mirror of
https://github.com/phil-opp/blog_os.git
synced 2025-12-16 22:37:49 +00:00
Merge pull request #692 from phil-opp/translations
Experimental Support for Community Translations
This commit is contained in:
@@ -6,6 +6,11 @@ highlight_code = true
|
||||
highlight_theme = "visual-studio-dark"
|
||||
generate_rss = true
|
||||
|
||||
languages = [
|
||||
{ code = "zh-CN" }, # Chinese (simplified)
|
||||
{ code = "zh-TW" }, # Chinese (tradictional)
|
||||
]
|
||||
|
||||
ignored_content = ["*/README.md"]
|
||||
|
||||
[extra]
|
||||
|
||||
@@ -0,0 +1,290 @@
|
||||
+++
|
||||
title = "独立式可执行程序"
|
||||
weight = 1
|
||||
path = "zh-CN/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
+++
|
||||
|
||||
创建一个不链接标准库的 Rust 可执行文件,将是我们迈出的第一步。无需底层操作系统的支撑,这样才能在**裸机**([bare metal])上运行 Rust 代码。
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
此博客在 [GitHub] 上公开开发. 如果您有任何问题或疑问,请在此处打开一个 issue。 您也可以在[底部][at the bottom]发表评论. 这篇文章的完整源代码可以在 [`post-01`] [post branch] 分支中找到。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 简介
|
||||
|
||||
要编写一个操作系统内核,我们需要编写不依赖任何操作系统特性的代码。这意味着我们不能使用线程、文件、堆内存、网络、随机数、标准输出,或其它任何需要操作系统抽象和特定硬件的特性;因为我们正在编写自己的操作系统和硬件驱动。
|
||||
|
||||
实现这一点,意味着我们不能使用 [Rust标准库](https://doc.rust-lang.org/std/)的大部分;但还有很多 Rust 特性是我们依然可以使用的。比如说,我们可以使用[迭代器](https://doc.rust-lang.org/book/ch13-02-iterators.html)、[闭包](https://doc.rust-lang.org/book/ch13-01-closures.html)、[模式匹配](https://doc.rust-lang.org/book/ch06-00-enums.html)、[Option](https://doc.rust-lang.org/core/option/)、[Result](https://doc.rust-lang.org/core/result/index.html)、[字符串格式化](https://doc.rust-lang.org/core/macro.write.html),当然还有[所有权系统](https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html)。这些功能让我们能够编写表达性强、高层抽象的操作系统,而无需关心[未定义行为](https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs)和[内存安全](https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention)。
|
||||
|
||||
为了用 Rust 编写一个操作系统内核,我们需要创建一个独立于操作系统的可执行程序。这样的可执行程序常被称作**独立式可执行程序**(freestanding executable)或**裸机程序**(bare-metal executable)。
|
||||
|
||||
在这篇文章里,我们将逐步地创建一个独立式可执行程序,并且详细解释为什么每个步骤都是必须的。如果读者只对最终的代码感兴趣,可以跳转到本篇文章的小结部分。
|
||||
|
||||
## 禁用标准库
|
||||
|
||||
在默认情况下,所有的 Rust **包**(crate)都会链接**标准库**([standard library](https://doc.rust-lang.org/std/)),而标准库依赖于操作系统功能,如线程、文件系统、网络。标准库还与 **Rust 的 C 语言标准库实现库**(libc)相关联,它也是和操作系统紧密交互的。既然我们的计划是编写自己的操作系统,我们就需要不使用任何与操作系统相关的库——因此我们必须禁用**标准库自动引用**(automatic inclusion)。使用 [no_std 属性](https://doc.rust-lang.org/book/first-edition/using-rust-without-the-standard-library.html)可以实现这一点。
|
||||
|
||||
我们可以从创建一个新的 cargo 项目开始。最简单的办法是使用下面的命令:
|
||||
|
||||
```bash
|
||||
> cargo new blog_os
|
||||
```
|
||||
|
||||
在这里我把项目命名为 `blog_os`,当然读者也可以选择自己的项目名称。这里,cargo 默认为我们添加了`--bin` 选项,说明我们将要创建一个可执行文件(而不是一个库);cargo还为我们添加了`--edition 2018` 标签,指明项目的包要使用 Rust 的 **2018 版次**([2018 edition](https://rust-lang-nursery.github.io/edition-guide/rust-2018/index.html))。当我们执行这行指令的时候,cargo 为我们创建的目录结构如下:
|
||||
|
||||
```
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
在这里,`Cargo.toml` 文件包含了包的**配置**(configuration),比如包的名称、作者、[semver版本](http://semver.org/) 和项目依赖项;`src/main.rs` 文件包含包的**根模块**(root module)和 main 函数。我们可以使用 `cargo build` 来编译这个包,然后在 `target/debug` 文件夹内找到编译好的 `blog_os` 二进制文件。
|
||||
|
||||
### no_std 属性
|
||||
|
||||
现在我们的包依然隐式地与标准库链接。为了禁用这种链接,我们可以尝试添加 [no_std 属性](https://doc.rust-lang.org/book/first-edition/using-rust-without-the-standard-library.html):
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
看起来很顺利。当我们使用 `cargo build` 来编译的时候,却出现了下面的错误:
|
||||
|
||||
```rust
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src\main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
出现这个错误的原因是:[println! 宏](https://doc.rust-lang.org/std/macro.println.html)是标准库的一部分,而我们的项目不再依赖于标准库。我们选择不再打印字符串。这也很好理解,因为 `println!` 将会向**标准输出**([standard output](https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29))打印字符,它依赖于特殊的文件描述符,而这是由操作系统提供的特性。
|
||||
|
||||
所以我们可以移除这行代码,使用一个空的 main 函数再次尝试编译:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
现在我们发现,编译器缺少一个 `#[panic_handler]` 函数和一个**语言项**(language item)。
|
||||
|
||||
## 实现 panic 处理函数
|
||||
|
||||
`panic_handler` 属性定义了一个函数,它会在一个 panic 发生时被调用。标准库中提供了自己的 panic 处理函数,但在 `no_std` 环境中,我们需要定义一个自己的 panic 处理函数:
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
类型为 [PanicInfo](https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html) 的参数包含了 panic 发生的文件名、代码行数和可选的错误信息。这个函数从不返回,所以他被标记为**发散函数**([diverging function](https://doc.rust-lang.org/book/first-edition/functions.html#diverging-functions))。发散函数的返回类型称作 **Never 类型**(["never" type](https://doc.rust-lang.org/nightly/std/primitive.never.html)),记为`!`。对这个函数,我们目前能做的很少,所以我们只需编写一个无限循环 `loop {}`。
|
||||
|
||||
## eh_personality 语言项
|
||||
|
||||
语言项是一些编译器需求的特殊函数或类型。举例来说,Rust 的 [Copy](https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html) trait 是一个这样的语言项,告诉编译器哪些类型需要遵循**复制语义**([copy semantics](https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html))——当我们查找 `Copy` trait 的[实现](https://github.com/rust-lang/rust/blob/485397e49a02a3b7ff77c17e4a3f16c653925cb3/src/libcore/marker.rs#L296-L299)时,我们会发现,一个特殊的 `#[lang = "copy"]` 属性将它定义为了一个语言项,达到与编译器联系的目的。
|
||||
|
||||
我们可以自己实现语言项,但这是下下策:目前来看,语言项是高度不稳定的语言细节实现,它们不会经过编译期类型检查(所以编译器甚至不确保它们的参数类型是否正确)。幸运的是,我们有更稳定的方式,来修复上面的语言项错误。
|
||||
|
||||
`eh_personality` 语言项标记的函数,将被用于实现**栈展开**([stack unwinding](http://www.bogotobogo.com/cplusplus/stackunwinding.php))。在使用标准库的情况下,当 panic 发生时,Rust 将使用栈展开,来运行在栈上所有活跃的变量的**析构函数**(destructor)——这确保了所有使用的内存都被释放,允许调用程序的**父进程**(parent thread)捕获 panic,处理并继续运行。但是,栈展开是一个复杂的过程,如 Linux 的 [libunwind](http://www.nongnu.org/libunwind/) 或 Windows 的**结构化异常处理**([structured exception handling, SEH](https://msdn.microsoft.com/en-us/library/windows/desktop/ms680657(v=vs.85).aspx)),通常需要依赖于操作系统的库;所以我们不在自己编写的操作系统中使用它。
|
||||
|
||||
### 禁用栈展开
|
||||
|
||||
在其它一些情况下,栈展开并不是迫切需求的功能;因此,Rust 提供了**在 panic 时中止**([abort on panic](https://github.com/rust-lang/rust/pull/32900))的选项。这个选项能禁用栈展开相关的标志信息生成,也因此能缩小生成的二进制程序的长度。有许多方式能打开这个选项,最简单的方式是把下面的几行设置代码加入我们的 `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
这些选项能将 **dev 配置**(dev profile)和 **release 配置**(release profile)的 panic 策略设为 `abort`。`dev` 配置适用于 `cargo build`,而 `release` 配置适用于 `cargo build --release`。现在编译器应该不再要求我们提供 `eh_personality` 语言项实现。
|
||||
|
||||
现在我们已经修复了出现的两个错误,可以开始编译了。然而,尝试编译运行后,一个新的错误出现了:
|
||||
|
||||
```bash
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
## start 语言项
|
||||
|
||||
这里,我们的程序遗失了 `start` 语言项,它将定义一个程序的**入口点**(entry point)。
|
||||
|
||||
我们通常会认为,当运行一个程序时,首先被调用的是 `main` 函数。但是,大多数语言都拥有一个**运行时系统**([runtime system](https://en.wikipedia.org/wiki/Runtime_system)),它通常为**垃圾回收**(garbage collection)或**绿色线程**(software threads,或 green threads)服务,如 Java 的 GC 或 Go 语言的协程(goroutine);这个运行时系统需要在 main 函数前启动,因为它需要让程序初始化。
|
||||
|
||||
在一个典型的使用标准库的 Rust 程序中,程序运行是从一个名为 `crt0` 的运行时库开始的。`crt0` 意为 C runtime zero,它能建立一个适合运行 C 语言程序的环境,这包含了栈的创建和可执行程序参数的传入。在这之后,这个运行时库会调用 [Rust 的运行时入口点](https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73),这个入口点被称作 **start语言项**("start" language item)。Rust 只拥有一个极小的运行时,它被设计为拥有较少的功能,如爆栈检测和打印**堆栈轨迹**(stack trace)。这之后,这个运行时将会调用 main 函数。
|
||||
|
||||
我们的独立式可执行程序并不能访问 Rust 运行时或 `crt0` 库,所以我们需要定义自己的入口点。只实现一个 `start` 语言项并不能帮助我们,因为这之后程序依然要求 `crt0` 库。所以,我们要做的是,直接重写整个 `crt0` 库和它定义的入口点。
|
||||
|
||||
### 重写入口点
|
||||
|
||||
要告诉 Rust 编译器我们不使用预定义的入口点,我们可以添加 `#![no_main]` 属性。
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
读者也许会注意到,我们移除了 `main` 函数。原因很显然,既然没有底层运行时调用它,`main` 函数也失去了存在的必要性。为了重写操作系统的入口点,我们转而编写一个 `_start` 函数:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我们使用 `no_mangle` 标记这个函数,来对它禁用**名称重整**([name mangling](https://en.wikipedia.org/wiki/Name_mangling))——这确保 Rust 编译器输出一个名为 `_start` 的函数;否则,编译器可能最终生成名为 `_ZN3blog_os4_start7hb173fedf945531caE` 的函数,无法让链接器正确辨别。
|
||||
|
||||
我们还将函数标记为 `extern "C"`,告诉编译器这个函数应当使用 [C 语言的调用约定](https://en.wikipedia.org/wiki/Calling_convention),而不是 Rust 语言的调用约定。函数名为 `_start` ,是因为大多数系统默认使用这个名字作为入口点名称。
|
||||
|
||||
与前文的 `panic` 函数类似,这个函数的返回值类型为`!`——它定义了一个发散函数,或者说一个不允许返回的函数。这一点很重要,因为这个入口点不会被任何函数调用,但将直接被操作系统或**引导程序**(bootloader)调用。所以作为函数返回的替代,这个入口点应该去调用,比如操作系统提供的 **exit 系统调用**(["exit" system call](https://en.wikipedia.org/wiki/Exit_(system_call)))函数。在我们编写操作系统的情况下,关机应该是一个合适的选择,因为**当一个独立式可执行程序返回时,不会留下任何需要做的事情**(there is nothing to do if a freestanding binary returns)。现在来看,我们可以添加一个无限循环,来满足对返回值类型的需求。
|
||||
|
||||
如果我们现在编译这段程序,会出来一大段不太好看的**链接器错误**(linker error)。
|
||||
|
||||
## 链接器错误
|
||||
|
||||
**链接器**(linker)是一个程序,它将生成的目标文件组合为一个可执行文件。不同的操作系统如 Windows、macOS、Linux,规定了不同的可执行文件格式,因此也各有自己的链接器,抛出不同的错误;但这些错误的根本原因还是相同的:链接器的默认配置假定程序依赖于C语言的运行时环境,但我们的程序并不依赖于它。
|
||||
|
||||
为了解决这个错误,我们需要告诉链接器,它不应该包含(include)C 语言运行环境。我们可以选择提供特定的**链接器参数**(linker argument),也可以选择编译为**裸机目标**(bare metal target)。
|
||||
|
||||
### 编译为裸机目标
|
||||
|
||||
在默认情况下,Rust 尝试适配当前的系统环境,编译可执行程序。举个例子,如果你使用 `x86_64` 平台的 Windows 系统,Rust 将尝试编译一个扩展名为 `.exe` 的 Windows 可执行程序,并使用 `x86_64` 指令集。这个环境又被称作为你的**宿主系统**("host" system)。
|
||||
|
||||
为了描述不同的环境,Rust 使用一个称为**目标三元组**(target triple)的字符串。要查看当前系统的目标三元组,我们可以运行 `rustc --version --verbose`:
|
||||
|
||||
```
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
上面这段输出来自一个 `x86_64` 平台下的 Linux 系统。我们能看到,`host` 字段的值为三元组 `x86_64-unknown-linux-gnu`,它包含了 CPU 架构 `x86_64` 、供应商 `unknown` 、操作系统 `linux` 和[二进制接口](https://en.wikipedia.org/wiki/Application_binary_interface) `gnu`。
|
||||
|
||||
Rust 编译器尝试为当前系统的三元组编译,并假定底层有一个类似于 Windows 或 Linux 的操作系统提供C语言运行环境——然而这将导致链接器错误。所以,为了避免这个错误,我们可以另选一个底层没有操作系统的运行环境。
|
||||
|
||||
这样的运行环境被称作裸机环境,例如目标三元组 `thumbv7em-none-eabihf` 描述了一个 ARM **嵌入式系统**([embedded system](https://en.wikipedia.org/wiki/Embedded_system))。我们暂时不需要了解它的细节,只需要知道这个环境底层没有操作系统——这是由三元组中的 `none` 描述的。要为这个目标编译,我们需要使用 rustup 添加它:
|
||||
|
||||
```
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
这行命令将为目标下载一个标准库和 core 库。这之后,我们就能为这个目标构建独立式可执行程序了:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
我们传递了 `--target` 参数,来为裸机目标系统**交叉编译**([cross compile](https://en.wikipedia.org/wiki/Cross_compiler))我们的程序。我们的目标并不包括操作系统,所以链接器不会试着链接 C 语言运行环境,因此构建过程成功会完成,不会产生链接器错误。
|
||||
|
||||
我们将使用这个方法编写自己的操作系统内核。我们不会编译到 `thumbv7em-none-eabihf`,而是使用描述 `x86_64` 环境的**自定义目标**([custom target](https://doc.rust-lang.org/rustc/targets/custom.html))。在下一篇文章中,我们将详细描述一些相关的细节。
|
||||
|
||||
### 链接器参数
|
||||
|
||||
我们也可以选择不编译到裸机系统,因为传递特定的参数也能解决链接器错误问题。虽然我们不会在后面使用到这个方法,为了教程的完整性,我们也撰写了专门的短文章,来提供这个途径的解决方案。
|
||||
|
||||
## 小结
|
||||
|
||||
一个用 Rust 编写的最小化的独立式可执行程序应该长这样:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // 不链接 Rust 标准库
|
||||
#![no_main] // 禁用所有 Rust 层级的入口点
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // 不重整函数名
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// 因为编译器会寻找一个名为 `_start` 的函数,所以这个函数就是入口点
|
||||
// 默认命名为 `_start`
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# 使用 `cargo build` 编译时需要的配置
|
||||
[profile.dev]
|
||||
panic = "abort" # 禁用panic时栈展开
|
||||
|
||||
# 使用 `cargo build --release` 编译时需要的配置
|
||||
[profile.release]
|
||||
panic = "abort" # 禁用 panic 时栈展开
|
||||
```
|
||||
|
||||
选用任意一个裸机目标来编译。比如对 `thumbv7em-none-eabihf`,我们使用以下命令:
|
||||
|
||||
```bash
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
要注意的是,现在我们的代码只是一个 Rust 编写的独立式可执行程序的一个例子。运行这个二进制程序还需要很多准备,比如在 `_start` 函数之前需要一个已经预加载完毕的栈。所以为了真正运行这样的程序,我们还有很多事情需要做。
|
||||
|
||||
## 下篇预览
|
||||
|
||||
下一篇文章要做的事情基于我们这篇文章的成果,它将详细讲述编写一个最小的操作系统内核需要的步骤:如何配置特定的编译目标,如何将可执行程序与引导程序拼接,以及如何把一些特定的字符串打印到屏幕上。
|
||||
|
||||
[next post]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
@@ -0,0 +1,518 @@
|
||||
+++
|
||||
title = "獨立的 Rust 二進制檔"
|
||||
weight = 1
|
||||
path = "zh-TW/freestanding-rust-binary"
|
||||
date = 2018-02-10
|
||||
|
||||
[extra]
|
||||
translation_based_on_commit = "24d04e0e39a3395ecdce795bab0963cb6afe1bfd"
|
||||
# GitHub usernames of the people that translated this post
|
||||
translators = ["wusyong"]
|
||||
+++
|
||||
|
||||
建立我們自己的作業系統核心的第一步是建立一個不連結標準函式庫的 Rust 執行檔,這使得無需基礎作業系統即可在[裸機][bare metal]上執行 Rust 程式碼。
|
||||
|
||||
[bare metal]: https://en.wikipedia.org/wiki/Bare_machine
|
||||
|
||||
<!-- more -->
|
||||
|
||||
此網誌在 [GitHub] 上公開開發,如果您有任何問題或疑問,請在那開一個 issue,您也可以在[下面][at the bottom]發表評論,這篇文章的完整開源程式碼可以在 [`post-01`][post branch] 分支中找到。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-01
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 介紹
|
||||
要編寫作業系統核心,我們需要不依賴於任何作業系統功能的程式碼。這代表我們不能使用執行緒、檔案系統、堆記憶體、網路、隨機數、標準輸出或任何其他需要作業系統抽象或特定硬體的功能。這也是理所當然的,因為我們正在嘗試寫出自己的 OS 和我們的驅動程式。
|
||||
|
||||
這意味著我們不能使用大多數的 [Rust 標準函式庫][Rust standard library],但是我們還是可以使用 _很多_ Rust 的功能。比如說我們可以使用[疊代器][iterators]、[閉包][closures]、[模式配對][pattern matching]、[option] 和 [result]、[字串格式化][string formatting],當然還有[所有權系統][ownership system]。這些功能讓我們能夠以非常有表達力且高階的方式編寫核心,而無需擔心[未定義行為][undefined behavior]或[記憶體安全][memory safety]。
|
||||
|
||||
[option]: https://doc.rust-lang.org/core/option/
|
||||
[result]:https://doc.rust-lang.org/core/result/
|
||||
[Rust standard library]: https://doc.rust-lang.org/std/
|
||||
[iterators]: https://doc.rust-lang.org/book/ch13-02-iterators.html
|
||||
[closures]: https://doc.rust-lang.org/book/ch13-01-closures.html
|
||||
[pattern matching]: https://doc.rust-lang.org/book/ch06-00-enums.html
|
||||
[string formatting]: https://doc.rust-lang.org/core/macro.write.html
|
||||
[ownership system]: https://doc.rust-lang.org/book/ch04-00-understanding-ownership.html
|
||||
[undefined behavior]: https://www.nayuki.io/page/undefined-behavior-in-c-and-cplusplus-programs
|
||||
[memory safety]: https://tonyarcieri.com/it-s-time-for-a-memory-safety-intervention
|
||||
|
||||
為了在 Rust 中建立 OS 核心,我們需要建立一個無須底層作業系統即可運行的執行檔,這類的執行檔通常稱為「獨立式(freestanding)」或「裸機(bare-metal)」的執行檔。
|
||||
|
||||
這篇文章描述了建立一個獨立的 Rust 執行檔的必要步驟,並解釋為什麼需要這些步驟。如果您只對簡單的範例感興趣,可以直接跳到 **[總結](#總結)**。
|
||||
|
||||
## 停用標準函式庫
|
||||
|
||||
Rust 所有的 crate 在預設情況下都會連結[標準函式庫][standard library],而標準函式庫會依賴作業系統的功能,像式執行緒、檔案系統或是網路。它也會依賴 C 語言的標準函式庫 `libc`,因為其與作業系統緊密相關。既然我們的計劃是編寫自己的作業系統,我們就得用到 [`no_std` 屬性][`no_std` attribute]來停止標準函式庫的自動引用(automatic inclusion)。
|
||||
|
||||
[standard library]: https://doc.rust-lang.org/std/
|
||||
[`no_std` attribute]: https://doc.rust-lang.org/1.30.0/book/first-edition/using-rust-without-the-standard-library.html
|
||||
|
||||
我們先從建立一個新的 cargo 專案開始,最簡單的辦法是輸入下面的命令:
|
||||
|
||||
```
|
||||
cargo new blog_os --bin --edition 2018
|
||||
```
|
||||
|
||||
我將專案命名為 `blog_os`,當然讀者也可以自己的名稱。`--bin` 選項說明我們將要建立一個執行檔(而不是一個函式庫),`--edition 2018` 選項指明我們的 crate 想使用 Rust [2018 版本][2018 edition]。當我們執行這行指令的時候,cargo 會為我們建立以下目錄結構:
|
||||
|
||||
[2018 edition]: https://rust-lang-nursery.github.io/edition-guide/rust-2018/index.html
|
||||
|
||||
```
|
||||
blog_os
|
||||
├── Cargo.toml
|
||||
└── src
|
||||
└── main.rs
|
||||
```
|
||||
|
||||
`Cargo.toml` 包含 crate 的設置,像是 crate 的名稱、作者、[語意化版本][semantic version]以及依賴套件。`src/main.rs` 檔案則包含 crate 的根模組(root module)以及我們的 `main` 函式。您可以用 `cargo build` 編譯您的 crate 然後在 `target/debug` 目錄下運行編譯過後的 `blog_os` 執行檔。
|
||||
|
||||
[semantic version]: https://semver.org/lang/zh-TW/
|
||||
|
||||
### no_std 屬性
|
||||
|
||||
現在我們的 crate 背後依然有和標準函式庫連結。讓我們加上 [`no_std` 屬性][`no_std` attribute] 來停用:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
當我們嘗試用 `cargo build` 編譯時會出現以下錯誤訊息:
|
||||
|
||||
```
|
||||
error: cannot find macro `println!` in this scope
|
||||
--> src/main.rs:4:5
|
||||
|
|
||||
4 | println!("Hello, world!");
|
||||
| ^^^^^^^
|
||||
```
|
||||
|
||||
出現這個錯誤的原因是因為 [`println` 巨集(macro)][`println` macro]是標準函式庫的一部份,而我們不再包含它,所以我們無法再輸出東西來。這也是理所當然因為 `println` 會寫到[標準輸出][standard output],而這是一個由作業系統提供的特殊檔案描述符。
|
||||
|
||||
[`println` macro]: https://doc.rust-lang.org/std/macro.println.html
|
||||
[standard output]: https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
|
||||
所以讓我們移除這行程式碼,然後用空的 main 函式再試一次:
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
#![no_std]
|
||||
|
||||
fn main() {}
|
||||
```
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: `#[panic_handler]` function required, but not found
|
||||
error: language item required, but not found: `eh_personality`
|
||||
```
|
||||
|
||||
現在編譯氣告訴我們缺少 `#[panic_handler]` 函式以及 _language item_。
|
||||
|
||||
## 實作 panic 處理函式
|
||||
|
||||
`panic_handler` 屬性定義了當 [panic] 發生時編譯器需要呼叫的函式。在標準函式庫中有自己的 panic 處理函式,但在 `no_std` 的環境中我們得定義我們自己的:
|
||||
|
||||
[panic]: https://doc.rust-lang.org/stable/book/ch09-01-unrecoverable-errors-with-panic.html
|
||||
|
||||
```rust
|
||||
// main.rs
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 此函式會在 panic 時呼叫。
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
[`PanicInfo` parameter][PanicInfo] 包含 panic 發生時的檔案、行數以及可選的錯誤訊息。這個函式不會返回,所以它被標記為[發散函式][diverging function],只會返回[“never” 型態][“never” type] `!`。現在我們什麼事可以做,所以我們只需寫一個無限迴圈。
|
||||
|
||||
[PanicInfo]: https://doc.rust-lang.org/nightly/core/panic/struct.PanicInfo.html
|
||||
[diverging function]: https://doc.rust-lang.org/1.30.0/book/first-edition/functions.html#diverging-functions
|
||||
[“never” type]: https://doc.rust-lang.org/nightly/std/primitive.never.html
|
||||
|
||||
## eh_personality Language Item
|
||||
|
||||
Language item 是一些編譯器需求的特殊函式或類型。舉例來說,Rust 的 [`Copy`] trait 就是一個 language item,告訴編譯器哪些類型擁有[_複製的語意_][`Copy`]。當我們搜尋 `Copy` trait 的[實作][copy code]時,我們會發現一個特殊的 `#[lang = "copy"]` 屬性將它定義為一個 language item。
|
||||
|
||||
我們可以自己實現 language item,但這只應是最後的手段。因為 language item 屬於非常不穩定的實作細節,而且不會做類型檢查(所以編譯器甚至不會確保它們的參數類型是否正確)。幸運的是,我們有更穩定的方式來修復上面關於 language item 的錯誤。
|
||||
|
||||
`eh_personality` language item 標記的函式將被用於實作[堆疊回溯][stack unwinding]。在預設情況下當 panic 發生時,Rust 會使用堆疊回溯來執行所有存在堆疊上變數的解構子(destructor)。這確保所有使用的記憶體都被釋放,並讓 parent thread 獲取 panic 資訊並繼續運行。但是堆疊回溯是一個複雜的過程,通常會需要一些 OS 的函式庫如 Linux 的 [libunwind] 或 Windows 的 [structured exception handling]。所以我們並不希望在我們的作業系統中使用它。
|
||||
|
||||
[stack unwinding]: http://www.bogotobogo.com/cplusplus/stackunwinding.php
|
||||
[libunwind]: http://www.nongnu.org/libunwind/
|
||||
[structured exception handling]: https://msdn.microsoft.com/en-us/library/windows/desktop/ms680657(v=vs.85).aspx
|
||||
|
||||
### 停用回溯
|
||||
|
||||
在某些狀況下回溯可能並不是我們要的功能,因此 Rust 提供了[在 panic 時中止][abort on panic]的選項。這個選項能停用回溯標誌訊息的產生,也因此能縮小生成的二進制檔案大小。我們能用許多方式開啟這個選項,而最簡單的方式就是把以下幾行設置加入我們的 `Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[profile.dev]
|
||||
panic = "abort"
|
||||
|
||||
[profile.release]
|
||||
panic = "abort"
|
||||
```
|
||||
|
||||
這些選項能將 `dev` 設置(用於 `cargo build`)和 `release` 設置(用於 `cargo build --release`)的 panic 策略設為 `abort`。現在編譯器不會再要求我們提供 `eh_personality` language item。
|
||||
|
||||
[abort on panic]: https://github.com/rust-lang/rust/pull/32900
|
||||
|
||||
現在我們已經修復了上面的錯誤,但是如果我們嘗試編譯的話,又會出現一個新的錯誤:
|
||||
|
||||
```
|
||||
> cargo build
|
||||
error: requires `start` lang_item
|
||||
```
|
||||
|
||||
我們的程式缺少 `start` 這個用來定義入口點(entry point)的 language item。
|
||||
|
||||
## `start` 屬性
|
||||
|
||||
我們通常會認為執行一個程式時,首先被呼叫的是 `main` 函式。但是大多數語言都擁有一個[執行時系統][runtime system],它通常負責垃圾回收(garbage collection)像是 Java 或軟體執行緒(software threads)像是 Go 的 goroutines。這個執行時系統需要在 main 函式前啟動,因為它需要讓先進行初始化。
|
||||
|
||||
[runtime system]: https://en.wikipedia.org/wiki/Runtime_system
|
||||
|
||||
在一個典型使用標準函式庫的 Rust 程式中,程式運行是從一個名為 `crt0`(“C runtime zero”)的執行時函式庫開始的,它會設置 C 程式的執行環境。這包含建立堆疊和可執行程式參數的傳入。在這之後,這個執行時函式庫會呼叫 [Rust 的執行時入口點][rt::lang_start],而此處就是由 `start` language item 標記。 Rust 只有一個非常小的執行時系統,負責處理一些小事情,像是堆疊溢位或是印出 panic 時回溯的訊息。再來執行時系統最終才會呼叫 main 函式。
|
||||
|
||||
[rt::lang_start]: https://github.com/rust-lang/rust/blob/bb4d1491466d8239a7a5fd68bd605e3276e97afb/src/libstd/rt.rs#L32-L73
|
||||
|
||||
我們的獨立式可執行檔並沒有辦法存取 Rust 執行時系統或 `crt0`,所以我們需要定義自己的入口點。實作 `start` language item 並沒有用,因為這樣還是會需要 `crt0`。所以我們要做的是直接覆寫 `crt0` 的入口點。
|
||||
|
||||
### 重寫入口點
|
||||
|
||||
為了告訴 Rust 編譯器我們不要使用一般的入口點呼叫順序,我們先加上 `#![no_main]` 屬性。
|
||||
|
||||
```rust
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 此函式會在 panic 時呼叫。
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
您可能會注意到我們移除了 `main` 函式,原因是因為既然沒有了底層的執行時系統呼叫,那麼 `main` 也沒必要存在。我們要重寫作業系統的入口點,定義為 `_start` 函式:
|
||||
|
||||
```rust
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我們使用 `no_mangle` 屬性來停用[名字修飾][name mangling],確保 Rust 編譯器輸出的函式名稱會是 `_start`。沒有這個屬性的話,編譯器會產生符號像是 `_ZN3blog_os4_start7hb173fedf945531caE` 來讓每個函式的名稱都是獨一無二的。我們會需要這項屬性的原因是因為我們接下來希望連結器能夠呼叫入口點函式的名稱。
|
||||
|
||||
我們還將函式標記為 `extern "C"` 來告訴編譯器這個函式應當使用 [C 的調用約定][C calling convention],而不是 Rust 的調用約定。而函式名稱選用 `_start` 的原因是因為這是大多數系統的預設入口點名稱。
|
||||
|
||||
[name mangling]: https://en.wikipedia.org/wiki/Name_mangling
|
||||
[C calling convention]: https://en.wikipedia.org/wiki/Calling_convention
|
||||
|
||||
`!` 返回型態代表這個函式是發散函式,它不允許返回。這是必要的因為入口點不會被任何函式呼叫,只會直接由作業系統或啟動程式(bootloader)執行。所以取代返回值的是入口點需要執行作業系統的 [`exit` 系統呼叫][`exit` system call]。在我們的例子中,關閉機器似乎是個理想的動作,因為獨立的二進制檔案返回後也沒什麼事可做。現在我們先寫一個無窮迴圈來滿足需求。
|
||||
|
||||
[`exit` system call]: https://en.wikipedia.org/wiki/Exit_(system_call)
|
||||
|
||||
當我們現在運行 `cargo build` 的話會看到很醜的 _連結器_ 錯誤。
|
||||
|
||||
## 連結器錯誤
|
||||
|
||||
連結器是用來將產生的程式碼結合起來成為執行檔的程式。因為 Linux、Windows 和 macOS 之間的執行檔格式都不同,每個系統都會有自己的連結器錯誤。不過造成錯誤的原因通常都差不多:連結器預設的設定會認為我們的程式依賴於 C 的執行時系統,但我們並沒有。
|
||||
|
||||
為了解決這個錯誤,我們需要告訴連結器它不需要包含 C 的執行時系統。我們可以選擇提供特定的連結器參數設定,或是選擇編譯為裸機目標。
|
||||
|
||||
### 編譯為裸機目標
|
||||
|
||||
Rust 在預設情況下會嘗試編譯出符合你目前系統環境的可執行檔。舉例來說,如果你正在 `x86_64` 上使用 Windows,那麼 Rust 就會嘗試編譯出 `.exe`,一個使用 `x86_64` 指令集的 Windows 執行檔。這樣的環境稱之為主機系統(host system)。
|
||||
|
||||
為了描述不同環境,Rust 使用 [_target triple_] 的字串。要查看目前系統的 target triple,你可以執行 `rustc --version --verbose`:
|
||||
|
||||
[_target triple_]: https://clang.llvm.org/docs/CrossCompilation.html#target-triple
|
||||
|
||||
```
|
||||
rustc 1.35.0-nightly (474e7a648 2019-04-07)
|
||||
binary: rustc
|
||||
commit-hash: 474e7a6486758ea6fc761893b1a49cd9076fb0ab
|
||||
commit-date: 2019-04-07
|
||||
host: x86_64-unknown-linux-gnu
|
||||
release: 1.35.0-nightly
|
||||
LLVM version: 8.0
|
||||
```
|
||||
|
||||
上面的輸出訊息來自 `x86_64` 上的 Linux 系統,我們可以看到 `host` 的 target triple 為 `x86_64-unknown-linux-gnu`,分別代表 CPU 架構 (`x86_64`)、供應商 (`unknown`) 以及作業系統 (`linux`) 和 [ABI] (`gnu`)。
|
||||
|
||||
[ABI]: https://en.wikipedia.org/wiki/Application_binary_interface
|
||||
|
||||
在依據主機的 triple 編譯時,Rust 編譯器和連結器理所當然地會認為預設是底層的作業系統並使用 C 執行時系統,這便是造成錯誤的原因。要避免這項錯誤,我們可以選擇編譯出沒有底層作業系統的不同環境。
|
||||
|
||||
其中一個裸機環境的例子是 `thumbv7em-none-eabihf` target triple,它描述了[嵌入式][embedded] [ARM] 系統。其中的細節目前並不重要,我們現在只需要知道沒有底層作業系統的 target triple 是用 `none` 描述的。想要編譯這樣的目標的話,我們需要將它新增至 rustup:
|
||||
|
||||
[embedded]: https://en.wikipedia.org/wiki/Embedded_system
|
||||
[ARM]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||
|
||||
```
|
||||
rustup target add thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
這會下載一份該系統的標準(以及 core)函式庫,現在我們可以用此目標建立我們的獨立執行檔了:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
我們傳入 `--target` [交叉編譯][cross compile]我們在裸機系統的執行檔。因為目標系統沒有作業系統,連結器不會嘗試連結 C 執行時系統並成功建立,不會產生任何連結器錯誤。
|
||||
|
||||
[cross compile]: https://en.wikipedia.org/wiki/Cross_compiler
|
||||
|
||||
這將會是我們到時候用來建立自己的作業系統核心的方法。不過我們不會用到 `thumbv7em-none-eabihf`,我們將會使用[自訂目標][custom target]來描述一個 `x86_64` 的裸機環境。
|
||||
|
||||
[custom target]: https://doc.rust-lang.org/rustc/targets/custom.html
|
||||
|
||||
### 連結器引數
|
||||
|
||||
除了編譯裸機系統為目標以外,我們也可以傳入特定的引數組合給連結器來解決錯誤。這不會是我們到時候用在我們核心的方法,所以以下的內容不是必需的,只是用來補齊資訊。點選下面的 _「連結器引數」_ 來顯示額外資訊。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>連結器引數</summary>
|
||||
|
||||
在這部份我們將討論 Linux、Windows 和 macOS 上發生的連結器錯誤,然後解釋如何傳入額外引數給連結器以解決錯誤。注意執行檔和連結器在不同作業系統之間都會相異,所以不同系統需要傳入不同引數。
|
||||
|
||||
#### Linux
|
||||
|
||||
以下是 Linux 上會出現的(簡化過)連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: /usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x12): undefined reference to `__libc_csu_fini'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x19): undefined reference to `__libc_csu_init'
|
||||
/usr/lib/gcc/../x86_64-linux-gnu/Scrt1.o: In function `_start':
|
||||
(.text+0x25): undefined reference to `__libc_start_main'
|
||||
collect2: error: ld returned 1 exit status
|
||||
```
|
||||
|
||||
問題的原因是因為連結器在一開始包含了 C 的執行時系統,而且剛好也叫做 `_start`。它需要一些 C 標準函式庫 `libc` 提供的符號,但我們用 `no_std` 來停用它了,所以連結器無法找出引用來源。我們可以用 `-nostartfiles` 來告訴連結器一開始不必連結 C 的執行時系統。
|
||||
|
||||
要傳入的其中一個方法是透過 cargo 的 `cargo rustc` 命令,此命令行為和 `cargo build` 一樣,不過允許傳入一些選項到 Rust 底層的編譯器 `rustc`。`rustc` 有 `-C link-arg` 的選項會繼續將引數傳到連結器,這樣一來我們的指令會長得像這樣:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
```
|
||||
|
||||
現在我們的 crate 便能產生出 Linux 上的獨立執行檔了!
|
||||
|
||||
我們不必再指明入口點的函式名稱,因為連結器預設會尋找 `_start` 函式。
|
||||
#### Windows
|
||||
|
||||
在 Windows 上會出現不一樣的(簡化過)連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1561
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1561: entry point must be defined
|
||||
```
|
||||
|
||||
"entry point must be defined" 錯誤表示連結器找不到入口點,在 Windows 上預設的入口點名稱會[依據使用的子系統][windows-subsystems]。如果是 `CONSOLE` 子系統的話,連結器會尋找 `mainCRTStartup` 函式名稱;而 `WINDOWS` 子系統的話則會尋找 `WinMainCRTStartup` 函式名稱。要覆蓋預設的選項並讓連結器尋找我們的 `_start` 函式的話,我們可以傳入 `/ENTRY` 引數給連結器:
|
||||
|
||||
[windows-subsystems]: https://docs.microsoft.com/en-us/cpp/build/reference/entry-entry-point-symbol
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-arg=/ENTRY:_start
|
||||
```
|
||||
|
||||
從引數格式來看我們可以清楚理解 Windows 連結器與 Linux 連結器是完全不同的程式。
|
||||
|
||||
現在會出現另一個連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `link.exe` failed: exit code: 1221
|
||||
|
|
||||
= note: "C:\\Program Files (x86)\\…\\link.exe" […]
|
||||
= note: LINK : fatal error LNK1221: a subsystem can't be inferred and must be
|
||||
defined
|
||||
```
|
||||
|
||||
此錯誤出現的原因是因為 Windows 執行檔可以使用不同的[子系統][windows-subsystems]。一般的程式會依據入口點名稱來決定:如果入口點名稱為 `main` 則會使用 `CONSOLE` 子系統;如果入口點名稱為 `WinMain` 則會使用 `WINDOWS` 子系統。由於我們的函式 `_start` 名稱不一樣,我們必須指明子系統:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
```
|
||||
|
||||
我們使用 `CONSOLE` 子系統不過 `WINDOWS` 一樣也可以。與其輸入好多次 `-C link-arg` ,我們可以用 `-C link-args` 來傳入許多引數。
|
||||
|
||||
使用此命令後,我們的執行檔應當能成功在 Windows 上建立。
|
||||
|
||||
#### macOS
|
||||
|
||||
以下是 Linux 上會出現的(簡化過)連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: entry point (_main) undefined. for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
此錯誤訊息告訴我們連結器無法找到入口點函式 `main`,基於某些原因 macOS 上的函式都會加上前綴 `_`。為了設定入口點為我們的函式 `_start`,我們傳入 `-e` 連結器引數:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start"
|
||||
```
|
||||
|
||||
`-e` 表示肉口點的函式名稱,然後由於 macOS 上所有的函式都會加上前綴 `_`,我們需要設置入口點為 `__start` 而不是 `_start`。
|
||||
|
||||
接下來會出現另一個連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: dynamic main executables must link with libSystem.dylib
|
||||
for architecture x86_64
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
macOS [官方並不支援靜態連結執行檔][does not officially support statically linked binaries]且要求程式預設要連結到 `libSystem` 函式庫。要覆蓋這個設定並連結靜態執行檔,我們傳入 `-static` 給連結器:
|
||||
|
||||
[does not officially support statically linked binaries]: https://developer.apple.com/library/content/qa/qa1118/_index.html
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static"
|
||||
```
|
||||
|
||||
但這樣還不夠,我們會遇到第三個連結器錯誤:
|
||||
|
||||
```
|
||||
error: linking with `cc` failed: exit code: 1
|
||||
|
|
||||
= note: "cc" […]
|
||||
= note: ld: library not found for -lcrt0.o
|
||||
clang: error: linker command failed with exit code 1 […]
|
||||
```
|
||||
|
||||
這錯誤出現的原因是因為 macOS 的程式預設都會連結到 `crt0` (“C runtime zero”)。這和我們在 Linux 上遇到的類似,所以也可以用 `-nostartfiles` 連結器引數來解決:
|
||||
|
||||
```
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
現在我們的程式應當能成功在 macOS 上建立。
|
||||
|
||||
#### 統一建構命令
|
||||
|
||||
現在我們得依據主機平台來使用不同的建構命令,這樣感覺不是很理想。我們可以建立個檔案 `.cargo/config` 來解決,裡面會包含平台相關的引數:
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
|
||||
[target.'cfg(target_os = "linux")']
|
||||
rustflags = ["-C", "link-arg=-nostartfiles"]
|
||||
|
||||
[target.'cfg(target_os = "windows")']
|
||||
rustflags = ["-C", "link-args=/ENTRY:_start /SUBSYSTEM:console"]
|
||||
|
||||
[target.'cfg(target_os = "macos")']
|
||||
rustflags = ["-C", "link-args=-e __start -static -nostartfiles"]
|
||||
```
|
||||
|
||||
`rustflags` 包含的引數會自動加到 `rustc` 如果條件符合的話。想了解更多關於 `.cargo/config` 的資訊請參考[官方文件][official documentation](https://doc.rust-lang.org/cargo/reference/config.html)。
|
||||
|
||||
這樣一來我們就能同時在三個平台只用 `cargo build` 來建立了。
|
||||
|
||||
#### 你該這麼作嗎?
|
||||
|
||||
雖然我們可以在 Linux、Windows 和 macOS 上建立獨立執行檔,不過這可能不是好主意。我們目前會需要這樣做的原因是因為我們的執行檔仍然需要仰賴一些事情,像是當 `_start` 函式呼叫時堆疊已經初始化完畢。少了 C 執行時系統,有些要求可能會無法達成,造成我們的程式失效,像是 segmentation fault。
|
||||
|
||||
如果你想要建立一個運行在已存作業系統上的最小執行檔,改用 `libc` 然後如這邊[所述](https://doc.rust-lang.org/1.16.0/book/no-stdlib.html)設置 `#[start]` 屬性可能會是更好的做法。
|
||||
|
||||
</details>
|
||||
|
||||
## 總結
|
||||
|
||||
一個最小的 Rust 獨立執行檔會看起來像這樣:
|
||||
|
||||
`src/main.rs`:
|
||||
|
||||
```rust
|
||||
#![no_std] // 不連結標準函式庫
|
||||
#![no_main] // 停用 Rust 層級的入口點
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // 不修飾函式名稱
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// 因為連結器預設會尋找 `_start` 函式名稱
|
||||
// 所以這個函式就是入口點
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// 此函式會在 panic 時呼叫
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
`Cargo.toml`:
|
||||
|
||||
```toml
|
||||
[package]
|
||||
name = "crate_name"
|
||||
version = "0.1.0"
|
||||
authors = ["Author Name <author@example.com>"]
|
||||
|
||||
# `cargo build` 時需要的設置
|
||||
[profile.dev]
|
||||
panic = "abort" # 停用 panic 時堆疊回溯
|
||||
|
||||
# `cargo build --release` 時需要的設置
|
||||
[profile.release]
|
||||
panic = "abort" # 停用 panic 時堆疊回溯
|
||||
```
|
||||
|
||||
要建構出此執行檔,我們需要選擇一個裸機目標來編譯像是 `thumbv7em-none-eabihf`:
|
||||
|
||||
```
|
||||
cargo build --target thumbv7em-none-eabihf
|
||||
```
|
||||
|
||||
不然我們也可以用主機系統來編譯,不過要加上額外的連結器引數:
|
||||
|
||||
```bash
|
||||
# Linux
|
||||
cargo rustc -- -C link-arg=-nostartfiles
|
||||
# Windows
|
||||
cargo rustc -- -C link-args="/ENTRY:_start /SUBSYSTEM:console"
|
||||
# macOS
|
||||
cargo rustc -- -C link-args="-e __start -static -nostartfiles"
|
||||
```
|
||||
|
||||
注意這只是最小的 Rust 獨立執行檔範例,它還是會仰賴一些事情發生,像是當 `_start` 函式呼叫時堆疊已經初始化完畢。**所以如果想真的使用這樣的執行檔的話還需要更多步驟。**
|
||||
|
||||
## 接下來呢?
|
||||
|
||||
[下一篇文章][next post] 將會講解如何將我們的獨立執行檔轉成最小的作業系統核心。這包含建立自訂目標、用啟動程式組合我們的執行檔,還有學習如何輸出一些東西到螢幕上。
|
||||
|
||||
[next post]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
@@ -0,0 +1,378 @@
|
||||
+++
|
||||
title = "最小化内核"
|
||||
weight = 2
|
||||
path = "zh-CN/minimal-rust-kernel"
|
||||
date = 2018-02-10
|
||||
|
||||
+++
|
||||
|
||||
在这篇文章中,我们将基于 **x86架构**(the x86 architecture),使用 Rust 语言,编写一个最小化的 64 位内核。我们将从上一章中构建的独立式可执行程序开始,构建自己的内核;它将向显示器打印字符串,并能被打包为一个能够引导启动的**磁盘映像**(disk image)。
|
||||
|
||||
[freestanding Rust binary]: @/second-edition/posts/01-freestanding-rust-binary/index.md
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-02`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-02
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 引导启动
|
||||
|
||||
当我们启动电脑时,主板 [ROM](https://en.wikipedia.org/wiki/Read-only_memory)内存储的**固件**(firmware)将会运行:它将负责电脑的**加电自检**([power-on self test](https://en.wikipedia.org/wiki/Power-on_self-test)),**可用内存**(available RAM)的检测,以及 CPU 和其它硬件的预加载。这之后,它将寻找一个**可引导的存储介质**(bootable disk),并开始引导启动其中的**内核**(kernel)。
|
||||
|
||||
x86 架构支持两种固件标准: **BIOS**([Basic Input/Output System](https://en.wikipedia.org/wiki/BIOS))和 **UEFI**([Unified Extensible Firmware Interface](https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface))。其中,BIOS 标准显得陈旧而过时,但实现简单,并为 1980 年代后的所有 x86 设备所支持;相反地,UEFI 更现代化,功能也更全面,但开发和构建更复杂(至少从我的角度看是如此)。
|
||||
|
||||
在这篇文章中,我们暂时只提供 BIOS 固件的引导启动方式。
|
||||
|
||||
### BIOS 启动
|
||||
|
||||
几乎所有的 x86 硬件系统都支持 BIOS 启动,这也包含新型的、基于 UEFI、用**模拟 BIOS**(emulated BIOS)的方式向后兼容的硬件系统。这可以说是一件好事情,因为无论是上世纪还是现在的硬件系统,你都只需编写同样的引导启动逻辑;但这种兼容性有时也是 BIOS 引导启动最大的缺点,因为这意味着在系统启动前,你的 CPU 必须先进入一个 16 位系统兼容的**实模式**([real mode](https://en.wikipedia.org/wiki/Real_mode)),这样 1980 年代古老的引导固件才能够继续使用。
|
||||
|
||||
让我们从头开始,理解一遍 BIOS 启动的过程。
|
||||
|
||||
当电脑启动时,主板上特殊的闪存中存储的 BIOS 固件将被加载。BIOS 固件将会加电自检、初始化硬件,然后它将寻找一个可引导的存储介质。如果找到了,那电脑的控制权将被转交给**引导程序**(bootloader):一段存储在存储介质的开头的、512字节长度的程序片段。大多数的引导程序长度都大于512字节——所以通常情况下,引导程序都被切分为一段优先启动、长度不超过512字节、存储在介质开头的**第一阶段引导程序**(first stage bootloader),和一段随后由其加载的、长度可能较长、存储在其它位置的**第二阶段引导程序**(second stage bootloader)。
|
||||
|
||||
引导程序必须决定内核的位置,并将内核加载到内存。引导程序还需要将 CPU 从 16 位的实模式,先切换到 32 位的**保护模式**([protected mode](https://en.wikipedia.org/wiki/Protected_mode)),最终切换到 64 位的**长模式**([long mode](https://en.wikipedia.org/wiki/Long_mode)):此时,所有的 64 位寄存器和整个**主内存**(main memory)才能被访问。引导程序的第三个作用,是从 BIOS 查询特定的信息,并将其传递到内核;如查询和传递**内存映射表**(memory map)。
|
||||
|
||||
编写一个引导程序并不是一个简单的任务,因为这需要使用汇编语言,而且必须经过许多意图并不明显的步骤——比如,把一些**魔术数字**(magic number)写入某个寄存器。因此,我们不会讲解如何编写自己的引导程序,而是推荐 [bootimage 工具](https://github.com/rust-osdev/bootimage)——它能够自动并且方便地为你的内核准备一个引导程序。
|
||||
|
||||
### Multiboot 标准
|
||||
|
||||
每个操作系统都实现自己的引导程序,而这只对单个操作系统有效。为了避免这样的僵局,1995 年,**自由软件基金会**([Free Software Foundation](https://en.wikipedia.org/wiki/Free_Software_Foundation))颁布了一个开源的引导程序标准——[Multiboot](https://wiki.osdev.org/Multiboot)。这个标准定义了引导程序和操作系统间的统一接口,所以任何适配 Multiboot 的引导程序,都能用来加载任何同样适配了 Multiboot 的操作系统。[GNU GRUB](https://en.wikipedia.org/wiki/GNU_GRUB) 是一个可供参考的 Multiboot 实现,它也是最热门的Linux系统引导程序之一。
|
||||
|
||||
要编写一款适配 Multiboot 的内核,我们只需要在内核文件开头,插入被称作 **Multiboot头**([Multiboot header](https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#OS-image-format))的数据片段。这让 GRUB 很容易引导任何操作系统,但是,GRUB 和 Multiboot 标准也有一些可预知的问题:
|
||||
|
||||
1. 它们只支持 32 位的保护模式。这意味着,在引导之后,你依然需要配置你的 CPU,让它切换到 64 位的长模式;
|
||||
2. 它们被设计为精简引导程序,而不是精简内核。举个例子,内核需要以调整过的**默认页长度**([default page size](https://wiki.osdev.org/Multiboot#Multiboot_2))被链接,否则 GRUB 将无法找到内核的 Multiboot 头。另一个例子是**引导信息**([boot information](https://www.gnu.org/software/grub/manual/multiboot/multiboot.html#Boot-information-format)),这个包含着大量与架构有关的数据,会在引导启动时,被直接传到操作系统,而不会经过一层清晰的抽象;
|
||||
3. GRUB 和 Multiboot 标准并没有被详细地解释,阅读相关文档需要一定经验;
|
||||
4. 为了创建一个能够被引导的磁盘映像,我们在开发时必须安装 GRUB:这加大了基于 Windows 或 macOS 开发内核的难度。
|
||||
|
||||
出于这些考虑,我们决定不使用 GRUB 或者 Multiboot 标准。然而,Multiboot 支持功能也在 bootimage 工具的开发计划之中,所以从原理上讲,如果选用 bootimage 工具,在未来使用 GRUB 引导你的系统内核是可能的。
|
||||
|
||||
## 最小化内核
|
||||
|
||||
现在我们已经明白电脑是如何启动的,那也是时候编写我们自己的内核了。我们的小目标是,创建一个内核的磁盘映像,它能够在启动时,向屏幕输出一行“Hello World!”;我们的工作将基于上一章构建的独立式可执行程序。
|
||||
|
||||
如果读者还有印象的话,在上一章,我们使用 `cargo` 构建了一个独立的二进制程序;但这个程序依然基于特定的操作系统平台:因平台而异,我们需要定义不同名称的函数,且使用不同的编译指令。这是因为在默认情况下,`cargo` 会为特定的**宿主系统**(host system)构建源码,比如为你正在运行的系统构建源码。这并不是我们想要的,因为我们的内核不应该基于另一个操作系统——我们想要编写的,就是这个操作系统。确切地说,我们想要的是,编译为一个特定的**目标系统**(target system)。
|
||||
|
||||
## 安装 Nightly Rust
|
||||
|
||||
Rust 语言有三个**发行频道**(release channel),分别是 stable、beta 和 nightly。《Rust 程序设计语言》中对这三个频道的区别解释得很详细,可以前往[这里](https://doc.rust-lang.org/book/appendix-07-nightly-rust.html)看一看。为了搭建一个操作系统,我们需要一些只有 nightly 会提供的实验性功能,所以我们需要安装一个 nightly 版本的 Rust。
|
||||
|
||||
要管理安装好的 Rust,我强烈建议使用 [rustup](https://www.rustup.rs/):它允许你同时安装 nightly、beta 和 stable 版本的编译器,而且让更新 Rust 变得容易。你可以输入 `rustup override add nightly` 来选择在当前目录使用 nightly 版本的 Rust。或者,你也可以在项目根目录添加一个名称为 `rust-toolchain`、内容为 `nightly` 的文件。要检查你是否已经安装了一个 nightly,你可以运行 `rustc --version`:返回的版本号末尾应该包含`-nightly`。
|
||||
|
||||
Nightly 版本的编译器允许我们在源码的开头插入**特性标签**(feature flag),来自由选择并使用大量实验性的功能。举个例子,要使用实验性的[内联汇编(asm!宏)](https://doc.rust-lang.org/nightly/unstable-book/language-features/asm.html),我们可以在 `main.rs` 的顶部添加 `#![feature(asm)]`。要注意的是,这样的实验性功能**不稳定**(unstable),意味着未来的 Rust 版本可能会修改或移除这些功能,而不会有预先的警告过渡。因此我们只有在绝对必要的时候,才应该使用这些特性。
|
||||
|
||||
### 目标配置清单
|
||||
|
||||
通过 `--target` 参数,`cargo` 支持不同的目标系统。这个目标系统可以使用一个**目标三元组**([target triple](https://clang.llvm.org/docs/CrossCompilation.html#target-triple))来描述,它描述了 CPU 架构、平台供应者、操作系统和**应用程序二进制接口**([Application Binary Interface, ABI](https://stackoverflow.com/a/2456882))。比方说,目标三元组` x86_64-unknown-linux-gnu` 描述一个基于 `x86_64` 架构 CPU 的、没有明确的平台供应者的 linux 系统,它遵循 GNU 风格的 ABI。Rust 支持[许多不同的目标三元组](https://forge.rust-lang.org/platform-support.html),包括安卓系统对应的 `arm-linux-androideabi` 和 [WebAssembly使用的wasm32-unknown-unknown](https://www.hellorust.com/setup/wasm-target/)。
|
||||
|
||||
为了编写我们的目标系统,并且鉴于我们需要做一些特殊的配置(比如没有依赖的底层操作系统),[已经支持的目标三元组](https://forge.rust-lang.org/platform-support.html)都不能满足我们的要求。幸运的是,只需使用一个 JSON 文件,Rust 便允许我们定义自己的目标系统;这个文件常被称作**目标配置清单**(target specification)。比如,一个描述 `x86_64-unknown-linux-gnu` 目标系统的配置清单大概长这样:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-linux-gnu",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "linux",
|
||||
"executables": true,
|
||||
"linker-flavor": "gcc",
|
||||
"pre-link-args": ["-m64"],
|
||||
"morestack": false
|
||||
}
|
||||
```
|
||||
|
||||
一个配置清单中包含多个**配置项**(field)。大多数的配置项都是 LLVM 需求的,它们将配置为特定平台生成的代码。打个比方,`data-layout` 配置项定义了不同的整数、浮点数、指针类型的长度;另外,还有一些 Rust 用作条件编译的配置项,如 `target-pointer-width`。还有一些类型的配置项,定义了这个包该如何被编译,例如,`pre-link-args` 配置项指定了应该向**链接器**([linker](https://en.wikipedia.org/wiki/Linker_(computing)))传入的参数。
|
||||
|
||||
我们将把我们的内核编译到 `x86_64` 架构,所以我们的配置清单将和上面的例子相似。现在,我们来创建一个名为 `x86_64-blog_os.json` 的文件——当然也可以选用自己喜欢的文件名——里面包含这样的内容:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
}
|
||||
```
|
||||
|
||||
需要注意的是,因为我们要在**裸机**(bare metal)上运行内核,我们已经修改了 `llvm-target` 的内容,并将 `os` 配置项的值改为 `none`。
|
||||
|
||||
我们还需要添加下面与编译相关的配置项:
|
||||
|
||||
```json
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
```
|
||||
|
||||
在这里,我们不使用平台默认提供的链接器,因为它可能不支持 Linux 目标系统。为了链接我们的内核,我们使用跨平台的 **LLD链接器**([LLD linker](https://lld.llvm.org/)),它是和 Rust 一起打包发布的。
|
||||
|
||||
```json
|
||||
"panic-strategy": "abort",
|
||||
```
|
||||
|
||||
这个配置项的意思是,我们的编译目标不支持 panic 时的**栈展开**([stack unwinding](http://www.bogotobogo.com/cplusplus/stackunwinding.php)),所以我们选择直接**在 panic 时中止**(abort on panic)。这和在 `Cargo.toml` 文件中添加 `panic = "abort"` 选项的作用是相同的,所以我们可以不在这里的配置清单中填写这一项。
|
||||
|
||||
```json
|
||||
"disable-redzone": true,
|
||||
```
|
||||
|
||||
我们正在编写一个内核,所以我们应该同时处理中断。要安全地实现这一点,我们必须禁用一个与**红区**(redzone)有关的栈指针优化:因为此时,这个优化可能会导致栈被破坏。我们撰写了一篇专门的短文,来更详细地解释红区及与其相关的优化。
|
||||
|
||||
```json
|
||||
"features": "-mmx,-sse,+soft-float",
|
||||
```
|
||||
|
||||
`features` 配置项被用来启用或禁用某个目标 **CPU 特征**(CPU feature)。通过在它们前面添加`-`号,我们将 `mmx` 和 `sse` 特征禁用;添加前缀`+`号,我们启用了 `soft-float` 特征。
|
||||
|
||||
`mmx` 和 `sse` 特征决定了是否支持**单指令多数据流**([Single Instruction Multiple Data,SIMD](https://en.wikipedia.org/wiki/SIMD))相关指令,这些指令常常能显著地提高程序层面的性能。然而,在内核中使用庞大的 SIMD 寄存器,可能会造成较大的性能影响:因为每次程序中断时,内核不得不储存整个庞大的 SIMD 寄存器以备恢复——这意味着,对每个硬件中断或系统调用,完整的 SIMD 状态必须存到主存中。由于 SIMD 状态可能相当大(512~1600 个字节),而中断可能时常发生,这些额外的存储与恢复操作可能显著地影响效率。为解决这个问题,我们对内核禁用 SIMD(但这不意味着禁用内核之上的应用程序的 SIMD 支持)。
|
||||
|
||||
禁用 SIMD 产生的一个问题是,`x86_64` 架构的浮点数指针运算默认依赖于 SIMD 寄存器。我们的解决方法是,启用 `soft-float` 特征,它将使用基于整数的软件功能,模拟浮点数指针运算。
|
||||
|
||||
为了让读者的印象更清晰,我们撰写了一篇关于禁用 SIMD 的短文。
|
||||
|
||||
现在,我们将各个配置项整合在一起。我们的目标配置清单应该长这样:
|
||||
|
||||
```json
|
||||
{
|
||||
"llvm-target": "x86_64-unknown-none",
|
||||
"data-layout": "e-m:e-i64:64-f80:128-n8:16:32:64-S128",
|
||||
"arch": "x86_64",
|
||||
"target-endian": "little",
|
||||
"target-pointer-width": "64",
|
||||
"target-c-int-width": "32",
|
||||
"os": "none",
|
||||
"executables": true,
|
||||
"linker-flavor": "ld.lld",
|
||||
"linker": "rust-lld",
|
||||
"panic-strategy": "abort",
|
||||
"disable-redzone": true,
|
||||
"features": "-mmx,-sse,+soft-float"
|
||||
}
|
||||
```
|
||||
|
||||
### 编译内核
|
||||
|
||||
要编译我们的内核,我们将使用 Linux 系统的编写风格(这可能是 LLVM 的默认风格)。这意味着,我们需要把前一篇文章中编写的入口点重命名为 `_start`:
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std] // 不链接 Rust 标准库
|
||||
#![no_main] // 禁用所有 Rust 层级的入口点
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
/// 这个函数将在 panic 时被调用
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[no_mangle] // 不重整函数名
|
||||
pub extern "C" fn _start() -> ! {
|
||||
// 因为编译器会寻找一个名为 `_start` 的函数,所以这个函数就是入口点
|
||||
// 默认命名为 `_start`
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
注意的是,无论你开发使用的是哪类操作系统,你都需要将入口点命名为 `_start`。前一篇文章中编写的 Windows 系统和 macOS 对应的入口点不应该被保留。
|
||||
|
||||
通过把 JSON 文件名传入 `--target` 选项,我们现在可以开始编译我们的内核。让我们试试看:
|
||||
|
||||
```
|
||||
> cargo build --target x86_64-blog_os.json
|
||||
|
||||
error[E0463]: can't find crate for `core`
|
||||
(或者是下面的错误)
|
||||
error[E0463]: can't find crate for `compiler_builtins`
|
||||
```
|
||||
|
||||
哇哦,编译失败了!输出的错误告诉我们,Rust 编译器找不到 `core` 或者 `compiler_builtins` 包;而所有 `no_std` 上下文都隐式地链接到这两个包。[`core` 包](https://doc.rust-lang.org/nightly/core/index.html)包含基础的 Rust 类型,如` Result`、`Option` 和迭代器等;[`compiler_builtins` 包](https://github.com/rust-lang-nursery/compiler-builtins)提供 LLVM 需要的许多底层操作,比如 `memcpy`。
|
||||
|
||||
通常状况下,`core` 库以**预编译库**(precompiled library)的形式与 Rust 编译器一同发布——这时,`core` 库只对支持的宿主系统有效,而我们自定义的目标系统无效。如果我们想为其它系统编译代码,我们需要为这些系统重新编译整个 `core` 库。
|
||||
|
||||
### Cargo xbuild
|
||||
|
||||
这就是为什么我们需要 [cargo xbuild 工具](https://github.com/rust-osdev/cargo-xbuild)。这个工具封装了 `cargo build`;但不同的是,它将自动交叉编译 `core` 库和一些**编译器内建库**(compiler built-in libraries)。我们可以用下面的命令安装它:
|
||||
|
||||
```bash
|
||||
cargo install cargo-xbuild
|
||||
```
|
||||
|
||||
这个工具依赖于Rust的源代码;我们可以使用 `rustup component add rust-src` 来安装源代码。
|
||||
|
||||
现在我们可以使用 `xbuild` 代替 `build` 重新编译:
|
||||
|
||||
```bash
|
||||
> cargo xbuild --target x86_64-blog_os.json
|
||||
Compiling core v0.0.0 (/…/rust/src/libcore)
|
||||
Compiling compiler_builtins v0.1.5
|
||||
Compiling rustc-std-workspace-core v1.0.0 (/…/rust/src/tools/rustc-std-workspace-core)
|
||||
Compiling alloc v0.0.0 (/tmp/xargo.PB7fj9KZJhAI)
|
||||
Finished release [optimized + debuginfo] target(s) in 45.18s
|
||||
Compiling blog_os v0.1.0 (file:///…/blog_os)
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
|
||||
```
|
||||
|
||||
我们能看到,`cargo xbuild` 为我们自定义的目标交叉编译了 `core`、`compiler_builtin` 和 `alloc` 三个部件。这些部件使用了大量的**不稳定特性**(unstable features),所以只能在[nightly 版本的 Rust 编译器](https://os.phil-opp.com/freestanding-rust-binary/#installing-rust-nightly)中工作。这之后,`cargo xbuild` 成功地编译了我们的 `blog_os` 包。
|
||||
|
||||
现在我们可以为裸机编译内核了;但是,我们提供给引导程序的入口点 `_start` 函数还是空的。我们可以添加一些东西进去,不过我们可以先做一些优化工作。
|
||||
|
||||
### 设置默认目标
|
||||
|
||||
为了避免每次使用`cargo xbuild`时传递`--target`参数,我们可以覆写默认的编译目标。我们创建一个名为`.cargo/config`的[cargo配置文件](https://doc.rust-lang.org/cargo/reference/config.html),添加下面的内容:
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
|
||||
[build]
|
||||
target = "x86_64-blog_os.json"
|
||||
```
|
||||
|
||||
这里的配置告诉 `cargo` 在没有显式声明目标的情况下,使用我们提供的 `x86_64-blog_os.json` 作为目标配置。这意味着保存后,我们可以直接使用:
|
||||
|
||||
```
|
||||
cargo build
|
||||
```
|
||||
|
||||
来编译我们的内核。[官方提供的一份文档](https://doc.rust-lang.org/cargo/reference/config.html)中有对 cargo 配置文件更详细的说明。
|
||||
|
||||
### 向屏幕打印字符
|
||||
|
||||
要做到这一步,最简单的方式是写入 **VGA 字符缓冲区**([VGA text buffer](https://en.wikipedia.org/wiki/VGA-compatible_text_mode)):这是一段映射到 VGA 硬件的特殊内存片段,包含着显示在屏幕上的内容。通常情况下,它能够存储 25 行、80 列共 2000 个**字符单元**(character cell);每个字符单元能够显示一个 ASCII 字符,也能设置这个字符的**前景色**(foreground color)和**背景色**(background color)。输出到屏幕的字符大概长这样:
|
||||
|
||||

|
||||
|
||||
我们将在下篇文章中详细讨论 VGA 字符缓冲区的内存布局;目前我们只需要知道,这段缓冲区的地址是 `0xb8000`,且每个字符单元包含一个 ASCII 码字节和一个颜色字节。
|
||||
|
||||
我们的实现就像这样:
|
||||
|
||||
```rust
|
||||
static HELLO: &[u8] = b"Hello World!";
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
let vga_buffer = 0xb8000 as *mut u8;
|
||||
|
||||
for (i, &byte) in HELLO.iter().enumerate() {
|
||||
unsafe {
|
||||
*vga_buffer.offset(i as isize * 2) = byte;
|
||||
*vga_buffer.offset(i as isize * 2 + 1) = 0xb;
|
||||
}
|
||||
}
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
在这段代码中,我们预先定义了一个**字节字符串**(byte string)类型的**静态变量**(static variable),名为 `HELLO`。我们首先将整数 `0xb8000` **转换**(cast)为一个**裸指针**([raw pointer](https://doc.rust-lang.org/stable/book/second-edition/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer))。这之后,我们迭代 `HELLO` 的每个字节,使用 [enumerate](https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate) 获得一个额外的序号变量 `i`。在 `for` 语句的循环体中,我们使用 [offset](https://doc.rust-lang.org/std/primitive.pointer.html#method.offset) 偏移裸指针,解引用它,来将字符串的每个字节和对应的颜色字节——`0xb` 代表淡青色——写入内存位置。
|
||||
|
||||
要注意的是,所有的裸指针内存操作都被一个 **unsafe 语句块**([unsafe block](https://doc.rust-lang.org/stable/book/second-edition/ch19-01-unsafe-rust.html))包围。这是因为,此时编译器不能确保我们创建的裸指针是有效的;一个裸指针可能指向任何一个你内存位置;直接解引用并写入它,也许会损坏正常的数据。使用 `unsafe` 语句块时,程序员其实在告诉编译器,自己保证语句块内的操作是有效的。事实上,`unsafe` 语句块并不会关闭 Rust 的安全检查机制;它允许你多做的事情[只有四件](https://doc.rust-lang.org/stable/book/second-edition/ch19-01-unsafe-rust.html#unsafe-superpowers)。
|
||||
|
||||
使用 `unsafe` 语句块要求程序员有足够的自信,所以必须强调的一点是,**肆意使用 unsafe 语句块并不是 Rust 编程的一贯方式**。在缺乏足够经验的前提下,直接在 `unsafe` 语句块内操作裸指针,非常容易把事情弄得很糟糕;比如,在不注意的情况下,我们很可能会意外地操作缓冲区以外的内存。
|
||||
|
||||
在这样的前提下,我们希望最小化 `unsafe ` 语句块的使用。使用 Rust 语言,我们能够将不安全操作将包装为一个安全的抽象模块。举个例子,我们可以创建一个 VGA 缓冲区类型,把所有的不安全语句封装起来,来确保从类型外部操作时,无法写出不安全的代码:通过这种方式,我们只需要最少的 `unsafe` 语句块来确保我们不破坏**内存安全**([memory safety](https://en.wikipedia.org/wiki/Memory_safety))。在下一篇文章中,我们将会创建这样的 VGA 缓冲区封装。
|
||||
|
||||
## 启动内核
|
||||
|
||||
既然我们已经有了一个能够打印字符的可执行程序,是时候把它运行起来试试看了。首先,我们将编译完毕的内核与引导程序链接,来创建一个引导映像;这之后,我们可以在 QEMU 虚拟机中运行它,或者通过 U 盘在真机上运行。
|
||||
|
||||
### 创建引导映像
|
||||
|
||||
要将可执行程序转换为**可引导的映像**(bootable disk image),我们需要把它和引导程序链接。这里,引导程序将负责初始化 CPU 并加载我们的内核。
|
||||
|
||||
编写引导程序并不容易,所以我们不编写自己的引导程序,而是使用已有的 [bootloader](https://crates.io/crates/bootloader) 包;无需依赖于 C 语言,这个包基于 Rust 代码和内联汇编,实现了一个五脏俱全的 BIOS 引导程序。为了用它启动我们的内核,我们需要将它添加为一个依赖项,在 `Cargo.toml` 中添加下面的代码:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
bootloader = "0.6.0"
|
||||
```
|
||||
|
||||
只添加引导程序为依赖项,并不足以创建一个可引导的磁盘映像;我们还需要内核编译完成之后,将内核和引导程序组合在一起。然而,截至目前,原生的 cargo 并不支持在编译完成后添加其它步骤(详见[这个 issue](https://github.com/rust-lang/cargo/issues/545))。
|
||||
|
||||
为了解决这个问题,我们建议使用 `bootimage` 工具——它将会在内核编译完毕后,将它和引导程序组合在一起,最终创建一个能够引导的磁盘映像。我们可以使用下面的命令来安装这款工具:
|
||||
|
||||
```bash
|
||||
cargo install bootimage --version "^0.7.3"
|
||||
```
|
||||
|
||||
参数 `^0.7.3` 是一个**脱字号条件**([caret requirement](https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html#caret-requirements)),它的意义是“ 0.7.3 版本或一个兼容 0.7.3 的新版本”。这意味着,如果这款工具发布了修复 bug 的版本 `0.7.4` 或 `0.7.5`,cargo 将会自动选择最新的版本,因为它依然兼容 `0.7.x`;但 cargo 不会选择 `0.8.0`,因为这个版本被认为并不和 `0.7.x` 系列版本兼容。需要注意的是,`Cargo.toml` 中定义的依赖包版本都默认是脱字号条件:刚才我们指定 `bootloader` 包的版本时,遵循的就是这个原则。
|
||||
|
||||
为了运行 `bootimage` 以及编译引导程序,我们需要安装 rustup 模块 `llvm-tools-preview`——我们可以使用 `rustup component add llvm-tools-preview` 来安装这个工具。
|
||||
|
||||
成功安装 `bootimage` 后,创建一个可引导的磁盘映像就变得相当容易。我们来输入下面的命令:
|
||||
|
||||
```bash
|
||||
> cargo bootimage
|
||||
```
|
||||
|
||||
可以看到的是,`bootimage` 工具开始使用 `cargo xbuild` 编译你的内核,所以它将增量编译我们修改后的源码。在这之后,它会编译内核的引导程序,这可能将花费一定的时间;但和所有其它依赖包相似的是,在首次编译后,产生的二进制文件将被缓存下来——这将显著地加速后续的编译过程。最终,`bootimage` 将把内核和引导程序组合为一个可引导的磁盘映像。
|
||||
|
||||
运行这行命令之后,我们应该能在 `target/x86_64-blog_os/debug` 目录内找到我们的映像文件 `bootimage-blog_os.bin`。我们可以在虚拟机内启动它,也可以刻录到 U 盘上以便在真机上启动。(需要注意的是,因为文件格式不同,这里的 bin 文件并不是一个光驱映像,所以将它刻录到光盘不会起作用。)
|
||||
|
||||
事实上,在这行命令背后,`bootimage` 工具执行了三个步骤:
|
||||
|
||||
1. 编译我们的内核为一个 **ELF**([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format))文件;
|
||||
2. 编译引导程序为独立的可执行文件;
|
||||
3. 将内核 ELF 文件**按字节拼接**(append by bytes)到引导程序的末端。
|
||||
|
||||
当机器启动时,引导程序将会读取并解析拼接在其后的 ELF 文件。这之后,它将把程序片段映射到**分页表**(page table)中的**虚拟地址**(virtual address),清零 **BSS段**(BSS segment),还将创建一个栈。最终它将读取**入口点地址**(entry point address)——我们程序中 `_start` 函数的位置——并跳转到这个位置。
|
||||
|
||||
### 在 QEMU 中启动内核
|
||||
|
||||
现在我们可以在虚拟机中启动内核了。为了在[ QEMU](https://www.qemu.org/) 中启动内核,我们使用下面的命令:
|
||||
|
||||
```bash
|
||||
> qemu-system-x86_64 -drive format=raw,file=bootimage-blog_os.bin
|
||||
```
|
||||
|
||||
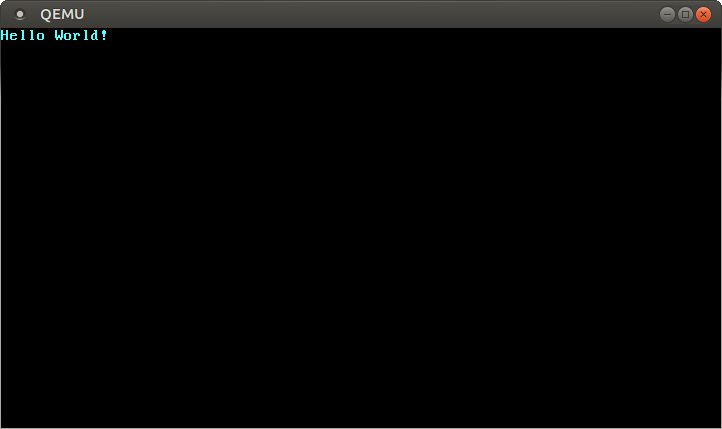
|
||||
|
||||
我们可以看到,屏幕窗口已经显示出 “Hello World!” 字符串。祝贺你!
|
||||
|
||||
### 在真机上运行内核
|
||||
|
||||
我们也可以使用 dd 工具把内核写入 U 盘,以便在真机上启动。可以输入下面的命令:
|
||||
|
||||
```bash
|
||||
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
|
||||
```
|
||||
|
||||
在这里,`sdX` 是U盘的**设备名**([device name](https://en.wikipedia.org/wiki/Device_file))。请注意,**在选择设备名的时候一定要极其小心,因为目标设备上已有的数据将全部被擦除**。
|
||||
|
||||
写入到 U 盘之后,你可以在真机上通过引导启动你的系统。视情况而定,你可能需要在 BIOS 中打开特殊的启动菜单,或者调整启动顺序。需要注意的是,`bootloader` 包暂时不支持 UEFI,所以我们并不能在 UEFI 机器上启动。
|
||||
|
||||
### 使用 `cargo run`
|
||||
|
||||
要让在 QEMU 中运行内核更轻松,我们可以设置在 cargo 配置文件中设置 `runner` 配置项:
|
||||
|
||||
```toml
|
||||
# in .cargo/config
|
||||
|
||||
[target.'cfg(target_os = "none")']
|
||||
runner = "bootimage runner"
|
||||
```
|
||||
|
||||
在这里,`target.'cfg(target_os = "none")'` 筛选了三元组中宿主系统设置为 `"none"` 的所有编译目标——这将包含我们的 `x86_64-blog_os.json` 目标。另外,`runner` 的值规定了运行 `cargo run` 使用的命令;这个命令将在成功编译后执行,而且会传递可执行文件的路径为第一个参数。[官方提供的 cargo 文档](https://doc.rust-lang.org/cargo/reference/config.html)讲述了更多的细节。
|
||||
|
||||
命令 `bootimage runner` 由 `bootimage` 包提供,参数格式经过特殊设计,可以用于 `runner` 命令。它将给定的可执行文件与项目的引导程序依赖项链接,然后在 QEMU 中启动它。`bootimage` 包的 [README文档](https://github.com/rust-osdev/bootimage) 提供了更多细节和可以传入的配置参数。
|
||||
|
||||
现在我们可以使用 `cargo xrun` 来编译内核并在 QEMU 中启动了。和 `xbuild` 类似,`xrun` 子命令将在调用 cargo 命令前编译内核所需的包。这个子命令也由 `cargo-xbuild` 工具提供,所以你不需要安装额外的工具。
|
||||
|
||||
## 下篇预告
|
||||
|
||||
在下篇文章中,我们将细致地探索 VGA 字符缓冲区,并包装它为一个安全的接口。我们还将基于它实现 `println!` 宏。
|
||||
@@ -0,0 +1,638 @@
|
||||
+++
|
||||
title = "VGA 字符模式"
|
||||
weight = 3
|
||||
path = "zh-CN/vga-text-mode"
|
||||
date = 2018-02-26
|
||||
|
||||
+++
|
||||
|
||||
**VGA 字符模式**([VGA text mode])是打印字符到屏幕的一种简单方式。在这篇文章中,为了包装这个模式为一个安全而简单的接口,我们将包装 unsafe 代码到独立的模块。我们还将实现对 Rust 语言**格式化宏**([formatting macros])的支持。
|
||||
|
||||
[VGA text mode]: https://en.wikipedia.org/wiki/VGA-compatible_text_mode
|
||||
[formatting macros]: https://doc.rust-lang.org/std/fmt/#related-macros
|
||||
|
||||
<!-- more -->
|
||||
|
||||
This blog is openly developed on [GitHub]. If you have any problems or questions, please open an issue there. You can also leave comments [at the bottom]. The complete source code for this post can be found in the [`post-03`][post branch] branch.
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-03
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## VGA 字符缓冲区
|
||||
|
||||
为了在 VGA 字符模式中向屏幕打印字符,我们必须将它写入硬件提供的 **VGA 字符缓冲区**(VGA text buffer)。通常状况下,VGA 字符缓冲区是一个 25 行、80 列的二维数组,它的内容将被实时渲染到屏幕。这个数组的元素被称作**字符单元**(character cell),它使用下面的格式描述一个屏幕上的字符:
|
||||
|
||||
| Bit(s) | Value |
|
||||
|-----|----------------|
|
||||
| 0-7 | ASCII code point |
|
||||
| 8-11 | Foreground color |
|
||||
| 12-14 | Background color |
|
||||
| 15 | Blink |
|
||||
|
||||
其中,**前景色**(foreground color)和**背景色**(background color)取值范围如下:
|
||||
|
||||
| Number | Color | Number + Bright Bit | Bright Color |
|
||||
|-----|----------|------|--------|
|
||||
| 0x0 | Black | 0x8 | Dark Gray |
|
||||
| 0x1 | Blue | 0x9 | Light Blue |
|
||||
| 0x2 | Green | 0xa | Light Green |
|
||||
| 0x3 | Cyan | 0xb | Light Cyan |
|
||||
| 0x4 | Red | 0xc | Light Red |
|
||||
| 0x5 | Magenta | 0xd | Pink |
|
||||
| 0x6 | Brown | 0xe | Yellow |
|
||||
| 0x7 | Light Gray | 0xf | White |
|
||||
|
||||
每个颜色的第四位称为**加亮位**(bright bit)。
|
||||
|
||||
要修改 VGA 字符缓冲区,我们可以通过**存储器映射输入输出**([memory-mapped I/O](https://en.wikipedia.org/wiki/Memory-mapped_I/O))的方式,读取或写入地址 `0xb8000`;这意味着,我们可以像操作普通的内存区域一样操作这个地址。
|
||||
|
||||
需要注意的是,一些硬件虽然映射到存储器,但可能不会完全支持所有的内存操作:可能会有一些设备支持按 `u8` 字节读取,但在读取 `u64` 时返回无效的数据。幸运的是,字符缓冲区都[支持标准的读写操作](https://web.stanford.edu/class/cs140/projects/pintos/specs/freevga/vga/vgamem.htm#manip),所以我们不需要用特殊的标准对待它。
|
||||
|
||||
## 包装到 Rust 模块
|
||||
|
||||
既然我们已经知道 VGA 文字缓冲区如何工作,也是时候创建一个 Rust 模块来处理文字打印了。我们输入这样的代码:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
mod vga_buffer;
|
||||
```
|
||||
|
||||
这行代码定义了一个 Rust 模块,它的内容应当保存在 `src/vga_buffer.rs` 文件中。使用 **2018 版次**(2018 edition)的 Rust 时,我们可以把模块的**子模块**(submodule)文件直接保存到 `src/vga_buffer/` 文件夹下,与 `vga_buffer.rs` 文件共存,而无需创建一个 `mod.rs` 文件。
|
||||
|
||||
我们的模块暂时不需要添加子模块,所以我们将它创建为 `src/vga_buffer.rs` 文件。除非另有说明,本文中的代码都保存到这个文件中。
|
||||
|
||||
### 颜色
|
||||
|
||||
首先,我们使用 Rust 的**枚举**(enum)表示一种颜色:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[allow(dead_code)]
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u8)]
|
||||
pub enum Color {
|
||||
Black = 0,
|
||||
Blue = 1,
|
||||
Green = 2,
|
||||
Cyan = 3,
|
||||
Red = 4,
|
||||
Magenta = 5,
|
||||
Brown = 6,
|
||||
LightGray = 7,
|
||||
DarkGray = 8,
|
||||
LightBlue = 9,
|
||||
LightGreen = 10,
|
||||
LightCyan = 11,
|
||||
LightRed = 12,
|
||||
Pink = 13,
|
||||
Yellow = 14,
|
||||
White = 15,
|
||||
}
|
||||
```
|
||||
|
||||
我们使用**类似于 C 语言的枚举**(C-like enum),为每个颜色明确指定一个数字。在这里,每个用 `repr(u8)` 注记标注的枚举类型,都会以一个 `u8` 的形式存储——事实上 4 个二进制位就足够了,但 Rust 语言并不提供 `u4` 类型。
|
||||
|
||||
通常来说,编译器会对每个未使用的变量发出**警告**(warning);使用 `#[allow(dead_code)]`,我们可以对 `Color` 枚举类型禁用这个警告。
|
||||
|
||||
我们还**生成**([derive](http://rustbyexample.com/trait/derive.html))了 [`Copy`](https://doc.rust-lang.org/nightly/core/marker/trait.Copy.html)、[`Clone`](https://doc.rust-lang.org/nightly/core/clone/trait.Clone.html)、[`Debug`](https://doc.rust-lang.org/nightly/core/fmt/trait.Debug.html)、[`PartialEq`](https://doc.rust-lang.org/nightly/core/cmp/trait.PartialEq.html) 和 [`Eq`](https://doc.rust-lang.org/nightly/core/cmp/trait.Eq.html) 这几个 trait:这让我们的类型遵循**复制语义**([copy semantics](https://doc.rust-lang.org/book/first-edition/ownership.html#copy-types)),也让它可以被比较、被调试和打印。
|
||||
|
||||
为了描述包含前景色和背景色的、完整的**颜色代码**(color code),我们基于 `u8` 创建一个新类型:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(transparent)]
|
||||
struct ColorCode(u8);
|
||||
|
||||
impl ColorCode {
|
||||
fn new(foreground: Color, background: Color) -> ColorCode {
|
||||
ColorCode((background as u8) << 4 | (foreground as u8))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里,`ColorCode` 类型包装了一个完整的颜色代码字节,它包含前景色和背景色信息。和 `Color` 类型类似,我们为它生成 `Copy` 和 `Debug` 等一系列 trait。为了确保 `ColorCode` 和 `u8` 有完全相同的内存布局,我们添加 [repr(transparent) 标记](https://doc.rust-lang.org/nomicon/other-reprs.html#reprtransparent)。
|
||||
|
||||
### 字符缓冲区
|
||||
|
||||
现在,我们可以添加更多的结构体,来描述屏幕上的字符和整个字符缓冲区:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(C)]
|
||||
struct ScreenChar {
|
||||
ascii_character: u8,
|
||||
color_code: ColorCode,
|
||||
}
|
||||
|
||||
const BUFFER_HEIGHT: usize = 25;
|
||||
const BUFFER_WIDTH: usize = 80;
|
||||
|
||||
#[repr(transparent)]
|
||||
struct Buffer {
|
||||
chars: [[ScreenChar; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
|
||||
在内存布局层面,Rust 并不保证按顺序布局成员变量。因此,我们需要使用 `#[repr(C)]` 标记结构体;这将按 C 语言约定的顺序布局它的成员变量,让我们能正确地映射内存片段。对 `Buffer` 类型,我们再次使用 `repr(transparent)`,来确保类型和它的单个成员有相同的内存布局。
|
||||
|
||||
为了输出字符到屏幕,我们来创建一个 `Writer` 类型:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub struct Writer {
|
||||
column_position: usize,
|
||||
color_code: ColorCode,
|
||||
buffer: &'static mut Buffer,
|
||||
}
|
||||
```
|
||||
|
||||
我们将让这个 `Writer` 类型将字符写入屏幕的最后一行,并在一行写满或接收到换行符 `\n` 的时候,将所有的字符向上位移一行。`column_position` 变量将跟踪光标在最后一行的位置。当前字符的前景和背景色将由 `color_code` 变量指定;另外,我们存入一个 VGA 字符缓冲区的可变借用到`buffer`变量中。需要注意的是,这里我们对借用使用**显式生命周期**([explicit lifetime](https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#lifetime-annotation-syntax)),告诉编译器这个借用在何时有效:我们使用** `'static` 生命周期 **(['static lifetime](https://doc.rust-lang.org/book/ch10-03-lifetime-syntax.html#the-static-lifetime)),意味着这个借用应该在整个程序的运行期间有效;这对一个全局有效的 VGA 字符缓冲区来说,是非常合理的。
|
||||
|
||||
### 打印字符
|
||||
|
||||
现在我们可以使用 `Writer` 类型来更改缓冲区内的字符了。首先,为了写入一个 ASCII 码字节,我们创建这样的函数:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
if self.column_position >= BUFFER_WIDTH {
|
||||
self.new_line();
|
||||
}
|
||||
|
||||
let row = BUFFER_HEIGHT - 1;
|
||||
let col = self.column_position;
|
||||
|
||||
let color_code = self.color_code;
|
||||
self.buffer.chars[row][col] = ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code,
|
||||
};
|
||||
self.column_position += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn new_line(&mut self) {/* TODO */}
|
||||
}
|
||||
```
|
||||
|
||||
如果这个字节是一个**换行符**([line feed](https://en.wikipedia.org/wiki/Newline))字节 `\n`,我们的 `Writer` 不应该打印新字符,相反,它将调用我们稍后会实现的 `new_line` 方法;其它的字节应该将在 `match` 语句的第二个分支中被打印到屏幕上。
|
||||
|
||||
当打印字节时,`Writer` 将检查当前行是否已满。如果已满,它将首先调用 `new_line` 方法来将这一行字向上提升,再将一个新的 `ScreenChar` 写入到缓冲区,最终将当前的光标位置前进一位。
|
||||
|
||||
要打印整个字符串,我们把它转换为字节并依次输出:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_string(&mut self, s: &str) {
|
||||
for byte in s.bytes() {
|
||||
match byte {
|
||||
// 可以是能打印的 ASCII 码字节,也可以是换行符
|
||||
0x20...0x7e | b'\n' => self.write_byte(byte),
|
||||
// 不包含在上述范围之内的字节
|
||||
_ => self.write_byte(0xfe),
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
VGA 字符缓冲区只支持 ASCII 码字节和**代码页 437**([Code page 437](https://en.wikipedia.org/wiki/Code_page_437))定义的字节。Rust 语言的字符串默认编码为 [UTF-8](http://www.fileformat.info/info/unicode/utf8.htm),也因此可能包含一些 VGA 字符缓冲区不支持的字节:我们使用 `match` 语句,来区别可打印的 ASCII 码或换行字节,和其它不可打印的字节。对每个不可打印的字节,我们打印一个 `■` 符号;这个符号在 VGA 硬件中被编码为十六进制的 `0xfe`。
|
||||
|
||||
我们可以亲自试一试已经编写的代码。为了这样做,我们可以临时编写一个函数:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello ");
|
||||
writer.write_string("Wörld!");
|
||||
}
|
||||
```
|
||||
|
||||
这个函数首先创建一个指向 `0xb8000` 地址VGA缓冲区的 `Writer`。实现这一点,我们需要编写的代码可能看起来有点奇怪:首先,我们把整数 `0xb8000` 强制转换为一个可变的**裸指针**([raw pointer](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#dereferencing-a-raw-pointer));之后,通过运算符`*`,我们将这个裸指针解引用;最后,我们再通过 `&mut`,再次获得它的可变借用。这些转换需要 **`unsafe` 语句块**([unsafe block](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html)),因为编译器并不能保证这个裸指针是有效的。
|
||||
|
||||
然后它将字节 `b'H'` 写入缓冲区内. 前缀 `b` 创建了一个字节常量([byte literal](https://doc.rust-lang.org/reference/tokens.html#byte-literals)),表示单个 ASCII 码字符;通过尝试写入 `"ello "` 和 `"Wörld!"`,我们可以测试 `write_string` 方法和其后对无法打印字符的处理逻辑。为了观察输出,我们需要在 `_start` 函数中调用 `print_something` 方法:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
vga_buffer::print_something();
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
编译运行后,黄色的 `Hello W■■rld!` 字符串将会被打印在屏幕的左下角:
|
||||
|
||||
|
||||
|
||||
需要注意的是,`ö` 字符被打印为两个 `■` 字符。这是因为在 [UTF-8](http://www.fileformat.info/info/unicode/utf8.htm) 编码下,字符 `ö` 是由两个字节表述的——而这两个字节并不处在可打印的 ASCII 码字节范围之内。事实上,这是 UTF-8 编码的基本特点之一:**如果一个字符占用多个字节,那么每个组成它的独立字节都不是有效的 ASCII 码字节**(the individual bytes of multi-byte values are never valid ASCII)。
|
||||
|
||||
### 易失操作
|
||||
|
||||
我们刚才看到,自己想要输出的信息被正确地打印到屏幕上。然而,未来 Rust 编译器更暴力的优化可能让这段代码不按预期工作。
|
||||
|
||||
产生问题的原因在于,我们只向 `Buffer` 写入,却不再从它读出数据。此时,编译器不知道我们事实上已经在操作 VGA 缓冲区内存,而不是在操作普通的 RAM——因此也不知道产生的**副效应**(side effect),即会有几个字符显示在屏幕上。这时,编译器也许会认为这些写入操作都没有必要,甚至会选择忽略这些操作!所以,为了避免这些并不正确的优化,这些写入操作应当被指定为[易失操作](https://en.wikipedia.org/wiki/Volatile_(computer_programming))。这将告诉编译器,这些写入可能会产生副效应,不应该被优化掉。
|
||||
|
||||
为了在我们的 VGA 缓冲区中使用易失的写入操作,我们使用 [volatile](https://docs.rs/volatile) 库。这个**包**(crate)提供一个名为 `Volatile` 的**包装类型**(wrapping type)和它的 `read`、`write` 方法;这些方法包装了 `core::ptr` 内的 [read_volatile](https://doc.rust-lang.org/nightly/core/ptr/fn.read_volatile.html) 和 [write_volatile](https://doc.rust-lang.org/nightly/core/ptr/fn.write_volatile.html) 函数,从而保证读操作或写操作不会被编译器优化。
|
||||
|
||||
要添加 `volatile` 包为项目的**依赖项**(dependency),我们可以在 `Cargo.toml` 文件的 `dependencies` 中添加下面的代码:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
volatile = "0.2.3"
|
||||
```
|
||||
|
||||
`0.2.3` 表示一个**语义版本号**([semantic version number](http://semver.org/)),在 cargo 文档的[《指定依赖项》章节](https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html)可以找到与它相关的使用指南。
|
||||
|
||||
现在,我们使用它来完成 VGA 缓冲区的 volatile 写入操作。我们将 `Buffer` 类型的定义修改为下列代码:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use volatile::Volatile;
|
||||
|
||||
struct Buffer {
|
||||
chars: [[Volatile<ScreenChar>; BUFFER_WIDTH]; BUFFER_HEIGHT],
|
||||
}
|
||||
```
|
||||
|
||||
在这里,我们不使用 `ScreenChar` ,而选择使用 `Volatile<ScreenChar>` ——在这里,`Volatile` 类型是一个**泛型**([generic](https://doc.rust-lang.org/book/ch10-01-syntax.html)),可以包装几乎所有的类型——这确保了我们不会通过普通的写入操作,意外地向它写入数据;我们转而使用提供的 `write` 方法。
|
||||
|
||||
这意味着,我们必须要修改我们的 `Writer::write_byte` 方法:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
pub fn write_byte(&mut self, byte: u8) {
|
||||
match byte {
|
||||
b'\n' => self.new_line(),
|
||||
byte => {
|
||||
...
|
||||
|
||||
self.buffer.chars[row][col].write(ScreenChar {
|
||||
ascii_character: byte,
|
||||
color_code: color_code,
|
||||
});
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
正如代码所示,我们不再使用普通的 `=` 赋值,而使用了 `write` 方法:这能确保编译器不再优化这个写入操作。
|
||||
|
||||
### 格式化宏
|
||||
|
||||
支持 Rust 提供的**格式化宏**(formatting macros)也是一个很好的思路。通过这种途径,我们可以轻松地打印不同类型的变量,如整数或浮点数。为了支持它们,我们需要实现 [`core::fmt::Write`](https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html) trait;要实现它,唯一需要提供的方法是 `write_str`,它和我们先前编写的 `write_string` 方法差别不大,只是返回值类型变成了 `fmt::Result`:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use core::fmt::Write;
|
||||
|
||||
impl fmt::Write for Writer {
|
||||
fn write_str(&mut self, s: &str) -> fmt::Result {
|
||||
self.write_string(s);
|
||||
Ok(())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里,`Ok(())` 属于 `Result` 枚举类型中的 `Ok`,包含一个值为 `()` 的变量。
|
||||
|
||||
现在我们就可以使用 Rust 内置的格式化宏 `write!` 和 `writeln!` 了:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub fn print_something() {
|
||||
use core::fmt::Write;
|
||||
let mut writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
|
||||
writer.write_byte(b'H');
|
||||
writer.write_string("ello! ");
|
||||
write!(writer, "The numbers are {} and {}", 42, 1.0/3.0).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
现在,你应该在屏幕下端看到一串 `Hello! The numbers are 42 and 0.3333333333333333`。`write!` 宏返回的 `Result` 类型必须被使用,所以我们调用它的 [`unwrap`](https://doc.rust-lang.org/core/result/enum.Result.html#method.unwrap) 方法,它将在错误发生时 panic。这里的情况下应该不会发生这样的问题,因为写入 VGA 字符缓冲区并没有可能失败。
|
||||
|
||||
### 换行
|
||||
|
||||
在之前的代码中,我们忽略了换行符,因此没有处理超出一行字符的情况。当换行时,我们想要把每个字符向上移动一行——此时最顶上的一行将被删除——然后在最后一行的起始位置继续打印。要做到这一点,我们要为 `Writer` 实现一个新的 `new_line` 方法:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn new_line(&mut self) {
|
||||
for row in 1..BUFFER_HEIGHT {
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
let character = self.buffer.chars[row][col].read();
|
||||
self.buffer.chars[row - 1][col].write(character);
|
||||
}
|
||||
}
|
||||
self.clear_row(BUFFER_HEIGHT - 1);
|
||||
self.column_position = 0;
|
||||
}
|
||||
|
||||
fn clear_row(&mut self, row: usize) {/* TODO */}
|
||||
}
|
||||
```
|
||||
|
||||
我们遍历每个屏幕上的字符,把每个字符移动到它上方一行的相应位置。这里,`..` 符号是**区间标号**(range notation)的一种;它表示左闭右开的区间,因此不包含它的上界。在外层的枚举中,我们从第 1 行开始,省略了对第 0 行的枚举过程——因为这一行应该被移出屏幕,即它将被下一行的字符覆写。
|
||||
|
||||
所以我们实现的 `clear_row` 方法代码如下:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
impl Writer {
|
||||
fn clear_row(&mut self, row: usize) {
|
||||
let blank = ScreenChar {
|
||||
ascii_character: b' ',
|
||||
color_code: self.color_code,
|
||||
};
|
||||
for col in 0..BUFFER_WIDTH {
|
||||
self.buffer.chars[row][col].write(blank);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
通过向对应的缓冲区写入空格字符,这个方法能清空一整行的字符位置。
|
||||
|
||||
## 全局接口
|
||||
|
||||
编写其它模块时,我们希望无需随时拥有 `Writer` 实例,便能使用它的方法。我们尝试创建一个静态的 `WRITER` 变量:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
pub static WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
```
|
||||
|
||||
我们尝试编译这些代码,却发生了下面的编译错误:
|
||||
|
||||
```
|
||||
error[E0015]: calls in statics are limited to constant functions, tuple structs and tuple variants
|
||||
--> src/vga_buffer.rs:7:17
|
||||
|
|
||||
7 | color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
error[E0396]: raw pointers cannot be dereferenced in statics
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ dereference of raw pointer in constant
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:22
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
|
||||
error[E0017]: references in statics may only refer to immutable values
|
||||
--> src/vga_buffer.rs:8:13
|
||||
|
|
||||
8 | buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ statics require immutable values
|
||||
```
|
||||
|
||||
为了明白现在发生了什么,我们需要知道一点:一般的变量在运行时初始化,而静态变量在编译时初始化。Rust编译器规定了一个称为**常量求值器**([const evaluator](https://rust-lang.github.io/rustc-guide/const-eval.html))的组件,它应该在编译时处理这样的初始化工作。虽然它目前的功能较为有限,但对它的扩展工作进展活跃,比如允许在常量中 panic 的[一篇 RFC 文档](https://github.com/rust-lang/rfcs/pull/2345)。
|
||||
|
||||
关于 `ColorCode::new` 的问题应该能使用**常函数**([`const` functions](https://doc.rust-lang.org/unstable-book/language-features/const-fn.html))解决,但常量求值器还存在不完善之处,它还不能在编译时直接转换裸指针到变量的引用——也许未来这段代码能够工作,但在那之前,我们需要寻找另外的解决方案。
|
||||
|
||||
### 延迟初始化
|
||||
|
||||
使用非常函数初始化静态变量是 Rust 程序员普遍遇到的问题。幸运的是,有一个叫做 [lazy_static](https://docs.rs/lazy_static/1.0.1/lazy_static/) 的包提供了一个很棒的解决方案:它提供了名为 `lazy_static!` 的宏,定义了一个**延迟初始化**(lazily initialized)的静态变量;这个变量的值将在第一次使用时计算,而非在编译时计算。这时,变量的初始化过程将在运行时执行,任意的初始化代码——无论简单或复杂——都是能够使用的。
|
||||
|
||||
现在,我们将 `lazy_static` 包导入到我们的项目:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies.lazy_static]
|
||||
version = "1.0"
|
||||
features = ["spin_no_std"]
|
||||
```
|
||||
|
||||
在这里,由于程序不连接标准库,我们需要启用 `spin_no_std` 特性。
|
||||
|
||||
使用 `lazy_static` 我们就可以定义一个不出问题的 `WRITER` 变量:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Writer = Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
然而,这个 `WRITER` 可能没有什么用途,因为它目前还是**不可变变量**(immutable variable):这意味着我们无法向它写入数据,因为所有与写入数据相关的方法都需要实例的可变引用 `&mut self`。一种解决方案是使用**可变静态**([mutable static](https://doc.rust-lang.org/book/ch19-01-unsafe-rust.html#accessing-or-modifying-a-mutable-static-variable))的变量,但所有对它的读写操作都被规定为不安全的(unsafe)操作,因为这很容易导致数据竞争或发生其它不好的事情——使用 `static mut` 极其不被赞成,甚至有一些提案认为[应该将它删除](https://internals.rust-lang.org/t/pre-rfc-remove-static-mut/1437)。也有其它的替代方案,比如可以尝试使用比如 [RefCell](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html#keeping-track-of-borrows-at-runtime-with-refcellt) 或甚至 [UnsafeCell](https://doc.rust-lang.org/nightly/core/cell/struct.UnsafeCell.html) 等类型提供的**内部可变性**([interior mutability](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html));但这些类型都被设计为非同步类型,即不满足 [Sync](https://doc.rust-lang.org/nightly/core/marker/trait.Sync.html) 约束,所以我们不能在静态变量中使用它们。
|
||||
|
||||
### 自旋锁
|
||||
|
||||
要定义同步的内部可变性,我们往往使用标准库提供的互斥锁类 [Mutex](https://doc.rust-lang.org/nightly/std/sync/struct.Mutex.html),它通过提供当资源被占用时将线程**阻塞**(block)的**互斥条件**(mutual exclusion)实现这一点;但我们初步的内核代码还没有线程和阻塞的概念,我们将不能使用这个类。不过,我们还有一种较为基础的互斥锁实现方式——**自旋锁**([spinlock](https://en.wikipedia.org/wiki/Spinlock))。自旋锁并不会调用阻塞逻辑,而是在一个小的无限循环中反复尝试获得这个锁,也因此会一直占用 CPU 时间,直到互斥锁被它的占用者释放。
|
||||
|
||||
为了使用自旋的互斥锁,我们添加 [spin包](https://crates.io/crates/spin) 到项目的依赖项列表:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
[dependencies]
|
||||
spin = "0.4.9"
|
||||
```
|
||||
|
||||
现在,我们能够使用自旋的互斥锁,为我们的 `WRITER` 类实现安全的[内部可变性](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html):
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
use spin::Mutex;
|
||||
...
|
||||
lazy_static! {
|
||||
pub static ref WRITER: Mutex<Writer> = Mutex::new(Writer {
|
||||
column_position: 0,
|
||||
color_code: ColorCode::new(Color::Yellow, Color::Black),
|
||||
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以删除 `print_something` 函数,尝试直接在 `_start` 函数中打印字符:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
use core::fmt::Write;
|
||||
vga_buffer::WRITER.lock().write_str("Hello again").unwrap();
|
||||
write!(vga_buffer::WRITER.lock(), ", some numbers: {} {}", 42, 1.337).unwrap();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
在这里,我们需要导入名为 `fmt::Write` 的 trait,来使用实现它的类的相应方法。
|
||||
|
||||
### 安全性
|
||||
|
||||
经过上面的努力后,我们现在的代码只剩一个 unsafe 语句块,它用于创建一个指向 `0xb8000` 地址的 `Buffer` 类型引用;在这步之后,所有的操作都是安全的。Rust 将为每个数组访问检查边界,所以我们不会在不经意间越界到缓冲区之外。因此,我们把需要的条件编码到 Rust 的类型系统,这之后,我们为外界提供的接口就符合内存安全原则了。
|
||||
|
||||
### `println!` 宏
|
||||
|
||||
现在我们有了一个全局的 `Writer` 实例,我们就可以基于它实现 `println!` 宏,这样它就能被任意地方的代码使用了。Rust 提供的[宏定义语法](https://doc.rust-lang.org/nightly/book/ch19-06-macros.html#declarative-macros-with-macro_rules-for-general-metaprogramming)需要时间理解,所以我们将不从零开始编写这个宏。我们先看看标准库中 [`println!` 宏的实现源码](https://doc.rust-lang.org/nightly/std/macro.println!.html):
|
||||
|
||||
```rust
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => (print!("\n"));
|
||||
($($arg:tt)*) => (print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
宏是通过一个或多个**规则**(rule)定义的,这就像 `match` 语句的多个分支。`println!` 宏有两个规则:第一个规则不要求传入参数——就比如 `println!()` ——它将被扩展为 `print!("\n")`,因此只会打印一个新行;第二个要求传入参数——好比 `println!("Rust 能够编写操作系统")` 或 `println!("我学习 Rust 已经{}年了", 3)`——它将使用 `print!` 宏扩展,传入它需求的所有参数,并在输出的字符串最后加入一个换行符 `\n`。
|
||||
|
||||
这里,`#[macro_export]` 属性让整个包(crate)和基于它的包都能访问这个宏,而不仅限于定义它的模块(module)。它还将把宏置于包的根模块(crate root)下,这意味着比如我们需要通过 `use std::println` 来导入这个宏,而不是通过 `std::macros::println`。
|
||||
|
||||
[`print!` 宏](https://doc.rust-lang.org/nightly/std/macro.print!.html)是这样定义的:
|
||||
|
||||
```
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::io::_print(format_args!($($arg)*)));
|
||||
}
|
||||
```
|
||||
|
||||
这个宏将扩展为一个对 `io` 模块中 [`_print` 函数](https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698)的调用。[`$crate` 变量](https://doc.rust-lang.org/1.30.0/book/first-edition/macros.html#the-variable-crate)将在 `std` 包之外被解析为 `std` 包,保证整个宏在 `std` 包之外也可以使用。
|
||||
|
||||
[`format_args!` 宏](https://doc.rust-lang.org/nightly/std/macro.format_args.html)将传入的参数搭建为一个 [fmt::Arguments](https://doc.rust-lang.org/nightly/core/fmt/struct.Arguments.html) 类型,这个类型将被传入 `_print` 函数。`std` 包中的 [`_print` 函数](https://github.com/rust-lang/rust/blob/29f5c699b11a6a148f097f82eaa05202f8799bbc/src/libstd/io/stdio.rs#L698)将调用复杂的私有函数 `print_to`,来处理对不同 `Stdout` 设备的支持。我们不需要编写这样的复杂函数,因为我们只需要打印到 VGA 字符缓冲区。
|
||||
|
||||
要打印到字符缓冲区,我们把 `println!` 和 `print!` 两个宏复制过来,但修改部分代码,让这些宏使用我们定义的 `_print` 函数:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! print {
|
||||
($($arg:tt)*) => ($crate::vga_buffer::_print(format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[macro_export]
|
||||
macro_rules! println {
|
||||
() => ($crate::print!("\n"));
|
||||
($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*)));
|
||||
}
|
||||
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
WRITER.lock().write_fmt(args).unwrap();
|
||||
}
|
||||
```
|
||||
|
||||
我们首先修改了 `println!` 宏,在每个使用的 `print!` 宏前面添加了 `$crate` 变量。这样我们在只需要使用 `println!` 时,不必也编写代码导入 `print!` 宏。
|
||||
|
||||
就像标准库做的那样,我们为两个宏都添加了 `#[macro_export]` 属性,这样在包的其它地方也可以使用它们。需要注意的是,这将占用包的**根命名空间**(root namespace),所以我们不能通过 `use crate::vga_buffer::println` 来导入它们;我们应该使用 `use crate::println`。
|
||||
|
||||
另外,`_print` 函数将占有静态变量 `WRITER` 的锁,并调用它的 `write_fmt` 方法。这个方法是从名为 `Write` 的 trait 中获得的,所以我们需要导入这个 trait。额外的 `unwrap()` 函数将在打印不成功的时候 panic;但既然我们的 `write_str` 总是返回 `Ok`,这种情况不应该发生。
|
||||
|
||||
如果这个宏将能在模块外访问,它们也应当能访问 `_print` 函数,因此这个函数必须是公有的(public)。然而,考虑到这是一个私有的实现细节,我们添加一个 [`doc(hidden)` 属性](https://doc.rust-lang.org/nightly/rustdoc/the-doc-attribute.html#dochidden),防止它在生成的文档中出现。
|
||||
|
||||
### 使用 `println!` 的 Hello World
|
||||
|
||||
现在,我们可以在 `_start` 里使用 `println!` 了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
要注意的是,我们在入口函数中不需要导入这个宏——因为它已经被置于包的根命名空间了。
|
||||
|
||||
运行这段代码,和我们预料的一样,一个 *“Hello World!”* 字符串被打印到了屏幕上:
|
||||
|
||||
|
||||
|
||||
### 打印 panic 信息
|
||||
|
||||
既然我们已经有了 `println!` 宏,我们可以在 panic 处理函数中,使用它打印 panic 信息和 panic 产生的位置:
|
||||
|
||||
```rust
|
||||
// in main.rs
|
||||
|
||||
/// 这个函数将在 panic 发生时被调用
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
当我们在 `_start` 函数中插入一行 `panic!("Some panic message");` 后,我们得到了这样的输出:
|
||||
|
||||
|
||||
|
||||
所以,现在我们不仅能知道 panic 已经发生,还能够知道 panic 信息和产生 panic 的代码。
|
||||
|
||||
## 小结
|
||||
|
||||
这篇文章中,我们学习了 VGA 字符缓冲区的结构,以及如何在 `0xb8000` 的内存映射地址访问它。我们将所有的不安全操作包装为一个 Rust 模块,以便在外界安全地访问它。
|
||||
|
||||
我们也发现了——感谢便于使用的 cargo——在 Rust 中使用第三方提供的包是及其容易的。我们添加的两个依赖项,`lazy_static` 和 `spin`,都在操作系统开发中及其有用;我们将在未来的文章中多次使用它们。
|
||||
|
||||
## 下篇预告
|
||||
|
||||
下一篇文章中,我们将会讲述如何配置 Rust 内置的单元测试框架。我们还将为本文编写的 VGA 缓冲区模块添加基础的单元测试项目。
|
||||
926
blog/content/second-edition/posts/04-testing/index.zh-CN.md
Normal file
926
blog/content/second-edition/posts/04-testing/index.zh-CN.md
Normal file
@@ -0,0 +1,926 @@
|
||||
+++
|
||||
title = "内核测试"
|
||||
weight = 4
|
||||
path = "zh-CN/testing"
|
||||
date = 2019-04-27
|
||||
|
||||
+++
|
||||
|
||||
本文主要讲述了在`no_std`环境下进行单元测试和集成测试的方法。我们将通过Rust的自定义测试框架来在我们的内核中执行一些测试函数。为了将结果反馈到QEMU上,我们需要使用QEMU的一些其他的功能以及`bootimage`工具。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
这个系列的blog在[GitHub]上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在[底部]留言。你可以在[这里][post branch]找到这篇文章的完整源码。
|
||||
|
||||
[GitHub]: https://github.com/phil-opp/blog_os
|
||||
[at the bottom]: #comments
|
||||
[post branch]: https://github.com/phil-opp/blog_os/tree/post-04
|
||||
|
||||
<!-- toc -->
|
||||
|
||||
## 阅读要求
|
||||
|
||||
这篇文章替换了此前的(现在已经过时了) [_单元测试(Unit Testing)_] 和 [_集成测试(Integration Tests)_] 两篇文章。这里我将假定你是在2019-04-27日后阅读的[_最小Rust内核_]一文。总而言之,本文要求你已经有一个[设置默认目标]的 `.cargo/config` 文件且[定义了一个runner可执行文件]。
|
||||
|
||||
[_单元测试(Unit Testing)_]: @/second-edition/posts/deprecated/04-unit-testing/index.md
|
||||
[_集成测试(Integration Tests)_]: @/second-edition/posts/deprecated/05-integration-tests/index.md
|
||||
[_最小Rust内核_]: @/second-edition/posts/02-minimal-rust-kernel/index.md
|
||||
[设置默认目标]: @/second-edition/posts/02-minimal-rust-kernel/index.md#set-a-default-target
|
||||
[定义了一个runner可执行文件]: @/second-edition/posts/02-minimal-rust-kernel/index.md#using-cargo-run
|
||||
|
||||
## Rust中的测试
|
||||
|
||||
Rust有一个**内置的测试框架**([built-in test framework]):无需任何设置就可以进行单元测试,只需要创建一个通过assert来检查结果的函数并在函数的头部加上`#[test]`属性即可。然后`cargo test`会自动找到并执行你的crate中的所有测试函数。
|
||||
|
||||
[built-in test framework]: https://doc.rust-lang.org/book/second-edition/ch11-00-testing.html
|
||||
|
||||
不幸的是,对于一个`no_std`的应用,比如我们的内核,这有点点复杂。现在的问题是,Rust的测试框架会隐式的调用内置的[`test`]库,但是这个库依赖于标准库。这也就是说我们的 `#[no_std]`内核无法使用默认的测试框架。
|
||||
|
||||
[`test`]: https://doc.rust-lang.org/test/index.html
|
||||
|
||||
当我们试图在我们的项目中执行`cargo xtest`时,我们可以看到如下信息:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Compiling blog_os v0.1.0 (/…/blog_os)
|
||||
error[E0463]: can't find crate for `test`
|
||||
```
|
||||
|
||||
由于`test`crate依赖于标准库,所以它在我们的裸机目标上并不可用。虽然将`test`crate移植到一个 `#[no_std]` 上下文环境中是[可能的][utest],但是这样做是高度不稳定的并且还会需要一些特殊的hacks,例如重定义 `panic` 宏。
|
||||
|
||||
[utest]: https://github.com/japaric/utest
|
||||
|
||||
### 自定义测试框架
|
||||
|
||||
幸运的是,Rust支持通过使用不稳定的**自定义测试框架**([`custom_test_frameworks`]) 功能来替换默认的测试框架。该功能不需要额外的库,因此在 `#[no_std]`环境中它也可以工作。它的工作原理是收集所有标注了 `#[test_case]`属性的函数,然后将这个测试函数的列表作为参数传递给用户指定的runner函数。因此,它实现了对测试过程的最大控制。
|
||||
|
||||
[`custom_test_frameworks`]: https://doc.rust-lang.org/unstable-book/language-features/custom-test-frameworks.html
|
||||
|
||||
与默认的测试框架相比,它的缺点是有一些高级功能诸如 [`should_panic` tests]都不可用了。相对的,如果需要这些功能,我们需要自己来实现。当然,这点对我们来说是好事,因为我们的环境非常特殊,在这个环境里,这些高级功能的默认实现无论如何都是无法工作的,举个例子, `#[should_panic]`属性依赖于堆栈展开来捕获内核panic,而我的内核早已将其禁用了。
|
||||
|
||||
[`should_panic` tests]: https://doc.rust-lang.org/book/ch11-01-writing-tests.html#checking-for-panics-with-should_panic
|
||||
|
||||
要为我们的内核实现自定义测试框架,我们需要将如下代码添加到我们的`main.rs`中去:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(crate::test_runner)]
|
||||
|
||||
#[cfg(test)]
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们的runner会打印一个简短的debug信息然后调用列表中的每个测试函数。参数类型 `&[&dyn Fn()]` 是[_Fn()_] trait的 [_trait object_] 引用的一个 [_slice_]。它基本上可以被看做一个可以像函数一样被调用的类型的引用列表。由于这个函数在不进行测试的时候没有什么用,这里我们使用 `#[cfg(test)]`属性保证它只会出现在测试中。
|
||||
|
||||
[_slice_]: https://doc.rust-lang.org/std/primitive.slice.html
|
||||
[_trait object_]: https://doc.rust-lang.org/1.30.0/book/first-edition/trait-objects.html
|
||||
[_Fn()_]: https://doc.rust-lang.org/std/ops/trait.Fn.html
|
||||
|
||||
现在当我们运行 `cargo xtest` ,我们可以发现运行成功了。然而,我们看到的仍然是"Hello World"而不是我们的 `test_runner`传递来的信息。这是由于我们的入口点仍然是 `_start` 函数——自定义测试框架会生成一个`main`函数来调用`test_runner`,但是由于我们使用了 `#[no_main]`并提供了我们自己的入口点,所以这个`main`函数就被忽略了。
|
||||
|
||||
为了修复这个问题,我们需要通过 `reexport_test_harness_main`属性来将生成的函数的名称更改为与`main`不同的名称。然后我们可以在我们的`_start`函数里调用这个重命名的函数:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
我们将测试框架的入口函数的名字设置为`test_main`,并在我们的 `_start`入口点里调用它。通过使用**条件编译**([conditional compilation]),我们能够只在上下文环境为测试(test)时调用`test_main`,因为该函数将不在非测试上下文中生成。
|
||||
|
||||
[ conditional compilation ]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
|
||||
|
||||
现在当我们执行 `cargo xtest`时,我们可以看到我们的`test_runner`将"Running 0 tests"信息显示在屏幕上了。我们可以创建第一个测试函数了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[test_case]
|
||||
fn trivial_assertion() {
|
||||
print!("trivial assertion... ");
|
||||
assert_eq!(1, 1);
|
||||
println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
现在,当我们运行 `cargo xtest`时,我们可以看到如下输出:
|
||||
|
||||
![QEMU printing "Hello World!", "Running 1 tests", and "trivial assertion... [ok]"](https://os.phil-opp.com/testing/qemu-test-runner-output.png)
|
||||
|
||||
传递给 `test_runner`函数的`tests`切片里包含了一个 `trivial_assertion` 函数的引用,从屏幕上输出的 `trivial assertion... [ok]`信息可见,我们的测试已被调用并且顺利通过。
|
||||
|
||||
在执行完tests后, `test_runner`会将结果返回给 `test_main`函数,而这个函数又返回到 `_start`入口点函数——这样我们就进入了一个死循环,因为入口点函数是不允许返回的。这将导致一个问题:我们希望`cargo xtest`在所有的测试运行完毕后,才返回并退出。
|
||||
|
||||
## 退出QEMU
|
||||
|
||||
现在我们在`_start`函数结束后进入了一个死循环,所以每次执行完`cargo xtest`后我们都需要手动去关闭QEMU;但是我们还想在没有用户交互的脚本环境下执行 `cargo xtest`。解决这个问题的最佳方式,是实现一个合适的方法来关闭我们的操作系统——不幸的是,这个方式实现起来相对有些复杂,因为这要求我们实现对[APM]或[ACPI]电源管理标准的支持。
|
||||
|
||||
[APM]: https://wiki.osdev.org/APM
|
||||
[ACPI]: https://wiki.osdev.org/ACPI
|
||||
|
||||
幸运的是,还有一个绕开这些问题的办法:QEMU支持一种名为 `isa-debug-exit`的特殊设备,它提供了一种从客户系统(guest system)里退出QEMU的简单方式。为了使用这个设备,我们需要向QEMU传递一个`-device`参数。当然,我们也可以通过将 `package.metadata.bootimage.test-args` 配置关键字添加到我们的`Cargo.toml`来达到目的:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
|
||||
```
|
||||
|
||||
`bootimage runner` 会在QEMU的默认测试命令后添加`test-args` 参数。(对于`cargo xrun`命令,这个参数会被忽略。)
|
||||
|
||||
在传递设备名 (`isa-debug-exit`)的同时,我们还传递了两个参数,`iobase` 和 `iosize` 。这两个参数指定了一个_I/O 端口_,我们的内核将通过它来访问设备。
|
||||
|
||||
### I/O 端口
|
||||
在x86平台上,CPU和外围硬件通信通常有两种方式,**内存映射I/O**和**端口映射I/O**。之前,我们已经使用内存映射的方式,通过内存地址`0xb8000`访问了[VGA文本缓冲区]。该地址并没有映射到RAM,而是映射到了VGA设备的一部分内存上。
|
||||
|
||||
[VGA text buffer]: @/second-edition/posts/03-vga-text-buffer/index.md
|
||||
|
||||
与内存映射不同,端口映射I/O使用独立的I/O总线来进行通信。每个外围设备都有一个或数个端口号。CPU采用了特殊的`in`和`out`指令来和端口通信,这些指令要求一个端口号和一个字节的数据作为参数(有些这种指令的变体也允许发送`u16`或是`u32`长度的数据)。
|
||||
|
||||
`isa-debug-exit`设备使用的就是端口映射I/O。其中, `iobase` 参数指定了设备对应的端口地址(在x86中,`0xf4`是一个[通常未被使用的端口][list of x86 I/O ports]),而`iosize`则指定了端口的大小(`0x04`代表4字节)。
|
||||
|
||||
[list of x86 I/O ports]: https://wiki.osdev.org/I/O_Ports#The_list
|
||||
|
||||
### 使用退出(Exit)设备
|
||||
|
||||
`isa-debug-exit`设备的功能非常简单。当一个 `value`写入`iobase`指定的端口时,它会导致QEMU以**退出状态**([exit status])`(value << 1) | 1`退出。也就是说,当我们向端口写入`0`时,QEMU将以退出状态`(0 << 1) | 1 = 1`退出,而当我们向端口写入`1`时,它将以退出状态`(1 << 1) | 1 = 3`退出。
|
||||
|
||||
[exit status]: https://en.wikipedia.org/wiki/Exit_status
|
||||
|
||||
这里我们使用 [`x86_64`] crate提供的抽象,而不是手动调用`in`或`out`指令。为了添加对该crate的依赖,我们可以将其添加到我们的 `Cargo.toml`中的 `dependencies` 小节中去:
|
||||
|
||||
|
||||
[`x86_64`]: https://docs.rs/x86_64/0.7.5/x86_64/
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
x86_64 = "0.7.5"
|
||||
```
|
||||
|
||||
现在我们可以使用crate中提供的[`Port`] 类型来创建一个`exit_qemu` 函数了:
|
||||
|
||||
[`Port`]: https://docs.rs/x86_64/0.7.0/x86_64/instructions/port/struct.Port.html
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u32)]
|
||||
pub enum QemuExitCode {
|
||||
Success = 0x10,
|
||||
Failed = 0x11,
|
||||
}
|
||||
|
||||
pub fn exit_qemu(exit_code: QemuExitCode) {
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
unsafe {
|
||||
let mut port = Port::new(0xf4);
|
||||
port.write(exit_code as u32);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
该函数在`0xf4`处创建了一个新的端口,该端口同时也是 `isa-debug-exit` 设备的 `iobase` 。然后它会向端口写入传递的退出代码。这里我们使用`u32`来传递数据,因为我们之前已经将 `isa-debug-exit`设备的 `iosize` 指定为4字节了。上述两个操作都是`unsafe`的,因为I/O端口的写入操作通常会导致一些不可预知的行为。
|
||||
|
||||
为了指定退出状态,我们创建了一个 `QemuExitCode`枚举。思路大体上是,如果所有的测试均成功,就以成功退出码退出;否则就以失败退出码退出。这个枚举类型被标记为 `#[repr(u32)]`,代表每个变量都是一个`u32`的整数类型。我们使用退出代码`0x10`代表成功,`0x11`代表失败。 实际的退出代码并不重要,只要它们不与QEMU的默认退出代码冲突即可。 例如,使用退出代码0表示成功可能并不是一个好主意,因为它在转换后就变成了`(0 << 1) | 1 = 1` ,而`1`是QEMU运行失败时的默认退出代码。 这样,我们就无法将QEMU错误与成功的测试运行区分开来了。
|
||||
|
||||
现在我们来更新`test_runner`的代码,让程序在运行所有测试完毕后退出QEMU:
|
||||
|
||||
```rust
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
}
|
||||
/// new
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
```
|
||||
|
||||
当我们现在运行`cargo xtest`时,QEMU会在测试运行后立刻退出。现在的问题是,即使我们传递了表示成功(`Success`)的退出代码, `cargo test`依然会将所有的测试都视为失败:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-5804fc7d2dd4c9be
|
||||
Building bootloader
|
||||
Compiling bootloader v0.5.3 (/home/philipp/Documents/bootloader)
|
||||
Finished release [optimized + debuginfo] target(s) in 1.07s
|
||||
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
|
||||
deps/bootimage-blog_os-5804fc7d2dd4c9be.bin -device isa-debug-exit,iobase=0xf4,
|
||||
iosize=0x04`
|
||||
error: test failed, to rerun pass '--bin blog_os'
|
||||
```
|
||||
|
||||
这里的问题在于,`cargo test`会将所有非`0`的错误码都视为测试失败。
|
||||
|
||||
### 成功退出(Exit)代码
|
||||
|
||||
为了解决这个问题, `bootimage`提供了一个 `test-success-exit-code`配置项,可以将指定的退出代码映射到退出代码`0`:
|
||||
|
||||
```toml
|
||||
[package.metadata.bootimage]
|
||||
test-args = […]
|
||||
test-success-exit-code = 33 # (0x10 << 1) | 1
|
||||
```
|
||||
|
||||
有了这个配置,`bootimage`就会将我们的成功退出码映射到退出码0;这样一来, `cargo xtest`就能正确的识别出测试成功的情况,而不会将其视为测试失败。
|
||||
|
||||
我们的测试runner现在会在正确报告测试结果后自动关闭QEMU。我们可以看到QEMU的窗口只会显示很短的时间——我们不容易看清测试的结果。如果测试结果会打印在控制台上而不是QEMU里,让我们能在QEMU退出后仍然能看到测试结果就好了。
|
||||
|
||||
## 打印到控制台
|
||||
|
||||
要在控制台上查看测试输出,我们需要以某种方式将数据从内核发送到宿主系统。 有多种方法可以实现这一点,例如通过TCP网络接口来发送数据。但是,设置网络堆栈是一项很复杂的任务——这里我们选择更简单的解决方案。
|
||||
|
||||
### 串口
|
||||
|
||||
发送数据的一个简单的方式是通过[串行端口],这是一个现代电脑中已经不存在的旧标准接口(译者注:玩过单片机的同学应该知道,其实译者上大学的时候有些同学的笔记本电脑还有串口的,没有串口的同学在烧录单片机程序的时候也都会需要usb转串口线,一般是51,像stm32有st-link,这个另说,不过其实也可以用串口来下载)。串口非常易于编程,QEMU可以将通过串口发送的数据重定向到宿主机的标准输出或是文件中。
|
||||
|
||||
[串行端口]: https://en.wikipedia.org/wiki/Serial_port
|
||||
|
||||
用来实现串行接口的芯片被称为 [UARTs]。在x86上,有[很多UART模型],但是幸运的是,它们之间仅有的那些不同之处都是我们用不到的高级功能。目前通用的UARTs都会兼容[16550 UART],所以我们在我们测试框架里采用该模型。
|
||||
|
||||
[UARTs]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter
|
||||
[很多UART模型]: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver-transmitter#UART_models
|
||||
[16550 UART]: https://en.wikipedia.org/wiki/16550_UART
|
||||
|
||||
我们使用[`uart_16550`] crate来初始化UART,并通过串口来发送数据。为了将该crate添加为依赖,我们将我们的`Cargo.toml`和`main.rs`修改为如下:
|
||||
|
||||
[`uart_16550`]: https://docs.rs/uart_16550
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[dependencies]
|
||||
uart_16550 = "0.2.0"
|
||||
```
|
||||
|
||||
`uart_16550` crate包含了一个代表UART寄存器的`SerialPort`结构体,但是我们仍然需要自己来创建一个相应的实例。我们使用以下内容来创建一个新的串口模块`serial`:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
mod serial;
|
||||
```
|
||||
|
||||
```rust
|
||||
// in src/serial.rs
|
||||
|
||||
use uart_16550::SerialPort;
|
||||
use spin::Mutex;
|
||||
use lazy_static::lazy_static;
|
||||
|
||||
lazy_static! {
|
||||
pub static ref SERIAL1: Mutex<SerialPort> = {
|
||||
let mut serial_port = unsafe { SerialPort::new(0x3F8) };
|
||||
serial_port.init();
|
||||
Mutex::new(serial_port)
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
就像[VGA文本缓冲区][vga lazy-static]一样,我们使用 `lazy_static` 和一个自旋锁来创建一个 `static` writer实例。通过使用 `lazy_static` ,我们可以保证`init`方法只会在该示例第一次被使用使被调用。
|
||||
|
||||
和 `isa-debug-exit`设备一样,UART也是用过I/O端口进行编程的。由于UART相对来讲更加复杂,它使用多个I/O端口来对不同的设备寄存器进行编程。不安全的`SerialPort::new`函数需要UART的第一个I/O端口的地址作为参数,从该地址中可以计算出所有所需端口的地址。我们传递的端口地址为`0x3F8` ,该地址是第一个串行接口的标准端口号。
|
||||
|
||||
[vga lazy-static]: @/second-edition/posts/03-vga-text-buffer/index.md#lazy-statics
|
||||
|
||||
为了使串口更加易用,我们添加了 `serial_print!` 和 `serial_println!`宏:
|
||||
|
||||
```rust
|
||||
#[doc(hidden)]
|
||||
pub fn _print(args: ::core::fmt::Arguments) {
|
||||
use core::fmt::Write;
|
||||
SERIAL1.lock().write_fmt(args).expect("Printing to serial failed");
|
||||
}
|
||||
|
||||
/// Prints to the host through the serial interface.
|
||||
#[macro_export]
|
||||
macro_rules! serial_print {
|
||||
($($arg:tt)*) => {
|
||||
$crate::serial::_print(format_args!($($arg)*));
|
||||
};
|
||||
}
|
||||
|
||||
/// Prints to the host through the serial interface, appending a newline.
|
||||
#[macro_export]
|
||||
macro_rules! serial_println {
|
||||
() => ($crate::serial_print!("\n"));
|
||||
($fmt:expr) => ($crate::serial_print!(concat!($fmt, "\n")));
|
||||
($fmt:expr, $($arg:tt)*) => ($crate::serial_print!(
|
||||
concat!($fmt, "\n"), $($arg)*));
|
||||
}
|
||||
```
|
||||
|
||||
该实现和我们此前的`print`和`println`宏的实现非常类似。 由于`SerialPort`类型已经实现了`fmt::Write` trait,所以我们不需要提供我们自己的实现了。
|
||||
|
||||
[`fmt::Write`]: https://doc.rust-lang.org/nightly/core/fmt/trait.Write.html
|
||||
|
||||
现在我们可以从测试代码里向串行接口打印而不是向VGA文本缓冲区打印了:
|
||||
|
||||
```rust
|
||||
// in src/main.rs
|
||||
|
||||
#[cfg(test)]
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
[…]
|
||||
}
|
||||
|
||||
#[test_case]
|
||||
fn trivial_assertion() {
|
||||
serial_print!("trivial assertion... ");
|
||||
assert_eq!(1, 1);
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
注意,由于我们使用了 `#[macro_export]` 属性, `serial_println`宏直接位于根命名空间下——所以通过`use crate::serial::serial_println` 来导入该宏是不起作用的。
|
||||
|
||||
### QEMU参数
|
||||
|
||||
为了查看QEMU的串行输出,我们需要使用`-serial`参数将输出重定向到stdout:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = [
|
||||
"-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio"
|
||||
]
|
||||
```
|
||||
|
||||
现在,当我们运行 `cargo xtest`时,我们可以直接在控制台里看到测试输出了:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
|
||||
Building bootloader
|
||||
Finished release [optimized + debuginfo] target(s) in 0.02s
|
||||
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
|
||||
deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
|
||||
isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
|
||||
Running 1 tests
|
||||
trivial assertion... [ok]
|
||||
```
|
||||
|
||||
然而,当测试失败时,我们仍然会在QEMU内看到输出结果,因为我们的panic handler还是用了`println`。为了模拟这个过程,我们将我们的 `trivial_assertion` test中的断言(assertion)修改为 `assert_eq!(0, 1)`:
|
||||
|
||||
|
||||
|
||||
可以看到,panic信息被打印到了VGA缓冲区里,而测试输出则被打印到串口上了。panic信息非常有用,所以我们希望能够在控制台中来查看它。
|
||||
|
||||
### 在panic时打印一个错误信息
|
||||
|
||||
为了在panic时使用错误信息来退出QEMU,我们可以使用**条件编译**([conditional compilation])在测试模式下使用(与非测试模式下)不同的panic处理方式:
|
||||
|
||||
[conditional compilation]: https://doc.rust-lang.org/1.30.0/book/first-edition/conditional-compilation.html
|
||||
|
||||
```rust
|
||||
// our existing panic handler
|
||||
#[cfg(not(test))] // new attribute
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
|
||||
// our panic handler in test mode
|
||||
#[cfg(test)]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
在我们的测试panic处理中,我们用 `serial_println`来代替`println` 并使用失败代码来退出QEMU。注意,在`exit_qemu`调用后,我们仍然需要一个无限循环的`loop`因为编译器并不知道 `isa-debug-exit`设备会导致程序退出。
|
||||
|
||||
现在,即使在测试失败的情况下QEMU仍然会存在,并会将一些有用的错误信息打印到控制台:
|
||||
|
||||
```
|
||||
> cargo xtest
|
||||
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
|
||||
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
|
||||
Building bootloader
|
||||
Finished release [optimized + debuginfo] target(s) in 0.02s
|
||||
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
|
||||
deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
|
||||
isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
|
||||
Running 1 tests
|
||||
trivial assertion... [failed]
|
||||
|
||||
Error: panicked at 'assertion failed: `(left == right)`
|
||||
left: `0`,
|
||||
right: `1`', src/main.rs:65:5
|
||||
```
|
||||
|
||||
由于现在所有的测试都将输出到控制台上,我们不再需要让QEMU窗口弹出一小会儿了——我们完全可以把窗口藏起来。
|
||||
|
||||
### 隐藏 QEMU
|
||||
|
||||
由于我们使用`isa-debug-exit`设备和串行端口来报告完整的测试结果,所以我们不再需要QMEU的窗口了。我们可以通过向QEMU传递 `-display none`参数来将其隐藏:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-args = [
|
||||
"-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio",
|
||||
"-display", "none"
|
||||
]
|
||||
```
|
||||
|
||||
现在QEMU完全在后台运行且没有任何窗口会被打开。这不仅不那么烦人,还允许我们的测试框架在没有图形界面的环境里,诸如CI服务器或是[SSH]连接里运行。
|
||||
|
||||
[SSH]: https://en.wikipedia.org/wiki/Secure_Shell
|
||||
|
||||
### 超时
|
||||
|
||||
由于 `cargo xtest` 会等待test runner退出,如果一个测试永远不返回那么它就会一直阻塞test runner。幸运的是,在实际应用中这并不是一个大问题,因为无限循环通常是很容易避免的。在我们的这个例子里,无限循环会发生在以下几种不同的情况中:
|
||||
|
||||
|
||||
- bootloader加载内核失败,导致系统不停重启;
|
||||
- BIOS/UEFI固件加载bootloader失败,同样会导致无限重启;
|
||||
- CPU在某些函数结束时进入一个`loop {}`语句,例如因为QEMU的exit设备无法正常工作而导致死循环;
|
||||
- 硬件触发了系统重置,例如未捕获CPU异常时(后续的文章将会详细解释)。
|
||||
|
||||
由于无限循环可能会在各种情况中发生,因此, `bootimage` 工具默认为每个可执行测试设置了一个长度为5分钟的超时时间。如果测试未在此时间内完成,则将其标记为失败,并向控制台输出"Timed Out(超时)"错误。这个功能确保了那些卡在无限循环里的测试不会一直阻塞`cargo xtest`。
|
||||
|
||||
你可以将`loop {}`语句添加到 `trivial_assertion`测试中来进行尝试。当你运行 `cargo xtest`时,你可以发现该测试会在五分钟后被标记为超时。超时持续的时间可以通过Cargo.toml中的`test-timeout`来进行[配置][bootimage config]:
|
||||
|
||||
[bootimage config]: https://github.com/rust-osdev/bootimage#configuration
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[package.metadata.bootimage]
|
||||
test-timeout = 300 # (in seconds)
|
||||
```
|
||||
|
||||
如果你不想为了观察`trivial_assertion` 测试超时等待5分钟之久,你可以暂时降低将上述值。
|
||||
|
||||
此后,我们不再需要 `trivial_assertion` 测试,所以我们可以将其删除。
|
||||
|
||||
## 测试VGA缓冲区
|
||||
|
||||
现在我们已经有了一个可以工作的测试框架了,我们可以为我们的VGA缓冲区实现创建一些测试。首先,我们创建了一个非常简单的测试来验证 `println`是否正常运行而不会panic:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[cfg(test)]
|
||||
use crate::{serial_print, serial_println};
|
||||
|
||||
#[test_case]
|
||||
fn test_println_simple() {
|
||||
serial_print!("test_println... ");
|
||||
println!("test_println_simple output");
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
这个测试所做的仅仅是将一些内容打印到VGA缓冲区。如果它正常结束并且没有panic,也就意味着`println`调用也没有panic。由于我们只需要将 `serial_println` 导入到测试模式里,所以我们添加了 `cfg(test)` 属性(attribute)来避免正常模式下 `cargo xbuild`会出现的未使用导入警告(unused import warning)。
|
||||
|
||||
为了确保即使打印很多行且有些行超出屏幕的情况下也没有panic发生,我们可以创建另一个测试:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_many() {
|
||||
serial_print!("test_println_many... ");
|
||||
for _ in 0..200 {
|
||||
println!("test_println_many output");
|
||||
}
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
我们还可以创建另一个测试函数,来验证打印的几行字符是否真的出现在了屏幕上:
|
||||
|
||||
```rust
|
||||
// in src/vga_buffer.rs
|
||||
|
||||
#[test_case]
|
||||
fn test_println_output() {
|
||||
serial_print!("test_println_output... ");
|
||||
|
||||
let s = "Some test string that fits on a single line";
|
||||
println!("{}", s);
|
||||
for (i, c) in s.chars().enumerate() {
|
||||
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
|
||||
assert_eq!(char::from(screen_char.ascii_character), c);
|
||||
}
|
||||
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
该函数定义了一个测试字符串,并通过 `println`将其输出,然后遍历静态 `WRITER`也就是vga字符缓冲区的屏幕字符。由于`println`在将字符串打印到屏幕上最后一行后会立刻附加一个新行(即输出完后有一个换行符),所以这个字符串应该会出现在第 `BUFFER_HEIGHT - 2`行。
|
||||
|
||||
通过使用[`enumerate`] ,我们统计了变量`i`的迭代次数,然后用它来加载对应于`c`的屏幕字符。 通过比较屏幕字符的`ascii_character`和`c` ,我们可以确保字符串的每个字符确实出现在vga文本缓冲区中。
|
||||
|
||||
[`enumerate`]: https://doc.rust-lang.org/core/iter/trait.Iterator.html#method.enumerate
|
||||
|
||||
如你所想,我们可以创建更多的测试函数:例如一个用来测试当打印一个很长的且包装正确的行时是否会发生panic的函数,或是一个用于测试换行符、不可打印字符、非unicode字符是否能被正确处理的函数。
|
||||
|
||||
在这篇文章的剩余部分,我们还会解释如何创建一个_集成测试_以测试不同组建之间的交互。
|
||||
|
||||
|
||||
## 集成测试
|
||||
|
||||
在Rust中,**集成测试**([integration tests])的约定是将其放到项目根目录中的`tests`目录下(即`src`的同级目录)。无论是默认测试框架还是自定义测试框架都将自动获取并执行该目录下所有的测试。
|
||||
|
||||
[integration tests]: https://doc.rust-lang.org/book/ch11-03-test-organization.html#integration-tests
|
||||
|
||||
所有的集成测试都是它们自己的可执行文件,并且与我们的`main.rs`完全独立。这也就意味着每个测试都需要定义它们自己的函数入口点。让我们创建一个名为`basic_boot`的例子来看看集成测试的工作细节吧:
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(crate::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
#[no_mangle] // don't mangle the name of this function
|
||||
pub extern "C" fn _start() -> ! {
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
|
||||
fn test_runner(tests: &[&dyn Fn()]) {
|
||||
unimplemented!();
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
由于集成测试都是单独的可执行文件,所以我们需要再次提供所有的crate属性(`no_std`, `no_main`, `test_runner`, 等等)。我们还需要创建一个新的入口点函数`_start`,用于调用测试入口函数`test_main`。我们不需要任何的`cfg(test)` attributes(属性),因为集成测试的二进制文件在非测试模式下根本不会被编译构建。
|
||||
|
||||
这里我们采用[`unimplemented`]宏,充当`test_runner`暂未实现的占位符;添加简单的`loop {}`循环,作为`panic`处理器的内容。理想情况下,我们希望能向我们在`main.rs`里所做的一样使用`serial_println`宏和`exit_qemu`函数来实现这个函数。但问题是,由于这些测试的构建和我们的`main.rs`的可执行文件是完全独立的,我们没有办法使用这些函数。
|
||||
|
||||
[`unimplemented`]: https://doc.rust-lang.org/core/macro.unimplemented.html
|
||||
|
||||
如果现阶段你运行`cargo xtest`,你将进入一个无限循环,因为目前panic的处理就是进入无限循环。你需要使用快捷键`Ctrl+c`,才可以退出QEMU。
|
||||
|
||||
### 创建一个库
|
||||
为了让这些函数能在我们的集成测试中使用,我们需要从我们的`main.rs`中分割出一个库,这个库应当可以被其他的crate和集成测试可执行文件使用。为了达成这个目的,我们创建了一个新文件,`src/lib.rs`:
|
||||
|
||||
```rust
|
||||
// src/lib.rs
|
||||
|
||||
#![no_std]
|
||||
```
|
||||
|
||||
和`main.rs`一样,`lib.rs`也是一个可以被cargo自动识别的特殊文件。该库是一个独立的编译单元,所以我们需要再次指定`#![no_std]` 属性。
|
||||
|
||||
为了让我们的库可以和`cargo xtest`一起协同工作,我们还需要添加以下测试函数和属性:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
#![cfg_attr(test, no_main)]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(crate::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
|
||||
pub fn test_runner(tests: &[&dyn Fn()]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
}
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
|
||||
pub fn test_panic_handler(info: &PanicInfo) -> ! {
|
||||
serial_println!("[failed]\n");
|
||||
serial_println!("Error: {}\n", info);
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// Entry point for `cargo xtest`
|
||||
#[cfg(test)]
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
test_main();
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
为了能在可执行文件和集成测试中使用`test_runner`,我们不对其应用`cfg(test)` attribute(属性),并将其设置为public。同时,我们还将panic的处理程序分解为public函数`test_panic_handler`,这样一来它也可以用于可执行文件了。
|
||||
|
||||
由于我们的`lib.rs`是独立于`main.rs`进行测试的,因此当该库实在测试模式下编译时我们需要添加一个`_start`入口点和一个panic处理程序。通过使用[`cfg_attr`] ,我们可以在这种情况下有条件地启用`no_main` 属性。
|
||||
|
||||
[`cfg_attr`]: https://doc.rust-lang.org/reference/conditional-compilation.html#the-cfg_attr-attribute
|
||||
|
||||
我们还将`QemuExitCode`枚举和`exit_qemu`函数从main.rs移动过来,并将其设置为公有函数:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
|
||||
#[repr(u32)]
|
||||
pub enum QemuExitCode {
|
||||
Success = 0x10,
|
||||
Failed = 0x11,
|
||||
}
|
||||
|
||||
pub fn exit_qemu(exit_code: QemuExitCode) {
|
||||
use x86_64::instructions::port::Port;
|
||||
|
||||
unsafe {
|
||||
let mut port = Port::new(0xf4);
|
||||
port.write(exit_code as u32);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
现在,可执行文件和集成测试都可以从库中导入这些函数,而不需要实现自己的定义。为了使`println` 和 `serial_println`可用,我们将以下的模块声明代码也移动到`lib.rs`中:
|
||||
|
||||
```rust
|
||||
// in src/lib.rs
|
||||
|
||||
pub mod serial;
|
||||
pub mod vga_buffer;
|
||||
```
|
||||
|
||||
我们将这些模块设置为public(公有),这样一来我们在库的外部也一样能使用它们了。由于这两者都用了该模块内的`_print`函数,所以这也是让`println` 和 `serial_println`宏可用的必要条件。
|
||||
|
||||
现在我们修改我们的`main.rs`代码来使用该库:
|
||||
|
||||
```rust
|
||||
// src/main.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(blog_os::test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
use blog_os::println;
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
println!("Hello World{}", "!");
|
||||
|
||||
#[cfg(test)]
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
|
||||
/// This function is called on panic.
|
||||
#[cfg(not(test))]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
println!("{}", info);
|
||||
loop {}
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,这个库用起来就像一个普通的外部crate。它的调用方法与其它crate无异;在我们的这个例子中,位置可能为`blog_os`。上述代码使用了`test_runner` attribute中的`blog_os::test_runner`函数和`cfg(test)`的panic处理中的`blog_os::test_panic_handler`函数。它还导入了`println`宏,这样一来,我们可以在我们的`_start` 和 `panic`中使用它了。
|
||||
|
||||
与此同时,`cargo xrun` 和 `cargo xtest`可以再次正常工作了。当然了,`cargo xtest`仍然会进入无限循环(你可以通过`ctrl+c`来退出)。接下来让我们在我们的集成测试中通过所需要的库函数来修复这个问题吧。
|
||||
|
||||
### 完成集成测试
|
||||
|
||||
就像我们的`src/main.rs`,我们的`tests/basic_boot.rs`可执行文件同样可以从我们的新库中导入类型。这也就意味着我们可以导入缺失的组件来完成我们的测试。
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
#![test_runner(blog_os::test_runner)]
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(info: &PanicInfo) -> ! {
|
||||
blog_os::test_panic_handler(info)
|
||||
}
|
||||
```
|
||||
|
||||
这里我们使用我们的库中的`test_runner`函数,而不是重新实现一个test runner。至于panic处理,调用`blog_os::test_panic_handler`函数即可,就像我们之前在我们的`main.rs`里面做的一样。
|
||||
|
||||
现在,`cargo xtest`又可以正常退出了。当你运行该命令时,你会发现它为我们的`lib.rs`, `main.rs`, 和 `basic_boot.rs`分别构建并运行了测试。其中,对于 `main.rs` 和 `basic_boot`的集成测试,它会报告"Running 0 tests"(正在运行0个测试),因为这些文件里面没有任何用 `#[test_case]`标注的函数。
|
||||
|
||||
现在我们可以在`basic_boot.rs`中添加测试了。举个例子,我们可以测试`println`是否能够正常工作而不panic,就像我们之前在vga缓冲区测试中做的那样:
|
||||
|
||||
```rust
|
||||
// in tests/basic_boot.rs
|
||||
|
||||
use blog_os::{println, serial_print, serial_println};
|
||||
|
||||
#[test_case]
|
||||
fn test_println() {
|
||||
serial_print!("test_println... ");
|
||||
println!("test_println output");
|
||||
serial_println!("[ok]");
|
||||
}
|
||||
```
|
||||
|
||||
现在当我们运行`cargo xtest`时,我们可以看到它会寻找并执行这些测试函数。
|
||||
|
||||
由于该测试和vga缓冲区测试中的一个几乎完全相同,所以目前它看起来似乎没什么用。然而,在将来,我们的`main.rs`和`lib.rs`中的`_start`函数的内容会不断增长,并且在运行`test_main`之前需要调用一系列的初始化进程,所以这两个测试将会运行在完全不同的环境中(译者注:也就是说虽然现在看起来差不多,但是在将来该测试和vga buffer中的测试会很不一样,有必要单独拿出来,这两者并没有重复)。
|
||||
|
||||
通过在`basic_boot`环境里不掉用任何初始化例程的`_start`中测试`println`函数,我们可以确保`println`在启动(boot)后可以正常工作。这一点非常重要,因为我们有很多部分依赖于`println`,例如打印panic信息。
|
||||
|
||||
### 未来的测试
|
||||
|
||||
集成测试的强大之处在于,它们可以被看成是完全独立的可执行文件;这也给了它们完全控制环境的能力,使得他们能够测试代码和CPU或是其他硬件的交互是否正确。
|
||||
|
||||
我们的`basic_boot`测试正是集成测试的一个非常简单的例子。在将来,我们的内核的功能会变得更多,和硬件交互的方式也会变得多种多样。通过添加集成测试,我们可以保证这些交互按预期工作(并一直保持工作)。下面是一些对于未来的测试的设想:
|
||||
|
||||
- **CPU异常**:当代码执行无效操作(例如除以零)时,CPU就会抛出异常。内核会为这些异常注册处理函数。集成测试可以验证在CPU异常时是否调用了正确的异常处理程序,或者在可解析的异常之后程序是否能正确执行;
|
||||
- **页表**:页表定义了哪些内存区域是有效且可访问的。通过修改页表,可以重新分配新的内存区域,例如,当你启动一个软件的时候。我们可以在集成测试中调整`_start`函数中的一些页表项,并确认这些改动是否会对`#[test_case]`的函数产生影响;
|
||||
- **用户空间程序**:用户空间程序是只能访问有限的系统资源的程序。例如,他们无法访问内核数据结构或是其他应用程序的内存。集成测试可以启动执行禁止操作的用户空间程序验证认内核是否会将这些操作全都阻止。
|
||||
|
||||
可以想象,还有更多的测试可以进行。通过添加各种各样的测试,我们确保在为我们的内核添加新功能或是重构代码时,不会意外地破坏他们。这一点在我们的内核变得更大和更复杂的时候显得尤为重要。
|
||||
|
||||
### 那些应该Panic的测试
|
||||
|
||||
标准库的测试框架支持允许构造失败测试的[`#[should_panic]` attribute][should_panic]。这个功能对于验证传递无效参数时函数是否会失败非常有用。不幸的是,这个属性需要标准库的支持,因此,在`#[no_std]`环境下无法使用。
|
||||
|
||||
[should_panic]: https://doc.rust-lang.org/rust-by-example/testing/unit_testing.html#testing-panics
|
||||
|
||||
尽管我们不能在我们的内核中使用`#[should_panic]` 属性,但是通过创建一个集成测试我们可以达到类似的效果——该集成测试可以从panic处理程序中返回一个成功错误代码。接下来让我一起来创建一个如上所述名为`should_panic`的测试吧:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
use blog_os::{QemuExitCode, exit_qemu, serial_println};
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
这个测试还没有完成,因为它尚未定义`_start`函数或是其他自定义的test runner attributes。让我们来补充缺少的内容吧:
|
||||
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
#![feature(custom_test_frameworks)]
|
||||
#![test_runner(test_runner)]
|
||||
#![reexport_test_harness_main = "test_main"]
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
test_main();
|
||||
|
||||
loop {}
|
||||
}
|
||||
|
||||
pub fn test_runner(tests: &[&dyn Fn()]) {
|
||||
serial_println!("Running {} tests", tests.len());
|
||||
for test in tests {
|
||||
test();
|
||||
serial_println!("[test did not panic]");
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
}
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
}
|
||||
```
|
||||
|
||||
这个测试定义了自己的`test_runner`函数,而不是复用`lib.rs`中的`test_runner`,该函数会在测试没有panic而是正常退出时返回一个错误退出代码(因为这里我们希望测试会panic)。如果没有定义测试函数,runner就会以一个成功错误代码退出。由于这个runner总是在执行完单个的测试后就退出,因此定义超过一个`#[test_case]`的函数都是没有意义的。
|
||||
|
||||
现在我们来创建一个应该失败的测试:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
use blog_os::serial_print;
|
||||
|
||||
#[test_case]
|
||||
fn should_fail() {
|
||||
serial_print!("should_fail... ");
|
||||
assert_eq!(0, 1);
|
||||
}
|
||||
```
|
||||
|
||||
该测试用 `assert_eq`来断言(assert)`0`和`1`是否相等。毫无疑问,这当然会失败(`0`当然不等于`1`),所以我们的测试就会像我们想要的那样panic。
|
||||
|
||||
当我们通过`cargo xtest --test should_panic`运行该测试时,我们会发现成功了因为该测试如我们预期的那样panic了。当我们将断言部分(即`assert_eq!(0, 1);`)注释掉后,我们就会发现测试失败并返回了_"test did not panic"_的信息。
|
||||
|
||||
这种方法的缺点是它只使用于单个的测试函数。对于多个`#[test_case]`函数,它只会执行第一个函数因为程序无法在panic处理被调用后继续执行。我目前没有想到解决这个问题的方法,如果你有任何想法,请务必告诉我!
|
||||
|
||||
### 无约束测试
|
||||
|
||||
对于那些只有单个测试函数的集成测试而言(例如我们的`should_panic`测试),其实并不需要test runner。对于这种情况,我们可以完全禁用test runner,直接在`_start`函数中直接运行我们的测试。
|
||||
|
||||
这里的关键就是在`Cargo.toml`中为测试禁用 `harness` flag,这个标志(flag)定义了是否将test runner用于集成测试中。如果该标志位被设置为`false`,那么默认的test runner和自定义的test runner功能都将被禁用,这样一来该测试就可以像一个普通的可执行程序一样运行了。
|
||||
|
||||
现在让我们为我们的`should_panic`测试禁用`harness` flag吧:
|
||||
|
||||
```toml
|
||||
# in Cargo.toml
|
||||
|
||||
[[test]]
|
||||
name = "should_panic"
|
||||
harness = false
|
||||
```
|
||||
|
||||
现在我们通过移除test runner相关的代码,大大简化了我们的`should_panic`测试。结果看起来如下:
|
||||
|
||||
```rust
|
||||
// in tests/should_panic.rs
|
||||
|
||||
#![no_std]
|
||||
#![no_main]
|
||||
|
||||
use core::panic::PanicInfo;
|
||||
use blog_os::{QemuExitCode, exit_qemu, serial_println};
|
||||
|
||||
#[no_mangle]
|
||||
pub extern "C" fn _start() -> ! {
|
||||
should_fail();
|
||||
serial_println!("[test did not panic]");
|
||||
exit_qemu(QemuExitCode::Failed);
|
||||
loop{}
|
||||
}
|
||||
|
||||
fn should_fail() {
|
||||
serial_print!("should_fail... ");
|
||||
assert_eq!(0, 1);
|
||||
}
|
||||
|
||||
#[panic_handler]
|
||||
fn panic(_info: &PanicInfo) -> ! {
|
||||
serial_println!("[ok]");
|
||||
exit_qemu(QemuExitCode::Success);
|
||||
loop {}
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以通过我们的`_start`函数来直接调用`should_fail`函数了,如果返回则返回一个失败退出代码并退出。现在当我们执行`cargo xtest --test should_panic`时,我们可以发现测试的行为和之前完全一样。
|
||||
|
||||
除了创建`should_panic`测试,禁用`harness` attribute对复杂集成测试也很有用,例如,当单个测试函数会产生一些边际效应需要通过特定的顺序执行时。
|
||||
|
||||
## 总结
|
||||
|
||||
测试是一种非常有用的技术,它能确保特定的部件拥有我们期望的行为。即使它们不能显示是否有bug,它们仍然是用来寻找bug的利器,尤其是用来避免回归。
|
||||
|
||||
本文讲述了如何为我们的Rust kernel创建一个测试框架。我们使用Rust的自定义框架功能为我们的裸机环境实现了一个简单的`#[test_case]` attribute支持。通过使用QEMU的`isa-debug-exit`设备,我们的test runner可以在运行测试后退出QEMU并报告测试状态。我们还为串行端口实现了一个简单的驱动,使得错误信息可以被打印到控制台而不是VGA buffer中。
|
||||
|
||||
在为我们的`println`宏创建了一些测试后,我们在本文的后半部分还探索了集成测试。我们了解到它们位于`tests`目录中,并被视为完全独立的可执行文件。为了使他们能够使用`exit_qemu` 函数和 `serial_println` 宏,我们将大部分代码移动到一个库里,使其能够被导入到所有可执行文件和集成测试中。由于集成测试在各自独立的环境中运行,所以能够测试与硬件的交互或是创建应该panic的测试。
|
||||
|
||||
我们现在有了一个在QEMU内部真是环境中运行的测试框架。在未来的文章里,我们会创建更多的测试,从而让我们的内核在变得更复杂的同时保持可维护性。
|
||||
|
||||
## 下期预告
|
||||
|
||||
在下一篇文章中,我们将会探索_CPU异常_。这些异常将在一些非法事件发生时由CPU抛出,例如抛出除以零或是访问没有映射的内存页(通常也被称为`page fault`即缺页异常)。能够捕获和检查这些异常,对将来的调试来说是非常重要的。异常处理与键盘支持所需的硬件中断处理十分相似。
|
||||
7
blog/content/second-edition/posts/_index.zh-CN.md
Normal file
7
blog/content/second-edition/posts/_index.zh-CN.md
Normal file
@@ -0,0 +1,7 @@
|
||||
+++
|
||||
title = "Posts"
|
||||
sort_by = "weight"
|
||||
insert_anchor_links = "left"
|
||||
render = false
|
||||
page_template = "second-edition/page.html"
|
||||
+++
|
||||
@@ -106,6 +106,11 @@ main img {
|
||||
margin-left: 5px;
|
||||
}
|
||||
|
||||
.no-translation {
|
||||
margin-top: .3rem;
|
||||
color: #999999;
|
||||
}
|
||||
|
||||
.post-category {
|
||||
margin-right: 0.5rem;
|
||||
text-transform: uppercase;
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
<!doctype html>
|
||||
|
||||
<html lang="{{ config.default_language }}">
|
||||
<html lang="{{ lang }}">
|
||||
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
|
||||
@@ -1,9 +1,22 @@
|
||||
{% macro post_link(page) %}
|
||||
<div>
|
||||
<h2 class="post-title"><a href="/{{ page.path | safe }}">{{ page.title }}</a></h2>
|
||||
{% set translations = page.translations | filter(attribute="lang", value=lang) %}
|
||||
{% if translations %}
|
||||
{% set post = get_page(path = translations.0.path) %}
|
||||
{% else %}
|
||||
{% set post = page %}
|
||||
{% set not_translated = true %}
|
||||
{% endif %}
|
||||
<h2 class="post-title"><a href="/{{ post.path | safe }}">{{ post.title }}</a></h2>
|
||||
<div class="post-summary">
|
||||
{{ page.summary | safe}}
|
||||
<a class="read-more" href="/{{ page.path | safe }}"><em>read more »</em></a>
|
||||
{{ post.summary | safe}}
|
||||
<a class="read-more" href="/{{ post.path | safe }}"><em>read more »</em></a>
|
||||
|
||||
{% if lang and not_translated %}
|
||||
<aside class="no-translation">
|
||||
(This post is not translated yet.)
|
||||
</aside>
|
||||
{% endif %}
|
||||
</div>
|
||||
</div>
|
||||
{% endmacro post_link %}
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
<!doctype html>
|
||||
|
||||
<html lang="{{ config.default_language }}">
|
||||
<html lang="{% if lang %}{{ lang }}{% else %}{{ config.default_language }}{% endif %}">
|
||||
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
|
||||
@@ -4,7 +4,11 @@
|
||||
|
||||
{% block title %}{{ page.title }} | {{ config.title }}{% endblock title %}
|
||||
{% block header %}
|
||||
{% if lang != "en" %}
|
||||
<aside id="all-posts-link"><a href="{{ config.base_url | safe }}/{{ lang }}" title="All Posts">« All Posts</a></aside>
|
||||
{% else %}
|
||||
<aside id="all-posts-link"><a href="{{ config.base_url | safe }}" title="All Posts">« All Posts</a></aside>
|
||||
{% endif %}
|
||||
{% endblock header %}
|
||||
|
||||
{% block description -%}
|
||||
@@ -39,6 +43,15 @@
|
||||
</div>
|
||||
{% endif %}
|
||||
|
||||
{% if page.lang != "en" %}
|
||||
<div class="warning">
|
||||
{% set translations = page.translations | filter(attribute="lang", value="en") %}
|
||||
{% set original = translations.0 %}
|
||||
<b>Translated Content:</b>
|
||||
This is a community translation of the <strong><a href="{{ original.permalink }}">{{ original.title }}</a></strong> post. It might be incomplete, outdated or contain errors. Please report any issues!
|
||||
</div>
|
||||
{% endif %}
|
||||
|
||||
{{ page.content | replace(from="<!-- toc -->", to=macros::toc(toc=page.toc)) | safe }}
|
||||
|
||||
<div class="post-footer-support">
|
||||
|
||||
Reference in New Issue
Block a user