的**枚举**(enum)表示一种颜色:
+首先,我们使用 Rust 的**枚举**(enum)表示特定的颜色:
```rust
// in src/vga_buffer.rs
@@ -213,7 +218,7 @@ impl Writer {
for byte in s.bytes() {
match byte {
// 可以是能打印的 ASCII 码字节,也可以是换行符
- 0x20...0x7e | b'\n' => self.write_byte(byte),
+ 0x20..=0x7e | b'\n' => self.write_byte(byte),
// 不包含在上述范围之内的字节
_ => self.write_byte(0xfe),
}
@@ -486,16 +491,16 @@ lazy_static! {
然而,这个 `WRITER` 可能没有什么用途,因为它目前还是**不可变变量**(immutable variable):这意味着我们无法向它写入数据,因为所有与写入数据相关的方法都需要实例的可变引用 `&mut self`。一种解决方案是使用**可变静态**([mutable static](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable))的变量,但所有对它的读写操作都被规定为不安全的(unsafe)操作,因为这很容易导致数据竞争或发生其它不好的事情——使用 `static mut` 极其不被赞成,甚至有一些提案认为[应该将它删除](https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437)。也有其它的替代方案,比如可以尝试使用比如 [RefCell](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt) 或甚至 [UnsafeCell](https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html) 等类型提供的**内部可变性**([interior mutability](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html));但这些类型都被设计为非同步类型,即不满足 [Sync](https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html) 约束,所以我们不能在静态变量中使用它们。
-### 自旋锁
+### spinlock
要定义同步的内部可变性,我们往往使用标准库提供的互斥锁类 [Mutex](https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html),它通过提供当资源被占用时将线程**阻塞**(block)的**互斥条件**(mutual exclusion)实现这一点;但我们初步的内核代码还没有线程和阻塞的概念,我们将不能使用这个类。不过,我们还有一种较为基础的互斥锁实现方式——**自旋锁**([spinlock](https://en.wikipedia.org/wiki/Spinlock))。自旋锁并不会调用阻塞逻辑,而是在一个小的无限循环中反复尝试获得这个锁,也因此会一直占用 CPU 时间,直到互斥锁被它的占用者释放。
-为了使用自旋的互斥锁,我们添加 [spin包](https://crates.io/crates/spin) 到项目的依赖项列表:
+为了使用自旋互斥锁,我们添加 [spin包](https://crates.io/crates/spin) 到项目的依赖项列表:
```toml
# in Cargo.toml
[dependencies]
-spin = "0.4.9"
+spin = "0.5.2"
```
现在,我们能够使用自旋的互斥锁,为我们的 `WRITER` 类实现安全的[内部可变性](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html):
@@ -592,7 +597,7 @@ pub fn _print(args: fmt::Arguments) {
另外,`_print` 函数将占有静态变量 `WRITER` 的锁,并调用它的 `write_fmt` 方法。这个方法是从名为 `Write` 的 trait 中获得的,所以我们需要导入这个 trait。额外的 `unwrap()` 函数将在打印不成功的时候 panic;但既然我们的 `write_str` 总是返回 `Ok`,这种情况不应该发生。
-如果这个宏将能在模块外访问,它们也应当能访问 `_print` 函数,因此这个函数必须是公有的(public)。然而,考虑到这是一个私有的实现细节,我们添加一个 [`doc(hidden)` 属性](https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden),防止它在生成的文档中出现。
+如果这个宏将能在模块外访问,它们也应当能访问 `_print` 函数,因此这个函数必须是公有的(public)。然而,考虑到这是一个私有的实现细节,我们添加一个 [`doc(hidden)` 属性](https://doc.rust-lang.org/nightly/rustdoc/write-documentation/the-doc-attribute.html#hidden),防止它在生成的文档中出现。
### 使用 `println!` 的 Hello World
diff --git a/blog/content/edition-2/posts/04-testing/index.ko.md b/blog/content/edition-2/posts/04-testing/index.ko.md
new file mode 100644
index 00000000..bb52e432
--- /dev/null
+++ b/blog/content/edition-2/posts/04-testing/index.ko.md
@@ -0,0 +1,1046 @@
++++
+title = "커널을 위한 테스트 작성 및 실행하기"
+weight = 4
+path = "ko/testing"
+date = 2019-04-27
+
+[extra]
+chapter = "Bare Bones"
+# Please update this when updating the translation
+translation_based_on_commit = "1c9b5edd6a5a667e282ca56d6103d3ff1fd7cfcb"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["SNOOPYOF", "dalinaum"]
++++
+
+이 글에서는 `no_std` 실행파일에 대한 유닛 테스트 및 통합 테스트 과정을 다룰 것입니다. Rust에서 지원하는 커스텀 테스트 프레임워크 기능을 이용해 우리가 작성한 커널 안에서 테스트 함수들을 실행할 것입니다. 그 후 테스트 결과를 QEMU 밖으로 가져오기 위해 QEMU 및 `bootimage` 도구가 제공하는 여러 기능들을 사용할 것입니다.
+
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 글과 관련된 모든 소스 코드는 저장소의 [`post-04 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-04
+
+
+
+## 전제 조건
+
+이 글은 이전에 작성된 글들 [_Unit Testing_]과 [_Integration Tests_]를 대체합니다 (예전에 작성된 이 두 포스트의 내용은 오래전 내용이라 현재는 더 이상 유효하지 않습니다). 이 글은 독자가 2019년 4월 27일 이후에 글 [_A Minimal Rust Kernel_]을 읽고 따라 실습해봤다는 가정하에 작성했습니다. 독자는 해당 포스트에서 작성했던 파일 ` .cargo/config.toml`을 가지고 있어야 합니다. 이 파일은 [컴파일 대상 환경을 설정][sets a default target]하고 [프로그램 실행 시작을 담당하는 실행 파일을 정의][defines a runner executable]합니다.
+
+[_Unit Testing_]: @/edition-2/posts/deprecated/04-unit-testing/index.md
+[_Integration Tests_]: @/edition-2/posts/deprecated/05-integration-tests/index.md
+[_A Minimal Rust Kernel_]: @/edition-2/posts/02-minimal-rust-kernel/index.md
+[sets a default target]: @/edition-2/posts/02-minimal-rust-kernel/index.md#set-a-default-target
+[defines a runner executable]: @/edition-2/posts/02-minimal-rust-kernel/index.md#using-cargo-run
+
+## Rust 프로그램 테스트하기
+
+Rust 언어에 [내장된 자체 테스트 프레임워크][built-in test framework]를 사용하면 복잡한 초기 설정 과정 없이 유닛 테스트들을 실행할 수 있습니다. 작성한 함수에 가정 설정문 (assertion check)들을 삽입한 후, 함수 선언 바로 앞에 `#[test]` 속성을 추가하기만 하면 됩니다. 그 후에 `cargo test` 명령어를 실행하면 `cargo`가 자동으로 크레이트의 모든 테스트 함수들을 발견하고 실행합니다.
+
+[built-in test framework]: https://doc.rust-lang.org/book/ch11-00-testing.html
+
+안타깝게도 우리의 커널처럼 `no_std` 환경에서 구동할 프로그램은 Rust가 기본으로 제공하는 테스트 프레임워크를 이용하기 어렵습니다. Rust의 테스트 프레임워크는 기본적으로 언어에 내장된 [`test`] 라이브러리를 사용하는데, 이 라이브러리는 Rust 표준 라이브러리를 이용합니다. 우리의 `#no_std` 커널을 테스트할 때는 Rust의 기본 테스트 프레임워크를 사용할 수 없습니다.
+
+[`test`]: https://doc.rust-lang.org/test/index.html
+
+프로젝트 디렉터리 안에서 `cargo test` 명령어를 실행하면 아래와 같은 오류가 발생합니다:
+
+```
+> cargo test
+ Compiling blog_os v0.1.0 (/…/blog_os)
+error[E0463]: can't find crate for `test`
+```
+
+`test` 크레이트가 표준 라이브러리에 의존하기에, 베어메탈 환경에서는 이 크레이트를 이용할 수 없습니다. `test` 크레이트를 `#[no_std]` 환경에서 이용할 수 있게 포팅(porting)하는 것이 [불가능한 것은 아니지만][utest], 일단 `test` 크레이트의 구현 변경이 잦아서 불안정하며 포팅 시 `panic` 매크로를 재정의하는 등 잡다하게 신경 써야 할 것들이 존재합니다.
+
+[utest]: https://github.com/japaric/utest
+
+### 커스텀 테스트 프레임워크
+
+다행히 Rust의 [`custom_test_frameworks`] 기능을 이용하면 Rust의 기본 테스트 프레임워크 대신 다른 것을 사용할 수 있습니다. 이 기능은 외부 라이브러리가 필요하지 않기에 `#[no_std]` 환경에서도 사용할 수 있습니다.
+이 기능은 `#[test case]` 속성이 적용된 함수들을 모두 리스트에 모은 후에 사용자가 작성한 테스트 실행 함수에 전달하는 방식으로 작동합니다. 따라서 사용자가 작성한 테스트 실행 함수 단에서 테스트 실행 과정을 전적으로 제어할 수 있습니다.
+
+[`custom_test_frameworks`]: https://doc.rust-lang.org/unstable-book/language-features/custom-test-frameworks.html
+
+기본 테스트 프레임워크와 비교했을 때의 단점은 [`should_panic` 테스트][`should_panic` tests]와 같은 고급 기능이 준비되어 있지 않다는 것입니다. 베어메탈 환경에서는 Rust의 기본 테스트 프레임워크가 제공하는 고급 기능들이 지원되지 않기에, 이 중 필요한 것이 있다면 우리가 직접 코드로 구현해야 합니다. 예를 들어 `#[should_panic]` 속성은 스택 되감기를 사용해 패닉을 잡아내는데, 우리의 커널에서는 스택 되감기가 해제되어 있어 사용할 수 없습니다.
+
+[`should_panic` tests]: https://doc.rust-lang.org/book/ch11-01-writing-tests.html#checking-for-panics-with-should_panic
+
+커널 테스트용 테스트 프레임워크 작성의 첫 단계로 아래의 코드를 `main.rs`에 추가합니다:
+
+```rust
+// in src/main.rs
+
+#![feature(custom_test_frameworks)]
+#![test_runner(crate::test_runner)]
+
+#[cfg(test)]
+fn test_runner(tests: &[&dyn Fn()]) {
+ println!("Running {} tests", tests.len());
+ for test in tests {
+ test();
+ }
+}
+```
+
+`test_runner`는 짧은 디버그 메시지를 출력한 후 주어진 리스트의 각 테스트 함수를 호출합니다. 인자 타입 `&[& dyn Fn()]`은 [_Fn()_] 트레이트를 구현하는 타입에 대한 레퍼런스들의 [_slice_]입니다. 좀 더 쉽게 말하면 이것은 함수처럼 호출될 수 있는 타입에 대한 레퍼런스들의 리스트입니다. `test_runner` 함수는 테스트 용도 외에 쓸모가 없기에 `#[cfg(test)]` 속성을 적용하여 테스트 시에만 빌드합니다.
+
+[_slice_]: https://doc.rust-lang.org/std/primitive.slice.html
+[_trait object_]: https://doc.rust-lang.org/1.30.0/book/first-edition/trait-objects.html
+[_Fn()_]: https://doc.rust-lang.org/std/ops/trait.Fn.html
+
+`cargo test`를 다시 시도하면 실행이 성공할 것입니다 (실행이 실패한다면 아래의 노트를 확인해주세요). 하지만 "Hello World" 메시지만 출력될 뿐 `test_runner`로부터의 메시지는 출력되지 않는데, 아직 `_start` 함수를 프로그램 실행 시작 함수로 이용하고 있기 때문입니다. 우리가 `#[no_main]` 속성을 통해 별도의 실행 시작 함수를 사용하고 있기에, 커스텀 테스트 프레임워크가 `test_runner`를 호출하려고 생성한 `main`함수가 이용되지 않고 있습니다.
+
+
+
+**각주:** 특정 상황에서 `cargo test` 실행 시 "duplicate lang item" 오류가 발생하는 버그가 존재합니다. `Cargo.toml`에 `panic = "abort"` 설정이 있으면 해당 오류가 발생할 수 있습니다. 해당 설정을 제거하면 `cargo test` 실행 시 오류가 발생하지 않을 것입니다. 더 자세한 정보는 [해당 버그에 대한 깃헙 이슈](https://github.com/rust-lang/cargo/issues/7359)를 참조해주세요.
+
+
+
+이 문제를 해결하려면 우선 `reexport_test_harness_main` 속성을 사용해 테스트 프레임워크가 생성하는 함수의 이름을 `main` 이외의 이름으로 변경해야 합니다. 그 후에 `_start` 함수로부터 이름이 변경된 이 함수를 호출할 것입니다.
+
+```rust
+// in src/main.rs
+
+#![reexport_test_harness_main = "test_main"]
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ #[cfg(test)]
+ test_main();
+
+ loop {}
+}
+```
+
+테스트 프레임워크의 시작 함수를 `test_main`으로 설정하고, 커널 시작 함수 `_start`에서 `test_main` 함수를 호출합니다. `test_main` 함수는 테스트 상황이 아니면 생성되지 않기 때문에, [조건부 컴파일][conditional compilation]을 통해 테스트 상황에서만 `test_main` 함수를 호출하도록 합니다.
+
+`cargo test` 명령어를 실행하면 "Running 0 tests"라는 메시지가 출력됩니다. 이제 첫 번째 테스트 함수를 작성할 준비가 되었습니다.
+
+```rust
+// in src/main.rs
+
+#[test_case]
+fn trivial_assertion() {
+ print!("trivial assertion... ");
+ assert_eq!(1, 1);
+ println!("[ok]");
+}
+```
+
+위의 테스트 함수를 작성한 뒤 다시 `cargo test`를 실행하면 아래의 내용이 출력됩니다:
+
+![QEMU printing "Hello World!", "Running 1 tests", and "trivial assertion... [ok]"](qemu-test-runner-output.png)
+
+`test_runner` 함수에 인자로 전달되는 `tests` 슬라이스에 `trivial_assertion` 함수에 대한 레퍼런스가 들어 있습니다.
+출력 메시지 `trivial assertion... [ok]`를 통해 테스트가 성공적으로 실행되었음을 확인할 수 있습니다.
+
+테스트 실행 완료 후 `test_runner` 함수가 반환되어 제어 흐름이 `test_main` 함수로 돌아오고, 다시 이 함수가 반환되어 `_start` 함수로 제어 흐름이 돌아갑니다. 실행 시작 함수는 반환할 수 없기에 `_start` 함수의 맨 끝에서 무한 루프에 진입하는데, `cargo test`의 실행 완료 후 종료하기를 바라는 우리의 입장에서는 해결해야 할 문제입니다.
+
+## QEMU 종료하기
+
+`_start` 함수의 맨 뒤에 무한루프가 있어 `cargo test`의 실행을 종료하려면 실행 중인 QEMU를 수동으로 종료해야 합니다. 이 때문에 각종 명령어 스크립트에서 사람의 개입 없이는 `cargo test`를 사용할 수 없습니다. 이 불편을 해소하는 가장 직관적인 방법은 정식으로 운영체제를 종료하는 기능을 구현하는 것입니다. 하지만 이를 구현하려면 [APM] 또는 [ACPI] 전원 제어 표준을 지원하도록 커널 코드를 짜야 해서 제법 복잡한 작업이 될 것입니다.
+
+[APM]: https://wiki.osdev.org/APM
+[ACPI]: https://wiki.osdev.org/ACPI
+
+다행히 이 불편을 해결할 차선책이 존재합니다: QEMU가 지원하는 `isa-debug-exit` 장치를 사용하면 게스트 시스템에서 쉽게 QEMU를 종료할 수 있습니다. QEMU 실행 시 `-device` 인자를 전달하여 이 장치를 활성화할 수 있습니다. `Cargo.toml`에 `package.metadata.bootimage.test-args`라는 설정 키 값을 추가하여 QEMU에 `device` 인자를 전달합니다:
+
+```toml
+# in Cargo.toml
+
+[package.metadata.bootimage]
+test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
+```
+
+`bootimage runner`는 테스트 실행 파일을 실행할 때 QEMU 실행 명령어의 마지막에 `test-args`를 추가합니다. `cargo run` 실행의 경우에는 QEMU 실행 명령어 끝에 `test-args`를 추가하지 않습니다.
+
+장치 이름(`isa-debug-exit`)과 함께 두 개의 인자 `iobase`와 `iosize`를 전달하는데, 이 두 인자는 우리의 커널이 어떤 _입출력 포트_ 를 이용해 `isa-debug-exit` 장치에 접근할 수 있는지 알립니다.
+
+### 입출력 포트
+
+x86 CPU와 주변 장치가 데이터를 주고받는 입출력 방법은 두 가지가 있습니다. 하나는 **메모리 맵 입출력(memory-mapped I/O)**이고 다른 하나는 **포트 맵 입출력(port-mapped I/O)**입니다. 예전에 우리는 메모리 맵 입출력을 이용해 [VGA 텍스트 버퍼][VGA text buffer]를 메모리 주소 `0xb8000`에 매핑하여 접근했었습니다. 이 주소는 RAM에 매핑되는 대신 VGA 장치의 메모리에 매핑됩니다.
+
+[VGA text buffer]: @/edition-2/posts/03-vga-text-buffer/index.md
+
+반면 포트 맵 입출력은 별도의 입출력 버스를 이용해 장치 간 통신을 합니다. CPU에 연결된 주변장치 당 1개 이상의 포트 번호가 배정됩니다. CPU 명령어 `in`과 `out`은 포트 번호와 1바이트의 데이터를 인자로 받습니다. CPU는 이 명령어들을 이용해 입출력 포트와 데이터를 주고받습니다 (`in`/`out`이 변형된 버전의 명령어로 `u16` 혹은 `u32` 단위로 데이터를 주고받을 수도 있습니다).
+
+`isa-debug-exit` 장치는 port-mapped I/O 를 사용합니다. `iobase` 인자는 이 장치를 어느 포트에 연결할지 정합니다 (`0xf4`는 [x86 시스템의 입출력 버스 중 잘 안 쓰이는][list of x86 I/O ports] 포트입니다). `iosize` 인자는 포트의 크기를 정합니다 (`0x04`는 4 바이트 크기를 나타냅니다).
+
+[list of x86 I/O ports]: https://wiki.osdev.org/I/O_Ports#The_list
+
+### 종료 장치 사용하기
+
+`isa-debug-exit` 장치가 하는 일은 매우 간단합니다. `iobase`가 가리키는 입출력 포트에 값 `value`가 쓰였을 때, 이 장치는 QEMU가 [종료 상태][exit status] `(value << 1) | 1`을 반환하며 종료하도록 합니다. 따라서 우리가 입출력 포트에 값 `0`을 보내면 QEMU가 `(0 << 1) | 1 = 1`의 종료 상태 코드를 반환하고, 값 `1`을 보내면 `(1 << 1) | 1 = 3`의 종료 상태 코드를 반환합니다.
+
+[exit status]: https://en.wikipedia.org/wiki/Exit_status
+
+`x86` 명령어 `in` 및 `out`을 사용하는 어셈블리 코드를 직접 작성하는 대신 `x86_64` 크레이트가 제공하는 추상화된 API를 사용할 것입니다. `Cargo.toml`의 `dependencies` 목록에 `x86_64` 크레이트를 추가합니다:
+
+[`x86_64`]: https://docs.rs/x86_64/0.14.2/x86_64/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+x86_64 = "0.14.2"
+```
+
+`x86_64` 크레이트가 제공하는 [`Port`] 타입을 사용해 아래처럼 `exit_qemu` 함수를 작성합니다:
+
+[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
+
+```rust
+// in src/main.rs
+
+#[derive(Debug, Clone, Copy, PartialEq, Eq)]
+#[repr(u32)]
+pub enum QemuExitCode {
+ Success = 0x10,
+ Failed = 0x11,
+}
+
+pub fn exit_qemu(exit_code: QemuExitCode) {
+ use x86_64::instructions::port::Port;
+
+ unsafe {
+ let mut port = Port::new(0xf4);
+ port.write(exit_code as u32);
+ }
+}
+```
+
+이 함수는 새로운 [`Port`]를 주소 `0xf4`(`isa-debug-exit` 장치의 `iobase`)에 생성합니다. 그다음 인자로 받은 종료 상태 코드를 포트로 전달합니다. 여기서 `u32` 타입을 사용하는 이유는 앞에서 우리가 `isa-debug-exit` 장치의 `iosize`를 4 바이트로 설정했기 때문입니다. 입출력 포트에 값을 쓰는 것은 잘못하면 프로그램이 예상치 못한 행동을 보일 수 있어 위험하다고 간주합니다. 따라서 이 함수가 처리하는 두 작업 모두 `unsafe` 블록 안에 배치해야 합니다.
+
+`QemuExitCode` enum 타입을 이용하여 프로그램 종료 상태를 표현합니다. 모든 테스트가 성공적으로 실행되었다면 "성공" 종료 코드를 반환하고 그렇지 않았다면 "실패" 종료 코드를 반환하도록 구현할 것입니다. enum에는 `#[repr(u32)]` 속성이 적용하여 enum의 각 분류 값은 `u32` 타입의 값으로 표현됩니다. `0x10`을 성공 종료 코드로 사용하고 `0x11`을 실패 종료 코드로 사용할 것입니다. QEMU가 이미 사용 중인 종료 코드와 중복되지만 않는다면, 어떤 값을 성공/실패 종료 코드로 사용하는지는 크게 중요하지 않습니다. `0`을 성공 종료 코드로 사용하는 것은 바람직하지 않은데, 그 이유는 종료 코드 변환 결과인 `(0 << 1) | 1 = 1`의 값이 QEMU가 실행 실패 시 반환하는 코드와 동일하기 때문입니다. 이 경우 종료 코드만으로는 QEMU가 실행을 실패한 것인지 모든 테스트가 성공적으로 실행된 것인지 구분하기 어렵습니다.
+
+이제 `test_runner` 함수를 수정하여 모든 테스트 실행 완료 시 QEMU가 종료하도록 합니다.
+
+```rust
+// in src/main.rs
+
+fn test_runner(tests: &[&dyn Fn()]) {
+ println!("Running {} tests", tests.len());
+ for test in tests {
+ test();
+ }
+ /// new
+ exit_qemu(QemuExitCode::Success);
+}
+```
+
+`cargo test`를 다시 실행하면 테스트 실행 완료 직후에 QEMU가 종료되는 것을 확인할 수 있습니다.
+여기서 문제는 우리가 `Success` 종료 코드를 전달했는데도 불구하고 `cargo test`는 테스트들이 전부 실패했다고 인식한다는 것입니다.
+
+```
+> cargo test
+ Finished dev [unoptimized + debuginfo] target(s) in 0.03s
+ Running target/x86_64-blog_os/debug/deps/blog_os-5804fc7d2dd4c9be
+Building bootloader
+ Compiling bootloader v0.5.3 (/home/philipp/Documents/bootloader)
+ Finished release [optimized + debuginfo] target(s) in 1.07s
+Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
+ deps/bootimage-blog_os-5804fc7d2dd4c9be.bin -device isa-debug-exit,iobase=0xf4,
+ iosize=0x04`
+error: test failed, to rerun pass '--bin blog_os'
+```
+
+`cargo test`는 `0` 이외의 모든 에러 코드 값을 보면 실행이 실패했다고 간주합니다.
+
+### 실행 성공 시 종료 코드
+
+`bootimage` 도구의 설정 키 `test-success-exit-code`를 이용하면 특정 종료 코드가 종료 코드 `0`처럼 취급되도록 할 수 있습니다.
+
+```toml
+# in Cargo.toml
+
+[package.metadata.bootimage]
+test-args = […]
+test-success-exit-code = 33 # (0x10 << 1) | 1
+```
+
+이 설정을 이용하면 우리가 반환하는 성공 종료 코드를 `bootimage` 도구가 종료 코드 0으로 변환합니다. 이제 `cargo test`는 테스트 실행이 성공했다고 인식합니다.
+
+test_runner는 이제 테스트 결과를 출력한 후 QEMU를 자동으로 종료합니다. QEMU 창이 매우 짧은 시간 동안만 떠 있기에 QEMU 창에 출력된 테스트 결과를 제대로 읽기 어렵습니다. QEMU 종료 후에도 충분한 시간을 갖고 테스트 결과를 읽을 수 있으려면 테스트 결과가 콘솔에 출력되는 편이 나을 것입니다.
+
+## 콘솔에 출력하기
+
+테스트 결과를 콘솔에서 확인하려면 우리의 커널에서 호스트 시스템으로 출력 결과 데이터를 전송해야 합니다. 이것을 달성하는 방법은 여러 가지 있습니다. 한 방법은 TCP 네트워크 통신을 이용해 데이터를 전달하는 것입니다. 하지만 네트워크 통신 스택을 구현하는 것은 상당히 복잡하기에, 우리는 좀 더 간단한 해결책을 이용할 것입니다.
+
+### 직렬 포트 (Serial Port)
+
+데이터를 전송하는 쉬운 방법 중 하나는 바로 [직렬 포트 (serial port)][serial port]를 이용하는 것입니다. 직렬 포트 하드웨어는 근대의 컴퓨터들에서는 찾아보기 어렵습니다. 하지만 직렬 포트의 기능 자체는 소프트웨어로 쉽게 구현할 수 있으며, 직렬 통신을 통해 우리의 커널에서 QEMU로 전송한 데이터를 다시 QEMU에서 호스트 시스템의 표준 출력 및 파일로 재전달할 수 있습니다.
+
+[serial port]: https://en.wikipedia.org/wiki/Serial_port
+
+직렬 통신을 구현하는 칩을 [UART][UARTs]라고 부릅니다. x86에서 사용할 수 있는 [다양한 종류의 UART 구현 모델들][lots of UART models]이 존재하며, 다양한 구현 모델들 간 차이는 우리가 쓰지 않을 고급 기능 사용 시에만 유의미합니다. 우리의 테스트 프레임워크에서는 대부분의 UART 구현 모델들과 호환되는 [16550 UART] 모델을 이용할 것입니다.
+
+[UARTs]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter
+[lots of UART models]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
+[16550 UART]: https://en.wikipedia.org/wiki/16550_UART
+
+[`uart_16550`] 크레이트를 이용해 UART 초기 설정을 마친 후 직렬 포트를 통해 데이터를 전송할 것입니다. `Cargo.toml`과 `main.rs`에 아래의 내용을 추가하여 의존 크레이트를 추가합니다.
+
+[`uart_16550`]: https://docs.rs/uart_16550
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+uart_16550 = "0.2.0"
+```
+
+`uart_16550` 크레이트는 UART 레지스터를 나타내는 `SerialPort` 구조체 타입을 제공합니다. 이 구조체 타입의 인스턴스를 생성하기 위해 아래와 같이 새 모듈 `serial`을 작성합니다.
+
+```rust
+// in src/main.rs
+
+mod serial;
+```
+
+```rust
+// in src/serial.rs
+
+use uart_16550::SerialPort;
+use spin::Mutex;
+use lazy_static::lazy_static;
+
+lazy_static! {
+ pub static ref SERIAL1: Mutex = {
+ let mut serial_port = unsafe { SerialPort::new(0x3F8) };
+ serial_port.init();
+ Mutex::new(serial_port)
+ };
+}
+```
+
+[VGA 텍스트 버퍼][vga lazy-static]를 구현할 때와 마찬가지로 `lazy_static` 매크로와 스핀 락을 사용해 정적 변수 `SERIAL1`을 생성했습니다. `lazy_static`을 사용함으로써 `SERIAL1`이 최초로 사용되는 시점에 단 한 번만 `init` 함수가 호출됩니다.
+
+`isa-debug-exit` 장치와 마찬가지로 UART 또한 포트 입출력을 통해 프로그래밍 됩니다. UART는 좀 더 복잡해서 장치의 레지스터 여러 개를 이용하기 위해 여러 개의 입출력 포트를 사용합니다. unsafe 함수 `SerialPort::new`는 첫 번째 입출력 포트의 주소를 인자로 받고 그것을 통해 필요한 모든 포트들의 주소들을 알아냅니다. 첫 번째 시리얼 통신 인터페이스의 표준 포트 번호인 `0x3F8`을 인자로 전달합니다.
+
+[vga lazy-static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
+
+직렬 포트를 쉽게 사용할 수 있도록 `serial_print!` 및 `serial_println!` 매크로를 추가해줍니다.
+
+```rust
+// in src/serial.rs
+
+#[doc(hidden)]
+pub fn _print(args: ::core::fmt::Arguments) {
+ use core::fmt::Write;
+ SERIAL1.lock().write_fmt(args).expect("Printing to serial failed");
+}
+
+/// Prints to the host through the serial interface.
+#[macro_export]
+macro_rules! serial_print {
+ ($($arg:tt)*) => {
+ $crate::serial::_print(format_args!($($arg)*));
+ };
+}
+
+/// Prints to the host through the serial interface, appending a newline.
+#[macro_export]
+macro_rules! serial_println {
+ () => ($crate::serial_print!("\n"));
+ ($fmt:expr) => ($crate::serial_print!(concat!($fmt, "\n")));
+ ($fmt:expr, $($arg:tt)*) => ($crate::serial_print!(
+ concat!($fmt, "\n"), $($arg)*));
+}
+```
+
+구현은 이전 포스트에서 작성했던 `print` 및 `println` 매크로와 매우 유사합니다. `SerialPort` 타입은 이미 [`fmt::Write`] 트레이트를 구현하기에 우리가 새로 구현할 필요가 없습니다.
+
+[`fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
+
+이제 VGA 텍스트 버퍼가 아닌 직렬 통신 인터페이스로 메시지를 출력할 수 있습니다.
+
+```rust
+// in src/main.rs
+
+#[cfg(test)]
+fn test_runner(tests: &[&dyn Fn()]) {
+ serial_println!("Running {} tests", tests.len());
+ […]
+}
+
+#[test_case]
+fn trivial_assertion() {
+ serial_print!("trivial assertion... ");
+ assert_eq!(1, 1);
+ serial_println!("[ok]");
+}
+```
+
+`serial_println` 매크로에 `#[macro_export]` 속성을 적용하여 이제 이 매크로는 프로젝트 루트 네임스페이스에 배정되어 있습니다.
+따라서 `use crate::serial::serial_println`을 이용해서는 해당 함수를 불러올 수 없습니다.
+
+### QEMU로 전달해야 할 인자들
+
+QEMU에서 직렬 통신 출력 내용을 확인하려면 QEMU에 `-serial` 인자를 전달하여 출력내용을 표준 출력으로 내보내야 합니다.
+
+```toml
+# in Cargo.toml
+
+[package.metadata.bootimage]
+test-args = [
+ "-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio"
+]
+```
+
+`cargo test` 실행 시 테스트 결과를 콘솔에서 바로 확인할 수 있습니다.
+
+```
+> cargo test
+ Finished dev [unoptimized + debuginfo] target(s) in 0.02s
+ Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
+Building bootloader
+ Finished release [optimized + debuginfo] target(s) in 0.02s
+Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
+ deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
+ isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
+Running 1 tests
+trivial assertion... [ok]
+```
+
+테스트 실패 시 여전히 출력 메시지가 QEMU에서 출력되는데, 그 이유는 패닉 핸들러가 `println`을 쓰고 있기 때문입니다.
+테스트 `trivial_assertion` 내의 가정문을 `assert_eq!(0, 1)`로 변경하고 다시 실행하여 출력 결과를 확인해보세요.
+
+
+
+다른 테스트 결과는 시리얼 포트를 통해 출력되지만, 패닉 메시지는 여전히 VGA 버퍼에 출력되고 있습니다. 패닉 메시지는 중요한 정보를 포함하기에 콘솔에서 다른 메시지들과 함께 볼 수 있는 편이 더 편리할 것입니다.
+
+### 패닉 시 오류 메시지 출력하기
+
+[조건부 컴파일][conditional compilation]을 통해 테스트 모드에서 다른 패닉 핸들러를 사용하도록 하면,
+패닉 발생 시 콘솔에 에러 메시지를 출력한 후 QEMU를 종료시킬 수 있습니다.
+
+[conditional compilation]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
+
+```rust
+// in src/main.rs
+
+// our existing panic handler
+#[cfg(not(test))] // new attribute
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ println!("{}", info);
+ loop {}
+}
+
+// our panic handler in test mode
+#[cfg(test)]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ serial_println!("[failed]\n");
+ serial_println!("Error: {}\n", info);
+ exit_qemu(QemuExitCode::Failed);
+ loop {}
+}
+```
+
+테스트용 패닉 핸들러에서는 `println` 대신 `serial_println`을 사용하고, QEMU는 실행 실패를 나타내는 종료 코드를 반환하면서 종료됩니다. 컴파일러는 `isa-debug-exit` 장치가 프로그램을 종료시킨다는 것을 알지 못하기에, `exit_qemu` 호출 이후의 무한 루프는 여전히 필요합니다.
+
+이제 테스트 실패 시에도 QEMU가 종료되고 콘솔에 에러 메시지가 출력됩니다.
+
+```
+> cargo test
+ Finished dev [unoptimized + debuginfo] target(s) in 0.02s
+ Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
+Building bootloader
+ Finished release [optimized + debuginfo] target(s) in 0.02s
+Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
+ deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
+ isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
+Running 1 tests
+trivial assertion... [failed]
+
+Error: panicked at 'assertion failed: `(left == right)`
+ left: `0`,
+ right: `1`', src/main.rs:65:5
+```
+
+이제 모든 테스트 결과 내용을 콘솔에서 확인할 수 있기에, 잠깐 생겼다가 사라지는 QEMU 윈도우 창은 더 이상 필요하지 않습니다. 이제 QEMU 창을 완전히 숨기는 방법에 대해 알아보겠습니다.
+
+### QEMU 창 숨기기
+
+우린 이제 `isa-debug-exit` 장치와 시리얼 포트를 통해 모든 테스트 결과를 보고하므로 더 이상 QEMU 윈도우 창이 필요하지 않습니다. `-display none` 인자를 QEMU에 전달하면 QEMU 윈도우 창을 숨길 수 있습니다:
+
+```toml
+# in Cargo.toml
+
+[package.metadata.bootimage]
+test-args = [
+ "-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio",
+ "-display", "none"
+]
+```
+
+이제 QEMU는 완전히 백그라운드에서 동작합니다 (QEMU 윈도우 창이 생성되지 않습니다). 이제 우리의 테스트 프레임워크를 그래픽 사용자 인터페이스가 지원되지 않는 환경(CI 서비스 혹은 [SSH] 연결)에서도 구동할 수 있게 되었습니다.
+
+[SSH]: https://en.wikipedia.org/wiki/Secure_Shell
+
+### 타임아웃
+
+`cargo test`는 test_runner가 종료할 때까지 기다리기 때문에, 실행이 끝나지 않는 테스트가 있다면 test_runner와 `cargo test`는 영원히 종료되지 않을 수 있습니다. 일반적인 소프트웨어 개발 상황에서는 무한 루프를 방지하는 것이 어렵지 않습니다. 하지만 커널을 작성하는 경우에는 다양한 상황에서 무한 루프가 발생할 수 있습니다:
+
+- 부트로더가 커널을 불러오는 것에 실패하는 경우, 시스템은 무한히 재부팅을 시도합니다.
+- BIOS/UEFI 펌웨어가 부트로더를 불러오는 것에 실패하는 경우, 시스템은 무한히 재부팅을 시도합니다.
+- QEMU의 `isa-debug-exit` 장치가 제대로 동작하지 않는 등의 이유로 제어 흐름이 우리가 구현한 함수들의 `loop {}`에 도착하는 경우.
+- CPU 예외가 제대로 처리되지 않는 등의 이유로 하드웨어가 시스템 리셋을 일으키는 경우.
+
+무한 루프가 발생할 수 있는 경우의 수가 너무 많기에 `bootimage` 도구는 각 테스트 실행에 5분의 시간 제한을 적용합니다. 제한 시간 안에 테스트 실행이 끝나지 않는다면 해당 테스트의 실행은 실패한 것으로 표기되며 "Timed Out"라는 오류 메시지가 콘솔에 출력됩니다. 덕분에 무한 루프에 갇힌 테스트가 있어도 `cargo test`의 실행이 무한히 지속되지는 않습니다.
+
+`trivial_assertion` 테스트에 무한 루프 `loop {}`를 추가한 후 실행해보세요. `cargo test` 실행 시 5분 후에 해당 테스트가 시간 제한을 초과했다는 메시지가 출력될 것입니다. Cargo.toml의 `test-timeout` 키 값을 변경하여 [제한 시간을 조정][bootimage config]할 수도 있습니다:
+
+[bootimage config]: https://github.com/rust-osdev/bootimage#configuration
+
+```toml
+# in Cargo.toml
+
+[package.metadata.bootimage]
+test-timeout = 300 # (in seconds)
+```
+
+`trivial_assertion` 테스트가 타임아웃 되도록 5분 동안이나 기다리고 싶지 않다면 위의 `test-timeout` 값을 낮추세요.
+
+### 자동으로 출력문 삽입하기
+
+현재 `trivial_assertion` 테스트의 상태 정보는 `serial_print!`/`serial_println!` 매크로를 직접 입력해서 출력하고 있습니다.
+
+```rust
+#[test_case]
+fn trivial_assertion() {
+ serial_print!("trivial assertion... ");
+ assert_eq!(1, 1);
+ serial_println!("[ok]");
+}
+```
+
+새로운 테스트를 작성할 때마다 매번 출력문을 직접 입력하지 않아도 되도록 `test_runner`를 수정해보겠습니다. 아래와 같이 새로운 `Testable` 트레이트를 작성합니다.
+
+```rust
+// in src/main.rs
+
+pub trait Testable {
+ fn run(&self) -> ();
+}
+```
+
+[`Fn()` 트레이트][`Fn()` trait]를 구현하는 모든 타입 `T`에 대해 `Testable` 트레이트를 구현하는 것이 핵심입니다.
+
+[`Fn()` trait]: https://doc.rust-lang.org/stable/core/ops/trait.Fn.html
+
+```rust
+// in src/main.rs
+
+impl Testable for T
+where
+ T: Fn(),
+{
+ fn run(&self) {
+ serial_print!("{}...\t", core::any::type_name::());
+ self();
+ serial_println!("[ok]");
+ }
+}
+```
+
+`run` 함수에서 먼저 [`any::type_name`] 함수를 이용해 테스트 함수의 이름을 출력합니다. 이 함수는 컴파일러 단에서 구현된 함수로, 주어진 타입의 이름을 문자열로 반환합니다. 함수 타입의 경우, 함수 이름이 곧 타입의 이름입니다. `\t` 문자는 [탭 문자][tab character]인데 `[ok]` 메시지를 출력 이전에 여백을 삽입합니다.
+
+[`any::type_name`]: https://doc.rust-lang.org/stable/core/any/fn.type_name.html
+[tab character]: https://en.wikipedia.org/wiki/Tab_key#Tab_characters
+
+함수명을 출력한 후 `self()`를 통해 테스트 함수를 호출합니다. `self`가 `Fn()` 트레이트를 구현한다는 조건을 걸어놨기 때문에 이것이 가능합니다. 테스트 함수가 반환된 후, `[ok]` 메시지를 출력하여 테스트 함수가 패닉하지 않았다는 것을 알립니다.
+
+마지막으로 `test_runner`가 `Testable` 트레이트를 사용하도록 변경해줍니다.
+
+```rust
+// in src/main.rs
+
+#[cfg(test)]
+pub fn test_runner(tests: &[&dyn Testable]) {
+ serial_println!("Running {} tests", tests.len());
+ for test in tests {
+ test.run(); // new
+ }
+ exit_qemu(QemuExitCode::Success);
+}
+```
+
+인자 `tests`의 타입을 `&[&dyn Fn()]`에서 `&[&dyn Testable]`로 변경했고, `test()` 대신 `test.run()`을 호출합니다.
+
+이제 메시지가 자동으로 출력되기에 테스트 `trivial_assertion`에서 출력문들을 전부 지워줍니다.
+
+```rust
+// in src/main.rs
+
+#[test_case]
+fn trivial_assertion() {
+ assert_eq!(1, 1);
+}
+```
+
+`cargo test` 실행 시 아래와 같은 출력 내용이 나타날 것입니다.
+
+```
+Running 1 tests
+blog_os::trivial_assertion... [ok]
+```
+
+함수의 크레이트 네임스페이스 안에서의 전체 경로가 함수 이름으로 출력됩니다. 크레이트 내 다른 모듈들이 같은 이름의 테스트를 갖더라도 구분할 수 있습니다. 그 외에 출력 내용이 크게 달라진 것은 없고, 매번 print문을 직접 입력해야 하는 번거로움을 덜었습니다.
+
+## VGA 버퍼 테스트 하기
+
+제대로 작동하는 테스트 프레임워크를 갖췄으니, VGA 버퍼 구현을 테스트할 테스트들을 몇 개 작성해봅시다. 우선 아주 간단한 테스트를 통해 `println`이 패닉하지 않고 실행되는지 확인해봅시다.
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_simple() {
+ println!("test_println_simple output");
+}
+```
+
+이 테스트는 VGA 버퍼에 간단한 메시지를 출력합니다. 이 테스트 함수가 패닉 없이 실행을 완료한다면 `println` 또한 패닉하지 않았다는 것을 확인할 수 있습니다.
+
+여러 행이 출력되고 기존 행이 화면 밖으로 나가 지워지더라도 패닉이 일어나지 않는다는 것을 확인하기 위해 또다른 테스트를 작성합니다.
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_many() {
+ for _ in 0..200 {
+ println!("test_println_many output");
+ }
+}
+```
+
+출력된 행들이 화면에 제대로 나타나는지 확인하는 테스트 또한 작성합니다.
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ let s = "Some test string that fits on a single line";
+ println!("{}", s);
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+}
+```
+
+이 함수는 테스트 문자열을 정의하여 `println`을 통해 출력한 후, VGA 텍스트 버퍼를 나타내는 `WRITER`를 통해 화면에 출력된 문자들을 하나씩 순회합니다. `println`은 화면의 가장 아래 행에 문자열을 출력한 후 개행 문자를 추가하기 때문에 출력된 문자열은 VGA 버퍼의 `BUFFER_HEIGHT - 2` 번째 행에 저장되어 있습니다.
+
+[`enumerate`]를 통해 문자열의 몇 번째 문자를 순회 중인지 변수 `i`에 기록하고, 변수 `c`로 `i`번째 문자에 접근합니다. screen_char의 `ascii_character`와 `c`를 비교하여 문자열 s의 각 문자가 실제로 VGA 텍스트 버퍼에 출력되었는지 점검합니다.
+
+[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
+
+이 외에도 추가로 작성해볼 수 있는 테스트가 많이 있습니다. 아주 긴 문자열을 `println`을 통해 출력했을 때 패닉이 발생 안 하는지와 문자열이 화면 크기에 맞게 적절히 여러 행에 나누어져 제대로 출력되는지 확인하는 테스트를 작성해볼 수 있을 것입니다. 또한 개행 문자와 출력할 수 없는 문자 및 유니코드가 아닌 문자가 오류 없이 처리되는지 점검하는 테스트도 작성해볼 수 있을 것입니다.
+
+이하 본문에서는 여러 컴포넌트들의 상호 작용을 테스트할 수 있는 _통합 테스트_ 를 어떻게 작성하는지 설명하겠습니다.
+
+## 통합 테스트 (Integration Tests)
+
+Rust에서는 [통합 테스트][integration tests]들을 프로젝트 루트에 `tests` 디렉터리를 만들어 저장하는 것이 관례입니다. Rust의 기본 테스트 프레임워크와 커스텀 테스트 프레임워크 모두 `tests` 디렉터리에 있는 테스트들을 자동으로 식별하고 실행합니다.
+
+[integration tests]: https://doc.rust-lang.org/book/ch11-03-test-organization.html#integration-tests
+
+각 통합 테스트는 `main.rs`와 별개로 독립적인 실행 파일이기에, 실행 시작 함수를 별도로 지정해줘야 합니다.
+예제 통합 테스트 `basic_boot`를 작성하면서 그 과정을 자세히 살펴봅시다:
+
+```rust
+// in tests/basic_boot.rs
+
+#![no_std]
+#![no_main]
+#![feature(custom_test_frameworks)]
+#![test_runner(crate::test_runner)]
+#![reexport_test_harness_main = "test_main"]
+
+use core::panic::PanicInfo;
+
+#[no_mangle] // don't mangle the name of this function
+pub extern "C" fn _start() -> ! {
+ test_main();
+
+ loop {}
+}
+
+fn test_runner(tests: &[&dyn Fn()]) {
+ unimplemented!();
+}
+
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ loop {}
+}
+```
+
+각 통합 테스트는 독립된 실행파일이기에 각각마다의 크레이트 속성(`no_std`, `no_main`, `test_runner` 등)들을 새로 설정해줘야 합니다. 테스트 시작 함수인 `test_main`을 호출할 실행 시작 함수 `_start` 또한 새로 만들어줘야 합니다. 통합 테스트는 테스트 모드가 아닌 이상 빌드되지 않기에 테스트 함수들에 `cfg(test)` 속성을 부여할 필요가 없습니다.
+
+`test_runner` 함수에는 항상 패닉하는 [`unimplemented`] 매크로를 넣었고, 패닉 핸들러에는 무한 루프를 넣었습니다.
+이 테스트 또한 `main.rs`에서 작성한 테스트와 동일하게 `serial_println` 매크로 및 `exit_qemu` 함수를 이용해 작성하면 좋겠지만, 해당 함수들은 별도의 컴파일 유닛인 `main.rs`에 정의되어 있기에 `basic_boot.rs`에서는 사용할 수 없습니다.
+
+[`unimplemented`]: https://doc.rust-lang.org/core/macro.unimplemented.html
+
+`cargo test` 명령어를 실행하면 패닉 핸들러 내의 무한 루프 때문에 실행이 끝나지 않습니다. 키보드에서 `Ctrl+c`를 입력해야 QEMU의 실행을 종료할 수 있습니다.
+
+### 라이브러리 생성하기
+
+`main.rs`에서 작성한 코드 일부를 따로 라이브러리 형태로 분리한 후, 통합 테스트에서 해당 라이브러리를 로드하여 필요한 함수들을 사용할 것입니다. 우선 아래와 같이 새 파일 `src/lib.rs`를 생성합니다.
+
+```rust
+// src/lib.rs
+
+#![no_std]
+
+```
+
+`lib.rs` 또한 `main.rs`와 마찬가지로 cargo가 자동으로 인식하는 특별한 파일입니다. `lib.rs`를 통해 생성되는 라이브러리는 별도의 컴파일 유닛이기에 `lib.rs`에 새로 `#![no_std]` 속성을 명시해야 합니다.
+
+이 라이브러리에 `cargo test`를 사용하도록 테스트 함수들과 속성들을 `main.rs`에서 `lib.rs`로 옮겨옵니다.
+
+```rust
+// in src/lib.rs
+
+#![cfg_attr(test, no_main)]
+#![feature(custom_test_frameworks)]
+#![test_runner(crate::test_runner)]
+#![reexport_test_harness_main = "test_main"]
+
+use core::panic::PanicInfo;
+
+pub trait Testable {
+ fn run(&self) -> ();
+}
+
+impl Testable for T
+where
+ T: Fn(),
+{
+ fn run(&self) {
+ serial_print!("{}...\t", core::any::type_name::());
+ self();
+ serial_println!("[ok]");
+ }
+}
+
+pub fn test_runner(tests: &[&dyn Testable]) {
+ serial_println!("Running {} tests", tests.len());
+ for test in tests {
+ test.run();
+ }
+ exit_qemu(QemuExitCode::Success);
+}
+
+pub fn test_panic_handler(info: &PanicInfo) -> ! {
+ serial_println!("[failed]\n");
+ serial_println!("Error: {}\n", info);
+ exit_qemu(QemuExitCode::Failed);
+ loop {}
+}
+
+/// Entry point for `cargo test`
+#[cfg(test)]
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ test_main();
+ loop {}
+}
+
+#[cfg(test)]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ test_panic_handler(info)
+}
+```
+
+실행 파일 및 통합 테스트에서 `test_runner`를 사용할 수 있도록, `test_runner`를 `public`으로 설정하고 `cfg(test)` 속성을 적용하지 않았습니다. 또한 다른 실행 파일에서 쓸 수 있도록 패닉 핸들러 구현도 public 함수 `test_panic_handler`로 옮겨놓습니다.
+
+`lib.rs`는 `main.rs`와는 독립적으로 테스트됩니다. 그렇기에 라이브러리를 테스트 모드로 빌드할 경우 실행 시작 함수 `_start` 및 패닉 핸들러를 별도로 제공해야 합니다. [`cfg_attr`] 속성을 사용하여 `no_main` 을 인자로 제공해 `no_main` 속성을 테스트 모드 빌드 시에 적용합니다.
+
+[`cfg_attr`]: https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute
+
+`QemuExitcode` enum 과 `exit_qemu` 함수 또한 `src/lib.rs`로 옮기고 public (pub) 키워드를 달아줍니다.
+
+```rust
+// in src/lib.rs
+
+#[derive(Debug, Clone, Copy, PartialEq, Eq)]
+#[repr(u32)]
+pub enum QemuExitCode {
+ Success = 0x10,
+ Failed = 0x11,
+}
+
+pub fn exit_qemu(exit_code: QemuExitCode) {
+ use x86_64::instructions::port::Port;
+
+ unsafe {
+ let mut port = Port::new(0xf4);
+ port.write(exit_code as u32);
+ }
+}
+```
+
+이제 실행 파일 및 통합 테스트에서 이 라이브러리로부터 함수들을 불러와 사용할 수 있습니다. `println` 와 `serial_println` 또한 사용 가능하도록 모듈 선언을 `lib.rs`로 옮깁니다.
+
+```rust
+// in src/lib.rs
+
+pub mod serial;
+pub mod vga_buffer;
+```
+
+각 모듈 선언에 `pub` 키워드를 달아주어 라이브러리 밖에서도 해당 모듈들을 사용할 수 있도록 합니다. `println` 및 `serial_println` 매크로가 각각 vga_buffer 모듈과 serial 모듈의 `_print` 함수 구현을 이용하기에 각 모듈 선언에 `pub` 키워드가 꼭 필요합니다.
+
+`main.rs`를 수정하여 우리가 만든 라이브러리를 사용해보겠습니다.
+
+```rust
+// in src/main.rs
+
+#![no_std]
+#![no_main]
+#![feature(custom_test_frameworks)]
+#![test_runner(blog_os::test_runner)]
+#![reexport_test_harness_main = "test_main"]
+
+use core::panic::PanicInfo;
+use blog_os::println;
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ #[cfg(test)]
+ test_main();
+
+ loop {}
+}
+
+/// This function is called on panic.
+#[cfg(not(test))]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ println!("{}", info);
+ loop {}
+}
+
+#[cfg(test)]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ blog_os::test_panic_handler(info)
+}
+```
+
+우리의 라이브러리는 외부 크레이트와 동일한 방식으로 사용 가능합니다. 라이브러리의 이름은 크레이트 이름 (`blog_os`)과 동일하게 설정됩니다. 위 코드에서 `test_runner` 속성에 `blog_os::test_runner` 함수를 사용하며, `cfg(test)` 속성이 적용된 패닉 핸들러에서 `blog_os::test_panic_handler` 함수를 사용합니다. 또한 라이브러리로부터 `println` 매크로를 가져와 `_start` 함수와 `panic` 함수에서 사용합니다.
+
+이제 `cargo run` 및 `cargo test`가 다시 제대로 동작합니다. 물론 `cargo test`는 여전히 무한히 루프하기에 `ctrl+c`를 통해 종료해야 합니다. 통합 테스트에서 우리의 라이브러리 함수들을 이용해 이것을 고쳐보겠습니다.
+
+### 통합 테스트 완료하기
+
+`src/main.rs`처럼 `tests/basic_boot.rs`에서도 우리가 만든 라이브러리에서 타입들을 불러와 사용할 수 있습니다.
+우린 이제 필요했던 타입 정보들을 불러와서 테스트 작성을 마칠 수 있게 되었습니다.
+
+```rust
+// in tests/basic_boot.rs
+
+#![test_runner(blog_os::test_runner)]
+
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ blog_os::test_panic_handler(info)
+}
+```
+
+테스트 실행 함수를 새로 작성하지 않는 대신 `#![test_runner(crate::test_runner)]` 속성을 `#![test_runner(blog_os::test_runner)]` 속성으로 변경하여 라이브러리의 `test_runner` 함수를 사용합니다. `basic_boot.rs`의 `test_runner` 함수는 이제 필요 없으니 지워줍니다. `main.rs`에서처럼 패닉 핸들러에서 `blog_os::test_panic_handler` 함수를 호출합니다.
+
+다시 `cargo test`를 시도하면 실행을 정상적으로 완료합니다. `lib.rs`와 `main.rs` 그리고 `basic_boot.rs` 각각의 빌드 및 테스트가 따로 실행되는 것을 확인하실 수 있습니다. `main.rs`와 통합 테스트 `basic_boot`의 경우 `#[test_case]` 속성이 적용된 함수가 하나도 없어 "Running 0 tests"라는 메시지가 출력됩니다.
+
+`basic_boot.rs`에 테스트들을 추가할 수 있게 되었습니다. VGA 버퍼를 테스트했던 것처럼, 여기서도 `println`이 패닉 없이 잘 동작하는지 테스트 해보겠습니다.
+
+```rust
+// in tests/basic_boot.rs
+
+use blog_os::println;
+
+#[test_case]
+fn test_println() {
+ println!("test_println output");
+}
+```
+
+`cargo test` 실행 시 테스트 함수들이 제대로 식별되고 실행되는 것을 확인할 수 있습니다.
+
+이 테스트가 VGA 버퍼 테스트 중 하나와 거의 동일해서 이 테스트가 쓸모없어 보일 수 있습니다. 하지만 운영체제 개발을 하면서 점점 `main.rs`의 `_start` 함수와 `lib.rs`의 `_start` 함수에는 서로 다른 초기화 코드가 추가될 수 있기에, 미래에 가서는 두 테스트가 서로 많이 다른 환경을 테스트하게 될 것입니다.
+
+`_start` 함수에서 별도의 초기화 함수를 호출하지 않고 바로 `println` 함수를 테스트함으로써 부팅 직후부터 `println`이 제대로 동작하는지를 확인할 수 있습니다. 패닉 메시지 출력에 `println`을 이용하고 있기에 이 함수가 제대로 동작하는 것이 상당히 중요합니다.
+
+### 앞으로 추가할 만한 테스트들
+
+통합 테스트는 크레이트 실행 파일과는 완전히 별개의 실행파일로 취급됩니다. 이 덕에 크레이트와는 별개의 독립적인 환경 설정을 적용할 수 있고, 또한 코드가 CPU 및 하드웨어 장치와 올바르게 상호 작용하는지 테스트할 수 있습니다.
+
+`basic_boot`는 통합 테스트의 매우 간단한 예시입니다. 커널을 작성해나가면서 커널의 기능도 점점 많아지고 하드웨어와 상호작용하는 방식도 다양해질 것입니다. 통합 테스트를 통해 커널과 하드웨어와의 상호작용이 예상대로 작동하는지 확인할 수 있습니다. 아래와 같은 방향으로 통합 테스트를 작성해볼 수 있을 것입니다.
+
+- **CPU 예외**: 프로그램 코드가 허용되지 않은 작업을 실행하는 경우 (예: 0으로 나누기 연산), CPU는 예외 시그널을 반환합니다. 커널은 이런 예외 상황에 대처할 예외 핸들러를 등록해놓을 수 있습니다. 통합 테스트를 통해 CPU 예외 발생 시 알맞은 예외 핸들러가 호출되는지, 혹은 예외 처리 후 원래 실행 중이던 코드가 문제없이 실행을 계속하는지 확인해볼 수 있습니다.
+
+- **페이지 테이블**: 페이지 테이블은 어떤 메모리 영역에 접근할 수 있고 유효한지 정의합니다. 페이지 테이블의 내용을 변경하여 새 프로그램의 실행에 필요한 메모리 영역을 할당할 수 있습니다. 통합 테스트를 통해 `_start` 함수에서 페이지 테이블의 내용을 변경한 후 `#[test_case]` 속성이 부여된 테스트에서 이상 상황이 발생하지 않았는지 확인해볼 수 있습니다.
+
+- **사용자 공간 프로그램**: 사용자 공간에서 실행되는 프로그램들은 시스템 자원에 대해 제한된 접근 권한을 가집니다. 예를 들면, 사용자 공간 프로그램은 커널의 자료구조 및 실행 중인 다른 프로그램의 메모리 영역에 접근할 수 없습니다. 통합 테스트를 통해 허용되지 않은 작업을 시도하는 사용자 공간 프로그램을 작성한 후 커널이 이를 제대로 차단하는지 확인해볼 수 있습니다.
+
+통합 테스트를 작성할 아이디어는 많이 있습니다. 테스트들을 작성해놓으면 이후에 커널에 새로운 기능을 추가하거나 코드를 리팩토링 할 때 우리가 실수를 저지르지 않는지 확인할 수 있습니다. 커널 코드 구현이 크고 복잡해질수록 더 중요한 사항입니다.
+
+### 패닉을 가정하는 테스트
+
+표준 라이브러리의 테스트 프레임워크는 [`#[should_panic]` 속성][should_panic]을 지원합니다. 이 속성은 패닉 발생을 가정하는 테스트를 작성할 때 쓰입니다. 예를 들어, 유효하지 않은 인자가 함수에 전달된 경우 실행이 실패하는지 확인할 때 이 속성을 사용합니다. 이 속성은 표준 라이브러리의 지원이 필요해서 `#[no_std]` 크레이트에서는 사용할 수 없습니다.
+
+[should_panic]: https://doc.rust-lang.org/rust-by-example/testing/unit_testing.html#testing-panics
+
+`#[should_panic]` 속성을 커널에서 직접 사용하지는 못하지만, 패닉 핸들러에서 실행 성공 여부 코드를 반환하는 통합 테스트를 작성하여 비슷한 기능을 얻을 수 있습니다. 아래처럼 `should_panic`이라는 통합 테스트를 작성해보겠습니다.
+
+```rust
+// in tests/should_panic.rs
+
+#![no_std]
+#![no_main]
+
+use core::panic::PanicInfo;
+use blog_os::{QemuExitCode, exit_qemu, serial_println};
+
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ serial_println!("[ok]");
+ exit_qemu(QemuExitCode::Success);
+ loop {}
+}
+```
+
+이 테스트는 아직 `_start` 함수 및 test_runner를 설정하는 속성들을 정의하지 않아 미완성인 상태입니다. 빠진 부분들을 채워줍시다.
+
+```rust
+// in tests/should_panic.rs
+
+#![feature(custom_test_frameworks)]
+#![test_runner(test_runner)]
+#![reexport_test_harness_main = "test_main"]
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ test_main();
+
+ loop {}
+}
+
+pub fn test_runner(tests: &[&dyn Fn()]) {
+ serial_println!("Running {} tests", tests.len());
+ for test in tests {
+ test();
+ serial_println!("[test did not panic]");
+ exit_qemu(QemuExitCode::Failed);
+ }
+ exit_qemu(QemuExitCode::Success);
+}
+```
+
+`lib.rs`에서의 `test_runner`를 재사용하지 않습니다. 이 테스트는 자체적인 `test_runner` 함수를 정의하며 이 함수는 테스트가 패닉 없이 반환하는 경우, 실행 실패 코드를 반환하며 종료합니다. 정의된 테스트 함수가 하나도 없다면, `test_runner`는 실행 성공 코드를 반환하며 종료합니다. `test_runner`는 테스트 1개 실행 후 종료할 것이기에 `#[test_case]` 속성이 붙은 함수를 1개 이상 선언하는 것은 무의미합니다.
+
+이제 패닉 발생을 가정하는 테스트를 작성할 수 있습니다.
+
+```rust
+// in tests/should_panic.rs
+
+use blog_os::serial_print;
+
+#[test_case]
+fn should_fail() {
+ serial_print!("should_panic::should_fail...\t");
+ assert_eq!(0, 1);
+}
+```
+
+테스트에서 `assert_eq` 매크로를 이용해 0과 1이 같다는 가정을 합니다. 이 가정은 늘 거짓이기에 테스트는 패닉할 것입니다. 여기서는 `Testable` 트레이트를 사용하지 않았기에, 수동으로 `serial_print!` 매크로를 삽입하여 테스트 함수 이름을 출력합니다.
+
+명령어 `cargo test --test should_panic`을 실행하면 패닉이 발생하여 테스트가 성공하는 것을 확인할 수 있습니다.
+`assert_eq` 매크로를 사용한 가정문을 지우고 다시 테스트를 실행하면 _"test did not panic"_ 이라는 메시지가 출력되며 테스트가 실패합니다.
+
+이 방식의 큰 문제는 바로 테스트 함수를 하나밖에 쓸 수 없다는 점입니다. 패닉 핸들러가 호출된 후에는 다른 테스트의 실행을 계속할 수가 없어서, `#[test_case]` 속성이 붙은 함수가 여럿 있더라도 첫 함수만 실행이 됩니다. 이 문제의 해결책을 알고 계신다면 제게 꼭 알려주세요!
+
+### 테스트 하네스 (test harness)를 쓰지 않는 테스트 {#no-harness-tests}
+
+테스트 함수가 1개인 통합 테스트 (예: 우리의 `should_panic` 테스트)는 별도의 test_runner가 필요하지 않습니다.
+이런 테스트들은 test_runner 사용을 해제하고 `_start` 함수에서 직접 실행해도 됩니다.
+
+여기서 핵심은 `Cargo.toml`에서 해당 테스트에 대해 `harness` 플래그를 해제하는 것입니다. 이 플래그는 통합 테스트에 대해 test_runner의 사용 유무를 설정합니다. 플래그가 `false`로 설정된 경우, 기본 및 커스텀 test_runner 모두 사용이 해제되고, 테스트는 일반 실행파일로 취급됩니다.
+
+`should_panic` 테스트에서 `harness` 플래그를 false로 설정합니다.
+
+```toml
+# in Cargo.toml
+
+[[test]]
+name = "should_panic"
+harness = false
+```
+
+`should_panic` 테스트에서 test_runner 사용에 필요한 코드를 모두 제거하면 아래처럼 간소해집니다.
+
+```rust
+// in tests/should_panic.rs
+
+#![no_std]
+#![no_main]
+
+use core::panic::PanicInfo;
+use blog_os::{exit_qemu, serial_print, serial_println, QemuExitCode};
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ should_fail();
+ serial_println!("[test did not panic]");
+ exit_qemu(QemuExitCode::Failed);
+ loop{}
+}
+
+fn should_fail() {
+ serial_print!("should_panic::should_fail...\t");
+ assert_eq!(0, 1);
+}
+
+#[panic_handler]
+fn panic(_info: &PanicInfo) -> ! {
+ serial_println!("[ok]");
+ exit_qemu(QemuExitCode::Success);
+ loop {}
+}
+```
+
+이제 `_start` 함수에서 직접 `should_fail` 함수를 호출하며, `should_fail` 함수가 반환하는 경우 `_start` 함수가 실행 실패를 나타내는 종료 코드를 반환하며 종료합니다. `cargo test --test should_panic`을 실행하여 테스트 결과는 이전과 동일함을 확인할 수 있습니다.
+
+`harness` 속성을 해제하는 것은 복잡한 통합 테스트들을 실행할 때도 유용할 수 있습니다. 예를 들면, 테스트 함수마다 실행 환경에 특정 side effect를 일으키는 경우, 테스트들 간의 실행 순서가 중요하기에 `harness` 속성을 해제하고 테스트들을 원하는 순서대로 실행할 수 있습니다.
+
+## 정리
+
+소프트웨어 테스트는 각 컴포넌트가 예상대로 동작하는지 확인하는 데에 매우 유용합니다. 테스트를 통해 버그의 부재를 보장할 수는 없지만, 개발 중 새롭게 등장한 버그 및 기존의 버그를 찾아내는 데에 여전히 도움이 많이 됩니다.
+
+이 글에서는 Rust 커널 테스트용 프레임워크를 설정하는 방법을 다뤘습니다. Rust가 지원하는 커스텀 테스트 프레임워크 기능을 통해 베어 메탈 환경에서 `#[test_case]` 속성이 적용된 테스트를 지원하는 기능을 구현했습니다. QEMU의 `isa-debug-exit` 장치를 사용해 `test_runner`가 테스트 완료 후 QEMU를 종료하고 테스트 결과를 보고하도록 만들었습니다. VGA 버퍼 대신 콘솔에 에러 메시지를 출력하기 위해 시리얼 포트를 이용하는 기초적인 드라이버 프로그램을 만들었습니다.
+
+`println` 매크로의 구현을 점검하는 테스트들을 작성한 후, 이 글의 후반부에서는 통합 테스트 작성에 대해 다뤘습니다. 통합 테스트는 `tests` 디렉터리에 저장되며 별도의 실행파일로 취급된다는 것을 배웠습니다. 통합 테스트에서 `exit_qemu` 함수 및 `serial_println` 매크로를 사용할 수 있도록 필요한 코드 구현을 크레이트 내 새 라이브러리로 옮겼습니다. 통합 테스트는 분리된 환경에서 실행됩니다. 따라서 통합 테스트를 통해 하드웨어와의 상호작용을 구현한 코드를 시험해볼 수 있으며, 패닉 발생을 가정하는 테스트를 작성할 수도 있습니다.
+
+실제 하드웨어 환경과 유사한 QEMU 상에서 동작하는 테스트 프레임워크를 완성했습니다. 앞으로 커널이 더 복잡해지더라도 더 많은 테스트를 작성하면서 커널 코드를 유지보수할 수 있을 것입니다.
+
+## 다음 단계는 무엇일까요?
+
+다음 글에서는 _CPU exception (예외)_ 에 대해 알아볼 것입니다. 분모가 0인 나누기 연산 혹은 매핑되지 않은 메모리 페이지에 대한 접근 (페이지 폴트) 등 허가되지 않은 작업이 일어났을 때 CPU가 예외를 발생시킵니다. 이러한 예외 발생을 포착하고 분석할 수 있어야 앞으로 커널에 발생할 수많은 오류를 디버깅할 수 있을 것입니다. 예외를 처리하는 과정은 하드웨어 인터럽트를 처리하는 과정(예: 컴퓨터의 키보드 입력을 지원할 때)과 매우 유사합니다.
\ No newline at end of file
diff --git a/blog/content/edition-2/posts/04-testing/index.md b/blog/content/edition-2/posts/04-testing/index.md
index 94b8d4ec..ad94046c 100644
--- a/blog/content/edition-2/posts/04-testing/index.md
+++ b/blog/content/edition-2/posts/04-testing/index.md
@@ -38,7 +38,7 @@ Rust has a [built-in test framework] that is capable of running unit tests witho
[built-in test framework]: https://doc.rust-lang.org/book/ch11-00-testing.html
-Unfortunately it's a bit more complicated for `no_std` applications such as our kernel. The problem is that Rust's test framework implicitly uses the built-in [`test`] library, which depends on the standard library. This means that we can't use the default test framework for our `#[no_std]` kernel.
+Unfortunately, it's a bit more complicated for `no_std` applications such as our kernel. The problem is that Rust's test framework implicitly uses the built-in [`test`] library, which depends on the standard library. This means that we can't use the default test framework for our `#[no_std]` kernel.
[`test`]: https://doc.rust-lang.org/test/index.html
@@ -50,17 +50,17 @@ We can see this when we try to run `cargo test` in our project:
error[E0463]: can't find crate for `test`
```
-Since the `test` crate depends on the standard library, it is not available for our bare metal target. While porting the `test` crate to a `#[no_std]` context [is possible][utest], it is highly unstable and requires some hacks such as redefining the `panic` macro.
+Since the `test` crate depends on the standard library, it is not available for our bare metal target. While porting the `test` crate to a `#[no_std]` context [is possible][utest], it is highly unstable and requires some hacks, such as redefining the `panic` macro.
[utest]: https://github.com/japaric/utest
### Custom Test Frameworks
-Fortunately, Rust supports replacing the default test framework through the unstable [`custom_test_frameworks`] feature. This feature requires no external libraries and thus also works in `#[no_std]` environments. It works by collecting all functions annotated with a `#[test_case]` attribute and then invoking a user-specified runner function with the list of tests as argument. Thus it gives the implementation maximal control over the test process.
+Fortunately, Rust supports replacing the default test framework through the unstable [`custom_test_frameworks`] feature. This feature requires no external libraries and thus also works in `#[no_std]` environments. It works by collecting all functions annotated with a `#[test_case]` attribute and then invoking a user-specified runner function with the list of tests as an argument. Thus, it gives the implementation maximal control over the test process.
[`custom_test_frameworks`]: https://doc.rust-lang.org/unstable-book/language-features/custom-test-frameworks.html
-The disadvantage compared to the default test framework is that many advanced features such as [`should_panic` tests] are not available. Instead, it is up to the implementation to provide such features itself if needed. This is ideal for us since we have a very special execution environment where the default implementations of such advanced features probably wouldn't work anyway. For example, the `#[should_panic]` attribute relies on stack unwinding to catch the panics, which we disabled for our kernel.
+The disadvantage compared to the default test framework is that many advanced features, such as [`should_panic` tests], are not available. Instead, it is up to the implementation to provide such features itself if needed. This is ideal for us since we have a very special execution environment where the default implementations of such advanced features probably wouldn't work anyway. For example, the `#[should_panic]` attribute relies on stack unwinding to catch the panics, which we disabled for our kernel.
[`should_panic` tests]: https://doc.rust-lang.org/book/ch11-01-writing-tests.html#checking-for-panics-with-should_panic
@@ -132,13 +132,13 @@ When we run `cargo test` now, we see the following output:
![QEMU printing "Hello World!", "Running 1 tests", and "trivial assertion... [ok]"](qemu-test-runner-output.png)
-The `tests` slice passed to our `test_runner` function now contains a reference to the `trivial_assertion` function. From the `trivial assertion... [ok]` output on the screen we see that the test was called and that it succeeded.
+The `tests` slice passed to our `test_runner` function now contains a reference to the `trivial_assertion` function. From the `trivial assertion... [ok]` output on the screen, we see that the test was called and that it succeeded.
After executing the tests, our `test_runner` returns to the `test_main` function, which in turn returns to our `_start` entry point function. At the end of `_start`, we enter an endless loop because the entry point function is not allowed to return. This is a problem, because we want `cargo test` to exit after running all tests.
## Exiting QEMU
-Right now we have an endless loop at the end of our `_start` function and need to close QEMU manually on each execution of `cargo test`. This is unfortunate because we also want to run `cargo test` in scripts without user interaction. The clean solution to this would be to implement a proper way to shutdown our OS. Unfortunately this is relatively complex, because it requires implementing support for either the [APM] or [ACPI] power management standard.
+Right now, we have an endless loop at the end of our `_start` function and need to close QEMU manually on each execution of `cargo test`. This is unfortunate because we also want to run `cargo test` in scripts without user interaction. The clean solution to this would be to implement a proper way to shutdown our OS. Unfortunately, this is relatively complex because it requires implementing support for either the [APM] or [ACPI] power management standard.
[APM]: https://wiki.osdev.org/APM
[ACPI]: https://wiki.osdev.org/ACPI
@@ -158,19 +158,19 @@ Together with the device name (`isa-debug-exit`), we pass the two parameters `io
### I/O Ports
-There are two different approaches for communicating between the CPU and peripheral hardware on x86, **memory-mapped I/O** and **port-mapped I/O**. We already used memory-mapped I/O for accessing the [VGA text buffer] through the memory address `0xb8000`. This address is not mapped to RAM, but to some memory on the VGA device.
+There are two different approaches for communicating between the CPU and peripheral hardware on x86, **memory-mapped I/O** and **port-mapped I/O**. We already used memory-mapped I/O for accessing the [VGA text buffer] through the memory address `0xb8000`. This address is not mapped to RAM but to some memory on the VGA device.
[VGA text buffer]: @/edition-2/posts/03-vga-text-buffer/index.md
-In contrast, port-mapped I/O uses a separate I/O bus for communication. Each connected peripheral has one or more port numbers. To communicate with such an I/O port there are special CPU instructions called `in` and `out`, which take a port number and a data byte (there are also variations of these commands that allow sending an `u16` or `u32`).
+In contrast, port-mapped I/O uses a separate I/O bus for communication. Each connected peripheral has one or more port numbers. To communicate with such an I/O port, there are special CPU instructions called `in` and `out`, which take a port number and a data byte (there are also variations of these commands that allow sending a `u16` or `u32`).
-The `isa-debug-exit` devices uses port-mapped I/O. The `iobase` parameter specifies on which port address the device should live (`0xf4` is a [generally unused][list of x86 I/O ports] port on the x86's IO bus) and the `iosize` specifies the port size (`0x04` means four bytes).
+The `isa-debug-exit` device uses port-mapped I/O. The `iobase` parameter specifies on which port address the device should live (`0xf4` is a [generally unused][list of x86 I/O ports] port on the x86's IO bus) and the `iosize` specifies the port size (`0x04` means four bytes).
[list of x86 I/O ports]: https://wiki.osdev.org/I/O_Ports#The_list
### Using the Exit Device
-The functionality of the `isa-debug-exit` device is very simple. When a `value` is written to the I/O port specified by `iobase`, it causes QEMU to exit with [exit status] `(value << 1) | 1`. So when we write `0` to the port QEMU will exit with exit status `(0 << 1) | 1 = 1` and when we write `1` to the port it will exit with exit status `(1 << 1) | 1 = 3`.
+The functionality of the `isa-debug-exit` device is very simple. When a `value` is written to the I/O port specified by `iobase`, it causes QEMU to exit with [exit status] `(value << 1) | 1`. So when we write `0` to the port, QEMU will exit with exit status `(0 << 1) | 1 = 1`, and when we write `1` to the port, it will exit with exit status `(1 << 1) | 1 = 3`.
[exit status]: https://en.wikipedia.org/wiki/Exit_status
@@ -209,11 +209,11 @@ pub fn exit_qemu(exit_code: QemuExitCode) {
}
```
-The function creates a new [`Port`] at `0xf4`, which is the `iobase` of the `isa-debug-exit` device. Then it writes the passed exit code to the port. We use `u32` because we specified the `iosize` of the `isa-debug-exit` device as 4 bytes. Both operations are unsafe, because writing to an I/O port can generally result in arbitrary behavior.
+The function creates a new [`Port`] at `0xf4`, which is the `iobase` of the `isa-debug-exit` device. Then it writes the passed exit code to the port. We use `u32` because we specified the `iosize` of the `isa-debug-exit` device as 4 bytes. Both operations are unsafe because writing to an I/O port can generally result in arbitrary behavior.
-For specifying the exit status, we create a `QemuExitCode` enum. The idea is to exit with the success exit code if all tests succeeded and with the failure exit code otherwise. The enum is marked as `#[repr(u32)]` to represent each variant by an `u32` integer. We use exit code `0x10` for success and `0x11` for failure. The actual exit codes do not matter much, as long as they don't clash with the default exit codes of QEMU. For example, using exit code `0` for success is not a good idea because it becomes `(0 << 1) | 1 = 1` after the transformation, which is the default exit code when QEMU failed to run. So we could not differentiate a QEMU error from a successful test run.
+To specify the exit status, we create a `QemuExitCode` enum. The idea is to exit with the success exit code if all tests succeeded and with the failure exit code otherwise. The enum is marked as `#[repr(u32)]` to represent each variant by a `u32` integer. We use the exit code `0x10` for success and `0x11` for failure. The actual exit codes don't matter much, as long as they don't clash with the default exit codes of QEMU. For example, using exit code `0` for success is not a good idea because it becomes `(0 << 1) | 1 = 1` after the transformation, which is the default exit code when QEMU fails to run. So we could not differentiate a QEMU error from a successful test run.
-We can now update our `test_runner` to exit QEMU after all tests ran:
+We can now update our `test_runner` to exit QEMU after all tests have run:
```rust
// in src/main.rs
@@ -259,11 +259,11 @@ test-success-exit-code = 33 # (0x10 << 1) | 1
With this configuration, `bootimage` maps our success exit code to exit code 0, so that `cargo test` correctly recognizes the success case and does not count the test as failed.
-Our test runner now automatically closes QEMU and correctly reports the test results out. We still see the QEMU window open for a very short time, but it does not suffice to read the results. It would be nice if we could print the test results to the console instead, so that we can still see them after QEMU exited.
+Our test runner now automatically closes QEMU and correctly reports the test results. We still see the QEMU window open for a very short time, but it does not suffice to read the results. It would be nice if we could print the test results to the console instead, so we can still see them after QEMU exits.
## Printing to the Console
-To see the test output on the console, we need to send the data from our kernel to the host system somehow. There are various ways to achieve this, for example by sending the data over a TCP network interface. However, setting up a networking stack is a quite complex task, so we will choose a simpler solution instead.
+To see the test output on the console, we need to send the data from our kernel to the host system somehow. There are various ways to achieve this, for example, by sending the data over a TCP network interface. However, setting up a networking stack is quite a complex task, so we will choose a simpler solution instead.
### Serial Port
@@ -271,7 +271,7 @@ A simple way to send the data is to use the [serial port], an old interface stan
[serial port]: https://en.wikipedia.org/wiki/Serial_port
-The chips implementing a serial interface are called [UARTs]. There are [lots of UART models] on x86, but fortunately the only differences between them are some advanced features we don't need. The common UARTs today are all compatible to the [16550 UART], so we will use that model for our testing framework.
+The chips implementing a serial interface are called [UARTs]. There are [lots of UART models] on x86, but fortunately the only differences between them are some advanced features we don't need. The common UARTs today are all compatible with the [16550 UART], so we will use that model for our testing framework.
[UARTs]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter
[lots of UART models]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
@@ -288,7 +288,7 @@ We will use the [`uart_16550`] crate to initialize the UART and send data over t
uart_16550 = "0.2.0"
```
-The `uart_16550` crate contains a `SerialPort` struct that represents the UART registers, but we still need to construct an instance of it ourselves. For that we create a new `serial` module with the following content:
+The `uart_16550` crate contains a `SerialPort` struct that represents the UART registers, but we still need to construct an instance of it ourselves. For that, we create a new `serial` module with the following content:
```rust
// in src/main.rs
@@ -314,7 +314,7 @@ lazy_static! {
Like with the [VGA text buffer][vga lazy-static], we use `lazy_static` and a spinlock to create a `static` writer instance. By using `lazy_static` we can ensure that the `init` method is called exactly once on its first use.
-Like the `isa-debug-exit` device, the UART is programmed using port I/O. Since the UART is more complex, it uses multiple I/O ports for programming different device registers. The unsafe `SerialPort::new` function expects the address of the first I/O port of the UART as argument, from which it can calculate the addresses of all needed ports. We're passing the port address `0x3F8`, which is the standard port number for the first serial interface.
+Like the `isa-debug-exit` device, the UART is programmed using port I/O. Since the UART is more complex, it uses multiple I/O ports for programming different device registers. The unsafe `SerialPort::new` function expects the address of the first I/O port of the UART as an argument, from which it can calculate the addresses of all needed ports. We're passing the port address `0x3F8`, which is the standard port number for the first serial interface.
[vga lazy-static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
@@ -374,7 +374,7 @@ Note that the `serial_println` macro lives directly under the root namespace bec
### QEMU Arguments
-To see the serial output from QEMU, we need use the `-serial` argument to redirect the output to stdout:
+To see the serial output from QEMU, we need to use the `-serial` argument to redirect the output to stdout:
```toml
# in Cargo.toml
@@ -400,7 +400,7 @@ Running 1 tests
trivial assertion... [ok]
```
-However, when a test fails we still see the output inside QEMU because our panic handler still uses `println`. To simulate this, we can change the assertion in our `trivial_assertion` test to `assert_eq!(0, 1)`:
+However, when a test fails, we still see the output inside QEMU because our panic handler still uses `println`. To simulate this, we can change the assertion in our `trivial_assertion` test to `assert_eq!(0, 1)`:

@@ -472,20 +472,20 @@ test-args = [
]
```
-Now QEMU runs completely in the background and no window is opened anymore. This is not only less annoying, but also allows our test framework to run in environments without a graphical user interface, such as CI services or [SSH] connections.
+Now QEMU runs completely in the background and no window gets opened anymore. This is not only less annoying, but also allows our test framework to run in environments without a graphical user interface, such as CI services or [SSH] connections.
[SSH]: https://en.wikipedia.org/wiki/Secure_Shell
### Timeouts
-Since `cargo test` waits until the test runner exits, a test that never returns can block the test runner forever. That's unfortunate, but not a big problem in practice since it's normally easy to avoid endless loops. In our case, however, endless loops can occur in various situations:
+Since `cargo test` waits until the test runner exits, a test that never returns can block the test runner forever. That's unfortunate, but not a big problem in practice since it's usually easy to avoid endless loops. In our case, however, endless loops can occur in various situations:
- The bootloader fails to load our kernel, which causes the system to reboot endlessly.
- The BIOS/UEFI firmware fails to load the bootloader, which causes the same endless rebooting.
- The CPU enters a `loop {}` statement at the end of some of our functions, for example because the QEMU exit device doesn't work properly.
- The hardware causes a system reset, for example when a CPU exception is not caught (explained in a future post).
-Since endless loops can occur in so many situations, the `bootimage` tool sets a timeout of 5 minutes for each test executable by default. If the test does not finish in this time, it is marked as failed and a "Timed Out" error is printed to the console. This feature ensures that tests that are stuck in an endless loop don't block `cargo test` forever.
+Since endless loops can occur in so many situations, the `bootimage` tool sets a timeout of 5 minutes for each test executable by default. If the test does not finish within this time, it is marked as failed and a "Timed Out" error is printed to the console. This feature ensures that tests that are stuck in an endless loop don't block `cargo test` forever.
You can try it yourself by adding a `loop {}` statement in the `trivial_assertion` test. When you run `cargo test`, you see that the test is marked as timed out after 5 minutes. The timeout duration is [configurable][bootimage config] through a `test-timeout` key in the Cargo.toml:
@@ -547,7 +547,7 @@ We implement the `run` function by first printing the function name using the [`
[`any::type_name`]: https://doc.rust-lang.org/stable/core/any/fn.type_name.html
[tab character]: https://en.wikipedia.org/wiki/Tab_key#Tab_characters
-After printing the function name, we invoke the test function through `self()`. This only works because we require that `self` implements the `Fn()` trait. After the test function returned, we print `[ok]` to indicate that the function did not panic.
+After printing the function name, we invoke the test function through `self()`. This only works because we require that `self` implements the `Fn()` trait. After the test function returns, we print `[ok]` to indicate that the function did not panic.
The last step is to update our `test_runner` to use the new `Testable` trait:
@@ -555,7 +555,7 @@ The last step is to update our `test_runner` to use the new `Testable` trait:
// in src/main.rs
#[cfg(test)]
-pub fn test_runner(tests: &[&dyn Testable]) {
+pub fn test_runner(tests: &[&dyn Testable]) { // new
serial_println!("Running {} tests", tests.len());
for test in tests {
test.run(); // new
@@ -564,7 +564,7 @@ pub fn test_runner(tests: &[&dyn Testable]) {
}
```
-The only two changes are the type of the `tests` argument from `&[&dyn Fn()]` to `&[&dyn Testable]` and that we now call `test.run()` instead of `test()`.
+The only two changes are the type of the `tests` argument from `&[&dyn Fn()]` to `&[&dyn Testable]` and the fact that we now call `test.run()` instead of `test()`.
We can now remove the print statements from our `trivial_assertion` test since they're now printed automatically:
@@ -584,7 +584,7 @@ Running 1 tests
blog_os::trivial_assertion... [ok]
```
-The function name now includes the full path to the function, which is useful when test functions in different modules have the same name. Otherwise the output looks the same as before, but we no longer need to manually add print statements to our tests.
+The function name now includes the full path to the function, which is useful when test functions in different modules have the same name. Otherwise, the output looks the same as before, but we no longer need to add print statements to our tests manually.
## Testing the VGA Buffer
@@ -630,19 +630,19 @@ fn test_println_output() {
}
```
-The function defines a test string, prints it using `println`, and then iterates over the screen characters of the static `WRITER`, which represents the vga text buffer. Since `println` prints to the last screen line and then immediately appends a newline, the string should appear on line `BUFFER_HEIGHT - 2`.
+The function defines a test string, prints it using `println`, and then iterates over the screen characters of the static `WRITER`, which represents the VGA text buffer. Since `println` prints to the last screen line and then immediately appends a newline, the string should appear on line `BUFFER_HEIGHT - 2`.
-By using [`enumerate`], we count the number of iterations in the variable `i`, which we then use for loading the screen character corresponding to `c`. By comparing the `ascii_character` of the screen character with `c`, we ensure that each character of the string really appears in the vga text buffer.
+By using [`enumerate`], we count the number of iterations in the variable `i`, which we then use for loading the screen character corresponding to `c`. By comparing the `ascii_character` of the screen character with `c`, we ensure that each character of the string really appears in the VGA text buffer.
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
-As you can imagine, we could create many more test functions, for example a function that tests that no panic occurs when printing very long lines and that they're wrapped correctly. Or a function for testing that newlines, non-printable characters, and non-unicode characters are handled correctly.
+As you can imagine, we could create many more test functions. For example, a function that tests that no panic occurs when printing very long lines and that they're wrapped correctly, or a function for testing that newlines, non-printable characters, and non-unicode characters are handled correctly.
For the rest of this post, however, we will explain how to create _integration tests_ to test the interaction of different components together.
## Integration Tests
-The convention for [integration tests] in Rust is to put them into a `tests` directory in the project root (i.e. next to the `src` directory). Both the default test framework and custom test frameworks will automatically pick up and execute all tests in that directory.
+The convention for [integration tests] in Rust is to put them into a `tests` directory in the project root (i.e., next to the `src` directory). Both the default test framework and custom test frameworks will automatically pick up and execute all tests in that directory.
[integration tests]: https://doc.rust-lang.org/book/ch11-03-test-organization.html#integration-tests
@@ -678,11 +678,11 @@ fn panic(info: &PanicInfo) -> ! {
Since integration tests are separate executables, we need to provide all the crate attributes (`no_std`, `no_main`, `test_runner`, etc.) again. We also need to create a new entry point function `_start`, which calls the test entry point function `test_main`. We don't need any `cfg(test)` attributes because integration test executables are never built in non-test mode.
-We use the [`unimplemented`] macro that always panics as a placeholder for the `test_runner` function and just `loop` in the `panic` handler for now. Ideally, we want to implement these functions exactly as we did in our `main.rs` using the `serial_println` macro and the `exit_qemu` function. The problem is that we don't have access to these functions since tests are built completely separately of our `main.rs` executable.
+We use the [`unimplemented`] macro that always panics as a placeholder for the `test_runner` function and just `loop` in the `panic` handler for now. Ideally, we want to implement these functions exactly as we did in our `main.rs` using the `serial_println` macro and the `exit_qemu` function. The problem is that we don't have access to these functions since tests are built completely separately from our `main.rs` executable.
[`unimplemented`]: https://doc.rust-lang.org/core/macro.unimplemented.html
-If you run `cargo test` at this stage, you will get an endless loop because the panic handler loops endlessly. You need to use the `Ctrl+c` keyboard shortcut for exiting QEMU.
+If you run `cargo test` at this stage, you will get an endless loop because the panic handler loops endlessly. You need to use the `ctrl+c` keyboard shortcut for exiting QEMU.
### Create a Library
@@ -754,7 +754,7 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-To make our `test_runner` available to executables and integration tests, we don't apply the `cfg(test)` attribute to it and make it public. We also factor out the implementation of our panic handler into a public `test_panic_handler` function, so that it is available for executables too.
+To make our `test_runner` available to executables and integration tests, we make it public and don't apply the `cfg(test)` attribute to it. We also factor out the implementation of our panic handler into a public `test_panic_handler` function, so that it is available for executables too.
Since our `lib.rs` is tested independently of our `main.rs`, we need to add a `_start` entry point and a panic handler when the library is compiled in test mode. By using the [`cfg_attr`] crate attribute, we conditionally enable the `no_main` attribute in this case.
@@ -791,7 +791,7 @@ pub mod serial;
pub mod vga_buffer;
```
-We make the modules public to make them usable from outside of our library. This is also required for making our `println` and `serial_println` macros usable, since they use the `_print` functions of the modules.
+We make the modules public to make them usable outside of our library. This is also required for making our `println` and `serial_println` macros usable since they use the `_print` functions of the modules.
Now we can update our `main.rs` to use the library:
@@ -832,7 +832,7 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-The library is usable like a normal external crate. It is called like our crate, which is `blog_os` in our case. The above code uses the `blog_os::test_runner` function in the `test_runner` attribute and the `blog_os::test_panic_handler` function in our `cfg(test)` panic handler. It also imports the `println` macro to make it available to our `_start` and `panic` functions.
+The library is usable like a normal external crate. It is called `blog_os`, like our crate. The above code uses the `blog_os::test_runner` function in the `test_runner` attribute and the `blog_os::test_panic_handler` function in our `cfg(test)` panic handler. It also imports the `println` macro to make it available to our `_start` and `panic` functions.
At this point, `cargo run` and `cargo test` should work again. Of course, `cargo test` still loops endlessly (you can exit with `ctrl+c`). Let's fix this by using the required library functions in our integration test.
@@ -853,9 +853,9 @@ fn panic(info: &PanicInfo) -> ! {
Instead of reimplementing the test runner, we use the `test_runner` function from our library by changing the `#![test_runner(crate::test_runner)]` attribute to `#![test_runner(blog_os::test_runner)]`. We then don't need the `test_runner` stub function in `basic_boot.rs` anymore, so we can remove it. For our `panic` handler, we call the `blog_os::test_panic_handler` function like we did in our `main.rs`.
-Now `cargo test` exits normally again. When you run it, you see that it builds and runs the tests for our `lib.rs`, `main.rs`, and `basic_boot.rs` separately after each other. For the `main.rs` and the `basic_boot` integration test, it reports "Running 0 tests" since these files don't have any functions annotated with `#[test_case]`.
+Now `cargo test` exits normally again. When you run it, you will see that it builds and runs the tests for our `lib.rs`, `main.rs`, and `basic_boot.rs` separately after each other. For the `main.rs` and the `basic_boot` integration tests, it reports "Running 0 tests" since these files don't have any functions annotated with `#[test_case]`.
-We can now add tests to our `basic_boot.rs`. For example, we can test that `println` works without panicking, like we did in the vga buffer tests:
+We can now add tests to our `basic_boot.rs`. For example, we can test that `println` works without panicking, like we did in the VGA buffer tests:
```rust
// in tests/basic_boot.rs
@@ -870,25 +870,25 @@ fn test_println() {
When we run `cargo test` now, we see that it finds and executes the test function.
-The test might seem a bit useless right now since it's almost identical to one of the VGA buffer tests. However, in the future the `_start` functions of our `main.rs` and `lib.rs` might grow and call various initialization routines before running the `test_main` function, so that the two tests are executed in very different environments.
+The test might seem a bit useless right now since it's almost identical to one of the VGA buffer tests. However, in the future, the `_start` functions of our `main.rs` and `lib.rs` might grow and call various initialization routines before running the `test_main` function, so that the two tests are executed in very different environments.
-By testing `println` in a `basic_boot` environment without calling any initialization routines in `_start`, we can ensure that `println` works right after booting. This is important because we rely on it e.g. for printing panic messages.
+By testing `println` in a `basic_boot` environment without calling any initialization routines in `_start`, we can ensure that `println` works right after booting. This is important because we rely on it, e.g., for printing panic messages.
### Future Tests
The power of integration tests is that they're treated as completely separate executables. This gives them complete control over the environment, which makes it possible to test that the code interacts correctly with the CPU or hardware devices.
-Our `basic_boot` test is a very simple example for an integration test. In the future, our kernel will become much more featureful and interact with the hardware in various ways. By adding integration tests, we can ensure that these interactions work (and keep working) as expected. Some ideas for possible future tests are:
+Our `basic_boot` test is a very simple example of an integration test. In the future, our kernel will become much more featureful and interact with the hardware in various ways. By adding integration tests, we can ensure that these interactions work (and keep working) as expected. Some ideas for possible future tests are:
-- **CPU Exceptions**: When the code performs invalid operations (e.g. divides by zero), the CPU throws an exception. The kernel can register handler functions for such exceptions. An integration test could verify that the correct exception handler is called when a CPU exception occurs or that the execution continues correctly after resolvable exceptions.
-- **Page Tables**: Page tables define which memory regions are valid and accessible. By modifying the page tables, it is possible to allocate new memory regions, for example when launching programs. An integration test could perform some modifications of the page tables in the `_start` function and then verify that the modifications have the desired effects in `#[test_case]` functions.
+- **CPU Exceptions**: When the code performs invalid operations (e.g., divides by zero), the CPU throws an exception. The kernel can register handler functions for such exceptions. An integration test could verify that the correct exception handler is called when a CPU exception occurs or that the execution continues correctly after a resolvable exception.
+- **Page Tables**: Page tables define which memory regions are valid and accessible. By modifying the page tables, it is possible to allocate new memory regions, for example when launching programs. An integration test could modify the page tables in the `_start` function and verify that the modifications have the desired effects in `#[test_case]` functions.
- **Userspace Programs**: Userspace programs are programs with limited access to the system's resources. For example, they don't have access to kernel data structures or to the memory of other programs. An integration test could launch userspace programs that perform forbidden operations and verify that the kernel prevents them all.
As you can imagine, many more tests are possible. By adding such tests, we can ensure that we don't break them accidentally when we add new features to our kernel or refactor our code. This is especially important when our kernel becomes larger and more complex.
### Tests that Should Panic
-The test framework of the standard library supports a [`#[should_panic]` attribute][should_panic] that allows to construct tests that should fail. This is useful for example to verify that a function fails when an invalid argument is passed. Unfortunately this attribute isn't supported in `#[no_std]` crates since it requires support from the standard library.
+The test framework of the standard library supports a [`#[should_panic]` attribute][should_panic] that allows constructing tests that should fail. This is useful, for example, to verify that a function fails when an invalid argument is passed. Unfortunately, this attribute isn't supported in `#[no_std]` crates since it requires support from the standard library.
[should_panic]: https://doc.rust-lang.org/rust-by-example/testing/unit_testing.html#testing-panics
@@ -954,7 +954,7 @@ fn should_fail() {
}
```
-The test uses the `assert_eq` to assert that `0` and `1` are equal. This of course fails, so that our test panics as desired. Note that we need to manually print the function name using `serial_print!` here because we don't use the `Testable` trait.
+The test uses `assert_eq` to assert that `0` and `1` are equal. Of course, this fails, so our test panics as desired. Note that we need to manually print the function name using `serial_print!` here because we don't use the `Testable` trait.
When we run the test through `cargo test --test should_panic` we see that it is successful because the test panicked as expected. When we comment out the assertion and run the test again, we see that it indeed fails with the _"test did not panic"_ message.
@@ -964,7 +964,7 @@ A significant drawback of this approach is that it only works for a single test
For integration tests that only have a single test function (like our `should_panic` test), the test runner isn't really needed. For cases like this, we can disable the test runner completely and run our test directly in the `_start` function.
-The key to this is disable the `harness` flag for the test in the `Cargo.toml`, which defines whether a test runner is used for an integration test. When it's set to `false`, both the default test runner and the custom test runner feature are disabled, so that the test is treated like a normal executable.
+The key to this is to disable the `harness` flag for the test in the `Cargo.toml`, which defines whether a test runner is used for an integration test. When it's set to `false`, both the default test runner and the custom test runner feature are disabled, so that the test is treated like a normal executable.
Let's disable the `harness` flag for our `should_panic` test:
@@ -976,7 +976,7 @@ name = "should_panic"
harness = false
```
-Now we vastly simplify our `should_panic` test by removing the test runner related code. The result looks like this:
+Now we vastly simplify our `should_panic` test by removing the `test_runner`-related code. The result looks like this:
```rust
// in tests/should_panic.rs
@@ -1010,13 +1010,13 @@ fn panic(_info: &PanicInfo) -> ! {
We now call the `should_fail` function directly from our `_start` function and exit with a failure exit code if it returns. When we run `cargo test --test should_panic` now, we see that the test behaves exactly as before.
-Apart from creating `should_panic` tests, disabling the `harness` attribute can also be useful for complex integration tests, for example when the individual test functions have side effects and need to be run in a specified order.
+Apart from creating `should_panic` tests, disabling the `harness` attribute can also be useful for complex integration tests, for example, when the individual test functions have side effects and need to be run in a specified order.
## Summary
-Testing is a very useful technique to ensure that certain components have a desired behavior. Even if they cannot show the absence of bugs, they're still an useful tool for finding them and especially for avoiding regressions.
+Testing is a very useful technique to ensure that certain components have the desired behavior. Even if they cannot show the absence of bugs, they're still a useful tool for finding them and especially for avoiding regressions.
-This post explained how to set up a test framework for our Rust kernel. We used the custom test frameworks feature of Rust to implement support for a simple `#[test_case]` attribute in our bare-metal environment. By using the `isa-debug-exit` device of QEMU, our test runner can exit QEMU after running the tests and report the test status out. To print error messages to the console instead of the VGA buffer, we created a basic driver for the serial port.
+This post explained how to set up a test framework for our Rust kernel. We used Rust's custom test frameworks feature to implement support for a simple `#[test_case]` attribute in our bare-metal environment. Using the `isa-debug-exit` device of QEMU, our test runner can exit QEMU after running the tests and report the test status. To print error messages to the console instead of the VGA buffer, we created a basic driver for the serial port.
After creating some tests for our `println` macro, we explored integration tests in the second half of the post. We learned that they live in the `tests` directory and are treated as completely separate executables. To give them access to the `exit_qemu` function and the `serial_println` macro, we moved most of our code into a library that can be imported by all executables and integration tests. Since integration tests run in their own separate environment, they make it possible to test interactions with the hardware or to create tests that should panic.
diff --git a/blog/content/edition-2/posts/04-testing/index.zh-CN.md b/blog/content/edition-2/posts/04-testing/index.zh-CN.md
index a343d67a..9d19e6ee 100644
--- a/blog/content/edition-2/posts/04-testing/index.zh-CN.md
+++ b/blog/content/edition-2/posts/04-testing/index.zh-CN.md
@@ -6,16 +6,18 @@ date = 2019-04-27
[extra]
# Please update this when updating the translation
-translation_based_on_commit = "bd6fbcb1c36705b2c474d7fcee387bfea1210851"
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
# GitHub usernames of the people that translated this post
-translators = ["luojia65", "Rustin-Liu"]
+translators = ["luojia65", "Rustin-Liu", "liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong"]
+++
本文主要讲述了在`no_std`环境下进行单元测试和集成测试的方法。我们将通过Rust的自定义测试框架来在我们的内核中执行一些测试函数。为了将结果反馈到QEMU上,我们需要使用QEMU的一些其他的功能以及`bootimage`工具。
-这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部]留言。你可以在[这里][post branch]找到这篇文章的完整源码。
+这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-04`][post branch]找到这篇文章的完整源码。
[GitHub]: https://github.com/phil-opp/blog_os
[at the bottom]: #comments
@@ -26,33 +28,33 @@ translators = ["luojia65", "Rustin-Liu"]
## 阅读要求
-这篇文章替换了此前的(现在已经过时了) [_单元测试(Unit Testing)_] 和 [_集成测试(Integration Tests)_] 两篇文章。这里我将假定你是在2019-04-27日后阅读的[_最小Rust内核_]一文。总而言之,本文要求你已经有一个[设置默认目标]的 `.cargo/config` 文件且[定义了一个runner可执行文件]。
+这篇文章替换了此前的(现在已经过时了) [_单元测试(Unit Testing)_][_Unit Testing_] 和 [_集成测试(Integration Tests)_][_Integration Tests_] 两篇文章。这里我将假定你是在2019-04-27日后阅读的[_最小Rust内核_][_A Minimal Rust Kernel_]一文。总而言之,本文要求你已经有一个[已设置默认目标][sets a default target]的 `.cargo/config` 文件且[定义了一个runner可执行文件][defines a runner executable]。
-[_单元测试(Unit Testing)_]: @/edition-2/posts/deprecated/04-unit-testing/index.md
-[_集成测试(Integration Tests)_]: @/edition-2/posts/deprecated/05-integration-tests/index.md
-[_最小Rust内核_]: @/edition-2/posts/02-minimal-rust-kernel/index.md
-[设置默认目标]: @/edition-2/posts/02-minimal-rust-kernel/index.md#set-a-default-target
-[定义了一个runner可执行文件]: @/edition-2/posts/02-minimal-rust-kernel/index.md#using-cargo-run
+[_Unit Testing_]: @/edition-2/posts/deprecated/04-unit-testing/index.md
+[_Integration Tests_]: @/edition-2/posts/deprecated/05-integration-tests/index.md
+[_A Minimal Rust Kernel_]: @/edition-2/posts/02-minimal-rust-kernel/index.md
+[sets a default target]: @/edition-2/posts/02-minimal-rust-kernel/index.md#set-a-default-target
+[defines a runner executable]: @/edition-2/posts/02-minimal-rust-kernel/index.md#using-cargo-run
## Rust中的测试
-Rust有一个**内置的测试框架**([built-in test framework]):无需任何设置就可以进行单元测试,只需要创建一个通过assert来检查结果的函数并在函数的头部加上`#[test]`属性即可。然后`cargo test`会自动找到并执行你的crate中的所有测试函数。
+Rust有一个**内置的测试框架**([built-in test framework]):无需任何设置就可以进行单元测试,只需要创建一个通过assert来检查结果的函数并在函数的头部加上 `#[test]` 属性即可。然后 `cargo test` 会自动找到并执行你的crate中的所有测试函数。
[built-in test framework]: https://doc.rust-lang.org/book/second-edition/ch11-00-testing.html
-不幸的是,对于一个`no_std`的应用,比如我们的内核,这有点点复杂。现在的问题是,Rust的测试框架会隐式的调用内置的[`test`]库,但是这个库依赖于标准库。这也就是说我们的 `#[no_std]`内核无法使用默认的测试框架。
+不幸的是,对于一个 `no_std` 的应用,比如我们的内核,这就有点复杂了。现在的问题是,Rust的测试框架会隐式的调用内置的[`test`]库,但是这个库依赖于标准库。这也就是说我们的 `#[no_std]` 内核无法使用默认的测试框架。
[`test`]: https://doc.rust-lang.org/test/index.html
-当我们试图在我们的项目中执行`cargo xtest`时,我们可以看到如下信息:
+当我们试图在我们的项目中执行 `cargo test` 时,我们可以看到如下信息:
```
-> cargo xtest
+> cargo test
Compiling blog_os v0.1.0 (/…/blog_os)
error[E0463]: can't find crate for `test`
```
-由于`test`crate依赖于标准库,所以它在我们的裸机目标上并不可用。虽然将`test`crate移植到一个 `#[no_std]` 上下文环境中是[可能的][utest],但是这样做是高度不稳定的并且还会需要一些特殊的hacks,例如重定义 `panic` 宏。
+由于 `test` 库依赖于标准库,所以它在我们的裸机目标上并不可用。虽然将 `test` 库移植到一个 `#[no_std]` 上下文环境中是[可能的][utest],但是这样做是高度不稳定的,并且还会需要一些特殊的hacks,例如重定义 `panic` 宏。
[utest]: https://github.com/japaric/utest
@@ -62,11 +64,11 @@ error[E0463]: can't find crate for `test`
[`custom_test_frameworks`]: https://doc.rust-lang.org/unstable-book/language-features/custom-test-frameworks.html
-与默认的测试框架相比,它的缺点是有一些高级功能诸如 [`should_panic` tests]都不可用了。相对的,如果需要这些功能,我们需要自己来实现。当然,这点对我们来说是好事,因为我们的环境非常特殊,在这个环境里,这些高级功能的默认实现无论如何都是无法工作的,举个例子, `#[should_panic]`属性依赖于堆栈展开来捕获内核panic,而我的内核早已将其禁用了。
+与默认的测试框架相比,它的缺点是有一些高级功能诸如 [`should_panic` tests] 都不可用了。相对的,如果需要这些功能,我们需要自己来实现。当然,这点对我们来说是好事,因为我们的环境非常特殊,在这个环境里,这些高级功能的默认实现无论如何都是无法工作的,举个例子, `#[should_panic]` 属性依赖于栈展开来捕获内核panic,而我们的内核早已将其禁用了。
[`should_panic` tests]: https://doc.rust-lang.org/book/ch11-01-writing-tests.html#checking-for-panics-with-should_panic
-要为我们的内核实现自定义测试框架,我们需要将如下代码添加到我们的`main.rs`中去:
+要为我们的内核实现自定义测试框架,我们需要将如下代码添加到我们的 `main.rs` 中去:
```rust
// in src/main.rs
@@ -89,7 +91,13 @@ fn test_runner(tests: &[&dyn Fn()]) {
[_trait object_]: https://doc.rust-lang.org/1.30.0/book/first-edition/trait-objects.html
[_Fn()_]: https://doc.rust-lang.org/std/ops/trait.Fn.html
-现在当我们运行 `cargo xtest` ,我们可以发现运行成功了。然而,我们看到的仍然是"Hello World"而不是我们的 `test_runner`传递来的信息。这是由于我们的入口点仍然是 `_start` 函数——自定义测试框架会生成一个`main`函数来调用`test_runner`,但是由于我们使用了 `#[no_main]`并提供了我们自己的入口点,所以这个`main`函数就被忽略了。
+现在当我们运行 `cargo test` ,我们可以发现运行成功了。然而,我们看到的仍然是"Hello World"而不是我们的 `test_runner`传递来的信息。这是由于我们的入口点仍然是 `_start` 函数——自定义测试框架会生成一个`main`函数来调用`test_runner`,但是由于我们使用了 `#[no_main]`并提供了我们自己的入口点,所以这个`main`函数就被忽略了。
+
+
为了修复这个问题,我们需要通过 `reexport_test_harness_main`属性来将生成的函数的名称更改为与`main`不同的名称。然后我们可以在我们的`_start`函数里调用这个重命名的函数:
@@ -109,11 +117,9 @@ pub extern "C" fn _start() -> ! {
}
```
-我们将测试框架的入口函数的名字设置为`test_main`,并在我们的 `_start`入口点里调用它。通过使用**条件编译**([conditional compilation]),我们能够只在上下文环境为测试(test)时调用`test_main`,因为该函数将不在非测试上下文中生成。
+我们将测试框架的入口函数的名字设置为`test_main`,并在我们的 `_start`入口点里调用它。通过使用**条件编译**([conditional compilation]),我们能够只在上下文环境为测试(test)时调用 `test_main` ,因为该函数将不在非测试上下文中生成。
-[ conditional compilation ]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
-
-现在当我们执行 `cargo xtest`时,我们可以看到我们的`test_runner`将"Running 0 tests"信息显示在屏幕上了。我们可以创建第一个测试函数了:
+现在当我们执行 `cargo test`时,我们可以看到我们的`test_runner`将"Running 0 tests"信息显示在屏幕上了。我们可以创建第一个测试函数了:
```rust
// in src/main.rs
@@ -126,22 +132,22 @@ fn trivial_assertion() {
}
```
-现在,当我们运行 `cargo xtest`时,我们可以看到如下输出:
+现在,当我们运行 `cargo test` 时,我们可以看到如下输出:
![QEMU printing "Hello World!", "Running 1 tests", and "trivial assertion... [ok]"](https://os.phil-opp.com/testing/qemu-test-runner-output.png)
-传递给 `test_runner`函数的`tests`切片里包含了一个 `trivial_assertion` 函数的引用,从屏幕上输出的 `trivial assertion... [ok]`信息可见,我们的测试已被调用并且顺利通过。
+传递给 `test_runner`函数的`tests`切片里包含了一个 `trivial_assertion` 函数的引用,从屏幕上输出的 `trivial assertion... [ok]` 信息可见,我们的测试已被调用并且顺利通过。
-在执行完tests后, `test_runner`会将结果返回给 `test_main`函数,而这个函数又返回到 `_start`入口点函数——这样我们就进入了一个死循环,因为入口点函数是不允许返回的。这将导致一个问题:我们希望`cargo xtest`在所有的测试运行完毕后,才返回并退出。
+在执行完tests后, `test_runner` 会将结果返回给 `test_main` 函数,而这个函数又返回到 `_start` 入口点函数——这样我们就进入了一个死循环,因为入口点函数是不允许返回的。这将导致一个问题:我们希望 `cargo test` 在所有的测试运行完毕后,直接返回并退出。
## 退出QEMU
-现在我们在`_start`函数结束后进入了一个死循环,所以每次执行完`cargo xtest`后我们都需要手动去关闭QEMU;但是我们还想在没有用户交互的脚本环境下执行 `cargo xtest`。解决这个问题的最佳方式,是实现一个合适的方法来关闭我们的操作系统——不幸的是,这个方式实现起来相对有些复杂,因为这要求我们实现对[APM]或[ACPI]电源管理标准的支持。
+现在我们在 `_start` 函数结束后进入了一个死循环,所以每次执行完 `cargo test` 后我们都需要手动去关闭QEMU;但是我们还想在没有用户交互的脚本环境下执行 `cargo test`。解决这个问题的最佳方式,是实现一个合适的方法来关闭我们的操作系统——不幸的是,这个方式实现起来相对有些复杂,因为这要求我们实现对[APM]或[ACPI]电源管理标准的支持。
[APM]: https://wiki.osdev.org/APM
[ACPI]: https://wiki.osdev.org/ACPI
-幸运的是,还有一个绕开这些问题的办法:QEMU支持一种名为 `isa-debug-exit`的特殊设备,它提供了一种从客户系统(guest system)里退出QEMU的简单方式。为了使用这个设备,我们需要向QEMU传递一个`-device`参数。当然,我们也可以通过将 `package.metadata.bootimage.test-args` 配置关键字添加到我们的`Cargo.toml`来达到目的:
+幸运的是,还有一个绕开这些问题的办法:QEMU支持一种名为 `isa-debug-exit` 的特殊设备,它提供了一种从客户系统(guest system)里退出QEMU的简单方式。为了使用这个设备,我们需要向QEMU传递一个 `-device` 参数。当然,我们也可以通过将 `package.metadata.bootimage.test-args` 配置关键字添加到我们的 `Cargo.toml` 来达到目的:
```toml
# in Cargo.toml
@@ -150,29 +156,29 @@ fn trivial_assertion() {
test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
```
- `bootimage runner` 会在QEMU的默认测试命令后添加`test-args` 参数。(对于`cargo xrun`命令,这个参数会被忽略。)
+`bootimage runner` 会在QEMU的默认测试命令后添加 `test-args` 参数。(对于 `cargo run` 命令,这个参数会被忽略。)
在传递设备名 (`isa-debug-exit`)的同时,我们还传递了两个参数,`iobase` 和 `iosize` 。这两个参数指定了一个_I/O 端口_,我们的内核将通过它来访问设备。
### I/O 端口
-在x86平台上,CPU和外围硬件通信通常有两种方式,**内存映射I/O**和**端口映射I/O**。之前,我们已经使用内存映射的方式,通过内存地址`0xb8000`访问了[VGA文本缓冲区]。该地址并没有映射到RAM,而是映射到了VGA设备的一部分内存上。
+
+在x86平台上,CPU和外围硬件通信通常有两种方式,**内存映射I/O**和**端口映射I/O**。之前,我们已经使用内存映射的方式,通过内存地址 `0xb8000` 访问了[VGA文本缓冲区]。该地址并没有映射到RAM,而是映射到了VGA设备的一部分内存上。
[VGA text buffer]: @/edition-2/posts/03-vga-text-buffer/index.md
-与内存映射不同,端口映射I/O使用独立的I/O总线来进行通信。每个外围设备都有一个或数个端口号。CPU采用了特殊的`in`和`out`指令来和端口通信,这些指令要求一个端口号和一个字节的数据作为参数(有些这种指令的变体也允许发送`u16`或是`u32`长度的数据)。
+与内存映射不同,端口映射I/O使用独立的I/O总线来进行通信。每个外围设备都有一个或数个端口号。CPU采用了特殊的`in`和`out`指令来和端口通信,这些指令要求一个端口号和一个字节的数据作为参数(有些这种指令的变体也允许发送 `u16` 或是 `u32` 长度的数据)。
-`isa-debug-exit`设备使用的就是端口映射I/O。其中, `iobase` 参数指定了设备对应的端口地址(在x86中,`0xf4`是一个[通常未被使用的端口][list of x86 I/O ports]),而`iosize`则指定了端口的大小(`0x04`代表4字节)。
+`isa-debug-exit` 设备使用的就是端口映射I/O。其中, `iobase` 参数指定了设备对应的端口地址(在x86中,`0xf4` 是一个[通常未被使用的端口][list of x86 I/O ports]),而 `iosize` 则指定了端口的大小(`0x04` 代表4字节)。
[list of x86 I/O ports]: https://wiki.osdev.org/I/O_Ports#The_list
### 使用退出(Exit)设备
- `isa-debug-exit`设备的功能非常简单。当一个 `value`写入`iobase`指定的端口时,它会导致QEMU以**退出状态**([exit status])`(value << 1) | 1`退出。也就是说,当我们向端口写入`0`时,QEMU将以退出状态`(0 << 1) | 1 = 1`退出,而当我们向端口写入`1`时,它将以退出状态`(1 << 1) | 1 = 3`退出。
+`isa-debug-exit` 设备的功能非常简单。当一个 `value` 写入 `iobase` 指定的端口时,它会导致QEMU以**退出状态**([exit status])`(value << 1) | 1` 退出。也就是说,当我们向端口写入 `0` 时,QEMU将以退出状态 `(0 << 1) | 1 = 1` 退出,而当我们向端口写入`1`时,它将以退出状态 `(1 << 1) | 1 = 3` 退出。
[exit status]: https://en.wikipedia.org/wiki/Exit_status
-这里我们使用 [`x86_64`] crate提供的抽象,而不是手动调用`in`或`out`指令。为了添加对该crate的依赖,我们可以将其添加到我们的 `Cargo.toml`中的 `dependencies` 小节中去:
-
+这里我们使用 [`x86_64`] crate提供的抽象,而不是手动调用 `in` 或 `out` 指令。为了添加对该crate的依赖,我们可以将其添加到我们的 `Cargo.toml`中的 `dependencies` 小节中去:
[`x86_64`]: https://docs.rs/x86_64/0.14.2/x86_64/
@@ -183,7 +189,7 @@ test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
x86_64 = "0.14.2"
```
-现在我们可以使用crate中提供的[`Port`] 类型来创建一个`exit_qemu` 函数了:
+现在我们可以使用crate中提供的 [`Port`] 类型来创建一个 `exit_qemu` 函数了:
[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
@@ -207,13 +213,15 @@ pub fn exit_qemu(exit_code: QemuExitCode) {
}
```
-该函数在`0xf4`处创建了一个新的端口,该端口同时也是 `isa-debug-exit` 设备的 `iobase` 。然后它会向端口写入传递的退出代码。这里我们使用`u32`来传递数据,因为我们之前已经将 `isa-debug-exit`设备的 `iosize` 指定为4字节了。上述两个操作都是`unsafe`的,因为I/O端口的写入操作通常会导致一些不可预知的行为。
+该函数在 `0xf4` 处创建了一个新的端口,该端口同时也是 `isa-debug-exit` 设备的 `iobase` 。然后它会向端口写入传递的退出代码。这里我们使用 `u32` 来传递数据,因为我们之前已经将 `isa-debug-exit` 设备的 `iosize` 指定为4字节了。上述两个操作都是 `unsafe` 的,因为I/O端口的写入操作通常会导致一些不可预知的行为。
-为了指定退出状态,我们创建了一个 `QemuExitCode`枚举。思路大体上是,如果所有的测试均成功,就以成功退出码退出;否则就以失败退出码退出。这个枚举类型被标记为 `#[repr(u32)]`,代表每个变量都是一个`u32`的整数类型。我们使用退出代码`0x10`代表成功,`0x11`代表失败。 实际的退出代码并不重要,只要它们不与QEMU的默认退出代码冲突即可。 例如,使用退出代码0表示成功可能并不是一个好主意,因为它在转换后就变成了`(0 << 1) | 1 = 1` ,而`1`是QEMU运行失败时的默认退出代码。 这样,我们就无法将QEMU错误与成功的测试运行区分开来了。
+为了指定退出状态,我们创建了一个 `QemuExitCode` 枚举。思路大体上是,如果所有的测试均成功,就以成功退出码退出;否则就以失败退出码退出。这个枚举类型被标记为 `#[repr(u32)]`,代表每个变量都是一个 `u32` 的整数类型。我们使用退出代码 `0x10` 代表成功,`0x11` 代表失败。 实际的退出代码并不重要,只要它们不与QEMU的默认退出代码冲突即可。 例如,使用退出代码0表示成功可能并不是一个好主意,因为它在转换后就变成了 `(0 << 1) | 1 = 1` ,而 `1` 是QEMU运行失败时的默认退出代码。 这样,我们就无法将QEMU错误与成功的测试运行区分开来了。
-现在我们来更新`test_runner`的代码,让程序在运行所有测试完毕后退出QEMU:
+现在我们来更新 `test_runner` 的代码,让程序在运行所有测试完毕后退出QEMU:
```rust
+// in src/main.rs
+
fn test_runner(tests: &[&dyn Fn()]) {
println!("Running {} tests", tests.len());
for test in tests {
@@ -224,10 +232,10 @@ fn test_runner(tests: &[&dyn Fn()]) {
}
```
-当我们现在运行`cargo xtest`时,QEMU会在测试运行后立刻退出。现在的问题是,即使我们传递了表示成功(`Success`)的退出代码, `cargo test`依然会将所有的测试都视为失败:
+当我们现在运行 `cargo test` 时,QEMU会在测试运行后立刻退出。现在的问题是,即使我们传递了表示成功(`Success`)的退出代码, `cargo test` 依然会将所有的测试都视为失败:
```
-> cargo xtest
+> cargo test
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Running target/x86_64-blog_os/debug/deps/blog_os-5804fc7d2dd4c9be
Building bootloader
@@ -239,39 +247,41 @@ Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/d
error: test failed, to rerun pass '--bin blog_os'
```
-这里的问题在于,`cargo test`会将所有非`0`的错误码都视为测试失败。
+这里的问题在于,`cargo test` 会将所有非 `0` 的错误码都视为测试失败。
### 成功退出(Exit)代码
-为了解决这个问题, `bootimage`提供了一个 `test-success-exit-code`配置项,可以将指定的退出代码映射到退出代码`0`:
+为了解决这个问题, `bootimage` 提供了一个 `test-success-exit-code` 配置项,可以将指定的退出代码映射到退出代码 `0`:
```toml
+# in Cargo.toml
+
[package.metadata.bootimage]
test-args = […]
test-success-exit-code = 33 # (0x10 << 1) | 1
```
-有了这个配置,`bootimage`就会将我们的成功退出码映射到退出码0;这样一来, `cargo xtest`就能正确的识别出测试成功的情况,而不会将其视为测试失败。
+有了这个配置,`bootimage` 就会将我们的成功退出码映射到退出码0;这样一来, `cargo test` 就能正确地识别出测试成功的情况,而不会将其视为测试失败。
-我们的测试runner现在会在正确报告测试结果后自动关闭QEMU。我们可以看到QEMU的窗口只会显示很短的时间——我们不容易看清测试的结果。如果测试结果会打印在控制台上而不是QEMU里,让我们能在QEMU退出后仍然能看到测试结果就好了。
+我们的 test runner 现在会在正确报告测试结果后自动关闭QEMU。我们可以看到QEMU的窗口只会显示很短的时间——我们很难看清测试的结果。如果测试结果会打印在控制台上而不是QEMU里,让我们能在QEMU退出后仍然能看到测试结果就好了。
## 打印到控制台
-要在控制台上查看测试输出,我们需要以某种方式将数据从内核发送到宿主系统。 有多种方法可以实现这一点,例如通过TCP网络接口来发送数据。但是,设置网络堆栈是一项很复杂的任务——这里我们选择更简单的解决方案。
+要在控制台上查看测试输出,我们需要以某种方式将数据从内核发送到宿主系统。 有多种方法可以实现这一点,例如通过TCP网络接口来发送数据。但是,设置网络堆栈是一项很复杂的任务,这里我们可以选择更简单的解决方案。
### 串口
-发送数据的一个简单的方式是通过[串行端口],这是一个现代电脑中已经不存在的旧标准接口(译者注:玩过单片机的同学应该知道,其实译者上大学的时候有些同学的笔记本电脑还有串口的,没有串口的同学在烧录单片机程序的时候也都会需要usb转串口线,一般是51,像stm32有st-link,这个另说,不过其实也可以用串口来下载)。串口非常易于编程,QEMU可以将通过串口发送的数据重定向到宿主机的标准输出或是文件中。
+发送数据的一个简单的方式是通过[串行端口][serial port],这是一个现代电脑中已经不存在的旧标准接口(译者注:玩过单片机的同学应该知道,其实译者上大学的时候有些同学的笔记本电脑还有串口的,没有串口的同学在烧录单片机程序的时候也都会需要usb转串口线,一般是51,像stm32有st-link,这个另说,不过其实也可以用串口来下载)。串口非常易于编程,QEMU可以将通过串口发送的数据重定向到宿主机的标准输出或是文件中。
-[串行端口]: https://en.wikipedia.org/wiki/Serial_port
+[serial port]: https://en.wikipedia.org/wiki/Serial_port
-用来实现串行接口的芯片被称为 [UARTs]。在x86上,有[很多UART模型],但是幸运的是,它们之间仅有的那些不同之处都是我们用不到的高级功能。目前通用的UARTs都会兼容[16550 UART],所以我们在我们测试框架里采用该模型。
+用来实现串行接口的芯片被称为 [UARTs]。在x86上,有[很多UART模型][lots of UART models],但是幸运的是,它们之间仅有的那些不同之处都是我们用不到的高级功能。目前通用的UARTs都会兼容[16550 UART],所以我们在我们测试框架里采用该模型。
[UARTs]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter
-[很多UART模型]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
+[lots of UART models]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
[16550 UART]: https://en.wikipedia.org/wiki/16550_UART
-我们使用[`uart_16550`] crate来初始化UART,并通过串口来发送数据。为了将该crate添加为依赖,我们将我们的`Cargo.toml`和`main.rs`修改为如下:
+我们使用 [`uart_16550`] crate来初始化UART,并通过串口来发送数据。为了将该crate添加为依赖,我们需要将 `Cargo.toml` 和 `main.rs` 修改为如下:
[`uart_16550`]: https://docs.rs/uart_16550
@@ -282,7 +292,7 @@ test-success-exit-code = 33 # (0x10 << 1) | 1
uart_16550 = "0.2.0"
```
- `uart_16550` crate包含了一个代表UART寄存器的`SerialPort`结构体,但是我们仍然需要自己来创建一个相应的实例。我们使用以下内容来创建一个新的串口模块`serial`:
+`uart_16550` crate包含了一个代表UART寄存器的 `SerialPort` 结构体,但是我们仍然需要自己来创建一个相应的实例。我们使用以下代码来创建一个新的串口模块 `serial`:
```rust
// in src/main.rs
@@ -306,15 +316,17 @@ lazy_static! {
}
```
-就像[VGA文本缓冲区][vga lazy-static]一样,我们使用 `lazy_static` 和一个自旋锁来创建一个 `static` writer实例。通过使用 `lazy_static` ,我们可以保证`init`方法只会在该示例第一次被使用使被调用。
+就像[VGA文本缓冲区][vga lazy-static]一样,我们使用 `lazy_static` 和一个自旋锁来创建一个 `static` writer实例。通过使用 `lazy_static` ,我们可以保证 `init` 方法只会在该示例第一次被使用使被调用。
-和 `isa-debug-exit`设备一样,UART也是用过I/O端口进行编程的。由于UART相对来讲更加复杂,它使用多个I/O端口来对不同的设备寄存器进行编程。不安全的`SerialPort::new`函数需要UART的第一个I/O端口的地址作为参数,从该地址中可以计算出所有所需端口的地址。我们传递的端口地址为`0x3F8` ,该地址是第一个串行接口的标准端口号。
+和 `isa-debug-exit` 设备一样,UART也是通过I/O端口进行编程的。由于UART相对来讲更加复杂,它使用多个I/O端口来对不同的设备寄存器进行编程。`unsafe` 的 `SerialPort::new` 函数需要UART的第一个I/O端口的地址作为参数,从该地址中可以计算出所有所需端口的地址。我们传递的端口地址为 `0x3F8` ,该地址是第一个串行接口的标准端口号。
[vga lazy-static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
为了使串口更加易用,我们添加了 `serial_print!` 和 `serial_println!`宏:
```rust
+// in src/serial.rs
+
#[doc(hidden)]
pub fn _print(args: ::core::fmt::Arguments) {
use core::fmt::Write;
@@ -339,7 +351,7 @@ macro_rules! serial_println {
}
```
-该实现和我们此前的`print`和`println`宏的实现非常类似。 由于`SerialPort`类型已经实现了`fmt::Write` trait,所以我们不需要提供我们自己的实现了。
+该实现和我们此前的 `print` 和 `println` 宏的实现非常类似。 由于 `SerialPort` 类型已经实现了 [`fmt::Write`] trait,所以我们不需要提供我们自己的实现了。
[`fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
@@ -362,11 +374,11 @@ fn trivial_assertion() {
}
```
-注意,由于我们使用了 `#[macro_export]` 属性, `serial_println`宏直接位于根命名空间下——所以通过`use crate::serial::serial_println` 来导入该宏是不起作用的。
+注意,由于我们使用了 `#[macro_export]` 属性, `serial_println` 宏直接位于根命名空间下,所以通过 `use crate::serial::serial_println` 来导入该宏是不起作用的。
### QEMU参数
-为了查看QEMU的串行输出,我们需要使用`-serial`参数将输出重定向到stdout:
+为了查看QEMU的串行输出,我们需要使用 `-serial` 参数将输出重定向到stdout:
```toml
# in Cargo.toml
@@ -377,10 +389,10 @@ test-args = [
]
```
-现在,当我们运行 `cargo xtest`时,我们可以直接在控制台里看到测试输出了:
+现在,当我们运行 `cargo test` 时,我们可以直接在控制台里看到测试输出了:
```
-> cargo xtest
+> cargo test
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
Building bootloader
@@ -392,7 +404,7 @@ Running 1 tests
trivial assertion... [ok]
```
-然而,当测试失败时,我们仍然会在QEMU内看到输出结果,因为我们的panic handler还是用了`println`。为了模拟这个过程,我们将我们的 `trivial_assertion` test中的断言(assertion)修改为 `assert_eq!(0, 1)`:
+然而,当测试失败时,我们仍然会在QEMU内看到输出结果,因为我们的panic handler还是用了 `println`。为了模拟这个过程,我们将我们的 `trivial_assertion` test中的断言(assertion)修改为 `assert_eq!(0, 1)`:
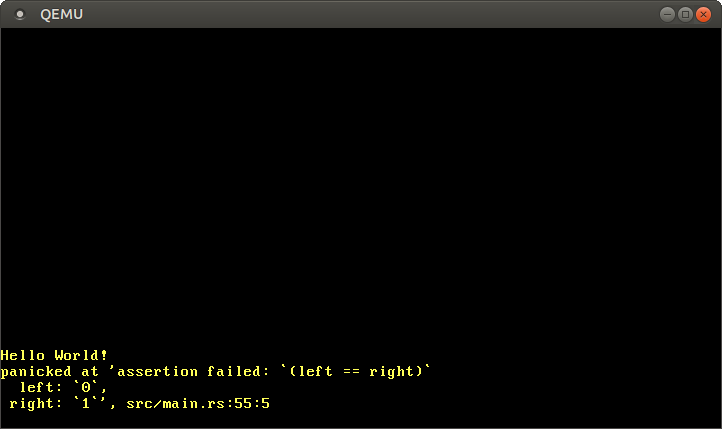
@@ -406,6 +418,8 @@ trivial assertion... [ok]
[conditional compilation]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
```rust
+// in src/main.rs
+
// our existing panic handler
#[cfg(not(test))] // new attribute
#[panic_handler]
@@ -425,12 +439,12 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-在我们的测试panic处理中,我们用 `serial_println`来代替`println` 并使用失败代码来退出QEMU。注意,在`exit_qemu`调用后,我们仍然需要一个无限循环的`loop`因为编译器并不知道 `isa-debug-exit`设备会导致程序退出。
+在我们的测试panic处理中,我们用 `serial_println` 来代替 `println` 并使用失败代码来退出QEMU。注意,在 `exit_qemu` 调用后,我们仍然需要一个无限循环的 `loop` 因为编译器并不知道 `isa-debug-exit` 设备会导致程序退出。
-现在,即使在测试失败的情况下QEMU仍然会存在,并会将一些有用的错误信息打印到控制台:
+现在,即使在测试失败的情况下QEMU仍然会退出,并会将一些有用的错误信息打印到控制台:
```
-> cargo xtest
+> cargo test
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
Building bootloader
@@ -450,7 +464,7 @@ Error: panicked at 'assertion failed: `(left == right)`
### 隐藏 QEMU
-由于我们使用`isa-debug-exit`设备和串行端口来报告完整的测试结果,所以我们不再需要QMEU的窗口了。我们可以通过向QEMU传递 `-display none`参数来将其隐藏:
+由于我们使用 `isa-debug-exit` 设备和串行端口来报告完整的测试结果,所以我们不再需要QEMU的窗口了。我们可以通过向QEMU传递 `-display none` 参数来将其隐藏:
```toml
# in Cargo.toml
@@ -462,23 +476,22 @@ test-args = [
]
```
-现在QEMU完全在后台运行且没有任何窗口会被打开。这不仅不那么烦人,还允许我们的测试框架在没有图形界面的环境里,诸如CI服务器或是[SSH]连接里运行。
+现在QEMU完全在后台运行,且没有任何窗口会被打开。这不仅很清爽,还允许我们的测试框架在没有图形界面的环境里,诸如CI服务器或是[SSH]连接里运行。
[SSH]: https://en.wikipedia.org/wiki/Secure_Shell
### 超时
-由于 `cargo xtest` 会等待test runner退出,如果一个测试永远不返回那么它就会一直阻塞test runner。幸运的是,在实际应用中这并不是一个大问题,因为无限循环通常是很容易避免的。在我们的这个例子里,无限循环会发生在以下几种不同的情况中:
-
+由于 `cargo test` 会等待test runner退出,如果一个测试永远不返回那么它就会一直阻塞test runner。幸运的是,在实际应用中这并不是一个大问题,因为无限循环通常是很容易避免的。在我们的这个例子里,无限循环会发生在以下几种不同的情况中:
- bootloader加载内核失败,导致系统不停重启;
- BIOS/UEFI固件加载bootloader失败,同样会导致无限重启;
-- CPU在某些函数结束时进入一个`loop {}`语句,例如因为QEMU的exit设备无法正常工作而导致死循环;
+- CPU在某些函数结束时进入一个 `loop {}` 语句,例如因为QEMU的exit设备无法正常工作而导致死循环;
- 硬件触发了系统重置,例如未捕获CPU异常时(后续的文章将会详细解释)。
-由于无限循环可能会在各种情况中发生,因此, `bootimage` 工具默认为每个可执行测试设置了一个长度为5分钟的超时时间。如果测试未在此时间内完成,则将其标记为失败,并向控制台输出"Timed Out(超时)"错误。这个功能确保了那些卡在无限循环里的测试不会一直阻塞`cargo xtest`。
+由于无限循环可能会在各种情况中发生,因此, `bootimage` 工具默认为每个可执行测试设置了一个长度为5分钟的超时时间。如果测试未在此时间内完成,则将其标记为失败,并向控制台输出"Timed Out(超时)"错误。这个功能确保了那些卡在无限循环里的测试不会一直阻塞 `cargo test`。
-你可以将`loop {}`语句添加到 `trivial_assertion`测试中来进行尝试。当你运行 `cargo xtest`时,你可以发现该测试会在五分钟后被标记为超时。超时持续的时间可以通过Cargo.toml中的`test-timeout`来进行[配置][bootimage config]:
+你可以将`loop {}`语句添加到 `trivial_assertion` 测试中来进行尝试。当你运行 `cargo test` 时,你可以发现该测试会在五分钟后被标记为超时。超时持续的时间可以通过Cargo.toml中的 `test-timeout` 配置项来进行[配置][bootimage config]:
[bootimage config]: https://github.com/rust-osdev/bootimage#configuration
@@ -489,9 +502,93 @@ test-args = [
test-timeout = 300 # (in seconds)
```
-如果你不想为了观察`trivial_assertion` 测试超时等待5分钟之久,你可以暂时降低将上述值。
+如果你不想为了观察 `trivial_assertion` 测试超时等待5分钟之久,你可以将这个配置数值调低一些。
-此后,我们不再需要 `trivial_assertion` 测试,所以我们可以将其删除。
+### 自动添加打印语句
+
+`trivial_assertion` 测试仅能使用 `serial_print!`/`serial_println!` 输出自己的状态信息:
+
+```rust
+#[test_case]
+fn trivial_assertion() {
+ serial_print!("trivial assertion... ");
+ assert_eq!(1, 1);
+ serial_println!("[ok]");
+}
+```
+
+为每一个测试手动添加固定的日志实在是太烦琐了,所以我们可以修改一下 `test_runner` 把这部分逻辑改进一下,使其可以自动添加日志输出。那么我们先建立一个 `Testable` trait:
+
+```rust
+// in src/main.rs
+
+pub trait Testable {
+ fn run(&self) -> ();
+}
+```
+
+下面这个 trick 将会实现上面书写的 trait,并约束只有满足 [`Fn()` trait] 的泛型可使用这个实现:
+
+[`Fn()` trait]: https://doc.rust-lang.org/stable/core/ops/trait.Fn.html
+
+```rust
+// in src/main.rs
+
+impl Testable for T
+where
+ T: Fn(),
+{
+ fn run(&self) {
+ serial_print!("{}...\t", core::any::type_name::());
+ self();
+ serial_println!("[ok]");
+ }
+}
+```
+
+我们实现的 `run` 函数中,首先使用 [`any::type_name`] 输出了函数名,这个函数事实上是被编译器实现的,可以返回任意类型的字符串形式。对于函数而言,其类型的字符串形式就是它的函数名,而函数名也正是我们想要的测试用例名称。至于 `\t` 则代表 [制表符][tab character],其作用是为后面的 `[ok]` 输出增加一点左边距。
+
+[`any::type_name`]: https://doc.rust-lang.org/stable/core/any/fn.type_name.html
+[tab character]: https://en.wikipedia.org/wiki/Tab_key#Tab_characters
+
+输出函数名之后,我们通过 `self()` 调用了测试函数本身,该调用方式属于 `Fn()` trait 独有,如果测试函数顺利执行完毕,则 `[ok]` 也会被输出出来。
+
+最后一步就是给 `test_runner` 的参数附加上 `Testable` trait:
+
+```rust
+// in src/main.rs
+
+#[cfg(test)]
+pub fn test_runner(tests: &[&dyn Testable]) {
+ serial_println!("Running {} tests", tests.len());
+ for test in tests {
+ test.run(); // new
+ }
+ exit_qemu(QemuExitCode::Success);
+}
+```
+
+仅有的两处修改,就是将 `tests` 参数的类型从 `&[&dyn Fn()]` 改为了 `&[&dyn Testable]`,以及将函数调用方式从 `test()` 改成了 `test.run()`。
+
+由于我们已经完成了首尾输出的自动化,所以 `trivial_assertion` 里那两行输出语句也就可以删掉了:
+
+```rust
+// in src/main.rs
+
+#[test_case]
+fn trivial_assertion() {
+ assert_eq!(1, 1);
+}
+```
+
+现在 `cargo test` 的输出就变成了下面这样:
+
+```
+Running 1 tests
+blog_os::trivial_assertion... [ok]
+```
+
+如你所见,自动生成的函数名包含了完整的内部路径,但是也因此可以区分不同模块下的同名函数。除此之外,其输出和之前看起来完全相同,我们也就不再需要在测试函数内部加输出语句了。
## 测试VGA缓冲区
@@ -500,18 +597,13 @@ test-timeout = 300 # (in seconds)
```rust
// in src/vga_buffer.rs
-#[cfg(test)]
-use crate::{serial_print, serial_println};
-
#[test_case]
fn test_println_simple() {
- serial_print!("test_println... ");
println!("test_println_simple output");
- serial_println!("[ok]");
}
```
-这个测试所做的仅仅是将一些内容打印到VGA缓冲区。如果它正常结束并且没有panic,也就意味着`println`调用也没有panic。由于我们只需要将 `serial_println` 导入到测试模式里,所以我们添加了 `cfg(test)` 属性(attribute)来避免正常模式下 `cargo xbuild`会出现的未使用导入警告(unused import warning)。
+这个测试所做的仅仅是将一些内容打印到VGA缓冲区。如果它正常结束并且没有panic,也就意味着 `println` 调用也没有panic。
为了确保即使打印很多行且有些行超出屏幕的情况下也没有panic发生,我们可以创建另一个测试:
@@ -520,11 +612,9 @@ fn test_println_simple() {
#[test_case]
fn test_println_many() {
- serial_print!("test_println_many... ");
for _ in 0..200 {
println!("test_println_many output");
}
- serial_println!("[ok]");
}
```
@@ -535,22 +625,18 @@ fn test_println_many() {
#[test_case]
fn test_println_output() {
- serial_print!("test_println_output... ");
-
let s = "Some test string that fits on a single line";
println!("{}", s);
for (i, c) in s.chars().enumerate() {
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
assert_eq!(char::from(screen_char.ascii_character), c);
}
-
- serial_println!("[ok]");
}
```
-该函数定义了一个测试字符串,并通过 `println`将其输出,然后遍历静态 `WRITER`也就是vga字符缓冲区的屏幕字符。由于`println`在将字符串打印到屏幕上最后一行后会立刻附加一个新行(即输出完后有一个换行符),所以这个字符串应该会出现在第 `BUFFER_HEIGHT - 2`行。
+该函数定义了一个测试字符串,并通过 `println`将其输出,然后遍历静态 `WRITER` 也就是vga字符缓冲区的屏幕字符。由于 `println` 在将字符串打印到屏幕上最后一行后会立刻附加一个新行(即输出完后有一个换行符),所以这个字符串应该会出现在第 `BUFFER_HEIGHT - 2`行。
-通过使用[`enumerate`] ,我们统计了变量`i`的迭代次数,然后用它来加载对应于`c`的屏幕字符。 通过比较屏幕字符的`ascii_character`和`c` ,我们可以确保字符串的每个字符确实出现在vga文本缓冲区中。
+通过使用[`enumerate`] ,我们统计了变量 `i` 的迭代次数,然后用它来加载对应于`c`的屏幕字符。 通过比较屏幕字符的 `ascii_character` 和 `c` ,我们可以确保字符串的每个字符确实出现在vga文本缓冲区中。
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
@@ -558,14 +644,13 @@ fn test_println_output() {
在这篇文章的剩余部分,我们还会解释如何创建一个_集成测试_以测试不同组建之间的交互。
-
## 集成测试
-在Rust中,**集成测试**([integration tests])的约定是将其放到项目根目录中的`tests`目录下(即`src`的同级目录)。无论是默认测试框架还是自定义测试框架都将自动获取并执行该目录下所有的测试。
+在Rust中,**集成测试**([integration tests])的约定是将其放到项目根目录中的 `tests` 目录下(即 `src` 的同级目录)。无论是默认测试框架还是自定义测试框架都将自动获取并执行该目录下所有的测试。
[integration tests]: https://doc.rust-lang.org/book/ch11-03-test-organization.html#integration-tests
-所有的集成测试都是它们自己的可执行文件,并且与我们的`main.rs`完全独立。这也就意味着每个测试都需要定义它们自己的函数入口点。让我们创建一个名为`basic_boot`的例子来看看集成测试的工作细节吧:
+所有的集成测试都是它们自己的可执行文件,并且与我们的 `main.rs` 完全独立。这也就意味着每个测试都需要定义它们自己的函数入口点。让我们创建一个名为 `basic_boot` 的例子来看看集成测试的工作细节吧:
```rust
// in tests/basic_boot.rs
@@ -595,26 +680,28 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-由于集成测试都是单独的可执行文件,所以我们需要再次提供所有的crate属性(`no_std`, `no_main`, `test_runner`, 等等)。我们还需要创建一个新的入口点函数`_start`,用于调用测试入口函数`test_main`。我们不需要任何的`cfg(test)` attributes(属性),因为集成测试的二进制文件在非测试模式下根本不会被编译构建。
+由于集成测试都是单独的可执行文件,所以我们需要再次提供所有的crate属性(`no_std`, `no_main`, `test_runner`, 等等)。我们还需要创建一个新的入口点函数 `_start`,用于调用测试入口函数 `test_main`。我们不需要任何的 `cfg(test)` 属性,因为集成测试的二进制文件在非测试模式下根本不会被编译构建。
-这里我们采用[`unimplemented`]宏,充当`test_runner`暂未实现的占位符;添加简单的`loop {}`循环,作为`panic`处理器的内容。理想情况下,我们希望能向我们在`main.rs`里所做的一样使用`serial_println`宏和`exit_qemu`函数来实现这个函数。但问题是,由于这些测试的构建和我们的`main.rs`的可执行文件是完全独立的,我们没有办法使用这些函数。
+这里我们采用[`unimplemented`]宏,充当 `test_runner` 暂未实现的占位符;添加简单的 `loop {}` 循环,作为 `panic` 处理器的内容。理想情况下,我们希望能向我们在 `main.rs` 里所做的一样使用 `serial_println` 宏和 `exit_qemu` 函数来实现这个函数。但问题是,由于这些测试的构建和我们的 `main.rs` 的可执行文件是完全独立的,我们没有办法使用这些函数。
[`unimplemented`]: https://doc.rust-lang.org/core/macro.unimplemented.html
-如果现阶段你运行`cargo xtest`,你将进入一个无限循环,因为目前panic的处理就是进入无限循环。你需要使用快捷键`Ctrl+c`,才可以退出QEMU。
+如果现阶段你运行 `cargo test`,你将进入一个无限循环,因为目前panic的处理就是进入无限循环。你需要使用快捷键 `Ctrl+c`,才可以退出QEMU。
### 创建一个库
-为了让这些函数能在我们的集成测试中使用,我们需要从我们的`main.rs`中分割出一个库,这个库应当可以被其他的crate和集成测试可执行文件使用。为了达成这个目的,我们创建了一个新文件,`src/lib.rs`:
+
+为了让这些函数能在我们的集成测试中使用,我们需要从我们的 `main.rs` 中分割出一个库,这个库应当可以被其他的crate和集成测试可执行文件使用。为了达成这个目的,我们创建了一个新文件,`src/lib.rs`:
```rust
// src/lib.rs
#![no_std]
+
```
-和`main.rs`一样,`lib.rs`也是一个可以被cargo自动识别的特殊文件。该库是一个独立的编译单元,所以我们需要再次指定`#![no_std]` 属性。
+和 `main.rs` 一样,`lib.rs` 也是一个可以被cargo自动识别的特殊文件。该库是一个独立的编译单元,所以我们需要再次指定 `#![no_std]` 属性。
-为了让我们的库可以和`cargo xtest`一起协同工作,我们还需要移动以下测试函数和属性:
+为了让我们的库可以和 `cargo test` 一起协同工作,我们还需要移动以下测试函数和属性:
```rust
// in src/lib.rs
@@ -626,10 +713,25 @@ fn panic(info: &PanicInfo) -> ! {
use core::panic::PanicInfo;
-pub fn test_runner(tests: &[&dyn Fn()]) {
+pub trait Testable {
+ fn run(&self) -> ();
+}
+
+impl Testable for T
+ where
+ T: Fn(),
+{
+ fn run(&self) {
+ serial_print!("{}...\t", core::any::type_name::());
+ self();
+ serial_println!("[ok]");
+ }
+}
+
+pub fn test_runner(tests: &[&dyn Testable]) {
serial_println!("Running {} tests", tests.len());
for test in tests {
- test();
+ test.run();
}
exit_qemu(QemuExitCode::Success);
}
@@ -641,7 +743,7 @@ pub fn test_panic_handler(info: &PanicInfo) -> ! {
loop {}
}
-/// Entry point for `cargo xtest`
+/// Entry point for `cargo test`
#[cfg(test)]
#[no_mangle]
pub extern "C" fn _start() -> ! {
@@ -656,13 +758,13 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-为了能在可执行文件和集成测试中使用`test_runner`,我们不对其应用`cfg(test)` attribute(属性),并将其设置为public。同时,我们还将panic的处理程序分解为public函数`test_panic_handler`,这样一来它也可以用于可执行文件了。
+为了能在可执行文件和集成测试中使用 `test_runner`,我们不对其应用 `cfg(test)` 属性,并将其设置为public。同时,我们还将panic的处理程序分解为public函数 `test_panic_handler`,这样一来它也可以用于可执行文件了。
-由于我们的`lib.rs`是独立于`main.rs`进行测试的,因此当该库实在测试模式下编译时我们需要添加一个`_start`入口点和一个panic处理程序。通过使用[`cfg_attr`] ,我们可以在这种情况下有条件地启用`no_main` 属性。
+由于我们的 `lib.rs` 是独立于 `main.rs` 进行测试的,因此当该库实在测试模式下编译时我们需要添加一个 `_start` 入口点和一个panic处理程序。通过使用[`cfg_attr`] ,我们可以在这种情况下有条件地启用 `no_main` 属性。
[`cfg_attr`]: https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute
-我们还将`QemuExitCode`枚举和`exit_qemu`函数从main.rs移动过来,并将其设置为公有函数:
+我们还将 `QemuExitCode` 枚举和 `exit_qemu` 函数从main.rs移动过来,并将其设置为公有函数:
```rust
// in src/lib.rs
@@ -684,7 +786,7 @@ pub fn exit_qemu(exit_code: QemuExitCode) {
}
```
-现在,可执行文件和集成测试都可以从库中导入这些函数,而不需要实现自己的定义。为了使`println` 和 `serial_println`可用,我们将以下的模块声明代码也移动到`lib.rs`中:
+现在,可执行文件和集成测试都可以从库中导入这些函数,而不需要实现自己的定义。为了使 `println` 和 `serial_println` 可用,我们将以下的模块声明代码也移动到 `lib.rs` 中:
```rust
// in src/lib.rs
@@ -693,9 +795,9 @@ pub mod serial;
pub mod vga_buffer;
```
-我们将这些模块设置为public(公有),这样一来我们在库的外部也一样能使用它们了。由于这两者都用了该模块内的`_print`函数,所以这也是让`println` 和 `serial_println`宏可用的必要条件。
+我们将这些模块设置为public(公有),这样一来我们在库的外部也一样能使用它们了。由于这两者都用了该模块内的 `_print` 函数,所以这也是让 `println` 和 `serial_println` 宏可用的必要条件。
-现在我们修改我们的`main.rs`代码来使用该库:
+现在我们修改我们的 `main.rs` 代码来使用该库:
```rust
// src/main.rs
@@ -734,13 +836,13 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-可以看到,这个库用起来就像一个普通的外部crate。它的调用方法与其它crate无异;在我们的这个例子中,位置可能为`blog_os`。上述代码使用了`test_runner` attribute中的`blog_os::test_runner`函数和`cfg(test)`的panic处理中的`blog_os::test_panic_handler`函数。它还导入了`println`宏,这样一来,我们可以在我们的`_start` 和 `panic`中使用它了。
+可以看到,这个库用起来就像一个普通的外部crate。它的调用方法与其它crate无异;在我们的这个例子中,位置可能为 `blog_os`。上述代码使用了 `test_runner` 属性中的 `blog_os::test_runner` 函数和 `cfg(test)` 的panic处理中的 `blog_os::test_panic_handler` 函数。它还导入了 `println` 宏,这样一来,我们可以在我们的 `_start` 和 `panic` 中使用它了。
-与此同时,`cargo xrun` 和 `cargo xtest`可以再次正常工作了。当然了,`cargo xtest`仍然会进入无限循环(你可以通过`ctrl+c`来退出)。接下来让我们在我们的集成测试中通过所需要的库函数来修复这个问题吧。
+与此同时,`cargo run` 和 `cargo test`可以再次正常工作了。当然了,`cargo test`仍然会进入无限循环(你可以通过`ctrl+c`来退出),接下来我们将在集成测试中通过所需要的库函数来修复这个问题。
### 完成集成测试
-就像我们的`src/main.rs`,我们的`tests/basic_boot.rs`可执行文件同样可以从我们的新库中导入类型。这也就意味着我们可以导入缺失的组件来完成我们的测试。
+就像我们的 `src/main.rs`,我们的 `tests/basic_boot.rs` 可执行文件同样可以从我们的新库中导入类型。这也就意味着我们可以导入缺失的组件来完成我们的测试。
```rust
// in tests/basic_boot.rs
@@ -753,50 +855,48 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-这里我们使用我们的库中的`test_runner`函数,而不是重新实现一个test runner。至于panic处理,调用`blog_os::test_panic_handler`函数即可,就像我们之前在我们的`main.rs`里面做的一样。
+这里我们使用我们的库中的 `test_runner` 函数,而不是重新实现一个test runner。至于panic处理,调用 `blog_os::test_panic_handler` 函数即可,就像我们之前在我们的 `main.rs` 里面做的一样。
-现在,`cargo xtest`又可以正常退出了。当你运行该命令时,你会发现它为我们的`lib.rs`, `main.rs`, 和 `basic_boot.rs`分别构建并运行了测试。其中,对于 `main.rs` 和 `basic_boot`的集成测试,它会报告"Running 0 tests"(正在运行0个测试),因为这些文件里面没有任何用 `#[test_case]`标注的函数。
+现在,`cargo test`又可以正常退出了。当你运行该命令时,你会发现它为我们的 `lib.rs`, `main.rs`, 和 `basic_boot.rs` 分别构建并运行了测试。其中,对于 `main.rs` 和 `basic_boot` 的集成测试,它会报告"Running 0 tests"(正在运行0个测试),因为这些文件里面没有任何用 `#[test_case]`标注的函数。
现在我们可以在`basic_boot.rs`中添加测试了。举个例子,我们可以测试`println`是否能够正常工作而不panic,就像我们之前在vga缓冲区测试中做的那样:
```rust
// in tests/basic_boot.rs
-use blog_os::{println, serial_print, serial_println};
+use blog_os::println;
#[test_case]
fn test_println() {
- serial_print!("test_println... ");
println!("test_println output");
- serial_println!("[ok]");
}
```
-现在当我们运行`cargo xtest`时,我们可以看到它会寻找并执行这些测试函数。
+现在当我们运行`cargo test`时,我们可以看到它会寻找并执行这些测试函数。
-由于该测试和vga缓冲区测试中的一个几乎完全相同,所以目前它看起来似乎没什么用。然而,在将来,我们的`main.rs`和`lib.rs`中的`_start`函数的内容会不断增长,并且在运行`test_main`之前需要调用一系列的初始化进程,所以这两个测试将会运行在完全不同的环境中(译者注:也就是说虽然现在看起来差不多,但是在将来该测试和vga buffer中的测试会很不一样,有必要单独拿出来,这两者并没有重复)。
+由于该测试和vga缓冲区测试中的一个几乎完全相同,所以目前它看起来似乎没什么用。然而在将来,我们的 `main.rs` 和 `lib.rs` 中的 `_start` 函数的内容会不断增长,并且在运行 `test_main` 之前需要调用一系列的初始化进程,所以这两个测试将会运行在完全不同的环境中(译者注:也就是说虽然现在看起来差不多,但是在将来该测试和vga buffer中的测试会很不一样,有必要单独拿出来,这两者并没有重复)。
-通过在`basic_boot`环境里不掉用任何初始化例程的`_start`中测试`println`函数,我们可以确保`println`在启动(boot)后可以正常工作。这一点非常重要,因为我们有很多部分依赖于`println`,例如打印panic信息。
+通过在 `basic_boot` 环境里不调用任何初始化例程的 `_start` 中测试 `println` 函数,我们可以确保 `println` 在启动(boot)后可以正常工作。这一点非常重要,因为我们有很多部分依赖于 `println`,例如打印panic信息。
### 未来的测试
集成测试的强大之处在于,它们可以被看成是完全独立的可执行文件;这也给了它们完全控制环境的能力,使得他们能够测试代码和CPU或是其他硬件的交互是否正确。
-我们的`basic_boot`测试正是集成测试的一个非常简单的例子。在将来,我们的内核的功能会变得更多,和硬件交互的方式也会变得多种多样。通过添加集成测试,我们可以保证这些交互按预期工作(并一直保持工作)。下面是一些对于未来的测试的设想:
+我们的 `basic_boot` 测试正是集成测试的一个非常简单的例子。在将来,我们的内核的功能会变得更多,和硬件交互的方式也会变得多种多样。通过添加集成测试,我们可以保证这些交互按预期工作(并一直保持工作)。下面是一些对于未来的测试的设想:
- **CPU异常**:当代码执行无效操作(例如除以零)时,CPU就会抛出异常。内核会为这些异常注册处理函数。集成测试可以验证在CPU异常时是否调用了正确的异常处理程序,或者在可解析的异常之后程序是否能正确执行;
-- **页表**:页表定义了哪些内存区域是有效且可访问的。通过修改页表,可以重新分配新的内存区域,例如,当你启动一个软件的时候。我们可以在集成测试中调整`_start`函数中的一些页表项,并确认这些改动是否会对`#[test_case]`的函数产生影响;
+- **页表**:页表定义了哪些内存区域是有效且可访问的。通过修改页表,可以重新分配新的内存区域,例如,当你启动一个软件的时候。我们可以在集成测试中调整 `_start` 函数中的一些页表项,并确认这些改动是否会对 `#[test_case]` 的函数产生影响;
- **用户空间程序**:用户空间程序是只能访问有限的系统资源的程序。例如,他们无法访问内核数据结构或是其他应用程序的内存。集成测试可以启动执行禁止操作的用户空间程序验证认内核是否会将这些操作全都阻止。
可以想象,还有更多的测试可以进行。通过添加各种各样的测试,我们确保在为我们的内核添加新功能或是重构代码时,不会意外地破坏他们。这一点在我们的内核变得更大和更复杂的时候显得尤为重要。
### 那些应该Panic的测试
-标准库的测试框架支持允许构造失败测试的[`#[should_panic]` attribute][should_panic]。这个功能对于验证传递无效参数时函数是否会失败非常有用。不幸的是,这个属性需要标准库的支持,因此,在`#[no_std]`环境下无法使用。
+标准库的测试框架支持 [`#[should_panic]` 属性][should_panic],这允许我们构造理应失败的测试。这个功能对于验证传递无效参数时函数是否会失败非常有用。不幸的是,这个属性需要标准库的支持,因此,在 `#[no_std]` 环境下无法使用。
[should_panic]: https://doc.rust-lang.org/rust-by-example/testing/unit_testing.html#testing-panics
-尽管我们不能在我们的内核中使用`#[should_panic]` 属性,但是通过创建一个集成测试我们可以达到类似的效果——该集成测试可以从panic处理程序中返回一个成功错误代码。接下来让我一起来创建一个如上所述名为`should_panic`的测试吧:
+尽管我们不能在我们的内核中使用 `#[should_panic]` 属性,但是通过创建一个集成测试我们可以达到类似的效果——该集成测试可以从panic处理程序中返回一个成功错误代码。接下来让我一起来创建一个如上所述名为 `should_panic` 的测试吧:
```rust
// in tests/should_panic.rs
@@ -815,8 +915,7 @@ fn panic(_info: &PanicInfo) -> ! {
}
```
-这个测试还没有完成,因为它尚未定义`_start`函数或是其他自定义的test runner attributes。让我们来补充缺少的内容吧:
-
+这个测试还没有完成,因为它尚未定义 `_start` 函数或是其他自定义的test runner属性。让我们来补充缺少的内容吧:
```rust
// in tests/should_panic.rs
@@ -843,7 +942,7 @@ pub fn test_runner(tests: &[&dyn Fn()]) {
}
```
-这个测试定义了自己的`test_runner`函数,而不是复用`lib.rs`中的`test_runner`,该函数会在测试没有panic而是正常退出时返回一个错误退出代码(因为这里我们希望测试会panic)。如果没有定义测试函数,runner就会以一个成功错误代码退出。由于这个runner总是在执行完单个的测试后就退出,因此定义超过一个`#[test_case]`的函数都是没有意义的。
+这个测试定义了自己的 `test_runner` 函数,而不是复用 `lib.rs` 中的 `test_runner`,该函数会在测试没有panic而是正常退出时返回一个错误退出代码(因为这里我们希望测试会panic)。如果没有定义测试函数,runner就会以一个成功错误代码退出。由于这个runner总是在执行完单个的测试后就退出,因此定义超过一个 `#[test_case]` 的函数都是没有意义的。
现在我们来创建一个应该失败的测试:
@@ -859,19 +958,19 @@ fn should_fail() {
}
```
-该测试用 `assert_eq`来断言(assert)`0`和`1`是否相等。毫无疑问,这当然会失败(`0`当然不等于`1`),所以我们的测试就会像我们想要的那样panic。
+该测试用 `assert_eq`来断言(assert)`0` 和 `1` 是否相等。毫无疑问,这当然会失败(`0` 当然不等于 `1`),所以我们的测试就会像我们想要的那样panic。
-当我们通过`cargo xtest --test should_panic`运行该测试时,我们会发现成功了因为该测试如我们预期的那样panic了。当我们将断言部分(即`assert_eq!(0, 1);`)注释掉后,我们就会发现测试失败并返回了_"test did not panic"_的信息。
+当我们通过 `cargo test --test should_panic` 运行该测试时,我们会发现测试成功,该测试如我们预期的那样panic了。当我们将断言部分(即 `assert_eq!(0, 1);`)注释掉后,我们就会发现测试失败,并返回了 _"test did not panic"_ 的信息。
-这种方法的缺点是它只使用于单个的测试函数。对于多个`#[test_case]`函数,它只会执行第一个函数因为程序无法在panic处理被调用后继续执行。我目前没有想到解决这个问题的方法,如果你有任何想法,请务必告诉我!
+这种方法的缺点是它只使用于单个的测试函数。对于多个 `#[test_case]` 函数,它只会执行第一个函数,因为程序无法在panic处理被调用后继续执行。我目前没有想到解决这个问题的方法,如果你有任何想法,请务必告诉我!
### 无约束测试
-对于那些只有单个测试函数的集成测试而言(例如我们的`should_panic`测试),其实并不需要test runner。对于这种情况,我们可以完全禁用test runner,直接在`_start`函数中直接运行我们的测试。
+对于那些只有单个测试函数的集成测试而言(例如我们的 `should_panic` 测试),其实并不需要test runner。对于这种情况,我们可以完全禁用test runner,直接在 `_start` 函数中直接运行我们的测试。
-这里的关键就是在`Cargo.toml`中为测试禁用 `harness` flag,这个标志(flag)定义了是否将test runner用于集成测试中。如果该标志位被设置为`false`,那么默认的test runner和自定义的test runner功能都将被禁用,这样一来该测试就可以像一个普通的可执行程序一样运行了。
+这里的关键就是在 `Cargo.toml` 中为测试禁用 `harness` flag,这个标志(flag)定义了是否将test runner用于集成测试中。如果该标志位被设置为 `false`,那么默认的test runner和自定义的test runner功能都将被禁用,这样一来该测试就可以像一个普通的可执行程序一样运行了。
-现在让我们为我们的`should_panic`测试禁用`harness` flag吧:
+现在为我们的 `should_panic` 测试禁用 `harness` flag吧:
```toml
# in Cargo.toml
@@ -881,7 +980,7 @@ name = "should_panic"
harness = false
```
-现在我们通过移除test runner相关的代码,大大简化了我们的`should_panic`测试。结果看起来如下:
+现在我们通过移除test runner相关的代码,大大简化了我们的 `should_panic` 测试。结果看起来如下:
```rust
// in tests/should_panic.rs
@@ -913,20 +1012,20 @@ fn panic(_info: &PanicInfo) -> ! {
}
```
-现在我们可以通过我们的`_start`函数来直接调用`should_fail`函数了,如果返回则返回一个失败退出代码并退出。现在当我们执行`cargo xtest --test should_panic`时,我们可以发现测试的行为和之前完全一样。
+现在我们可以通过我们的 `_start` 函数来直接调用 `should_fail` 函数了,如果返回则返回一个失败退出代码并退出。现在当我们执行 `cargo test --test should_panic` 时,我们可以发现测试的行为和之前完全一样。
-除了创建`should_panic`测试,禁用`harness` attribute对复杂集成测试也很有用,例如,当单个测试函数会产生一些边际效应需要通过特定的顺序执行时。
+除了创建 `should_panic` 测试,禁用 `harness` 属性对复杂集成测试也很有用,例如,当单个测试函数会产生一些边际效应,需要通过特定的顺序执行时。
## 总结
测试是一种非常有用的技术,它能确保特定的部件拥有我们期望的行为。即使它们不能显示是否有bug,它们仍然是用来寻找bug的利器,尤其是用来避免回归。
-本文讲述了如何为我们的Rust kernel创建一个测试框架。我们使用Rust的自定义框架功能为我们的裸机环境实现了一个简单的`#[test_case]` attribute支持。通过使用QEMU的`isa-debug-exit`设备,我们的test runner可以在运行测试后退出QEMU并报告测试状态。我们还为串行端口实现了一个简单的驱动,使得错误信息可以被打印到控制台而不是VGA buffer中。
+本文讲述了如何为我们的Rust kernel创建一个测试框架。我们使用Rust的自定义框架功能为我们的裸机环境实现了一个简单的 `#[test_case]` 属性支持。通过使用QEMU的 `isa-debug-exit` 设备,我们的test runner可以在运行测试后退出QEMU并报告测试状态。我们还为串行端口实现了一个简单的驱动,使得错误信息可以被打印到控制台而不是VGA buffer中。
-在为我们的`println`宏创建了一些测试后,我们在本文的后半部分还探索了集成测试。我们了解到它们位于`tests`目录中,并被视为完全独立的可执行文件。为了使他们能够使用`exit_qemu` 函数和 `serial_println` 宏,我们将大部分代码移动到一个库里,使其能够被导入到所有可执行文件和集成测试中。由于集成测试在各自独立的环境中运行,所以能够测试与硬件的交互或是创建应该panic的测试。
+在为我们的 `println` 宏创建了一些测试后,我们在本文的后半部分还探索了集成测试。我们了解到它们位于 `tests` 目录中,并被视为完全独立的可执行文件。为了使他们能够使用 `exit_qemu` 函数和 `serial_println` 宏,我们将大部分代码移动到一个库里,使其能够被导入到所有可执行文件和集成测试中。由于集成测试在各自独立的环境中运行,所以能够测试与硬件的交互或是创建应该panic的测试。
我们现在有了一个在QEMU内部真是环境中运行的测试框架。在未来的文章里,我们会创建更多的测试,从而让我们的内核在变得更复杂的同时保持可维护性。
## 下期预告
-在下一篇文章中,我们将会探索_CPU异常_。这些异常将在一些非法事件发生时由CPU抛出,例如抛出除以零或是访问没有映射的内存页(通常也被称为`page fault`即缺页异常)。能够捕获和检查这些异常,对将来的调试来说是非常重要的。异常处理与键盘支持所需的硬件中断处理十分相似。
+在下一篇文章中,我们将会探索_CPU异常_。这些异常将在一些非法事件发生时由CPU抛出,例如抛出除以零或是访问没有映射的内存页(通常也被称为 `page fault` 即页异常)。能够捕获和检查这些异常,对将来的调试来说是非常重要的。异常处理与键盘支持所需的硬件中断处理十分相似。
diff --git a/blog/content/edition-2/posts/05-cpu-exceptions/index.ko.md b/blog/content/edition-2/posts/05-cpu-exceptions/index.ko.md
new file mode 100644
index 00000000..e18329c5
--- /dev/null
+++ b/blog/content/edition-2/posts/05-cpu-exceptions/index.ko.md
@@ -0,0 +1,478 @@
++++
+title = "CPU 예외 (Exception)"
+weight = 5
+path = "ko/cpu-exceptions"
+date = 2018-06-17
+
+[extra]
+chapter = "Interrupts"
+# Please update this when updating the translation
+translation_based_on_commit = "1c9b5edd6a5a667e282ca56d6103d3ff1fd7cfcb"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["KimWang906"]
++++
+
+CPU 예외 (exception)는 유효하지 않은 메모리 주소에 접근하거나 분모가 0인 나누기 연산을 하는 등 허용되지 않은 작업 실행 시 발생합니다. CPU 예외를 처리할 수 있으려면 예외 처리 함수 정보를 제공하는 _인터럽트 서술자 테이블 (interrupt descriptor table; IDT)_ 을 설정해 두어야 합니다. 이 글에서는 커널이 [breakpoint 예외][breakpoint exceptions]를 처리한 후 정상 실행을 재개할 수 있도록 구현할 것입니다.
+
+[breakpoint exceptions]: https://wiki.osdev.org/Exceptions#Breakpoint
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-05 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-05
+
+
+
+## 개요
+예외 (exception)는 현재 실행 중인 CPU 명령어에 문제가 있음을 알립니다. 예를 들면, 분모가 0인 나누기 연산을 CPU 명령어가 하려고 하면 CPU가 예외를 발생시킵니다. 예외가 발생하게 되면 CPU는 진행 중인 작업을 일시 중단한 후 즉시 예외 처리 함수 (exception handler)를 호출합니다 (발생한 예외의 종류에 따라 호출될 예외 처리 함수가 결정됩니다).
+
+x86 아키텍처에는 20가지 정도의 CPU 예외가 존재합니다. 그 중 제일 중요한 것들은 아래와 같습니다:
+
+- **페이지 폴트 (Page Fault)**: 접근이 허용되지 않은 메모리에 접근을 시도하는 경우 페이지 폴트가 발생하게 됩니다. 예를 들면, CPU가 실행하려는 명령어가 (1) 매핑되지 않은 페이지로부터 데이터를 읽어오려고 하거나, (2) 읽기 전용 페이지에 데이터를 쓰려고 하는 경우에 페이지 폴트가 발생합니다.
+- **유효하지 않은 Opcode**: CPU에 주어진 명령어의 Opcode를 CPU가 지원하지 않을 때 발생합니다. 새로 출시된 [SSE 명령어][SSE instructions]를 구식 CPU에서 실행하려 하면 예외가 발생하게 됩니다.
+- **General Protection Fault**: 이 예외는 가장 광범위한 원인을 가진 예외입니다. 사용자 레벨 코드에서 권한 수준이 높은 명령어 (privileged instruction)를 실행하거나 configuration 레지스터를 덮어 쓰는 등 다양한 접근 권한 위반 상황에 발생합니다.
+- **더블 폴트 (Double Fault)**: 예외 발생 시 CPU는 알맞은 예외 처리 함수의 호출을 시도합니다. _예외 처리 함수를 호출하는 도중에_ 또 예외가 발생하는 경우, CPU는 더블 폴트 (double fault) 예외를 발생시킵니다. 또한 예외를 처리할 예외 처리 함수가 등록되지 않은 경우에도 더블 폴트 예외가 발생합니다.
+- **트리플 폴트 (Triple Fault)** : CPU가 더블 폴트 예외 처리 함수를 호출하려고 하는 사이에 예외가 발생하는 경우, CPU는 치명적인 _트리플 폴트 (triple fault)_ 예외를 발생시킵니다. 트리플 폴트 예외를 처리하는 것은 불가능 하므로 대부분의 프로세서들은 트리플 폴트 발생 시 프로세서를 초기화하고 운영체제를 재부팅합니다.
+
+[SSE instructions]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
+
+모든 CPU 예외들의 목록을 보시려면 [OSDev wiki][exceptions]를 확인해주세요.
+
+[exceptions]: https://wiki.osdev.org/Exceptions
+
+### 인터럽트 서술사 테이블 (Interrupt Descriptor Table) {#the-interrupt-descriptor-table}
+예외 발생을 포착하고 대응할 수 있으려면 _인터럽트 서술자 테이블 (Interrupt Descriptor Table; IDT)_ 이 필요합니다.
+이 테이블을 통해 우리는 각각의 CPU 예외를 어떤 예외 처리 함수가 처리할지 지정합니다. 하드웨어에서 이 테이블을 직접 사용하므로 테이블의 형식은 정해진 표준에 따라야 합니다. 테이블의 각 엔트리는 아래와 같은 16 바이트 구조를 따릅니다:
+
+| 타입 | 이름 | 설명 |
+| ---- | ------------------------ | ------------------------------------------------------------------------------------------------------------- |
+| u16 | Function Pointer [0:15] | 예외 처리 함수에 대한 64비트 포인터의 하위 16비트 |
+| u16 | GDT selector | [전역 서술자 테이블 (global descriptor table)][global descriptor table]에서 코드 세그먼트를 선택하는 값 |
+| u16 | Options | (표 아래의 설명 참조) |
+| u16 | Function Pointer [16:31] | 예외 처리 함수에 대한 64비트 포인터의 2번째 하위 16비트 |
+| u32 | Function Pointer [32:63] | 예외 처리 함수에 대한 64비트 포인터의 상위 32비트 |
+| u32 | Reserved | 사용 보류 중인 영역 |
+
+[global descriptor table]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
+
+Options 필드는 아래의 형식을 갖습니다:
+
+| 비트 구간 | 이름 | 설명 |
+| --------- | -------------------------------- | -------------------------------------------------------------------------------------------------------------------- |
+| 0-2 | Interrupt Stack Table Index | 0: 스택을 교체하지 않는다, 1-7: 이 인터럽트 처리 함수가 호출된 경우 Interrupt Stack Table의 n번째 스택으로 교체한다. |
+| 3-7 | Reserved | 사용 보류 중인 영역 |
+| 8 | 0: Interrupt Gate, 1: Trap Gate | 비트가 0이면 이 예외 처리 함수가 호출 이후 인터럽트 발생 억제 |
+| 9-11 | must be one | 각 비트는 언제나 1 |
+| 12 | must be zero | 언제나 0 |
+| 13‑14 | Descriptor Privilege Level (DPL) | 이 예외 처리 함수를 호출하는 데에 필요한 최소 특권 레벨 |
+| 15 | Present |
+
+각 예외마다 IDT에서의 인덱스가 배정되어 있습니다. invalid opcode 예외는 테이블 인덱스 6이 배정되어 있고, 페이지 폴트 예외는 테이블 인덱스 14가 배정되어 있습니다. 하드웨어는 미리 배정된 인덱스를 이용해 각 예외에 대응하는 IDT 엔트리를 자동으로 불러올 수 있습니다. OSDev 위키의 [Exception Table][exceptions]의 “Vector nr.”로 명명된 열을 보시면 모든 예외 및 배정된 인덱스를 확인하실 수 있습니다.
+
+예외가 발생하면 CPU는 대략 아래의 작업들을 순서대로 진행합니다:
+
+1. Instruction Pointer 레지스터와 [RFLAGS] 레지스터를 비롯해 몇몇 레지스터들의 값을 스택에 push (저장)합니다 (나중에 이 값들을 사용할 것입니다).
+2. 발생한 예외의 엔트리를 인터럽트 서술사 테이블 (IDT)로부터 읽어옵니다. 예를 들면, 페이지 폴트 발생 시 CPU는 IDT의 14번째 엔트리를 읽어옵니다.
+3. 등록된 엔트리가 없을 경우, 더블 폴트 예외를 발생시킵니다.
+4. 해당 엔트리가 인터럽트 게이트인 경우 (40번 비트 = 0), 하드웨어 인터럽트 발생을 억제합니다.
+5. 지정된 [GDT] 선택자를 CS 세그먼트로 읽어옵니다.
+6. 지정된 예외 처리 함수로 점프합니다.
+
+[RFLAGS]: https://en.wikipedia.org/wiki/FLAGS_register
+[GDT]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
+
+위의 4단계와 5단계가 잘 이해되지 않아도 걱정 마세요. 전역 서술자 테이블 (Global Descriptor Table; GDT)과 하드웨어 인터럽트는 이후에 다른 글에서 더 설명할 것입니다.
+
+## IDT 타입
+IDT를 나타내는 타입을 직접 구현하지 않고 `x86_64` 크레이트의 [`InterruptDescriptorTable` 구조체][`InterruptDescriptorTable` struct] 타입을 사용합니다:
+
+[`InterruptDescriptorTable` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+
+``` rust
+#[repr(C)]
+pub struct InterruptDescriptorTable {
+ pub divide_by_zero: Entry,
+ pub debug: Entry,
+ pub non_maskable_interrupt: Entry,
+ pub breakpoint: Entry,
+ pub overflow: Entry,
+ pub bound_range_exceeded: Entry,
+ pub invalid_opcode: Entry,
+ pub device_not_available: Entry,
+ pub double_fault: Entry,
+ pub invalid_tss: Entry,
+ pub segment_not_present: Entry,
+ pub stack_segment_fault: Entry,
+ pub general_protection_fault: Entry,
+ pub page_fault: Entry,
+ pub x87_floating_point: Entry,
+ pub alignment_check: Entry,
+ pub machine_check: Entry,
+ pub simd_floating_point: Entry,
+ pub virtualization: Entry,
+ pub security_exception: Entry,
+ // 일부 필드는 생략했습니다
+}
+```
+
+구조체의 각 필드는 IDT의 엔트리를 나타내는 `idt::Entry` 타입을 가집니다. 타입 인자 `F`는 사용될 예외 처리 함수의 타입을 정의합니다. 어떤 엔트리는 `F`에 [`HandlerFunc`]를 또는 `F`에 [`HandlerFuncWithErrCode`]를 필요로 하며 페이지 폴트는 [`PageFaultHandlerFunc`]를 필요로 합니다.
+
+[`idt::Entry`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.Entry.html
+[`HandlerFunc`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.HandlerFunc.html
+[`HandlerFuncWithErrCode`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.HandlerFuncWithErrCode.html
+[`PageFaultHandlerFunc`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.PageFaultHandlerFunc.html
+
+`HandlerFunc` 타입을 먼저 살펴보겠습니다:
+
+```rust
+type HandlerFunc = extern "x86-interrupt" fn(_: InterruptStackFrame);
+```
+
+`HandlerFunc`는 함수 타입 `extern "x86-interrupt" fn`의 [타입 별칭][type alias]입니다. `extern` 키워드는 [외부 함수 호출 규약 (foreign calling convention)][foreign calling convention]을 사용하는 함수를 정의할 때 쓰이는데, 주로 C 함수와 상호작용하는 경우에 쓰입니다 (`extern "C" fn`). `x86-interrupt` 함수 호출 규약은 무엇일까요?
+
+[type alias]: https://doc.rust-lang.org/book/ch19-04-advanced-types.html#creating-type-synonyms-with-type-aliases
+[foreign calling convention]: https://doc.rust-lang.org/nomicon/ffi.html#foreign-calling-conventions
+
+## 인터럽트 호출 규약
+예외는 함수 호출과 유사한 점이 많습니다: 호출된 함수의 첫 명령어로 CPU가 점프한 후 함수 안의 명령어들을 차례대로 실행합니다. 그 후 CPU가 반환 주소로 점프하고, 기존에 실행 중이었던 함수의 실행을 이어갑니다.
+
+하지만 예외와 함수 호출 사이에 중요한 차이점이 있습니다: 일반 함수의 경우 컴파일러가 삽입한 `call` 명령어를 통해 호출하지만, 예외는 _어떤 명령어 실행 도중에라도_ 발생할 수 있습니다. 이 차이점의 중대성을 이해하려면 함수 호출 과정을 더 면밀히 살펴봐야 합니다.
+
+[함수 호출 규약][Calling conventions]은 함수 호출 과정의 세부 사항들을 규정합니다. 예를 들면, 함수 인자들이 어디에 저장되는지 (레지스터 또는 스택), 함수의 반환 값을 어떻게 전달할지 등을 정합니다. x86_64 리눅스에서 C 함수 호출 시 [System V ABI]가 규정하는 아래의 규칙들이 적용됩니다:
+
+[Calling conventions]: https://en.wikipedia.org/wiki/Calling_convention
+[System V ABI]: https://refspecs.linuxbase.org/elf/x86_64-abi-0.99.pdf
+
+- 함수의 첫 여섯 인자들은 `rdi`, `rsi`, `rdx`, `rcx`, `r8`, `r9` 레지스터에 저장합니다
+- 7번째 함수 인자부터는 모두 스택에 저장합니다
+- 함수의 반환 값은 `rax`와 `rdx` 레지스터에 저장됩니다
+
+참고로 Rust는 C ABI를 따르지 않기에 (사실, [Rust는 규정된 ABI가 존재하지 않습니다][rust abi]), 이 법칙들은 `extern "C" fn`으로 정의된 함수들에만 적용됩니다.
+
+[rust abi]: https://github.com/rust-lang/rfcs/issues/600
+
+### Preserved 레지스터와 Scratch 레지스터
+함수 호출 규약은 레지스터들을 크게 두 가지 (_preserved_ 레지스터와 _scratch_ 레지스터)로 분류합니다.
+
+_preserved_ 레지스터들의 값은 함수 호출 전/후에 보존되어야 합니다. 호출된 함수 (callee)가 이 레지스터들에 다른 값을 저장해 사용하려면 반환 직전에 이 레지스터들에 원래 저장되어 있던 값을 복원해 놓아야 합니다. preserved 레지스터는 _“callee-saved”_ 레지스터라고도 불립니다. 함수 실행 시작 시 이 레지스터들의 값들을 스택에 저장했다가 함수 반환 직전에 복구하는 것이 일반적입니다.
+
+반면, 호출된 함수가 _scratch_ 레지스터들의 값을 자유롭게 덮어 쓰는 것은 괜찮습니다. 함수 호출 전/후로 scratch 레지스터의 값을 보존하고 싶다면, 호출하는 측 (caller)이 함수 호출 전에 레지스터의 값을 스택에 저장해뒀다가 함수의 실행이 끝난 후 레지스터의 값을 본래 값으로 복원해야 합니다. scratch 레지스터는 _“caller-saved”_ 레지스터라고도 불립니다.
+
+x86_64에서는 C 함수 호출 규약이 preserved 레지스터와 scratch 레지스터를 아래와 같이 정합니다:
+
+| preserved 레지스터 | scratch 레지스터 |
+| ----------------------------------------------- | ----------------------------------------------------------- |
+| `rbp`, `rbx`, `rsp`, `r12`, `r13`, `r14`, `r15` | `rax`, `rcx`, `rdx`, `rsi`, `rdi`, `r8`, `r9`, `r10`, `r11` |
+| _callee-saved_ | _caller-saved_ |
+
+컴파일러는 이 규칙들에 따라 코드를 컴파일 합니다. 예를 들면 대부분의 함수들은 `push rbp` 로 시작하는데, 이는 callee-saved 레지스터인 `rbp`를 스택에 저장합니다.
+
+### 모든 레지스터들의 값 보존하기
+함수 호출과 달리 예외는 _어떤_ 명령어가 실행 중이든 관계 없이 발생할 수 있습니다. 대체로 컴파일 시간에는 컴파일 결과 생성된 코드가 예외를 발생시킬지의 유무를 장담하기 어렵습니다. 예를 들어, 컴파일러는 임의의 명령어가 스택 오버플로우 또는 페이지 폴트를 일으킬지 판별하기 어렵습니다.
+
+예외가 언제 발생할지 알 수 없다보니 레지스터에 저장된 값들을 미리 백업해놓을 수가 없습니다. 즉, 예외 처리 함수 구현 시 caller-saved 레지스터에 의존하는 함수 호출 규약을 사용할 수가 없습니다. 예외 처리 함수 구현 시 _모든 레지스터_ 들의 값을 보존하는 함수 호출 규약을 사용해야 합니다. 예시로 `x86-interrupt` 함수 호출 규약은 함수 반환 시 모든 레지스터들의 값이 함수 호출 이전과 동일하게 복원되도록 보장합니다.
+
+함수 실행 시작 시 모든 레지스터들의 값이 스택에 저장된다는 뜻은 아닙니다. 호출된 함수가 덮어 쓸 레지스터들만을 컴파일러가 스택에 백업합니다. 이렇게 하면 적은 수의 레지스터를 사용하는 함수를 컴파일 할 때 짧고 효율적인 코드를 생성할 수 있습니다.
+
+### 인터럽트 스택 프레임 {# the-interrupt-stack-frame}
+일반적인 함수 호출 시 (`call` 명령어 이용), CPU는 호출된 함수로 제어 흐름을 넘기기 전에 반환 주소를 스택에 push (저장)합니다. 함수 반환 시 (`ret` 명령어 이용), CPU는 스택에 저장해뒀던 반환 주소를 읽어온 후 해당 주소로 점프합니다. 일반적인 함수 호출 시 스택 프레임의 모습은 아래와 같습니다:
+
+
+
+예외 및 인터럽트 처리 함수의 경우, 일반 함수가 실행되는 CPU 컨텍스트 (스택 포인터, CPU 플래그 등)가 아닌 별개의 CPU 컨텍스트에서 실행됩니다. 따라서 단순히 스택에 반환 주소를 push하는 것보다 더 복잡한 사전 처리가 필요합니다. 인터럽트 발생 시 CPU가 아래의 작업들을 처리합니다.
+
+1. **스택 포인터 정렬**: 인터럽트는 어느 명령어의 실행 중에도 발생할 수 있고, 따라서 스택 포인터 또한 임의의 값을 가질 수 있습니다. 하지만 특정 CPU 명령어들 (예: 일부 SSE 명령어)은 스택 포인터가 16바이트 단위 경계에 정렬되어 있기를 요구합니다. 따라서 CPU는 인터럽트 발생 직후에 스택 포인터를 알맞게 정렬합니다.
+2. **스택 교체** (경우에 따라서): CPU의 특권 레벨 (privilege level)이 바뀌는 경우에 스택 교체가 일어납니다 (예: 사용자 모드 프로그램에서 CPU 예외가 발생할 때). 또한 _인터럽트 스택 테이블 (Interrupt Stack Table)_ 을 이용해 특정 인터럽트 발생 시 스택 교체가 이뤄지도록 설정하는 것 또한 가능합니다 (이후 다른 글에서 설명할 내용입니다).
+3. **이전의 스택 포인터 push**: 인터럽트 발생 시, CPU는 스택 포인터를 정렬하기에 앞서 스택 포인터 (`rsp`)와 스택 세그먼트 (`ss`) 레지스터들을 저장 (push)합니다. 이로써 인터럽트 처리 함수로부터 반환 시 이전의 스택 포인터를 복원할 수 있습니다.
+4. **`RFLAGS` 레지스터 push 및 수정**: [`RFLAGS`] 레지스터는 CPU의 다양한 제어 및 상태 비트들을 저장합니다. 인터럽트 발생 시 CPU는 기존 값을 push한 후 일부 비트들의 값을 변경합니다.
+5. **instruction pointer push**: 인터럽트 처리 함수로 점프하기 전에, CPU는 instruction pointer (`rip`)와 code segment (`cs`) 레지스터들을 push합니다. 이는 일반 함수 호출 시 반환 주소를 push하는 것과 유사합니다.
+6. **오류 코드 push** (일부 예외만 해당): 페이지 폴트 같은 일부 예외의 경우, CPU는 예외의 원인을 설명하는 오류 코드를 push합니다.
+7. **인터럽트 처리 함수 호출**: CPU는 IDT로부터 인터럽트 처리 함수의 주소와 세그먼트 서술자 (segment descriptor)를 읽어옵니다. 읽어온 값들을 각각 `rip` 레지스터와 `cs` 레지스터에 저장함으로써 인터럽트 처리 함수를 호출합니다.
+
+[`RFLAGS`]: https://en.wikipedia.org/wiki/FLAGS_register
+
+_인터럽트 스택 프레임_ 은 아래와 같은 모습을 가집니다:
+
+
+
+`x86_64` 크레이트에서는 [`InterruptStackFrame`] 구조체 타입을 통해 인터럽트 스택 프레임을 구현합니다. 예외 처리 함수들은 `&mut InterruptStackFrame`를 인자로 받아서 예외 발생 원인에 대한 추가 정보를 얻을 수 있습니다. 이 구조체는 오류 코드를 저장하는 필드를 갖고 있지 않은데, 그 이유는 아주 일부의 예외들만이 오류 코드를 반환하기 때문입니다. 오류 코드를 반환하는 예외들은 [`HandlerFuncWithErrCode`] 함수 타입을 사용하는데, 이 함수 타입은 추가적으로 `error_code` 인자를 받습니다.
+
+[`InterruptStackFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptStackFrame.html
+
+### 무대 뒤의 상황
+함수 호출 규약 `x86-interrupt`는 예외 처리 과정의 세부적인 사항들을 대부분 숨겨주는 강력한 추상화 계층입니다. 하지만 때로는 추상화 계층 안에서 무슨 일이 일어나는지 알아두는 것이 도움이 됩니다. 아래는 함수 호출 규약 `x86-interrupt`가 처리하는 작업들의 개요입니다.
+
+- **함수 인자 읽어오기**: 대부분의 함수 호출 규약들은 함수 인자들이 레지스터를 통해 전달되는 것으로 생각합니다. 그러나 예외 처리 함수는 그렇게 할 수가 없습니다. 그 이유는 스택에 레지스터들의 값들을 백업하기 전에는 어떤 레지스터도 덮어 쓸 수 없기 때문입니다. 함수 호출 규약 `x86-interrupt`는 함수 인자들이 레지스터가 아니라 스택의 특정 위치에 저장되어 있다고 가정합니다.
+- **`iretq`를 통해 반환**: 인터럽트 스택 프레임은 일반 함수 호출 시 사용되는 스택 프레임과는 완전히 별개의 것이라서 `ret` 명령어를 사용해서는 인터럽트 처리 함수로부터 제대로 반환할 수 없습니다. 대신 `iretq` 명령어를 사용하여 반환합니다.
+- **오류 코드 처리**: 일부 예외에 한해 push되는 오류 코드는 일을 번거롭게 합니다. 이 오류 코드로 인해 스택 정렬이 망가뜨려지며 (아래 '스택 정렬' 항목 참고), 예외 처리 함수로부터 반환하기 전에 오류 코드를 스택으로부터 pop (제거)해야 합니다. 함수 호출 규약 `x86-interrupt`가 오류 코드로 인한 번거로움을 대신 감당해줍니다. `x86-interrupt`는 어떤 예외 처리 함수가 어떤 예외에 대응하는지 알지 못하기에, 함수의 인자 개수를 통해 해당 정보를 유추합니다. 따라서 개발자는 오류 코드가 push되는 예외와 그렇지 않은 예외에 대해 각각 정확한 함수 타입을 사용해야만 합니다. 다행히 `x86_64` 크레이트가 제공하는 `InterruptDescriptorTable` 타입이 각 경우에 정확한 함수 타입이 사용되도록 보장합니다.
+- **스택 정렬**: 일부 명령어들 (특히 SSE 명령어)은 스택이 16 바이트 경계에 정렬되어 있기를 요구합니다. 예외 발생 시 CPU는 해당 정렬이 맞춰져 있도록 보장하지만, 일부 예외의 경우에는 오류 코드를 push하면서 맞춰져 있던 정렬을 망가뜨립니다. 함수 호출 규약 `x86-interrupt`는 해당 상황에서 망가진 정렬을 다시 맞춰줍니다.
+
+더 자세한 내용이 궁금하시다면, [naked 함수][naked functions]를 사용한 예외 처리 과정을 설명하는 저희 블로그의 또다른 글 시리즈를 참고하세요 (링크는 [이 글의 맨 마지막][too-much-magic]을 참조).
+
+[naked functions]: https://github.com/rust-lang/rfcs/blob/master/text/1201-naked-fns.md
+[too-much-magic]: #too-much-magic
+
+## 구현
+이론적 배경 설명은 끝났고, 이제 CPU 예외 처리 기능을 커널에 구현해보겠습니다. 새로운 모듈 `interrupts`를 `src/interrupts.rs`에 만든 후, 새로운 `InterruptDescriptorTable`을 생성하는 함수 `init_idt`를 작성합니다.
+
+``` rust
+// in src/lib.rs
+
+pub mod interrupts;
+
+// in src/interrupts.rs
+
+use x86_64::structures::idt::InterruptDescriptorTable;
+
+pub fn init_idt() {
+ let mut idt = InterruptDescriptorTable::new();
+}
+```
+
+이제 예외 처리 함수들을 추가할 수 있습니다. [breakpoint 예외][breakpoint exception]를 위한 예외 처리 함수부터 작성해보겠습니다. breakpoint 예외는 예외 처리를 테스트하는 용도에 안성맞춤입니다. breakpoint 예외의 유일한 용도는 breakpoint 명령어 `int3`가 실행되었을 때 실행 중인 프로그램을 잠시 멈추는 것입니다.
+
+[breakpoint exception]: https://wiki.osdev.org/Exceptions#Breakpoint
+
+breakpoint 예외는 디버거 (debugger)에서 자주 사용됩니다: 사용자가 breakpoint를 설정하면 디버거는 breakpoint에 대응되는 명령어를 `int3` 명령어로 치환하는데, 이로써 해당 명령어에 도달했을 때 CPU가 breakpoint 예외를 발생시킵니다. 사용자가 프로그램 실행을 재개하면 디버거는 `int3` 명령어를 원래의 명령어로 다시 교체한 후 프로그램 실행을 재개합니다. 더 자세한 내용이 궁금하시면 ["_How debuggers work_"] 시리즈를 읽어보세요.
+
+["_How debuggers work_"]: https://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
+
+지금 우리가 breakpoint 예외를 사용하는 상황에서는 명령어를 덮어쓸 필요가 전혀 없습니다. 우리는 breakpoint 예외가 발생했을 때 그저 메시지를 출력한 후 프로그램 실행을 재개하기만 하면 됩니다. 간단한 예외 처리 함수 `breakpoint_handler`를 만들고 IDT에 추가합니다:
+
+```rust
+// in src/interrupts.rs
+
+use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
+use crate::println;
+
+pub fn init_idt() {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+}
+
+extern "x86-interrupt" fn breakpoint_handler(
+ stack_frame: InterruptStackFrame)
+{
+ println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
+}
+```
+
+이 예외 처리 함수는 간단한 메시지와 함께 인터럽트 스택 프레임의 정보를 출력합니다.
+
+컴파일을 시도하면 아래와 같은 오류 메시지가 출력됩니다:
+
+```
+error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
+ --> src/main.rs:53:1
+ |
+53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: InterruptStackFrame) {
+54 | | println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
+55 | | }
+ | |_^
+ |
+ = help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
+```
+
+이 오류는 함수 호출 규약 `x86-interrupt`가 아직 unstable 하여 발생합니다. `lib.rs`의 맨 위에 `#![feature(abi_x86_interrupt)]` 속성을 추가하여 함수 호출 규약 `x86-interrupt`의 사용을 강제합니다.
+
+### IDT 불러오기
+우리가 만든 인터럽트 서술사 테이블을 CPU가 사용하도록 하려면, 먼저 [`lidt`] 명령어를 통해 해당 테이블을 불러와야 합니다. `x86_64` 크레이트가 제공하는 `InterruptDescriptorTable` 구조체의 함수 [`load`][InterruptDescriptorTable::load]를 통해 테이블을 불러옵니다:
+
+[`lidt`]: https://www.felixcloutier.com/x86/lgdt:lidt
+[InterruptDescriptorTable::load]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html#method.load
+
+```rust
+// in src/interrupts.rs
+
+pub fn init_idt() {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ idt.load();
+}
+```
+
+컴파일 시 아래와 같은 오류가 발생합니다:
+
+```
+error: `idt` does not live long enough
+ --> src/interrupts/mod.rs:43:5
+ |
+43 | idt.load();
+ | ^^^ does not live long enough
+44 | }
+ | - borrowed value only lives until here
+ |
+ = note: borrowed value must be valid for the static lifetime...
+```
+
+`load` 함수는 `&'static self` 타입의 인자를 받는데, 이 타입은 프로그램 실행 시간 전체 동안 유효한 레퍼런스 타입입니다. 우리가 새로운 IDT를 로드하지 않는 이상 프로그램 실행 중 인터럽트가 발생할 때마다 CPU가 이 테이블에 접근할 것이기에, `'static` 라이프타임보다 짧은 라이프타임을 사용하면 use-after-free 버그가 발생할 수 있습니다.
+
+`idt`는 스택에 생성되어 `init` 함수 안에서만 유효합니다. `init` 함수를 벗어나면 해당 스택 메모리는 다른 함수에 의해 재사용되므로 해당 메모리를 IDT로서 간주하고 참조한다면 임의의 함수의 스택 메모리로부터 데이터를 읽어오게 됩니다.
+다행히 `InterruptDescriptorTable::load` 함수 정의에 라이프타임 요구 사항이 포함되어 있어 Rust 컴파일러가 잠재적인 use-after-free 버그를 컴파일 도중에 막아줍니다.
+
+이 문제를 해결하려면 `idt`를 `'static` 라이프타임을 갖는 곳에 저장해야 합니다. [`Box`]를 통해 IDT를 힙 (heap) 메모리에 할당한 뒤 Box 에 저장된 IDT에 대한 `'static` 레퍼런스를 얻는 것은 해결책이 되지 못합니다. 그 이유는 아직 우리가 커널에 힙 메모리를 구현하지 않았기 때문입니다.
+
+[`Box`]: https://doc.rust-lang.org/std/boxed/struct.Box.html
+
+
+대안으로 `IDT`를 `static` 변수에 저장하는 것을 시도해보겠습니다:
+
+```rust
+static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
+
+pub fn init_idt() {
+ IDT.breakpoint.set_handler_fn(breakpoint_handler);
+ IDT.load();
+}
+```
+
+문제는 static 변수의 값은 변경할 수가 없어서, `init` 함수 실행 시 breakpoint 예외에 대응하는 IDT 엔트리를 수정할 수 없습니다.
+대신 `IDT`를 [`static mut`] 변수에 저장해보겠습니다:
+
+[`static mut`]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
+
+```rust
+static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
+
+pub fn init_idt() {
+ unsafe {
+ IDT.breakpoint.set_handler_fn(breakpoint_handler);
+ IDT.load();
+ }
+}
+```
+
+이제 컴파일 오류가 발생하지는 않지만, Rust에서 `static mut`의 사용은 권장되지 않습니다. `static mut`는 데이터 레이스 (data race)를 일으키기 쉽기에, `static mut` 변수에 접근할 때마다 [`unsafe` 블록][`unsafe` block]을 반드시 사용해야 합니다.
+
+[`unsafe` block]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
+
+#### 초기화 지연이 가능한 Static 변수 (Lazy Statics)
+다행히 `lazy_static` 매크로를 사용하면 `static` 변수의 초기화를 컴파일 도중이 아니라 프로그램 실행 중 해당 변수가 처음 읽어지는 시점에 일어나게 할 수 있습니다. 따라서 프로그램 실행 시간에 다른 변수의 값을 읽어오는 등 거의 모든 작업을 변수 초기화 블록 안에서 제약 없이 진행할 수 있습니다.
+
+이전에 [VGA 텍스트 버퍼에 대한 추상 인터페이스][vga text buffer lazy static]를 구현 시 의존 크레이트 목록에 `lazy_static`을 이미 추가했습니다. `lazy_static!` 매크로를 바로 사용하여 static 타입의 IDT를 생성합니다:
+
+[vga text buffer lazy static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
+
+```rust
+// in src/interrupts.rs
+
+use lazy_static::lazy_static;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ idt
+ };
+}
+
+pub fn init_idt() {
+ IDT.load();
+}
+```
+
+이 코드에서는 `unsafe` 블록이 필요하지 않습니다. `lazy_static!` 매크로의 내부 구현에서는 `unsafe`가 사용되지만, 안전한 추상 인터페이스 덕분에 `unsafe`가 외부로 드러나지 않습니다.
+
+### 실행하기
+
+마지막으로 `main.rs`에서 `init_idt` 함수를 호출하면 커널에서 예외 발생 및 처리가 제대로 작동합니다.
+직접 `init_idt` 함수를 호출하는 대신 범용 초기화 함수 `init`을 `lib.rs`에 추가합니다:
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ interrupts::init_idt();
+}
+```
+
+`main.rs`와 `lib.rs` 및 통합 테스트들의 `_start` 함수들에서 공용으로 사용하는 초기화 루틴들의 호출은 앞으로 이 `init` 함수에 한데 모아 관리할 것입니다.
+
+`main.rs`의 `_start_` 함수가 `init` 함수를 호출한 후 breakpoint exception을 발생시키도록 코드를 추가합니다:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init(); // 새로 추가한 코드
+
+ // invoke a breakpoint exception
+ x86_64::instructions::interrupts::int3(); // 새로 추가한 코드
+
+ // as before
+ #[cfg(test)]
+ test_main();
+
+ println!("It did not crash!");
+ loop {}
+}
+```
+
+`cargo run`을 통해 QEMU에서 커널을 실행하면 아래의 출력 내용을 얻습니다:
+
+
+
+성공입니다! CPU가 성공적으로 예외 처리 함수 `breakpoint_handler`를 호출했고, 예외 처리 함수가 메시지를 출력했으며, 그 후 `_start` 함수로 제어 흐름이 돌아와 `It did not crash!` 메시지도 출력됐습니다.
+
+예외가 발생한 시점의 명령어 및 스택 포인터들을 인터럽트 스택 프레임이 알려줍니다. 이 정보는 예상치 못한 예외를 디버깅할 때 매우 유용합니다.
+
+### 테스트 추가하기
+
+위에서 확인한 동작을 위한 테스트를 작성해봅시다. 우선 `_start` 함수가 `init` 함수를 호출하도록 수정합니다:
+
+```rust
+// in src/lib.rs
+
+/// Entry point for `cargo test`
+#[cfg(test)]
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ init(); // 새로 추가한 코드
+ test_main();
+ loop {}
+}
+```
+
+Rust는 `lib.rs`를 `main.rs`와는 독립적으로 테스트하기 때문에 이 `_start` 함수는 `cargo test --lib` 실행 시에만 사용된다는 것을 기억하세요. 테스트 실행 전에 `init` 함수를 먼저 호출하여 IDT를 만들고 테스트 실행 시 사용되도록 설정합니다.
+
+이제 `test_breakpoint_exception` 테스트를 생성할 수 있습니다:
+
+```rust
+// in src/interrupts.rs
+
+#[test_case]
+fn test_breakpoint_exception() {
+ // invoke a breakpoint exception
+ x86_64::instructions::interrupts::int3();
+}
+```
+
+테스트는 `int3` 함수를 호출하여 breakpoint 예외를 발생시킵니다. 예외 처리 후, 이전에 실행 중이었던 프로그램의 실행이 재개함을 확인함으로써 breakpoint handler가 제대로 작동하는지 점검합니다.
+
+`cargo test` (모든 테스트 실행) 혹은 `cargo test --lib` (`lib.rs` 및 그 하위 모듈의 테스트만 실행) 커맨드를 통해 이 새로운 테스트를 실행해보세요. 테스트 실행 결과가 아래처럼 출력될 것입니다:
+
+```
+blog_os::interrupts::test_breakpoint_exception... [ok]
+```
+
+## 더 자세히 파헤치고 싶은 분들께 {#too-much-magic}
+`x86-interrupt` 함수 호출 규약과 [`InterruptDescriptorTable`] 타입 덕분에 비교적 쉽게 예외 처리를 구현할 수 있었습니다. 예외 처리 시 우리가 이용한 추상화 단계 아래에서 일어나는 일들을 자세히 알고 싶으신가요? 그런 분들을 위해 준비했습니다: 저희 블로그의 또다른 글 시리즈 [“Handling Exceptions with Naked Functions”]는 `x86-interrupt` 함수 호출 규약 없이 예외 처리를 구현하는 과정을 다루며, IDT 타입을 직접 구현하여 사용합니다. 해당 글 시리즈는 `x86-interrupt` 함수 호출 규약 및 `x86_64` 크레이트가 생기기 이전에 작성되었습니다. 해당 시리즈는 이 블로그의 [첫 번째 버전][first edition]에 기반하여 작성되었기에 오래되어 더 이상 유효하지 않은 정보가 포함되어 있을 수 있으니 참고 부탁드립니다.
+
+[“Handling Exceptions with Naked Functions”]: @/edition-1/extra/naked-exceptions/_index.md
+[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+[first edition]: @/edition-1/_index.md
+
+## 다음 단계는 무엇일까요?
+이번 포스트에서 예외 (exception)를 발생시키고 처리한 후 예외로부터 반환하는 것까지 성공했습니다. 다음 단계는 우리의 커널이 모든 예외를 처리할 수 있게 하는 것입니다. 제대로 처리되지 않은 예외는 치명적인 [트리플 폴트 (triple fault)][triple fault]를 발생시켜 시스템이 리셋하도록 만듭니다. 다음 포스트에서는 트리플 폴트가 발생하지 않도록 [더블 폴트 (double fault)][double faults]를 처리하는 방법을 다뤄보겠습니다.
+
+[triple fault]: https://wiki.osdev.org/Triple_Fault
+[double faults]: https://wiki.osdev.org/Double_Fault#Double_Fault
diff --git a/blog/content/edition-2/posts/05-cpu-exceptions/index.md b/blog/content/edition-2/posts/05-cpu-exceptions/index.md
index 4bf60143..d017a735 100644
--- a/blog/content/edition-2/posts/05-cpu-exceptions/index.md
+++ b/blog/content/edition-2/posts/05-cpu-exceptions/index.md
@@ -8,7 +8,7 @@ date = 2018-06-17
chapter = "Interrupts"
+++
-CPU exceptions occur in various erroneous situations, for example when accessing an invalid memory address or when dividing by zero. To react to them we have to set up an _interrupt descriptor table_ that provides handler functions. At the end of this post, our kernel will be able to catch [breakpoint exceptions] and to resume normal execution afterwards.
+CPU exceptions occur in various erroneous situations, for example, when accessing an invalid memory address or when dividing by zero. To react to them, we have to set up an _interrupt descriptor table_ that provides handler functions. At the end of this post, our kernel will be able to catch [breakpoint exceptions] and resume normal execution afterward.
[breakpoint exceptions]: https://wiki.osdev.org/Exceptions#Breakpoint
@@ -26,22 +26,22 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
## Overview
An exception signals that something is wrong with the current instruction. For example, the CPU issues an exception if the current instruction tries to divide by 0. When an exception occurs, the CPU interrupts its current work and immediately calls a specific exception handler function, depending on the exception type.
-On x86 there are about 20 different CPU exception types. The most important are:
+On x86, there are about 20 different CPU exception types. The most important are:
- **Page Fault**: A page fault occurs on illegal memory accesses. For example, if the current instruction tries to read from an unmapped page or tries to write to a read-only page.
-- **Invalid Opcode**: This exception occurs when the current instruction is invalid, for example when we try to use newer [SSE instructions] on an old CPU that does not support them.
-- **General Protection Fault**: This is the exception with the broadest range of causes. It occurs on various kinds of access violations such as trying to execute a privileged instruction in user level code or writing reserved fields in configuration registers.
+- **Invalid Opcode**: This exception occurs when the current instruction is invalid, for example, when we try to use new [SSE instructions] on an old CPU that does not support them.
+- **General Protection Fault**: This is the exception with the broadest range of causes. It occurs on various kinds of access violations, such as trying to execute a privileged instruction in user-level code or writing reserved fields in configuration registers.
- **Double Fault**: When an exception occurs, the CPU tries to call the corresponding handler function. If another exception occurs _while calling the exception handler_, the CPU raises a double fault exception. This exception also occurs when there is no handler function registered for an exception.
- **Triple Fault**: If an exception occurs while the CPU tries to call the double fault handler function, it issues a fatal _triple fault_. We can't catch or handle a triple fault. Most processors react by resetting themselves and rebooting the operating system.
[SSE instructions]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
-For the full list of exceptions check out the [OSDev wiki][exceptions].
+For the full list of exceptions, check out the [OSDev wiki][exceptions].
[exceptions]: https://wiki.osdev.org/Exceptions
### The Interrupt Descriptor Table
-In order to catch and handle exceptions, we have to set up a so-called _Interrupt Descriptor Table_ (IDT). In this table we can specify a handler function for each CPU exception. The hardware uses this table directly, so we need to follow a predefined format. Each entry must have the following 16-byte structure:
+In order to catch and handle exceptions, we have to set up a so-called _Interrupt Descriptor Table_ (IDT). In this table, we can specify a handler function for each CPU exception. The hardware uses this table directly, so we need to follow a predefined format. Each entry must have the following 16-byte structure:
Type| Name | Description
----|--------------------------|-----------------------------------
@@ -66,21 +66,21 @@ Bits | Name | Description
13‑14 | Descriptor Privilege Level (DPL) | The minimal privilege level required for calling this handler.
15 | Present |
-Each exception has a predefined IDT index. For example the invalid opcode exception has table index 6 and the page fault exception has table index 14. Thus, the hardware can automatically load the corresponding IDT entry for each exception. The [Exception Table][exceptions] in the OSDev wiki shows the IDT indexes of all exceptions in the “Vector nr.” column.
+Each exception has a predefined IDT index. For example, the invalid opcode exception has table index 6 and the page fault exception has table index 14. Thus, the hardware can automatically load the corresponding IDT entry for each exception. The [Exception Table][exceptions] in the OSDev wiki shows the IDT indexes of all exceptions in the “Vector nr.” column.
When an exception occurs, the CPU roughly does the following:
1. Push some registers on the stack, including the instruction pointer and the [RFLAGS] register. (We will use these values later in this post.)
-2. Read the corresponding entry from the Interrupt Descriptor Table (IDT). For example, the CPU reads the 14-th entry when a page fault occurs.
-3. Check if the entry is present. Raise a double fault if not.
+2. Read the corresponding entry from the Interrupt Descriptor Table (IDT). For example, the CPU reads the 14th entry when a page fault occurs.
+3. Check if the entry is present and, if not, raise a double fault.
4. Disable hardware interrupts if the entry is an interrupt gate (bit 40 not set).
-5. Load the specified [GDT] selector into the CS segment.
+5. Load the specified [GDT] selector into the CS (code segment).
6. Jump to the specified handler function.
[RFLAGS]: https://en.wikipedia.org/wiki/FLAGS_register
[GDT]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
-Don't worry about steps 4 and 5 for now, we will learn about the global descriptor table and hardware interrupts in future posts.
+Don't worry about steps 4 and 5 for now; we will learn about the global descriptor table and hardware interrupts in future posts.
## An IDT Type
Instead of creating our own IDT type, we will use the [`InterruptDescriptorTable` struct] of the `x86_64` crate, which looks like this:
@@ -133,9 +133,9 @@ It's a [type alias] for an `extern "x86-interrupt" fn` type. The `extern` keywor
[foreign calling convention]: https://doc.rust-lang.org/nomicon/ffi.html#foreign-calling-conventions
## The Interrupt Calling Convention
-Exceptions are quite similar to function calls: The CPU jumps to the first instruction of the called function and executes it. Afterwards the CPU jumps to the return address and continues the execution of the parent function.
+Exceptions are quite similar to function calls: The CPU jumps to the first instruction of the called function and executes it. Afterwards, the CPU jumps to the return address and continues the execution of the parent function.
-However, there is a major difference between exceptions and function calls: A function call is invoked voluntary by a compiler inserted `call` instruction, while an exception might occur at _any_ instruction. In order to understand the consequences of this difference, we need to examine function calls in more detail.
+However, there is a major difference between exceptions and function calls: A function call is invoked voluntarily by a compiler-inserted `call` instruction, while an exception might occur at _any_ instruction. In order to understand the consequences of this difference, we need to examine function calls in more detail.
[Calling conventions] specify the details of a function call. For example, they specify where function parameters are placed (e.g. in registers or on the stack) and how results are returned. On x86_64 Linux, the following rules apply for C functions (specified in the [System V ABI]):
@@ -151,11 +151,11 @@ Note that Rust does not follow the C ABI (in fact, [there isn't even a Rust ABI
[rust abi]: https://github.com/rust-lang/rfcs/issues/600
### Preserved and Scratch Registers
-The calling convention divides the registers in two parts: _preserved_ and _scratch_ registers.
+The calling convention divides the registers into two parts: _preserved_ and _scratch_ registers.
-The values of _preserved_ registers must remain unchanged across function calls. So a called function (the _“callee”_) is only allowed to overwrite these registers if it restores their original values before returning. Therefore these registers are called _“callee-saved”_. A common pattern is to save these registers to the stack at the function's beginning and restore them just before returning.
+The values of _preserved_ registers must remain unchanged across function calls. So a called function (the _“callee”_) is only allowed to overwrite these registers if it restores their original values before returning. Therefore, these registers are called _“callee-saved”_. A common pattern is to save these registers to the stack at the function's beginning and restore them just before returning.
-In contrast, a called function is allowed to overwrite _scratch_ registers without restrictions. If the caller wants to preserve the value of a scratch register across a function call, it needs to backup and restore it before the function call (e.g. by pushing it to the stack). So the scratch registers are _caller-saved_.
+In contrast, a called function is allowed to overwrite _scratch_ registers without restrictions. If the caller wants to preserve the value of a scratch register across a function call, it needs to backup and restore it before the function call (e.g., by pushing it to the stack). So the scratch registers are _caller-saved_.
On x86_64, the C calling convention specifies the following preserved and scratch registers:
@@ -167,11 +167,11 @@ _callee-saved_ | _caller-saved_
The compiler knows these rules, so it generates the code accordingly. For example, most functions begin with a `push rbp`, which backups `rbp` on the stack (because it's a callee-saved register).
### Preserving all Registers
-In contrast to function calls, exceptions can occur on _any_ instruction. In most cases we don't even know at compile time if the generated code will cause an exception. For example, the compiler can't know if an instruction causes a stack overflow or a page fault.
+In contrast to function calls, exceptions can occur on _any_ instruction. In most cases, we don't even know at compile time if the generated code will cause an exception. For example, the compiler can't know if an instruction causes a stack overflow or a page fault.
-Since we don't know when an exception occurs, we can't backup any registers before. This means that we can't use a calling convention that relies on caller-saved registers for exception handlers. Instead, we need a calling convention means that preserves _all registers_. The `x86-interrupt` calling convention is such a calling convention, so it guarantees that all register values are restored to their original values on function return.
+Since we don't know when an exception occurs, we can't backup any registers before. This means we can't use a calling convention that relies on caller-saved registers for exception handlers. Instead, we need a calling convention that preserves _all registers_. The `x86-interrupt` calling convention is such a calling convention, so it guarantees that all register values are restored to their original values on function return.
-Note that this does not mean that all registers are saved to the stack at function entry. Instead, the compiler only backs up the registers that are overwritten by the function. This way, very efficient code can be generated for short functions that only use a few registers.
+Note that this does not mean all registers are saved to the stack at function entry. Instead, the compiler only backs up the registers that are overwritten by the function. This way, very efficient code can be generated for short functions that only use a few registers.
### The Interrupt Stack Frame
On a normal function call (using the `call` instruction), the CPU pushes the return address before jumping to the target function. On function return (using the `ret` instruction), the CPU pops this return address and jumps to it. So the stack frame of a normal function call looks like this:
@@ -180,12 +180,13 @@ On a normal function call (using the `call` instruction), the CPU pushes the ret
For exception and interrupt handlers, however, pushing a return address would not suffice, since interrupt handlers often run in a different context (stack pointer, CPU flags, etc.). Instead, the CPU performs the following steps when an interrupt occurs:
-1. **Aligning the stack pointer**: An interrupt can occur at any instructions, so the stack pointer can have any value, too. However, some CPU instructions (e.g. some SSE instructions) require that the stack pointer is aligned on a 16 byte boundary, therefore the CPU performs such an alignment right after the interrupt.
-2. **Switching stacks** (in some cases): A stack switch occurs when the CPU privilege level changes, for example when a CPU exception occurs in a user mode program. It is also possible to configure stack switches for specific interrupts using the so-called _Interrupt Stack Table_ (described in the next post).
-3. **Pushing the old stack pointer**: The CPU pushes the values of the stack pointer (`rsp`) and the stack segment (`ss`) registers at the time when the interrupt occurred (before the alignment). This makes it possible to restore the original stack pointer when returning from an interrupt handler.
+0. **Saving the old stack pointer**: The CPU reads the stack pointer (`rsp`) and stack segment (`ss`) register values and remembers them in an internal buffer.
+1. **Aligning the stack pointer**: An interrupt can occur at any instruction, so the stack pointer can have any value, too. However, some CPU instructions (e.g., some SSE instructions) require that the stack pointer be aligned on a 16-byte boundary, so the CPU performs such an alignment right after the interrupt.
+2. **Switching stacks** (in some cases): A stack switch occurs when the CPU privilege level changes, for example, when a CPU exception occurs in a user-mode program. It is also possible to configure stack switches for specific interrupts using the so-called _Interrupt Stack Table_ (described in the next post).
+3. **Pushing the old stack pointer**: The CPU pushes the `rsp` and `ss` values from step 0 to the stack. This makes it possible to restore the original stack pointer when returning from an interrupt handler.
4. **Pushing and updating the `RFLAGS` register**: The [`RFLAGS`] register contains various control and status bits. On interrupt entry, the CPU changes some bits and pushes the old value.
5. **Pushing the instruction pointer**: Before jumping to the interrupt handler function, the CPU pushes the instruction pointer (`rip`) and the code segment (`cs`). This is comparable to the return address push of a normal function call.
-6. **Pushing an error code** (for some exceptions): For some specific exceptions such as page faults, the CPU pushes an error code, which describes the cause of the exception.
+6. **Pushing an error code** (for some exceptions): For some specific exceptions, such as page faults, the CPU pushes an error code, which describes the cause of the exception.
7. **Invoking the interrupt handler**: The CPU reads the address and the segment descriptor of the interrupt handler function from the corresponding field in the IDT. It then invokes this handler by loading the values into the `rip` and `cs` registers.
[`RFLAGS`]: https://en.wikipedia.org/wiki/FLAGS_register
@@ -194,19 +195,19 @@ So the _interrupt stack frame_ looks like this:

-In the `x86_64` crate, the interrupt stack frame is represented by the [`InterruptStackFrame`] struct. It is passed to interrupt handlers as `&mut` and can be used to retrieve additional information about the exception's cause. The struct contains no error code field, since only some few exceptions push an error code. These exceptions use the separate [`HandlerFuncWithErrCode`] function type, which has an additional `error_code` argument.
+In the `x86_64` crate, the interrupt stack frame is represented by the [`InterruptStackFrame`] struct. It is passed to interrupt handlers as `&mut` and can be used to retrieve additional information about the exception's cause. The struct contains no error code field, since only a few exceptions push an error code. These exceptions use the separate [`HandlerFuncWithErrCode`] function type, which has an additional `error_code` argument.
[`InterruptStackFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptStackFrame.html
### Behind the Scenes
The `x86-interrupt` calling convention is a powerful abstraction that hides almost all of the messy details of the exception handling process. However, sometimes it's useful to know what's happening behind the curtain. Here is a short overview of the things that the `x86-interrupt` calling convention takes care of:
-- **Retrieving the arguments**: Most calling conventions expect that the arguments are passed in registers. This is not possible for exception handlers, since we must not overwrite any register values before backing them up on the stack. Instead, the `x86-interrupt` calling convention is aware that the arguments already lie on the stack at a specific offset.
-- **Returning using `iretq`**: Since the interrupt stack frame completely differs from stack frames of normal function calls, we can't return from handlers functions through the normal `ret` instruction. Instead, the `iretq` instruction must be used.
-- **Handling the error code**: The error code, which is pushed for some exceptions, makes things much more complex. It changes the stack alignment (see the next point) and needs to be popped off the stack before returning. The `x86-interrupt` calling convention handles all that complexity. However, it doesn't know which handler function is used for which exception, so it needs to deduce that information from the number of function arguments. That means that the programmer is still responsible to use the correct function type for each exception. Luckily, the `InterruptDescriptorTable` type defined by the `x86_64` crate ensures that the correct function types are used.
-- **Aligning the stack**: There are some instructions (especially SSE instructions) that require a 16-byte stack alignment. The CPU ensures this alignment whenever an exception occurs, but for some exceptions it destroys it again later when it pushes an error code. The `x86-interrupt` calling convention takes care of this by realigning the stack in this case.
+- **Retrieving the arguments**: Most calling conventions expect that the arguments are passed in registers. This is not possible for exception handlers since we must not overwrite any register values before backing them up on the stack. Instead, the `x86-interrupt` calling convention is aware that the arguments already lie on the stack at a specific offset.
+- **Returning using `iretq`**: Since the interrupt stack frame completely differs from stack frames of normal function calls, we can't return from handler functions through the normal `ret` instruction. So instead, the `iretq` instruction must be used.
+- **Handling the error code**: The error code, which is pushed for some exceptions, makes things much more complex. It changes the stack alignment (see the next point) and needs to be popped off the stack before returning. The `x86-interrupt` calling convention handles all that complexity. However, it doesn't know which handler function is used for which exception, so it needs to deduce that information from the number of function arguments. That means the programmer is still responsible for using the correct function type for each exception. Luckily, the `InterruptDescriptorTable` type defined by the `x86_64` crate ensures that the correct function types are used.
+- **Aligning the stack**: Some instructions (especially SSE instructions) require a 16-byte stack alignment. The CPU ensures this alignment whenever an exception occurs, but for some exceptions it destroys it again later when it pushes an error code. The `x86-interrupt` calling convention takes care of this by realigning the stack in this case.
-If you are interested in more details: We also have a series of posts that explains exception handling using [naked functions] linked [at the end of this post][too-much-magic].
+If you are interested in more details, we also have a series of posts that explain exception handling using [naked functions] linked [at the end of this post][too-much-magic].
[naked functions]: https://github.com/rust-lang/rfcs/blob/master/text/1201-naked-fns.md
[too-much-magic]: #too-much-magic
@@ -272,10 +273,10 @@ error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue
= help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
```
-This error occurs because the `x86-interrupt` calling convention is still unstable. To use it anyway, we have to explicitly enable it by adding `#![feature(abi_x86_interrupt)]` on the top of our `lib.rs`.
+This error occurs because the `x86-interrupt` calling convention is still unstable. To use it anyway, we have to explicitly enable it by adding `#![feature(abi_x86_interrupt)]` at the top of our `lib.rs`.
### Loading the IDT
-In order that the CPU uses our new interrupt descriptor table, we need to load it using the [`lidt`] instruction. The `InterruptDescriptorTable` struct of the `x86_64` provides a [`load`][InterruptDescriptorTable::load] method function for that. Let's try to use it:
+In order for the CPU to use our new interrupt descriptor table, we need to load it using the [`lidt`] instruction. The `InterruptDescriptorTable` struct of the `x86_64` crate provides a [`load`][InterruptDescriptorTable::load] method for that. Let's try to use it:
[`lidt`]: https://www.felixcloutier.com/x86/lgdt:lidt
[InterruptDescriptorTable::load]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html#method.load
@@ -304,16 +305,16 @@ error: `idt` does not live long enough
= note: borrowed value must be valid for the static lifetime...
```
-So the `load` methods expects a `&'static self`, that is a reference that is valid for the complete runtime of the program. The reason is that the CPU will access this table on every interrupt until we load a different IDT. So using a shorter lifetime than `'static` could lead to use-after-free bugs.
+So the `load` method expects a `&'static self`, that is, a reference valid for the complete runtime of the program. The reason is that the CPU will access this table on every interrupt until we load a different IDT. So using a shorter lifetime than `'static` could lead to use-after-free bugs.
-In fact, this is exactly what happens here. Our `idt` is created on the stack, so it is only valid inside the `init` function. Afterwards the stack memory is reused for other functions, so the CPU would interpret random stack memory as IDT. Luckily, the `InterruptDescriptorTable::load` method encodes this lifetime requirement in its function definition, so that the Rust compiler is able to prevent this possible bug at compile time.
+In fact, this is exactly what happens here. Our `idt` is created on the stack, so it is only valid inside the `init` function. Afterwards, the stack memory is reused for other functions, so the CPU would interpret random stack memory as IDT. Luckily, the `InterruptDescriptorTable::load` method encodes this lifetime requirement in its function definition, so that the Rust compiler is able to prevent this possible bug at compile time.
-In order to fix this problem, we need to store our `idt` at a place where it has a `'static` lifetime. To achieve this we could allocate our IDT on the heap using [`Box`] and then convert it to a `'static` reference, but we are writing an OS kernel and thus don't have a heap (yet).
+In order to fix this problem, we need to store our `idt` at a place where it has a `'static` lifetime. To achieve this, we could allocate our IDT on the heap using [`Box`] and then convert it to a `'static` reference, but we are writing an OS kernel and thus don't have a heap (yet).
[`Box`]: https://doc.rust-lang.org/std/boxed/struct.Box.html
-As an alternative we could try to store the IDT as a `static`:
+As an alternative, we could try to store the IDT as a `static`:
```rust
static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
@@ -344,7 +345,7 @@ This variant compiles without errors but it's far from idiomatic. `static mut`s
[`unsafe` block]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
#### Lazy Statics to the Rescue
-Fortunately the `lazy_static` macro exists. Instead of evaluating a `static` at compile time, the macro performs the initialization when the `static` is referenced the first time. Thus, we can do almost everything in the initialization block and are even able to read runtime values.
+Fortunately, the `lazy_static` macro exists. Instead of evaluating a `static` at compile time, the macro performs the initialization when the `static` is referenced the first time. Thus, we can do almost everything in the initialization block and are even able to read runtime values.
We already imported the `lazy_static` crate when we [created an abstraction for the VGA text buffer][vga text buffer lazy static]. So we can directly use the `lazy_static!` macro to create our static IDT:
@@ -382,7 +383,7 @@ pub fn init() {
}
```
-With this function we now have a central place for initialization routines that can be shared between the different `_start` functions in our `main.rs`, `lib.rs`, and integration tests.
+With this function, we now have a central place for initialization routines that can be shared between the different `_start` functions in our `main.rs`, `lib.rs`, and integration tests.
Now we can update the `_start` function of our `main.rs` to call `init` and then trigger a breakpoint exception:
@@ -432,7 +433,7 @@ pub extern "C" fn _start() -> ! {
}
```
-Remember, this `_start` function is used when running `cargo test --lib`, since Rust's tests the `lib.rs` completely independent of the `main.rs`. We need to call `init` here to set up an IDT before running the tests.
+Remember, this `_start` function is used when running `cargo test --lib`, since Rust tests the `lib.rs` completely independently of the `main.rs`. We need to call `init` here to set up an IDT before running the tests.
Now we can create a `test_breakpoint_exception` test:
@@ -446,7 +447,7 @@ fn test_breakpoint_exception() {
}
```
-The test invokes the `int3` function to trigger a breakpoint exception. By checking that the execution continues afterwards, we verify that our breakpoint handler is working correctly.
+The test invokes the `int3` function to trigger a breakpoint exception. By checking that the execution continues afterward, we verify that our breakpoint handler is working correctly.
You can try this new test by running `cargo test` (all tests) or `cargo test --lib` (only tests of `lib.rs` and its modules). You should see the following in the output:
@@ -455,14 +456,14 @@ blog_os::interrupts::test_breakpoint_exception... [ok]
```
## Too much Magic?
-The `x86-interrupt` calling convention and the [`InterruptDescriptorTable`] type made the exception handling process relatively straightforward and painless. If this was too much magic for you and you like to learn all the gory details of exception handling, we got you covered: Our [“Handling Exceptions with Naked Functions”] series shows how to handle exceptions without the `x86-interrupt` calling convention and also creates its own IDT type. Historically, these posts were the main exception handling posts before the `x86-interrupt` calling convention and the `x86_64` crate existed. Note that these posts are based on the [first edition] of this blog and might be out of date.
+The `x86-interrupt` calling convention and the [`InterruptDescriptorTable`] type made the exception handling process relatively straightforward and painless. If this was too much magic for you and you like to learn all the gory details of exception handling, we've got you covered: Our [“Handling Exceptions with Naked Functions”] series shows how to handle exceptions without the `x86-interrupt` calling convention and also creates its own IDT type. Historically, these posts were the main exception handling posts before the `x86-interrupt` calling convention and the `x86_64` crate existed. Note that these posts are based on the [first edition] of this blog and might be out of date.
[“Handling Exceptions with Naked Functions”]: @/edition-1/extra/naked-exceptions/_index.md
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
[first edition]: @/edition-1/_index.md
## What's next?
-We've successfully caught our first exception and returned from it! The next step is to ensure that we catch all exceptions, because an uncaught exception causes a fatal [triple fault], which leads to a system reset. The next post explains how we can avoid this by correctly catching [double faults].
+We've successfully caught our first exception and returned from it! The next step is to ensure that we catch all exceptions because an uncaught exception causes a fatal [triple fault], which leads to a system reset. The next post explains how we can avoid this by correctly catching [double faults].
[triple fault]: https://wiki.osdev.org/Triple_Fault
[double faults]: https://wiki.osdev.org/Double_Fault#Double_Fault
diff --git a/blog/content/edition-2/posts/05-cpu-exceptions/index.zh-CN.md b/blog/content/edition-2/posts/05-cpu-exceptions/index.zh-CN.md
new file mode 100644
index 00000000..08c34708
--- /dev/null
+++ b/blog/content/edition-2/posts/05-cpu-exceptions/index.zh-CN.md
@@ -0,0 +1,473 @@
++++
+title = "CPU异常处理"
+weight = 5
+path = "zh-CN/cpu-exceptions"
+date = 2018-06-17
+
+[extra]
+# Please update this when updating the translation
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
+# GitHub usernames of the people that translated this post
+translators = ["liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong", "Byacrya"]
++++
+
+CPU异常在很多情况下都有可能发生,比如访问无效的内存地址,或者在除法运算里除以0。为了处理这些错误,我们需要设置一个 _中断描述符表_ 来提供异常处理函数。在文章的最后,我们的内核将能够捕获 [断点异常][breakpoint exceptions] 并在处理后恢复正常执行。
+
+[breakpoint exceptions]: https://wiki.osdev.org/Exceptions#Breakpoint
+
+
+
+这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-05`][post branch]找到这篇文章的完整源码。
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-05
+
+
+
+## 简述
+异常信号会在当前指令触发错误时被触发,例如执行了除数为0的除法。当异常发生后,CPU会中断当前的工作,并立即根据异常类型调用对应的错误处理函数。
+
+在x86架构中,存在20种不同的CPU异常类型,以下为最重要的几种:
+
+- **Page Fault**: 页错误是被非法内存访问触发的,例如当前指令试图访问未被映射过的页,或者试图写入只读页。
+- **Invalid Opcode**: 该错误是说当前指令操作符无效,比如在不支持SSE的旧式CPU上执行了 [SSE 指令][SSE instructions]。
+- **General Protection Fault**: 该错误的原因有很多,主要原因就是权限异常,即试图使用用户态代码执行核心指令,或是修改配置寄存器的保留字段。
+- **Double Fault**: 当错误发生时,CPU会尝试调用错误处理函数,但如果 _在调用错误处理函数过程中_ 再次发生错误,CPU就会触发该错误。另外,如果没有注册错误处理函数也会触发该错误。
+- **Triple Fault**: 如果CPU调用了对应 `Double Fault` 异常的处理函数依然没有成功,该错误会被抛出。这是一个致命级别的 _三重异常_,这意味着我们已经无法捕捉它,对于大多数操作系统而言,此时就应该重置数据并重启操作系统。
+
+[SSE instructions]: https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
+
+在 [OSDev wiki][exceptions] 可以看到完整的异常类型列表。
+
+[exceptions]: https://wiki.osdev.org/Exceptions
+
+### 中断描述符表
+要捕捉CPU异常,我们需要设置一个 _中断描述符表_ (_Interrupt Descriptor Table_, IDT),用来捕获每一个异常。由于硬件层面会不加验证的直接使用,所以我们需要根据预定义格式直接写入数据。符表的每一行都遵循如下的16字节结构。
+
+| Type | Name | Description |
+| ---- | ------------------------ | ------------------------------------------------------- |
+| u16 | Function Pointer [0:15] | 处理函数地址的低位(最后16位) |
+| u16 | GDT selector | [全局描述符表][global descriptor table]中的代码段标记。 |
+| u16 | Options | (如下所述) |
+| u16 | Function Pointer [16:31] | 处理函数地址的中位(中间16位) |
+| u32 | Function Pointer [32:63] | 处理函数地址的高位(剩下的所有位) |
+| u32 | Reserved |
+
+[global descriptor table]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
+
+Options字段的格式如下:
+
+| Bits | Name | Description |
+| ----- | -------------------------------- | --------------------------------------------------------------- |
+| 0-2 | Interrupt Stack Table Index | 0: 不要切换栈, 1-7: 当处理函数被调用时,切换到中断栈表的第n层。 |
+| 3-7 | Reserved |
+| 8 | 0: Interrupt Gate, 1: Trap Gate | 如果该比特被置为0,当处理函数被调用时,中断会被禁用。 |
+| 9-11 | must be one |
+| 12 | must be zero |
+| 13‑14 | Descriptor Privilege Level (DPL) | 执行处理函数所需的最小特权等级。 |
+| 15 | Present |
+
+每个异常都具有一个预定义的IDT序号,比如 invalid opcode 异常对应6号,而 page fault 异常对应14号,因此硬件可以直接寻找到对应的IDT条目。 OSDev wiki中的 [异常对照表][exceptions] 可以查到所有异常的IDT序号(在Vector nr.列)。
+
+通常而言,当异常发生时,CPU会执行如下步骤:
+
+1. 将一些寄存器数据入栈,包括指令指针以及 [RFLAGS] 寄存器。(我们会在文章稍后些的地方用到这些数据。)
+2. 读取中断描述符表(IDT)的对应条目,比如当发生 page fault 异常时,调用14号条目。
+3. 判断该条目确实存在,如果不存在,则触发 double fault 异常。
+4. 如果该条目属于中断门(interrupt gate,bit 40 被设置为0),则禁用硬件中断。
+5. 将 [GDT] 选择器载入代码段寄存器(CS segment)。
+6. 跳转执行处理函数。
+
+[RFLAGS]: https://en.wikipedia.org/wiki/FLAGS_register
+[GDT]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
+
+不过现在我们不必为4和5多加纠结,未来我们会单独讲解全局描述符表和硬件中断的。
+
+## IDT类型
+与其创建我们自己的IDT类型映射,不如直接使用 `x86_64` crate 内置的 [`InterruptDescriptorTable` 结构][`InterruptDescriptorTable` struct],其实现是这样的:
+
+[`InterruptDescriptorTable` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+
+``` rust
+#[repr(C)]
+pub struct InterruptDescriptorTable {
+ pub divide_by_zero: Entry,
+ pub debug: Entry,
+ pub non_maskable_interrupt: Entry,
+ pub breakpoint: Entry,
+ pub overflow: Entry,
+ pub bound_range_exceeded: Entry,
+ pub invalid_opcode: Entry,
+ pub device_not_available: Entry,
+ pub double_fault: Entry,
+ pub invalid_tss: Entry,
+ pub segment_not_present: Entry,
+ pub stack_segment_fault: Entry,
+ pub general_protection_fault: Entry,
+ pub page_fault: Entry,
+ pub x87_floating_point: Entry,
+ pub alignment_check: Entry,
+ pub machine_check: Entry,
+ pub simd_floating_point: Entry,
+ pub virtualization: Entry,
+ pub security_exception: Entry,
+ // some fields omitted
+}
+```
+
+每一个字段都是 [`idt::Entry`] 类型,这个类型包含了一条完整的IDT条目(定义参见上文)。 其泛型参数 `F` 定义了中断处理函数的类型,在有些字段中该参数为 [`HandlerFunc`],而有些则是 [`HandlerFuncWithErrCode`],而对于 page fault 这种特殊异常,则为 [`PageFaultHandlerFunc`]。
+
+[`idt::Entry`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.Entry.html
+[`HandlerFunc`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.HandlerFunc.html
+[`HandlerFuncWithErrCode`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.HandlerFuncWithErrCode.html
+[`PageFaultHandlerFunc`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/type.PageFaultHandlerFunc.html
+
+首先让我们看一看 `HandlerFunc` 类型的定义:
+
+```rust
+type HandlerFunc = extern "x86-interrupt" fn(_: InterruptStackFrame);
+```
+
+这是一个针对 `extern "x86-interrupt" fn` 类型的 [类型别名][type alias]。`extern` 关键字使用 [外部调用约定][foreign calling convention] 定义了一个函数,这种定义方式多用于和C语言代码通信(`extern "C" fn`),那么这里的外部调用约定又究竟调用了哪些东西?
+
+[type alias]: https://doc.rust-lang.org/book/ch19-04-advanced-types.html#creating-type-synonyms-with-type-aliases
+[foreign calling convention]: https://doc.rust-lang.org/nomicon/ffi.html#foreign-calling-conventions
+
+## 中断调用约定
+异常触发十分类似于函数调用:CPU会直接跳转到处理函数的第一个指令处开始执行,执行结束后,CPU会跳转到返回地址,并继续执行之前的函数调用。
+
+然而两者最大的不同点是:函数调用是由编译器通过 `call` 指令主动发起的,而错误处理函数则可能会由 _任何_ 指令触发。要了解这两者所造成影响的不同,我们需要更深入的追踪函数调用。
+
+[调用约定][Calling conventions] 指定了函数调用的详细信息,比如可以指定函数的参数存放在哪里(寄存器,或者栈,或者别的什么地方)以及如何返回结果。在 x86_64 Linux 中,以下规则适用于C语言函数(指定于 [System V ABI] 标准):
+
+[Calling conventions]: https://en.wikipedia.org/wiki/Calling_convention
+[System V ABI]: https://refspecs.linuxbase.org/elf/x86_64-abi-0.99.pdf
+
+- 前六个整型参数从寄存器传入 `rdi`, `rsi`, `rdx`, `rcx`, `r8`, `r9`
+- 其他参数从栈传入
+- 函数返回值存放在 `rax` 和 `rdx`
+
+注意,Rust并不遵循C ABI,而是遵循自己的一套规则,即 [尚未正式发布的 Rust ABI 草案][rust abi],所以这些规则仅在使用 `extern "C" fn` 对函数进行定义时才会使用。
+
+[rust abi]: https://github.com/rust-lang/rfcs/issues/600
+
+### 保留寄存器和临时寄存器
+调用约定将寄存器分为两部分:_保留寄存器_ 和 _临时寄存器_ 。
+
+_保留寄存器_ 的值应当在函数调用时保持不变,所以被调用的函数( _"callee"_ )只有在保证"返回之前将这些寄存器的值恢复到初始值"的前提下,才被允许覆写这些寄存器的值, 在函数开始时将这类寄存器的值存入栈中,并在返回之前将之恢复到寄存器中是一种十分常见的做法。
+
+而 _临时寄存器_ 则相反,被调用函数可以无限制的反复写入寄存器,若调用者希望此类寄存器在函数调用后保持数值不变,则需要自己来处理备份和恢复过程(例如将其数值保存在栈中),因而这类寄存器又被称为 _caller-saved_。
+
+在 x86_64 架构下,C调用约定指定了这些寄存器分类:
+
+| 保留寄存器 | 临时寄存器 |
+| ----------------------------------------------- | ----------------------------------------------------------- |
+| `rbp`, `rbx`, `rsp`, `r12`, `r13`, `r14`, `r15` | `rax`, `rcx`, `rdx`, `rsi`, `rdi`, `r8`, `r9`, `r10`, `r11` |
+| _callee-saved_ | _caller-saved_ |
+
+编译器已经内置了这些规则,因而可以自动生成保证程序正常执行的指令。例如绝大多数函数的汇编指令都以 `push rbp` 开头,也就是将 `rbp` 的值备份到栈中(因为它是 `callee-saved` 型寄存器)。
+
+### 保存所有寄存器数据
+区别于函数调用,异常在执行 _任何_ 指令时都有可能发生。在大多数情况下,我们在编译期不可能知道程序跑起来会发生什么异常。比如编译器无法预知某条指令是否会触发 page fault 或者 stack overflow。
+
+正因我们不知道异常会何时发生,所以我们无法预先保存寄存器。这意味着我们无法使用依赖调用方备份 (caller-saved) 的寄存器的调用传统作为异常处理程序。因此,我们需要一个保存所有寄存器的传统。x86-interrupt 恰巧就是其中之一,它可以保证在函数返回时,寄存器里的值均返回原样。
+
+但请注意,这并不意味着所有寄存器都会在进入函数时备份入栈。编译器仅会备份被函数覆写的寄存器,继而为只使用几个寄存器的短小函数生成高效的代码。
+
+### 中断栈帧
+当一个常规函数调用发生时(使用 `call` 指令),CPU会在跳转目标函数之前,将返回地址入栈。当函数返回时(使用 `ret` 指令),CPU会在跳回目标函数之前弹出返回地址。所以常规函数调用的栈帧看起来是这样的:
+
+
+
+对于错误和中断处理函数,仅仅压入一个返回地址并不足够,因为中断处理函数通常会运行在一个不那么一样的上下文中(栈指针、CPU flags等等)。所以CPU在遇到中断发生时是这么处理的:
+
+1. **对齐栈指针**: 任何指令都有可能触发中断,所以栈指针可能是任何值,而部分CPU指令(比如部分SSE指令)需要栈指针16字节边界对齐,因此CPU会在中断触发后立刻为其进行对齐。
+2. **切换栈** (部分情况下): 当CPU特权等级改变时,例如当一个用户态程序触发CPU异常时,会触发栈切换。该行为也可能被所谓的 _中断栈表_ 配置,在特定中断中触发,关于该表,我们会在下一篇文章做出讲解。
+3. **压入旧的栈指针**: 当中断发生后,栈指针对齐之前,CPU会将栈指针寄存器(`rsp`)和栈段寄存器(`ss`)的数据入栈,由此可在中断处理函数返回后,恢复上一层的栈指针。
+4. **压入并更新 `RFLAGS` 寄存器**: [`RFLAGS`] 寄存器包含了各式各样的控制位和状态位,当中断发生时,CPU会改变其中的部分数值,并将旧值入栈。
+5. **压入指令指针**: 在跳转中断处理函数之前,CPU会将指令指针寄存器(`rip`)和代码段寄存器(`cs`)的数据入栈,此过程与常规函数调用中返回地址入栈类似。
+6. **压入错误码** (针对部分异常): 对于部分特定的异常,比如 page faults ,CPU会推入一个错误码用于标记错误的成因。
+7. **执行中断处理函数**: CPU会读取对应IDT条目中描述的中断处理函数对应的地址和段描述符,将两者载入 `rip` 和 `cs` 以开始运行处理函数。
+
+[`RFLAGS`]: https://en.wikipedia.org/wiki/FLAGS_register
+
+所以 _中断栈帧_ 看起来是这样的:
+
+
+
+在 `x86_64` crate 中,中断栈帧已经被 [`InterruptStackFrame`] 结构完整表达,该结构会以 `&mut` 的形式传入处理函数,并可以用于查询错误发生的更详细的原因。但该结构并不包含错误码字段,因为只有极少量的错误会传入错误码,所以对于这类需要传入 `error_code` 的错误,其函数类型变为了 [`HandlerFuncWithErrCode`]。
+
+[`InterruptStackFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptStackFrame.html
+
+### 幕后花絮
+`x86-interrupt` 调用约定是一个十分厉害的抽象,它几乎隐藏了所有错误处理函数中的凌乱细节,但尽管如此,了解一下水面下发生的事情还是有用的。我们来简单介绍一下被 `x86-interrupt` 隐藏起来的行为:
+
+- **传递参数**: 绝大多数指定参数的调用约定都是期望通过寄存器取得参数的,但事实上这是无法实现的,因为我们不能在备份寄存器数据之前就将其复写。`x86-interrupt` 的解决方案时,将参数以指定的偏移量放到栈上。
+- **使用 `iretq` 返回**: 由于中断栈帧和普通函数调用的栈帧是完全不同的,我们无法通过 `ret` 指令直接返回,所以此时必须使用 `iretq` 指令。
+- **处理错误码**: 部分异常传入的错误码会让错误处理更加复杂,它会造成栈指针对齐失效(见下一条),而且需要在返回之前从栈中弹出去。好在 `x86-interrupt` 为我们挡住了这些额外的复杂度。但是它无法判断哪个异常对应哪个处理函数,所以它需要从函数参数数量上推断一些信息,因此程序员需要为每个异常使用正确的函数类型。当然你已经不需要烦恼这些, `x86_64` crate 中的 `InterruptDescriptorTable` 已经帮助你完成了定义。
+- **对齐栈**: 对于一些指令(尤其是SSE指令)而言,它们需要提前进行16字节边界对齐操作,通常而言CPU在异常发生之后就会自动完成这一步。但是部分异常会由于传入错误码而破坏掉本应完成的对齐操作,此时 `x86-interrupt` 会为我们重新完成对齐。
+
+如果你对更多细节有兴趣:我们还有关于使用 [裸函数][naked functions] 展开异常处理的一个系列章节,参见 [文末][too-much-magic]。
+
+[naked functions]: https://github.com/rust-lang/rfcs/blob/master/text/1201-naked-fns.md
+[too-much-magic]: #hei-mo-fa-you-dian-duo
+
+## 实现
+那么理论知识暂且到此为止,该开始为我们的内核实现CPU异常处理了。首先我们在 `src/interrupts.rs` 创建一个模块,并加入函数 `init_idt` 用来创建一个新的 `InterruptDescriptorTable`:
+
+``` rust
+// in src/lib.rs
+
+pub mod interrupts;
+
+// in src/interrupts.rs
+
+use x86_64::structures::idt::InterruptDescriptorTable;
+
+pub fn init_idt() {
+ let mut idt = InterruptDescriptorTable::new();
+}
+```
+
+现在我们就可以添加处理函数了,首先给 [breakpoint exception] 添加。该异常是一个绝佳的测试途径,因为它唯一的目的就是在 `int3` 指令执行时暂停程序运行。
+
+[breakpoint exception]: https://wiki.osdev.org/Exceptions#Breakpoint
+
+breakpoint exception 通常被用在调试器中:当程序员为程序打上断点,调试器会将对应的位置覆写为 `int3` 指令,CPU执行该指令后,就会抛出 breakpoint exception 异常。在调试完毕,需要程序继续运行时,调试器就会将原指令覆写回 `int3` 的位置。如果要了解更多细节,请查阅 ["_调试器是如何工作的_"]["_How debuggers work_"] 系列。
+
+["_How debuggers work_"]: https://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
+
+不过现在我们还不需要覆写指令,只需要打印一行日志,表明接收到了这个异常,然后让程序继续运行即可。那么我们就来创建一个简单的 `breakpoint_handler` 方法并加入IDT中:
+
+```rust
+// in src/interrupts.rs
+
+use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
+use crate::println;
+
+pub fn init_idt() {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+}
+
+extern "x86-interrupt" fn breakpoint_handler(
+ stack_frame: InterruptStackFrame)
+{
+ println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
+}
+```
+
+现在,我们的处理函数应当会输出一行信息以及完整的栈帧。
+
+但当我们尝试编译的时候,报出了下面的错误:
+
+```
+error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
+ --> src/main.rs:53:1
+ |
+53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: InterruptStackFrame) {
+54 | | println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
+55 | | }
+ | |_^
+ |
+ = help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
+```
+
+这是因为 `x86-interrupt` 并不是稳定特性,需要手动启用,只需要在我们的 `lib.rs` 中加入 `#![feature(abi_x86_interrupt)]` 开关即可。
+
+### 载入 IDT
+要让CPU使用新的中断描述符表,我们需要使用 [`lidt`] 指令来装载一下,`x86_64` 的 `InterruptDescriptorTable` 结构提供了 [`load`][InterruptDescriptorTable::load] 函数用来实现这个需求。让我们来试一下:
+
+[`lidt`]: https://www.felixcloutier.com/x86/lgdt:lidt
+[InterruptDescriptorTable::load]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html#method.load
+
+```rust
+// in src/interrupts.rs
+
+pub fn init_idt() {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ idt.load();
+}
+```
+
+再次尝试编译,又出现了新的错误:
+
+```
+error: `idt` does not live long enough
+ --> src/interrupts/mod.rs:43:5
+ |
+43 | idt.load();
+ | ^^^ does not live long enough
+44 | }
+ | - borrowed value only lives until here
+ |
+ = note: borrowed value must be valid for the static lifetime...
+```
+
+原来 `load` 函数要求的生命周期为 `&'static self` ,也就是整个程序的生命周期,其原因就是CPU在接收到下一个IDT之前会一直使用这个描述符表。如果生命周期小于 `'static` ,很可能就会出现使用已释放对象的bug。
+
+问题至此已经很清晰了,我们的 `idt` 是创建在栈上的,它的生命周期仅限于 `init` 函数执行期间,之后这部分栈内存就会被其他函数调用,CPU再来访问IDT的话,只会读取到一段随机数据。好在 `InterruptDescriptorTable::load` 被严格定义了函数生命周期限制,这样 Rust 编译器就可以在编译时就发现这些潜在问题。
+
+要修复这些错误很简单,让 `idt` 具备 `'static` 类型的生命周期即可,我们可以使用 [`Box`] 在堆上申请一段内存,并转化为 `'static` 指针即可,但问题是我们正在写的东西是操作系统内核,(暂时)并没有堆这种东西。
+
+[`Box`]: https://doc.rust-lang.org/std/boxed/struct.Box.html
+
+
+作为替代,我们可以试着直接将IDT定义为 `'static` 变量:
+
+```rust
+static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
+
+pub fn init_idt() {
+ IDT.breakpoint.set_handler_fn(breakpoint_handler);
+ IDT.load();
+}
+```
+
+然而这样就会引入一个新问题:静态变量是不可修改的,这样我们就无法在 `init` 函数中修改里面的数据了,所以需要把变量类型修改为 [`static mut`]:
+
+[`static mut`]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable
+
+```rust
+static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
+
+pub fn init_idt() {
+ unsafe {
+ IDT.breakpoint.set_handler_fn(breakpoint_handler);
+ IDT.load();
+ }
+}
+```
+
+这样就不会有编译错误了,但是这并不符合官方推荐的编码习惯,因为理论上说 `static mut` 类型的变量很容易形成数据竞争,所以需要用 [`unsafe` 代码块][`unsafe` block] 修饰调用语句。
+
+[`unsafe` block]: https://doc.rust-lang.org/1.30.0/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers
+
+#### 懒加载拯救世界
+好在还有 `lazy_static` 宏可以用,区别于普通 `static` 变量在编译器求值,这个宏可以使代码块内的 `static` 变量在第一次取值时求值。所以,我们完全可以把初始化代码写在变量定义的代码块里,同时也不影响后续的取值。
+
+在 [创建VGA字符缓冲的单例][vga text buffer lazy static] 时我们已经引入了 `lazy_static` crate,所以我们可以直接使用 `lazy_static!` 来创建IDT:
+
+[vga text buffer lazy static]: @/edition-2/posts/03-vga-text-buffer/index.md#lazy-statics
+
+```rust
+// in src/interrupts.rs
+
+use lazy_static::lazy_static;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ idt
+ };
+}
+
+pub fn init_idt() {
+ IDT.load();
+}
+```
+
+现在碍眼的 `unsafe` 代码块成功被去掉了,尽管 `lazy_static!` 的内部依然使用了 `unsafe` 代码块,但是至少它已经抽象为了一个安全接口。
+
+### 跑起来
+
+最后一步就是在 `main.rs` 里执行 `init_idt` 函数以在我们的内核里装载IDT,但不要直接调用,而应在 `lib.rs` 里封装一个 `init` 函数出来:
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ interrupts::init_idt();
+}
+```
+
+这样我们就可以把所有初始化逻辑都集中在一个函数里,从而让 `main.rs` 、 `lib.rs` 以及单元测试中的 `_start` 共享初始化逻辑。
+
+现在我们更新一下 `main.rs` 中的 `_start` 函数,调用 `init` 并手动触发一次 breakpoint exception:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init(); // new
+
+ // invoke a breakpoint exception
+ x86_64::instructions::interrupts::int3(); // new
+
+ // as before
+ #[cfg(test)]
+ test_main();
+
+ println!("It did not crash!");
+ loop {}
+}
+```
+
+当我们在QEMU中运行之后(`cargo run`),效果是这样的:
+
+
+
+成功了!CPU成功调用了中断处理函数并打印出了信息,然后返回 `_start` 函数打印出了 `It did not crash!`。
+
+我们可以看到,中断栈帧告诉了我们当错误发生时指令和栈指针的具体数值,这些信息在我们调试意外错误的时候非常有用。
+
+### 添加测试
+
+那么让我们添加一个测试用例,用来确保以上工作成果可以顺利运行。首先需要在 `_start` 函数中调用 `init`:
+
+```rust
+// in src/lib.rs
+
+/// Entry point for `cargo test`
+#[cfg(test)]
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ init(); // new
+ test_main();
+ loop {}
+}
+```
+
+注意,这里的 `_start` 会在 `cargo test --lib` 这条命令的上下文中运行,而 `lib.rs` 的执行环境完全独立于 `main.rs`,所以我们需要在运行测试之前调用 `init` 装载IDT。
+
+那么我们接着创建一个测试用例 `test_breakpoint_exception`:
+
+```rust
+// in src/interrupts.rs
+
+#[test_case]
+fn test_breakpoint_exception() {
+ // invoke a breakpoint exception
+ x86_64::instructions::interrupts::int3();
+}
+```
+
+该测试仅调用了 `int3` 函数以触发 breakpoint exception,通过查看这个函数是否能够继续运行下去,就可以确认我们对应的中断处理函数是否工作正常。
+
+现在,你可以执行 `cargo test` 来运行所有测试,或者执行 `cargo test --lib` 来运行 `lib.rs` 及其子模块中包含的测试,最终输出如下:
+
+```
+blog_os::interrupts::test_breakpoint_exception... [ok]
+```
+
+## 黑魔法有点多?
+相对来说,`x86-interrupt` 调用约定和 [`InterruptDescriptorTable`] 类型让错误处理变得直截了当,如果这对你来说太过于神奇,进而想要了解错误处理中的所有隐秘细节,我们推荐读一下这些:[“使用裸函数处理错误”][“Handling Exceptions with Naked Functions”] 系列文章展示了如何在不使用 `x86-interrupt` 的前提下创建IDT。但是需要注意的是,这些文章都是在 `x86-interrupt` 调用约定和 `x86_64` crate 出现之前的产物,这些东西属于博客的 [第一版][first edition],不排除信息已经过期了的可能。
+
+[“Handling Exceptions with Naked Functions”]: @/edition-1/extra/naked-exceptions/_index.md
+[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+[first edition]: @/edition-1/_index.md
+
+## 接下来是?
+我们已经成功捕获了第一个异常,并从异常中成功恢复,下一步就是试着捕获所有异常,如果有未捕获的异常就会触发致命的[triple fault],那就只能重启整个系统了。下一篇文章会展开说我们如何通过正确捕捉[double faults]来避免这种情况。
+
+[triple fault]: https://wiki.osdev.org/Triple_Fault
+[double faults]: https://wiki.osdev.org/Double_Fault#Double_Fault
diff --git a/blog/content/edition-2/posts/06-double-faults/index.ja.md b/blog/content/edition-2/posts/06-double-faults/index.ja.md
index fbce089c..dc048eba 100644
--- a/blog/content/edition-2/posts/06-double-faults/index.ja.md
+++ b/blog/content/edition-2/posts/06-double-faults/index.ja.md
@@ -142,7 +142,7 @@ CPUはダブルフォルトハンドラを呼べるようになったので、
[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
-例えばページフォルトに続いてゼロ除算例外が起きた場合は問題ありません(ページフォルトハンドラが呼び出される)が、一般保護違反に続いてゼロ除算例外が起きた場合はダブルフォルトが発生します。
+例えばゼロ除算例外に続いてページフォルトが起きた場合は問題ありません(ページフォルトハンドラが呼び出される)が、ゼロ除算例外に続いて一般保護違反が起きた場合はダブルフォルトが発生します。
この表を見れば、先程の質問のうち最初の3つに答えることができます:
@@ -382,7 +382,7 @@ pub fn init() {
[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
-これで正常なTSSと割り込みスタックテーブルを読み込みこんだので、私達はIDT内のダブルフォルトハンドラにスタックインデックスをセットすることができます:
+これで正常なTSSと割り込みスタックテーブルを読み込んだので、私達はIDT内のダブルフォルトハンドラにスタックインデックスをセットすることができます:
```rust
// in src/interrupts.rs
diff --git a/blog/content/edition-2/posts/06-double-faults/index.ko.md b/blog/content/edition-2/posts/06-double-faults/index.ko.md
new file mode 100644
index 00000000..4440fccc
--- /dev/null
+++ b/blog/content/edition-2/posts/06-double-faults/index.ko.md
@@ -0,0 +1,558 @@
++++
+title = "더블 폴트 (Double Fault)"
+weight = 6
+path = "ko/double-fault-exceptions"
+date = 2018-06-18
+
+[extra]
+chapter = "Interrupts"
+# Please update this when updating the translation
+translation_based_on_commit = "a108367d712ef97c28e8e4c1a22da4697ba6e6cd"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["dalinaum"]
++++
+
+이번 글에서는 CPU가 예외 처리 함수를 호출하는 데에 실패할 때 발생하는 더블 폴트 (double fault) 예외에 대해 자세히 다룹니다. 더블 폴트 예외를 처리함으로써 시스템 재부팅을 발생시키는 치명적인 _트리플 폴트 (triple fault)_ 예외를 피할 수 있습니다. 트리플 폴트가 발생할 수 있는 모든 경우에 대비하기 위해 _Interrupt Stack Table_ 을 만들고 별도의 커널 스택에서 더블 폴트를 처리할 것입니다.
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-06 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-06
+
+
+
+## 더블 폴트 (Double Fault)란 무엇일까요?
+간단히 말하면, 더블 폴트는 CPU가 예외 처리 함수를 호출하는 것에 실패했을 때 발생하는 예외입니다. 예를 들면 페이지 폴트가 발생했는데 [인터럽트 서술자 테이블 (Interrupt Descriptor Table; IDT)][IDT] 에 등록된 페이지 폴트 처리 함수가 없을 때 더블 폴트가 예외가 발생합니다. 비유한다면 C++의 `catch(..)`문이나 Java 및 C#의 `catch(Exception e)`문처럼 모든 종류의 예외를 처리할 수 있다는 점에서 유사합니다.
+
+[IDT]: @/edition-2/posts/05-cpu-exceptions/index.ko.md#the-interrupt-descriptor-table
+
+더블 폴트는 다른 예외들과 다를 게 없습니다. IDT 내에서 배정된 벡터 인덱스(`8`)가 있고, IDT에 해당 예외를 처리할 일반 함수를 정의할 수 있습니다. 더블 폴트 처리 함수를 제공하는 것은 매우 중요한데, 더블 폴트가 처리되지 않으면 치명적인 _트리플 폴트_ 가 발생하기 때문입니다. 트리플 폴트를 처리하는 것은 불가능해서 대부분의 하드웨어는 시스템을 리셋하는 방식으로 대응합니다.
+
+### 더블 폴트 일으키기
+예외 처리 함수가 등록되지 않은 예외를 발생시켜 더블 폴트를 일으켜 보겠습니다.
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init();
+
+ // 페이지 폴트 일으키기
+ unsafe {
+ *(0xdeadbeef as *mut u64) = 42;
+ };
+
+ // 이전과 동일
+ #[cfg(test)]
+ test_main();
+
+ println!("It did not crash!");
+ loop {}
+}
+```
+
+`unsafe` 키워드를 사용해 유효하지 않은 메모리 주소 `0xdeadbeef`에 값을 씁니다. 페이지 테이블에서 해당 가상 주소는 실제 물리 주소에 매핑되지 않았기에 페이지 폴트가 발생합니다. 아직 우리가 [IDT]에 페이지 폴트 처리 함수를 등록하지 않았기 때문에 이어서 더블 폴트가 발생합니다.
+
+이제 커널을 실행시키면 커널이 무한히 부팅하는 루프에 갇히는 것을 확인하실 수 있습니다. 커널이 루프에 갇히는 이유는 아래와 같습니다.
+
+1. CPU가 메모리 주소 `0xdeadbeef`에 값을 쓰려고 시도한 것 때문에 페이지 폴트가 발생합니다.
+2. CPU는 IDT에서 페이지 폴트에 대응하는 엔트리를 확인하지만, 페이지 폴트 처리 함수가 등록되어 있지 않습니다. 호출할 수 있는 페이지 폴트 처리 함수가 없어 더블 폴트가 발생합니다.
+3. CPU는 IDT에서 더블 폴트에 대응하는 엔트리를 확인하지만, 더블 폴트 처리 함수가 등록되어 있지 않습니다. 이후 _트리플 폴트_ 가 발생합니다.
+4. 트리플 폴트는 치명적입니다. 다른 실제 하드웨어들처럼 QEMU 또한 시스템을 리셋합니다.
+
+이런 상황에서 트리플 폴트 발생을 막으려면 페이지 폴트 또는 더블 폴트의 처리 함수를 등록해야 합니다. 어떤 경우에서든 트리플 폴트만은 막아야 하므로, 처리되지 않은 예외가 있을 때 호출되는 더블 폴트의 처리 함수부터 먼저 작성하겠습니다.
+
+## 더블 폴트 처리 함수
+더블 폴트도 일반적인 예외로서 오류 코드를 가집니다. 따라서 더블 폴트 처리 함수를 작성할 때 이전에 작성한 breakpoint 예외 처리 함수와 비슷하게 작성할 수 있습니다.
+
+```rust
+// in src/interrupts.rs
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ idt.double_fault.set_handler_fn(double_fault_handler); // 새롭게 추가함
+ idt
+ };
+}
+
+// 새롭게 추가함
+extern "x86-interrupt" fn double_fault_handler(
+ stack_frame: InterruptStackFrame, _error_code: u64) -> !
+{
+ panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
+}
+```
+
+우리가 작성한 더블 폴트 처리 함수는 짧은 오류 메시지와 함께 예외 스택 프레임의 정보를 출력합니다. 더블 폴트 처리 함수의 오류 코드가 0인 것은 이미 아는 사실이니 굳이 출력할 필요가 없습니다. breakpoint 예외 처리 함수와 비교해 하나 다른 점은 더블 폴트 처리 함수가 [발산하는][_diverging_] 함수라는 것인데, 그 이유는 더블 폴트로부터 반환하는 것을 `x86_64` 아키텍처에서 허용하지 않기 때문입니다.
+
+[_diverging_]: https://doc.rust-lang.org/stable/rust-by-example/fn/diverging.html
+
+이제 커널을 실행시키면 더블 폴트 처리 함수가 호출되는 것을 확인하실 수 있습니다.
+
+
+
+성공입니다! 어떤 일들이 일어났는지 단계별로 살펴보겠습니다.
+
+1. CPU가 메모리 주소 `0xdeadbeef`에 값을 적으려 하고, 그 결과 페이지 폴트가 발생합니다.
+2. 이전처럼 CPU는 IDT에서 페이지 폴트에 대응하는 엔트리를 확인하지만, 등록된 처리 함수가 없음을 확인합니다. 그 결과 더블 폴트가 발생합니다.
+3. CPU의 제어 흐름이 등록된 더블 폴트 처리 함수로 점프합니다.
+
+CPU가 더블 폴트 처리 함수를 호출할 수 있기에, 트리플 폴트와 무한 재부팅 루프는 더 이상 발생하지 않습니다.
+
+별로 어렵지 않군요! 그럼에도 이 주제 하나에 이 글 전체를 할애한 이유가 궁금하신가요? 사실, 현재 우리는 _대부분의_ 더블 폴트를 처리할 수는 있지만, 현재의 커널 구현으로는 더블 폴트를 처리하지 못하는 특수한 경우들이 아직 남아 있습니다.
+
+## 더블 폴트의 원인들
+특수한 경우들을 살펴보기 전에, 우선 더블 폴트가 일어나는 엄밀한 원인에 대해 파악해야 합니다. 본문의 윗부분에서는 더블 폴트를 설명할 때 다소 애매하고 느슨한 정의를 사용했습니다.
+
+> 더블 폴트는 CPU가 예외 처리 함수를 호출하는 것에 실패했을 때 발생하는 예외입니다.
+
+_“예외 처리 함수를 호출하는 것에 실패했을 때”_ 라는 게 정확히 무슨 뜻일까요? 예외 처리 함수가 등록되어 있지 않아 호출에 실패했다? 예외 처리 함수가 [스왑-아웃][swapped out] 되어 있어 호출에 실패했다? 그리고 예외 처리 함수 자체가 다시 예외를 발생시키면 어떻게 될까요?
+
+[swapped out]: http://pages.cs.wisc.edu/~remzi/OSTEP/vm-beyondphys.pdf
+
+예를 들어, 아래의 각각의 상황들을 가정했을 때 무슨 일이 일어날지 고민해 봅시다.
+
+1. breakpoint 예외가 발생한 시점에 breakpoint 예외 처리 함수가 스왑-아웃 되어 있는 경우?
+2. 페이지 폴트가 발생한 시점에 페이지 폴트 처리 함수가 스왓-아웃 되어 있는 경우?
+3. divide-by-zero 예외 처리 함수가 breakpoint 예외를 발생시킨 시점에 breakpoint 예외 처리 함수가 스왑-아웃 되어 있는 경우?
+4. 커널이 스택 오버 플로우를 일으켜 _보호 페이지 (guard page)_ 에 접근하는 경우?
+
+다행히 AMD64 매뉴얼 ([PDF][AMD64 manual])에서 더블 폴트의 명확한 정의를 제시합니다 (매뉴얼 섹션 8.2.9 참조). 매뉴얼의 정의에 따르면, “더블 폴트 예외는 1번째 발생한 예외를 처리하는 도중 2번째 예외가 발생한 경우에 _발생할 수 있다_” 합니다. 여기서 _“발생할 수 있다”_ 라는 표현이 중요한데, 더블 폴트는 아래의 표에서 보이는 것처럼 특수한 조합의 예외들이 순서대로 일어났을 때에만 발생합니다.
+
+1번째 발생한 예외 | 2번째 발생한 예외
+----------------|-----------------
+[Divide-by-zero], [Invalid TSS], [Segment Not Present], [Stack-Segment Fault], [General Protection Fault] | [Invalid TSS], [Segment Not Present], [Stack-Segment Fault], [General Protection Fault]
+[Page Fault] | [Page Fault], [Invalid TSS], [Segment Not Present], [Stack-Segment Fault], [General Protection Fault]
+
+[Divide-by-zero]: https://wiki.osdev.org/Exceptions#Divide-by-zero_Error
+[Invalid TSS]: https://wiki.osdev.org/Exceptions#Invalid_TSS
+[Segment Not Present]: https://wiki.osdev.org/Exceptions#Segment_Not_Present
+[Stack-Segment Fault]: https://wiki.osdev.org/Exceptions#Stack-Segment_Fault
+[General Protection Fault]: https://wiki.osdev.org/Exceptions#General_Protection_Fault
+[Page Fault]: https://wiki.osdev.org/Exceptions#Page_Fault
+
+
+[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
+
+예를 들면 divide-by-zero 예외 뒤에 페이지 폴트가 발생하는 것은 괜찮지만 (페이지 폴트 처리 함수가 호출됨), divide-by-zero 예외 뒤에 general-protection fault 예외가 발생하면 더블 폴트가 발생합니다.
+
+위 테이블을 이용하면 위에서 했던 질문 중 첫 3개에 대해 대답할 수 있습니다.
+
+1. breakpoint 예외가 발생한 시점에 해당 예외 처리 함수가 스왑-아웃 되어 있는 경우, _페이지 폴트_ 가 발생하고 _페이지 폴트 처리 함수_ 가 호출됩니다.
+2. 페이지 폴트가 발생한 시점에 페이지 폴트 처리 함수가 스왑-아웃 되어 있는 경우, _더블 폴트_ 가 발생하고 _더블 폴트 처리 함수_ 가 호출됩니다.
+3. divide-by-zero 예외 처리 함수가 breakpoint 예외를 일으키는 경우, CPU가 breakpoint 예외 처리 함수의 호출을 시도합니다. breakpoint 예외 처리 함수가 스왑-아웃 되어 있는 경우, _페이지 폴트_ 가 발생하고 _페이지 폴트 처리 함수_ 가 호출됩니다.
+
+사실 임의의 예외에 대한 처리 함수가 IDT에 없다는 것만으로 더블 폴트가 발생하는 것이 아닙니다. 예외가 발생하면 CPU는 그 예외에 대응하는 IDT 엔트리를 참조합니다. 해당 엔트리 값이 0인 경우 (= 예외 처리 함수가 등록되어 있지 않음), _general protection fault_ 예외가 발생합니다. 우리는 해당 예외를 처리할 함수를 등록하지 않았기 때문에, 새로운 general protection fault 예외가 또 발생합니다. general protection fault가 이어서 2번 일어났으니, 위 테이블에 따라 더블 폴트가 발생합니다.
+
+### 커널 스택 오버플로우
+이제 위의 질문들 중 마지막 4번째 질문을 살펴보겠습니다.
+
+> 커널이 스택 오버 플로우를 일으켜 _보호 페이지 (guard page)_ 에 접근하는 경우, 무슨 일이 일어날까요?
+
+보호 페이지는 스택의 맨 아래에 위치하면서 스택 오버플로우를 감지하는 특별한 메모리 페이지입니다. 해당 페이지는 어떤 물리 프레임에도 매핑되지 않으며, CPU가 해당 페이지에 접근하면 물리 메모리에 접근하는 대신 페이지 폴트가 발생합니다. 부트로더가 커널 스택의 보호 페이지를 초기화하며, 이후 커널 스택 오버플로우가 발생하면 _페이지 폴트_ 가 발생합니다.
+
+페이지 폴트가 발생하면 CPU는 IDT에서 페이지 폴트 처리 함수를 찾고 스택에 [인터럽트 스택 프레임 (interrupt stack frame)][interrupt stack frame]을 push 하려고 합니다. 하지만 현재의 스택 포인터는 물리 프레임이 매핑되지 않은 보호 페이지를 가리키고 있습니다. 따라서 2번째 페이지 폴트가 발생하고, 그 결과 더블 폴트가 발생합니다 (위 테이블 참조).
+
+[interrupt stack frame]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
+
+CPU는 이제 _더블 폴트 처리 함수_ 를 호출하려고 시도합니다. 하지만, 더블 폴트 발생 시 CPU는 또 예외 스택 프레임 (= 인터럽트 스택 프레임)을 스택에 push하려고 합니다. 스택 포인터는 여전히 보호 페이지를 가리키고, 따라서 _3번째_ 페이지 폴트 발생 후 _트리플 폴트_ 가 발생하고 시스템이 재부팅 됩니다. 우리가 지금 가진 더블 폴트 처리 함수로는 이 상황에서 트리플 폴트를 막을 수 없습니다.
+
+역시 백문이 불여일견이죠! 무한 재귀 함수를 호출해 손쉽게 커널 스택오버플로우를 일으켜 봅시다.
+
+```rust
+// in src/main.rs
+
+#[no_mangle] // 이 함수의 이름을 mangle하지 않습니다
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init();
+
+ fn stack_overflow() {
+ stack_overflow(); // 재귀 호출할 때마다 스택에 반환 주소를 push 합니다
+ }
+
+ // 스택 오버플로우 일으키기
+ stack_overflow();
+
+ […] // test_main(), println(…), and loop {}
+}
+```
+
+이 코드를 QEMU에서 실행하면 시스템이 또 무한 재부팅 루프에 갇히는 것을 확인할 수 있습니다.
+
+이 문제를 어떻게 피할 수 있을까요? CPU 하드웨어가 예외 스택 프레임을 push 하는 것이라서, 커널 코드를 통해 스택 프레임의 push 과정을 생략할 수는 없습니다. 그래서 더블 폴트가 발생한 시점에는 늘 커널 스택이 유효하도록 보장할 수 있는 방법을 찾아야 합니다. 다행히도, x86_64 아키텍처는 이 문제에 대한 해답을 가지고 있습니다.
+
+## 스택 교체하기
+x86_64 아키텍처는 예외 발생 시 스택을 미리 지정한 다른 안전한 스택으로 교체하는 것이 가능합니다. 이러한 스택 교체는 하드웨어 단에서 일어나고, 따라서 CPU가 예외 스택 프레임을 스택에 push 하기 전에 스택을 교체하는 것이 가능합니다.
+
+이러한 스택 교체는 _인터럽트 스택 테이블 (Interrupt Stack Table; IST)_ 을 사용해 진행됩니다. IST는 안전한 것으로 알려진 7개의 다른 스택들의 주소를 저장하는 테이블입니다. IST의 구조를 Rust 코드 형식으로 표현하자면 아래와 같습니다.
+
+```rust
+struct InterruptStackTable {
+ stack_pointers: [Option; 7],
+}
+```
+
+각 예외 처리 함수는 [IDT 엔트리][IDT entry]의 `stack_pointers` 필드를 통해 IST의 스택 중 하나를 사용하도록 선택할 수 있습니다. 예를 들어, 우리의 더블 폴트 처리 함수가 IST의 1번째 스택을 사용하도록 설정할 수 있습니다. 그 후에는 더블 폴트가 발생할 때마다 CPU가 스택을 IST의 1번째 스택으로 교체합니다. 스택에 새로운 데이터가 push 되기 전에 스택 교체가 이뤄지기 때문에 트리플 폴트를 피할 수 있습니다.
+
+[IDT entry]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
+
+### IST와 TSS
+인터럽트 스택 테이블 (IST)은 오래되어 이젠 구식이 된 _[Task State Segment]_ (TSS)라는 구조체의 일부입니다. 예전에 TSS는 다양한 정보 (예: 프로세서 레지스터들의 상태 값)를 저장하거나 [하드웨어를 이용한 컨텍스트 스위치][hardware context switching]을 지원하는 용도로 사용됐습니다. 하지만 하드웨어를 이용한 컨텍스트 스위치를 64비트 모드에서부터는 지원하지 않게 되었고, 그 이후 TSS의 구조는 완전히 바뀌었습니다.
+
+[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
+[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
+
+x86_64 아키텍처에서 TSS는 특정 태스크 (task) 관련 정보를 보관하지 않습니다. 대신 TSS는 두 개의 스택 테이블을 보관합니다 (IST가 그중 하나입니다). 32비트 시스템의 TSS와 64비트 시스템의 TSS의 유일한 공통 필드는 [I/O port permissions bitmap]에 대한 포인터 하나 뿐입니다.
+
+[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
+
+64비트 TSS는 아래의 구조를 가집니다.
+
+Field | Type
+------ | ----------------
+(reserved) | `u32`
+Privilege Stack Table | `[u64; 3]`
+(reserved) | `u64`
+Interrupt Stack Table | `[u64; 7]`
+(reserved) | `u64`
+(reserved) | `u16`
+I/O Map Base Address | `u16`
+
+CPU가 특권 레벨을 교체할 때 _Privilege Stack Table_ 을 사용합니다. CPU가 사용자 모드일 때 (특권 레벨 = 3) 예외가 발생하면, CPU는 예외 처리 함수를 호출에 앞서 커널 모드로 전환합니다 (특권 레벨 = 0). 이 경우 CPU는 스택을 Privilege Stack Table의 0번째 스택으로 교체합니다 (특권 레벨이 0이라서). 아직 우리의 커널에서 동작하는 사용자 모드 프로그램이 없으므로, 일단은 이 테이블에 대해 걱정하지 않아도 됩니다.
+
+### TSS 생성하기
+새로운 TSS를 생성하고 TSS의 인터럽트 스택 테이블에 별도의 더블 폴트 스택을 갖추도록 코드를 작성하겠습니다. 우선 TSS를 나타낼 구조체가 필요하기에, `x86_64` 크레이트가 제공하는 [`TaskStateSegment` 구조체][`TaskStateSegment` struct]를 사용하겠습니다.
+
+[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/tss/struct.TaskStateSegment.html
+
+새로운 모듈 `gdt`에 TSS를 생성합니다 (모듈 이름이 왜 gdt인지는 이후에 납득이 가실 겁니다).
+
+```rust
+// in src/lib.rs
+
+pub mod gdt;
+
+// in src/gdt.rs
+
+use x86_64::VirtAddr;
+use x86_64::structures::tss::TaskStateSegment;
+use lazy_static::lazy_static;
+
+pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
+
+lazy_static! {
+ static ref TSS: TaskStateSegment = {
+ let mut tss = TaskStateSegment::new();
+ tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
+ const STACK_SIZE: usize = 4096 * 5;
+ static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
+
+ let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
+ let stack_end = stack_start + STACK_SIZE;
+ stack_end
+ };
+ tss
+ };
+}
+```
+
+Rust의 const evaluator가 위와 같은 TSS의 초기화를 컴파일 중에 진행하지 못해서 `lazy_static`을 사용합니다. IST의 0번째 엔트리가 더블 폴트 스택이 되도록 정합니다 (꼭 0번째일 필요는 없음). 그다음 더블 폴트 스택의 최상단 주소를 IST의 0번째 엔트리에 저장합니다. 스택의 최상단 주소를 저장하는 이유는 x86 시스템에서 스택은 높은 주소에서 출발해 낮은 주소 영역 쪽으로 성장하기 때문입니다.
+
+우리가 아직 커널에 메모리 관리 (memory management) 기능을 구현하지 않아서 스택을 할당할 정규적인 방법이 없습니다. 임시방편으로 `static mut` 배열을 스택 메모리인 것처럼 사용할 것입니다. 값 변경이 가능한 static 변수에 접근하는 경우 컴파일러가 데이터 경쟁 상태 (data race)의 부재를 보장하지 못해 `unsafe` 키워드가 필요합니다. 배열은 꼭 `static`이 아닌 `static mut`로 설정해야 하는데, 그 이유는 부트로더가 `static` 변수를 읽기 전용 메모리 페이지에 배치하기 때문입니다. 이후에 다른 글에서 이 임시적인 스택 메모리 구현을 정석적인 구현으로 수정할 계획이며, 그 후에는 스택 메모리 접근에 더 이상 `unsafe`가 필요하지 않을 것입니다.
+
+이 더블 폴트 스택에 스택 오버플로우를 감지하기 위한 보호 페이지가 없다는 것에 유의해야 합니다. 더블 폴트 스택에서 스택 오버플로우가 발생하면 스택 아래의 메모리 영역을 일부 덮어쓸 수 있기 때문에, 더블 폴트 처리 함수 안에서 스택 메모리를 과도하게 소모해서는 안됩니다.
+
+#### TSS 불러오기
+새로운 TSS도 만들었으니, 이제 CPU에게 이 TSS를 쓰도록 지시할 방법이 필요합니다. TSS가 역사적 이유로 인해 세그멘테이션 (segmentation) 시스템을 사용하는 탓에, CPU에 TSS를 쓰도록 지시하는 과정이 꽤 번거롭습니다. TSS를 직접 불러오는 대신, [전역 서술자 테이블 (Global Descriptor Table; GDT)][Global Descriptor Table]을 가리키는 새로운 세그먼트 서술자 (segment descriptor)를 추가해야 합니다. 그 후 [`ltr` 명령어][`ltr` instruction]에 GDT 안에서의 TSS의 인덱스를 주고 호출하여 TSS를 불러올 수 있습니다. (이것이 모듈 이름을 `gdt`로 설정한 이유입니다.)
+
+[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
+[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
+
+### 전역 서술자 테이블 (Global Descriptor Table)
+전역 서술자 테이블 (Global Descriptor Table; GDT)는 메모리 페이징이 표준이 되기 이전, [메모리 세그멘테이션 (memory segmentation)][memory segmentation]을 지원하는 데 쓰인 오래된 물건입니다. 64비트 모드에서도 여전히 여러 쓰임새가 있는데, 커널/사용자 모드 설정 및 TSS 불러오기 등의 용도에 쓰입니다.
+
+[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
+
+GDT는 프로그램의 _세그먼트_ 들을 저장하는 구조체입니다. 메모리 페이징이 표준화되어 쓰이기 이전의 오래된 아키텍처들에서 프로그램들을 서로 격리할 때 GDT를 사용했습니다. 세그멘테이션에 대한 자세한 정보는 무료 공개된 [책 “Three Easy Pieces”][“Three Easy Pieces” book]의 Segmentation 챕터를 참고해 주세요. 세그멘테이션은 64비트 모드에서는 더 이상 지원되지 않지만, 그래도 GDT는 남아 있습니다. GDT는 대체로 2가지 용도에 쓰입니다: 1) 커널 공간과 사용자 공간 사이 교체를 진행할 때. 2) TSS 구조체를 불러올 때.
+
+[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
+
+#### GDT 만들기
+static 변수 `TSS`의 세그먼트를 포함하는 static `GDT`를 만듭니다.
+
+```rust
+// in src/gdt.rs
+
+use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
+
+lazy_static! {
+ static ref GDT: GlobalDescriptorTable = {
+ let mut gdt = GlobalDescriptorTable::new();
+ gdt.add_entry(Descriptor::kernel_code_segment());
+ gdt.add_entry(Descriptor::tss_segment(&TSS));
+ gdt
+ };
+}
+```
+
+이전처럼 `lazy_static`을 사용했습니다. 코드 세그먼트와 TSS 세그먼트를 포함하는 GDT를 만듭니다.
+
+#### GDT 불러오기
+
+GDT를 불러오는 용도의 함수 `gdt::init` 함수를 만들고, `init` 함수로부터 해당 함수를 호출합니다.
+
+```rust
+// in src/gdt.rs
+
+pub fn init() {
+ GDT.load();
+}
+
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+}
+```
+
+이제 GDT를 불러온 상태입니다만 (`_start` 함수가 `init` 함수를 호출했기 때문에), 여전히 커널 스택 오버플로우 발생 시 커널이 무한 재부팅 루프에 갇힙니다.
+
+### 최종 단계
+
+세그먼트 레지스터 및 TSS 레지스터가 기존의 GDT로부터 읽어온 값들을 저장하고 있는 탓에, 우리가 만든 GDT의 세그먼트들이 활성화되지 않은 상황입니다. 또한 더블 폴트 처리 함수가 새로운 스택을 쓰도록 IDT에서 더블 폴트 처리 함수의 엔트리를 알맞게 수정해야 합니다.
+
+정리하자면 우리는 아래의 작업을 순차적으로 진행해야 합니다.
+
+1. **code segment 레지스터의 값 갱신하기**: GDT를 변경하였으니 코드 세그먼트 레지스터 `cs`의 값도 갱신해야 합니다. 기존의 세그먼트 선택자는 새 GDT 안에서 코드 세그먼트가 아닌 다른 세그먼트의 선택자와 동일할 수도 있습니다 (예: TSS 선택자).
+2. **TSS 불러오기**: GDT와 TSS 선택자를 불러오고, 그 후 CPU가 해당 TSS를 사용하도록 지시해야 합니다.
+3. **IDT 엔트리 수정하기**: TSS를 불러온 시점부터 CPU는 유효한 인터럽트 스택 테이블 (IST)에 접근할 수 있습니다. 앞으로 더블 폴트 발생 시 CPU가 새로운 더블 폴트 스택으로 교체하도록, IDT에서 더블 폴트에 대응하는 엔트리를 알맞게 수정합니다.
+
+첫 두 단계를 수행하려면 `gdt::init` 함수에서 두 변수 `code_selector`와 `tss_selector`에 대한 접근할 수 있어야 합니다. `Selectors` 라는 새로운 구조체를 통해 해당 변수들을 `gdt::init` 함수에서 접근할 수 있게 만듭니다.
+
+```rust
+// in src/gdt.rs
+
+use x86_64::structures::gdt::SegmentSelector;
+
+lazy_static! {
+ static ref GDT: (GlobalDescriptorTable, Selectors) = {
+ let mut gdt = GlobalDescriptorTable::new();
+ let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
+ let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
+ (gdt, Selectors { code_selector, tss_selector })
+ };
+}
+
+struct Selectors {
+ code_selector: SegmentSelector,
+ tss_selector: SegmentSelector,
+}
+```
+
+이제 접근 가능해진 선택자들을 사용해 `cs` 레지스터의 값을 갱신하고 우리가 만든 `TSS`를 불러옵니다.
+
+```rust
+// in src/gdt.rs
+
+pub fn init() {
+ use x86_64::instructions::tables::load_tss;
+ use x86_64::instructions::segmentation::{CS, Segment};
+
+ GDT.0.load();
+ unsafe {
+ CS::set_reg(GDT.1.code_selector);
+ load_tss(GDT.1.tss_selector);
+ }
+}
+```
+
+[`set_cs`] 함수로 코드 세그먼트 레지스터의 값을 갱신하고, [`load_tss`] 함수로 우리가 만든 TSS를 불러옵니다. 이 함수들은 `unsafe` 함수로 정의되어 있어 `unsafe` 블록 안에서만 호출할 수 있습니다. 이 함수들이 `unsafe`로 정의된 이유는 해당 함수들에 유효하지 않은 선택자를 전달할 경우 메모리 안전성을 해칠 수 있기 때문입니다.
+
+[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
+[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
+
+유효한 TSS와 인터럽트 스택 테이블을 불러왔으니, 이제 더블 폴트 처리 함수가 사용할 스택의 인덱스를 IDT에서 지정해 봅시다.
+
+```rust
+// in src/interrupts.rs
+
+use crate::gdt;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ unsafe {
+ idt.double_fault.set_handler_fn(double_fault_handler)
+ .set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // 새롭게 추가함
+ }
+
+ idt
+ };
+}
+```
+
+`set_stack_index`가 unsafe 함수인 이유는, 이 함수를 호출하는 측에서 인덱스가 유효하고 다른 예외 처리 시 사용 중이지 않다는 것을 보장해야 하기 때문입니다.
+
+수고하셨습니다! 이제부터 더블 폴트가 일어난다면 CPU는 스택을 더블 폴트 스택으로 교체할 것입니다. 드디어 커널 스택 오버플로우가 발생하는 상황을 포함하여 더블 폴트가 일어나는 _어떤 경우라도_ 더블 폴트를 처리할 수 있게 됐습니다.
+
+
+
+앞으로 트리플 폴트를 볼 일은 없을 겁니다! 위에서 구현한 내용을 우리가 미래에 실수로라도 훼손하지 않도록, 위 구현의 작동을 점검하는 테스트를 추가해 보겠습니다.
+
+## 커널 스택 오버플로우 테스트
+
+`gdt` 모듈을 테스트하고 커널 스택 오버플로우 발생 시 더블 폴트 처리 함수가 호출되는지 확인하는 용도의 통합 테스트를 추가할 것입니다. 테스트 함수에서 더블 폴트를 일으킨 후에 더블 폴트 처리 함수가 호출되었는지 확인하는 테스트를 작성하겠습니다.
+
+최소한의 뼈대 코드에서부터 테스트 작성을 시작해 봅시다.
+
+```rust
+// in tests/stack_overflow.rs
+
+#![no_std]
+#![no_main]
+
+use core::panic::PanicInfo;
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ unimplemented!();
+}
+
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ blog_os::test_panic_handler(info)
+}
+```
+
+이전에 작성한 `panic_handler` 테스트처럼 이 테스트 또한 [테스트 하네스 (test harness) 없이][without a test harness] 실행될 것입니다. 그 이유는 더블 폴트가 발생한 후에는 프로그램의 정상 실행을 재개할 수가 없기 때문에 어차피 1개 이상의 테스트를 두는 것이 의미가 없기 때문입니다. 테스트 하네스를 사용하지 않도록 `Cargo.toml`에 아래의 코드를 추가합니다.
+
+```toml
+# in Cargo.toml
+
+[[test]]
+name = "stack_overflow"
+harness = false
+```
+
+[without a test harness]: @/edition-2/posts/04-testing/index.ko.md#no-harness-tests
+
+`cargo test --test stack_overflow` 실행 시 컴파일은 성공할 것이고, 테스트 내의 `unimplemented` 매크로 때문에 테스트 실행은 실패할 것입니다.
+
+### `_start` 함수 구현
+
+`_start` 함수의 코드 구현은 아래와 같습니다.
+
+```rust
+// in tests/stack_overflow.rs
+
+use blog_os::serial_print;
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ serial_print!("stack_overflow::stack_overflow...\t");
+
+ blog_os::gdt::init();
+ init_test_idt();
+
+ // 스택 오버플로우 일으키기
+ stack_overflow();
+
+ panic!("Execution continued after stack overflow");
+}
+
+#[allow(unconditional_recursion)]
+fn stack_overflow() {
+ stack_overflow(); // 재귀 호출할 때마다 반환 주소가 스택에 push 됩니다
+ volatile::Volatile::new(0).read(); // "tail call elimination" 방지하기
+}
+```
+
+`gdt::init` 함수를 호출해 새 GDT를 초기화합니다. `interrupts::init_idt` 함수 대신 `init_test_idt` 함수를 호출하는데, 그 이유는 패닉하지 않고 `exit_qemu(QemuExitCode::Success)`를 호출하는 새로운 더블 폴트 처리 함수를 등록해 사용할 것이기 때문입니다.
+
+`stack_overflow` 함수는 `main.rs`에서 작성했던 것과 거의 동일합니다. 유일한 차이점은 함수 마지막에 추가로 [`Volatile`] 타입을 이용한 [volatile] 읽기를 통해 [_tail call elimination_]을 방지한다는 것입니다. 주어진 함수의 맨 마지막 구문이 재귀 함수에 대한 호출인 경우, 컴파일러는 tail call elimination 기법을 통해 재귀 함수 호출을 평범한 반복문으로 변환할 수 있습니다. 그렇게 하면 재귀 함수 호출 시 새로운 스택 프레임이 생성되지 않고, 스택 메모리 사용량은 일정하게 유지됩니다.
+
+[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
+[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
+[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
+
+이 테스트에서 우리는 스택 오버플로우가 발생하기를 원하기 때문에, 함수의 맨 마지막에 컴파일러가 제거할 수 없는 volatile 읽기 작업을 삽입합니다. 따라서 `stack_overflow` 함수는 더 이상 _꼬리 재귀 (tail recursive)_ 함수가 아니게 되고, tail call elimination 기법을 통한 최적화 역시 할 수 없게 됩니다. 또 `allow(unconditional_recursion)` 속성을 함수에 추가해 "함수가 무한히 재귀한다"는 경고 메시지가 출력되지 않게 합니다.
+
+### 테스트용 IDT
+
+위에서 언급했듯이, 살짝 변경된 새로운 더블 폴트 처리 함수가 등록된 테스트용 IDT가 필요합니다. 테스트 용 IDT의 구현은 아래와 같습니다.
+
+```rust
+// in tests/stack_overflow.rs
+
+use lazy_static::lazy_static;
+use x86_64::structures::idt::InterruptDescriptorTable;
+
+lazy_static! {
+ static ref TEST_IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ unsafe {
+ idt.double_fault
+ .set_handler_fn(test_double_fault_handler)
+ .set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
+ }
+
+ idt
+ };
+}
+
+pub fn init_test_idt() {
+ TEST_IDT.load();
+}
+```
+
+코드 구현은 우리가 `interrupts.rs`에서 작성한 IDT와 매우 흡사합니다. 기존과 마찬가지로 더블 폴트 처리 함수가 사용할 스택의 인덱스를 정해줍니다. `init_test_idt` 함수는 `load` 함수를 통해 테스트 용 IDT를 CPU로 불러옵니다.
+
+### 더블 폴트 처리 함수
+
+마지막 남은 단계는 더블 폴트 처리 함수를 작성하는 것입니다. 코드 구현은 아래와 같습니다.
+
+```rust
+// in tests/stack_overflow.rs
+
+use blog_os::{exit_qemu, QemuExitCode, serial_println};
+use x86_64::structures::idt::InterruptStackFrame;
+
+extern "x86-interrupt" fn test_double_fault_handler(
+ _stack_frame: InterruptStackFrame,
+ _error_code: u64,
+) -> ! {
+ serial_println!("[ok]");
+ exit_qemu(QemuExitCode::Success);
+ loop {}
+}
+```
+
+더블 폴트 처리 함수가 호출되면 우리는 성공 종료 코드와 함께 QEMU를 종료시키고, 테스트는 성공한 것으로 처리됩니다. 통합 테스트는 완전히 독립적인 실행 파일로 간주하기 때문에, 다시 한번 테스트 파일의 맨 위에 `#![feature(abi_x86_interrupt)]` 속성을 추가해야 합니다.
+
+`cargo test --test stack_overflow`를 통해 새로 작성한 테스트를 실행할 수 있습니다 (또는 `cargo test`로 모든 테스트 실행). 예상대로 콘솔에
+`stack_overflow... [ok]` 라는 메시지가 출력될 것입니다. 테스트 코드에서 `set_stack_index`를 호출하지 않게 주석 처리한 후 테스트를 실행하면 테스트가 실패하는 것 또한 확인할 수 있을 것입니다.
+
+## 정리
+이 글에서는 더블 폴트와 더블 폴트의 발생 조건에 대해 배웠습니다. 오류 메시지를 출력하는 간단한 더블 폴트 처리 함수를 커널에 추가했고, 해당 함수의 올바른 동작을 점검하는 통합 테스트도 추가했습니다.
+
+또한 우리는 더블 폴트 발생 시 하드웨어의 스택 교체 기능을 통해 커널 스택 오버 플로우 발생 시에도 더블 폴트가 제대로 처리되도록 구현했습니다. 구현 과정에서 Task State Segment (TSS)와 그 안에 포함된 인터럽트 스택 테이블 (Interrupt Stack Table; IST), 그리고 오래된 아키텍처들에서 세그멘테이션 (segmentation)에 사용됐던 전역 서술자 테이블 (Global Descriptor Table; GDT)에 대해 배웠습니다.
+
+## 다음 단계는 무엇일까요?
+다음 글에서는 타이머, 키보드, 네트워크 컨트롤러 등의 외부 장치로부터 전송되어 오는 인터럽트들을 처리하는 방법에 대해 설명하겠습니다. 이러한 하드웨어 인터럽트들은 예외와 마찬가지로 IDT에 등록된 처리 함수를 통해 처리된다는 점에서 유사합니다. 인터럽트가 예외와 다른 점은 예외와 달리 CPU로부터 발생하지 않는다는 것입니다. 대신에 _인터럽트 컨트롤러 (interrupt controller)_ 가 외부 장치로부터 전송되어 오는 인터럽트들을 수합한 후 인터럽트 우선 순위에 맞춰 CPU로 인터럽트들을 전달합니다. 다음 글에서 [Intel 8259] (“PIC”) 인터럽트 컨트롤러에 대해 알아보고, 키보드 입력을 지원하는 법을 배울 것입니다.
+
+[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
diff --git a/blog/content/edition-2/posts/06-double-faults/index.md b/blog/content/edition-2/posts/06-double-faults/index.md
index 02a13d01..e45468d4 100644
--- a/blog/content/edition-2/posts/06-double-faults/index.md
+++ b/blog/content/edition-2/posts/06-double-faults/index.md
@@ -8,7 +8,7 @@ date = 2018-06-18
chapter = "Interrupts"
+++
-This post explores the double fault exception in detail, which occurs when the CPU fails to invoke an exception handler. By handling this exception we avoid fatal _triple faults_ that cause a system reset. To prevent triple faults in all cases we also set up an _Interrupt Stack Table_ to catch double faults on a separate kernel stack.
+This post explores the double fault exception in detail, which occurs when the CPU fails to invoke an exception handler. By handling this exception, we avoid fatal _triple faults_ that cause a system reset. To prevent triple faults in all cases, we also set up an _Interrupt Stack Table_ to catch double faults on a separate kernel stack.
@@ -22,14 +22,14 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
## What is a Double Fault?
-In simplified terms, a double fault is a special exception that occurs when the CPU fails to invoke an exception handler. For example, it occurs when a page fault is triggered but there is no page fault handler registered in the [Interrupt Descriptor Table][IDT] (IDT). So it's kind of similar to catch-all blocks in programming languages with exceptions, e.g. `catch(...)` in C++ or `catch(Exception e)` in Java or C#.
+In simplified terms, a double fault is a special exception that occurs when the CPU fails to invoke an exception handler. For example, it occurs when a page fault is triggered but there is no page fault handler registered in the [Interrupt Descriptor Table][IDT] (IDT). So it's kind of similar to catch-all blocks in programming languages with exceptions, e.g., `catch(...)` in C++ or `catch(Exception e)` in Java or C#.
[IDT]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
-A double fault behaves like a normal exception. It has the vector number `8` and we can define a normal handler function for it in the IDT. It is really important to provide a double fault handler, because if a double fault is unhandled a fatal _triple fault_ occurs. Triple faults can't be caught and most hardware reacts with a system reset.
+A double fault behaves like a normal exception. It has the vector number `8` and we can define a normal handler function for it in the IDT. It is really important to provide a double fault handler, because if a double fault is unhandled, a fatal _triple fault_ occurs. Triple faults can't be caught, and most hardware reacts with a system reset.
### Triggering a Double Fault
-Let's provoke a double fault by triggering an exception for that we didn't define a handler function:
+Let's provoke a double fault by triggering an exception for which we didn't define a handler function:
```rust
// in src/main.rs
@@ -96,7 +96,7 @@ When we start our kernel now, we should see that the double fault handler is inv

-It worked! Here is what happens this time:
+It worked! Here is what happened this time:
1. The CPU tries to write to `0xdeadbeef`, which causes a page fault.
2. Like before, the CPU looks at the corresponding entry in the IDT and sees that no handler function is defined. Thus, a double fault occurs.
@@ -139,7 +139,7 @@ First Exception | Second Exception
[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
-So for example a divide-by-zero fault followed by a page fault is fine (the page fault handler is invoked), but a divide-by-zero fault followed by a general-protection fault leads to a double fault.
+So, for example, a divide-by-zero fault followed by a page fault is fine (the page fault handler is invoked), but a divide-by-zero fault followed by a general-protection fault leads to a double fault.
With the help of this table, we can answer the first three of the above questions:
@@ -156,11 +156,11 @@ Let's look at the fourth question:
A guard page is a special memory page at the bottom of a stack that makes it possible to detect stack overflows. The page is not mapped to any physical frame, so accessing it causes a page fault instead of silently corrupting other memory. The bootloader sets up a guard page for our kernel stack, so a stack overflow causes a _page fault_.
-When a page fault occurs the CPU looks up the page fault handler in the IDT and tries to push the [interrupt stack frame] onto the stack. However, the current stack pointer still points to the non-present guard page. Thus, a second page fault occurs, which causes a double fault (according to the above table).
+When a page fault occurs, the CPU looks up the page fault handler in the IDT and tries to push the [interrupt stack frame] onto the stack. However, the current stack pointer still points to the non-present guard page. Thus, a second page fault occurs, which causes a double fault (according to the above table).
[interrupt stack frame]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
-So the CPU tries to call the _double fault handler_ now. However, on a double fault the CPU tries to push the exception stack frame, too. The stack pointer still points to the guard page, so a _third_ page fault occurs, which causes a _triple fault_ and a system reboot. So our current double fault handler can't avoid a triple fault in this case.
+So the CPU tries to call the _double fault handler_ now. However, on a double fault, the CPU tries to push the exception stack frame, too. The stack pointer still points to the guard page, so a _third_ page fault occurs, which causes a _triple fault_ and a system reboot. So our current double fault handler can't avoid a triple fault in this case.
Let's try it ourselves! We can easily provoke a kernel stack overflow by calling a function that recurses endlessly:
@@ -184,14 +184,14 @@ pub extern "C" fn _start() -> ! {
}
```
-When we try this code in QEMU, we see that the system enters a boot-loop again.
+When we try this code in QEMU, we see that the system enters a bootloop again.
So how can we avoid this problem? We can't omit the pushing of the exception stack frame, since the CPU itself does it. So we need to ensure somehow that the stack is always valid when a double fault exception occurs. Fortunately, the x86_64 architecture has a solution to this problem.
## Switching Stacks
The x86_64 architecture is able to switch to a predefined, known-good stack when an exception occurs. This switch happens at hardware level, so it can be performed before the CPU pushes the exception stack frame.
-The switching mechanism is implemented as an _Interrupt Stack Table_ (IST). The IST is a table of 7 pointers to known-good stacks. In Rust-like pseudo code:
+The switching mechanism is implemented as an _Interrupt Stack Table_ (IST). The IST is a table of 7 pointers to known-good stacks. In Rust-like pseudocode:
```rust
struct InterruptStackTable {
@@ -199,17 +199,17 @@ struct InterruptStackTable {
}
```
-For each exception handler, we can choose a stack from the IST through the `stack_pointers` field in the corresponding [IDT entry]. For example, we could use the first stack in the IST for our double fault handler. Then the CPU would automatically switch to this stack whenever a double fault occurs. This switch would happen before anything is pushed, so it would prevent the triple fault.
+For each exception handler, we can choose a stack from the IST through the `stack_pointers` field in the corresponding [IDT entry]. For example, our double fault handler could use the first stack in the IST. Then the CPU automatically switches to this stack whenever a double fault occurs. This switch would happen before anything is pushed, preventing the triple fault.
[IDT entry]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
### The IST and TSS
-The Interrupt Stack Table (IST) is part of an old legacy structure called _[Task State Segment]_ \(TSS). The TSS used to hold various information (e.g. processor register state) about a task in 32-bit mode and was for example used for [hardware context switching]. However, hardware context switching is no longer supported in 64-bit mode and the format of the TSS changed completely.
+The Interrupt Stack Table (IST) is part of an old legacy structure called _[Task State Segment]_ \(TSS). The TSS used to hold various pieces of information (e.g., processor register state) about a task in 32-bit mode and was, for example, used for [hardware context switching]. However, hardware context switching is no longer supported in 64-bit mode and the format of the TSS has changed completely.
[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
-On x86_64, the TSS no longer holds any task specific information at all. Instead, it holds two stack tables (the IST is one of them). The only common field between the 32-bit and 64-bit TSS is the pointer to the [I/O port permissions bitmap].
+On x86_64, the TSS no longer holds any task-specific information at all. Instead, it holds two stack tables (the IST is one of them). The only common field between the 32-bit and 64-bit TSS is the pointer to the [I/O port permissions bitmap].
[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
@@ -225,10 +225,10 @@ Interrupt Stack Table | `[u64; 7]`
(reserved) | `u16`
I/O Map Base Address | `u16`
-The _Privilege Stack Table_ is used by the CPU when the privilege level changes. For example, if an exception occurs while the CPU is in user mode (privilege level 3), the CPU normally switches to kernel mode (privilege level 0) before invoking the exception handler. In that case, the CPU would switch to the 0th stack in the Privilege Stack Table (since 0 is the target privilege level). We don't have any user mode programs yet, so we ignore this table for now.
+The _Privilege Stack Table_ is used by the CPU when the privilege level changes. For example, if an exception occurs while the CPU is in user mode (privilege level 3), the CPU normally switches to kernel mode (privilege level 0) before invoking the exception handler. In that case, the CPU would switch to the 0th stack in the Privilege Stack Table (since 0 is the target privilege level). We don't have any user-mode programs yet, so we will ignore this table for now.
### Creating a TSS
-Let's create a new TSS that contains a separate double fault stack in its interrupt stack table. For that we need a TSS struct. Fortunately, the `x86_64` crate already contains a [`TaskStateSegment` struct] that we can use.
+Let's create a new TSS that contains a separate double fault stack in its interrupt stack table. For that, we need a TSS struct. Fortunately, the `x86_64` crate already contains a [`TaskStateSegment` struct] that we can use.
[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/tss/struct.TaskStateSegment.html
@@ -263,24 +263,24 @@ lazy_static! {
}
```
-We use `lazy_static` because Rust's const evaluator is not yet powerful enough to do this initialization at compile time. We define that the 0th IST entry is the double fault stack (any other IST index would work too). Then we write the top address of a double fault stack to the 0th entry. We write the top address because stacks on x86 grow downwards, i.e. from high addresses to low addresses.
+We use `lazy_static` because Rust's const evaluator is not yet powerful enough to do this initialization at compile time. We define that the 0th IST entry is the double fault stack (any other IST index would work too). Then we write the top address of a double fault stack to the 0th entry. We write the top address because stacks on x86 grow downwards, i.e., from high addresses to low addresses.
-We haven't implemented memory management yet, so we don't have a proper way to allocate a new stack. Instead, we use a `static mut` array as stack storage for now. The `unsafe` is required because the compiler can't guarantee race freedom when mutable statics are accessed. It is important that it is a `static mut` and not an immutable `static`, because otherwise the bootloader will map it to a read-only page. We will replace this with a proper stack allocation in a later post, then the `unsafe` will be no longer needed at this place.
+We haven't implemented memory management yet, so we don't have a proper way to allocate a new stack. Instead, we use a `static mut` array as stack storage for now. The `unsafe` is required because the compiler can't guarantee race freedom when mutable statics are accessed. It is important that it is a `static mut` and not an immutable `static`, because otherwise the bootloader will map it to a read-only page. We will replace this with a proper stack allocation in a later post, then the `unsafe` will no longer be needed at this place.
-Note that this double fault stack has no guard page that protects against stack overflow. This means that we should not do anything stack intensive in our double fault handler because a stack overflow might corrupt the memory below the stack.
+Note that this double fault stack has no guard page that protects against stack overflow. This means that we should not do anything stack-intensive in our double fault handler because a stack overflow might corrupt the memory below the stack.
#### Loading the TSS
-Now that we created a new TSS, we need a way to tell the CPU that it should use it. Unfortunately this is a bit cumbersome, since the TSS uses the segmentation system (for historical reasons). Instead of loading the table directly, we need to add a new segment descriptor to the [Global Descriptor Table] \(GDT). Then we can load our TSS invoking the [`ltr` instruction] with the respective GDT index. (This is the reason why we named our module `gdt`.)
+Now that we've created a new TSS, we need a way to tell the CPU that it should use it. Unfortunately, this is a bit cumbersome since the TSS uses the segmentation system (for historical reasons). Instead of loading the table directly, we need to add a new segment descriptor to the [Global Descriptor Table] \(GDT). Then we can load our TSS by invoking the [`ltr` instruction] with the respective GDT index. (This is the reason why we named our module `gdt`.)
[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
### The Global Descriptor Table
-The Global Descriptor Table (GDT) is a relict that was used for [memory segmentation] before paging became the de facto standard. It is still needed in 64-bit mode for various things such as kernel/user mode configuration or TSS loading.
+The Global Descriptor Table (GDT) is a relic that was used for [memory segmentation] before paging became the de facto standard. However, it is still needed in 64-bit mode for various things, such as kernel/user mode configuration or TSS loading.
[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
-The GDT is a structure that contains the _segments_ of the program. It was used on older architectures to isolate programs from each other, before paging became the standard. For more information about segmentation check out the equally named chapter of the free [“Three Easy Pieces” book]. While segmentation is no longer supported in 64-bit mode, the GDT still exists. It is mostly used for two things: Switching between kernel space and user space, and loading a TSS structure.
+The GDT is a structure that contains the _segments_ of the program. It was used on older architectures to isolate programs from each other before paging became the standard. For more information about segmentation, check out the equally named chapter of the free [“Three Easy Pieces” book]. While segmentation is no longer supported in 64-bit mode, the GDT still exists. It is mostly used for two things: Switching between kernel space and user space, and loading a TSS structure.
[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
@@ -306,7 +306,7 @@ As before, we use `lazy_static` again. We create a new GDT with a code segment a
#### Loading the GDT
-To load our GDT we create a new `gdt::init` function, that we call from our `init` function:
+To load our GDT, we create a new `gdt::init` function that we call from our `init` function:
```rust
// in src/gdt.rs
@@ -325,14 +325,14 @@ pub fn init() {
Now our GDT is loaded (since the `_start` function calls `init`), but we still see the boot loop on stack overflow.
-### The final Steps
+### The Final Steps
The problem is that the GDT segments are not yet active because the segment and TSS registers still contain the values from the old GDT. We also need to modify the double fault IDT entry so that it uses the new stack.
In summary, we need to do the following:
-1. **Reload code segment register**: We changed our GDT, so we should reload `cs`, the code segment register. This is required since the old segment selector could point to a different GDT descriptor now (e.g. a TSS descriptor).
-2. **Load the TSS** : We loaded a GDT that contains a TSS selector, but we still need to tell the CPU that it should use that TSS.
+1. **Reload code segment register**: We changed our GDT, so we should reload `cs`, the code segment register. This is required since the old segment selector could now point to a different GDT descriptor (e.g., a TSS descriptor).
+2. **Load the TSS**: We loaded a GDT that contains a TSS selector, but we still need to tell the CPU that it should use that TSS.
3. **Update the IDT entry**: As soon as our TSS is loaded, the CPU has access to a valid interrupt stack table (IST). Then we can tell the CPU that it should use our new double fault stack by modifying our double fault IDT entry.
For the first two steps, we need access to the `code_selector` and `tss_selector` variables in our `gdt::init` function. We can achieve this by making them part of the static through a new `Selectors` struct:
@@ -357,18 +357,18 @@ struct Selectors {
}
```
-Now we can use the selectors to reload the `cs` segment register and load our `TSS`:
+Now we can use the selectors to reload the `cs` register and load our `TSS`:
```rust
// in src/gdt.rs
pub fn init() {
- use x86_64::instructions::segmentation::set_cs;
use x86_64::instructions::tables::load_tss;
-
+ use x86_64::instructions::segmentation::{CS, Segment};
+
GDT.0.load();
unsafe {
- set_cs(GDT.1.code_selector);
+ CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}
@@ -379,7 +379,7 @@ We reload the code segment register using [`set_cs`] and load the TSS using [`lo
[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
-Now that we loaded a valid TSS and interrupt stack table, we can set the stack index for our double fault handler in the IDT:
+Now that we have loaded a valid TSS and interrupt stack table, we can set the stack index for our double fault handler in the IDT:
```rust
// in src/interrupts.rs
@@ -400,17 +400,17 @@ lazy_static! {
}
```
-The `set_stack_index` method is unsafe because the the caller must ensure that the used index is valid and not already used for another exception.
+The `set_stack_index` method is unsafe because the caller must ensure that the used index is valid and not already used for another exception.
That's it! Now the CPU should switch to the double fault stack whenever a double fault occurs. Thus, we are able to catch _all_ double faults, including kernel stack overflows:

-From now on we should never see a triple fault again! To ensure that we don't accidentally break the above, we should add a test for this.
+From now on, we should never see a triple fault again! To ensure that we don't accidentally break the above, we should add a test for this.
## A Stack Overflow Test
-To test our new `gdt` module and ensure that the double fault handler is correctly called on a stack overflow, we can add an integration test. The idea is to do provoke a double fault in the test function and verify that the double fault handler is called.
+To test our new `gdt` module and ensure that the double fault handler is correctly called on a stack overflow, we can add an integration test. The idea is to provoke a double fault in the test function and verify that the double fault handler is called.
Let's start with a minimal skeleton:
@@ -445,7 +445,7 @@ harness = false
[without a test harness]: @/edition-2/posts/04-testing/index.md#no-harness-tests
-Now `cargo test --test stack_overflow` should compile successfully. The test fails of course, since the `unimplemented` macro panics.
+Now `cargo test --test stack_overflow` should compile successfully. The test fails, of course, since the `unimplemented` macro panics.
### Implementing `_start`
@@ -476,15 +476,15 @@ fn stack_overflow() {
}
```
-We call our `gdt::init` function to initialize a new GDT. Instead of calling our `interrupts::init_idt` function, we call a `init_test_idt` function that will be explained in a moment. The reason is that we want to register a custom double fault handler that does a `exit_qemu(QemuExitCode::Success)` instead of panicking.
+We call our `gdt::init` function to initialize a new GDT. Instead of calling our `interrupts::init_idt` function, we call an `init_test_idt` function that will be explained in a moment. The reason is that we want to register a custom double fault handler that does an `exit_qemu(QemuExitCode::Success)` instead of panicking.
-The `stack_overflow` function is almost identical to the function in our `main.rs`. The only difference is that we do an additional [volatile] read at the end of the function using the [`Volatile`] type to prevent a compiler optimization called [_tail call elimination_]. Among other things, this optimization allows the compiler to transform a function whose last statement is a recursive function call into a normal loop. Thus, no additional stack frame is created for the function call, so that the stack usage does remain constant.
+The `stack_overflow` function is almost identical to the function in our `main.rs`. The only difference is that at the end of the function, we perform an additional [volatile] read using the [`Volatile`] type to prevent a compiler optimization called [_tail call elimination_]. Among other things, this optimization allows the compiler to transform a function whose last statement is a recursive function call into a normal loop. Thus, no additional stack frame is created for the function call, so the stack usage remains constant.
[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
-In our case, however, we want that the stack overflow happens, so we add a dummy volatile read statement at the end of the function, which the compiler is not allowed to remove. Thus, the function is no longer _tail recursive_ and the transformation into a loop is prevented. We also add the `allow(unconditional_recursion)` attribute to silence the compiler warning that the function recurses endlessly.
+In our case, however, we want the stack overflow to happen, so we add a dummy volatile read statement at the end of the function, which the compiler is not allowed to remove. Thus, the function is no longer _tail recursive_, and the transformation into a loop is prevented. We also add the `allow(unconditional_recursion)` attribute to silence the compiler warning that the function recurses endlessly.
### The Test IDT
@@ -514,7 +514,7 @@ pub fn init_test_idt() {
}
```
-The implementation is very similar to our normal IDT in `interrupts.rs`. Like in the normal IDT, we set a stack index into the IST for the double fault handler in order to switch to a separate stack. The `init_test_idt` function loads the IDT on the CPU through the `load` method.
+The implementation is very similar to our normal IDT in `interrupts.rs`. Like in the normal IDT, we set a stack index in the IST for the double fault handler in order to switch to a separate stack. The `init_test_idt` function loads the IDT on the CPU through the `load` method.
### The Double Fault Handler
@@ -536,16 +536,16 @@ extern "x86-interrupt" fn test_double_fault_handler(
}
```
-When the double fault handler is called, we exit QEMU with a success exit code, which marks the test as passed. Since integration tests are completely separate executables, we need to set `#![feature(abi_x86_interrupt)]` attribute again at the top of our test file.
+When the double fault handler is called, we exit QEMU with a success exit code, which marks the test as passed. Since integration tests are completely separate executables, we need to set the `#![feature(abi_x86_interrupt)]` attribute again at the top of our test file.
-Now we can run our test through `cargo test --test stack_overflow` (or `cargo test` to run all tests). As expected, we see the `stack_overflow... [ok]` output in the console. Try to comment out the `set_stack_index` line: it should cause the test to fail.
+Now we can run our test through `cargo test --test stack_overflow` (or `cargo test` to run all tests). As expected, we see the `stack_overflow... [ok]` output in the console. Try to comment out the `set_stack_index` line; it should cause the test to fail.
## Summary
-In this post we learned what a double fault is and under which conditions it occurs. We added a basic double fault handler that prints an error message and added an integration test for it.
+In this post, we learned what a double fault is and under which conditions it occurs. We added a basic double fault handler that prints an error message and added an integration test for it.
-We also enabled the hardware supported stack switching on double fault exceptions so that it also works on stack overflow. While implementing it, we learned about the task state segment (TSS), the contained interrupt stack table (IST), and the global descriptor table (GDT), which was used for segmentation on older architectures.
+We also enabled the hardware-supported stack switching on double fault exceptions so that it also works on stack overflow. While implementing it, we learned about the task state segment (TSS), the contained interrupt stack table (IST), and the global descriptor table (GDT), which was used for segmentation on older architectures.
## What's next?
-The next post explains how to handle interrupts from external devices such as timers, keyboards, or network controllers. These hardware interrupts are very similar to exceptions, e.g. they are also dispatched through the IDT. However, unlike exceptions, they don't arise directly on the CPU. Instead, an _interrupt controller_ aggregates these interrupts and forwards them to CPU depending on their priority. In the next post we will explore the [Intel 8259] \(“PIC”) interrupt controller and learn how to implement keyboard support.
+The next post explains how to handle interrupts from external devices such as timers, keyboards, or network controllers. These hardware interrupts are very similar to exceptions, e.g., they are also dispatched through the IDT. However, unlike exceptions, they don't arise directly on the CPU. Instead, an _interrupt controller_ aggregates these interrupts and forwards them to the CPU depending on their priority. In the next post, we will explore the [Intel 8259] \(“PIC”) interrupt controller and learn how to implement keyboard support.
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
diff --git a/blog/content/edition-2/posts/06-double-faults/index.zh-CN.md b/blog/content/edition-2/posts/06-double-faults/index.zh-CN.md
new file mode 100644
index 00000000..232249d1
--- /dev/null
+++ b/blog/content/edition-2/posts/06-double-faults/index.zh-CN.md
@@ -0,0 +1,562 @@
++++
+title = "Double Faults"
+weight = 6
+path = "zh-CN/double-fault-exceptions"
+date = 2018-06-18
+
+[extra]
+# Please update this when updating the translation
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
+# GitHub usernames of the people that translated this post
+translators = ["liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong"]
++++
+
+在这篇文章中,我们会探索 double fault 异常的细节,它的触发条件是调用错误处理函数失败。通过捕获该异常,我们可以阻止致命的 _triple faults_ 异常导致系统重启。为了尽可能避免 triple faults ,我们会在一个独立的内核栈配置 _中断栈表_ 来捕捉 double faults。
+
+
+
+这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-06`][post branch]找到这篇文章的完整源码。
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-06
+
+
+
+## 何谓 Double Fault
+简而言之,double fault 就是当CPU执行错误处理函数失败时抛出的特殊异常。比如,你没有注册在 [中断描述符表][IDT] 中注册对应 page fault 异常的处理函数,然后程序偏偏就抛出了一个 page fault 异常,这时候就会接着抛出 double fault 异常。这个异常的处理函数就比较类似于具备异常处理功能的编程语言里的 catch-all 语法的效果,比如 C++ 里的 `catch(...)` 和 JAVA/C# 里的 `catch(Exception e)`。
+
+[IDT]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
+
+double fault 的行为和普通异常十分相似,我们可以通过在IDT中注册 `8` 号位的处理函数来拦截该异常。这个处理函数十分重要,如果你不处理这个异常,CPU就会直接抛出 _triple fault_ 异常,该异常无法被任何方式处理,而且会直接导致绝大多数硬件强制重启。
+
+### 捕捉 Double Fault
+我们先来试试看不捕捉 double fault 的情况下触发它会有什么后果:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init();
+
+ // trigger a page fault
+ unsafe {
+ *(0xdeadbeef as *mut u64) = 42;
+ };
+
+ // as before
+ #[cfg(test)]
+ test_main();
+
+ println!("It did not crash!");
+ loop {}
+}
+```
+
+这里我们使用 `unsafe` 块直接操作了一个无效的内存地址 `0xdeadbeef`,由于该虚拟地址并未在页表中映射到物理内存,所以必然会抛出 page fault 异常。我们又并未在 [IDT] 中注册对应的处理器,所以 double fault 会紧接着被抛出。
+
+现在启动内核,我们可以看到它直接陷入了崩溃和重启的无限循环,其原因如下:
+
+1. CPU试图向 `0xdeadbeef` 写入数据,这就造成了 page fault 异常。
+2. CPU没有在IDT中找到相应的处理函数,所以又抛出了 double fault 异常。
+3. CPU再一次没有在IDT中找到相应的处理函数,所以又抛出了 _triple fault_ 异常。
+4. 在抛出 triple fault 之后就没有然后了,这个错误是致命级别,如同大多数硬件一样,QEMU对此的处理方式就是重置系统,也就是重启。
+
+通过这个小实验,我们知道在这种情况下,需要提前注册 page faults 或者 double fault 的处理函数才行,但如果想要在任何场景下避免触发 triple faults 异常,则必须注册能够捕捉一切未注册异常类型的 double fault 处理函数。
+
+## 处理 Double Fault
+double fault 是一个带错误码的常规错误,所以我们可以参照 breakpoint 处理函数定义一个 double fault 处理函数:
+
+```rust
+// in src/interrupts.rs
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ idt.double_fault.set_handler_fn(double_fault_handler); // new
+ idt
+ };
+}
+
+// new
+extern "x86-interrupt" fn double_fault_handler(
+ stack_frame: InterruptStackFrame, _error_code: u64) -> !
+{
+ panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
+}
+```
+
+我们的处理函数打印了一行简短的信息,并将栈帧转写了出来。其中错误码一直是0,所以没有必要把它打印出来。要说这和 breakpoint 处理函数有什么区别,那就是 double fault 的处理函数是 [发散的][_diverging_],这是因为 `x86_64` 架构不允许从 double fault 异常中返回任何东西。
+
+[_diverging_]: https://doc.rust-lang.org/stable/rust-by-example/fn/diverging.html
+
+那么再次启动内核,我们可以看到 double fault 的处理函数被成功调用:
+
+
+
+让我们来分析一下又发生了什么:
+
+1. CPU尝试往 `0xdeadbeef` 写入数据,引发了 page fault 异常。
+2. 如同上次运行一样,CPU并没有在IDT里找到对应的处理函数,所以又引发了 double fault 异常。
+3. CPU又跳转到了我们刚刚定义的 double fault 处理函数。
+
+现在 triple fault 及其衍生的重启循环不会再出现了,因为CPU已经妥善处理了 double fault 异常。
+
+这还真是直截了当对吧,但为什么要为这点内容单独写一篇文章呢?没错,我们的确已经可以捕获 _大部分_ double faults 异常,但在部分情况下,这样的做法依然不够。
+
+## Double Faults 的成因
+在解释这些部分情况之前,我们需要先明确一下 double faults 的成因,上文中我们使用了一个模糊的定义:
+
+> double fault 就是当CPU执行错误处理函数失败时抛出的特殊异常。
+
+但究竟什么叫 _“调用失败”_ ?没有提供处理函数?处理函数被[换出][swapped out]内存了?或者处理函数本身也出现了异常?
+
+[swapped out]: http://pages.cs.wisc.edu/~remzi/OSTEP/vm-beyondphys.pdf
+
+比如以下情况出现时:
+
+1. 如果 breakpoint 异常被触发,但其对应的处理函数已经被换出内存了?
+2. 如果 page fault 异常被触发,但其对应的处理函数已经被换出内存了?
+3. 如果 divide-by-zero 异常处理函数又触发了 breakpoint 异常,但 breakpoint 异常处理函数已经被换出内存了?
+4. 如果我们的内核发生了栈溢出,意外访问到了 _guard page_ ?
+
+幸运的是,AMD64手册([PDF][AMD64 manual])给出了一个准确的定义(在8.2.9这个章节中)。
+根据里面的说法,“double fault” 异常 _会_ 在执行主要(一层)异常处理函数时触发二层异常时触发。
+这个“会”字十分重要:只有特定的两个异常组合会触发 double fault。
+这些异常组合如下:
+
+| 一层异常 | 二层异常 |
+| --------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------- |
+| [Divide-by-zero], [Invalid TSS], [Segment Not Present], [Stack-Segment Fault], [General Protection Fault] | [Invalid TSS], [Segment Not Present], [Stack-Segment Fault], [General Protection Fault] |
+| [Page Fault] | [Page Fault], [Invalid TSS], [Segment Not Present], [Stack-Segment Fault], [General Protection Fault] |
+
+[Divide-by-zero]: https://wiki.osdev.org/Exceptions#Divide-by-zero_Error
+[Invalid TSS]: https://wiki.osdev.org/Exceptions#Invalid_TSS
+[Segment Not Present]: https://wiki.osdev.org/Exceptions#Segment_Not_Present
+[Stack-Segment Fault]: https://wiki.osdev.org/Exceptions#Stack-Segment_Fault
+[General Protection Fault]: https://wiki.osdev.org/Exceptions#General_Protection_Fault
+[Page Fault]: https://wiki.osdev.org/Exceptions#Page_Fault
+
+
+[AMD64 manual]: https://www.amd.com/system/files/TechDocs/24593.pdf
+
+所以那些假设里的 divide-by-zero 异常处理函数触发了 page fault 并不会出问题,只会紧接着触发下一个异常处理函数。但如果 divide-by-zero 异常处理函数触发的是 general-protection fault,则一定会触发 double fault。
+
+那么根据上表,我们可以回答刚刚的假设中的前三个:
+
+1. 如果 breakpoint 异常被触发,但对应的处理函数被换出了内存,_page fault_ 异常就会被触发,并调用其对应的异常处理函数。
+2. 如果 page fault 异常被触发,但对应的处理函数被换出了内存,那么 _double fault_ 异常就会被触发,并调用其对应的处理函数。
+3. 如果 divide-by-zero 异常处理函数又触发了 breakpoint 异常,但 breakpoint 异常处理函数已经被换出内存了,那么被触发的就是 _page fault_ 异常。
+
+实际上,因在IDT里找不到对应处理函数而抛出异常的内部机制是:当异常发生时,CPU会去试图读取对应的IDT条目,如果该条目不是一个有效的条目,即其值为0,就会触发 _general protection fault_ 异常。但我们同样没有为该异常注册处理函数,所以又一个 general protection fault 被触发了,随后 double fault 也被触发了。
+
+### 内核栈溢出
+现在让我们看一下第四个假设:
+
+> 如果我们的内核发生了栈溢出,意外访问到了 _guard page_ ?
+
+guard page 是一类位于栈底部的特殊内存页,所以如果发生了栈溢出,最典型的现象就是访问这里。这类内存页不会映射到物理内存中,所以访问这里只会造成 page fault 异常,而不会污染其他内存。bootloader 已经为我们的内核栈设置好了一个 guard page,所以栈溢出会导致 _page fault_ 异常。
+
+当 page fault 发生时,CPU会在IDT寻找对应的处理函数,并尝试将 [中断栈帧][interrupt stack frame] 入栈,但此时栈指针指向了一个实际上并不存在的 guard page,然后第二个 page fault 异常就被触发了,根据上面的表格,double fault 也随之被触发了。
+
+[interrupt stack frame]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-stack-frame
+
+这时,CPU会尝试调用 _double fault_ 对应的处理函数,然而CPU依然会试图将错误栈帧入栈,由于栈指针依然指向 guard page,于是 _第三次_ page fault 发生了,最终导致 _triple fault_ 异常的抛出,系统因此重启。所以仅仅是注册错误处理函数并不能在此种情况下阻止 triple fault 的发生。
+
+让我们来尝试一下,写一个能造成栈溢出的递归函数非常简单:
+
+```rust
+// in src/main.rs
+
+#[no_mangle] // 禁止函数名自动修改
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init();
+
+ fn stack_overflow() {
+ stack_overflow(); // 每一次递归都会将返回地址入栈
+ }
+
+ // 触发 stack overflow
+ stack_overflow();
+
+ […] // test_main(), println(…), and loop {}
+}
+```
+
+我们在QEMU执行这段程序,然后系统就再次进入了重启循环。
+
+所以我们要如何避免这种情况?我们无法忽略异常栈帧入栈这一步,因为这个逻辑是内置在CPU里的。所以我们需要找个办法,让栈在 double fault 异常发生后始终有效。幸运的是,x86_64 架构对于这个问题已经给出了解决方案。
+
+## 切换栈
+x86_64 架构允许在异常发生时,将栈切换为一个预定义的完好栈,这个切换是执行在硬件层次的,所以完全可以在CPU将异常栈帧入栈之前执行。
+
+这个切换机制是由 _中断栈表_ (IST)实现的,IST是一个由7个确认可用的完好栈的指针组成的,用 Rust 语言可以表述为:
+
+```rust
+struct InterruptStackTable {
+ stack_pointers: [Option; 7],
+}
+```
+
+对于每一个错误处理函数,我们都可以通过对应的[IDT条目][IDT entry]中的 `stack_pointers` 条目指定IST中的一个栈。比如我们可以让 double fault 对应的处理函数使用IST中的第一个栈指针,则CPU会在这个异常发生时,自动将栈切换为该栈。该切换行为会在所有入栈操作之前进行,由此可以避免进一步触发 triple fault 异常。
+
+[IDT entry]: @/edition-2/posts/05-cpu-exceptions/index.md#the-interrupt-descriptor-table
+
+### IST和TSS
+中断栈表(IST)其实是一个名叫 _[任务状态段][Task State Segment](TSS)_ 的古老遗留结构的一部分。
+TSS是用来存储32位任务中的零碎信息,比如处理器寄存器的状态,一般用于 [硬件上下文切换][hardware context switching]。但是硬件上下文切换已经不再适用于64位模式,并且TSS的实际数据结构也已经发生了彻底的改变。
+
+[Task State Segment]: https://en.wikipedia.org/wiki/Task_state_segment
+[hardware context switching]: https://wiki.osdev.org/Context_Switching#Hardware_Context_Switching
+
+在 x86_64 架构中,TSS已经不再存储任何任务相关信息,取而代之的是两个栈表(IST正是其中之一)。
+32位TSS和64位TSS唯一的共有字段恐怕就是指向 [I/O端口权限位图][I/O port permissions bitmap] 的指针了。
+
+[I/O port permissions bitmap]: https://en.wikipedia.org/wiki/Task_state_segment#I.2FO_port_permissions
+
+64位TSS的格式如下:
+
+| 字段 | 类型 |
+| ---------------------------------------- | ---------- |
+| (保留) | `u32` |
+| 特权栈表 | `[u64; 3]` |
+| (保留) | `u64` |
+| 中断栈表 | `[u64; 7]` |
+| (保留) | `u64` |
+| (保留) | `u16` |
+| I/O映射基准地址 | `u16` |
+
+_特权栈表_ 在 CPU 特权等级变更的时候会被用到。例如当 CPU 在用户态(特权等级3)中触发一个异常时,一般情况下 CPU 会在执行错误处理函数前切换到内核态(特权等级0),在这种情况下,CPU 会切换为特权栈表的第0层(0层是目标特权等级)。但是目前我们还没有用户态的程序,所以暂且可以忽略这个表。
+
+### 创建一个TSS
+那么我们来创建一个新的包含单独的 double fault 专属栈以及中断栈表的TSS。为此我们需要一个TSS结构体,幸运的是 `x86_64` crate 也已经自带了 [`TaskStateSegment` 结构][`TaskStateSegment` struct] 用来映射它。
+
+[`TaskStateSegment` struct]: https://docs.rs/x86_64/0.14.2/x86_64/structures/tss/struct.TaskStateSegment.html
+
+那么我们新建一个 `gdt` 模块(稍后会说明为何要使用这个名字)用来创建TSS:
+
+```rust
+// in src/lib.rs
+
+pub mod gdt;
+
+// in src/gdt.rs
+
+use x86_64::VirtAddr;
+use x86_64::structures::tss::TaskStateSegment;
+use lazy_static::lazy_static;
+
+pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
+
+lazy_static! {
+ static ref TSS: TaskStateSegment = {
+ let mut tss = TaskStateSegment::new();
+ tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
+ const STACK_SIZE: usize = 4096 * 5;
+ static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
+
+ let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
+ let stack_end = stack_start + STACK_SIZE;
+ stack_end
+ };
+ tss
+ };
+}
+```
+
+这次依然是使用 `lazy_static`,Rust的静态变量求值器还没有强大到能够在编译器执行初始化代码。我们将IST的0号位定义为 double fault 的专属栈(其他IST序号也可以如此施为)。然后我们将栈的高地址指针写入0号位,之所以这样做,那是因为 x86 的栈内存分配是从高地址到低地址的。
+
+由于我们还没有实现内存管理机制,所以目前无法直接申请新栈,但我们可以使用 `static mut` 形式的数组来在内存中模拟出栈存储区。`unsafe` 块也是必须的,因为编译器认为这种可以被竞争的变量是不安全的,而且这里必须是 `static mut` 而不是不可修改的 `static`,否则 bootloader 会将其分配到只读页中。当然,在后续的文章中,我们会将其修改为真正的栈分配,`unsafe` 块也一定会去掉的。
+
+但要注意,由于现在 double fault 获取的栈不再具有用于防止栈溢出的 guard page,所以我们不应该做任何栈密集型操作了,否则就有可能会污染到栈下方的内存区域。
+
+#### 加载TSS
+我们已经创建了一个TSS,现在的问题就是怎么让CPU使用它。不幸的是这事有点繁琐,因为TSS用到了分段系统(历史原因)。但我们可以不直接加载,而是在[全局描述符表][Global Descriptor Table](GDT)中添加一个段描述符,然后我们就可以通过[`ltr` 指令][`ltr` instruction]加上GDT序号加载我们的TSS。(这也是为什么我们将模块取名为 `gdt`。)
+
+[Global Descriptor Table]: https://web.archive.org/web/20190217233448/https://www.flingos.co.uk/docs/reference/Global-Descriptor-Table/
+[`ltr` instruction]: https://www.felixcloutier.com/x86/ltr
+
+### 全局描述符表
+全局描述符表(GDT)是分页模式成为事实标准之前,用于[内存分段][memory segmentation]的遗留结构,但它在64位模式下仍然需要处理一些事情,比如内核态/用户态的配置以及TSS载入。
+
+[memory segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
+
+GDT是包含了程序 _段信息_ 的结构,在分页模式成为标准前,它在旧架构下起到隔离程序执行环境的作用。要了解更多关于分段的知识,可以查看 [“Three Easy Pieces” book] 这本书的同名章节。尽管GDT在64位模式下已经不再受到支持,但其依然有两个作用,切换内核空间和用户空间,以及加载TSS结构。
+
+[“Three Easy Pieces” book]: http://pages.cs.wisc.edu/~remzi/OSTEP/
+
+#### 创建GDT
+我们来创建一个包含了静态 `TSS` 段的 `GDT` 静态结构:
+
+```rust
+// in src/gdt.rs
+
+use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
+
+lazy_static! {
+ static ref GDT: GlobalDescriptorTable = {
+ let mut gdt = GlobalDescriptorTable::new();
+ gdt.add_entry(Descriptor::kernel_code_segment());
+ gdt.add_entry(Descriptor::tss_segment(&TSS));
+ gdt
+ };
+}
+```
+
+就像以前一样,我们依然使用了 `lazy_static` 宏,我们通过这段代码创建了TSS和GDT两个结构。
+
+#### 加载GDT
+
+我们先创建一个在 `init` 函数中调用的 `gdt::init` 函数:
+
+```rust
+// in src/gdt.rs
+
+pub fn init() {
+ GDT.load();
+}
+
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+}
+```
+
+现在GDT成功加载了进去(`_start` 会调用 `init` 函数),但我们依然会看到由于栈溢出引发的重启循环。
+
+### 最终步骤
+
+现在的问题就变成了GDT并未被激活,代码段寄存器和TSS实际上依然引用着旧的GDT,并且我们也需要修改 double fault 对应的IDT条目,使其使用新的栈。
+
+总结一下,我们需要做这些事情:
+
+1. **重载代码段寄存器**: 我们修改了GDT,所以就需要重载代码段寄存器 `cs`,这一步对于修改GDT信息而言是必须的,比如覆写TSS。
+2. **加载TSS** : 我们已经加载了包含TSS信息的GDT,但我们还需要告诉CPU使用新的TSS。
+3. **更新IDT条目**: 当TSS加载完毕后,CPU就可以访问到新的中断栈表(IST)了,下面我们需要通过修改IDT条目告诉CPU使用新的 double fault 专属栈。
+
+通过前两步,我们可以在 `gdt::init` 函数中调用 `code_selector` 和 `tss_selector` 两个变量,我们可以将两者打包为一个 `Selectors` 结构便于使用:
+
+```rust
+// in src/gdt.rs
+
+use x86_64::structures::gdt::SegmentSelector;
+
+lazy_static! {
+ static ref GDT: (GlobalDescriptorTable, Selectors) = {
+ let mut gdt = GlobalDescriptorTable::new();
+ let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
+ let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
+ (gdt, Selectors { code_selector, tss_selector })
+ };
+}
+
+struct Selectors {
+ code_selector: SegmentSelector,
+ tss_selector: SegmentSelector,
+}
+```
+
+现在我们可以使用这两个变量去重载代码段寄存器 `cs` 并重载 `TSS`:
+
+```rust
+// in src/gdt.rs
+
+pub fn init() {
+ use x86_64::instructions::tables::load_tss;
+ use x86_64::instructions::segmentation::{CS, Segment};
+
+ GDT.0.load();
+ unsafe {
+ CS::set_reg(GDT.1.code_selector);
+ load_tss(GDT.1.tss_selector);
+ }
+}
+```
+
+我们通过 [`set_cs`] 覆写了代码段寄存器,然后使用 [`load_tss`] 来重载了TSS,不过这两个函数都被标记为 `unsafe`,所以 `unsafe` 代码块是必须的。
+原因很简单,如果通过这两个函数加载了无效的指针,那么很可能就会破坏掉内存安全性。
+
+[`set_cs`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/segmentation/fn.set_cs.html
+[`load_tss`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tables/fn.load_tss.html
+
+现在我们已经加载了有效的TSS和中断栈表,我们可以在IDT中为 double fault 对应的处理函数设置栈序号:
+
+```rust
+// in src/interrupts.rs
+
+use crate::gdt;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ unsafe {
+ idt.double_fault.set_handler_fn(double_fault_handler)
+ .set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
+ }
+
+ idt
+ };
+}
+```
+
+`set_stack_index` 函数也是不安全的,因为栈序号的有效性和引用唯一性是需要调用者去确保的。
+
+搞定!现在CPU会在 double fault 异常被触发时自动切换到安全栈了,我们可以捕捉到 _所有_ 的 double fault,包括内核栈溢出:
+
+
+
+现在开始我们应该不会再看到 triple fault 了,但要确保这部分逻辑不被破坏,我们还需要为其添加一个测试。
+
+## 栈溢出测试
+
+要测试我们的 `gdt` 模块,并确保在栈溢出时可以正确捕捉 double fault,我们可以添加一个集成测试。基本上就是在测试函数中主动触发一个 double fault 异常,确认异常处理函数是否正确运行了。
+
+让我们建立一个最小化框架:
+
+```rust
+// in tests/stack_overflow.rs
+
+#![no_std]
+#![no_main]
+
+use core::panic::PanicInfo;
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ unimplemented!();
+}
+
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ blog_os::test_panic_handler(info)
+}
+```
+
+就如同 `panic_handler` 这个测试一样,该测试应该是一个 [无约束测试][without a test harness],其原因就是我们无法在 double fault 被抛出后继续运行,所以连续进行多个测试其实是说不通的。要将测试修改为无约束模式,我们需要将这一段配置加入 `Cargo.toml`:
+
+```toml
+# in Cargo.toml
+
+[[test]]
+name = "stack_overflow"
+harness = false
+```
+
+[without a test harness]: @/edition-2/posts/04-testing/index.md#no-harness-tests
+
+现在 `cargo test --test stack_overflow` 命令应当可以通过编译了。但是毫无疑问的是还是会执行失败,因为 `unimplemented` 宏必然会导致程序报错。
+
+### 实现 `_start`
+
+`_start` 函数实现后的样子是这样的:
+
+```rust
+// in tests/stack_overflow.rs
+
+use blog_os::serial_print;
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ serial_print!("stack_overflow::stack_overflow...\t");
+
+ blog_os::gdt::init();
+ init_test_idt();
+
+ // trigger a stack overflow
+ stack_overflow();
+
+ panic!("Execution continued after stack overflow");
+}
+
+#[allow(unconditional_recursion)]
+fn stack_overflow() {
+ stack_overflow(); // for each recursion, the return address is pushed
+ volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
+}
+```
+
+我们调用了 `gdt::init` 函数来初始化GDT,但我们并没有调用 `interrupts::init_idt` 函数,而是调用了一个全新的 `init_test_idt` 函数,我们稍后来实现它。原因就是,我们需要注册一个自定义的 double fault 处理函数,在被触发的时候调用 `exit_qemu(QemuExitCode::Success)` 函数,而非使用默认的逻辑。
+
+`stack_overflow` 函数和我们之前在 `main.rs` 中写的那个函数几乎一模一样,唯一的区别就是在函数的最后使用 [`Volatile`] 类型 加入了一个 [volatile] 读取操作,用来阻止编译器进行 [_尾调用优化_][_tail call elimination_]。除却其他乱七八糟的效果,这个优化最主要的影响就是会让编辑器将最后一行是递归语句的函数转化为普通的循环。由于没有通过递归创建新的栈帧,所以栈自然也不会出问题。
+
+[volatile]: https://en.wikipedia.org/wiki/Volatile_(computer_programming)
+[`Volatile`]: https://docs.rs/volatile/0.2.6/volatile/struct.Volatile.html
+[_tail call elimination_]: https://en.wikipedia.org/wiki/Tail_call
+
+在当前用例中,stack overflow 是必须要触发的,所以我们在函数尾部加入了一个无效的 volatile 读取操作来让编译器无法进行此类优化,递归也就无法被自动降级为循环了。当然,为了关闭编译器针对递归的安全警告,我们也需要为这个函数加上 `allow(unconditional_recursion)` 开关。
+
+### 测试 IDT
+
+作为上一小节的补充,我们说过要在测试专用的IDT中实现一个自定义的 double fault 异常处理函数,就像这样:
+
+```rust
+// in tests/stack_overflow.rs
+
+use lazy_static::lazy_static;
+use x86_64::structures::idt::InterruptDescriptorTable;
+
+lazy_static! {
+ static ref TEST_IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ unsafe {
+ idt.double_fault
+ .set_handler_fn(test_double_fault_handler)
+ .set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
+ }
+
+ idt
+ };
+}
+
+pub fn init_test_idt() {
+ TEST_IDT.load();
+}
+```
+
+这和我们在 `interrupts.rs` 中实现的版本十分相似,如同正常的IDT一样,我们都为 double fault 使用IST序号设置了特殊的栈,而上文中提到的 `init_test_idt` 函数则通过 `load` 函数将配置成功装载到CPU。
+
+### Double Fault 处理函数
+
+那么现在就差处理函数本身了,它看起来是这样子的:
+
+```rust
+// in tests/stack_overflow.rs
+
+use blog_os::{exit_qemu, QemuExitCode, serial_println};
+use x86_64::structures::idt::InterruptStackFrame;
+
+extern "x86-interrupt" fn test_double_fault_handler(
+ _stack_frame: InterruptStackFrame,
+ _error_code: u64,
+) -> ! {
+ serial_println!("[ok]");
+ exit_qemu(QemuExitCode::Success);
+ loop {}
+}
+```
+
+这个处理函数被调用后,我们会使用代表成功的返回值退出QEMU,以此即可标记测试完成,但由于集成测试处于完全独立的运行环境,也记得在测试入口文件的头部再次加入 `#![feature(abi_x86_interrupt)]` 开关。
+
+现在我们可以执行 `cargo test --test stack_overflow` 运行当前测试(或者执行 `cargo test` 运行所有测试),应当可以在控制台看到 `stack_overflow... [ok]` 这样的输出。另外,也可以试一下注释掉 `set_stack_index` 这一行的命令,可以观察到失败情况下的输出。
+
+## 总结
+在本文中,我们学到了 double fault 是什么,以及触发它的原因。我们为 double fault 写了相应的处理函数、将错误信息打印到控制台并为它添加了一个集成测试。
+
+同时,我们为 double fault 启用了栈指针切换功能,使其在栈溢出时也可以正常工作。在实现这个功能的同时,我们也学习了在旧架构中用于内存分段的任务状态段(TSS),而该结构又包含了中断栈表(IST)和全局描述符表(GDT)。
+
+## 下期预告
+在下一篇文章中,我们会展开来说外部设备(如定时器、键盘、网络控制器)中断的处理方式。这些硬件中断十分类似于上文所说的异常,都需要通过IDT进行处理,只是中断并不是由CPU抛出的。 _中断控制器_ 会代理这些中断事件,并根据中断的优先级将其转发给CPU处理。我们将会以 [Intel 8259] (PIC) 中断控制器为例对其进行探索,并实现对键盘的支持。
+
+[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
diff --git a/blog/content/edition-2/posts/07-hardware-interrupts/index.ja.md b/blog/content/edition-2/posts/07-hardware-interrupts/index.ja.md
new file mode 100644
index 00000000..3ea10335
--- /dev/null
+++ b/blog/content/edition-2/posts/07-hardware-interrupts/index.ja.md
@@ -0,0 +1,740 @@
++++
+title = "ハードウェア割り込み"
+weight = 7
+path = "ja/hardware-interrupts"
+date = 2018-10-22
+
+[extra]
+chapter = "Interrupts"
+# Please update this when updating the translation
+translation_based_on_commit = "81d4f49f153eb5f390681f5c13018dd2aa6be0b1"
+# GitHub usernames of the people that translated this post
+translators = ["shimomura1004", "woodyZootopia"]
++++
+
+この記事では、ハードウェア割り込みを正しく CPU に転送するためにプログラム可能な割り込みコントローラの設定を行います。これらの割り込みに対処するため、例外ハンドラのときに行ったのと同じように割り込み記述子表に新しいエントリを追加しなくてはいけません。ここでは周期タイマ割り込みの受け方と、キーボードからの入力の受け方を学びます。
+
+
+
+このブログの内容は [GitHub] 上で公開・開発されています。何か問題や質問などがあれば issue をたててください (訳注: リンクは原文(英語)のものになります)。また[こちら][at the bottom]にコメントを残すこともできます。この記事の完全なソースコードは[`post-07` ブランチ][post branch]にあります。
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-07
+
+
+
+## 概要
+
+割り込みは、接続されたハードウェアデバイスから CPU に通知を行う方法を提供します。よって、新しい文字がないか定期的にカーネルにキーボードを確認させるかわりに ([ポーリング][_polling_]と呼ばれます)、キー入力のたびにキーボードのほうからカーネルに通知することができます。この方法の場合、カーネルはなにかが起きたときだけ処置を行えばよいので、とても効率がいいです。カーネルは次のポーリングのタイミングを待たずとも即座に反応することができるので、応答時間も短くなります。
+
+[_polling_]: https://ja.wikipedia.org/wiki/%E3%83%9D%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0_(%E6%83%85%E5%A0%B1)
+
+すべてのハードウェアを直接 CPU に接続することはできません。そのかわりに、独立した _割り込みコントローラ_ がすべてのデバイスからの割り込みを取りまとめて CPU に通知します:
+
+```
+ ____________ _____
+ Timer ------------> | | | |
+ Keyboard ---------> | Interrupt |---------> | CPU |
+ Other Hardware ---> | Controller | |_____|
+ Etc. -------------> |____________|
+
+```
+
+多くの割り込みコントローラはプログラム可能です。これはそれぞれの割り込みに対して異なる優先度を設定することができるということです。例えば正確な時間管理を保証するために、キーボード割り込みよりもタイマ割り込みに高い優先度を設定することができます。
+
+例外とは異なり、ハードウェア割り込みは _非同期的_ です。これは、ハードウェア割り込みは実行コードからは完全に独立していて、どんなタイミングでもハードウェア割り込みが発生する可能性があるということです。よって突如として私達のカーネルはある種の並行性を持つようになり、これにより並行処理に関するあらゆる潜在的なバグを持つことになります。Rust の厳格な所有権モデルはグローバルな状態を変更可能にすることを禁止しているため、この問題に役立ちます。ただしこの記事の後半で見るとおり、それでもデッドロックは発生してしまいます。
+
+## 8259 PIC
+
+[Intel 8259] は 1976 年に登場したプログラム可能な割り込みコントローラ (programmable interrupt controller: PIC) です。ずいぶん前に、より新しい [APIC] によって置き換えられましたが、そのインタフェースは現在のシステムでも後方互換性のためにサポートされています。8259 PIC は APIC よりも設定がかなり簡単なので、後の記事で APIC に切り替える前に、8259 PIC を使って割り込み処理に入門することにしましょう。
+
+[APIC]: https://ja.wikipedia.org/wiki/APIC
+
+8259 PIC は、割り込み線8本と、CPU と通信するための線を数本持っています。当時の典型的なシステムは 8259 PIC をプライマリとセカンダリの2つ搭載しており、セカンダリの PIC はプライマリの PIC の割り込み線のひとつに接続されていました:
+
+[Intel 8259]: https://ja.wikipedia.org/wiki/Intel_8259
+
+```
+ ____________ ____________
+Real Time Clock --> | | Timer -------------> | |
+ACPI -------------> | | Keyboard-----------> | | _____
+Available --------> | Secondary |----------------------> | Primary | | |
+Available --------> | Interrupt | Serial Port 2 -----> | Interrupt |---> | CPU |
+Mouse ------------> | Controller | Serial Port 1 -----> | Controller | |_____|
+Co-Processor -----> | | Parallel Port 2/3 -> | |
+Primary ATA ------> | | Floppy disk -------> | |
+Secondary ATA ----> |____________| Parallel Port 1----> |____________|
+
+```
+
+この図は典型的な割り込み線の割り当てを示しています。15本の線の多くは割り当てが固定されています。例えば、セカンダリの PIC の4番目の線はマウスに割り当てられています。
+
+それぞれのコントローラは、"コマンド" ポートと "データ" ポートという2つの [I/O ポート][I/O ports] を通じて設定を行うことができます。プライマリコントローラでは、これらのポートは `0x20` (コマンド) と `0x21` (データ) になります。セカンダリコントローラでは、`0xa0` (コマンド) と `0xa1` (データ) になります。PIC の設定方法の詳細は [osdev.org の記事][article on osdev.org]を見てください。
+
+[I/O ports]: @/edition-2/posts/04-testing/index.md#i-o-ports
+[article on osdev.org]: https://wiki.osdev.org/8259_PIC
+
+### 実装
+
+PIC のデフォルト設定では、0から15の割り込みベクタ番号を CPU に送るようになっているため使うことができません。これらの番号は既に CPU 例外で使われており、例えば8番はダブルフォルトに対応します。この重複による問題を解決するためには PIC の割り込みを別の番号にマッピングし直さないといけません。割り込み番号の範囲は例外と重複しなければ問題になりませんが、32個の例外スロットのあとの最初の空き番号である32から47の範囲がよく使われます。
+
+コマンドポートとデータポートに特別な値を書き込むことで PIC の設定を行います。幸い [`pic8259`] というクレートが既にありますので、初期化シーケンスを自分たちで書く必要はありません。クレートの動作に興味があるなら[ソースコード][pic crate source]を確認してみてください。とても小さくドキュメントも豊富です。
+
+[pic crate source]: https://docs.rs/crate/pic8259/0.10.1/source/src/lib.rs
+
+クレートを依存関係を追加するため、以下の内容をプロジェクトに追加します:
+
+[`pic8259`]: https://docs.rs/pic8259/0.10.1/pic8259/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+pic8259 = "0.10.1"
+```
+
+このクレートが提供する主な抽象化は、上で見たようなプライマリとセカンダリの PIC からなるレイアウトを表わす [`ChainedPics`] 構造体です。これは以下のように使うように設計されています:
+
+[`ChainedPics`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html
+
+```rust
+// in src/interrupts.rs
+
+use pic8259::ChainedPics;
+use spin;
+
+pub const PIC_1_OFFSET: u8 = 32;
+pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
+
+pub static PICS: spin::Mutex =
+ spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
+```
+
+上で述べたように、PIC のオフセットを32から47の範囲に設定しています。`ChainedPics` 構造体を `Mutex` でラップすることで、次のステップで必要になる安全な可変アクセスを ([`lock` メソッド][spin mutex lock]を使って) 得ることができます。間違ったオフセットを指定すると未定義動作となるため、`ChainedPics::new` 関数は unsafe です。
+
+[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
+
+8259 PIC の初期化は `init` 関数内で行うことができます:
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+ unsafe { interrupts::PICS.lock().initialize() }; // new
+}
+```
+
+PIC の初期化を行うために [`initialize`] 関数を使います。`ChainedPics::new` 関数と同じように、PIC を間違って設定すると未定義動作となるため、この関数も unsafe になります。
+
+[`initialize`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html#method.initialize
+
+すべてうまくいけば、`cargo run` を実行すると "It did not crash" というメッセージが引き続き表示されるはずです。
+
+## 割り込みの有効化
+
+CPU の設定で割り込みが無効化されていたため、これまではなにも起きませんでした。これは CPU が割り込みコントローラからの信号をすべて無視していたため、割り込みが CPU に届かなかったということです。これを変更しましょう:
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+ unsafe { interrupts::PICS.lock().initialize() };
+ x86_64::instructions::interrupts::enable(); // new
+}
+```
+
+`x86_64` クレートの `interrupts::enable` 関数は、特別な `sti` ("set interrupts") 命令を実行し外部割り込みを有効にします。ここで `cargo run` を実行するとダブルフォルトが発生します:
+
+
+
+ダブルフォルトが発生する理由は、ハードウェアタイマ (正確には [Intel 8253]) がデフォルトで有効になっているため、割り込みを有効にするとすぐにタイマ割り込みを受け取り始めるためです。この割り込みのためのハンドラ関数を定義していないため、ダブルフォルトのハンドラが呼ばれることになります。
+
+[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
+
+## タイマ割り込みの処理
+
+[上述](#8259-pic)した図にある通り、タイマはプライマリの PIC の0番目の線を使います。これはタイマ割り込みは32番 (0 + オフセットの32) の割り込みとして CPU に届くということです。32をハードコーディングする代わりに `InterruptIndex` enum に保存することにしましょう:
+
+```rust
+// in src/interrupts.rs
+
+#[derive(Debug, Clone, Copy)]
+#[repr(u8)]
+pub enum InterruptIndex {
+ Timer = PIC_1_OFFSET,
+}
+
+impl InterruptIndex {
+ fn as_u8(self) -> u8 {
+ self as u8
+ }
+
+ fn as_usize(self) -> usize {
+ usize::from(self.as_u8())
+ }
+}
+```
+
+Rust の enum は [C 言語ライクな enum][C-like enum] であるため、各ヴァリアントに直接インデックスを指定できます。 `repr(u8)` アトリビュートは、各ヴァリアントが `u8` 型で表されるよう指定しています。今後、他の例外に対してヴァリアントを追加していきます。
+
+[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
+
+さて、タイマ割り込みへのハンドラ関数を追加していきます:
+
+```rust
+// in src/interrupts.rs
+
+use crate::print;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ […]
+ idt[InterruptIndex::Timer.as_usize()]
+ .set_handler_fn(timer_interrupt_handler); // new
+
+ idt
+ };
+}
+
+extern "x86-interrupt" fn timer_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!(".");
+}
+```
+
+CPU は例外に対しても外部割り込みに対しても同じように反応するため、我々が定義した `timer_interrupt_handler` は例外ハンドラと同じシグニチャを持っています (唯一の違いは、一部の例外はエラーコードをプッシュすることです)。[`InterruptDescriptorTable`] 構造体は [`IndexMut`] トレイトを実装しているので、配列の添字記法でそれぞれのエントリにアクセスすることができます。
+
+[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
+
+我々のタイマ割り込みハンドラでは画面にドットを表示します。タイマ割り込みは定期的に発生するので、タイマティックのたびに新たなドットが現れるだろうと思うでしょう。しかし実行してみると、ドットはひとつしか表示されません:
+
+
+
+### 割り込みの終了
+
+この理由は、PIC は明示的な "割り込みの終了" (end of interrupt: EOI) 信号を割り込みハンドラが通知してくると期待しているからです。この信号は、割り込みが既に処理されシステムが次の割り込みを受け取る準備ができたことをコントローラに伝えます。そのため PIC は、我々のシステムはまだ最初のタイマ割り込みを処理している最中だと考え、次の割り込みを送らずに辛抱強く EOI 信号を待ち続けているのです。
+
+EOI を送るためには、再び静的な `PICS` 構造体を使います:
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn timer_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!(".");
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
+ }
+}
+```
+
+`notify_end_of_interrupt` は、プライマリとセカンダリのどちらの PIC が割り込みを送ったかを判断し、コマンドポートとデータポートを使って EOI 信号をそれぞれのコントローラに送ります。セカンダリの PIC はプライマリの PIC の入力線に接続されているため、もしセカンダリの PIC が割り込みを送った場合は、両方の PIC に信号を送る必要があります。
+
+正しい割り込みベクタ番号を使うよう気をつけないと、まだ送信されていない重要な割り込みを間違って消してしまったり、システムがハングしてしまうかもしれません。この関数が unsafe になっているのはこのためです。
+
+`cargo run` を実行すると、画面上にドットが定期的に表示されるでしょう:
+
+
+
+### タイマの設定
+
+我々が使ったハードウェアタイマは _プログラム可能インターバルタイマ_ 、もしくは短く PIT と呼ばれています。名前が示すように、PIT は2つの割り込みの間の間隔を設定することができます。すぐに [APIC タイマ][APIC timer]に切り替えるのでここで詳細に入ることはしませんが、OSDev wiki には [PIT の設定][configuring the PIT]に関する記事が豊富にあります。
+
+[APIC timer]: https://wiki.osdev.org/APIC_timer
+[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
+
+## デッドロック
+
+これで我々のカーネルはある種の並行性を持ちました: タイマ割り込みは非同期に発生するので、どんなタイミングでも `_start` 関数に割り込み得るのです。幸い、Rust の所有権システムは並行性に関連する多くのバグをコンパイル時に防ぐことができます。特筆すべき例外のひとつがデッドロックです。デッドロックはスレッドが決して解放されないロックを取得しようとしたときに起こり、そのスレッドは永遠にハングしてしまいます。
+
+我々のカーネルでは、既にデッドロックが起きる可能性があります。我々が実装した `prinln` マクロは `vga_buffer::_print` 関数を呼び出しており、_print 関数はスピンロックを使って[グローバルな `WRITER` をロックする][vga spinlock]ということを思い出してください:
+
+[vga spinlock]: @/edition-2/posts/03-vga-text-buffer/index.md#spinlocks
+
+```rust
+// in src/vga_buffer.rs
+
+[…]
+
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ WRITER.lock().write_fmt(args).unwrap();
+}
+```
+
+_print 関数は `WRITER` をロックし、`write_fmt` を呼び出し、そして関数の最後で暗黙にロックを解放します。では、`WRITER` がロックされている間に割り込みが発生し、割り込みハンドラもなにかを表示しようとしていると想像してみてください:
+
+時刻 | _start | 割り込みハンドラ
+---------|------|------------------
+0 | `println!` を呼び出す |
+1 | `print` が `WRITER` をロック |
+2 | | **割り込みが発生**、割り込みハンドラが動き出す
+3 | | `println!` を呼び出す |
+4 | | `print` が `WRITER` をロックしようとする (既にロック済み)
+5 | | `print` が `WRITER` をロックしようとする (既にロック済み)
+… | | …
+_(決して起こらない)_ | _`WRITER` のロックを解放する_ |
+
+`WRITER` はロックされているので、割り込みハンドラはそれが解放されるのを待ちます。しかし `_start` 関数は割り込みハンドラから処理が戻らないと実行されることはないので、ロックが解放されることはありません。このためシステム全体がハングしてしまいます。
+
+### デッドロックを起こす
+
+我々のカーネルでは、`_start` 関数の最後のループの中で何かを表示するだけで簡単にデッドロックを起こすことができます:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ […]
+ loop {
+ use blog_os::print;
+ print!("-"); // new
+ }
+}
+```
+
+QEMU で実行すると以下のような出力が得られます:
+
+
+
+限られた数のハイフンが表示されたのち、最初のタイマ割り込みが発生したことがわかります。そしてタイマ割り込みハンドラがドットを表示しようとするとデッドロックするので、システムがハングしてしまいます。これが上記の出力でドットが表示されていない理由です。
+
+タイマ割り込みは非同期に発生するので、実際のハイフンの数は実行するたびに変わります。この非決定性が、並行性に関するバグのデバッグを非常に難しくします。
+
+### デッドロックを修正する
+
+このデッドロックを回避するため、`Mutex` がロックされている間は割り込みを無効化することができます:
+
+```rust
+// in src/vga_buffer.rs
+
+/// グローバルな `WRITER` インスタンスを使って
+/// フォーマット済み文字列を VGA テキストバッファに出力する
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts; // new
+
+ interrupts::without_interrupts(|| { // new
+ WRITER.lock().write_fmt(args).unwrap();
+ });
+}
+```
+
+[`without_interrupts`] 関数は[クロージャ][closure]を引数に取り、これを割り込みが発生しない状態で実行します。これを使えば `Mutex` がロックされている間は割り込みが発生しないことを保証できます。このように修正したカーネルを実行すると、今度はハングせずに実行が続きます。(ドットがないように見えますが、これはスクロールが速すぎるためです。例えば `for _ in 0..10000 {}` をループ内で実行するなどで表示速度を遅くしてみてください。)
+
+[`without_interrupts`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/interrupts/fn.without_interrupts.html
+[closure]: https://doc.rust-lang.org/book/ch13-01-closures.html
+
+シリアル出力関数でもデッドロックが起きないことを保証するために、同等の変更を加えます:
+
+```rust
+// in src/serial.rs
+
+#[doc(hidden)]
+pub fn _print(args: ::core::fmt::Arguments) {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts; // new
+
+ interrupts::without_interrupts(|| { // new
+ SERIAL1
+ .lock()
+ .write_fmt(args)
+ .expect("Printing to serial failed");
+ });
+}
+```
+
+割り込みを無効化することを一般的な解決策としてはならないことは覚えておいてください。割り込みの無効化は、レイテンシ、つまりシステムが割り込みに反応するまでの時間の最悪値を増加させるという問題があります。そのため割り込みの無効化はごく短時間に限るべきです。
+
+## 競合状態を修正する
+
+`cargo test` を実行すると、`test_println_output` テストが失敗することが確認できるかもしれません:
+
+```
+> cargo test --lib
+[…]
+Running 4 tests
+test_breakpoint_exception...[ok]
+test_println... [ok]
+test_println_many... [ok]
+test_println_output... [failed]
+
+Error: panicked at 'assertion failed: `(left == right)`
+ left: `'.'`,
+ right: `'S'`', src/vga_buffer.rs:205:9
+```
+
+この理由はテスト関数とタイマ割り込みハンドラの間の _競合状態_ です。テスト処理は以下のようになっていました:
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ let s = "Some test string that fits on a single line";
+ println!("{}", s);
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+}
+```
+
+このテストでは、VGA バッファに文字列を出力したあと `buffer_chars` 配列を手動でひとつずつチェックしています。`println` 関数を実行したあと、表示された文字の読み取り処理を行うまでの間にタイマ割り込みハンドラが動作するかもしれず、このとき競合状態になります。ただ、これは危険な _データ競合_ ではないことに注意してください―― Rust はデータ競合をコンパイル時に完全に防ぐことができます。詳細は [_Rustonomicon_][nomicon-races] を参照してください。
+
+[nomicon-races]: https://doc.rust-lang.org/nomicon/races.html
+
+これを修正するため、タイマ割り込みハンドラがテストの途中で `.` を画面に出力できないように、テストが完了するまでの間は `WRITER` をロックし続ける必要があります。修正されたテストはこのようになります:
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts;
+
+ let s = "Some test string that fits on a single line";
+ interrupts::without_interrupts(|| {
+ let mut writer = WRITER.lock();
+ writeln!(writer, "\n{}", s).expect("writeln failed");
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+ });
+}
+```
+
+以下のような変更を行いました:
+
+- `lock()` メソッドを明示的に使い、テスト実行中はずっと writer をロックし続けるようにします。`println` の代わりに、既にロックされた writer に表示を行うことができる [`writeln`] マクロを使います。
+- 他のデッドロックを防ぐため、テスト実行中は割り込みを無効化します。そうでないと writer がロックされている間に割り込みが入ってきてしまうかもしれません。
+- テスト実行前にタイマ割り込みハンドラが実行される可能性は依然としてあるので、文字列 `s` を出力する前に追加で改行文字 `\n` を出力するようにします。これにより、タイマハンドラが現在の行に既に出力した `.` 文字によってテストが失敗するのを避けています。
+
+[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
+
+上記の変更によって、`cargo test` は再び必ず成功するようになります。
+
+これはテストが失敗するだけの無害な競合状態でした。想像できると思いますが、他の競合状態はその非決定的な性質のためずっとデバッグが大変になり得ます。幸運なことに Rust は、システムのクラッシュや無兆候でのメモリ破壊を含むあらゆる種類の未定義動作を引き起こす最も深刻なタイプの競合状態であるデータ競合から我々を守ってくれます。
+
+## `hlt` 命令
+
+これまで我々は、`_start` や `panic` 関数の末尾で単純なループ文を使ってきました。これはずっと CPU を回し続けるので、期待通りに動作します。しかしこれはなにも仕事がない場合でも CPU が全速力で動作し続けることになるので、とても非効率です。カーネルを動かしているときにタスクマネージャを見ればこの問題がすぐに確認できるでしょう: QEMU のプロセスは、常時 CPU 時間のほぼ 100% を必要とします。
+
+我々が本当にやりたいことは、次の割り込みが入るまで CPU を停止することです。これにより CPU はほとんど電力を使わないスリープ状態に入ることができます。[hlt 命令][`hlt` instruction]はまさにこれを行うものです。この命令を使ってエネルギー効率のいい無限ループを作ってみましょう:
+
+[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
+
+```rust
+// in src/lib.rs
+
+pub fn hlt_loop() -> ! {
+ loop {
+ x86_64::instructions::hlt();
+ }
+}
+```
+
+`instructions::hlt` 関数はアセンブリ命令の[薄いラッパ][thin wrapper]です。この命令はメモリ安全性を損なわないので unsafe ではありません。
+
+[thin wrapper]: https://github.com/rust-osdev/x86_64/blob/5e8e218381c5205f5777cb50da3ecac5d7e3b1ab/src/instructions/mod.rs#L16-L22
+
+これで `hlt_loop` を `_start` や `panic` 関数内の無限ループの代わりに使うことができます:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ […]
+
+ println!("It did not crash!");
+ blog_os::hlt_loop(); // new
+}
+
+
+#[cfg(not(test))]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ println!("{}", info);
+ blog_os::hlt_loop(); // new
+}
+
+```
+
+`lib.rs` も同様に更新しましょう:
+
+```rust
+// in src/lib.rs
+
+/// `cargo test` のエントリポイント
+#[cfg(test)]
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ init();
+ test_main();
+ hlt_loop(); // new
+}
+
+pub fn test_panic_handler(info: &PanicInfo) -> ! {
+ serial_println!("[failed]\n");
+ serial_println!("Error: {}\n", info);
+ exit_qemu(QemuExitCode::Failed);
+ hlt_loop(); // new
+}
+```
+
+QEMU でカーネルを動かすと、CPU 時間の消費が大幅に減っていることがわかります。
+
+## キーボード入力
+
+外部デバイスからの割り込みを扱うことができるようになったので、ついにキーボード入力へのサポートを追加することができます。これにより、我々は初めてカーネルと対話することができるようになります。
+
+
+
+[PS/2]: https://ja.wikipedia.org/wiki/PS/2%E3%82%B3%E3%83%8D%E3%82%AF%E3%82%BF
+
+ハードウェアタイマのように、キーボードコントローラは既にデフォルトで有効になっています。なのでキーを押すと、キーボードコントローラは PIC に割り込みを送り、CPU に転送されます。CPU は IDT の中からハンドラ関数を探しますが、対応するエントリは空です。よってダブルフォルトが発生します。
+
+ではキーボード割り込みへのハンドラ関数を追加しましょう。異なる割り込み番号を使うだけで、タイマ割り込み用のハンドラを定義した方法とほとんど同じです:
+
+```rust
+// in src/interrupts.rs
+
+#[derive(Debug, Clone, Copy)]
+#[repr(u8)]
+pub enum InterruptIndex {
+ Timer = PIC_1_OFFSET,
+ Keyboard, // new
+}
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ […]
+ // new
+ idt[InterruptIndex::Keyboard.as_usize()]
+ .set_handler_fn(keyboard_interrupt_handler);
+
+ idt
+ };
+}
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!("k");
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+[上述](#8259-pic)した図で見たように、キーボードはプライマリ PIC の1番目の線を使います。これはキーボード割り込みは33番(1 + オフセットの32)の割り込みとして CPU に届くということです。このインデックスを `Keyboard` というヴァリアントとして新たに `InterruptIndex` enum に追加します。enum ヴァリアントの値はデフォルトでは前の値に1を足したもの、すなわち33になるので、値を明示的に指定する必要はありません。割り込みハンドラでは、`k` の文字を表示して割り込みコントローラに EOI 信号を送ります。
+[上述](#8259-pic)した図で見たように、キーボードはプライマリ PIC の1番目の線を使います。これはキーボード割り込みは33番 (1 + オフセットの32) の割り込みとして CPU に届くということです。このインデックスを新たな `Keyboard` のヴァリアントとして `InterruptIndex` enum に追加します。enum ヴァリアントの値はデフォルトでは前の値に1を足したもの、すなわち33になるので、値を明示的に指定する必要はありません。割り込みハンドラでは、`k` の文字を表示して割り込みコントローラに EOI 信号を送ります。
+
+これでキーを押したときに画面上に `k` の文字が表示されます。しかしこれは最初のキー入力に対してしか動作しません。キーを押し続けたとしても、それ以上 `k` の文字が画面上に表示されることはありません。この理由は、我々が押されたキーの _スキャンコード_ と呼ばれる値を読み取らない限りは、キーボードコントローラは別の割り込みを送らないためです。
+
+### スキャンコードの読み取り
+
+_どの_ キーが押されたか知るためにはキーボードコントローラに問い合わせる必要があります。これは [I/O ポート][I/O port]の `0x60` に割り当てられた PS/2 コントローラのデータポートを読み取ることで行います:
+
+[I/O port]: @/edition-2/posts/04-testing/index.md#i-o-ports
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use x86_64::instructions::port::Port;
+
+ let mut port = Port::new(0x60);
+ let scancode: u8 = unsafe { port.read() };
+ print!("{}", scancode);
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+キーボードのデータポートから1バイトのデータを読み取るため、`x86_64` クレートに含まれる [`Port`] 型を使います。この1バイトは[スキャンコード][_scancode_]と呼ばれ、キーのプレス/リリースの状態を表します。今のところはスキャンコードを画面に表示する以外にはなにもしません:
+
+[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
+[_scancode_]: https://ja.wikipedia.org/wiki/%E3%82%B9%E3%82%AD%E3%83%A3%E3%83%B3%E3%82%B3%E3%83%BC%E3%83%89
+
+
+
+上の画像は、私がゆっくりと "123" とタイプしたときの様子です。隣り合うキーは隣り合うスキャンコードを持ち、キーを押したときと離したときのスキャンコードは異なることがわかります。ではスキャンコードを実際のキー操作に正確に変換するためにはどうしたらいいのでしょうか。
+
+### スキャンコードの解釈
+
+_スキャンコードセット_ と呼ばれるスキャンコードとキーのマッピングの標準は3つあります。3つのどれもが、 [IBM XT]、[IBM 3270 PC]、[IBM AT] という、初期の IBM コンピュータのキーボードにさかのぼります。幸運なことに、その後のコンピュータは新たなスキャンコードセットを定義するという流れには乗らず、既存のセットをエミュレートして拡張しました。現在では、多くのキーボードは3つのセットのどれでもエミュレートするよう設定できるようになっています。
+
+[IBM XT]: https://ja.wikipedia.org/wiki/IBM_PC_XT
+[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
+[IBM AT]: https://ja.wikipedia.org/wiki/PC/AT
+
+デフォルトでは、PS/2 キーボードはスキャンコードセット1 ("XT") をエミュレートします。このセットでは、スキャンコードの下位の7ビットでキーを表し、最上位の1ビットで押したか ("0") 離したか ("1") を表します。例えばエンターキーのような元の IBM XT のキーボードに存在しないキーに対しては、エスケープである `0xe0` とそのキーを表すバイトという連続した2つのスキャンコードを生成します。スキャンコードセット1の全てのスキャンコードと対応するキーについては [OSDev Wiki][scancode set 1] を確認してください。
+
+[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
+
+スキャンコードをキーに変換するために `match` 文を使います:
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use x86_64::instructions::port::Port;
+
+ let mut port = Port::new(0x60);
+ let scancode: u8 = unsafe { port.read() };
+
+ // new
+ let key = match scancode {
+ 0x02 => Some('1'),
+ 0x03 => Some('2'),
+ 0x04 => Some('3'),
+ 0x05 => Some('4'),
+ 0x06 => Some('5'),
+ 0x07 => Some('6'),
+ 0x08 => Some('7'),
+ 0x09 => Some('8'),
+ 0x0a => Some('9'),
+ 0x0b => Some('0'),
+ _ => None,
+ };
+ if let Some(key) = key {
+ print!("{}", key);
+ }
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+上記のコードは、0から9の数字キーが押された場合に変換を行い、それ以外のキーは無視します。全てのスキャンコードに対し、[match] 文を使って対応する文字か `None` を割り当てます。そのあと [`if let`] 構文を使ってオプション型の `key` から値を取り出します。パターン部分に `key` という同じ変数名を使うことでそれ以前の宣言を[シャドーイング][shadow]します。これは Rust において `Option` 型から値を取り出すときによく使うパターンです。
+
+[match]: https://doc.rust-lang.org/book/ch06-02-match.html
+[`if let`]: https://doc.rust-lang.org/book/ch18-01-all-the-places-for-patterns.html#conditional-if-let-expressions
+[shadow]: https://doc.rust-lang.org/book/ch03-01-variables-and-mutability.html#shadowing
+
+これで数字が表示できるようになりました:
+
+
+
+他の文字も同じように変換することができます。幸運なことに、スキャンコードセットの1と2のスキャンコードを変換するための [`pc-keyboard`] というクレートがありますので、これを自分で実装する必要はありません。このクレートを使うために `Cargo.toml` に以下を追加し、`lib.rs` でインポートしましょう:
+
+[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+pc-keyboard = "0.5.0"
+```
+
+これでこのクレートを使って `keyboard_interrupt_handler` を書き直すことができます:
+
+```rust
+// in/src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
+ use spin::Mutex;
+ use x86_64::instructions::port::Port;
+
+ lazy_static! {
+ static ref KEYBOARD: Mutex> =
+ Mutex::new(Keyboard::new(layouts::Us104Key, ScancodeSet1,
+ HandleControl::Ignore)
+ );
+ }
+
+ let mut keyboard = KEYBOARD.lock();
+ let mut port = Port::new(0x60);
+
+ let scancode: u8 = unsafe { port.read() };
+ if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
+ if let Some(key) = keyboard.process_keyevent(key_event) {
+ match key {
+ DecodedKey::Unicode(character) => print!("{}", character),
+ DecodedKey::RawKey(key) => print!("{:?}", key),
+ }
+ }
+ }
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+ミューテックスで保護された静的な [`Keyboard`] オブジェクトを作るために `lazy_static` マクロを使います。`Keyboard` は、レイアウトを US キーボードに、スキャンコードセットは1として初期化を行います。[`HandleControl`] パラメタは、`ctrl+[a-z]` を Unicode 文字の `U+0001` から `U+001A` にマッピングさせることができます。この機能は使いたくないので、`Ignore` オプションを使い `ctrl` キーを通常のキーと同様に扱います。
+
+[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
+
+各割り込みでは、ミューテックスをロックし、キーボードコントローラからスキャンコードを読み取り、それを読み取ったスキャンコードを `Option` に変換する [`add_byte`] メソッドに渡します。[`KeyEvent`] は、そのイベントを起こしたキーと、それが押されたのか離されたのかの情報を含んでいます。
+
+[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
+[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
+[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
+
+このキーイベントを解釈するために、変換可能であればキーイベントを文字に変換する [`process_keyevent`] メソッドにキーイベントを渡します。例えば `A` キーの押下イベントを、シフトキーが押されていたかによって小文字の `a` か大文字の `A` に変換します。
+
+[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
+
+修正した割り込みハンドラで、テキストが入力できるようになります:
+
+
+
+### キーボードの設定
+
+例えば使用するスキャンコードセットを変えるなど、PS/2 キーボードの一部の設定を変えることができます。もうこの記事は長くなりすぎたのでそれについて説明することはしませんが、OSDev Wiki に[設定コマンド][configuration commands]の概要が記載されています。
+
+[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
+
+## まとめ
+
+この記事では、外部割り込みを有効にする方法とそれを処理する方法について説明しました。8259 PIC とそのプライマリ/セカンダリレイアウト、割り込み番号をマッピングし直す方法、そして "end of interrupt" 信号について学びました。我々はハードウェアタイマとキーボード向けの割り込みハンドラを実装し、次の割り込みまで CPU を停止させる `hlt` 命令について学びました。
+
+これで我々はカーネルと対話することができるようになり、小さなシェルやシンプルなゲームを作るための基本的な構成要素を得ることができました。
+
+## 次は?
+
+タイマ割り込みは、定期的に動作中のプロセスに割り込み、制御をカーネルに戻す方法を提供するという意味で OS にとって必要不可欠なものです。この上でカーネルは別のプロセスに実行を切り替えることで、まるで複数のプロセスが並列に動いているように見せているのです。
+
+ただし、プロセスやスレッドを作る前に、それらにメモリを割り当てる方法が必要です。次の記事では、メモリ管理という基本的な構成要素を提供するため、メモリ管理について調査していきます。
diff --git a/blog/content/edition-2/posts/07-hardware-interrupts/index.ko.md b/blog/content/edition-2/posts/07-hardware-interrupts/index.ko.md
new file mode 100644
index 00000000..7bef3b59
--- /dev/null
+++ b/blog/content/edition-2/posts/07-hardware-interrupts/index.ko.md
@@ -0,0 +1,740 @@
++++
+title = "하드웨어 인터럽트"
+weight = 7
+path = "ko/hardware-interrupts"
+date = 2018-10-22
+
+[extra]
+chapter = "Interrupts"
+# Please update this when updating the translation
+translation_based_on_commit = "a108367d712ef97c28e8e4c1a22da4697ba6e6cd"
+# GitHub usernames of the people that translated this post
+translators = ["JOE1994"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["dalinaum"]
++++
+
+이 글에서는 프로그래밍 할 수 있는 인터럽트 컨트롤러가 인터럽트들을 CPU로 정확히 전달하도록 설정할 것입니다. 새로운 인터럽트들을 처리하기 위해 인터럽트 서술자 테이블 (interrupt descriptor table)에 새로운 엔트리들을 추가할 것입니다 (이전에 예외 처리 함수를 등록했듯이). 또한 일정 주기마다 타이머 인터럽트를 일으키는 방법 및 키보드 입력 받는 방법도 알아볼 것입니다.
+
+
+
+이 블로그는 [GitHub 저장소][GitHub]에서 오픈 소스로 개발되고 있으니, 문제나 문의사항이 있다면 저장소의 'Issue' 기능을 이용해 제보해주세요. [페이지 맨 아래][at the bottom]에 댓글을 남기실 수도 있습니다. 이 포스트와 관련된 모든 소스 코드는 저장소의 [`post-07 브랜치`][post branch]에서 확인하실 수 있습니다.
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-07
+
+
+
+## 개요
+
+CPU에 연결된 주변 장치들은 인터럽트를 통해 CPU에 알림을 보낼 수 있습니다. 그래서 커널이 주기적으로 키보드 입력이 들어왔는지 확인하게 하는 대신 (이를 [_폴링(polling)_][_polling_] 방식이라고 합니다), 키보드 입력이 들어올 때마다 키보드가 직접 커널에 알림을 보낼 수 있습니다. 이 방식을 사용하면 이벤트 발생 시에만 커널이 행동을 취하면 되므로 에너지 효율성이 더 좋습니다. 또한 이벤트가 발생 시 커널이 다음 poll까지 기다리지 않고 바로 반응할 수 있기에 이벤트에 대한 반응 속도도 더 빠릅니다.
+
+[_polling_]: https://en.wikipedia.org/wiki/Polling_(computer_science)
+
+하드웨어 장치들을 모두 CPU에 직접 연결하는 것은 불가능합니다. 대신 별도의 _인터럽트 컨트롤러 (interrupt controller)_ 가 주변 장치로부터 전송된 인터럽트들을 수합한 뒤 CPU에 알림을 보냅니다.
+
+```
+ ____________ _____
+ Timer ------------> | | | |
+ Keyboard ---------> | Interrupt |---------> | CPU |
+ Other Hardware ---> | Controller | |_____|
+ Etc. -------------> |____________|
+
+```
+
+대부분의 인터럽트 컨트롤러들은 프로그래밍을 통해 인터럽트마다 다른 우선순위 레벨을 배정하는 것이 가능합니다. 예를 들어, 키보드 인터럽트보다 타이머 인터럽트에 더 높은 우선순위 레벨을 배정하여 CPU에서 시간을 더 정확히 측정할 수 있습니다.
+
+예외와 달리 하드웨어 인터럽트는 _비동기적으로 (asynchronously)_ 일어납니다. 즉 CPU에서 실행 중인 코드와 별개로 인터럽트는 언제든 발생할 수 있다는 것입니다. 따라서, 커널에 인터럽트를 도입하면서 동시성(concurrency)의 형태가 등장하고 동시성 관련 버그 발생의 가능성도 생깁니다. Rust의 엄격한 소유권 (ownership) 모델이 전역 가변 변수 사용을 금지해 동시성 관련 버그 발생 가능성을 줄여주지만, 교착 상태(deadlock)를 막아주지는 못하며 이는 본문 아래에서 곧 확인하실 수 있습니다.
+
+## 8259 PIC
+
+[Intel 8259] 는 프로그래밍 가능한 인터럽트 컨트롤러 (PIC; Programmable Interrupt Controller)이며, 1976년에 처음 도입되었습니다. 이 장치는 오래전에 신형 장치 [APIC]로 대체됐지만, 이전 버전과의 호환성 유지를 위해 그 인터페이스만은 최신 시스템들도 지원하고 있습니다. 8259 PIC를 다루는 것이 APIC를 다루는 것보다 쉽습니다. 그렇기에 인터럽트에 대해 배우고 입문하는 현재 단계에서는 8259 PIC를 쓰고, 이 블로그 시리즈의 이후 글에서는 APIC로 교체하여 사용하겠습니다.
+
+[APIC]: https://en.wikipedia.org/wiki/Intel_APIC_Architecture
+
+Intel 8259 PIC는 8개의 인터럽트 통신선과 CPU와 통신하기 위한 몇 개의 통신선을 가집니다. 과거의 전형적인 PC 시스템은 8259 PIC를 2개 장착하고 있었는데 (주 PIC와 부 PIC), 주 PIC의 인터럽트 통신선 중 하나를 부 PIC에 연결했습니다.
+
+[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
+
+```
+ ____________ ____________
+Real Time Clock --> | | Timer -------------> | |
+ACPI -------------> | | Keyboard-----------> | | _____
+Available --------> | Secondary |----------------------> | Primary | | |
+Available --------> | Interrupt | Serial Port 2 -----> | Interrupt |---> | CPU |
+Mouse ------------> | Controller | Serial Port 1 -----> | Controller | |_____|
+Co-Processor -----> | | Parallel Port 2/3 -> | |
+Primary ATA ------> | | Floppy disk -------> | |
+Secondary ATA ----> |____________| Parallel Port 1----> |____________|
+
+```
+
+위 도표는 인터럽트 통신선을 배정하는 전형적인 방식을 보여줍니다. 15개의 선 중 대부분은 어떤 장치와 연결할지 이미 정해져 있습니다. 예를 들어, 부 PIC의 4번 통신선은 마우스에 연결됩니다.
+
+각 컨트롤러는 "command" 포트와 "data" 포트, 이 2개의 [입출력 포트][I/O ports]들을 사용해 설정합니다. 주 PIC는 `0x20`번 포트가 command 포트, `0x21`번 포트가 data 포트입니다. 부 PIC는 `0xa0`번 포트가 command 포트, `0xa1` 포트가 data 포트입니다. PIC를 설정하는 자세한 방법에 대해서는 [osdev.org의 글][article on osdev.org]을 찾아보시길 바랍니다.
+
+[I/O ports]: @/edition-2/posts/04-testing/index.md#i-o-ports
+[article on osdev.org]: https://wiki.osdev.org/8259_PIC
+
+### 구현
+
+위 PIC들의 기본 설정에서 PIC는 0-15 구간의 인터럽트 벡터 번호를 CPU에 전송합니다. IDT에서 이 구간의 인터럽트 벡터 번호들은 이미 CPU 예외들에 배정되어 있기에, PIC의 기본 설정을 그대로 사용하지 못합니다. 예를 들면 벡터 번호 8은 더블 폴트에 배정되어 있습니다. 벡터 번호가 중복되는 문제를 해결하려면 PIC가 전송하는 인터럽트들을 다른 벡터 번호에 재배정 해야 합니다. 기존 예외들의 벡터 번호와 겹치지 않는 이상 인터럽트들에 어떤 번호를 배정하는지는 크게 중요하지 않습니다만, 예외들에 배정된 첫 32개의 슬롯 다음 비는 32-47 구간의 벡터 번호를 고르는 것이 일반적입니다.
+
+PIC 장치의 command 포트 및 data 포트에 특수한 값을 쓰면 장치 설정을 변경할 수 있습니다. 운 좋게도 [`pic8259`] 크레이트 덕에 우리가 장치 설정 초기화/변경 로직을 직접 작성할 필요는 없습니다. 작동 원리가 궁금하시다면 해당 크레이트의 [소스 코드][pic crate source]를 직접 확인해보세요. 코드양이 많지 않고 문서화도 잘 되어 있습니다.
+
+[pic crate source]: https://docs.rs/crate/pic8259/0.10.1/source/src/lib.rs
+
+의존 크레이트로 해당 크레이트를 추가하기 위해 아래의 코드를 추가합니다.
+
+[`pic8259`]: https://docs.rs/pic8259/0.10.1/pic8259/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+pic8259 = "0.10.1"
+```
+
+이 크레이트의 [`ChainedPics`] 구조체는 위에서 봤던 주/부 PIC 연결 방식을 적절한 추상 레벨에서 표현합니다. 이 구조체는 아래처럼 사용하도록 설계되었습니다.
+
+[`ChainedPics`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html
+
+```rust
+// in src/interrupts.rs
+
+use pic8259::ChainedPics;
+use spin;
+
+pub const PIC_1_OFFSET: u8 = 32;
+pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
+
+pub static PICS: spin::Mutex =
+ spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
+```
+
+위에서 언급했듯이 PIC들이 사용할 벡터 번호의 오프셋을 32-47 구간에서 선택합니다. `ChainedPics` 구조체를 감싼 `Mutex`의 `lock` 함수를 통해 안전하게 값을 수정할 수 있는데, 이는 다음 단계에서 유용합니다. `ChainedPics::new` 함수에 잘못된 오프셋을 넘기면 undefined behavior가 일어날 수 있어 이 함수는 unsafe 함수로 정의되었습니다.
+
+[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
+
+이제 `init` 함수에서 8259 PIC 장치를 초기화할 수 있습니다.
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+ unsafe { interrupts::PICS.lock().initialize() }; // 새로 추가함
+}
+```
+
+[`initialize`] 함수를 사용해 PIC 장치를 초기화합니다. PIC 장치를 잘못 초기화하면 undefined behavior를 일으킬 수 있으므로, `ChainedPics::new` 함수와 마찬가지로 이 함수도 unsafe 함수로 정의되었습니다.
+
+[`initialize`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html#method.initialize
+
+추가한 코드에 문제가 없었다면, 다시 `cargo run`을 실행해도 예전처럼 "It did not crash"라는 메시지가 출력될 것입니다.
+
+## 인터럽트 활성화하기
+
+CPU 설정에서 인터럽트 사용이 해제되어 있었기에 아직 아무 일도 일어나지 않았습니다. 인터럽트 사용이 해제되어 있으면 CPU는 인터럽트 컨트롤러부터 오는 신호를 전혀 받지 않고, 따라서 어떤 인터럽트도 CPU에 도달할 수 없습니다. CPU 설정을 바꿔보겠습니다.
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+ unsafe { interrupts::PICS.lock().initialize() };
+ x86_64::instructions::interrupts::enable(); // 새로 추가함
+}
+```
+
+`x86_64` 크레이트의 `interrupts::enable` 함수는 `sti` 명령어 (“set interrupts”)를 실행해 외부 인터럽트를 사용하도록 설정합니다. 이제 `cargo run`을 실행하면 더블 폴트가 발생하는 것을 확인할 수 있습니다.
+
+
+
+더블 폴트가 발생하는 이유는, [Intel 8253] 장치에서 기본적으로 하드웨어 타이머를 사용하도록 설정이 되어 있고, CPU에서 인터럽트 사용을 활성화한 직후부터 타이머 인터럽트가 CPU로 전송되기 때문입니다. 우리가 아직 타이머 인터럽트 처리 함수를 정의하지 않았기 때문에 더블 폴트 처리 함수가 호출됩니다.
+
+[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
+
+## 타이머 인터럽트 처리하기
+
+[위 도표](#8259-pic)를 보면 타이머는 주 PIC의 0번 통신선을 사용합니다. 이는 즉 타이머 인터럽트가 CPU에 인터럽트 벡터 번호가 32 (0 + 오프셋 32)인 인터럽트로 전송된다는 것을 뜻합니다. 코드에 번호 32를 그대로 적지 않고 `InterruptIndex` enum에 저장합니다.
+
+```rust
+// in src/interrupts.rs
+
+#[derive(Debug, Clone, Copy)]
+#[repr(u8)]
+pub enum InterruptIndex {
+ Timer = PIC_1_OFFSET,
+}
+
+impl InterruptIndex {
+ fn as_u8(self) -> u8 {
+ self as u8
+ }
+
+ fn as_usize(self) -> usize {
+ usize::from(self.as_u8())
+ }
+}
+```
+
+[C언어의 enum][C-like enum]처럼 이 enum은 각 분류에 사용할 인덱스 값을 지정할 수 있습니다. `repr(u8)` 속성은 해당 enum을 `u8` 타입으로서 저장 및 표현되도록 합니다. 향후에 새로운 인터럽트들을 지원해야 할 때 이 enum에 새로운 분류를 추가할 것입니다.
+
+[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
+
+이제 타이머 인터럽트를 처리할 함수를 작성할 수 있습니다.
+
+```rust
+// in src/interrupts.rs
+
+use crate::print;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ […]
+ idt[InterruptIndex::Timer.as_usize()]
+ .set_handler_fn(timer_interrupt_handler); // 새로 추가함
+
+ idt
+ };
+}
+
+extern "x86-interrupt" fn timer_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!(".");
+}
+```
+
+`timer_interrupt_handler` 함수는 우리가 가진 다른 예외 처리 함수들과 같은 함수 원형을 가지는데, 그 이유는 CPU가 예외와 인터럽트에 같은 방식으로 대응하기 때문입니다 (유일한 차이점은 일부 예외들이 오류 코드를 추가로 push한다는 것). [`InterruptDescriptorTable`] 구조체는 [`IndexMut`] 트레이트를 구현해서 배열을 색인하는 것과 동일한 문법을 써서 테이블의 각 엔트리에 접근할 수 있습니다.
+
+[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
+
+우리가 작성한 타이머 인트럽트 처리 함수는 화면에 점을 출력합니다. 타이머 인터럽트는 주기적으로 발생하므로, 타이머 주기마다 화면에 새로운 점이 출력되기를 기대하는 것이 자연스럽습니다. 하지만 커널을 실행해 보면 화면에 점이 단 1개만 출력될 것입니다.
+
+
+
+### End of Interrupt
+
+점이 1개만 출력되는 이유는 PIC가 인터럽트 처리 함수로부터 명시적으로 “end of interrupt” (EOI) 신호가 전송되어 오기를 기다리기 때문입니다. 이 신호는 PIC에 해당 인터럽트가 처리되었으며 시스템이 다음 인터럽트를 받을 준비가 된 것을 알립니다. 신호를 받지 못한 PIC는 시스템이 아직 첫 타이머 인터럽트를 처리 중이라 생각하고 EOI 신호가 올 때까지 다음 인터럽트를 보내지 않고 기다리는 것입니다.
+
+static으로 선언된 `PICS` 구조체를 다시 사용해 EOI 신호를 보냅니다.
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn timer_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!(".");
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
+ }
+}
+```
+
+`notify_end_of_interrupt` 함수는 주 PIC와 부 PIC 중 누가 인터럽트를 보냈었는지 파악하고, 그 후 `command` 포트와 `data` 포트를 사용해 인터럽트를 전송했던 PIC로 EOI 신호를 보냅니다. 부 PIC가 인터럽트를 보냈었다면, 부 PIC가 주 PIC의 입력 통신선에 연결되어 있다 보니 두 PIC 모두 EOI 신호를 받게 됩니다.
+
+여기서 우리는 올바른 인터럽트 벡터 번호를 사용하도록 주의해야 합니다. 잘못된 번호를 쓰면, 아직 CPU로 전송하지 않은 중요한 인터럽트가 소실되거나 시스템이 아무 반응도 하지 않게 될 수 있습니다. 이런 이유로 `notify_end_of_interrupt` 함수가 `unsafe`로 선언된 것입니다.
+
+다시 `cargo run`을 실행하면 화면에 주기적으로 점이 찍히는 것을 확인할 수 있습니다.
+
+
+
+### 타이머 설정하기
+
+우리가 쓰는 하드웨어 타이머는 _Programmable Interval Timer_, 또는 줄여서 PIT라고 부릅니다. 이름에서 알 수 있듯이, 프로그래밍을 통해 인터럽트 사이 시간 간격을 조정할 수 있습니다. 곧 [APIC 타이머][APIC timer]로 교체해 사용할 것이기 때문에 PIT에 대해 자세히 다루지는 않겠습니다만, OSDev 위키에 [PIT를 설정하는 방법][configuring the PIT]에 대한 자세한 글이 있으니 참고하시기 바랍니다.
+
+[APIC timer]: https://wiki.osdev.org/APIC_timer
+[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
+
+## 교착 상태 (Deadlock)
+
+이제 우리의 커널에 동시성의 개념이 등장했습니다. 타이머 인터럽트는 비동기적으로 발생하기에 `_start` 함수 실행 중 언제든 발생할 수 있습니다. Rust의 소유권 (ownership) 시스템이 다양한 동시성 관련 버그를 컴파일 시간에 방지하지만, 교착 상태는 막지 못합니다. 스레드(thread)가 해제되지 않을 lock을 얻으려고 할 때 교착 상태가 일어나며, 해당 스레드는 영원히 대기 상태에 갇히게 됩니다.
+
+현재 우리의 커널에서 교착 상태를 일으킬 수 있습니다. 우리가 쓰는 `println` 매크로가 호출하는 `vga_buffer::_print` 함수는 스핀 락(spinlock)을 통해 [전역 변수 `WRITER`에 대한 lock을 잠급니다][vga spinlock].
+
+[vga spinlock]: @/edition-2/posts/03-vga-text-buffer/index.md#spinlocks
+
+```rust
+// in src/vga_buffer.rs
+
+[…]
+
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ WRITER.lock().write_fmt(args).unwrap();
+}
+```
+
+위 함수는 `WRITER`에 대한 lock을 잠그고 `write_fmt`를 호출하며, 위 함수의 반환 직전에 `WRITER`에 대한 lock을 암묵적으로 해제합니다. `WRITER`에 대한 lock이 잠긴 상태에서 인터럽트가 발생하고, 해당 인터럽트의 처리 함수가 화면에 뭔가 출력하려 한다고 가정해봅시다.
+
+| 시간 순서 | _start | 인터럽트 처리 함수 |
+| --------- | ------------------------- | ----------------------------------------------- |
+| 0 | `println!` 호출 | |
+| 1 | `print`가 `WRITER`를 잠금 | |
+| 2 | | **인터럽트 발생**, 인터럽트 처리 함수 실행 시작 |
+| 3 | | `println!` 호출 |
+| 4 | | `print`가 이미 잠긴 `WRITER`를 또 잠그려고 함 |
+| 5 | | `print`가 이미 잠긴 `WRITER`를 또 잠그려고 함 |
+| … | | … |
+| _never_ | _`WRITER` 잠금 해제_ |
+
+`WRITER`에 대한 lock이 잠겨 있으니, 인터럽트 처리 함수는 해당 lock이 풀릴 때까지 기다립니다. 하지만 `_start` 함수는 인터럽트 처리 함수가 반환한 후에 실행을 재개하기 때문에 lock이 풀리지 않습니다. 그 결과, 시스템 전체가 응답 불가 상태가 됩니다.
+
+### 교착 상태 일으키기
+
+`_start` 함수의 맨 마지막 loop 안에서 화면에 출력을 시도하면 쉽게 커널에 교착 상태를 일으킬 수 있습니다.
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ […]
+ loop {
+ use blog_os::print;
+ print!("-"); // 새로 추가함
+ }
+}
+```
+
+QEMU에서 실행하면 아래와 같은 출력을 얻게 됩니다.
+
+
+
+첫 타이머 인터럽트 발생 전까지는 제한된 수의 붙임표(`-`)가 출력됩니다. 첫 타이머 인터럽트 후, 타이머 인터럽트 처리 함수가 온점(`.`)을 출력하려다 교착 상태에 빠지고 시스템은 아무 반응을 하지 않습니다. 이것이 출력 내용에 온점이 전혀 없는 이유입니다.
+
+타이머 인터럽트가 비동기적으로 발생하다보니 커널을 실행할 때마다 출력되는 붙임표의 수가 다를 수 있습니다. 동시성 관련 버그들은 실행 결과가 이렇게 비결정론적(non-deterministic)인 경우가 많아 디버깅하기 쉽지 않습니다.
+
+### 교착 상태 방지하기
+
+`Mutex`가 잠긴 동안 인터럽트를 해제하면 교착 상태를 방지할 수 있습니다.
+
+```rust
+// in src/vga_buffer.rs
+
+/// Prints the given formatted string to the VGA text buffer
+/// through the global `WRITER` instance.
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts; // 새로 추가함
+
+ interrupts::without_interrupts(|| { // 새로 추가함
+ WRITER.lock().write_fmt(args).unwrap();
+ });
+}
+```
+
+[`without_interrupts`] 함수는 인자로 받은 [클로저(closure)][closure]를 인터럽트가 없는 환경에서 실행합니다. 이 함수를 통해 `Mutex`가 잠긴 동안 인터럽트가 발생하지 않게 보장합니다. 커널을 다시 실행하면 커널이 응답 불가 상태에 빠지지 않고 계속 실행되는 것을 확인할 수 있습니다. (화면 스크롤이 너무 빠르게 내려가다 보니 화면에 점이 출력되는 것을 확인하기 어려울 수 있습니다. `_start` 함수의 loop 안에 `for _ in 0..10000 {}`를 삽입하는 등의 방법으로 출력 속도를 늦춰 보세요.)
+
+[`without_interrupts`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/interrupts/fn.without_interrupts.html
+[closure]: https://doc.rust-lang.org/book/ch13-01-closures.html
+
+직렬 포트를 이용한 출력 함수 코드 역시 같은 방식으로 수정하여 교착 상태를 방지합니다.
+
+```rust
+// in src/serial.rs
+
+#[doc(hidden)]
+pub fn _print(args: ::core::fmt::Arguments) {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts; // 새로 추가함
+
+ interrupts::without_interrupts(|| { // 새로 추가함
+ SERIAL1
+ .lock()
+ .write_fmt(args)
+ .expect("Printing to serial failed");
+ });
+}
+```
+
+인터럽트를 해제하는 것이 일반적으로 사용할 해결 방식이 아니라는 것을 아셔야 합니다. 인터럽트를 해제하면 인터럽트가 최대로 많이 몰렸을 때 시스템이 인터럽트에 반응할 수 있는 시간 (worst-case interrupt latency)이 늦어집니다. 따라서 인터럽트를 해제하려면 아주 짧은 시간 동안만 해야 합니다.
+
+## 경쟁 상태 (Race Condition) 예방하기
+
+`cargo test`를 실행하면 테스트 `test_println_output`가 때때로 실패하는 것을 확인할 수 있습니다:
+
+```
+> cargo test --lib
+[…]
+Running 4 tests
+test_breakpoint_exception...[ok]
+test_println... [ok]
+test_println_many... [ok]
+test_println_output... [failed]
+
+Error: panicked at 'assertion failed: `(left == right)`
+ left: `'.'`,
+ right: `'S'`', src/vga_buffer.rs:205:9
+```
+
+이 테스트가 때때로 실패하는 것은 이 테스트와 우리가 작성한 타이머 처리 함수 간 _경쟁 상태 (race condition)_ 때문입니다. 예전에 작성했던 이 테스트의 코드를 다시 살펴보겠습니다.
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ let s = "Some test string that fits on a single line";
+ println!("{}", s);
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+}
+```
+
+이 테스트는 VGA 버퍼에 문자열에 출력한 후 `buffer_chars` 배열을 직접 순회하여 출력된 내용을 확인합니다. 경쟁 상태가 생기는 이유는, `println`과 `screen_char`를 읽는 코드 사이에 타이머 인터럽트 처리 함수가 호출될 수 있기 때문입니다. 이는 컴파일 시간에 Rust가 막아주는 위험한 _데이터 레이스 (data race)_ 와는 다릅니다. 자세한 내용은 [_Rustonomicon_][nomicon-races]을 참고해주세요.
+
+[nomicon-races]: https://doc.rust-lang.org/nomicon/races.html
+
+이 문제를 고치려면 위 테스트가 실행 중에 `WRITER`에 대한 lock을 계속 잠그고 있어야 합니다. 그렇게 해야 타이머 처리 함수가 그 사이에 `.`을 출력하지 못합니다. 아래와 같이 테스트를 수정합니다.
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts;
+
+ let s = "Some test string that fits on a single line";
+ interrupts::without_interrupts(|| {
+ let mut writer = WRITER.lock();
+ writeln!(writer, "\n{}", s).expect("writeln failed");
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+ });
+}
+```
+
+변경 사항들을 정리하면 아래와 같습니다.
+
+- 테스트 실행 중에는 `lock()` 함수를 사용해 WRITER를 잠가 놓습니다. `println` 대신 [`writeln`] 매크로를 써서 이미 잠긴 WRITER를 이용해 메시지를 출력합니다.
+- 또 다른 교착 상태를 피하려고 테스트 중에는 인터럽트의 사용을 해제합니다. 그렇게 하지 않으면 테스트 실행 중 WRITER가 잠긴 상태에서 발생한 다른 인터럽트가 테스트 실행을 방해할 수 있습니다.
+- 테스트 실행 시작 전에 타이머 인터럽트 처리 함수가 실행될 수 있으니 문자열 `s` 출력 전에 개행 문자 `\n`을 출력합니다. 이렇게 하면 타이머 인터럽트 처리 함수가 현재 행에 이미 `.` 문자를 여럿 출력했더라도 이 테스트가 실패하지 않을 것입니다.
+
+[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
+
+이제 다시 `cargo test`를 실행하면 항상 성공하는 것을 확인하실 수 있습니다.
+
+위에서 다룬 경쟁 상태 (race condition)는 테스트 실패를 일으키는 것 외에 큰 해를 끼치지는 않았습니다. 하지만 비결정론적인 결과를 낳는다는 본질적인 특성 때문에 이보다 디버깅하기 더 까다로운 경쟁 상태 역시 존재할 수 있습니다. 데이터 레이스(data race)라는 가장 위험한 종류의 경쟁 상태는 시스템 크래시나 메모리 커럽션 (memory corruption) 등 온갖 undefined behavior를 일으킬 수 있지만, 다행히 Rust가 우리를 데이터 레이스로부터 지켜줍니다.
+
+## `hlt` 명령어
+
+여태까지는 `_start` 및 `panic` 함수들의 맨 마지막에 간단한 빈 loop를 사용했습니다. 이 loop 때문에 CPU는 실행을 종료하지 않는데, CPU가 딱히 할 일이 없는데 CPU를 최고 속도로 가동하는 것은 에너지 효율성 측면에서 매우 비효율적입니다. 커널 실행 후 태스크 매니저를 보시면 QEMU 프로세스가 항상 CPU 시간을 100% 가까이 사용하고 있을 것입니다.
+
+우리가 정말 해야 할 일은 다음 인터럽트 전까지 CPU가 정지하도록 하는 것입니다. CPU는 저전력 상태의 대기 모드에서 실행을 정지하고 대기할 수 있습니다. `hlt` 명령어를 쓰면 CPU가 저전력 대기 상태에 들어가게 할 수 있습니다. 이 명령어를 사용해 에너지를 효율적으로 사용하는 무한 루프를 작성합니다.
+
+[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
+
+```rust
+// in src/lib.rs
+
+pub fn hlt_loop() -> ! {
+ loop {
+ x86_64::instructions::hlt();
+ }
+}
+```
+
+함수 `instructions::hlt`는 그저 hlt 어셈블리 명령어를 [얇게 감싸 포장][thin wrapper]합니다. 이 명령어로는 메모리 안전성을 해칠 방법이 없어 안전합니다.
+
+[thin wrapper]: https://github.com/rust-osdev/x86_64/blob/5e8e218381c5205f5777cb50da3ecac5d7e3b1ab/src/instructions/mod.rs#L16-L22
+
+`_start` 및 `panic` 함수에서 사용하던 무한 루프를 방금 작성한 `hlt_loop`로 교체합니다.
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ […]
+
+ println!("It did not crash!");
+ blog_os::hlt_loop(); // 새로 추가함
+}
+
+
+#[cfg(not(test))]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ println!("{}", info);
+ blog_os::hlt_loop(); // 새로 추가함
+}
+
+```
+
+`lib.rs` 또한 마찬가지로 수정합니다.
+
+```rust
+// in src/lib.rs
+
+/// `cargo test`의 실행 시작 지점
+#[cfg(test)]
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ init();
+ test_main();
+ hlt_loop(); // 새로 추가함
+}
+
+pub fn test_panic_handler(info: &PanicInfo) -> ! {
+ serial_println!("[failed]\n");
+ serial_println!("Error: {}\n", info);
+ exit_qemu(QemuExitCode::Failed);
+ hlt_loop(); // 새로 추가함
+}
+```
+
+이제 QEMU에서 커널을 실행하면 CPU 사용량이 훨씬 감소한 것을 확인할 수 있습니다.
+
+## 키보드 입력
+
+외부 장치로부터 오는 인터럽트를 커널에서 처리할 수 있게 되었으니, 이제 드디어 커널이 키보드 입력을 지원하도록 만들 차례입니다. 키보드 입력을 지원함으로써 커널과 상호작용할 수 있게 될 것입니다.
+
+
+
+[PS/2]: https://en.wikipedia.org/wiki/PS/2_port
+
+하드웨어 타이머와 마찬가지로, 키보드 컨트롤러의 인터럽트도 기본적으로 사용이 활성화되어 있습니다. 키보드 키를 누르면 키보드 컨트롤러는 PIC로 인터럽트를 보내고, PIC는 다시 그 인터럽트를 CPU로 전달합니다. CPU는 IDT에서 키보드 인터럽트의 엔트리를 조회하지만, 등록된 인터럽트 처리 함수가 없어 더블 폴트가 발생합니다.
+
+키보드 인터럽트를 처리하는 함수를 추가합니다. 다른 인터럽트 번호를 사용한다는 점을 빼면, 이전에 타이머 인터럽트 처리 함수를 작성했던 것과 매우 유사합니다.
+
+```rust
+// in src/interrupts.rs
+
+#[derive(Debug, Clone, Copy)]
+#[repr(u8)]
+pub enum InterruptIndex {
+ Timer = PIC_1_OFFSET,
+ Keyboard, // 새로 추가함
+}
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ […]
+ // 새로 추가함
+ idt[InterruptIndex::Keyboard.as_usize()]
+ .set_handler_fn(keyboard_interrupt_handler);
+
+ idt
+ };
+}
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!("k");
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+[위 도표](#8259-pic)를 보면 키보드는 주 PIC의 1번 통신선을 사용합니다. 즉 CPU에 전달된 키보드 인터럽트의 벡터 번호는 33 (1 + 오프셋 32)이 됩니다. 해당 번호를 `InterruptIndex` enum의 새 분류 `Keyboard`에 배정합니다. `Keyboard`의 값을 명시적으로 정해주지 않아도 바로 이전 분류의 값에 1을 더한 값(=33)이 배정됩니다. 인터럽트 처리 함수는 `k`를 출력한 후 인터럽트 컨트롤러에 EOI 신호를 전송합니다.
+
+이제 아무 키를 하나 입력하면 화면에 `k`가 출력됩니다. 하지만 아무 키를 하나 새로 입력하면 화면에 `k`가 새로 출력되지 않습니다. 그 이유는 기존에 입력된 키의 _스캔 코드 (scancode)_ 를 우리가 읽어 가지 않는 한 키보드 컨트롤러가 새 인터럽트를 보내지 않기 때문입니다.
+
+### 스캔 코드 읽기
+
+_어떤_ 키가 입력됐는지 확인하려면 키보드 컨트롤러에 저장된 정보를 확인해야 합니다. PS/2 컨트롤러의 데이터 포트, 즉 `0x60`번 [입출력 포트 (I/O port)][I/O port]를 읽어 들여 어떤 키가 입력됐는지 확인할 수 있습니다.
+
+[I/O port]: @/edition-2/posts/04-testing/index.md#i-o-ports
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use x86_64::instructions::port::Port;
+
+ let mut port = Port::new(0x60);
+ let scancode: u8 = unsafe { port.read() };
+ print!("{}", scancode);
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+`x86_64` 크레이트의 [`Port`] 타입을 사용해 키보드의 데이터 포트로부터 1바이트를 읽어옵니다. 이 1바이트의 데이터를 [_스캔 코드 (scancode)_][_scancode_]라고 부르며, 누른 키 또는 누른 상태에서 뗀 키의 정보를 가집니다. 일단은 스캔 코드를 출력하기만 할 뿐, 읽은 스캔 코드 값을 이용한 작업은 하지 않습니다.
+
+[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
+[_scancode_]: https://en.wikipedia.org/wiki/Scancode
+
+
+
+위 이미지는 제가 키보드로 천천히 "123"을 입력했을 때의 화면을 보여줍니다. 이를 통해 인접한 키들은 인접한 값의 스캔 코드를 가진다는 것, 그리고 키를 누를 때와 누른 키를 뗄 때 서로 다른 스캔 코드가 발생한다는 것을 알 수 있습니다. 근데 각 스캔 코드는 실제 키 누름/뗌에 어떤 기준으로 배정된 것일까요?
+
+### 스캔 코드 해석하기
+스캔 코드를 키보드 키에 배정하는 표준을 _스캔코드 셋 (scancode set)_ 이라 부르며, 서로 다른 3가지 표준이 존재합니다. 셋 모두 초기의 IBM 컴퓨터들 ([IBM XT], [IBM 3270 PC], [IBM AT])로부터 기원합니다. 이후의 컴퓨터들은 새로운 스캔코드 셋을 정의하는 대신 기존의 것들을 지원하거나 확장해 사용했습니다. 오늘날 대부분의 키보드는 에뮬레이팅을 통해 이 3가지 셋 중 어느 것이든 사용할 수 있습니다.
+
+[IBM XT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer_XT
+[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
+[IBM AT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer/AT
+
+PS/2 키보드는 기본적으로 1번 스캔 코드 셋 ("XT")를 사용하게 되어 있습니다. 이 셋에서 스캔 코드의 하위 7비트는 입력된 키를 표현하고, 최상위 비트는 키를 누른 것인지 ("0") 혹은 키에서 손을 뗀 것인지 ("1") 표현합니다. 엔터 키처럼 [IBM XT] 키보드에 없었던 키들은 2개의 스캔 코드 (`0xe0` 그리고 그 후 키를 나타내는 1바이트)를 연이어 생성합니다. [OSDev Wiki][scancode set 1]를 보시면 1번 스캔코드 셋의 모든 스캔 코드와 그에 대응하는 키를 확인하실 수 있습니다.
+
+[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
+
+`match`문을 사용해 스캔 코드를 알맞는 키에 대응시켜 해석합니다.
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use x86_64::instructions::port::Port;
+
+ let mut port = Port::new(0x60);
+ let scancode: u8 = unsafe { port.read() };
+
+ // 새로 추가함
+ let key = match scancode {
+ 0x02 => Some('1'),
+ 0x03 => Some('2'),
+ 0x04 => Some('3'),
+ 0x05 => Some('4'),
+ 0x06 => Some('5'),
+ 0x07 => Some('6'),
+ 0x08 => Some('7'),
+ 0x09 => Some('8'),
+ 0x0a => Some('9'),
+ 0x0b => Some('0'),
+ _ => None,
+ };
+ if let Some(key) = key {
+ print!("{}", key);
+ }
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+위 코드는 0-9의 숫자 키 누름을 인식하고 출력하며, 다른 키는 무시합니다. [match]문을 사용해 각 스캔코드에 문자 또는 `None`을 배정합니다. 그 후 [`if let`]을 사용해 스캔 코드에 배정된 문자 `key`를 추출합니다. 이미 존재하던 변수 `key`와 같은 이름을 패턴에서 사용해 기존 변수의 정의를 [shadow]하는데, 이는 Rust에서 `Option` 타입 안의 값을 추출할 때 자주 사용되는 방식입니다.
+
+[match]: https://doc.rust-lang.org/book/ch06-02-match.html
+[`if let`]: https://doc.rust-lang.org/book/ch18-01-all-the-places-for-patterns.html#conditional-if-let-expressions
+[shadow]: https://doc.rust-lang.org/book/ch03-01-variables-and-mutability.html#shadowing
+
+이제 키보드로 숫자를 입력할 수 있습니다.
+
+
+
+나머지 키를 인식하는 것도 위와 마찬가지 방법으로 진행하면 됩니다. 다행히도, [`pc-keyboard`] 크레이트가 1번/2번 스캔코드 셋을 해석하는 기능을 제공합니다. `Cargo.toml`에 이 크레이트를 추가하고 `lib.rs`에서 불러와 사용합니다.
+
+[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+pc-keyboard = "0.5.0"
+```
+
+`pc-keyboard` 크레이트를 사용해 `keyboard_interrupt_handler` 함수를 새로 작성합니다.
+
+```rust
+// in/src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
+ use spin::Mutex;
+ use x86_64::instructions::port::Port;
+
+ lazy_static! {
+ static ref KEYBOARD: Mutex> =
+ Mutex::new(Keyboard::new(layouts::Us104Key, ScancodeSet1,
+ HandleControl::Ignore)
+ );
+ }
+
+ let mut keyboard = KEYBOARD.lock();
+ let mut port = Port::new(0x60);
+
+ let scancode: u8 = unsafe { port.read() };
+ if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
+ if let Some(key) = keyboard.process_keyevent(key_event) {
+ match key {
+ DecodedKey::Unicode(character) => print!("{}", character),
+ DecodedKey::RawKey(key) => print!("{:?}", key),
+ }
+ }
+ }
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+`lazy_static` 매크로를 사용해 Mutex로 감싼 [`Keyboard`] 타입의 static 오브젝트를 얻습니다. `Keyboard`가 미국 키보드 레이아웃과 1번 스캔코드 셋을 사용하도록 초기화합니다. [`HandleControl`] 매개변수를 사용하면 `ctrl+[a-z]` 키 입력을 유니코드 `U+0001`에서 `U+001A`까지 값에 대응시킬 수 있습니다. 우리는 그렇게 하지 않기 위해 해당 매개변수에 `Ignore` 옵션을 주고 `ctrl` 키를 일반 키로서 취급합니다.
+
+[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
+
+인터럽트마다 우리는 Mutex를 잠그고 키보드 컨트롤러로부터 스캔 코드를 읽어온 후, 그 스캔 코드를 [`add_byte`] 함수에 전달합니다. 이 함수는 스캔 코드를 `Option`으로 변환합니다. [`KeyEvent`] 타입은 입력된 키의 정보와 키의 누름/뗌 정보를 저장합니다.
+
+[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
+[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
+[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
+
+[`process_keyevent`] 함수가 인자로 받은 `KeyEvent`를 변환하여 입력된 키의 문자를 반환합니다 (변환 불가한 경우 `None` 반환). 예를 들어, `A`키 입력 시 shift키 입력 여부에 따라 소문자 `a` 또는 대문자 `A`를 얻습니다.
+
+[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
+
+수정한 인터럽트 처리 함수를 통해 텍스트를 입력한 대로 화면에 출력할 수 있습니다.
+
+
+
+### 키보드 설정하기
+
+PS/2 키보드의 일부 설정을 변경하는 것이 가능한데, 예를 들면 어떤 스캔 코드 집합을 사용할지 지정할 수 있습니다. 본문이 너무 길어지니 해당 내용까지 다루지는 않겠지만, OSDev 위키를 확인하시면 [키보드 설정을 변경할 때 사용할 수 있는 명령어][configuration commands]들의 목록을 보실 수 있습니다.
+
+[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
+
+## 정리
+
+이 글에서는 인터럽트를 활성화하고 외부 인터럽트를 처리하는 방법에 대해 설명했습니다. 우리는 8259 PIC 장치, 주 PIC와 부 PIC를 연결하는 방식, 인터럽트 번호를 재배정하는 방법, 그리고 "end of interrupt" 신호 등에 대해 배웠습니다. 우리는 하드웨어 타이머와 키보드의 인터럽트 처리 함수를 구현했고, CPU를 다음 인터럽트까지 멈추는 `hlt` 명령어에 대해 배웠습니다.
+
+이제 커널과 상호작용할 수 있게 되었으니, 간단한 커맨드 쉘이나 게임을 작성할 기본적인 도구를 갖춘 셈입니다.
+
+## 다음 단계는 무엇일까요?
+
+운영체제에서 타이머 인터럽트는 필수적인 존재입니다. 그 이유는 타이머 인터럽트를 사용해 주기적으로 실행 중인 프로세스를 멈추고 커널로 제어 흐름을 가져올 수 있기 때문입니다. 그 후 커널은 다른 프로세스를 실행시킬 수 있고, 여러 프로세스가 동시에 실행 중인 듯한 사용자 경험을 제공할 수 있습니다.
+
+프로세스나 스레드를 만들려면 우선 그들이 사용할 메모리를 할당할 방법이 필요합니다. 다음 몇 글들에서는 메모리 할당 기능을 제공하기 위한 메모리 관리 (memory management)에 대해 알아보겠습니다.
diff --git a/blog/content/edition-2/posts/07-hardware-interrupts/index.md b/blog/content/edition-2/posts/07-hardware-interrupts/index.md
index bc0aa50a..7548a13e 100644
--- a/blog/content/edition-2/posts/07-hardware-interrupts/index.md
+++ b/blog/content/edition-2/posts/07-hardware-interrupts/index.md
@@ -8,7 +8,7 @@ date = 2018-10-22
chapter = "Interrupts"
+++
-In this post we set up the programmable interrupt controller to correctly forward hardware interrupts to the CPU. To handle these interrupts we add new entries to our interrupt descriptor table, just like we did for our exception handlers. We will learn how to get periodic timer interrupts and how to get input from the keyboard.
+In this post, we set up the programmable interrupt controller to correctly forward hardware interrupts to the CPU. To handle these interrupts, we add new entries to our interrupt descriptor table, just like we did for our exception handlers. We will learn how to get periodic timer interrupts and how to get input from the keyboard.
@@ -23,7 +23,7 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
## Overview
-Interrupts provide a way to notify the CPU from attached hardware devices. So instead of letting the kernel periodically check the keyboard for new characters (a process called [_polling_]), the keyboard can notify the kernel of each keypress. This is much more efficient because the kernel only needs to act when something happened. It also allows faster reaction times, since the kernel can react immediately and not only at the next poll.
+Interrupts provide a way to notify the CPU from attached hardware devices. So instead of letting the kernel periodically check the keyboard for new characters (a process called [_polling_]), the keyboard can notify the kernel of each keypress. This is much more efficient because the kernel only needs to act when something happened. It also allows faster reaction times since the kernel can react immediately and not only at the next poll.
[_polling_]: https://en.wikipedia.org/wiki/Polling_(computer_science)
@@ -38,9 +38,9 @@ Connecting all hardware devices directly to the CPU is not possible. Instead, a
```
-Most interrupt controllers are programmable, which means that they support different priority levels for interrupts. For example, this allows to give timer interrupts a higher priority than keyboard interrupts to ensure accurate timekeeping.
+Most interrupt controllers are programmable, which means they support different priority levels for interrupts. For example, this allows to give timer interrupts a higher priority than keyboard interrupts to ensure accurate timekeeping.
-Unlike exceptions, hardware interrupts occur _asynchronously_. This means that they are completely independent from the executed code and can occur at any time. Thus we suddenly have a form of concurrency in our kernel with all the potential concurrency-related bugs. Rust's strict ownership model helps us here because it forbids mutable global state. However, deadlocks are still possible, as we will see later in this post.
+Unlike exceptions, hardware interrupts occur _asynchronously_. This means they are completely independent from the executed code and can occur at any time. Thus, we suddenly have a form of concurrency in our kernel with all the potential concurrency-related bugs. Rust's strict ownership model helps us here because it forbids mutable global state. However, deadlocks are still possible, as we will see later in this post.
## The 8259 PIC
@@ -48,7 +48,7 @@ The [Intel 8259] is a programmable interrupt controller (PIC) introduced in 1976
[APIC]: https://en.wikipedia.org/wiki/Intel_APIC_Architecture
-The 8259 has 8 interrupt lines and several lines for communicating with the CPU. The typical systems back then were equipped with two instances of the 8259 PIC, one primary and one secondary PIC connected to one of the interrupt lines of the primary:
+The 8259 has eight interrupt lines and several lines for communicating with the CPU. The typical systems back then were equipped with two instances of the 8259 PIC, one primary and one secondary PIC, connected to one of the interrupt lines of the primary:
[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
@@ -65,22 +65,22 @@ Secondary ATA ----> |____________| Parallel Port 1----> |____________|
```
-This graphic shows the typical assignment of interrupt lines. We see that most of the 15 lines have a fixed mapping, e.g. line 4 of the secondary PIC is assigned to the mouse.
+This graphic shows the typical assignment of interrupt lines. We see that most of the 15 lines have a fixed mapping, e.g., line 4 of the secondary PIC is assigned to the mouse.
-Each controller can be configured through two [I/O ports], one “command” port and one “data” port. For the primary controller these ports are `0x20` (command) and `0x21` (data). For the secondary controller they are `0xa0` (command) and `0xa1` (data). For more information on how the PICs can be configured see the [article on osdev.org].
+Each controller can be configured through two [I/O ports], one “command” port and one “data” port. For the primary controller, these ports are `0x20` (command) and `0x21` (data). For the secondary controller, they are `0xa0` (command) and `0xa1` (data). For more information on how the PICs can be configured, see the [article on osdev.org].
[I/O ports]: @/edition-2/posts/04-testing/index.md#i-o-ports
[article on osdev.org]: https://wiki.osdev.org/8259_PIC
### Implementation
-The default configuration of the PICs is not usable, because it sends interrupt vector numbers in the range 0–15 to the CPU. These numbers are already occupied by CPU exceptions, for example number 8 corresponds to a double fault. To fix this overlapping issue, we need to remap the PIC interrupts to different numbers. The actual range doesn't matter as long as it does not overlap with the exceptions, but typically the range 32–47 is chosen, because these are the first free numbers after the 32 exception slots.
+The default configuration of the PICs is not usable because it sends interrupt vector numbers in the range of 0–15 to the CPU. These numbers are already occupied by CPU exceptions. For example, number 8 corresponds to a double fault. To fix this overlapping issue, we need to remap the PIC interrupts to different numbers. The actual range doesn't matter as long as it does not overlap with the exceptions, but typically the range of 32–47 is chosen, because these are the first free numbers after the 32 exception slots.
-The configuration happens by writing special values to the command and data ports of the PICs. Fortunately there is already a crate called [`pic8259`], so we don't need to write the initialization sequence ourselves. In case you are interested how it works, check out [its source code][pic crate source], it's fairly small and well documented.
+The configuration happens by writing special values to the command and data ports of the PICs. Fortunately, there is already a crate called [`pic8259`], so we don't need to write the initialization sequence ourselves. However, if you are interested in how it works, check out [its source code][pic crate source]. It's fairly small and well documented.
[pic crate source]: https://docs.rs/crate/pic8259/0.10.1/source/src/lib.rs
-To add the crate as dependency, we add the following to our project:
+To add the crate as a dependency, we add the following to our project:
[`pic8259`]: https://docs.rs/pic8259/0.10.1/pic8259/
@@ -108,7 +108,7 @@ pub static PICS: spin::Mutex =
spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
```
-We're setting the offsets for the pics to the range 32–47 as we noted above. By wrapping the `ChainedPics` struct in a `Mutex` we are able to get safe mutable access (through the [`lock` method][spin mutex lock]), which we need in the next step. The `ChainedPics::new` function is unsafe because wrong offsets could cause undefined behavior.
+As noted above, we're setting the offsets for the PICs to the range 32–47. By wrapping the `ChainedPics` struct in a `Mutex`, we can get safe mutable access (through the [`lock` method][spin mutex lock]), which we need in the next step. The `ChainedPics::new` function is unsafe because wrong offsets could cause undefined behavior.
[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
@@ -128,11 +128,11 @@ We use the [`initialize`] function to perform the PIC initialization. Like the `
[`initialize`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html#method.initialize
-If all goes well we should continue to see the "It did not crash" message when executing `cargo run`.
+If all goes well, we should continue to see the "It did not crash" message when executing `cargo run`.
## Enabling Interrupts
-Until now nothing happened because interrupts are still disabled in the CPU configuration. This means that the CPU does not listen to the interrupt controller at all, so no interrupts can reach the CPU. Let's change that:
+Until now, nothing happened because interrupts are still disabled in the CPU configuration. This means that the CPU does not listen to the interrupt controller at all, so no interrupts can reach the CPU. Let's change that:
```rust
// in src/lib.rs
@@ -149,7 +149,7 @@ The `interrupts::enable` function of the `x86_64` crate executes the special `st

-The reason for this double fault is that the hardware timer (the [Intel 8253] to be exact) is enabled by default, so we start receiving timer interrupts as soon as we enable interrupts. Since we didn't define a handler function for it yet, our double fault handler is invoked.
+The reason for this double fault is that the hardware timer (the [Intel 8253], to be exact) is enabled by default, so we start receiving timer interrupts as soon as we enable interrupts. Since we didn't define a handler function for it yet, our double fault handler is invoked.
[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
@@ -177,7 +177,7 @@ impl InterruptIndex {
}
```
-The enum is a [C-like enum] so that we can directly specify the index for each variant. The `repr(u8)` attribute specifies that each variant is represented as an `u8`. We will add more variants for other interrupts in the future.
+The enum is a [C-like enum] so that we can directly specify the index for each variant. The `repr(u8)` attribute specifies that each variant is represented as a `u8`. We will add more variants for other interrupts in the future.
[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
@@ -212,7 +212,7 @@ Our `timer_interrupt_handler` has the same signature as our exception handlers,
[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
-In our timer interrupt handler, we print a dot to the screen. As the timer interrupt happens periodically, we would expect to see a dot appearing on each timer tick. However, when we run it we see that only a single dot is printed:
+In our timer interrupt handler, we print a dot to the screen. As the timer interrupt happens periodically, we would expect to see a dot appearing on each timer tick. However, when we run it, we see that only a single dot is printed:

@@ -237,7 +237,7 @@ extern "x86-interrupt" fn timer_interrupt_handler(
}
```
-The `notify_end_of_interrupt` figures out whether the primary or secondary PIC sent the interrupt and then uses the `command` and `data` ports to send an EOI signal to respective controllers. If the secondary PIC sent the interrupt both PICs need to be notified because the secondary PIC is connected to an input line of the primary PIC.
+The `notify_end_of_interrupt` figures out whether the primary or secondary PIC sent the interrupt and then uses the `command` and `data` ports to send an EOI signal to the respective controllers. If the secondary PIC sent the interrupt, both PICs need to be notified because the secondary PIC is connected to an input line of the primary PIC.
We need to be careful to use the correct interrupt vector number, otherwise we could accidentally delete an important unsent interrupt or cause our system to hang. This is the reason that the function is unsafe.
@@ -247,14 +247,14 @@ When we now execute `cargo run` we see dots periodically appearing on the screen
### Configuring the Timer
-The hardware timer that we use is called the _Programmable Interval Timer_ or PIT for short. Like the name says, it is possible to configure the interval between two interrupts. We won't go into details here because we will switch to the [APIC timer] soon, but the OSDev wiki has an extensive article about the [configuring the PIT].
+The hardware timer that we use is called the _Programmable Interval Timer_, or PIT, for short. Like the name says, it is possible to configure the interval between two interrupts. We won't go into details here because we will switch to the [APIC timer] soon, but the OSDev wiki has an extensive article about the [configuring the PIT].
[APIC timer]: https://wiki.osdev.org/APIC_timer
[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
## Deadlocks
-We now have a form of concurrency in our kernel: The timer interrupts occur asynchronously, so they can interrupt our `_start` function at any time. Fortunately Rust's ownership system prevents many types of concurrency related bugs at compile time. One notable exception are deadlocks. Deadlocks occur if a thread tries to acquire a lock that will never become free. Thus the thread hangs indefinitely.
+We now have a form of concurrency in our kernel: The timer interrupts occur asynchronously, so they can interrupt our `_start` function at any time. Fortunately, Rust's ownership system prevents many types of concurrency-related bugs at compile time. One notable exception is deadlocks. Deadlocks occur if a thread tries to acquire a lock that will never become free. Thus, the thread hangs indefinitely.
We can already provoke a deadlock in our kernel. Remember, our `println` macro calls the `vga_buffer::_print` function, which [locks a global `WRITER`][vga spinlock] using a spinlock:
@@ -285,7 +285,7 @@ Timestep | _start | interrupt_handler
… | | …
_never_ | _unlock `WRITER`_ |
-The `WRITER` is locked, so the interrupt handler waits until it becomes free. But this never happens, because the `_start` function only continues to run after the interrupt handler returns. Thus the complete system hangs.
+The `WRITER` is locked, so the interrupt handler waits until it becomes free. But this never happens, because the `_start` function only continues to run after the interrupt handler returns. Thus, the entire system hangs.
### Provoking a Deadlock
@@ -304,13 +304,13 @@ pub extern "C" fn _start() -> ! {
}
```
-When we run it in QEMU we get output of the form:
+When we run it in QEMU, we get an output of the form:

-We see that only a limited number of hyphens is printed, until the first timer interrupt occurs. Then the system hangs because the timer interrupt handler deadlocks when it tries to print a dot. This is the reason that we see no dots in the above output.
+We see that only a limited number of hyphens are printed until the first timer interrupt occurs. Then the system hangs because the timer interrupt handler deadlocks when it tries to print a dot. This is the reason that we see no dots in the above output.
-The actual number of hyphens varies between runs because the timer interrupt occurs asynchronously. This non-determinism is what makes concurrency related bugs so difficult to debug.
+The actual number of hyphens varies between runs because the timer interrupt occurs asynchronously. This non-determinism is what makes concurrency-related bugs so difficult to debug.
### Fixing the Deadlock
@@ -332,7 +332,7 @@ pub fn _print(args: fmt::Arguments) {
}
```
-The [`without_interrupts`] function takes a [closure] and executes it in an interrupt-free environment. We use it to ensure that no interrupt can occur as long as the `Mutex` is locked. When we run our kernel now we see that it keeps running without hanging. (We still don't notice any dots, but this is because they're scrolling by too fast. Try to slow down the printing, e.g. by putting a `for _ in 0..10000 {}` inside the loop.)
+The [`without_interrupts`] function takes a [closure] and executes it in an interrupt-free environment. We use it to ensure that no interrupt can occur as long as the `Mutex` is locked. When we run our kernel now, we see that it keeps running without hanging. (We still don't notice any dots, but this is because they're scrolling by too fast. Try to slow down the printing, e.g., by putting a `for _ in 0..10000 {}` inside the loop.)
[`without_interrupts`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/interrupts/fn.without_interrupts.html
[closure]: https://doc.rust-lang.org/book/ch13-01-closures.html
@@ -356,11 +356,11 @@ pub fn _print(args: ::core::fmt::Arguments) {
}
```
-Note that disabling interrupts shouldn't be a general solution. The problem is that it increases the worst case interrupt latency, i.e. the time until the system reacts to an interrupt. Therefore interrupts should be only disabled for a very short time.
+Note that disabling interrupts shouldn't be a general solution. The problem is that it increases the worst-case interrupt latency, i.e., the time until the system reacts to an interrupt. Therefore, interrupts should only be disabled for a very short time.
## Fixing a Race Condition
-If you run `cargo test` you might see the `test_println_output` test failing:
+If you run `cargo test`, you might see the `test_println_output` test failing:
```
> cargo test --lib
@@ -421,8 +421,8 @@ fn test_println_output() {
We performed the following changes:
- We keep the writer locked for the complete test by using the `lock()` method explicitly. Instead of `println`, we use the [`writeln`] macro that allows printing to an already locked writer.
-- To avoid another deadlock, we disable interrupts for the tests duration. Otherwise the test might get interrupted while the writer is still locked.
-- Since the timer interrupt handler can still run before the test, we print an additional newline `\n` before printing the string `s`. This way, we avoid test failure when the timer handler already printed some `.` characters to the current line.
+- To avoid another deadlock, we disable interrupts for the test's duration. Otherwise, the test might get interrupted while the writer is still locked.
+- Since the timer interrupt handler can still run before the test, we print an additional newline `\n` before printing the string `s`. This way, we avoid test failure when the timer handler has already printed some `.` characters to the current line.
[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
@@ -432,9 +432,9 @@ This was a very harmless race condition that only caused a test failure. As you
## The `hlt` Instruction
-Until now we used a simple empty loop statement at the end of our `_start` and `panic` functions. This causes the CPU to spin endlessly and thus works as expected. But it is also very inefficient, because the CPU continues to run at full speed even though there's no work to do. You can see this problem in your task manager when you run your kernel: The QEMU process needs close to 100% CPU the whole time.
+Until now, we used a simple empty loop statement at the end of our `_start` and `panic` functions. This causes the CPU to spin endlessly, and thus works as expected. But it is also very inefficient, because the CPU continues to run at full speed even though there's no work to do. You can see this problem in your task manager when you run your kernel: The QEMU process needs close to 100% CPU the whole time.
-What we really want to do is to halt the CPU until the next interrupt arrives. This allows the CPU to enter a sleep state in which it consumes much less energy. The [`hlt` instruction] does exactly that. Let's use this instruction to create an energy efficient endless loop:
+What we really want to do is to halt the CPU until the next interrupt arrives. This allows the CPU to enter a sleep state in which it consumes much less energy. The [`hlt` instruction] does exactly that. Let's use this instruction to create an energy-efficient endless loop:
[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
@@ -501,19 +501,19 @@ When we run our kernel now in QEMU, we see a much lower CPU usage.
## Keyboard Input
-Now that we are able to handle interrupts from external devices we are finally able to add support for keyboard input. This will allow us to interact with our kernel for the first time.
+Now that we are able to handle interrupts from external devices, we are finally able to add support for keyboard input. This will allow us to interact with our kernel for the first time.
[PS/2]: https://en.wikipedia.org/wiki/PS/2_port
-Like the hardware timer, the keyboard controller is already enabled by default. So when you press a key the keyboard controller sends an interrupt to the PIC, which forwards it to the CPU. The CPU looks for a handler function in the IDT, but the corresponding entry is empty. Therefore a double fault occurs.
+Like the hardware timer, the keyboard controller is already enabled by default. So when you press a key, the keyboard controller sends an interrupt to the PIC, which forwards it to the CPU. The CPU looks for a handler function in the IDT, but the corresponding entry is empty. Therefore, a double fault occurs.
-So let's add a handler function for the keyboard interrupt. It's quite similar to how we defined the handler for the timer interrupt, it just uses a different interrupt number:
+So let's add a handler function for the keyboard interrupt. It's quite similar to how we defined the handler for the timer interrupt; it just uses a different interrupt number:
```rust
// in src/interrupts.rs
@@ -552,11 +552,11 @@ extern "x86-interrupt" fn keyboard_interrupt_handler(
As we see from the graphic [above](#the-8259-pic), the keyboard uses line 1 of the primary PIC. This means that it arrives at the CPU as interrupt 33 (1 + offset 32). We add this index as a new `Keyboard` variant to the `InterruptIndex` enum. We don't need to specify the value explicitly, since it defaults to the previous value plus one, which is also 33. In the interrupt handler, we print a `k` and send the end of interrupt signal to the interrupt controller.
-We now see that a `k` appears on the screen when we press a key. However, this only works for the first key we press, even if we continue to press keys no more `k`s appear on the screen. This is because the keyboard controller won't send another interrupt until we have read the so-called _scancode_ of the pressed key.
+We now see that a `k` appears on the screen when we press a key. However, this only works for the first key we press. Even if we continue to press keys, no more `k`s appear on the screen. This is because the keyboard controller won't send another interrupt until we have read the so-called _scancode_ of the pressed key.
### Reading the Scancodes
-To find out _which_ key was pressed, we need to query the keyboard controller. We do this by reading from the data port of the PS/2 controller, which is the [I/O port] with number `0x60`:
+To find out _which_ key was pressed, we need to query the keyboard controller. We do this by reading from the data port of the PS/2 controller, which is the [I/O port] with the number `0x60`:
[I/O port]: @/edition-2/posts/04-testing/index.md#i-o-ports
@@ -579,7 +579,7 @@ extern "x86-interrupt" fn keyboard_interrupt_handler(
}
```
-We use the [`Port`] type of the `x86_64` crate to read a byte from the keyboard's data port. This byte is called the [_scancode_] and is a number that represents the key press/release. We don't do anything with the scancode yet, we just print it to the screen:
+We use the [`Port`] type of the `x86_64` crate to read a byte from the keyboard's data port. This byte is called the [_scancode_] and it represents the key press/release. We don't do anything with the scancode yet, other than print it to the screen:
[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
[_scancode_]: https://en.wikipedia.org/wiki/Scancode
@@ -589,7 +589,7 @@ We use the [`Port`] type of the `x86_64` crate to read a byte from the keyboard'
The above image shows me slowly typing "123". We see that adjacent keys have adjacent scancodes and that pressing a key causes a different scancode than releasing it. But how do we translate the scancodes to the actual key actions exactly?
### Interpreting the Scancodes
-There are three different standards for the mapping between scancodes and keys, the so-called _scancode sets_. All three go back to the keyboards of early IBM computers: the [IBM XT], the [IBM 3270 PC], and the [IBM AT]. Later computers fortunately did not continue the trend of defining new scancode sets, but rather emulated the existing sets and extended them. Today most keyboards can be configured to emulate any of the three sets.
+There are three different standards for the mapping between scancodes and keys, the so-called _scancode sets_. All three go back to the keyboards of early IBM computers: the [IBM XT], the [IBM 3270 PC], and the [IBM AT]. Later computers fortunately did not continue the trend of defining new scancode sets, but rather emulated the existing sets and extended them. Today, most keyboards can be configured to emulate any of the three sets.
[IBM XT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer_XT
[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
@@ -599,7 +599,7 @@ By default, PS/2 keyboards emulate scancode set 1 ("XT"). In this set, the lower
[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
-To translate the scancodes to keys, we can use a match statement:
+To translate the scancodes to keys, we can use a `match` statement:
```rust
// in src/interrupts.rs
@@ -647,7 +647,7 @@ Now we can write numbers:

-Translating the other keys works in the same way. Fortunately there is a crate named [`pc-keyboard`] for translating scancodes of scancode sets 1 and 2, so we don't have to implement this ourselves. To use the crate, we add it to our `Cargo.toml` and import it in our `lib.rs`:
+Translating the other keys works in the same way. Fortunately, there is a crate named [`pc-keyboard`] for translating scancodes of scancode sets 1 and 2, so we don't have to implement this ourselves. To use the crate, we add it to our `Cargo.toml` and import it in our `lib.rs`:
[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
@@ -697,27 +697,27 @@ extern "x86-interrupt" fn keyboard_interrupt_handler(
}
```
-We use the `lazy_static` macro to create a static [`Keyboard`] object protected by a Mutex. We initialize the `Keyboard` with an US keyboard layout and the scancode set 1. The [`HandleControl`] parameter allows to map `ctrl+[a-z]` to the Unicode characters `U+0001` through `U+001A`. We don't want to do that, so we use the `Ignore` option to handle the `ctrl` like normal keys.
+We use the `lazy_static` macro to create a static [`Keyboard`] object protected by a Mutex. We initialize the `Keyboard` with a US keyboard layout and the scancode set 1. The [`HandleControl`] parameter allows to map `ctrl+[a-z]` to the Unicode characters `U+0001` through `U+001A`. We don't want to do that, so we use the `Ignore` option to handle the `ctrl` like normal keys.
[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
-On each interrupt, we lock the Mutex, read the scancode from the keyboard controller and pass it to the [`add_byte`] method, which translates the scancode into an `Option`. The [`KeyEvent`] contains which key caused the event and whether it was a press or release event.
+On each interrupt, we lock the Mutex, read the scancode from the keyboard controller, and pass it to the [`add_byte`] method, which translates the scancode into an `Option`. The [`KeyEvent`] contains the key which caused the event and whether it was a press or release event.
[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
-To interpret this key event, we pass it to the [`process_keyevent`] method, which translates the key event to a character if possible. For example, translates a press event of the `A` key to either a lowercase `a` character or an uppercase `A` character, depending on whether the shift key was pressed.
+To interpret this key event, we pass it to the [`process_keyevent`] method, which translates the key event to a character, if possible. For example, it translates a press event of the `A` key to either a lowercase `a` character or an uppercase `A` character, depending on whether the shift key was pressed.
[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
-With this modified interrupt handler we can now write text:
+With this modified interrupt handler, we can now write text:

### Configuring the Keyboard
-It's possible to configure some aspects of a PS/2 keyboard, for example which scancode set it should use. We won't cover it here because this post is already long enough, but the OSDev Wiki has an overview of possible [configuration commands].
+It's possible to configure some aspects of a PS/2 keyboard, for example, which scancode set it should use. We won't cover it here because this post is already long enough, but the OSDev Wiki has an overview of possible [configuration commands].
[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
@@ -729,6 +729,6 @@ Now we are able to interact with our kernel and have some fundamental building b
## What's next?
-Timer interrupts are essential for an operating system, because they provide a way to periodically interrupt the running process and regain control in the kernel. The kernel can then switch to a different process and create the illusion that multiple processes run in parallel.
+Timer interrupts are essential for an operating system because they provide a way to periodically interrupt the running process and let the kernel regain control. The kernel can then switch to a different process and create the illusion of multiple processes running in parallel.
But before we can create processes or threads, we need a way to allocate memory for them. The next posts will explore memory management to provide this fundamental building block.
diff --git a/blog/content/edition-2/posts/07-hardware-interrupts/index.zh-CN.md b/blog/content/edition-2/posts/07-hardware-interrupts/index.zh-CN.md
new file mode 100644
index 00000000..d18b49ab
--- /dev/null
+++ b/blog/content/edition-2/posts/07-hardware-interrupts/index.zh-CN.md
@@ -0,0 +1,740 @@
++++
+title = "硬件中断"
+weight = 7
+path = "zh-CN/hardware-interrupts"
+date = 2018-10-22
+
+[extra]
+# Please update this when updating the translation
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
+# GitHub usernames of the people that translated this post
+translators = ["liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong"]
++++
+
+在本文中,我们会对可编程的中断控制器进行设置,以将硬件中断转发给CPU,而要处理这些中断,只需要像处理异常一样在中断描述符表中加入一个新条目即可,在这里我们会以获取周期计时器的中断和获取键盘输入为例进行讲解。
+
+
+
+这个系列的 blog 在[GitHub]上开放开发,如果你有任何问题,请在这里开一个 issue 来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-07`][post branch]找到这篇文章的完整源码。
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-07
+
+
+
+## 前言
+
+中断是其他硬件对CPU发送通知的一种方式,所以除了使用 [_轮询_][_polling_] 进程在内核层面定时检查键盘输入以外,由键盘主动通知内核按键输入的结果也是个可行的方案。相比之下,后者可能还更加有用,此时内核只需要处理接收到的事件即可。这也可以极大降低系统的反应延时,因为内核无需等待下一次轮询周期。
+
+[_polling_]: https://en.wikipedia.org/wiki/Polling_(computer_science)
+
+根据常识,将所有硬件直连CPU是不可能的,所以需要一个统一的 _中断控制器_ 对所有设备中断进行代理,并由它间接通知CPU:
+
+```
+ ____________ _____
+ Timer ------------> | | | |
+ Keyboard ---------> | Interrupt |---------> | CPU |
+ Other Hardware ---> | Controller | |_____|
+ Etc. -------------> |____________|
+
+```
+
+绝大多数中断控制器都是可编程的,也就是说可以自行设定中断的优先级,比如我们可以为计时器中断设定比键盘中断更高的优先级,以保证系统时间的精确性。
+
+和异常不同,硬件中断完全是 _异步的_ ,也就是说它们可以在任何时候发生,且时序完全独立于正在运行的代码。所以我们的内核里就突然添加了一种异步的逻辑形式,并且也引入了所有潜在的与异步逻辑相关的Bug可能性。此时Rust严格的所有权模型此时就开始具备优势,因为它从根本上禁止了可变的全局状态。但尽管如此,死锁很难完全避免,这个问题我们会在文章稍后的部分进行说明。
+
+## The 8259 PIC
+
+[Intel 8259] 是一款于1976年发布的可编程中断控制器(PIC),事实上,它已经被更先进的 [APIC] 替代很久了,但其接口依然出于兼容问题被现有系统所支持。但是 8259 PIC 的设置方式比起APIC实在简单太多了,所以我们先以前者为例解说一下基本原理,在下一篇文章中再切换为APIC。
+
+[APIC]: https://en.wikipedia.org/wiki/Intel_APIC_Architecture
+
+8529具有8个中断管脚和一个和CPU通信的独立管脚,而当年的典型系统一般会安装两片 8259 PIC ,一个作为主芯片,另一个则作为副芯片,就像下面这样:
+
+[Intel 8259]: https://en.wikipedia.org/wiki/Intel_8259
+
+```
+ ____________ ____________
+Real Time Clock --> | | Timer -------------> | |
+ACPI -------------> | | Keyboard-----------> | | _____
+Available --------> | Secondary |----------------------> | Primary | | |
+Available --------> | Interrupt | Serial Port 2 -----> | Interrupt |---> | CPU |
+Mouse ------------> | Controller | Serial Port 1 -----> | Controller | |_____|
+Co-Processor -----> | | Parallel Port 2/3 -> | |
+Primary ATA ------> | | Floppy disk -------> | |
+Secondary ATA ----> |____________| Parallel Port 1----> |____________|
+
+```
+
+上图展示了中断管脚的典型逻辑定义,我们可以看到,实际上可定义的管脚共有15个,例如副PIC的4号管脚被定义为了鼠标。
+
+每个控制器都可以通过两个 [I/O 端口][I/O ports] 进行配置,一个是“指令”端口,另一个是“数据”端口。对于主控制器,端口地址是 `0x20`(指令)和 `0x21`(数据),而对于副控制器,端口地址是 `0xa0`(指令)和 `0xa1`(数据)。要查看更多关于PIC配置的细节,请参见 [article on osdev.org]。
+
+[I/O ports]: @/edition-2/posts/04-testing/index.md#i-o-ports
+[article on osdev.org]: https://wiki.osdev.org/8259_PIC
+
+### 实现
+
+PIC默认的配置其实是无法使用的,因为它仅仅是将0-15之间的中断向量编号发送给了CPU,然而这些编号已经用在了CPU的异常编号中了,比如8号代指 double fault 异常。要修复这个错误,我们需要对PIC中断序号进行重映射,新的序号只需要避开已被定义的CPU异常即可,CPU定义的异常数量有32个,所以通常会使用32-47这个区段。
+
+我们需要通过往指令和数据端口写入特定数据才能对配置进行编程,幸运的是已经有了一个名叫 [`pic8259`] 的crate封装了这些东西,我们无需自己去处理这些初始化方面的细节。
+如果你十分好奇其中的细节,这里是 [它的源码][pic crate source],他的内部逻辑其实十分简洁,而且具备完善的文档。
+
+[pic crate source]: https://docs.rs/crate/pic8259/0.10.1/source/src/lib.rs
+
+我们可以这样将 crate 作为依赖加入工程中:
+
+[`pic8259`]: https://docs.rs/pic8259/0.10.1/pic8259/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+pic8259 = "0.10.1"
+```
+
+这个 crate 提供的主要抽象结构就是 [`ChainedPics`],用于映射上文所说的主副PIC的映射布局,它可以这样使用:
+
+[`ChainedPics`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html
+
+```rust
+// in src/interrupts.rs
+
+use pic8259::ChainedPics;
+use spin;
+
+pub const PIC_1_OFFSET: u8 = 32;
+pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
+
+pub static PICS: spin::Mutex =
+ spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
+```
+
+我们成功将PIC的中断编号范围设定为了32–47。我们使用 `Mutex` 容器包裹了 `ChainedPics`,这样就可以通过([`lock` 函数][spin mutex lock])拿到被定义为安全的变量修改权限,我们在下文会用到这个权限。`ChainedPics::new` 处于unsafe块,因为错误的偏移量可能会导致一些未定义行为。
+
+[spin mutex lock]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html#method.lock
+
+那么现在,我们就可以在 `init` 函数中初始化 8259 PIC 配置了:
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+ unsafe { interrupts::PICS.lock().initialize() }; // new
+}
+```
+
+我们使用 [`initialize`] 函数进行PIC的初始化。正如 `ChainedPics::new` ,这个函数也是 unsafe 的,因为里面的不安全逻辑可能会导致PIC配置失败,进而出现一些未定义行为。
+
+[`initialize`]: https://docs.rs/pic8259/0.10.1/pic8259/struct.ChainedPics.html#method.initialize
+
+如果一切顺利,我们在运行 `cargo run` 后应当能看到诸如 "It did not crash" 此类的输出信息。
+
+## 启用中断
+
+不过现在什么都不会发生,因为CPU配置里面中断还是禁用状态呢,也就是说CPU现在根本不会监听来自中断控制器的信息,即任何中断都无法到达CPU。我们来启用它:
+
+```rust
+// in src/lib.rs
+
+pub fn init() {
+ gdt::init();
+ interrupts::init_idt();
+ unsafe { interrupts::PICS.lock().initialize() };
+ x86_64::instructions::interrupts::enable(); // new
+}
+```
+
+`x86_64` crate 中的 `interrupts::enable` 会执行特殊的 `sti` (“set interrupts”) 指令来启用外部中断。当我们试着执行 `cargo run` 后,double fault 异常几乎是立刻就被抛出了:
+
+
+
+其原因就是硬件计时器(准确的说,是[Intel 8253])默认是被启用的,所以在启用中断控制器之后,CPU开始接收到计时器中断信号,而我们又并未设定相对应的处理函数,所以就抛出了 double fault 异常。
+
+[Intel 8253]: https://en.wikipedia.org/wiki/Intel_8253
+
+## 处理计时器中断
+
+我们已经知道 [计时器组件](#the-8259-pic) 使用了主PIC的0号管脚,根据上文中我们定义的序号偏移量32,所以计时器对应的中断序号也是32。但是不要将32硬编码进去,我们将其存储到枚举类型 `InterruptIndex` 中:
+
+```rust
+// in src/interrupts.rs
+
+#[derive(Debug, Clone, Copy)]
+#[repr(u8)]
+pub enum InterruptIndex {
+ Timer = PIC_1_OFFSET,
+}
+
+impl InterruptIndex {
+ fn as_u8(self) -> u8 {
+ self as u8
+ }
+
+ fn as_usize(self) -> usize {
+ usize::from(self.as_u8())
+ }
+}
+```
+
+这是一个 [C语言风格的枚举][C-like enum],我们可以为每个枚举值指定其对应的数值,`repr(u8)` 开关使枚举值对应的数值以 `u8` 格式进行存储,这样未来我们可以在这里加入更多的中断枚举。
+
+[C-like enum]: https://doc.rust-lang.org/reference/items/enumerations.html#custom-discriminant-values-for-fieldless-enumerations
+
+那么开始为计时器中断添加一个处理函数:
+
+```rust
+// in src/interrupts.rs
+
+use crate::print;
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ […]
+ idt[InterruptIndex::Timer.as_usize()]
+ .set_handler_fn(timer_interrupt_handler); // new
+
+ idt
+ };
+}
+
+extern "x86-interrupt" fn timer_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!(".");
+}
+```
+
+`timer_interrupt_handler` 和错误处理函数具有相同的函数签名,这是因为CPU对异常和外部中断的处理方式是相同的(除了个别异常会传入错误码以外)。[`InterruptDescriptorTable`] 结构实现了 [`IndexMut`] trait,所以我们可以通过序号来单独修改某一个条目。
+
+[`InterruptDescriptorTable`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.InterruptDescriptorTable.html
+[`IndexMut`]: https://doc.rust-lang.org/core/ops/trait.IndexMut.html
+
+在我们刚刚写好的处理函数中,我们会往屏幕上输出一个点,随着计时器中断周期性触发,我们应该能看到每一个计时周期过后屏幕上都会多出一个点。然而事实却并不是如此,我们只能在屏幕上看到一个点:
+
+
+
+### 结束中断
+
+这是因为PIC还在等着我们的处理函数返回 “中断结束” (EOI) 信号。该信号会通知控制器终端已处理,系统已准备好接收下一个中断。所以如果始终不发送EOI信号,那么PIC就会认为我们还在一直处理第一个计时器中断,然后暂停了后续的中断信号发送,直到接收到EOI信号。
+
+要发送EOI信号,我们可以再使用一下 `PICS`:
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn timer_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!(".");
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
+ }
+}
+```
+
+`notify_end_of_interrupt` 会自行判断中断信号发送的源头(主PIC或者副PIC),并使用指令和数据端口将信号发送到目标控制器。当然,如果是要发送到副PIC,那么结果上必然等同于同时发送到两个PIC,因为副PIC的输入管脚连在主PIC上面。
+
+请注意,这里的中断编码一定不可以写错,不然可能会导致某个中断信号迟迟得不到回应导致系统整体挂起。这也是该函数被标记为不安全的原因。
+
+现在我们再次运行 `cargo run`,就可以看到屏幕上开始正常输出点号了:
+
+
+
+### 配置计时器
+
+我们所使用的硬件计时器叫做 _可编程周期计时器_ (PIT),就如同字面上的意思一样,其两次中断之间的间隔是可配置的。当然,不会在此展开说,因为我们很快就会使用 [APIC计时器][APIC timer] 来代替它,但是你可以在OSDev wiki中找到一些关于[配置PIT计时器][configuring the PIT]的拓展文章。
+
+[APIC timer]: https://wiki.osdev.org/APIC_timer
+[configuring the PIT]: https://wiki.osdev.org/Programmable_Interval_Timer
+
+## 死锁
+
+现在,我们的内核里就出现了一种全新的异步逻辑:计时器中断是异步的,所以它可能会在任何时候中断 `_start` 函数的运行。幸运的是Rust的所有权体系为我们在编译期避免了相当比例的bug,其中最典型的就是死锁 —— 当一个线程试图使用一个永远不会被释放的锁时,这个线程就会被永久性挂起。
+
+我们可以在内核里主动引发一次死锁看看,请回忆一下,我们的 `println` 宏调用了 `vga_buffer::_print` 函数,而这个函数又使用了 [`WRITER`][vga spinlock] 变量,该变量被定义为带同步锁的变量:
+
+[vga spinlock]: @/edition-2/posts/03-vga-text-buffer/index.md#spinlocks
+
+```rust
+// in src/vga_buffer.rs
+
+[…]
+
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ WRITER.lock().write_fmt(args).unwrap();
+}
+```
+
+获取到 `WRITER` 变量的锁后,调用其内部的 `write_fmt` 函数,然后在结尾隐式解锁该变量。但是假如在函数执行一半的时候,中断处理函数触发,同样试图打印日志的话:
+
+| Timestep | _start | interrupt_handler |
+| -------- | ---------------------- | ----------------------------------------------- |
+| 0 | calls `println!` | |
+| 1 | `print` locks `WRITER` | |
+| 2 | | **interrupt occurs**, handler begins to run |
+| 3 | | calls `println!` |
+| 4 | | `print` tries to lock `WRITER` (already locked) |
+| 5 | | `print` tries to lock `WRITER` (already locked) |
+| … | | … |
+| _never_ | _unlock `WRITER`_ |
+
+`WRITER` 被锁定,所以中断处理函数就会一直等待到它被解锁为止,然而后续永远不会发生了,因为只有当中断处理函数返回,`_start` 函数才会继续运行,`WRITER` 才可能被解锁,所以整个系统就这么挂起了。
+
+### 引发死锁
+
+基于这个原理,我们可以通过在 `_start` 函数中构建一个输出循环来很轻易地触发死锁:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ […]
+ loop {
+ use blog_os::print;
+ print!("-"); // new
+ }
+}
+```
+
+在QEMU中运行后,输出是这样的:
+
+
+
+我们可以看到,这段程序只输出了有限的中划线,在第一次计时器中断触发后就不再动弹了,这是因为计时器中断对应的处理函数触发了输出宏中潜在的死锁,这也是为什么我们没有在上面的输出中看到点号的原因。
+
+由于计时器中断是完全异步的,所以每次运行能够输出的中划线数量都是不确定的,这种特性也导致和并发相关的bug非常难以调试。
+
+### 修复死锁
+
+要避免死锁,我们可以在 `Mutex` 被锁定时禁用中断:
+
+```rust
+// in src/vga_buffer.rs
+
+/// Prints the given formatted string to the VGA text buffer
+/// through the global `WRITER` instance.
+#[doc(hidden)]
+pub fn _print(args: fmt::Arguments) {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts; // new
+
+ interrupts::without_interrupts(|| { // new
+ WRITER.lock().write_fmt(args).unwrap();
+ });
+}
+```
+
+[`without_interrupts`] 函数可以使一个 [闭包][closure] 代码块在无中断环境下执行,由此我们可以让 `Mutex` 变量在锁定期间的执行逻辑不会被中断信号打断。再次运行我们的内核,此时程序就不会被挂起了。(然而我们依然不会看到任何点号,因为输出速度实在是太快了,试着降低一下输出速度就可以了,比如在循环里插入一句 `for _ in 0..10000 {}`。)
+
+[`without_interrupts`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/interrupts/fn.without_interrupts.html
+[closure]: https://doc.rust-lang.org/book/ch13-01-closures.html
+
+我们也可以在串行输出函数里也加入同样的逻辑来避免死锁:
+
+```rust
+// in src/serial.rs
+
+#[doc(hidden)]
+pub fn _print(args: ::core::fmt::Arguments) {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts; // new
+
+ interrupts::without_interrupts(|| { // new
+ SERIAL1
+ .lock()
+ .write_fmt(args)
+ .expect("Printing to serial failed");
+ });
+}
+```
+
+但请注意,禁用中断不应是被广泛使用的手段,它可能会造成中断的处理延迟增加,比如操作系统是依靠中断信号进行计时的。因此,中断仅应在极短的时间内被禁用。
+
+## 修复竞态条件
+
+如果你运行 `cargo test` 命令,则会发现`test_println_output` 测试执行失败:
+
+```
+> cargo test --lib
+[…]
+Running 4 tests
+test_breakpoint_exception...[ok]
+test_println... [ok]
+test_println_many... [ok]
+test_println_output... [failed]
+
+Error: panicked at 'assertion failed: `(left == right)`
+ left: `'.'`,
+ right: `'S'`', src/vga_buffer.rs:205:9
+```
+
+其原因就是测试函数和计时器中断处理函数出现了 _竞态条件_,测试函数是这样的:
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ let s = "Some test string that fits on a single line";
+ println!("{}", s);
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+}
+```
+
+该测试将一串字符打印到VGA缓冲区,并通过一个循环检测 `buffer_chars` 数组的内容。竞态条件出现的原因就是在 `println` 和检测逻辑之间触发了计时器中断,其处理函数同样调用了输出语句。不过这并非危险的 _数据竞争_,该种竞争可以被Rust语言在编译期完全避免。如果你对此感兴趣,可以查阅一下 [_Rustonomicon_][nomicon-races]。
+
+[nomicon-races]: https://doc.rust-lang.org/nomicon/races.html
+
+要修复这个问题,我们需要让 `WRITER` 加锁的范围扩大到整个测试函数,使计时器中断处理函数无法输出 `.`,就像这样:
+
+```rust
+// in src/vga_buffer.rs
+
+#[test_case]
+fn test_println_output() {
+ use core::fmt::Write;
+ use x86_64::instructions::interrupts;
+
+ let s = "Some test string that fits on a single line";
+ interrupts::without_interrupts(|| {
+ let mut writer = WRITER.lock();
+ writeln!(writer, "\n{}", s).expect("writeln failed");
+ for (i, c) in s.chars().enumerate() {
+ let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
+ assert_eq!(char::from(screen_char.ascii_character), c);
+ }
+ });
+}
+```
+
+我们进行了如下修改:
+
+- 我们使用 `lock()` 函数显式加锁,然后将 `println` 改为 [`writeln`] 宏,以此绕开输出必须加锁的限制。
+- 为了避免死锁,我们同时在测试函数执行期间禁用中断,否则中断处理函数可能会意外被触发。
+- 为了防止在测试执行前计时器中断被触发所造成的干扰,我们先输出一句 `\n`,即可避免行首出现多余的 `.` 造成的干扰。
+
+[`writeln`]: https://doc.rust-lang.org/core/macro.writeln.html
+
+经过以上修改,`cargo test` 就可以正确运行了。
+
+好在这是一种十分无害的竞态条件,仅仅会导致测试失败,但如你所想,其它形式的竞态条件可能会更加难以调试。幸运的是,更加恶性的数据竞争已经被Rust从根本上避免了,大部分数据竞争都会造成无法预知的行为,比如系统崩溃,或者悄无声息的内存破坏。
+
+## `hlt` 指令
+
+目前我们在 `_start` 和 `panic` 函数的末尾都使用了一个空白的循环,这的确能让整体逻辑正常运行,但也会让CPU全速运转 —— 尽管此时并没有什么需要计算的工作。如果你在执行内核时打开任务管理器,便会发现QEMU的CPU占用率全程高达100%。
+
+但是,我们可以让CPU在下一个中断触发之前休息一下,也就是进入休眠状态来节省一点点能源。[`hlt` instruction][`hlt` 指令] 可以让我们做到这一点,那就来用它写一个节能的无限循环:
+
+[`hlt` instruction]: https://en.wikipedia.org/wiki/HLT_(x86_instruction)
+
+```rust
+// in src/lib.rs
+
+pub fn hlt_loop() -> ! {
+ loop {
+ x86_64::instructions::hlt();
+ }
+}
+```
+
+`instructions::hlt` 只是对应汇编指令的 [薄包装][thin wrapper],并且它是内存安全的,没有破坏内存的风险。
+
+[thin wrapper]: https://github.com/rust-osdev/x86_64/blob/5e8e218381c5205f5777cb50da3ecac5d7e3b1ab/src/instructions/mod.rs#L16-L22
+
+现在我们来试着在 `_start` 和 `panic` 中使用 `hlt_loop`:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ […]
+
+ println!("It did not crash!");
+ blog_os::hlt_loop(); // new
+}
+
+
+#[cfg(not(test))]
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ println!("{}", info);
+ blog_os::hlt_loop(); // new
+}
+
+```
+
+接下来再更新一下 `lib.rs` :
+
+```rust
+// in src/lib.rs
+
+/// Entry point for `cargo test`
+#[cfg(test)]
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ init();
+ test_main();
+ hlt_loop(); // new
+}
+
+pub fn test_panic_handler(info: &PanicInfo) -> ! {
+ serial_println!("[failed]\n");
+ serial_println!("Error: {}\n", info);
+ exit_qemu(QemuExitCode::Failed);
+ hlt_loop(); // new
+}
+```
+
+再次在QEMU中执行我们的内核,CPU使用率已经降低到了比较低的水平了。
+
+## 键盘输入
+
+现在,我们已经知道了如何接收外部设备的中断信号,我们可以进一步对键盘添加支持,由此我们可以与内核进行交互。
+
+
+
+[PS/2]: https://en.wikipedia.org/wiki/PS/2_port
+
+就如同硬件计时器一样,键盘控制器也是默认启用的,所以当你敲击键盘上某个按键时,键盘控制器就会经由PIC向CPU发送中断信号。然而CPU此时是无法在IDT找到相关的中断处理函数的,所以 double fault 异常会被抛出。
+
+所以我们需要为键盘中断添加一个处理函数,它十分类似于计时器中断处理的实现,只不过需要对中断编号做出一点小小的修改:
+
+```rust
+// in src/interrupts.rs
+
+#[derive(Debug, Clone, Copy)]
+#[repr(u8)]
+pub enum InterruptIndex {
+ Timer = PIC_1_OFFSET,
+ Keyboard, // new
+}
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+ idt.breakpoint.set_handler_fn(breakpoint_handler);
+ […]
+ // new
+ idt[InterruptIndex::Keyboard.as_usize()]
+ .set_handler_fn(keyboard_interrupt_handler);
+
+ idt
+ };
+}
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ print!("k");
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+[上文](#the-8259-pic) 提到,键盘使用的是主PIC的1号管脚,在CPU的中断编号为33(1 + 偏移量32)。我们需要在 `InterruptIndex` 枚举类型里添加一个 `Keyboard`,但是无需显式指定对应值,因为在默认情况下,它的对应值是上一个枚举对应值加一也就是33。在处理函数中,我们先输出一个 `k`,并发送结束信号来结束中断。
+
+现在当我们按下任意一个按键,就会在屏幕上输出一个 `k`,然而这只会生效一次,因为键盘控制器在我们 _获取扫描码_ 之前,是不会发送下一个中断的。
+
+### 读取扫描码
+
+要找到哪个按键被按下,我们还需要询问一下键盘控制器,我们可以从 PS/2 控制器(即地址为 `0x60` 的 [I/O端口][I/O port])的数据端口获取到该信息:
+
+[I/O port]: @/edition-2/posts/04-testing/index.md#i-o-ports
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use x86_64::instructions::port::Port;
+
+ let mut port = Port::new(0x60);
+ let scancode: u8 = unsafe { port.read() };
+ print!("{}", scancode);
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+我们使用了 `x86_64` crate 中的 [`Port`] 来从键盘数据端口中读取名为 [_扫描码_] 的随着按键按下/释放而不断变化的数字。我们暂且不处理它,只是在屏幕上打印出来:
+
+[`Port`]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/port/struct.Port.html
+[_scancode_]: https://en.wikipedia.org/wiki/Scancode
+
+
+
+在上图中,演示的正是缓慢输入 `123` 的结果。我们可以看到,相邻的按键具备相邻的扫描码,而按下按键和松开按键也会出现不同的扫描码,那么问题来了,我们该如何对这些扫描码进行译码?
+
+### 扫描码转义
+关于按键与键位码之间的映射关系,目前存在三种不同的标准(所谓的 _扫描码映射集_)。三种标准都可以追溯到早期的IBM电脑键盘:[IBM XT]、 [IBM 3270 PC]和[IBM AT]。好在之后的电脑并未另起炉灶定义新的扫描码映射集,但也对现有类型进行模拟并加以扩展,如今的绝大多数键盘都可以模拟成这三种类型之一。
+
+[IBM XT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer_XT
+[IBM 3270 PC]: https://en.wikipedia.org/wiki/IBM_3270_PC
+[IBM AT]: https://en.wikipedia.org/wiki/IBM_Personal_Computer/AT
+
+默认情况下,PS/2 键盘会模拟Set-1(XT),在该布局下,扫描码的低7位表示按键,而其他的比特位则定义了是按下(0)还是释放(1)。不过这些按键并非都存在于原本的 [IBM XT] 键盘上,比如小键盘的回车键,此时就会连续生成两个扫描码:`0xe0` 以及一个自定义的代表该键位的数字。[OSDev Wiki][scancode set 1] 可以查阅到Set-1下的扫描码对照表。
+
+[scancode set 1]: https://wiki.osdev.org/Keyboard#Scan_Code_Set_1
+
+要将扫描码译码成按键,我们可以用一个match匹配语句:
+
+```rust
+// in src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use x86_64::instructions::port::Port;
+
+ let mut port = Port::new(0x60);
+ let scancode: u8 = unsafe { port.read() };
+
+ // new
+ let key = match scancode {
+ 0x02 => Some('1'),
+ 0x03 => Some('2'),
+ 0x04 => Some('3'),
+ 0x05 => Some('4'),
+ 0x06 => Some('5'),
+ 0x07 => Some('6'),
+ 0x08 => Some('7'),
+ 0x09 => Some('8'),
+ 0x0a => Some('9'),
+ 0x0b => Some('0'),
+ _ => None,
+ };
+ if let Some(key) = key {
+ print!("{}", key);
+ }
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+以上代码可以对数字按键0-9进行转义,并忽略其他键位。具体到程序逻辑中,就是使用 [match] 匹配映射数字0-9,对于其他扫描码则返回 `None`,然后使用 [`if let`] 语句对 `key` 进行解构取值,在这个语法中,代码块中的 `key` 会 [遮蔽][shadow] 掉代码块外的同名 `Option` 型变量。
+
+[match]: https://doc.rust-lang.org/book/ch06-02-match.html
+[`if let`]: https://doc.rust-lang.org/book/ch18-01-all-the-places-for-patterns.html#conditional-if-let-expressions
+[shadow]: https://doc.rust-lang.org/book/ch03-01-variables-and-mutability.html#shadowing
+
+现在我们就可以向控制台写入数字了:
+
+
+
+其他扫描码也可以通过同样的手段进行译码,不过真的很麻烦,好在 [`pc-keyboard`] crate 已经帮助我们实现了Set-1和Set-2的译码工作,所以无需自己去实现。所以我们只需要将下述内容添加到 `Cargo.toml`,并在 `lib.rs` 里进行引用:
+
+[`pc-keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+pc-keyboard = "0.5.0"
+```
+
+现在我们可以使用新的crate对 `keyboard_interrupt_handler` 进行改写:
+
+```rust
+// in/src/interrupts.rs
+
+extern "x86-interrupt" fn keyboard_interrupt_handler(
+ _stack_frame: InterruptStackFrame)
+{
+ use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
+ use spin::Mutex;
+ use x86_64::instructions::port::Port;
+
+ lazy_static! {
+ static ref KEYBOARD: Mutex> =
+ Mutex::new(Keyboard::new(layouts::Us104Key, ScancodeSet1,
+ HandleControl::Ignore)
+ );
+ }
+
+ let mut keyboard = KEYBOARD.lock();
+ let mut port = Port::new(0x60);
+
+ let scancode: u8 = unsafe { port.read() };
+ if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
+ if let Some(key) = keyboard.process_keyevent(key_event) {
+ match key {
+ DecodedKey::Unicode(character) => print!("{}", character),
+ DecodedKey::RawKey(key) => print!("{:?}", key),
+ }
+ }
+ }
+
+ unsafe {
+ PICS.lock()
+ .notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
+ }
+}
+```
+
+首先我们使用 `lazy_static` 宏创建一个受到Mutex同步锁保护的 [`Keyboard`] 对象,初始化参数为美式键盘布局以及Set-1。至于 [`HandleControl`],它可以设定为将 `ctrl+[a-z]` 映射为Unicode字符 `U+0001` 至 `U+001A`,但我们不想这样,所以使用了 `Ignore` 选项让 `ctrl` 仅仅表现为一个正常键位。
+
+[`HandleControl`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/enum.HandleControl.html
+
+对于每一个中断,我们都会为 KEYBOARD 加锁,从键盘控制器获取扫描码并将其传入 [`add_byte`] 函数,并将其转化为 `Option` 结构。[`KeyEvent`] 包括了触发本次中断的按键信息,以及子动作是按下还是释放。
+
+[`Keyboard`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html
+[`add_byte`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.add_byte
+[`KeyEvent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.KeyEvent.html
+
+要处理KeyEvent,我们还需要将其传入 [`process_keyevent`] 函数,将其转换为人类可读的字符,若果有必要,也会对字符进行一些处理。典型例子就是,要判断 `A` 键按下后输入的是小写 `a` 还是大写 `A`,这要取决于shift键是否同时被按下。
+
+[`process_keyevent`]: https://docs.rs/pc-keyboard/0.5.0/pc_keyboard/struct.Keyboard.html#method.process_keyevent
+
+进行这些修改之后,我们就可以正常输入英文了:
+
+
+
+### 配置键盘
+
+PS/2 键盘可以配置的地方其实还有很多,比如设定它使用何种扫描码映射集,然而这篇文章已经够长了,就不在此展开说明,如果有兴趣,可以在OSDev wiki查看[更详细的资料][configuration commands]。
+
+[configuration commands]: https://wiki.osdev.org/PS/2_Keyboard#Commands
+
+## 小结
+
+本文描述了如何启用并处理外部中断。我们学习了关于8259 PIC的主副布局、重映射中断编号以及结束中断信号的基础知识,实现了简单的硬件计时器和键盘的中断处理器,以及如何使用 `hlt` 指令让CPU休眠至下次接收到中断信号。
+
+现在我们已经可以和内核进行交互,满足了创建简易控制台或简易游戏的基础条件。
+
+## 下文预告
+
+计时器中断对操作系统而言至关重要,它可以使内核定期重新获得控制权,由此内核可以对线程进行调度,创造出多个线程并行执行的错觉。
+
+然而在我们创建进程或线程之前,我们还需要解决内存分配问题。下一篇文章中,我们就会对内存管理进行阐述,以提供后续功能会使用到的基础设施。
diff --git a/blog/content/edition-2/posts/08-paging-introduction/index.md b/blog/content/edition-2/posts/08-paging-introduction/index.md
index 283b339a..ab1e8941 100644
--- a/blog/content/edition-2/posts/08-paging-introduction/index.md
+++ b/blog/content/edition-2/posts/08-paging-introduction/index.md
@@ -23,9 +23,9 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
## Memory Protection
-One main task of an operating system is to isolate programs from each other. Your web browser shouldn't be able to interfere with your text editor, for example. To achieve this goal, operating systems utilize hardware functionality to ensure that memory areas of one process are not accessible by other processes. There are different approaches, depending on the hardware and the OS implementation.
+One main task of an operating system is to isolate programs from each other. Your web browser shouldn't be able to interfere with your text editor, for example. To achieve this goal, operating systems utilize hardware functionality to ensure that memory areas of one process are not accessible by other processes. There are different approaches depending on the hardware and the OS implementation.
-As an example, some ARM Cortex-M processors (used for embedded systems) have a [_Memory Protection Unit_] (MPU), which allows you to define a small number (e.g. 8) of memory regions with different access permissions (e.g. no access, read-only, read-write). On each memory access the MPU ensures that the address is in a region with correct access permissions and throws an exception otherwise. By changing the regions and access permissions on each process switch, the operating system can ensure that each process only accesses its own memory, and thus isolate processes from each other.
+As an example, some ARM Cortex-M processors (used for embedded systems) have a [_Memory Protection Unit_] (MPU), which allows you to define a small number (e.g., 8) of memory regions with different access permissions (e.g., no access, read-only, read-write). On each memory access, the MPU ensures that the address is in a region with correct access permissions and throws an exception otherwise. By changing the regions and access permissions on each process switch, the operating system can ensure that each process only accesses its own memory and thus isolates processes from each other.
[_Memory Protection Unit_]: https://developer.arm.com/docs/ddi0337/e/memory-protection-unit/about-the-mpu
@@ -36,11 +36,11 @@ On x86, the hardware supports two different approaches to memory protection: [se
## Segmentation
-Segmentation was already introduced in 1978, originally to increase the amount of addressable memory. The situation back then was that CPUs only used 16-bit addresses, which limited the amount of addressable memory to 64KiB. To make more than these 64KiB accessible, additional segment registers were introduced, each containing an offset address. The CPU automatically added this offset on each memory access, so that up to 1MiB of memory were accessible.
+Segmentation was already introduced in 1978, originally to increase the amount of addressable memory. The situation back then was that CPUs only used 16-bit addresses, which limited the amount of addressable memory to 64 KiB. To make more than these 64 KiB accessible, additional segment registers were introduced, each containing an offset address. The CPU automatically added this offset on each memory access, so that up to 1 MiB of memory was accessible.
-The segment register is chosen automatically by the CPU, depending on the kind of memory access: For fetching instructions the code segment `CS` is used and for stack operations (push/pop) the stack segment `SS` is used. Other instructions use data segment `DS` or the extra segment `ES`. Later two additional segment registers `FS` and `GS` were added, which can be used freely.
+The segment register is chosen automatically by the CPU depending on the kind of memory access: For fetching instructions, the code segment `CS` is used, and for stack operations (push/pop), the stack segment `SS` is used. Other instructions use the data segment `DS` or the extra segment `ES`. Later, two additional segment registers, `FS` and `GS`, were added, which can be used freely.
-In the first version of segmentation, the segment registers directly contained the offset and no access control was performed. This was changed later with the introduction of the [_protected mode_]. When the CPU runs in this mode, the segment descriptors contain an index into a local or global [_descriptor table_], which contains – in addition to an offset address – the segment size and access permissions. By loading separate global/local descriptor tables for each process that confine memory accesses to the process's own memory areas, the OS can isolate processes from each other.
+In the first version of segmentation, the segment registers directly contained the offset and no access control was performed. This was changed later with the introduction of the [_protected mode_]. When the CPU runs in this mode, the segment descriptors contain an index into a local or global [_descriptor table_], which contains – in addition to an offset address – the segment size and access permissions. By loading separate global/local descriptor tables for each process, which confine memory accesses to the process's own memory areas, the OS can isolate processes from each other.
[_protected mode_]: https://en.wikipedia.org/wiki/X86_memory_segmentation#Protected_mode
[_descriptor table_]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
@@ -49,18 +49,18 @@ By modifying the memory addresses before the actual access, segmentation already
### Virtual Memory
-The idea behind virtual memory is to abstract away the memory addresses from the underlying physical storage device. Instead of directly accessing the storage device, a translation step is performed first. For segmentation, the translation step is to add the offset address of the active segment. Imagine a program accessing memory address `0x1234000` in a segment with offset `0x1111000`: The address that is really accessed is `0x2345000`.
+The idea behind virtual memory is to abstract away the memory addresses from the underlying physical storage device. Instead of directly accessing the storage device, a translation step is performed first. For segmentation, the translation step is to add the offset address of the active segment. Imagine a program accessing memory address `0x1234000` in a segment with an offset of `0x1111000`: The address that is really accessed is `0x2345000`.
-To differentiate the two address types, addresses before the translation are called _virtual_ and addresses after the translation are called _physical_. One important difference between these two kinds of addresses is that physical addresses are unique and always refer to the same, distinct memory location. Virtual addresses on the other hand depend on the translation function. It is entirely possible that two different virtual addresses refer to the same physical address. Also, identical virtual addresses can refer to different physical addresses when they use different translation functions.
+To differentiate the two address types, addresses before the translation are called _virtual_, and addresses after the translation are called _physical_. One important difference between these two kinds of addresses is that physical addresses are unique and always refer to the same distinct memory location. Virtual addresses, on the other hand, depend on the translation function. It is entirely possible that two different virtual addresses refer to the same physical address. Also, identical virtual addresses can refer to different physical addresses when they use different translation functions.
An example where this property is useful is running the same program twice in parallel:

-Here the same program runs twice, but with different translation functions. The first instance has an segment offset of 100, so that its virtual addresses 0–150 are translated to the physical addresses 100–250. The second instance has offset 300, which translates its virtual addresses 0–150 to physical addresses 300–450. This allows both programs to run the same code and use the same virtual addresses without interfering with each other.
+Here the same program runs twice, but with different translation functions. The first instance has a segment offset of 100, so that its virtual addresses 0–150 are translated to the physical addresses 100–250. The second instance has an offset of 300, which translates its virtual addresses 0–150 to physical addresses 300–450. This allows both programs to run the same code and use the same virtual addresses without interfering with each other.
-Another advantage is that programs can be placed at arbitrary physical memory locations now, even if they use completely different virtual addresses. Thus, the OS can utilize the full amount of available memory without needing to recompile programs.
+Another advantage is that programs can now be placed at arbitrary physical memory locations, even if they use completely different virtual addresses. Thus, the OS can utilize the full amount of available memory without needing to recompile programs.
### Fragmentation
@@ -76,39 +76,39 @@ One way to combat this fragmentation is to pause execution, move the used parts
Now there is enough continuous space to start the third instance of our program.
-The disadvantage of this defragmentation process is that is needs to copy large amounts of memory which decreases performance. It also needs to be done regularly before the memory becomes too fragmented. This makes performance unpredictable, since programs are paused at random times and might become unresponsive.
+The disadvantage of this defragmentation process is that it needs to copy large amounts of memory, which decreases performance. It also needs to be done regularly before the memory becomes too fragmented. This makes performance unpredictable since programs are paused at random times and might become unresponsive.
-The fragmentation problem is one of the reasons that segmentation is no longer used by most systems. In fact, segmentation is not even supported in 64-bit mode on x86 anymore. Instead _paging_ is used, which completely avoids the fragmentation problem.
+The fragmentation problem is one of the reasons that segmentation is no longer used by most systems. In fact, segmentation is not even supported in 64-bit mode on x86 anymore. Instead, _paging_ is used, which completely avoids the fragmentation problem.
## Paging
-The idea is to divide both the virtual and the physical memory space into small, fixed-size blocks. The blocks of the virtual memory space are called _pages_ and the blocks of the physical address space are called _frames_. Each page can be individually mapped to a frame, which makes it possible to split larger memory regions across non-continuous physical frames.
+The idea is to divide both the virtual and physical memory space into small, fixed-size blocks. The blocks of the virtual memory space are called _pages_, and the blocks of the physical address space are called _frames_. Each page can be individually mapped to a frame, which makes it possible to split larger memory regions across non-continuous physical frames.
The advantage of this becomes visible if we recap the example of the fragmented memory space, but use paging instead of segmentation this time:
-
+
-In this example we have a page size of 50 bytes, which means that each of our memory regions is split across three pages. Each page is mapped to a frame individually, so a continuous virtual memory region can be mapped to non-continuous physical frames. This allows us to start the third instance of the program without performing any defragmentation before.
+In this example, we have a page size of 50 bytes, which means that each of our memory regions is split across three pages. Each page is mapped to a frame individually, so a continuous virtual memory region can be mapped to non-continuous physical frames. This allows us to start the third instance of the program without performing any defragmentation before.
### Hidden Fragmentation
-Compared to segmentation, paging uses lots of small, fixed sized memory regions instead of a few large, variable sized regions. Since every frame has the same size, there are no frames that are too small to be used so that no fragmentation occurs.
+Compared to segmentation, paging uses lots of small, fixed-sized memory regions instead of a few large, variable-sized regions. Since every frame has the same size, there are no frames that are too small to be used, so no fragmentation occurs.
Or it _seems_ like no fragmentation occurs. There is still some hidden kind of fragmentation, the so-called _internal fragmentation_. Internal fragmentation occurs because not every memory region is an exact multiple of the page size. Imagine a program of size 101 in the above example: It would still need three pages of size 50, so it would occupy 49 bytes more than needed. To differentiate the two types of fragmentation, the kind of fragmentation that happens when using segmentation is called _external fragmentation_.
-Internal fragmentation is unfortunate, but often better than the external fragmentation that occurs with segmentation. It still wastes memory, but does not require defragmentation and makes the amount of fragmentation predictable (on average half a page per memory region).
+Internal fragmentation is unfortunate but often better than the external fragmentation that occurs with segmentation. It still wastes memory, but does not require defragmentation and makes the amount of fragmentation predictable (on average half a page per memory region).
### Page Tables
-We saw that each of the potentially millions of pages is individually mapped to a frame. This mapping information needs to be stored somewhere. Segmentation uses an individual segment selector register for each active memory region, which is not possible for paging since there are way more pages than registers. Instead paging uses a table structure called _page table_ to store the mapping information.
+We saw that each of the potentially millions of pages is individually mapped to a frame. This mapping information needs to be stored somewhere. Segmentation uses an individual segment selector register for each active memory region, which is not possible for paging since there are way more pages than registers. Instead, paging uses a table structure called _page table_ to store the mapping information.
-For our above example the page tables would look like this:
+For our above example, the page tables would look like this:
-
+
We see that each program instance has its own page table. A pointer to the currently active table is stored in a special CPU register. On `x86`, this register is called `CR3`. It is the job of the operating system to load this register with the pointer to the correct page table before running each program instance.
-On each memory access, the CPU reads the table pointer from the register and looks up the mapped frame for the accessed page in the table. This is entirely done in hardware and completely transparent to the running program. To speed up the translation process, many CPU architectures have a special cache that remembers the results of the last translations.
+On each memory access, the CPU reads the table pointer from the register and looks up the mapped frame for the accessed page in the table. This is entirely done in hardware and completely invisible to the running program. To speed up the translation process, many CPU architectures have a special cache that remembers the results of the last translations.
Depending on the architecture, page table entries can also store attributes such as access permissions in a flags field. In the above example, the "r/w" flag makes the page both readable and writable.
@@ -118,41 +118,39 @@ The simple page tables we just saw have a problem in larger address spaces: they

-It only needs 4 physical frames, but the page table has over a million entries. We can't omit the empty entries because then the CPU would no longer be able to jump directly to the correct entry in the translation process (e.g. it is no longer guaranteed that the fourth page uses the fourth entry).
+It only needs 4 physical frames, but the page table has over a million entries. We can't omit the empty entries because then the CPU would no longer be able to jump directly to the correct entry in the translation process (e.g., it is no longer guaranteed that the fourth page uses the fourth entry).
To reduce the wasted memory, we can use a **two-level page table**. The idea is that we use different page tables for different address regions. An additional table called _level 2_ page table contains the mapping between address regions and (level 1) page tables.
This is best explained by an example. Let's define that each level 1 page table is responsible for a region of size `10_000`. Then the following tables would exist for the above example mapping:
-
+
Page 0 falls into the first `10_000` byte region, so it uses the first entry of the level 2 page table. This entry points to level 1 page table T1, which specifies that page `0` points to frame `0`.
-The pages `1_000_000`, `1_000_050`, and `1_000_100` all fall into the 100th `10_000` byte region, so they use the 100th entry of the level 2 page table. This entry points at a different level 1 page table T2, which maps the three pages to frames `100`, `150`, and `200`. Note that the page address in level 1 tables does not include the region offset, so e.g. the entry for page `1_000_050` is just `50`.
+The pages `1_000_000`, `1_000_050`, and `1_000_100` all fall into the 100th `10_000` byte region, so they use the 100th entry of the level 2 page table. This entry points to a different level 1 page table T2, which maps the three pages to frames `100`, `150`, and `200`. Note that the page address in level 1 tables does not include the region offset. For example, the entry for page `1_000_050` is just `50`.
-We still have 100 empty entries in the level 2 table, but much fewer than the million empty entries before. The reason for this savings is that we don't need to create level 1 page tables for the unmapped memory regions between `10_000` and `1_000_000`.
+We still have 100 empty entries in the level 2 table, but much fewer than the million empty entries before. The reason for these savings is that we don't need to create level 1 page tables for the unmapped memory regions between `10_000` and `1_000_000`.
-The principle of two-level page tables can be extended to three, four, or more levels. Then the page table register points at the highest level table, which points to the next lower level table, which points to the next lower level, and so on. The level 1 page table then points at the mapped frame. The principle in general is called a _multilevel_ or _hierarchical_ page table.
+The principle of two-level page tables can be extended to three, four, or more levels. Then the page table register points to the highest level table, which points to the next lower level table, which points to the next lower level, and so on. The level 1 page table then points to the mapped frame. The principle in general is called a _multilevel_ or _hierarchical_ page table.
-Now that we know how paging and multilevel page tables works, we can look at how paging is implemented in the x86_64 architecture (we assume in the following that the CPU runs in 64-bit mode).
+Now that we know how paging and multilevel page tables work, we can look at how paging is implemented in the x86_64 architecture (we assume in the following that the CPU runs in 64-bit mode).
## Paging on x86_64
-The x86_64 architecture uses a 4-level page table and a page size of 4KiB. Each page table, independent of the level, has a fixed size of 512 entries. Each entry has a size of 8 bytes, so each table is 512 * 8B = 4KiB large and thus fits exactly into one page.
+The x86_64 architecture uses a 4-level page table and a page size of 4 KiB. Each page table, independent of the level, has a fixed size of 512 entries. Each entry has a size of 8 bytes, so each table is 512 * 8 B = 4 KiB large and thus fits exactly into one page.
-The page table index for level is derived directly from the virtual address:
+The page table index for each level is derived directly from the virtual address:

-We see that each table index consists of 9 bits, which makes sense because each table has 2^9 = 512 entries. The lowest 12 bits are the offset in the 4KiB page (2^12 bytes = 4KiB). Bits 48 to 64 are discarded, which means that x86_64 is not really 64-bit since it only supports 48-bit addresses.
+We see that each table index consists of 9 bits, which makes sense because each table has 2^9 = 512 entries. The lowest 12 bits are the offset in the 4 KiB page (2^12 bytes = 4 KiB). Bits 48 to 64 are discarded, which means that x86_64 is not really 64-bit since it only supports 48-bit addresses.
-[5-level page table]: https://en.wikipedia.org/wiki/Intel_5-level_paging
-
-Even though bits 48 to 64 are discarded, they can't be set to arbitrary values. Instead all bits in this range have to be copies of bit 47 in order to keep addresses unique and allow future extensions like the 5-level page table. This is called _sign-extension_ because it's very similar to the [sign extension in two's complement]. When an address is not correctly sign-extended, the CPU throws an exception.
+Even though bits 48 to 64 are discarded, they can't be set to arbitrary values. Instead, all bits in this range have to be copies of bit 47 in order to keep addresses unique and allow future extensions like the 5-level page table. This is called _sign-extension_ because it's very similar to the [sign extension in two's complement]. When an address is not correctly sign-extended, the CPU throws an exception.
[sign extension in two's complement]: https://en.wikipedia.org/wiki/Two's_complement#Sign_extension
-It's worth noting that the recent "Ice Lake" Intel CPUs optionally support [5-level page tables] to extends virtual addresses from 48-bit to 57-bit. Given that optimizing our kernel for a specific CPU does not make sense at this stage, we will only work with standard 4-level page tables in this post.
+It's worth noting that the recent "Ice Lake" Intel CPUs optionally support [5-level page tables] to extend virtual addresses from 48-bit to 57-bit. Given that optimizing our kernel for a specific CPU does not make sense at this stage, we will only work with standard 4-level page tables in this post.
[5-level page tables]: https://en.wikipedia.org/wiki/Intel_5-level_paging
@@ -160,26 +158,26 @@ It's worth noting that the recent "Ice Lake" Intel CPUs optionally support [5-le
Let's go through an example to understand how the translation process works in detail:
-
+
The physical address of the currently active level 4 page table, which is the root of the 4-level page table, is stored in the `CR3` register. Each page table entry then points to the physical frame of the next level table. The entry of the level 1 table then points to the mapped frame. Note that all addresses in the page tables are physical instead of virtual, because otherwise the CPU would need to translate those addresses too (which could cause a never-ending recursion).
-The above page table hierarchy maps two pages (in blue). From the page table indices we can deduce that the virtual addresses of these two pages are `0x803FE7F000` and `0x803FE00000`. Let's see what happens when the program tries to read from address `0x803FE7F5CE`. First, we convert the address to binary and determine the page table indices and the page offset for the address:
+The above page table hierarchy maps two pages (in blue). From the page table indices, we can deduce that the virtual addresses of these two pages are `0x803FE7F000` and `0x803FE00000`. Let's see what happens when the program tries to read from address `0x803FE7F5CE`. First, we convert the address to binary and determine the page table indices and the page offset for the address:

With these indices, we can now walk the page table hierarchy to determine the mapped frame for the address:
- We start by reading the address of the level 4 table out of the `CR3` register.
-- The level 4 index is 1, so we look at the entry with index 1 of that table, which tells us that the level 3 table is stored at address 16KiB.
-- We load the level 3 table from that address and look at the entry with index 0, which points us to the level 2 table at 24KiB.
+- The level 4 index is 1, so we look at the entry with index 1 of that table, which tells us that the level 3 table is stored at address 16 KiB.
+- We load the level 3 table from that address and look at the entry with index 0, which points us to the level 2 table at 24 KiB.
- The level 2 index is 511, so we look at the last entry of that page to find out the address of the level 1 table.
-- Through the entry with index 127 of the level 1 table we finally find out that the page is mapped to frame 12KiB, or 0x3000 in hexadecimal.
+- Through the entry with index 127 of the level 1 table, we finally find out that the page is mapped to frame 12 KiB, or 0x3000 in hexadecimal.
- The final step is to add the page offset to the frame address to get the physical address 0x3000 + 0x5ce = 0x35ce.

-The permissions for the page in the level 1 table are `r`, which means read-only. The hardware enforces these permissions and would throw an exception if we tried to write to that page. Permissions in higher level pages restrict the possible permissions in lower level, so if we set the level 3 entry to read-only, no pages that use this entry can be writable, even if lower levels specify read/write permissions.
+The permissions for the page in the level 1 table are `r`, which means read-only. The hardware enforces these permissions and would throw an exception if we tried to write to that page. Permissions in higher level pages restrict the possible permissions in lower levels, so if we set the level 3 entry to read-only, no pages that use this entry can be writable, even if lower levels specify read/write permissions.
It's important to note that even though this example used only a single instance of each table, there are typically multiple instances of each level in each address space. At maximum, there are:
@@ -199,7 +197,7 @@ pub struct PageTable {
}
```
-As indicated by the `repr` attribute, page tables need to be page aligned, i.e. aligned on a 4KiB boundary. This requirement guarantees that a page table always fills a complete page and allows an optimization that makes entries very compact.
+As indicated by the `repr` attribute, page tables need to be page-aligned, i.e., aligned on a 4 KiB boundary. This requirement guarantees that a page table always fills a complete page and allows an optimization that makes entries very compact.
Each entry is 8 bytes (64 bits) large and has the following format:
@@ -208,28 +206,28 @@ Bit(s) | Name | Meaning
0 | present | the page is currently in memory
1 | writable | it's allowed to write to this page
2 | user accessible | if not set, only kernel mode code can access this page
-3 | write through caching | writes go directly to memory
+3 | write-through caching | writes go directly to memory
4 | disable cache | no cache is used for this page
5 | accessed | the CPU sets this bit when this page is used
6 | dirty | the CPU sets this bit when a write to this page occurs
-7 | huge page/null | must be 0 in P1 and P4, creates a 1GiB page in P3, creates a 2MiB page in P2
+7 | huge page/null | must be 0 in P1 and P4, creates a 1 GiB page in P3, creates a 2 MiB page in P2
8 | global | page isn't flushed from caches on address space switch (PGE bit of CR4 register must be set)
9-11 | available | can be used freely by the OS
12-51 | physical address | the page aligned 52bit physical address of the frame or the next page table
52-62 | available | can be used freely by the OS
63 | no execute | forbid executing code on this page (the NXE bit in the EFER register must be set)
-We see that only bits 12–51 are used to store the physical frame address, the remaining bits are used as flags or can be freely used by the operating system. This is possible because we always point to a 4096-byte aligned address, either to a page-aligned page table or to the start of a mapped frame. This means that bits 0–11 are always zero, so there is no reason to store these bits because the hardware can just set them to zero before using the address. The same is true for bits 52–63, because the x86_64 architecture only supports 52-bit physical addresses (similar to how it only supports 48-bit virtual addresses).
+We see that only bits 12–51 are used to store the physical frame address. The remaining bits are used as flags or can be freely used by the operating system. This is possible because we always point to a 4096-byte aligned address, either to a page-aligned page table or to the start of a mapped frame. This means that bits 0–11 are always zero, so there is no reason to store these bits because the hardware can just set them to zero before using the address. The same is true for bits 52–63, because the x86_64 architecture only supports 52-bit physical addresses (similar to how it only supports 48-bit virtual addresses).
Let's take a closer look at the available flags:
-- The `present` flag differentiates mapped pages from unmapped ones. It can be used to temporarily swap out pages to disk when main memory becomes full. When the page is accessed subsequently, a special exception called _page fault_ occurs, to which the operating system can react by reloading the missing page from disk and then continuing the program.
-- The `writable` and `no execute` flags control whether the contents of the page are writable or contain executable instructions respectively.
-- The `accessed` and `dirty` flags are automatically set by the CPU when a read or write to the page occurs. This information can be leveraged by the operating system e.g. to decide which pages to swap out or whether the page contents were modified since the last save to disk.
-- The `write through caching` and `disable cache` flags allow to control the caches for every page individually.
-- The `user accessible` flag makes a page available to userspace code, otherwise it is only accessible when the CPU is in kernel mode. This feature can be used to make [system calls] faster by keeping the kernel mapped while an userspace program is running. However, the [Spectre] vulnerability can allow userspace programs to read these pages nonetheless.
+- The `present` flag differentiates mapped pages from unmapped ones. It can be used to temporarily swap out pages to disk when the main memory becomes full. When the page is accessed subsequently, a special exception called _page fault_ occurs, to which the operating system can react by reloading the missing page from disk and then continuing the program.
+- The `writable` and `no execute` flags control whether the contents of the page are writable or contain executable instructions, respectively.
+- The `accessed` and `dirty` flags are automatically set by the CPU when a read or write to the page occurs. This information can be leveraged by the operating system, e.g., to decide which pages to swap out or whether the page contents have been modified since the last save to disk.
+- The `write-through caching` and `disable cache` flags allow the control of caches for every page individually.
+- The `user accessible` flag makes a page available to userspace code, otherwise, it is only accessible when the CPU is in kernel mode. This feature can be used to make [system calls] faster by keeping the kernel mapped while a userspace program is running. However, the [Spectre] vulnerability can allow userspace programs to read these pages nonetheless.
- The `global` flag signals to the hardware that a page is available in all address spaces and thus does not need to be removed from the translation cache (see the section about the TLB below) on address space switches. This flag is commonly used together with a cleared `user accessible` flag to map the kernel code to all address spaces.
-- The `huge page` flag allows to create pages of larger sizes by letting the entries of the level 2 or level 3 page tables directly point to a mapped frame. With this bit set, the page size increases by factor 512 to either 2MiB = 512 * 4KiB for level 2 entries or even 1GiB = 512 * 2MiB for level 3 entries. The advantage of using larger pages is that fewer lines of the translation cache and fewer page tables are needed.
+- The `huge page` flag allows the creation of pages of larger sizes by letting the entries of the level 2 or level 3 page tables directly point to a mapped frame. With this bit set, the page size increases by factor 512 to either 2 MiB = 512 * 4 KiB for level 2 entries or even 1 GiB = 512 * 2 MiB for level 3 entries. The advantage of using larger pages is that fewer lines of the translation cache and fewer page tables are needed.
[system calls]: https://en.wikipedia.org/wiki/System_call
[Spectre]: https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
@@ -241,28 +239,28 @@ The `x86_64` crate provides types for [page tables] and their [entries], so we d
### The Translation Lookaside Buffer
-A 4-level page table makes the translation of virtual addresses expensive, because each translation requires 4 memory accesses. To improve performance, the x86_64 architecture caches the last few translations in the so-called _translation lookaside buffer_ (TLB). This allows to skip the translation when the translation is still cached.
+A 4-level page table makes the translation of virtual addresses expensive because each translation requires four memory accesses. To improve performance, the x86_64 architecture caches the last few translations in the so-called _translation lookaside buffer_ (TLB). This allows skipping the translation when it is still cached.
Unlike the other CPU caches, the TLB is not fully transparent and does not update or remove translations when the contents of page tables change. This means that the kernel must manually update the TLB whenever it modifies a page table. To do this, there is a special CPU instruction called [`invlpg`] (“invalidate page”) that removes the translation for the specified page from the TLB, so that it is loaded again from the page table on the next access. The TLB can also be flushed completely by reloading the `CR3` register, which simulates an address space switch. The `x86_64` crate provides Rust functions for both variants in the [`tlb` module].
[`invlpg`]: https://www.felixcloutier.com/x86/INVLPG.html
[`tlb` module]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tlb/index.html
-It is important to remember flushing the TLB on each page table modification because otherwise the CPU might keep using the old translation, which can lead to non-deterministic bugs that are very hard to debug.
+It is important to remember to flush the TLB on each page table modification because otherwise, the CPU might keep using the old translation, which can lead to non-deterministic bugs that are very hard to debug.
## Implementation
-One thing that we did not mention yet: **Our kernel already runs on paging**. The bootloader that we added in the ["A minimal Rust Kernel"] post already set up a 4-level paging hierarchy that maps every page of our kernel to a physical frame. The bootloader does this because paging is mandatory in 64-bit mode on x86_64.
+One thing that we did not mention yet: **Our kernel already runs on paging**. The bootloader that we added in the ["A minimal Rust Kernel"] post has already set up a 4-level paging hierarchy that maps every page of our kernel to a physical frame. The bootloader does this because paging is mandatory in 64-bit mode on x86_64.
["A minimal Rust kernel"]: @/edition-2/posts/02-minimal-rust-kernel/index.md#creating-a-bootimage
This means that every memory address that we used in our kernel was a virtual address. Accessing the VGA buffer at address `0xb8000` only worked because the bootloader _identity mapped_ that memory page, which means that it mapped the virtual page `0xb8000` to the physical frame `0xb8000`.
-Paging makes our kernel already relatively safe, since every memory access that is out of bounds causes a page fault exception instead of writing to random physical memory. The bootloader even set the correct access permissions for each page, which means that only the pages containing code are executable and only data pages are writable.
+Paging makes our kernel already relatively safe, since every memory access that is out of bounds causes a page fault exception instead of writing to random physical memory. The bootloader even sets the correct access permissions for each page, which means that only the pages containing code are executable and only data pages are writable.
### Page Faults
-Let's try to cause a page fault by accessing some memory outside of our kernel. First, we create a page fault handler and register it in our IDT, so that we see a page fault exception instead of a generic [double fault] :
+Let's try to cause a page fault by accessing some memory outside of our kernel. First, we create a page fault handler and register it in our IDT, so that we see a page fault exception instead of a generic [double fault]:
[double fault]: @/edition-2/posts/06-double-faults/index.md
@@ -298,7 +296,7 @@ extern "x86-interrupt" fn page_fault_handler(
}
```
-The [`CR2`] register is automatically set by the CPU on a page fault and contains the accessed virtual address that caused the page fault. We use the [`Cr2::read`] function of the `x86_64` crate to read and print it. The [`PageFaultErrorCode`] type provides more information about the type of memory access that caused the page fault, for example whether it was caused by a read or write operation. For this reason we print it too. We can't continue execution without resolving the page fault, so we enter a [`hlt_loop`] at the end.
+The [`CR2`] register is automatically set by the CPU on a page fault and contains the accessed virtual address that caused the page fault. We use the [`Cr2::read`] function of the `x86_64` crate to read and print it. The [`PageFaultErrorCode`] type provides more information about the type of memory access that caused the page fault, for example, whether it was caused by a read or write operation. For this reason, we print it too. We can't continue execution without resolving the page fault, so we enter a [`hlt_loop`] at the end.
[`CR2`]: https://en.wikipedia.org/wiki/Control_register#CR2
[`Cr2::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr2.html#method.read
@@ -358,7 +356,7 @@ By commenting out the last line, we see that the read access works, but the writ

-We see that the _"read worked"_ message is printed, which indicates that the read operation did not cause any errors. However, instead of the _"write worked"_ message a page fault occurs. This time the [`PROTECTION_VIOLATION`] flag is set in addition to the [`CAUSED_BY_WRITE`] flag, which indicates that the page was present, but the operation was not allowed on it. In this case, writes to the page are not allowed since code pages are mapped as read-only.
+We see that the _"read worked"_ message is printed, which indicates that the read operation did not cause any errors. However, instead of the _"write worked"_ message, a page fault occurs. This time the [`PROTECTION_VIOLATION`] flag is set in addition to the [`CAUSED_BY_WRITE`] flag, which indicates that the page was present, but the operation was not allowed on it. In this case, writes to the page are not allowed since code pages are mapped as read-only.
[`PROTECTION_VIOLATION`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.PROTECTION_VIOLATION
@@ -400,7 +398,7 @@ So the currently active level 4 page table is stored at address `0x1000` in _phy
[`PhysAddr`]: https://docs.rs/x86_64/0.14.2/x86_64/addr/struct.PhysAddr.html
-Accessing physical memory directly is not possible when paging is active, since programs could easily circumvent memory protection and access memory of other programs otherwise. So the only way to access the table is through some virtual page that is mapped to the physical frame at address `0x1000`. This problem of creating mappings for page table frames is a general problem, since the kernel needs to access the page tables regularly, for example when allocating a stack for a new thread.
+Accessing physical memory directly is not possible when paging is active, since programs could easily circumvent memory protection and access the memory of other programs otherwise. So the only way to access the table is through some virtual page that is mapped to the physical frame at address `0x1000`. This problem of creating mappings for page table frames is a general problem since the kernel needs to access the page tables regularly, for example, when allocating a stack for a new thread.
Solutions to this problem are explained in detail in the next post.
@@ -408,10 +406,10 @@ Solutions to this problem are explained in detail in the next post.
This post introduced two memory protection techniques: segmentation and paging. While the former uses variable-sized memory regions and suffers from external fragmentation, the latter uses fixed-sized pages and allows much more fine-grained control over access permissions.
-Paging stores the mapping information for pages in page tables with one or more levels. The x86_64 architecture uses 4-level page tables and a page size of 4KiB. The hardware automatically walks the page tables and caches the resulting translations in the translation lookaside buffer (TLB). This buffer is not updated transparently and needs to be flushed manually on page table changes.
+Paging stores the mapping information for pages in page tables with one or more levels. The x86_64 architecture uses 4-level page tables and a page size of 4 KiB. The hardware automatically walks the page tables and caches the resulting translations in the translation lookaside buffer (TLB). This buffer is not updated transparently and needs to be flushed manually on page table changes.
We learned that our kernel already runs on top of paging and that illegal memory accesses cause page fault exceptions. We tried to access the currently active page tables, but we weren't able to do it because the CR3 register stores a physical address that we can't access directly from our kernel.
## What's next?
-The next post explains how to implement support for paging in our kernel. It presents different ways to access physical memory from our kernel, which makes it possible to access the page tables that our kernel runs on. At this point we are able to implement functions for translating virtual to physical addresses and for creating new mappings in the page tables.
+The next post explains how to implement support for paging in our kernel. It presents different ways to access physical memory from our kernel, which makes it possible to access the page tables that our kernel runs on. At this point, we are able to implement functions for translating virtual to physical addresses and for creating new mappings in the page tables.
diff --git a/blog/content/edition-2/posts/08-paging-introduction/index.zh-CN.md b/blog/content/edition-2/posts/08-paging-introduction/index.zh-CN.md
new file mode 100644
index 00000000..f535bfb9
--- /dev/null
+++ b/blog/content/edition-2/posts/08-paging-introduction/index.zh-CN.md
@@ -0,0 +1,423 @@
++++
+title = "内存分页初探"
+weight = 8
+path = "zh-CN/paging-introduction"
+date = 2019-01-14
+
+[extra]
+# Please update this when updating the translation
+translation_based_on_commit = "096c044b4f3697e91d8e30a2e817e567d0ef21a2"
+# GitHub usernames of the people that translated this post
+translators = ["liuyuran"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["JiangengDong"]
++++
+
+本文主要讲解 _内存分页_ 机制,一种我们将会应用到操作系统里的十分常见的内存模型。同时,也会展开说明为何需要进行内存隔离、_分段机制_ 是如何运作的、_虚拟内存_ 是什么,以及内存分页是如何解决内存碎片问题的,同时也会对x86_64的多级页表布局进行探索。
+
+
+
+这个系列的 blog 在[GitHub]上开放开发,如果你有任何问题,请在这里开一个 issue 来讨论。当然你也可以在[底部][at the bottom]留言。你可以在[`post-08`][post branch]找到这篇文章的完整源码。
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-08
+
+
+
+## 内存保护
+
+操作系统的主要任务之一就是隔离各个应用程序的执行环境,比如你的浏览器不应对你的文本编辑器造成影响,因此,操作系统会利用硬件级别的功能确保一个进程无法访问另一个进程的内存区域,但具体实现方式因硬件和操作系统实现而异。
+
+比如一些 ARM Cortex-M 处理器(用于嵌入式系统)搭载了 [_内存保护单元_][_Memory Protection Unit_] (MPU),该单元允许你定义少量具有不同读写权限的内存区域。MPU可以确保每一次对内存的访问都需要具备对应的权限,否则就会抛出异常。而操作系统则会在进程切换时,确保当前进程仅能访问自己所持有的内存区域,由此实现内存隔离。
+
+[_Memory Protection Unit_]: https://developer.arm.com/docs/ddi0337/e/memory-protection-unit/about-the-mpu
+
+在x86架构下,硬件层次为内存保护提供了两种不同的途径:[段][segmentation] 和 [页][paging]。
+
+[segmentation]: https://en.wikipedia.org/wiki/X86_memory_segmentation
+[paging]: https://en.wikipedia.org/wiki/Virtual_memory#Paged_virtual_memory
+
+## 内存分段
+
+内存分段技术出现于1978年,初衷是用于扩展可用内存,该技术的最初背景是当时的CPU仅使用16位地址,而可使用的内存也只有64KiB。为了扩展可用内存,用于存储偏移量的段寄存器这个概念应运而生,CPU可以据此访问更多的内存,因此可用内存被成功扩展到了1MiB。
+
+CPU可根据内存访问方式自动确定段寄存器的定义:对于指令获取操作,使用代码段寄存器 `CS`;对于栈操作(入栈/出栈),使用栈段寄存器 `SS`;对于其他指令,则使用数据段寄存器 `DS` 或额外段寄存器 `ES`。另外还有两个后来添加的扩展段寄存器 `FS` 和 `GS`,可以随意使用。
+
+在最初版本的内存分段中,段寄存器仅仅是直接包含了偏移量,并不包含任何权限控制,直到 [_保护模式_][_protected mode_] 这个概念的出现。当CPU进入此模式后,段描述符会包含一个本地或全局的 [_描述符表_][_descriptor table_] 索引,它对应的数据包含了偏移量、段的大小和访问权限。通过加载各个进程所属的全局/本地描述符表,可以实现进程仅能访问属于自己的内存区域的效果,操作系统也由此实现了进程隔离。
+
+[_protected mode_]: https://en.wikipedia.org/wiki/X86_memory_segmentation#Protected_mode
+[_descriptor table_]: https://en.wikipedia.org/wiki/Global_Descriptor_Table
+
+针对在判断权限前如何更正内存地址这个问题,内存分段使用了一个如今已经高度普及的技术:_虚拟内存_。
+
+### 虚拟内存
+
+所谓虚拟内存,就是将物理存储器地址抽象为一段完全独立的内存区域,在直接访问物理存储器之前,加入了一个地址转换的步骤。对于内存分页机制而言,地址转换就是在虚拟地址的基础上加入偏移量,如在偏移量为 `0x1111000` 的段中,虚拟地址 `0x1234000` 的对应的物理内存地址是 `0x2345000`。
+
+首先我们需要明确两个名词,执行地址转换步骤之前的地址叫做 _虚拟地址_,而转换后的地址叫做 _物理地址_,两者最显著的区别就是物理地址是全局唯一的,而两个虚拟地址理论上可能指向同一个物理地址。同样的,如果使用不同的地址偏移量,同一个虚拟地址可能会对应不同的物理地址。
+
+最直观的例子就是同时执行两个相同的程序:
+
+
+
+
+如你所见,这就是两个相同程序的内存分配情况,两者具有不同的地址偏移量(即 _段基址_)。第一个程序实例的段基址为100,所以其虚拟地址范围0-150换算成物理地址就是100-250。第二个程序实例的段基址为300,所以其虚拟地址范围0-150换算成物理地址就是300-450。所以该机制允许程序共用同一套代码逻辑,使用同样的虚拟地址,并且不会干扰到彼此。
+
+该机制的另一个优点就是让程序不局限于特定的某一段物理内存,而是依赖另一套虚拟内存地址,从而让操作系统在不重编译程序的前提下使用全部的内存区域。
+
+### 内存碎片
+
+虚拟内存机制已经让内存分段机制十分强大,但也有碎片化的问题,请看,如果我们同时执行三个程序实例的话:
+
+
+
+在不能重叠使用的前提下,我们完全找不到足够的地方来容纳第三个程序,因为剩余的连续空间已经不够了。此时的问题在于,我们需要使用 _连续_ 的内存区域,不要将那些中间的空白部分白白浪费掉。
+
+比较合适的办法就是暂停程序运行,将内存块移动到一个连续区间内,更新段基址信息,然后恢复程序运行:
+
+
+
+这样我们就有足够的内存空间来运行第三个程序实例了。
+
+但这样做也有一些问题,内存整理程序往往需要拷贝一段比较大的内存,这会很大程度上影响性能,但是又必须在碎片问题变得过于严重前完成这个操作。同时由于其消耗时间的不可预测性,程序很可能会随机挂起,甚至在用户视角下失去响应。
+
+这也是大多数系统放弃内存分段技术的原因之一,事实上,该技术已经被x86平台的64位模式所抛弃,因为 _内存分页技术_ 已经完全解决了碎片化问题。
+
+## 内存分页
+
+内存分页的思想依然是使用虚拟地址映射物理地址,但是其分配单位变成了固定长度的较小的内存区域。这些虚拟内存块被称为 _页_,而其对应的物理内存则被称为 _页帧_,每一页都可以映射到一个对应的页帧中。这也就意味着我们可以将程序所使用的一大块内存区域打散到所有物理内存中,而不必分配一块连续的区域。
+
+其优势就在于,如果我们遇到上文中提到的内存碎片问题时,内存分页技术会这样解决它:
+
+
+
+例如我们将页的单位设置为50字节,也就是说我们的每一个程序实例所使用的内存都被分割为三页。每一页都可以独立映射到一个页帧中,因此连续的虚拟内存并不一定需要对应连续的物理内存区域,因此也就无需进行内存碎片整理了。
+
+### 潜在碎片
+
+对比内存分段,内存分页选择用较多的较小且固定长度的内存区域代替较少的较大且长度不固定的内存区域。正因为如此,不会有页帧因为长度过小而产生内存碎片。
+
+然而这只是 _表面上如此_,实际上依然存在着名为 _内部碎片_ 的隐蔽内存碎片,造成内部碎片的原因是并非每个内存区域都是分页单位的整数倍。比如一个程序需要101字节的内存,但它依然需要分配3个长度为50字节的页,最终造成了49字节的内存浪费,区别于内存分段造成的内存碎片,这种情况被称为 _内部碎片_。
+
+内部碎片虽然也很可恶,但是无论如何也比内存分段造成的内存碎片要好得多,尽管其依然会浪费内存空间,但是无需碎片整理,且碎片数量是可预测的(每一个虚拟内存空间平均会造成半个页帧的内存浪费)。
+
+### 页表
+
+我们应当预见到,在操作系统开始运行后,会存在数以百万计的页-页帧映射关系,这些映射关系需要存储在某个地方。分段技术可以为每个活动的内存区域都指定一个段寄存器,但是分页技术不行,因为其使用到的页的数量实在是太多了,远多于寄存器数量,所以分页技术采用了一种叫做 _页表_ 的结构来存储映射信息。
+
+以上面的应用场合为例,页表看起来是这样子的:
+
+
+
+我们可以看到每个程序实例都有其专有的页表,但当前正在活跃的页表指针会被存储到特定的CPU寄存器中,在 `x86` 架构中,该寄存器被称为 `CR3`。操作系统的任务之一,就是在程序运行前,把当前所使用的页表指针推进对应的寄存器中。
+
+每次内存访问CPU都会从寄存器获取页表指针,并从页表中获取虚拟地址所对应的页帧,这一步操作完全由硬件完成,对于程序而言是完全透明的。为了加快地址转换的速度,许多CPU架构都加入了一个能够存储最后一次地址转换相关信息的特殊缓存。
+
+根据架构实现的不同,页表也可以在 flags 字段存储一些额外的属性,如访问权限之类。在上面的场景下。 "r/w" 这个 flag 可以使该页同时能够读和写。
+
+### 多级页表
+
+上文中的简单页表在较大的地址空间下会有个问题:太浪费内存了。打个比方,一个程序需要使用4个虚拟内存页 `0`、`1_000_000`、`1_000_050` 和 `1_000_100`(假设以 `_` 为千位分隔符):
+
+
+
+尽管它仅仅会使用4个页帧,但是页表中有百万级别的映射条目,而我们还不能释放那些空白的条目,因为这会对地址转换造成很大的风险(比如可能无法保证4号页依然对应4号页帧)。
+
+我们可以使用 **两级页表** 来避免内存浪费,其基本思路就是对不同的地址区域使用不同的页表。地址区域和一级页表的映射关系被存储在一个被称为 _二级页表_ 的额外表格中。
+
+举个例子,我们先假设每个一级页表映射 `10_000` 字节的内存空间,在上文所述的应用场合下,此时的页表结构看上去是这样的:
+
+
+
+页 `0` 位于第一个 `10_000` 字节的内存区域内,位于内存区域 `0` 内,对应一级页表 `T1`,所以它所在的内存位置也可以被表述为 `页 0 帧 0`.
+
+页 `1_000_000`、 `1_000_050` 和 `1_000_100` 均可以映射到第100个 `10_000` 字节的内存区域内,所以位于内存区域 `1_000_100` 中,该内存区域指向一级页表 T2。但这三个页分别对应该一级页表 T2 中的页帧 `100`、`150` 和 `200`,因为一级页表中是不存储内存区域偏移量的。
+
+在这个场合中,二级页表中还是出现了100个被浪费的位置,不过无论如何也比之前数以百万计的浪费好多了,因为我们没有额外创建指向 `10_000` 到 `1_000_000` 这段内存区域的一级页表。
+
+同理,两级页表的原理可以扩展到三级、四级甚至更多的级数。通常而言,可以让页表寄存器指向最高级数的表,然后一层一层向下寻址,直到抵达一级页表,获取页帧地址。这种技术就叫做 _多级_ 或 _多层_ 页表。
+
+那么现在我们已经明白了内存分页和多级页表机制的工作原理,下面我们会探索一下在 x86_64 平台下内存分页机制是如何实现的(假设CPU运行在64位模式下)。
+
+## x86_64中的分页
+
+x86_64 平台使用4级页表,页大小为4KiB,无论层级,每个页表均具有512个条目,每个条目占用8字节,所以每个页表固定占用 512 * 8B = 4KiB,正好占满一个内存页。
+
+每一级的页表索引号都可以通过虚拟地址推导出来:
+
+
+
+我们可以看到,每个表索引号占据9个字节,这当然是有道理的,每个表都有 2^9 = 512 个条目,低12位用来表示内存页的偏移量(2^12 bytes = 4KiB,而上文提到页大小为4KiB)。第48-64位毫无用处,这也就意味着 x86_64 并非真正的64位,因为它实际上支持48位地址。
+
+[5-level page table]: https://en.wikipedia.org/wiki/Intel_5-level_paging
+
+尽管48-64位毫无用处,但依然不被允许随意赋值,而是必须将其设置为与47位相同的值以保证地址唯一性,由此留出未来对此进行扩展的可能性,如实现5级页表。该技术被称为 _符号扩展_,理由是它与 [二进制补码][sign extension in two's complement] 机制真的太相似了。当地址不符合该机制定义的规则时,CPU会抛出异常。
+
+[sign extension in two's complement]: https://en.wikipedia.org/wiki/Two's_complement#Sign_extension
+
+值得注意的是,英特尔最近发布了一款代号是冰湖的CPU,它的新功能之一就是可选支持能够将虚拟地址从48位扩展到57位的 [5级页表][5-level page tables]。但是针对一款特定的CPU做优化在现阶段并没有多少意义,所以本文仅会涉及标准的4级页表。
+
+[5-level page tables]: https://en.wikipedia.org/wiki/Intel_5-level_paging
+
+### 地址转换范例
+
+请看下图,这就是一个典型的地址转换过程的范例:
+
+
+
+`CR3` 寄存器中存储着指向4级页表的物理地址,而在每一级的页表(除一级页表外)中,都存在着指向下一级页表的指针,1级页表则存放着直接指向页帧地址的指针。注意,这里的指针,都是指页表的物理地址,而非虚拟地址,否则CPU会因为需要进行额外的地址转换而陷入无限递归中。
+
+最终,寻址结果是上图中的两个蓝色区域,根据页表查询结果,它们的虚拟地址分别是 `0x803FE7F000` 和 `0x803FE00000`,那么让我们看一看当程序尝试访问内存地址 `0x803FE7F5CE` 时会发生什么事情。首先我们需要把地址转换为二进制,然后确定该地址所对应的页表索引和页偏移量:
+
+
+
+通过这些索引,我们就可以通过依次查询多级页表来定位最终要指向的页帧:
+
+- 首先,我们需要从 `CR3` 寄存器中读出4级页表的物理地址。
+- 4级页表的索引号是1,所以我们可以看到3级页表的地址是16KiB。
+- 载入3级页表,根据索引号0,确定2级页表的地址是24KiB。
+- 载入2级页表,根据索引号511,确定1级页表的地址是32KiB。
+- 载入1级页表,根据索引号127,确定该地址所对应的页帧地址为12KiB,使用Hex表达可写作 0x3000。
+- 最终步骤就是将最后的页偏移量拼接到页帧地址上,即可得到物理地址,即 0x3000 + 0x5ce = 0x35ce。
+
+
+
+由上图可知,该页帧在一级页表中的权限被标记为 `r`,即只读,硬件层面已经确保当我们试图写入数据的时候会抛出异常。较高级别的页表的权限设定会覆盖较低级别的页表,如3级页表中设定为只读的区域,其所关联的所有下级页表对应的内存区域均会被认为是只读,低级别的页表本身的设定会被忽略。
+
+注意,示例图片中为了简化显示,看起来每个页表都只有一个条目,但实际上,4级以下的页表每一层都可能存在多个实例,其数量上限如下:
+
+- 1个4级页表
+- 512个3级页表(因为4级页表可以有512个条目)
+- 512*512个2级页表(因为每个3级页表可以有512个条目)
+- 512*512*512个1级页表(因为每个2级页表可以有512个条目)
+
+### 页表格式
+
+在 x86_64 平台下,页表是一个具有512个条目的数组,于Rust而言就是这样:
+
+```rust
+#[repr(align(4096))]
+pub struct PageTable {
+ entries: [PageTableEntry; 512],
+}
+```
+
+`repr` 属性定义了内存页的大小,这里将其设定为了4KiB,该设置确保了页表总是能填满一整个内存页,并允许编译器进行一些优化,使其存储方式更加紧凑。
+
+每个页表条目长度都是8字节(64比特),其内部结构如下:
+
+| Bit(s) | 名字 | 含义 |
+| ------ | --------------------- | ----------------------------------------------------------------------------- |
+| 0 | present | 该页目前在内存中 |
+| 1 | writable | 该页可写 |
+| 2 | user accessible | 如果没有设定,仅内核代码可以访问该页 |
+| 3 | write through caching | 写操作直接应用到内存 |
+| 4 | disable cache | 对该页禁用缓存 |
+| 5 | accessed | 当该页正在被使用时,CPU设置该比特的值 |
+| 6 | dirty | 当该页正在被写入时,CPU设置该比特的值 |
+| 7 | huge page/null | 在P1和P4状态时必须为0,在P3时创建一个1GiB的内存页,在P2时创建一个2MiB的内存页 |
+| 8 | global | 当地址空间切换时,该页尚未应用更新(CR4寄存器中的PGE比特位必须一同被设置) |
+| 9-11 | available | 可被操作系统自由使用 |
+| 12-51 | physical address | 经过52比特对齐过的页帧地址,或下一级的页表地址 |
+| 52-62 | available | 可被操作系统自由使用 |
+| 63 | no execute | 禁止在该页中运行代码(EFER寄存器中的NXE比特位必须一同被设置) |
+
+我们可以看到,仅12–51位会用于存储页帧地址或页表地址,其余比特都用于存储标志位,或由操作系统自由使用。
+其原因就是,该地址总是指向一个4096比特对齐的地址、页表或者页帧的起始地址。
+这也就意味着0-11位始终为0,没有必要存储这些东西,硬件层面在使用该地址之前,也会将这12位比特设置为0,52-63位同理,因为x86_64平台仅支持52位物理地址(类似于上文中提到的仅支持48位虚拟地址的原因)。
+
+进一步说明一下可用的标志位:
+
+- `present` 标志位并非是指未映射的页,而是指其对应的内存页由于物理内存已满而被交换到硬盘中,如果该页在换出之后再度被访问,则会抛出 _page fault_ 异常,此时操作系统应该将此页重新载入物理内存以继续执行程序。
+- `writable` 和 `no execute` 标志位分别控制该页是否可写,以及是否包含可执行指令。
+- `accessed` 和 `dirty` 标志位由CPU在读写该页时自动设置,该状态信息可用于辅助操作系统的内存控制,如判断哪些页可以换出,以及换出到硬盘后页里的内容是否已被修改。
+- `write through caching` 和 `disable cache` 标志位可以单独控制每一个页对应的缓存。
+- `user accessible` 标志位决定了页中是否包含用户态的代码,否则它仅当CPU处于核心态时可访问。该特性可用于在用户态程序运行时保持内核代码映射以加速[系统调用][system calls]。然而,[Spectre] 漏洞会允许用户态程序读取到此类页的数据。
+- `global` 标志位决定了该页是否会在所有地址空间都存在,即使切换地址空间,也不会从地址转换缓存(参见下文中关于TLB的章节)中被移除。一般和 `user accessible` 标志位共同使用,在所有地址空间映射内核代码。
+- `huge page` 标志位允许2级页表或3级页表直接指向页帧来分配一块更大的内存空间,该标志位被启用后,页大小会增加512倍。就结果而言,对于2级页表的条目,其会直接指向一个 2MiB = 512 * 4KiB 大小的大型页帧,而对于3级页表的条目,就会直接指向一个 1GiB = 512 * 2MiB 大小的巨型页帧。通常而言,这个功能会用于节省地址转换缓存的空间,以及降低逐层查找页表的耗时。
+
+[system calls]: https://en.wikipedia.org/wiki/System_call
+[Spectre]: https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
+
+`x86_64` crate 为我们提供了 [page tables] 的结构封装,以及其内部条目 [entries],所以我们无需自己实现具体的结构。
+
+[page tables]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTable.html
+[entries]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTableEntry.html
+
+### 地址转换后备缓冲区(TLB)
+
+显而易见,4级页表使地址转换过程变得有点慢,每次转换都需要进行4次内存访问。为了改善这个问题,x86_64平台将最后几次转换结果放在所谓的 _地址转换后备缓冲区_(TLB)中,这样对同样地址的连续重复转换就可以直接返回缓存中存储的结果。
+
+不同于CPU缓存,TLB并非是完全对外透明的,它在页表变化时并不会自动更新或删除被缓存的结果。这也就是说,内核需要在页表发生变化时,自己来处理TLB的更新。针对这个需要,CPU也提供了一个用于从TLB删除特定页的缓存的指令 [`invlpg`] (“invalidate page”),调用该指令之后,下次访问该页就会重新生成缓存。不过还有一个更彻底的办法,通过手动写入 `CR3` 寄存器可以制造出模拟地址空间切换的效果,TLB也会被完全刷新。`x86_64` crate 中的 [`tlb` module] 提供了上面的两种手段,并封装了对应的函数。
+
+[`invlpg`]: https://www.felixcloutier.com/x86/INVLPG.html
+[`tlb` module]: https://docs.rs/x86_64/0.14.2/x86_64/instructions/tlb/index.html
+
+请注意,在修改页表之后,同步修改TLB是十分十分重要的事情,不然CPU可能会返回一个错误的物理地址,因为这种原因造成的bug是非常难以追踪和调试的。
+
+## 具体实现
+
+有件事我们还没有提过:**我们的内核已经是在页上运行的**。在前文 ["最小内核"]["A minimal Rust Kernel"] 中,我们添加的bootloader已经搭建了一个4级页表结构,并将内核中使用的每个页都映射到了物理页帧上,其原因就是,在64位的 x86_64 平台下分页是被强制使用的。
+
+["A minimal Rust kernel"]: @/edition-2/posts/02-minimal-rust-kernel/index.md#creating-a-bootimage
+
+这也就是说,我们在内核中所使用的每一个内存地址其实都是虚拟地址,VGA缓冲区是唯一的例外,因为bootloader为这个地址使用了 _一致映射_,令其直接指向地址 `0xb8000`。所谓一致映射,就是能将虚拟页 `0xb8000` 直接映射到物理页帧 `0xb8000`。
+
+使用分页技术后,我们的内核在某种意义上已经十分安全了,因为越界的内存访问会导致 page fault 异常而不是访问到一个随机物理地址。bootloader已经为每一个页都设置了正确的权限,比如仅代码页具有执行权限、仅数据页具有写权限。
+
+### Page Faults
+
+那么我们来通过内存越界访问手动触发一次 page fault,首先我们先写一个错误处理函数并注册到IDT中,这样我们就可以正常接收到这个异常,而非 [double fault] 了:
+
+[double fault]: @/edition-2/posts/06-double-faults/index.md
+
+```rust
+// in src/interrupts.rs
+
+lazy_static! {
+ static ref IDT: InterruptDescriptorTable = {
+ let mut idt = InterruptDescriptorTable::new();
+
+ […]
+
+ idt.page_fault.set_handler_fn(page_fault_handler); // new
+
+ idt
+ };
+}
+
+use x86_64::structures::idt::PageFaultErrorCode;
+use crate::hlt_loop;
+
+extern "x86-interrupt" fn page_fault_handler(
+ stack_frame: InterruptStackFrame,
+ error_code: PageFaultErrorCode,
+) {
+ use x86_64::registers::control::Cr2;
+
+ println!("EXCEPTION: PAGE FAULT");
+ println!("Accessed Address: {:?}", Cr2::read());
+ println!("Error Code: {:?}", error_code);
+ println!("{:#?}", stack_frame);
+ hlt_loop();
+}
+```
+
+[`CR2`] 寄存器会在 page fault 发生时,被CPU自动写入导致异常的虚拟地址,我们可以用 `x86_64` crate 提供的 [`Cr2::read`] 函数来读取并打印该寄存器。[`PageFaultErrorCode`] 类型为我们提供了内存访问型异常的具体信息,比如究竟是因为读取还是写入操作,我们同样将其打印出来。并且不要忘记,在显式结束异常处理前,程序是不会恢复运行的,所以要在最后调用 [`hlt_loop`] 函数。
+
+[`CR2`]: https://en.wikipedia.org/wiki/Control_register#CR2
+[`Cr2::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr2.html#method.read
+[`PageFaultErrorCode`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html
+[LLVM bug]: https://github.com/rust-lang/rust/issues/57270
+[`hlt_loop`]: @/edition-2/posts/07-hardware-interrupts/index.md#the-hlt-instruction
+
+那么可以开始触发内存越界访问了:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init();
+
+ // new
+ let ptr = 0xdeadbeaf as *mut u32;
+ unsafe { *ptr = 42; }
+
+ // as before
+ #[cfg(test)]
+ test_main();
+
+ println!("It did not crash!");
+ blog_os::hlt_loop();
+}
+```
+
+启动执行后,我们可以看到,page fault 的处理函数被触发了:
+
+
+
+`CR2` 确实保存了导致异常的虚拟地址 `0xdeadbeaf`,而错误码 [`CAUSED_BY_WRITE`] 也说明了导致异常的操作是写入。甚至于可以通过 [未设置的比特位][`PageFaultErrorCode`] 看出更多的信息,例如 `PROTECTION_VIOLATION` 未被设置说明目标页根本就不存在。
+
+[`CAUSED_BY_WRITE`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.CAUSED_BY_WRITE
+
+并且我们可以看到当前指令指针是 `0x2031b2`,根据上文的知识,我们知道它应该属于一个代码页。而代码页被bootloader设定为只读权限,所以读取是正常的,但写入就会触发 page fault 异常。比如你可以试着将上面代码中的 `0xdeadbeaf` 换成 `0x2031b2`:
+
+```rust
+// Note: The actual address might be different for you. Use the address that
+// your page fault handler reports.
+let ptr = 0x2031b2 as *mut u32;
+
+// read from a code page
+unsafe { let x = *ptr; }
+println!("read worked");
+
+// write to a code page
+unsafe { *ptr = 42; }
+println!("write worked");
+```
+
+执行后,我们可以看到读取操作成功了,但写入操作抛出了 page fault 异常:
+
+
+
+我们可以看到 _"read worked"_ 这条日志,说明读操作没有出问题,而 _"write worked"_ 这条日志则没有被打印,起而代之的是一个异常日志。这一次 [`PROTECTION_VIOLATION`] 标志位的 [`CAUSED_BY_WRITE`] 比特位被设置,说明异常正是被非法写入操作引发的,因为我们之前为该页设置了只读权限。
+
+[`PROTECTION_VIOLATION`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/idt/struct.PageFaultErrorCode.html#associatedconstant.PROTECTION_VIOLATION
+
+### 访问页表
+
+那么我们来看看内核中页表的存储方式:
+
+```rust
+// in src/main.rs
+
+#[no_mangle]
+pub extern "C" fn _start() -> ! {
+ println!("Hello World{}", "!");
+
+ blog_os::init();
+
+ use x86_64::registers::control::Cr3;
+
+ let (level_4_page_table, _) = Cr3::read();
+ println!("Level 4 page table at: {:?}", level_4_page_table.start_address());
+
+ […] // test_main(), println(…), and hlt_loop()
+}
+```
+`x86_64` crate 中的 [`Cr3::read`] 函数可以返回 `CR3` 寄存器中的当前使用的4级页表,它返回的是 [`PhysFrame`] 和 [`Cr3Flags`] 两个类型组成的元组结构。不过此时我们只关心页帧信息,所以第二个元素暂且不管。
+
+[`Cr3::read`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr3.html#method.read
+[`PhysFrame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/frame/struct.PhysFrame.html
+[`Cr3Flags`]: https://docs.rs/x86_64/0.14.2/x86_64/registers/control/struct.Cr3Flags.html
+
+然后我们会看到如下输出:
+
+```
+Level 4 page table at: PhysAddr(0x1000)
+```
+
+所以当前的4级页表存储在 _物理地址_ `0x1000` 处,而且地址的外层数据结构是 [`PhysAddr`],那么问题来了:我们如何在内核中直接访问这个页表?
+
+[`PhysAddr`]: https://docs.rs/x86_64/0.14.2/x86_64/addr/struct.PhysAddr.html
+
+当分页功能启用时,直接访问物理内存是被禁止的,否则程序就可以很轻易的侵入其他程序的内存,所以唯一的途径就是通过某些手段构建一个指向 `0x1000` 的虚拟页。那么问题就变成了如何手动创建页映射,但其实该功能在很多地方都会用到,例如内核在创建新的线程时需要额外创建栈,同样需要用到该功能。
+
+我们将在下一篇文章中对此问题进行展开。
+
+## 小结
+
+本文介绍了两种内存保护技术:分段和分页。前者每次分配的内存区域大小是可变的,但会受到内存碎片的影响;而后者使用固定大小的页,并允许对访问权限进行精确控制。
+
+分页技术将映射信息存储在一级或多级页表中,x86_64 平台使用4级页表和4KiB的页大小,硬件会自动逐级寻址并将地址转换结果存储在地址转换后备缓冲区(TLB)中,然而此缓冲区并非完全对用户透明,需要在页表发生变化时进行手动干预。
+
+并且我们知道了内核已经被预定义了一个分页机制,内存越界访问会导致 page fault 异常。并且我们暂时无法访问当前正在使用的页表,因为 CR3 寄存器存储的地址无法在内核中直接访问。
+
+## 下文预告
+
+在下一篇文章中,我们会详细讲解如何在内核中实现对分页机制的支持,这会提供一种直接访问物理内存的特别手段,也就是说我们可以直接访问页表。由此,我们可以在程序中实现虚拟地址到物理地址的转换函数,也使得在页表中手动创建映射成为了可能。
diff --git a/blog/content/edition-2/posts/09-paging-implementation/index.ja.md b/blog/content/edition-2/posts/09-paging-implementation/index.ja.md
index bfb3d52b..f260d73a 100644
--- a/blog/content/edition-2/posts/09-paging-implementation/index.ja.md
+++ b/blog/content/edition-2/posts/09-paging-implementation/index.ja.md
@@ -281,7 +281,7 @@ frame.map(|frame| frame.start_address() + u64::from(addr.page_offset()))
```toml
[dependencies]
-bootloader = { version = "0.9.8", features = ["map_physical_memory"]}
+bootloader = { version = "0.9.23", features = ["map_physical_memory"]}
```
この機能を有効化すると、ブートローダは物理メモリの全体を、ある未使用の仮想アドレス空間にマッピングします。この仮想アドレスの範囲をカーネルに伝えるために、ブートローダは**boot information**構造体を渡します。
diff --git a/blog/content/edition-2/posts/09-paging-implementation/index.md b/blog/content/edition-2/posts/09-paging-implementation/index.md
index e9803ff2..98709044 100644
--- a/blog/content/edition-2/posts/09-paging-implementation/index.md
+++ b/blog/content/edition-2/posts/09-paging-implementation/index.md
@@ -27,7 +27,7 @@ The [previous post] gave an introduction to the concept of paging. It motivated
[previous post]: @/edition-2/posts/08-paging-introduction/index.md
-The post ended with the problem that we [can't access the page tables from our kernel][end of previous post] because they are stored in physical memory and our kernel already runs on virtual addresses. This post continues at this point and explores different approaches of making the page table frames accessible to our kernel. We will discuss the advantages and drawbacks of each approach and then decide for an approach for our kernel.
+The post ended with the problem that we [can't access the page tables from our kernel][end of previous post] because they are stored in physical memory and our kernel already runs on virtual addresses. This post explores different approaches to making the page table frames accessible to our kernel. We will discuss the advantages and drawbacks of each approach and then decide on an approach for our kernel.
[end of previous post]: @/edition-2/posts/08-paging-introduction/index.md#accessing-the-page-tables
@@ -35,13 +35,13 @@ To implement the approach, we will need support from the bootloader, so we'll co
## Accessing Page Tables
-Accessing the page tables from our kernel is not as easy as it may seem. To understand the problem let's take a look at the example 4-level page table hierarchy of the previous post again:
+Accessing the page tables from our kernel is not as easy as it may seem. To understand the problem, let's take a look at the example 4-level page table hierarchy from the previous post again:

The important thing here is that each page entry stores the _physical_ address of the next table. This avoids the need to run a translation for these addresses too, which would be bad for performance and could easily cause endless translation loops.
-The problem for us is that we can't directly access physical addresses from our kernel since our kernel also runs on top of virtual addresses. For example, when we access address `4 KiB` we access the _virtual_ address `4 KiB`, not the _physical_ address `4 KiB` where the level 4 page table is stored. When we want to access the physical address `4 KiB`, we can only do so through some virtual address that maps to it.
+The problem for us is that we can't directly access physical addresses from our kernel since our kernel also runs on top of virtual addresses. For example, when we access address `4 KiB` we access the _virtual_ address `4 KiB`, not the _physical_ address `4 KiB` where the level 4 page table is stored. When we want to access the physical address `4 KiB`, we can only do so through some virtual address that maps to it.
So in order to access page table frames, we need to map some virtual pages to them. There are different ways to create these mappings that all allow us to access arbitrary page table frames.
@@ -51,22 +51,22 @@ A simple solution is to **identity map all page tables**:

-In this example, we see various identity-mapped page table frames. This way the physical addresses of page tables are also valid virtual addresses so that we can easily access the page tables of all levels starting from the CR3 register.
+In this example, we see various identity-mapped page table frames. This way, the physical addresses of page tables are also valid virtual addresses so that we can easily access the page tables of all levels starting from the CR3 register.
-However, it clutters the virtual address space and makes it more difficult to find continuous memory regions of larger sizes. For example, imagine that we want to create a virtual memory region of size 1000 KiB in the above graphic, e.g. for [memory-mapping a file]. We can't start the region at `28 KiB` because it would collide with the already mapped page at `1004 KiB`. So we have to look further until we find a large enough unmapped area, for example at `1008 KiB`. This is a similar fragmentation problem as with [segmentation].
+However, it clutters the virtual address space and makes it more difficult to find continuous memory regions of larger sizes. For example, imagine that we want to create a virtual memory region of size 1000 KiB in the above graphic, e.g., for [memory-mapping a file]. We can't start the region at `28 KiB` because it would collide with the already mapped page at `1004 KiB`. So we have to look further until we find a large enough unmapped area, for example at `1008 KiB`. This is a similar fragmentation problem as with [segmentation].
[memory-mapping a file]: https://en.wikipedia.org/wiki/Memory-mapped_file
[segmentation]: @/edition-2/posts/08-paging-introduction/index.md#fragmentation
-Equally, it makes it much more difficult to create new page tables, because we need to find physical frames whose corresponding pages aren't already in use. For example, let's assume that we reserved the _virtual_ 1000 KiB memory region starting at `1008 KiB` for our memory-mapped file. Now we can't use any frame with a _physical_ address between `1000 KiB` and `2008 KiB` anymore, because we can't identity map it.
+Equally, it makes it much more difficult to create new page tables because we need to find physical frames whose corresponding pages aren't already in use. For example, let's assume that we reserved the _virtual_ 1000 KiB memory region starting at `1008 KiB` for our memory-mapped file. Now we can't use any frame with a _physical_ address between `1000 KiB` and `2008 KiB` anymore, because we can't identity map it.
### Map at a Fixed Offset
-To avoid the problem of cluttering the virtual address space, we can **use a separate memory region for page table mappings**. So instead of identity mapping page table frames, we map them at a fixed offset in the virtual address space. For example, the offset could be 10 TiB:
+To avoid the problem of cluttering the virtual address space, we can **use a separate memory region for page table mappings**. So instead of identity mapping page table frames, we map them at a fixed offset in the virtual address space. For example, the offset could be 10 TiB:

-By using the virtual memory in the range `10TiB..(10TiB + physical memory size)` exclusively for page table mappings, we avoid the collision problems of the identity mapping. Reserving such a large region of the virtual address space is only possible if the virtual address space is much larger than the physical memory size. This isn't a problem on x86_64 since the 48-bit address space is 256 TiB large.
+By using the virtual memory in the range `10 TiB..(10 TiB + physical memory size)` exclusively for page table mappings, we avoid the collision problems of the identity mapping. Reserving such a large region of the virtual address space is only possible if the virtual address space is much larger than the physical memory size. This isn't a problem on x86_64 since the 48-bit address space is 256 TiB large.
This approach still has the disadvantage that we need to create a new mapping whenever we create a new page table. Also, it does not allow accessing page tables of other address spaces, which would be useful when creating a new process.
@@ -74,23 +74,23 @@ This approach still has the disadvantage that we need to create a new mapping wh
We can solve these problems by **mapping the complete physical memory** instead of only page table frames:
-
+
This approach allows our kernel to access arbitrary physical memory, including page table frames of other address spaces. The reserved virtual memory range has the same size as before, with the difference that it no longer contains unmapped pages.
The disadvantage of this approach is that additional page tables are needed for storing the mapping of the physical memory. These page tables need to be stored somewhere, so they use up a part of physical memory, which can be a problem on devices with a small amount of memory.
-On x86_64, however, we can use [huge pages] with size 2MiB for the mapping, instead of the default 4KiB pages. This way, mapping 32 GiB of physical memory only requires 132 KiB for page tables since only one level 3 table and 32 level 2 tables are needed. Huge pages are also more cache efficient since they use fewer entries in the translation lookaside buffer (TLB).
+On x86_64, however, we can use [huge pages] with a size of 2 MiB for the mapping, instead of the default 4 KiB pages. This way, mapping 32 GiB of physical memory only requires 132 KiB for page tables since only one level 3 table and 32 level 2 tables are needed. Huge pages are also more cache efficient since they use fewer entries in the translation lookaside buffer (TLB).
[huge pages]: https://en.wikipedia.org/wiki/Page_%28computer_memory%29#Multiple_page_sizes
### Temporary Mapping
-For devices with very small amounts of physical memory, we could **map the page tables frames only temporarily** when we need to access them. To be able to create the temporary mappings we only need a single identity-mapped level 1 table:
+For devices with very small amounts of physical memory, we could **map the page table frames only temporarily** when we need to access them. To be able to create the temporary mappings, we only need a single identity-mapped level 1 table:
-
+
-The level 1 table in this graphic controls the first 2 MiB of the virtual address space. This is because it is reachable by starting at the CR3 register and following the 0th entry in the level 4, level 3, and level 2 page tables. The entry with index `8` maps the virtual page at address `32 KiB` to the physical frame at address `32 KiB`, thereby identity mapping the level 1 table itself. The graphic shows this identity-mapping by the horizontal arrow at `32 KiB`.
+The level 1 table in this graphic controls the first 2 MiB of the virtual address space. This is because it is reachable by starting at the CR3 register and following the 0th entry in the level 4, level 3, and level 2 page tables. The entry with index `8` maps the virtual page at address `32 KiB` to the physical frame at address `32 KiB`, thereby identity mapping the level 1 table itself. The graphic shows this identity-mapping by the horizontal arrow at `32 KiB`.
By writing to the identity-mapped level 1 table, our kernel can create up to 511 temporary mappings (512 minus the entry required for the identity mapping). In the above example, the kernel created two temporary mappings:
@@ -104,13 +104,13 @@ The process for accessing an arbitrary page table frame with temporary mappings
- Search for a free entry in the identity-mapped level 1 table.
- Map that entry to the physical frame of the page table that we want to access.
- Access the target frame through the virtual page that maps to the entry.
-- Set the entry back to unused thereby removing the temporary mapping again.
+- Set the entry back to unused, thereby removing the temporary mapping again.
-This approach reuses the same 512 virtual pages for creating the mappings and thus requires only 4KiB of physical memory. The drawback is that it is a bit cumbersome, especially since a new mapping might require modifications of multiple table levels, which means that we would need to repeat the above process multiple times.
+This approach reuses the same 512 virtual pages for creating the mappings and thus requires only 4 KiB of physical memory. The drawback is that it is a bit cumbersome, especially since a new mapping might require modifications to multiple table levels, which means that we would need to repeat the above process multiple times.
### Recursive Page Tables
-Another interesting approach, that requires no additional page tables at all, is to **map the page table recursively**. The idea behind this approach is to map some entry of the level 4 page table to the level 4 table itself. By doing this, we effectively reserve a part of the virtual address space and map all current and future page table frames to that space.
+Another interesting approach, which requires no additional page tables at all, is to **map the page table recursively**. The idea behind this approach is to map an entry from the level 4 page table to the level 4 table itself. By doing this, we effectively reserve a part of the virtual address space and map all current and future page table frames to that space.
Let's go through an example to understand how this all works:
@@ -120,9 +120,9 @@ The only difference to the [example at the beginning of this post] is the additi
[example at the beginning of this post]: #accessing-page-tables
-By letting the CPU follow this entry on a translation, it doesn't reach a level 3 table, but the same level 4 table again. This is similar to a recursive function that calls itself, therefore this table is called a _recursive page table_. The important thing is that the CPU assumes that every entry in the level 4 table points to a level 3 table, so it now treats the level 4 table as a level 3 table. This works because tables of all levels have the exact same layout on x86_64.
+By letting the CPU follow this entry on a translation, it doesn't reach a level 3 table but the same level 4 table again. This is similar to a recursive function that calls itself, therefore this table is called a _recursive page table_. The important thing is that the CPU assumes that every entry in the level 4 table points to a level 3 table, so it now treats the level 4 table as a level 3 table. This works because tables of all levels have the exact same layout on x86_64.
-By following the recursive entry one or multiple times before we start the actual translation, we can effectively shorten the number of levels that the CPU traverses. For example, if we follow the recursive entry once and then proceed to the level 3 table, the CPU thinks that the level 3 table is a level 2 table. Going further, it treats the level 2 table as a level 1 table and the level 1 table as the mapped frame. This means that we can now read and write the level 1 page table because the CPU thinks that it is the mapped frame. The graphic below illustrates the 5 translation steps:
+By following the recursive entry one or multiple times before we start the actual translation, we can effectively shorten the number of levels that the CPU traverses. For example, if we follow the recursive entry once and then proceed to the level 3 table, the CPU thinks that the level 3 table is a level 2 table. Going further, it treats the level 2 table as a level 1 table and the level 1 table as the mapped frame. This means that we can now read and write the level 1 page table because the CPU thinks that it is the mapped frame. The graphic below illustrates the five translation steps:

@@ -130,15 +130,15 @@ Similarly, we can follow the recursive entry twice before starting the translati

-Let's go through it step by step: First, the CPU follows the recursive entry on the level 4 table and thinks that it reaches a level 3 table. Then it follows the recursive entry again and thinks that it reaches a level 2 table. But in reality, it is still on the level 4 table. When the CPU now follows a different entry, it lands on a level 3 table but thinks it is already on a level 1 table. So while the next entry points at a level 2 table, the CPU thinks that it points to the mapped frame, which allows us to read and write the level 2 table.
+Let's go through it step by step: First, the CPU follows the recursive entry on the level 4 table and thinks that it reaches a level 3 table. Then it follows the recursive entry again and thinks that it reaches a level 2 table. But in reality, it is still on the level 4 table. When the CPU now follows a different entry, it lands on a level 3 table but thinks it is already on a level 1 table. So while the next entry points to a level 2 table, the CPU thinks that it points to the mapped frame, which allows us to read and write the level 2 table.
-Accessing the tables of levels 3 and 4 works in the same way. For accessing the level 3 table, we follow the recursive entry three times, tricking the CPU into thinking it is already on a level 1 table. Then we follow another entry and reach a level 3 table, which the CPU treats as a mapped frame. For accessing the level 4 table itself, we just follow the recursive entry four times until the CPU treats the level 4 table itself as the mapped frame (in blue in the graphic below).
+Accessing the tables of levels 3 and 4 works in the same way. To access the level 3 table, we follow the recursive entry three times, tricking the CPU into thinking it is already on a level 1 table. Then we follow another entry and reach a level 3 table, which the CPU treats as a mapped frame. For accessing the level 4 table itself, we just follow the recursive entry four times until the CPU treats the level 4 table itself as the mapped frame (in blue in the graphic below).
-
+
It might take some time to wrap your head around the concept, but it works quite well in practice.
-In the section below we explain how to construct virtual addresses for following the recursive entry one or multiple times. We will not use recursive paging for our implementation, so you don't need to read it to continue with the post. If it interests you, just click on _"Address Calculation"_ to expand it.
+In the section below, we explain how to construct virtual addresses for following the recursive entry one or multiple times. We will not use recursive paging for our implementation, so you don't need to read it to continue with the post. If it interests you, just click on _"Address Calculation"_ to expand it.
---
@@ -149,7 +149,7 @@ We saw that we can access tables of all levels by following the recursive entry

-Let's assume that we want to access the level 1 page table that maps a specific page. As we learned above, this means that we have to follow the recursive entry one time before continuing with the level 4, level 3, and level 2 indexes. To do that we move each block of the address one block to the right and set the original level 4 index to the index of the recursive entry:
+Let's assume that we want to access the level 1 page table that maps a specific page. As we learned above, this means that we have to follow the recursive entry once before continuing with the level 4, level 3, and level 2 indexes. To do that, we move each block of the address one block to the right and set the original level 4 index to the index of the recursive entry:

@@ -163,7 +163,7 @@ Accessing the level 3 table works by moving each block three blocks to the right
Finally, we can access the level 4 table by moving each block four blocks to the right and using the recursive index for all address blocks except for the offset:
-
+
We can now calculate virtual addresses for the page tables of all four levels. We can even calculate an address that points exactly to a specific page table entry by multiplying its index by 8, the size of a page table entry.
@@ -185,7 +185,7 @@ Whereas `AAA` is the level 4 index, `BBB` the level 3 index, `CCC` the level 2 i
[sign extension]: @/edition-2/posts/08-paging-introduction/index.md#paging-on-x86-64
-We use [octal] numbers for representing the addresses since each octal character represents three bits, which allows us to clearly separate the 9-bit indexes of the different page table levels. This isn't possible with the hexadecimal system where each character represents four bits.
+We use [octal] numbers for representing the addresses since each octal character represents three bits, which allows us to clearly separate the 9-bit indexes of the different page table levels. This isn't possible with the hexadecimal system, where each character represents four bits.
##### In Rust Code
@@ -257,7 +257,7 @@ Recursive Paging is an interesting technique that shows how powerful a single ma
However, it also has some disadvantages:
-- It occupies a large amount of virtual memory (512GiB). This isn't a big problem in the large 48-bit address space, but it might lead to suboptimal cache behavior.
+- It occupies a large amount of virtual memory (512 GiB). This isn't a big problem in the large 48-bit address space, but it might lead to suboptimal cache behavior.
- It only allows accessing the currently active address space easily. Accessing other address spaces is still possible by changing the recursive entry, but a temporary mapping is required for switching back. We described how to do this in the (outdated) [_Remap The Kernel_] post.
- It heavily relies on the page table format of x86 and might not work on other architectures.
@@ -271,14 +271,14 @@ This means that we need the help of the bootloader, which creates the page table
[cargo features]: https://doc.rust-lang.org/cargo/reference/features.html#the-features-section
-- The `map_physical_memory` feature maps the complete physical memory somewhere into the virtual address space. Thus, the kernel can access all physical memory and can follow the [_Map the Complete Physical Memory_](#map-the-complete-physical-memory) approach.
+- The `map_physical_memory` feature maps the complete physical memory somewhere into the virtual address space. Thus, the kernel has access to all physical memory and can follow the [_Map the Complete Physical Memory_](#map-the-complete-physical-memory) approach.
- With the `recursive_page_table` feature, the bootloader maps an entry of the level 4 page table recursively. This allows the kernel to access the page tables as described in the [_Recursive Page Tables_](#recursive-page-tables) section.
We choose the first approach for our kernel since it is simple, platform-independent, and more powerful (it also allows access to non-page-table-frames). To enable the required bootloader support, we add the `map_physical_memory` feature to our `bootloader` dependency:
```toml
[dependencies]
-bootloader = { version = "0.9.8", features = ["map_physical_memory"]}
+bootloader = { version = "0.9.23", features = ["map_physical_memory"]}
```
With this feature enabled, the bootloader maps the complete physical memory to some unused virtual address range. To communicate the virtual address range to our kernel, the bootloader passes a _boot information_ structure.
@@ -292,6 +292,7 @@ The `bootloader` crate defines a [`BootInfo`] struct that contains all the infor
- The `memory_map` field contains an overview of the available physical memory. This tells our kernel how much physical memory is available in the system and which memory regions are reserved for devices such as the VGA hardware. The memory map can be queried from the BIOS or UEFI firmware, but only very early in the boot process. For this reason, it must be provided by the bootloader because there is no way for the kernel to retrieve it later. We will need the memory map later in this post.
- The `physical_memory_offset` tells us the virtual start address of the physical memory mapping. By adding this offset to a physical address, we get the corresponding virtual address. This allows us to access arbitrary physical memory from our kernel.
+- This physical memory offset can be customized by adding a `[package.metadata.bootloader]` table in Cargo.toml and setting the field `physical-memory-offset = "0x0000f00000000000"` (or any other value). However, note that the bootloader can panic if it runs into physical address values that start to overlap with the the space beyond the offset, i.e., areas it would have previously mapped to some other early physical addresses. So in general, the higher the value (> 1 TiB), the better.
The bootloader passes the `BootInfo` struct to our kernel in the form of a `&'static BootInfo` argument to our `_start` function. We don't have this argument declared in our function yet, so let's add it:
@@ -312,7 +313,7 @@ It wasn't a problem to leave off this argument before because the x86_64 calling
Since our `_start` function is called externally from the bootloader, no checking of our function signature occurs. This means that we could let it take arbitrary arguments without any compilation errors, but it would fail or cause undefined behavior at runtime.
-To make sure that the entry point function has always the correct signature that the bootloader expects, the `bootloader` crate provides an [`entry_point`] macro that provides a type-checked way to define a Rust function as the entry point. Let's rewrite our entry point function to use this macro:
+To make sure that the entry point function always has the correct signature that the bootloader expects, the `bootloader` crate provides an [`entry_point`] macro that provides a type-checked way to define a Rust function as the entry point. Let's rewrite our entry point function to use this macro:
[`entry_point`]: https://docs.rs/bootloader/0.6.4/bootloader/macro.entry_point.html
@@ -355,7 +356,7 @@ Since the entry point is only used in test mode, we add the `#[cfg(test)]` attri
## Implementation
-Now that we have access to physical memory, we can finally start to implement our page table code. First, we will take a look at the currently active page tables that our kernel runs on. In the second step, we will create a translation function that returns the physical address that a given virtual address is mapped to. As the last step, we will try to modify the page tables in order to create a new mapping.
+Now that we have access to physical memory, we can finally start to implement our page table code. First, we will take a look at the currently active page tables that our kernel runs on. In the second step, we will create a translation function that returns the physical address that a given virtual address is mapped to. As a last step, we will try to modify the page tables in order to create a new mapping.
Before we begin, we create a new `memory` module for our code:
@@ -365,7 +366,7 @@ Before we begin, we create a new `memory` module for our code:
pub mod memory;
```
-For the module we create an empty `src/memory.rs` file.
+For the module, we create an empty `src/memory.rs` file.
### Accessing the Page Tables
@@ -402,9 +403,9 @@ pub unsafe fn active_level_4_table(physical_memory_offset: VirtAddr)
}
```
-First, we read the physical frame of the active level 4 table from the `CR3` register. We then take its physical start address, convert it to an `u64`, and add it to `physical_memory_offset` to get the virtual address where the page table frame is mapped. Finally, we convert the virtual address to a `*mut PageTable` raw pointer through the `as_mut_ptr` method and then unsafely create a `&mut PageTable` reference from it. We create a `&mut` reference instead of a `&` reference because we will mutate the page tables later in this post.
+First, we read the physical frame of the active level 4 table from the `CR3` register. We then take its physical start address, convert it to a `u64`, and add it to `physical_memory_offset` to get the virtual address where the page table frame is mapped. Finally, we convert the virtual address to a `*mut PageTable` raw pointer through the `as_mut_ptr` method and then unsafely create a `&mut PageTable` reference from it. We create a `&mut` reference instead of a `&` reference because we will mutate the page tables later in this post.
-We don't need to use an unsafe block here because Rust treats the complete body of an `unsafe fn` like a large `unsafe` block. This makes our code more dangerous since we could accidentally introduce an unsafe operation in previous lines without noticing. It also makes it much more difficult to spot the unsafe operations. There is an [RFC](https://github.com/rust-lang/rfcs/pull/2585) to change this behavior.
+We don't need to use an unsafe block here because Rust treats the complete body of an `unsafe fn` like a large `unsafe` block. This makes our code more dangerous since we could accidentally introduce an unsafe operation in previous lines without noticing. It also makes it much more difficult to spot unsafe operations in between safe operations. There is an [RFC](https://github.com/rust-lang/rfcs/pull/2585) to change this behavior.
We can now use this function to print the entries of the level 4 table:
@@ -445,9 +446,9 @@ When we run it, we see the following output:

-We see that there are various non-empty entries, which all map to different level 3 tables. There are so many regions because kernel code, kernel stack, the physical memory mapping, and the boot information all use separate memory areas.
+We see that there are various non-empty entries, which all map to different level 3 tables. There are so many regions because kernel code, kernel stack, physical memory mapping, and boot information all use separate memory areas.
-To traverse the page tables further and take a look at a level 3 table, we can take the mapped frame of an entry convert it to a virtual address again:
+To traverse the page tables further and take a look at a level 3 table, we can take the mapped frame of an entry and convert it to a virtual address again:
```rust
// in the `for` loop in src/main.rs
@@ -472,13 +473,13 @@ if !entry.is_unused() {
}
```
-For looking at the level 2 and level 1 tables, we repeat that process for the level 3 and level 2 entries. As you can imagine, this gets very verbose quickly, so we don't show the full code here.
+For looking at the level 2 and level 1 tables, we repeat that process for the level 3 and level 2 entries. As you can imagine, this gets very verbose very quickly, so we don't show the full code here.
-Traversing the page tables manually is interesting because it helps to understand how the CPU performs the translation. However, most of the time we are only interested in the mapped physical address for a given virtual address, so let's create a function for that.
+Traversing the page tables manually is interesting because it helps to understand how the CPU performs the translation. However, most of the time, we are only interested in the mapped physical address for a given virtual address, so let's create a function for that.
### Translating Addresses
-For translating a virtual to a physical address, we have to traverse the four-level page table until we reach the mapped frame. Let's create a function that performs this translation:
+To translate a virtual to a physical address, we have to traverse the four-level page table until we reach the mapped frame. Let's create a function that performs this translation:
```rust
// in src/memory.rs
@@ -498,7 +499,7 @@ pub unsafe fn translate_addr(addr: VirtAddr, physical_memory_offset: VirtAddr)
}
```
-We forward the function to a safe `translate_addr_inner` function to limit the scope of `unsafe`. As we noted above, Rust treats the complete body of an unsafe fn like a large unsafe block. By calling into a private safe function, we make each `unsafe` operation explicit again.
+We forward the function to a safe `translate_addr_inner` function to limit the scope of `unsafe`. As we noted above, Rust treats the complete body of an `unsafe fn` like a large unsafe block. By calling into a private safe function, we make each `unsafe` operation explicit again.
The private inner function contains the real implementation:
@@ -547,9 +548,9 @@ fn translate_addr_inner(addr: VirtAddr, physical_memory_offset: VirtAddr)
Instead of reusing our `active_level_4_table` function, we read the level 4 frame from the `CR3` register again. We do this because it simplifies this prototype implementation. Don't worry, we will create a better solution in a moment.
-The `VirtAddr` struct already provides methods to compute the indexes into the page tables of the four levels. We store these indexes in a small array because it allows us to traverse the page tables using a `for` loop. Outside of the loop, we remember the last visited `frame` to calculate the physical address later. The `frame` points to page table frames while iterating, and to the mapped frame after the last iteration, i.e. after following the level 1 entry.
+The `VirtAddr` struct already provides methods to compute the indexes into the page tables of the four levels. We store these indexes in a small array because it allows us to traverse the page tables using a `for` loop. Outside of the loop, we remember the last visited `frame` to calculate the physical address later. The `frame` points to page table frames while iterating and to the mapped frame after the last iteration, i.e., after following the level 1 entry.
-Inside the loop, we again use the `physical_memory_offset` to convert the frame into a page table reference. We then read the entry of the current page table and use the [`PageTableEntry::frame`] function to retrieve the mapped frame. If the entry is not mapped to a frame we return `None`. If the entry maps a huge 2MiB or 1GiB page we panic for now.
+Inside the loop, we again use the `physical_memory_offset` to convert the frame into a page table reference. We then read the entry of the current page table and use the [`PageTableEntry::frame`] function to retrieve the mapped frame. If the entry is not mapped to a frame, we return `None`. If the entry maps a huge 2 MiB or 1 GiB page, we panic for now.
[`PageTableEntry::frame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page_table/struct.PageTableEntry.html#method.frame
@@ -601,10 +602,10 @@ Since each physical address can be accessed by adding the `physical_memory_offse
Translating virtual to physical addresses is a common task in an OS kernel, therefore the `x86_64` crate provides an abstraction for it. The implementation already supports huge pages and several other page table functions apart from `translate_addr`, so we will use it in the following instead of adding huge page support to our own implementation.
-The base of the abstraction are two traits that define various page table mapping functions:
+At the basis of the abstraction are two traits that define various page table mapping functions:
- The [`Mapper`] trait is generic over the page size and provides functions that operate on pages. Examples are [`translate_page`], which translates a given page to a frame of the same size, and [`map_to`], which creates a new mapping in the page table.
-- The [`Translate`] trait provides functions that work with multiple page sizes such as [`translate_addr`] or the general [`translate`].
+- The [`Translate`] trait provides functions that work with multiple page sizes, such as [`translate_addr`] or the general [`translate`].
[`Mapper`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/trait.Mapper.html
[`translate_page`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/trait.Mapper.html#tymethod.translate_page
@@ -645,9 +646,9 @@ The function takes the `physical_memory_offset` as an argument and returns a new
[`OffsetPageTable::new`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/struct.OffsetPageTable.html#method.new
-The `active_level_4_table` function should be only called from the `init` function from now on because it can easily lead to aliased mutable references when called multiple times, which can cause undefined behavior. For this reason, we make the function private by removing the `pub` specifier.
+The `active_level_4_table` function should only be called from the `init` function from now on because it can easily lead to aliased mutable references when called multiple times, which can cause undefined behavior. For this reason, we make the function private by removing the `pub` specifier.
-We now can use the `Translate::translate_addr` method instead of our own `memory::translate_addr` function. We only need to change a few lines in our `kernel_main`:
+We can now use the `Translate::translate_addr` method instead of our own `memory::translate_addr` function. We only need to change a few lines in our `kernel_main`:
```rust
// in src/main.rs
@@ -684,13 +685,13 @@ When we run it now, we see the same translation results as before, with the diff
As expected, the translations of `0xb8000` and the code and stack addresses stay the same as with our own translation function. Additionally, we now see that the virtual address `physical_memory_offset` is mapped to the physical address `0x0`.
-By using the translation function of the `MappedPageTable` type we can spare ourselves the work of implementing huge page support. We also have access to other page functions such as `map_to`, which we will use in the next section.
+By using the translation function of the `MappedPageTable` type, we can spare ourselves the work of implementing huge page support. We also have access to other page functions, such as `map_to`, which we will use in the next section.
-At this point we no longer need our `memory::translate_addr` and `memory::translate_addr_inner` functions, so we can delete them.
+At this point, we no longer need our `memory::translate_addr` and `memory::translate_addr_inner` functions, so we can delete them.
### Creating a new Mapping
-Until now we only looked at the page tables without modifying anything. Let's change that by creating a new mapping for a previously unmapped page.
+Until now, we only looked at the page tables without modifying anything. Let's change that by creating a new mapping for a previously unmapped page.
We will use the [`map_to`] function of the [`Mapper`] trait for our implementation, so let's take a look at that function first. The documentation tells us that it takes four arguments: the page that we want to map, the frame that the page should be mapped to, a set of flags for the page table entry, and a `frame_allocator`. The frame allocator is needed because mapping the given page might require creating additional page tables, which need unused frames as backing storage.
@@ -730,7 +731,7 @@ pub fn create_example_mapping(
}
```
-In addition to the `page` that should be mapped, the function expects a mutable reference to an `OffsetPageTable` instance and a `frame_allocator`. The `frame_allocator` parameter uses the [`impl Trait`][impl-trait-arg] syntax to be [generic] over all types that implement the [`FrameAllocator`] trait. The trait is generic over the [`PageSize`] trait to work with both standard 4KiB pages and huge 2MiB/1GiB pages. We only want to create a 4KiB mapping, so we set the generic parameter to `Size4KiB`.
+In addition to the `page` that should be mapped, the function expects a mutable reference to an `OffsetPageTable` instance and a `frame_allocator`. The `frame_allocator` parameter uses the [`impl Trait`][impl-trait-arg] syntax to be [generic] over all types that implement the [`FrameAllocator`] trait. The trait is generic over the [`PageSize`] trait to work with both standard 4 KiB pages and huge 2 MiB/1 GiB pages. We only want to create a 4 KiB mapping, so we set the generic parameter to `Size4KiB`.
[impl-trait-arg]: https://doc.rust-lang.org/book/ch10-02-traits.html#traits-as-parameters
[generic]: https://doc.rust-lang.org/book/ch10-00-generics.html
@@ -753,7 +754,7 @@ The [`map_to`] function can fail, so it returns a [`Result`]. Since this is just
#### A dummy `FrameAllocator`
-To be able to call `create_example_mapping` we need to create a type that implements the `FrameAllocator` trait first. As noted above, the trait is responsible for allocating frames for new page table if they are needed by `map_to`.
+To be able to call `create_example_mapping`, we need to create a type that implements the `FrameAllocator` trait first. As noted above, the trait is responsible for allocating frames for new page tables if they are needed by `map_to`.
Let's start with the simple case and assume that we don't need to create new page tables. For this case, a frame allocator that always returns `None` suffices. We create such an `EmptyFrameAllocator` for testing our mapping function:
@@ -770,7 +771,7 @@ unsafe impl FrameAllocator for EmptyFrameAllocator {
}
```
-Implementing the `FrameAllocator` is unsafe because the implementer must guarantee that the allocator yields only unused frames. Otherwise undefined behavior might occur, for example when two virtual pages are mapped to the same physical frame. Our `EmptyFrameAllocator` only returns `None`, so this isn't a problem in this case.
+Implementing the `FrameAllocator` is unsafe because the implementer must guarantee that the allocator yields only unused frames. Otherwise, undefined behavior might occur, for example when two virtual pages are mapped to the same physical frame. Our `EmptyFrameAllocator` only returns `None`, so this isn't a problem in this case.
#### Choosing a Virtual Page
@@ -778,21 +779,21 @@ We now have a simple frame allocator that we can pass to our `create_example_map

-The graphic shows the virtual address space on the left, the physical address space on the right, and the page tables in between. The page tables are stored in physical memory frames, indicated by the dashed lines. The virtual address space contains a single mapped page at address `0x803fe00000`, marked in blue. To translate this page to its frame, the CPU walks the 4-level page table until it reaches the frame at address 36 KiB.
+The graphic shows the virtual address space on the left, the physical address space on the right, and the page tables in between. The page tables are stored in physical memory frames, indicated by the dashed lines. The virtual address space contains a single mapped page at address `0x803fe00000`, marked in blue. To translate this page to its frame, the CPU walks the 4-level page table until it reaches the frame at address 36 KiB.
Additionally, the graphic shows the physical frame of the VGA text buffer in red. Our goal is to map a previously unmapped virtual page to this frame using our `create_example_mapping` function. Since our `EmptyFrameAllocator` always returns `None`, we want to create the mapping so that no additional frames are needed from the allocator. This depends on the virtual page that we select for the mapping.
-The graphic shows two candidate pages in the virtual address space, both marked in yellow. One page is at address `0x803fdfd000`, which is 3 pages before the mapped page (in blue). While the level 4 and level 3 page table indices are the same as for the blue page, the level 2 and level 1 indices are different (see the [previous post][page-table-indices]). The different index into the level 2 table means that a different level 1 table is used for this page. Since this level 1 table does not exist yet, we would need to create it if we chose that page for our example mapping, which would require an additional unused physical frame. In contrast, the second candidate page at address `0x803fe02000` does not have this problem because it uses the same level 1 page table than the blue page. Thus, all required page tables already exist.
+The graphic shows two candidate pages in the virtual address space, both marked in yellow. One page is at address `0x803fdfd000`, which is 3 pages before the mapped page (in blue). While the level 4 and level 3 page table indices are the same as for the blue page, the level 2 and level 1 indices are different (see the [previous post][page-table-indices]). The different index into the level 2 table means that a different level 1 table is used for this page. Since this level 1 table does not exist yet, we would need to create it if we chose that page for our example mapping, which would require an additional unused physical frame. In contrast, the second candidate page at address `0x803fe02000` does not have this problem because it uses the same level 1 page table as the blue page. Thus, all the required page tables already exist.
[page-table-indices]: @/edition-2/posts/08-paging-introduction/index.md#paging-on-x86-64
-In summary, the difficulty of creating a new mapping depends on the virtual page that we want to map. In the easiest case, the level 1 page table for the page already exists and we just need to write a single entry. In the most difficult case, the page is in a memory region for that no level 3 exists yet so that we need to create new level 3, level 2 and level 1 page tables first.
+In summary, the difficulty of creating a new mapping depends on the virtual page that we want to map. In the easiest case, the level 1 page table for the page already exists and we just need to write a single entry. In the most difficult case, the page is in a memory region for which no level 3 exists yet, so we need to create new level 3, level 2 and level 1 page tables first.
-For calling our `create_example_mapping` function with the `EmptyFrameAllocator`, we need to choose a page for that all page tables already exist. To find such a page, we can utilize the fact that the bootloader loads itself in the first megabyte of the virtual address space. This means that a valid level 1 table exists for all pages this region. Thus, we can choose any unused page in this memory region for our example mapping, such as the page at address `0`. Normally, this page should stay unused to guarantee that dereferencing a null pointer causes a page fault, so we know that the bootloader leaves it unmapped.
+For calling our `create_example_mapping` function with the `EmptyFrameAllocator`, we need to choose a page for which all page tables already exist. To find such a page, we can utilize the fact that the bootloader loads itself in the first megabyte of the virtual address space. This means that a valid level 1 table exists for all pages in this region. Thus, we can choose any unused page in this memory region for our example mapping, such as the page at address `0`. Normally, this page should stay unused to guarantee that dereferencing a null pointer causes a page fault, so we know that the bootloader leaves it unmapped.
#### Creating the Mapping
-We now have all the required parameters for calling our `create_example_mapping` function, so let's modify our `kernel_main` function to map the page at virtual address `0`. Since we map the page to the frame of the VGA text buffer, we should be able to write to the screen through it afterwards. The implementation looks like this:
+We now have all the required parameters for calling our `create_example_mapping` function, so let's modify our `kernel_main` function to map the page at virtual address `0`. Since we map the page to the frame of the VGA text buffer, we should be able to write to the screen through it afterward. The implementation looks like this:
```rust
// in src/main.rs
@@ -821,7 +822,7 @@ fn kernel_main(boot_info: &'static BootInfo) -> ! {
We first create the mapping for the page at address `0` by calling our `create_example_mapping` function with a mutable reference to the `mapper` and the `frame_allocator` instances. This maps the page to the VGA text buffer frame, so we should see any write to it on the screen.
-Then we convert the page to a raw pointer and write a value to offset `400`. We don't write to the start of the page because the top line of the VGA buffer is directly shifted off the screen by the next `println`. We write the value `0x_f021_f077_f065_f04e`, which represents the string _"New!"_ on white background. As we learned [in the _“VGA Text Mode”_ post], writes to the VGA buffer should be volatile, so we use the [`write_volatile`] method.
+Then we convert the page to a raw pointer and write a value to offset `400`. We don't write to the start of the page because the top line of the VGA buffer is directly shifted off the screen by the next `println`. We write the value `0x_f021_f077_f065_f04e`, which represents the string _"New!"_ on a white background. As we learned [in the _“VGA Text Mode”_ post], writes to the VGA buffer should be volatile, so we use the [`write_volatile`] method.
[in the _“VGA Text Mode”_ post]: @/edition-2/posts/03-vga-text-buffer/index.md#volatile
[`write_volatile`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.write_volatile
@@ -830,9 +831,9 @@ When we run it in QEMU, we see the following output:

-The _"New!"_ on the screen is by our write to page `0`, which means that we successfully created a new mapping in the page tables.
+The _"New!"_ on the screen is caused by our write to page `0`, which means that we successfully created a new mapping in the page tables.
-Creating that mapping only worked because the level 1 table responsible for the page at address `0` already exists. When we try to map a page for that no level 1 table exists yet, the `map_to` function fails because it tries to allocate frames from the `EmptyFrameAllocator` for creating new page tables. We can see that happen when we try to map page `0xdeadbeaf000` instead of `0`:
+Creating that mapping only worked because the level 1 table responsible for the page at address `0` already exists. When we try to map a page for which no level 1 table exists yet, the `map_to` function fails because it tries to create new page tables by allocating frames with the `EmptyFrameAllocator`. We can see that happen when we try to map page `0xdeadbeaf000` instead of `0`:
```rust
// in src/main.rs
@@ -850,11 +851,11 @@ When we run it, a panic with the following error message occurs:
panicked at 'map_to failed: FrameAllocationFailed', /…/result.rs:999:5
```
-To map pages that don't have a level 1 page table yet we need to create a proper `FrameAllocator`. But how do we know which frames are unused and how much physical memory is available?
+To map pages that don't have a level 1 page table yet, we need to create a proper `FrameAllocator`. But how do we know which frames are unused and how much physical memory is available?
### Allocating Frames
-In order to create new page tables, we need to create a proper frame allocator. For that we use the `memory_map` that is passed by the bootloader as part of the `BootInfo` struct:
+In order to create new page tables, we need to create a proper frame allocator. To do that, we use the `memory_map` that is passed by the bootloader as part of the `BootInfo` struct:
```rust
// in src/memory.rs
@@ -882,7 +883,7 @@ impl BootInfoFrameAllocator {
}
```
-The struct has two fields: A `'static` reference to the memory map passed by the bootloader and a `next` field that keeps track of number of the next frame that the allocator should return.
+The struct has two fields: A `'static` reference to the memory map passed by the bootloader and a `next` field that keeps track of the number of the next frame that the allocator should return.
As we explained in the [_Boot Information_](#boot-information) section, the memory map is provided by the BIOS/UEFI firmware. It can only be queried very early in the boot process, so the bootloader already calls the respective functions for us. The memory map consists of a list of [`MemoryRegion`] structs, which contain the start address, the length, and the type (e.g. unused, reserved, etc.) of each memory region.
@@ -918,10 +919,10 @@ impl BootInfoFrameAllocator {
This function uses iterator combinator methods to transform the initial `MemoryMap` into an iterator of usable physical frames:
- First, we call the `iter` method to convert the memory map to an iterator of [`MemoryRegion`]s.
-- Then we use the [`filter`] method to skip any reserved or otherwise unavailable regions. The bootloader updates the memory map for all the mappings it creates, so frames that are used by our kernel (code, data or stack) or to store the boot information are already marked as `InUse` or similar. Thus we can be sure that `Usable` frames are not used somewhere else.
+- Then we use the [`filter`] method to skip any reserved or otherwise unavailable regions. The bootloader updates the memory map for all the mappings it creates, so frames that are used by our kernel (code, data, or stack) or to store the boot information are already marked as `InUse` or similar. Thus, we can be sure that `Usable` frames are not used somewhere else.
- Afterwards, we use the [`map`] combinator and Rust's [range syntax] to transform our iterator of memory regions to an iterator of address ranges.
-- Next, we use [`flat_map`] to transform the address ranges into an iterator of frame start addresses, choosing every 4096th address using [`step_by`]. Since 4096 bytes (= 4 KiB) is the page size, we get the start address of each frame. The bootloader page aligns all usable memory areas so that we don't need any alignment or rounding code here. By using [`flat_map`] instead of `map`, we get an `Iterator` instead of an `Iterator>`.
-- Finally, we convert the start addresses to `PhysFrame` types to construct the an `Iterator`.
+- Next, we use [`flat_map`] to transform the address ranges into an iterator of frame start addresses, choosing every 4096th address using [`step_by`]. Since 4096 bytes (= 4 KiB) is the page size, we get the start address of each frame. The bootloader page-aligns all usable memory areas so that we don't need any alignment or rounding code here. By using [`flat_map`] instead of `map`, we get an `Iterator` instead of an `Iterator>`.
+- Finally, we convert the start addresses to `PhysFrame` types to construct an `Iterator`.
[`MemoryRegion`]: https://docs.rs/bootloader/0.6.4/bootloader/bootinfo/struct.MemoryRegion.html
[`filter`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.filter
@@ -930,7 +931,7 @@ This function uses iterator combinator methods to transform the initial `MemoryM
[`step_by`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.step_by
[`flat_map`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.flat_map
-The return type of the function uses the [`impl Trait`] feature. This way, we can specify that we return some type that implements the [`Iterator`] trait with item type `PhysFrame`, but don't need to name the concrete return type. This is important here because we _can't_ name the concrete type since it depends on unnamable closure types.
+The return type of the function uses the [`impl Trait`] feature. This way, we can specify that we return some type that implements the [`Iterator`] trait with item type `PhysFrame` but don't need to name the concrete return type. This is important here because we _can't_ name the concrete type since it depends on unnamable closure types.
[`impl Trait`]: https://doc.rust-lang.org/book/ch10-02-traits.html#returning-types-that-implement-traits
[`Iterator`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html
@@ -979,7 +980,7 @@ fn kernel_main(boot_info: &'static BootInfo) -> ! {
With the boot info frame allocator, the mapping succeeds and we see the black-on-white _"New!"_ on the screen again. Behind the scenes, the `map_to` method creates the missing page tables in the following way:
-- Allocate an unused frame from the passed `frame_allocator`.
+- Use the passed `frame_allocator` to allocate an unused frame.
- Zero the frame to create a new, empty page table.
- Map the entry of the higher level table to that frame.
- Continue with the next table level.
@@ -992,7 +993,7 @@ At this point, we should delete the `create_example_mapping` function again to a
In this post we learned about different techniques to access the physical frames of page tables, including identity mapping, mapping of the complete physical memory, temporary mapping, and recursive page tables. We chose to map the complete physical memory since it's simple, portable, and powerful.
-We can't map the physical memory from our kernel without page table access, so we needed support from the bootloader. The `bootloader` crate supports creating the required mapping through optional cargo features. It passes the required information to our kernel in the form of a `&BootInfo` argument to our entry point function.
+We can't map the physical memory from our kernel without page table access, so we need support from the bootloader. The `bootloader` crate supports creating the required mapping through optional cargo crate features. It passes the required information to our kernel in the form of a `&BootInfo` argument to our entry point function.
For our implementation, we first manually traversed the page tables to implement a translation function, and then used the `MappedPageTable` type of the `x86_64` crate. We also learned how to create new mappings in the page table and how to create the necessary `FrameAllocator` on top of the memory map passed by the bootloader.
diff --git a/blog/content/edition-2/posts/10-heap-allocation/index.ja.md b/blog/content/edition-2/posts/10-heap-allocation/index.ja.md
new file mode 100644
index 00000000..85bcb85a
--- /dev/null
+++ b/blog/content/edition-2/posts/10-heap-allocation/index.ja.md
@@ -0,0 +1,808 @@
++++
+title = "ヒープ割り当て"
+weight = 10
+path = "ja/heap-allocation"
+date = 2019-06-26
+
+[extra]
+chapter = "Memory Management"
+# Please update this when updating the translation
+translation_based_on_commit = "afeed7477bb19a29d94a96b8b0620fd241b0d55f"
+# GitHub usernames of the people that translated this post
+translators = ["woodyZootopia", "garasubo"]
++++
+
+この記事では、私たちのカーネルにヒープ割り当ての機能を追加します。まず動的メモリの基礎を説明し、どのようにして借用チェッカがありがちなアロケーションエラーを防いでくれるのかを示します。その後Rustの基本的なアロケーションインターフェースを実装し、ヒープメモリ領域を作成し、アロケータクレートを設定します。この記事を終える頃には、Rustに組み込みの`alloc`クレートのすべてのアロケーション・コレクション型が私たちのカーネルで利用可能になっているでしょう。
+
+
+
+このブログの内容は [GitHub] 上で公開・開発されています。何か問題や質問などがあれば issue をたててください (訳注: リンクは原文(英語)のものになります)。また[こちら][at the bottom]にコメントを残すこともできます。この記事の完全なソースコードは[`post-10` ブランチ][post branch]にあります。
+
+[GitHub]: https://github.com/phil-opp/blog_os
+[at the bottom]: #comments
+
+[post branch]: https://github.com/phil-opp/blog_os/tree/post-10
+
+
+
+## 局所変数と静的変数
+
+私たちのカーネルでは現在二種類の変数が使用されています:局所変数と`static`変数です。局所変数は[コールスタック][call stack]に格納されており、変数の定義された関数がリターンするまでの間のみ有効です。静的変数はメモリ上の固定された場所に格納されており、プログラムのライフタイム全体で常に生存しています。
+
+### 局所変数
+
+局所変数は[コールスタック][call stack]に格納されています。これはプッシュ (`push`) とポップ (`pop`) という命令をサポートする[スタックというデータ構造][stack data structure]です。関数に入るたびに、パラメータ、リターンアドレス、呼び出された関数の局所変数がコンパイラによってプッシュされます:
+
+[call stack]: https://ja.wikipedia.org/wiki/%E3%82%B3%E3%83%BC%E3%83%AB%E3%82%B9%E3%82%BF%E3%83%83%E3%82%AF
+[stack data structure]: https://ja.wikipedia.org/wiki/%E3%82%B9%E3%82%BF%E3%83%83%E3%82%AF
+
+
+
+上の例は、`outer`関数が`inner`関数を呼び出した後のコールスタックを示しています。コールスタックは`outer`の局所変数を先に持っていることが分かります。`inner`を呼び出すと、パラメータ`1`とこの関数のリターンアドレスがプッシュされます。そこで制御は`inner`へと移り、`inner`は自身の局所変数をプッシュします。
+
+`inner`関数がリターンすると、コールスタックのこの関数に対応する部分がポップされ、`outer`の局所変数のみが残ります:
+
+
+
+`inner`関数の局所変数はリターンまでしか生存していないことが分かります。Rustコンパイラはこの生存期間を強制し、私たちが値を長く使いすぎてしまうとエラーを投げます。例えば、局所変数への参照を返そうとしたときがそうです:
+
+```rust
+fn inner(i: usize) -> &'static u32 {
+ let z = [1, 2, 3];
+ &z[i]
+}
+```
+
+([この例をplaygroundで実行する](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=6186a0f3a54f468e1de8894996d12819))
+
+上の例の場合、参照を返すことには意味がありませんが、変数に関数よりも長く生存して欲しいというケースは存在します。すでに私たちのカーネルでそのようなケースに遭遇しています。それは[割り込み記述子表 (IDT) を読み込][load an interrupt descriptor table]もうとしたときで、ライフタイムを延ばすために`static`変数を使う必要がありました。
+
+[load an interrupt descriptor table]: @/edition-2/posts/05-cpu-exceptions/index.ja.md#idtwodu-miip-mu
+
+### 静的変数
+
+静的変数は、スタックとは別の固定されたメモリ位置に格納されます。このメモリ位置はコンパイル時にリンカによって指定され、実行可能ファイルにエンコードされています。静的変数はプログラムの実行中ずっと生存するため、`'static`ライフタイムを持っており、局所変数によっていつでも参照することができます。
+
+![同じouter/innerの例ですが、innerが`static Z: [u32; 3] = [1,2,3];`を持っており、参照`&Z[i]`を返します](call-stack-static.svg)
+
+上の例で`inner`関数がリターンするとき、それに対応するコールスタックは破棄されます。(しかし)静的変数は絶対に破棄されない別のメモリ領域にあるため、参照`&Z[1]`はリターン後も有効です。
+
+`'static`ライフタイムの他にも静的変数には利点があります。それらは位置がコンパイル時に分かるため、アクセスするために参照が必要ないのです。この特性を私たちの`println`マクロを作る際に利用しました:[静的な`Writer`][static `Writer`]をその内部で使うことで、マクロを呼び出す際に`&mut Writer`参照が必要でなくなります。これは他の変数にアクセスできない[例外処理関数][exception handlers]においてとても有用です。
+
+[static `Writer`]: @/edition-2/posts/03-vga-text-buffer/index.ja.md#da-yu-de-global-naintahuesu
+[exception handlers]: @/edition-2/posts/05-cpu-exceptions/index.ja.md#shi-zhuang
+
+しかし、静的変数のこの特性には重大な欠点がついてきます:デフォルトでは読み込み専用なのです。Rustがこのルールを強制するのは、例えば二つのスレッドがある静的変数を同時に変更した場合[データ競合][data race]が発生するためです。静的変数を変更する唯一の方法は、それを[`Mutex`]型にカプセル化し、あらゆる時刻において`&mut`参照が一つしか存在しないことを保証することです。`Mutex`は[VGAバッファへの静的な`Writer`][vga mutex]を作ったときにすでに使いました。
+
+[data race]: https://doc.rust-jp.rs/rust-nomicon-ja/races.html
+[`Mutex`]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html
+[vga mutex]: @/edition-2/posts/03-vga-text-buffer/index.ja.md#supinrotuku
+
+## 動的メモリ
+
+局所変数と静的変数を組み合わせれば、それら自体とても強力であり、ほとんどのユースケースを満足します。しかし、どちらにも制限が存在することも見てきました:
+
+- 局所変数はそれを定義する関数やブロックが終わるまでしか生存しません。なぜなら、これらはコールスタックに存在し、関数がリターンした段階で破棄されるからです。
+- 静的変数はプログラムの実行中常に生存するため、必要なくなったときでもメモリを取り戻したり再利用したりする方法がありません。また、所有権のセマンティクスが不明瞭であり、すべての関数からアクセスできてしまうため、変更しようと思ったときには[`Mutex`]で保護してやらないといけません。
+
+局所変数・静的変数の制約としてもう一つ、固定サイズであることが挙げられます。従ってこれらは要素が追加されたときに動的に大きくなるコレクションを格納することができません(Rustにおいて動的サイズの局所変数を可能にする[unsized rvalues]の提案が行われていますが、これはいくつかの特定のケースでしかうまく動きません)。
+
+[unsized rvalues]: https://github.com/rust-lang/rust/issues/48055
+
+これらの欠点を回避するために、プログラミング言語はしばしば、変数を格納するための第三の領域である**ヒープ**をサポートします。ヒープは、`allocate`と`deallocate`という二つの関数を通じて、実行時の**動的メモリ割り当て**をサポートします。仕組みとしては以下のようになります:`allocate`関数は、変数を格納するのに使える、指定されたサイズの解放されたメモリの塊を返します。変数への参照を引数に`deallocate`関数を呼び出すことによってその変数を解放するまで、この変数は生存します。
+
+例を使って見てみましょう:
+
+![inner関数は`allocate(size_of([u32; 3]))`を呼び、`z.write([1,2,3]);`で書き込みを行い、`(z as *mut u32).offset(i)`を返します。outer関数は返された値`y`に対して`deallocate(y, size_of(u32))`を行います。](call-stack-heap.svg)
+
+ここで`inner`関数は`z`を格納するために静的変数ではなくヒープメモリを使っています。まず要求されたサイズのメモリブロックを割り当て、`*mut u32`の[生ポインタ][raw pointer]を受け取ります。その後で[`ptr::write`]メソッドを使ってこれに配列`[1,2,3]`を書き込みます。最後のステップとして、[`offset`]関数を使って`i`番目の要素へのポインタを計算しそれを返します(簡単のため、必要なキャストやunsafeブロックをいくつか省略しました)。
+
+[raw pointer]: https://doc.rust-jp.rs/book-ja/ch19-01-unsafe-rust.html#%E7%94%9F%E3%83%9D%E3%82%A4%E3%83%B3%E3%82%BF%E3%82%92%E5%8F%82%E7%85%A7%E5%A4%96%E3%81%97%E3%81%99%E3%82%8B
+[`ptr::write`]: https://doc.rust-lang.org/core/ptr/fn.write.html
+[`offset`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.offset
+
+割り当てられたメモリは`deallocate`の呼び出しによって明示的に解放されるまで生存します。したがって、返されたポインタは、`inner`がリターンしコールスタックの対応する部分が破棄された後も有効です。スタティックメモリと比較したときのヒープメモリの長所は、解放(`outer`内の`deallocate`呼び出しでまさにこれを行っています)後に再利用できるということです。この呼び出しの後、状況は以下のようになります。
+
+![コールスタックはouterの局所変数を持っており、ヒープはz[0]とz[2]を持っているが、z[1]はもう持っていない。](call-stack-heap-freed.svg)
+
+`z[1]`スロットが解放され、次の`allocate`呼び出しで再利用できることが分かります。しかし、`z[0]`と`z[2]`は永久にdeallocateされず、したがって永久に解放されないことも分かります。このようなバグは**メモリリーク**と呼ばれており、しばしばプログラムの過剰なメモリ消費を引き起こします(`inner`をループで何度も呼び出したらどんなことになるか、想像してみてください)。これ自体良くないことに思われるかもしれませんが、動的割り当てはもっと危険性の高いバグを発生させうるのです。
+
+### よくあるミス
+
+メモリリークは困りものですが、プログラムを攻撃者に対して脆弱にはしません。しかしこのほかに、より深刻な結果を招く二種類のバグが存在します:
+
+- もし変数に対して`deallocate`を呼んだ後にも間違ってそれを使い続けたら、いわゆるuse-after-free脆弱性が発生します。このようなバグは未定義動作を引き起こし、しばしば攻撃者が任意コードを実行するのに利用されます。
+- 間違ってある変数を二度解放したら、double-free脆弱性が発生します。これが問題になるのは、最初の`deallocate`呼び出しの後に同じ場所にallocateされた別の割り当てを解放してしまうかもしれないからです。従って、これもまたuse-after-free脆弱性につながりかねません。
+
+これらの脆弱性は広く知られているため、回避する方法も解明されているはずだとお思いになるかもしれません。しかし答えはいいえで、このような脆弱性は未だ散見され、例えば最近でも任意コード実行を許す[Linuxのuse-after-free脆弱性][linux vulnerability]が存在しました。このことは、最高のプログラマーであっても、複雑なプロジェクトにおいて常に正しく動的メモリを扱えはしないということを示しています。
+
+[linux vulnerability]: https://securityboulevard.com/2019/02/linux-use-after-free-vulnerability-found-in-linux-2-6-through-4-20-11/
+
+これらの問題を回避するため、JavaやPythonといった多くの言語では[**ガベージコレクション**][_garbage collection_]という技術を使って自動的に動的メモリを管理しています。発想としては、プログラマが絶対に自分の手で`deallocate`を呼び出すことがないようにするというものです。代わりに、プログラムが定期的に一時停止されてスキャンされ、未使用のヒープ変数が見つかったら自動的にdeallocateされるのです。従って、上のような脆弱性は絶対に発生し得ません。欠点としては,定期的にスキャンすることによる性能のオーバーヘッドが発生することと、一時停止の時間が長くなりがちであることが挙げられます。
+
+[_garbage collection_]: https://ja.wikipedia.org/wiki/%E3%82%AC%E3%83%99%E3%83%BC%E3%82%B8%E3%82%B3%E3%83%AC%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3
+
+Rustはこの問題に対して別のアプローチを取ります:[**所有権**][_ownership_]と呼ばれる概念を使って、動的メモリの操作の正確性をコンパイル時にチェックするのです。従って前述の脆弱性を回避するためのガベージコレクションの必要がなく、性能のオーバーヘッドが存在しません。このアプローチのもう一つの利点として、CやC++と同様、プログラマが動的メモリの使用に関して精緻な制御を行うことができるということが挙げられます。
+
+[_ownership_]: https://doc.rust-jp.rs/book-ja/ch04-01-what-is-ownership.html
+
+### Rustにおける割り当て
+
+プログラマーに自分の手で`allocate`と`deallocate`を呼ばせる代わりに、Rustの標準ライブラリはこれらの関数を暗黙の内に呼ぶ抽象型を提供しています。最も重要な型は[**`Box`**]で、これはヒープに割り当てられた値の抽象化です。これは[`Box::new`]コンストラクタ関数を提供しており、これは値を引数として、その値のサイズを引数に`allocate`を呼び出し、ヒープ上に新しく割り当てられたスロットにその値を移動します。ヒープメモリを解放するために、スコープから出た際に`deallocate`を呼ぶような[`Drop`トレイト][`Drop` trait]を`Box`型は実装しています。
+
+[**`Box`**]: https://doc.rust-lang.org/std/boxed/index.html
+[`Box::new`]: https://doc.rust-lang.org/alloc/boxed/struct.Box.html#method.new
+[`Drop` trait]: https://doc.rust-jp.rs/book-ja/ch15-03-drop.html
+
+```rust
+{
+ let z = Box::new([1,2,3]);
+ […]
+} // zがスコープから出たので`deallocate`が呼ばれる
+```
+
+このような記法のパターンは[リソース取得は初期化である][_resource acquisition is initialization_](resource acquisition is initialization、略してRAII)という奇妙な名前を持っています。C++で[`std::unique_ptr`]という同じような抽象型を実装するのに使われたのが始まりです。
+
+[_resource acquisition is initialization_]: https://ja.wikipedia.org/wiki/RAII
+[`std::unique_ptr`]: https://en.cppreference.com/w/cpp/memory/unique_ptr
+
+このような型自体ではすべてのuse-after-freeバグを防ぐのに十分ではありません。なぜなら、プログラマは、`Box`がスコープ外に出て対応するヒープメモリスロットがdeallocateされた後でも参照を利用し続けることができてしまうからです:
+
+```rust
+let x = {
+ let z = Box::new([1,2,3]);
+ &z[1]
+}; // zがスコープから出たので`deallocate`が呼ばれる
+println!("{}", x);
+```
+
+ここでRustの所有権の出番です。所有権システムは、参照が有効なスコープを表す抽象[ライフタイム][lifetime]をそれぞれの参照に指定します。上の例では、参照`x`は配列`z`から取られているので、`z`がスコープ外に出ると無効になります。[上の例をplaygroundで実行する][playground-2]と、確かにRustコンパイラがエラーを投げるのが分かります:
+
+[lifetime]: https://doc.rust-jp.rs/book-ja/ch10-03-lifetime-syntax.html
+[playground-2]: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=28180d8de7b62c6b4a681a7b1f745a48
+
+```
+error[E0597]: `z[_]` does not live long enough
+ --> src/main.rs:4:9
+ |
+2 | let x = {
+ | - borrow later stored here
+3 | let z = Box::new([1,2,3]);
+4 | &z[1]
+ | ^^^^^ borrowed value does not live long enough
+5 | }; // z goes out of scope and `deallocate` is called
+ | - `z[_]` dropped here while still borrowed
+```
+
+ここで使われている用語は初見では少しわかりにくいかもしれません。値の参照を取ることは値を借用する (borrow) と呼ばれています。これは現実での借用と似ているためです:オブジェクトに一時的にアクセスできるようになりますが、それをいつか返さなければならず、また破壊することも許されません。オブジェクトが破壊される前にすべての借用が終了することを確かめることにより、Rustコンパイラはuse-after-freeが起こりえないことを保証できるのです。
+
+Rustの所有権システムはさらに突き詰められており、use-after-freeバグを防ぐだけでなく、JavaやPythonのようなガベージコレクション型言語と同じ完全な[メモリ安全性][_memory safety_]を提供しています。さらに[スレッド安全性][_thread safety_]も保証されており、マルチスレッドのプログラムにおいてはこれらの言語よりもさらに安全です。さらに最も重要なことに、これらのチェックは全てコンパイル時に行われるため、C言語で手書きされたメモリ管理と比べても実行時のオーバーヘッドはありません。
+
+[_memory safety_]: https://ja.wikipedia.org/wiki/%E3%83%A1%E3%83%A2%E3%83%AA%E5%AE%89%E5%85%A8%E6%80%A7
+[_thread safety_]: https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%AC%E3%83%83%E3%83%89%E3%82%BB%E3%83%BC%E3%83%95
+
+### 使用例
+
+Rustにおける動的メモリ割り当ての基礎を学んだわけですが、これをいつ使えば良いのでしょうか?私たちのカーネルは動的メモリ割り当てなしにこれだけやってこられたのに、どうして今になってこれが必要なのでしょうか?
+
+まず覚えておいて欲しいのは、割り当てを行うたびにヒープから空いているスロットを探してこないといけないので、動的メモリ割り当てには少しだけ性能オーバーヘッドがあるということです。このため、特に性能が重要となるカーネルのプログラムにおいては、一般に局所変数の方が好ましいです。しかし、動的メモリ割り当てが最良の選択肢であるようなケースも存在するのです。
+
+基本的なルールとして、動的メモリは動的なライフタイムや可変サイズを持つような変数に必要とされます。動的なライフタイムを持つ最も重要な型は[**`Rc`**]で、これはラップされた値に対する参照を数えておき、すべての参照がスコープから外れたらそれをdeallocateするというものです。可変サイズを持つ型の例には、[**`Vec`**]、[**`String`**]、その他の[コレクション型][collection types]といった、要素が追加されたときに動的に大きくなるような型が挙げられます。これらの型は、容量が一杯になると、より大きい量のメモリを割り当て、すべての要素をコピーし、古い割り当てをdeallocateすることにより対処します。
+
+[**`Rc`**]: https://doc.rust-lang.org/alloc/rc/index.html
+[**`Vec`**]: https://doc.rust-lang.org/alloc/vec/index.html
+[**`String`**]: https://doc.rust-lang.org/alloc/string/index.html
+[collection types]: https://doc.rust-lang.org/alloc/collections/index.html
+
+私たちのカーネルでは主にコレクション型を必要とし、例えば、将来の記事でマルチタスキングを実行するときにアクティブなタスクのリストを格納するために使います。
+
+## アロケータインターフェース
+
+ヒープアロケータを実装するための最初のステップは、組み込みの[`alloc`]クレートへの依存関係を追加することです。[`core`]クレートと同様、これは標準ライブラリのサブセットであり、アロケーション型やコレクション型を含んでいます。`alloc`への依存関係を追加するために、以下を`lib.rs`に追加します:
+
+[`alloc`]: https://doc.rust-lang.org/alloc/
+[`core`]: https://doc.rust-lang.org/core/
+
+```rust
+// in src/lib.rs
+
+extern crate alloc;
+```
+
+通常の依存関係と異なり`Cargo.toml`を修正する必要はありません。その理由は、`alloc`クレートは標準ライブラリの一部としてRustコンパイラに同梱されているため、コンパイラはすでにこのクレートのことを知っているからです。この`extern crate`宣言を追加することで、コンパイラにこれをインクルードしようと試みるよう指定しています(昔はすべての依存関係が`extern crate`宣言を必要としていたのですが、いまは任意です)。
+
+
+
+カスタムターゲット向けにコンパイルしようとしているので、Rustインストール時に同梱されていたコンパイル済みの`alloc`を使用することはできません。代わりにcargoにこのクレートをソースから再コンパイルするよう命令する必要があります。これは、配列`unstable.build-std`を`.cargo/config.toml`ファイルに追加することで行えます。
+
+```toml
+# in .cargo/config.toml
+
+[unstable]
+build-std = ["core", "compiler_builtins", "alloc"]
+````
+
+これでコンパイラは`alloc`クレートを再コンパイルして私たちのカーネルにインクルードしてくれます。
+
+`alloc`クレートが`#[no_std]`なクレートで標準では無効化されている理由は、これが追加の要件を持っているからです。今私たちのプロジェクトをコンパイルしようとすると、その要件をエラーとして目にすることになります:
+
+```
+error: no global memory allocator found but one is required; link to std or add
+ #[global_allocator] to a static item that implements the GlobalAlloc trait.
+(エラー:グローバルメモリアロケータが見つかりませんが、一つ必要です。
+ stdをリンクするか、GlobalAllocトレイトを実装する静的な要素に#[global_allocator]を付けてください。)
+
+error: `#[alloc_error_handler]` function required, but not found
+(エラー:`#[alloc_error_handler]`関数が必要ですが、見つかりません)
+```
+
+最初のエラーは、`alloc`クレートが、ヒープアロケータという`allocate`と`deallocate`関数を提供するオブジェクトを必要とするために発生します。Rustにおいては、ヒープアロケータ(の満たすべき性質)は[`GlobalAlloc`]トレイトによって記述されており、エラーメッセージでもそのことについて触れられています。クレートのヒープアロケータを設定するためには、`#[global_allocator]`属性を`GlobalAlloc`トレイトを実装する何らかの`static`変数に適用する必要があります。
+
+二つ目のエラーは、(主にメモリが不足している場合)`allocate`の呼び出しが失敗しうるために発生します。私たちのプログラムはこのケースに対処できるようになっている必要があり、そのために使われる関数が`#[alloc_error_handler]`なのです。
+
+[`GlobalAlloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html
+
+次のセクションでこのトレイトと属性について説明します。
+
+### `GlobalAlloc`トレイト
+
+[`GlobalAlloc`]トレイトはヒープアロケータの提供しなければならない関数を定義します。このトレイトは、プログラマが絶対に直接使わないという点において特別です。代わりに、`alloc`のアロケーション・コレクション型を使うときに、コンパイラがトレイトメソッドへの適切な呼び出しを自動的に挿入します。
+
+このトレイトを私たちのアロケータ型全てに実装しなければならないので、その宣言は詳しく見ておく価値があるでしょう:
+
+```rust
+pub unsafe trait GlobalAlloc {
+ unsafe fn alloc(&self, layout: Layout) -> *mut u8;
+ unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
+
+ unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
+ unsafe fn realloc(
+ &self,
+ ptr: *mut u8,
+ layout: Layout,
+ new_size: usize
+ ) -> *mut u8 { ... }
+}
+```
+
+このトレイトは[`alloc`]と[`dealloc`]という必須メソッドを定義しており、これは上の例で使った`allocate`と`deallocate`関数に相当します:
+- [`alloc`]メソッドは[`Layout`]インスタンス(割り当てられたメモリの持つべきサイズとアラインメントを記述する)を引数として取ります。メソッドは割り当てられたメモリブロックの最初のバイトへの[生ポインタ][raw pointer]を返します。割り当てエラーが起きたことを示す際は、明示的なエラー値を返す代わりにヌルポインタを返します。このやり方は(Rustの)慣習とはやや外れていますが、同じ慣習に従っている既存のシステムのアロケータをラップするのが簡単になるという利点があります。
+- [`dealloc`]はその対で、メモリブロックを開放する役割を持ちます。このメソッドは、`alloc`によって返されたポインタと割り当ての際に使われた`Layout`という二つの引数を取ります。
+
+[`alloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.alloc
+[`dealloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.dealloc
+[`Layout`]: https://doc.rust-lang.org/alloc/alloc/struct.Layout.html
+
+このトレイトは[`alloc_zeroed`]と[`realloc`]という二つのデフォルト実装付きメソッドも定義しています。
+
+- [`alloc_zeroed`]メソッドは`alloc`を呼んでから割り当てられたメモリブロックの値を0にするのに等しく、デフォルト実装でもまさに同じことをしています。もし、より効率的なカスタム実装があるならば、デフォルト実装を上書きすることもできます。
+- [`realloc`]メソッドは割り当てたメモリを拡大したり縮小したりすることができます。デフォルト実装では、要求されたサイズの新しいメモリブロックを割り当て、以前のアロケーションから中身を全てコピーします。同じく、アロケータの実装によってはこのメソッドをより効率的に実装することができるかもしれません。例えば、可能な場合はその場でアロケーションを拡大・縮小するなど。
+
+[`alloc_zeroed`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#method.alloc_zeroed
+[`realloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#method.realloc
+
+#### Unsafe
+
+トレイト自体とすべてのトレイトメソッドが`unsafe`として宣言されていることに気をつけましょう:
+
+- トレイトを`unsafe`として宣言する理由は、プログラマがアロケータ型のトレイト実装が正しいことを保証しなければならないからです。例えば、`alloc`メソッドは他のどこかですでに使用されているメモリブロックを決して返してはならず、もしそうすると未定義動作が発生してしまいます。
+- 同様に、メソッドが`unsafe`である理由は、メソッドを呼び出す際に呼び出し元がいくつかの不変条件を保証しなければならないからです。例えば、`alloc`に渡される`Layout`の指定するサイズが非ゼロであることなどです。実際にはこれは大して重要ではなく、というのもこれらのメソッドはコンパイラによって直接呼び出されるため、これらの要件が満たされていることは保証されているからです。
+
+### `DummyAllocator`
+
+アロケータ型が何を提供しないといけないかを理解したので、シンプルなダミーのアロケータを作ることができます。そのためまず新しく`allocator`モジュールを作りましょう:
+
+```rust
+// in src/lib.rs
+
+pub mod allocator;
+```
+
+私たちのダミーアロケータでは、トレイトを実装するための最小限のことしかせず、`alloc`が呼び出されたら常にエラーを返すようにします。以下のようになります:
+
+```rust
+// in src/allocator.rs
+
+use alloc::alloc::{GlobalAlloc, Layout};
+use core::ptr::null_mut;
+
+pub struct Dummy;
+
+unsafe impl GlobalAlloc for Dummy {
+ unsafe fn alloc(&self, _layout: Layout) -> *mut u8 {
+ null_mut()
+ }
+
+ unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
+ panic!("dealloc should be never called")
+ }
+}
+```
+
+この構造体はフィールドを必要としないので、[サイズがゼロの型][zero sized type]として作成します。上で述べたように、`alloc`は常に割り当てエラーに相当するヌルポインタを返すようにします。アロケータがメモリを返すことは絶対に起きないのだから、`dealloc`の呼び出しも絶対に起きないはずです。このため`dealloc`メソッドでは単にpanicすることにします。`alloc_zeroed`と`realloc`メソッドにはデフォルト実装があるので、これらを実装する必要はありません。
+
+[zero sized type]: https://doc.rust-jp.rs/rust-nomicon-ja/exotic-sizes.html#%E3%82%B5%E3%82%A4%E3%82%BA%E3%81%8C-0-%E3%81%AE%E5%9E%8Bzst-zero-sized-type
+
+こうして単純なアロケータを手に入れたわけですが、さらにRustコンパイラにこのアロケータを使うよう指示しないといけません。ここで`#[global_allocator]`属性の出番です。
+
+### `#[global_allocator]`属性
+
+`#[global_allocator]`属性は、どのアロケータインスタンスをグローバルヒープアロケータとして使うべきかをRustコンパイラに指示します。この属性は`GlobalAlloc`トレイトを実装する`static`にのみ適用できます。私たちの`Dummy`アロケータのインスタンスをグローバルアロケータとして登録してみましょう:
+
+```rust
+// in src/allocator.rs
+
+#[global_allocator]
+static ALLOCATOR: Dummy = Dummy;
+```
+
+`Dummy`アロケータは[サイズがゼロの型][zero sized type]なので、初期化式でフィールドを指定する必要はありません。
+
+これをコンパイルしようとすると、最初のエラーは消えているはずです。残っている二つ目のエラーを修正しましょう:
+
+```
+error: `#[alloc_error_handler]` function required, but not found
+```
+
+### `#[alloc_error_handler]`属性
+
+`GlobalAlloc`トレイトについて議論したときに学んだように、`alloc`関数はヌルポインタを返すことによって割り当てエラーを示します。ここで生じる疑問は、そのように割り当てが失敗したときRustランタイムはどう対処するべきなのかということです。ここで`#[alloc_error_handler]`属性の出番です。この属性は、パニックが起こったときにパニックハンドラが呼ばれるのと同じように、割り当てエラーが起こったときに呼ばれる関数を指定するのです。
+
+コンパイルエラーを修正するためにそのような関数を追加してみましょう:
+
+```rust
+// in src/lib.rs
+
+#![feature(alloc_error_handler)] // ファイルの先頭に書く
+
+#[alloc_error_handler]
+fn alloc_error_handler(layout: alloc::alloc::Layout) -> ! {
+ panic!("allocation error: {:?}", layout)
+}
+```
+
+`alloc_error_handler`関数はまだunstableなので、feature gateによってこれを有効化する必要があります。この関数は引数を一つ取ります:割り当てエラーが起こったとき`alloc`関数に渡されていた`Layout`のインスタンスです。割り当ての失敗を解決するためにできることはないので、`Layout`インスタンスを含めたメッセージを表示してただpanicすることにしましょう。
+
+この関数を追加したことで、コンパイルエラーは修正されたはずです。これで`alloc`のアロケーション・コレクション型を使えるようになりました。例えば、[`Box`]を使ってヒープに値を割り当てることができます:
+
+[`Box`]: https://doc.rust-lang.org/alloc/boxed/struct.Box.html
+
+```rust
+// in src/main.rs
+
+extern crate alloc;
+
+use alloc::boxed::Box;
+
+fn kernel_main(boot_info: &'static BootInfo) -> ! {
+ // […] "Hello World!"を表示, `init`の呼び出し, `mapper`と`frame_allocator`を作成
+
+ let x = Box::new(41);
+
+ // […] テストモードでは`test_main`を呼ぶ
+
+ println!("It did not crash!");
+ blog_os::hlt_loop();
+}
+
+```
+
+`main.rs`においても`extern crate alloc`文を指定する必要があることに注意してください。`lib.rs`と`main.rs`は別のクレートとして取り扱われているためです。しかしながら、グローバルアロケータはプロジェクト内のすべてのクレートに適用されるため、`#[global_allocator]`静的変数をもう一つ作る必要はありません。実際、別のクレートで新しいアロケータを指定するとエラーになります。
+
+上のコードを実行すると、`alloc_error_handler`関数が呼ばれるのが分かります:
+
+
+
+`Box::new`関数は暗黙のうちにグローバルアロケータの`alloc`関数を呼び出すため、エラーハンドラが呼ばれました。私たちのダミーアロケータは常にヌルポインタを返すので、あらゆる割り当てが失敗するのです。これを修正するためには、使用可能なメモリを実際に返すアロケータを作る必要があります。
+
+## Creating a Kernel Heap
+
+適切なアロケータを作りたいですが、その前にまず、そのアロケータがメモリを割り当てるためのヒープメモリ領域を作らないといけません。このために、ヒープ領域のための仮想メモリ範囲を定義し、その領域を物理フレームに対応付ける必要があります。仮想メモリとページテーブルの概要については、[ページング入門][_"Introduction To Paging"_]の記事を読んでください。
+
+[_"Introduction To Paging"_]: @/edition-2/posts/08-paging-introduction/index.ja.md
+
+最初のステップはヒープのための仮想メモリ領域を定義することです。他のメモリ領域に使われていない限り、どんな仮想アドレス範囲でも構いません。ここでは、あとからそこがヒープポインタだと簡単に分かるよう、`0x_4444_4444_0000`から始まるメモリとしましょう。
+
+```rust
+// in src/allocator.rs
+
+pub const HEAP_START: usize = 0x_4444_4444_0000;
+pub const HEAP_SIZE: usize = 100 * 1024; // 100 KiB
+```
+
+今のところヒープの大きさは100 KiBとします。将来より多くの領域が必要になったら大きくすれば良いです。
+
+今このヒープ領域を使おうとすると、仮想メモリ領域が物理メモリにまだ対応付けられていないためページフォルトが発生します。これを解決するために、[ページング入門][_"Paging Implementation"_]の記事で導入した[`Mapper` API]を使ってヒープページを対応付ける関数`init_heap`を作ります:
+
+[`Mapper` API]: @/edition-2/posts/09-paging-implementation/index.ja.md#offsetpagetablewoshi-u
+[_"Paging Implementation"_]: @/edition-2/posts/09-paging-implementation/index.ja.md
+
+```rust
+// in src/allocator.rs
+
+use x86_64::{
+ structures::paging::{
+ mapper::MapToError, FrameAllocator, Mapper, Page, PageTableFlags, Size4KiB,
+ },
+ VirtAddr,
+};
+
+pub fn init_heap(
+ mapper: &mut impl Mapper,
+ frame_allocator: &mut impl FrameAllocator,
+) -> Result<(), MapToError> {
+ let page_range = {
+ let heap_start = VirtAddr::new(HEAP_START as u64);
+ let heap_end = heap_start + HEAP_SIZE - 1u64;
+ let heap_start_page = Page::containing_address(heap_start);
+ let heap_end_page = Page::containing_address(heap_end);
+ Page::range_inclusive(heap_start_page, heap_end_page)
+ };
+
+ for page in page_range {
+ let frame = frame_allocator
+ .allocate_frame()
+ .ok_or(MapToError::FrameAllocationFailed)?;
+ let flags = PageTableFlags::PRESENT | PageTableFlags::WRITABLE;
+ unsafe {
+ mapper.map_to(page, frame, flags, frame_allocator)?.flush()
+ };
+ }
+
+ Ok(())
+}
+```
+
+この関数は[`Mapper`]と[`FrameAllocator`]への可変参照を取ります。これらはどちらも[`Size4KiB`]をジェネリックパラメータとすることで4KiBページのみに制限しています。この関数の戻り値は[`Result`]で、成功ヴァリアントが`()`、失敗ヴァリアントが([`Mapper::map_to`]メソッドによって失敗時に返されるエラー型である)[`MapToError`]です。この関数における主なエラーの原因は`map_to`メソッドであるため、このエラー型を流用するのは理にかなっています。
+
+[`Mapper`]:https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/trait.Mapper.html
+[`FrameAllocator`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/trait.FrameAllocator.html
+[`Size4KiB`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page/enum.Size4KiB.html
+[`Result`]: https://doc.rust-lang.org/core/result/enum.Result.html
+[`MapToError`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/enum.MapToError.html
+[`Mapper::map_to`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/trait.Mapper.html#method.map_to
+
+実装内容は以下の二つに分けられます:
+
+- **ページ範囲の作成:** 対応付けたいページ領域を作成するために、ポインタ`HEAP_START`を[`VirtAddr`]型に変換します。つぎに`HEAP_SIZE`を足すことによってヒープの終端アドレスを計算します。端が含まれる境界にしたい(ヒープの最後のバイトのアドレスとしたい)ので1を引きます。次に、これらのアドレスを[`containing_address`]関数を使って[`Page`]型に変換します。最後に、[`Page::range_inclusive`]関数を使って最初と最後のページからページ範囲を作成します。
+
+- **ページの対応付け:** 二つ目のステップは、今作ったページ範囲のすべてのページに対して対応付けを行うことです。これを行うため、`for`ループを使ってこのページ範囲に対して繰り返し処理を行います。それぞれのページに対して以下を行います:
+
+ - [`FrameAllocator::allocate_frame`]メソッドを使って、ページのマップされるべき物理フレームを割り当てます。このメソッドはもうフレームが残っていないとき[`None`]を返します。このケースに対処するため、[`Option::ok_or`]メソッドを使ってこれを[`MapToError::FrameAllocationFailed`]に変換し、エラーの場合は[`?`演算子][question mark operator]を使って早期リターンしています。
+
+ - このページに対し、必要となる`PRESENT`フラグと`WRITABLE`フラグをセットします。これらのフラグにより読み書きのアクセスが許可されますが、これはヒープメモリとして理にかなっています。
+
+ - [`Mapper::map_to`]メソッドを使ってアクティブなページテーブルに対応付けを作成します。このメソッドは失敗しうるので、同様に[`?`演算子][question mark operator]を使ってエラーを呼び出し元に受け渡します。成功時には、このメソッドは[`MapperFlush`]インスタンスを返しますが、これを使って[`flush`]メソッドを呼ぶことで[**トランスレーション・ルックアサイド・バッファ**][_translation lookaside buffer_]を更新することができます。
+
+[`VirtAddr`]: https://docs.rs/x86_64/0.14.2/x86_64/addr/struct.VirtAddr.html
+[`Page`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page/struct.Page.html
+[`containing_address`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page/struct.Page.html#method.containing_address
+[`Page::range_inclusive`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page/struct.Page.html#method.range_inclusive
+[`FrameAllocator::allocate_frame`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/trait.FrameAllocator.html#tymethod.allocate_frame
+[`None`]: https://doc.rust-lang.org/core/option/enum.Option.html#variant.None
+[`MapToError::FrameAllocationFailed`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/enum.MapToError.html#variant.FrameAllocationFailed
+[`Option::ok_or`]: https://doc.rust-lang.org/core/option/enum.Option.html#method.ok_or
+[question mark operator]: https://doc.rust-jp.rs/book-ja/ch09-02-recoverable-errors-with-result.html#%E3%82%A8%E3%83%A9%E3%83%BC%E5%A7%94%E8%AD%B2%E3%81%AE%E3%82%B7%E3%83%A7%E3%83%BC%E3%83%88%E3%82%AB%E3%83%83%E3%83%88-%E6%BC%94%E7%AE%97%E5%AD%90
+[`MapperFlush`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/struct.MapperFlush.html
+[_translation lookaside buffer_]: @/edition-2/posts/08-paging-introduction/index.ja.md#toransuresiyonrutukuasaidobatuhua
+[`flush`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/struct.MapperFlush.html#method.flush
+
+最後のステップは、この関数を`kernel_main`から呼び出すことです:
+
+```rust
+// in src/main.rs
+
+fn kernel_main(boot_info: &'static BootInfo) -> ! {
+ use blog_os::allocator; // 新しいインポート
+ use blog_os::memory::{self, BootInfoFrameAllocator};
+
+ println!("Hello World{}", "!");
+ blog_os::init();
+
+ let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
+ let mut mapper = unsafe { memory::init(phys_mem_offset) };
+ let mut frame_allocator = unsafe {
+ BootInfoFrameAllocator::init(&boot_info.memory_map)
+ };
+
+ // ここを追加
+ allocator::init_heap(&mut mapper, &mut frame_allocator)
+ .expect("heap initialization failed");
+
+ let x = Box::new(41);
+
+ // […] テストモードでは`test_main`を呼ぶ
+
+ println!("It did not crash!");
+ blog_os::hlt_loop();
+}
+```
+
+ここで、文脈が分かるよう関数の全体を示しています。(しかし)新しい行は`blog_os::allocator`のインポートと`allocator::init_heap`の呼び出しだけです。`init_heap`関数がエラーを返した場合、これを処理する良い方法は今のところないため、[`Result::expect`]メソッドを使ってパニックします。
+
+[`Result::expect`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.expect
+
+これで、使用する準備のできた、対応付けられたヒープメモリ領域を手に入れました。`Box::new`の呼び出しはまだ私たちの古い`Dummy`アロケータを使っているので、実行しても依然として「メモリ不足」のエラーを見ることになるでしょう。適切なアロケータを使うようにして、このエラーを修正してみましょう。
+
+## アロケータクレートを使う
+
+アロケータを実装するのは少々複雑なので、まずは既製のアロケータを使うことにしましょう。アロケータを自作する方法については次の記事で学びます。
+
+`no_std`のアプリケーションのためのシンプルなアロケータのひとつに[`linked_list_allocator`]クレートがあります。この名前は、割り当てられていないメモリ領域を連結リストを使って管理しているところから来ています。この手法のより詳しい説明については次の記事を読んでください。
+
+このクレートを使うためには、まず依存関係を`Cargo.toml`に追加する必要があります:
+
+[`linked_list_allocator`]: https://github.com/phil-opp/linked-list-allocator/
+
+```toml
+# in Cargo.toml
+
+[dependencies]
+linked_list_allocator = "0.9.0"
+```
+
+次に私たちのダミーアロケータをこのクレートによって提供されるアロケータで置き換えます:
+
+```rust
+// in src/allocator.rs
+
+use linked_list_allocator::LockedHeap;
+
+#[global_allocator]
+static ALLOCATOR: LockedHeap = LockedHeap::empty();
+```
+
+この構造体は同期のために`spinning_top::Spinlock`型を使うため`LockedHeap`という名前が付いています。これが必要なのは、`ALLOCATOR`静的変数に複数のスレッドが同時にアクセスすることがありえるからです。スピンロックやmutexを使うときはいつもそうであるように、誤ってデッドロックを起こさないように注意する必要があります。これが意味するのは、我々は割り込みハンドラ内で一切アロケーションを行ってはいけないと言うことです。なぜなら、割り込みハンドラはどんなタイミングでも走る可能性があるため、進行中のアロケーションに割り込んでいることがあるからです。
+
+[`spinning_top::Spinlock`]: https://docs.rs/spinning_top/0.1.0/spinning_top/type.Spinlock.html
+
+`LockedHeap`をグローバルアロケータとして設定するだけでは十分ではありません。いま[`empty`]コンストラクタ関数を使っていますが、この関数はメモリを与えることなくアロケータを作るからです。私たちのダミーアロケータと同じく、これ(今の状態の`LockedHeap`)は`alloc`を行うと常にエラーを返します。この問題を修正するため、ヒープを作った後でアロケータを初期化する必要があります:
+
+[`empty`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.LockedHeap.html#method.empty
+
+```rust
+// in src/allocator.rs
+
+pub fn init_heap(
+ mapper: &mut impl Mapper,
+ frame_allocator: &mut impl FrameAllocator,
+) -> Result<(), MapToError> {
+ // […] すべてのヒープページを物理フレームにマップする
+
+ // new
+ unsafe {
+ ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE);
+ }
+
+ Ok(())
+}
+```
+
+`LockedHeap`型の内部のスピンロックの[`lock`]メソッドを呼ぶことで、ラップされた[`Heap`]インスタンスへの排他参照を得て、これの[`init`]メソッドをヒープの境界を引数として呼んでいます。`init`関数自体がヒープメモリに書き込もうとするので、ヒープページを対応付けた **後に** ヒープを初期化することが重要です。
+
+[`lock`]: https://docs.rs/lock_api/0.3.3/lock_api/struct.Mutex.html#method.lock
+[`Heap`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.Heap.html
+[`init`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.Heap.html#method.init
+
+ヒープを初期化できたら、組み込みの[`alloc`]クレートのあらゆるアロケーション・コレクション型がエラーなく使用できます:
+
+```rust
+// in src/main.rs
+
+use alloc::{boxed::Box, vec, vec::Vec, rc::Rc};
+
+fn kernel_main(boot_info: &'static BootInfo) -> ! {
+ // […] initialize interrupts, mapper, frame_allocator, heap
+
+ // ヒープに数字をアロケートする
+ let heap_value = Box::new(41);
+ println!("heap_value at {:p}", heap_value);
+
+ // 動的サイズのベクタを作成する
+ let mut vec = Vec::new();
+ for i in 0..500 {
+ vec.push(i);
+ }
+ println!("vec at {:p}", vec.as_slice());
+
+ // 参照カウントされたベクタを作成する -> カウントが0になると解放される
+ let reference_counted = Rc::new(vec![1, 2, 3]);
+ let cloned_reference = reference_counted.clone();
+ println!("current reference count is {}", Rc::strong_count(&cloned_reference));
+ core::mem::drop(reference_counted);
+ println!("reference count is {} now", Rc::strong_count(&cloned_reference));
+
+ // […] テストでは `test_main` を呼ぶ
+ println!("It did not crash!");
+ blog_os::hlt_loop();
+}
+```
+
+このコード例では[`Box`], [`Vec`], [`Rc`]型を使ってみました。`Box`型と`Vec`型については対応するヒープポインタを[`{:p}`フォーマット指定子][`{:p}` formatting specifier]を使って出力しています。`Rc`についての例を示すために、参照カウントされたヒープ値を作成し、インスタンスを([`core::mem::drop`]を使って)ドロップする前と後に[`Rc::strong_count`]関数を使って現在の参照カウントを出力しています。
+
+[`Vec`]: https://doc.rust-lang.org/alloc/vec/
+[`Rc`]: https://doc.rust-lang.org/alloc/rc/
+[`{:p}` formatting specifier]: https://doc.rust-lang.org/core/fmt/trait.Pointer.html
+[`Rc::strong_count`]: https://doc.rust-lang.org/alloc/rc/struct.Rc.html#method.strong_count
+[`core::mem::drop`]: https://doc.rust-lang.org/core/mem/fn.drop.html
+
+実行すると、以下のような結果を得ます:
+
+
+
+ポインタが`0x_4444_4444_*`で始まることから、`Box`と`Vec`の値は想定通りヒープ上にあることが分かります。参照カウントされた値も期待したとおり振る舞っており、`clone`呼び出しの後では参照カウントは2になり、インスタンスの一方がドロップされた後では再び1になっています。
+
+ベクタがヒープメモリの先頭から`0x800`だけずれた場所から始まるのは、Box内の値が`0x800`バイトの大きさがあるためではなく、ベクタが容量を増やさなければならないときに発生する[再割り当て][reallocations]のためです。例えば、ベクタの容量が32の際に次の要素を追加しようとすると、ベクタは内部で容量64の配列を新たに割り当て、すべての要素をコピーします。その後古い割り当てを解放しています。
+
+[reallocations]: https://doc.rust-lang.org/alloc/vec/struct.Vec.html#capacity-and-reallocation
+
+もちろん`alloc`クレートにはもっと多くのアロケーション・コレクション型があり、今やそれらのすべてを私たちのカーネルで使うことができます。それには以下が含まれます:
+
+- スレッドセーフな参照カウントポインタ[`Arc`]
+- 文字列を所有する型[`String`]と[`format!`]マクロ
+- [`LinkedList`]
+- 必要に応じてサイズを大きくできるリングバッファ[`VecDeque`]
+- プライオリティキューである[`BinaryHeap`]
+- [`BTreeMap`]と[`BTreeSet`]
+
+[`Arc`]: https://doc.rust-lang.org/alloc/sync/struct.Arc.html
+[`String`]: https://doc.rust-lang.org/alloc/string/struct.String.html
+[`format!`]: https://doc.rust-lang.org/alloc/macro.format.html
+[`LinkedList`]: https://doc.rust-lang.org/alloc/collections/linked_list/struct.LinkedList.html
+[`VecDeque`]: https://doc.rust-lang.org/alloc/collections/vec_deque/struct.VecDeque.html
+[`BinaryHeap`]: https://doc.rust-lang.org/alloc/collections/binary_heap/struct.BinaryHeap.html
+[`BTreeMap`]: https://doc.rust-lang.org/alloc/collections/btree_map/struct.BTreeMap.html
+[`BTreeSet`]: https://doc.rust-lang.org/alloc/collections/btree_set/struct.BTreeSet.html
+
+これらの型は、スレッドリスト、スケジュールキュー、async/awaitのサポートを実装しようとするときにとても有用になります。
+
+## テストを追加する
+
+いま新しく作ったアロケーションコードを間違って壊してしまうことがないことを保証するために、結合テストを追加するべきでしょう。まず、次のような内容のファイル`tests/heap_allocation.rs`を作成します。
+
+```rust
+// in tests/heap_allocation.rs
+
+#![no_std]
+#![no_main]
+#![feature(custom_test_frameworks)]
+#![test_runner(blog_os::test_runner)]
+#![reexport_test_harness_main = "test_main"]
+
+extern crate alloc;
+
+use bootloader::{entry_point, BootInfo};
+use core::panic::PanicInfo;
+
+entry_point!(main);
+
+fn main(boot_info: &'static BootInfo) -> ! {
+ unimplemented!();
+}
+
+#[panic_handler]
+fn panic(info: &PanicInfo) -> ! {
+ blog_os::test_panic_handler(info)
+}
+```
+
+`lib.rs`の`test_runner`関数と`test_panic_handler`関数を再利用します。私たちはアロケーションをテストしたいので、`extern crate alloc`宣言を使って`alloc`クレートを有効化します。テストに共通する定型部については[テスト][_Testing_]の記事を読んでください。
+
+[_Testing_]: @/edition-2/posts/04-testing/index.ja.md
+
+`main`関数の実装は以下のようになります:
+
+```rust
+// in tests/heap_allocation.rs
+
+fn main(boot_info: &'static BootInfo) -> ! {
+ use blog_os::allocator;
+ use blog_os::memory::{self, BootInfoFrameAllocator};
+ use x86_64::VirtAddr;
+
+ blog_os::init();
+ let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
+ let mut mapper = unsafe { memory::init(phys_mem_offset) };
+ let mut frame_allocator = unsafe {
+ BootInfoFrameAllocator::init(&boot_info.memory_map)
+ };
+ allocator::init_heap(&mut mapper, &mut frame_allocator)
+ .expect("heap initialization failed");
+
+ test_main();
+ loop {}
+}
+```
+
+私たちの`main.rs`内の`kernel_main`関数によく似ていますが、`println`を呼び出さず、例示のため行ったアロケーションも行わず、また`test_main`を無条件で呼び出しているという違いがあります。
+
+これでテストケースを追加する準備ができました。まず、[`Box`]を使って単純な割り当てを行い、割り当てられた値を確かめることで基本的なアロケーションがうまくいっていることを確かめるテストを追加しましょう:
+
+```rust
+// in tests/heap_allocation.rs
+use alloc::boxed::Box;
+
+#[test_case]
+fn simple_allocation() {
+ let heap_value_1 = Box::new(41);
+ let heap_value_2 = Box::new(13);
+ assert_eq!(*heap_value_1, 41);
+ assert_eq!(*heap_value_2, 13);
+}
+```
+
+最も重要なのは、このテストはアロケーションエラーが起きないことを検証してくれるということです。
+
+次に、反復によって少しずつ大きなベクタを作ることで、大きな割り当てと(再割り当てによる)複数回の割り当ての両方をテストしましょう:
+
+```rust
+// in tests/heap_allocation.rs
+
+use alloc::vec::Vec;
+
+#[test_case]
+fn large_vec() {
+ let n = 1000;
+ let mut vec = Vec::new();
+ for i in 0..n {
+ vec.push(i);
+ }
+ assert_eq!(vec.iter().sum::(), (n - 1) * n / 2);
+}
+```
+
+このベクタの和を[n次部分和][n-th partial sum]の公式と比較することで検証しています。これにより、割り当てられた値はすべて正しいことをある程度保証できます。
+
+[n-th partial sum]: https://ja.wikipedia.org/wiki/1%2B2%2B3%2B4%2B%E2%80%A6
+
+3つ目のテストとして、10000回次々にアロケーションを行います:
+
+```rust
+// in tests/heap_allocation.rs
+
+use blog_os::allocator::HEAP_SIZE;
+
+#[test_case]
+fn many_boxes() {
+ for i in 0..HEAP_SIZE {
+ let x = Box::new(i);
+ assert_eq!(*x, i);
+ }
+}
+```
+
+このテストではアロケータが解放されたメモリを次の割り当てで再利用していることを保証してくれます。もしそうなっていなければメモリ不足が起きるでしょう。こんなことアロケータにとって当たり前の要件だと思われるかもしれませんが、これを行わないようなアロケータの設計も存在するのです。その例として、次の記事で説明するbump allocatorがあります。
+
+では、私たちの新しい結合テストを実行してみましょう:
+
+```
+> cargo test --test heap_allocation
+[…]
+Running 3 tests
+simple_allocation... [ok]
+large_vec... [ok]
+many_boxes... [ok]
+```
+
+すべてのテストが成功しました!`cargo test`コマンドを(`--test`引数なしに)呼ぶことで、すべての結合テストを実行することもできます。
+
+## まとめ
+
+この記事では動的メモリに入門し、なぜ、そしていつそれが必要になるのかを説明しました。Rustの借用チェッカがどのようにしてよくある脆弱性を防ぐのか、そしてRustのアロケーションAPIがどのような仕組みなのかを理解しました。
+
+ダミーアロケータでRustのアロケータインターフェースの最小限の実装を作成した後、私たちのカーネル用の適切なヒープメモリ領域を作成しました。これを行うために、ヒープ用の仮想アドレス範囲を定義し、前の記事で説明した`Mapper`と`FrameAllocator`を使ってその範囲のすべてのページを物理フレームに対応付けました。
+
+最後に、`linked_list_allocator`クレートへの依存関係を追加し、適切なアロケータを私たちのカーネルに追加しました。このアロケータのおかげで、`alloc`クレートに含まれる`Box`、`Vec`、その他のアロケーション・コレクション型を使えるようになりました。
+
+## 次は?
+
+この記事ではヒープ割り当て機能のサポートを追加しましたが、ほとんどの仕事は`linked_list_allocator`クレートに任せてしまっています。次の記事では、アロケータをゼロから実装する方法を詳細にお伝えします。可能なアロケータの設計を複数提示し、それらを単純化したものを実装する方法を示し、それらの利点と欠点を説明します。
diff --git a/blog/content/edition-2/posts/10-heap-allocation/index.md b/blog/content/edition-2/posts/10-heap-allocation/index.md
index c56b5f10..75dfdbf4 100644
--- a/blog/content/edition-2/posts/10-heap-allocation/index.md
+++ b/blog/content/edition-2/posts/10-heap-allocation/index.md
@@ -8,7 +8,7 @@ date = 2019-06-26
chapter = "Memory Management"
+++
-This post adds support for heap allocation to our kernel. First, it gives an introduction to dynamic memory and shows how the borrow checker prevents common allocation errors. It then implements the basic allocation interface of Rust, creates a heap memory region, and sets up an allocator crate. At the end of this post all the allocation and collection types of the built-in `alloc` crate will be available to our kernel.
+This post adds support for heap allocation to our kernel. First, it gives an introduction to dynamic memory and shows how the borrow checker prevents common allocation errors. It then implements the basic allocation interface of Rust, creates a heap memory region, and sets up an allocator crate. At the end of this post, all the allocation and collection types of the built-in `alloc` crate will be available to our kernel.
@@ -32,15 +32,15 @@ Local variables are stored on the [call stack], which is a [stack data structure
[call stack]: https://en.wikipedia.org/wiki/Call_stack
[stack data structure]: https://en.wikipedia.org/wiki/Stack_(abstract_data_type)
-
+
-The above example shows the call stack after an `outer` function called an `inner` function. We see that the call stack contains the local variables of `outer` first. On the `inner` call, the parameter `1` and the return address for the function were pushed. Then control was transferred to `inner`, which pushed its local variables.
+The above example shows the call stack after the `outer` function called the `inner` function. We see that the call stack contains the local variables of `outer` first. On the `inner` call, the parameter `1` and the return address for the function were pushed. Then control was transferred to `inner`, which pushed its local variables.
After the `inner` function returns, its part of the call stack is popped again and only the local variables of `outer` remain:
-
+
-We see that the local variables of `inner` only live until the function returns. The Rust compiler enforces these lifetimes and throws an error when we use a value too long, for example when we try to return a reference to a local variable:
+We see that the local variables of `inner` only live until the function returns. The Rust compiler enforces these lifetimes and throws an error when we use a value for too long, for example when we try to return a reference to a local variable:
```rust
fn inner(i: usize) -> &'static u32 {
@@ -59,16 +59,16 @@ While returning a reference makes no sense in this example, there are cases wher
Static variables are stored at a fixed memory location separate from the stack. This memory location is assigned at compile time by the linker and encoded in the executable. Statics live for the complete runtime of the program, so they have the `'static` lifetime and can always be referenced from local variables:
-![The same outer/inner example with the difference that inner has a `static Z: [u32; 3] = [1,2,3];` and returns a `&Z[i]` reference](call-stack-static.svg)
+![The same outer/inner example, except that inner has a `static Z: [u32; 3] = [1,2,3];` and returns a `&Z[i]` reference](call-stack-static.svg)
-When the `inner` function returns in the above example, it's part of the call stack is destroyed. The static variables live in a separate memory range that is never destroyed, so the `&Z[1]` reference is still valid after the return.
+When the `inner` function returns in the above example, its part of the call stack is destroyed. The static variables live in a separate memory range that is never destroyed, so the `&Z[1]` reference is still valid after the return.
-Apart from the `'static` lifetime, static variables also have the useful property that their location is known at compile time, so that no reference is needed for accessing it. We utilized that property for our `println` macro: By using a [static `Writer`] internally there is no `&mut Writer` reference needed to invoke the macro, which is very useful in [exception handlers] where we don't have access to any additional variables.
+Apart from the `'static` lifetime, static variables also have the useful property that their location is known at compile time, so that no reference is needed for accessing them. We utilized that property for our `println` macro: By using a [static `Writer`] internally, there is no `&mut Writer` reference needed to invoke the macro, which is very useful in [exception handlers], where we don't have access to any additional variables.
[static `Writer`]: @/edition-2/posts/03-vga-text-buffer/index.md#a-global-interface
[exception handlers]: @/edition-2/posts/05-cpu-exceptions/index.md#implementation
-However, this property of static variables brings a crucial drawback: They are read-only by default. Rust enforces this because a [data race] would occur if e.g. two threads modify a static variable at the same time. The only way to modify a static variable is to encapsulate it in a [`Mutex`] type, which ensures that only a single `&mut` reference exists at any point in time. We already used a `Mutex` for our [static VGA buffer `Writer`][vga mutex].
+However, this property of static variables brings a crucial drawback: they are read-only by default. Rust enforces this because a [data race] would occur if, e.g., two threads modified a static variable at the same time. The only way to modify a static variable is to encapsulate it in a [`Mutex`] type, which ensures that only a single `&mut` reference exists at any point in time. We already used a `Mutex` for our [static VGA buffer `Writer`][vga mutex].
[data race]: https://doc.rust-lang.org/nomicon/races.html
[`Mutex`]: https://docs.rs/spin/0.5.2/spin/struct.Mutex.html
@@ -89,9 +89,9 @@ To circumvent these drawbacks, programming languages often support a third memor
Let's go through an example:
-![The inner function calls `allocate(size_of([u32; 3]))`, writes `z.write([1,2,3]);`, and returns `(z as *mut u32).offset(i)`. The outer function does `deallocate(y, size_of(u32))` on the returned value `y`.](call-stack-heap.svg)
+![The inner function calls `allocate(size_of([u32; 3]))`, writes `z.write([1,2,3]);`, and returns `(z as *mut u32).offset(i)`. On the returned value `y`, the outer function performs `deallocate(y, size_of(u32))`.](call-stack-heap.svg)
-Here the `inner` function uses heap memory instead of static variables for storing `z`. It first allocates a memory block of the required size, which returns a `*mut u32` [raw pointer]. It then uses the [`ptr::write`] method to write the array `[1,2,3]` to it. In the last step, it uses the [`offset`] function to calculate a pointer to the `i`th element and then returns it. (Note that we omitted some required casts and unsafe blocks in this example function for brevity.)
+Here the `inner` function uses heap memory instead of static variables for storing `z`. It first allocates a memory block of the required size, which returns a `*mut u32` [raw pointer]. It then uses the [`ptr::write`] method to write the array `[1,2,3]` to it. In the last step, it uses the [`offset`] function to calculate a pointer to the `i`-th element and then returns it. (Note that we omitted some required casts and unsafe blocks in this example function for brevity.)
[raw pointer]: https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer
[`ptr::write`]: https://doc.rust-lang.org/core/ptr/fn.write.html
@@ -99,26 +99,26 @@ Here the `inner` function uses heap memory instead of static variables for stori
The allocated memory lives until it is explicitly freed through a call to `deallocate`. Thus, the returned pointer is still valid even after `inner` returned and its part of the call stack was destroyed. The advantage of using heap memory compared to static memory is that the memory can be reused after it is freed, which we do through the `deallocate` call in `outer`. After that call, the situation looks like this:
-![The call stack contains the local variables of outer, the heap contains z[0] and z[2], but no longer z[1].](call-stack-heap-freed.svg)
+![The call stack contains the local variables of `outer`, the heap contains `z[0]` and `z[2]`, but no longer `z[1]`.](call-stack-heap-freed.svg)
-We see that the `z[1]` slot is free again and can be reused for the next `allocate` call. However, we also see that `z[0]` and `z[2]` are never freed because we never deallocate them. Such a bug is called a _memory leak_ and often the cause of excessive memory consumption of programs (just imagine what happens when we call `inner` repeatedly in a loop). This might seem bad, but there are much more dangerous types of bugs that can happen with dynamic allocation.
+We see that the `z[1]` slot is free again and can be reused for the next `allocate` call. However, we also see that `z[0]` and `z[2]` are never freed because we never deallocate them. Such a bug is called a _memory leak_ and is often the cause of excessive memory consumption of programs (just imagine what happens when we call `inner` repeatedly in a loop). This might seem bad, but there are much more dangerous types of bugs that can happen with dynamic allocation.
### Common Errors
Apart from memory leaks, which are unfortunate but don't make the program vulnerable to attackers, there are two common types of bugs with more severe consequences:
- When we accidentally continue to use a variable after calling `deallocate` on it, we have a so-called **use-after-free** vulnerability. Such a bug causes undefined behavior and can often be exploited by attackers to execute arbitrary code.
-- When we accidentally free a variable twice, we have a **double-free** vulnerability. This is problematic because it might free a different allocation that was allocated in the same spot after the first `deallocate` call. Thus, it can lead to an use-after-free vulnerability again.
+- When we accidentally free a variable twice, we have a **double-free** vulnerability. This is problematic because it might free a different allocation that was allocated in the same spot after the first `deallocate` call. Thus, it can lead to a use-after-free vulnerability again.
-These types of vulnerabilities are commonly known, so one might expect that people learned how to avoid them by now. But no, such vulnerabilities are still regularly found, for example this recent [use-after-free vulnerability in Linux][linux vulnerability] that allowed arbitrary code execution. This shows that even the best programmers are not always able to correctly handle dynamic memory in complex projects.
+These types of vulnerabilities are commonly known, so one might expect that people have learned how to avoid them by now. But no, such vulnerabilities are still regularly found, for example this [use-after-free vulnerability in Linux][linux vulnerability] (2019), that allowed arbitrary code execution. A web search like `use-after-free linux {current year}` will probably always yield results. This shows that even the best programmers are not always able to correctly handle dynamic memory in complex projects.
[linux vulnerability]: https://securityboulevard.com/2019/02/linux-use-after-free-vulnerability-found-in-linux-2-6-through-4-20-11/
-To avoid these issues, many languages such as Java or Python manage dynamic memory automatically using a technique called [_garbage collection_]. The idea is that the programmer never invokes `deallocate` manually. Instead, the program is regularly paused and scanned for unused heap variables, which are then automatically deallocated. Thus, the above vulnerabilities can never occur. The drawbacks are the performance overhead of the regular scan and the probably long pause times.
+To avoid these issues, many languages, such as Java or Python, manage dynamic memory automatically using a technique called [_garbage collection_]. The idea is that the programmer never invokes `deallocate` manually. Instead, the program is regularly paused and scanned for unused heap variables, which are then automatically deallocated. Thus, the above vulnerabilities can never occur. The drawbacks are the performance overhead of the regular scan and the probably long pause times.
[_garbage collection_]: https://en.wikipedia.org/wiki/Garbage_collection_(computer_science)
-Rust takes a different approach to the problem: It uses a concept called [_ownership_] that is able to check the correctness of dynamic memory operations at compile time. Thus no garbage collection is needed to avoid the mentioned vulnerabilities, which means that there is no performance overhead. Another advantage of this approach is that the programmer still has fine-grained control over the use of dynamic memory, just like with C or C++.
+Rust takes a different approach to the problem: It uses a concept called [_ownership_] that is able to check the correctness of dynamic memory operations at compile time. Thus, no garbage collection is needed to avoid the mentioned vulnerabilities, which means that there is no performance overhead. Another advantage of this approach is that the programmer still has fine-grained control over the use of dynamic memory, just like with C or C++.
[_ownership_]: https://doc.rust-lang.org/book/ch04-01-what-is-ownership.html
@@ -170,9 +170,9 @@ error[E0597]: `z[_]` does not live long enough
| - `z[_]` dropped here while still borrowed
```
-The terminology can be a bit confusing at first. Taking a reference to a value is called _borrowing_ the value since it's similar to a borrow in real life: You have temporary access to an object but need to return it sometime and you must not destroy it. By checking that all borrows end before an object is destroyed, the Rust compiler can guarantee that no use-after-free situation can occur.
+The terminology can be a bit confusing at first. Taking a reference to a value is called _borrowing_ the value since it's similar to a borrow in real life: You have temporary access to an object but need to return it sometime, and you must not destroy it. By checking that all borrows end before an object is destroyed, the Rust compiler can guarantee that no use-after-free situation can occur.
-Rust's ownership system goes even further and does not only prevent use-after-free bugs, but provides complete [_memory safety_] like garbage collected languages like Java or Python do. Additionally, it guarantees [_thread safety_] and is thus even safer than those languages in multi-threaded code. And most importantly, all these checks happen at compile time, so there is no runtime overhead compared to hand written memory management in C.
+Rust's ownership system goes even further, preventing not only use-after-free bugs but also providing complete [_memory safety_], as garbage collected languages like Java or Python do. Additionally, it guarantees [_thread safety_] and is thus even safer than those languages in multi-threaded code. And most importantly, all these checks happen at compile time, so there is no runtime overhead compared to hand-written memory management in C.
[_memory safety_]: https://en.wikipedia.org/wiki/Memory_safety
[_thread safety_]: https://en.wikipedia.org/wiki/Thread_safety
@@ -181,16 +181,16 @@ Rust's ownership system goes even further and does not only prevent use-after-fr
We now know the basics of dynamic memory allocation in Rust, but when should we use it? We've come really far with our kernel without dynamic memory allocation, so why do we need it now?
-First, dynamic memory allocation always comes with a bit of performance overhead, since we need to find a free slot on the heap for every allocation. For this reason local variables are generally preferable, especially in performance sensitive kernel code. However, there are cases where dynamic memory allocation is the best choice.
+First, dynamic memory allocation always comes with a bit of performance overhead since we need to find a free slot on the heap for every allocation. For this reason, local variables are generally preferable, especially in performance-sensitive kernel code. However, there are cases where dynamic memory allocation is the best choice.
-As a basic rule, dynamic memory is required for variables that have a dynamic lifetime or a variable size. The most important type with a dynamic lifetime is [**`Rc`**], which counts the references to its wrapped value and deallocates it after all references went out of scope. Examples for types with a variable size are [**`Vec`**], [**`String`**], and other [collection types] that dynamically grow when more elements are added. These types work by allocating a larger amount of memory when they become full, copying all elements over, and then deallocating the old allocation.
+As a basic rule, dynamic memory is required for variables that have a dynamic lifetime or a variable size. The most important type with a dynamic lifetime is [**`Rc`**], which counts the references to its wrapped value and deallocates it after all references have gone out of scope. Examples for types with a variable size are [**`Vec`**], [**`String`**], and other [collection types] that dynamically grow when more elements are added. These types work by allocating a larger amount of memory when they become full, copying all elements over, and then deallocating the old allocation.
[**`Rc`**]: https://doc.rust-lang.org/alloc/rc/index.html
[**`Vec`**]: https://doc.rust-lang.org/alloc/vec/index.html
[**`String`**]: https://doc.rust-lang.org/alloc/string/index.html
[collection types]: https://doc.rust-lang.org/alloc/collections/index.html
-For our kernel we will mostly need the collection types, for example for storing a list of active tasks when implementing multitasking in future posts.
+For our kernel, we will mostly need the collection types, for example, to store a list of active tasks when implementing multitasking in future posts.
## The Allocator Interface
@@ -207,7 +207,7 @@ extern crate alloc;
Contrary to normal dependencies, we don't need to modify the `Cargo.toml`. The reason is that the `alloc` crate ships with the Rust compiler as part of the standard library, so the compiler already knows about the crate. By adding this `extern crate` statement, we specify that the compiler should try to include it. (Historically, all dependencies needed an `extern crate` statement, which is now optional).
-Since we are compiling for a custom target, we can't use the precompiled version of `alloc` that is shipped with the Rust installation. Instead, we have to tell cargo to recompile the crate from source. We can do that, by adding it to the `unstable.build-std` array in our `.cargo/config.toml` file:
+Since we are compiling for a custom target, we can't use the precompiled version of `alloc` that is shipped with the Rust installation. Instead, we have to tell cargo to recompile the crate from source. We can do that by adding it to the `unstable.build-std` array in our `.cargo/config.toml` file:
```toml
# in .cargo/config.toml
@@ -218,7 +218,7 @@ build-std = ["core", "compiler_builtins", "alloc"]
Now the compiler will recompile and include the `alloc` crate in our kernel.
-The reason that the `alloc` crate is disabled by default in `#[no_std]` crates is that it has additional requirements. We can see these requirements as errors when we try to compile our project now:
+The reason that the `alloc` crate is disabled by default in `#[no_std]` crates is that it has additional requirements. When we try to compile our project now, we will see these requirements as errors:
```
error: no global memory allocator found but one is required; link to std or add
@@ -227,7 +227,7 @@ error: no global memory allocator found but one is required; link to std or add
error: `#[alloc_error_handler]` function required, but not found
```
-The first error occurs because the `alloc` crate requires an heap allocator, which is an object that provides the `allocate` and `deallocate` functions. In Rust, heap allocators are described by the [`GlobalAlloc`] trait, which is mentioned in the error message. To set the heap allocator for the crate, the `#[global_allocator]` attribute must be applied to a `static` variable that implements the `GlobalAlloc` trait.
+The first error occurs because the `alloc` crate requires a heap allocator, which is an object that provides the `allocate` and `deallocate` functions. In Rust, heap allocators are described by the [`GlobalAlloc`] trait, which is mentioned in the error message. To set the heap allocator for the crate, the `#[global_allocator]` attribute must be applied to a `static` variable that implements the `GlobalAlloc` trait.
The second error occurs because calls to `allocate` can fail, most commonly when there is no more memory available. Our program must be able to react to this case, which is what the `#[alloc_error_handler]` function is for.
@@ -257,8 +257,8 @@ pub unsafe trait GlobalAlloc {
```
It defines the two required methods [`alloc`] and [`dealloc`], which correspond to the `allocate` and `deallocate` functions we used in our examples:
-- The [`alloc`] method takes a [`Layout`] instance as argument, which describes the desired size and alignment that the allocated memory should have. It returns a [raw pointer] to the first byte of the allocated memory block. Instead of an explicit error value, the `alloc` method returns a null pointer to signal an allocation error. This is a bit non-idiomatic, but it has the advantage that wrapping existing system allocators is easy, since they use the same convention.
-- The [`dealloc`] method is the counterpart and responsible for freeing a memory block again. It receives two arguments, the pointer returned by `alloc` and the `Layout` that was used for the allocation.
+- The [`alloc`] method takes a [`Layout`] instance as an argument, which describes the desired size and alignment that the allocated memory should have. It returns a [raw pointer] to the first byte of the allocated memory block. Instead of an explicit error value, the `alloc` method returns a null pointer to signal an allocation error. This is a bit non-idiomatic, but it has the advantage that wrapping existing system allocators is easy since they use the same convention.
+- The [`dealloc`] method is the counterpart and is responsible for freeing a memory block again. It receives two arguments: the pointer returned by `alloc` and the `Layout` that was used for the allocation.
[`alloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.alloc
[`dealloc`]: https://doc.rust-lang.org/alloc/alloc/trait.GlobalAlloc.html#tymethod.dealloc
@@ -277,11 +277,11 @@ The trait additionally defines the two methods [`alloc_zeroed`] and [`realloc`]
One thing to notice is that both the trait itself and all trait methods are declared as `unsafe`:
- The reason for declaring the trait as `unsafe` is that the programmer must guarantee that the trait implementation for an allocator type is correct. For example, the `alloc` method must never return a memory block that is already used somewhere else because this would cause undefined behavior.
-- Similarly, the reason that the methods are `unsafe` is that the caller must ensure various invariants when calling the methods, for example that the `Layout` passed to `alloc` specifies a non-zero size. This is not really relevant in practice since the methods are normally called directly by the compiler, which ensures that the requirements are met.
+- Similarly, the reason that the methods are `unsafe` is that the caller must ensure various invariants when calling the methods, for example, that the `Layout` passed to `alloc` specifies a non-zero size. This is not really relevant in practice since the methods are normally called directly by the compiler, which ensures that the requirements are met.
### A `DummyAllocator`
-Now that we know what an allocator type should provide, we can create a simple dummy allocator. For that we create a new `allocator` module:
+Now that we know what an allocator type should provide, we can create a simple dummy allocator. For that, we create a new `allocator` module:
```rust
// in src/lib.rs
@@ -289,7 +289,7 @@ Now that we know what an allocator type should provide, we can create a simple d
pub mod allocator;
```
-Our dummy allocator does the absolute minimum to implement the trait and always return an error when `alloc` is called. It looks like this:
+Our dummy allocator does the absolute minimum to implement the trait and always returns an error when `alloc` is called. It looks like this:
```rust
// in src/allocator.rs
@@ -310,9 +310,9 @@ unsafe impl GlobalAlloc for Dummy {
}
```
-The struct does not need any fields, so we create it as a [zero sized type]. As mentioned above, we always return the null pointer from `alloc`, which corresponds to an allocation error. Since the allocator never returns any memory, a call to `dealloc` should never occur. For this reason we simply panic in the `dealloc` method. The `alloc_zeroed` and `realloc` methods have default implementations, so we don't need to provide implementations for them.
+The struct does not need any fields, so we create it as a [zero-sized type]. As mentioned above, we always return the null pointer from `alloc`, which corresponds to an allocation error. Since the allocator never returns any memory, a call to `dealloc` should never occur. For this reason, we simply panic in the `dealloc` method. The `alloc_zeroed` and `realloc` methods have default implementations, so we don't need to provide implementations for them.
-[zero sized type]: https://doc.rust-lang.org/nomicon/exotic-sizes.html#zero-sized-types-zsts
+[zero-sized type]: https://doc.rust-lang.org/nomicon/exotic-sizes.html#zero-sized-types-zsts
We now have a simple allocator, but we still have to tell the Rust compiler that it should use this allocator. This is where the `#[global_allocator]` attribute comes in.
@@ -327,7 +327,7 @@ The `#[global_allocator]` attribute tells the Rust compiler which allocator inst
static ALLOCATOR: Dummy = Dummy;
```
-Since the `Dummy` allocator is a [zero sized type], we don't need to specify any fields in the initialization expression.
+Since the `Dummy` allocator is a [zero-sized type], we don't need to specify any fields in the initialization expression.
When we now try to compile it, the first error should be gone. Let's fix the remaining second error:
@@ -354,7 +354,7 @@ fn alloc_error_handler(layout: alloc::alloc::Layout) -> ! {
The `alloc_error_handler` function is still unstable, so we need a feature gate to enable it. The function receives a single argument: the `Layout` instance that was passed to `alloc` when the allocation failure occurred. There's nothing we can do to resolve the failure, so we just panic with a message that contains the `Layout` instance.
-With this function, the compilation errors should be fixed. Now we can use the allocation and collection types of `alloc`, for example we can use a [`Box`] to allocate a value on the heap:
+With this function, the compilation errors should be fixed. Now we can use the allocation and collection types of `alloc`. For example, we can use a [`Box`] to allocate a value on the heap:
[`Box`]: https://doc.rust-lang.org/alloc/boxed/struct.Box.html
@@ -378,13 +378,13 @@ fn kernel_main(boot_info: &'static BootInfo) -> ! {
```
-Note that we need to specify the `extern crate alloc` statement in our `main.rs` too. This is required because the `lib.rs` and `main.rs` part are treated as separate crates. However, we don't need to create another `#[global_allocator]` static because the global allocator applies to all crates in the project. In fact, specifying an additional allocator in another crate would be an error.
+Note that we need to specify the `extern crate alloc` statement in our `main.rs` too. This is required because the `lib.rs` and `main.rs` parts are treated as separate crates. However, we don't need to create another `#[global_allocator]` static because the global allocator applies to all crates in the project. In fact, specifying an additional allocator in another crate would be an error.
When we run the above code, we see that our `alloc_error_handler` function is called:

-The error handler is called because the `Box::new` function implicitly calls the `alloc` function of the global allocator. Our dummy allocator always returns a null pointer, so every allocation fails. To fix this we need to create an allocator that actually returns usable memory.
+The error handler is called because the `Box::new` function implicitly calls the `alloc` function of the global allocator. Our dummy allocator always returns a null pointer, so every allocation fails. To fix this, we need to create an allocator that actually returns usable memory.
## Creating a Kernel Heap
@@ -401,7 +401,7 @@ pub const HEAP_START: usize = 0x_4444_4444_0000;
pub const HEAP_SIZE: usize = 100 * 1024; // 100 KiB
```
-We set the heap size to 100 KiB for now. If we need more space in the future, we can simply increase it.
+We set the heap size to 100 KiB for now. If we need more space in the future, we can simply increase it.
If we tried to use this heap region now, a page fault would occur since the virtual memory region is not mapped to physical memory yet. To resolve this, we create an `init_heap` function that maps the heap pages using the [`Mapper` API] that we introduced in the [_"Paging Implementation"_] post:
@@ -444,7 +444,7 @@ pub fn init_heap(
}
```
-The function takes mutable references to a [`Mapper`] and a [`FrameAllocator`] instance, both limited to 4KiB pages by using [`Size4KiB`] as generic parameter. The return value of the function is a [`Result`] with the unit type `()` as success variant and a [`MapToError`] as error variant, which is the error type returned by the [`Mapper::map_to`] method. Reusing the error type makes sense here because the `map_to` method is the main source of errors in this function.
+The function takes mutable references to a [`Mapper`] and a [`FrameAllocator`] instance, both limited to 4 KiB pages by using [`Size4KiB`] as the generic parameter. The return value of the function is a [`Result`] with the unit type `()` as the success variant and a [`MapToError`] as the error variant, which is the error type returned by the [`Mapper::map_to`] method. Reusing the error type makes sense here because the `map_to` method is the main source of errors in this function.
[`Mapper`]:https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/mapper/trait.Mapper.html
[`FrameAllocator`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/trait.FrameAllocator.html
@@ -457,13 +457,13 @@ The implementation can be broken down into two parts:
- **Creating the page range:**: To create a range of the pages that we want to map, we convert the `HEAP_START` pointer to a [`VirtAddr`] type. Then we calculate the heap end address from it by adding the `HEAP_SIZE`. We want an inclusive bound (the address of the last byte of the heap), so we subtract 1. Next, we convert the addresses into [`Page`] types using the [`containing_address`] function. Finally, we create a page range from the start and end pages using the [`Page::range_inclusive`] function.
-- **Mapping the pages:** The second step is to map all pages of the page range we just created. For that we iterate over the pages in that range using a `for` loop. For each page, we do the following:
+- **Mapping the pages:** The second step is to map all pages of the page range we just created. For that, we iterate over these pages using a `for` loop. For each page, we do the following:
- - We allocate a physical frame that the page should be mapped to using the [`FrameAllocator::allocate_frame`] method. This method returns [`None`] when there are no more frames left. We deal with that case by mapping it to a [`MapToError::FrameAllocationFailed`] error through the [`Option::ok_or`] method and then apply the [question mark operator] to return early in the case of an error.
+ - We allocate a physical frame that the page should be mapped to using the [`FrameAllocator::allocate_frame`] method. This method returns [`None`] when there are no more frames left. We deal with that case by mapping it to a [`MapToError::FrameAllocationFailed`] error through the [`Option::ok_or`] method and then applying the [question mark operator] to return early in the case of an error.
- - We set the required `PRESENT` flag and the `WRITABLE` flag for the page. With these flags both read and write accesses are allowed, which makes sense for heap memory.
+ - We set the required `PRESENT` flag and the `WRITABLE` flag for the page. With these flags, both read and write accesses are allowed, which makes sense for heap memory.
- - We use the [`Mapper::map_to`] method for creating the mapping in the active page table. The method can fail, therefore we use the [question mark operator] again to forward the error to the caller. On success, the method returns a [`MapperFlush`] instance that we can use to update the [_translation lookaside buffer_] using the [`flush`] method.
+ - We use the [`Mapper::map_to`] method for creating the mapping in the active page table. The method can fail, so we use the [question mark operator] again to forward the error to the caller. On success, the method returns a [`MapperFlush`] instance that we can use to update the [_translation lookaside buffer_] using the [`flush`] method.
[`VirtAddr`]: https://docs.rs/x86_64/0.14.2/x86_64/addr/struct.VirtAddr.html
[`Page`]: https://docs.rs/x86_64/0.14.2/x86_64/structures/paging/page/struct.Page.html
@@ -509,7 +509,7 @@ fn kernel_main(boot_info: &'static BootInfo) -> ! {
}
```
-We show the full function for context here. The only new lines are the `blog_os::allocator` import and the call to `allocator::init_heap` function. In case the `init_heap` function returns an error, we panic using the [`Result::expect`] method since there is currently no sensible way for us to handle this error.
+We show the full function for context here. The only new lines are the `blog_os::allocator` import and the call to the `allocator::init_heap` function. In case the `init_heap` function returns an error, we panic using the [`Result::expect`] method since there is currently no sensible way for us to handle this error.
[`Result::expect`]: https://doc.rust-lang.org/core/result/enum.Result.html#method.expect
@@ -519,7 +519,7 @@ We now have a mapped heap memory region that is ready to be used. The `Box::new`
Since implementing an allocator is somewhat complex, we start by using an external allocator crate. We will learn how to implement our own allocator in the next post.
-A simple allocator crate for `no_std` applications is the [`linked_list_allocator`] crate. It's name comes from the fact that it uses a linked list data structure to keep track of deallocated memory regions. See the next post for a more detailed explanation of this approach.
+A simple allocator crate for `no_std` applications is the [`linked_list_allocator`] crate. Its name comes from the fact that it uses a linked list data structure to keep track of deallocated memory regions. See the next post for a more detailed explanation of this approach.
To use the crate, we first need to add a dependency on it in our `Cargo.toml`:
@@ -543,7 +543,7 @@ use linked_list_allocator::LockedHeap;
static ALLOCATOR: LockedHeap = LockedHeap::empty();
```
-The struct is named `LockedHeap` because it uses the [`spinning_top::Spinlock`] type for synchronization. This is required because multiple threads could access the `ALLOCATOR` static at the same time. As always when using a spinlock or a mutex, we need to be careful to not accidentally cause a deadlock. This means that we shouldn't perform any allocations in interrupt handlers, since they can run at an arbitrary time and might interrupt an in-progress allocation.
+The struct is named `LockedHeap` because it uses the [`spinning_top::Spinlock`] type for synchronization. This is required because multiple threads could access the `ALLOCATOR` static at the same time. As always, when using a spinlock or a mutex, we need to be careful to not accidentally cause a deadlock. This means that we shouldn't perform any allocations in interrupt handlers, since they can run at an arbitrary time and might interrupt an in-progress allocation.
[`spinning_top::Spinlock`]: https://docs.rs/spinning_top/0.1.0/spinning_top/type.Spinlock.html
@@ -569,7 +569,7 @@ pub fn init_heap(
}
```
-We use the [`lock`] method on the inner spinlock of the `LockedHeap` type to get an exclusive reference to the wrapped [`Heap`] instance, on which we then call the [`init`] method with the heap bounds as arguments. It is important that we initialize the heap _after_ mapping the heap pages, since the [`init`] function already tries to write to the heap memory.
+We use the [`lock`] method on the inner spinlock of the `LockedHeap` type to get an exclusive reference to the wrapped [`Heap`] instance, on which we then call the [`init`] method with the heap bounds as arguments. Because the [`init`] function already tries to write to the heap memory, we must initialize the heap only _after_ mapping the heap pages.
[`lock`]: https://docs.rs/lock_api/0.3.3/lock_api/struct.Mutex.html#method.lock
[`Heap`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.Heap.html
@@ -609,7 +609,7 @@ fn kernel_main(boot_info: &'static BootInfo) -> ! {
}
```
-This code example shows some uses of the [`Box`], [`Vec`], and [`Rc`] types. For the `Box` and `Vec` types we print the underlying heap pointers using the [`{:p}` formatting specifier]. For showcasing `Rc`, we create a reference counted heap value and use the [`Rc::strong_count`] function to print the current reference count, before and after dropping an instance (using [`core::mem::drop`]).
+This code example shows some uses of the [`Box`], [`Vec`], and [`Rc`] types. For the `Box` and `Vec` types, we print the underlying heap pointers using the [`{:p}` formatting specifier]. To showcase `Rc`, we create a reference-counted heap value and use the [`Rc::strong_count`] function to print the current reference count before and after dropping an instance (using [`core::mem::drop`]).
[`Vec`]: https://doc.rust-lang.org/alloc/vec/
[`Rc`]: https://doc.rust-lang.org/alloc/rc/
@@ -628,11 +628,11 @@ reference count is 1 now
As expected, we see that the `Box` and `Vec` values live on the heap, as indicated by the pointer starting with the `0x_4444_4444_*` prefix. The reference counted value also behaves as expected, with the reference count being 2 after the `clone` call, and 1 again after one of the instances was dropped.
-The reason that the vector starts at offset `0x800` is not that the boxed value is `0x800` bytes large, but the [reallocations] that occur when the vector needs to increase its capacity. For example, when the vector's capacity is 32 and we try to add the next element, the vector allocates a new backing array with capacity 64 behind the scenes and copies all elements over. Then it frees the old allocation.
+The reason that the vector starts at offset `0x800` is not that the boxed value is `0x800` bytes large, but the [reallocations] that occur when the vector needs to increase its capacity. For example, when the vector's capacity is 32 and we try to add the next element, the vector allocates a new backing array with a capacity of 64 behind the scenes and copies all elements over. Then it frees the old allocation.
[reallocations]: https://doc.rust-lang.org/alloc/vec/struct.Vec.html#capacity-and-reallocation
-Of course there are many more allocation and collection types in the `alloc` crate that we can now all use in our kernel, including:
+Of course, there are many more allocation and collection types in the `alloc` crate that we can now all use in our kernel, including:
- the thread-safe reference counted pointer [`Arc`]
- the owned string type [`String`] and the [`format!`] macro
@@ -682,7 +682,7 @@ fn panic(info: &PanicInfo) -> ! {
}
```
-We reuse the `test_runner` and `test_panic_handler` functions from our `lib.rs`. Since we want to test allocations, we enable the `alloc` crate through the `extern crate alloc` statement. For more information about the test boilerplate check out the [_Testing_] post.
+We reuse the `test_runner` and `test_panic_handler` functions from our `lib.rs`. Since we want to test allocations, we enable the `alloc` crate through the `extern crate alloc` statement. For more information about the test boilerplate, check out the [_Testing_] post.
[_Testing_]: @/edition-2/posts/04-testing/index.md
@@ -712,7 +712,7 @@ fn main(boot_info: &'static BootInfo) -> ! {
It is very similar to the `kernel_main` function in our `main.rs`, with the differences that we don't invoke `println`, don't include any example allocations, and call `test_main` unconditionally.
-Now we're ready to add a few test cases. First, we add a test that performs some simple allocations using [`Box`] and checks the allocated values, to ensure that basic allocations work:
+Now we're ready to add a few test cases. First, we add a test that performs some simple allocations using [`Box`] and checks the allocated values to ensure that basic allocations work:
```rust
// in tests/heap_allocation.rs
@@ -780,16 +780,16 @@ large_vec... [ok]
many_boxes... [ok]
```
-All three tests succeeded! You can also invoke `cargo test` (without `--test` argument) to run all unit and integration tests.
+All three tests succeeded! You can also invoke `cargo test` (without the `--test` argument) to run all unit and integration tests.
## Summary
This post gave an introduction to dynamic memory and explained why and where it is needed. We saw how Rust's borrow checker prevents common vulnerabilities and learned how Rust's allocation API works.
-After creating a minimal implementation of Rust's allocator interface using a dummy allocator, we created a proper heap memory region for our kernel. For that we defined a virtual address range for the heap and then mapped all pages of that range to physical frames using the `Mapper` and `FrameAllocator` from the previous post.
+After creating a minimal implementation of Rust's allocator interface using a dummy allocator, we created a proper heap memory region for our kernel. For that, we defined a virtual address range for the heap and then mapped all pages of that range to physical frames using the `Mapper` and `FrameAllocator` from the previous post.
Finally, we added a dependency on the `linked_list_allocator` crate to add a proper allocator to our kernel. With this allocator, we were able to use `Box`, `Vec`, and other allocation and collection types from the `alloc` crate.
## What's next?
-While we already added heap allocation support in this post, we left most of the work to the `linked_list_allocator` crate. The next post will show in detail how an allocator can be implemented from scratch. It will present multiple possible allocator designs, shows how to implement simple versions of them, and explain their advantages and drawbacks.
+While we already added heap allocation support in this post, we left most of the work to the `linked_list_allocator` crate. The next post will show in detail how an allocator can be implemented from scratch. It will present multiple possible allocator designs, show how to implement simple versions of them, and explain their advantages and drawbacks.
diff --git a/blog/content/edition-2/posts/11-allocator-designs/index.md b/blog/content/edition-2/posts/11-allocator-designs/index.md
index eb19d14f..259e24ec 100644
--- a/blog/content/edition-2/posts/11-allocator-designs/index.md
+++ b/blog/content/edition-2/posts/11-allocator-designs/index.md
@@ -23,7 +23,7 @@ This blog is openly developed on [GitHub]. If you have any problems or questions
## Introduction
-In the [previous post] we added basic support for heap allocations to our kernel. For that, we [created a new memory region][map-heap] in the page tables and [used the `linked_list_allocator` crate][use-alloc-crate] to manage that memory. While we have a working heap now, we left most of the work to the allocator crate without trying to understand how it works.
+In the [previous post], we added basic support for heap allocations to our kernel. For that, we [created a new memory region][map-heap] in the page tables and [used the `linked_list_allocator` crate][use-alloc-crate] to manage that memory. While we have a working heap now, we left most of the work to the allocator crate without trying to understand how it works.
[previous post]: @/edition-2/posts/10-heap-allocation/index.md
[map-heap]: @/edition-2/posts/10-heap-allocation/index.md#creating-a-kernel-heap
@@ -41,11 +41,11 @@ Apart from correctness, there are many secondary design goals. For example, the
[_fragmentation_]: https://en.wikipedia.org/wiki/Fragmentation_(computing)
[false sharing]: https://mechanical-sympathy.blogspot.de/2011/07/false-sharing.html
-These requirements can make good allocators very complex. For example, [jemalloc] has over 30.000 lines of code. This complexity is often undesired in kernel code where a single bug can lead to severe security vulnerabilities. Fortunately, the allocation patterns of kernel code are often much simpler compared to userspace code, so that relatively simple allocator designs often suffice.
+These requirements can make good allocators very complex. For example, [jemalloc] has over 30.000 lines of code. This complexity is often undesired in kernel code, where a single bug can lead to severe security vulnerabilities. Fortunately, the allocation patterns of kernel code are often much simpler compared to userspace code, so that relatively simple allocator designs often suffice.
[jemalloc]: http://jemalloc.net/
-In the following we present three possible kernel allocator designs and explain their advantages and drawbacks.
+In the following, we present three possible kernel allocator designs and explain their advantages and drawbacks.
## Bump Allocator
@@ -53,16 +53,16 @@ The most simple allocator design is a _bump allocator_ (also known as _stack all
### Idea
-The idea behind a bump allocator is to linearly allocate memory by increasing (_"bumping"_) a `next` variable, which points at the beginning of the unused memory. At the beginning, `next` is equal to the start address of the heap. On each allocation, `next` is increased by the allocation so that it always points to the boundary between used and unused memory:
+The idea behind a bump allocator is to linearly allocate memory by increasing (_"bumping"_) a `next` variable, which points to the start of the unused memory. At the beginning, `next` is equal to the start address of the heap. On each allocation, `next` is increased by the allocation size so that it always points to the boundary between used and unused memory:

+ 1: A single allocation exists at the start of the heap; the `next` pointer points to its end.
+ 2: A second allocation was added right after the first; the `next` pointer points to the end of the second allocation.
+ 3: A third allocation was added right after the second one; the `next` pointer points to the end of the third allocation.](bump-allocation.svg)
The `next` pointer only moves in a single direction and thus never hands out the same memory region twice. When it reaches the end of the heap, no more memory can be allocated, resulting in an out-of-memory error on the next allocation.
-A bump allocator is often implemented with an allocation counter, which is increased by 1 on each `alloc` call and decreased by 1 on each `dealloc` call. When the allocation counter reaches zero it means that all allocations on the heap were deallocated. In this case, the `next` pointer can be reset to the start address of the heap, so that the complete heap memory is available to allocations again.
+A bump allocator is often implemented with an allocation counter, which is increased by 1 on each `alloc` call and decreased by 1 on each `dealloc` call. When the allocation counter reaches zero, it means that all allocations on the heap have been deallocated. In this case, the `next` pointer can be reset to the start address of the heap, so that the complete heap memory is available for allocations again.
### Implementation
@@ -109,11 +109,11 @@ impl BumpAllocator {
}
```
-The `heap_start` and `heap_end` fields keep track of the lower and upper bound of the heap memory region. The caller needs to ensure that these addresses are valid, otherwise the allocator would return invalid memory. For this reason, the `init` function needs to be `unsafe` to call.
+The `heap_start` and `heap_end` fields keep track of the lower and upper bounds of the heap memory region. The caller needs to ensure that these addresses are valid, otherwise the allocator would return invalid memory. For this reason, the `init` function needs to be `unsafe` to call.
-The purpose of the `next` field is to always point to the first unused byte of the heap, i.e. the start address of the next allocation. It is set to `heap_start` in the `init` function because at the beginning the complete heap is unused. On each allocation, this field will be increased by the allocation size (_"bumped"_) to ensure that we don't return the same memory region twice.
+The purpose of the `next` field is to always point to the first unused byte of the heap, i.e., the start address of the next allocation. It is set to `heap_start` in the `init` function because at the beginning, the entire heap is unused. On each allocation, this field will be increased by the allocation size (_"bumped"_) to ensure that we don't return the same memory region twice.
-The `allocations` field is a simple counter for the active allocations with the goal of resetting the allocator after the last allocation was freed. It is initialized with 0.
+The `allocations` field is a simple counter for the active allocations with the goal of resetting the allocator after the last allocation has been freed. It is initialized with 0.
We chose to create a separate `init` function instead of performing the initialization directly in `new` in order to keep the interface identical to the allocator provided by the `linked_list_allocator` crate. This way, the allocators can be switched without additional code changes.
@@ -139,7 +139,7 @@ pub unsafe trait GlobalAlloc {
}
```
-Only the `alloc` and `dealloc` methods are required, the other two methods have default implementations and can be omitted.
+Only the `alloc` and `dealloc` methods are required; the other two methods have default implementations and can be omitted.
#### First Implementation Attempt
@@ -165,7 +165,7 @@ unsafe impl GlobalAlloc for BumpAllocator {
}
```
-First, we use the `next` field as the start address for our allocation. Then we update the `next` field to point at the end address of the allocation, which is the next unused address on the heap. Before returning the start address of the allocation as a `*mut u8` pointer, we increase the `allocations` counter by 1.
+First, we use the `next` field as the start address for our allocation. Then we update the `next` field to point to the end address of the allocation, which is the next unused address on the heap. Before returning the start address of the allocation as a `*mut u8` pointer, we increase the `allocations` counter by 1.
Note that we don't perform any bounds checks or alignment adjustments, so this implementation is not safe yet. This does not matter much because it fails to compile anyway with the following error:
@@ -190,7 +190,7 @@ Before we look at a possible solution to this mutability problem, let's try to u
[global-allocator]: @/edition-2/posts/10-heap-allocation/index.md#the-global-allocator-attribute
-Fortunately there is a way how to get a `&mut self` reference from a `&self` reference: We can use synchronized [interior mutability] by wrapping the allocator in a [`spin::Mutex`] spinlock. This type provides a `lock` method that performs [mutual exclusion] and thus safely turns a `&self` reference to a `&mut self` reference. We already used the wrapper type multiple times in our kernel, for example for the [VGA text buffer][vga-mutex].
+Fortunately, there is a way to get a `&mut self` reference from a `&self` reference: We can use synchronized [interior mutability] by wrapping the allocator in a [`spin::Mutex`] spinlock. This type provides a `lock` method that performs [mutual exclusion] and thus safely turns a `&self` reference to a `&mut self` reference. We've already used the wrapper type multiple times in our kernel, for example for the [VGA text buffer][vga-mutex].
[interior mutability]: https://doc.rust-lang.org/book/ch15-05-interior-mutability.html
[vga-mutex]: @/edition-2/posts/03-vga-text-buffer/index.md#spinlocks
@@ -199,7 +199,7 @@ Fortunately there is a way how to get a `&mut self` reference from a `&self` ref
#### A `Locked` Wrapper Type
-With the help of the `spin::Mutex` wrapper type we can implement the `GlobalAlloc` trait for our bump allocator. The trick is to implement the trait not for the `BumpAllocator` directly, but for the wrapped `spin::Mutex` type:
+With the help of the `spin::Mutex` wrapper type, we can implement the `GlobalAlloc` trait for our bump allocator. The trick is to implement the trait not for the `BumpAllocator` directly, but for the wrapped `spin::Mutex` type:
```rust
unsafe impl GlobalAlloc for spin::Mutex {…}
@@ -330,8 +330,9 @@ fn align_up(addr: usize, align: usize) -> usize {
}
```
-This method utilizes that the `GlobalAlloc` trait guarantees that `align` is always a power of two. This makes it possible to create a [bitmask] to align the address in a very efficient way. To understand how it works, let's go through it step by step starting on the right side:
+This method requires `align` to be a power of two, which can be guaranteed by utilizing the `GlobalAlloc` trait (and its [`Layout`] parameter). This makes it possible to create a [bitmask] to align the address in a very efficient way. To understand how it works, let's go through it step by step, starting on the right side:
+[`Layout`]: https://doc.rust-lang.org/alloc/alloc/struct.Layout.html
[bitmask]: https://en.wikipedia.org/wiki/Mask_(computing)
- Since `align` is a power of two, its [binary representation] has only a single bit set (e.g. `0b000100000`). This means that `align - 1` has all the lower bits set (e.g. `0b00011111`).
@@ -343,7 +344,7 @@ This method utilizes that the `GlobalAlloc` trait guarantees that `align` is alw
[bitwise `NOT`]: https://en.wikipedia.org/wiki/Bitwise_operation#NOT
[bitwise `AND`]: https://en.wikipedia.org/wiki/Bitwise_operation#AND
-Which variant you choose it up to you. Both compute the same result, only using different methods.
+Which variant you choose is up to you. Both compute the same result, only using different methods.
### Using It
@@ -358,7 +359,7 @@ use bump::BumpAllocator;
static ALLOCATOR: Locked = Locked::new(BumpAllocator::new());
```
-Here it becomes important that we declared `BumpAllocator::new` and `Locked::new` as [`const` functions]. If they were normal functions, a compilation error would occur because the initialization expression of a `static` must evaluable at compile time.
+Here it becomes important that we declared `BumpAllocator::new` and `Locked::new` as [`const` functions]. If they were normal functions, a compilation error would occur because the initialization expression of a `static` must be evaluable at compile time.
[`const` functions]: https://doc.rust-lang.org/reference/items/functions.html#const-functions
@@ -384,7 +385,7 @@ The big advantage of bump allocation is that it's very fast. Compared to other a
[bump downwards]: https://fitzgeraldnick.com/2019/11/01/always-bump-downwards.html
[virtual DOM library]: https://hacks.mozilla.org/2019/03/fast-bump-allocated-virtual-doms-with-rust-and-wasm/
-While a bump allocator is seldom used as the global allocator, the principle of bump allocation is often applied in form of [arena allocation], which basically batches individual allocations together to improve performance. An example for an arena allocator for Rust is the [`toolshed`] crate.
+While a bump allocator is seldom used as the global allocator, the principle of bump allocation is often applied in the form of [arena allocation], which basically batches individual allocations together to improve performance. An example of an arena allocator for Rust is contained in the [`toolshed`] crate.
[arena allocation]: https://mgravell.github.io/Pipelines.Sockets.Unofficial/docs/arenas.html
[`toolshed`]: https://docs.rs/toolshed/0.8.1/toolshed/index.html
@@ -409,7 +410,7 @@ fn many_boxes_long_lived() {
Like the `many_boxes` test, this test creates a large number of allocations to provoke an out-of-memory failure if the allocator does not reuse freed memory. Additionally, the test creates a `long_lived` allocation, which lives for the whole loop execution.
-When we try run our new test, we see that it indeed fails:
+When we try to run our new test, we see that it indeed fails:
```
> cargo test --test heap_allocation
@@ -422,16 +423,16 @@ many_boxes_long_lived... [failed]
Error: panicked at 'allocation error: Layout { size_: 8, align_: 8 }', src/lib.rs:86:5
```
-Let's try to understand why this failure occurs in detail: First, the `long_lived` allocation is created at the start of the heap, thereby increasing the `allocations` counter by 1. For each iteration of the loop, a short lived allocation is created and directly freed again before the next iteration starts. This means that the `allocations` counter is temporarily increased to 2 at the beginning of an iteration and decreased to 1 at the end of it. The problem now is that the bump allocator can only reuse memory when _all_ allocations have been freed, i.e. the `allocations` counter falls to 0. Since this doesn't happen before the end of the loop, each loop iteration allocates a new region of memory, leading to an out-of-memory error after a number of iterations.
+Let's try to understand why this failure occurs in detail: First, the `long_lived` allocation is created at the start of the heap, thereby increasing the `allocations` counter by 1. For each iteration of the loop, a short-lived allocation is created and directly freed again before the next iteration starts. This means that the `allocations` counter is temporarily increased to 2 at the beginning of an iteration and decreased to 1 at the end of it. The problem now is that the bump allocator can only reuse memory after _all_ allocations have been freed, i.e., when the `allocations` counter falls to 0. Since this doesn't happen before the end of the loop, each loop iteration allocates a new region of memory, leading to an out-of-memory error after a number of iterations.
#### Fixing the Test?
There are two potential tricks that we could utilize to fix the test for our bump allocator:
- We could update `dealloc` to check whether the freed allocation was the last allocation returned by `alloc` by comparing its end address with the `next` pointer. In case they're equal, we can safely reset `next` back to the start address of the freed allocation. This way, each loop iteration reuses the same memory block.
-- We could add an `alloc_back` method that allocates memory from the _end_ of the heap using an additional `next_back` field. Then we could manually use this allocation method for all long-lived allocations, thereby separating short-lived and long-lived allocations on the heap. Note that this separation only works if it's clear beforehand how long each allocation lives. Another drawback of this approach is that manually performing allocations is cumbersome and potentially unsafe.
+- We could add an `alloc_back` method that allocates memory from the _end_ of the heap using an additional `next_back` field. Then we could manually use this allocation method for all long-lived allocations, thereby separating short-lived and long-lived allocations on the heap. Note that this separation only works if it's clear beforehand how long each allocation will live. Another drawback of this approach is that manually performing allocations is cumbersome and potentially unsafe.
-While both of these approaches work to fix the test, they are no general solution since they are only able to reuse memory in very specific cases. The question is: Is there a general solution that reuses _all_ freed memory?
+While both of these approaches work to fix the test, they are not a general solution since they are only able to reuse memory in very specific cases. The question is: Is there a general solution that reuses _all_ freed memory?
#### Reusing All Freed Memory?
@@ -441,21 +442,21 @@ As we learned [in the previous post][heap-intro], allocations can live arbitrari

-The graphic shows the heap over the course of time. At the beginning, the complete heap is unused and the `next` address is equal to `heap_start` (line 1). Then the first allocation occurs (line 2). In line 3, a second memory block is allocated and the first allocation is freed. Many more allocations are added in line 4. Half of them are very short-lived and already get freed in line 5, where also another new allocation is added.
+The graphic shows the heap over the course of time. At the beginning, the complete heap is unused, and the `next` address is equal to `heap_start` (line 1). Then the first allocation occurs (line 2). In line 3, a second memory block is allocated and the first allocation is freed. Many more allocations are added in line 4. Half of them are very short-lived and already get freed in line 5, where another new allocation is also added.
-Line 5 shows the fundamental problem: We have five unused memory regions with different sizes in total, but the `next` pointer can only point to the beginning of the last region. While we could store the start addresses and sizes of the other unused memory regions in an array of size 4 for this example, this isn't a general solution since we could easily create an example with 8, 16, or 1000 unused memory regions.
+Line 5 shows the fundamental problem: We have five unused memory regions with different sizes, but the `next` pointer can only point to the beginning of the last region. While we could store the start addresses and sizes of the other unused memory regions in an array of size 4 for this example, this isn't a general solution since we could easily create an example with 8, 16, or 1000 unused memory regions.
-Normally when we have a potentially unbounded number of items, we can just use a heap allocated collection. This isn't really possible in our case, since the heap allocator can't depend on itself (it would cause endless recursion or deadlocks). So we need to find a different solution.
+Normally, when we have a potentially unbounded number of items, we can just use a heap-allocated collection. This isn't really possible in our case, since the heap allocator can't depend on itself (it would cause endless recursion or deadlocks). So we need to find a different solution.
## Linked List Allocator
-A common trick to keep track of an arbitrary number of free memory areas when implementing allocators is to use these areas itself as backing storage. This utilizes the fact that the regions are still mapped to a virtual address and backed by a physical frame, but the stored information is not needed anymore. By storing the information about the freed region in the region itself, we can keep track of an unbounded number of freed regions without needing additional memory.
+A common trick to keep track of an arbitrary number of free memory areas when implementing allocators is to use these areas themselves as backing storage. This utilizes the fact that the regions are still mapped to a virtual address and backed by a physical frame, but the stored information is not needed anymore. By storing the information about the freed region in the region itself, we can keep track of an unbounded number of freed regions without needing additional memory.
The most common implementation approach is to construct a single linked list in the freed memory, with each node being a freed memory region:

-Each list node contains two fields: The size of the memory region and a pointer to the next unused memory region. With this approach, we only need a pointer to the first unused region (called `head`) to keep track of all unused regions, independent of their number. The resulting data structure is often called a [_free list_].
+Each list node contains two fields: the size of the memory region and a pointer to the next unused memory region. With this approach, we only need a pointer to the first unused region (called `head`) to keep track of all unused regions, regardless of their number. The resulting data structure is often called a [_free list_].
[_free list_]: https://en.wikipedia.org/wiki/Free_list
@@ -513,7 +514,7 @@ The type has a simple constructor function named `new` and methods to calculate
[const function]: https://doc.rust-lang.org/reference/items/functions.html#const-functions
-With the `ListNode` struct as building block, we can now create the `LinkedListAllocator` struct:
+With the `ListNode` struct as a building block, we can now create the `LinkedListAllocator` struct:
```rust
// in src/allocator/linked_list.rs
@@ -548,11 +549,11 @@ impl LinkedListAllocator {
The struct contains a `head` node that points to the first heap region. We are only interested in the value of the `next` pointer, so we set the `size` to 0 in the `ListNode::new` function. Making `head` a `ListNode` instead of just a `&'static mut ListNode` has the advantage that the implementation of the `alloc` method will be simpler.
-Like for the bump allocator, the `new` function doesn't initialize the allocator with the heap bounds. In addition to maintaining API compatibility, the reason is that the initialization routine requires to write a node to the heap memory, which can only happen at runtime. The `new` function, however, needs to be a [`const` function] that can be evaluated at compile time, because it will be used for initializing the `ALLOCATOR` static. For this reason, we again provide a separate, non-constant `init` method.
+Like for the bump allocator, the `new` function doesn't initialize the allocator with the heap bounds. In addition to maintaining API compatibility, the reason is that the initialization routine requires writing a node to the heap memory, which can only happen at runtime. The `new` function, however, needs to be a [`const` function] that can be evaluated at compile time because it will be used for initializing the `ALLOCATOR` static. For this reason, we again provide a separate, non-constant `init` method.
[`const` function]: https://doc.rust-lang.org/reference/items/functions.html#const-functions
-The `init` method uses a `add_free_region` method, whose implementation will be shown in a moment. For now, we use the [`todo!`] macro to provide a placeholder implementation that always panics.
+The `init` method uses an `add_free_region` method, whose implementation will be shown in a moment. For now, we use the [`todo!`] macro to provide a placeholder implementation that always panics.
[`todo!`]: https://doc.rust-lang.org/core/macro.todo.html
@@ -585,7 +586,7 @@ impl LinkedListAllocator {
}
```
-The method takes a memory region represented by an address and size as argument and adds it to the front of the list. First, it ensures that the given region has the necessary size and alignment for storing a `ListNode`. Then it creates the node and inserts it to the list through the following steps:
+The method takes the address and size of a memory region as an argument and adds it to the front of the list. First, it ensures that the given region has the necessary size and alignment for storing a `ListNode`. Then it creates the node and inserts it into the list through the following steps:

@@ -593,7 +594,7 @@ Step 0 shows the state of the heap before `add_free_region` is called. In step 1
[`Option::take`]: https://doc.rust-lang.org/core/option/enum.Option.html#method.take
-In step 2, the method writes the newly created `node` to the beginning of the freed memory region through the [`write`] method. It then points the `head` pointer to the new node. The resulting pointer structure looks a bit chaotic because the freed region is always inserted at the beginning of the list, but if we follow the pointers we see that each free region is still reachable from the `head` pointer.
+In step 2, the method writes the newly created `node` to the beginning of the freed memory region through the [`write`] method. It then points the `head` pointer to the new node. The resulting pointer structure looks a bit chaotic because the freed region is always inserted at the beginning of the list, but if we follow the pointers, we see that each free region is still reachable from the `head` pointer.
[`write`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.write
@@ -638,7 +639,7 @@ The method uses a `current` variable and a [`while let` loop] to iterate over th
[`while let` loop]: https://doc.rust-lang.org/reference/expressions/loop-expr.html#predicate-pattern-loops
-When the `current.next` pointer becomes `None`, the loop exits. This means that we iterated over the whole list but found no region that is suitable for an allocation. In that case, we return `None`. The check whether a region is suitable is done by a `alloc_from_region` function, whose implementation will be shown in a moment.
+When the `current.next` pointer becomes `None`, the loop exits. This means we iterated over the whole list but found no region suitable for an allocation. In that case, we return `None`. Whether a region is suitable is checked by the `alloc_from_region` function, whose implementation will be shown in a moment.
Let's take a more detailed look at how a suitable region is removed from the list:
@@ -646,11 +647,11 @@ Let's take a more detailed look at how a suitable region is removed from the lis
Step 0 shows the situation before any pointer adjustments. The `region` and `current` regions and the `region.next` and `current.next` pointers are marked in the graphic. In step 1, both the `region.next` and `current.next` pointers are reset to `None` by using the [`Option::take`] method. The original pointers are stored in local variables called `next` and `ret`.
-In step 2, the `current.next` pointer is set to the local `next` pointer, which is the original `region.next` pointer. The effect is that `current` now directly points to the region after `region`, so that `region` is no longer element of the linked list. The function then returns the pointer to `region` stored in the local `ret` variable.
+In step 2, the `current.next` pointer is set to the local `next` pointer, which is the original `region.next` pointer. The effect is that `current` now directly points to the region after `region`, so that `region` is no longer an element of the linked list. The function then returns the pointer to `region` stored in the local `ret` variable.
##### The `alloc_from_region` Function
-The `alloc_from_region` function returns whether a region is suitable for an allocation with given size and alignment. It is defined like this:
+The `alloc_from_region` function returns whether a region is suitable for an allocation with a given size and alignment. It is defined like this:
```rust
// in src/allocator/linked_list.rs
@@ -690,7 +691,7 @@ The function performs a less obvious check after that. This check is necessary b
#### Implementing `GlobalAlloc`
-With the fundamental operations provided by the `add_free_region` and `find_region` methods, we can now finally implement the `GlobalAlloc` trait. As with the bump allocator, we don't implement the trait directly for the `LinkedListAllocator`, but only for a wrapped `Locked`. The [`Locked` wrapper] adds interior mutability through a spinlock, which allows us to modify the allocator instance even though the `alloc` and `dealloc` methods only take `&self` references.
+With the fundamental operations provided by the `add_free_region` and `find_region` methods, we can now finally implement the `GlobalAlloc` trait. As with the bump allocator, we don't implement the trait directly for the `LinkedListAllocator` but only for a wrapped `Locked`. The [`Locked` wrapper] adds interior mutability through a spinlock, which allows us to modify the allocator instance even though the `alloc` and `dealloc` methods only take `&self` references.
[`Locked` wrapper]: @/edition-2/posts/11-allocator-designs/index.md#a-locked-wrapper-type
@@ -730,7 +731,7 @@ unsafe impl GlobalAlloc for Locked {
}
```
-Let's start with the `dealloc` method because it is simpler: First, it performs some layout adjustments, which we will explain in a moment, and retrieves a `&mut LinkedListAllocator` reference by calling the [`Mutex::lock`] function on the [`Locked` wrapper]. Then it calls the `add_free_region` function to add the deallocated region to the free list.
+Let's start with the `dealloc` method because it is simpler: First, it performs some layout adjustments, which we will explain in a moment. Then, it retrieves a `&mut LinkedListAllocator` reference by calling the [`Mutex::lock`] function on the [`Locked` wrapper]. Lastly, it calls the `add_free_region` function to add the deallocated region to the free list.
The `alloc` method is a bit more complex. It starts with the same layout adjustments and also calls the [`Mutex::lock`] function to receive a mutable allocator reference. Then it uses the `find_region` method to find a suitable memory region for the allocation and remove it from the list. If this doesn't succeed and `None` is returned, it returns `null_mut` to signal an error as there is no suitable memory region.
@@ -738,9 +739,9 @@ In the success case, the `find_region` method returns a tuple of the suitable re
#### Layout Adjustments
-So what are these layout adjustments that we do at the beginning of both `alloc` and `dealloc`? They ensure that each allocated block is capable of storing a `ListNode`. This is important because the memory block is going to be deallocated at some point, where we want to write a `ListNode` to it. If the block is smaller than a `ListNode` or does not have the correct alignment, undefined behavior can occur.
+So what are these layout adjustments that we make at the beginning of both `alloc` and `dealloc`? They ensure that each allocated block is capable of storing a `ListNode`. This is important because the memory block is going to be deallocated at some point, where we want to write a `ListNode` to it. If the block is smaller than a `ListNode` or does not have the correct alignment, undefined behavior can occur.
-The layout adjustments are performed by a `size_align` function, which is defined like this:
+The layout adjustments are performed by the `size_align` function, which is defined like this:
```rust
// in src/allocator/linked_list.rs
@@ -762,7 +763,7 @@ impl LinkedListAllocator {
```
First, the function uses the [`align_to`] method on the passed [`Layout`] to increase the alignment to the alignment of a `ListNode` if necessary. It then uses the [`pad_to_align`] method to round up the size to a multiple of the alignment to ensure that the start address of the next memory block will have the correct alignment for storing a `ListNode` too.
-In the second step it uses the [`max`] method to enforce a minimum allocation size of `mem::size_of::`. This way, the `dealloc` function can safely write a `ListNode` to the freed memory block.
+In the second step, it uses the [`max`] method to enforce a minimum allocation size of `mem::size_of::`. This way, the `dealloc` function can safely write a `ListNode` to the freed memory block.
[`align_to`]: https://doc.rust-lang.org/core/alloc/struct.Layout.html#method.align_to
[`pad_to_align`]: https://doc.rust-lang.org/core/alloc/struct.Layout.html#method.pad_to_align
@@ -798,31 +799,31 @@ This shows that our linked list allocator is able to reuse freed memory for subs
### Discussion
-In contrast to the bump allocator, the linked list allocator is much more suitable as a general purpose allocator, mainly because it is able to directly reuse freed memory. However, it also has some drawbacks. Some of them are only caused by our basic implementation, but there are also fundamental drawbacks of the allocator design itself.
+In contrast to the bump allocator, the linked list allocator is much more suitable as a general-purpose allocator, mainly because it is able to directly reuse freed memory. However, it also has some drawbacks. Some of them are only caused by our basic implementation, but there are also fundamental drawbacks of the allocator design itself.
#### Merging Freed Blocks
-The main problem of our implementation is that it only splits the heap into smaller blocks, but never merges them back together. Consider this example:
+The main problem with our implementation is that it only splits the heap into smaller blocks but never merges them back together. Consider this example:

-In the first line, three allocations are created on the heap. Two of them are freed again in line 2 and the third is freed in line 3. Now the complete heap is unused again, but it is still split into four individual blocks. At this point, a large allocation might not be possible anymore because none of the four blocks is large enough. Over time, the process continues and the heap is split into smaller and smaller blocks. At some point, the heap is so fragmented that even normal sized allocations will fail.
+In the first line, three allocations are created on the heap. Two of them are freed again in line 2 and the third is freed in line 3. Now the complete heap is unused again, but it is still split into four individual blocks. At this point, a large allocation might not be possible anymore because none of the four blocks is large enough. Over time, the process continues, and the heap is split into smaller and smaller blocks. At some point, the heap is so fragmented that even normal sized allocations will fail.
To fix this problem, we need to merge adjacent freed blocks back together. For the above example, this would mean the following:

-Like before, two of the three allocations are freed in line `2`. Instead of keeping the fragmented heap, we now perform an additional step in line `2a` to merge the two rightmost blocks back together. In line `3`, the third allocation is freed (like before), resulting in a completely unused heap represented by three distinct blocks. In an additional merging step in line `3a` we then merge the three adjacent blocks back together.
+Like before, two of the three allocations are freed in line `2`. Instead of keeping the fragmented heap, we now perform an additional step in line `2a` to merge the two rightmost blocks back together. In line `3`, the third allocation is freed (like before), resulting in a completely unused heap represented by three distinct blocks. In an additional merging step in line `3a`, we then merge the three adjacent blocks back together.
-The `linked_list_allocator` crate implements this merging strategy in the following way: Instead of inserting freed memory blocks at the beginning of the linked list on `deallocate`, it always keeps the list sorted by start address. This way, merging can be performed directly on the `deallocate` call by examining the addresses and sizes of the two neighbor blocks in the list. Of course, the deallocation operation is slower this way, but it prevents the heap fragmentation we saw above.
+The `linked_list_allocator` crate implements this merging strategy in the following way: Instead of inserting freed memory blocks at the beginning of the linked list on `deallocate`, it always keeps the list sorted by start address. This way, merging can be performed directly on the `deallocate` call by examining the addresses and sizes of the two neighboring blocks in the list. Of course, the deallocation operation is slower this way, but it prevents the heap fragmentation we saw above.
#### Performance
As we learned above, the bump allocator is extremely fast and can be optimized to just a few assembly operations. The linked list allocator performs much worse in this category. The problem is that an allocation request might need to traverse the complete linked list until it finds a suitable block.
-Since the list length depends on the number of unused memory blocks, the performance can vary extremely for different programs. A program that only creates a couple of allocations will experience a relatively fast allocation performance. For a program that fragments the heap with many allocations, however, the allocation performance will be very bad because the linked list will be very long and mostly contain very small blocks.
+Since the list length depends on the number of unused memory blocks, the performance can vary extremely for different programs. A program that only creates a couple of allocations will experience relatively fast allocation performance. For a program that fragments the heap with many allocations, however, the allocation performance will be very bad because the linked list will be very long and mostly contain very small blocks.
-It's worth noting that this performance issue isn't a problem caused by our basic implementation, but a fundamental problem of the linked list approach. Since allocation performance can be very important for kernel-level code, we explore a third allocator design in the following that trades improved performance for reduced memory utilization.
+It's worth noting that this performance issue isn't a problem caused by our basic implementation but a fundamental problem of the linked list approach. Since allocation performance can be very important for kernel-level code, we explore a third allocator design in the following that trades improved performance for reduced memory utilization.
## Fixed-Size Block Allocator
@@ -830,9 +831,9 @@ In the following, we present an allocator design that uses fixed-size memory blo
### Introduction
-The idea behind a _fixed-size block allocator_ is the following: Instead of allocating exactly as much memory as requested, we define a small number of block sizes and round up each allocation to the next block size. For example, with block sizes of 16, 64, and 512 bytes, an allocation of 4 bytes would return a 16-byte block, an allocation of 48 bytes a 64-byte block, and an allocation of 128 bytes an 512-byte block.
+The idea behind a _fixed-size block allocator_ is the following: Instead of allocating exactly as much memory as requested, we define a small number of block sizes and round up each allocation to the next block size. For example, with block sizes of 16, 64, and 512 bytes, an allocation of 4 bytes would return a 16-byte block, an allocation of 48 bytes a 64-byte block, and an allocation of 128 bytes a 512-byte block.
-Like the linked list allocator, we keep track of the unused memory by creating a linked list in the unused memory. However, instead of using a single list with different block sizes, we create a separate list for each size class. Each list then only stores blocks of a single size. For example, with block sizes 16, 64, and 512 there would be three separate linked lists in memory:
+Like the linked list allocator, we keep track of the unused memory by creating a linked list in the unused memory. However, instead of using a single list with different block sizes, we create a separate list for each size class. Each list then only stores blocks of a single size. For example, with block sizes of 16, 64, and 512, there would be three separate linked lists in memory:
.
@@ -840,35 +841,35 @@ Instead of a single `head` pointer, we have the three head pointers `head_16`, `
Since each element in a list has the same size, each list element is equally suitable for an allocation request. This means that we can very efficiently perform an allocation using the following steps:
-- Round up the requested allocation size to the next block size. For example, when an allocation of 12 bytes is requested, we would choose the block size 16 in the above example.
-- Retrieve the head pointer for the list, e.g. from an array. For block size 16, we need to use `head_16`.
+- Round up the requested allocation size to the next block size. For example, when an allocation of 12 bytes is requested, we would choose the block size of 16 in the above example.
+- Retrieve the head pointer for the list, e.g., for block size 16, we need to use `head_16`.
- Remove the first block from the list and return it.
Most notably, we can always return the first element of the list and no longer need to traverse the full list. Thus, allocations are much faster than with the linked list allocator.
#### Block Sizes and Wasted Memory
-Depending on the block sizes, we lose a lot of memory by rounding up. For example, when a 512-byte block is returned for a 128 byte allocation, three quarters of the allocated memory are unused. By defining reasonable block sizes, it is possible to limit the amount of wasted memory to some degree. For example, when using the powers of 2 (4, 8, 16, 32, 64, 128, …) as block sizes, we can limit the memory waste to half of the allocation size in the worst case and a quarter of the allocation size in the average case.
+Depending on the block sizes, we lose a lot of memory by rounding up. For example, when a 512-byte block is returned for a 128-byte allocation, three-quarters of the allocated memory is unused. By defining reasonable block sizes, it is possible to limit the amount of wasted memory to some degree. For example, when using the powers of 2 (4, 8, 16, 32, 64, 128, …) as block sizes, we can limit the memory waste to half of the allocation size in the worst case and a quarter of the allocation size in the average case.
-It is also common to optimize block sizes based on common allocation sizes in a program. For example, we could additionally add block size 24 to improve memory usage for programs that often perform allocations of 24 bytes. This way, the amount of wasted memory can be often reduced without losing the performance benefits.
+It is also common to optimize block sizes based on common allocation sizes in a program. For example, we could additionally add block size 24 to improve memory usage for programs that often perform allocations of 24 bytes. This way, the amount of wasted memory can often be reduced without losing the performance benefits.
#### Deallocation
-Like allocation, deallocation is also very performant. It involves the following steps:
+Much like allocation, deallocation is also very performant. It involves the following steps:
-- Round up the freed allocation size to the next block size. This is required since the compiler only passes the requested allocation size to `dealloc`, not the size of the block that was returned by `alloc`. By using the same size-adjustment function in both `alloc` and `dealloc` we can make sure that we always free the correct amount of memory.
-- Retrieve the head pointer for the list, e.g. from an array.
+- Round up the freed allocation size to the next block size. This is required since the compiler only passes the requested allocation size to `dealloc`, not the size of the block that was returned by `alloc`. By using the same size-adjustment function in both `alloc` and `dealloc`, we can make sure that we always free the correct amount of memory.
+- Retrieve the head pointer for the list.
- Add the freed block to the front of the list by updating the head pointer.
Most notably, no traversal of the list is required for deallocation either. This means that the time required for a `dealloc` call stays the same regardless of the list length.
#### Fallback Allocator
-Given that large allocations (>2KB) are often rare, especially in operating system kernels, it might make sense to fall back to a different allocator for these allocations. For example, we could fall back to a linked list allocator for allocations greater than 2048 bytes in order to reduce memory waste. Since only very few allocations of that size are expected, the linked list would stay small so that (de)allocations would be still reasonably fast.
+Given that large allocations (>2 KB) are often rare, especially in operating system kernels, it might make sense to fall back to a different allocator for these allocations. For example, we could fall back to a linked list allocator for allocations greater than 2048 bytes in order to reduce memory waste. Since only very few allocations of that size are expected, the linked list would stay small and the (de)allocations would still be reasonably fast.
#### Creating new Blocks
-Above, we always assumed that there are always enough blocks of a specific size in the list to fulfill all allocation requests. However, at some point the linked list for a block size becomes empty. At this point, there are two ways how we can create new unused blocks of a specific size to fulfill an allocation request:
+Above, we always assumed that there are always enough blocks of a specific size in the list to fulfill all allocation requests. However, at some point, the linked list for a given block size becomes empty. At this point, there are two ways we can create new unused blocks of a specific size to fulfill an allocation request:
- Allocate a new block from the fallback allocator (if there is one).
- Split a larger block from a different list. This best works if block sizes are powers of two. For example, a 32-byte block can be split into two 16-byte blocks.
@@ -897,7 +898,7 @@ struct ListNode {
}
```
-This type is similar to the `ListNode` type of our [linked list allocator implementation], with the difference that we don't have a second `size` field. The `size` field isn't needed because every block in a list has the same size with the fixed-size block allocator design.
+This type is similar to the `ListNode` type of our [linked list allocator implementation], with the difference that we don't have a `size` field. It isn't needed because every block in a list has the same size with the fixed-size block allocator design.
[linked list allocator implementation]: #the-allocator-type
@@ -915,9 +916,9 @@ Next, we define a constant `BLOCK_SIZES` slice with the block sizes used for our
const BLOCK_SIZES: &[usize] = &[8, 16, 32, 64, 128, 256, 512, 1024, 2048];
```
-As block sizes, we use powers of 2 starting from 8 up to 2048. We don't define any block sizes smaller than 8 because each block must be capable of storing a 64-bit pointer to the next block when freed. For allocations greater than 2048 bytes we will fall back to a linked list allocator.
+As block sizes, we use powers of 2, starting from 8 up to 2048. We don't define any block sizes smaller than 8 because each block must be capable of storing a 64-bit pointer to the next block when freed. For allocations greater than 2048 bytes, we will fall back to a linked list allocator.
-To simplify the implementation, we define that the size of a block is also its required alignment in memory. So a 16 byte block is always aligned on a 16-byte boundary and a 512 byte block is aligned on a 512-byte boundary. Since alignments always need to be powers of 2, this rules out any other block sizes. If we need block sizes that are not powers of 2 in the future, we can still adjust our implementation for this (e.g. by defining a second `BLOCK_ALIGNMENTS` array).
+To simplify the implementation, we define the size of a block as its required alignment in memory. So a 16-byte block is always aligned on a 16-byte boundary and a 512-byte block is aligned on a 512-byte boundary. Since alignments always need to be powers of 2, this rules out any other block sizes. If we need block sizes that are not powers of 2 in the future, we can still adjust our implementation for this (e.g., by defining a second `BLOCK_ALIGNMENTS` array).
#### The Allocator Type
@@ -932,7 +933,7 @@ pub struct FixedSizeBlockAllocator {
}
```
-The `list_heads` field is an array of `head` pointers, one for each block size. This is implemented by using the `len()` of the `BLOCK_SIZES` slice as the array length. As a fallback allocator for allocations larger than the largest block size we use the allocator provided by the `linked_list_allocator`. We could also used the `LinkedListAllocator` we implemented ourselves instead, but it has the disadvantage that it does not [merge freed blocks].
+The `list_heads` field is an array of `head` pointers, one for each block size. This is implemented by using the `len()` of the `BLOCK_SIZES` slice as the array length. As a fallback allocator for allocations larger than the largest block size, we use the allocator provided by the `linked_list_allocator`. We could also use the `LinkedListAllocator` we implemented ourselves instead, but it has the disadvantage that it does not [merge freed blocks].
[merge freed blocks]: #merging-freed-blocks
@@ -962,11 +963,11 @@ impl FixedSizeBlockAllocator {
}
```
-The `new` function just initializes the `list_heads` array with empty nodes and creates an [`empty`] linked list allocator as `fallback_allocator`. The `EMPTY` constant is needed because to tell the Rust compiler that we want to initialize the array with a constant value. Initializing the array directly as `[None; BLOCK_SIZES.len()]` does not work because then the compiler requires that `Option<&'static mut ListNode>` implements the `Copy` trait, which it does not. This is a current limitation of the Rust compiler, which might go away in the future.
+The `new` function just initializes the `list_heads` array with empty nodes and creates an [`empty`] linked list allocator as `fallback_allocator`. The `EMPTY` constant is needed to tell the Rust compiler that we want to initialize the array with a constant value. Initializing the array directly as `[None; BLOCK_SIZES.len()]` does not work, because then the compiler requires `Option<&'static mut ListNode>` to implement the `Copy` trait, which it does not. This is a current limitation of the Rust compiler, which might go away in the future.
[`empty`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.Heap.html#method.empty
-If you haven't done so already for the `LinkedListAllocator` implementation, you also need to add **`#![feature(const_mut_refs)]`** to the beginning of your `lib.rs`. The reason is that any use of mutable reference types in const functions is still unstable, including the `Option<&'static mut ListNode>` array element type of the `list_heads` field (even if we set it to `None`).
+If you haven't done so already for the `LinkedListAllocator` implementation, you also need to add **`#![feature(const_mut_refs)]`** to the top of your `lib.rs`. The reason is that any use of mutable reference types in const functions is still unstable, including the `Option<&'static mut ListNode>` array element type of the `list_heads` field (even if we set it to `None`).
The unsafe `init` function only calls the [`init`] function of the `fallback_allocator` without doing any additional initialization of the `list_heads` array. Instead, we will initialize the lists lazily on `alloc` and `dealloc` calls.
@@ -991,7 +992,7 @@ impl FixedSizeBlockAllocator {
}
```
-Since the [`Heap`] type of the `linked_list_allocator` crate does not implement [`GlobalAlloc`] (as it's [not possible without locking]). Instead, it provides an [`allocate_first_fit`] method that has a slightly different interface. Instead of returning a `*mut u8` and using a null pointer to signal an error, it returns a `Result, ()>`. The [`NonNull`] type is an abstraction for a raw pointer that is guaranteed to be not the null pointer. By mapping the `Ok` case to the [`NonNull::as_ptr`] method and the `Err` case to a null pointer, we can easily translate this back to a `*mut u8` type.
+The [`Heap`] type of the `linked_list_allocator` crate does not implement [`GlobalAlloc`] (as it's [not possible without locking]). Instead, it provides an [`allocate_first_fit`] method that has a slightly different interface. Instead of returning a `*mut u8` and using a null pointer to signal an error, it returns a `Result, ()>`. The [`NonNull`] type is an abstraction for a raw pointer that is guaranteed to not be a null pointer. By mapping the `Ok` case to the [`NonNull::as_ptr`] method and the `Err` case to a null pointer, we can easily translate this back to a `*mut u8` type.
[`Heap`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.Heap.html
[not possible without locking]: #globalalloc-and-mutability
@@ -1015,7 +1016,7 @@ fn list_index(layout: &Layout) -> Option {
}
```
-The block must have at least the size and alignment required by the given `Layout`. Since we defined that the block size is also its alignment, this means that the `required_block_size` is the [maximum] of the layout's [`size()`] and [`align()`] attributes. To find the next-larger block in the `BLOCK_SIZES` slice, we first use the [`iter()`] method to get an iterator and then the [`position()`] method to find the index of the first block that is as least as large as the `required_block_size`.
+The block must have at least the size and alignment required by the given `Layout`. Since we defined that the block size is also its alignment, this means that the `required_block_size` is the [maximum] of the layout's [`size()`] and [`align()`] attributes. To find the next-larger block in the `BLOCK_SIZES` slice, we first use the [`iter()`] method to get an iterator and then the [`position()`] method to find the index of the first block that is at least as large as the `required_block_size`.
[maximum]: https://doc.rust-lang.org/core/cmp/trait.Ord.html#method.max
[`size()`]: https://doc.rust-lang.org/core/alloc/struct.Layout.html#method.size
@@ -1123,19 +1124,19 @@ unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
}
```
-Like in `alloc`, we first use the `lock` method to get a mutable allocator reference and then the `list_index` function to get the block list corresponding to the given `Layout`. If the index is `None`, no fitting block size exists in `BLOCK_SIZES`, which indicates that the allocation was created by the fallback allocator. Therefore we use its [`deallocate`][`Heap::deallocate`] to free the memory again. The method expects a [`NonNull`] instead of a `*mut u8`, so we need to convert the pointer first. (The `unwrap` call only fails when the pointer is null, which should never happen when the compiler calls `dealloc`.)
+Like in `alloc`, we first use the `lock` method to get a mutable allocator reference and then the `list_index` function to get the block list corresponding to the given `Layout`. If the index is `None`, no fitting block size exists in `BLOCK_SIZES`, which indicates that the allocation was created by the fallback allocator. Therefore, we use its [`deallocate`][`Heap::deallocate`] to free the memory again. The method expects a [`NonNull`] instead of a `*mut u8`, so we need to convert the pointer first. (The `unwrap` call only fails when the pointer is null, which should never happen when the compiler calls `dealloc`.)
[`Heap::deallocate`]: https://docs.rs/linked_list_allocator/0.9.0/linked_list_allocator/struct.Heap.html#method.deallocate
-If `list_index` returns a block index, we need to add the freed memory block to the list. For that, we first create a new `ListNode` that points to the current list head (by using [`Option::take`] again). Before we write the new node into the freed memory block, we first assert that the current block size specified by `index` has the required size and alignment for storing a `ListNode`. Then we perform the write by converting the given `*mut u8` pointer to a `*mut ListNode` pointer and then calling the unsafe [`write`][`pointer::write`] method on it. The last step is to set the head pointer of the list, which is currently `None` since we called `take` on it, to our newly written `ListNode`. For that we convert the raw `new_node_ptr` to a mutable reference.
+If `list_index` returns a block index, we need to add the freed memory block to the list. For that, we first create a new `ListNode` that points to the current list head (by using [`Option::take`] again). Before we write the new node into the freed memory block, we first assert that the current block size specified by `index` has the required size and alignment for storing a `ListNode`. Then we perform the write by converting the given `*mut u8` pointer to a `*mut ListNode` pointer and then calling the unsafe [`write`][`pointer::write`] method on it. The last step is to set the head pointer of the list, which is currently `None` since we called `take` on it, to our newly written `ListNode`. For that, we convert the raw `new_node_ptr` to a mutable reference.
[`pointer::write`]: https://doc.rust-lang.org/std/primitive.pointer.html#method.write
There are a few things worth noting:
- We don't differentiate between blocks allocated from a block list and blocks allocated from the fallback allocator. This means that new blocks created in `alloc` are added to the block list on `dealloc`, thereby increasing the number of blocks of that size.
-- The `alloc` method is the only place where new blocks are created in our implementation. This means that we initially start with empty block lists and only fill the lists lazily when allocations for that block size are performed.
-- We don't need `unsafe` blocks in `alloc` and `dealloc`, even though we perform some `unsafe` operations. The reason is that Rust currently treats the complete body of unsafe functions as one large `unsafe` block. Since using explicit `unsafe` blocks has the advantage that it's obvious which operations are unsafe and which not, there is a [proposed RFC](https://github.com/rust-lang/rfcs/pull/2585) to change this behavior.
+- The `alloc` method is the only place where new blocks are created in our implementation. This means that we initially start with empty block lists and only fill these lists lazily when allocations of their block size are performed.
+- We don't need `unsafe` blocks in `alloc` and `dealloc`, even though we perform some `unsafe` operations. The reason is that Rust currently treats the complete body of unsafe functions as one large `unsafe` block. Since using explicit `unsafe` blocks has the advantage that it's obvious which operations are unsafe and which are not, there is a [proposed RFC](https://github.com/rust-lang/rfcs/pull/2585) to change this behavior.
### Using it
@@ -1167,19 +1168,19 @@ Our new allocator seems to work!
### Discussion
-While the fixed-size block approach has a much better performance than the linked list approach, it wastes up to half of the memory when using powers of 2 as block sizes. Whether this tradeoff is worth it heavily depends on the application type. For an operating system kernel, where performance is critical, the fixed-size block approach seems to be the better choice.
+While the fixed-size block approach has much better performance than the linked list approach, it wastes up to half of the memory when using powers of 2 as block sizes. Whether this tradeoff is worth it heavily depends on the application type. For an operating system kernel, where performance is critical, the fixed-size block approach seems to be the better choice.
On the implementation side, there are various things that we could improve in our current implementation:
- Instead of only allocating blocks lazily using the fallback allocator, it might be better to pre-fill the lists to improve the performance of initial allocations.
-- To simplify the implementation, we only allowed block sizes that are powers of 2 so that we could use them also as the block alignment. By storing (or calculating) the alignment in a different way, we could also allow arbitrary other block sizes. This way, we could add more block sizes, e.g. for common allocation sizes, in order to minimize the wasted memory.
+- To simplify the implementation, we only allowed block sizes that are powers of 2 so that we could also use them as the block alignment. By storing (or calculating) the alignment in a different way, we could also allow arbitrary other block sizes. This way, we could add more block sizes, e.g., for common allocation sizes, in order to minimize the wasted memory.
- We currently only create new blocks, but never free them again. This results in fragmentation and might eventually result in allocation failure for large allocations. It might make sense to enforce a maximum list length for each block size. When the maximum length is reached, subsequent deallocations are freed using the fallback allocator instead of being added to the list.
-- Instead of falling back to a linked list allocator, we could have a special allocator for allocations greater than 4KiB. The idea is to utilize [paging], which operates on 4KiB pages, to map a continuous block of virtual memory to non-continuous physical frames. This way, fragmentation of unused memory is no longer a problem for large allocations.
-- With such a page allocator, it might make sense to add block sizes up to 4KiB and drop the linked list allocator completely. The main advantages of this would be reduced fragmentation and improved performance predictability, i.e. better worse-case performance.
+- Instead of falling back to a linked list allocator, we could have a special allocator for allocations greater than 4 KiB. The idea is to utilize [paging], which operates on 4 KiB pages, to map a continuous block of virtual memory to non-continuous physical frames. This way, fragmentation of unused memory is no longer a problem for large allocations.
+- With such a page allocator, it might make sense to add block sizes up to 4 KiB and drop the linked list allocator completely. The main advantages of this would be reduced fragmentation and improved performance predictability, i.e., better worst-case performance.
[paging]: @/edition-2/posts/08-paging-introduction/index.md
-It's important to note that the implementation improvements outlined above are only suggestions. Allocators used in operating system kernels are typically highly optimized to the specific workload of the kernel, which is only possible through extensive profiling.
+It's important to note that the implementation improvements outlined above are only suggestions. Allocators used in operating system kernels are typically highly optimized for the specific workload of the kernel, which is only possible through extensive profiling.
### Variations
@@ -1197,7 +1198,7 @@ Slab allocation is often combined with other allocators. For example, it can be
#### Buddy Allocator
-Instead of using a linked list to manage freed blocks, the [buddy allocator] design uses a [binary tree] data structure together with power-of-2 block sizes. When a new block of a certain size is required, it splits a larger sized block into two halves, thereby creating two child nodes in the tree. Whenever a block is freed again, the neighbor block in the tree is analyzed. If the neighbor is also free, the two blocks are joined back together to a block of twice the size.
+Instead of using a linked list to manage freed blocks, the [buddy allocator] design uses a [binary tree] data structure together with power-of-2 block sizes. When a new block of a certain size is required, it splits a larger sized block into two halves, thereby creating two child nodes in the tree. Whenever a block is freed again, its neighbor block in the tree is analyzed. If the neighbor is also free, the two blocks are joined back together to form a block of twice the size.
The advantage of this merge process is that [external fragmentation] is reduced so that small freed blocks can be reused for a large allocation. It also does not use a fallback allocator, so the performance is more predictable. The biggest drawback is that only power-of-2 block sizes are possible, which might result in a large amount of wasted memory due to [internal fragmentation]. For this reason, buddy allocators are often combined with a slab allocator to further split an allocated block into multiple smaller blocks.
@@ -1209,7 +1210,7 @@ The advantage of this merge process is that [external fragmentation] is reduced
## Summary
-This post gave an overview over different allocator designs. We learned how to implement a basic [bump allocator], which hands out memory linearly by increasing a single `next` pointer. While bump allocation is very fast, it can only reuse memory after all allocations have been freed. For this reason, it is rarely used as a global allocator.
+This post gave an overview of different allocator designs. We learned how to implement a basic [bump allocator], which hands out memory linearly by increasing a single `next` pointer. While bump allocation is very fast, it can only reuse memory after all allocations have been freed. For this reason, it is rarely used as a global allocator.
[bump allocator]: @/edition-2/posts/11-allocator-designs/index.md#bump-allocator
@@ -1230,7 +1231,7 @@ There are many more allocator designs with different tradeoffs. [Slab allocation
## What's next?
-With this post, we conclude our memory management implementation for now. Next, we will start exploring [_multitasking_], starting with [_threads_]. In subsequent post we will then explore [_multiprocessing_], [_processes_], and cooperative multitasking in the form of [_async/await_].
+With this post, we conclude our memory management implementation for now. Next, we will start exploring [_multitasking_], starting with cooperative multitasking in the form of [_async/await_]. In subsequent posts, we will then explore [_threads_], [_multiprocessing_], and [_processes_].
[_multitasking_]: https://en.wikipedia.org/wiki/Computer_multitasking
[_threads_]: https://en.wikipedia.org/wiki/Thread_(computing)
diff --git a/blog/content/edition-2/posts/12-async-await/index.ja.md b/blog/content/edition-2/posts/12-async-await/index.ja.md
index 121bcfc1..3941a628 100644
--- a/blog/content/edition-2/posts/12-async-await/index.ja.md
+++ b/blog/content/edition-2/posts/12-async-await/index.ja.md
@@ -8,8 +8,10 @@ date = 2020-03-27
chapter = "Multitasking"
# Please update this when updating the translation
translation_based_on_commit = "bf4f88107966c7ab1327c3cdc0ebfbd76bad5c5f"
-# GitHub usernames of the people that translated this post
+# GitHub usernames of the authors of this translation
translators = ["kahirokunn", "garasubo", "sozysozbot", "woodyZootopia"]
+# GitHub usernames of the people that contributed to this translation
+translation_contributors = ["asami-kawasaki", "Foo-x"]
+++
この記事では、Rustの**協調的マルチタスク**と**async/await**機能について説明します。Rustのasync/await機能については、`Future` trait の設計、ステートマシンの変換、 **pinning** などを含めて詳しく説明します。そして、非同期キーボードタスクと基本的なexecutorを作成することで、カーネルにasync/awaitの基本的なサポートを追加します。
@@ -425,7 +427,7 @@ ExampleStateMachine::WaitingOnFooTxt(state) => {
};
*self = ExampleStateMachine::WaitingOnBarTxt(state);
} else {
- *self = ExampleStateMachine::End(EndState));
+ *self = ExampleStateMachine::End(EndState);
return Poll::Ready(content);
}
}
@@ -446,7 +448,7 @@ ExampleStateMachine::WaitingOnBarTxt(state) => {
match state.bar_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(bar_txt) => {
- *self = ExampleStateMachine::End(EndState));
+ *self = ExampleStateMachine::End(EndState);
// from body of `example`
return Poll::Ready(state.content + &bar_txt);
}
@@ -604,7 +606,7 @@ println!("internal reference: {:p}", stack_value.self_ptr);
[`Pin`]: https://doc.rust-lang.org/stable/core/pin/struct.Pin.html
[`Unpin`]: https://doc.rust-lang.org/nightly/std/marker/trait.Unpin.html
[pin-get-mut]: https://doc.rust-lang.org/nightly/core/pin/struct.Pin.html#method.get_mut
-[pin-deref-mut]: https://doc.rust-lang.org/nightly/core/pin/struct.Pin.html#impl-DerefMut
+[pin-deref-mut]: https://doc.rust-lang.org/nightly/core/pin/struct.Pin.html#method.deref_mut
[_auto trait_]: https://doc.rust-lang.org/reference/special-types-and-traits.html#auto-traits
例として、上記の `SelfReferential` 型を更新して、`Unpin` を使用しないようにしてみましょう:
@@ -701,7 +703,7 @@ unsafe {
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll
```
-このメソッドが通常の`&mut self`ではなく`self: Pin<&mut Self>`を取る理由は、[上][self-ref-async-await]で見たように、async/awaitから生成されるfutureのインスタンスはしばしば自己参照しているためです。`Self` を `Pin` にラップして、async/await から生成された自己参照のfutureに対して、コンパイラに `Unpin` を選択させることで、`poll` 呼び出しの間にfutureがメモリ内で移動しないことが保証されます。これにより、すべての内部参照が有効であることが保証されます。
+このメソッドが通常の`&mut self`ではなく`self: Pin<&mut Self>`を取る理由は、[上][self-ref-async-await]で見たように、async/awaitから生成されるfutureのインスタンスはしばしば自己参照しているためです。`Self` を `Pin` にラップして、async/await から生成された自己参照のfutureに対して、コンパイラに `Unpin` をオプトアウトさせることで、`poll` 呼び出しの間にfutureがメモリ内で移動しないことが保証されます。これにより、すべての内部参照が有効であることが保証されます。
[self-ref-async-await]: @/edition-2/posts/12-async-await/index.md#self-referential-structs
diff --git a/blog/content/edition-2/posts/12-async-await/index.md b/blog/content/edition-2/posts/12-async-await/index.md
index fbe7e69f..87c9a83a 100644
--- a/blog/content/edition-2/posts/12-async-await/index.md
+++ b/blog/content/edition-2/posts/12-async-await/index.md
@@ -8,7 +8,7 @@ date = 2020-03-27
chapter = "Multitasking"
+++
-In this post we explore _cooperative multitasking_ and the _async/await_ feature of Rust. We take a detailed look how async/await works in Rust, including the design of the `Future` trait, the state machine transformation, and _pinning_. We then add basic support for async/await to our kernel by creating an asynchronous keyboard task and a basic executor.
+In this post, we explore _cooperative multitasking_ and the _async/await_ feature of Rust. We take a detailed look at how async/await works in Rust, including the design of the `Future` trait, the state machine transformation, and _pinning_. We then add basic support for async/await to our kernel by creating an asynchronous keyboard task and a basic executor.
@@ -52,7 +52,7 @@ Since tasks are interrupted at arbitrary points in time, they might be in the mi
[call stack]: https://en.wikipedia.org/wiki/Call_stack
[_context switch_]: https://en.wikipedia.org/wiki/Context_switch
-As the call stack can be very large, the operating system typically sets up a separate call stack for each task instead of backing up the call stack content on each task switch. Such a task with a separate stack is called a [_thread of execution_] or _thread_ for short. By using a separate stack for each task, only the register contents need to be saved on a context switch (including the program counter and stack pointer). This approach minimizes the performance overhead of a context switch, which is very important since context switches often occur up to 100 times per second.
+As the call stack can be very large, the operating system typically sets up a separate call stack for each task instead of backing up the call stack content on each task switch. Such a task with its own stack is called a [_thread of execution_] or _thread_ for short. By using a separate stack for each task, only the register contents need to be saved on a context switch (including the program counter and stack pointer). This approach minimizes the performance overhead of a context switch, which is very important since context switches often occur up to 100 times per second.
[_thread of execution_]: https://en.wikipedia.org/wiki/Thread_(computing)
@@ -60,21 +60,21 @@ As the call stack can be very large, the operating system typically sets up a se
The main advantage of preemptive multitasking is that the operating system can fully control the allowed execution time of a task. This way, it can guarantee that each task gets a fair share of the CPU time, without the need to trust the tasks to cooperate. This is especially important when running third-party tasks or when multiple users share a system.
-The disadvantage of preemption is that each task requires its own stack. Compared to a shared stack, this results in a higher memory usage per task and often limits the number of tasks in the system. Another disadvantage is that the operating system always has to save the complete CPU register state on each task switch, even if the task only used a small subset of the registers.
+The disadvantage of preemption is that each task requires its own stack. Compared to a shared stack, this results in higher memory usage per task and often limits the number of tasks in the system. Another disadvantage is that the operating system always has to save the complete CPU register state on each task switch, even if the task only used a small subset of the registers.
Preemptive multitasking and threads are fundamental components of an operating system because they make it possible to run untrusted userspace programs. We will discuss these concepts in full detail in future posts. For this post, however, we will focus on cooperative multitasking, which also provides useful capabilities for our kernel.
### Cooperative Multitasking
-Instead of forcibly pausing running tasks at arbitrary points in time, cooperative multitasking lets each task run until it voluntarily gives up control of the CPU. This allows tasks to pause themselves at convenient points in time, for example when it needs to wait for an I/O operation anyway.
+Instead of forcibly pausing running tasks at arbitrary points in time, cooperative multitasking lets each task run until it voluntarily gives up control of the CPU. This allows tasks to pause themselves at convenient points in time, for example, when they need to wait for an I/O operation anyway.
-Cooperative multitasking is often used at the language level, for example in form of [coroutines] or [async/await]. The idea is that either the programmer or the compiler inserts [_yield_] operations into the program, which give up control of the CPU and allow other tasks to run. For example, a yield could be inserted after each iteration of a complex loop.
+Cooperative multitasking is often used at the language level, like in the form of [coroutines] or [async/await]. The idea is that either the programmer or the compiler inserts [_yield_] operations into the program, which give up control of the CPU and allow other tasks to run. For example, a yield could be inserted after each iteration of a complex loop.
[coroutines]: https://en.wikipedia.org/wiki/Coroutine
[async/await]: https://rust-lang.github.io/async-book/01_getting_started/04_async_await_primer.html
[_yield_]: https://en.wikipedia.org/wiki/Yield_(multithreading)
-It is common to combine cooperative multitasking with [asynchronous operations]. Instead of waiting until an operation is finished and preventing other tasks to run in this time, asynchronous operations return a "not ready" status if the operation is not finished yet. In this case, the waiting task can execute a yield operation to let other tasks run.
+It is common to combine cooperative multitasking with [asynchronous operations]. Instead of waiting until an operation is finished and preventing other tasks from running during this time, asynchronous operations return a "not ready" status if the operation is not finished yet. In this case, the waiting task can execute a yield operation to let other tasks run.
[asynchronous operations]: https://en.wikipedia.org/wiki/Asynchronous_I/O
@@ -82,11 +82,11 @@ It is common to combine cooperative multitasking with [asynchronous operations].
Since tasks define their pause points themselves, they don't need the operating system to save their state. Instead, they can save exactly the state they need for continuation before they pause themselves, which often results in better performance. For example, a task that just finished a complex computation might only need to backup the final result of the computation since it does not need the intermediate results anymore.
-Language-supported implementations of cooperative tasks are often even able to backup up the required parts of the call stack before pausing. As an example, Rust's async/await implementation stores all local variables that are still needed in an automatically generated struct (see below). By backing up the relevant parts of the call stack before pausing, all tasks can share a single call stack, which results in a much smaller memory consumption per task. This makes it possible to create an almost arbitrary number of cooperative tasks without running out of memory.
+Language-supported implementations of cooperative tasks are often even able to backup the required parts of the call stack before pausing. As an example, Rust's async/await implementation stores all local variables that are still needed in an automatically generated struct (see below). By backing up the relevant parts of the call stack before pausing, all tasks can share a single call stack, which results in much lower memory consumption per task. This makes it possible to create an almost arbitrary number of cooperative tasks without running out of memory.
#### Discussion
-The drawback of cooperative multitasking is that an uncooperative task can potentially run for an unlimited amount of time. Thus, a malicious or buggy task can prevent other tasks from running and slow down or even block the whole system. For this reason, cooperative multitasking should only be used when all tasks are known to cooperate. As a counterexample, it's not a good idea to make the operating system rely on the cooperation of arbitrary userlevel programs.
+The drawback of cooperative multitasking is that an uncooperative task can potentially run for an unlimited amount of time. Thus, a malicious or buggy task can prevent other tasks from running and slow down or even block the whole system. For this reason, cooperative multitasking should only be used when all tasks are known to cooperate. As a counterexample, it's not a good idea to make the operating system rely on the cooperation of arbitrary user-level programs.
However, the strong performance and memory benefits of cooperative multitasking make it a good approach for usage _within_ a program, especially in combination with asynchronous operations. Since an operating system kernel is a performance-critical program that interacts with asynchronous hardware, cooperative multitasking seems like a good approach for implementing concurrency.
@@ -96,17 +96,17 @@ The Rust language provides first-class support for cooperative multitasking in t
### Futures
-A _future_ represents a value that might not be available yet. This could be for example an integer that is computed by another task or a file that is downloaded from the network. Instead of waiting until the value is available, futures make it possible to continue execution until the value is needed.
+A _future_ represents a value that might not be available yet. This could be, for example, an integer that is computed by another task or a file that is downloaded from the network. Instead of waiting until the value is available, futures make it possible to continue execution until the value is needed.
#### Example
The concept of futures is best illustrated with a small example:
-
+
-This sequence diagram shows a `main` function that reads a file from the file system and then calls a function `foo`. This process is repeated two times: Once with a synchronous `read_file` call and once with an asynchronous `async_read_file` call.
+This sequence diagram shows a `main` function that reads a file from the file system and then calls a function `foo`. This process is repeated two times: once with a synchronous `read_file` call and once with an asynchronous `async_read_file` call.
-With the synchronous call, the `main` function needs to wait until the file is loaded from the file system. Only then it can call the `foo` function, which requires it to again wait for the result.
+With the synchronous call, the `main` function needs to wait until the file is loaded from the file system. Only then can it call the `foo` function, which requires it to again wait for the result.
With the asynchronous `async_read_file` call, the file system directly returns a future and loads the file asynchronously in the background. This allows the `main` function to call `foo` much earlier, which then runs in parallel with the file load. In this example, the file load even finishes before `foo` returns, so `main` can directly work with the file without further waiting after `foo` returns.
@@ -139,19 +139,19 @@ pub enum Poll {
}
```
-When the value is already available (e.g. the file was fully read from disk), it is returned wrapped in the `Ready` variant. Otherwise, the `Pending` variant is returned, which signals the caller that the value is not yet available.
+When the value is already available (e.g. the file was fully read from disk), it is returned wrapped in the `Ready` variant. Otherwise, the `Pending` variant is returned, which signals to the caller that the value is not yet available.
-The `poll` method takes two arguments: `self: Pin<&mut Self>` and `cx: &mut Context`. The former behaves like a normal `&mut self` reference, with the difference that the `Self` value is [_pinned_] to its memory location. Understanding `Pin` and why it is needed is difficult without understanding how async/await works first. We will therefore explain it later in this post.
+The `poll` method takes two arguments: `self: Pin<&mut Self>` and `cx: &mut Context`. The former behaves similarly to a normal `&mut self` reference, except that the `Self` value is [_pinned_] to its memory location. Understanding `Pin` and why it is needed is difficult without understanding how async/await works first. We will therefore explain it later in this post.
[_pinned_]: https://doc.rust-lang.org/nightly/core/pin/index.html
-The purpose of the `cx: &mut Context` parameter is to pass a [`Waker`] instance to the asynchronous task, e.g. the file system load. This `Waker` allows the asynchronous task to signal that it (or a part of it) is finished, e.g. that the file was loaded from disk. Since the main task knows that it will be notified when the `Future` is ready, it does not need to call `poll` over and over again. We will explain this process in more detail later in this post when we implement our own waker type.
+The purpose of the `cx: &mut Context` parameter is to pass a [`Waker`] instance to the asynchronous task, e.g., the file system load. This `Waker` allows the asynchronous task to signal that it (or a part of it) is finished, e.g., that the file was loaded from disk. Since the main task knows that it will be notified when the `Future` is ready, it does not need to call `poll` over and over again. We will explain this process in more detail later in this post when we implement our own waker type.
[`Waker`]: https://doc.rust-lang.org/nightly/core/task/struct.Waker.html
### Working with Futures
-We now know how futures are defined and understand the basic idea behind the `poll` method. However, we still don't know how to effectively work with futures. The problem is that futures represent results of asynchronous tasks, which might be not available yet. In practice, however, we often need these values directly for further calculations. So the question is: How can we efficiently retrieve the value of a future when we need it?
+We now know how futures are defined and understand the basic idea behind the `poll` method. However, we still don't know how to effectively work with futures. The problem is that futures represent the results of asynchronous tasks, which might not be available yet. In practice, however, we often need these values directly for further calculations. So the question is: How can we efficiently retrieve the value of a future when we need it?
#### Waiting on Futures
@@ -169,11 +169,11 @@ let file_content = loop {
Here we _actively_ wait for the future by calling `poll` over and over again in a loop. The arguments to `poll` don't matter here, so we omitted them. While this solution works, it is very inefficient because we keep the CPU busy until the value becomes available.
-A more efficient approach could be to _block_ the current thread until the future becomes available. This is of course only possible if you have threads, so this solution does not work for our kernel, at least not yet. Even on systems where blocking is supported, it is often not desired because it turns an asynchronous task into a synchronous task again, thereby inhibiting the potential performance benefits of parallel tasks.
+A more efficient approach could be to _block_ the current thread until the future becomes available. This is, of course, only possible if you have threads, so this solution does not work for our kernel, at least not yet. Even on systems where blocking is supported, it is often not desired because it turns an asynchronous task into a synchronous task again, thereby inhibiting the potential performance benefits of parallel tasks.
#### Future Combinators
-An alternative to waiting is to use future combinators. Future combinators are methods like `map` that allow chaining and combining futures together, similar to the methods on [`Iterator`]. Instead of waiting on the future, these combinators return a future themselves, which applies the mapping operation on `poll`.
+An alternative to waiting is to use future combinators. Future combinators are methods like `map` that allow chaining and combining futures together, similar to the methods of the [`Iterator`] trait. Instead of waiting on the future, these combinators return a future themselves, which applies the mapping operation on `poll`.
[`Iterator`]: https://doc.rust-lang.org/stable/core/iter/trait.Iterator.html
@@ -214,9 +214,9 @@ This code does not quite work because it does not handle [_pinning_], but it suf
[_pinning_]: https://doc.rust-lang.org/stable/core/pin/index.html
-With this `string_len` function, we can calculate the length of an asynchronous string without waiting for it. Since the function returns a `Future` again, the caller can't work directly on the returned value, but needs to use combinator functions again. This way, the whole call graph becomes asynchronous and we can efficiently wait for multiple futures at once at some point, e.g. in the main function.
+With this `string_len` function, we can calculate the length of an asynchronous string without waiting for it. Since the function returns a `Future` again, the caller can't work directly on the returned value, but needs to use combinator functions again. This way, the whole call graph becomes asynchronous and we can efficiently wait for multiple futures at once at some point, e.g., in the main function.
-Manually writing combinator functions is difficult, therefore they are often provided by libraries. While the Rust standard library itself provides no combinator methods yet, the semi-official (and `no_std` compatible) [`futures`] crate does. Its [`FutureExt`] trait provides high-level combinator methods such as [`map`] or [`then`], which can be used to manipulate the result with arbitrary closures.
+Because manually writing combinator functions is difficult, they are often provided by libraries. While the Rust standard library itself provides no combinator methods yet, the semi-official (and `no_std` compatible) [`futures`] crate does. Its [`FutureExt`] trait provides high-level combinator methods such as [`map`] or [`then`], which can be used to manipulate the result with arbitrary closures.
[`futures`]: https://docs.rs/futures/0.3.4/futures/
[`FutureExt`]: https://docs.rs/futures/0.3.4/futures/future/trait.FutureExt.html
@@ -231,7 +231,7 @@ The big advantage of future combinators is that they keep the operations asynchr
##### Drawbacks
-While future combinators make it possible to write very efficient code, they can be difficult to use in some situations because of the type system and the closure based interface. For example, consider code like this:
+While future combinators make it possible to write very efficient code, they can be difficult to use in some situations because of the type system and the closure-based interface. For example, consider code like this:
```rust
fn example(min_len: usize) -> impl Future